- 1、[CV] Factors of Influence for Transfer Learning across Diverse Appearance Domains and Task Types
- 2、[AI] Explaining Black-Box Algorithms Using Probabilistic Contrastive Counterfactuals
- 3、[CV] Vision Transformers for Dense Prediction
- 4、[CV] Is Medical Chest X-ray Data Anonymous?
- 5、[LG] Student-Teacher Learning from Clean Inputs to Noisy Inputs
- [CV] UNETR: Transformers for 3D Medical Image Segmentation
- [CV] Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking
- [LG] Replacing Rewards with Examples: Example-Based Policy Search via Recursive Classification
- [CV] Instance-level Image Retrieval using Reranking Transformers
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Factors of Influence for Transfer Learning across Diverse Appearance Domains and Task Types
T Mensink, J Uijlings, A Kuznetsova, M Gygli, V Ferrari
[Google Research]
跨各种表现域和任务类型的迁移学习影响因素研究。对迁移学习进行了广泛的实验探索,跨越了大量不同的图像领域(消费者照片、自动驾驶、航空图像、水下、室内场景、合成、特写)和任务类型(语义分割、目标检测、深度估计、关键点检测),这些都是与现代计算机视觉应用相关的复杂、结构化的输出任务类型,总共进行了超过1200次的迁移实验,包括许多源和目标来自不同的图像域、任务类型或两者都有的实验,系统分析了这些实验,以了解图像域、任务类型和数据集大小对转移学习性能的影响,并得出以下结论:(1)对大多数任务来说,存在一个显著优于ILSVRC’12预训练的源;(2)图像域是实现正向迁移的最重要因素;(3)源任务应该包括目标任务的图像域,以达到最佳效果;(4)相反,当源任务的图像域比目标任务的图像域宽泛得多时,我们观察到的负面效应很小;(5)跨任务类型的迁移是有益的,但其成功与否很大程度上取决于源和目标任务类型。
Transfer learning enables to re-use knowledge learned on a source task to help learning a target task. A simple form of transfer learning is common in current state-of-the-art computer vision models, i.e. pre-training a model for image classification on the ILSVRC dataset, and then fine-tune on any target task. However, previous systematic studies of transfer learning have been limited and the circumstances in which it is expected to work are not fully understood. In this paper we carry out an extensive experimental exploration of transfer learning across vastly different image domains (consumer photos, autonomous driving, aerial imagery, underwater, indoor scenes, synthetic, close-ups) and task types (semantic segmentation, object detection, depth estimation, keypoint detection). Importantly, these are all complex, structured output tasks types relevant to modern computer vision applications. In total we carry out over 1200 transfer experiments, including many where the source and target come from different image domains, task types, or both. We systematically analyze these experiments to understand the impact of image domain, task type, and dataset size on transfer learning performance. Our study leads to several insights and concrete recommendations for practitioners.
