- 1、[CV] VideoGPT: Video Generation using VQ-VAE and Transformers
- 2、[CL] RoFormer: Enhanced Transformer with Rotary Position Embedding
- 3、[CL] SummVis: Interactive Visual Analysis of Models, Data, and Evaluation for Text Summarization
- 4、[CV] Style-Aware Normalized Loss for Improving Arbitrary Style Transfer
- 5、[CL] Lessons on Parameter Sharing across Layers in Transformers
- [AI] MBRL-Lib: A Modular Library for Model-based Reinforcement Learning
- [CV] GENESIS-V2: Inferring Unordered Object Representations without Iterative Refinement
- [CL] Frustratingly Easy Edit-based Linguistic Steganography with a Masked Language Model
- [CV] Large Scale Interactive Motion Forecasting for Autonomous Driving : The Waymo Open Motion Dataset
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] VideoGPT: Video Generation using VQ-VAE and Transformers
W Yan, Y Zhang, P Abbeel, A Srinivas
[UC Berkeley]
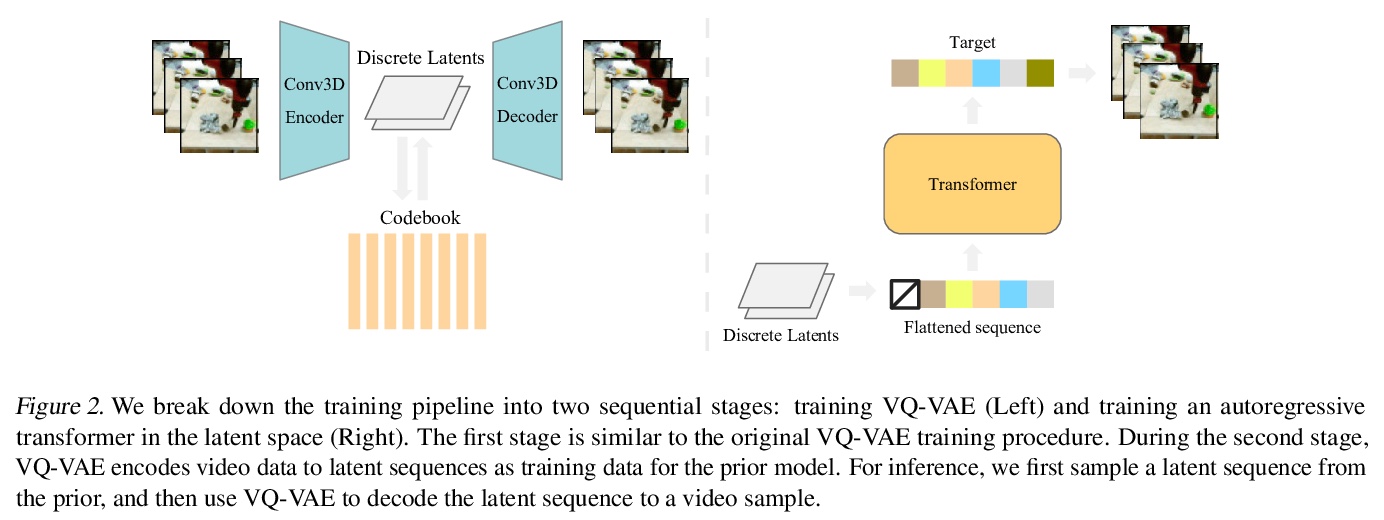
VideoGPT: 基于VQ-VAE和Transformer的视频生成。提出VideoGPT,一种新的视频生成架构,将通常用于图像生成的VQ-VAE和Transformer模型以最小的修改用于视频领域。VideoGPT使用VQVAE,采用三维卷积和轴向自注意力来学习原始视频的降采样离散潜表示,采用简单的类似GPT的架构,用空间-时间位置编码对离散潜在值进行自回归建模。VideoGPT能合成与最先进的基于GAN的视频生成模型相竞争的视频。
We present VideoGPT: a conceptually simple architecture for scaling likelihood based generative modeling to natural videos. VideoGPT uses VQ-VAE that learns downsampled discrete latent representations of a raw video by employing 3D convolutions and axial self-attention. A simple GPT-like architecture is then used to autoregressively model the discrete latents using spatio-temporal position encodings. Despite the simplicity in formulation and ease of training, our architecture is able to generate samples competitive with state-of-the-art GAN models for video generation on the BAIR Robot dataset, and generate high fidelity natural images from UCF-101 and Tumbler GIF Dataset (TGIF). We hope our proposed architecture serves as a reproducible reference for a minimalistic implementation of transformer based video generation models. Samples and code are available atthis https URL
