LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
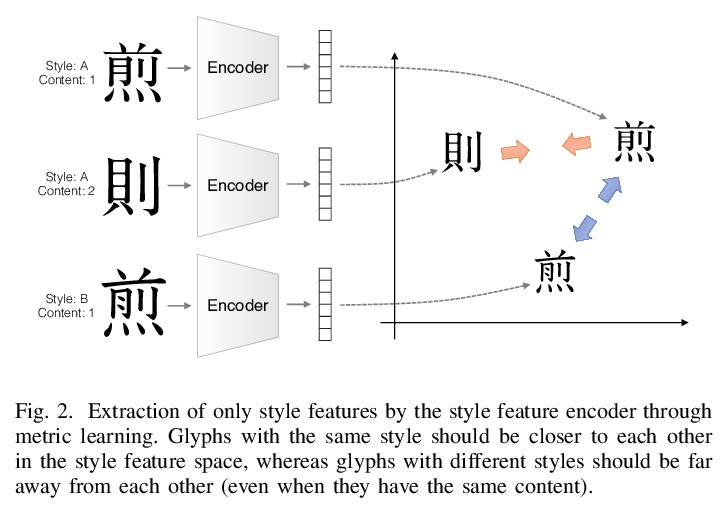
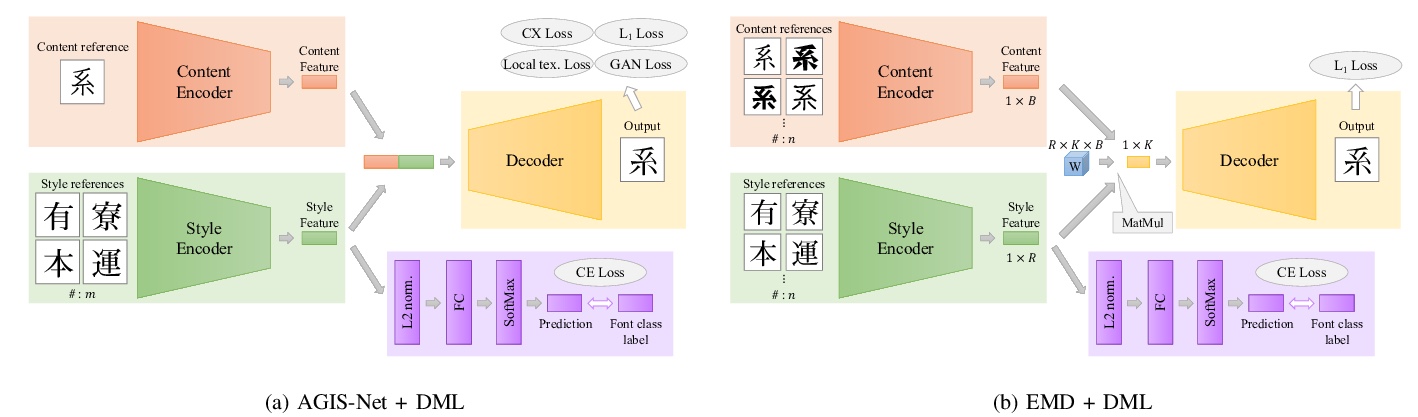
1、[CV] **Few-Shot Font Generation with Deep Metric Learning
H Aoki, K Tsubota, H Ikuta, K Aizawa
[The University of Tokyo]
深度度量学习少样本字体生成。提出一种用来处理日文排版字体的强大而简单的框架,在风格编码器中加入深度度量学习,通过L2约束Softmax损失引入DML,改善了现有的少样本字体生成方法的性能,解决了从少数字体样本自动生成日文排版字体的问题,合成字形预期具有一致性特征,如骨架、轮廓和衬线。该框架有助于风格编码器更突出风格特征,而不受内容属性的影响。**
Designing fonts for languages with a large number of characters, such as Japanese and Chinese, is an extremely labor-intensive and time-consuming task. In this study, we addressed the problem of automatically generating Japanese typographic fonts from only a few font samples, where the synthesized glyphs are expected to have coherent characteristics, such as skeletons, contours, and serifs. Existing methods often fail to generate fine glyph images when the number of style reference glyphs is extremely limited. Herein, we proposed a simple but powerful framework for extracting better style features. This framework introduces deep metric learning to style encoders. We performed experiments using black-and-white and shape-distinctive font datasets and demonstrated the effectiveness of the proposed framework.