https://weibo.com/1402400261/K8nncdf1a

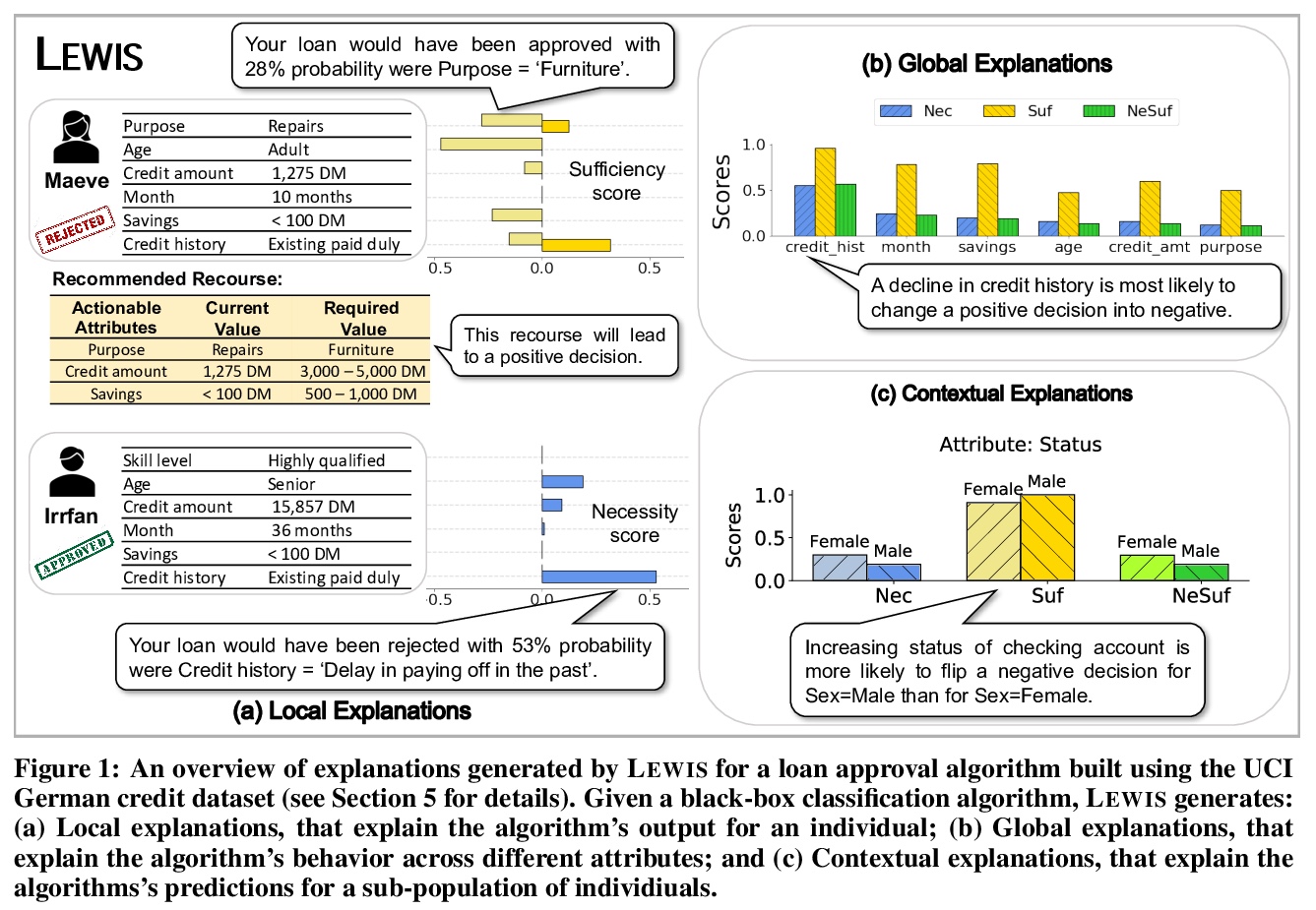
2、[AI] Explaining Black-Box Algorithms Using Probabilistic Contrastive Counterfactuals
S Galhotra, R Pradhan, B Salimi
[University of Massachusetts Amherst & University of California, San Diego]
用概率对比反设事实解释黑盒算法。提出了一种基于原则性因果关系的方法来解释黑箱决策系统,以解决XAI中现有方法的局限性。框架的核心是概率反事实,该概念可追溯到哲学、认知和社会基础上的人类如何产生和选择解释的理论。展示了这样的反事实如何量化变量对算法决策的直接和间接影响,并为受算法决策负面影响的个体提供可操作的追索。与之前的工作不同,该系统LEWIS:(1)可在局部、全局和上下文层面上计算出可证明有效的解释和追索权;(2)被设计成可与具有不同程度的基础因果模型背景知识的用户一起工作;(3)除了输入-输出数据的可用性之外,不对算法系统的内部进行假设。在三个真实世界的数据集上对LEWIS进行了实证评估,并表明它产生的人类可理解的解释比XAI中最先进的方法有所改进,包括流行的LIME和SHAP。
There has been a recent resurgence of interest in explainable artificial intelligence (XAI) that aims to reduce the opaqueness of AI-based decision-making systems, allowing humans to scrutinize and trust them. Prior work in this context has focused on the attribution of responsibility for an algorithm’s decisions to its inputs wherein responsibility is typically approached as a purely associational concept. In this paper, we propose a principled causality-based approach for explaining black-box decision-making systems that addresses limitations of existing methods in XAI. At the core of our framework lies probabilistic contrastive counterfactuals, a concept that can be traced back to philosophical, cognitive, and social foundations of theories on how humans generate and select explanations. We show how such counterfactuals can quantify the direct and indirect influences of a variable on decisions made by an algorithm, and provide actionable recourse for individuals negatively affected by the algorithm’s decision. Unlike prior work, our system, LEWIS: (1)can compute provably effective explanations and recourse at local, global and contextual levels (2)is designed to work with users with varying levels of background knowledge of the underlying causal model and (3)makes no assumptions about the internals of an algorithmic system except for the availability of its input-output data. We empirically evaluate LEWIS on three real-world datasets and show that it generates human-understandable explanations that improve upon state-of-the-art approaches in XAI, including the popular LIME and SHAP. Experiments on synthetic data further demonstrate the correctness of LEWIS’s explanations and the scalability of its recourse algorithm.