https://weibo.com/1402400261/Kc1e7xbyH


2、[CL] RoFormer: Enhanced Transformer with Rotary Position Embedding
J Su, Y Lu, S Pan, B Wen, Y Liu
[Zhuiyi Technology Co., Ltd]
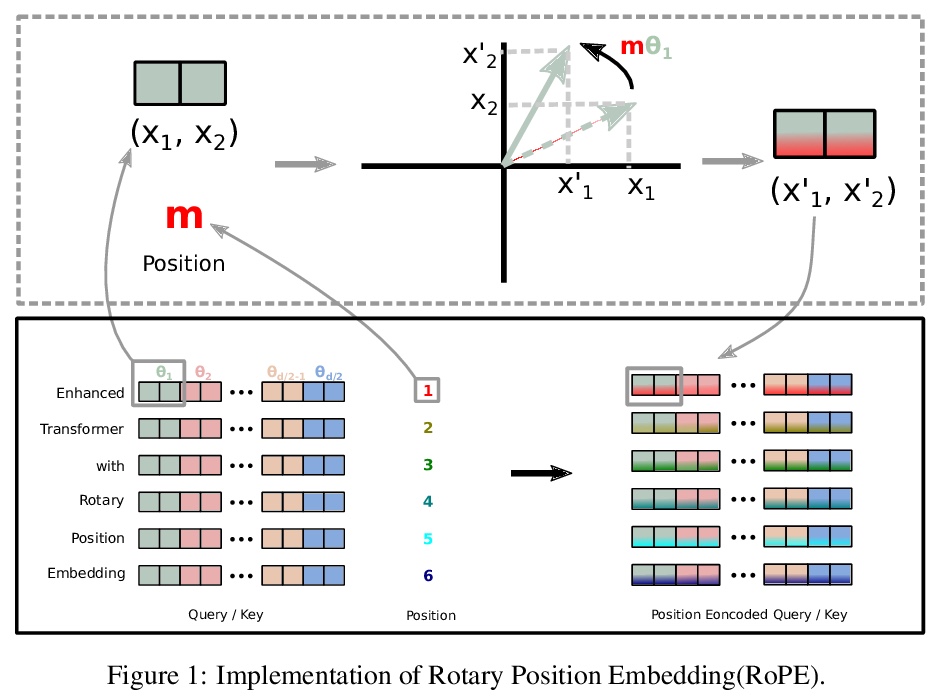
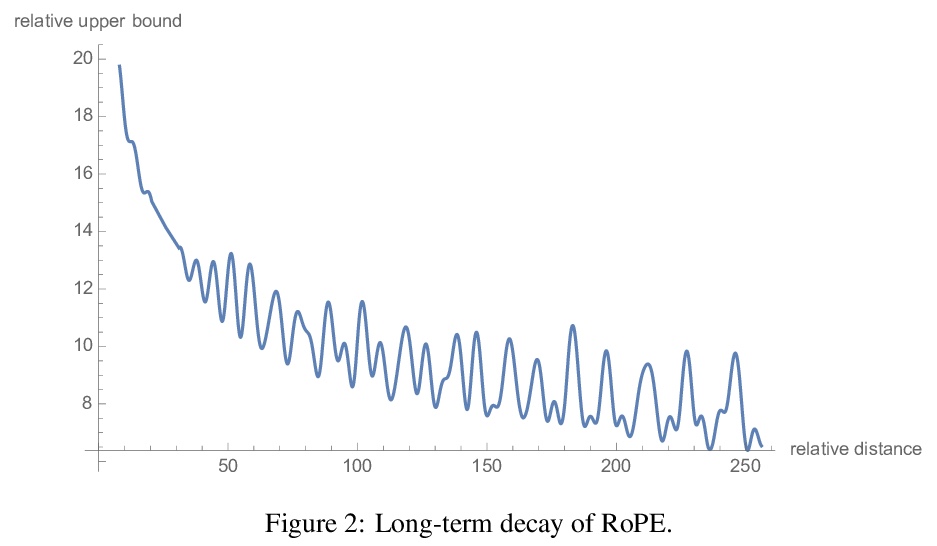
RoFormer:旋转位置嵌入增强型Transformer。Transformer结构中的位置编码,为序列中不同位置的元素间的依赖性建模提供了监督。本文研究了在基于Transformer的语言模型中编码位置信息的各种方法,提出旋转位置嵌入(RoPE)的新实现方法,RoPE用旋转矩阵来编码绝对位置信息,自然地将明确的相对位置依赖性纳入自注意力的表达中。RoPE具有一些有价值的特性,如可以灵活地扩展到任意序列长度,随着相对距离的增加,标记间的依赖性会逐渐减弱,并且能为线性自注意力配备相对位置编码。通过实验证明了RoFormer在处理长文本时显示出比之前模型更优越的性能。
Position encoding in transformer architecture provides supervision for dependency modeling between elements at different positions in the sequence. We investigate various methods to encode positional information in transformer-based language models and propose a novel implementation named Rotary Position Embedding(RoPE). The proposed RoPE encodes absolute positional information with rotation matrix and naturally incorporates explicit relative position dependency in self-attention formulation. Notably, RoPE comes with valuable properties such as flexibility of being expand to any sequence lengths, decaying inter-token dependency with increasing relative distances, and capability of equipping the linear self-attention with relative position encoding. As a result, the enhanced transformer with rotary position embedding, or RoFormer, achieves superior performance in tasks with long texts. We release the theoretical analysis along with some preliminary experiment results on Chinese data. The undergoing experiment for English benchmark will soon be updated.
