LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] *Combining Label Propagation and Simple Models Out-performs Graph Neural Networks
Q Huang, H He, A Singh, S Lim, A R. Benson
[Cornell University & Facebook & Facebook AI]
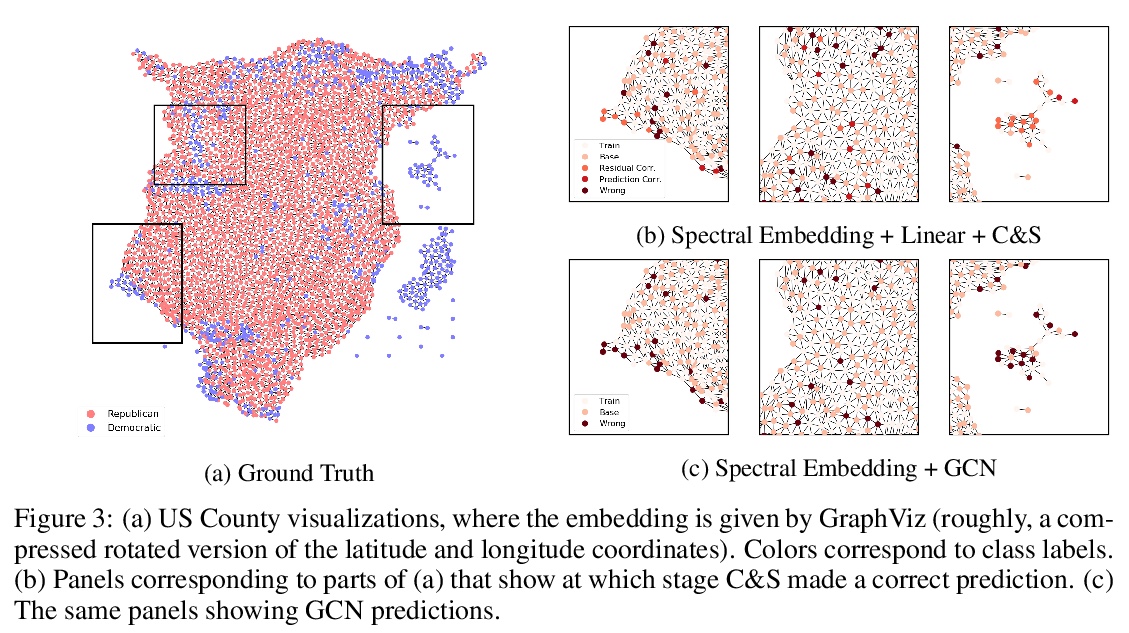
优于图神经网络的标签传播简单模型。将忽略图结构的浅层模型,与利用标签结构相似性的两个后处理步骤相结合——通过“误差相关”传播训练数据残差误差纠正测试数据误差&通过“预测相关”平滑测试数据上的预测——后处理步骤通过对早期基于图的半监督学习方法中标准标签传播技术的简单修改实现。在各种基准测试中,该方法性能超过或接近于最先进的GNN,只需要很小一部分参数,即可达到数量级的运行速度提升。在OGB-Products数据集上,参数减少137倍,训练时间缩短100倍。该方法体现了直接将标签信息合并到学习算法中即可产生简单和实质性的性能收益。还可将该技术合并到大的GNN模型中,也能获得性能上的收益。**
Graph Neural Networks (GNNs) are the predominant technique for learning over graphs. However, there is relatively little understanding of why GNNs are successful in practice and whether they are necessary for good performance. Here, we show that for many standard transductive node classification benchmarks, we can exceed or match the performance of state-of-the-art GNNs by combining shallow models that ignore the graph structure with two simple post-processing steps that exploit correlation in the label structure: (i) an “error correlation” that spreads residual errors in training data to correct errors in test data and (ii) a “prediction correlation” that smooths the predictions on the test data. We call this overall procedure Correct and Smooth (C&S), and the post-processing steps are implemented via simple modifications to standard label propagation techniques from early graph-based semi-supervised learning methods. Our approach exceeds or nearly matches the performance of state-of-the-art GNNs on a wide variety of benchmarks, with just a small fraction of the parameters and orders of magnitude faster runtime. For instance, we exceed the best known GNN performance on the OGB-Products dataset with 137 times fewer parameters and greater than 100 times less training time. The performance of our methods highlights how directly incorporating label information into the learning algorithm (as was done in traditional techniques) yields easy and substantial performance gains. We can also incorporate our techniques into big GNN models, providing modest gains. Our code for the OGB results is at > this https URL.