https://weibo.com/1402400261/K8nqCBgC2
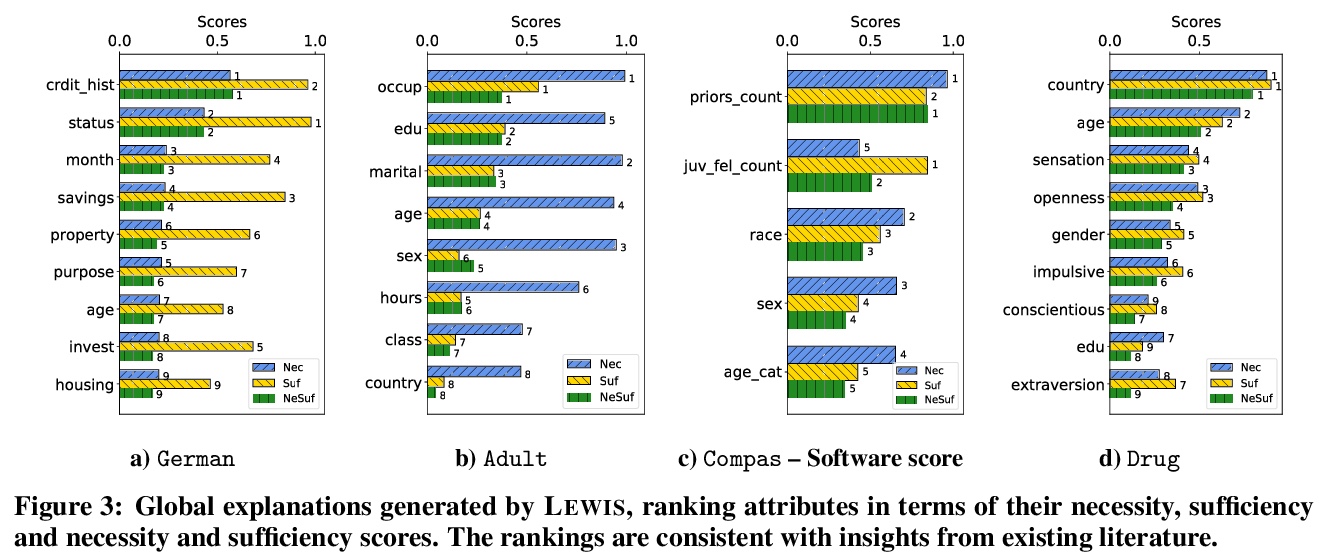
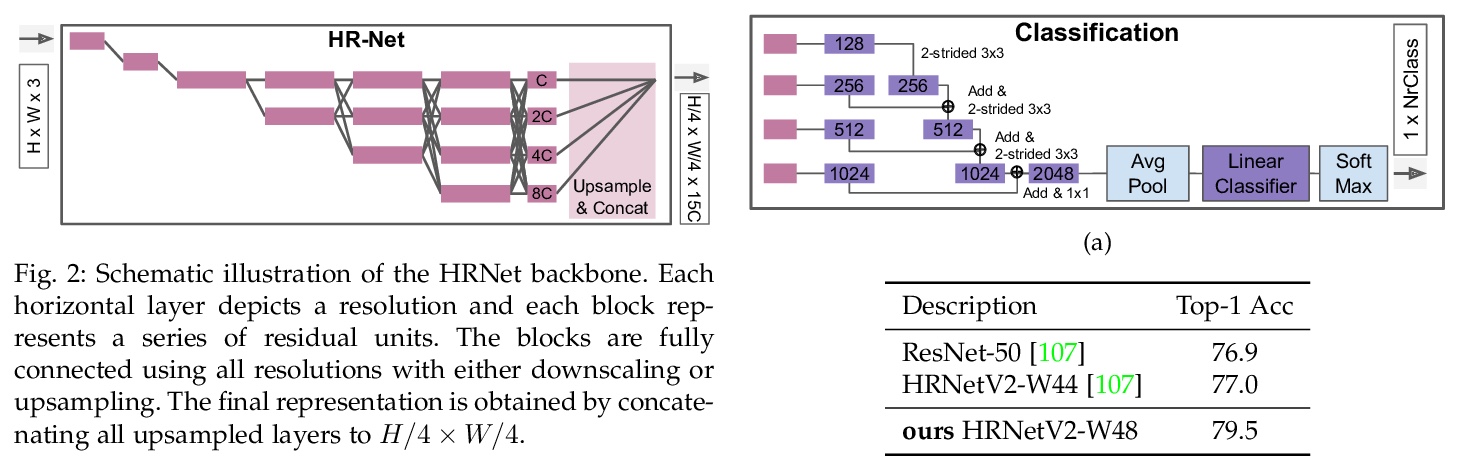
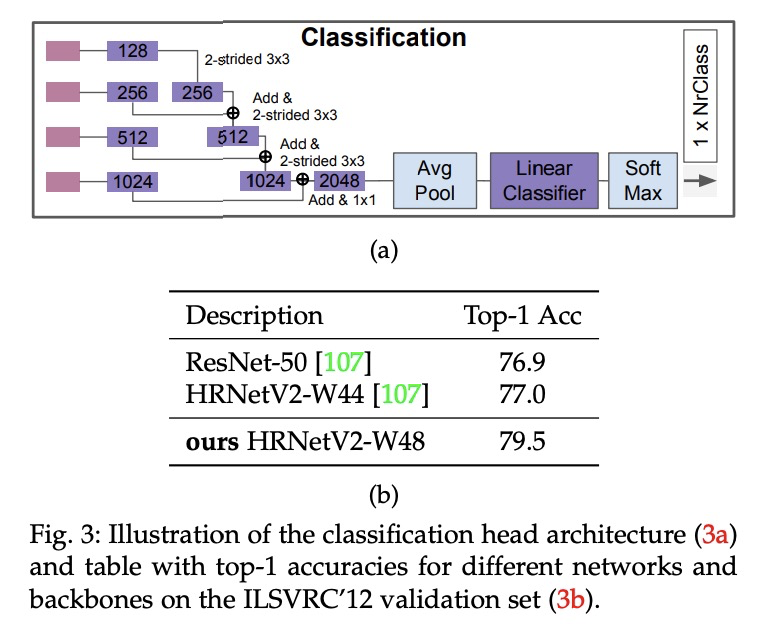
3、[CV] Vision Transformers for Dense Prediction
R Ranftl, A Bochkovskiy, V Koltun
[Intel Labs]
密集预测视觉Transformer。引入密集预测Transformer(DPT),一个有效利用视觉Transformer完成密集预测任务的神经网络架构。将来自视觉Transformer各阶段的token组合成不同分辨率的类图像表征,用卷积解码器将其逐步组合成全分辨率的预测。Transformer主干以恒定的、相对较高的分辨率处理表征,在每个阶段都有一个全局感受野。在单目深度估计和语义分割上的实验表明,与全卷积架构相比,所提出的架构能产生更细粒度和全局一致性的预测。
We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art. Our models are available at > this https URL.
