LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
(*表示值得重点关注)
1、[CV] *MonoRec: Semi-Supervised Dense Reconstruction in Dynamic Environments from a Single Moving Camera
F Wimbauer, N Yang, L v Stumberg, N Zeller, D Cremers
[Technical University of Munich]
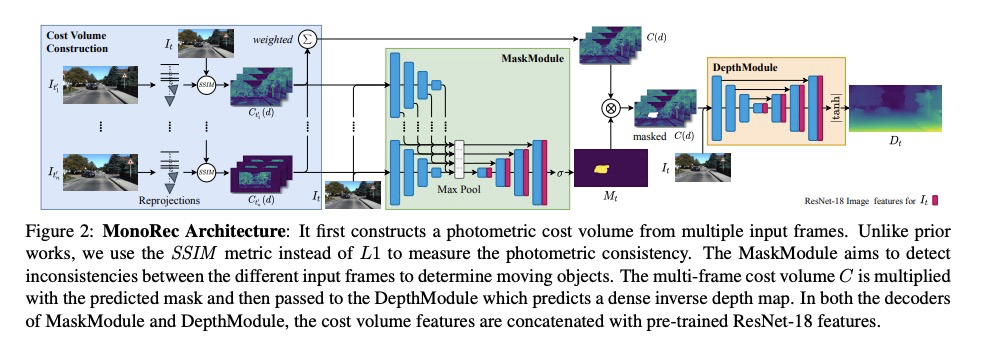
MonoRec:动态环境单移动相机半监督密集3D重建。提出用于单个移动摄像机精确估计密集3D重建的深度架构MonoRec,用SSIM作为光度测量构造成本量,针对外景中典型的动态对象,提出基于输入成本预测运动对象掩模的MaskModule,用于估算静态和动态物体的精确深度;提出了新的多阶段训练方案和半监督损失来训练深度预测。在KITTI上,MonoRec的表现超过了最先进的MVS和单眼深度预测方法。
In this paper, we propose MonoRec, a semi-supervised monocular dense reconstruction architecture that predicts depth maps from a single moving camera in dynamic environments. MonoRec is based on a MVS setting which encodes the information of multiple consecutive images in a cost volume. To deal with dynamic objects in the scene, we introduce a MaskModule that predicts moving object masks by leveraging the photometric inconsistencies encoded in the cost volumes. Unlike other MVS methods, MonoRec is able to predict accurate depths for both static and moving objects by leveraging the predicted masks. Furthermore, we present a novel multi-stage training scheme with a semi-supervised loss formulation that does not require LiDAR depth values. We carefully evaluate MonoRec on the KITTI dataset and show that it achieves state-of-the-art performance compared to both multi-view and single-view methods. With the model trained on KITTI, we further demonstrate that MonoRec is able to generalize well to both the Oxford RobotCar dataset and the more challenging TUM-Mono dataset recorded by a handheld camera. Training code and pre-trained model will be published soon.
https://weibo.com/1402400261/JvCZCCtZq

2、[CV] *Is a Green Screen Really Necessary for Real-Time Human Matting?