https://weibo.com/1402400261/JshoCkiTK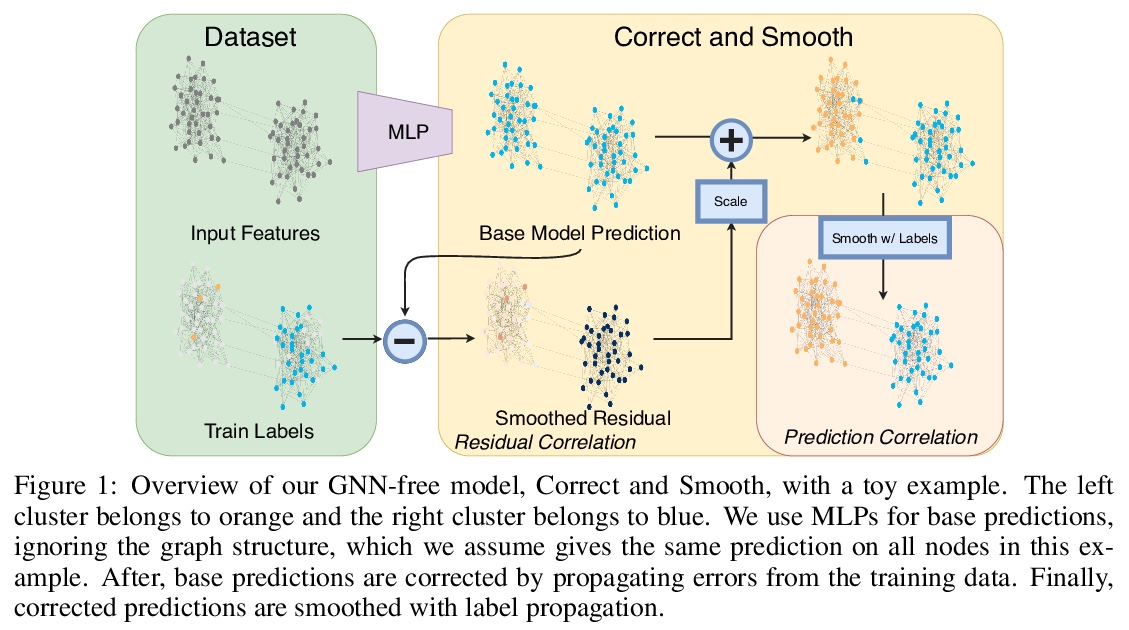
2、[CV] *Do 2D GANs Know 3D Shape? Unsupervised 3D shape reconstruction from 2D Image GANs
X Pan, B Dai, Z Liu, C C Loy, P Luo
[The Chinese University of Hong Kong & Nanyang Technological University & The University of Hong Kong]
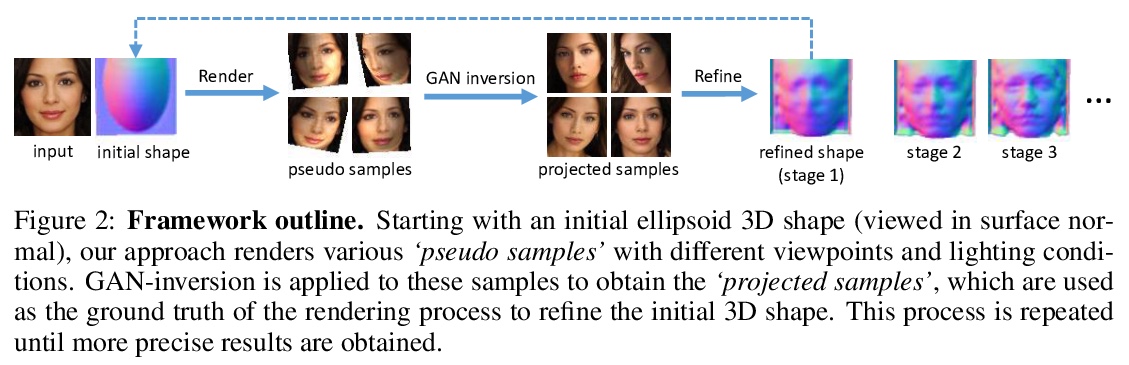
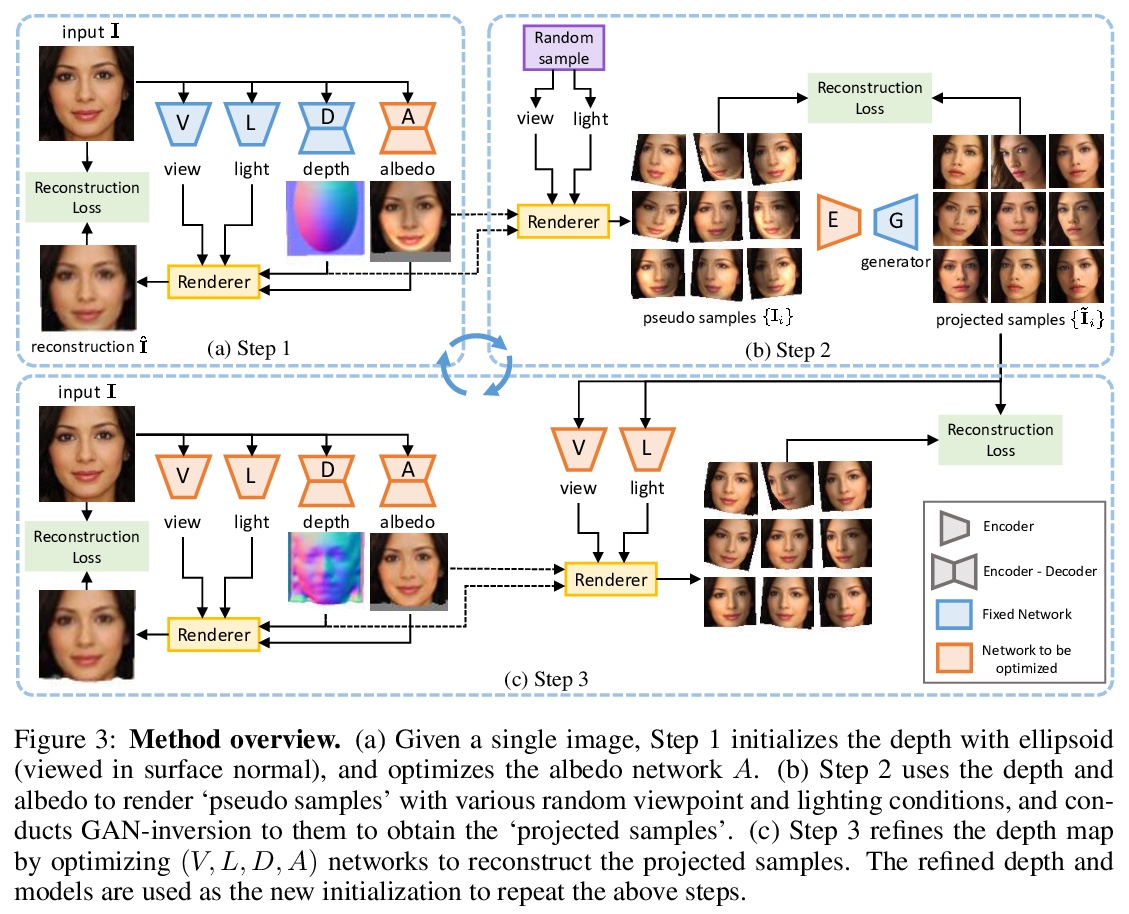
基于2D图像GAN的无监督3D形状重建。尝试从2D GAN挖掘3D几何线索,发现2D GAN本身就能捕捉足够的知识,用来恢复许多物体类别的3D形状,包括人脸、猫、汽车和建筑物。基于弱凸形状先验,该方法可探索GAN图像流形中的视角和光照变化,并利用这些变化以迭代方式细化底层目标形状,无需2D关键点或3D标记,也无需对物体形状进行强假设(例如形状是对称的)。进一步在3D感知图像操作的应用,包括目标旋转和重打光等,也揭示了在2D GAN在2D图像流形3D几何建模方面的潜力。
Natural images are projections of 3D objects on a 2D image plane. While state-of-the-art 2D generative models like GANs show unprecedented quality in modeling the natural image manifold, it is unclear whether they implicitly capture the underlying 3D object structures. And if so, how could we exploit such knowledge to recover the 3D shapes of objects in the images? To answer these questions, in this work, we present the first attempt to directly mine 3D geometric clues from an off-the-shelf 2D GAN that is trained on RGB images only. Through our investigation, we found that such a pre-trained GAN indeed contains rich 3D knowledge and thus can be used to recover 3D shape from a single 2D image in an unsupervised manner. The core of our framework is an iterative strategy that explores and exploits diverse viewpoint and lighting variations in the GAN image manifold. The framework does not require 2D keypoint or 3D annotations, or strong assumptions on object shapes (e.g. shapes are symmetric), yet it successfully recovers 3D shapes with high precision for human faces, cats, cars, and buildings. The recovered 3D shapes immediately allow high-quality image editing like relighting and object rotation. We quantitatively demonstrate the effectiveness of our approach compared to previous methods in both 3D shape reconstruction and face rotation. Our code and models will be released at > this https URL.