https://weibo.com/1402400261/Kc1jZzWaZ
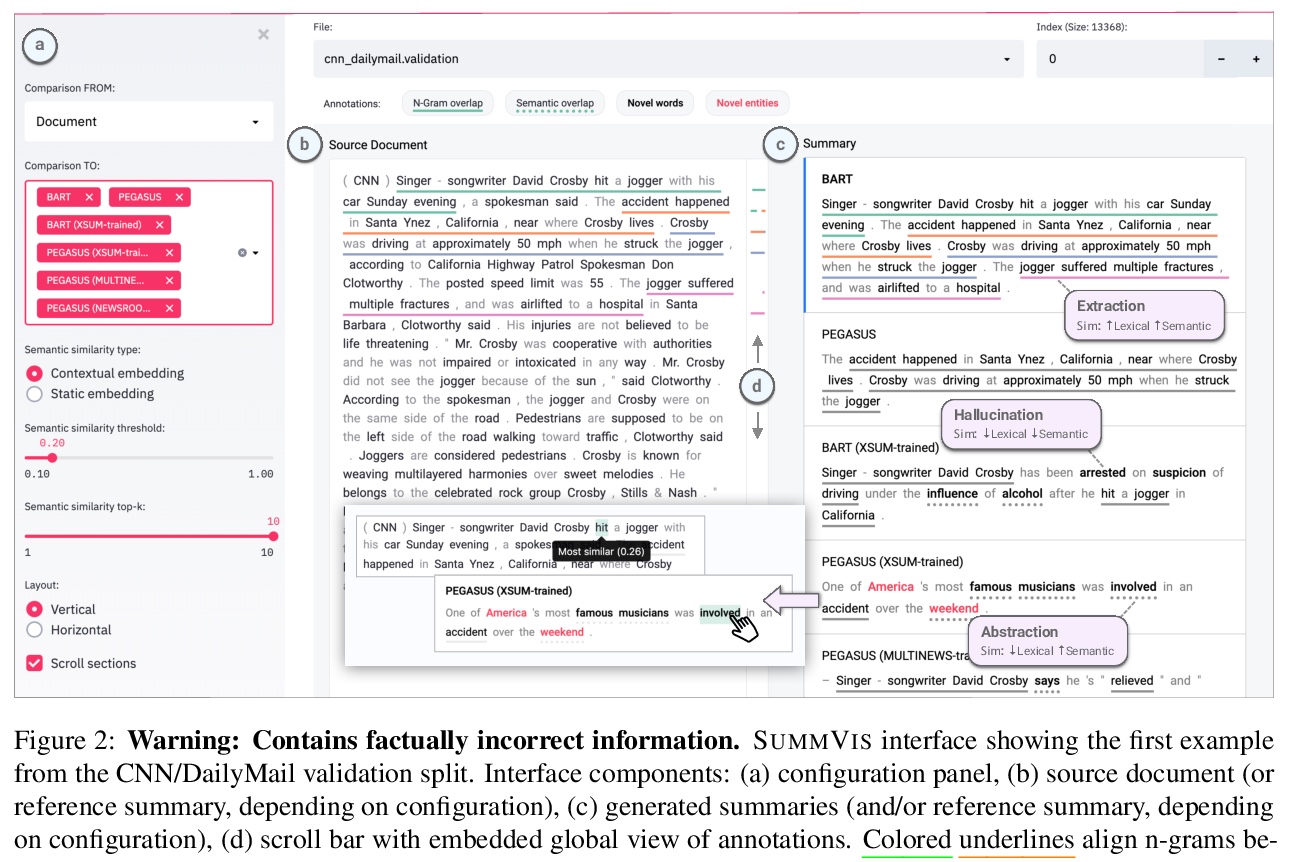
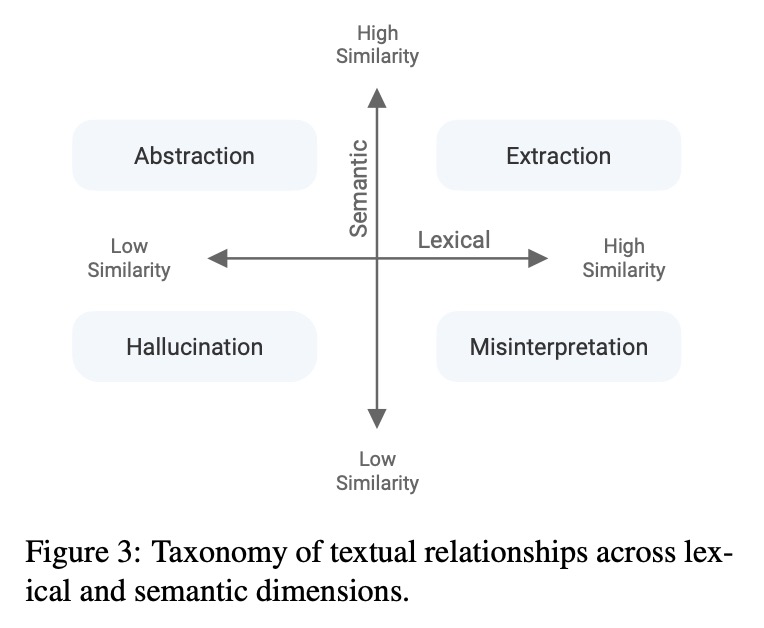
3、[CL] SummVis: Interactive Visual Analysis of Models, Data, and Evaluation for Text Summarization
J Vig, W Kryscinski, K Goel, N F Rajani
[Salesforce Research & Stanford University]
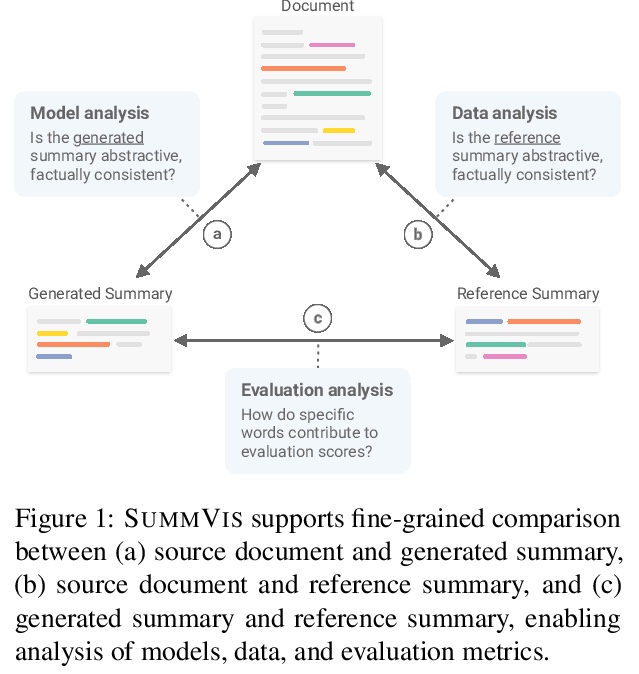
SummVis:文本摘要模型、数据和评价的交互可视化分析。新的神经结构、训练策略和大规模语料库,是最近在抽象文本摘要方面取得进展的动力。但是,由于神经模型的黑箱性质、无信息的评价指标以及用于模型和数据分析的工具的稀缺,摘要模型的真正性能和失败模式在很大程度上仍未可知。为解决这个问题,本文提出了SummVis,一个用于抽象摘要可视化的开源工具,可对与文本摘要相关的模型、数据和评估指标进行细粒度分析,通过其词汇和语义的可视化,为深入的模型预测探索提供简单的入口,跨越重要的维度,如事实的一致性或抽象性。
Novel neural architectures, training strategies, and the availability of large-scale corpora haven been the driving force behind recent progress in abstractive text summarization. However, due to the black-box nature of neural models, uninformative evaluation metrics, and scarce tooling for model and data analysis, the true performance and failure modes of summarization models remain largely unknown. To address this limitation, we introduce SummVis, an open-source tool for visualizing abstractive summaries that enables fine-grained analysis of the models, data, and evaluation metrics associated with text summarization. Through its lexical and semantic visualizations, the tools offers an easy entry point for in-depth model prediction exploration across important dimensions such as factual consistency or abstractiveness. The tool together with several pre-computed model outputs is available atthis https URL.
