- 1、 [LG] Self-supervised self-supervision by combining deep learning and probabilistic logic
- 2、[CV] Low Bandwidth Video-Chat Compression using Deep Generative Models
- 3、 [LG] GPU Accelerated Exhaustive Search for Optimal Ensemble of Black-Box Optimization Algorithms
- 4、 [LG] A complete, parallel and autonomous photonic neural network in a semiconductor multimode laser
- 5、[LG] Driving Behavior Explanation with Multi-level Fusion
- [CV] Lifting 2D StyleGAN for 3D-Aware Face Generation
- [CV] Unsupervised Learning of Local Discriminative Representation for Medical Images
- [CV] Encoding the latent posterior of Bayesian Neural Networks for uncertainty quantification
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、 [LG] Self-supervised self-supervision by combining deep learning and probabilistic logic
H Lang, H Poon
[MIT & Microsoft Research]
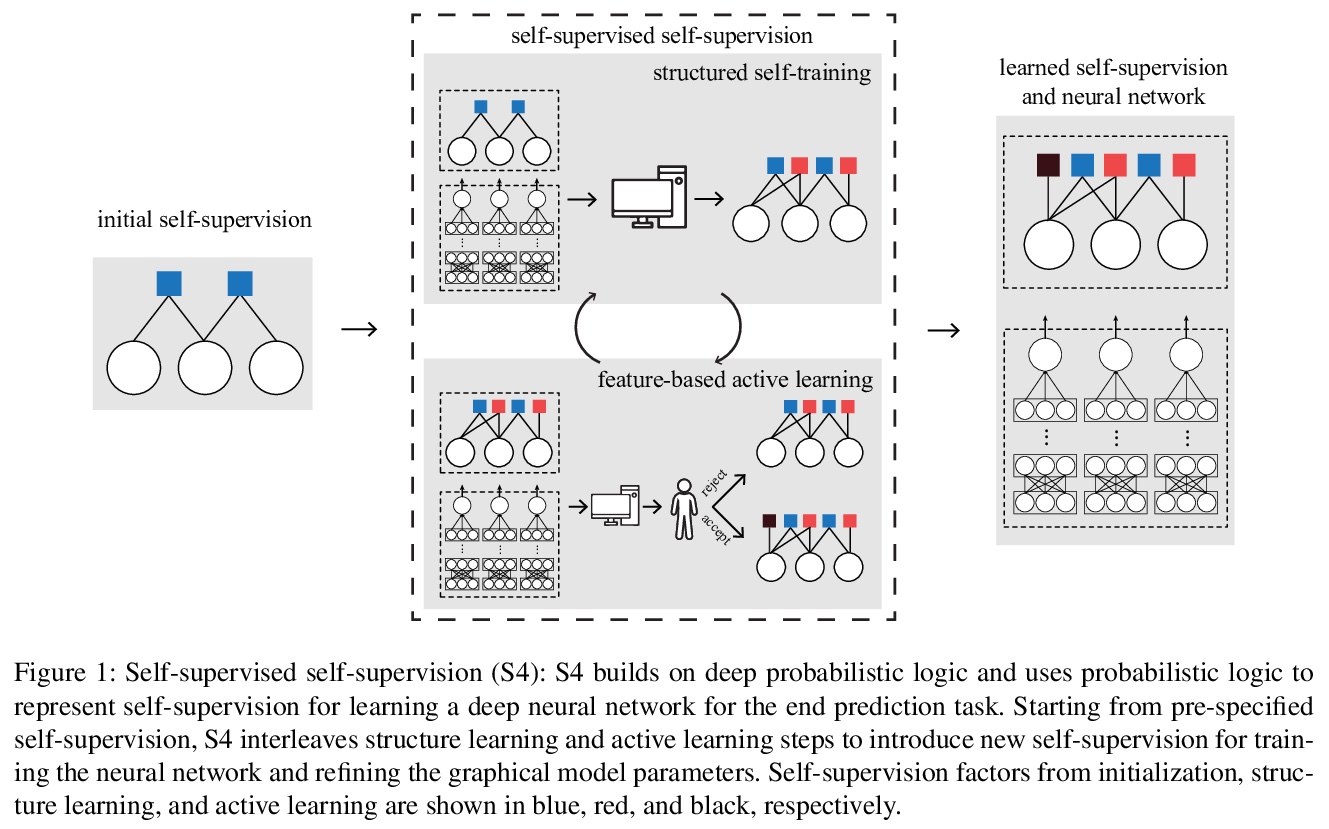
结合深度学习和概率逻辑的自动化自监督。提出通用自监督框架Self-Supervised Self-Supervision(S4),扩展了深度概率逻辑(DPL)的结构学习和主动学习能力,为DPL增加了自动学习新的自监督的能力。从初始“种子”开始,S4迭代使用深度神经网络提出新的自监督。这些内容或者直接添加(结构化自训练的一种形式),或者由人类专家验证(如基于特征的主动学习)。在各种自然语言处理任务上的实验表明,与之前的Snorkel和DPL等针对特定任务的自监督系统相比,S4可在同样的监督量下获得高达20个绝对精度点的增益。
Labeling training examples at scale is a perennial challenge in machine learning. Self-supervision methods compensate for the lack of direct supervision by leveraging prior knowledge to automatically generate noisy labeled examples. Deep probabilistic logic (DPL) is a unifying framework for self-supervised learning that represents unknown labels as latent variables and incorporates diverse self-supervision using probabilistic logic to train a deep neural network end-to-end using variational EM. While DPL is successful at combining pre-specified self-supervision, manually crafting self-supervision to attain high accuracy may still be tedious and challenging. In this paper, we propose Self-Supervised Self-Supervision (S4), which adds to DPL the capability to learn new self-supervision automatically. Starting from an initial “seed,” S4 iteratively uses the deep neural network to propose new self supervision. These are either added directly (a form of structured self-training) or verified by a human expert (as in feature-based active learning). Experiments show that S4 is able to automatically propose accurate self-supervision and can often nearly match the accuracy of supervised methods with a tiny fraction of the human effort.