https://weibo.com/1402400261/Jshwjt018

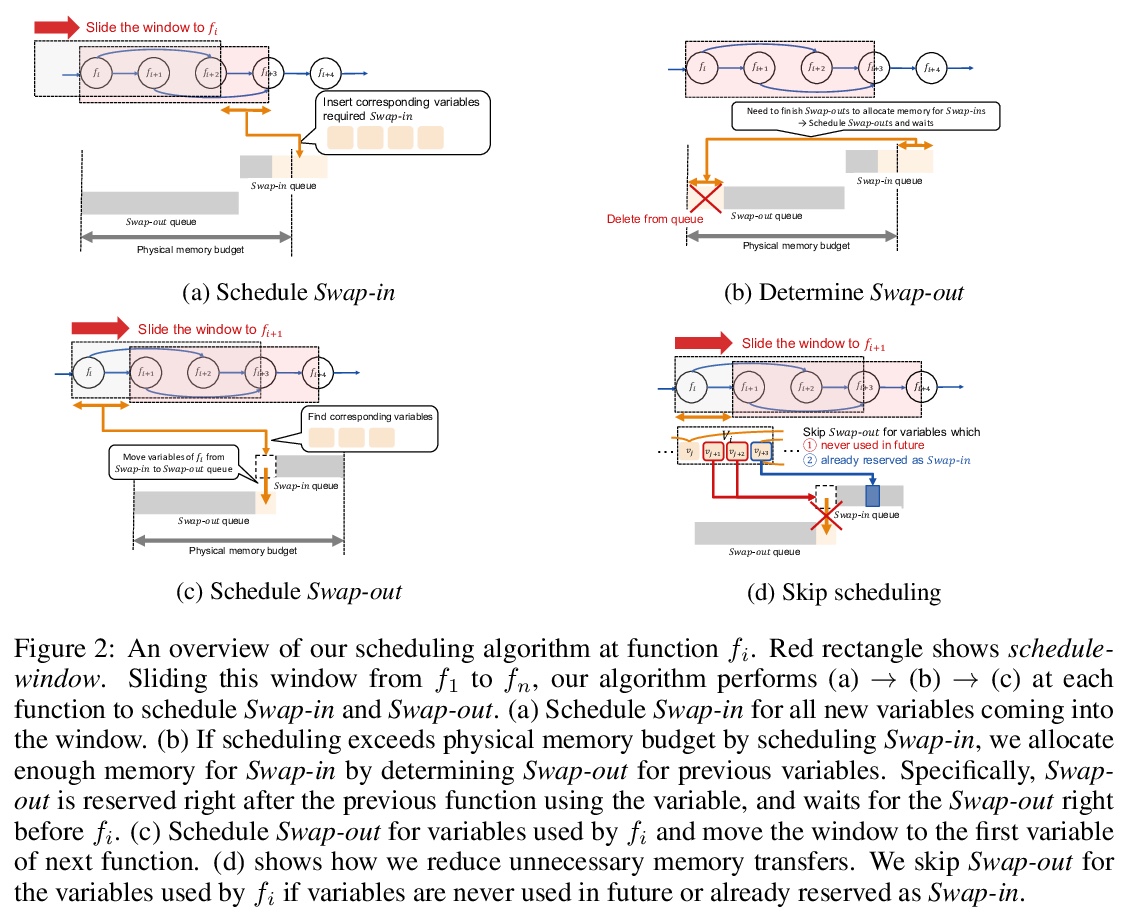
3、[LG] *Out-of-core Training for Extremely Large-Scale Neural Networks With Adaptive Window-Based Scheduling
A Hayakawa, T Narihira
[Sony Corporation]
基于自适应窗调度的大规模神经网络核外训练。提出了一种新的核外算法,能更快地训练比可用GPU内存更大的大规模神经网络。在给定内存预算约束下,调度算法根据函数内存使用情况,局部调整内存传输时间,改善了计算和内存传输的重叠。将操作系统中常见的虚拟寻址技术,应用于核外执行的神经网络训练,大大降低了频繁的内存传输所造成的内存碎片量。除了GPU内存的限制,该方法能训练比现有方法更大的网络,而不牺牲训练时间。**
While large neural networks demonstrate higher performance in various tasks, training large networks is difficult due to limitations on GPU memory size. We propose a novel out-of-core algorithm that enables faster training of extremely large-scale neural networks with sizes larger than allotted GPU memory. Under a given memory budget constraint, our scheduling algorithm locally adapts the timing of memory transfers according to memory usage of each function, which improves overlap between computation and memory transfers. Additionally, we apply virtual addressing technique, commonly performed in OS, to training of neural networks with out-of-core execution, which drastically reduces the amount of memory fragmentation caused by frequent memory transfers. With our proposed algorithm, we successfully train ResNet-50 with 1440 batch-size with keeping training speed at 55%, which is 7.5x larger than the upper bound of physical memory. It also outperforms a previous state-of-the-art substantially, i.e. it trains a 1.55x larger network than state-of-the-art with faster execution. Moreover, we experimentally show that our approach is also scalable for various types of networks.
