- 1、[CV] Efficient-CapsNet: Capsule Network with Self-Attention Routing
- 2、[CV] NeMo: Neural Mesh Models of Contrastive Features for Robust 3D Pose Estimation
- 3、[LG] Predicting Nanorobot Shapes via Generative Models
- 4、[CL] Attention Can Reflect Syntactic Structure (If You Let It)
- 5、[CV] Domain Adaptation by Topology Regularization
- [CL] LSOIE: A Large-Scale Dataset for Supervised Open Information Extraction
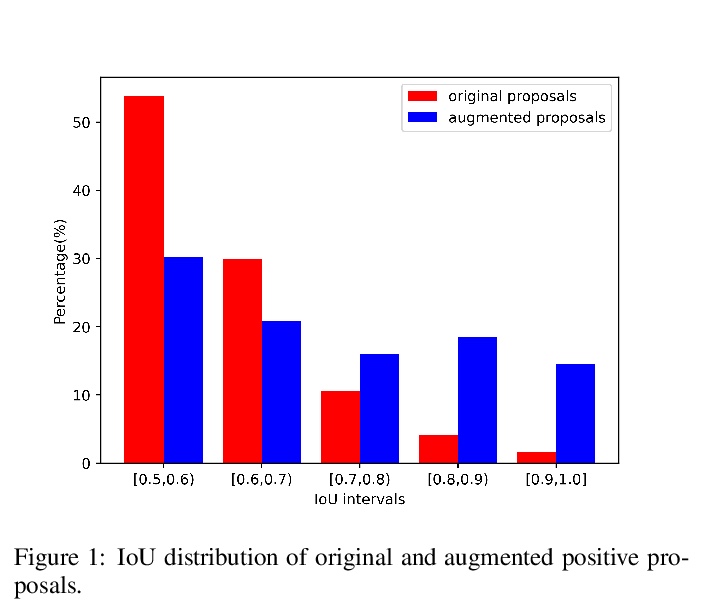
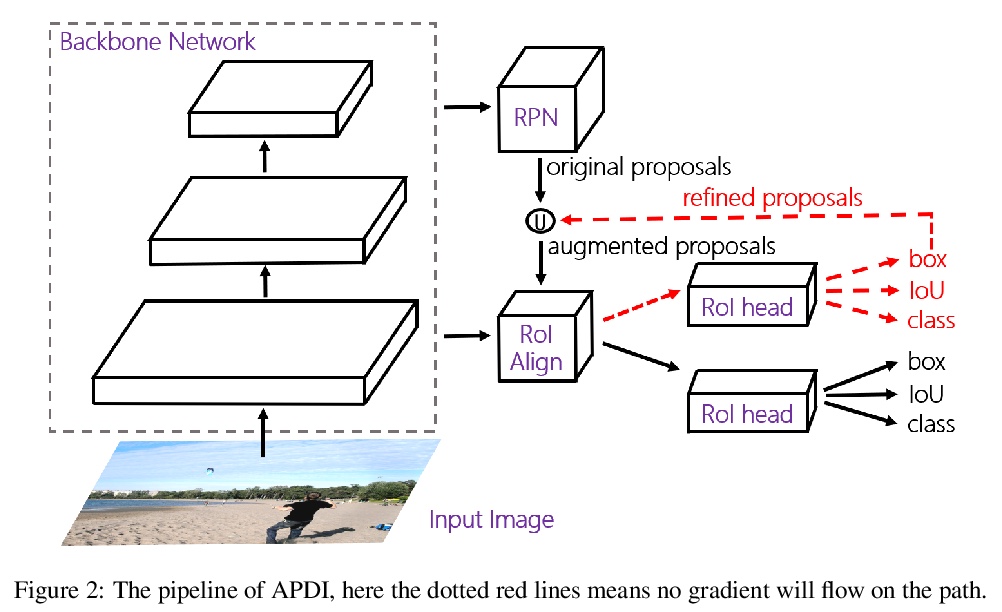
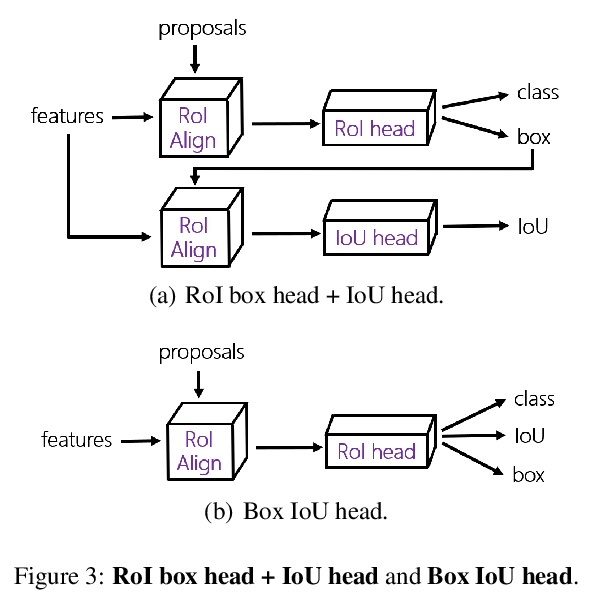
- [CV] Augmenting Proposals by the Detector Itself
- [CL] PPT: Parsimonious Parser Transfer for Unsupervised Cross-Lingual Adaptation
- [CL] On the Evolution of Syntactic Information Encoded by BERT’s Contextualized Representations
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Efficient-CapsNet: Capsule Network with Self-Attention Routing
V Mazzia, F Salvetti, M Chiaberge
[Politecnico di Torino]