https://weibo.com/1402400261/JAE0ACboz

2、[CV] Low Bandwidth Video-Chat Compression using Deep Generative Models
M Oquab, P Stock, O Gafni, D Haziza, T Xu, P Zhang, O Celebi, Y Hasson, P Labatut, B Bose-Kolanu, T Peyronel, C Couprie
[Facebook & INRIA]
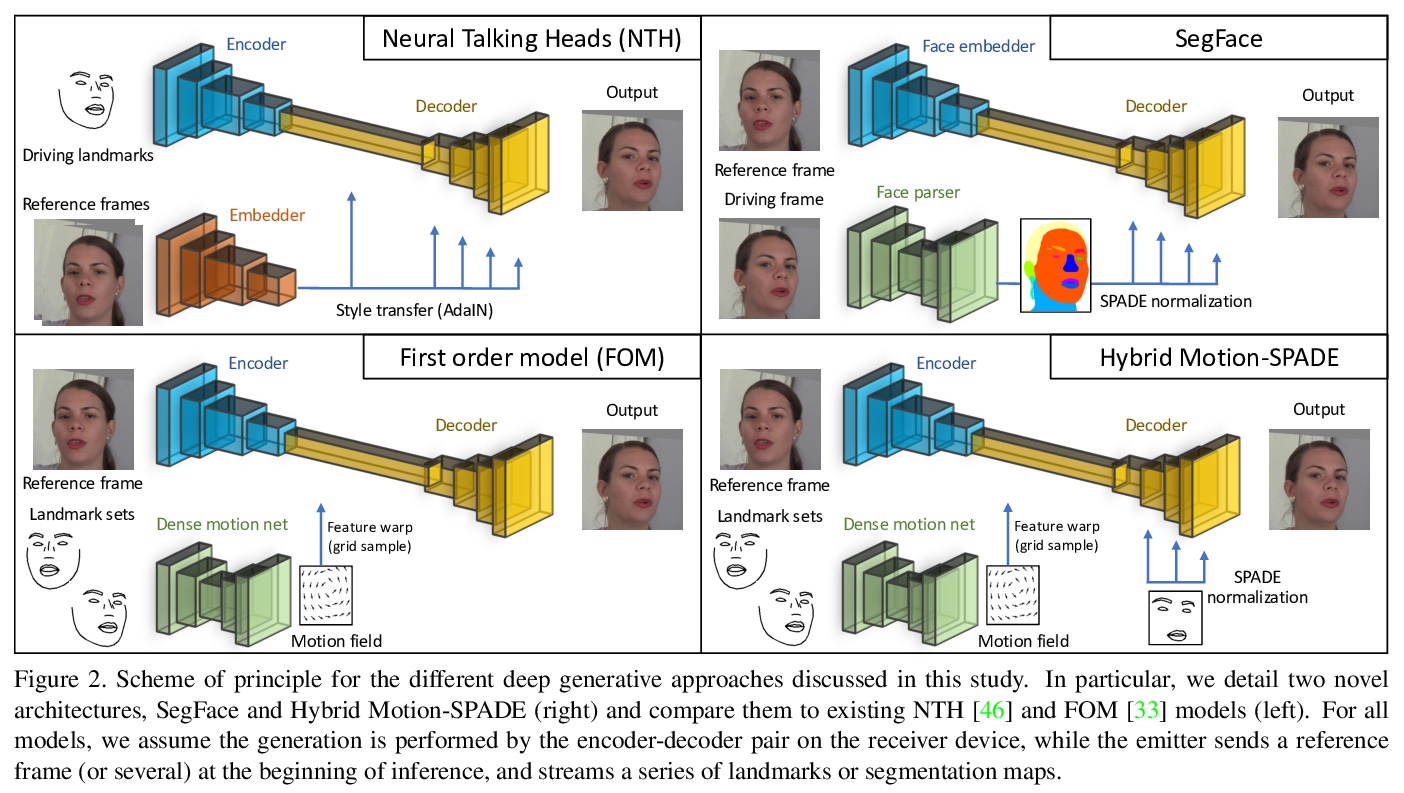
用深度生成模型实现视频通话低带宽压缩。提出在发送方提取面部特征点进行网络传输,在接收方设备上逼真重建人脸。讨论并评价了几种深度对抗式方法的优缺点,探讨了基于静态特征点、动态特征点或分割图方法的质量和带宽权衡。基于一阶动画模型设计了移动兼容架构,利用SPADE块来完善眼睛和嘴唇等重要区域的结果。在最终实验中,网络被压缩到3MB左右,并在iPhone 8(CPU)上实时运行,能以每秒几kb的速度进行视频通话,比目前可用的替代方案低一个数量级。
To unlock video chat for hundreds of millions of people hindered by poor connectivity or unaffordable data costs, we propose to authentically reconstruct faces on the receiver’s device using facial landmarks extracted at the sender’s side and transmitted over the network. In this context, we discuss and evaluate the benefits and disadvantages of several deep adversarial approaches. In particular, we explore quality and bandwidth trade-offs for approaches based on static landmarks, dynamic landmarks or segmentation maps. We design a mobile-compatible architecture based on the first order animation model of Siarohin et al. In addition, we leverage SPADE blocks to refine results in important areas such as the eyes and lips. We compress the networks down to about 3MB, allowing models to run in real time on iPhone 8 (CPU). This approach enables video calling at a few kbits per second, an order of magnitude lower than currently available alternatives.