https://weibo.com/1402400261/JshBmpGvH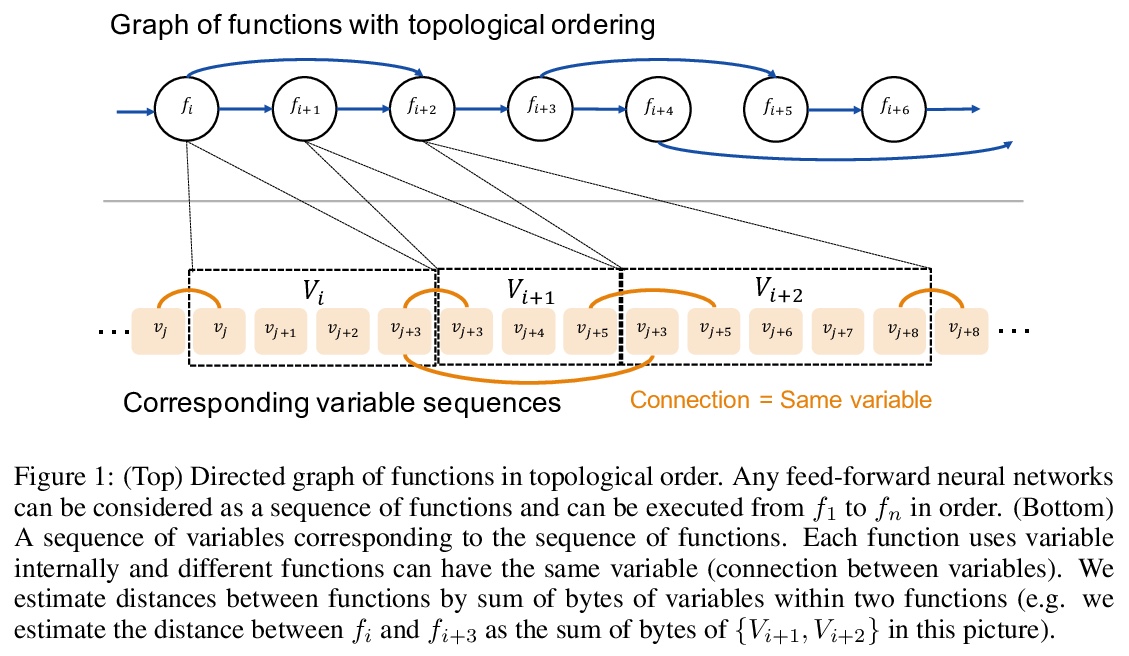
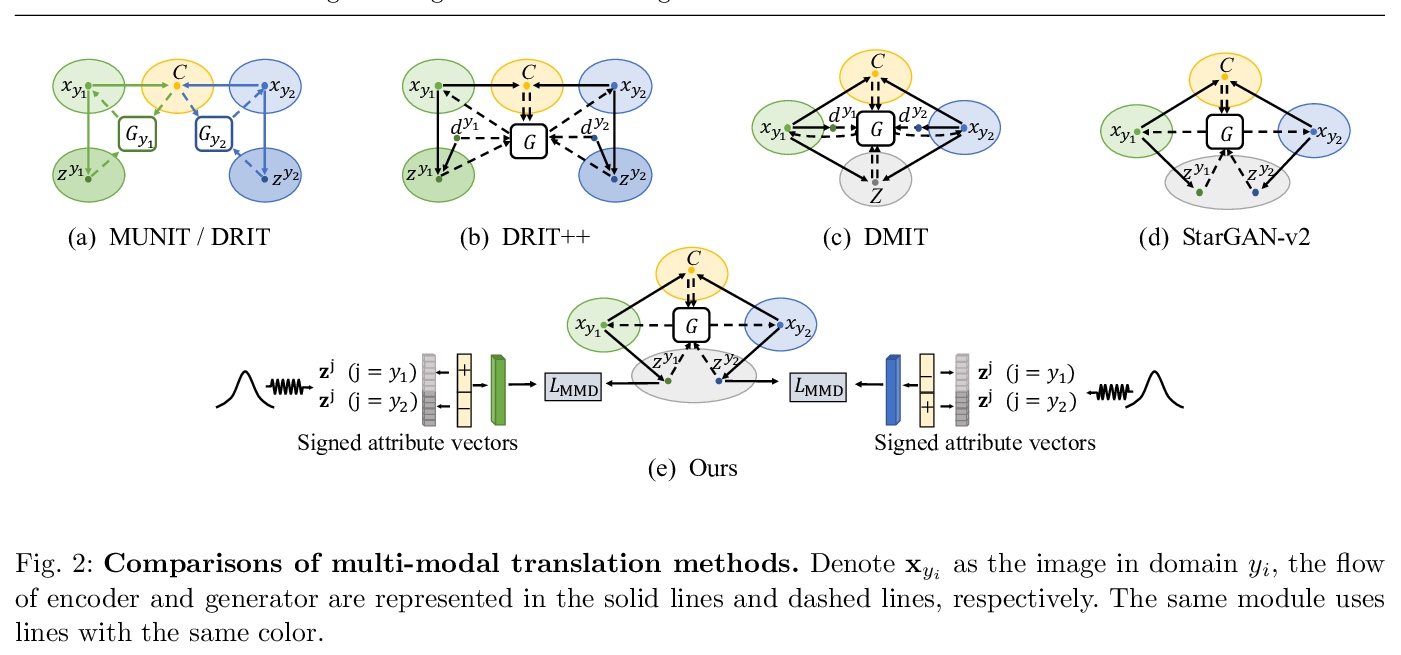
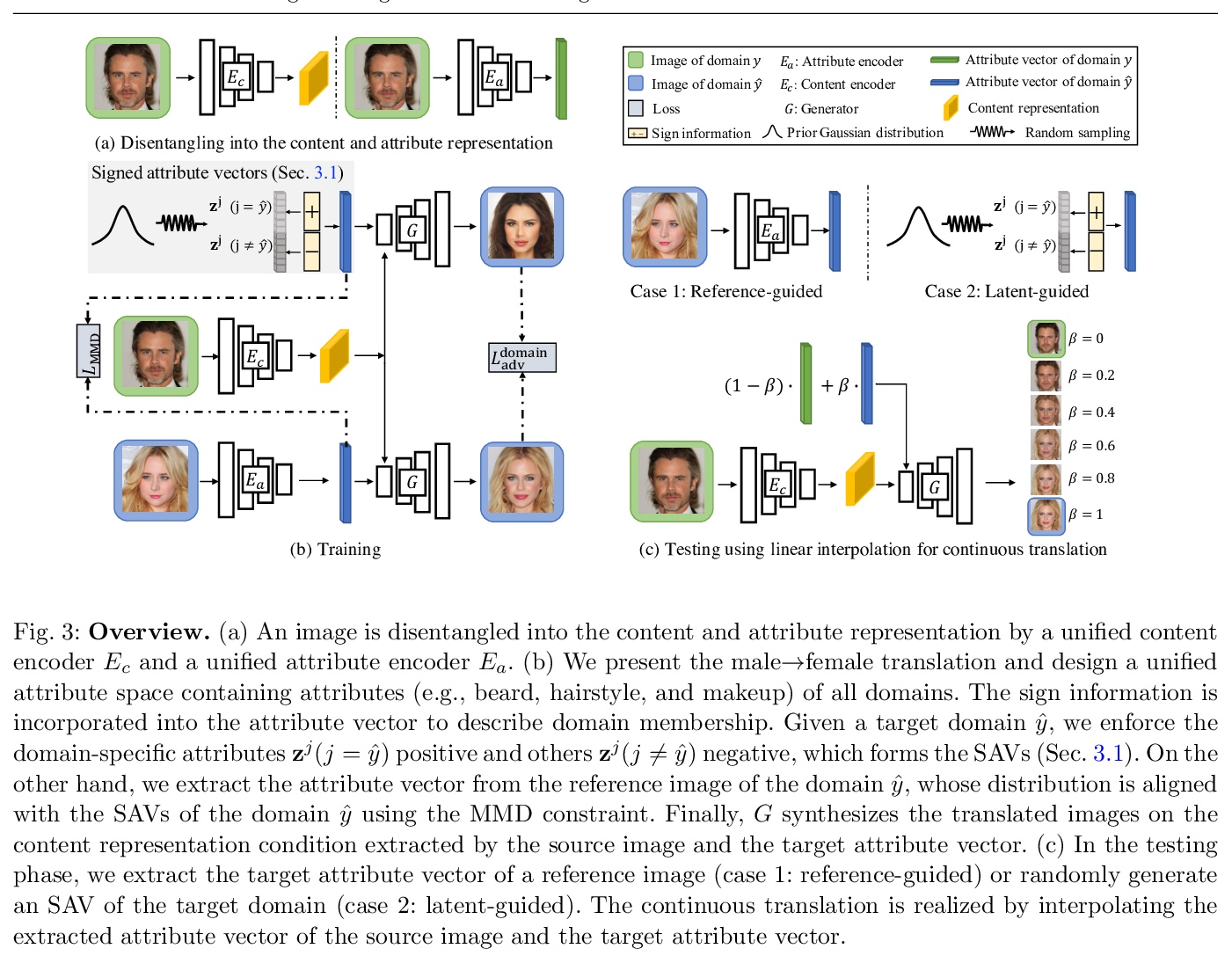
4、[CV] **Continuous and Diverse Image-to-Image Translation via Signed Attribute Vectors
Q Mao, H Lee, H Tseng, J Huang, S Ma, M Yang
[Peking University & the Snap Research & Virginia Tech & University of California at Merced]
基于有符号属性向量的图-图连续/多样变换。提出了有符号的属性向量,以支持跨域的连续、多样的图-图变换。为提高连续变换的质量,提出用符号对称的属性向量,形成不同领域间的变换轨迹,利用中间结果的领域信息实现对抗性训练。**
Recent image-to-image (I2I) translation algorithms focus on learning the mapping from a source to a target domain. However, the continuous translation problem that synthesizes intermediate results between the two domains has not been well-studied in the literature. Generating a smooth sequence of intermediate results bridges the gap of two different domains, facilitating the morphing effect across domains. Existing I2I approaches are limited to either intra-domain or deterministic inter-domain continuous translation. In this work, we present an effective signed attribute vector, which enables continuous translation on diverse mapping paths across various domains. In particular, utilizing the sign operation to encode the domain information, we introduce a unified attribute space shared by all domains, thereby allowing the interpolation on attribute vectors of different domains. To enhance the visual quality of continuous translation results, we generate a trajectory between two sign-symmetrical attribute vectors and leverage the domain information of the interpolated results along the trajectory for adversarial training. We evaluate the proposed method on a wide range of I2I translation tasks. Both qualitative and quantitative results demonstrate that the proposed framework generates more high-quality continuous translation results against the state-of-the-art methods.
