- 1、[CV] Dataset Condensation with Gradient Matching
- 2、[CV] Deformable DETR: Deformable Transformers for End-to-End Object Detection
- 3、[CV] Learning Generalizable Visual Representations via Interactive Gameplay
- 4、[LG] Augmenting Physical Models with Deep Networks for Complex Dynamics Forecasting
- 5、[CL] How Can We Know When Language Models Know?
- [CV] Practical Face Reconstruction via Differentiable Ray Tracing
- [LG] The Shapley Value of Classifiers in Ensemble Games
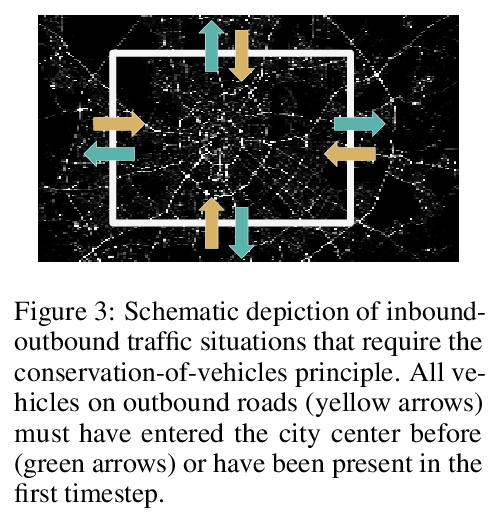
- [LG] MC-LSTM: Mass-Conserving LSTM
- [CL] TextBox: A Unified, Modularized, and Extensible Framework for Text Generation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Dataset Condensation with Gradient Matching
B Zhao, KR Mopuri, H Bilen
[The University of Edinburgh]
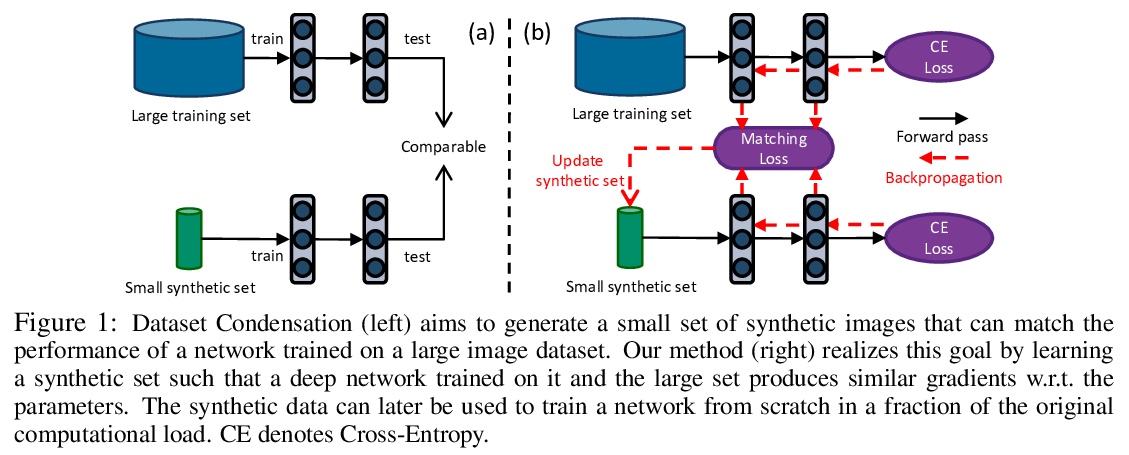
基于梯度匹配的数据集浓缩。提出一种面向数据高效学习的训练数据集合成技术——数据浓缩(Dataset Condensation),学习将大型数据集浓缩成信息更集中的小样本集,用于从头训练深度网络,其核心是将原始数据上训练的深度神经网络梯度与合成数据之间的梯度进行匹配。该方法不依赖于架构,可用来训练不同的深度网络,计算成本很小,同时实现了尽可能接近的结果。在几个计算机视觉基准上评价了其性能,证明其显著优于最先进方法。
As the state-of-the-art machine learning methods in many fields rely on larger datasets, storing them and training models on them becomes more expensive. This paper proposes a training set synthesis technique for data-efficient learning, called Dataset Condensation, that learns to condense a large dataset into a small set of informative samples for training deep neural networks from scratch. We formulate this goal as a gradient matching problem between the gradients of a deep neural network trained on the original data and our synthetic data. We rigorously evaluate its performance in several computer vision benchmarks and demonstrate that it significantly outperforms the state-of-the-art methods. Finally we explore the use of our method in continual learning and neural architecture search and show that it achieves promising gains on a tight budget of memory and computations.