https://weibo.com/1402400261/K8ntHwMVt
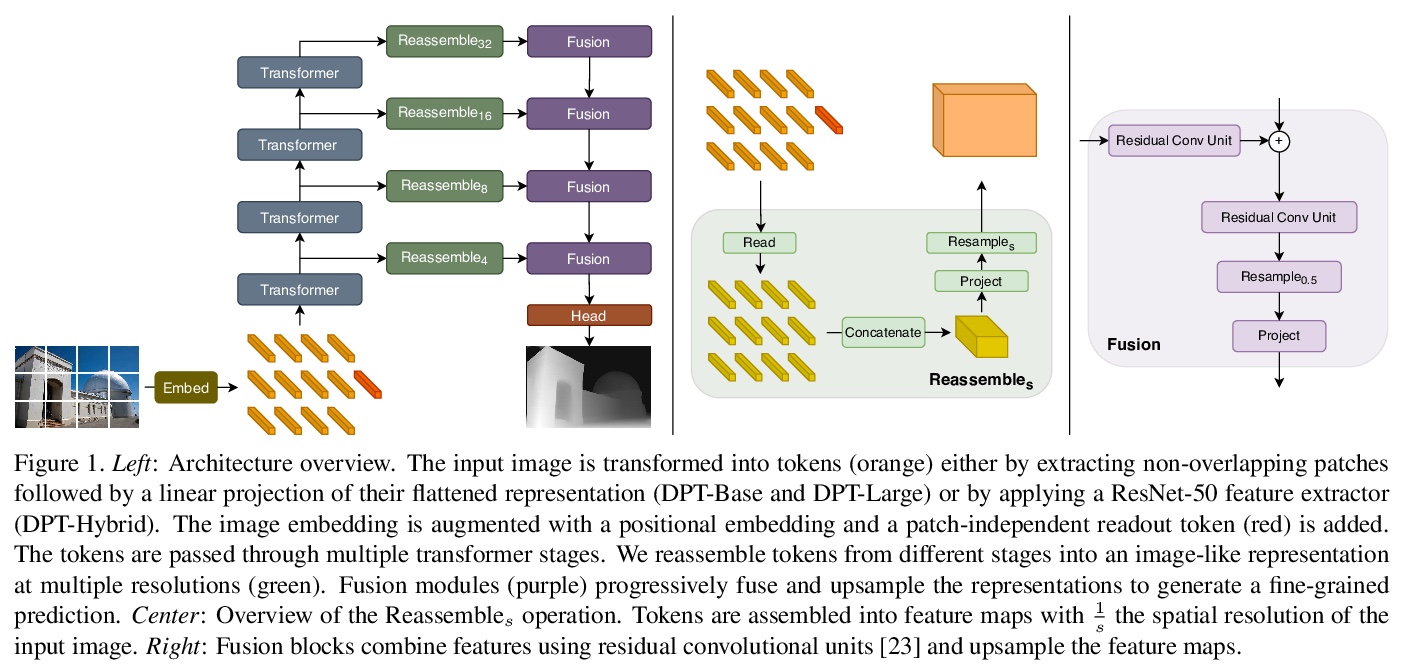

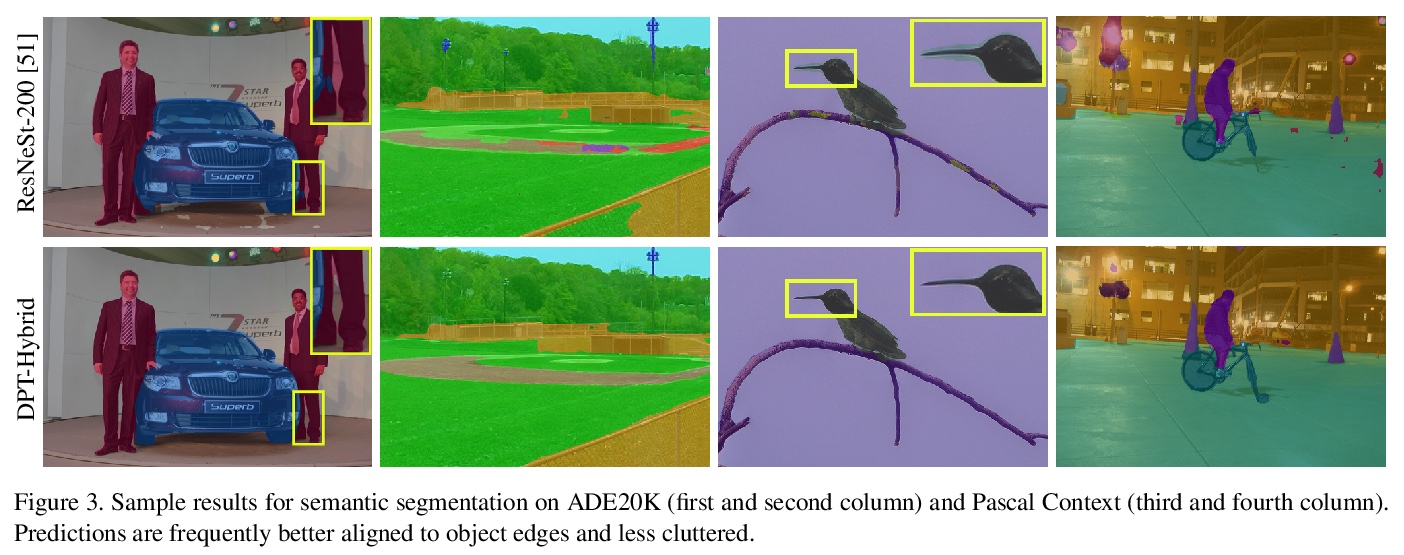
4、[CV] Is Medical Chest X-ray Data Anonymous?
