LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] *Do Wide and Deep Networks Learn the Same Things? Uncovering How Neural Network Representations Vary with Width and Depth
T Nguyen, M Raghu, S Kornblith
[Google Research]
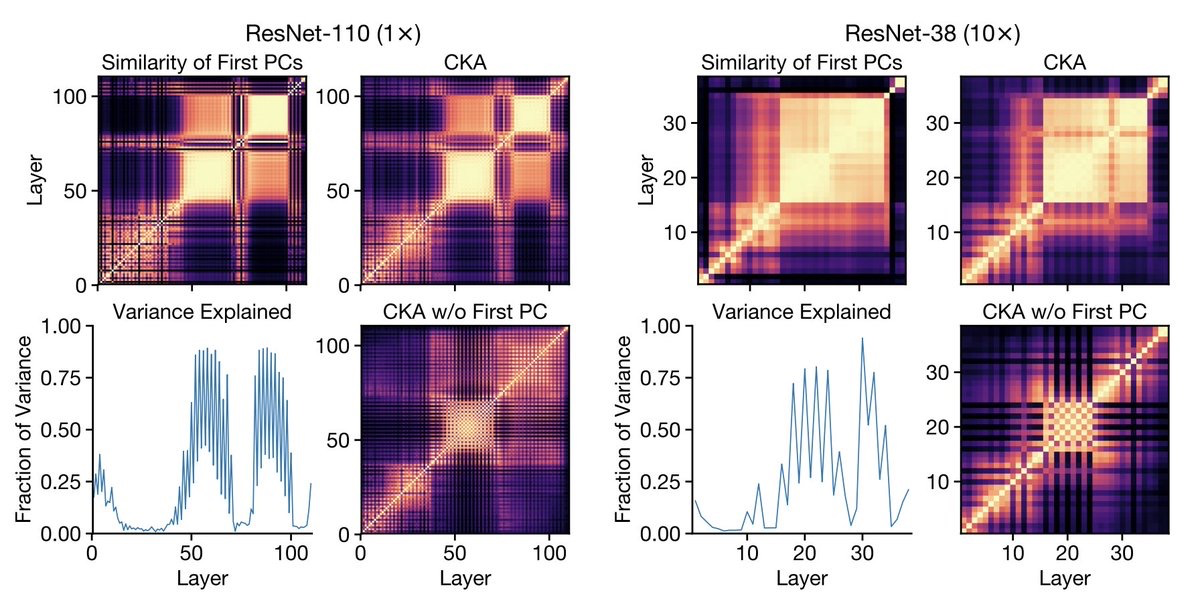
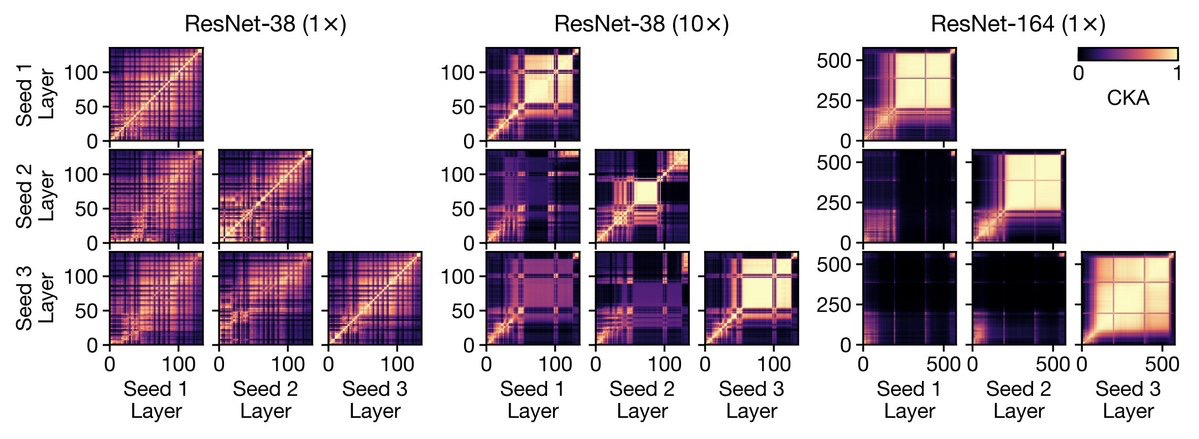
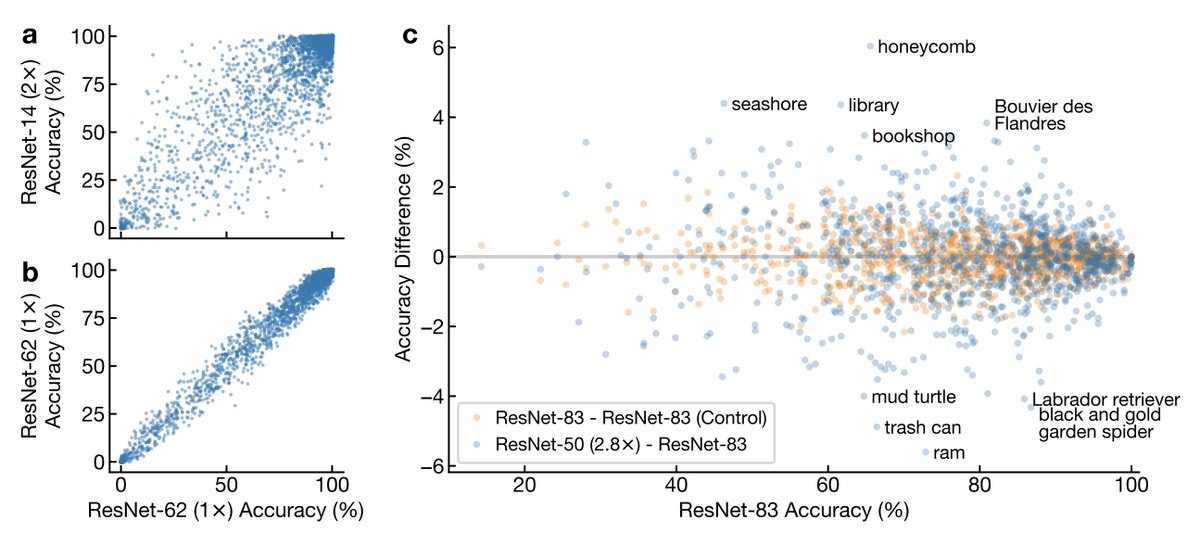
宽度和深度对神经网络表示的影响。研究了在CIFAR和 ImageNet上训练的模型内和跨模型的宽度和深度如何影响学到的表示,提出了高效的计算中心核对齐(CKA)方法,用来度量表示的相似度,通过实验发现,在大型(宽和/或深)模型中,模型层表示中出现了一种特有的块结构。通过改变训练数据集大小,发现当模型容量相对训练集较大时,就会出现块结构。块结构源于层表示第一主成分的保持和传播,对于线性探测的精度有明显影响,且组成层是坍缩的。在不同随机初始化和配置模型间,块结构以外的表示通常是相似的,但每个模型的块结构是独一无二的。对于常见的数据集,如CIFAR-10和ImageNet,宽度和深度模型在实例级和类级都会系统性地出现不同的错误。**
A key factor in the success of deep neural networks is the ability to scale models to improve performance by varying the architecture depth and width. This simple property of neural network design has resulted in highly effective architectures for a variety of tasks. Nevertheless, there is limited understanding of effects of depth and width on the learned representations. In this paper, we study this fundamental question. We begin by investigating how varying depth and width affects model hidden representations, finding a characteristic block structure in the hidden representations of larger capacity (wider or deeper) models. We demonstrate that this block structure arises when model capacity is large relative to the size of the training set, and is indicative of the underlying layers preserving and propagating the dominant principal component of their representations. This discovery has important ramifications for features learned by different models, namely, representations outside the block structure are often similar across architectures with varying widths and depths, but the block structure is unique to each model. We analyze the output predictions of different model architectures, finding that even when the overall accuracy is similar, wide and deep models exhibit distinctive error patterns and variations across classes.