https://weibo.com/1402400261/JAE81eftL

3、 [LG] GPU Accelerated Exhaustive Search for Optimal Ensemble of Black-Box Optimization Algorithms
J Liu, B Tunguz, G Titericz
[Nvidia]
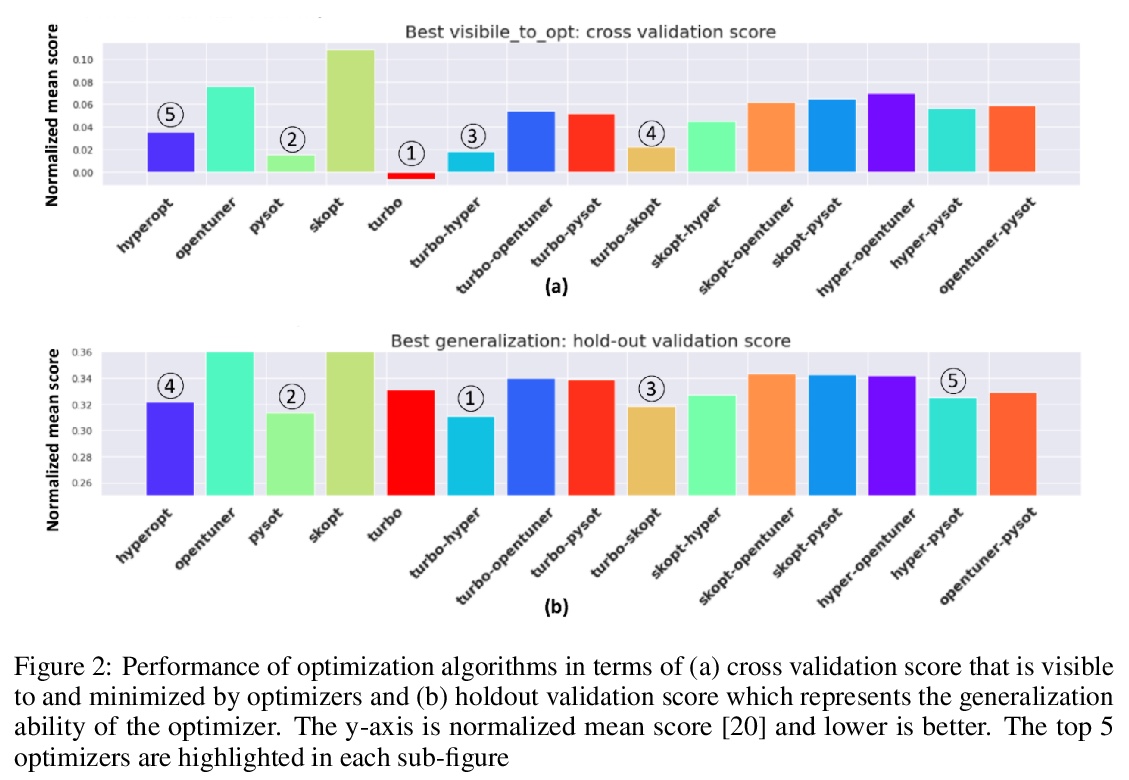
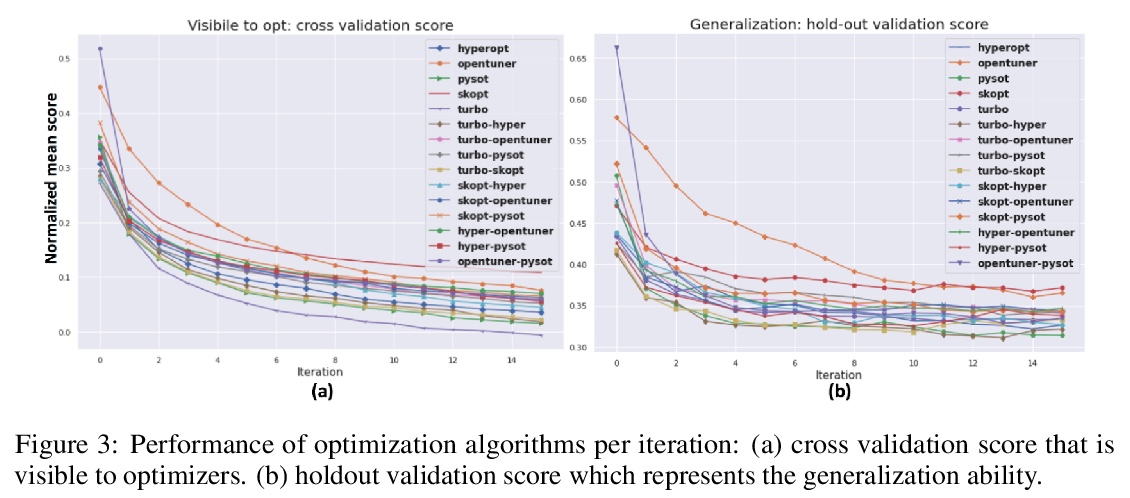
GPU加速的黑盒优化算法集成穷举式搜索优化。证明了简单的黑盒优化算法集成能胜过任一单独算法。提出一种快速的多GPU加速穷举搜索框架,通过并行运行多个实验,加速暴力搜索黑盒优化算法最佳集成。集成算法可推广到多优化器,框架也可扩展到多GPU。轻量优化由CPU执行,高计算量的模型训练和评价分配给GPU完成。通过训练270万个模型、运行541,440次优化对15个优化器进行了评价,在DGX-1上,搜索时间从两个20核CPU上超过10天减少到8个GPU上不到24小时。通过GPU加速穷尽搜索找到的最优集成,获得了NeurIPS 2020黑箱优化挑战赛第二名。
Black-box optimization is essential for tuning complex machine learning algorithms which are easier to experiment with than to understand. In this paper, we show that a simple ensemble of black-box optimization algorithms can outperform any single one of them. However, searching for such an optimal ensemble requires a large number of experiments. We propose a Multi-GPU-optimized framework to accelerate a brute force search for the optimal ensemble of black-box optimization algorithms by running many experiments in parallel. The lightweight optimizations are performed by CPU while expensive model training and evaluations are assigned to GPUs. We evaluate 15 optimizers by training 2.7 million models and running 541,440 optimizations. On a DGX-1, the search time is reduced from more than 10 days on two 20-core CPUs to less than 24 hours on 8-GPUs. With the optimal ensemble found by GPU-accelerated exhaustive search, we won the 2nd place of NeurIPS 2020 black-box optimization challenge.
