- 1、[CV] Efficient DETR: Improving End-to-End Object Detector with Dense Prior
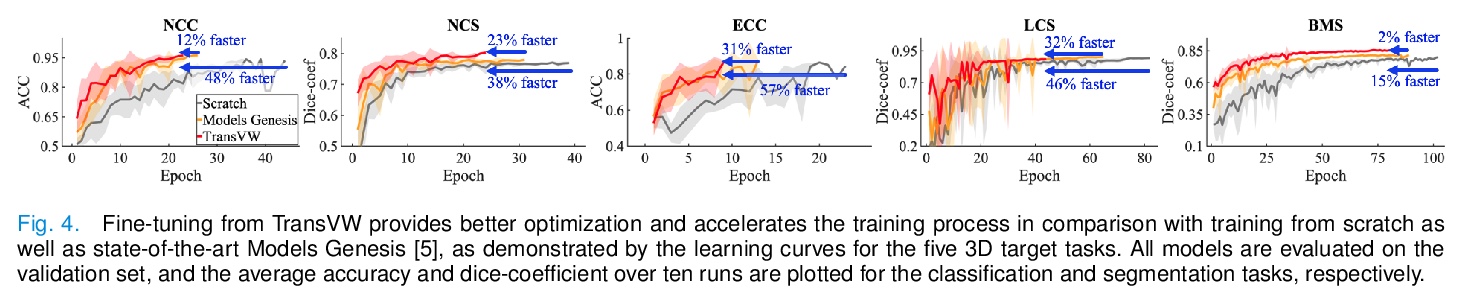
- 2、[CV] Transferable Visual Words: Exploiting the Semantics of Anatomical Patterns for Self-supervised Learning
- 3、[CV] Convolutional Neural Opacity Radiance Fields
- 4、[CV] An Empirical Study of Training Self-Supervised Visual Transformers
- 5、[CV] Generating Furry Cars: Disentangling Object Shape & Appearance across Multiple Domains
- [CV] Hierarchical Pyramid Representations for Semantic Segmentation
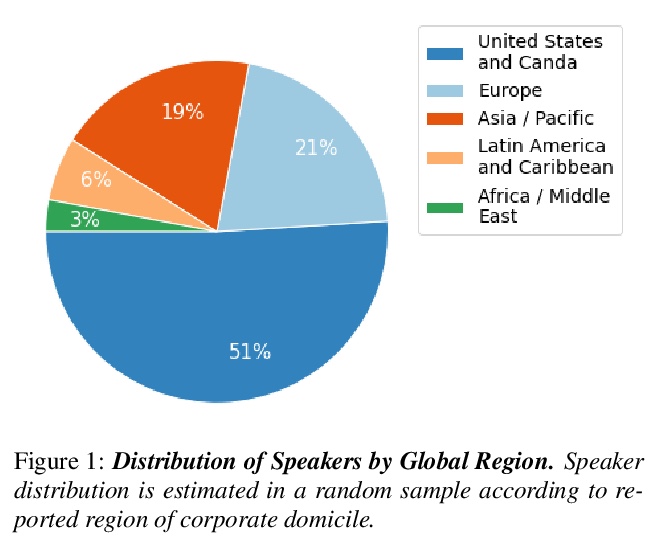
- [CL] SPGISpeech: 5,000 hours of transcribed financial audio for fully formatted end-to-end speech recognition
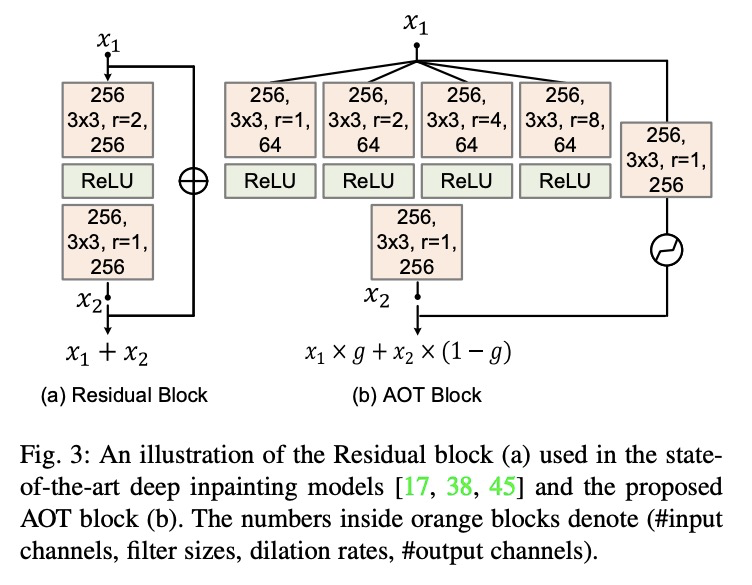
- [CV] Aggregated Contextual Transformations for High-Resolution Image Inpainting
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Efficient DETR: Improving End-to-End Object Detector with Dense Prior
Z Yao, J Ai, B Li, C Zhang
[Megvii Technology]
Efficient DETR:基于密集先验改进端到端目标检测器。提出Efficient DETR,一种简单高效的端到端目标检测管线。Efficient DETR的两部分:密集和稀疏,共享同一个检测头。在密集部分,基于滑动窗口进行特定类的密集预测来生成候选分割。利用密集检测和稀疏集检测的优势,Efficient DETR利用密集先验初始化目标容器,结合了密集检测和集合检测的特点,实现了高性能和更快的收敛速度。在MS COCO上进行的实验表明,该方法只用3个编码器层和1个解码器层,达到了与最先进的目标检测方法竞争的性能。
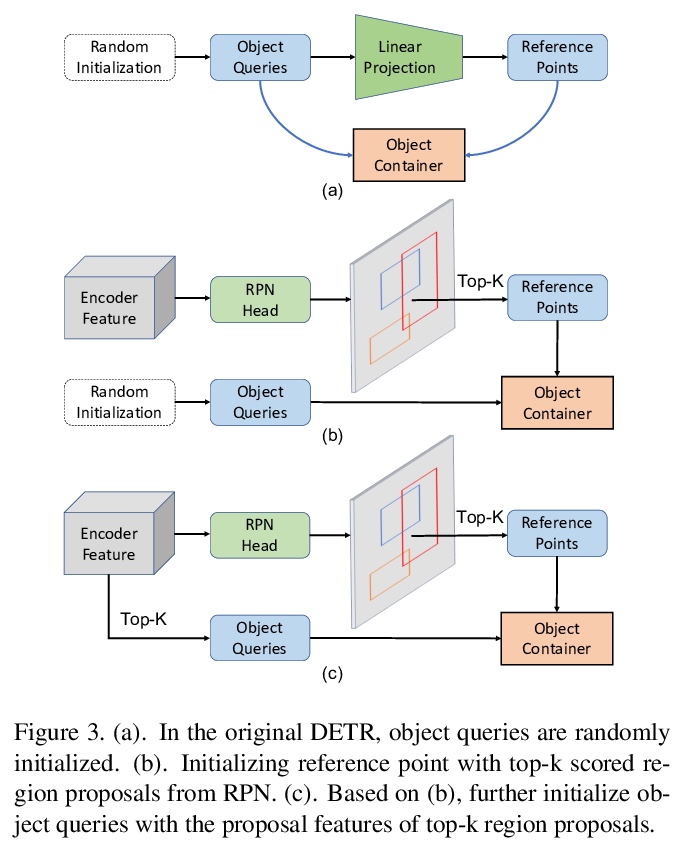
The recently proposed end-to-end transformer detectors, such as DETR and Deformable DETR, have a cascade structure of stacking 6 decoder layers to update object queries iteratively, without which their performance degrades seriously. In this paper, we investigate that the random initialization of object containers, which include object queries and reference points, is mainly responsible for the requirement of multiple iterations. Based on our findings, we propose Efficient DETR, a simple and efficient pipeline for end-to-end object detection. By taking advantage of both dense detection and sparse set detection, Efficient DETR leverages dense prior to initialize the object containers and brings the gap of the 1-decoder structure and 6-decoder structure. Experiments conducted on MS COCO show that our method, with only 3 encoder layers and 1 decoder layer, achieves competitive performance with state-of-the-art object detection methods. Efficient DETR is also robust in crowded scenes. It outperforms modern detectors on CrowdHuman dataset by a large margin.
