- 1、[CL] Can Small and Synthetic Benchmarks Drive Modeling Innovation? A Retrospective Study of Question Answering Modeling Approaches
- 2、[CV] Video Transformer Network
- 3、[LG] Sparsity in Deep Learning: Pruning and growth for efficient inference and training in neural networks
- 4、[CL] Measuring and Improving Consistency in Pretrained Language Models
- 5、[CV] Neural 3D Clothes Retargeting from a Single Image
- [CV] Evaluating Large-Vocabulary Object Detectors: The Devil is in the Details
- [CV] Bridging Unpaired Facial Photos And Sketches By Line-drawings
- [AI] Using Multiple Generative Adversarial Networks to Build Better-Connected Levels for Mega Man
- [CL] Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] Can Small and Synthetic Benchmarks Drive Modeling Innovation? A Retrospective Study of Question Answering Modeling Approaches
N F. Liu, T Lee, R Jia, P Liang
[Stanford University]
针对小型/合成基准数据对QA建模创新推动作用的回顾性研究。大型自然语言数据集是训练准确、可部署的NLP系统的关键要素,但它们对于推动建模创新是必要的?合成的或更小的基准数据能否带来类似的创新?为了考察这个问题,对20种SQuAD建模方法进行了回顾性研究,调研了32种现有的和合成的基准与SQuAD的一致程度,构建了小型的、有针对性的合成基准,这些基准与自然语言并不相似,但与SQuAD有很高的一致性,证明自然度和大小对于反映SQuAD上的历史建模改进并不是必须的。实验结果进一步表明,小型和精心设计的合成基准可能对新建模方法的开发也有推动作用。
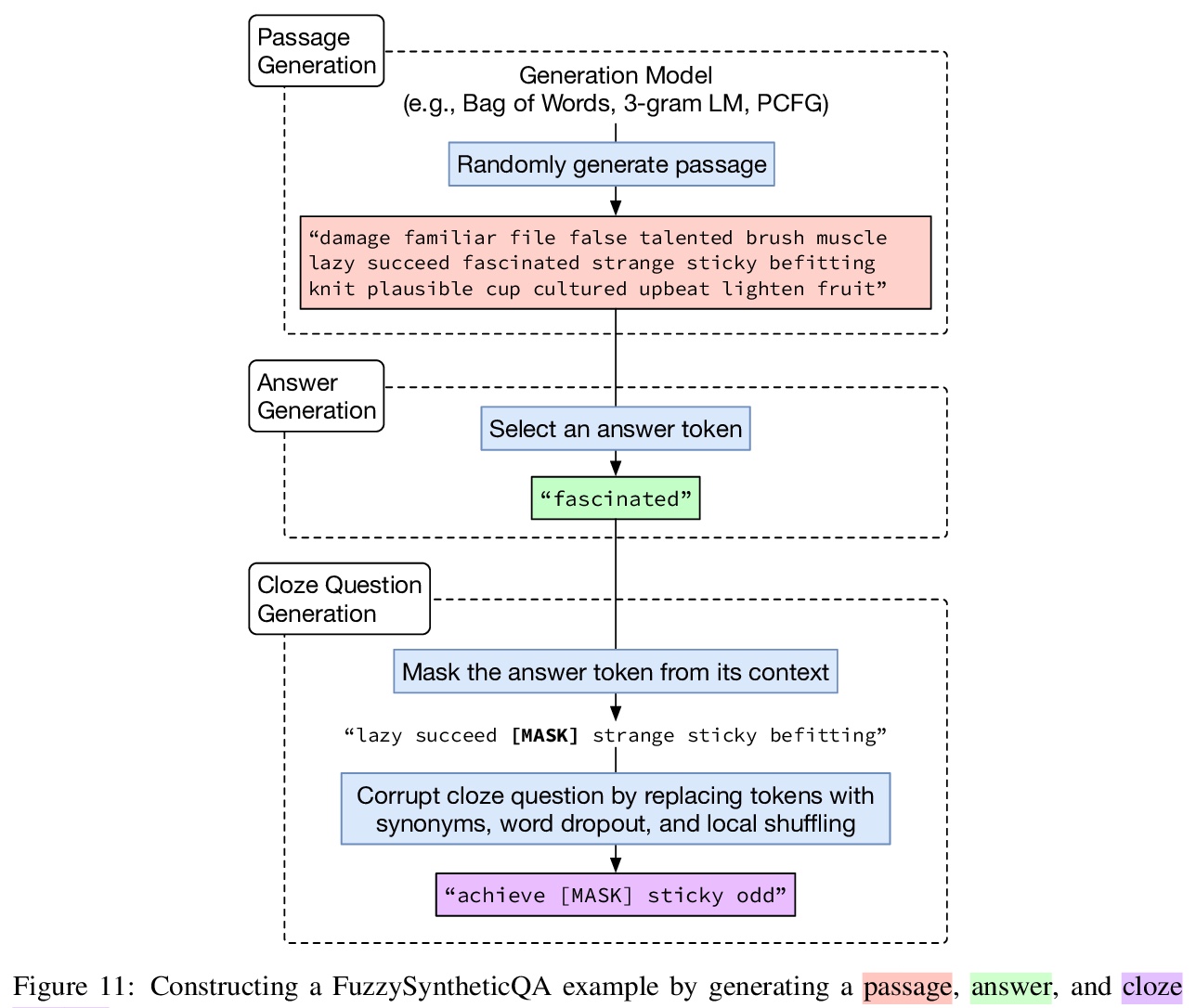
Datasets are not only resources for training accurate, deployable systems, but are also benchmarks for developing new modeling approaches. While large, natural datasets are necessary for training accurate systems, are they necessary for driving modeling