https://weibo.com/1402400261/JAEdrteaK

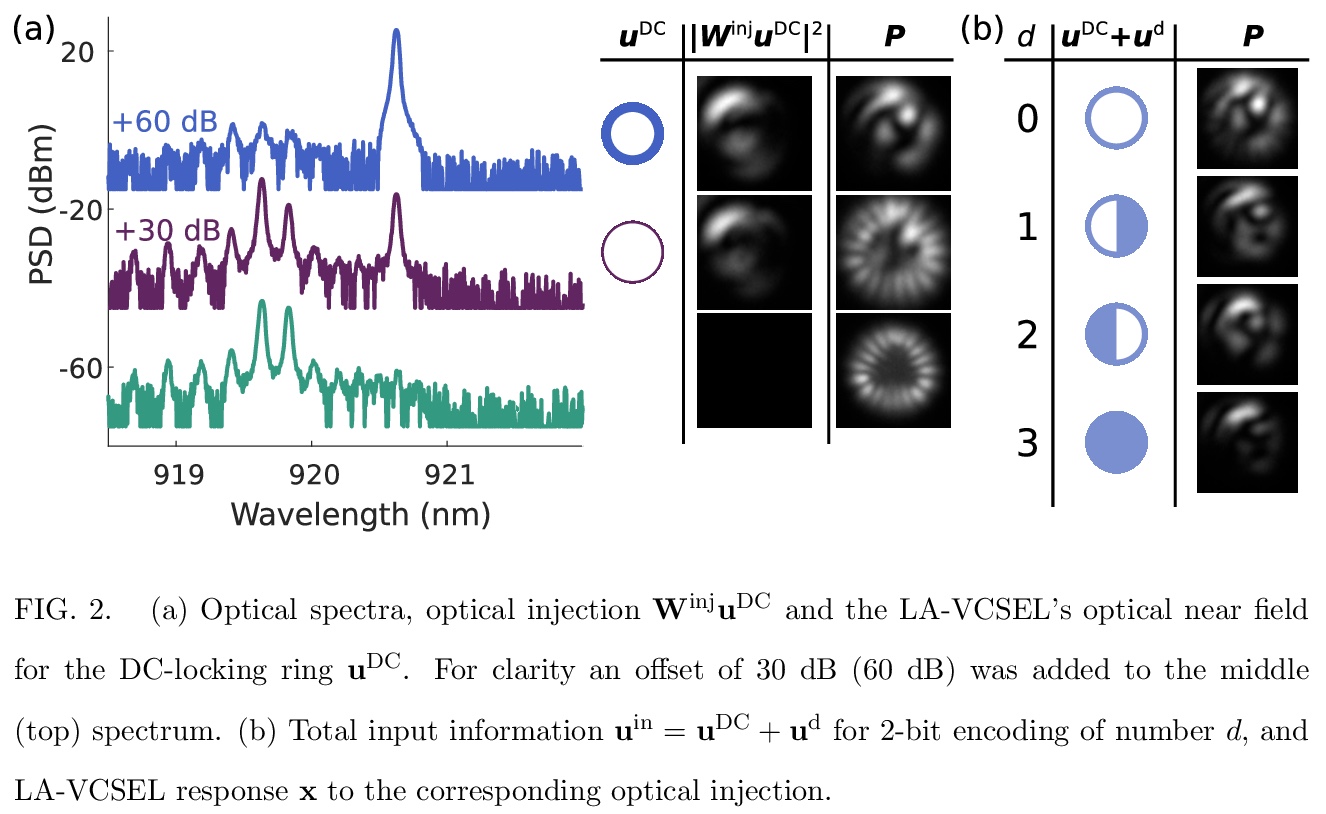
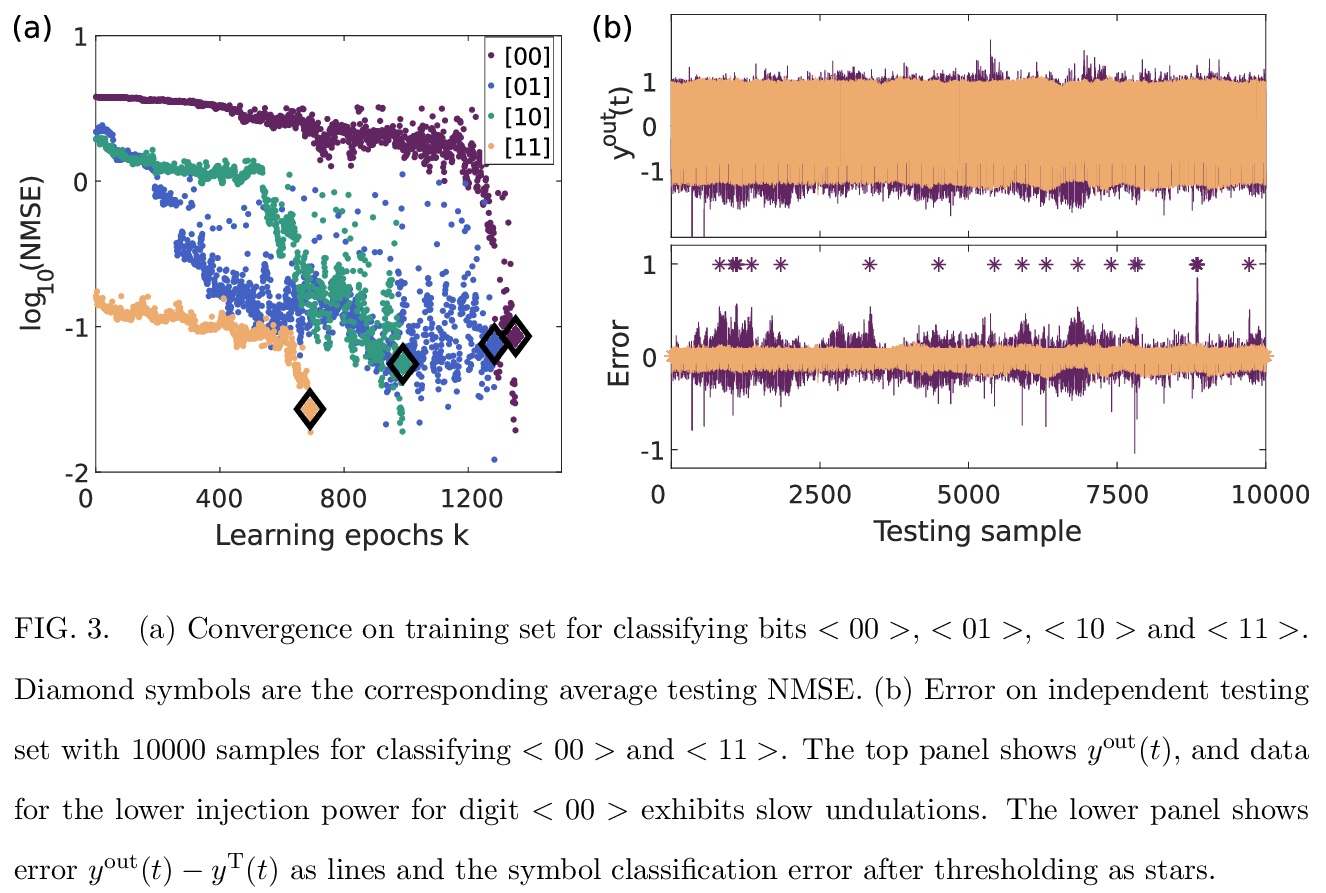
4、 [LG] A complete, parallel and autonomous photonic neural network in a semiconductor multimode laser
X Porte, A Skalli, N Haghighi, S Reitzenstein, J A. Lott, D Brunner
[Univ. Bourgogne Franche-Comte & Technische Universitat Berlin]
基于半导体多模激光器的完整并行自主光子神经网络。利用高效、快速的半导体激光器的空间分布模式,来实现全并行、全实现的光子神经网络,所有的神经网络连接都在硬件中实现,产生结果无需预处理或后处理。训练和测试了光子神经网络在2位序列任务如模式分类、异或任务和DAC上的性能,只是概念验证,大规模应用预计会有约9个数量级的加速。
Neural networks are one of the disruptive computing concepts of our time. However, they fundamentally differ from classical, algorithmic computing in a number of fundamental aspects. These differences result in equally fundamental, severe and relevant challenges for neural network computing using current computing substrates. Neural networks urge for parallelism across the entire processor and for a co-location of memory and arithmetic, i.e. beyond von Neumann architectures. Parallelism in particular made photonics a highly promising platform, yet until now scalable and integratable concepts are