https://weibo.com/1402400261/K9JVftAfI


2、[CV] Transferable Visual Words: Exploiting the Semantics of Anatomical Patterns for Self-supervised Learning
F Haghighi, M R H Taher, Z Zhou, M B. Gotway, J Liang
[Arizona State University & Mayo Clinic]
可迁移视觉词:基于解剖模式语义学的自监督学习。引入概念”可迁移视觉词”(TransVW),旨在提高医学影像分析中深度学习的标注效率。设计了一个自监督学习框架,允许深度模型直接从图像数据中学习通用的视觉表示,利用与整个医学图像中反复出现的解剖模式相关的语义,获得通用的语义丰富的图像表示。通过实验证明了TransVW的标注效率,可提供更高的性能和更快的收敛性,与公开3D模型相比,不仅可通过自我督,还可通过全监督进行预训练,从而降低标注成本。
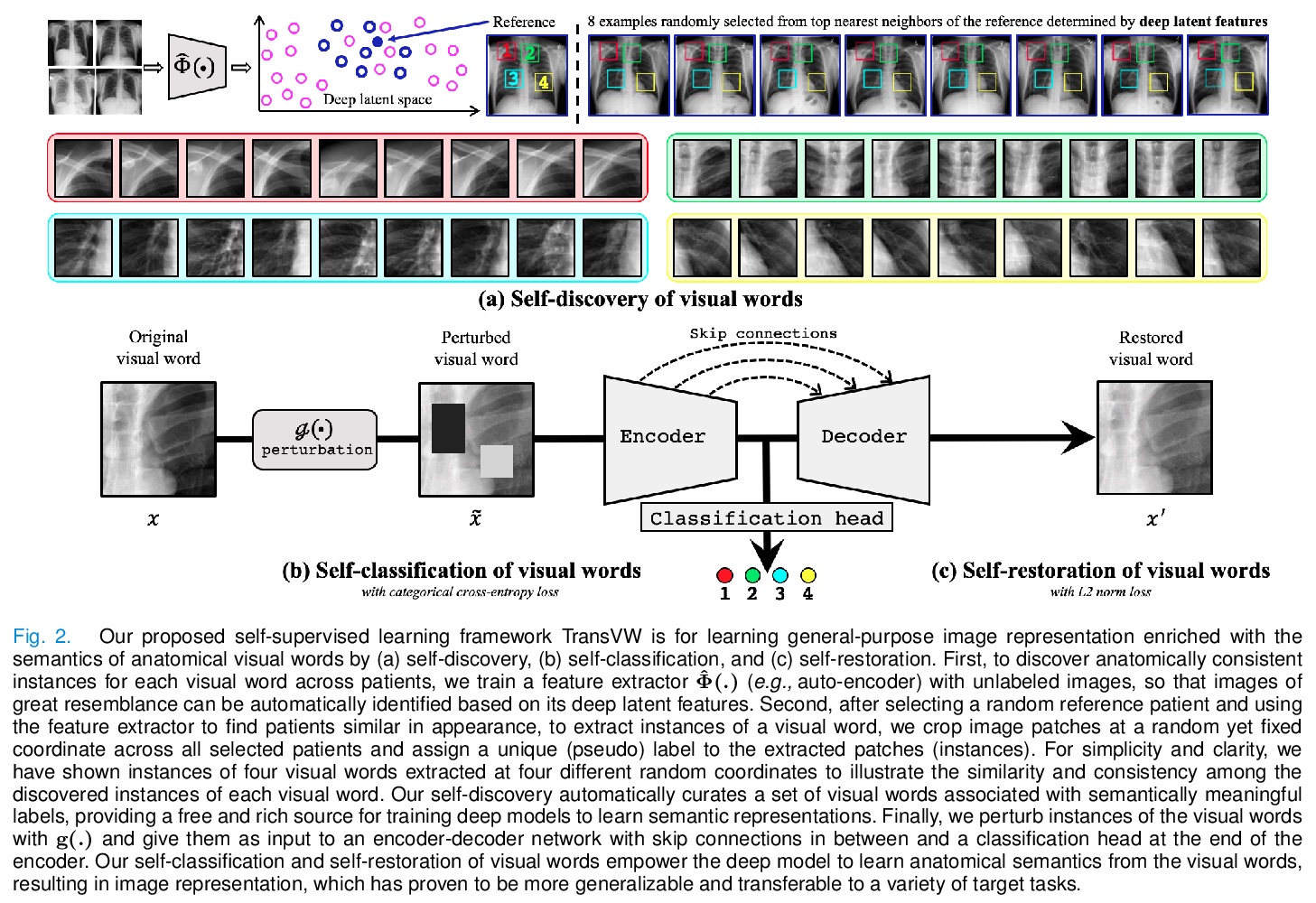
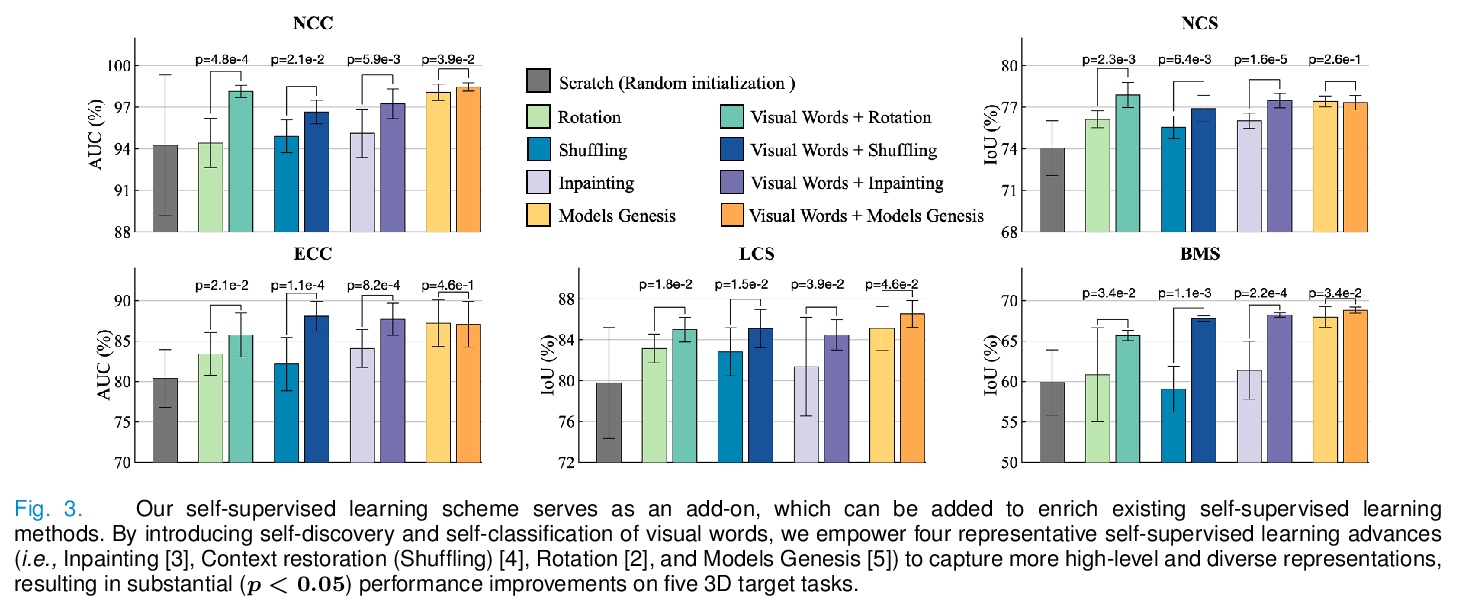
This paper introduces a new concept called “transferable visual words” (TransVW), aiming to achieve annotation efficiency for deep learning in medical image analysis. Medical imaging—focusing on particular parts of the body for defined clinical purposes—generates images of great similarity in anatomy across patients and yields sophisticated anatomical patterns across images, which are associated with rich semantics about human anatomy and which are natural visual words. We show that these visual words can be automatically harvested according to anatomical consistency via self-discovery, and that the self-discovered visual words can serve as strong yet free supervision signals for deep models to learn semantics-enriched generic image representation via self-supervision (self-classification and self-restoration). Our extensive experiments