https://weibo.com/1402400261/JrYLLz285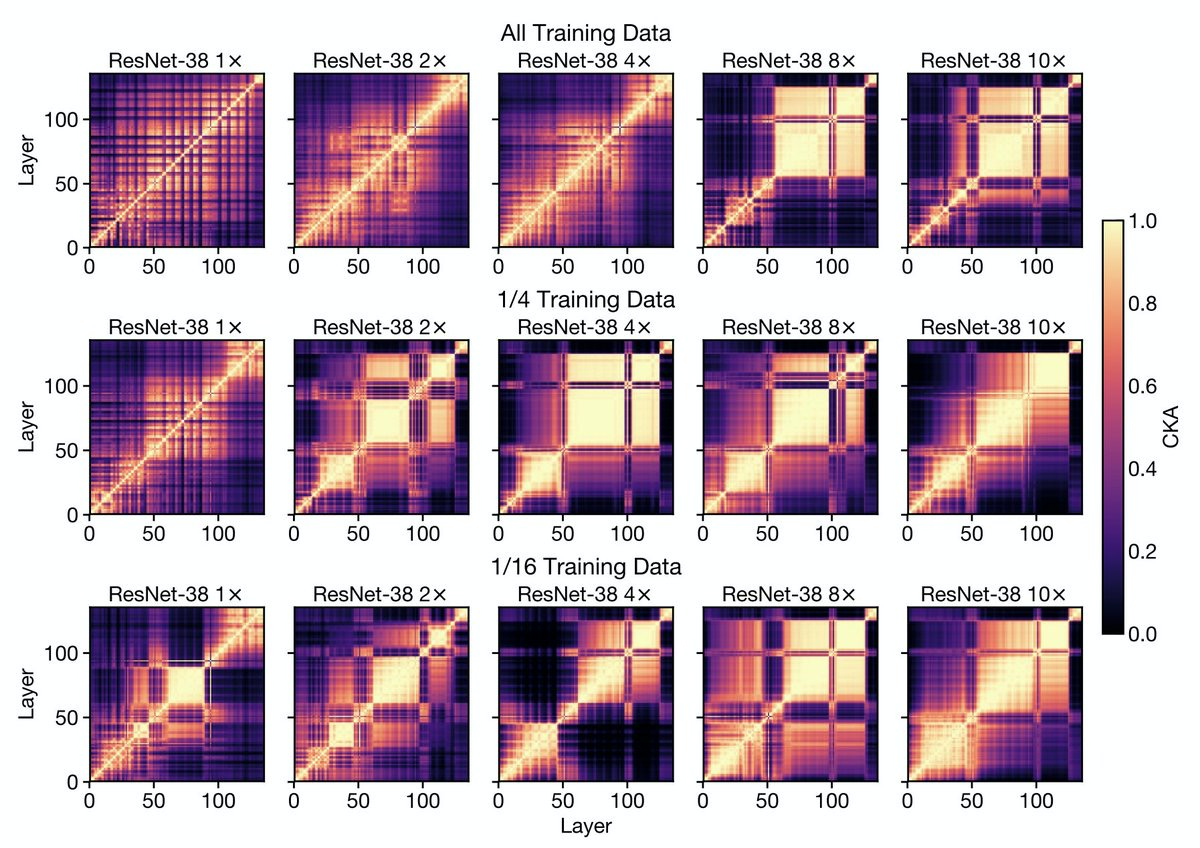
2、[CV] *Permute, Quantize, and Fine-tune: Efficient Compression of Neural Networks
J Martinez, J Shewakramani, T W Liu, I A Bârsan, W Zeng, R Urtasun
[Uber Advanced Technologies Group]
排列、量化和微调:神经网络的高精度压缩。提出一种方法,利用网络相邻层权值置换的功能等价性,找到更容易量化的权值配置;通过与速率失真理论建立联系,搜索让网络更容易压缩的排列;用退火K均值算法进一步减少量化误差,以产生更准确的模型。实验表明,该方法压缩的模型,相对于目前的最高水平,与未压缩模型精度的差距缩小了40 - 70%。**
Compressing large neural networks is an important step for their deployment in resource-constrained computational platforms. In this context, vector quantization is an appealing framework that expresses multiple parameters using a single code, and has recently achieved state-of-the-art network compression on a range of core vision and natural language processing tasks. Key to the success of vector quantization is deciding which parameter groups should be compressed together. Previous work has relied on heuristics that group the spatial dimension of individual convolutional filters, but a general solution remains unaddressed. This is desirable for pointwise convolutions (which dominate modern architectures), linear layers (which have no notion of spatial dimension), and convolutions (when more than one filter is compressed to the same codeword). In this paper we make the observation that the weights of two adjacent layers can be permuted while expressing the same function. We then establish a connection to rate-distortion theory and search for permutations that result in networks that are easier to compress. Finally, we rely on an annealed quantization algorithm to better compress the network and achieve higher final accuracy. We show results on image classification, object detection, and segmentation, reducing the gap with the uncompressed model by 40 to 70% with respect to the current state of the art.
