LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Graph Kernels: State-of-the-Art and Future Challenges
K Borgwardt, E Ghisu, F Llinares-López, L O’Bray, B Rieck
[ETH Zurich]
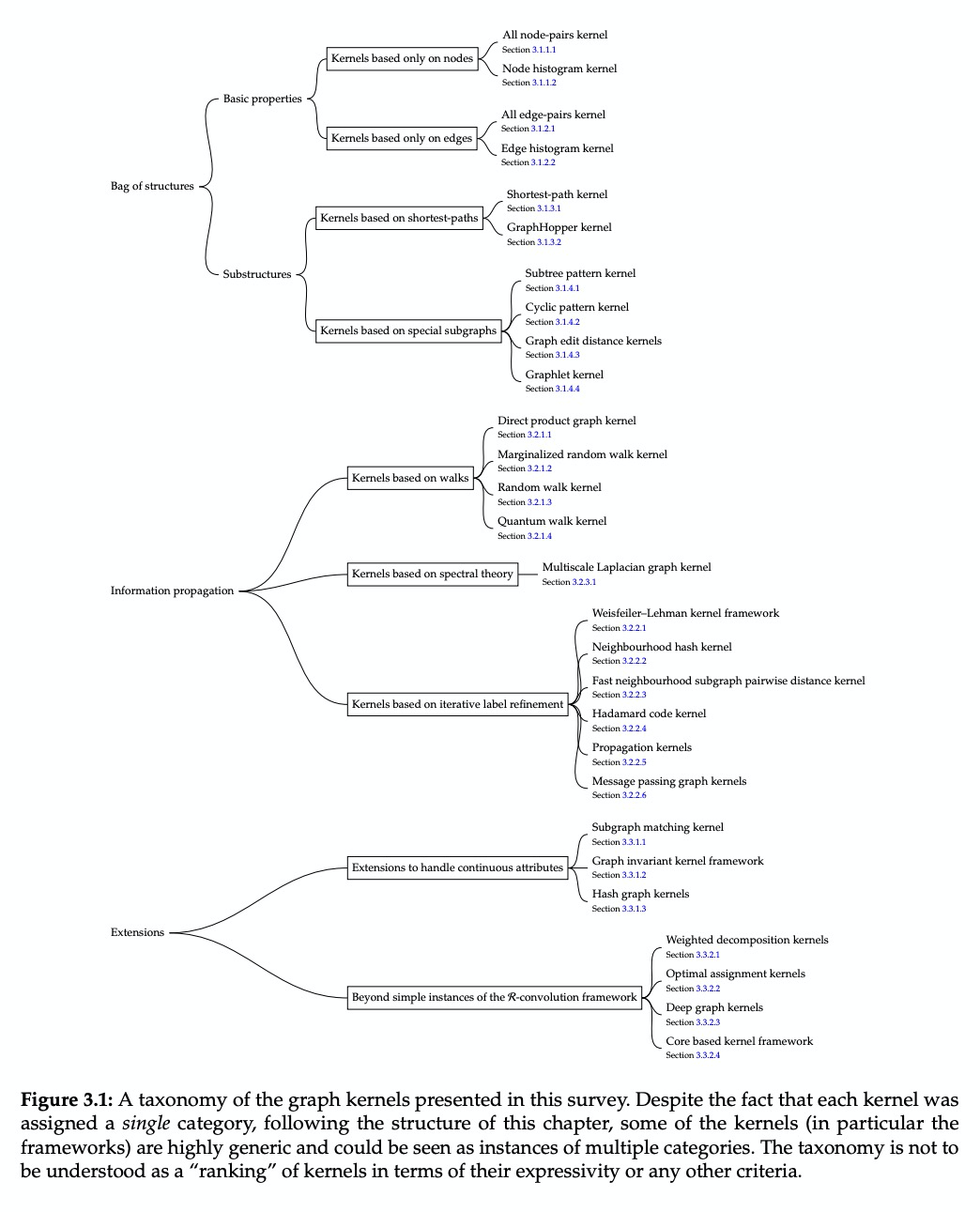
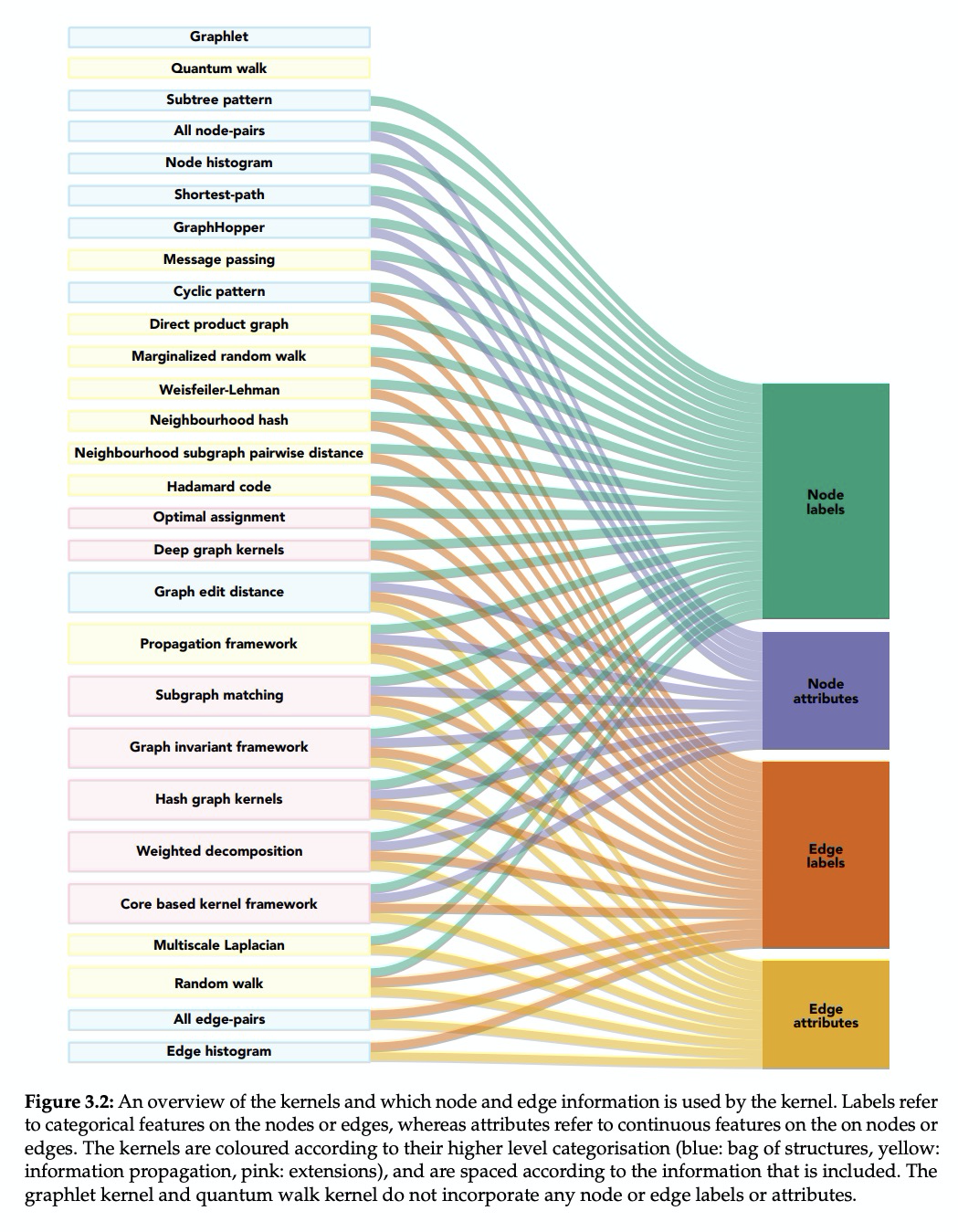
图核(Graph Kernels)(图上的核函数)综述。图结构数据是许多应用领域不可或缺的一部分,包括化学信息学、计算生物学、神经成像和社会网络分析。过去15年,人们提出了大量的图核,即图上的核函数,来解决图之间相似性评价的问题,使得分类和回归的预测成为可能。本文对现有图核应用、软件和数据资源进行了总结,对最新图核进行了实证比较研究,从核函数特性的理论评价,到新的图特征集成的实证评价,希望能为新的图核研究提供一点激励。
Graph-structured data are an integral part of many application domains, including chemoinformatics, computational biology, neuroimaging, and social network analysis. Over the last fifteen years, numerous graph kernels, i.e. kernel functions between graphs, have been proposed to solve the problem of assessing the similarity between