https://weibo.com/1402400261/JDxifpKZD

2、[CV] Deformable DETR: Deformable Transformers for End-to-End Object Detection
X Zhu, W Su, L Lu, B Li, X Wang, J Dai
[SenseTime Research & University of Science and Technology of China]
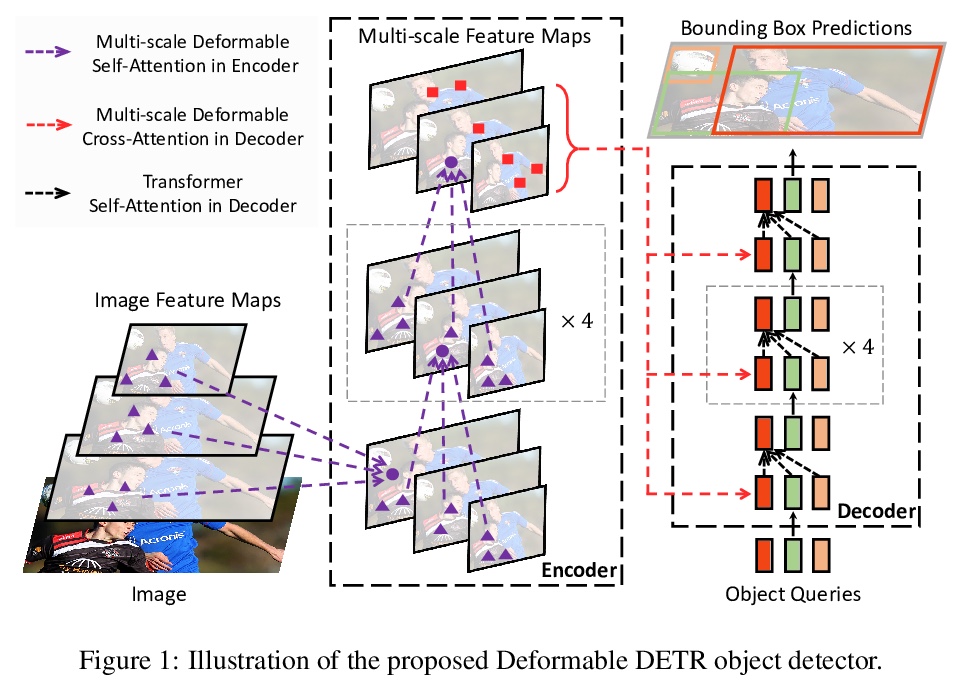
Deformable DETR:面向端到端目标检测的可变形Transformers。提出Deformable DETR端到端目标检测器,效率高、转换快,缓解了DETR的高复杂度和收敛慢的问题。其核心是(多尺度)可变形注意力模块,只关注参考目标周围的一小组关键采样点,是处理图像特征图的高效注意力机制。Deformable DETR可用少10倍的训练周期实现比DETR更好的性能(尤其是小目标),在COCO基准上进行的大量实验证明了方法的有效性。
DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Transformer attention modules in processing image feature maps. To mitigate these issues, we proposed Deformable DETR, whose attention modules only attend to a small set of key sampling points around a reference. Deformable DETR can achieve better performance than DETR (especially on small objects) with 10 times less training epochs. Extensive experiments on the COCO benchmark demonstrate the effectiveness of our approach. Code is released at > this https URL.