https://weibo.com/1402400261/JrYS57XsS
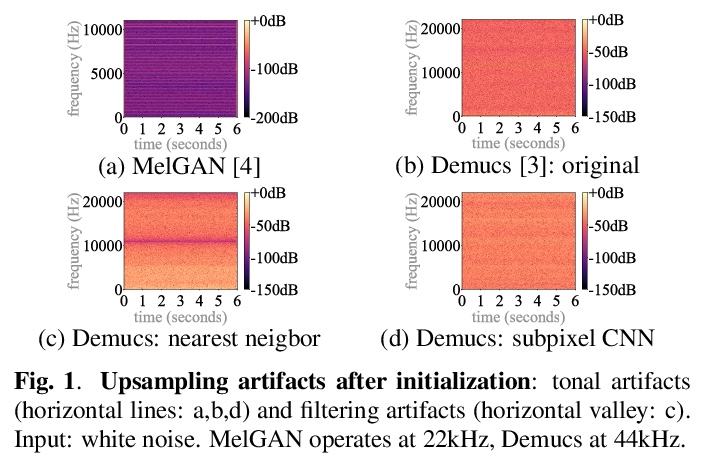
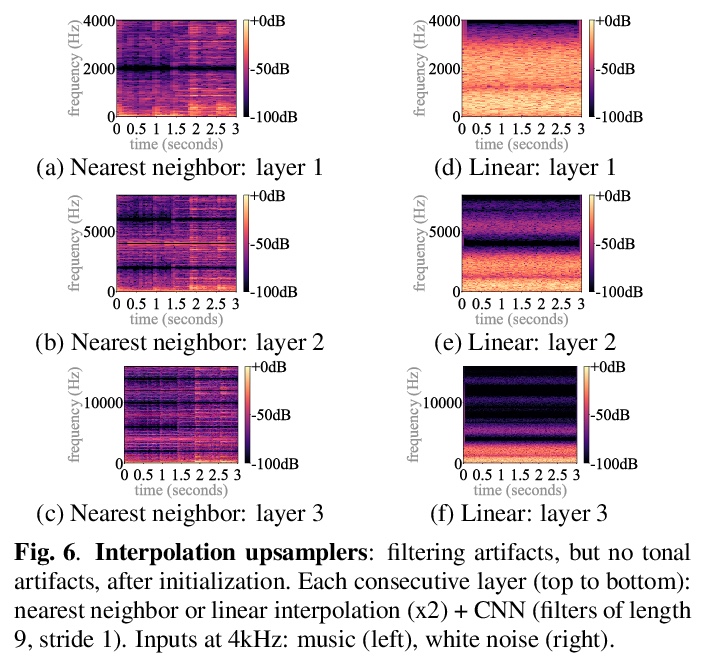
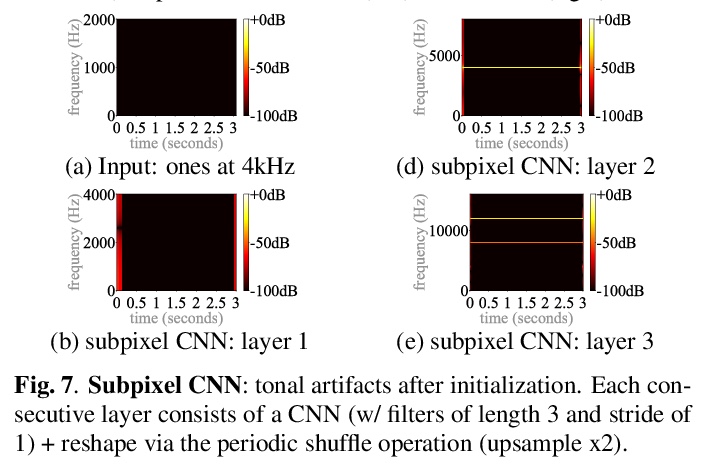
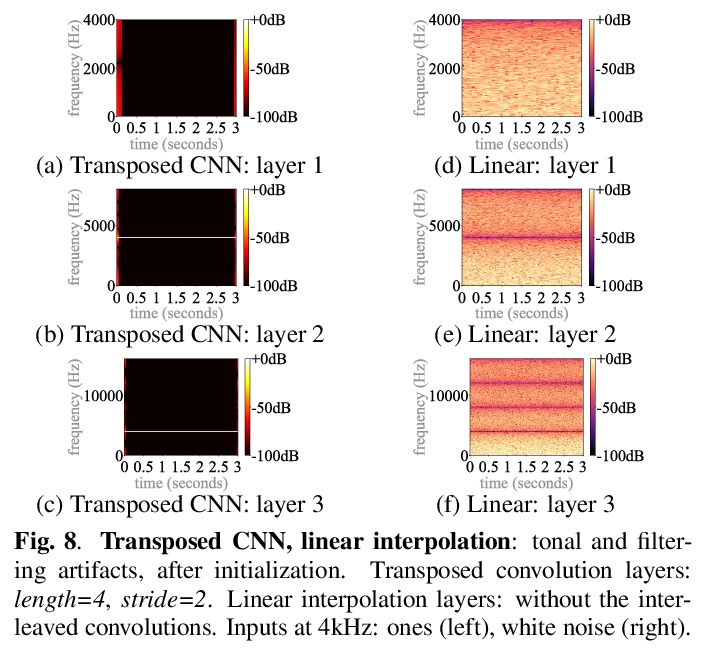
3、[AS] *Upsampling artifacts in neural audio synthesis
J Pons, S Pascual, G Cengarle, J Serrà
[Dolby Laboratories]
神经网络音频合成中的上采样伪影。从音频信号处理的角度,研究神经网络上采样器带来的伪影(artifacts)效应。发现上采样伪影的主要来源包括:有问题的上采样操作子带来的有问题的音调和滤波伪影,以及上采样时出现的谱重复。比较了不同的神经网络上采样器,表明最近邻插值上采样器可以替代容易引入音调伪像的(但最先进的)转置和亚像素卷积。**
A number of recent advances in audio synthesis rely on neural upsamplers, which can introduce undesired artifacts. In computer vision, upsampling artifacts have been studied and are known as checkerboard artifacts (due to their characteristic visual pattern). However, their effect has been overlooked so far in audio processing. Here, we address this gap by studying this problem from the audio signal processing perspective. We first show that the main sources of upsampling artifacts are: (i) the tonal and filtering artifacts introduced by problematic upsampling operators, and (ii) the spectral replicas that emerge while upsampling. We then compare different neural upsamplers, showing that nearest neighbor interpolation upsamplers can be an alternative to the problematic (but state-of-the-art) transposed and subpixel convolutions which are prone to introduce tonal artifacts.