graphs, thereby making it possible to perform predictions in both classification and regression settings. This manuscript provides a review of existing graph kernels, their applications, software plus data resources, and an empirical comparison of state-of-the-art graph kernels.
https://weibo.com/1402400261/JtlwAsVY1

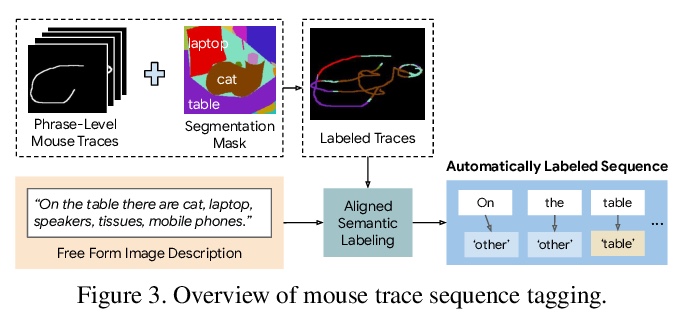
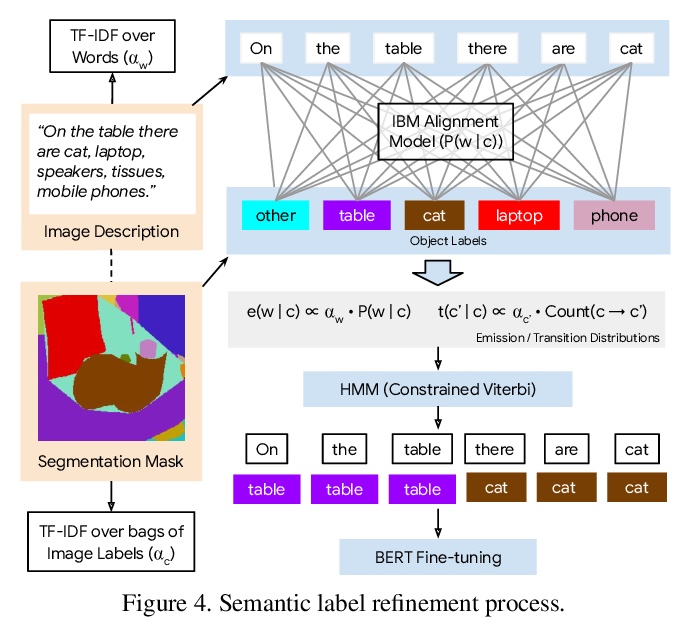
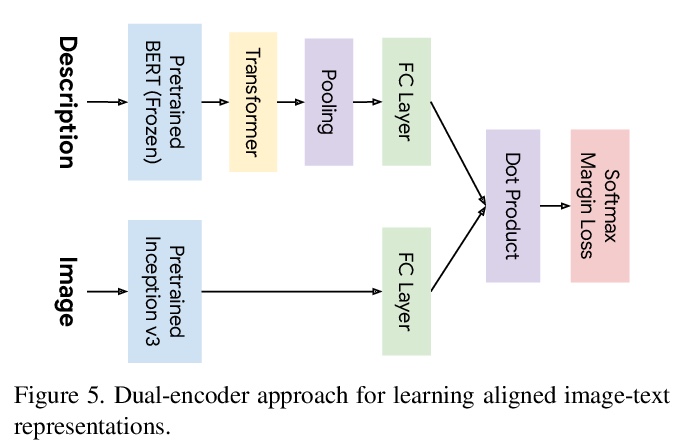
2、[CV] Text-to-Image Generation Grounded by Fine-Grained User Attention
J Y Koh, J Baldridge, H Lee, Y Yang
[Google Research]
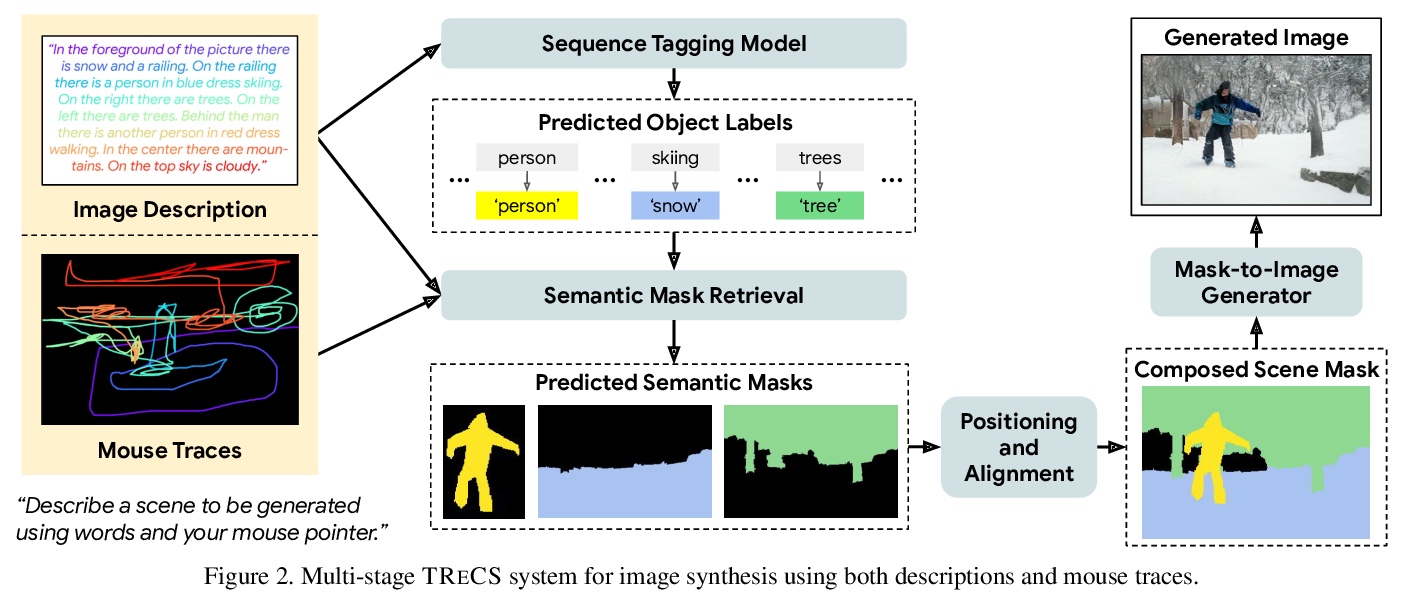
基于细粒度用户注意力的文本到图像生成。Localized Narratives是图像详细自然语言描述+鼠标轨迹的数据集,鼠标轨迹为短语提供了稀疏的、细粒度的视觉基础。提出了序列模型TReCS,利用该基础来生成图像,用文字描述检索分割掩码和预测与鼠标轨迹对齐的目标标签。TReCS允许用户在描述场景的同时自然地控制大小和位置,在产生更高质量的图像方面优于AttnGAN,能更好地与描述对齐。
Localized Narratives is a dataset with detailed natural language descriptions of images paired with mouse traces that provide a sparse, fine-grained visual grounding for phrases. We propose TReCS, a sequential model that exploits this grounding to generate images. TReCS uses descriptions to retrieve segmentation masks and predict object labels aligned with mouse traces. These alignments are used to select and position masks to generate a fully covered segmentation canvas; the final image is produced by a segmentation-to-image generator using this canvas. This multi-step, retrieval-based approach outperforms existing direct text-to-image generation models on both automatic metrics and human evaluations: overall, its generated images are more photo-realistic and better match descriptions.
