LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] *Simplifying Hamiltonian and Lagrangian Neural Networks via Explicit Constraints
M Finzi, K A Wang, A G Wilson
[New York University & Cornell University]
通过显式约束简化哈密顿和拉格朗日神经网络。引入了一系列挑战性的混沌和扩展体系统,包括带有N摆、弹簧耦合、磁场、刚性转子和陀螺仪的系统,以推进当前方法的极限。证明了笛卡尔坐标与显式约束相结合,可以使物理系统的哈密顿量和拉格朗日更容易学习,将数据效率和轨迹预测精度提高了100倍。
Reasoning about the physical world requires models that are endowed with the right inductive biases to learn the underlying dynamics. Recent works improve generalization for predicting trajectories by learning the Hamiltonian or Lagrangian of a system rather than the differential equations directly. While these methods encode the constraints of the systems using generalized coordinates, we show that embedding the system into Cartesian coordinates and enforcing the constraints explicitly with Lagrange multipliers dramatically simplifies the learning problem. We introduce a series of challenging chaotic and extended-body systems, including systems with N-pendulums, spring coupling, magnetic fields, rigid rotors, and gyroscopes, to push the limits of current approaches. Our experiments show that Cartesian coordinates with explicit constraints lead to a 100x improvement in accuracy and data efficiency.
https://weibo.com/1402400261/JrdwR10nj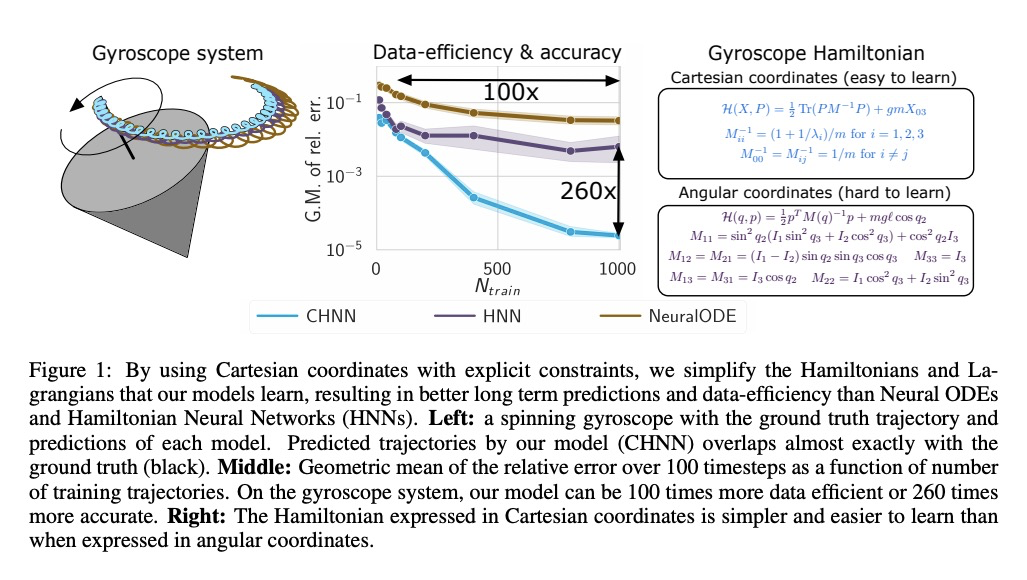

2、[LG] *Hyperparameter Ensembles for Robustness and Uncertainty Quantification
F Wenzel, J Snoek, D Tran, R Jenatton
[Google Research]
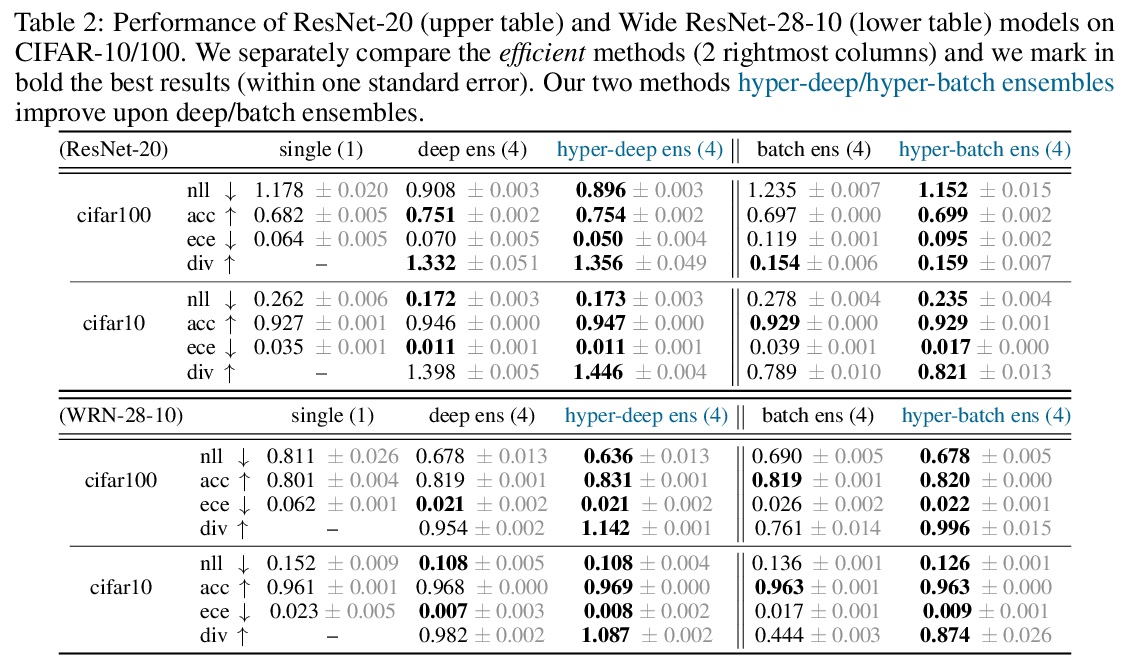
面向鲁棒性和不确定性量化的超参数集成。提出了超深集成(hyper-deep ensembles),涉及对不同超参数的随机搜索,在多个随机初始化过程中分层。通过模型权重和超参数多样性集成,实现了强大性能。在批量集成和自调优网络基础上,进一步提出了参数高效的超批量集成(hyper-batch ensembles),计算和内存成本明显低于典型的深度集成方法。**
Ensembles over neural network weights trained from different random initialization, known as deep ensembles, achieve state-of-the-art accuracy and calibration. The recently introduced batch ensembles provide a drop-in replacement that is more parameter efficient. In this paper, we design ensembles not only over weights, but over hyperparameters to improve the state of the art in both settings. For best performance independent of budget, we propose hyper-deep ensembles, a simple procedure that involves a random search over different hyperparameters, themselves stratified across multiple random initializations. Its strong performance highlights the benefit of combining models with both weight and hyperparameter diversity. We further propose a parameter efficient version, hyper-batch ensembles, which builds on the layer structure of batch ensembles and self-tuning networks. The computational and memory costs of our method are notably lower than typical ensembles. On image classification tasks, with MLP, LeNet, ResNet 20 and Wide ResNet 28-10 architectures, we improve upon both deep and batch ensembles.