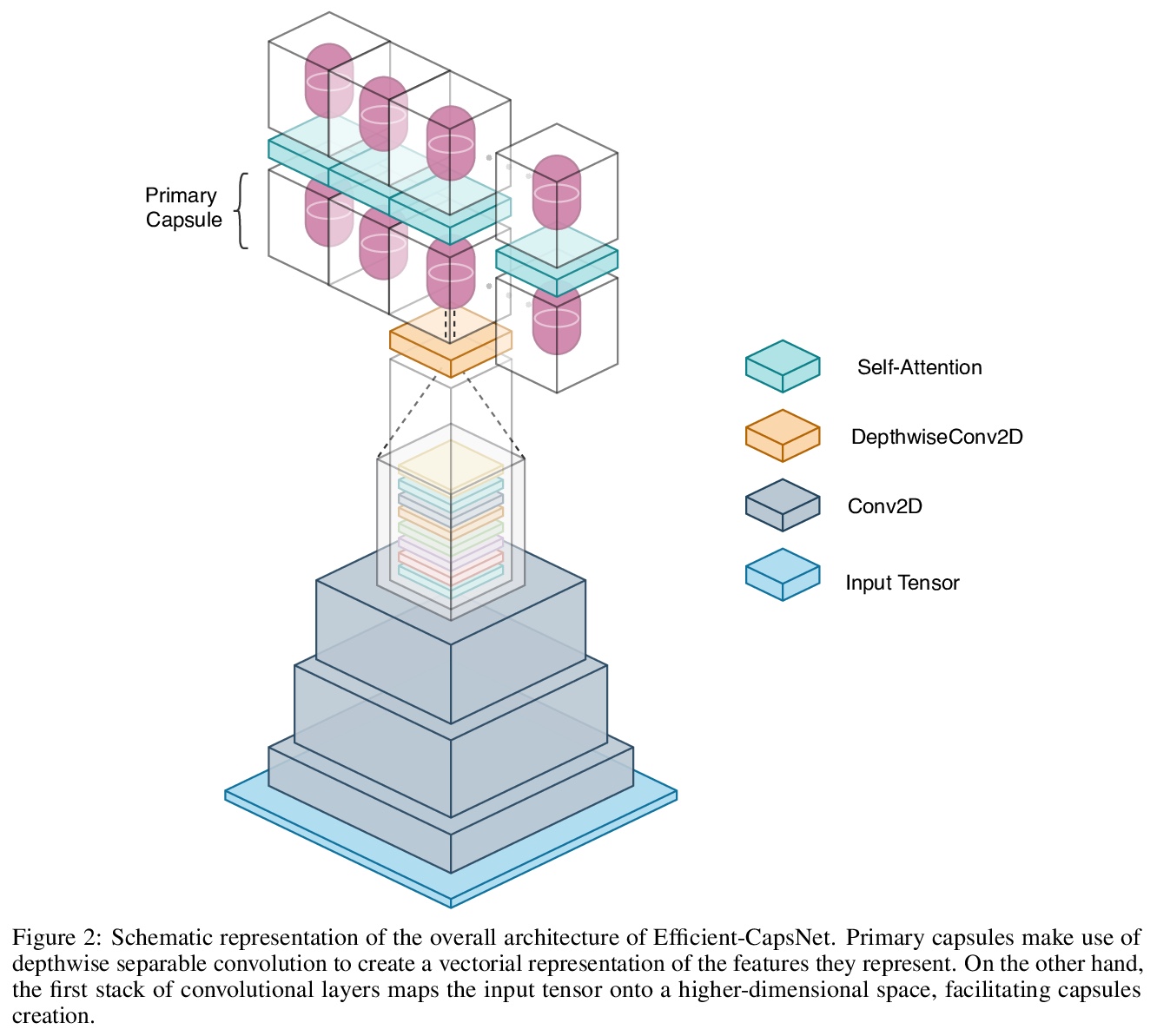
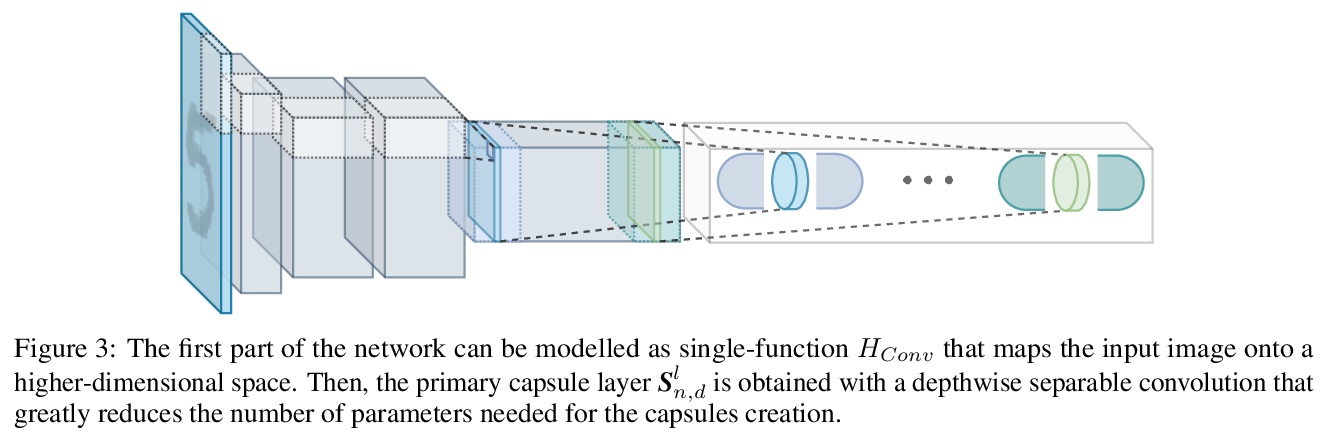
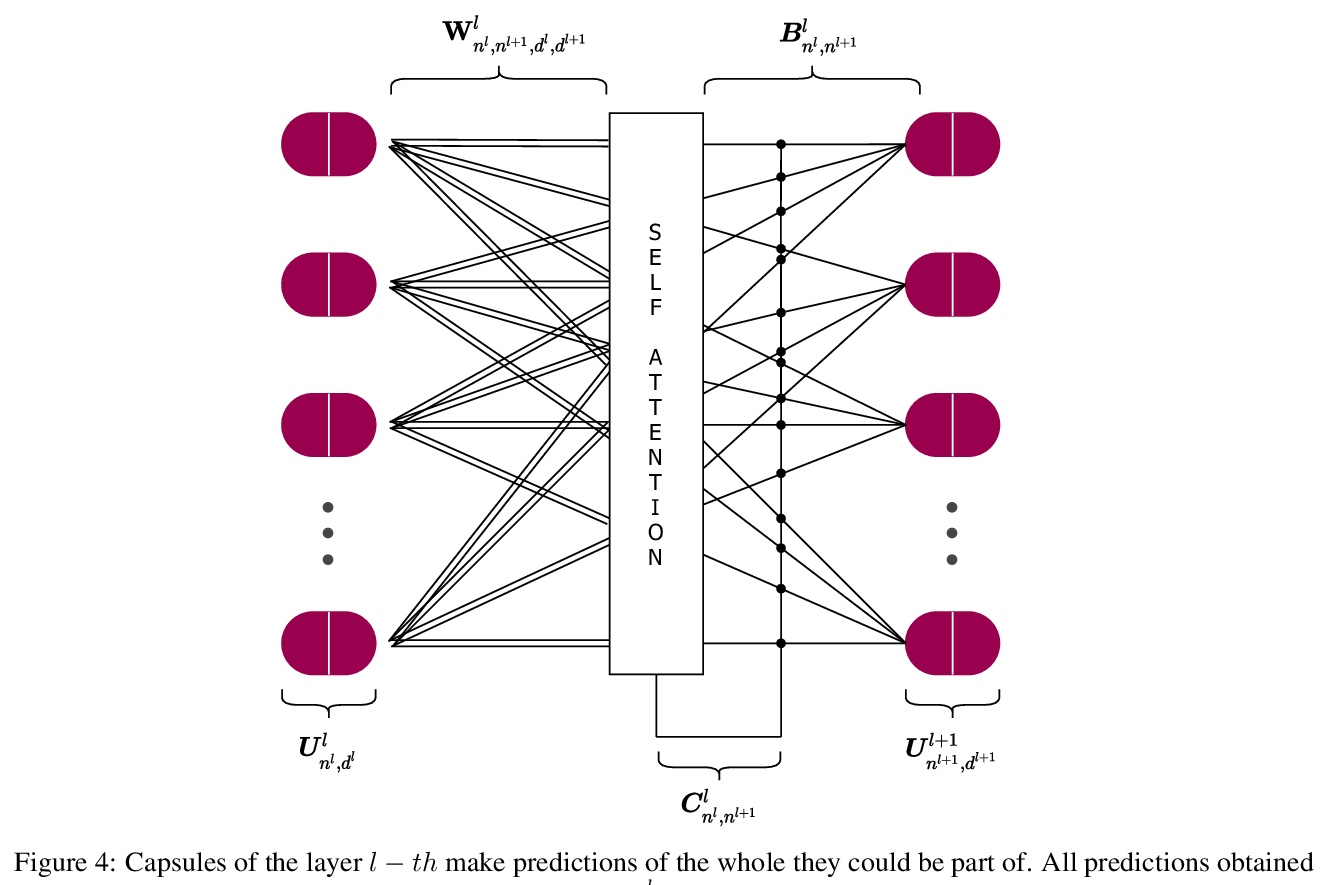
Efficient-CapsNet:自注意力路由胶囊网络。提出Efficient-CapsNet,仅用160K参数,在原CapsNet模型基础上改进了85%的TOPs。相比于传统CNN,Efficient-CapsNet强烈凸显了胶囊的泛化能力,训练后表现出更强的知识表达能力。提出一种新型的非迭代、高度可并行的路由算法,利用自注意力机制来高效路由减少数量的胶囊。
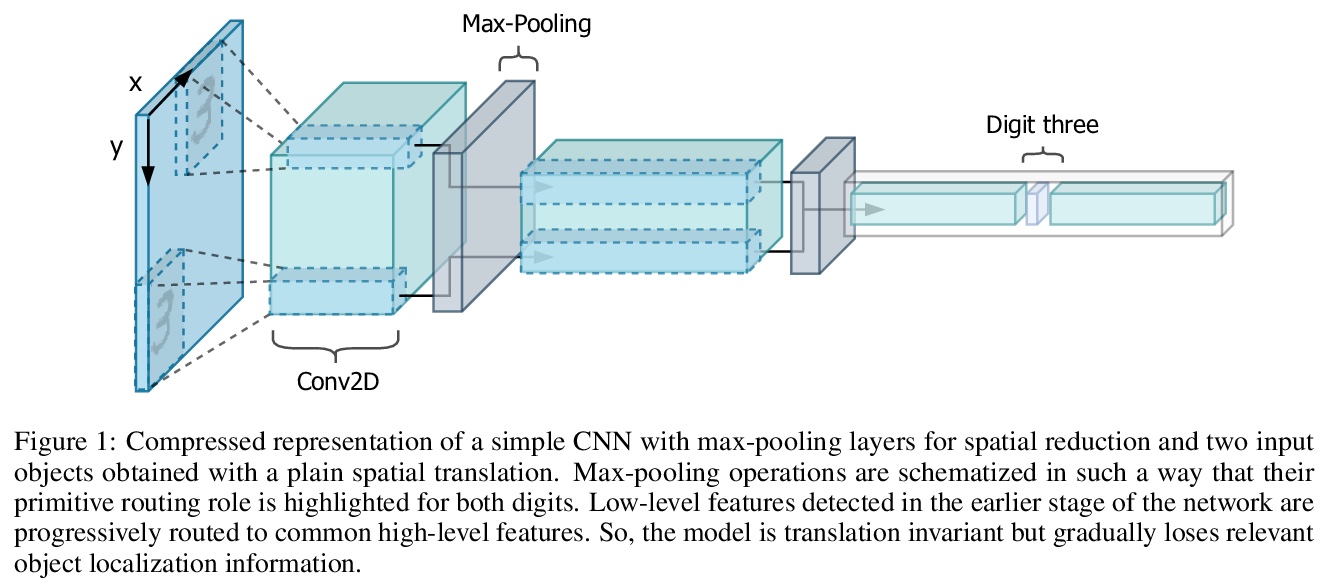
Deep convolutional neural networks, assisted by architectural design strategies, make extensive use of data augmentation techniques and layers with a high number of feature maps to embed object transformations. That is highly inefficient and for large datasets implies a massive redundancy of features detectors. Even though capsules networks are still in their infancy, they constitute a promising solution to extend current convolutional networks and endow artificial visual perception with a process to encode more efficiently all feature affine transformations. Indeed, a properly working capsule network should theoretically achieve higher results with a considerably lower number of parameters count due to intrinsic capability to generalize to novel viewpoints. Nevertheless, little attention has been given to this relevant aspect. In this paper, we investigate the efficiency of capsule networks and, pushing their capacity to the limits with an extreme architecture with barely 160K parameters, we prove that the proposed architecture is still able to achieve state-of-the-art results on three different datasets with only 2% of the original CapsNet parameters. Moreover, we replace dynamic routing with a novel non-iterative, highly parallelizable routing algorithm that can easily cope with a reduced number of capsules. Extensive experimentation with other capsule implementations has proved the effectiveness of our methodology and the capability of capsule networks to efficiently embed visual representations more prone to generalization.
