- 1、[CL] Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention
- 2、[CV] Colorization Transformer
- 3、[CV] Solid Texture Synthesis using Generative Adversarial Networks
- 4、[CV] Learning N:M Fine-grained Structured Sparse Neural Networks From Scratch
- 5、[LG] Learning Curve Theory
- [LG] Grid-to-Graph: Flexible Spatial Relational Inductive Biases for Reinforcement Learning
- [AS] End-to-End Multi-Channel Transformer for Speech Recognition
- [CV] Template-Free Try-on Image Synthesis via Semantic-guided Optimization
- [CV] An Efficient Framework for Zero-Shot Sketch-Based Image Retrieval
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CL] Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention
Y Xiong, Z Zeng, R Chakraborty, M Tan, G Fung, Y Li, V Singh
[University of Wisconsin-Madison & UC Berkeley & Google Brain & American Family Insurance]
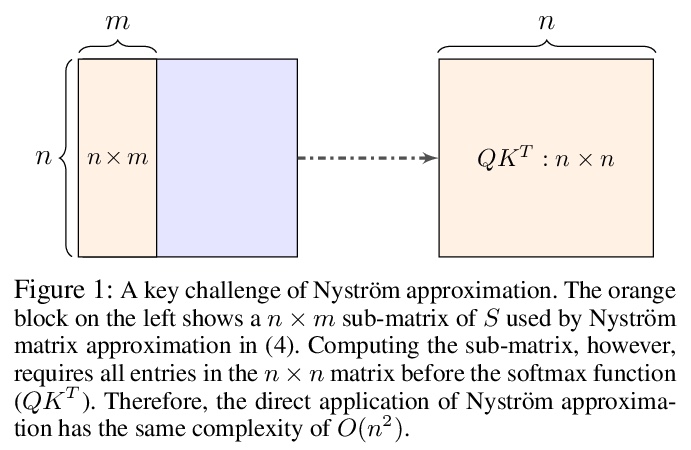
Nyströmformer: 基于Nyström的自注意力近似算法。为突破自注意力输入序列长度二次复杂度对长序列应用的限制,提出Nyströmformer,在深度Transformer架构中进行调整和部署,以提供高效自注意力近似。其核心思想是基于Nyström方法(一种广泛使用的矩阵近似策略)的自适应,以O(n)复杂度来近似标准自注意力。Nyströmformer的可扩展性使其能用于数千词项的长序列,保持了其他自注意力近似方法的性能,提供了额外的资源利用率效益。在GLUE基准和IMDB评论的标准序列长度上,对多个下游任务进行了评价,Nyströmformer的表现与标准Transformer相当,在少数情况下,甚至略胜一筹。
Transformers have emerged as a powerful tool for a broad range of natural language processing tasks. A key component that drives the impressive performance of Transformers is the self-attention mechanism that encodes the influence or dependence of other tokens on each specific token. While beneficial, the quadratic complexity of self-attention on the input sequence length has limited its application to longer sequences — a topic being actively studied in the community. To address this limitation, we propose Nyströmformer — a model that exhibits favorable scalability as a function of sequence length. Our idea is based on adapting the Nyström method to approximate standard self-attention with > O(n) complexity. The scalability of Nyströmformer enables application to longer sequences with thousands of tokens. We perform evaluations on multiple downstream tasks on the GLUE benchmark and IMDB reviews with standard sequence length, and find that our Nyströmformer performs comparably, or in a few cases, even slightly better, than standard Transformer. Our code is at > this https URL.