https://weibo.com/1402400261/JrdD3vjJd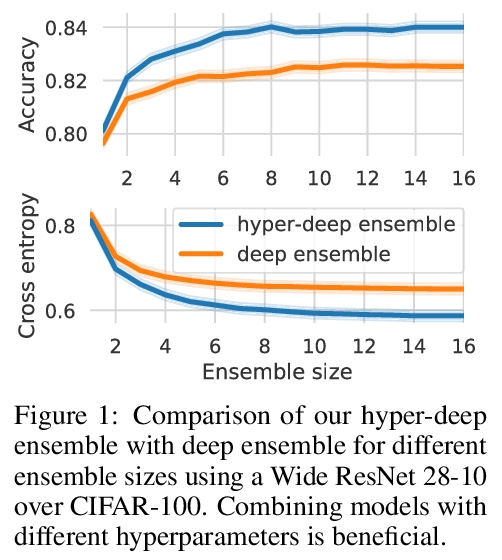


3、[CV] **Exemplary Natural Images Explain CNN Activations Better than Feature Visualizations
J Borowski, R S. Zimmermann, J Schepers, R Geirhos, T S. A. Wallis, M Bethge, W Brendel
[University of Tubingen]
典型自然图像能比特征可视化更好地解释CNN的激活。测量极端的激活图在多大程度上帮人们预测出CNN的激活,用一种良好控制的心理-物理范式,将合成图像的信息性与简单基线可视化——可强烈激活特定特征图的示范性自然图像——进行比较,发现在评价CNN激活方面,特征可视化的流行合成图像提供的信息,要比自然图像少得多。**
Feature visualizations such as synthetic maximally activating images are a widely used explanation method to better understand the information processing of convolutional neural networks (CNNs). At the same time, there are concerns that these visualizations might not accurately represent CNNs’ inner workings. Here, we measure how much extremely activating images help humans to predict CNN activations. Using a well-controlled psychophysical paradigm, we compare the informativeness of synthetic images (Olah et al., 2017) with a simple baseline visualization, namely exemplary natural images that also strongly activate a specific feature map. Given either synthetic or natural reference images, human participants choose which of two query images leads to strong positive activation. The experiment is designed to maximize participants’ performance, and is the first to probe intermediate instead of final layer representations. We find that synthetic images indeed provide helpful information about feature map activations (82% accuracy; chance would be 50%). However, natural images-originally intended to be a baseline-outperform synthetic images by a wide margin (92% accuracy). Additionally, participants are faster and more confident for natural images, whereas subjective impressions about the interpretability of feature visualization are mixed. The higher informativeness of natural images holds across most layers, for both expert and lay participants as well as for hand- and randomly-picked feature visualizations. Even if only a single reference image is given, synthetic images provide less information than natural images (65% vs. 73%). In summary, popular synthetic images from feature visualizations are significantly less informative for assessing CNN activations than natural images. We argue that future visualization methods should improve over this simple baseline.