Z Ke, K Li, Y Zhou, Q Wu, X Mao, Q Yan, R W.H. Lau
[City University of Hong Kong & SenseTime Research]
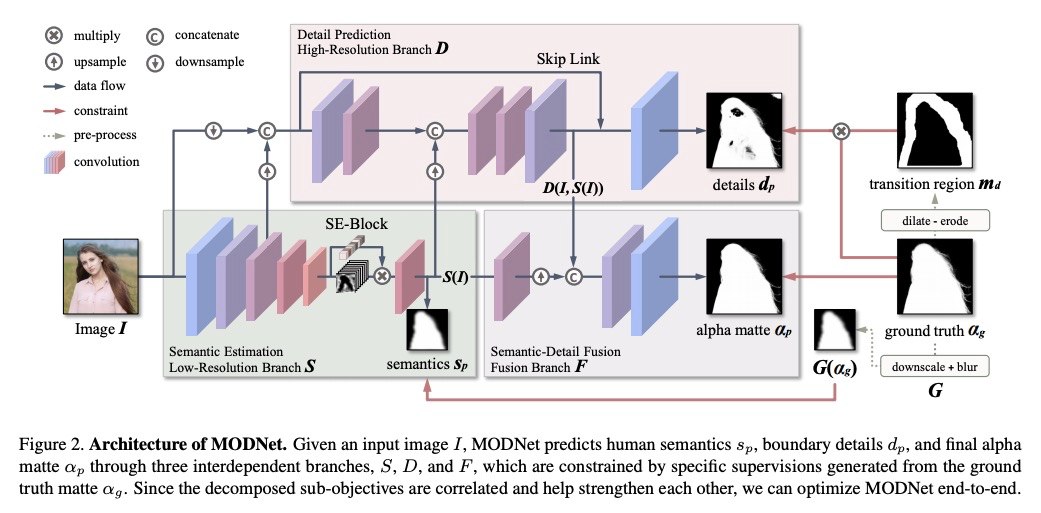
无需绿幕的实时人体抠图。提出了一种轻量网格目标分解网络(MODNet),从单个输入图像中实时处理人体网格,实现无需绿幕的实时人体抠图,该方法能预测变化场景下的半透明(Alpha)抠图。MODNet很容易以端到端方式进行训练,比之前的抠图方法快得多,运行速度可达到每秒63帧。
For human matting without the green screen, existing works either require auxiliary inputs that are costly to obtain or use multiple models that are computationally expensive. Consequently, they are unavailable in real-time applications. In contrast, we present a light-weight matting objective decomposition network (MODNet), which can process human matting from a single input image in real time. The design of MODNet benefits from optimizing a series of correlated sub-objectives simultaneously via explicit constraints. Moreover, since trimap-free methods usually suffer from the domain shift problem in practice, we introduce (1) a self-supervised strategy based on sub-objectives consistency to adapt MODNet to real-world data and (2) a one-frame delay trick to smooth the results when applying MODNet to video human matting.MODNet is easy to be trained in an end-to-end style. It is much faster than contemporaneous matting methods and runs at 63 frames per second. On a carefully designed human matting benchmark newly proposed in this work, MODNet greatly outperforms prior trimap-free methods. More importantly, our method achieves remarkable results in daily photos and videos. Now, do you really need a green screen for real-time human matting?
https://weibo.com/1402400261/JvD5qvZ66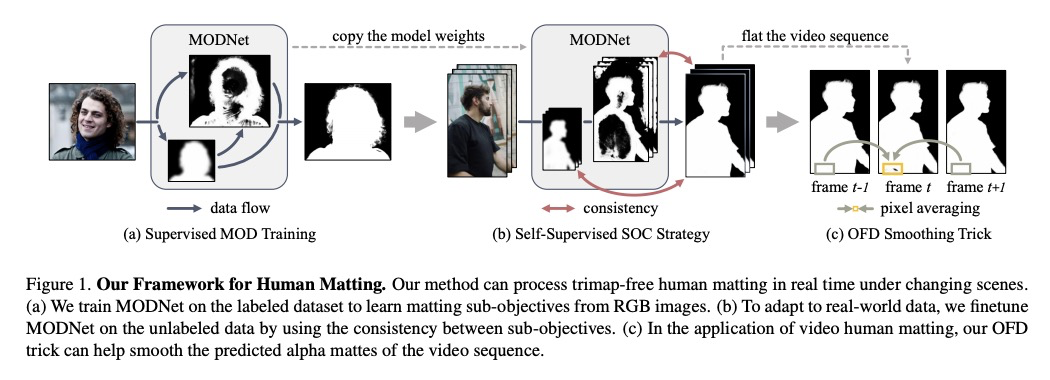


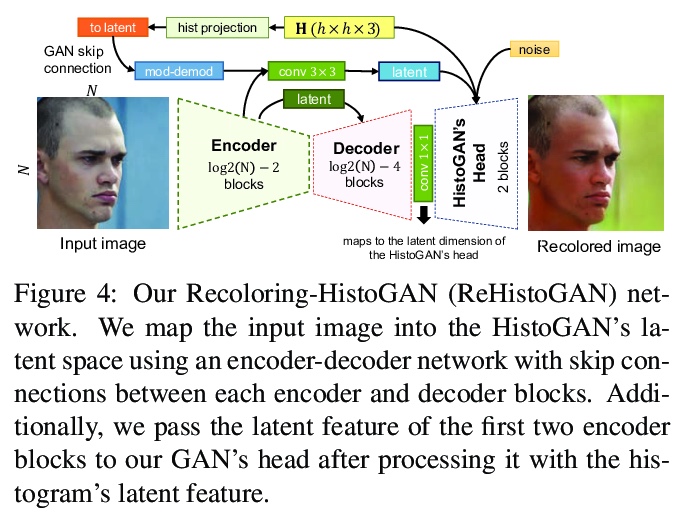