https://weibo.com/1402400261/K00Cl6lE8
2、[CV] NeMo: Neural Mesh Models of Contrastive Features for Robust 3D Pose Estimation
A Wang, A Kortylewski, A Yuille
[Johns Hopkins University]
NeMo: 面向鲁棒3D姿态估计的对比特征神经网格模型。提出将深度神经网络与目标3D生成式表示,整合成统一神经架构NeMo,在密集3D网格上学习每个顶点的神经特征激活的生成模型。用可微渲染,通过最小化NeMo和目标图像特征表示间的重建误差,来估计3D对象姿态。为避免重建损失的局部最优,用对比学习训练特征提取器最大化网格上各特征表示间的距离。在PASCAL3D+, occluded-PASCAL3D+ 和 ObjectNet3D上的大量实验表明,与标准深度网络相比,NeMo对部分遮挡和未见姿态的鲁棒性更强,同时在常规数据上保持了有竞争力的性能。
3D pose estimation is a challenging but important task in computer vision. In this work, we show that standard deep learning approaches to 3D pose estimation are not robust when objects are partially occluded or viewed from a previously unseen pose. Inspired by the robustness of generative vision models to partial occlusion, we propose to integrate deep neural networks with 3D generative representations of objects into a unified neural architecture that we term NeMo. In particular, NeMo learns a generative model of neural feature activations at each vertex on a dense 3D mesh. Using differentiable rendering we estimate the 3D object pose by minimizing the reconstruction error between NeMo and the feature representation of the target image. To avoid local optima in the reconstruction loss, we train the feature extractor to maximize the distance between the individual feature representations on the mesh using contrastive learning. Our extensive experiments on PASCAL3D+, occluded-PASCAL3D+ and ObjectNet3D show that NeMo is much more robust to partial occlusion and unseen pose compared to standard deep networks, while retaining competitive performance on regular data. Interestingly, our experiments also show that NeMo performs reasonably well even when the mesh representation only crudely approximates the true object geometry with a cuboid, hence revealing that the detailed 3D geometry is not needed for accurate 3D pose estimation. The code is publicly available at > this https URL.