https://weibo.com/1402400261/JrdKubMU5

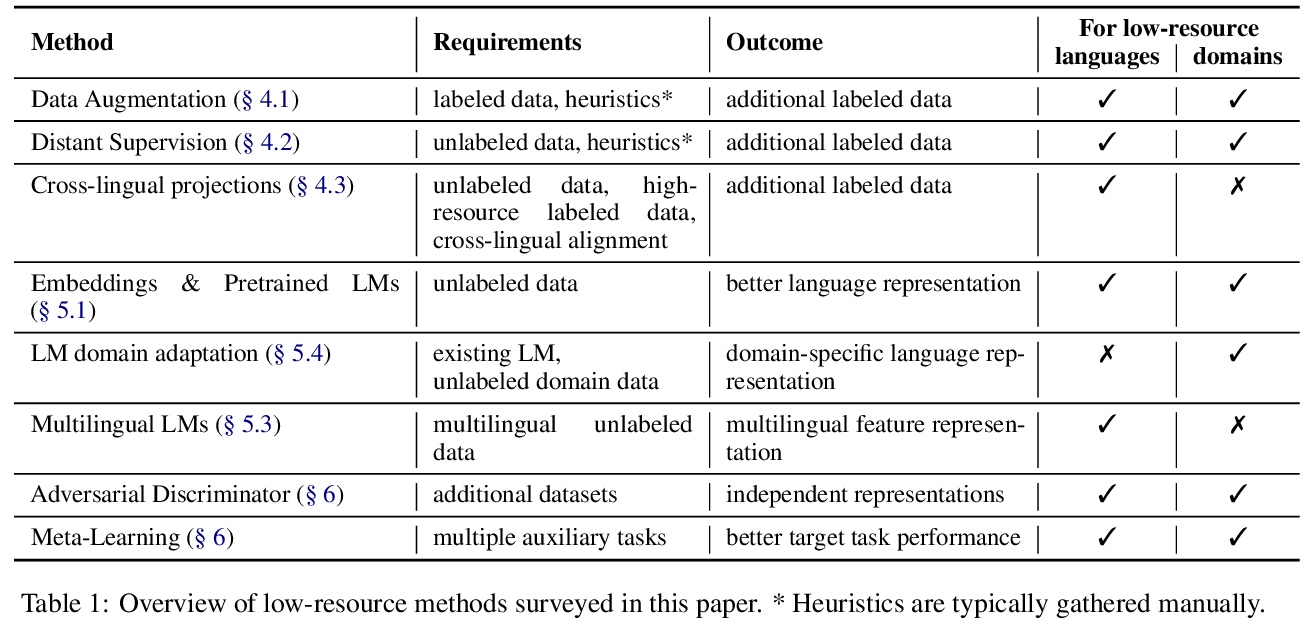
4、[CL] **A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios
M A. Hedderich, L Lange, H Adel, J Strötgen, D Klakow
[Saarland University & Bosch Center for Artificial Intelligence]
低资源自然语言处理新方法综述。给出了在低资源自然语言处理领域最近工作的结构化综述,展示了跨数据可用性不同维度分析资源精益场景的重要性。**
Current developments in natural language processing offer challenges and opportunities for low-resource languages and domains. Deep neural networks are known for requiring large amounts of training data which might not be available in resource-lean scenarios. However, there is also a growing body of works to improve the performance in low-resource settings. Motivated by fundamental changes towards neural models and the currently popular pre-train and fine-tune paradigm, we give an overview of promising approaches for low-resource natural language processing. After a discussion about the definition of low-resource scenarios and the different dimensions of data availability, we then examine methods that enable learning when training data is sparse. This includes mechanisms to create additional labeled data like data augmentation and distant supervision as well as transfer learning settings that reduce the need for target supervision. The survey closes with a brief look into methods suggested in non-NLP machine learning communities, which might be beneficial for NLP in low-resource scenarios