https://weibo.com/1402400261/JDxqwiIKL
3、[CV] Learning Generalizable Visual Representations via Interactive Gameplay
L Weihs, A Kembhavi, K Ehsani, S M Pratt, W Han, A Herrasti, E Kolve, D Schwenk, R Mottaghi, A Farhadi
[Allen Institute for Artificial Intelligence]
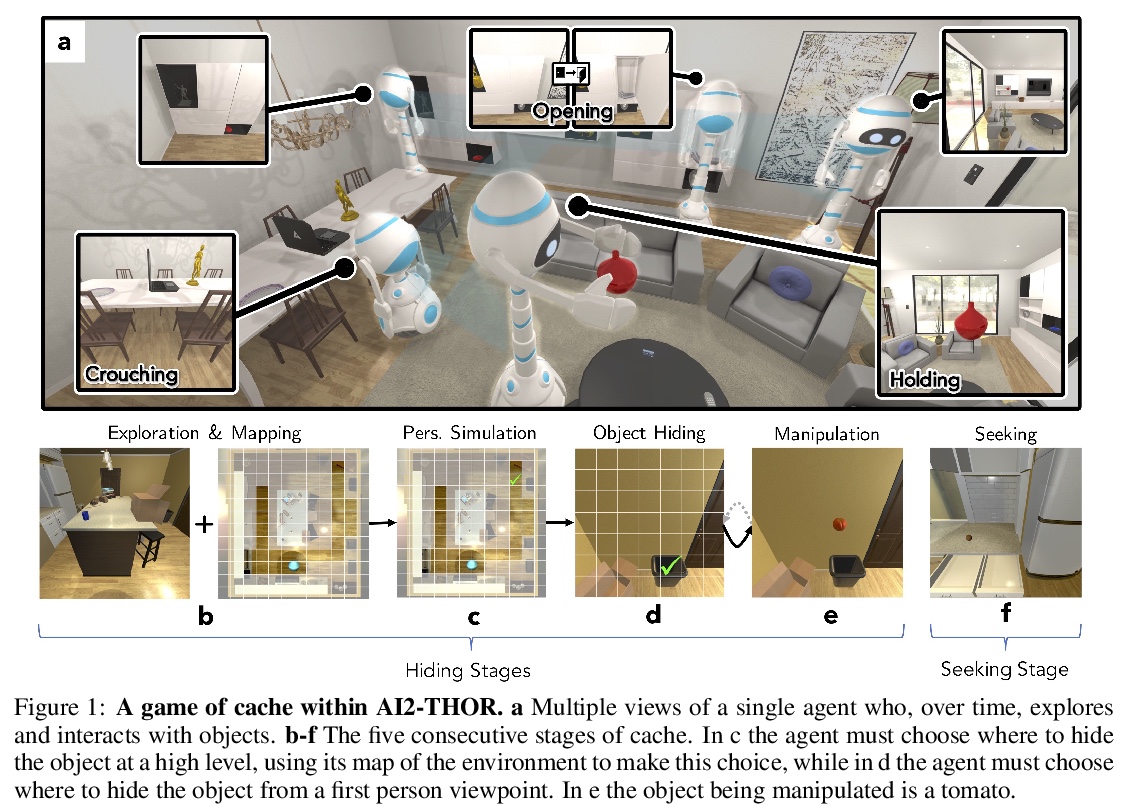
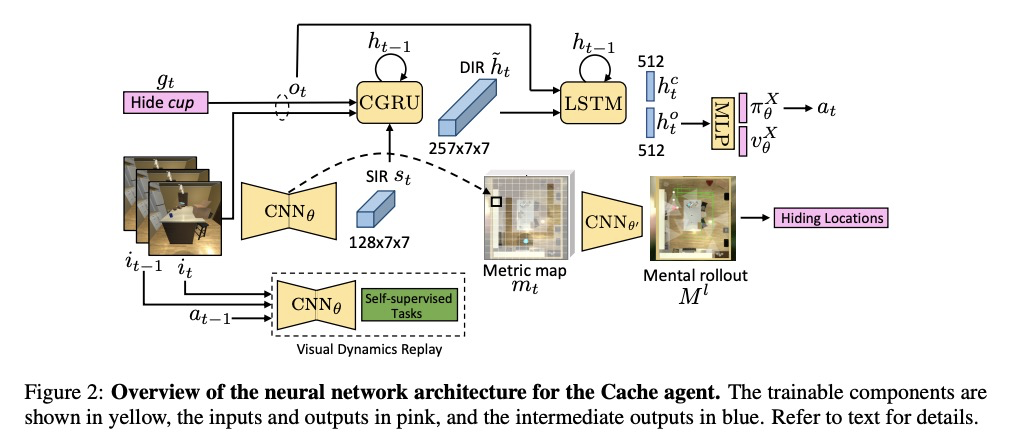
基于交互式游戏的可泛化视觉表示学习。考虑由静态标记/非标记数据集上的视觉表示学习范式,转向体验式、互动式的视觉表示学习范式。在高度还原、交互式环境中,具身对抗性强化学习智能体通过玩Cache(捉迷藏的一种变体),可学到其观察到的编码信息的可泛化表示,如对象的持久性、自由空间和包含关系。这些结果为通过互动得到的视觉模型,提供了一个实验框架,对智能体学到的内容进行评价,也展示了从大型、静态数据集学习转向体验、互动表示学习的价值。
A growing body of research suggests that embodied gameplay, prevalent not just in human cultures but across a variety of animal species including turtles and ravens, is critical in developing the neural flexibility for creative problem solving, decision making, and socialization. Comparatively little is known regarding the impact of embodied gameplay upon artificial agents. While recent work has produced agents proficient in abstract games, these environments are far removed the real world and thus these agents can provide little insight into the advantages of embodied play. Hiding games, such as hide-and-seek, played universally, provide a rich ground for studying the impact of embodied gameplay on representation learning in the context of perspective taking, secret keeping, and false belief understanding. Here we are the first to show that embodied adversarial reinforcement learning agents playing Cache, a variant of hide-and-seek, in a high fidelity, interactive, environment, learn generalizable representations of their observations encoding information such as object permanence, free space, and containment. Moving closer to biologically motivated learning strategies, our agents’ representations, enhanced by intentionality and memory, are developed through interaction and play. These results serve as a model for studying how facets of vision develop through interaction, provide an experimental framework for assessing what is learned by artificial agents, and demonstrates the value of moving from large, static, datasets towards experiential, interactive, representation learning.