innovation? For example, while the popular SQuAD question answering benchmark has driven the development of new modeling approaches, could synthetic or smaller benchmarks have led to similar innovations?This counterfactual question is impossible to answer, but we can study a necessary condition: the ability for a benchmark to recapitulate findings made on SQuAD. We conduct a retrospective study of 20 SQuAD modeling approaches, investigating how well 32 existing and synthesized benchmarks concur with SQuAD — i.e., do they rank the approaches similarly? We carefully construct small, targeted synthetic benchmarks that do not resemble natural language, yet have high concurrence with SQuAD, demonstrating that naturalness and size are not necessary for reflecting historical modeling improvements on SQuAD. Our results raise the intriguing possibility that small and carefully designed synthetic benchmarks may be useful for driving the development of new modeling approaches.
https://weibo.com/1402400261/K0a2v0MO3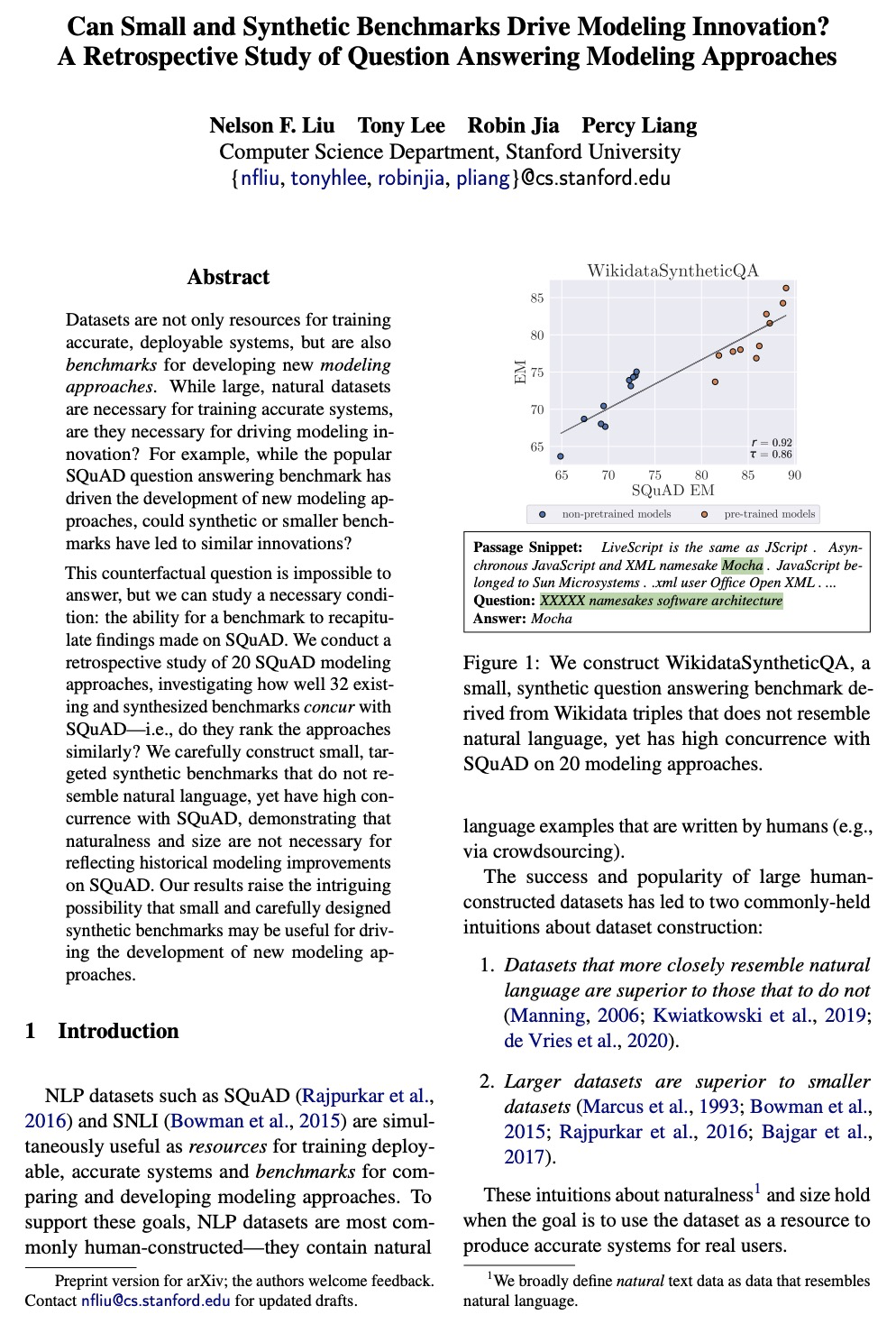


2、[CV] Video Transformer Network
D Neimark, O Bar, M Zohar, D Asselmann
[Theator]
高效的视频Transformer网络。提出了基于Transformer的视频识别框架VTN,引入了一种通过关注整个视频序列信息对动作进行分类的方法。该方法是通用的,可建立在任意给定2D空间网络之上,与其他最先进方法相比,训练速度快了16.1倍,推理过程运行速度快了5.1倍,同时保持了具有竞争力的准确性,可通过单一的端到端通道,实现整个视频分析,需要的GFLOPs减少了1.5倍。