4、[LG] Scaling Laws for Autoregressive Generative Modeling
T Henighan, J Kaplan, M Katz, M Chen, C Hesse, J Jackson, H Jun, T B. Brown, P Dhariwal, S Gray, C Hallacy, B Mann, A Radford, A Ramesh, N Ryder, D M. Ziegler, J Schulman, D Amodei, S McCandlish
[OpenAI]
自回归生成模型的尺度律。自回归Transformer遵循鲁棒幂律,自回归Transformer的性能随着模型大小和计算成本的增加而平稳提高,遵循幂律和常数比例律,预训练模型的微调也遵循类似的幂律。**
We identify empirical scaling laws for the cross-entropy loss in four domains: generative image modeling, video modeling, multimodal image> ↔text models, and mathematical problem solving. In all cases autoregressive Transformers smoothly improve in performance as model size and compute budgets increase, following a power-law plus constant scaling law. The optimal model size also depends on the compute budget through a power-law, with exponents that are nearly universal across all data domains.The cross-entropy loss has an information theoretic interpretation as > S(True> )+DKL(True> ||Model> ), and the empirical scaling laws suggest a prediction for both the true data distribution’s entropy and the KL divergence between the true and model distributions. With this interpretation, billion-parameter Transformers are nearly perfect models of the YFCC100M image distribution downsampled to an > 8×8 resolution, and we can forecast the model size needed to achieve any given reducible loss (ie > DKL) in nats/image for other resolutions.We find a number of additional scaling laws in specific domains: (a) we identify a scaling relation for the mutual information between captions and images in multimodal models, and show how to answer the question “Is a picture worth a thousand words?”; (b) in the case of mathematical problem solving, we identify scaling laws for model performance when extrapolating beyond the training distribution; (c) we finetune generative image models for ImageNet classification and find smooth scaling of the classification loss and error rate, even as the generative loss levels off. Taken together, these results strengthen the case that scaling laws have important implications for neural network performance, including on downstream tasks.
https://weibo.com/1402400261/JrZ3kaMHP
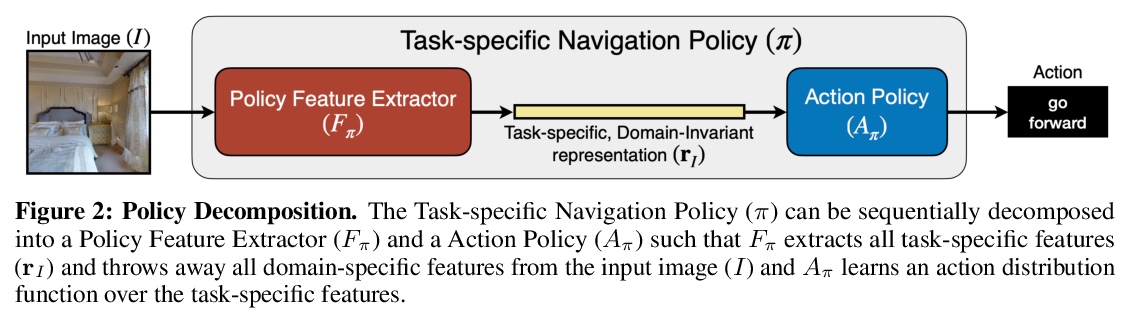
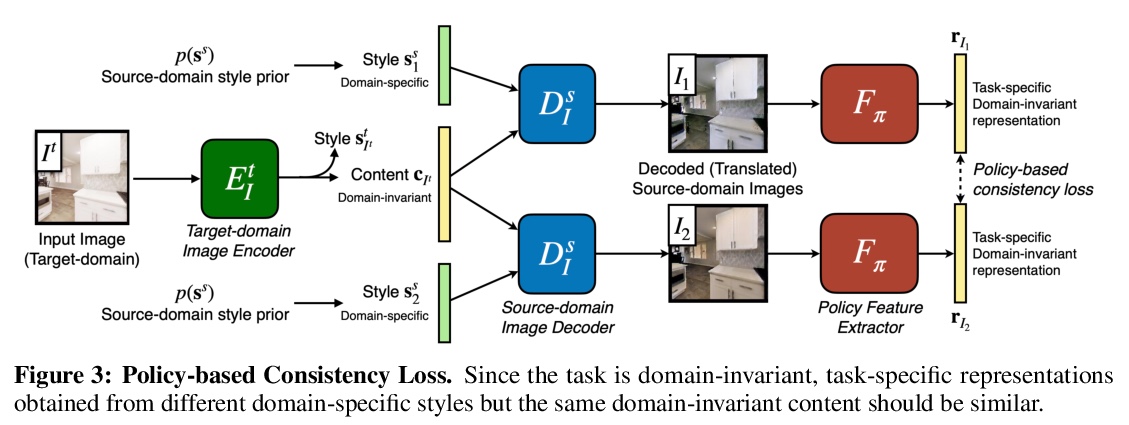
5、[CV] **Unsupervised Domain Adaptation for Visual Navigation
S Li, D S Chaplot, Y H Tsai, Y Wu, L Morency, R Salakhutdinov
[CMU]
无监督域自适应视觉导航。提出了一种域自适应方法,将导航策略从仿真迁移到现实中。给定源域中的导航策略,该方法将图像从目标域迁移到源域,与给定策略学习到的任务特定和域不变表示一致。在两种不同任务下的仿真实验表明,该方法可提高基线上迁移导航策略的性能。**
Advances in visual navigation methods have led to intelligent embodied navigation agents capable of learning meaningful representations from raw RGB images and perform a wide variety of tasks involving structural and semantic reasoning. However, most learning-based navigation policies are trained and tested in simulation environments. In order for these policies to be practically useful, they need to be transferred to the real-world. In this paper, we propose an unsupervised domain adaptation method for visual navigation. Our method translates the images in the target domain to the source domain such that the translation is consistent with the representations learned by the navigation policy. The proposed method outperforms several baselines across two different navigation tasks in simulation. We further show that our method can be used to transfer the navigation policies learned in simulation to the real world.