https://weibo.com/1402400261/K00Kpmjmn



3、[LG] Predicting Nanorobot Shapes via Generative Models
E Benjaminson, R E. Taylor, M Travers
[CMU]
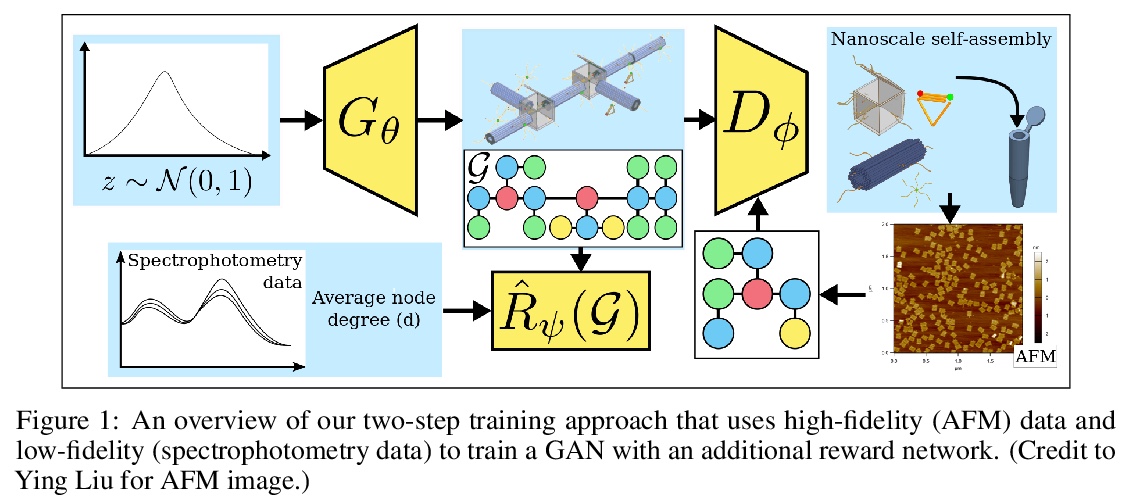
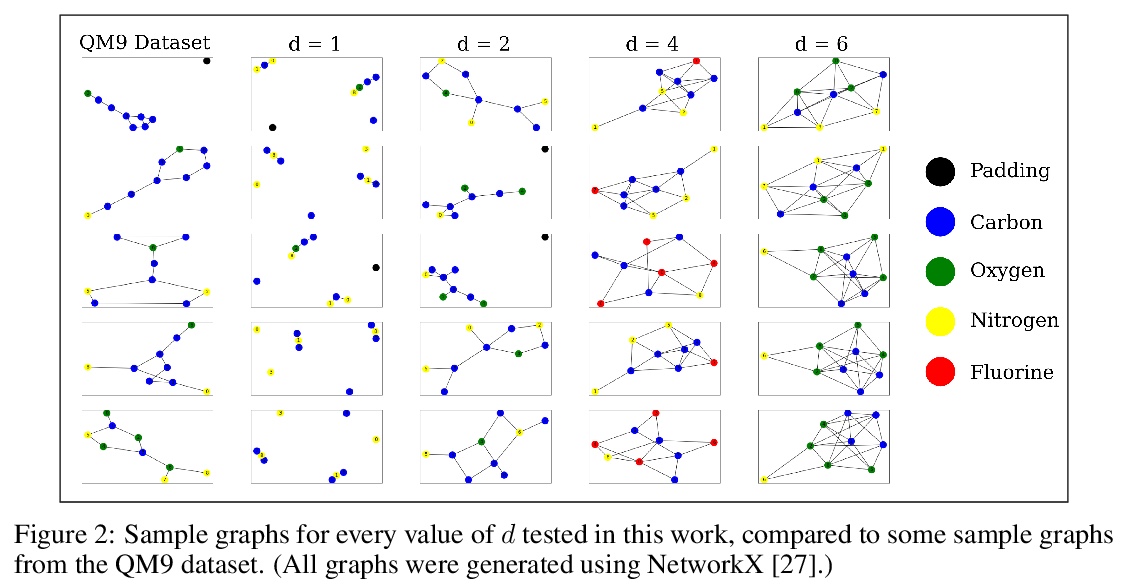
基于生成模型的纳米机器人形状预测。将低保真数据和高保真数据结合起来,采用两步法训练生成模型。先用一个相对较小的高保真数据集来训练生成模型,在运行时,模型采用低保真数据,并用其逼近高保真内容。通过将模型偏向于低保真数据测量的具有特定属性的样本来实现,采用新的奖励函数来偏置生成模型输出。实验结果表明,这种方法能够生成与训练数据集相似的新样本,并且还具有奖励函数所决定的期望特性。
The field of DNA nanotechnology has made it possible to assemble, with high yields, different structures that have actionable properties. For example, researchers have created components that can be actuated. An exciting next step is to combine these components into multifunctional nanorobots that could, potentially, perform complex tasks like swimming to a target location in the human body, detect an adverse reaction and then release a drug load to stop it. However, as we start to assemble more complex nanorobots, the yield of the desired nanorobot begins to decrease as the number of possible component combinations increases. Therefore, the ultimate goal of this work is to develop a predictive model to maximize yield. However, training predictive models typically requires a large dataset. For the nanorobots we are interested in assembling, this will be difficult to collect. This is because high-fidelity data, which allows us to characterize the shape and size of individual structures, is very time-consuming to collect, whereas low-fidelity data is readily available but only captures bulk statistics for different processes. Therefore, this work combines low- and high-fidelity data to train a generative model using a two-step process. We first use a relatively small, high-fidelity