- 1、[CL] The NLP Cookbook: Modern Recipes for Transformer based Deep Learning Architectures
- 2、[LG] Carbon Emissions and Large Neural Network Training
- 3、[LG] Manipulating SGD with Data Ordering Attacks
- 4、[RO] Contingencies from Observations: Tractable Contingency Planning with Learned Behavior Models
- 5、[CL] Timers and Such: A Practical Benchmark for Spoken Language Understanding with Numbers
- [CV] PARE: Part Attention Regressor for 3D Human Body Estimation
- [CV] PP-YOLOv2: A Practical Object Detector
- [CL] Leveraging neural representations for facilitating access to untranscribed speech from endangered languages
- [RO] Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] The NLP Cookbook: Modern Recipes for Transformer based Deep Learning Architectures
S Singh, A Mahmood
[University of Bridgeport]
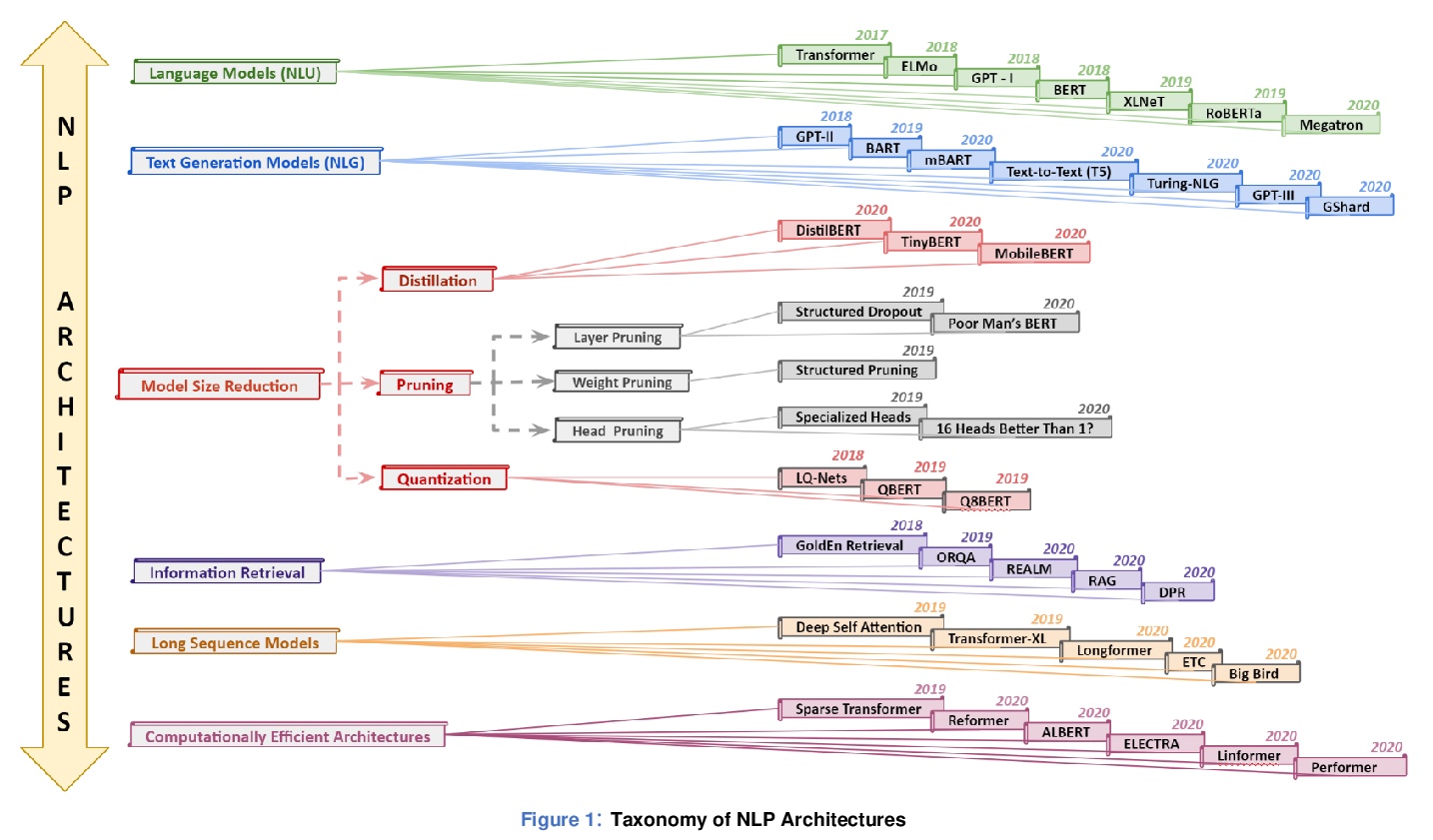
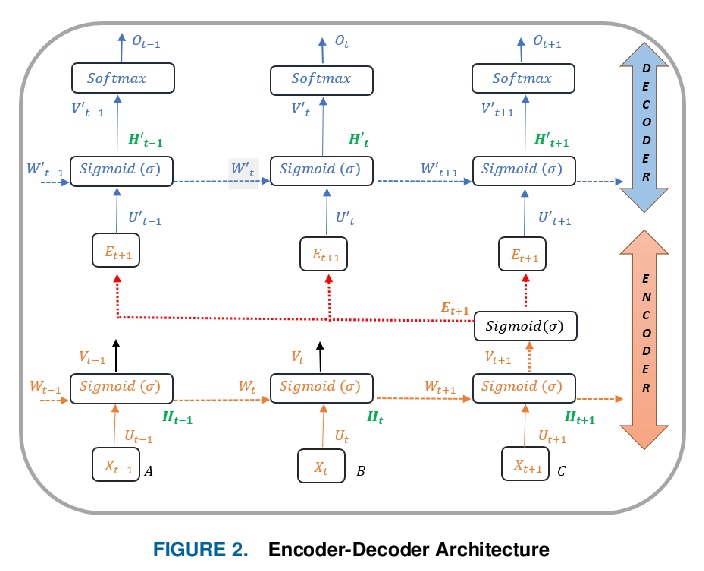
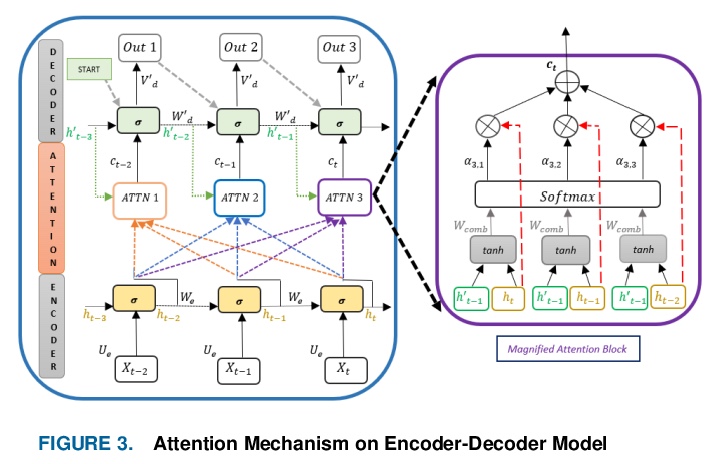
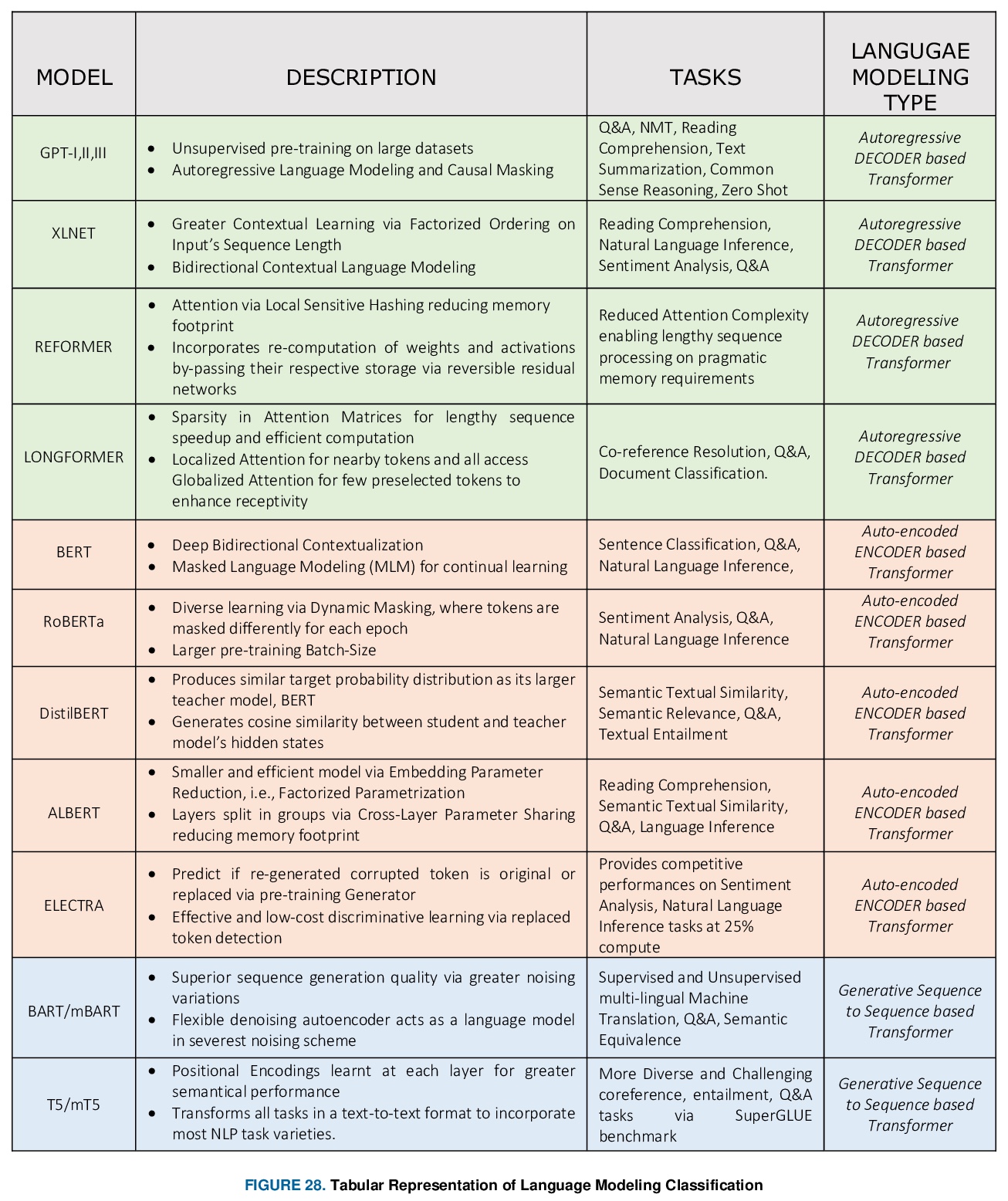
NLP实操手册: 基于Transformer的深度学习架构的应用指南。近年来,自然语言处理(NLP)模型在语言和语义任务上取得了巨大的成功,如机器翻译、认知对话系统、通过自然语言理解(NLU)和自然语言生成(NLG)进行信息检索。这一突破主要归功于开创性的Transformer架构,导致了诸如BERT、GPT(I、II、III)等设计。尽管这些大尺寸的模型已经取得了前所未有的性能,但其计算成本很高。因此,最近的一些NLP架构利用迁移学习、剪枝、量化和知识蒸馏等概念来实现适度的模型约减,同时保持与原模型几乎近似的性能。此外,为了从知识蒸馏的角度缓解语言模型带来的数据规模挑战,知识检索器被建立起来,以更高的效率和准确性从大型数据库语料库中析出确切的数据文档。最近的研究也集中在通过对较长的输入序列,提供有效的注意力,来实现卓越的推理。本文总结并研究了目前最先进的(SOTA)NLP模型,这些模型被用于众多NLP任务,以获得最佳性能和效率。本文对不同架构、NLP设计的分类、比较评价以及NLP的未来方向进行了详细的了解和讨论,一个有前途的未来改进领域,是将强化学习纳入机器翻译、文本摘要和问答任务中。
In recent years, Natural Language Processing (NLP) models have achieved phenomenal success in linguistical and semantical tasks like machine translation, cognitive dialogue systems, information retrieval via Natural Language Understanding (NLU), and Natural Language Generation (NLG). This feat is primarily attributed due to the seminal Transformer architecture, leading to designs such as BERT, GPT (I, II, III), etc. Although these large-size models have achieved unprecedented performances, they come at high computational costs. Consequently, some of the recent NLP architectures have utilized concepts of transfer learning, pruning, quantization, and knowledge distillation to achieve moderate model sizes while keeping nearly similar performances as achieved by their predecessors. Additionally, to mitigate the data size challenge raised by language models from a knowledge extraction perspective, Knowledge Retrievers have been built to extricate explicit data documents from a large corpus of databases with greater efficiency and accuracy. Recent research has also focused on superior inference by providing efficient attention on longer input sequences. In this paper, we summarize and examine the current state-of-the-art (SOTA) NLP models that have been employed for numerous NLP tasks for optimal performance and efficiency. We provide a detailed understanding and functioning of the different architectures, the taxonomy of NLP designs, comparative evaluations, and future directions in NLP.