https://weibo.com/1402400261/K1e0efhp8


2、[CV] Colorization Transformer
M Kumar, D Weissenborn, N Kalchbrenner
[Google Research]
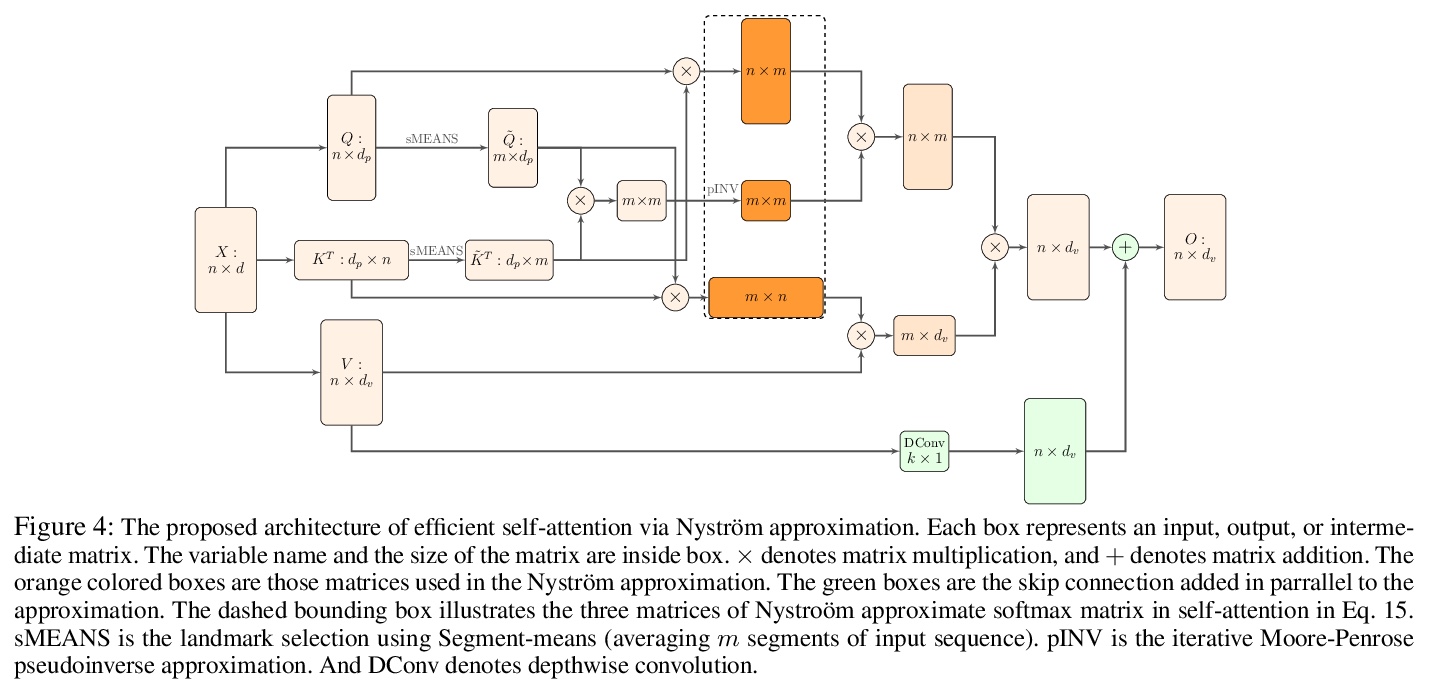
基于Transformer的自动着色架构。提出了完全依靠自注意力进行多样化高保真图像着色的架构Colorization Transformer(ColTran),引入条件Transformer层,一种基于自注意力的条件生成模型新构件。给定一幅灰度图像,先用条件自回归Transformer生成低分辨率粗着色,用条件Transformer层有效调节灰度输入,由两个全并行网络将粗着色低分辨率图像上采样为细着色高分辨率图像。从ColTran采样产生多样化着色,基于Mechanical Turk众包测试得到的人工评价结果,其保真度超过了之前基于FID的ImageNet最先进着色结果。超过60%的情况下,人工评价者更倾向于三个生成着色中评分最高的一个,而不是原始彩色图像。
We present the Colorization Transformer, a novel approach for diverse high fidelity image colorization based on self-attention. Given a grayscale image, the colorization proceeds in three steps. We first use a conditional autoregressive transformer to produce a low resolution coarse coloring of the grayscale image. Our architecture adopts conditional transformer layers to effectively condition grayscale input. Two subsequent fully parallel