https://weibo.com/1402400261/JsApJze5u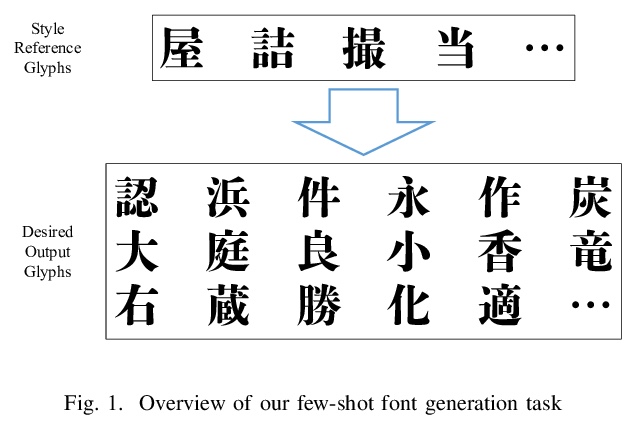
2、[CV] **Deep Image Compositing
H Zhang, J Zhang, F Perazzi, Z Lin, V M. Patel
[Adobe Research & Johns Hopkins University]
深度图像合成。提出一个将带细化的显著性分割模型嵌入到网络的端到端图像合成框架。为了有效利用不同尺度的前景和背景特征,提出一种多流融合网络来生成最终的合成结果。利用自学数据扩充算法来扩充当前的合成数据集。**
Image compositing is a task of combining regions from different images to compose a new image. A common use case is background replacement of portrait images. To obtain high quality composites, professionals typically manually perform multiple editing steps such as segmentation, matting and foreground color decontamination, which is very time consuming even with sophisticated photo editing tools. In this paper, we propose a new method which can automatically generate high-quality image compositing without any user input. Our method can be trained end-to-end to optimize exploitation of contextual and color information of both foreground and background images, where the compositing quality is considered in the optimization. Specifically, inspired by Laplacian pyramid blending, a dense-connected multi-stream fusion network is proposed to effectively fuse the information from the foreground and background images at different scales. In addition, we introduce a self-taught strategy to progressively train from easy to complex cases to mitigate the lack of training data. Experiments show that the proposed method can automatically generate high-quality composites and outperforms existing methods both qualitatively and quantitatively.



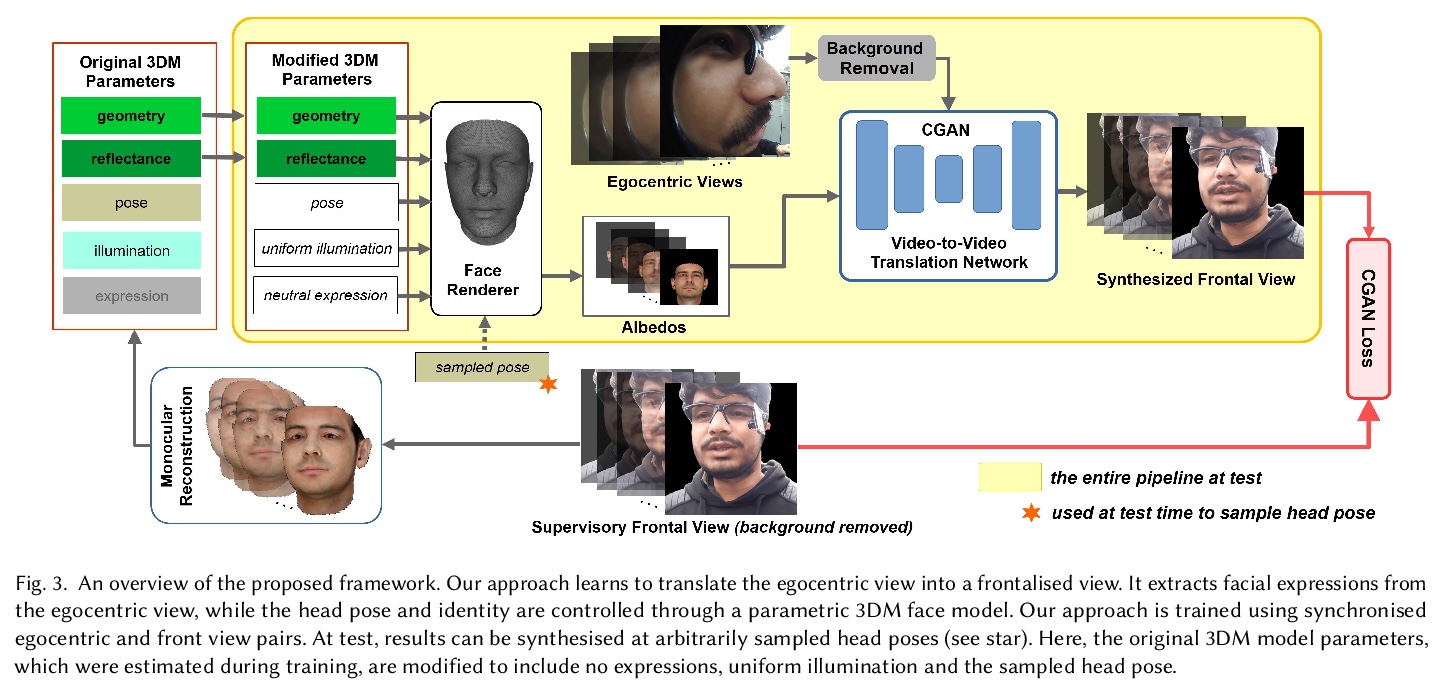
3、[CV] *Egocentric Videoconferencing
M ELGHARIB, M MENDIRATTA…
[Max Planck Institute for Informatics & Technical University of Munich]
用于智能眼镜的自我中心视频会议方法,可以让人们戴着智能眼镜或其他混合现实设备进行免手持视频通话。用条件生成对抗神经网络,学习从高度扭曲的自我中心视点到视频会议中常见的正面视点的过渡,把智能眼镜相机的自我中心视角转换成正面的视频,该方法学习直接从自我中心视点迁移表情细节,而不用复杂的中间参数表情模型,可用于相关的人脸重现。该系统可以用参数模型和基于图像变换的条件反射来捕捉细节,有望成为迈向新的混合面部动画系统的垫脚石。**