https://weibo.com/1402400261/JrZ9glGqt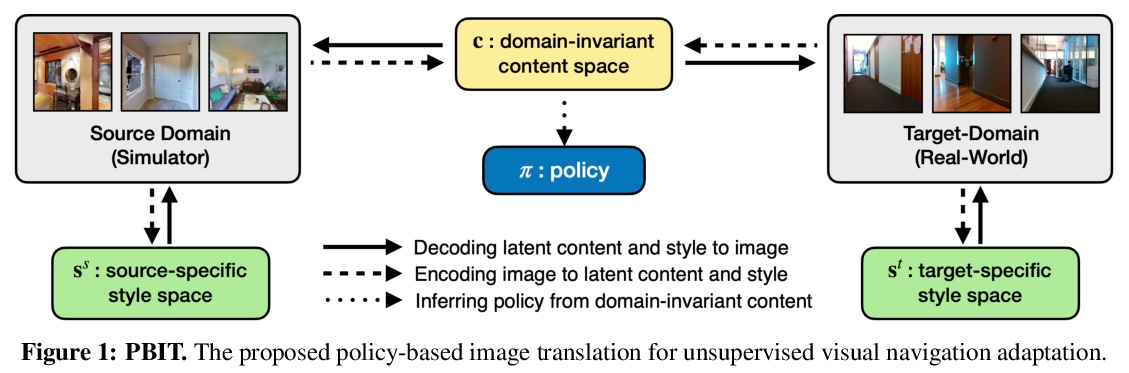
另外几篇值得关注的论文:
[CL] Topic Modeling with Contextualized Word Representation Clusters
上下文词表示聚类主题建模
L Thompson, D Mimno
[University of Massachusetts Amherst & Cornell University]
https://weibo.com/1402400261/JrZbVi6Tz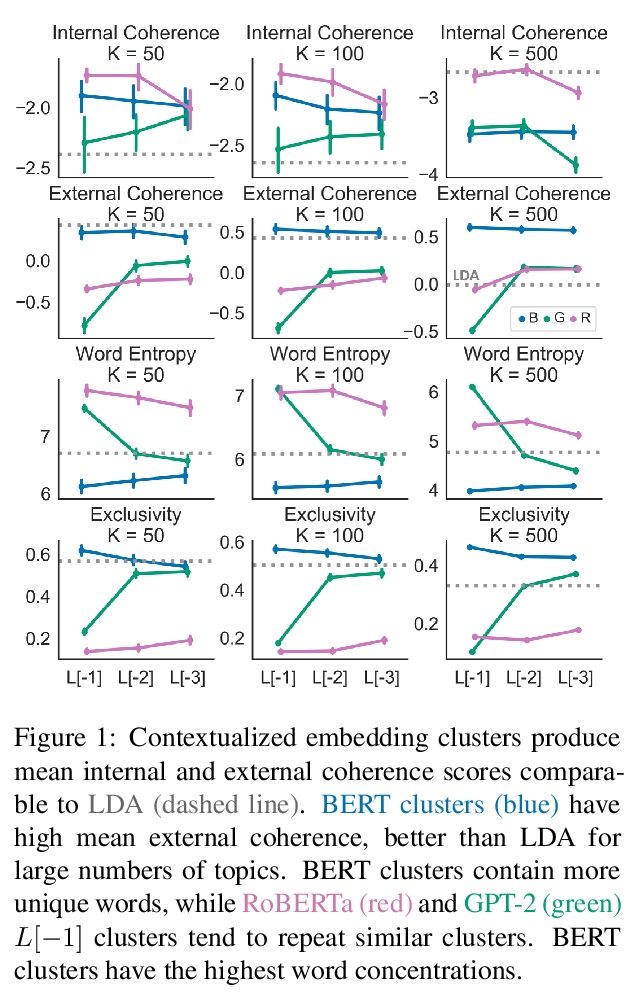

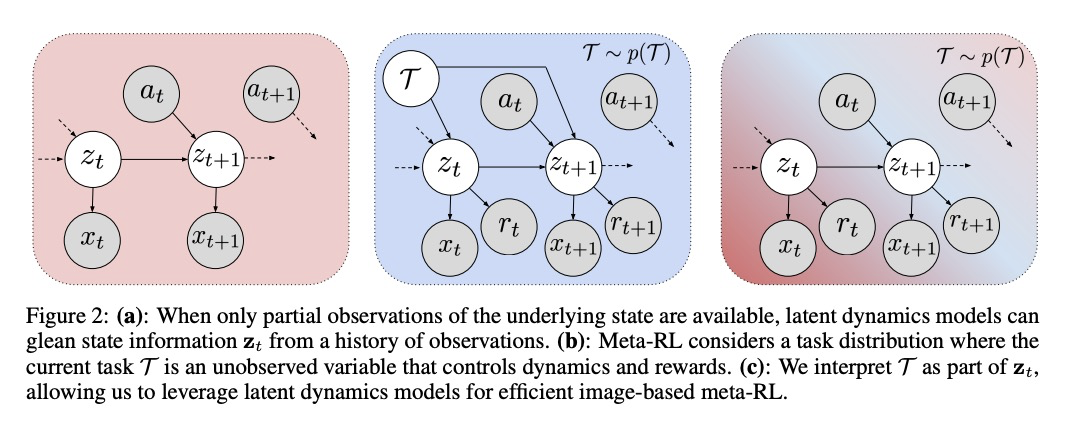
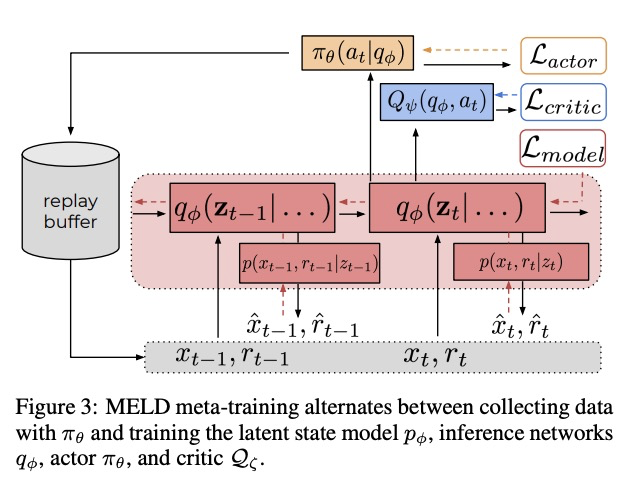
[LG] MELD: Meta-Reinforcement Learning from Images via Latent State Models
MELD: 潜状态模型图像元强化学习
T Z. Zhao, A Nagabandi, K Rakelly, C Finn, S Levine
