- 1、[CV] Generative Adversarial Transformers
- 2、[CV] Transformer in Transformer
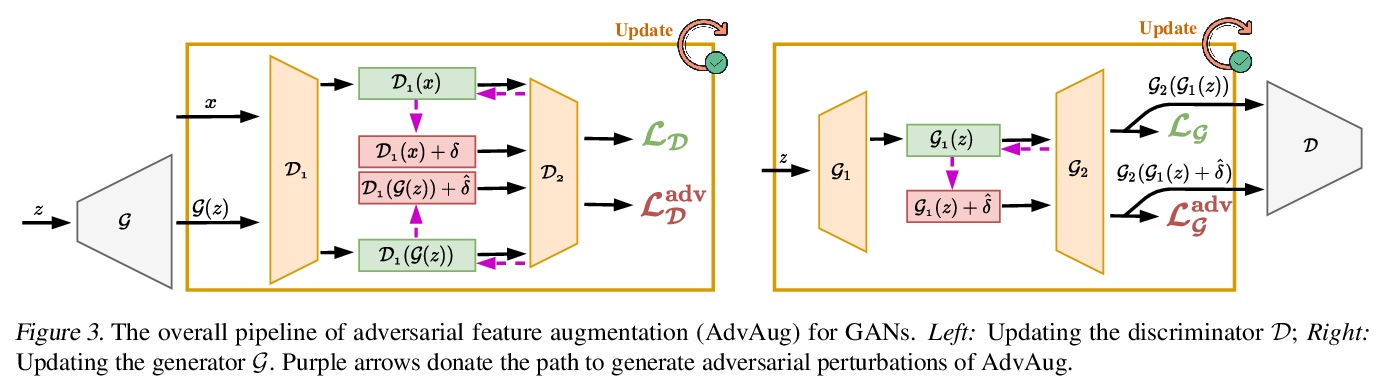
- 3、[CV] Training Generative Adversarial Networks in One Stage
- 4、[LG] Persistent Message Passing
- 5、[LG] Ultra-Data-Efficient GAN Training: Drawing A Lottery Ticket First, Then Training It Toughly
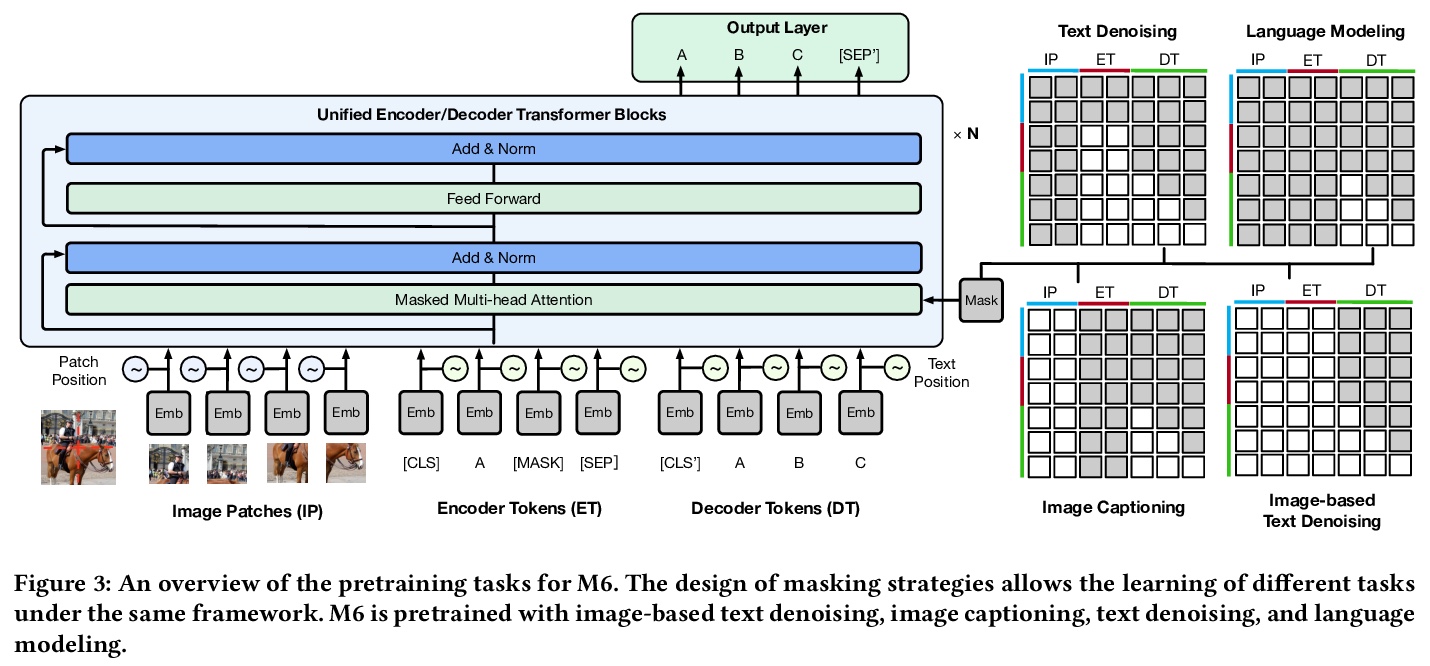
- [CL] M6: A Chinese Multimodal Pretrainer
- [CL] Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based Bias in NLP
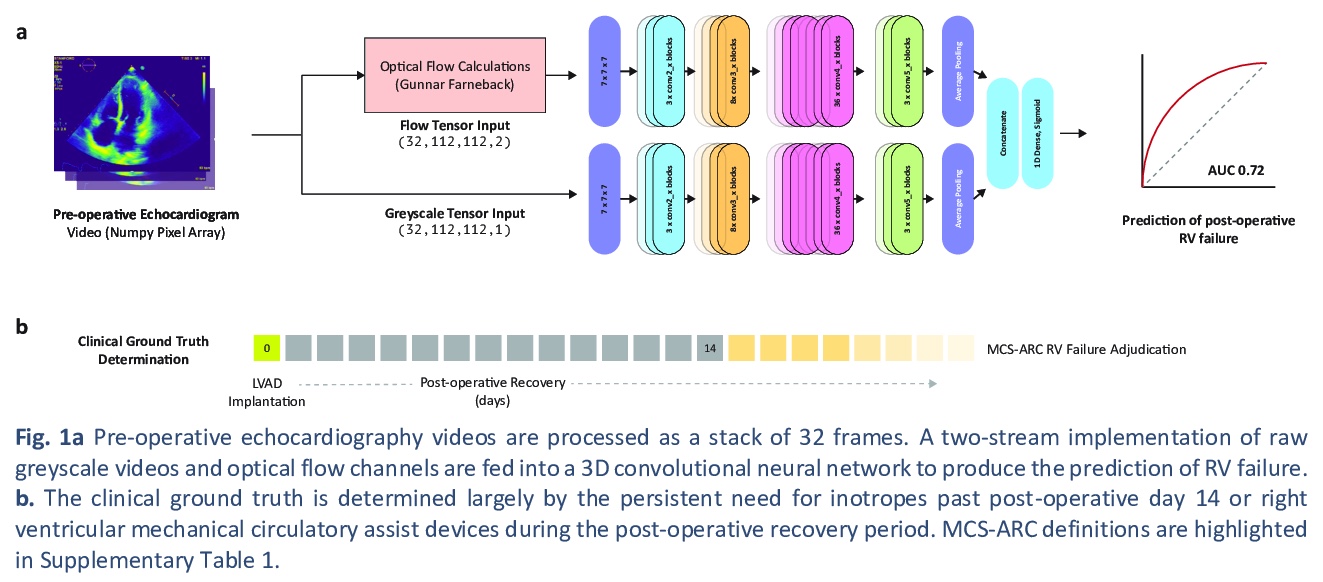
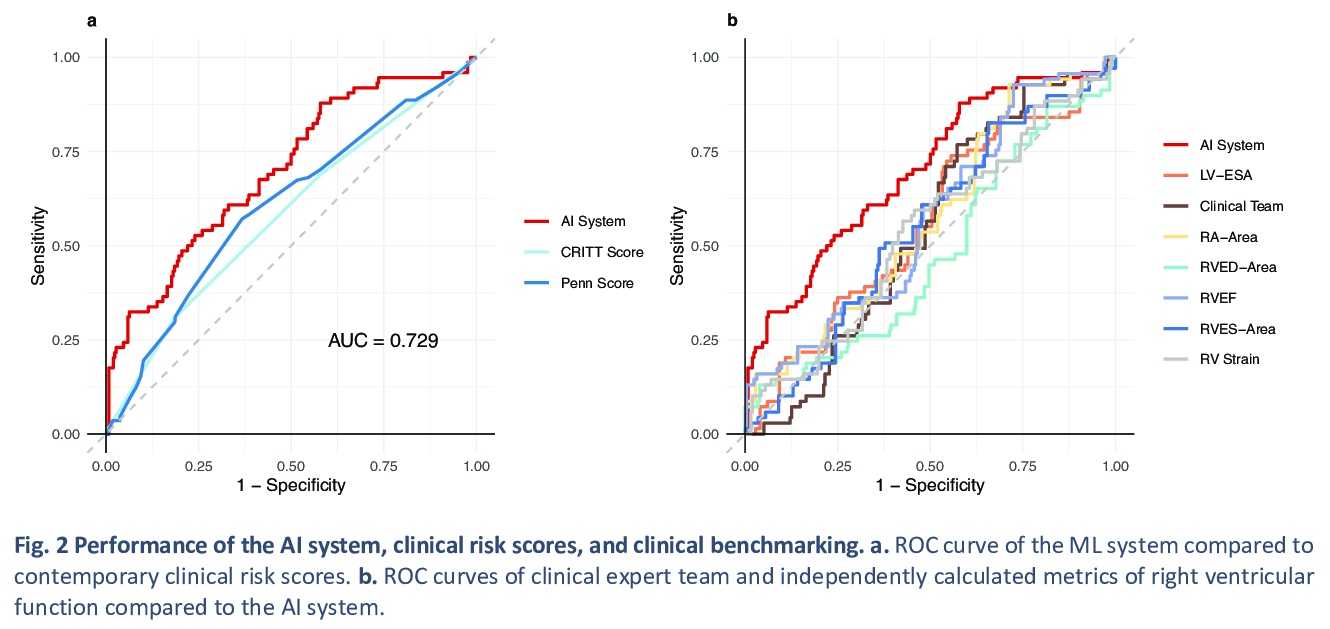
- [CV] Predicting post-operative right ventricular failure using video-based deep learning
- [CL] A Survey on Stance Detection for Mis- and Disinformation Identification
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Generative Adversarial Transformers
D A. Hudson, C. L Zitnick
[Stanford University & Facebook, Inc]
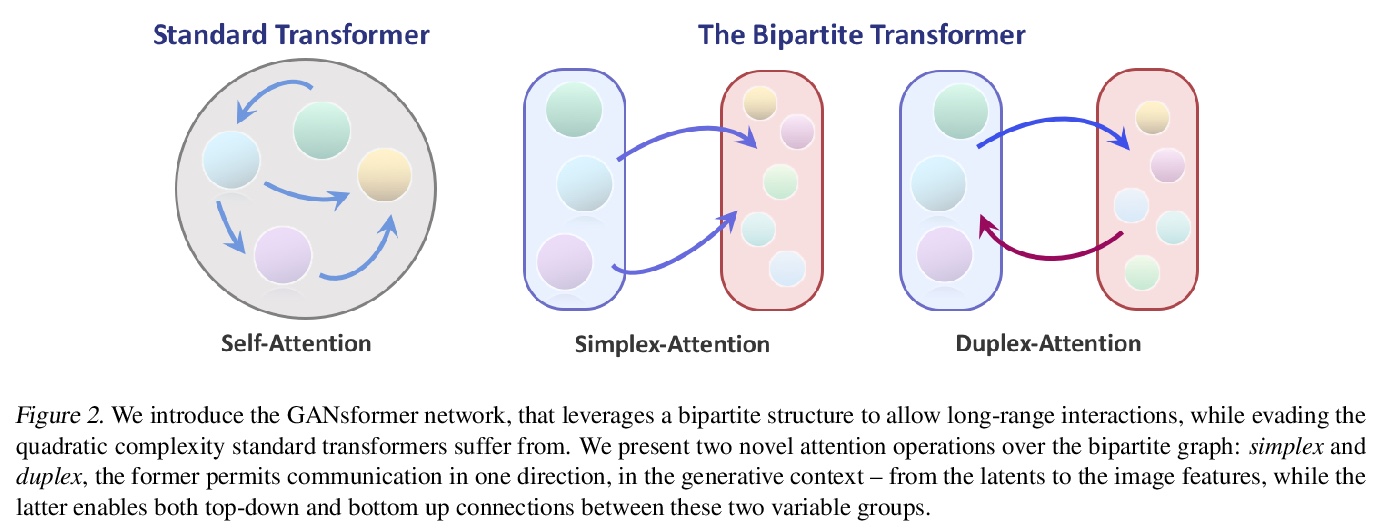