demonstrate the annotation efficiency of TransVW by offering higher performance and faster convergence with reduced annotation cost in several applications. Our TransVW has several important advantages, including (1) TransVW is a fully autodidactic scheme, which exploits the semantics of visual words for self-supervised learning, requiring no expert annotation; (2) visual word learning is an add-on strategy, which complements existing self-supervised methods, boosting their performance; and (3) the learned image representation is semantics-enriched models, which have proven to be more robust and generalizable, saving annotation efforts for a variety of applications through transfer learning. Our code, pre-trained models, and curated visual words are available at > this https URL.
https://weibo.com/1402400261/K9K1Uxdkc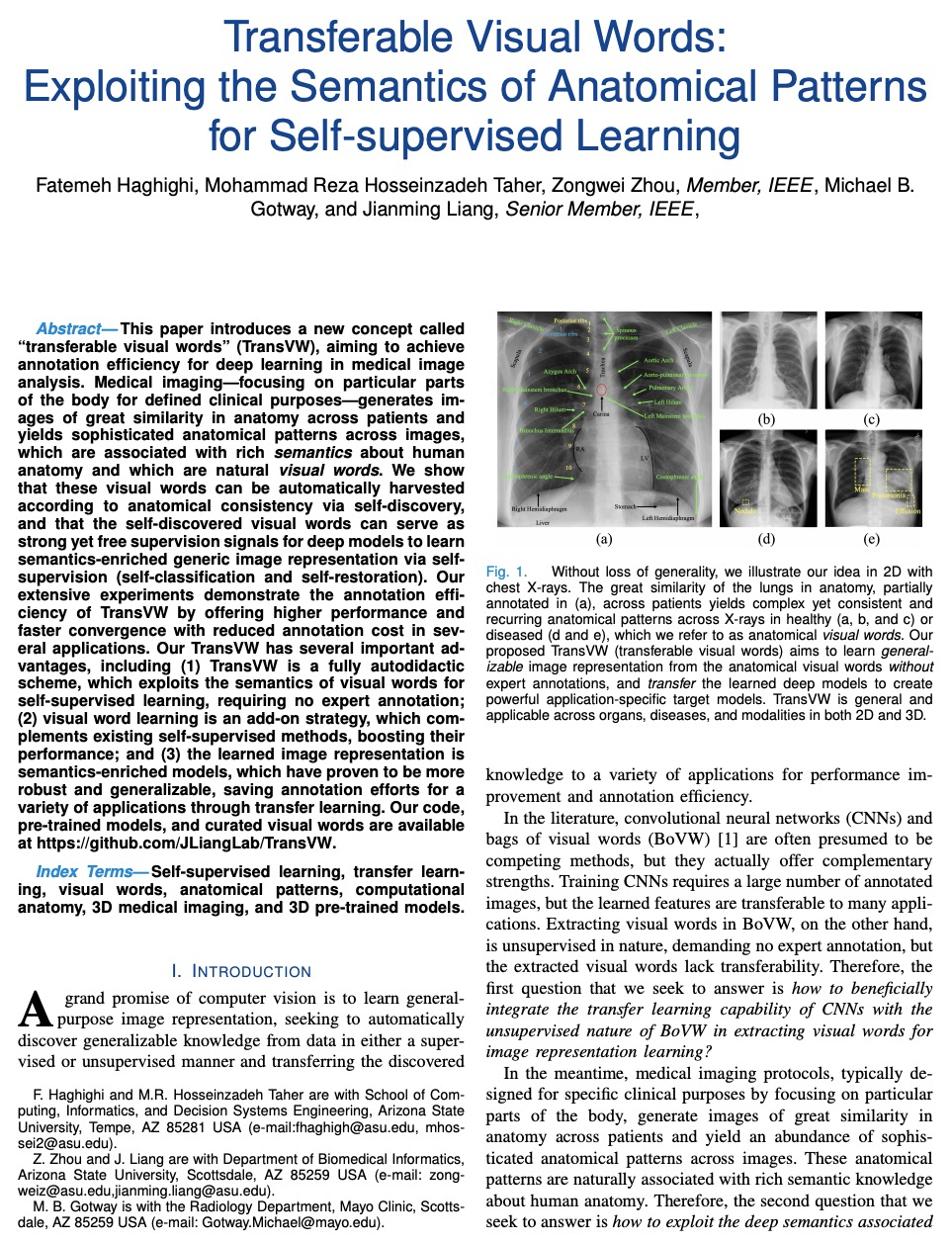
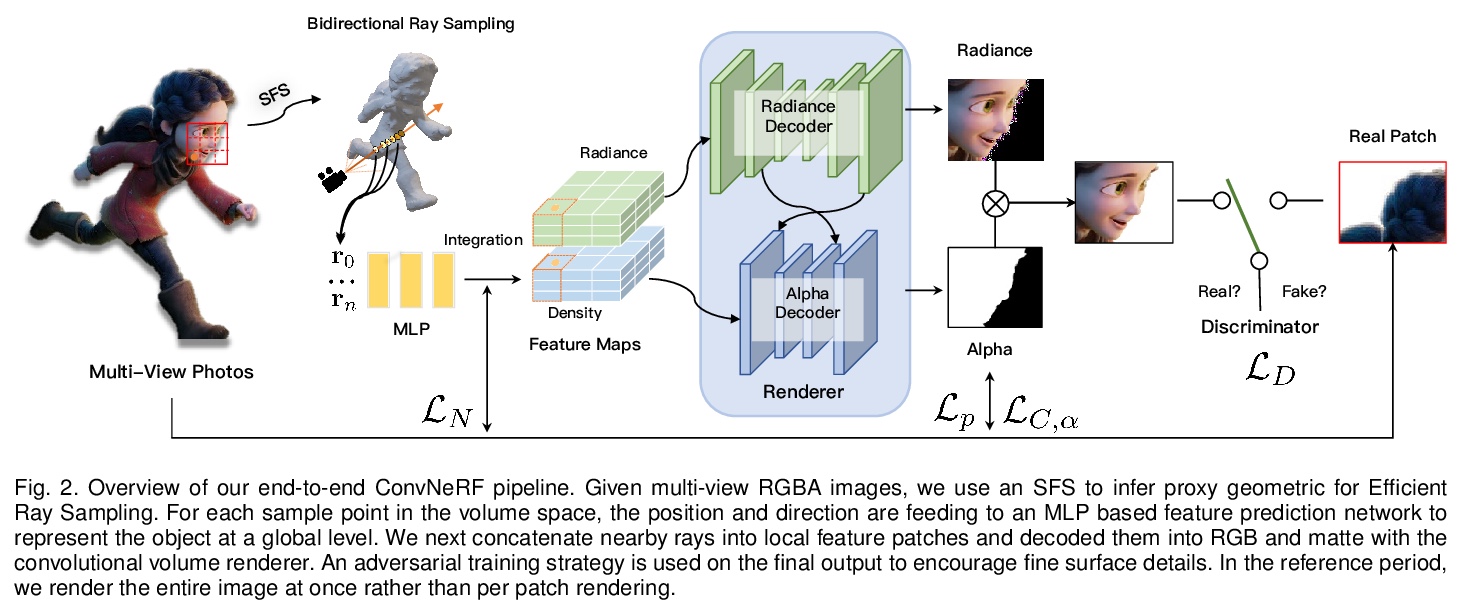
3、[CV] Convolutional Neural Opacity Radiance Fields
H Luo, A Chen, Q Zhang, B Pang, M Wu, L Xu, J Yu
[ShanghaiTech University & Chinese Academy of Sciences]
卷积神经不透明度辐射场。提出一种新的用卷积神经渲染器生成模糊目标不透明度辐射场的方案,将显式不透明度监督和卷积机制结合到神经辐射场框架中,在任意新视图中实现高质量外观和全局一致的alpha抠图。提出一种高效的采样策略,在摄像机射线和图像平面上都能实现高效的辐射场采样和学习,提出一种新的体特征集成方案,可生成每个图块的混合特征嵌入,以重构视图一致的精细细节外观和不透明度输出。引入了有效的多视图系统来捕获具有挑战性的模糊目标的颜色和alpha图。
Photo-realistic modeling and rendering of fuzzy objects with complex opacity are critical for numerous immersive VR/AR applications, but it suffers from strong view-dependent brightness, color. In this paper, we propose a novel scheme to generate opacity radiance fields with a convolutional neural renderer for fuzzy objects, which is the first to combine both explicit opacity supervision and convolutional mechanism into the neural radiance field framework so as to enable high-quality appearance and global consistent alpha mattes generation in arbitrary novel views. More specifically, we propose an efficient sampling strategy along with both the camera rays and image plane, which enables efficient radiance field sampling and learning in a patch-wise manner, as well as a novel volumetric feature integration scheme that generates per-patch hybrid feature embeddings to reconstruct the view-consistent fine-detailed appearance and opacity output. We further adopt a patch-wise adversarial training scheme to preserve both high-frequency appearance and opacity details in a self-supervised framework. We also introduce an effective multi-view image capture system to capture high-quality color and alpha maps for challenging fuzzy objects. Extensive experiments on existing and our new challenging fuzzy object dataset demonstrate that our method achieves photo-realistic, globally consistent, and fined detailed appearance and opacity free-viewpoint rendering for various fuzzy objects.