https://weibo.com/1402400261/JtlCWrW4G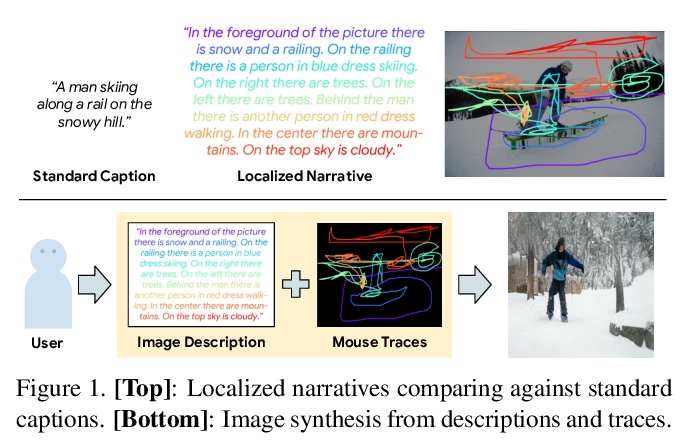
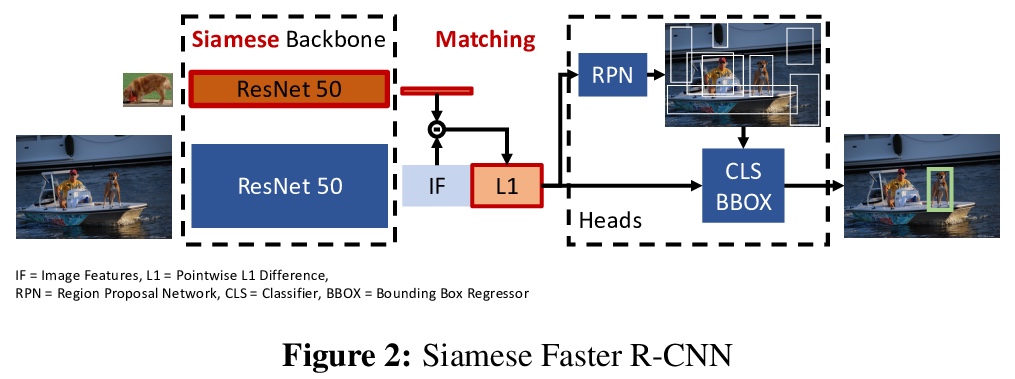
3、[CV] **Closing the Generalization Gap in One-Shot Object Detection
C Michaelis, M Bethge, A S. Ecker
[University of Tubingen & University of Gottingen]
One-Shot目标检测中泛化差距的减小。One-Shot目标检测经训练的模型往往表现出很大的泛化差距,在训练中使用的目标类检测比新对象更可靠。通过增加训练中使用的目标类别数量,可以大幅度缩小这种泛化差距。模型从记忆单个类别转变为学习类别分布上的目标相似度,使得在测试时具有更强的泛化能力。**
Despite substantial progress in object detection and few-shot learning, detecting objects based on a single example - one-shot object detection - remains a challenge: trained models exhibit a substantial generalization gap, where object categories used during training are detected much more reliably than novel ones. Here we show that this generalization gap can be nearly closed by increasing the number of object categories used during training. Our results show that the models switch from memorizing individual categories to learning object similarity over the category distribution, enabling strong generalization at test time. Importantly, in this regime standard methods to improve object detection models like stronger backbones or longer training schedules also benefit novel categories, which was not the case for smaller datasets like COCO. Our results suggest that the key to strong few-shot detection models may not lie in sophisticated metric learning approaches, but instead in scaling the number of categories. Future data annotation efforts should therefore focus on wider datasets and annotate a larger number of categories rather than gathering more images or instances per category.
https://weibo.com/1402400261/JtlHvso3L