https://weibo.com/1402400261/Kc1oHuwRY
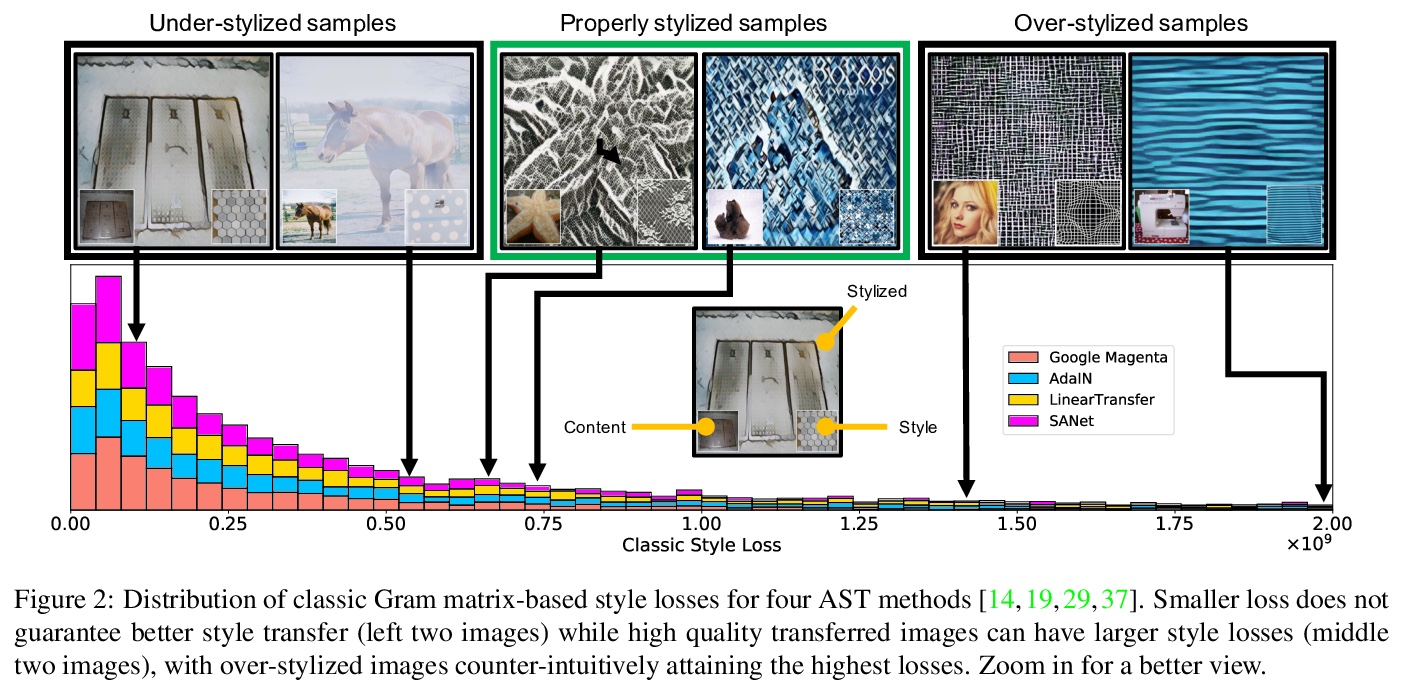
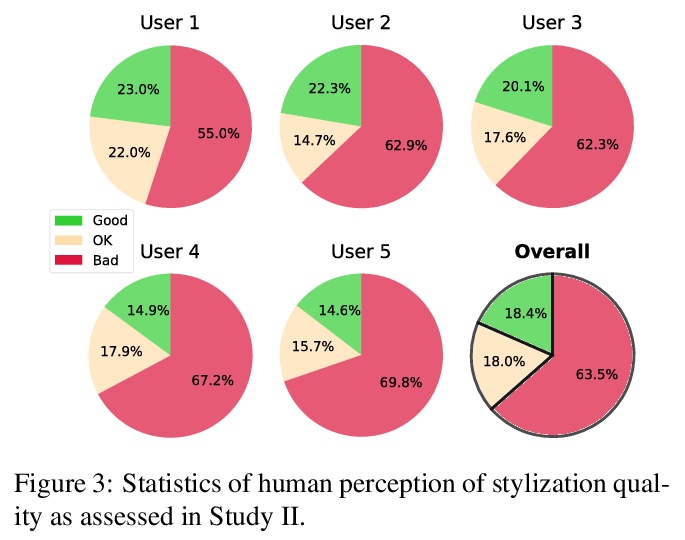
4、[CV] Style-Aware Normalized Loss for Improving Arbitrary Style Transfer
J Cheng, A Jaiswal, Y Wu, P Natarajan, P Natarajan
[USC Information Sciences Institute & Amazon Alexa Natural Understanding]
用于改进任意画风迁移的风格感知归一化损失。任意画风迁移(AST)风格化的图像不能被人工接受,通常是由于不足或过度风格化。本文系统研究了经典AST风格损失和风格化质量人工感知间的差异,找出了不平衡风格迁移性问题的根源,即在训练过程中对样本损失的风格不可知的聚合,并得出了风格损失的理论界限,以设计一个新的具有风格感知的归一化的风格平衡损失,与经典损失不同,新损失与人工感知是正相关的。实验结果显示,欺骗率和人工偏好的相对改进分别达到111%和98%。
Neural Style Transfer (NST) has quickly evolved from single-style to infinite-style models, also known as Arbitrary Style Transfer (AST). Although appealing results have been widely reported in literature, our empirical studies on four well-known AST approaches (GoogleMagenta, AdaIN, LinearTransfer, and SANet) show that more than 50% of the time, AST stylized images are not acceptable to human users, typically due to under- or over-stylization. We systematically study the cause of this imbalanced style transferability (IST) and propose a simple yet effective solution to mitigate this issue. Our studies show that the IST issue is related to the conventional AST style loss, and reveal that the root cause is the equal weightage of training samples irrespective of the properties of their corresponding style images, which biases the model towards certain styles. Through investigation of the theoretical bounds of the AST style loss, we propose a new loss that largely overcomes IST. Theoretical analysis and experimental results validate the effectiveness of our loss, with over 80% relative improvement in style deception rate and 98% relatively higher preference in human evaluation.