scarce. Here, we demonstrate for the first time how a fully parallel and fully implemented photonic neural network can be realized using spatially distributed modes of an efficient and fast semiconductor laser. Importantly, all neural network connections are realized in hardware, and our processor produces results without pre- or post-processing. 130+ nodes are implemented in a large-area vertical cavity surface emitting laser, input and output weights are realized via the complex transmission matrix of a multimode fiber and a digital micro-mirror array, respectively. We train the readout weights to perform 2-bit header recognition, a 2-bit XOR and 2-bit digital analog conversion, and obtain < 0.9 10^-3 and 2.9 10^-2 error rates for digit recognition and XOR, respectively. Finally, the digital analog conversion can be realized with a standard deviation of only 5.4 10^-2. Our system is scalable to much larger sizes and to bandwidths in excess of 20 GHz.
https://weibo.com/1402400261/JAEkE4gru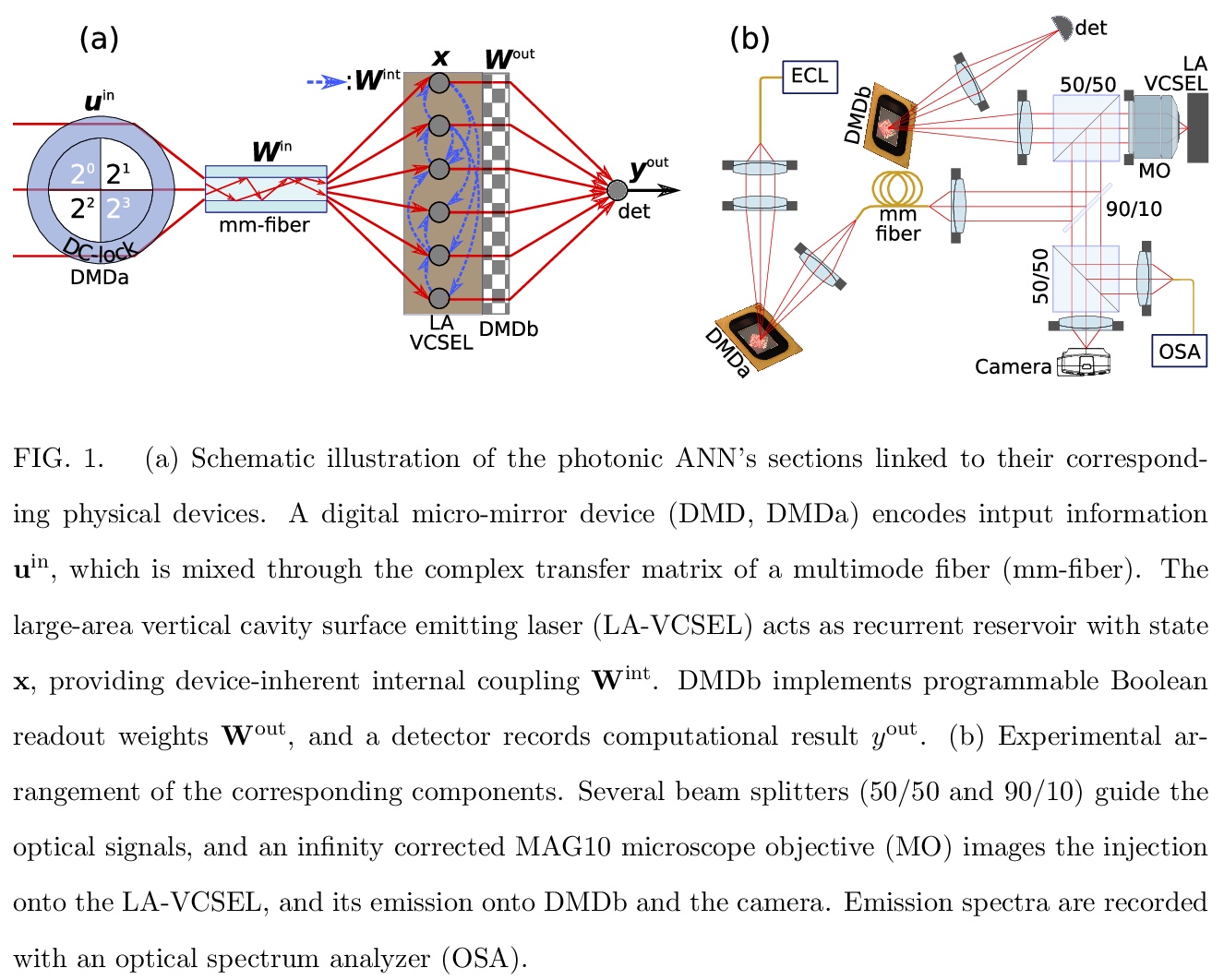
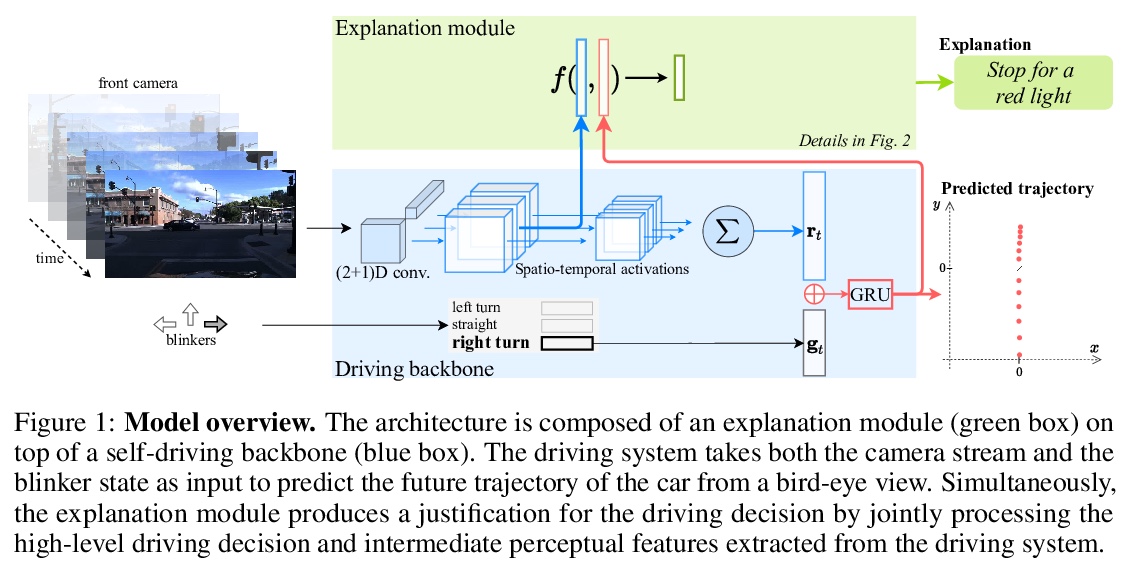
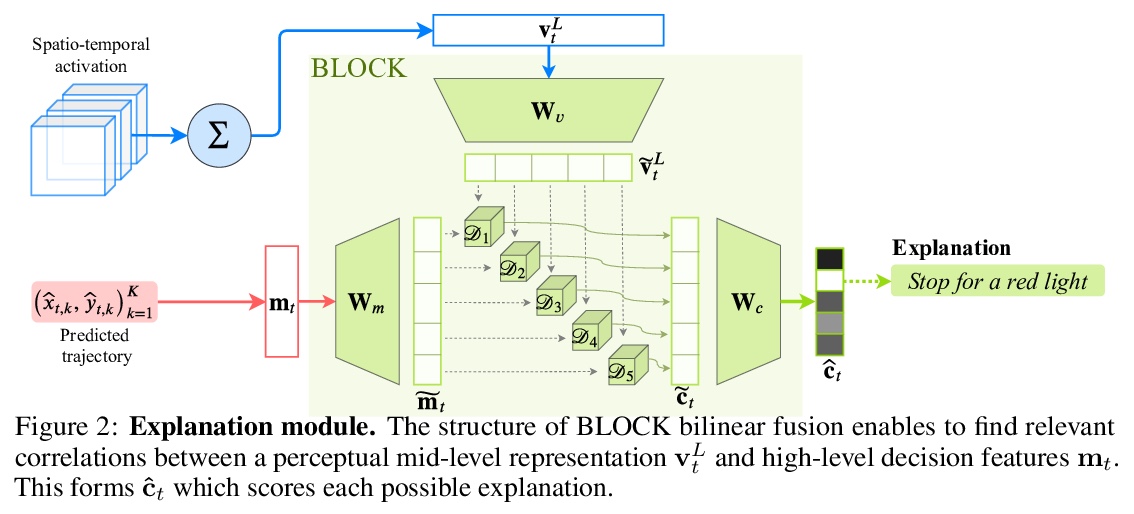
5、[LG] Driving Behavior Explanation with Multi-level Fusion
H Ben-Younes, É Zablocki, P Pérez, M Cord
[Valeo.ai]
基于多级融合的驾驶行为解释。提出了解释轨迹预测模型行为的深度架构BEEF(BEhavior Explanation with Fusion),为自动驾驶系统所做决策提供解释。在人工驾驶决策理由标记监督下,BEEF学会了从多个层次融合特征,对高层决策特征和中层感知特征的相关性进行建模。采用该方法在HDD和BDD-X两个大型真实驾驶数据集上进行了验证,其解释质量超过了之前的技术水平。
In this era of active development of autonomous vehicles, it becomes crucial to provide driving systems with the capacity to explain their decisions. In this work, we focus on generating high-level driving explanations as the vehicle drives. We present BEEF, for BEhavior Explanation with Fusion, a deep architecture which explains the behavior of a trajectory prediction model. Supervised by annotations of human driving decisions justifications, BEEF learns to fuse features from multiple levels. Leveraging recent advances in the multi-modal fusion literature, BEEF is carefully designed to model the correlations between high-level decisions features and mid-level perceptual features. The flexibility and efficiency of our approach are validated with extensive experiments on the HDD and BDD-X datasets.