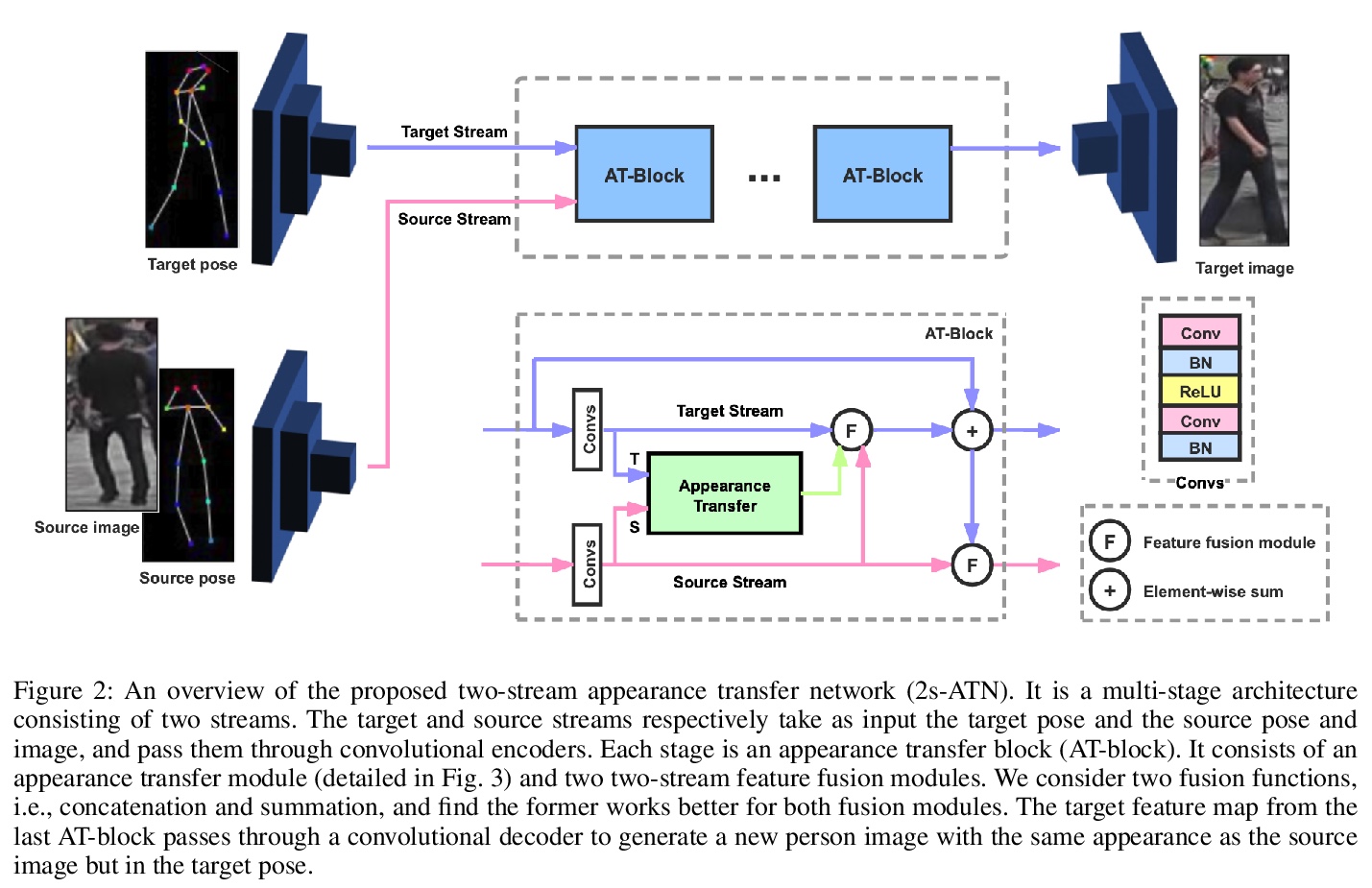
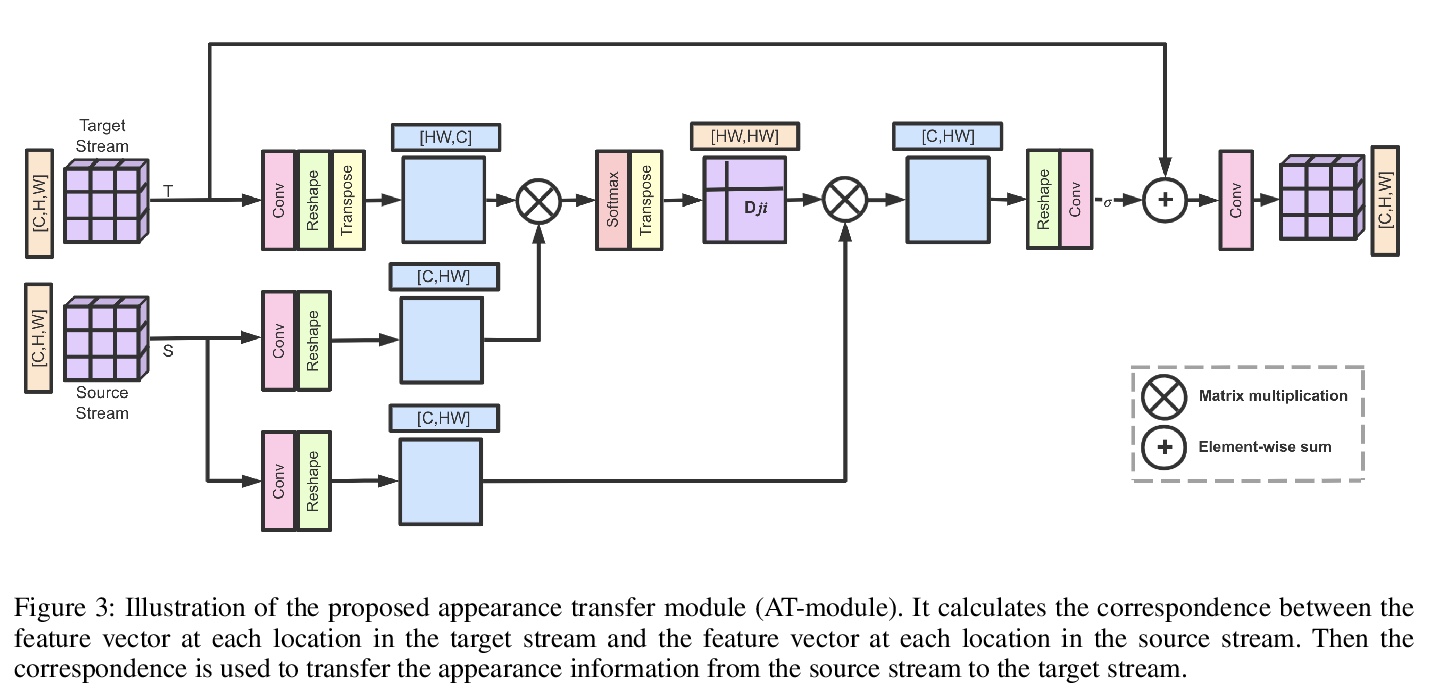
4、[CV] **Two-Stream Appearance Transfer Network for Person Image Generation
C Shen, P Wang, W Tang
[University of Illinois at Chicago & Purdue University]
面向人物图像生成的双流外观迁移网络(2s-ATN)。提出了一种用于姿态引导人物图像生成的双流外观迁移网络(2s-ATN),采用新的多阶段架构,由源流和目标流组成,其核心是在每阶段采用新的外观迁移模块(AT-module),通过学习找到两流特征图间结构对应关系,将外观信息从源流迁移到目标流,在保留纹理细节的同时有效地处理大变形和遮挡问题。**
Pose guided person image generation means to generate a photo-realistic person image conditioned on an input person image and a desired pose. This task requires spatial manipulation of the source image according to the target pose. However, the generative adversarial networks (GANs) widely used for image generation and translation rely on spatially local and translation equivariant operators, i.e., convolution, pooling and unpooling, which cannot handle large image deformation. This paper introduces a novel two-stream appearance transfer network (2s-ATN) to address this challenge. It is a multi-stage architecture consisting of a source stream and a target stream. Each stage features an appearance transfer module and several two-stream feature fusion modules. The former finds the dense correspondence between the two-stream feature maps and then transfers the appearance information from the source stream to the target stream. The latter exchange local information between the two streams and supplement the non-local appearance transfer. Both quantitative and qualitative results indicate the proposed 2s-ATN can effectively handle large spatial deformation and occlusion while retaining the appearance details. It outperforms prior states of the art on two widely used benchmarks.