https://weibo.com/1402400261/K9K7fyHuW

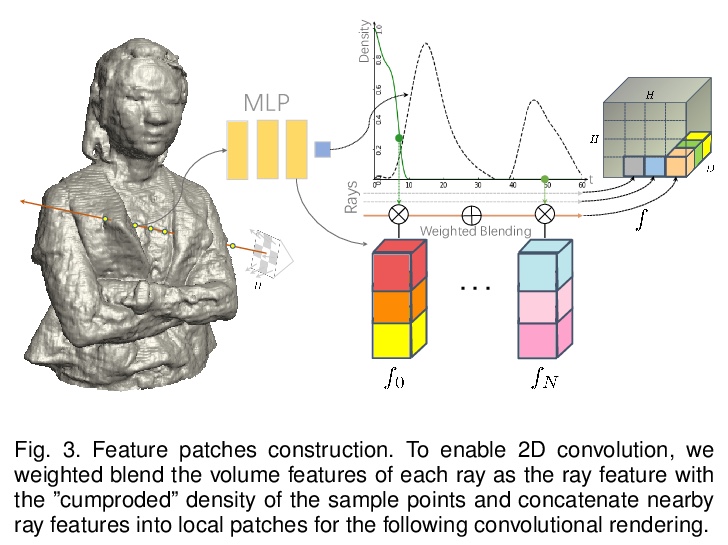
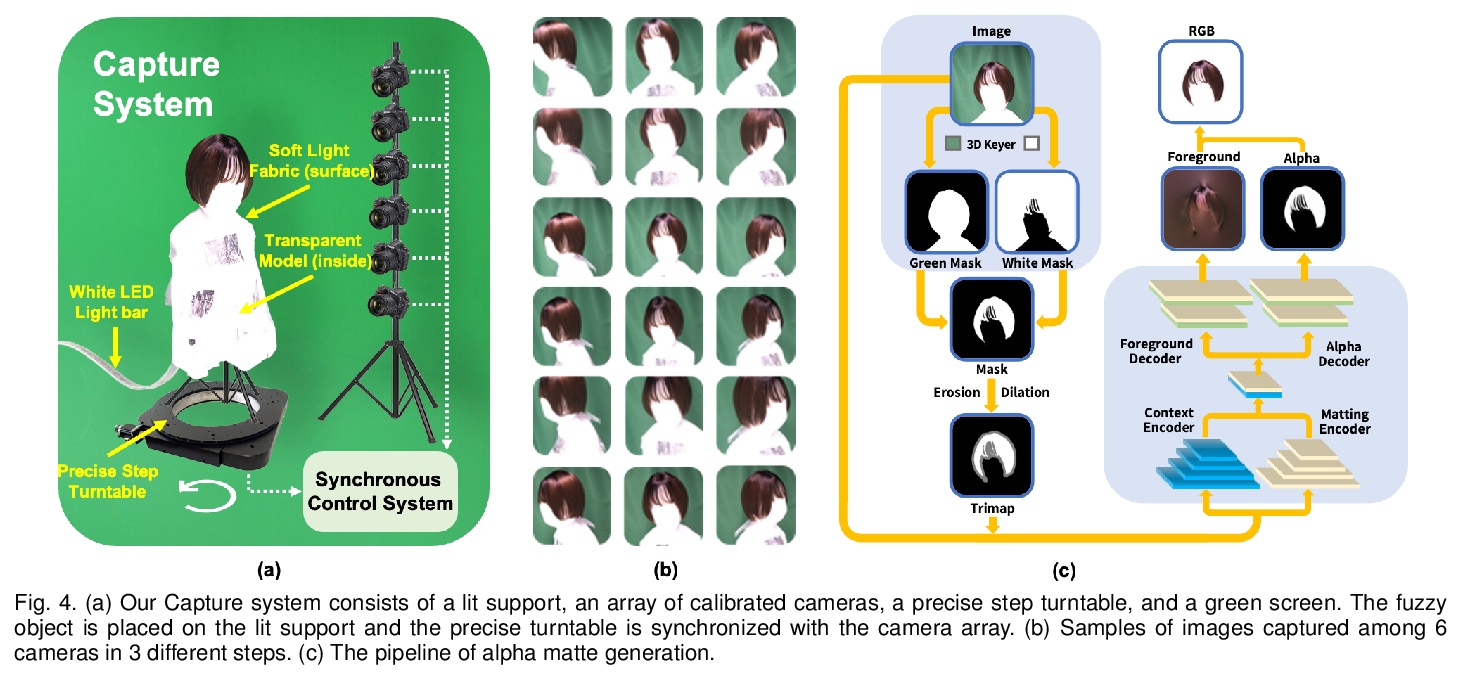

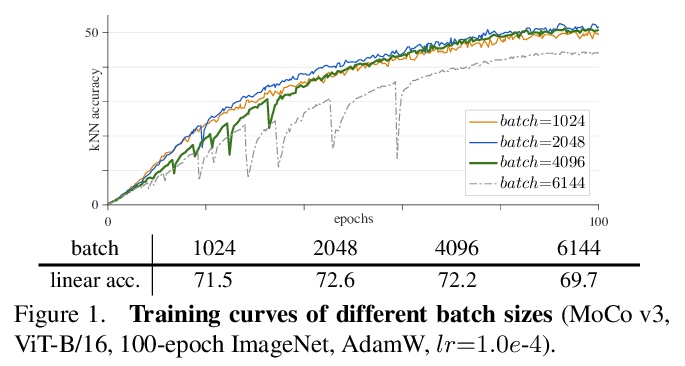
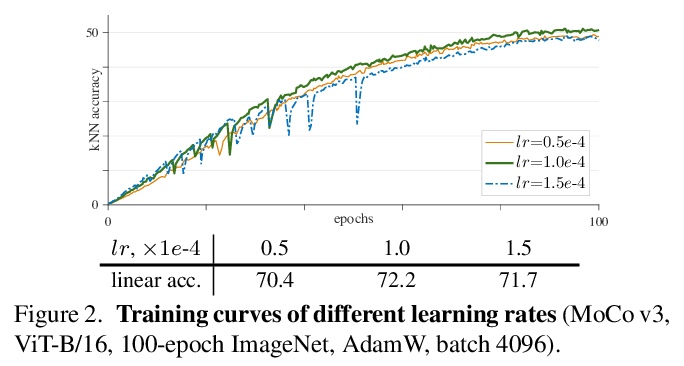
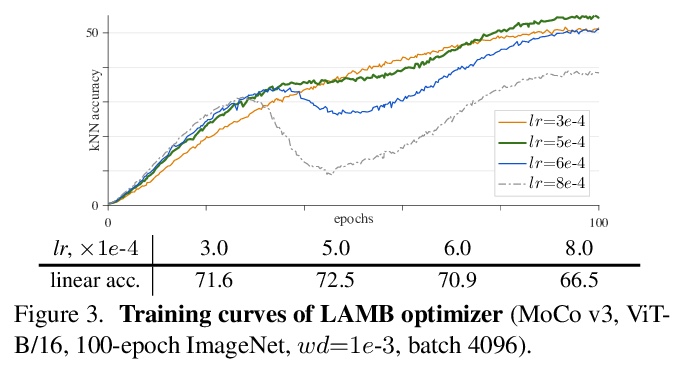
4、[CV] An Empirical Study of Training Self-Supervised Visual Transformers
X Chen, S Xie, K He
[Facebook AI Research (FAIR)]
自监督视觉Transformer训练的实证研究。探讨了在自监督框架中训练视觉Transformer(ViT),比较涉及几个方面,包括ViT与标准卷积网络,监督与自监督,以及对比学习与掩蔽自编码,通过实验观察到,不稳定性是降低准确度的主要问题,可能会被明显的好结果所掩盖。揭示了这些结果确实是部分失败,当训练变得更加稳定时,它们可以得到改善。对MoCo v3和其他几个自监督框架中的ViT结果进行了基准测试,并在各方面进行了消融,提供了积极的证据以及挑战、开放的问题和机会。
This paper does not describe a novel method. Instead, it studies a straightforward, incremental, yet must-know baseline given the recent progress in computer vision: self-supervised learning for Visual Transformers (ViT). While the training recipes for standard convolutional networks have been highly mature and robust, the recipes for ViT are yet to be built, especially in the self-supervised scenarios where training becomes more challenging. In this work, we go back to basics