dataset to train a generative model. At run time, the model takes low-fidelity data and uses it to approximate the high-fidelity content. We do this by biasing the model towards samples with specific properties as measured by low-fidelity data. In this work we bias our distribution towards a desired node degree of a graphical model that we take as a surrogate representation of the nanorobots that this work will ultimately focus on. We have not yet accumulated a high-fidelity dataset of nanorobots, so we leverage the MolGAN architecture [1] and the QM9 small molecule dataset [2-3] to demonstrate our approach.
https://weibo.com/1402400261/K00PGtWGc
4、[CL] Attention Can Reflect Syntactic Structure (If You Let It)
V Ravishankar, A Kulmizev, M Abdou, A Søgaard, J Nivre
[University of Oslo & Uppsala University & University of Copenhagen]
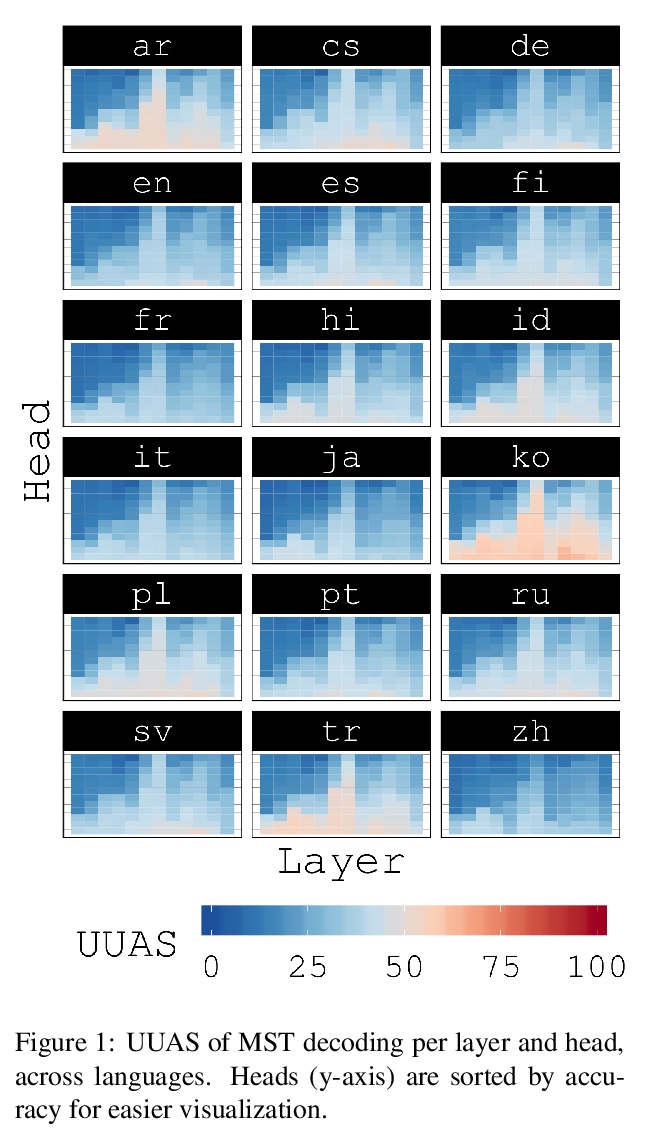
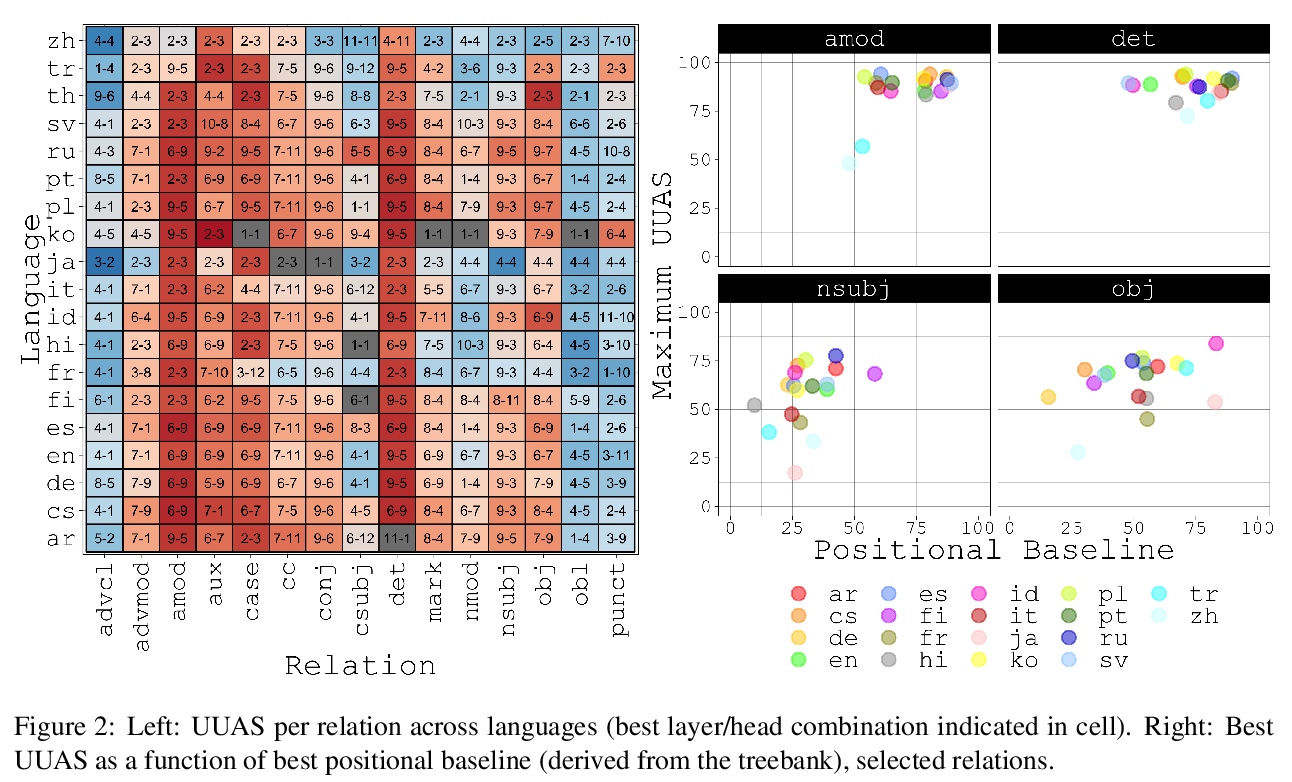
注意力反映了句法结构。进行了跨18种语言的多语言BERT的解码实验,以测试依存语法反映在注意力模式中这一说法的可推广性。实验表明,在所有语言中,相较于相邻链接方法,从注意力模式中能更准确地解码依存树,这意味着注意力机制确实跟踪到了一些结构特征。为解决关于注意力作为解释机制的争论,尝试在冻结不同系列参数的同时,对监督解析目标上的mBERT进行微调。在引导目标学习显性语言结构的过程中,发现在所产生的注意力模式中代表了很多相同的结构,但在冻结哪些参数方面存在差异。
Since the popularization of the Transformer as a general-purpose feature encoder for NLP, many studies have attempted to decode linguistic structure from its novel multi-head attention mechanism. However, much of such work focused almost exclusively on English — a language with rigid word order and a lack of inflectional morphology. In this study, we present decoding experiments for multilingual BERT across 18 languages in order to test the generalizability of the claim that dependency syntax is reflected in attention patterns. We show that full trees can be decoded above baseline accuracy from single attention heads, and that individual relations are often