This paper presents VTN, a transformer-based framework for video recognition. Inspired by recent developments in vision transformers, we ditch the standard approach in video action recognition that relies on 3D ConvNets and introduce a method that classifies actions by attending to the entire video sequence information. Our approach is generic and builds on top of any given 2D spatial network. In terms of wall runtime, it trains > 16.1× faster and runs > 5.1× faster during inference while maintaining competitive accuracy compared to other state-of-the-art methods. It enables whole video analysis, via a single end-to-end pass, while requiring > 1.5× fewer GFLOPs. We report competitive results on Kinetics-400 and present an ablation study of VTN properties and the trade-off between accuracy and inference speed. We hope our approach will serve as a new baseline and start a fresh line of research in the video recognition domain. Code and models will be available soon.
https://weibo.com/1402400261/K0aaeBKbx



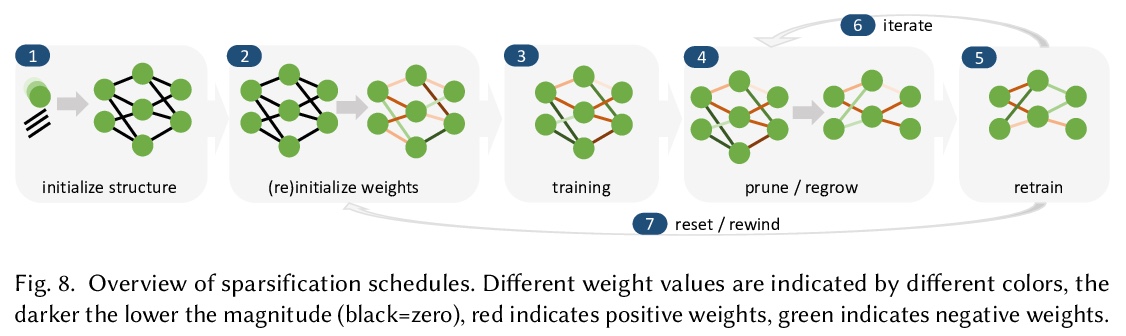
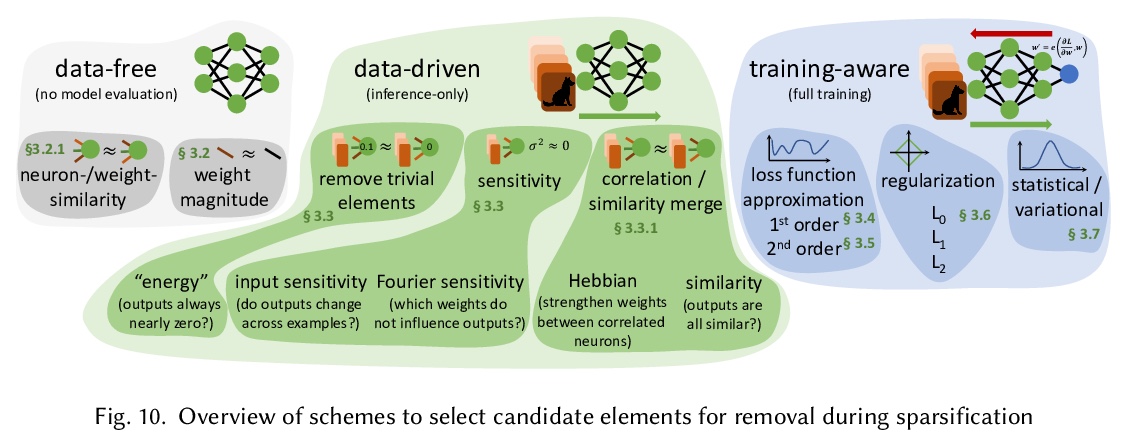
3、[LG] Sparsity in Deep Learning: Pruning and growth for efficient inference and training in neural networks
T Hoefler, D Alistarh, T Ben-Nun, N Dryden, A Peste
[ETH Zürich & IST Austria]
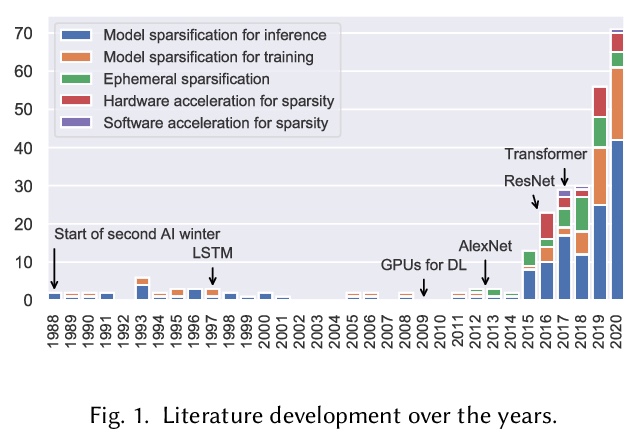
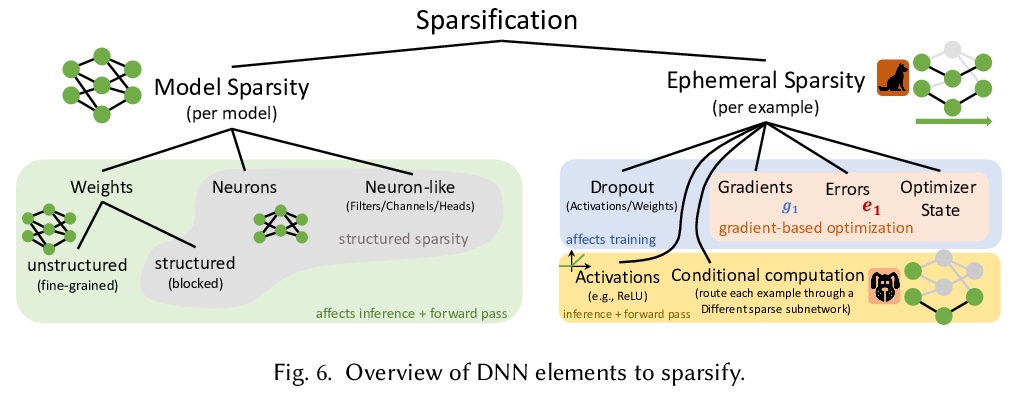
深度学习中的稀疏性:面向高效推理与训练的神经网络修剪与增长。调研了深度学习中关于稀疏性的已有工作,提供了面向推理和训练的稀疏化的相关教程。描述了删除和添加神经网络元素的方法,实现模型稀疏性的不同训练策略,以及在实践中利用稀疏性的机制。本文观点来自于300多篇研究论文,为希望利用稀疏性的实践者,以及有志于推动前沿的研究者提供指导。本文包括了稀疏化必要的数学背景,描述了早期结构自适应等现象,稀疏度和训练过程之间的复杂关系,展示了在真实硬件上实现加速的技术。
The growing energy and performance costs of deep learning have driven the community to reduce the size of neural networks by selectively pruning components. Similarly to their biological counterparts, sparse networks generalize just as well, if not better than, the original dense networks. Sparsity can reduce the memory footprint of regular networks to fit mobile devices, as well as shorten training time for ever growing networks. In this paper, we survey prior work on sparsity in deep learning and provide an extensive tutorial of sparsification for both inference and training. We describe approaches to remove and add elements of neural networks, different training strategies to achieve model sparsity, and mechanisms to exploit sparsity in practice. Our work distills ideas from more than 300 research papers and provides guidance to practitioners who wish to utilize sparsity today, as well as to researchers whose goal is to push the frontier forward. We include the necessary background on mathematical methods in sparsification, describe phenomena such as early structure adaptation, the intricate relations between sparsity and the training process, and show techniques for achieving acceleration on real hardware. We also define a metric of pruned parameter efficiency that could serve as a baseline for comparison of different sparse networks. We close by speculating on how sparsity can improve future workloads and outline major open problems in the field.