https://weibo.com/1402400261/JtlQMdwF7
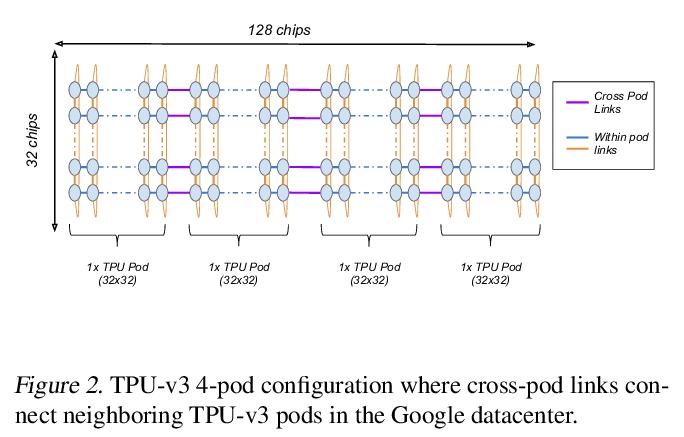
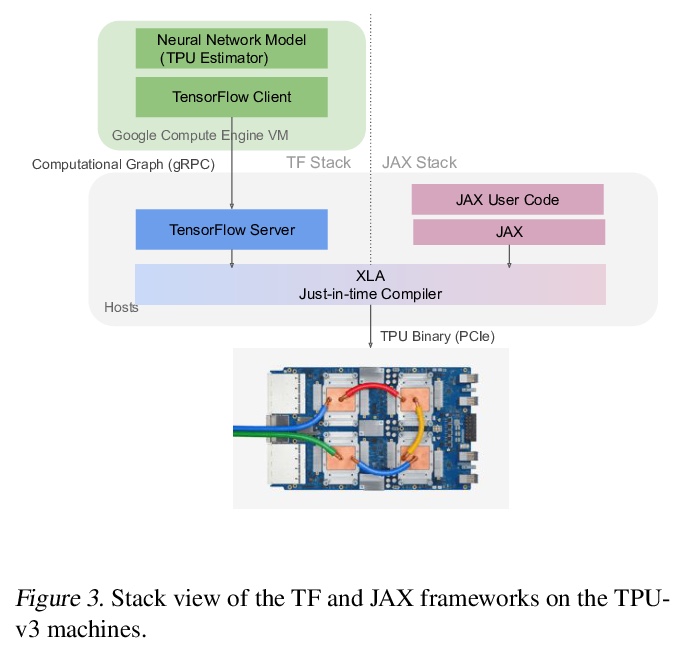
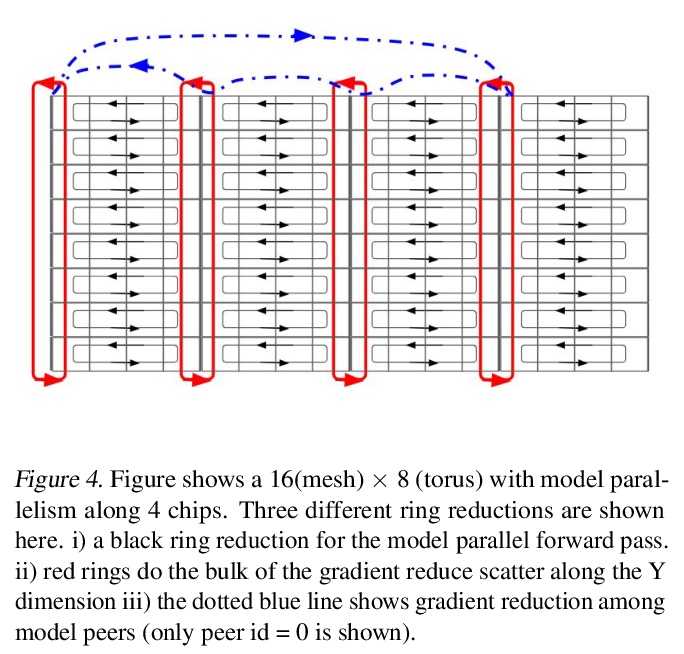
5、[LG] **Exploring the limits of Concurrency in ML Training on Google TPUs
S Kumar, J Bradbury, C Young, Y E Wang, A Levskaya, B Hechtman, D Chen, H Lee, M Deveci, N Kumar, P Kanwar, S Wang, S Wanderman-Milne, S Lacy, T Wang, T Oguntebi, Y Zu, Y Xu, A Swing
[Google]
Google TPU机器学习训练并发性限制探索。介绍了基于4096个TPU-v3芯片的谷歌TPU Multipod网格的scaleML建模技术,讨论了如何增强模型并行性,克服数据并行批处理规模、通信/协同优化、训练指标的分布式评价和主输入处理规模优化中的规模化限制。**
Recent results in language understanding using neural networks have required training hardware of unprecedentedscale, with thousands of chips cooperating on a single training run. This paper presents techniques to scaleML models on the Google TPU Multipod, a mesh with 4096 TPU-v3 chips. We discuss model parallelism toovercome scaling limitations from the fixed batch size in data parallelism, communication/collective optimizations,distributed evaluation of training metrics, and host input processing scaling optimizations. These techniques aredemonstrated in both the TensorFlow and JAX programming frameworks. We also present performance resultsfrom the recent Google submission to the MLPerf-v0.7 benchmark contest, achieving record training times from16 to 28 seconds in four MLPerf models on the Google TPU-v3 Multipod machine.