[UC Berkeley & Stanford University]
https://weibo.com/1402400261/JrZgCEmLp
[CV] Self-Learning Transformations for Improving Gaze and Head Redirection
用自学习转换改进注视和头部重定向
Y Zheng, S Park, X Zhang, S D Mello, O Hilliges
[ETH Zurich & NVIDIA]
https://weibo.com/1402400261/JrZiRcoNa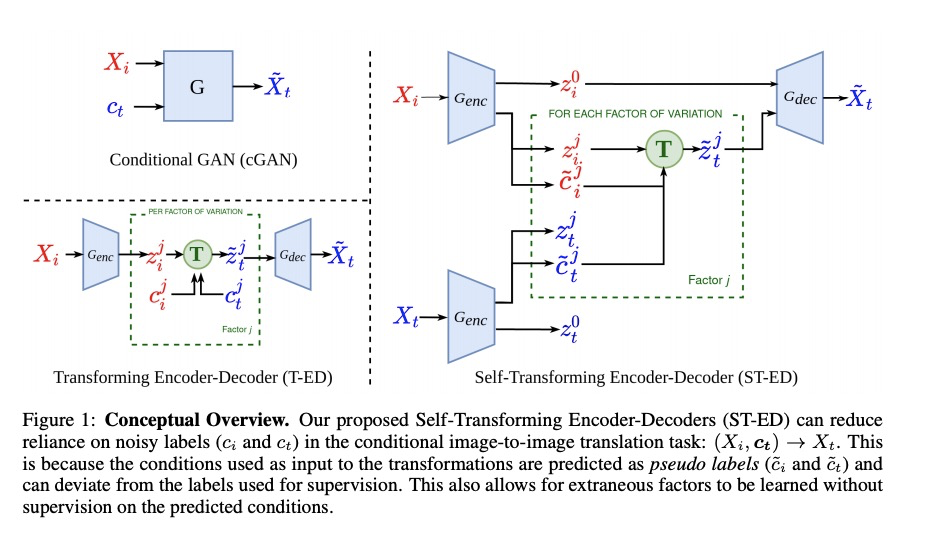

[CV] An Overview Of 3D Object Detection
3D目标检测综述
Y Wang, J Ye
[University of Alberta]
https://weibo.com/1402400261/JrZjMgn1s


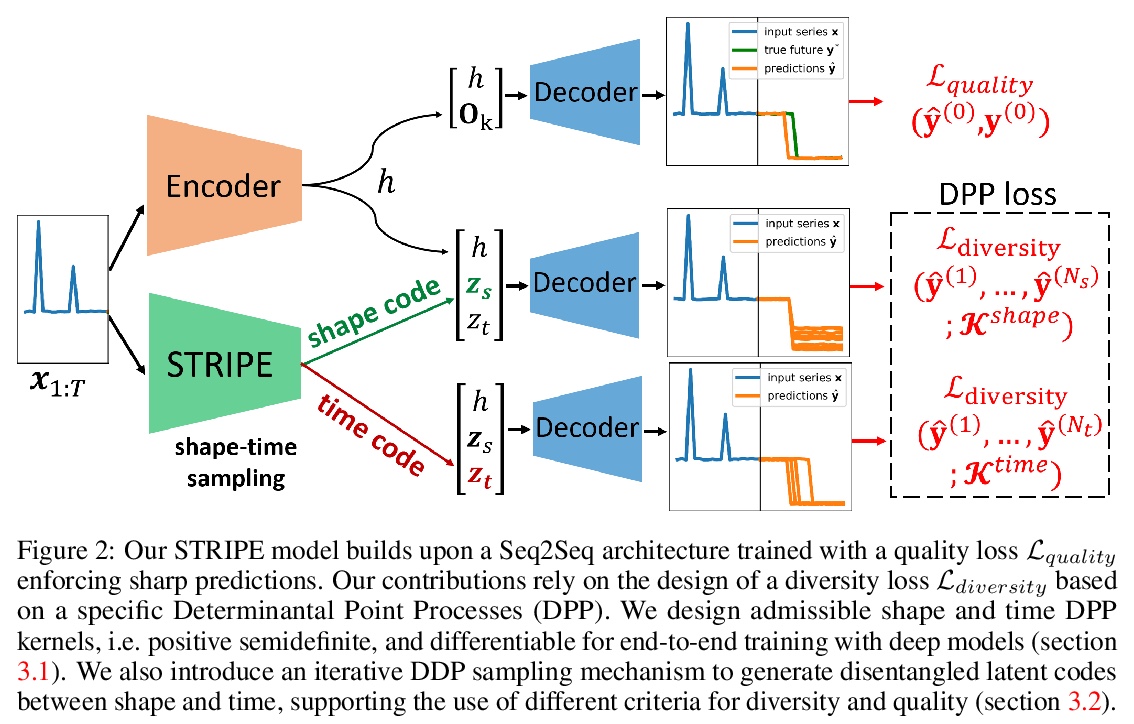
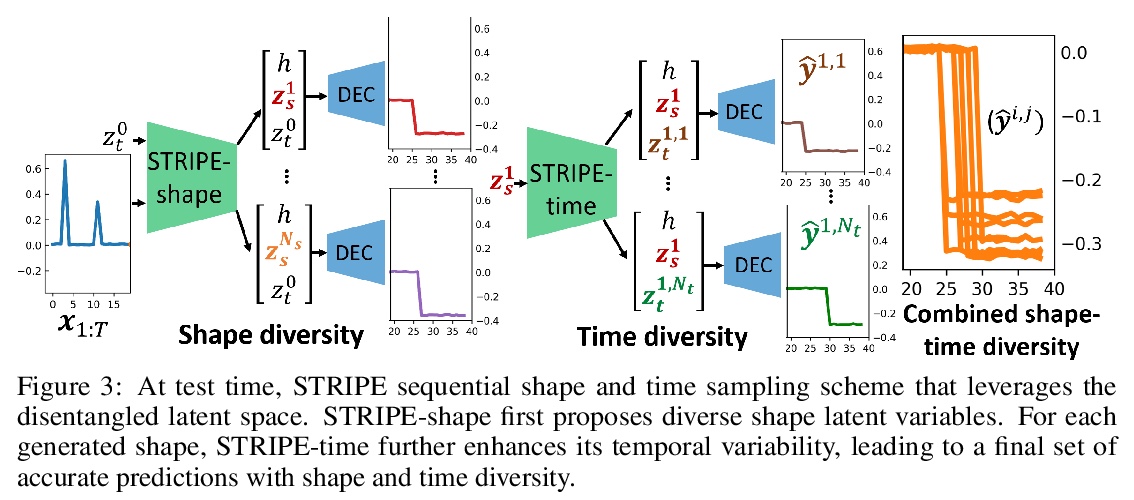
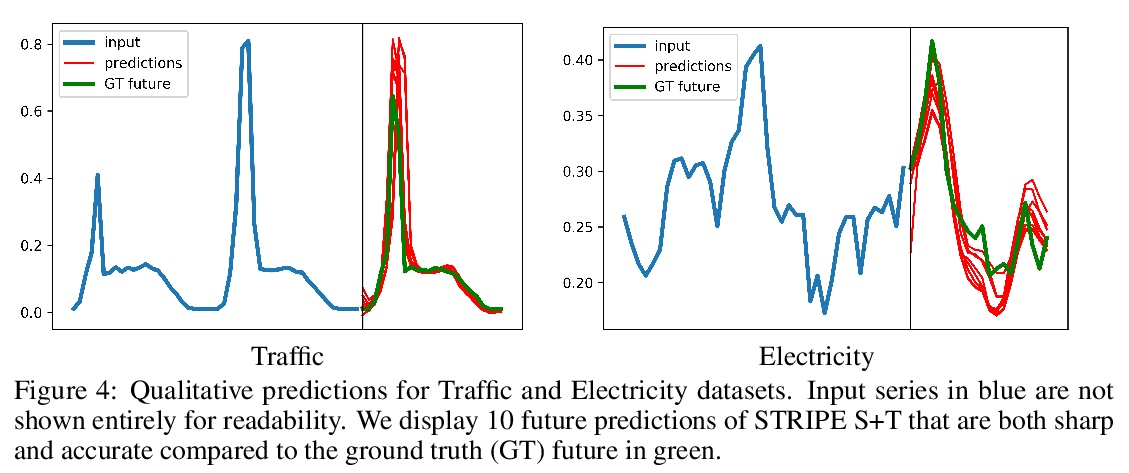