https://weibo.com/1402400261/JDxxou9ge
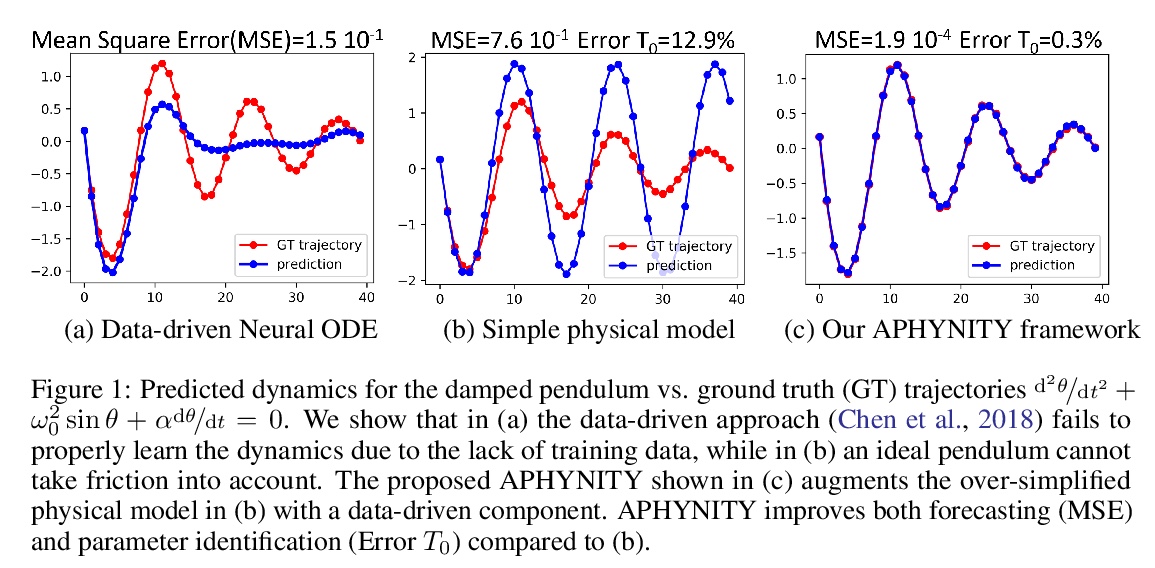
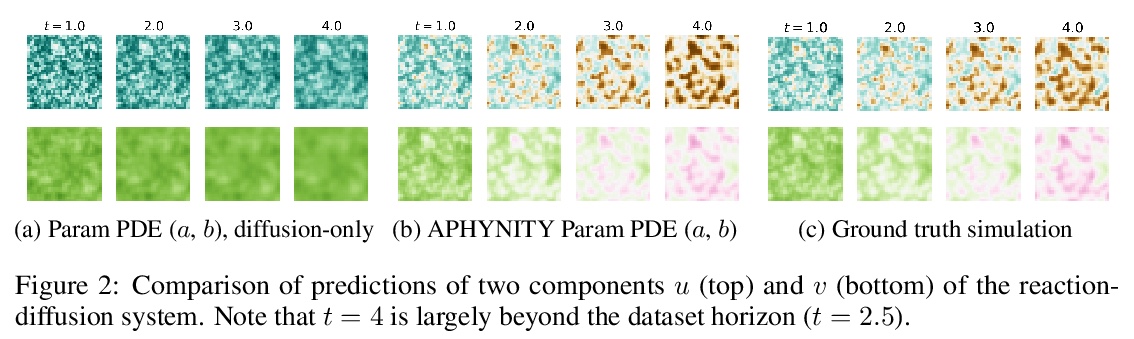
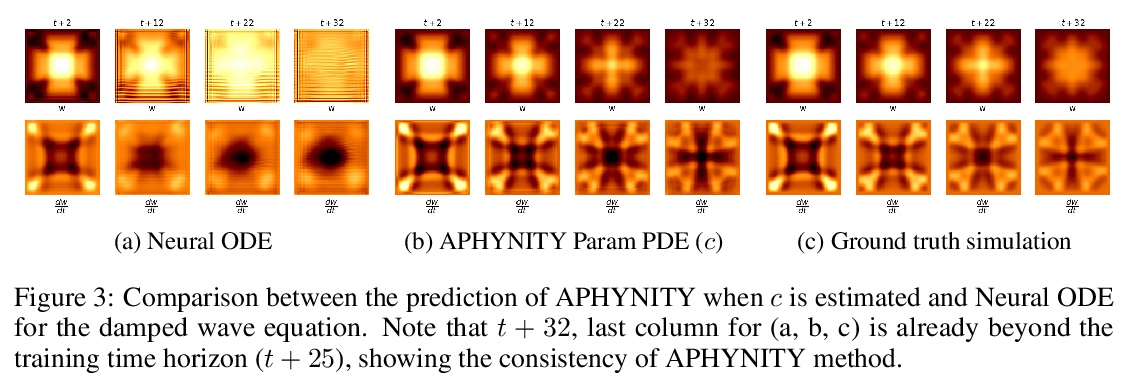
4、[LG] Augmenting Physical Models with Deep Networks for Complex Dynamics Forecasting
V L Guen, Y Yin, J Dona, I Ayed, E d Bézenac, N Thome, P Gallinari
[Conservatoire National des Arts et Métiers & Sorbonne Université]
用深度网络增强物理模型预测复杂动力学。引入原则框架APHYNITY,用数据驱动度深度模型,来增强微分方程描述的不完全物理动力学,将动力学分解为两部分:物理部分,对应于已有部分先验知识的动力学;数据驱动部分,对应于物理模型的误差。学习问题的设定原则,是使物理模型能解释尽可能多的数据,而数据驱动部分只描述物理模型无法捕捉的适量信息。这不仅为这种分解提供了存在性和唯一性,还保证了其可解释性,有利于推广。在三个重要的用例上所做的实验,每个用例代表了不同的现象系列,即反应-扩散方程、波浪方程和非线性阻尼摆,表明APHYNITY可有效地利用近似物理模型来准确预测系统演化,并正确识别相关的物理参数。
Forecasting complex dynamical phenomena in settings where only partial knowledge of their dynamics is available is a prevalent problem across various scientific fields. While purely data-driven approaches are arguably insufficient in this context, standard physical modeling based approaches tend to be over-simplistic, inducing non-negligible errors. In this work, we introduce the APHYNITY framework, a principled approach for augmenting incomplete physical dynamics described by differential equations with deep data-driven models. It consists in decomposing the dynamics into two components: a physical component accounting for the dynamics for which we have some prior knowledge, and a data-driven component accounting for errors of the physical model. The learning problem is carefully formulated such that the physical model explains as much of the data as possible, while the data-driven component only describes information that cannot be captured by the physical model, no more, no less. This not only provides the existence and uniqueness for this decomposition, but also ensures interpretability and benefits generalization. Experiments made on three important use cases, each representative of a different family of phenomena, i.e. reaction-diffusion equations, wave equations and the non-linear damped pendulum, show that APHYNITY can efficiently leverage approximate physical models to accurately forecast the evolution of the system and correctly identify relevant physical parameters.