https://weibo.com/1402400261/JtlUsBayI
其他几篇值得关注的论文:
[LG] Fairness Under Partial Compliance
部分依从下的公平(机器学习)
J Dai, S Fazelpour, Z C. Lipton
[Brown University & CMU]
https://weibo.com/1402400261/JtlMCfDwJ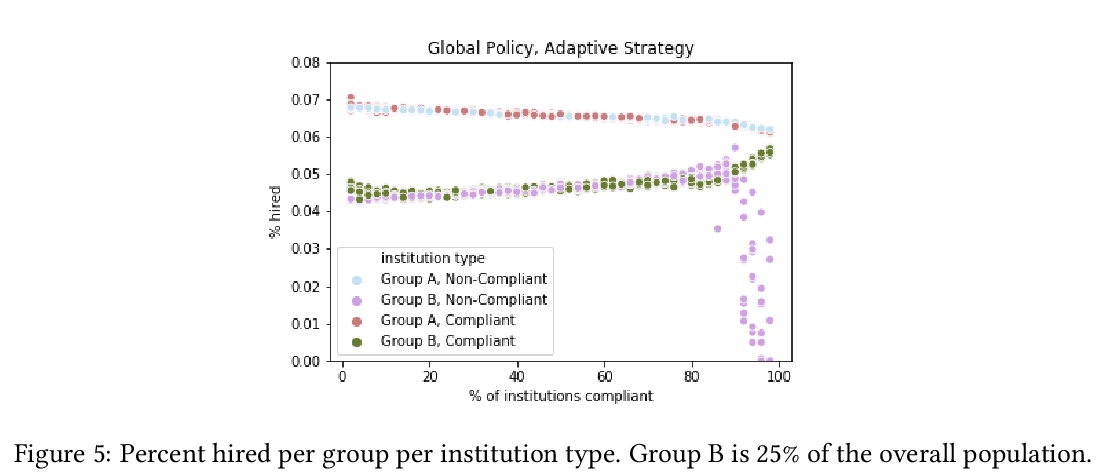
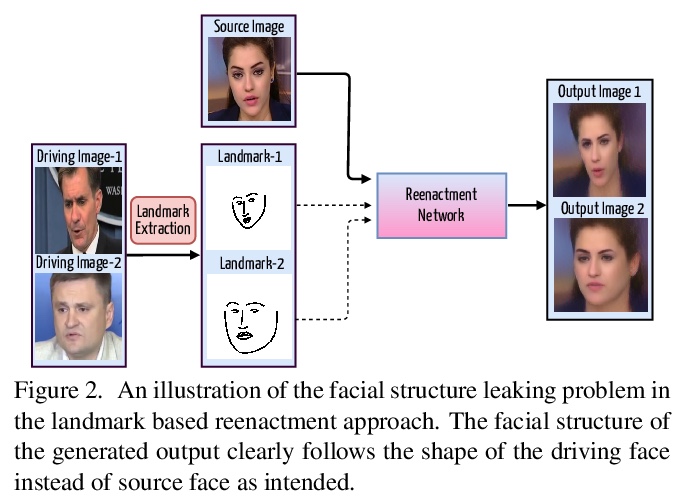
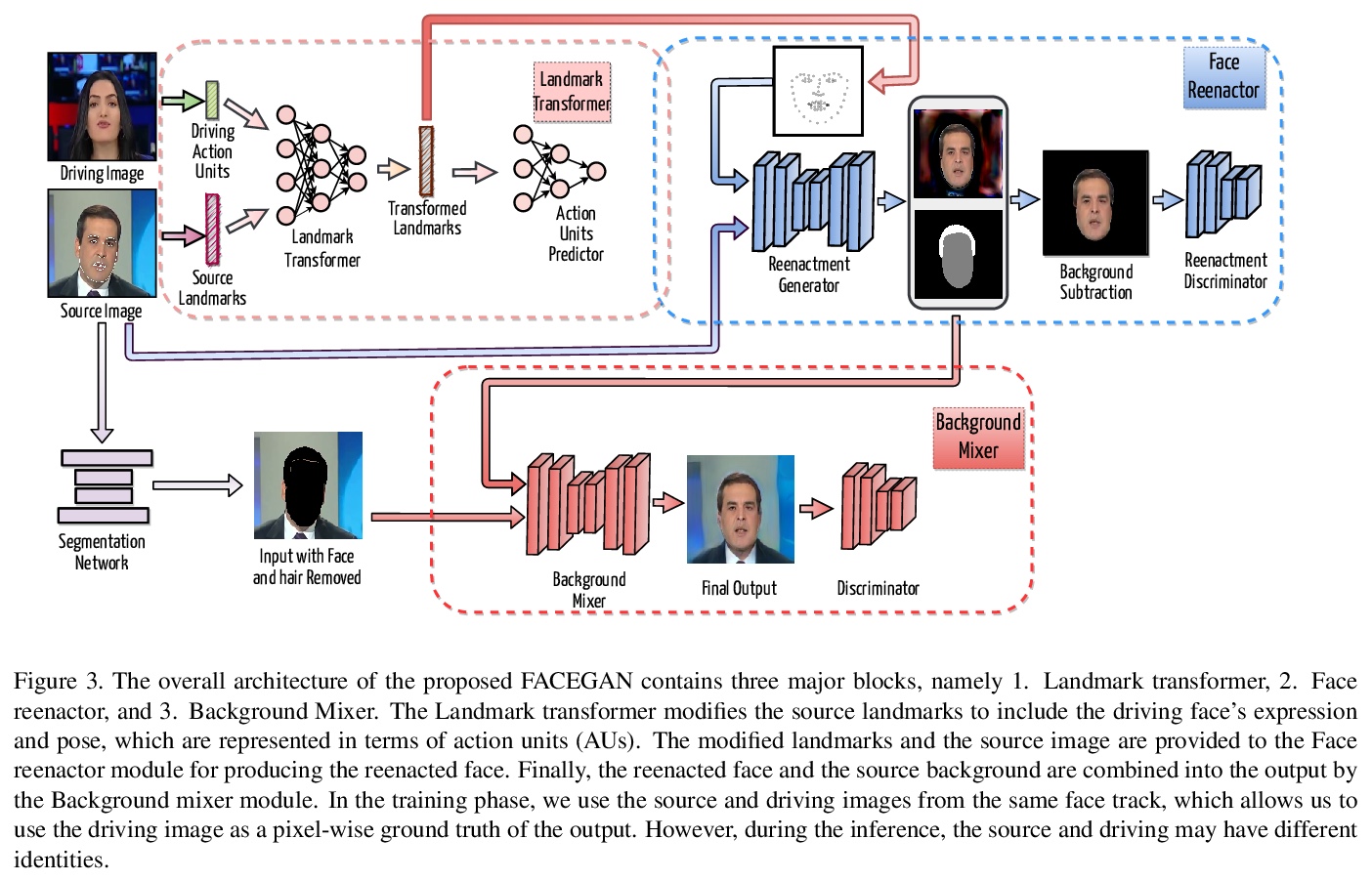
[CV] FACEGAN: Facial Attribute Controllable rEenactment GAN