We introduce a method for egocentric videoconferencing that enables handsfree video calls, for instance by people wearing smart glasses or other mixedreality devices. Videoconferencing portrays valuable non-verbal communication and face expression cues, but usually requires a front-facing camera. Using a frontal camera in a hands-free setting when a person is on the move is impractical. Even holding a mobile phone camera in the front of the face while sitting for a long duration is not convenient. To overcome these issues, we propose a low-cost wearable egocentric camera setup that can be integrated into smart glasses. Our goal is to mimic a classical video call, and therefore, we transform the egocentric perspective of this camera into a front facing video. To this end, we employ a conditional generative adversarial neural network that learns a transition from the highly distorted egocentric views to frontal views common in videoconferencing. Our approach learns to transfer expression details directly from the egocentric view without using a complex intermediate parametric expressions model, as it is used by related face reenactment methods. We successfully handle subtle expressions, not easily captured by parametric blendshape-based solutions, e.g., tongue movement, eye movements, eye blinking, strong expressions and depth varying movements. To get control over the rigid head movements in the target view, we condition the generator on synthetic renderings of a moving neutral face. This allows us to synthesis results at different head poses. Our technique produces temporally smooth video-realistic renderings in real-time using a video-to-video translation network in conjunction with a temporal discriminator. We demonstrate the improved capabilities of our technique by comparing against related state-of-the art approaches.