https://weibo.com/1402400261/JDxMwFiGq
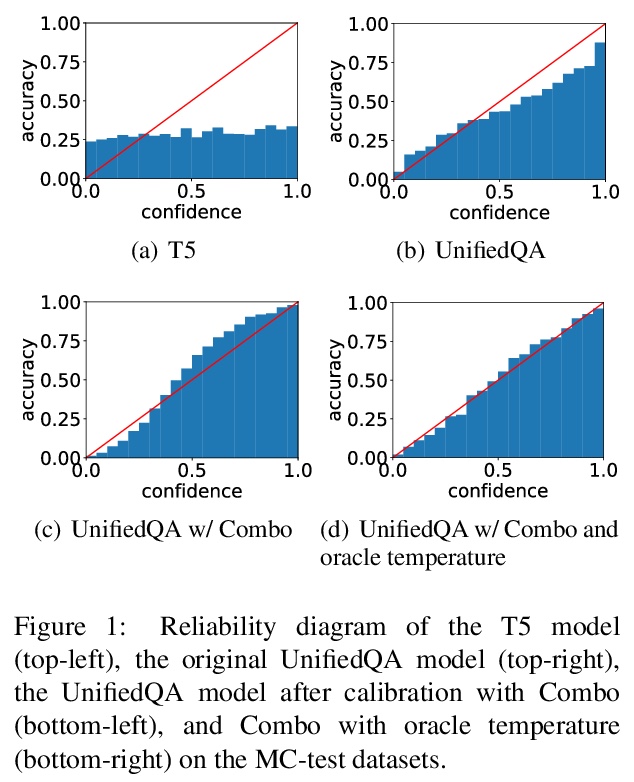
5、[CL] How Can We Know When Language Models Know?
Z Jiang, FF Xu, J Araki, G Neubig
[CMU & Bosch Research]
语言模型是否(确信)知道基于知识的问题的答案。围绕问题:”我们如何知道语言模型何时能够有把握地知道某个特定查询的答案?”,研究了用于QA任务的语言模型的校准问题,基于语言模型的QA模型具有令人印象深刻的性能,但其概率估计往往校准得很差,重点研究了校准这类模型的方法,通过微调、事后概率修改或调整预测输出/输入,使置信度得分与正确的可能性有更好的相关性。在不同数据集上的实验证明了方法的有效性。
Recent works have shown that language models (LM) capture different types of knowledge regarding facts or common sense. However, because no model is perfect, they still fail to provide appropriate answers in many cases. In this paper, we ask the question “how can we know when language models know, with confidence, the answer to a particular query?” We examine this question from the point of view of calibration, the property of a probabilistic model’s predicted probabilities actually being well correlated with the probability