https://weibo.com/1402400261/JrdPk7hTR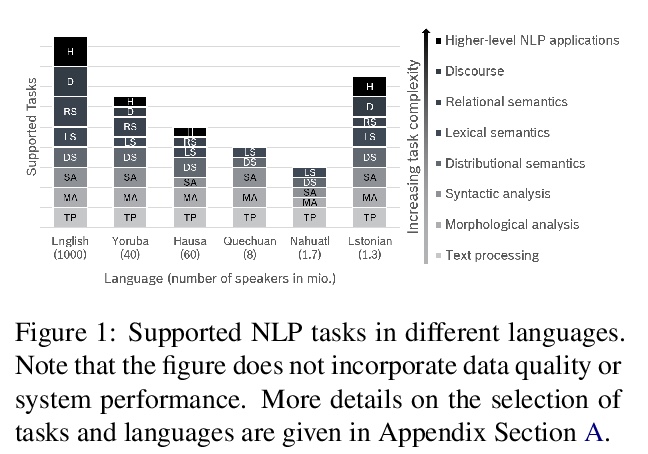

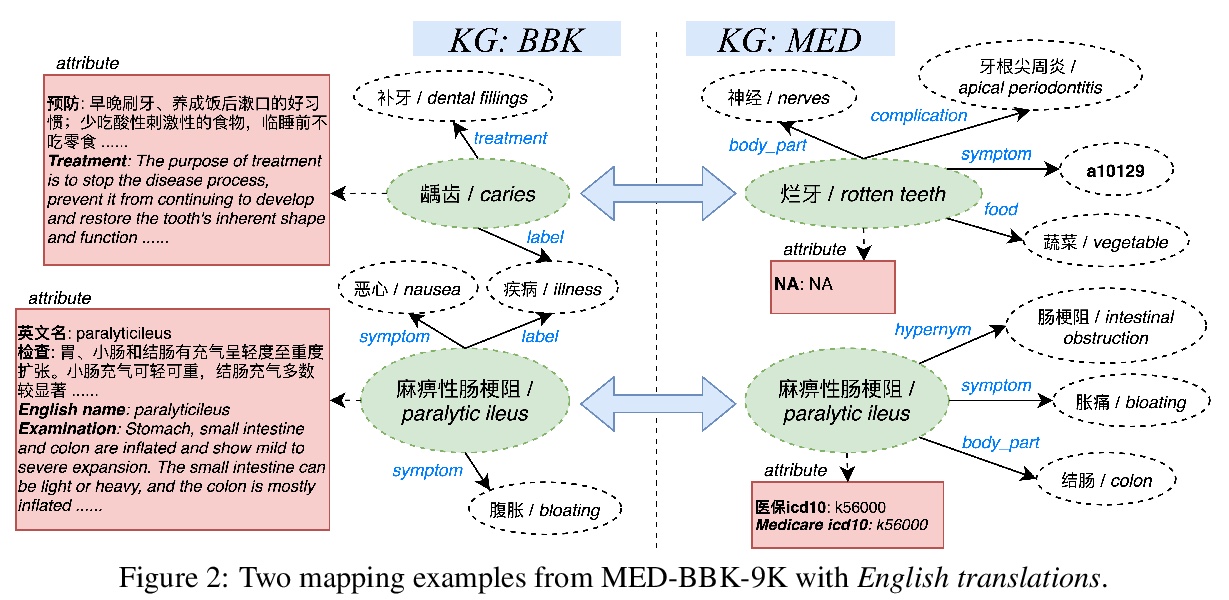
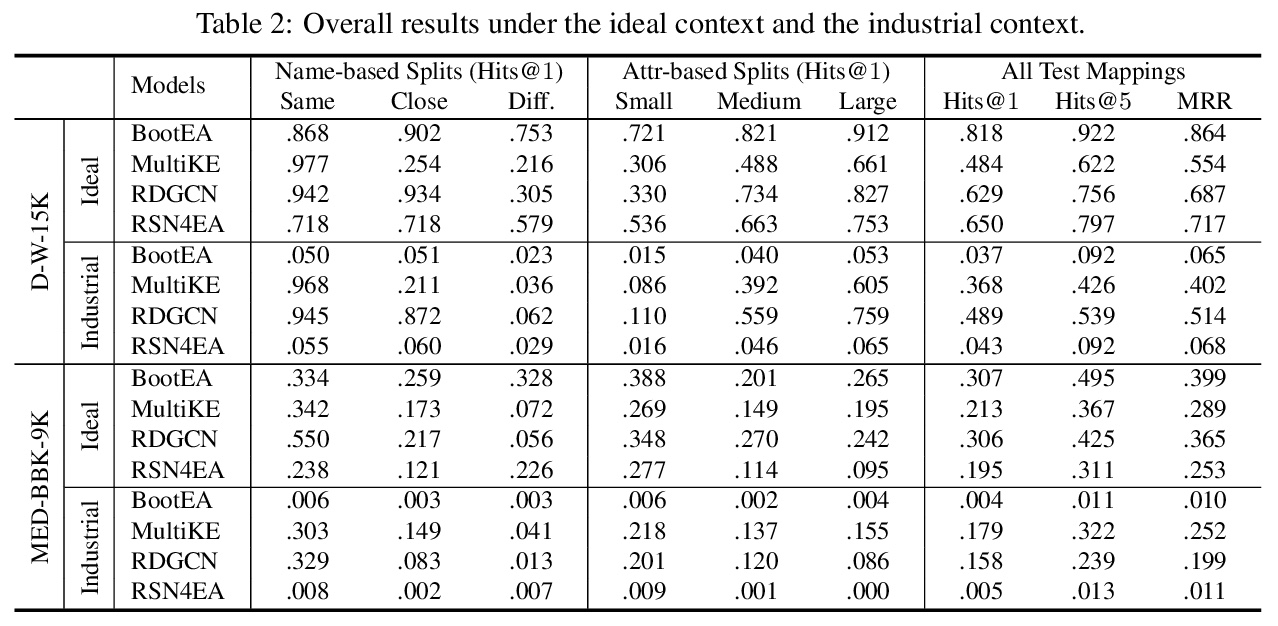
5、[CL] **An Industry Evaluation of Embedding-based Entity Alignment
Z Zhang, J Chen, X Chen, H Liu, Y Xiang, B Liu, Y Zheng
[Tencent Jarvis Lab & University of Oxford]
基于嵌入实体对齐的行业评价。在理想背景下和行业背景下,评价了四种最先进的基于嵌入的实体对齐方法,探讨了不同大小和不同偏差的种子映射的影响。提出了一个新的行业基准测试,从为医疗应用部署的两个异构知识图中提取而来。**
Embedding-based entity alignment has been widely investigated in recent years, but most proposed methods still rely on an ideal supervised learning setting with a large number of unbiased seed mappings for training and validation, which significantly limits their usage. In this study, we evaluate those state-of-the-art methods in an industrial context, where the impact of seed mappings with different sizes and different biases is explored. Besides the popular benchmarks from DBpedia and Wikidata, we contribute and evaluate a new industrial benchmark that is extracted from two heterogeneous knowledge graphs (KGs) under deployment for medical applications. The experimental results enable the analysis of the advantages and disadvantages of these alignment methods and the further discussion of suitable strategies for their industrial deployment.