https://weibo.com/1402400261/K0ahSdV2P
4、[CL] Measuring and Improving Consistency in Pretrained Language Models
Y Elazar, N Kassner, S Ravfogel, A Ravichander, E Hovy, H Schütze, Y Goldberg
[Bar Ilan University & LMU Munich & CMU]
预训练语言模型一致性的度量和提高。在自然语言处理中,模型的一致性——即模型对意义不变形式变化的输入所具有的行为不变性—是非常理想的特性。本文研究预训练语言模型的一致性问题,建立了名为PARAREL的高质量资源,包含38种关系的328个高质量模式。利用PARAREL测量了多个预训练语言模型的一致性,包括BERT、RoBERTa和ALBERT,结果表明,虽然后两个预训练语言模型在其他任务中优于BERT,但在一致性方面略显不足。总体上,这些模型的一致性能力偏低。提出了新的简单方法来提高预训练语言模型的一致性,通过用新的损失继续预训练步骤,可提高模型的一致性以及它们提取正确事实的能力。
Consistency of a model — that is, the invariance of its behavior under meaning-preserving alternations in its input — is a highly desirable property in natural language processing. In this paper we study the question: Are Pretrained Language Models (PLMs) consistent with respect to factual knowledge? To this end, we create ParaRel, a high-quality resource of cloze-style query English paraphrases. It contains a total of 328 paraphrases for thirty-eight relations. Using ParaRel, we show that the consistency of all PLMs we experiment with is poor — though with high variance between relations. Our analysis of the representational spaces of PLMs suggests that they have a poor structure and are currently not suitable for representing knowledge in a robust way. Finally, we propose a method for improving model consistency and experimentally demonstrate its effectiveness.
https://weibo.com/1402400261/K0ancl42U


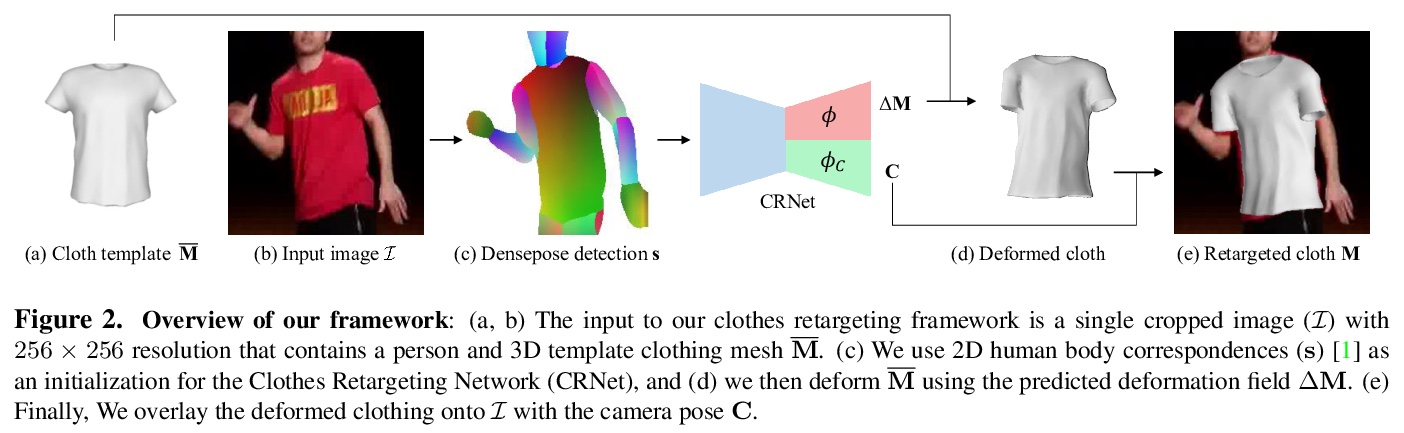