https://weibo.com/1402400261/JAEprzrKU
另外几篇值得关注的论文:
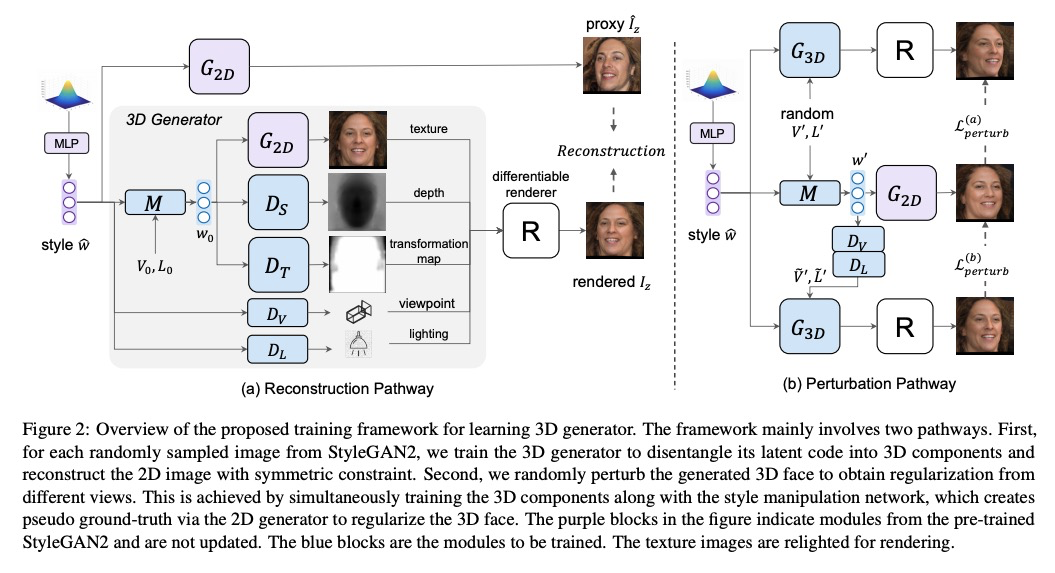
[CV] Lifting 2D StyleGAN for 3D-Aware Face Generation
基于提升2D StyleGAN(LiftedGAN)的3D感知人脸生成
Y Shi, D Aggarwal, A K. Jain
[Michigan State University]
https://weibo.com/1402400261/JAExTckLi

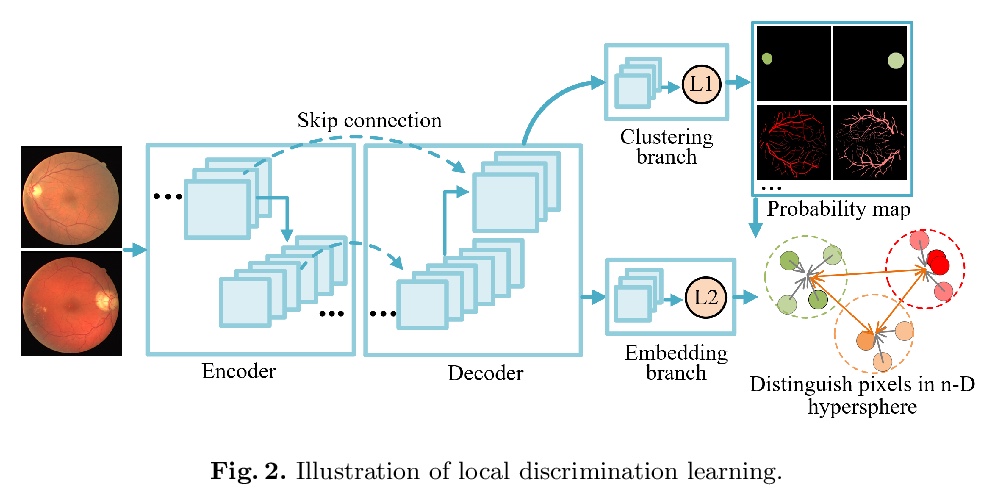
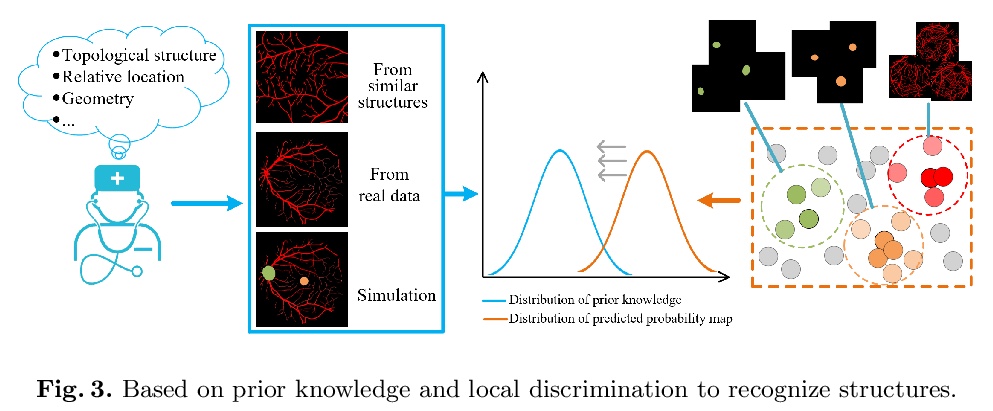
[CV] Unsupervised Learning of Local Discriminative Representation for Medical Images
面向医学图像的局部判别表示无监督学习
H Chen, J Li, R Wang, Y Huang, F Meng, D Meng, Q Peng, L Wang