生成式对抗Transformer。提出一种新的自上而下和自下而上交互结合的高效Transformer——GANsformer,并针对视觉生成建模任务进行探索。该网络采用二段式结构,可实现跨图像的远距离交互,同时保持线性效率计算,很容易扩展到高分辨率合成。GANsformer通过迭代的方式,将信息从一组潜变量传播到不断变化的视觉特征,并进行反向的传播,根据彼此情况对各变量进行细化,鼓励目标与场景的合成表示。GANsformer符合一般的理念,即旨在将更强的归纳偏差纳入神经网络,以鼓励理想的属性,如透明度、数据效率和合成性——这些属性是人类智能的核心,是推理、计划、学习和想象力的基础。与经典Transformer架构相比,利用乘性集成,允许灵活的基于区域的调节,可看作是成功的StyleGAN网络的泛化。通过在一系列数据集上的评价,从模拟的多目标环境到丰富的真实世界的室内外场景,展示了该模型的优势和鲁棒性,表明其在图像质量和多样性方面取得了最先进的结果,同时享有快速学习和更好的数据效率。
We introduce the GANsformer, a novel and efficient type of transformer, and explore it for the task of visual generative modeling. The network employs a bipartite structure that enables long-range interactions across the image, while maintaining computation of linearly efficiency, that can readily scale to high-resolution synthesis. It iteratively propagates information from a set of latent variables to the evolving visual features and vice versa, to support the refinement of each in light of the other and encourage the emergence of compositional representations of objects and scenes. In contrast to the classic transformer architecture, it utilizes multiplicative integration that allows flexible region-based modulation, and can thus be seen as a generalization of the successful StyleGAN network. We demonstrate the model’s strength and robustness through a careful evaluation over a range of datasets, from simulated multi-object environments to rich real-world indoor and outdoor scenes, showing it achieves state-of-the-art results in terms of image quality and diversity, while enjoying fast learning and better data-efficiency. Further qualitative and quantitative experiments offer us an insight into the model’s inner workings, revealing improved interpretability and stronger disentanglement, and illustrating the benefits and efficacy of our approach. An implementation of the model is available at > this http URL.