3、[CV] HistoGAN: Controlling Colors of GAN-Generated and Real Images via Color Histograms
M Afifi, M A. Brubaker, M S. Brown
[York University]
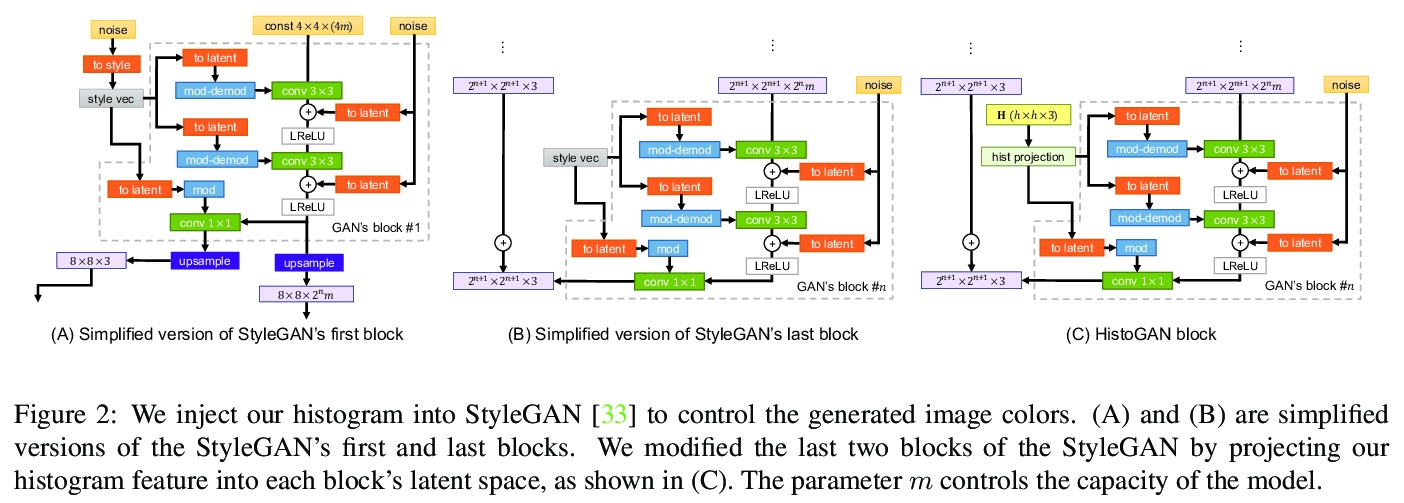
HistoGAN:用颜色直方图控制GAN生成图像和真实图像的颜色。对StyleGAN架构进行了有效修改,通过目标颜色直方图特征来控制GAN生成图像的颜色,通过扩展HistoGAN、联合训练编码器网络可对真实图像进行再着色。再着色模型(ReHistoGAN)是一种无监督方法,鼓励网络根据给定目标直方图改变颜色的同时保留原始图像的内容。
While generative adversarial networks (GANs) can successfully produce high-quality images, they can be challenging to control. Simplifying GAN-based image generation is critical for their adoption in graphic design and artistic work. This goal has led to significant interest in methods that can intuitively control the appearance of images generated by GANs. In this paper, we present HistoGAN, a color histogram-based method for controlling GAN-generated images’ colors. We focus on color histograms as they provide an intuitive way to describe image color while remaining decoupled from domain-specific semantics. Specifically, we introduce an effective modification of the recent StyleGAN architecture to control the colors of GAN-generated images specified by a target color histogram feature. We then describe how to expand HistoGAN to recolor real images. For image recoloring, we jointly train an encoder network along with HistoGAN. The recoloring model, ReHistoGAN, is an unsupervised approach trained to encourage the network to keep the original image’s content while changing the colors based on the given target histogram. We show that this histogram-based approach offers a better way to control GAN-generated and real images’ colors while producing more compelling results compared to existing alternative strategies.