K Packhäuser, S Gündel, N Münster, C Syben, V Christlein, A Maier
[Friedrich-Alexander University Erlangen-Nurnberg]
医学胸部X光片数据是匿名的吗?表明一个经过训练的深度学习系统,是能够从胸部X射线数据中恢复患者身份采 。用公开的大规模ChestX-ray14数据集来证明这一点,该数据集收集了来自30,805名独特患者的112,120张正视胸部X射线图像,验证系统能够识别两个正面胸部X射线图像是否来自同一个人,AUC为0.9940,分类准确率为95.55%。所提出的系统能够揭示同一个人,即使是在初始扫描后十年甚至更久。当探索检索方法时,观察到mAP@R为0.9748,精度@1为0.9963。基于这种高识别率,潜在的攻击者可能会泄露与患者相关的信息,另外还可以交叉参考图像以获得更多信息。因此,敏感内容极有可能落入未经授权的人手中,或违背相关患者的意愿进行传播。特别是在COVID-19大流行期间,许多胸部X射线数据集已被公布,以促进研究。因此,这些数据可能容易受到基于深度学习的再识别算法的潜在攻击。
With the rise and ever-increasing potential of deep learning techniques in recent years, publicly available medical data sets became a key factor to enable reproducible development of diagnostic algorithms in the medical domain. Medical data contains sensitive patient-related information and is therefore usually anonymized by removing patient identifiers, e.g., patient names before publication. To the best of our knowledge, we are the first to show that a well-trained deep learning system is able to recover the patient identity from chest X-ray data. We demonstrate this using the publicly available large-scale ChestX-ray14 dataset, a collection of 112,120 frontal-view chest X-ray images from 30,805 