https://weibo.com/1402400261/Kc1tRwHeY

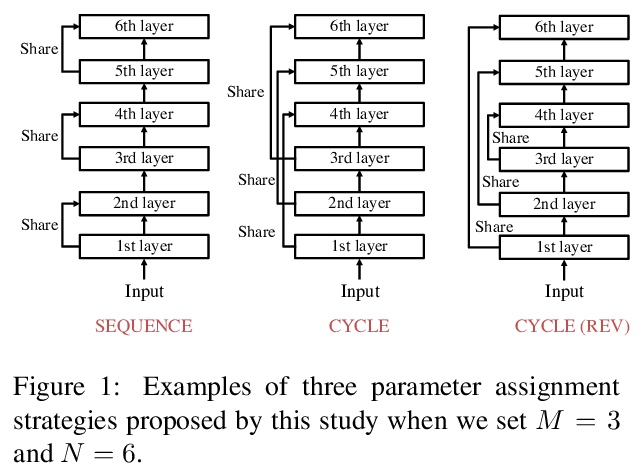
5、[CL] Lessons on Parameter Sharing across Layers in Transformers
S Takase, S Kiyono
[Tokyo Institute of Technology & RIKEN]
Transformer跨层参数共享的教训。提出Transformer的三种参数共享策略:SEQUENCE、CYCLE和CYCLE(REV),用于Transformer的内部层,与之前策略相比,即只为一层准备参数并在各层之间共享,所提出的策略为M层准备参数以构建N层。实验结果表明,为每种方法准备几乎相同的参数时,所提出的策略与统一策略取得了相当的BLEU分数,且计算时间较短,所提出策略在参数大小和计算时间上是有效的。此外,CYCLE和CYCLE(REV)适用于构建深度模型。通过在高资源环境下的实验,证明CYCLE (REV)能够以较少的参数获得与WMT 2020新闻翻译任务最佳系统相当的分数。
We propose a parameter sharing method for Transformers (Vaswani et al., 2017). The proposed approach relaxes a widely used technique, which shares parameters for one layer with all layers such as Universal Transformers (Dehghani et al., 2019), to increase the efficiency in the computational time. We propose three strategies: Sequence, Cycle, and Cycle (rev) to assign parameters to each layer. Experimental results show that the proposed strategies are efficient in the parameter size and computational time. Moreover, we indicate that the proposed strategies are also effective in the configuration where we use many training data such as the recent WMT competition.
https://weibo.com/1402400261/Kc1xtvGuo

另外几篇值得关注的论文:
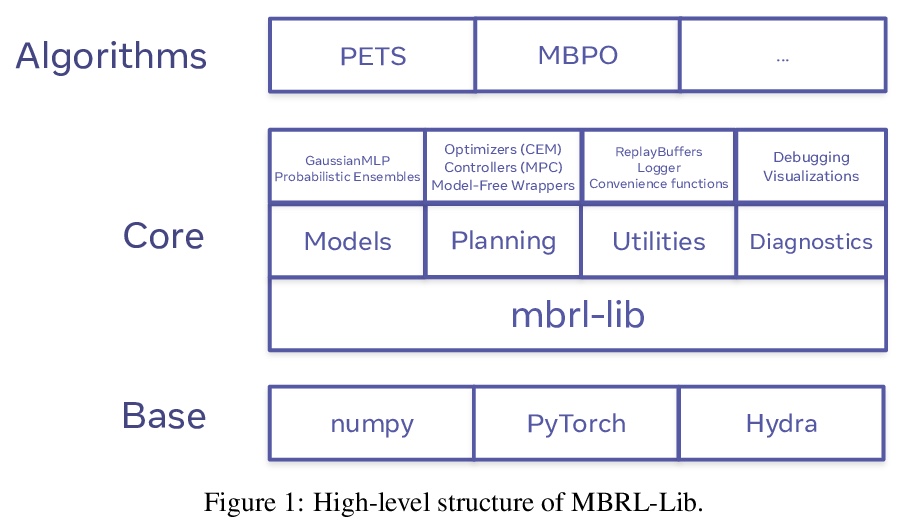
[AI] MBRL-Lib: A Modular Library for Model-based Reinforcement Learning
MBRL-Lib:基于模型强化学习的模块化库
L Pineda, B Amos, A Zhang, N O. Lambert, R Calandra
[Facebook AI Research & UC Berkeley]
https://weibo.com/1402400261/Kc1AW4CLS

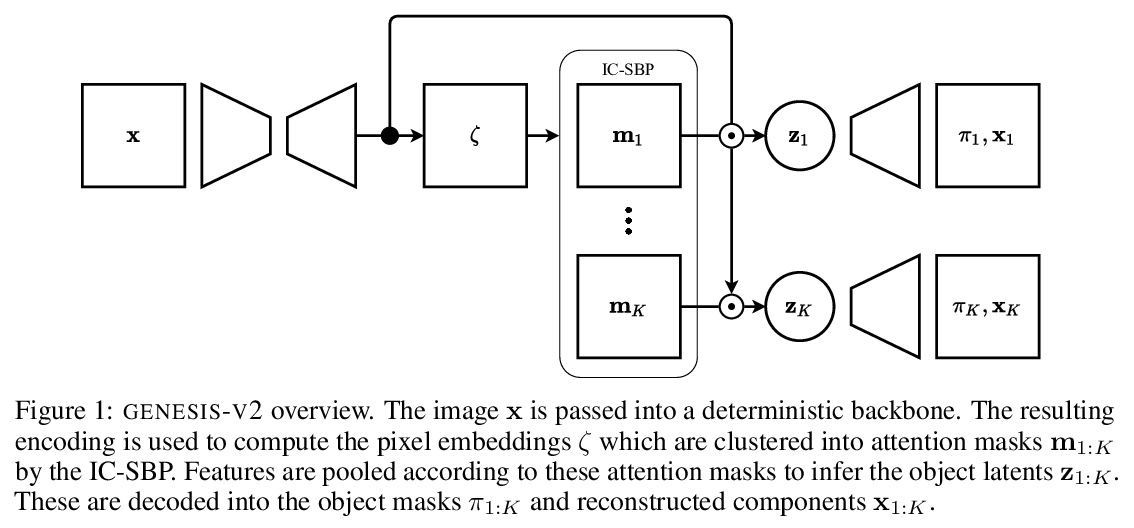
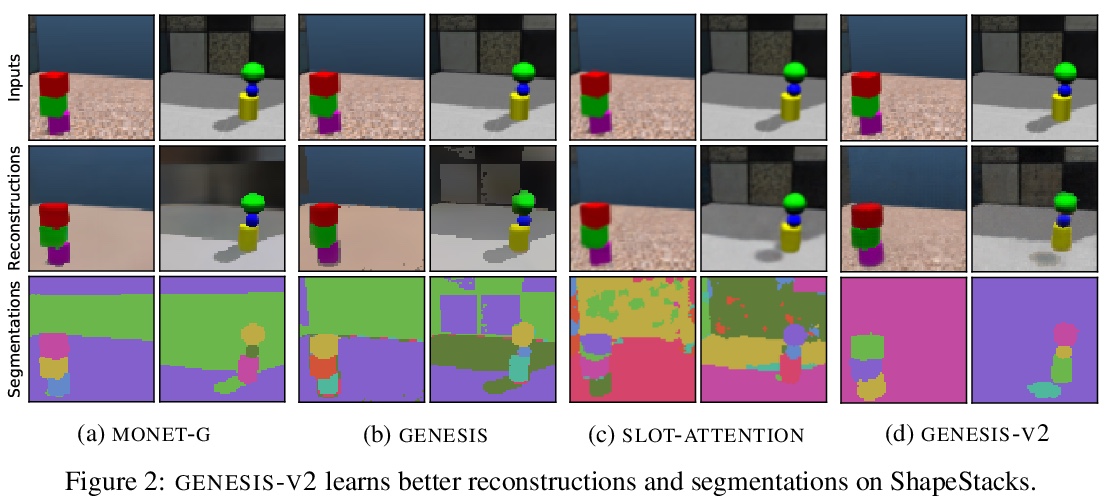
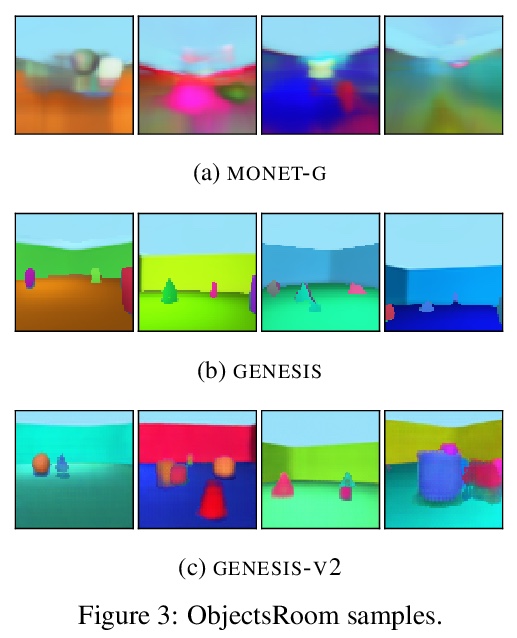
[CV] GENESIS-V2: Inferring Unordered Object Representations without Iterative Refinement