https://weibo.com/1402400261/JvD9v7Ako

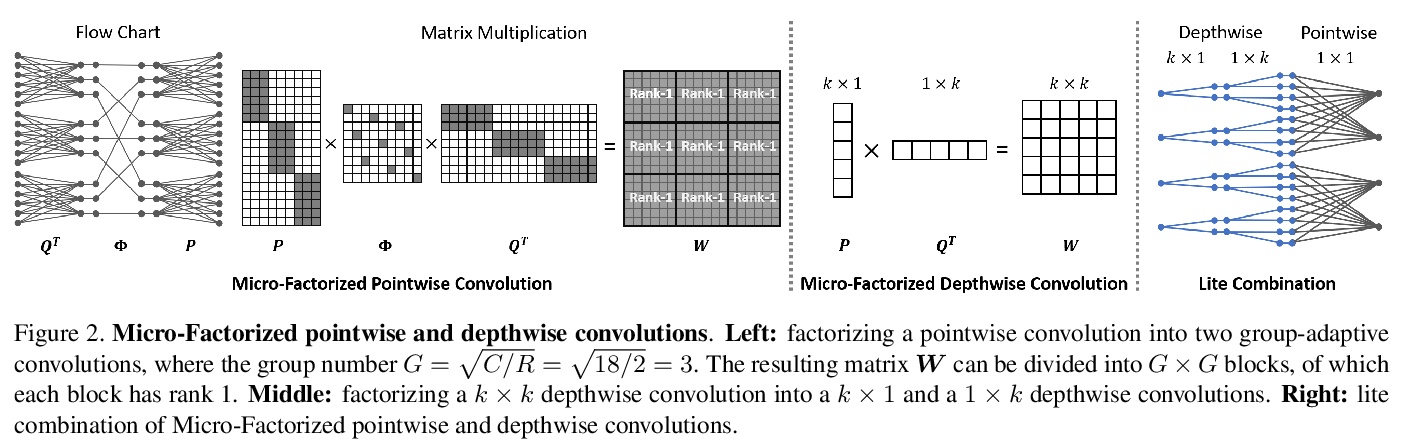
4、[CV] **MicroNet: Towards Image Recognition with Extremely Low FLOPs
Y Li, Y Chen, X Dai, D Chen, M Liu, L Yuan, Z Liu, L Zhang, N Vasconcelos
[UC San Diego & Microsoft]
MicroNet:超低FLOPs图像识别。提出了极低计算代价的高效卷积网络MicroNet,基于提出的两个算子:微分解卷积(Micro-Factorized convolution)和动态最大移位(Dynamic Shift-Max)。前者通过逐点和逐深度卷积上的低秩近似来平衡通道数量和输入/输出的连接性;后者动态融合连续的通道组,增强节点的连通性和非线性,以补偿深度的减少。MicroNet-M1在ImageNet分类中以12 MFLOPs实现了61.1%的top-1精度,比MobileNetV3高出11.3%。**
In this paper, we present MicroNet, which is an efficient convolutional neural network using extremely low computational cost (e.g. 6 MFLOPs on ImageNet classification). Such a low cost network is highly desired on edge devices, yet usually suffers from a significant performance degradation. We handle the extremely low FLOPs based upon two design principles: (a) avoiding the reduction of network width by lowering the node connectivity, and (b) compensating for the reduction of network depth by introducing more complex non-linearity per layer. Firstly, we propose Micro-Factorized convolution to factorize both pointwise and depthwise convolutions into low rank matrices for a good tradeoff between the number of channels and input/output connectivity. Secondly, we propose a new activation function, named Dynamic Shift-Max, to improve the non-linearity via maxing out multiple dynamic fusions between an input feature map and its circular channel shift. The fusions are dynamic as their parameters are adapted to the input. Building upon Micro-Factorized convolution and dynamic Shift-Max, a family of MicroNets achieve a significant performance gain over the state-of-the-art in the low FLOP regime. For instance, MicroNet-M1 achieves 61.1% top-1 accuracy on ImageNet classification with 12 MFLOPs, outperforming MobileNetV3 by 11.3%.