unique patients. Our verification system is able to identify whether two frontal chest X-ray images are from the same person with an AUC of 0.9940 and a classification accuracy of 95.55%. We further highlight that the proposed system is able to reveal the same person even ten and more years after the initial scan. When pursuing a retrieval approach, we observe an mAP@R of 0.9748 and a precision@1 of 0.9963. Based on this high identification rate, a potential attacker may leak patient-related information and additionally cross-reference images to obtain more information. Thus, there is a great risk of sensitive content falling into unauthorized hands or being disseminated against the will of the concerned patients. Especially during the COVID-19 pandemic, numerous chest X-ray datasets have been published to advance research. Therefore, such data may be vulnerable to potential attacks by deep learning-based re-identification algorithms.
https://weibo.com/1402400261/K8nws2WP6
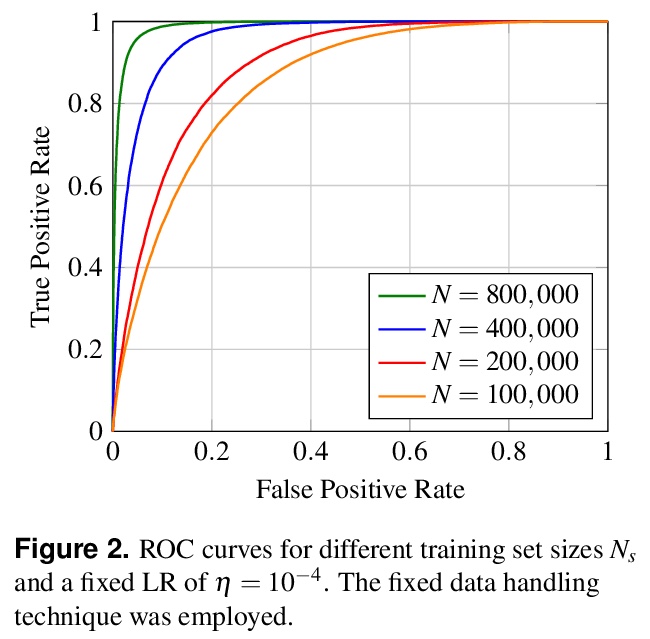
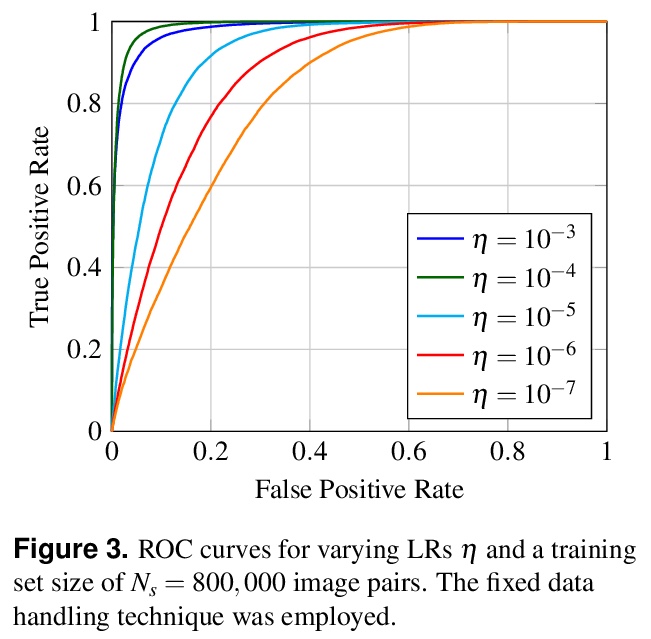
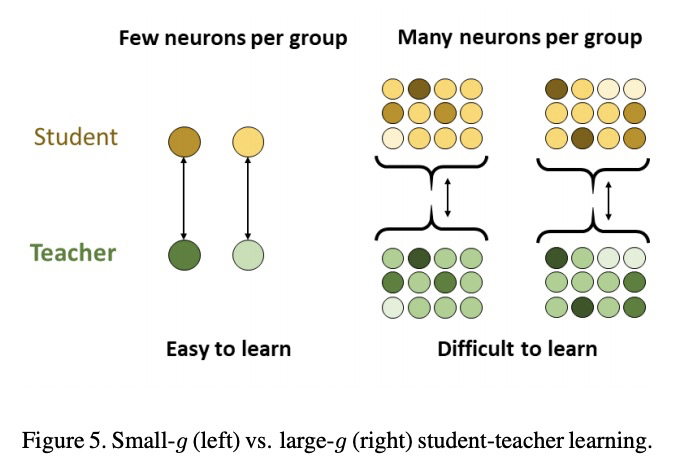
5、[LG] Student-Teacher Learning from Clean Inputs to Noisy Inputs
G Hong, Z Mao, X Lin, S H. Chan
[Purdue University]