https://weibo.com/1402400261/K4pXRd1v0

2、[CV] Transformer in Transformer
K Han, A Xiao, E Wu, J Guo, C Xu, Y Wang
[Noah’s Ark Lab & State Key Lab of Computer Science, ISCAS & UCAS]
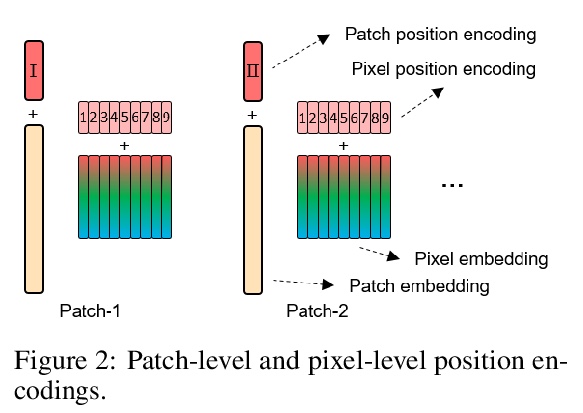
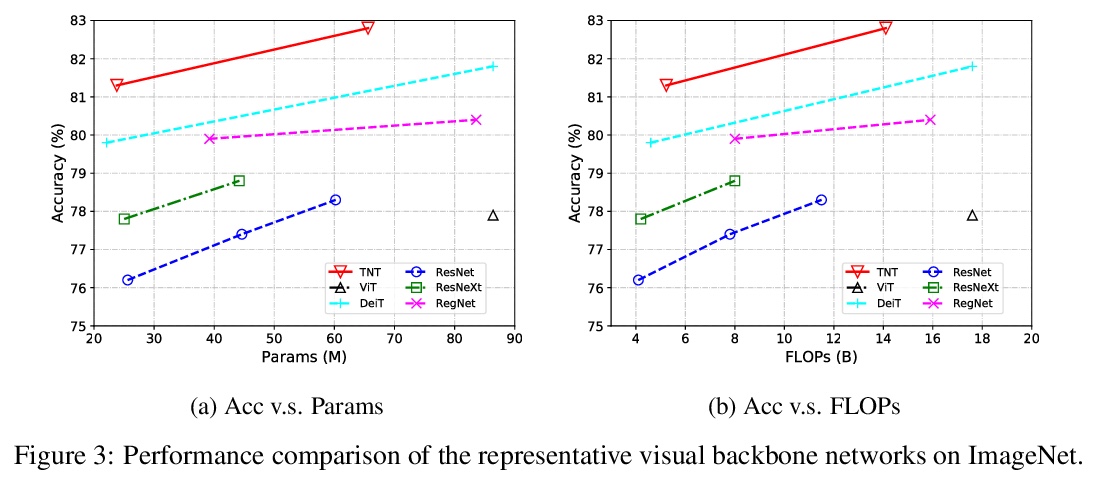
Transformer-iN-Transformer(TNT)模型。提出一种新的Transformer-iN-Transformer(TNT)模型,将图像统一分割成图块序列,将每个图块看作一个像素序列,对图块级和像素级表示进行建模。在每个TNT块中,利用外部Transformer块处理图块嵌入,而内部Transformer块从像素嵌入中提取局部特征。像素级特征通过线性变换层,投射到图块嵌入空间,并加到图块中。TNT可以更好地保存和模拟局部信息,用于视觉识别。通过对TNT块的堆叠,建立了图像识别的TNT模型。ImageNet基准和下游任务的实验,表明了所提出TNT架构的优越性和效率。
Transformer is a type of self-attention-based neural networks originally applied for NLP tasks. Recently, pure transformer-based models are proposed to solve computer vision problems. These visual transformers usually view an image as a sequence of patches while they ignore the intrinsic structure information inside each patch. In this paper, we propose a novel Transformer-iN-Transformer (TNT) model for modeling both patch-level and pixel-level representation. In each TNT block, an outer transformer block is utilized to process patch embeddings, and an inner transformer block extracts local features from pixel embeddings. The pixel-level feature is projected to the space of patch embedding by a linear transformation layer and then added into the patch. By stacking the TNT blocks, we build the TNT model for image recognition. Experiments on ImageNet benchmark and downstream tasks demonstrate the superiority and efficiency of the proposed TNT architecture. For example, our TNT achieves > 81.3% top-1 accuracy on ImageNet which is > 1.5% higher than that of DeiT with similar computational cost. The code will be available at > this https URL.
https://weibo.com/1402400261/K4q5bl1ym