https://weibo.com/1402400261/KcaLIliqE
2、[LG] Carbon Emissions and Large Neural Network Training
D Patterson, J Gonzalez, Q Le, C Liang, L Munguia, D Rothchild, D So, M Texier, J Dean
[Google & UC Berkeley]
碳排放和大规模神经网络训练。机器学习(ML)的计算需求最近迅速增长,一些成本伴随而来。估算能源成本有助于衡量其对环境的影响和寻找更环保的策略,然而,如果没有详细的信息,这是很有挑战性的。本文计算了最近几个大型模型——T5、Meena、GShard、Switch Transformer和GPT-3的能源使用和碳足迹,完善了对发现进化 Transformer的神经架构搜索(NAS)的前期估计。强调了以下提高能源效率和二氧化碳当量排放(CO2e)的机会。大型但稀疏激活的DNN可消耗<1/10的大型密集DNN的能量,尽管使用同等甚至更多的参数,也不会牺牲准确性。机器工作负载安排的地理位置很重要,无碳能源的比例和由此产生的CO2e有5倍到10倍的差异,即使在同一个国家和同一个组织内也是如此。具体的数据中心基础设施很重要,因为云计算数据中心的能源效率比典型的数据中心高1.4-2倍,而其中面向机器学习的加速器比现成系统有效2-5倍。对DNN、数据中心和处理器的选择,可以将碳足迹减少到~100-1000倍。为了帮助减少机器学习的碳足迹,能源使用和CO2e应该是评估模型的一个关键指标。
The computation demand for machine learning (ML) has grown rapidly recently, which comes with a number of costs. Estimating the energy cost helps measure its environmental impact and finding greener strategies, yet it is challenging without detailed information. We calculate the energy use and carbon footprint of several recent large models-T5, Meena, GShard, Switch Transformer, and GPT-3-and refine earlier estimates for the neural architecture search that found Evolved Transformer. We highlight the following opportunities to improve energy efficiency and CO2 equivalent emissions (CO2e): Large but sparsely activated DNNs can consume <1/10th the energy of large, dense DNNs without sacrificing accuracy despite using as many or even more parameters. Geographic location matters for ML workload scheduling since the fraction of carbon-free energy and resulting CO2e vary ~5X-10X, even within the same country and the same organization. We are now optimizing where and when large models are trained. Specific datacenter infrastructure matters, as Cloud datacenters can be ~1.4-2X more energy efficient than typical datacenters, and the ML-oriented accelerators inside them can be ~2-5X more effective than off-the-shelf systems. Remarkably, the choice of DNN, datacenter, and processor can reduce the carbon footprint up to ~100-1000X. These large factors also make retroactive estimates of energy cost difficult. To avoid miscalculations, we believe ML papers requiring large computational resources should make energy consumption and CO2e explicit when practical. We are working to be more transparent about energy use and CO2e in our future research. To help reduce the carbon footprint of ML, we believe energy usage and CO2e should be a key metric in evaluating models, and we are collaborating with MLPerf developers to include energy usage during training and inference in this industry standard benchmark.