and investigate the effects of several fundamental components for training self-supervised ViT. We observe that instability is a major issue that degrades accuracy, and it can be hidden by apparently good results. We reveal that these results are indeed partial failure, and they can be improved when training is made more stable. We benchmark ViT results in MoCo v3 and several other self-supervised frameworks, with ablations in various aspects. We discuss the currently positive evidence as well as challenges and open questions. We hope that this work will provide useful data points and experience for future research.
https://weibo.com/1402400261/K9KbK8isF
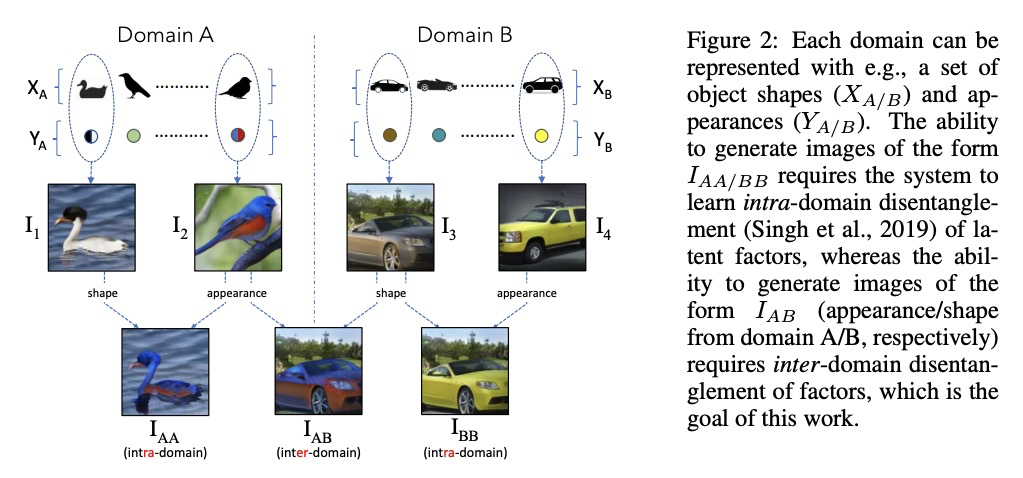
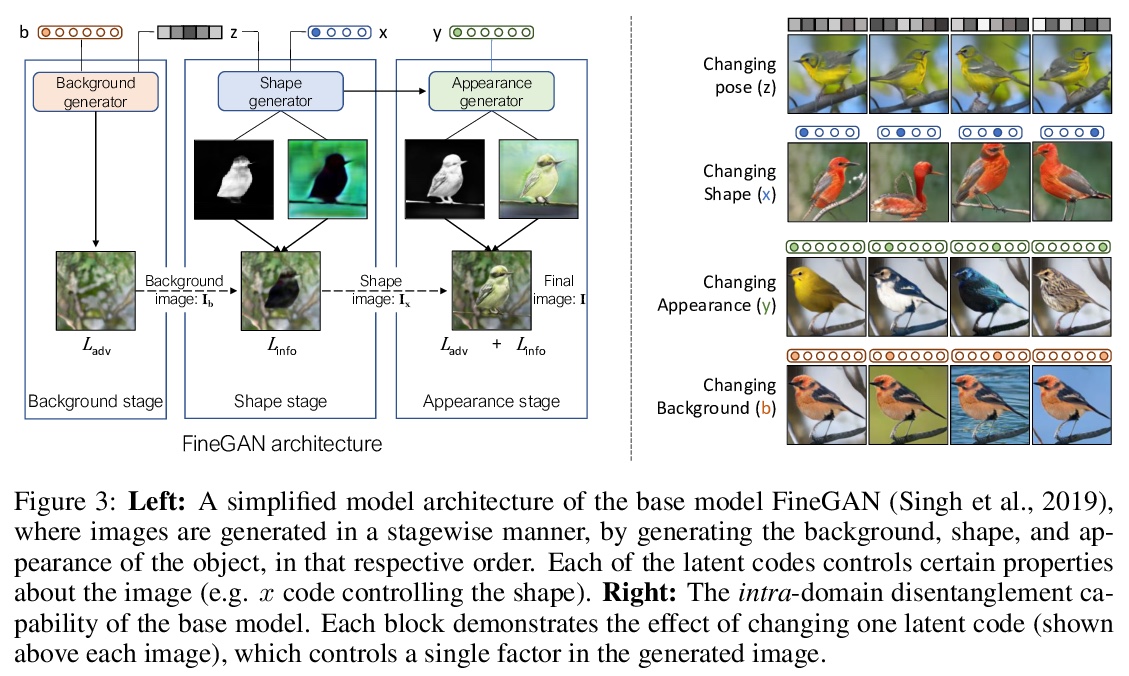
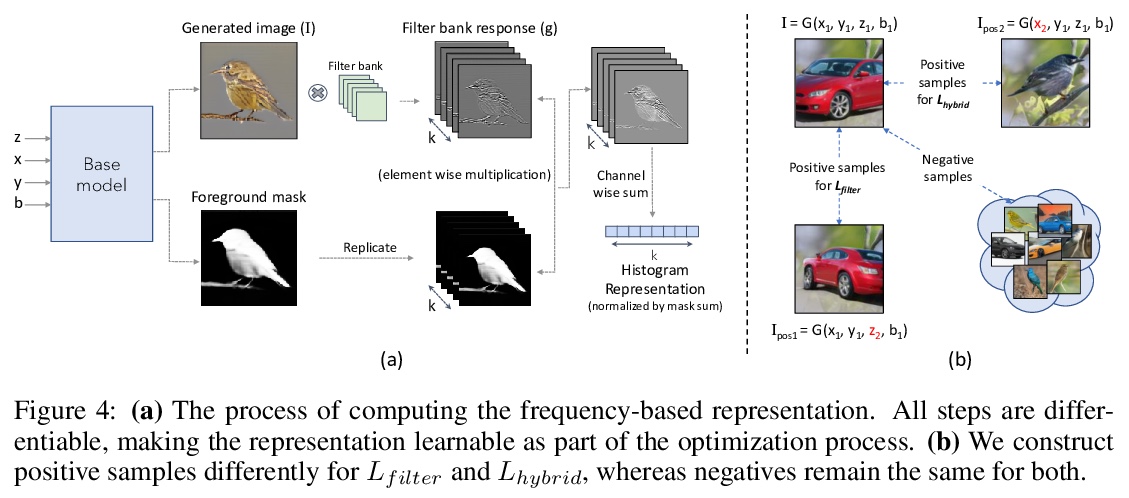
5、[CV] Generating Furry Cars: Disentangling Object Shape & Appearance across Multiple Domains
U Ojha, K K Singh, Y J Lee
[University of California, Davis]
生成毛茸茸的汽车:跨多域的物体形状和外观解缠。考虑了学习跨多域(如狗和汽车)物体形状和外观的解缠表示的新任务。目标是学习一个生成模型,学习一个中间分布,从每个域中借用一个属性子集,使生成的图像不单独存在于任何域。这个具有挑战性的问题需要准确分离各个域的物体形状、外观和背景,从而使两个域的外观和形状因素可以互换。对现有的一种方法进行了增强,用一个可微的视觉特征直方图来表示物体外观,并优化生成器,使两个具有相同潜外观因子但不同潜形状因子的图像产生相似的直方图。在多个多域数据集上,证明了该方法可导致准确和一致的外观和形状跨域迁移。