[Shanghai Jiao Tong University & Xi’an Jiaotong University & Shanghai Tenth People’s Hospital]
https://weibo.com/1402400261/JAEzZw107

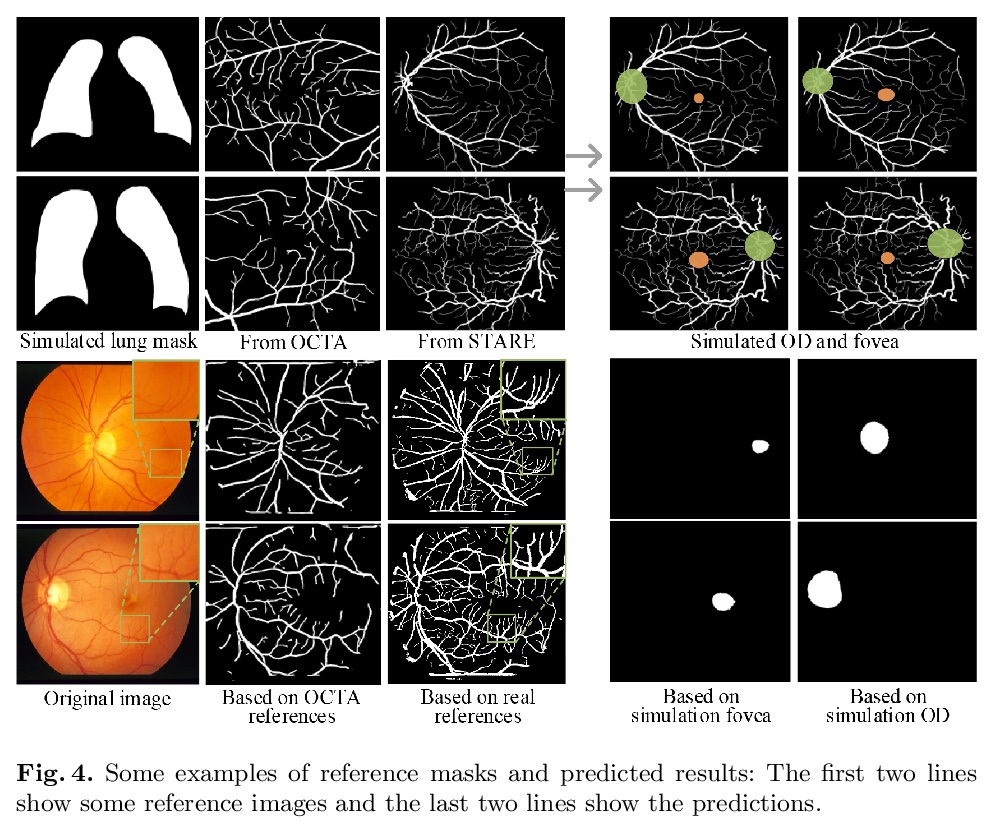
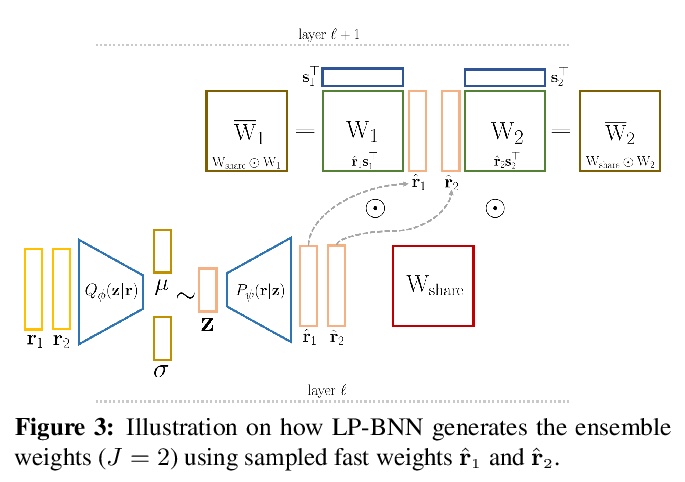
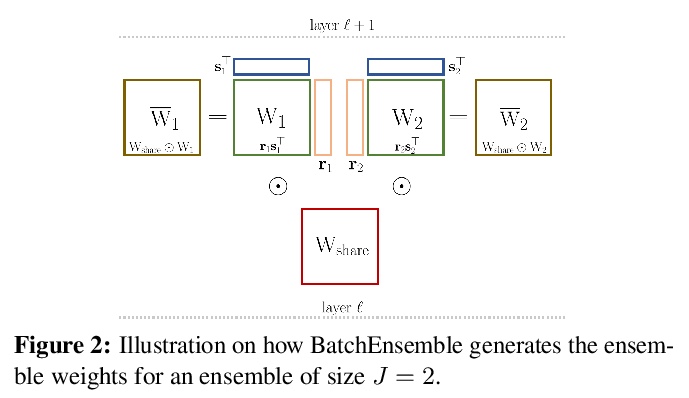
[CV] Encoding the latent posterior of Bayesian Neural Networks for uncertainty quantification
不确定性量化的贝叶斯神经网络潜后验编码
G Franchi, A Bursuc, E Aldea, S Dubuisson, I Bloch
[ENSTA Paris & valeo.ai & Université Paris-Sud]
https://weibo.com/1402400261/JAECckRJR


若有收获,就点个赞吧
0 人点赞