GENESIS-V2:无需迭代细化的无序对象表示推断
M Engelcke, O P Jones, I Posner
[University of Oxford]
https://weibo.com/1402400261/Kc1DqmCUy
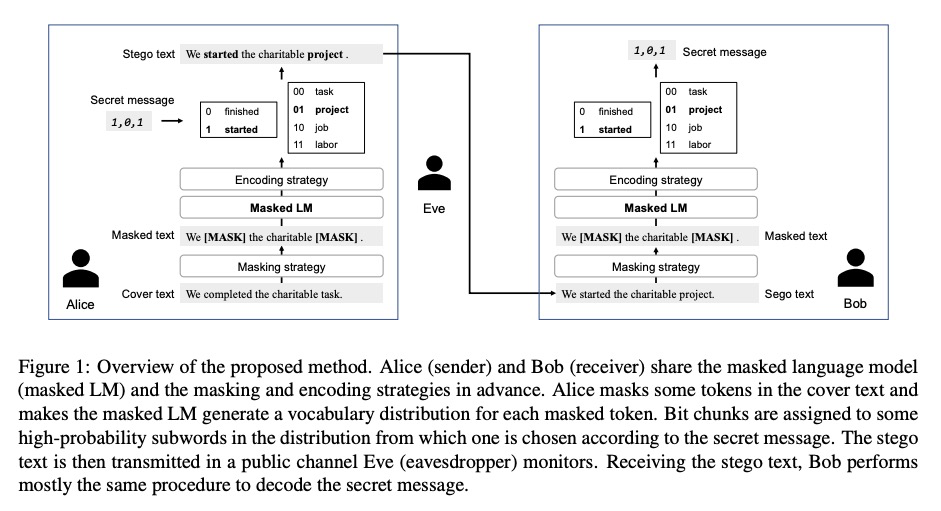
[CL] Frustratingly Easy Edit-based Linguistic Steganography with a Masked Language Model
基于掩码语言模型的超易编辑语言隐写术
H Ueoka, Y Murawaki, S Kurohashi
[Kyoto University]
https://weibo.com/1402400261/Kc1IObwPK


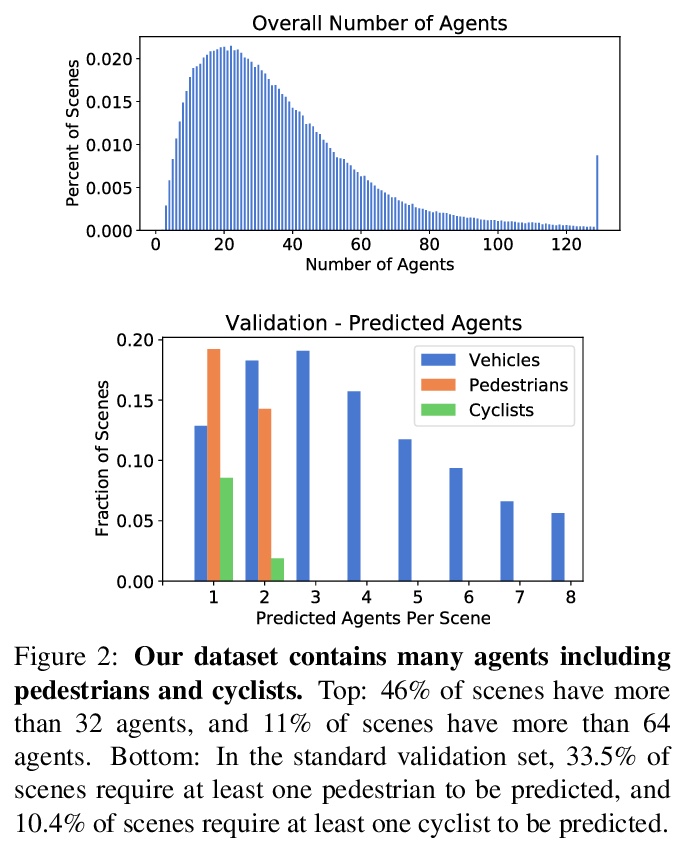
[CV] Large Scale Interactive Motion Forecasting for Autonomous Driving : The Waymo Open Motion Dataset
无人驾驶大规模交互式运动预测:Waymo开放运动数据集
S Ettinger, S Cheng, B Caine, C Liu, H Zhao, S Pradhan, Y Chai, B Sapp, C Qi, Y Zhou, Z Yang, A Chouard, P Sun, J Ngiam, V Vasudevan, A McCauley, J Shlens, D Anguelov
[Waymo LLC & Google Brain]
https://weibo.com/1402400261/Kc1KODSHP


若有收获,就点个赞吧
0 人点赞