https://weibo.com/1402400261/JsAAqoQdR

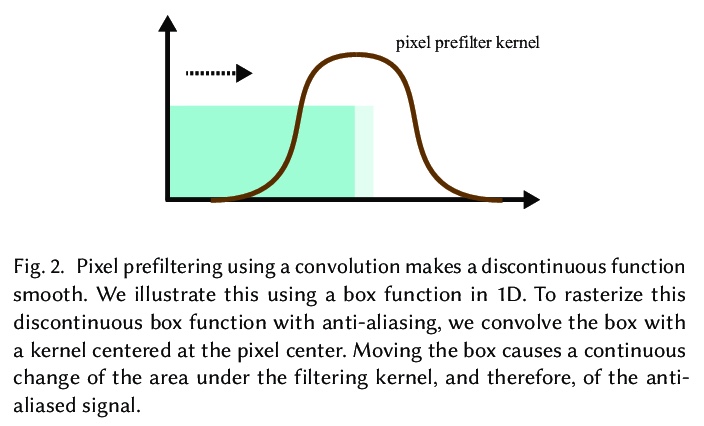
4、[CV] *Differentiable Vector Graphics Rasterization for Editing and Learning
T LI, M LUKÁČ…
[MIT & Adobe Research]
面向编辑和学习的可微矢量图形光栅化。提供了一种矢量图形可微光栅化器,能将矢量数据转换为光栅表示,同时促进两个域之间的反向传播。该可微光栅化器提供了两种预滤波选项:解析预滤波技术和多采样反混叠技术。既便于基于栅格标准对矢量数据进行直接优化,又便于将矢量图形组件无缝集成到严重依赖于图像空间卷积的深度学习模型中,有望开启视觉数据跨表示学习和优化的新思路。**
We introduce a differentiable rasterizer that bridges the vector graphics and raster image domains, enabling powerful raster-based loss functions, optimization procedures, and machine learning techniques to edit and generate vector content. We observe that vector graphics rasterization is differentiable after pixel prefiltering. Our differentiable rasterizer offers two prefiltering options: an analytical prefiltering technique and a multisampling anti-aliasing technique. The analytical variant is faster but can suffer from artifacts such as conflation. The multisampling variant is still efficient, and can render high-quality images while computing unbiased gradients for each pixel with respect to curve parameters. We demonstrate that our rasterizer enables new applications, including a vector graphics editor guided by image metrics, a painterly rendering algorithm that fits vector primitives to an image by minimizing a deep perceptual loss function, new vector graphics editing algorithms that exploit well-known image processing methods such as seam carving, and deep generative models that generate vector content from raster-only supervision under a VAE or GAN training objective.