tracked by the same heads across languages. Furthermore, in an attempt to address recent debates about the status of attention as an explanatory mechanism, we experiment with fine-tuning mBERT on a supervised parsing objective while freezing different series of parameters. Interestingly, in steering the objective to learn explicit linguistic structure, we find much of the same structure represented in the resulting attention patterns, with interesting differences with respect to which parameters are frozen.
https://weibo.com/1402400261/K00THyN9j

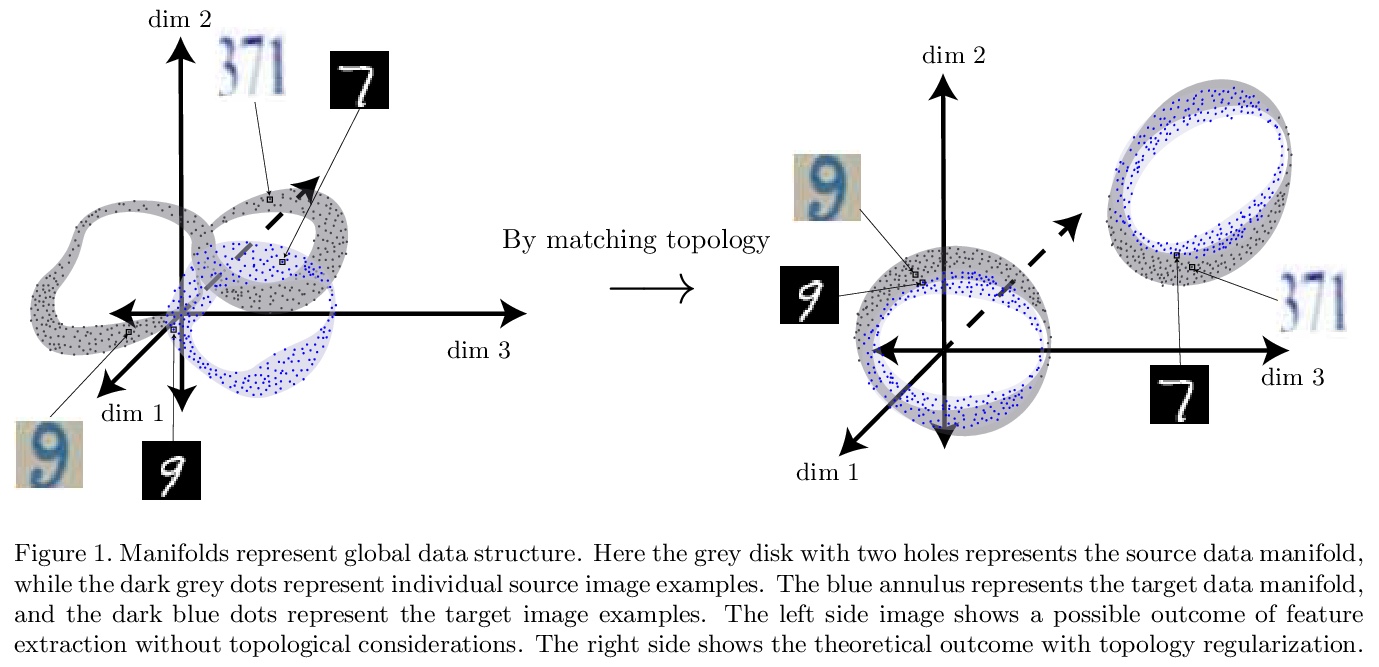
5、[CV] Domain Adaptation by Topology Regularization
D Weeks, S Rivera
[George Washington University & Matrix Research]
基于拓扑正则化的域自适应。提出通过将持久同源拓扑数据分析技术应用于迁移学习,来分析和对齐神经网络源和目标特征表示的全局结构。研究了持久同源性在域对抗卷积神经网络架构中的使用,提供了一些关于拓扑学用于分类和迁移学习的有意义的经验发现。
Deep learning has become the leading approach to assisted target recognition. While these methods typically require large amounts of labeled training data, domain adaptation (DA) or transfer learning (TL) enables these algorithms to transfer knowledge from a labelled (source) data set to an unlabelled but related (target) data set of interest. DA enables networks to overcome the distribution mismatch between the source and target that leads to poor generalization in the target domain. DA techniques align these distributions by minimizing a divergence measurement between source and target, making the transfer of knowledge from source to target possible. While these algorithms have advanced significantly in recent years, most do not explicitly leverage global data manifold structure in aligning the source and target. We propose to leverage global data structure by applying a topological data analysis (TDA) technique called persistent homology to TL.In this paper, we examine the use of persistent