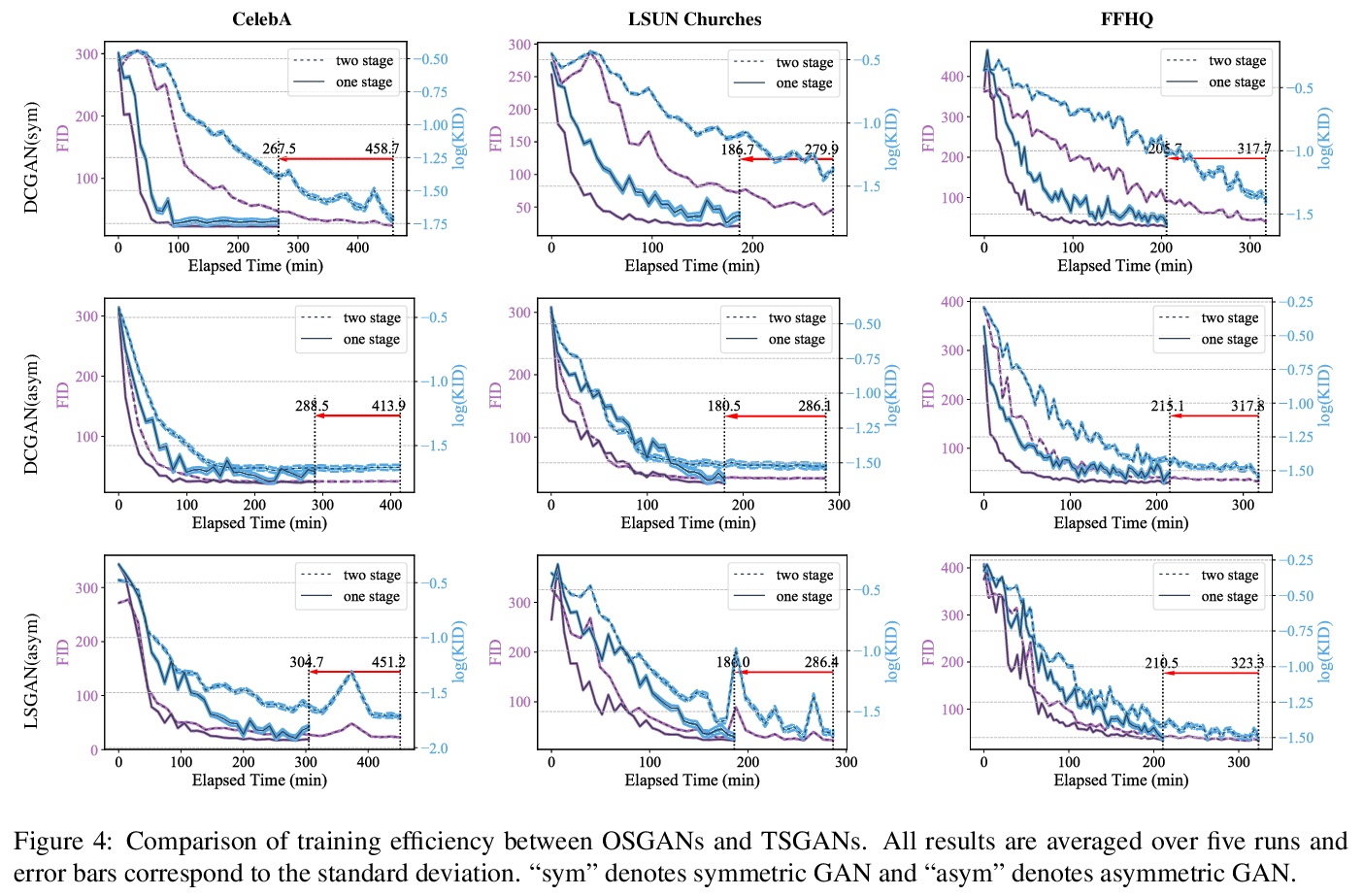
3、[CV] Training Generative Adversarial Networks in One Stage
C Shen, Y Yin, X Wang, X LI, J Song, M Song
[Zhejiang University & Stevens Institute of Technology & Alibaba Group]
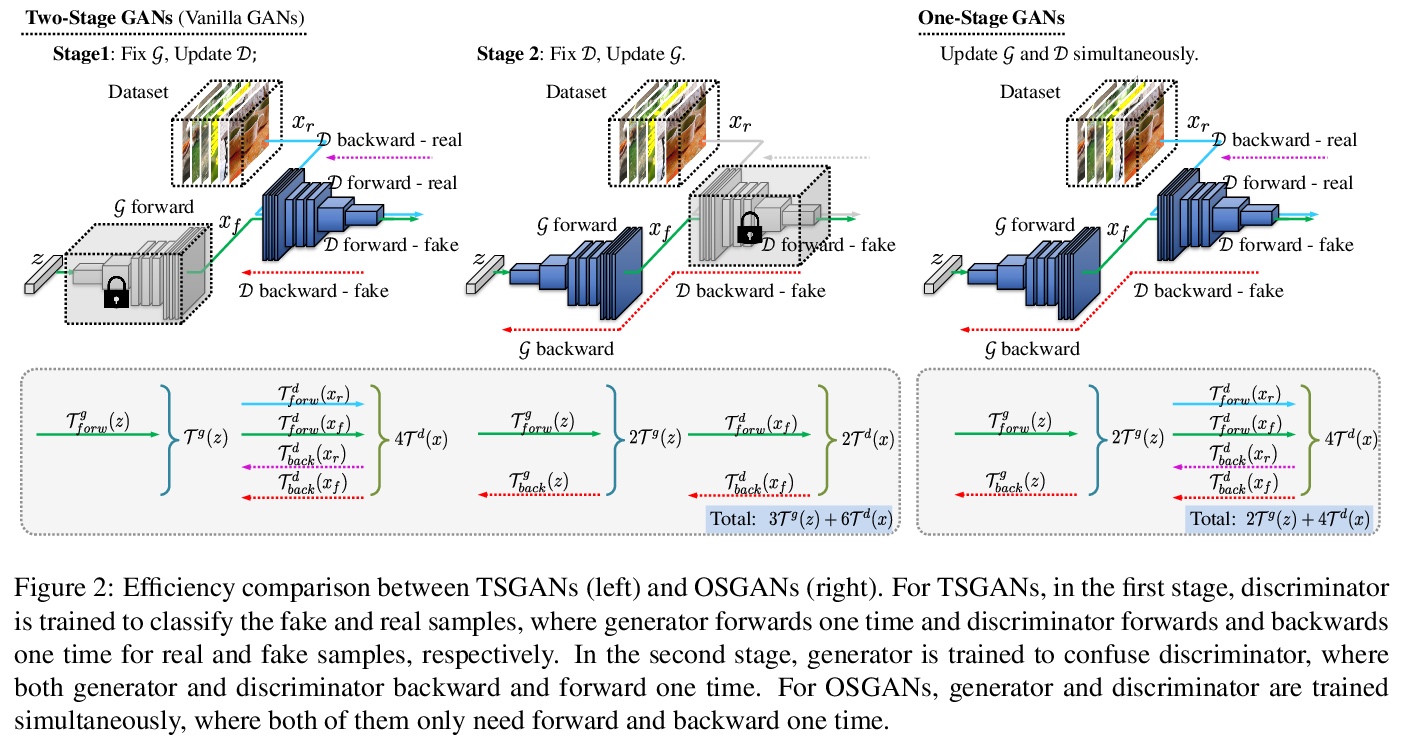
单阶段生成式对抗网络训练。提出一种通用训练方案,可在单个阶段内高效训练GAN,根据生成器和判别器的对抗性损失,将GAN分为对称式GAN和非对称式GAN两类,对于对称式GAN,生成器梯度计算可以在判别器训练过程中从判别器反向传播中获得,生成器和判别器参数都可以在同一阶段更新,对于非对称式GAN,提出了一种梯度分解方法,整合了前向推理过程中的不对称对抗损失,并将其在反向传播过程中的梯度分解,在单个阶段分别更新生成器和判别器,减少训练但运算量。在多个数据集和各种网络架构上的计算分析和实验结果表明,无论生成器和判别器的网络架构如何,所提出的单阶段训练方案都比传统训练方案有1.5倍的加速,同时保留了网络的原始性能。
Generative Adversarial Networks (GANs) have demonstrated unprecedented success in various image generation tasks. The encouraging results, however, come at the price of a cumbersome training process, during which the generator and discriminator are alternately updated in two stages. In this paper, we investigate a general training scheme that enables training GANs efficiently in only one stage. Based on the adversarial losses of the generator and discriminator, we categorize GANs into two classes, Symmetric GANs and Asymmetric GANs, and introduce a novel gradient decomposition method to unify the two, allowing us to train both classes in one stage and hence alleviate the training effort. Computational analysis and experimental results on several datasets and various network architectures demonstrate that, the proposed one-stage training scheme yields a solid 1.5> × acceleration over conventional training schemes, regardless of the network architectures of the generator and discriminator. Furthermore, we show that the proposed method is readily applicable to other adversarial-training scenarios, such as data-free knowledge distillation. Our source code will be published soon.