https://weibo.com/1402400261/JsAGneGxy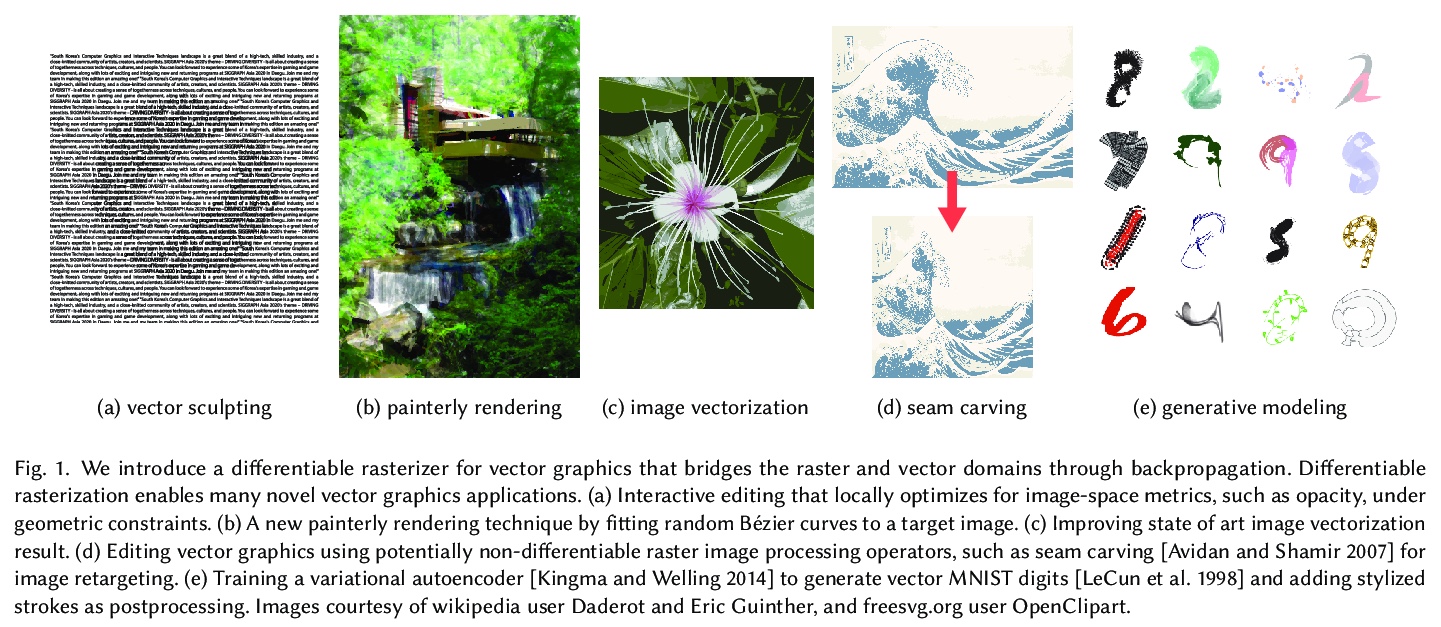

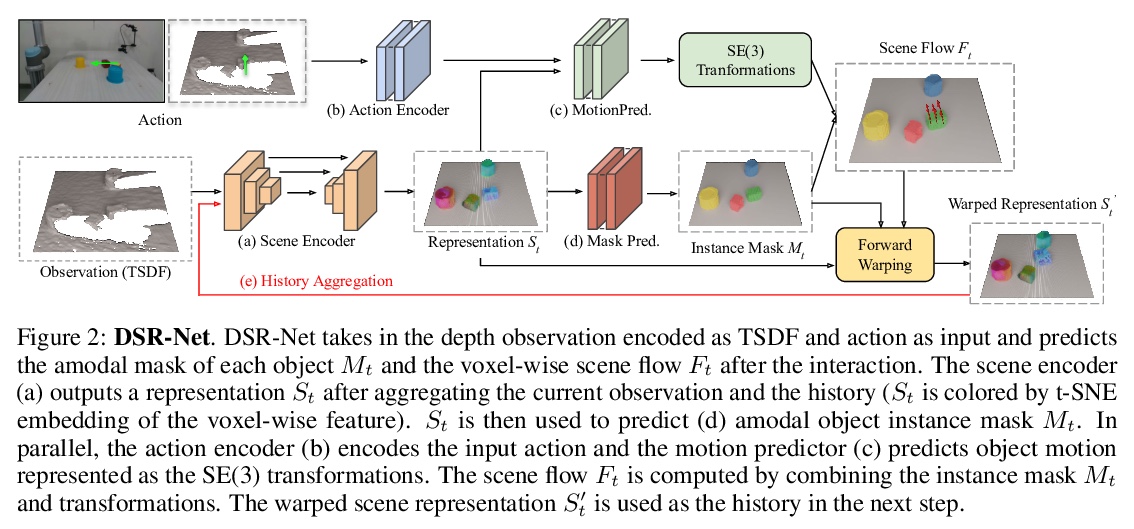
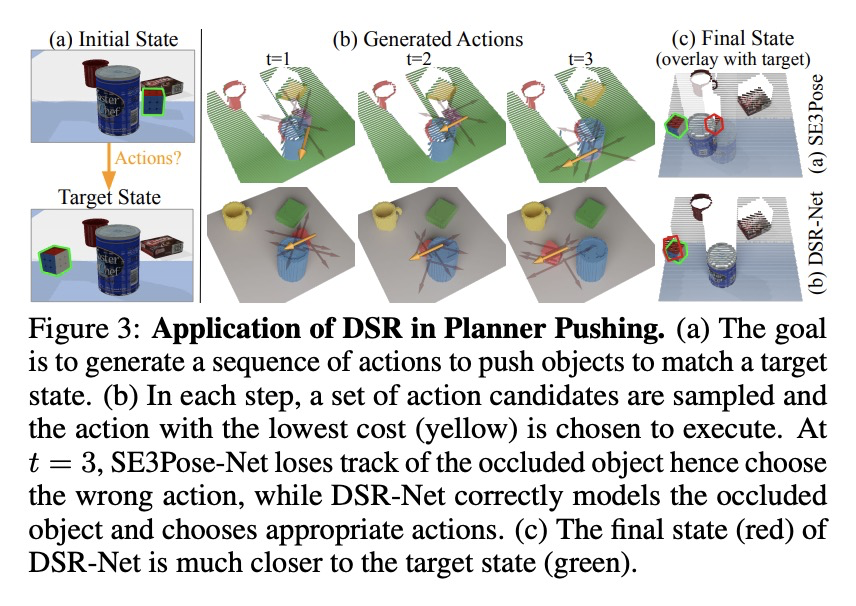
5、[RO] **Learning 3D Dynamic Scene Representations for Robot Manipulation
Z Xu, Z He, J Wu, S Song
[Columbia University & Stanford University]
用于机器人操作的三维动态场景表示学习。提出了三维动态场景表示(DSR),一种三维体场景表示,发现、跟踪、重建对象,并预测其动态,同时捕捉物体的持久性、稳定性和时空连续性。提出DSR-Net,学习在多个交互过程中汇聚视觉观察,逐步建立和完善DSR。基于该模型的仿真和真实数据三维场景动态建模达到了最先进的性能。**
3D scene representation for robot manipulation should capture three key object properties: permanency — objects that become occluded over time continue to exist; amodal completeness — objects have 3D occupancy, even if only partial observations are available; spatiotemporal continuity — the movement of each object is continuous over space and time. In this paper, we introduce 3D Dynamic Scene Representation (DSR), a 3D volumetric scene representation that simultaneously discovers, tracks, reconstructs objects, and predicts their dynamics while capturing all three properties. We further propose DSR-Net, which learns to aggregate visual observations over multiple interactions to gradually build and refine DSR. Our model achieves state-of-the-art performance in modeling 3D scene dynamics with DSR on both simulated and real data. Combined with model predictive control, DSR-Net enables accurate planning in downstream robotic manipulation tasks such as planar pushing. Video is available at > this https URL.