https://weibo.com/1402400261/JshFkl7iQ
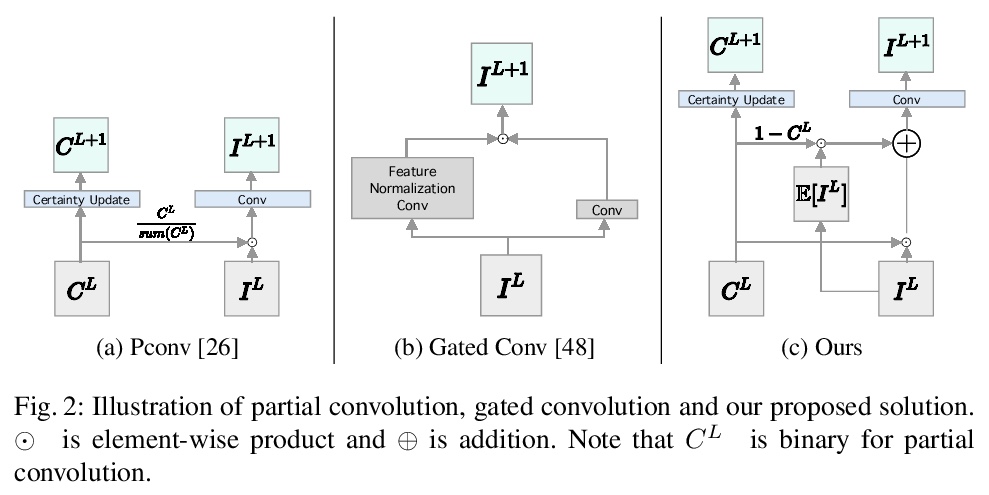
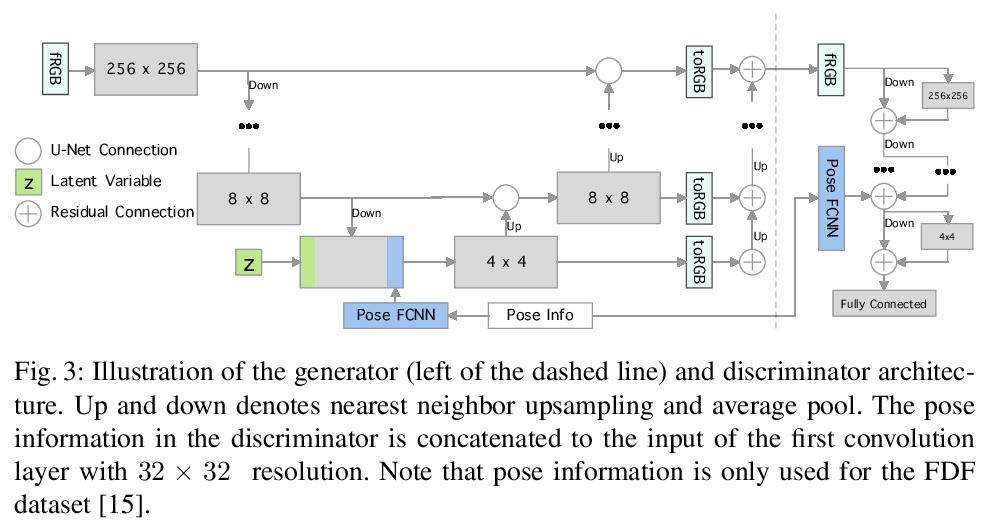
5、[CV] **Image Inpainting with Learnable Feature Imputation
H Hukkelås, F Lindseth, R Mester
[Norwegian University of Science and Technology]
基于可学习特征注入的图像补全。提出一种简单的单级生成器架构,用于自由形式的图像补全。改进了卷积网络中处理缺失值的卷积算法,改进了图像补全的梯度惩罚算法,大大提高了训练的稳定性。提出一种新的基于U-Net的GAN结构,保证了全局和局部的一致性。**
A regular convolution layer applying a filter in the same way over known and unknown areas causes visual artifacts in the inpainted image. Several studies address this issue with feature re-normalization on the output of the convolution. However, these models use a significant amount of learnable parameters for feature re-normalization, or assume a binary representation of the certainty of an output. We propose (layer-wise) feature imputation of the missing input values to a convolution. In contrast to learned feature re-normalization, our method is efficient and introduces a minimal number of parameters. Furthermore, we propose a revised gradient penalty for image inpainting, and a novel GAN architecture trained exclusively on adversarial loss. Our quantitative evaluation on the FDF dataset reflects that our revised gradient penalty and alternative convolution improves generated image quality significantly. We present comparisons on CelebA-HQ and Places2 to current state-of-the-art to validate our model.