https://weibo.com/1402400261/K4q8L0xiM

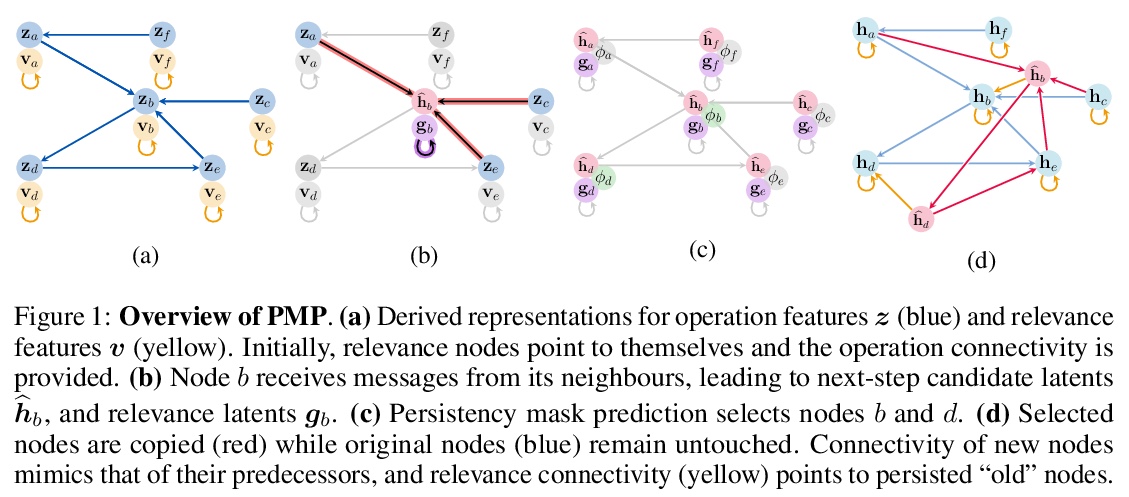
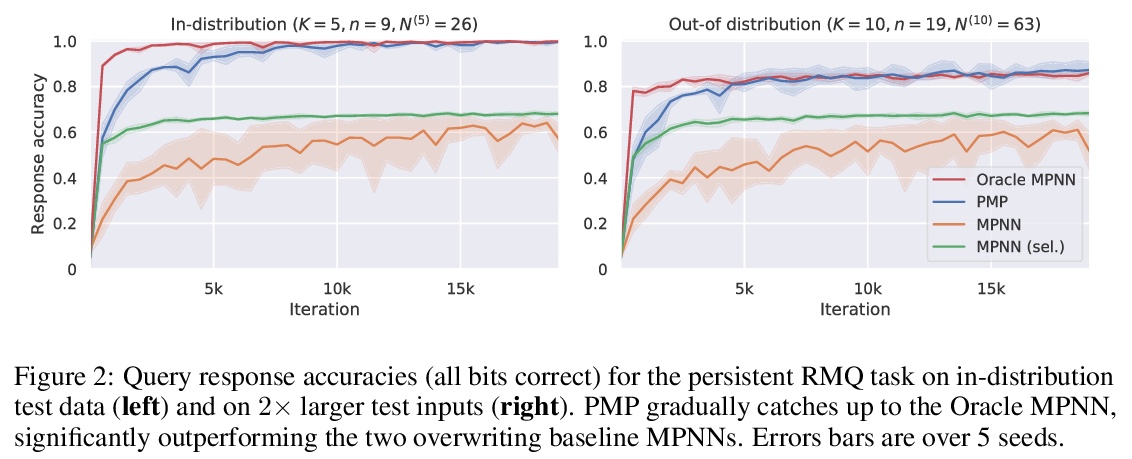
4、[LG] Persistent Message Passing
H Strathmann, M Barekatain, C Blundell, P Veličković
[DeepMind]
持久性消息传递。对于算法推理过程和数据结构进行的建模来说,图神经网络(GNN)是一种强大的归纳偏差,其强大主要表现在以马尔科夫动力学为特征的任务上,在这些任务中,查询任何相关数据结构只取决于其最新状态。然而,对许多感兴趣的任务来说,支持依赖于以前状态的高效数据结构查询可能是非常有益的。这就需要跟踪数据结构在一段时间内的演化,对于GNN的潜表示带来了巨大的压力。提出了持久消息传递(PMP)机制,通过显式持久化,赋予GNN查询过去状态的能力:不覆盖节点表示,而是在需要时创建新节点。PMP在动态时空范围查询上,将分布外泛化为2倍以上大的测试输入,明显优于覆盖状态的GNN。
Graph neural networks (GNNs) are a powerful inductive bias for modelling algorithmic reasoning procedures and data structures. Their prowess was mainly demonstrated on tasks featuring Markovian dynamics, where querying any associated data structure depends only on its latest state. For many tasks of interest, however, it may be highly beneficial to support efficient data structure queries dependent on previous states. This requires tracking the data structure’s evolution through time, placing significant pressure on the GNN’s latent representations. We introduce Persistent Message Passing (PMP), a mechanism which endows GNNs with capability of querying past state by explicitly persisting it: rather than overwriting node representations, it creates new nodes whenever required. PMP generalises out-of-distribution to more than 2x larger test inputs on dynamic temporal range queries, significantly outperforming GNNs which overwrite states.