https://weibo.com/1402400261/JsALZfCZy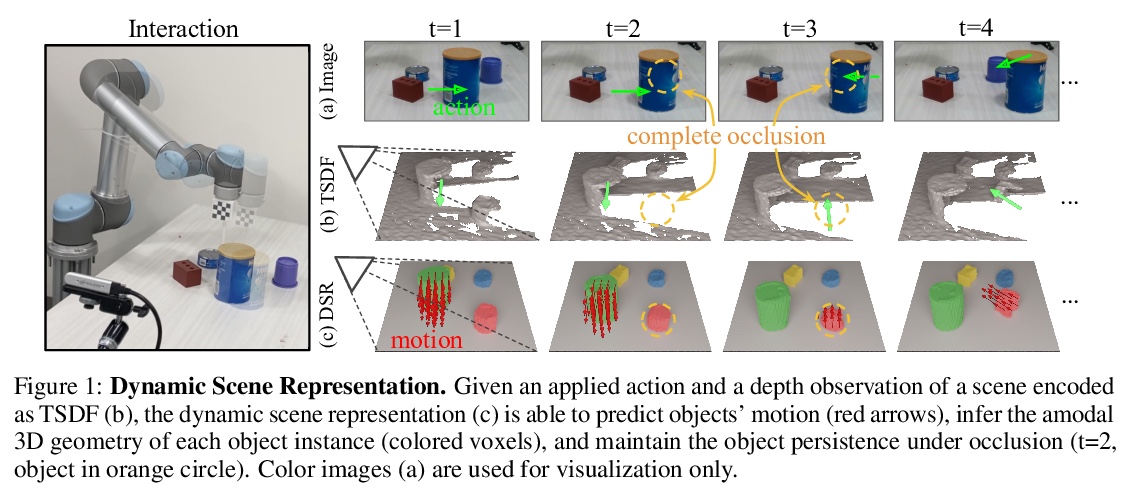
另外几篇值得关注的论文:
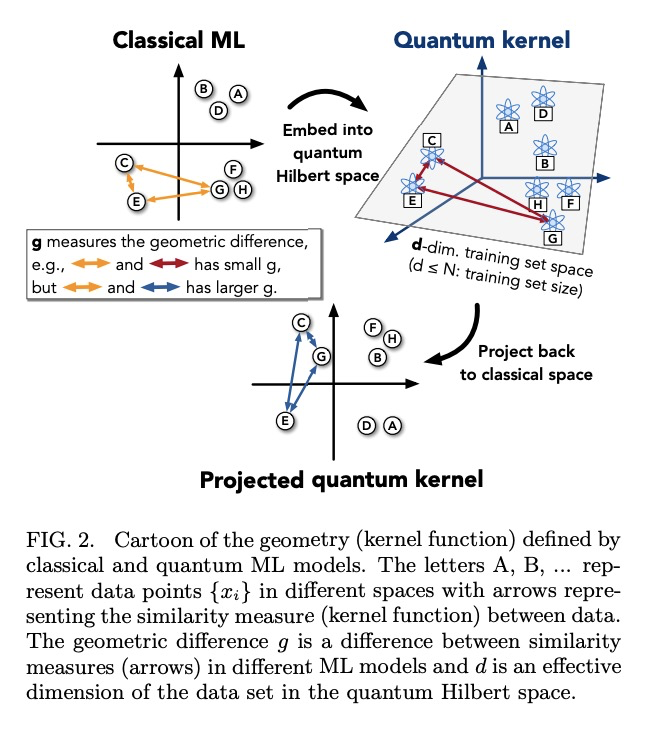
[LG] Power of data in quantum machine learning
量子机器学习数据之力
H Huang, M Broughton, M Mohseni, R Babbush, S Boixo, H Neven, J R. McClean
[Google Research & Caltech]
https://weibo.com/1402400261/JsARUxizu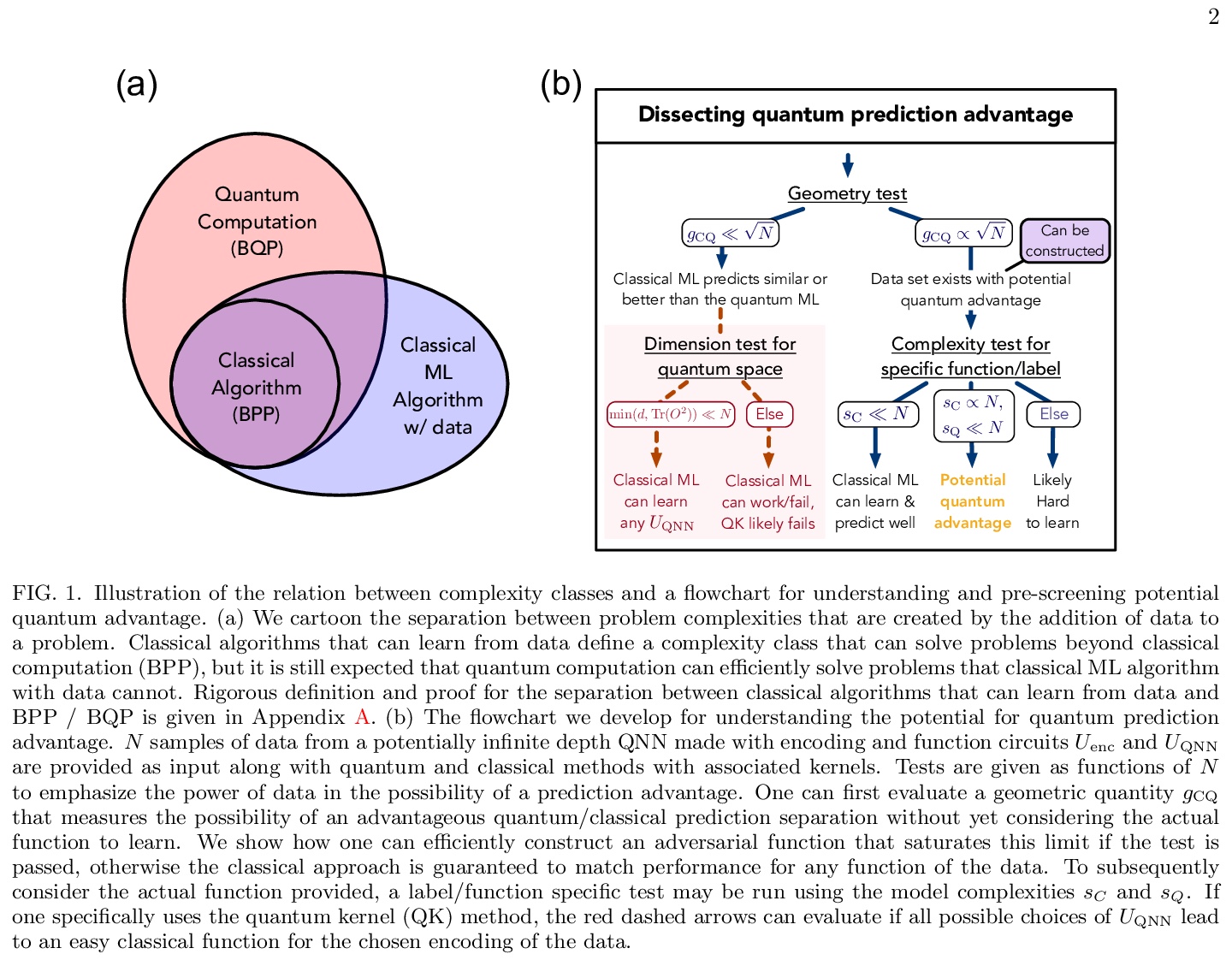
[AI] Rearrangement: A Challenge for Embodied AI
重排:具身人工智能的挑战