https://weibo.com/1402400261/KcaRPcP5T
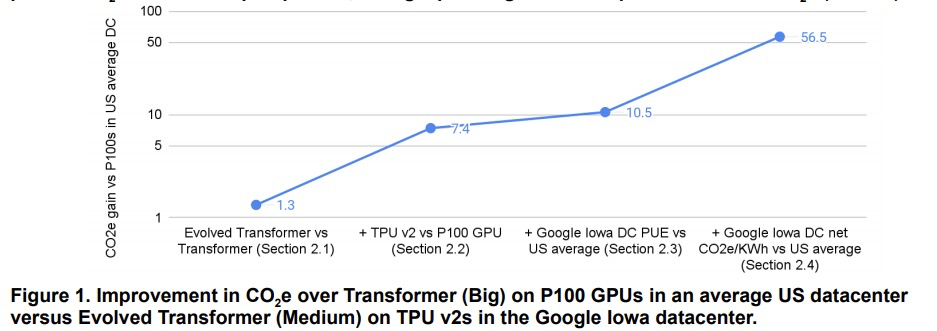
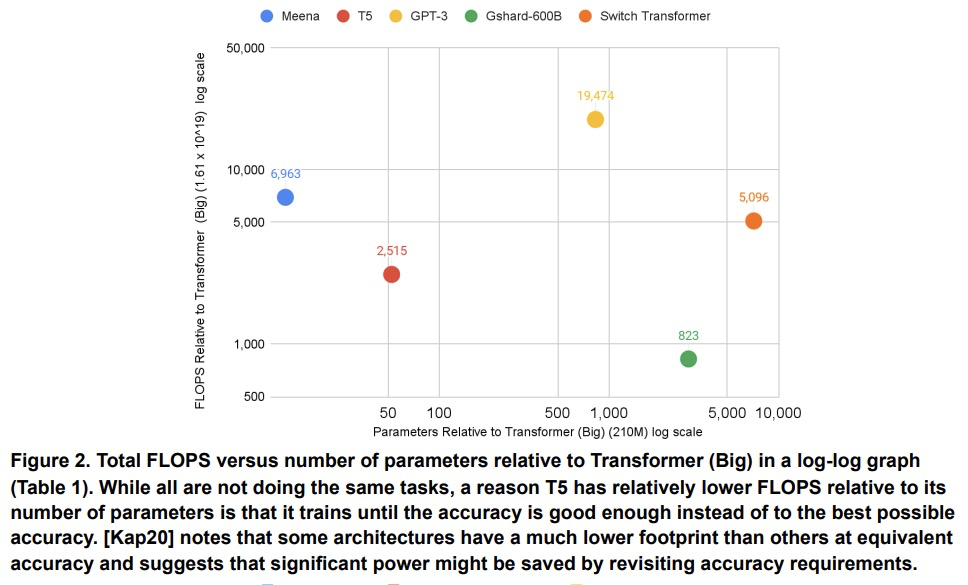
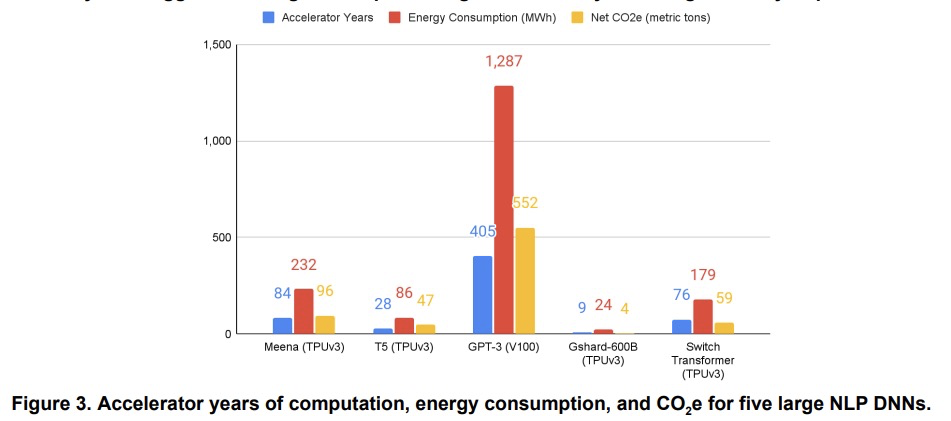
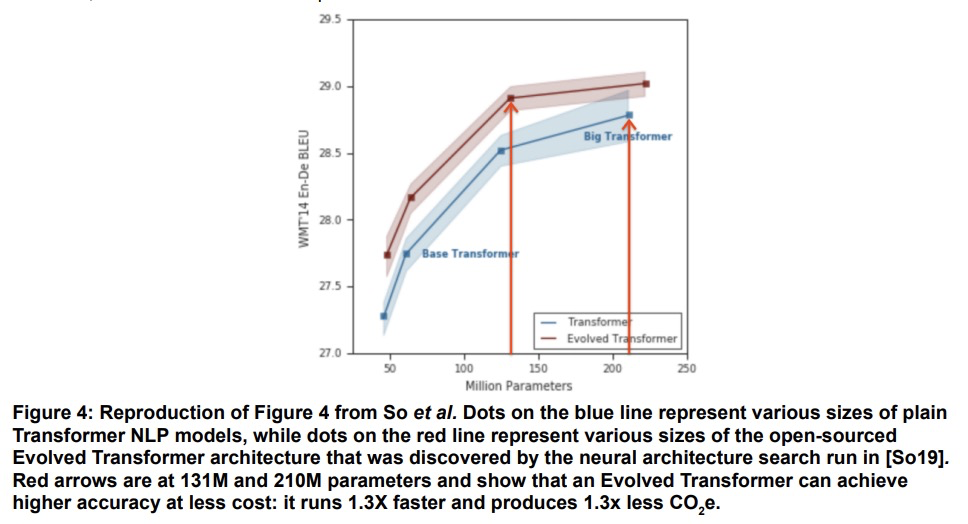
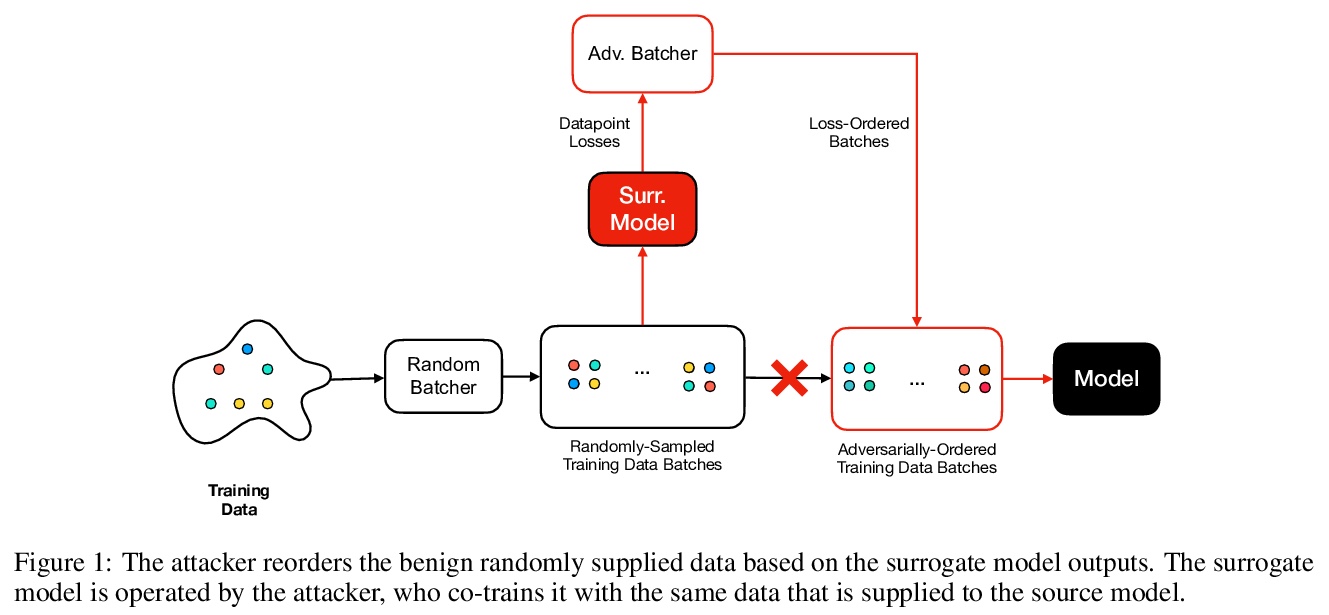
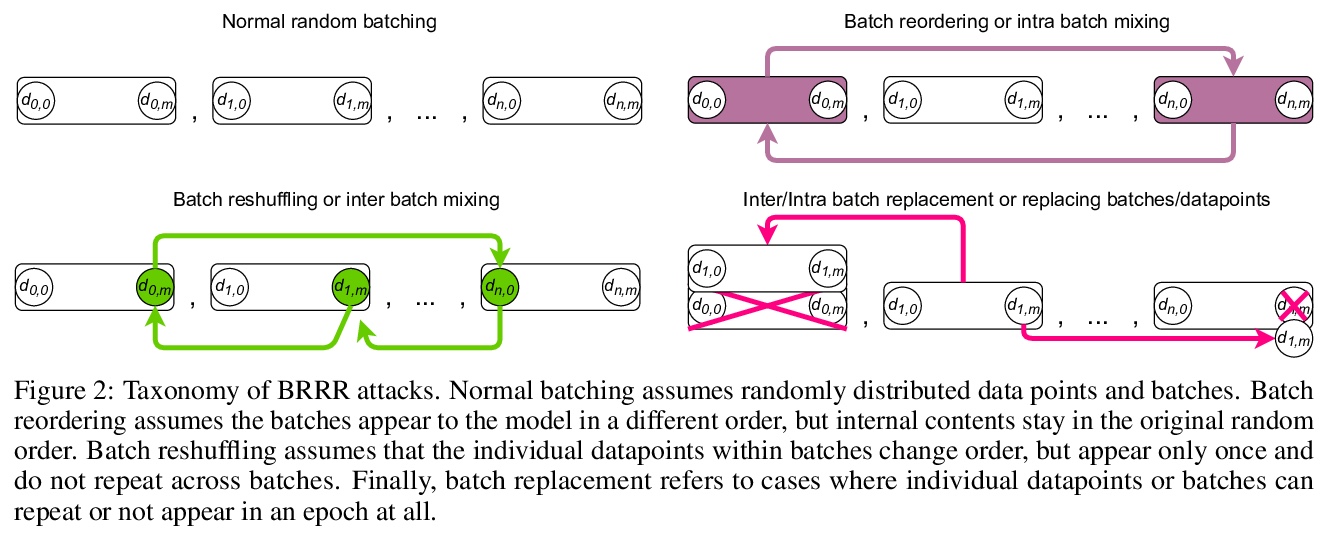
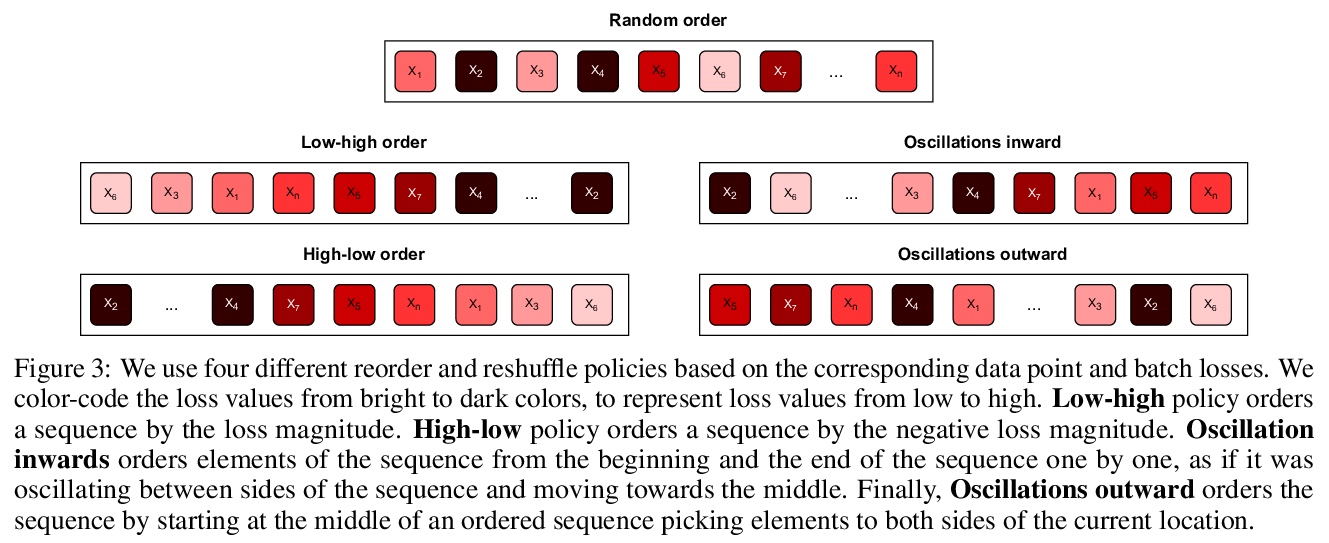
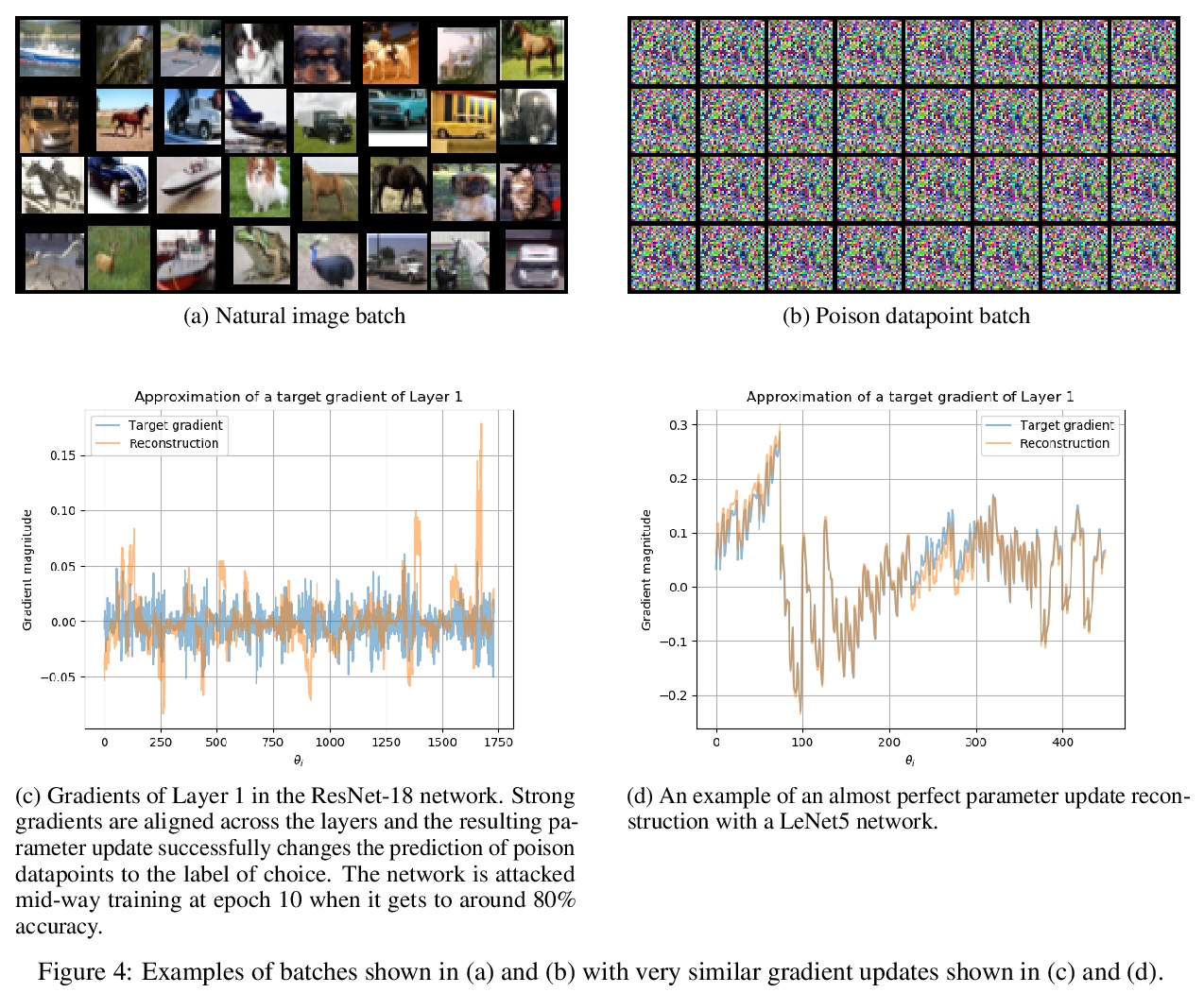
3、[LG] Manipulating SGD with Data Ordering Attacks
I Shumailov, Z Shumaylov, D Kazhdan, Y Zhao, N Papernot, M A. Erdogdu, R Anderson
[University of Cambridge & University of Toronto]
用数据排序攻击操纵SGD。机器学习很容易受到各种不同的攻击。现已明确,通过改变底层数据分布,攻击者可以干扰甚至破坏用它训练的模型或引入后门。本文提出一类新的攻击,通过改变批次顺序,或其中数据点的顺序,来操纵模型训练的完整性和可用性。对一个模型的训练数据进行仔细的重新排序,可以在不改变训练数据集的情况下,使其中毒或被引入后门。所提出的攻击完全是黑箱的,不依赖于目标模型的知识或训练数据的先验知识。攻击者可以引入后门而不破坏整个模型的泛化性,即使只用自然数据。采样程序可以被确定性地操纵,以控制模型的行为方式。本文工作强调,如果要建立值得信赖的机器学习系统,需要把它们建立在默认安全的管道上,并允许进行检查。大型模型复杂度不断增加,导致单个组件相互隐藏,降低了整体的透明度。复杂度和不透明度将导致未来的问题和被利用的隐患。一个可能的方法,是用密码学来确保在训练期间用于驱动选择数据点和批次的随机性是可审计的,魔鬼总在细节中。
Machine learning is vulnerable to a wide variety of different attacks. It is now well understood that by changing the underlying data distribution, an adversary can poison the model trained with it or introduce backdoors. In this paper we present a novel class of training-time attacks that require no changes