https://weibo.com/1402400261/K4qc5zqFh
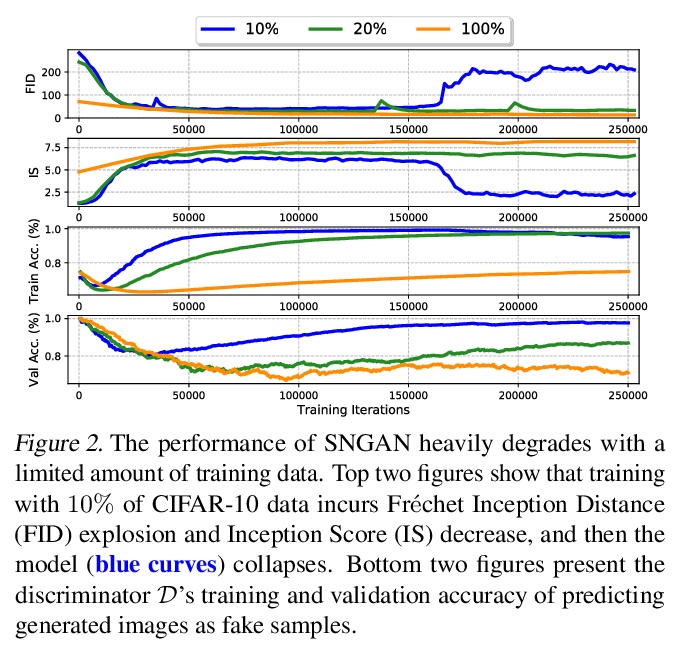
5、[LG] Ultra-Data-Efficient GAN Training: Drawing A Lottery Ticket First, Then Training It Toughly
T Chen, Y Cheng, Z Gan, J Liu, Z Wang
[University of Texas at Austin & Microsoft Dynamics 365 AI Research]
数据超高效GAN训练:先抽奖,再严格训练。用有限数据训练生成式对抗网络(GAN)通常会导致性能恶化和模型崩溃。为征服这一挑战,受到从GAN中发现可独立训练且高度稀疏的子网络(即彩票)的启发,将其视为归纳性先验,将对数据要求很高的GAN训练,分解为两个连续的子问题:(i)从原始GAN中识别彩票;然后(ii)用激进的数据和特征增强训练发现的稀疏子网络。两个子问题都重复使用相同的真实图像小训练集。这样的协调框架能专注于复杂度较低、数据效率较高的子问题,有效地稳定训练并提高收敛性。综合实验证明了提出的数据超高效训练框架在各种GAN架构(SNGAN、BigGAN和StyleGAN2)和不同数据集(CIFAR-10、CIFAR-100、Tiny-ImageNet和ImageNet)上的有效性。此外,该训练框架还表现出强大的少样本泛化能力,只用100张真实图像从头开始训练,无需任何预训练,就能生成高保真图像。
Training generative adversarial networks (GANs) with limited data generally results in deteriorated performance and collapsed models. To conquer this challenge, we are inspired by the latest observation of Kalibhat et al. (2020); Chen et al.(2021d), that one can discover independently trainable and highly sparse subnetworks (a.k.a., lottery tickets) from GANs. Treating this as an inductive prior, we decompose the data-hungry GAN training into two sequential sub-problems: (i) identifying the lottery ticket from the original GAN; then (ii) training the found sparse subnetwork with aggressive data and feature augmentations. Both sub-problems re-use the same small training set of real images. Such a coordinated framework enables us to focus on lower-complexity and more data-efficient sub-problems, effectively stabilizing training and improving convergence. Comprehensive experiments endorse the effectiveness of our proposed ultra-data-efficient training framework, across various GAN architectures (SNGAN, BigGAN, and StyleGAN2) and diverse datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet). Besides, our training framework also displays powerful few-shot generalization ability, i.e., generating high-fidelity images by training from scratch with just 100 real images, without any pre-training. Codes are available at: > this https URL.