https://weibo.com/1402400261/JshKtrQhq
另外几篇值得关注的论文:
[CL] Reducing Confusion in Active Learning for Part-Of-Speech Tagging
减少主动学习词性标注中特定输出标签对之间的混淆
A Chaudhary, A Anastasopoulos, Z Sheikh, G Neubig
[CMU]
https://weibo.com/1402400261/JshNTzmUu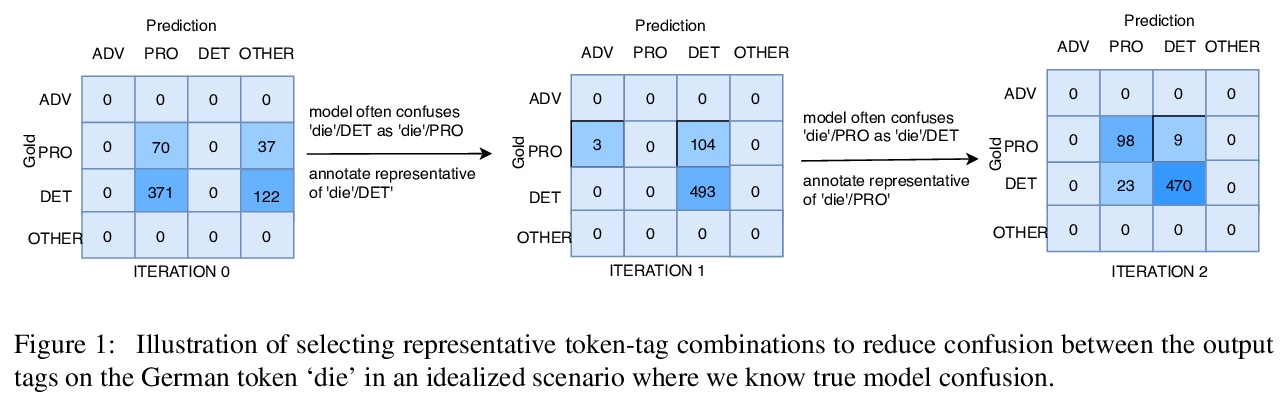
[CL] Dual-decoder Transformer for Joint Automatic Speech Recognition and Multilingual Speech Translation
用于联合自动语音识别和多语言语音翻译的双解码器Transformer
H Le, J Pino, C Wang, J Gu, D Schwab, L Besacier
[Univ. Grenoble Alpes & Facebook AI]
https://weibo.com/1402400261/JshRJbbWO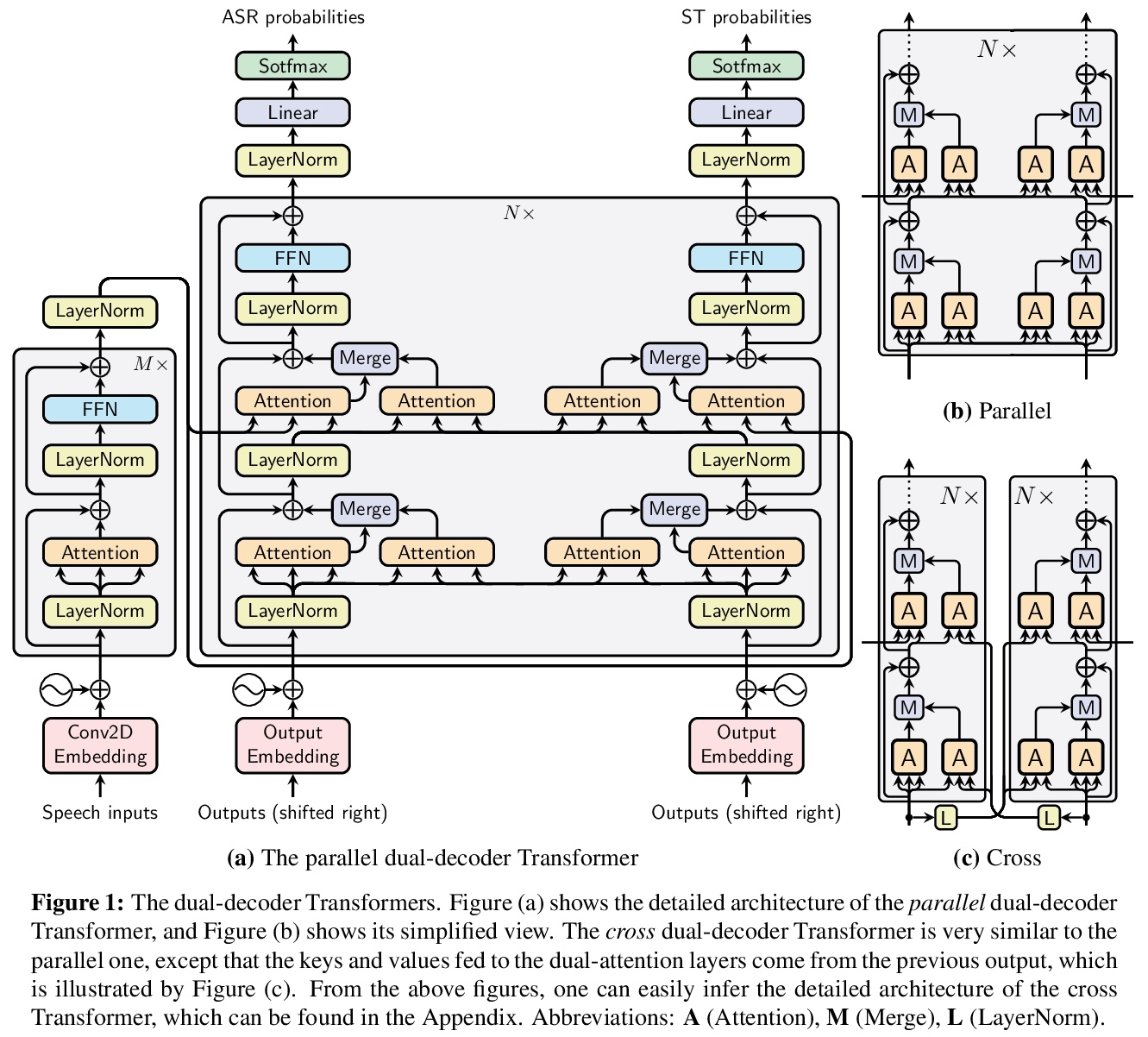
[LG] Learning to Represent Action Values as a Hypergraph on the Action Vertices
用行为超图网络框架学习行为价值估计
A Tavakoli, M Fatemi, P Kormushev
[Imperial College London & Microsoft Research Montréal]