to the underlying model dataset or architecture, but instead only change the order in which data are supplied to the model. In particular, an attacker can disrupt the integrity and availability of a model by simply reordering training batches, with no knowledge about either the model or the dataset. Indeed, the attacks presented here are not specific to the model or dataset, but rather target the stochastic nature of modern learning procedures. We extensively evaluate our attacks to find that the adversary can disrupt model training and even introduce backdoors.For integrity we find that the attacker can either stop the model from learning, or poison it to learn behaviours specified by the attacker. For availability we find that a single adversarially-ordered epoch can be enough to slow down model learning, or even to reset all of the learning progress. Such attacks have a long-term impact in that they decrease model performance hundreds of epochs after the attack took place. Reordering is a very powerful adversarial paradigm in that it removes the assumption that an adversary must inject adversarial data points or perturbations to perform training-time attacks. It reminds us that stochastic gradient descent relies on the assumption that data are sampled at random. If this randomness is compromised, then all bets are off.
https://weibo.com/1402400261/KcaXuenvE
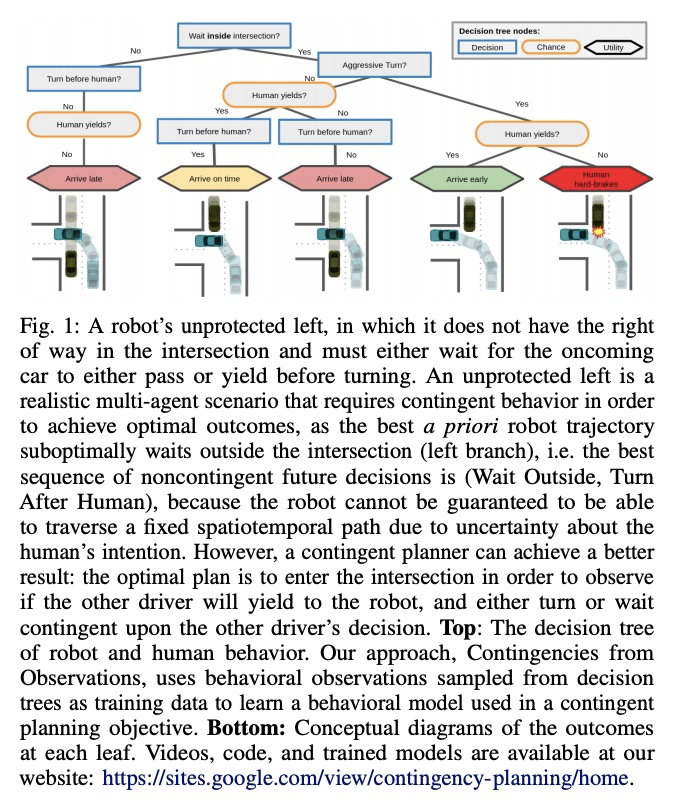
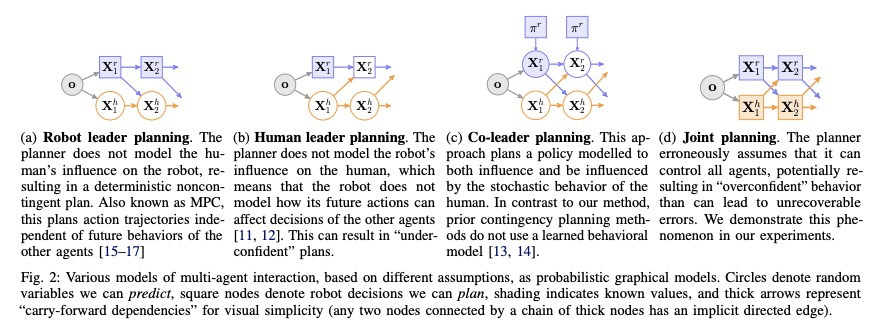
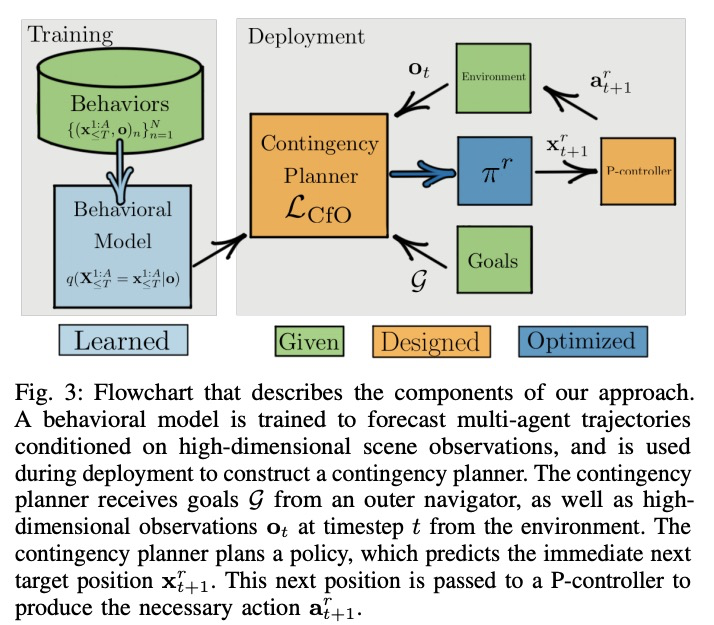
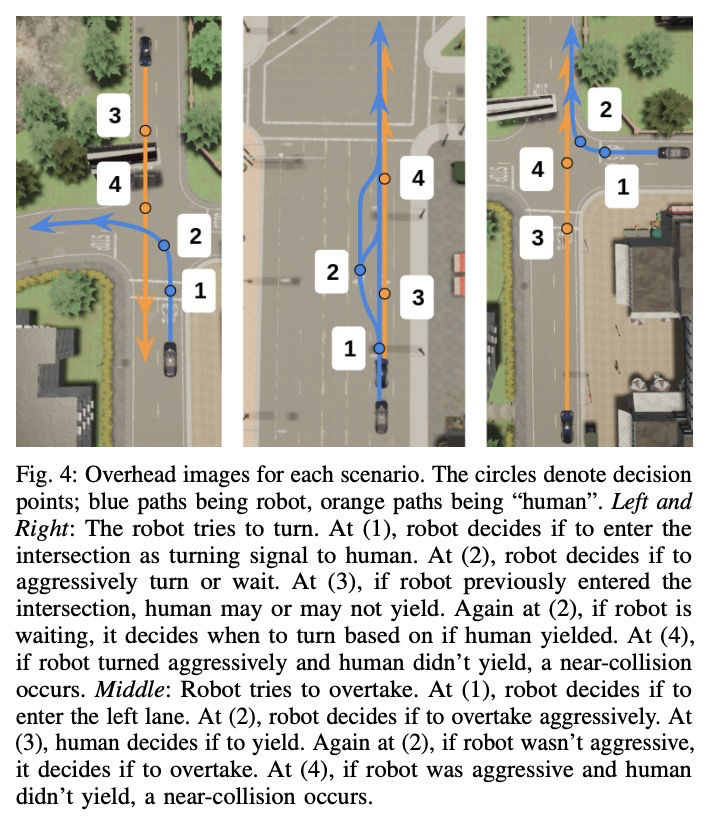
4、[RO] Contingencies from Observations: Tractable Contingency Planning with Learned Behavior Models
N Rhinehart, J He, C Packer, M A. Wright, R McAllister, J E. Gonzalez, S Levine
[UC Berkeley]
基于观察的应急措施:基于习得行为模型的可操作应急计划。人类有一种非凡的能力,可通过准确推理未来事件,包括其他个体的未来行为和心理状态来做出决定。考虑驾驶汽车通过一个繁忙的十字路口的例子:有必要对车辆的物理特性、其他司机的意图以及他们对你自己意图的信念进行推理。如果发出转弯信号,另一个司机可能会让给你,或者如果你进入超车道,另一个司机可能会减速,给你留出空间在前面并线。有能力的司机必须在做出下一步行动之前,计划如何对其他个体的各种潜在的未来行为作出安全反应。这就需要应急计划:明确计划一套取决于未来事件随机结果的条件性行动。应急规划输出的策略,是未来时间段和观察结果的函数,而基于标准模型预测控制的规划,输出的是未来行动的序列,这相当于一个仅是未来时间段函数的策略。本文开发了一个通用的应急规划器,利用高维场景观测和低维行为观测,进行端到端学习。用条件自回归流模型来创建紧凑的应急规划空间,并展示该模型如何从行为观察中切实地学习应急措施。在驾驶模拟器(CARLA)中开发了一个现实的多智能体场景的闭环控制基准,在此基础上,将该方法与各种推理多智能体未来行为的非权变方法进行了比较,包括几种基于深度学习的规划方法。实验说明,这些非权变规划方法在这个基准上根本上是失败的,所提出的深度权变规划方法取得了明显的优越性能。
Humans have a remarkable ability to make decisions by accurately reasoning about future events, including the future behaviors and states of mind of other agents. Consider driving a car through a busy intersection: it is necessary to