We consider the novel task of learning disentangled representations of object shape and appearance across multiple domains (e.g., dogs and cars). The goal is to learn a generative model that learns an intermediate distribution, which borrows a subset of properties from each domain, enabling the generation of images that did not exist in any domain exclusively. This challenging problem requires an accurate disentanglement of object shape, appearance, and background from each domain, so that the appearance and shape factors from the two domains can be interchanged. We augment an existing approach that can disentangle factors within a single domain but struggles to do so across domains. Our key technical contribution is to represent object appearance with a differentiable histogram of visual features, and to optimize the generator so that two images with the same latent appearance factor but different latent shape factors produce similar histograms. On multiple multi-domain datasets, we demonstrate our method leads to accurate and consistent appearance and shape transfer across domains.
https://weibo.com/1402400261/K9KeWcAn0
另外几篇值得关注的论文:
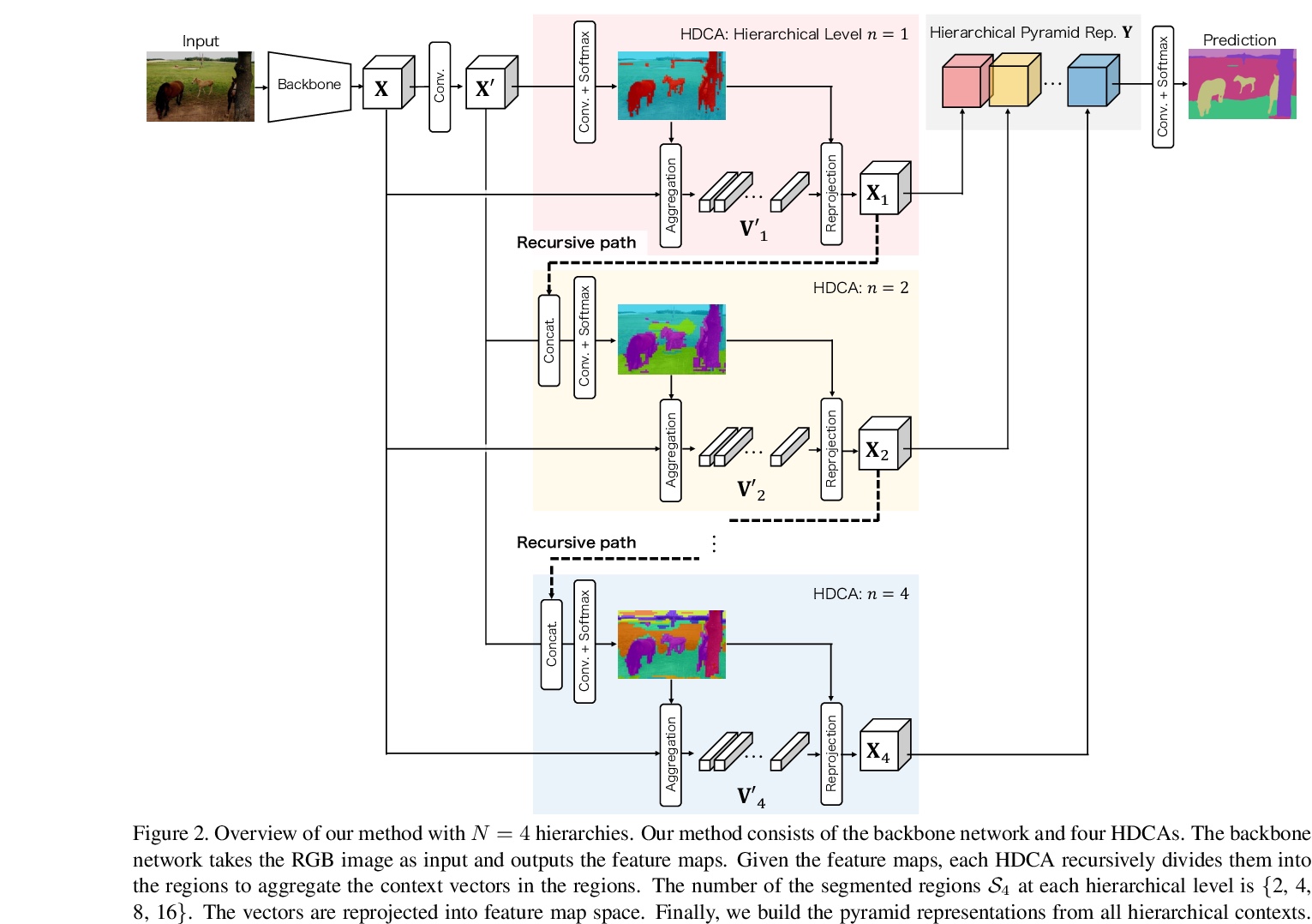
[CV] Hierarchical Pyramid Representations for Semantic Segmentation
语义分割的层次金字塔表示
H Aizawa, Y Domae, K Kato
[Hiroshima University & Gifu Univeristy]
https://weibo.com/1402400261/K9KiVb9z7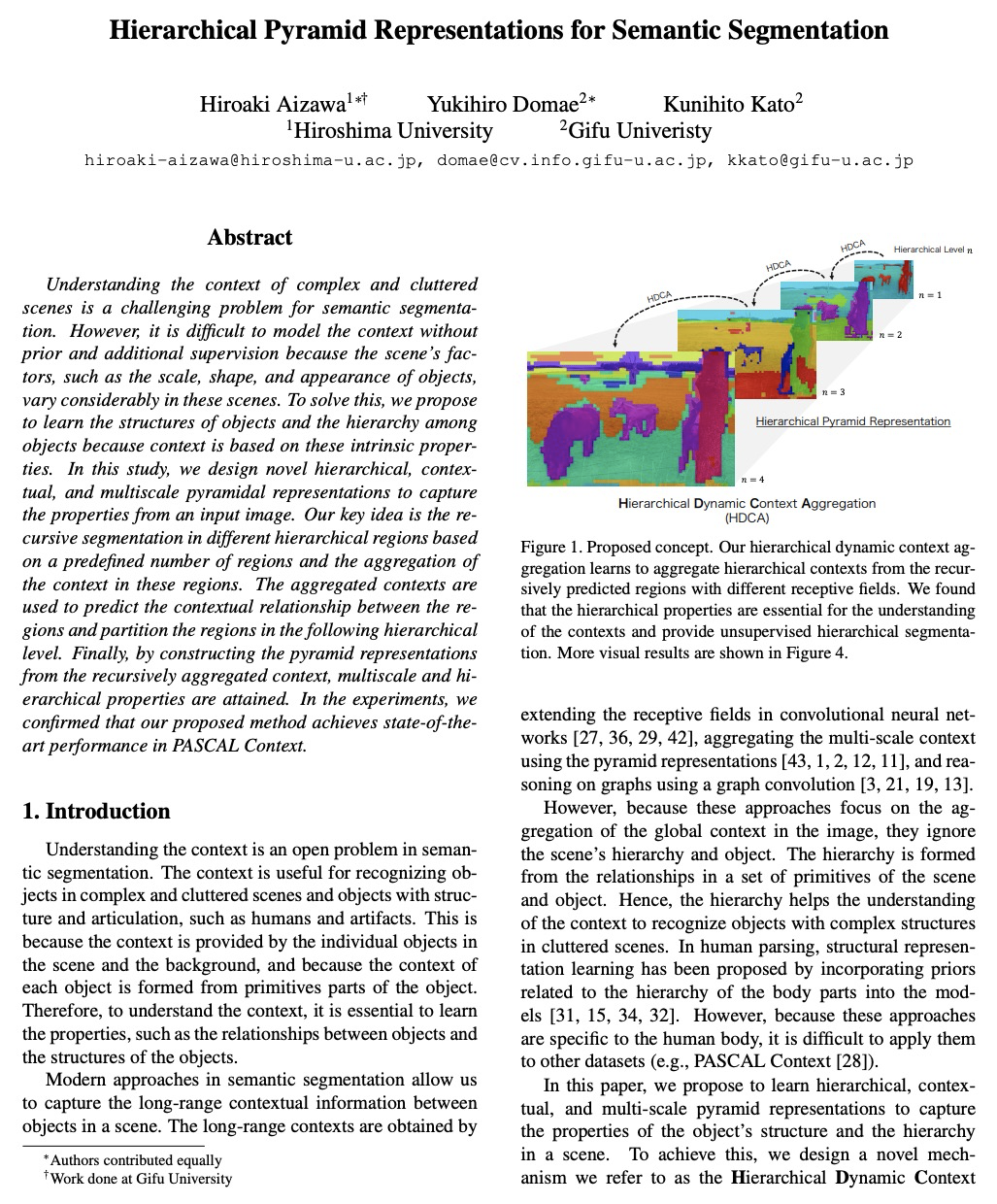

[CL] SPGISpeech: 5,000 hours of transcribed financial audio for fully formatted end-to-end speech recognition
SPGISpeech:面向全格式化端到端语音识别的5000小时转录金融音频
P K. O’Neill, V Lavrukhin, S Majumdar, V Noroozi, Y Zhang, O Kuchaiev, J Balam, Y Dovzhenko, K Freyberg, M D. Shulman, B Ginsburg, S Watanabe, G Kucsko
[Kensho Technologies & NVIDIA Technologies & Johns Hopkins University]
https://weibo.com/1402400261/K9KkFzuQp
[CV] Aggregated Contextual Transformations for High-Resolution Image Inpainting
用于高分辨率图像修复的聚合上下文变换
Y Zeng, J Fu, H Chao, B Guo
[ Sun Yatsen University & Microsoft Research]
https://weibo.com/1402400261/K9KnStIVi



若有收获,就点个赞吧
0 人点赞