https://weibo.com/1402400261/K4qfEgcAz
另外几篇值得关注的论文:
[CL] M6: A Chinese Multimodal Pretrainer
M6:大规模中文多模态预训练
J Lin, R Men, A Yang, C Zhou, M Ding, Y Zhang, P Wang, A Wang, L Jiang, X Jia, J Zhang, J Zhang, X Zou, Z Li, X Deng, J Liu, J Xue, H Zhou, J Ma, J Yu, Y Li, W Lin, J Zhou, J i Tang, H Yang
[Alibaba Group & Tsinghua University]
https://weibo.com/1402400261/K4qjskWLv


[CL] Self-Diagnosis and Self-Debiasing: A Proposal for Reducing Corpus-Based Bias in NLP
自诊断与自纠偏:减少自然语言处理语料库偏差的建议
T Schick, S Udupa, H Schütze
[LMU Munich]
https://weibo.com/1402400261/K4qlqpqfg

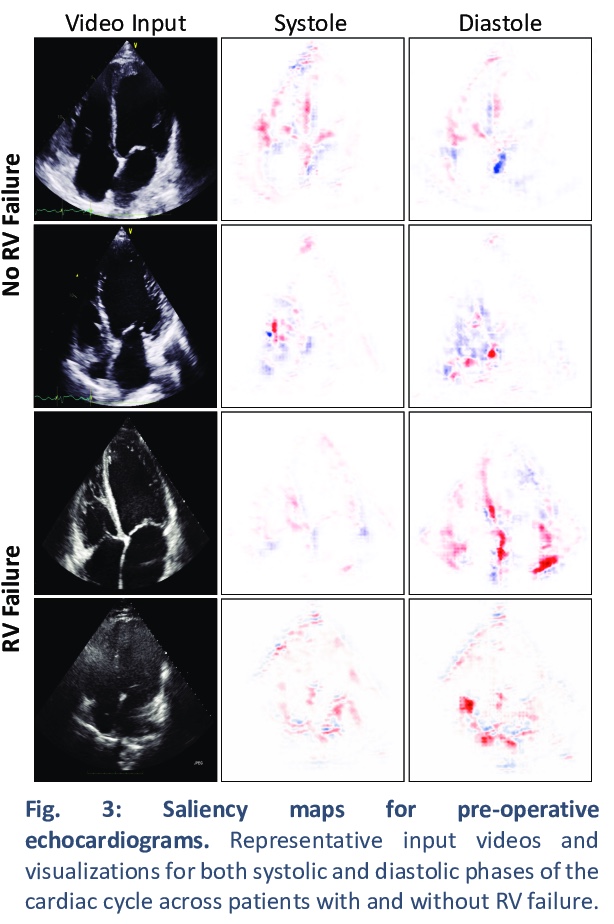
[CV] Predicting post-operative right ventricular failure using video-based deep learning
基于视频深度学习的术后右心室衰竭预测
R Shad, N Quach, R Fong, P Kasinpila, C Bowles, M Castro, A Guha, E Suarez, S Jovinge, S Lee, T Boeve, M Amsallem, X Tang, F Haddad, Y Shudo, Y. J Woo, J Teuteberg, J P. Cunningham, C P. Langlotz, W Hiesinger
[Stanford University & Columbia University]
https://weibo.com/1402400261/K4qpW13zf
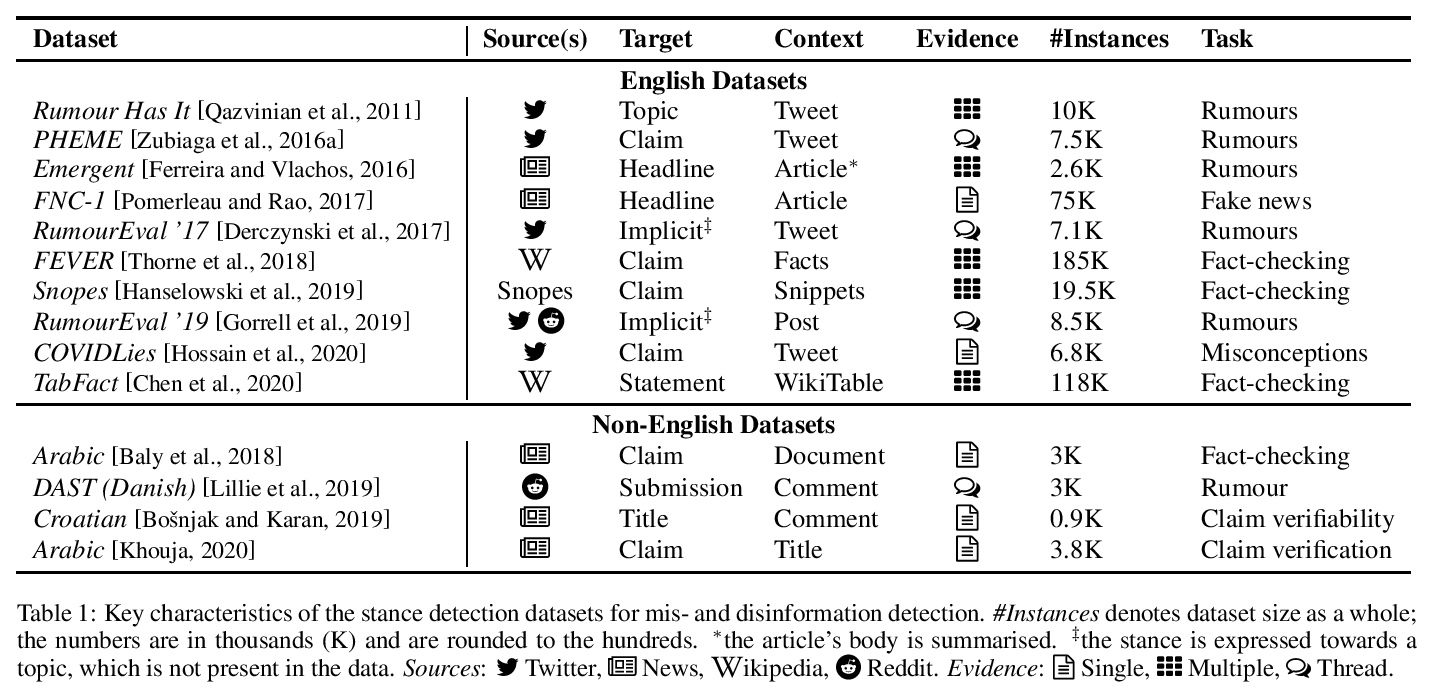
[CL] A Survey on Stance Detection for Mis- and Disinformation Identification
面向误导信息和虚假信息识别的立场检测综述
M Hardalov, A Arora, P Nakov, I Augenstein
[CheckStep Research]
https://weibo.com/1402400261/K4qr912f9

若有收获,就点个赞吧
0 人点赞