https://weibo.com/1402400261/JshTh9YyL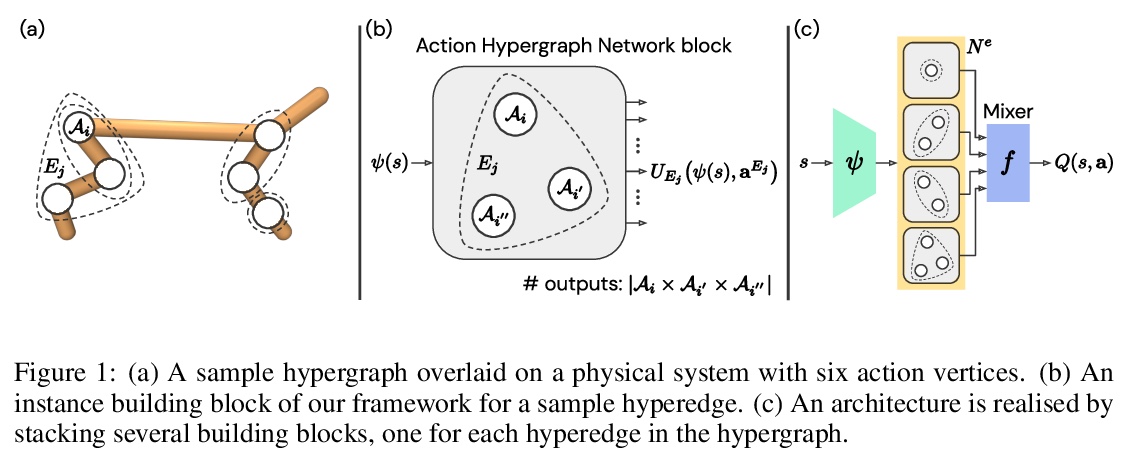
[LG] Causal Campbell-Goodhart’s law and Reinforcement Learning
因果Campbell-Goodhart定律与强化学习
H Ashton
[University College London]
https://weibo.com/1402400261/JshV63OwL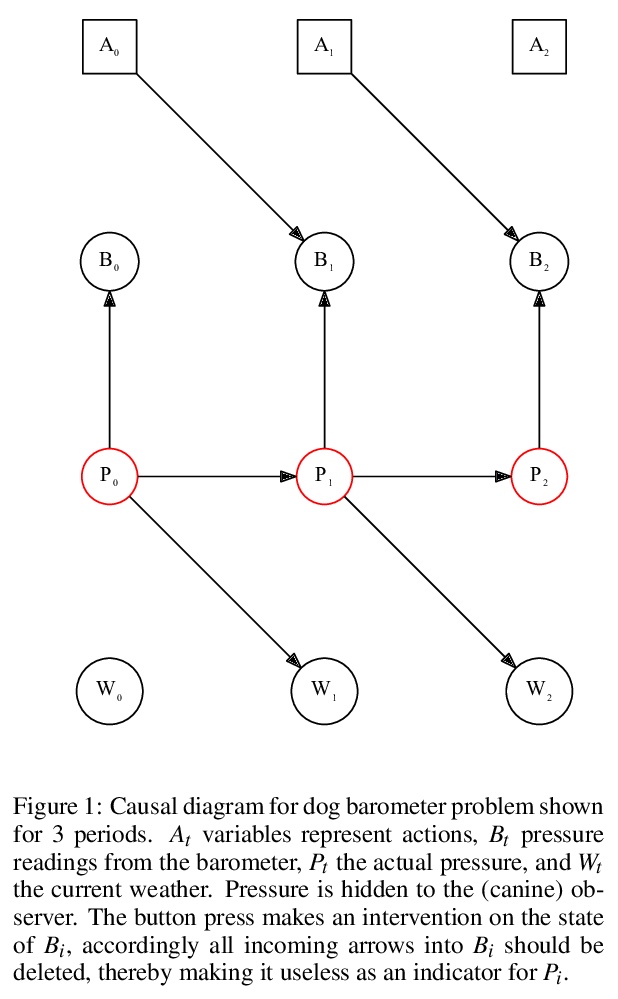
[LG] Meta-Learning with Adaptive Hyperparameters
自适应超参数元学习
S Baik, M Choi, J Choi, H Kim, K M Lee
[Seoul National University]
https://weibo.com/1402400261/JshWHBing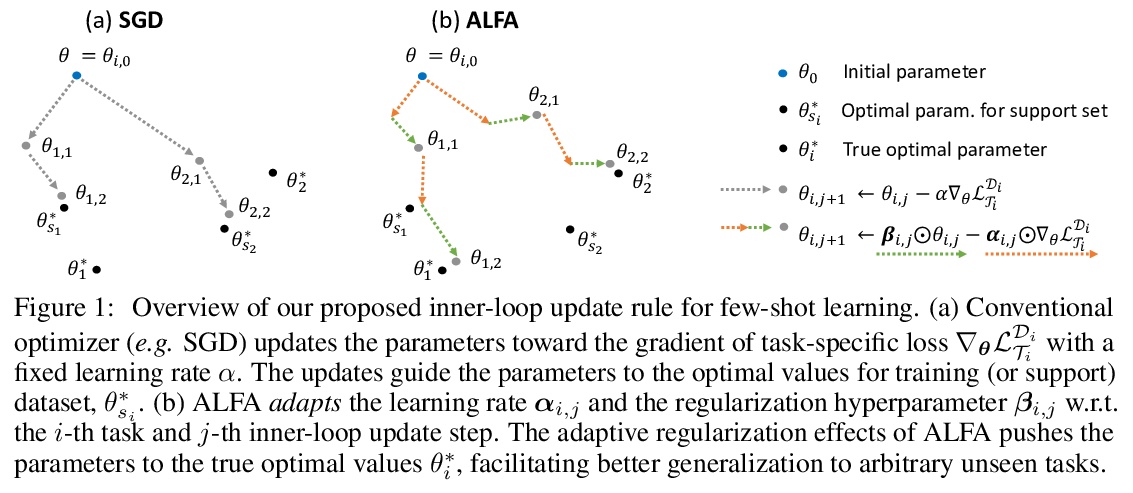
[CL] MixKD: Towards Efficient Distillation of Large-scale Language Models
MixKD:大规模语言模型的高效蒸馏
K J Liang, W Hao, D Shen, Y Zhou, W Chen, C Chen, L Carin
[Duke University & Microsoft Dynamics 365 AI & State University of New York at Buffalo]
https://weibo.com/1402400261/JshXCD5Cr

若有收获,就点个赞吧
0 人点赞