https://weibo.com/1402400261/JvDe56LH1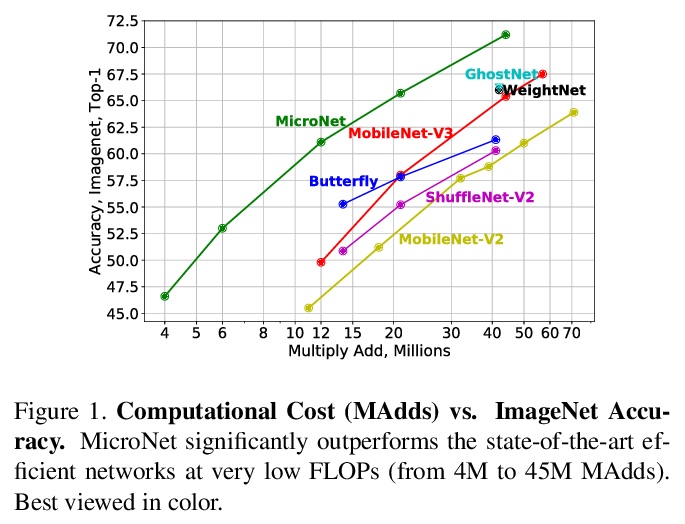
5、[CV] **Adversarial Generation of Continuous Images
I Skorokhodov, S Ignatyev, M Elhoseiny
[KAUST & Skoltech]
连续图像的对抗性生成。探索了用内隐神经表征(INRs)形式表示的连续图像的对抗生成。提出了两种基本的架构技术:因子乘性调制(FMM)和多尺度INRs,缓解基于INRs解码器的两个主要问题:1)难以承受的大规模和底层超网络的训练不稳定性;2)在高分辨率图像上评价INRs的高昂计算成本。在现代真实世界数据集上,连续图像生成任务的结果比其他方法好6-40倍。**
In most existing learning systems, images are typically viewed as 2D pixel arrays. However, in another paradigm gaining popularity, a 2D image is represented as an implicit neural representation (INR) — an MLP that predicts an RGB pixel value given its (x,y) coordinate. In this paper, we propose two novel architectural techniques for building INR-based image decoders: factorized multiplicative modulation and multi-scale INRs, and use them to build a state-of-the-art continuous image GAN. Previous attempts to adapt INRs for image generation were limited to MNIST-like datasets and do not scale to complex real-world data. Our proposed architectural design improves the performance of continuous image generators by x6-40 times and reaches FID scores of 6.27 on LSUN bedroom 256x256 and 16.32 on FFHQ 1024x1024, greatly reducing the gap between continuous image GANs and pixel-based ones. To the best of our knowledge, these are the highest reported scores for an image generator, that consists entirely of fully-connected layers. Apart from that, we explore several exciting properties of INR-based decoders, like out-of-the-box superresolution, meaningful image-space interpolation, accelerated inference of low-resolution images, an ability to extrapolate outside of image boundaries and strong geometric prior. The source code is available at > this https URL
https://weibo.com/1402400261/JvDi0yABr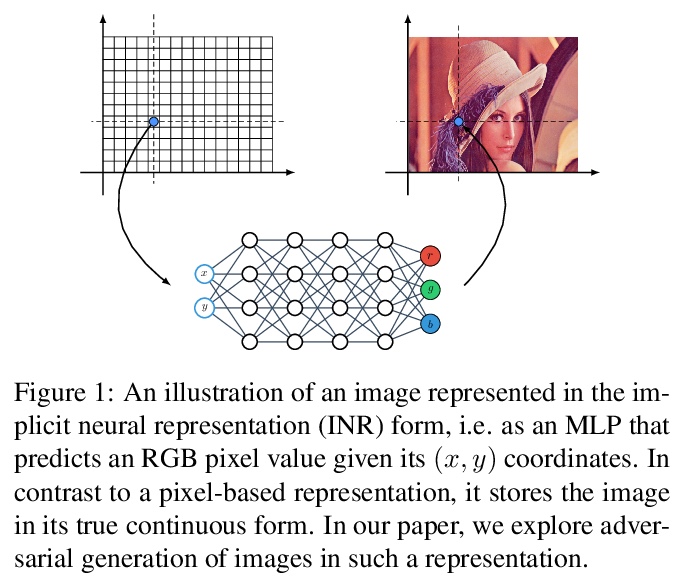


其他几篇值得关注的论文:
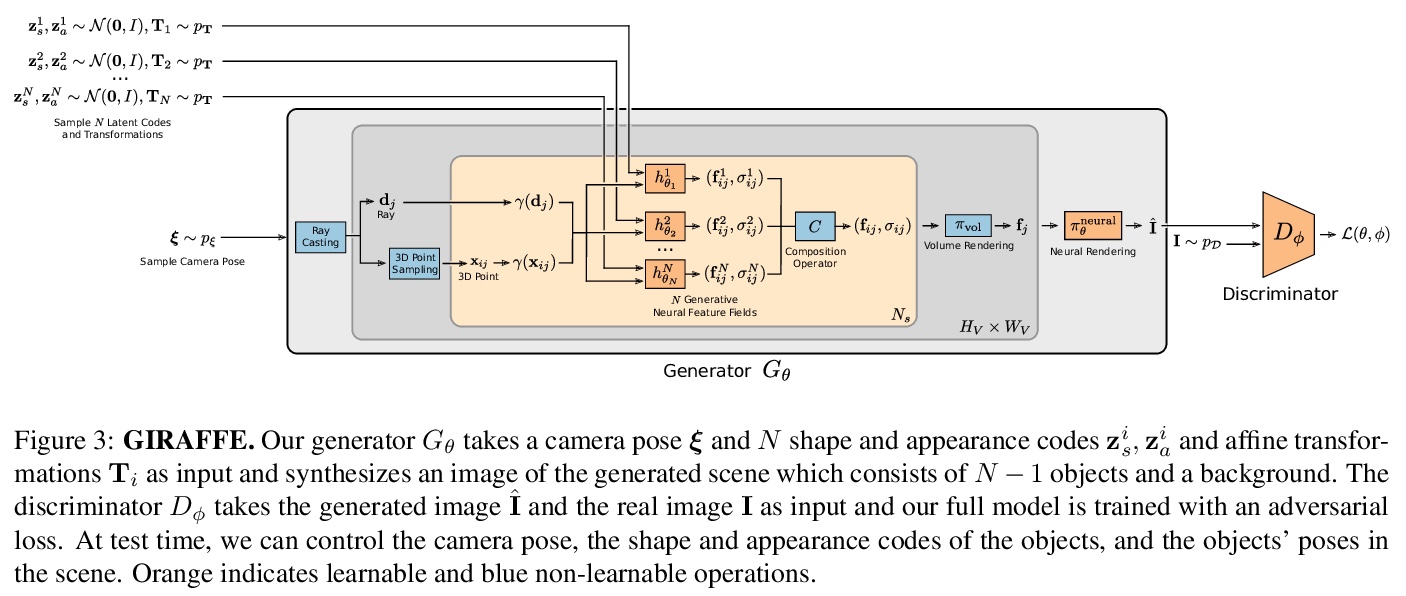
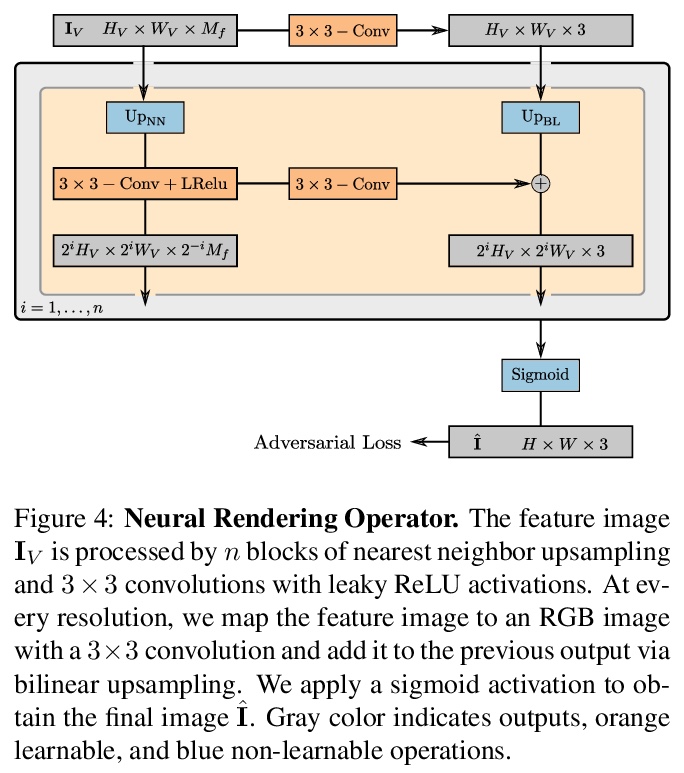
[CV] GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
GIRAFFE:将场景表示为合成生成式神经特征场
M Niemeyer, A Geiger
[Max Planck Institute for Intelligent Systems]
https://weibo.com/1402400261/JvDlYad3H

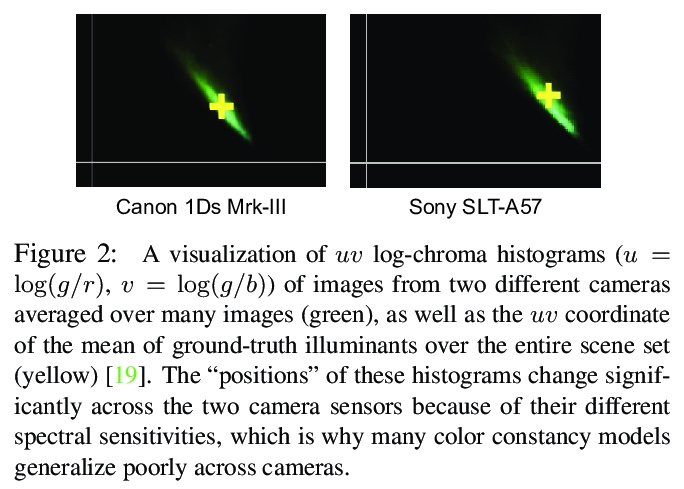
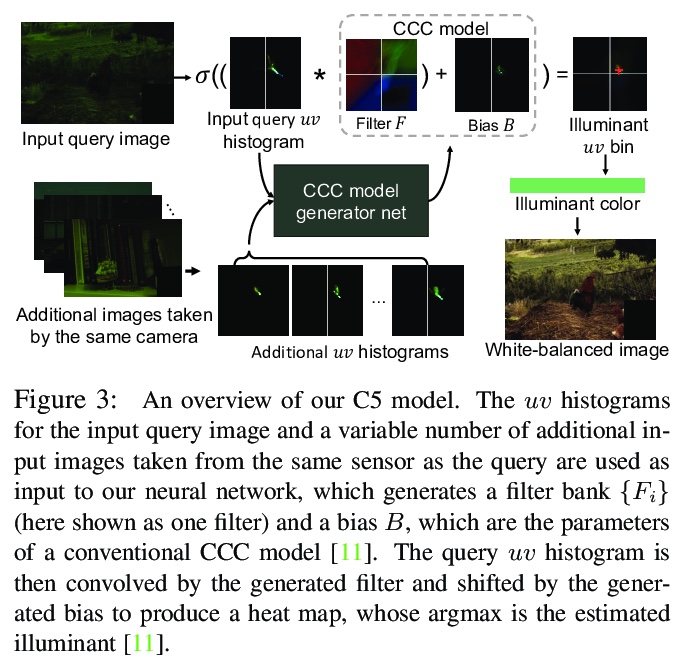
[CV] Cross-Camera Convolutional Color Constancy