reason about the physics of the vehicle, the intentions of other drivers, and their beliefs about your own intentions. If you signal a turn, another driver might yield to you, or if you enter the passing lane, another driver might decelerate to give you room to merge in front. Competent drivers must plan how they can safely react to a variety of potential future behaviors of other agents before they make their next move. This requires contingency planning: explicitly planning a set of conditional actions that depend on the stochastic outcome of future events. In this work, we develop a general-purpose contingency planner that is learned end-to-end using high-dimensional scene observations and low-dimensional behavioral observations. We use a conditional autoregressive flow model to create a compact contingency planning space, and show how this model can tractably learn contingencies from behavioral observations. We developed a closed-loop control benchmark of realistic multi-agent scenarios in a driving simulator (CARLA), on which we compare our method to various noncontingent methods that reason about multi-agent future behavior, including several state-of-the-art deep learning-based planning approaches. We illustrate that these noncontingent planning methods fundamentally fail on this benchmark, and find that our deep contingency planning method achieves significantly superior performance. Code to run our benchmark and reproduce our results is available atthis https URL
https://weibo.com/1402400261/Kcb2Jj286
5、[CL] Timers and Such: A Practical Benchmark for Spoken Language Understanding with Numbers
L Lugosch, P Papreja, M Ravanelli, A Heba, T Parcollet
[McGill University & Mila & Universite Paul Sabatier]
Timers and Such:数字口语理解实用基准。创建了一个新的开源数据集Timers and Such,包含涉及数字的常见语音控制用例的英语口语命令。Timer and Such填补了现有口语理解数据集的空白,设计和创建了该数据集,并对一些基于ASR和端到端基线模型进行了实验。
This paper introduces Timers and Such, a new open source dataset of spoken English commands for common voice control use cases involving numbers. We describe the gap in existing spoken language understanding datasets that Timers and Such fills, the design and creation of the dataset, and experiments with a number of ASR-based and end-to-end baseline models, the code for which has been made available as part of the SpeechBrain toolkit.
https://weibo.com/1402400261/Kcb6ihpby

另外几篇值得关注的论文:
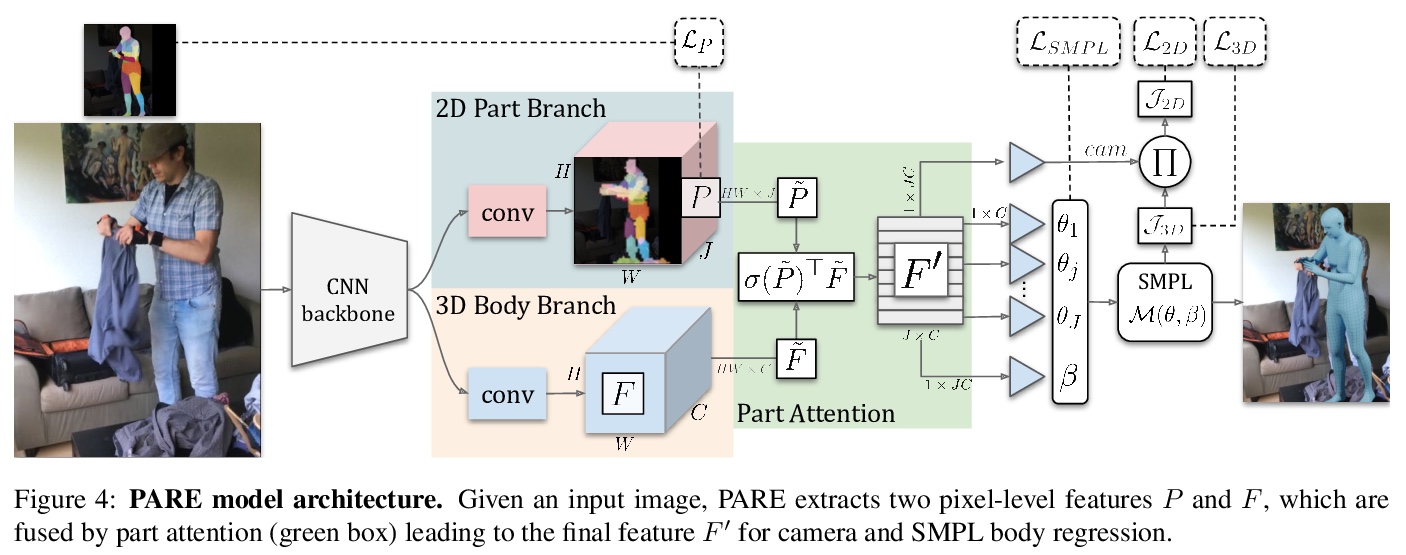
[CV] PARE: Part Attention Regressor for 3D Human Body Estimation
PARE:面向3D人体估计的部分注意力回归器
M Kocabas, C P. Huang, O Hilliges, M J. Black