FACEGAN:属性可控人脸重现GAN
S Tripathy, J Kannala, E Rahtu
[Tampere University & Aalto University]
https://weibo.com/1402400261/Jtm1ssBpw
[CV] EDEN: Multimodal Synthetic Dataset of Enclosed GarDEN Scenes
EDEN:封闭花园场景多模态合成数据集
H Le, T Mensink, P Das, S Karaoglu, T Gevers
[University of Amsterdam]
https://weibo.com/1402400261/Jtm2Sb4st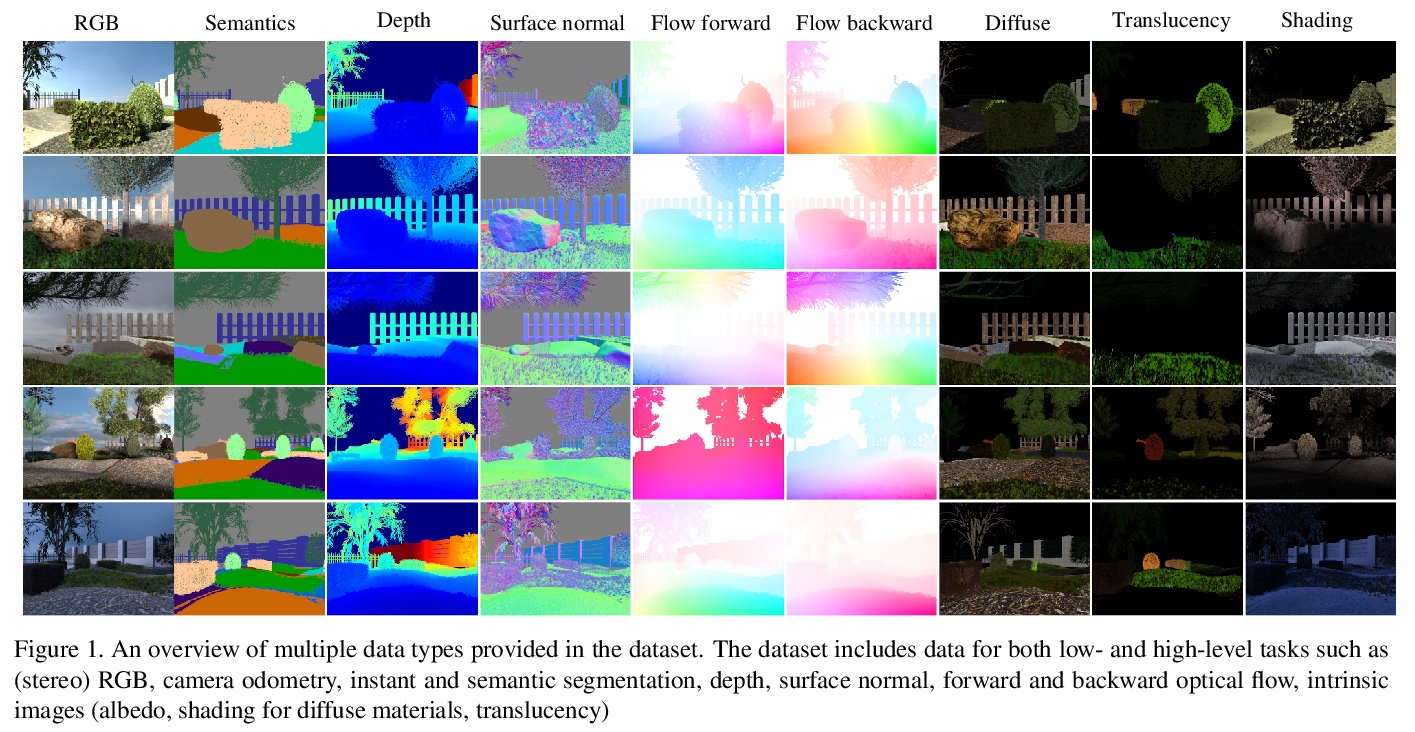

若有收获,就点个赞吧
0 人点赞