[LG] Probabilistic Time Series Forecasting with Structured Shape and Temporal Diversity
具有结构化形状和时间多样性的概率时间序列预测
V L Guen, N Thome
[EDF R&D & Conservatoire National des Arts et Métiers]
https://weibo.com/1402400261/JrZlj6wrh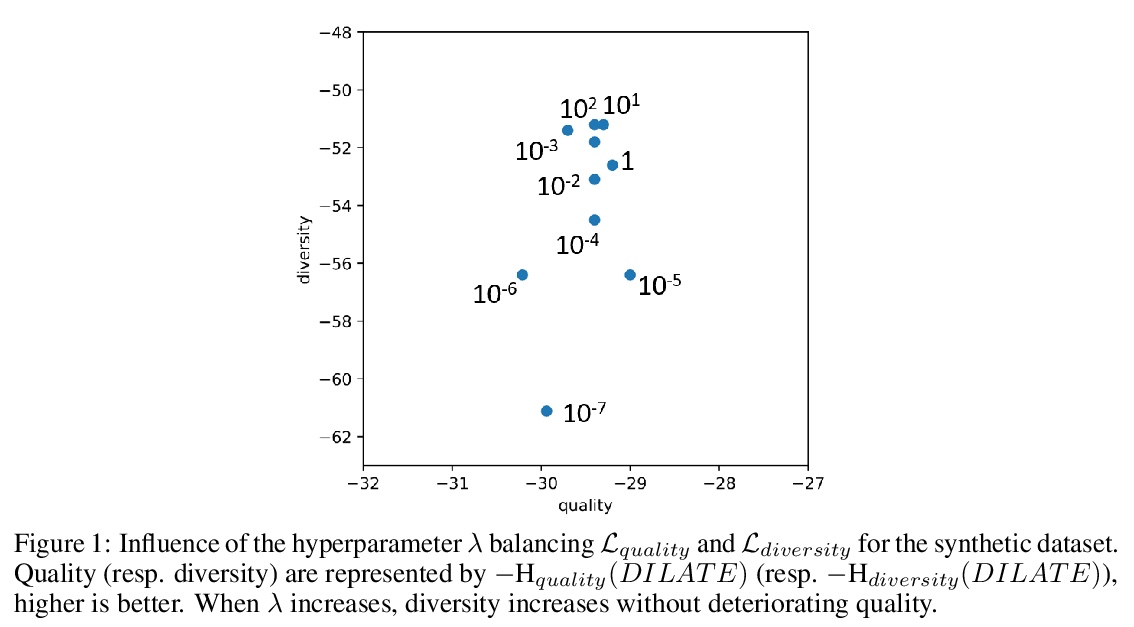
[LG] Memory Optimization for Deep Networks
深度网络的内存优化
A Shah, C Wu, J Mohan, V Chidambaram, P Krähenbühl
[University of Texas at Austin]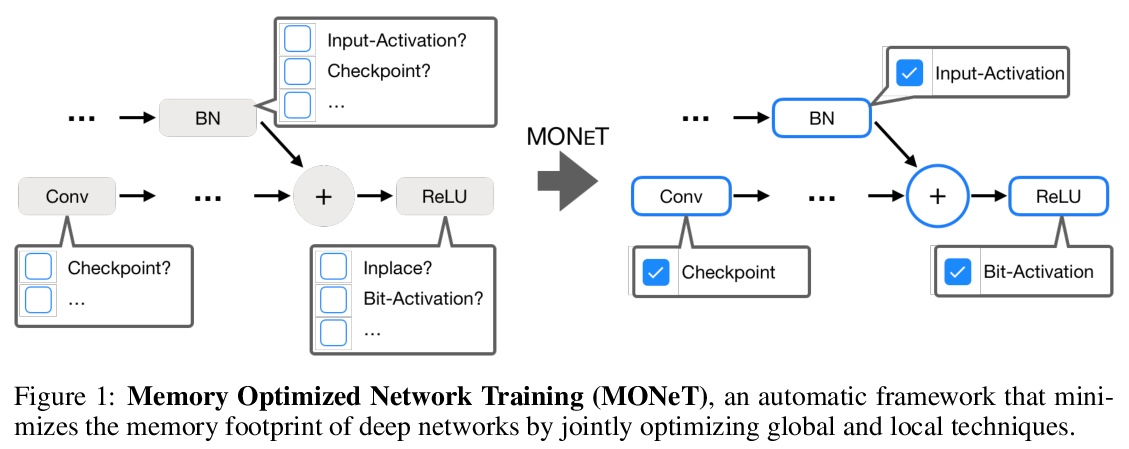
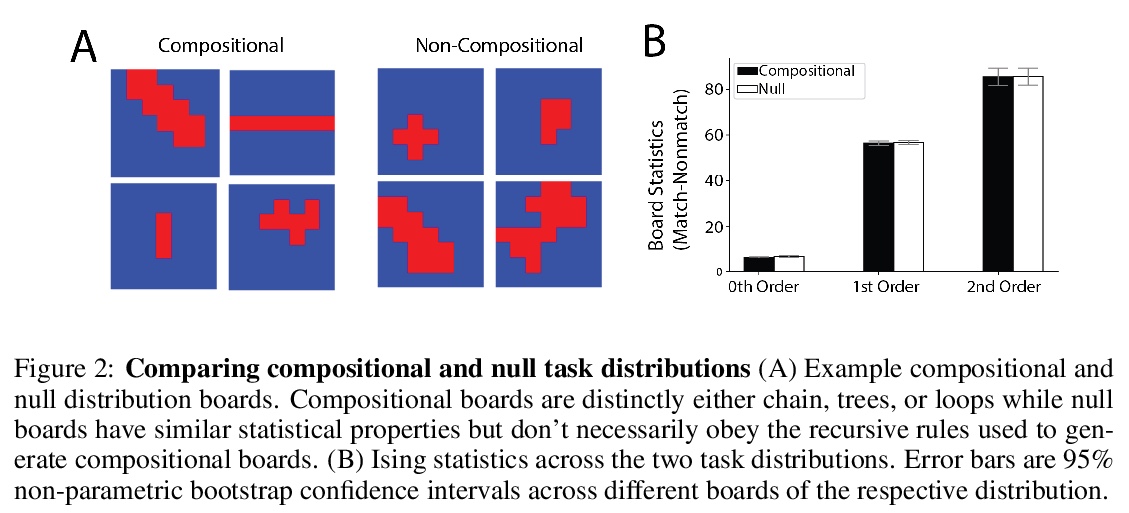
[LG] Meta-Learning of Compositional Task Distributions in Humans and Machines