of correctness. We first examine a state-ofthe-art generative QA model, T5, and examine whether its probabilities are well calibrated, finding the answer is a relatively emphatic no. We then examine methods to calibrate such models to make their confidence scores correlate better with the likelihood of correctness through fine-tuning, post-hoc probability modification, or adjustment of the predicted outputs or inputs. Experiments on a diverse range of datasets demonstrate the effectiveness of our methods. We also perform analysis to study the strengths and limitations of these methods, shedding light on further improvements that may be made in methods for calibrating LMs.
https://weibo.com/1402400261/JDxTXlM7k
另外几篇值得关注的论文:
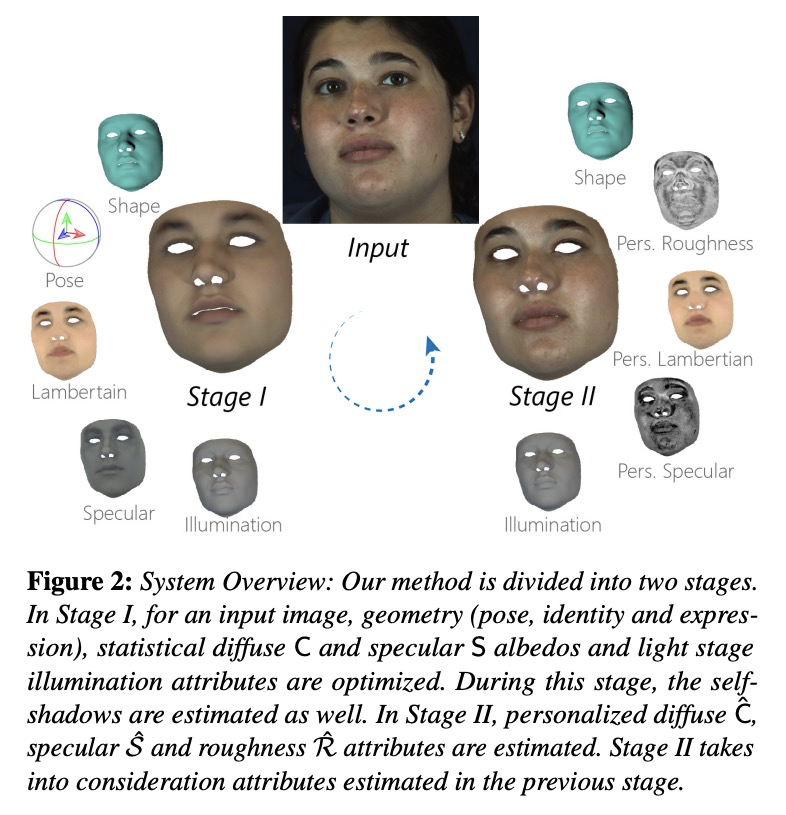
[CV] Practical Face Reconstruction via Differentiable Ray Tracing
可微光线追踪人脸重建
A Dib, G Bharaj, J Ahn, C Thébault, P Gosselin, M Romeo, L Chevallier