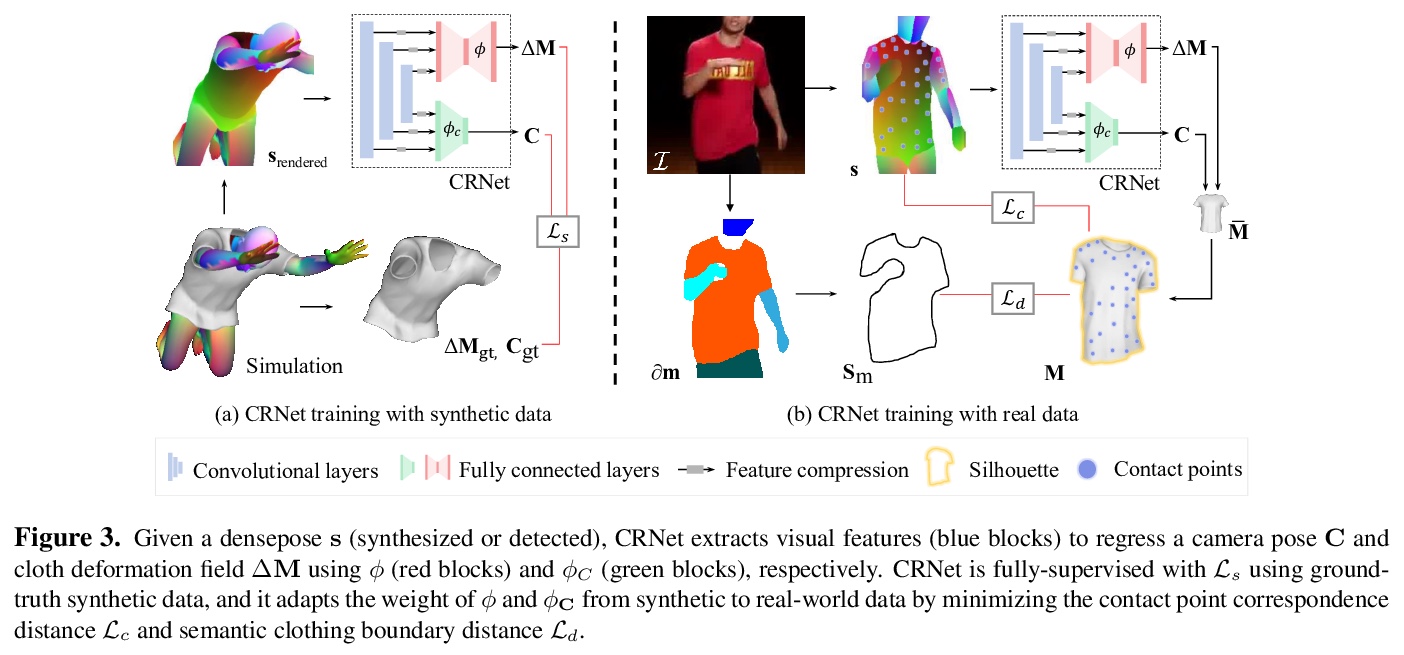
5、[CV] Neural 3D Clothes Retargeting from a Single Image
J S Yoon, K Kim, J Kautz, H S Park
[University of Minnesota & NVIDIA]
单幅图像的神经网络3D服装重定位。提出了一种基于学习的方法,将给定的3D服装网格,重新定位到单幅2D图像中的人物身上。为准确地将服装模板迁移和拟合到图像中,基于半监督训练,估计出最合理的服装模型变形,使身体姿态与图像中服装轮廓的语义边界最一致。设计了新的神经网络服装重定向网络(CRNet),以端到端方式整合半监督重定向任务。实验结果表明,该方法可预测真实世界例子中重定向衣服模型所需的真实3D姿势和变形场。
In this paper, we present a method of clothes retargeting; generating the potential poses and deformations of a given 3D clothing template model to fit onto a person in a single RGB image. The problem is fundamentally ill-posed as attaining the ground truth data is impossible, i.e., images of people wearing the different 3D clothing template model at exact same pose. We address this challenge by utilizing large-scale synthetic data generated from physical simulation, allowing us to map 2D dense body pose to 3D clothing deformation. With the simulated data, we propose a semi-supervised learning framework that validates the physical plausibility of the 3D deformation by matching with the prescribed body-to-cloth contact points and clothing silhouette to fit onto the unlabeled real images. A new neural clothes retargeting network (CRNet) is designed to integrate the semi-supervised retargeting task in an end-to-end fashion. In our evaluation, we show that our method can predict the realistic 3D pose and deformation field needed for retargeting clothes models in real-world examples.