[Max Planck Institute for Intelligent Systems & ETH Zurich]
https://weibo.com/1402400261/Kcb9OnXER


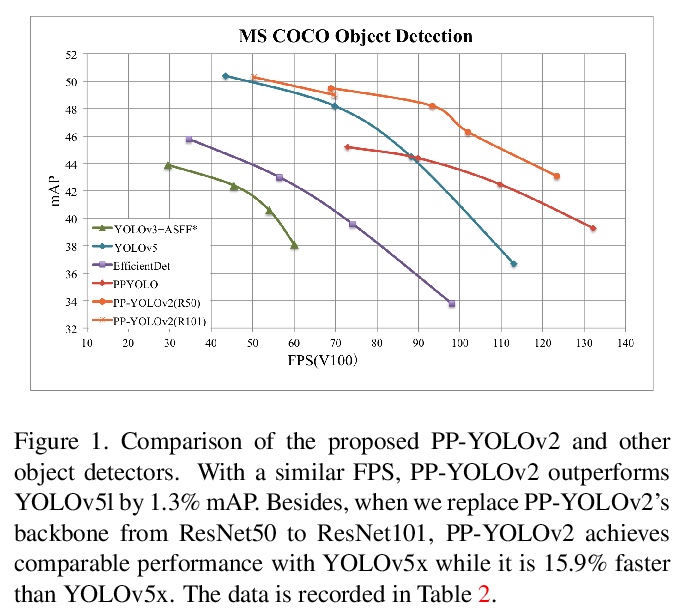
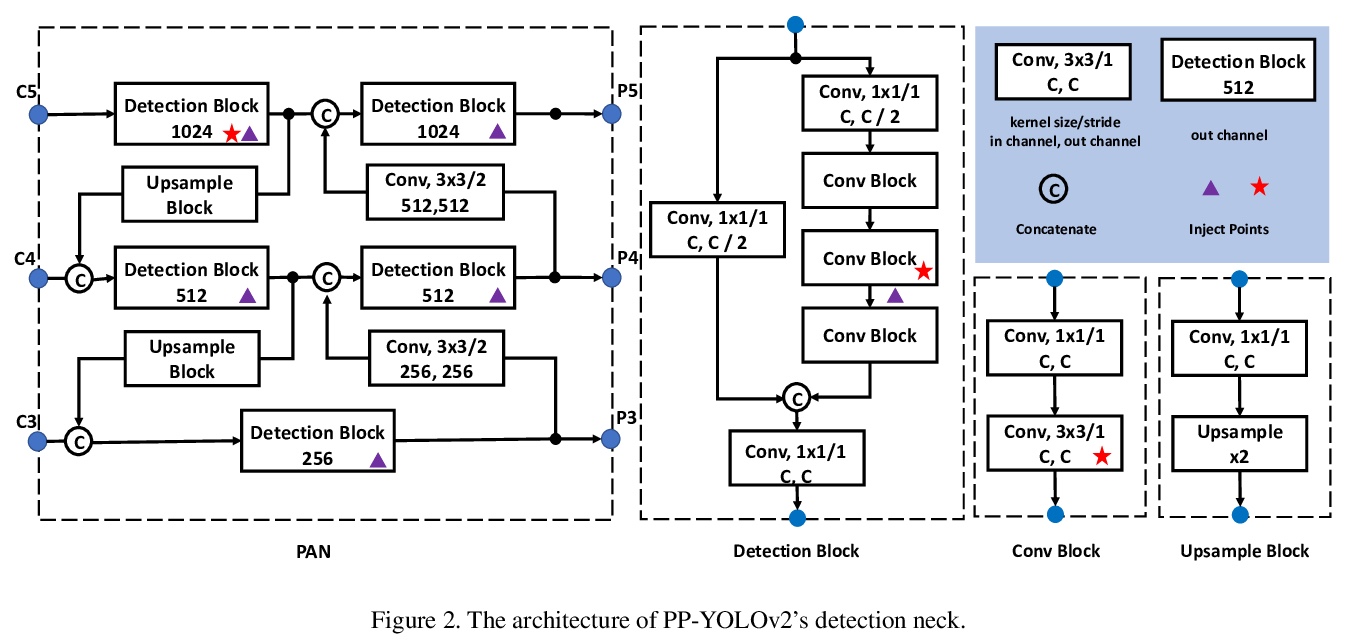
[CV] PP-YOLOv2: A Practical Object Detector
PP-YOLOv2:实用的目标检测器
X Huang, X Wang, W Lv, X Bai, X Long, K Deng, Q Dang, S Han, Q Liu, X Hu, D Yu, Y Ma, O Yoshie
[Baidu Inc & Waseda University]
https://weibo.com/1402400261/Kcbb3wpBy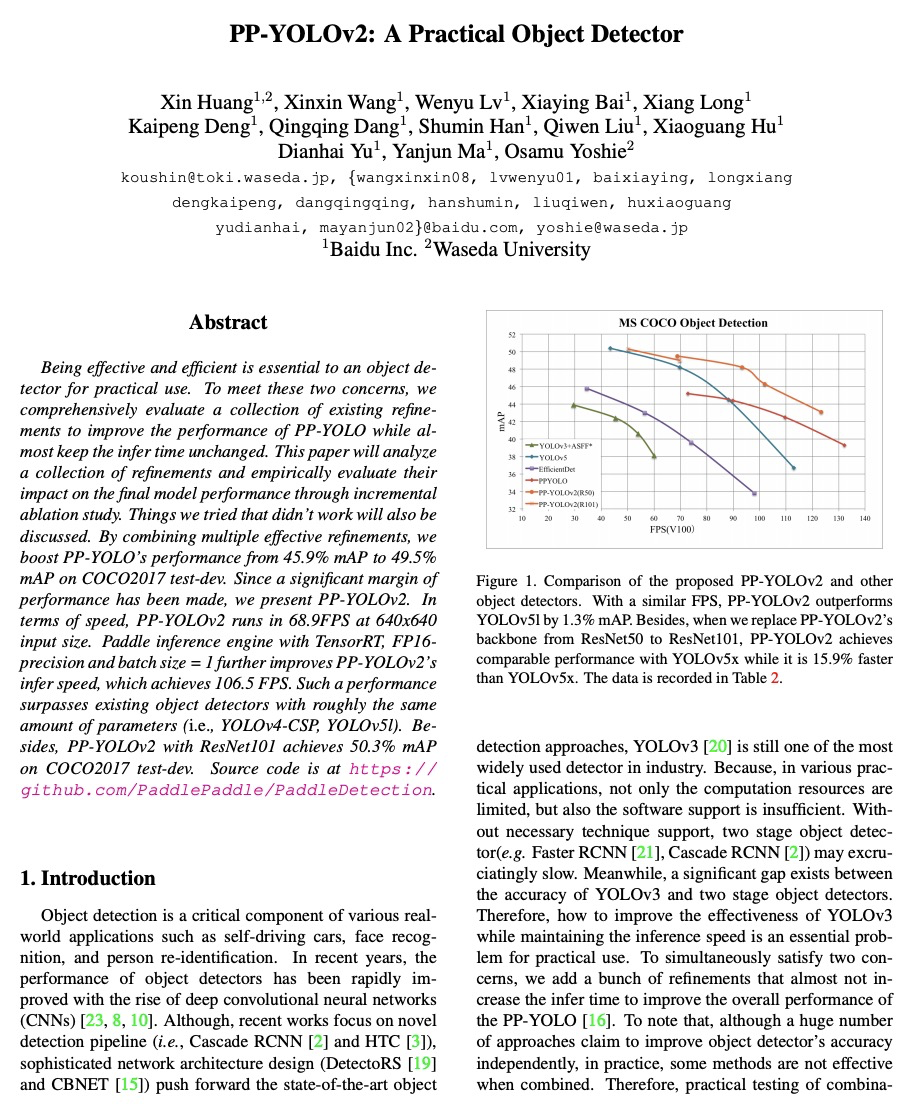
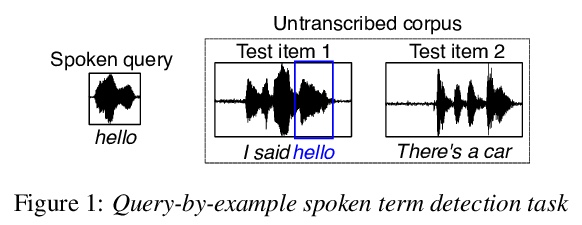
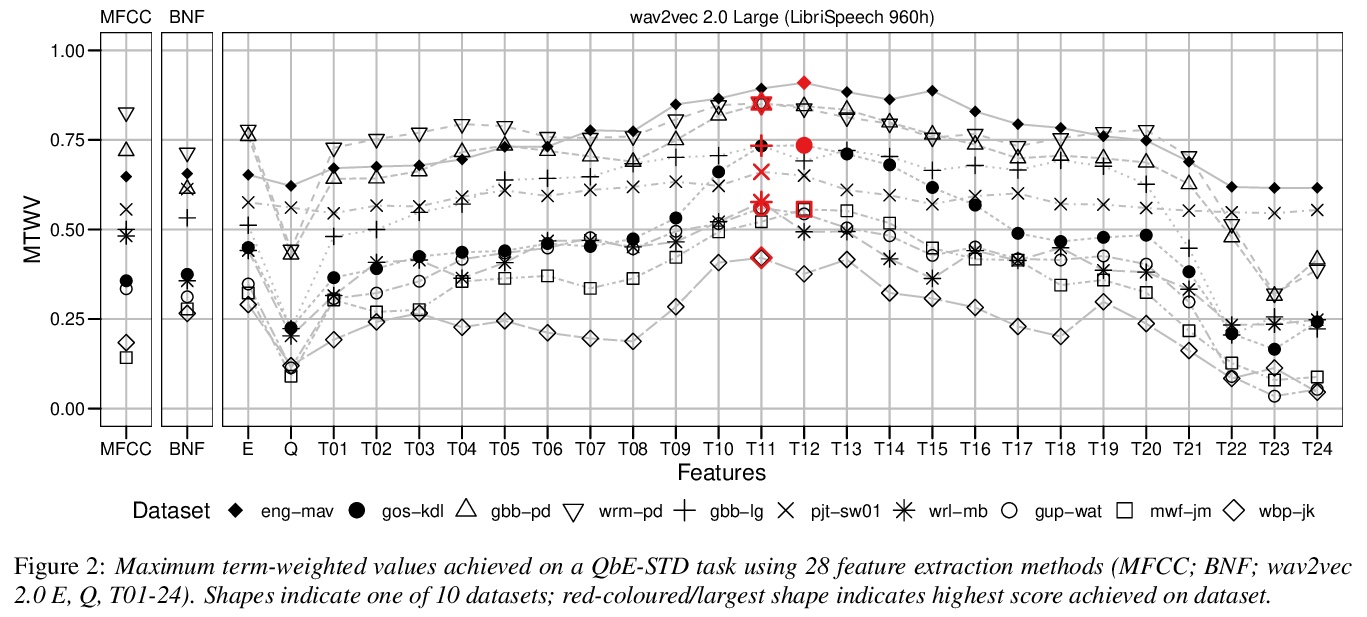
[CL] Leveraging neural representations for facilitating access to untranscribed speech from endangered languages
用神经表征促进从濒危语言中获取未被转录的语音
N San, M Bartelds, M Browne, L Clifford, F Gibson, J Mansfield, D Nash, J Simpson, M Turpin, M Vollmer, S Wilmoth, D Jurafsky
[Stanford University & ARC Centre of Excellence for the Dynamics of Language & University of Groningen]
https://weibo.com/1402400261/KcbccrxgT
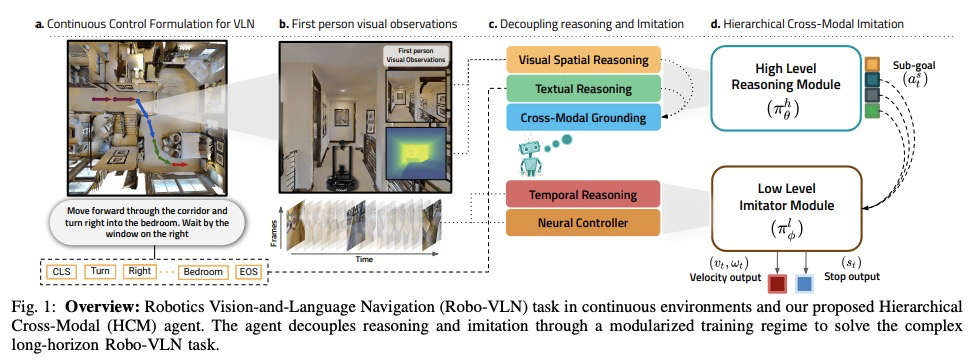
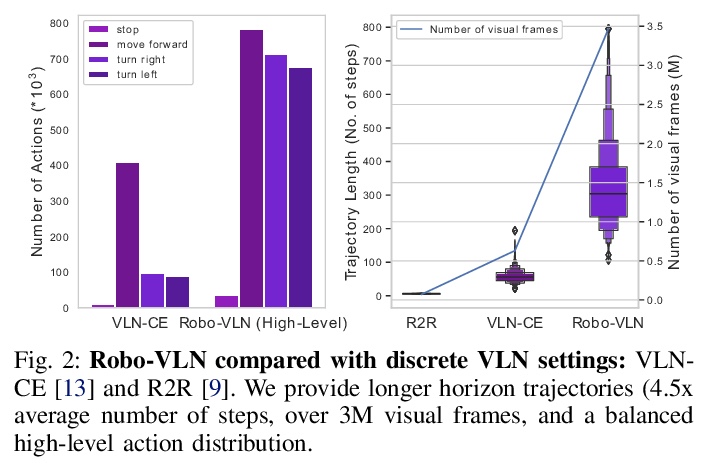
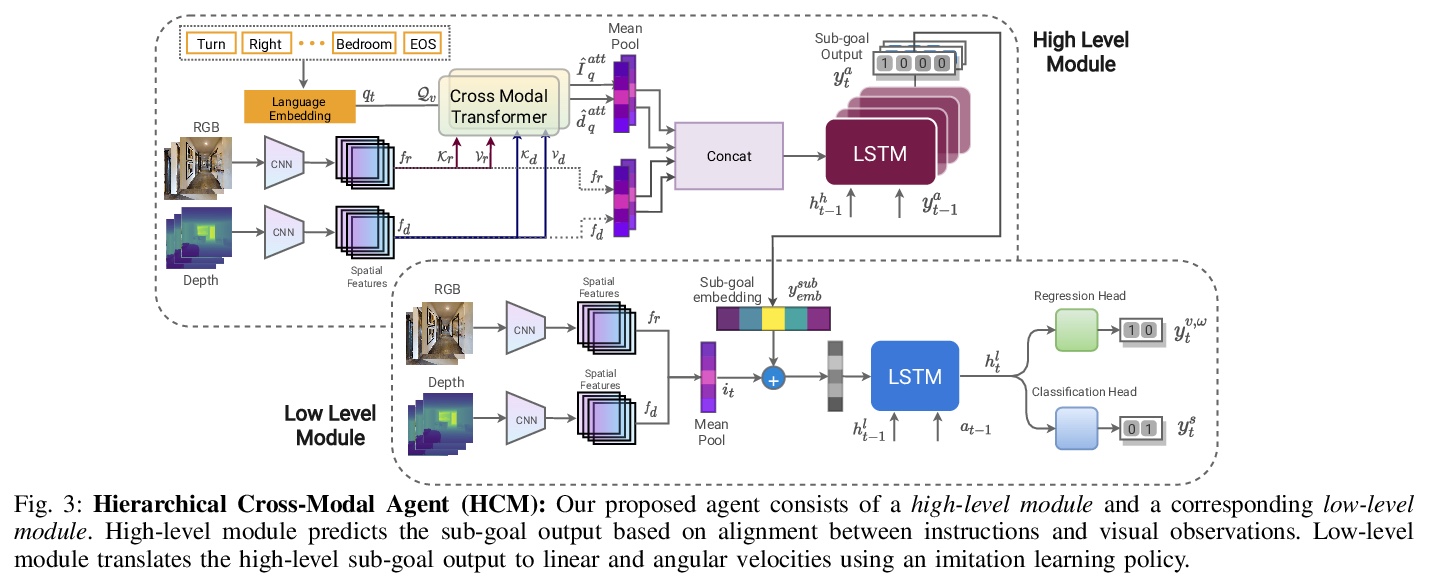
[RO] Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation
机器人视觉-语言导航的分层跨模态智能体
M Z Irshad, C Ma, Z Kira
[Georgia Institute of Technology]
https://weibo.com/1402400261/KcbdzvoDc

若有收获,就点个赞吧
0 人点赞