从干净输入到噪声输入的学生-老师学习。对基于特征的师生学习机制进行了系统分析。研究了学生-老师学习成功的“何时”和“为何”的泛化问题。通过理论分析和数字分析,得出了三个结论:使用提前停止、用知识广博的老师、确保老师能很好地分解其隐藏特征,这三个因素中任何一个因素缺乏适当控制,都会导致师生学习方法的失败。
Feature-based student-teacher learning, a training method that encourages the student’s hidden features to mimic those of the teacher network, is empirically successful in transferring the knowledge from a pre-trained teacher network to the student network. Furthermore, recent empirical results demonstrate that, the teacher’s features can boost the student network’s generalization even when the student’s input sample is corrupted by noise. However, there is a lack of theoretical insights into why and when this method of transferring knowledge can be successful between such heterogeneous tasks. We analyze this method theoretically using deep linear networks, and experimentally using nonlinear networks. We identify three vital factors to the success of the method: (1) whether the student is trained to zero training loss; (2) how knowledgeable the teacher is on the clean-input problem; (3) how the teacher decomposes its knowledge in its hidden features. Lack of proper control in any of the three factors leads to failure of the student-teacher learning method.
https://weibo.com/1402400261/K8nzchg2q
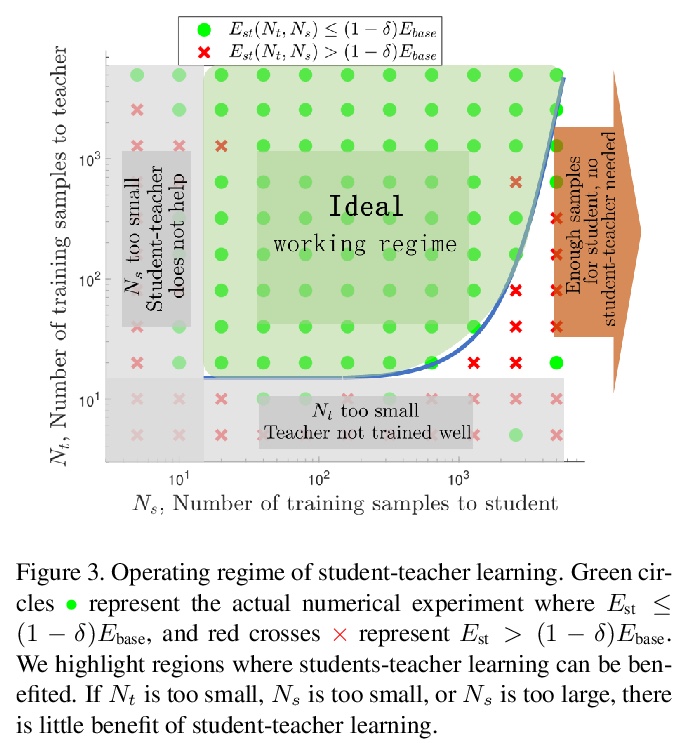
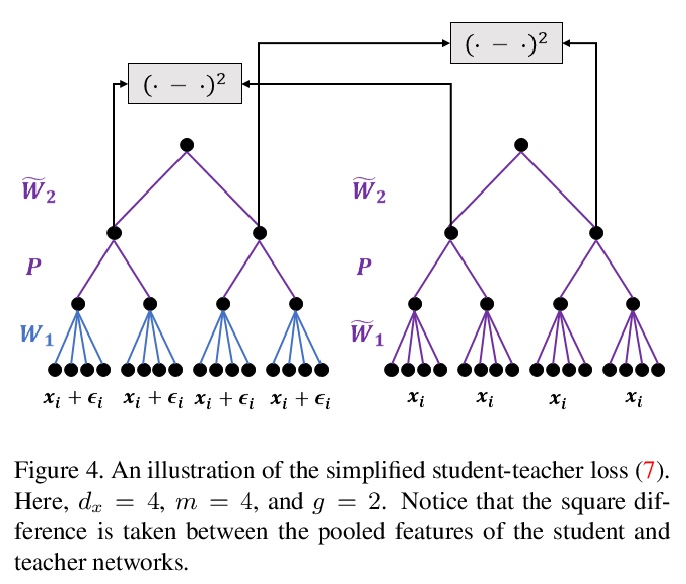
另外几篇值得关注的论文:
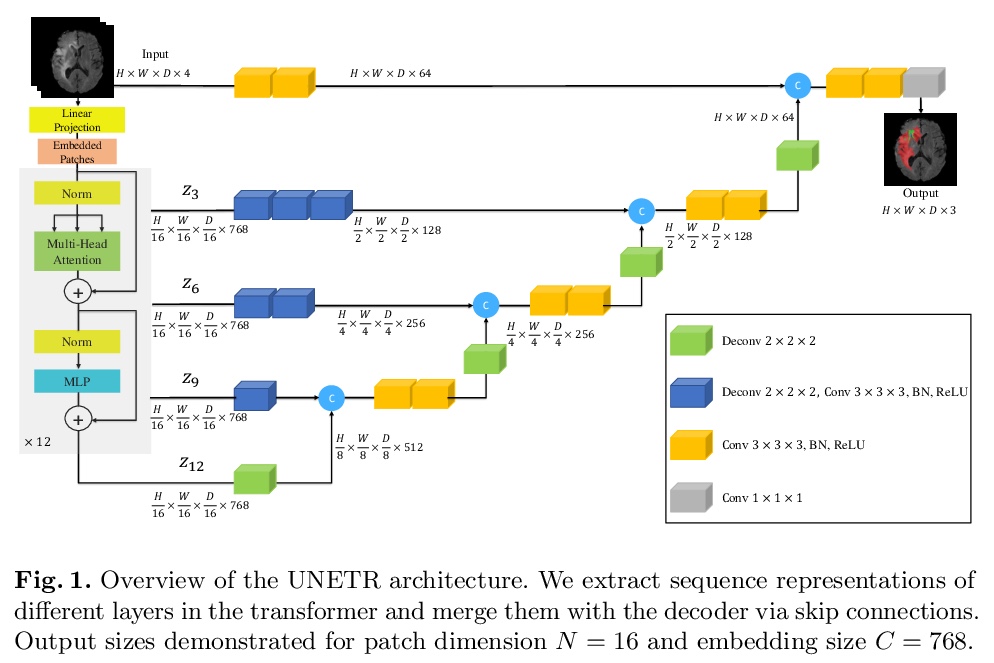
[CV] UNETR: Transformers for 3D Medical Image Segmentation
UNETR:面向3D医学图像分割的Transformer
A Hatamizadeh, D Yang, H Roth, D Xu
[NVIDIA]
https://weibo.com/1402400261/K8nBYeKAP
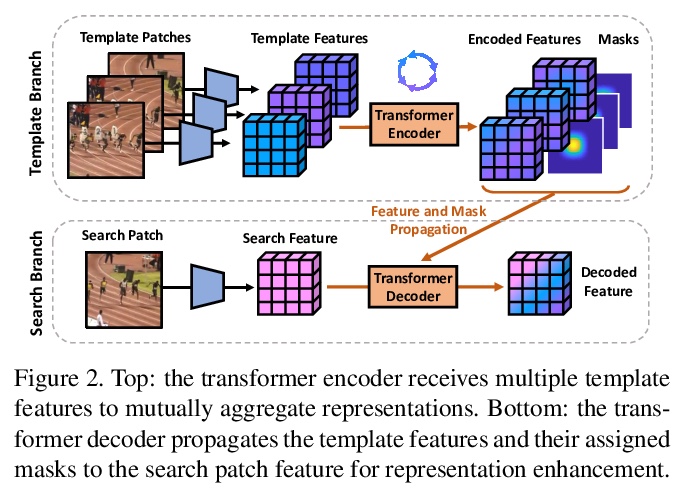
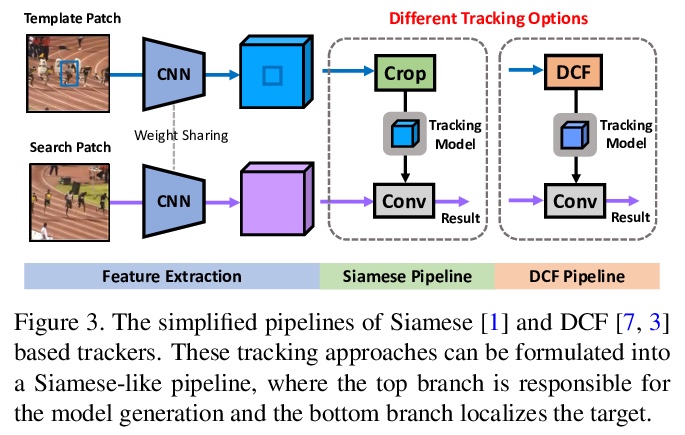
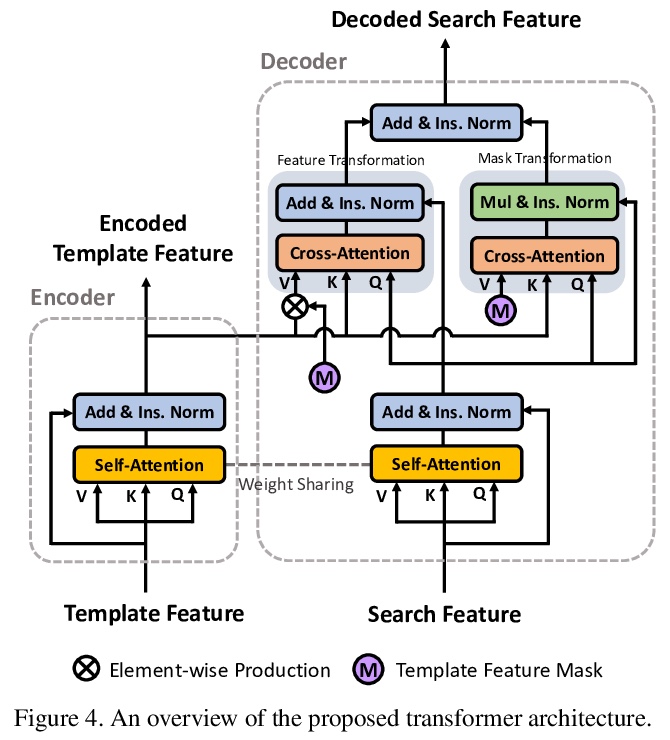
[CV] Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking
Transformer追踪器:利用时间上下文进行鲁棒视觉追踪
N Wang, W Zhou, J Wang, H Li
[University of Science and Technology of China (USTC)]
https://weibo.com/1402400261/K8nDxsLQn
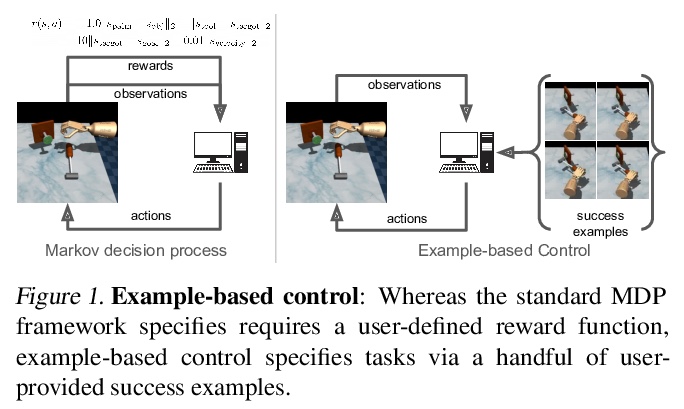
[LG] Replacing Rewards with Examples: Example-Based Policy Search via Recursive Classification
用实例代替奖励:基于实例的递归分类策略搜索
B Eysenbach, S Levine, R Salakhutdinov
[CMU & UC Berkeley]
https://weibo.com/1402400261/K8nFu2C0B


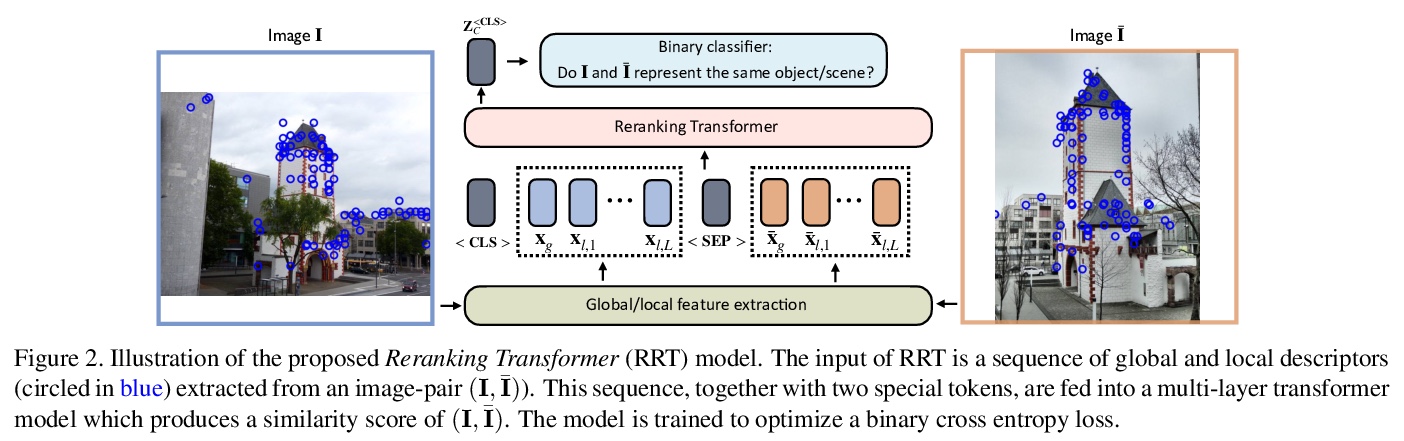
[CV] Instance-level Image Retrieval using Reranking Transformers
基于重排Transformer的实例级图像检索
F Tan, J Yuan, V Ordonez
[University of Virginia & eBay Computer Vision]
https://weibo.com/1402400261/K8nGRrmEZ



若有收获,就点个赞吧
0 人点赞