https://weibo.com/1402400261/K0atRnBh3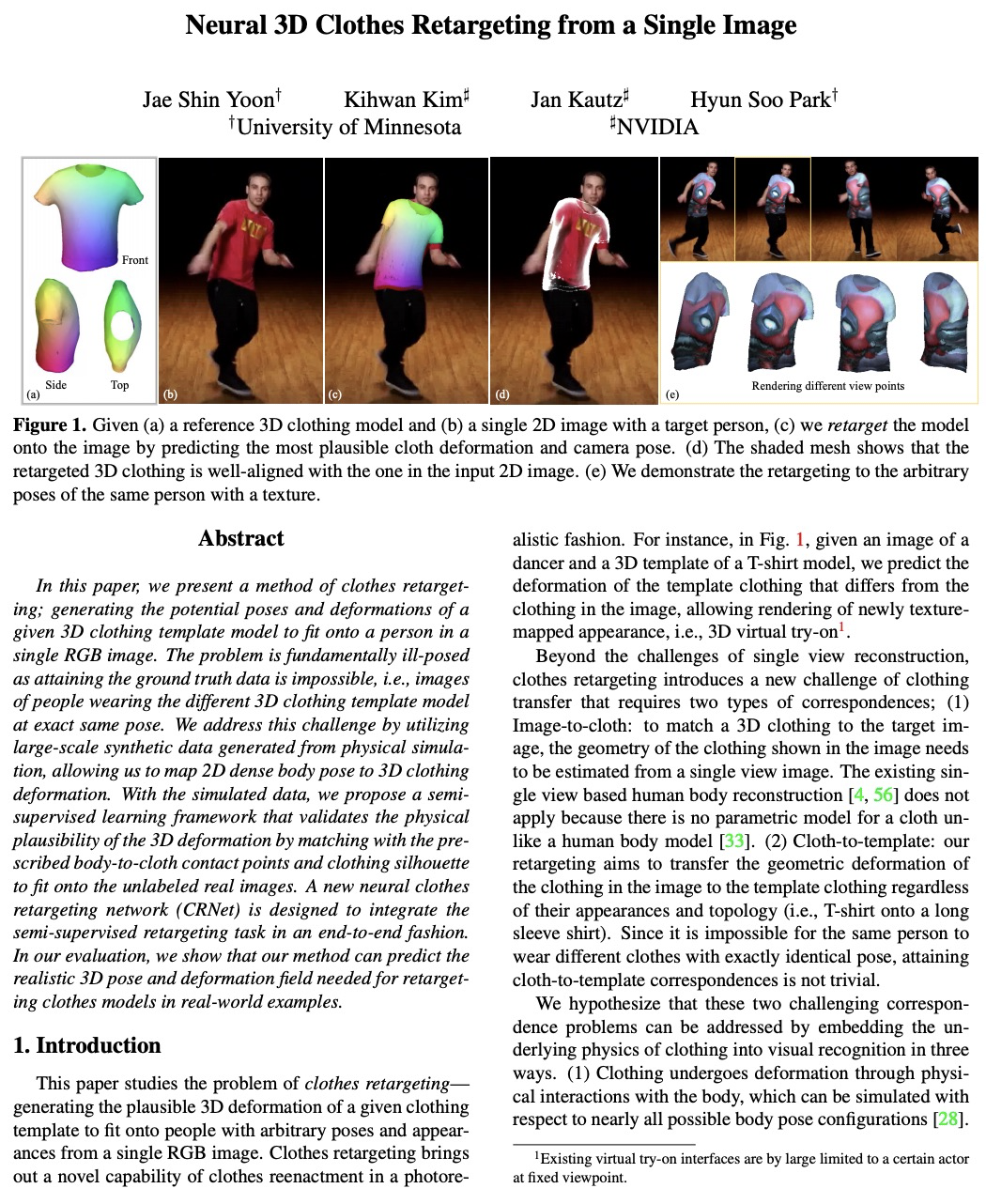
另外几篇值得关注的论文:
[CV] Evaluating Large-Vocabulary Object Detectors: The Devil is in the Details
大词表目标检测器评价:细节决定成败
A Dave, P Dollár, D Ramanan, A Kirillov, R Girshick
[CMU & Facebook AI Research (FAIR)]
https://weibo.com/1402400261/K0axbjZGx


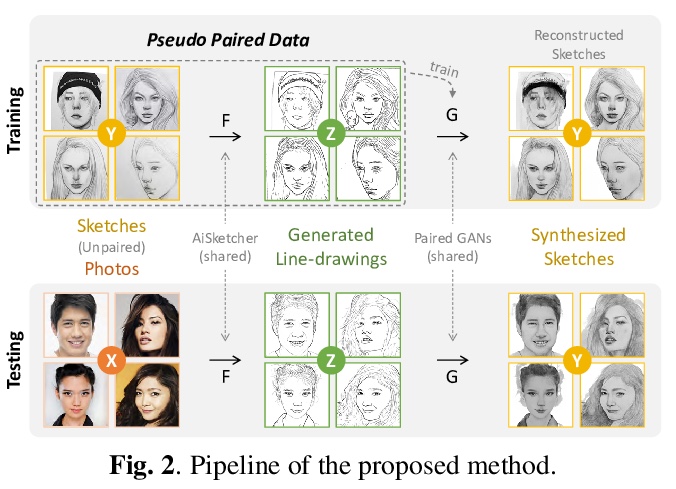
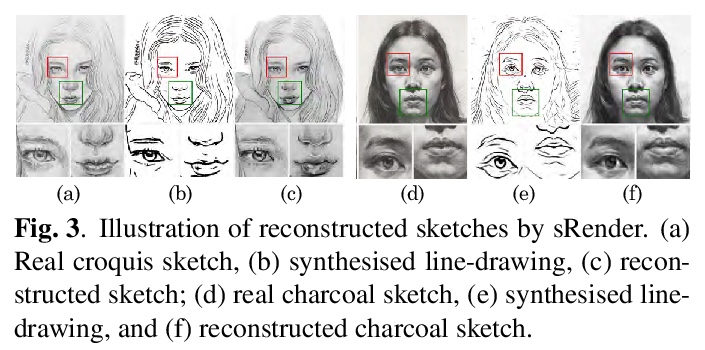
[CV] Bridging Unpaired Facial Photos And Sketches By Line-drawings
从未配对样本中学习的人脸草图合成方法
F Gao, M Shang, X Li, J Zhu, L Dai