另外几篇值得关注的论文:
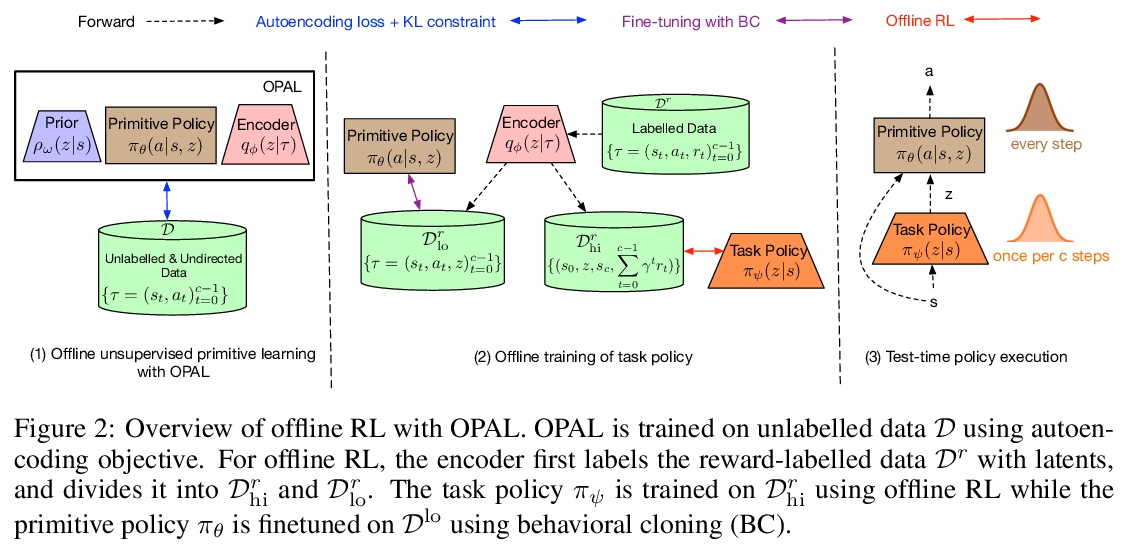
[LG] OPAL: Offline Primitive Discovery for Accelerating Offline Reinforcement Learning
OPAL:用离线原语发现加速离线强化学习
A Ajay, A Kumar, P Agrawal, S Levine, O Nachum
[MIT & Google Research]
https://weibo.com/1402400261/JrdXyFr0g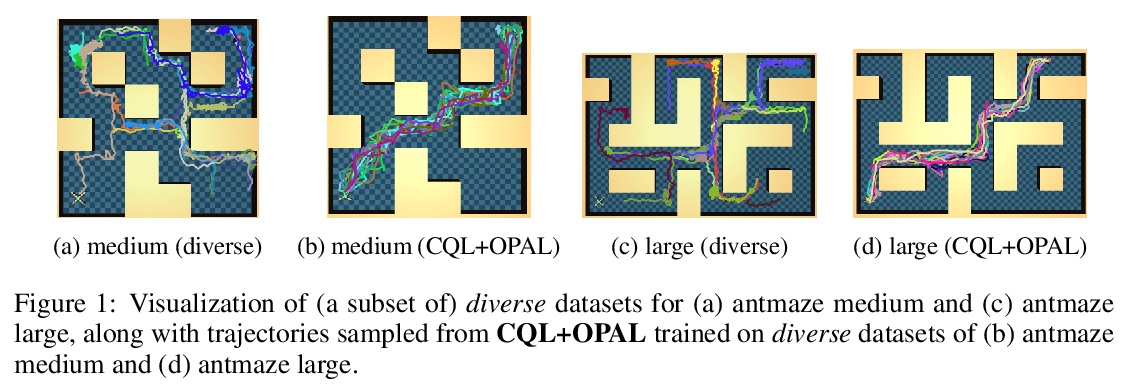

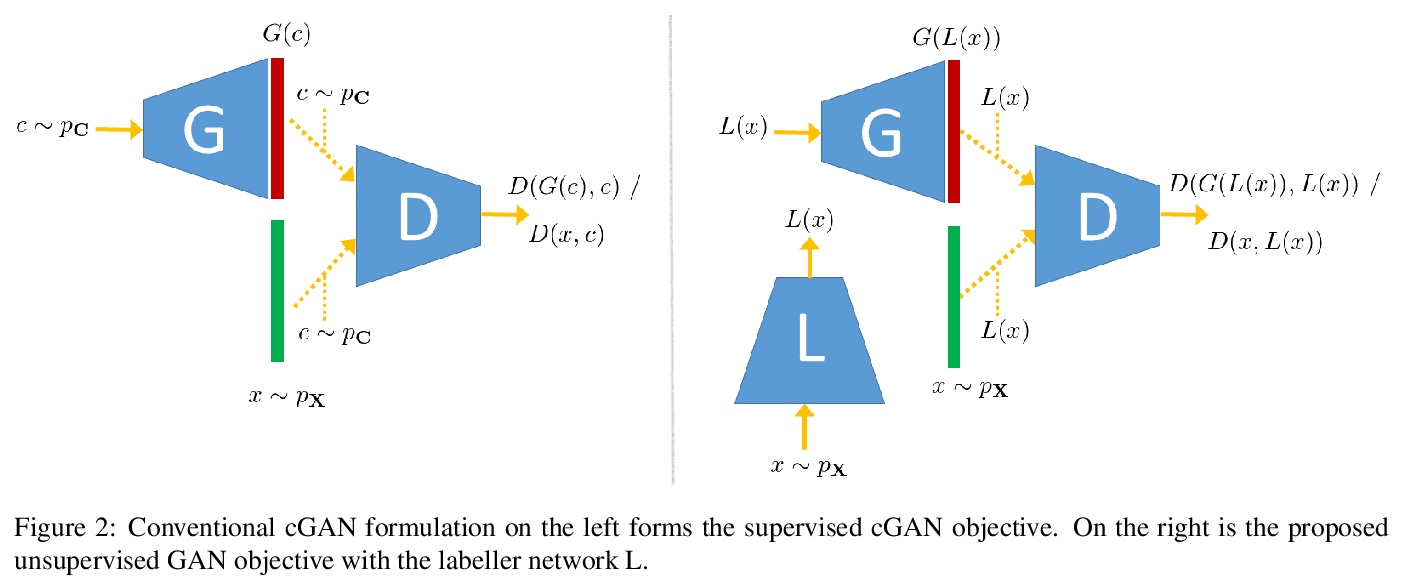
[LG] S2cGAN: Semi-Supervised Training of Conditional GANs with Fewer Labels
S2 GAN:少标签的条件GAN半监督训练
A Chakraborty, R Ragesh, M Shah, N Kwatra
[Microsoft Research India]
https://weibo.com/1402400261/Jre1tkRst
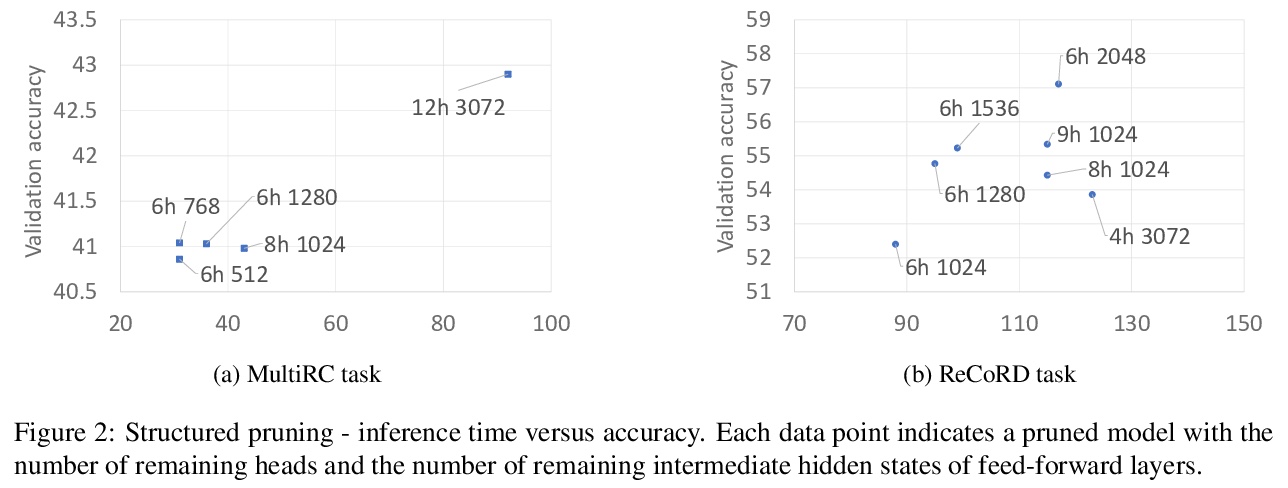