[InterDigital R&I & AI Foundation & Technicolor Inc]
https://weibo.com/1402400261/JDy97jpj5

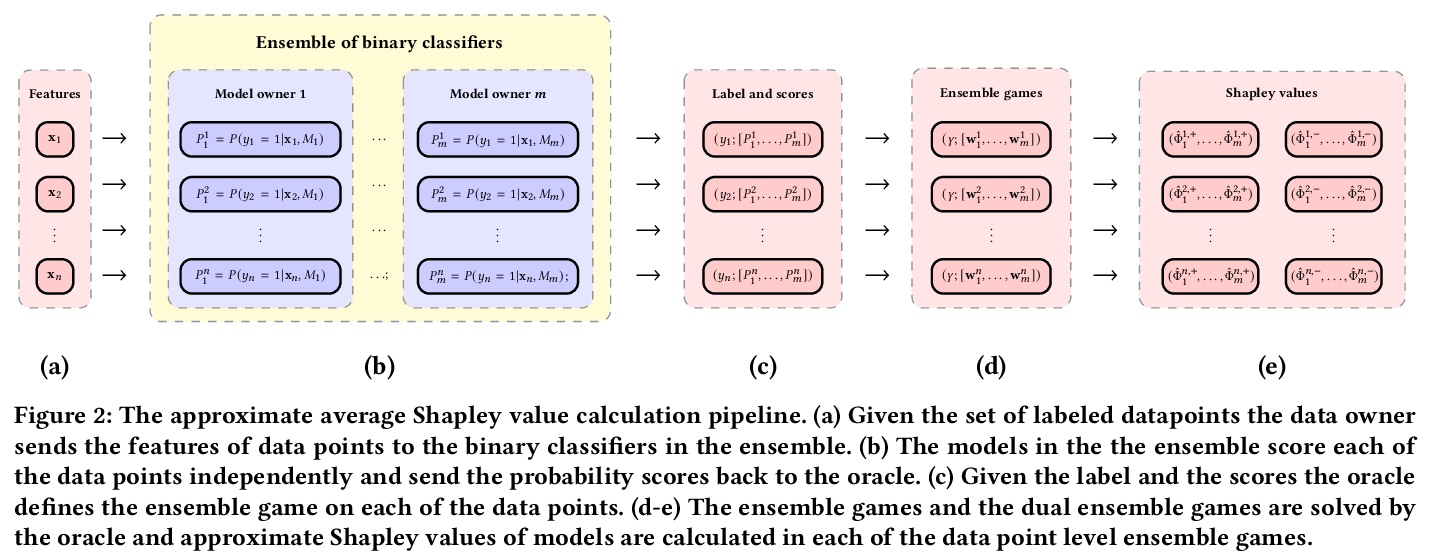
[LG] The Shapley Value of Classifiers in Ensemble Games
集成博弈中分类器的Shapley值估计
B Rozemberczki, R Sarkar
[The University of Edinburgh]
https://weibo.com/1402400261/JDybk3SZ6
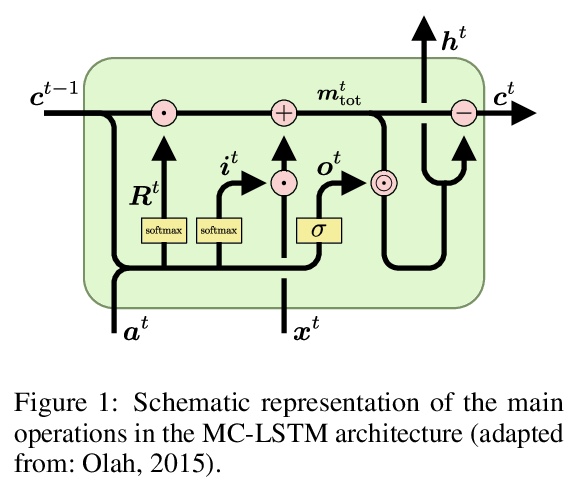
[LG] MC-LSTM: Mass-Conserving LSTM
MC-LSTM:质量守恒LSTM
P Hoedt, F Kratzert, D Klotz, C Halmich, M Holzleitner, G Nearing, S Hochreiter, G Klambauer
[Johannes Kepler University Linz & Google Research]
https://weibo.com/1402400261/JDydOhuBJ
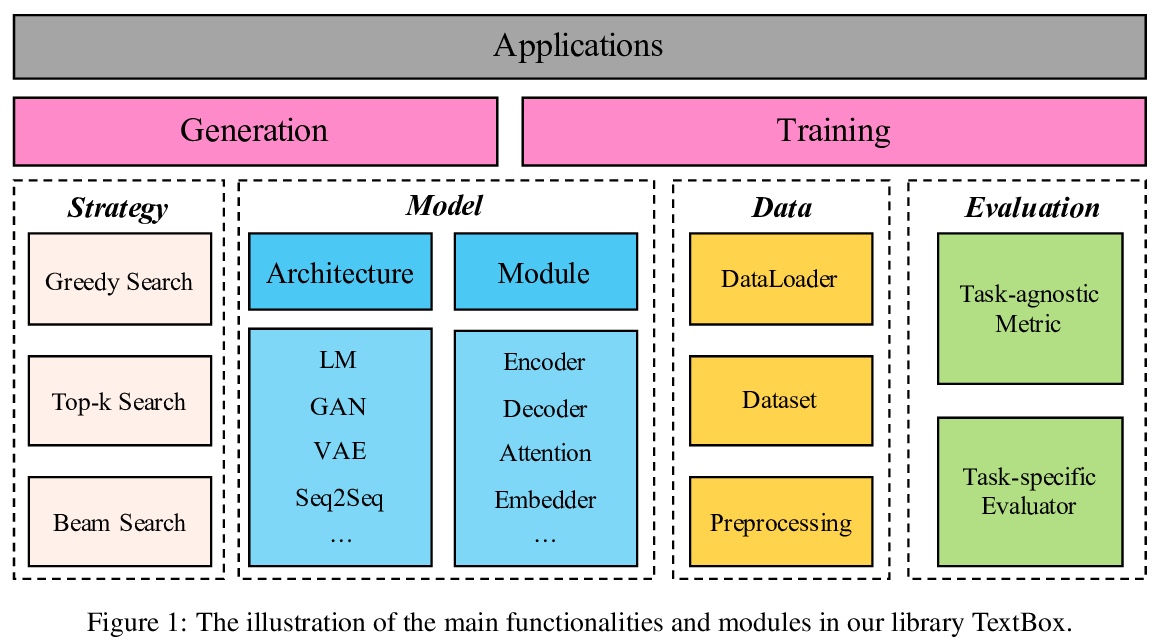
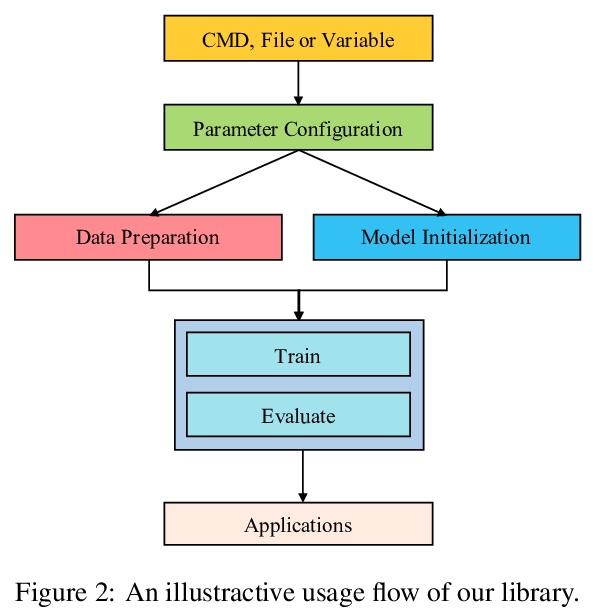
[CL] TextBox: A Unified, Modularized, and Extensible Framework for Text Generation
TextBox:通用模块化可扩展文本生成框架
J Li, T Tang, G He, J Jiang, X Hu, P Xie, W X Zhao, J Wen
[Renmin University of China]
https://weibo.com/1402400261/JDyfK1n46

若有收获,就点个赞吧
0 人点赞