networks upsample the coarse colored low resolution image into a finely colored high resolution image. Sampling from the Colorization Transformer produces diverse colorings whose fidelity outperforms the previous state-of-the-art on colorising ImageNet based on FID results and based on a human evaluation in a Mechanical Turk test. Remarkably, in more than 60% of cases human evaluators prefer the highest rated among three generated colorings over the ground truth. The code and pre-trained checkpoints for Colorization Transformer are publicly available at > this https URL
https://weibo.com/1402400261/K1e9jERsy


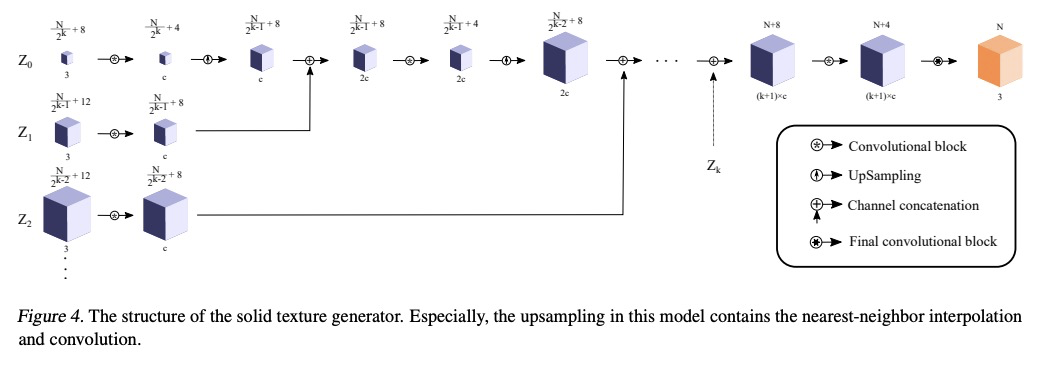
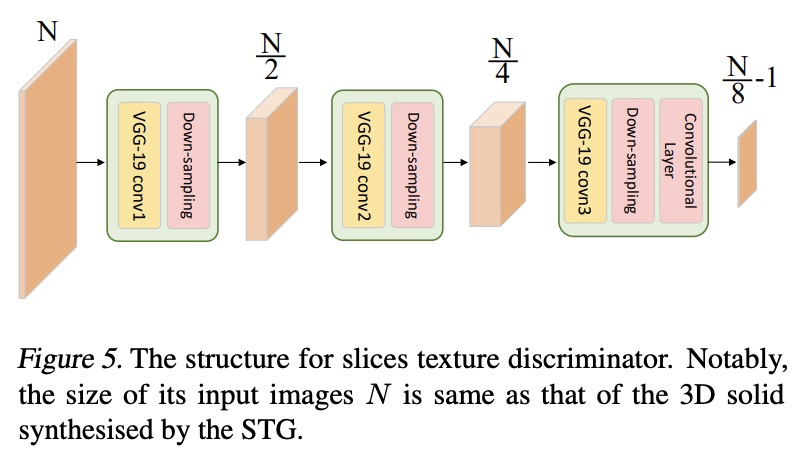
3、[CV] Solid Texture Synthesis using Generative Adversarial Networks
X Zhao, L Wang, J Guo, B Yang, J Zheng, F Li
[University of Jinan]
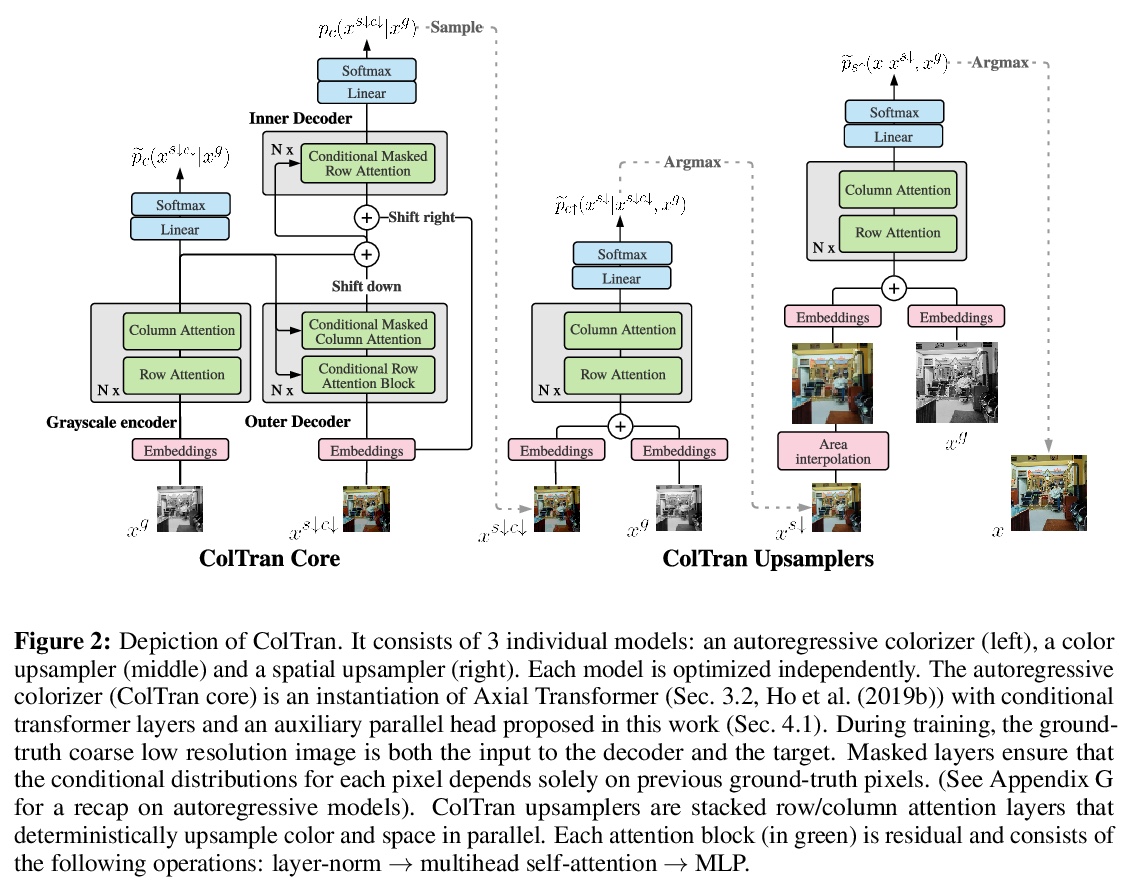
基于生成对抗网络的固体纹理合成。提出一种新的基于生成对抗网络的神经网络实体纹理合成方法STS-GAN,由多尺度模块组成的生成器学习2D实例的内部分布,并进一步将其扩展为3D实体纹理。判别器对2D样板和切片之间的相似性进行评价,协助生成器合成真实实体纹理。实验结果表明,所提出方法可合成高质量3D实体纹理,视觉特征与样板相似。
Solid texture synthesis, as an effective way to extend 2D texture to 3D solid texture, exhibits advantages in numerous application domains. However, existing methods generally suffer from synthesis distortion due to the underutilization of texture information. In this paper, we proposed a novel neural network-based approach for the solid texture synthesis based on generative adversarial networks, namely STS-GAN, in which the generator composed of multi-scale modules learns the internal distribution of 2D exemplar and further extends it to a 3D solid texture. In addition, the discriminator evaluates the similarity between 2D exemplar and slices, promoting the generator to synthesize realistic solid texture. Experiment results demonstrate that the proposed method can synthesize high-quality 3D solid texture with similar visual characteristics to the exemplar.