[CL] FastFormers: Highly Efficient Transformer Models for Natural Language Understanding
FastFormers:面向自然语言理解的高效Transformer模型
Y J Kim, H H Awadalla
[Microsoft]
https://weibo.com/1402400261/Jre2b2Ky0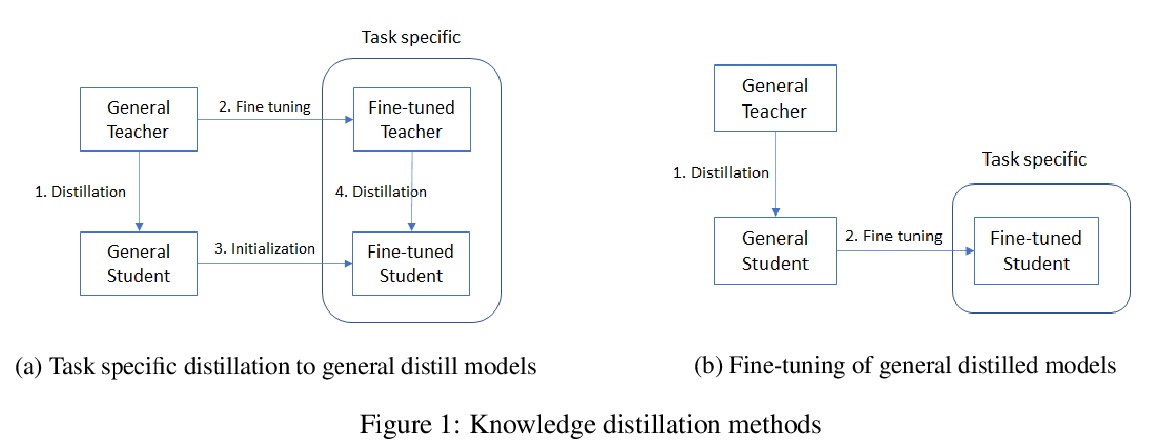
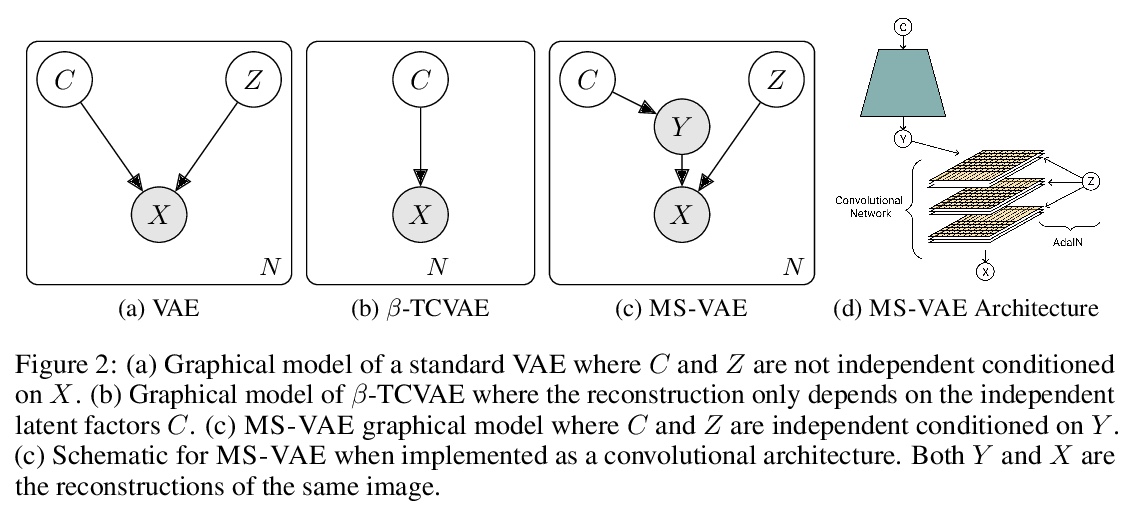
[LG] Improving the Reconstruction of Disentangled Representation Learners via Multi-Stage Modelling
用多阶段建模改善解缠表示学习器重构
A Srivastava, Y Bansal, Y Ding, C Hurwitz, K Xu, B Egger, P Sattigeri, J Tenenbaum, D D. Cox, D Gutfreund
[IBM Research & Harvard University & University of Edinburgh & MIT]
https://weibo.com/1402400261/Jre4dfnBN

[RO] High Acceleration Reinforcement Learning for Real-World Juggling with Binary Rewards