[Hangzhou Dianzi University & AiSketcher Technology]
https://weibo.com/1402400261/K0azAj0wx
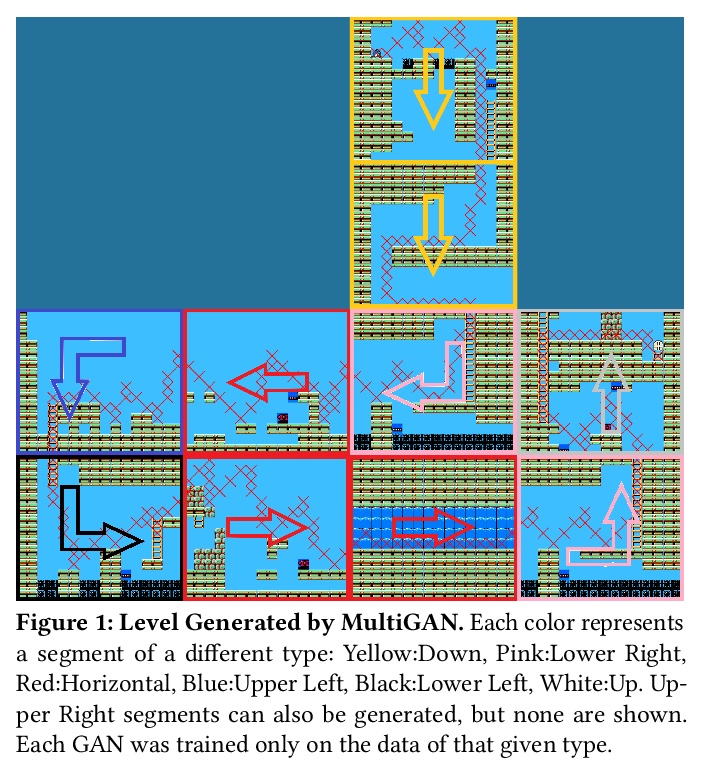
[AI] Using Multiple Generative Adversarial Networks to Build Better-Connected Levels for Mega Man
用多个GAN为《洛克人》生成更好的连接性关卡
B Capps, J Schrum
[Southwestern University]
https://weibo.com/1402400261/K0aCD63B2

[CL] Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers
多模态Transformers中数据/注意力/损失作用解耦
L A Hendricks, J Mellor, R Schneider, J Alayrac, A Nematzadeh
[DeepMind]
https://weibo.com/1402400261/K0aFPE2PU



若有收获,就点个赞吧
0 人点赞