https://weibo.com/1402400261/K1efxj9sC

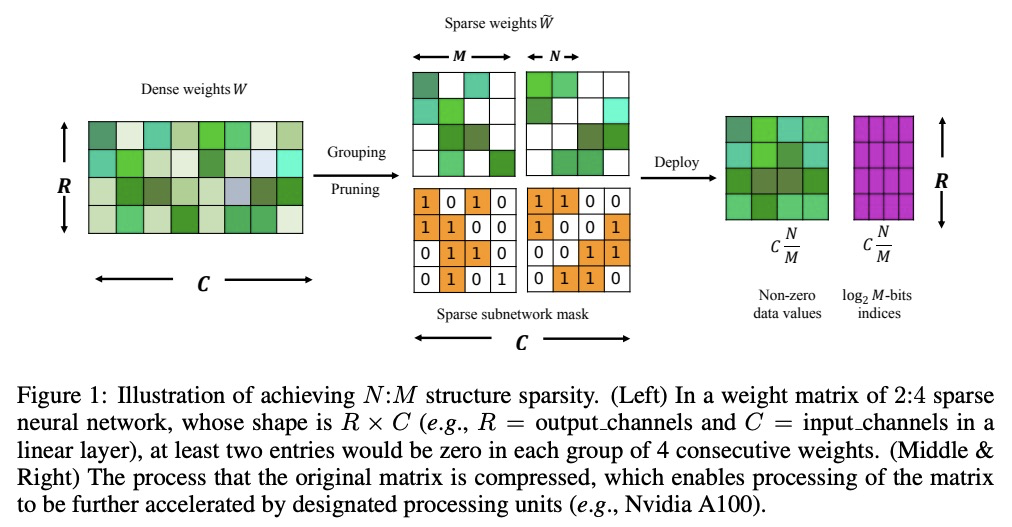
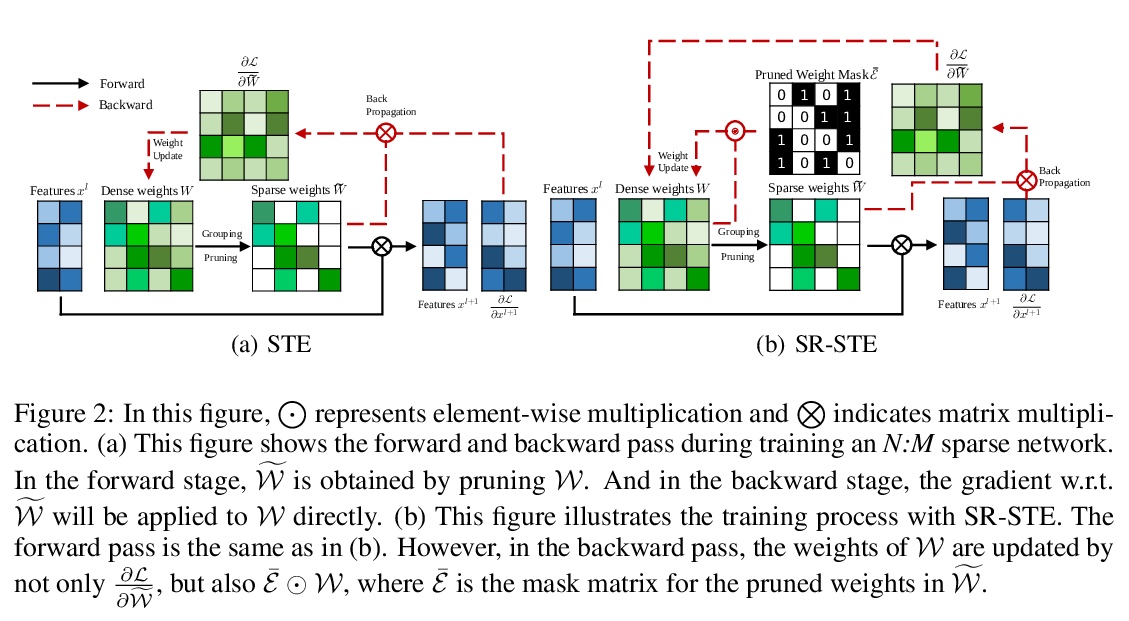
4、[CV] Learning N:M Fine-grained Structured Sparse Neural Networks From Scratch
A Zhou, Y Ma, J Zhu, J Liu, Z Zhang, K Yuan, W Sun, H Li
[Sensetime & CUHK-Sensetime Joint Lab & Northwestern University]
从头学习N:M细粒度结构化稀疏神经网络。提出用稀疏精炼直通估计器(SR-STE)从头开始训练N:M细粒度结构化稀疏网络,可在专门设计的GPU上同时保持非结构化细粒度稀疏和结构化粗粒度稀疏的优势。SR-STE扩展了直通估计器,加入正则化项,以缓解由STE修改的链式法则计算的粗梯度带来的无效稀疏架构更新。2:4的稀疏网络可在Nvidia A100 GPU上实现2倍提速而不降低性能。定义了一个度量标准,即稀疏架构差异(SAD),用于衡量稀疏网络在训练过程中的拓扑变化。实验结果表明,SAD与修剪网络性能有很强的相关性。
Sparsity in Deep Neural Networks (DNNs) has been widely studied to compress and accelerate the models on resource-constrained environments. It can be generally categorized into unstructured fine-grained sparsity that zeroes out multiple