用二元奖励高加速强化学习实现真实世界中的杂耍
K Ploeger, M Lutter, J Peters
[Technical University of Darmstadt]
https://weibo.com/1402400261/Jre5EqhrG

[CV] APB2FaceV2: Real-Time Audio-Guided Multi-Face Reenactment
APB2FaceV2:音频引导实时多人脸重塑
J Zhang, X Zeng, C Xu, J Chen, Y Liu, Y Jiang
[Zhejiang University & Huzhou University]
https://weibo.com/1402400261/Jre7t2vUX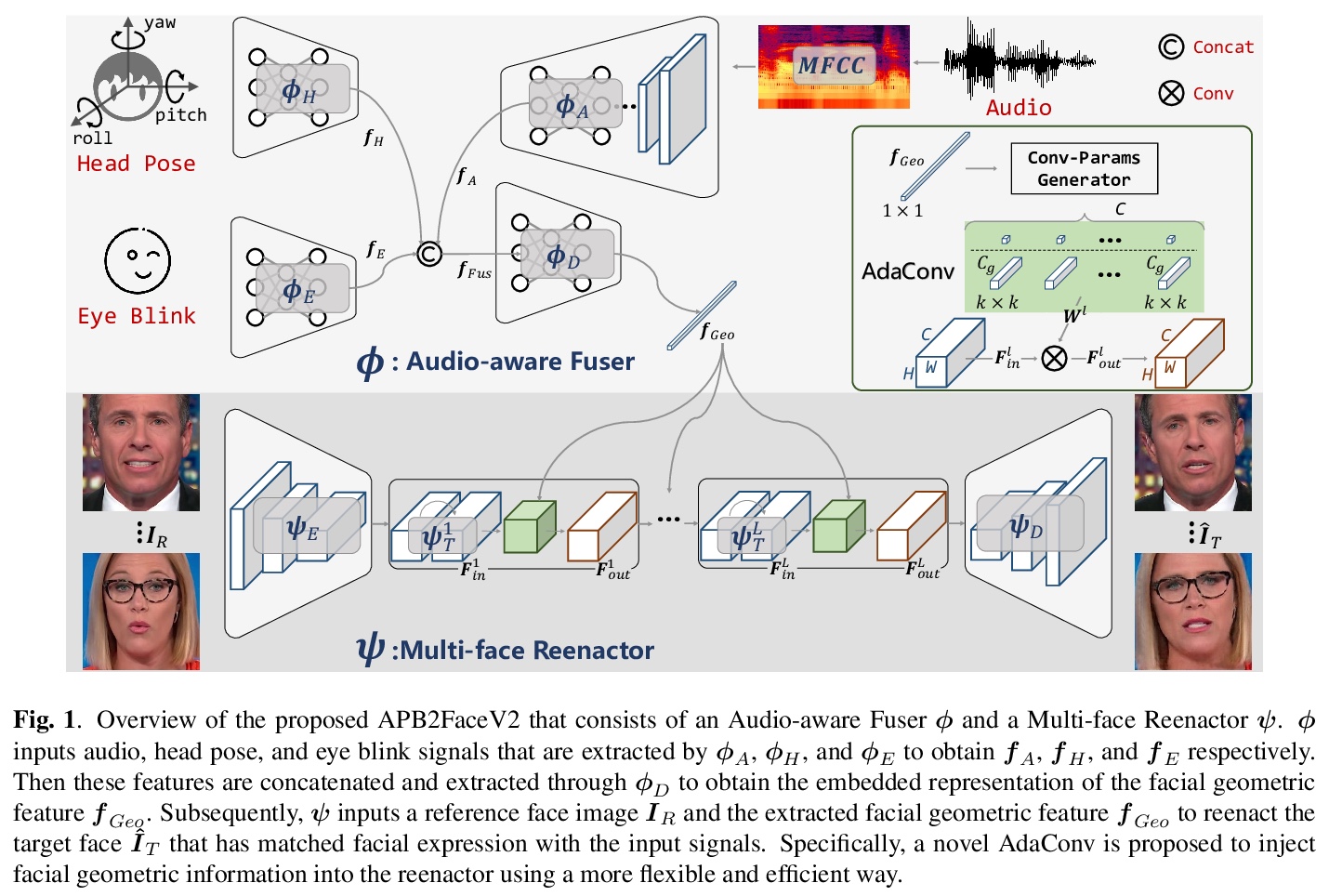
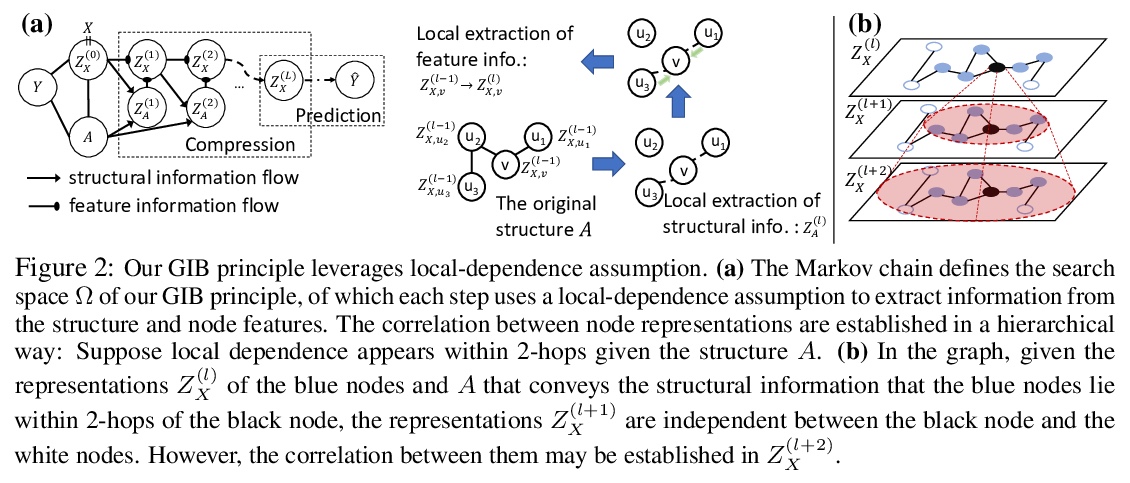
[LG] Graph Information Bottleneck
图信息瓶颈
T Wu, H Ren, P Li, J Leskovec
[Stanford University]
https://weibo.com/1402400261/Jre8V9XWq
[LG] XLVIN: eXecuted Latent Value Iteration Nets