跨摄像机卷积颜色恒定性
M Afifi, J T. Barron, C LeGendre, Y Tsai, F Bleibel
[Google Research]
https://weibo.com/1402400261/JvDpO4JA8
[CV] Benchmarking Image Retrieval for Visual Localization
视觉定位图像检索基准
N Pion, M Humenberger, G Csurka, Y Cabon, T Sattler
[NAVER LABS Europe & Czech Technical University in Prague]
https://weibo.com/1402400261/JvDr8sSu2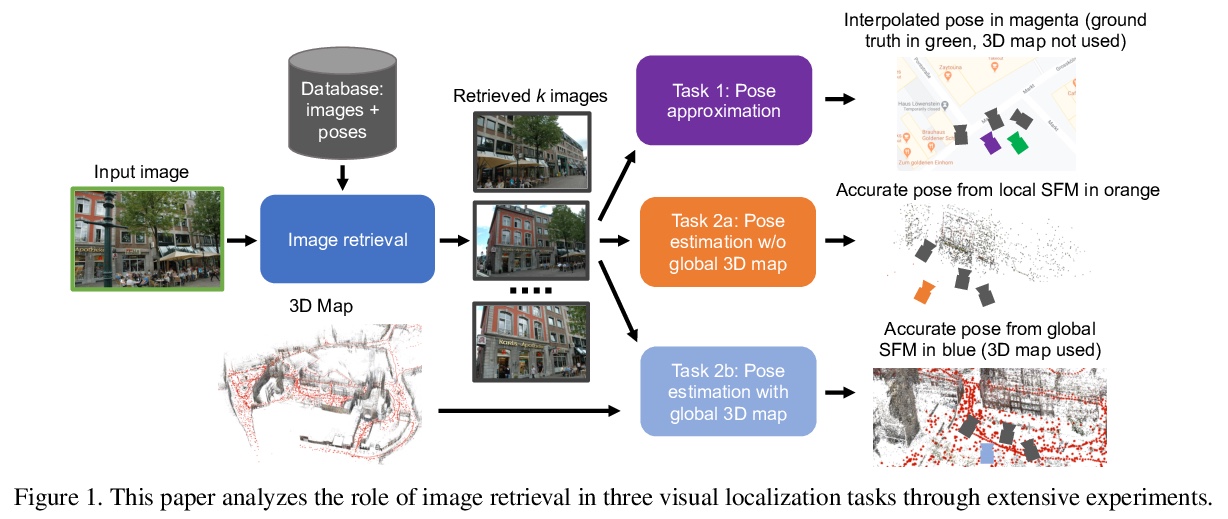
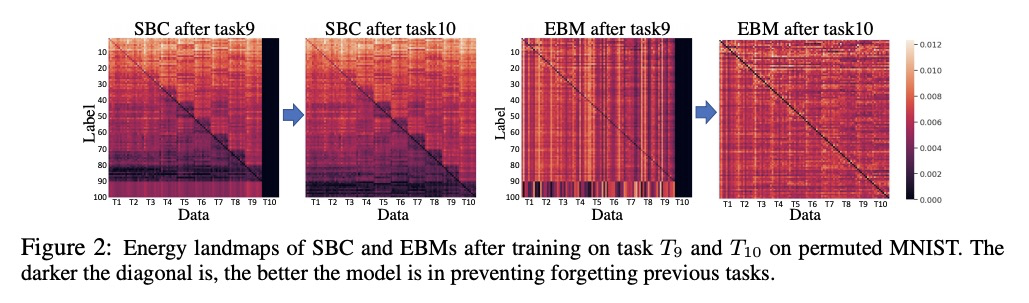
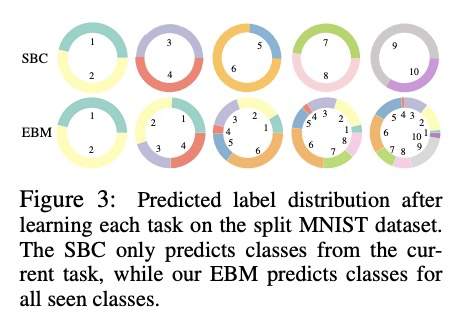
[LG] Energy-Based Models for Continual Learning
基于能量的持续学习模型
S Li, Y Du, G M. v d Ven, A Torralba, I Mordatch
[MIT CSAIL & Baylor College of Medicine & Google]
https://weibo.com/1402400261/JvDsnhwKP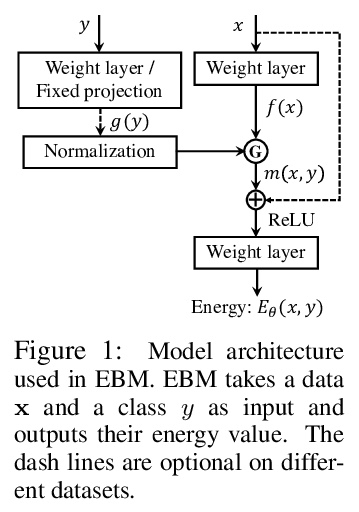

若有收获,就点个赞吧
0 人点赞