D Batra, A X. Chang, S Chernova, A J. Davison, J Deng, V Koltun, S Levine, J Malik, I Mordatch, R Mottaghi, M Savva, H Su
[Georgia Tech & Simon Fraser University & Imperial College London & Princeton University & Intel Labs & UC Berkeley & Allen Institute for AI & UC San Diego]
https://weibo.com/1402400261/JsAVID9dX


[LG] Surgical Data Science — from Concepts to Clinical Translation
外科医学数据科学——从概念到临床翻译
L Maier-Hein, M Eisenmann, D Sarikaya…
[German Cancer Research Center & Gazi University…]
https://weibo.com/1402400261/JsAXw5D57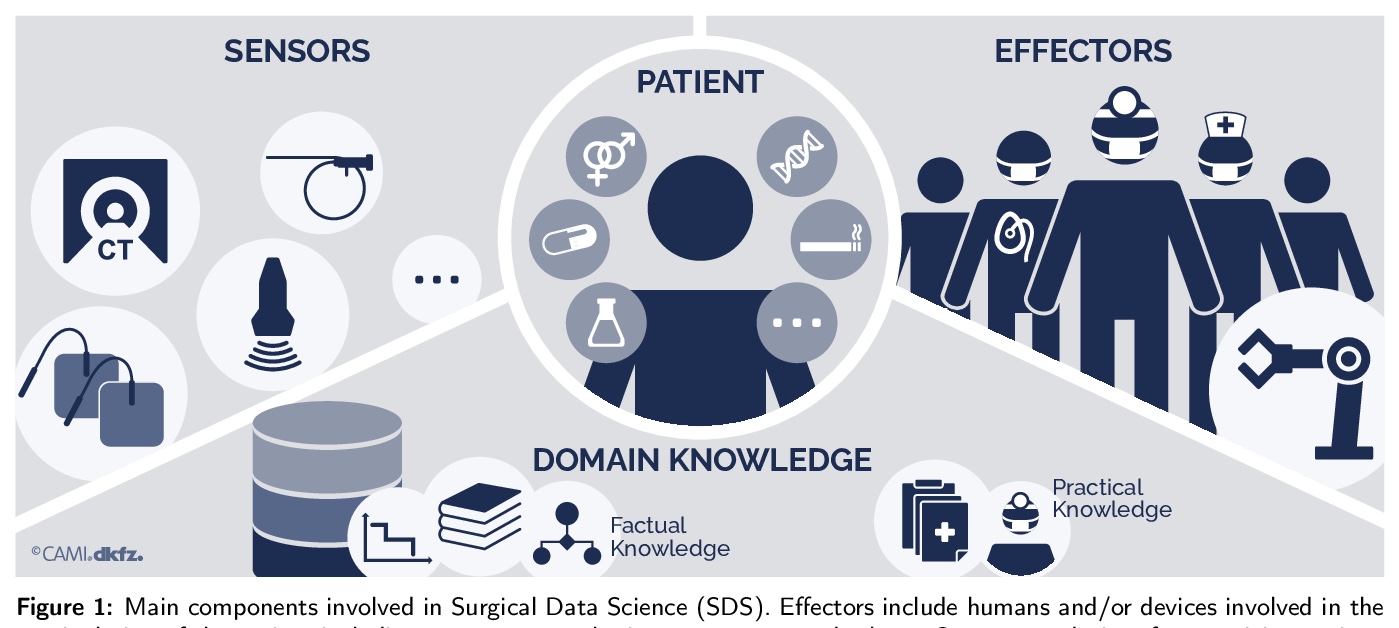
[LG] Debiasing classifiers: is reality at variance with expectation?
分类器去偏化:现实与期望不一致吗?
A Agrawal, F Pfisterer, B Bischl, J Chen, S Sood, S Shah, F Buet-Golfouse, B A Mateen, S Vollmer
[Birla Institute of Technology and Science & Ludwig Maximilians University & J. P. Morgan AI Research & Alan Turing Institute & University of Warwick]
https://weibo.com/1402400261/JsAZzoHPv

若有收获,就点个赞吧
0 人点赞