XLVIN:执行潜价值迭代网络
A Deac, P Veličković, O Milinković, P Bacon, J Tang, M Nikolić
[Mila & DeepMind & University of Belgrade]
https://weibo.com/1402400261/Jrec0hABy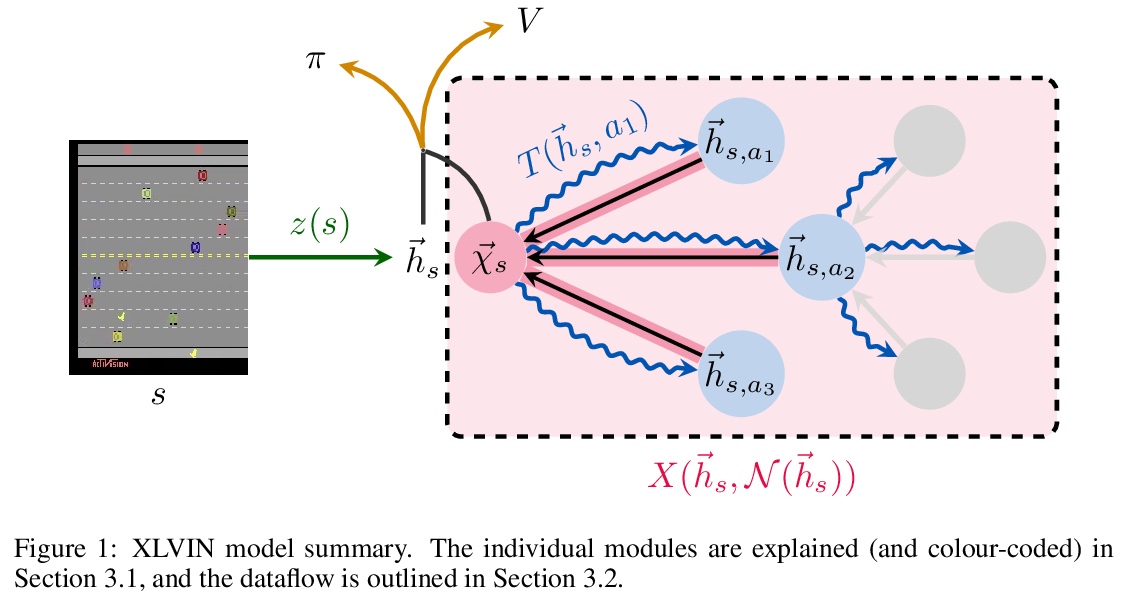
[CL] Long Document Ranking with Query-Directed Sparse Transformer
查询导向稀疏Transformer长文档排序
J Jiang, C Xiong, C Lee, W Wang
[Microsoft Research AI]
https://weibo.com/1402400261/Jredy5mZl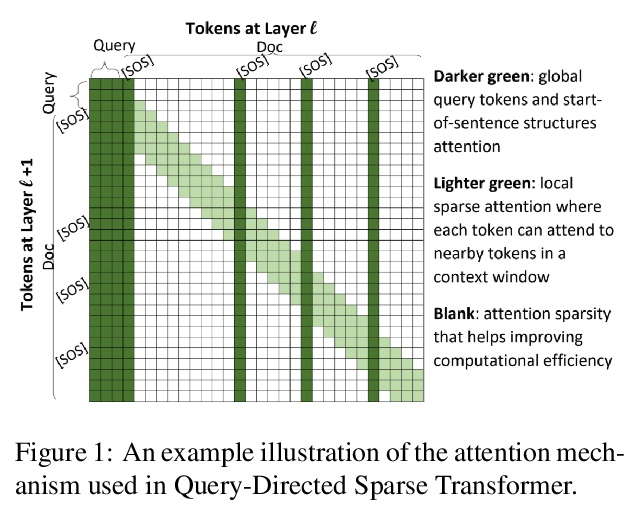

[CL] Automatically Identifying Words That Can Serve as Labels for Few-Shot Text Classification
少样本文本分类标签词自动识别
T Schick, H Schmid, H Schütze
[LMU Munich]
https://weibo.com/1402400261/Jref2vbJj

若有收获,就点个赞吧
0 人点赞