homology in a domain adversarial (DAd) convolutional neural network (CNN) architecture. The experiments show that aligning persistence alone is insufficient for transfer, but must be considered along with the lifetimes of the topological singularities. In addition, we found that longer lifetimes indicate robust discriminative features and more favorable structure in data. We found that existing divergence minimization based approaches to DA improve the topological structure, as indicated over a baseline without these regularization techniques. We hope these experiments highlight how topological structure can be leveraged to boost performance in TL tasks.
https://weibo.com/1402400261/K010DzG2O
另外几篇值得关注的论文:
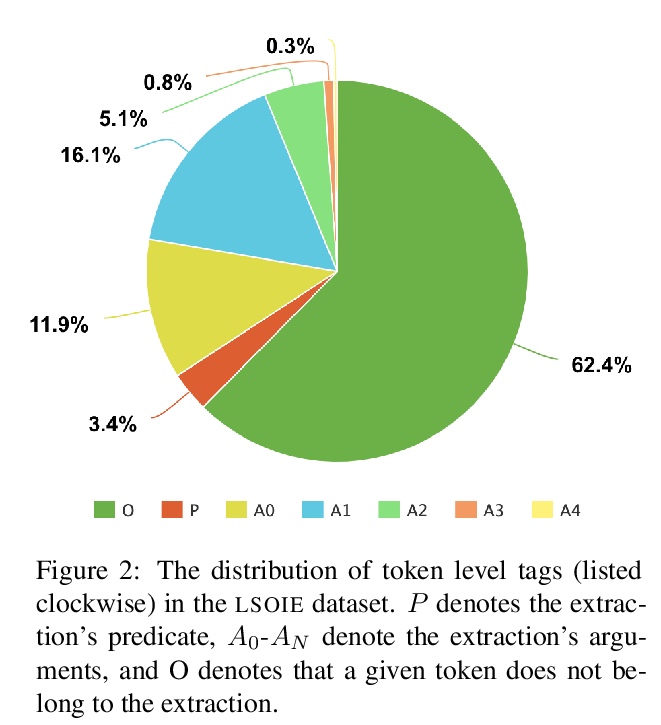
[CL] LSOIE: A Large-Scale Dataset for Supervised Open Information Extraction
LSOIE:面向有监督开放信息抽取的大规模数据集
J Solawetz, S Larson
[Roboflow & Rosegold AI]
https://weibo.com/1402400261/K01619aZK

[CV] Augmenting Proposals by the Detector Itself
目标检测器自身的候选域增强
X Wan, Z Guo, C He, Y Yang, F Tao
[Tsinghua University & Alibaba Group]
https://weibo.com/1402400261/K017nCuJ1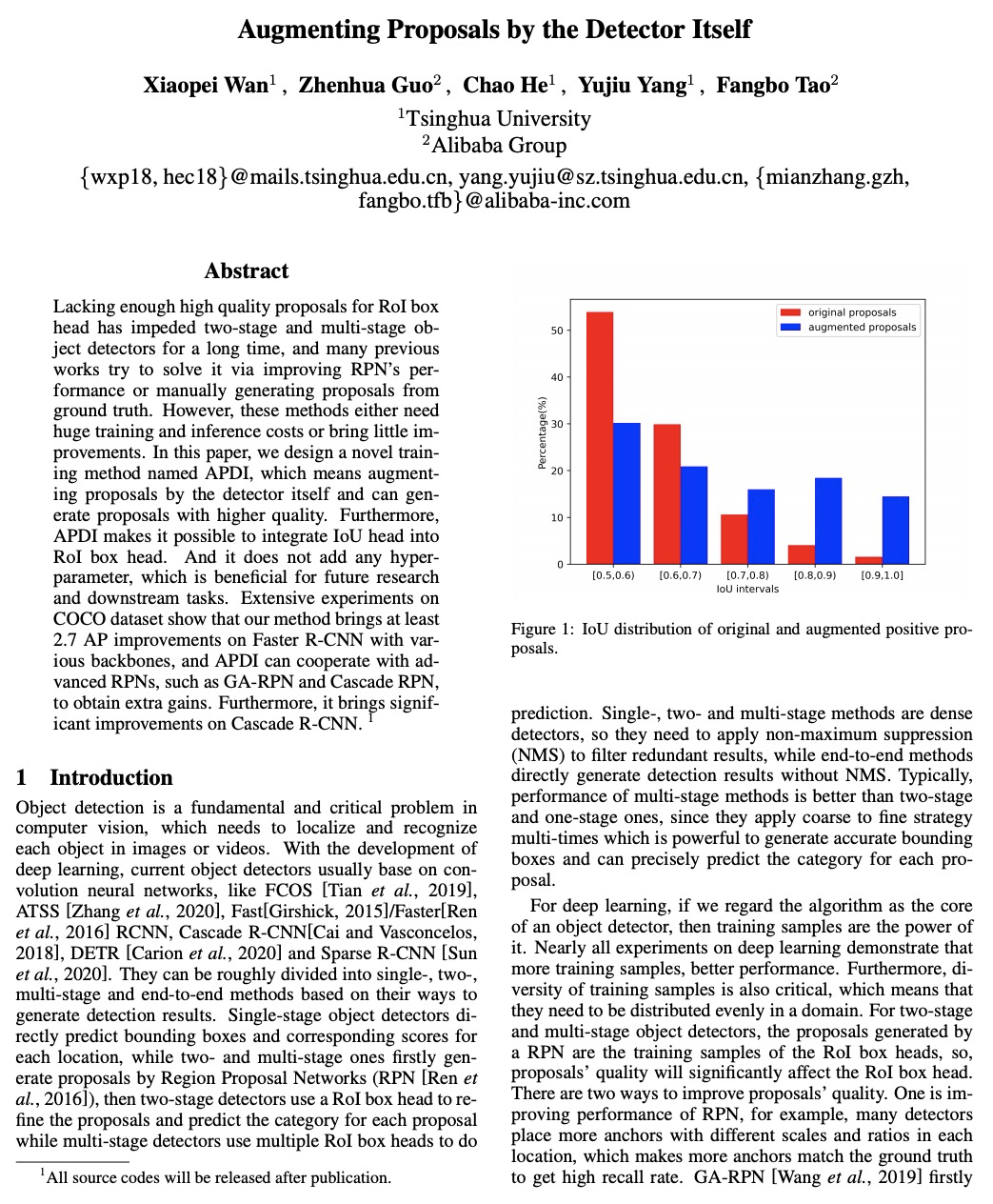
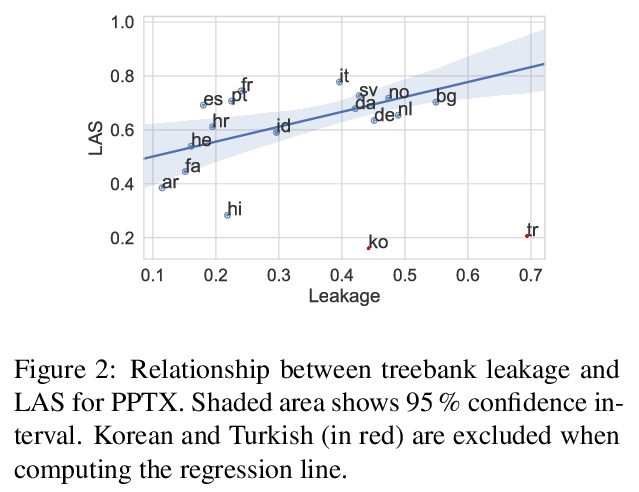
[CL] PPT: Parsimonious Parser Transfer for Unsupervised Cross-Lingual Adaptation
PPT:面向无监督跨语言自适应的简约解析器迁移
K Kurniawan, L Frermann, P Schulz, T Cohn
[University of Melbourne & Amazon Research]
https://weibo.com/1402400261/K01cZaPXH
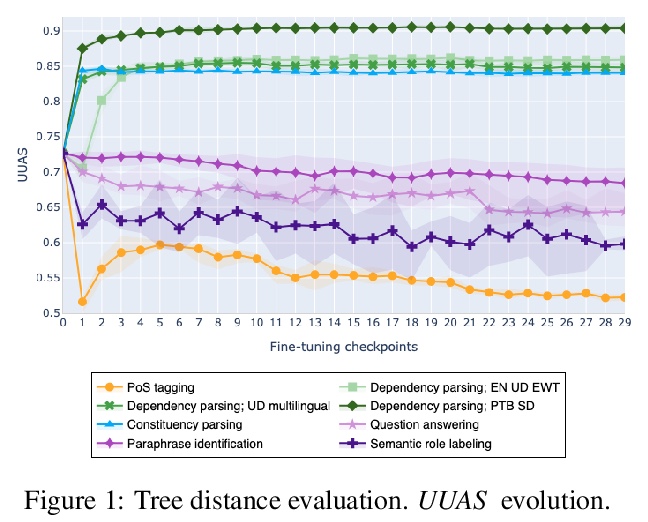
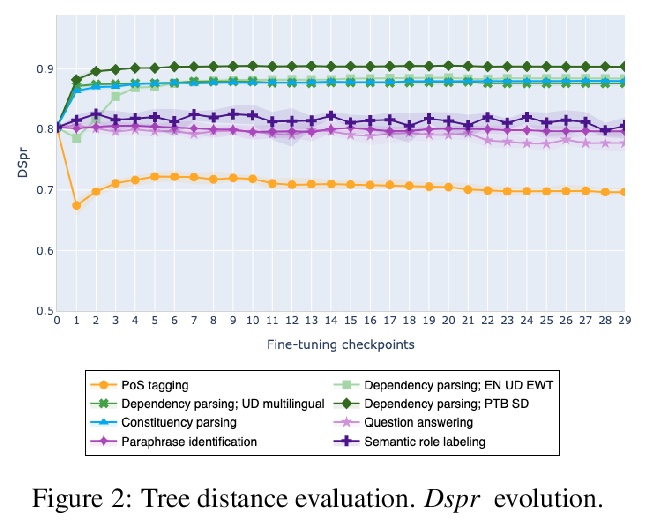
[CL] On the Evolution of Syntactic Information Encoded by BERT’s Contextualized Representations
BERT语境化表示编码句法信息的演化
L Perez-Mayos, R Carlini, M Ballesteros, L Wanner
[Pompeu Fabra University & Amazon AI & Catalan Institute for Research and Advanced Studies (ICREA)]
https://weibo.com/1402400261/K01fE54im

若有收获,就点个赞吧
0 人点赞