人机合成任务分布元学习
S Kumar, I Dasgupta, J D. Cohen, N D. Daw, T L. Griffiths
[Princeton Neuroscience Institute & Princeton University]
https://weibo.com/1402400261/JrZnodapB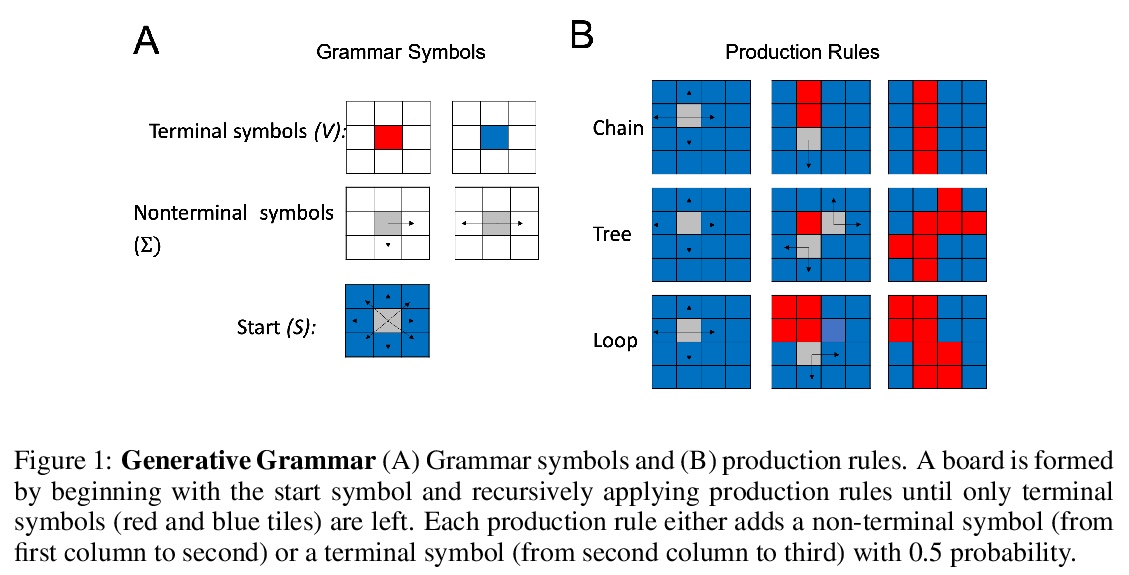
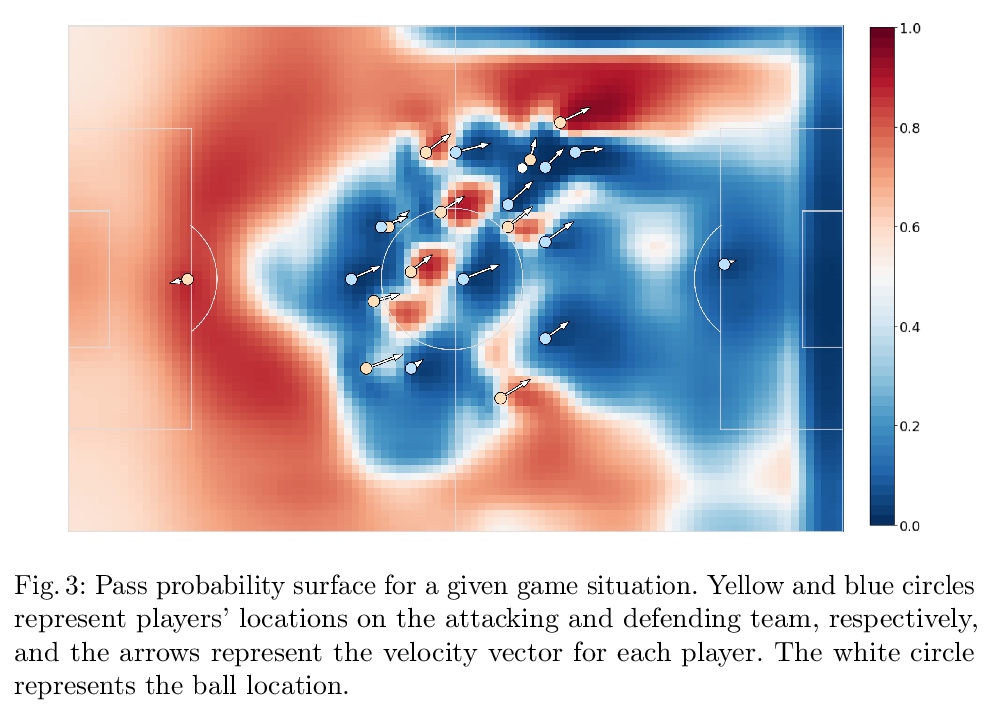
[LG] SoccerMap: A Deep Learning Architecture for Visually-Interpretable Analysis in Soccer
SoccerMap:深度学习足球视觉可解释分析架构
J Fernández, L Born
[Polytechnic University of Cataloni & Simon Fraser Universit]
https://weibo.com/1402400261/JrZoJfadv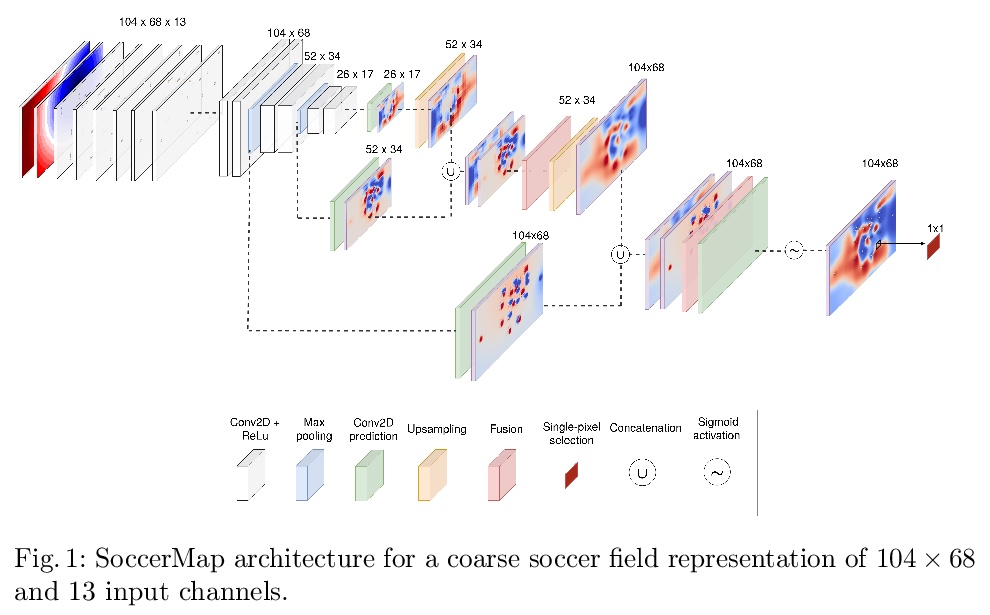

若有收获,就点个赞吧
0 人点赞