individual weights distributed across the neural network, and structured coarse-grained sparsity which prunes blocks of sub-networks of a neural network. Fine-grained sparsity can achieve a high compression ratio but is not hardware friendly and hence receives limited speed gains. On the other hand, coarse-grained sparsity cannot concurrently achieve both apparent acceleration on modern GPUs and decent performance. In this paper, we are the first to study training from scratch an N:M fine-grained structured sparse network, which can maintain the advantages of both unstructured fine-grained sparsity and structured coarse-grained sparsity simultaneously on specifically designed GPUs. Specifically, a 2:4 sparse network could achieve 2x speed-up without performance drop on Nvidia A100 GPUs. Furthermore, we propose a novel and effective ingredient, sparse-refined straight-through estimator (SR-STE), to alleviate the negative influence of the approximated gradients computed by vanilla STE during optimization. We also define a metric, Sparse Architecture Divergence (SAD), to measure the sparse network’s topology change during the training process. Finally, We justify SR-STE’s advantages with SAD and demonstrate the effectiveness of SR-STE by performing comprehensive experiments on various tasks. Source codes and models are available at > this https URL.
https://weibo.com/1402400261/K1eiuugEl
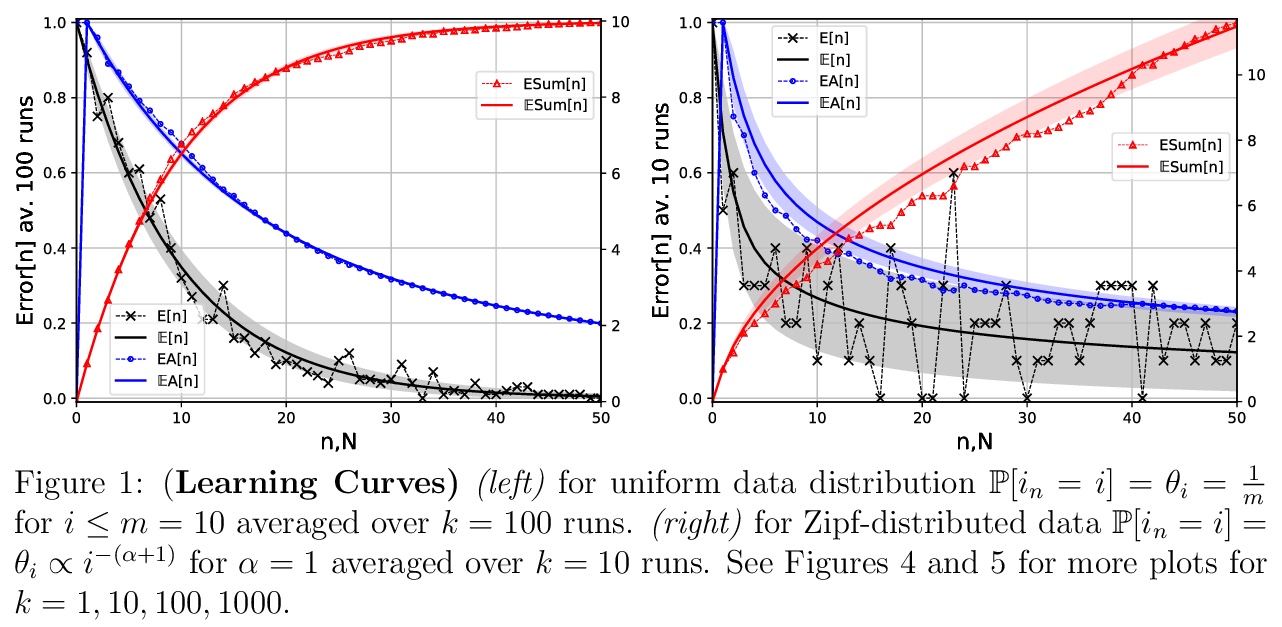
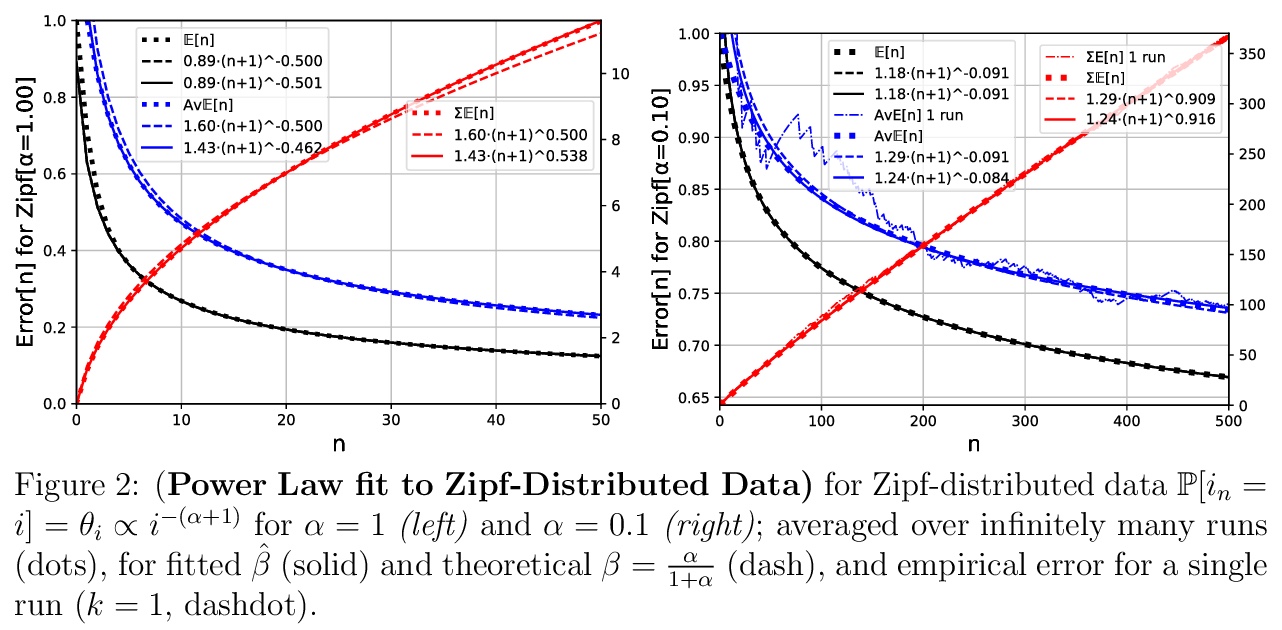
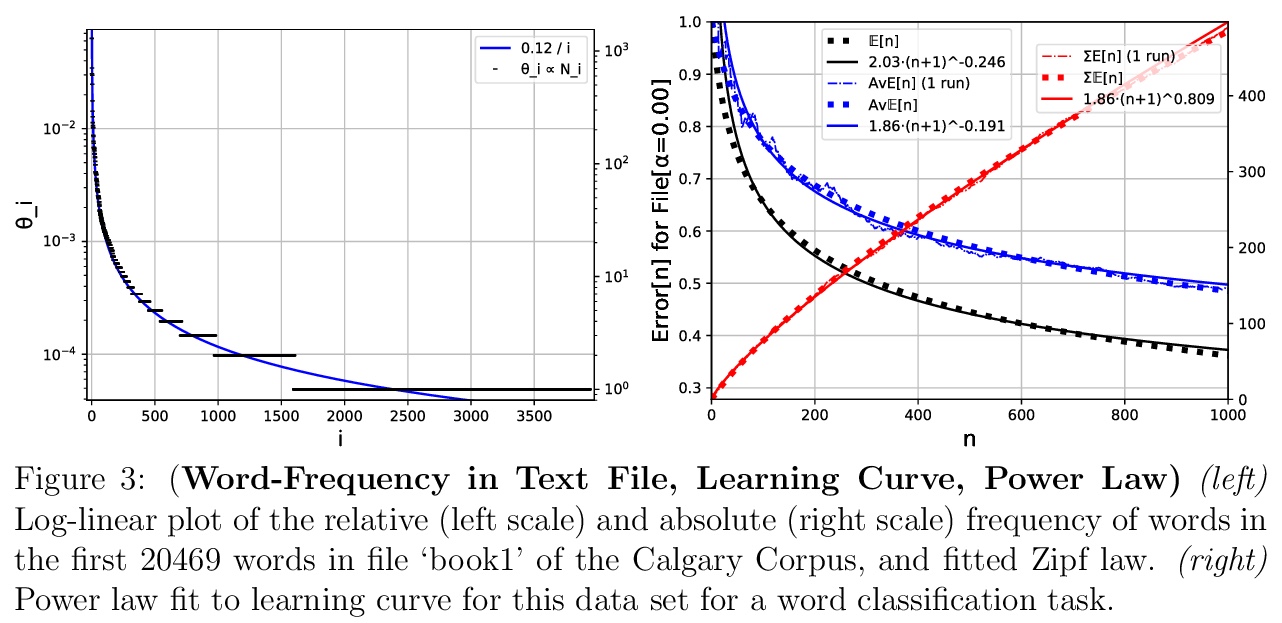
5、[LG] Learning Curve Theory
M Hutter
[DeepMind]
学习曲线理论。研究训练/测试误差随更多数据的幂律下降规律,开发并从理论上分析了一个最简单的可能的(玩具)模型,可表现出与最近在深度学习中发现一致的幂律(随数据增大误差的降低),并确定幂律是普遍的还是取决于数据分布。
Recently a number of empirical “universal” scaling law papers have been published, most notably by OpenAI. `Scaling laws’ refers to power-law decreases of training or test error w.r.t. more data, larger neural networks, and/or more compute. In this work we focus on scaling w.r.t. data size > n. Theoretical understanding of this phenomenon is largely lacking, except in finite-dimensional models for which error typically decreases with > n> −1/2 or > n> −1, where > n is the sample size. We develop and theoretically analyse the simplest possible (toy) model that can exhibit > n> −β learning curves for arbitrary power > β>0, and determine whether power laws are universal or depend on the data distribution.
https://weibo.com/1402400261/K1epGEF9k
另外几篇值得关注的论文:
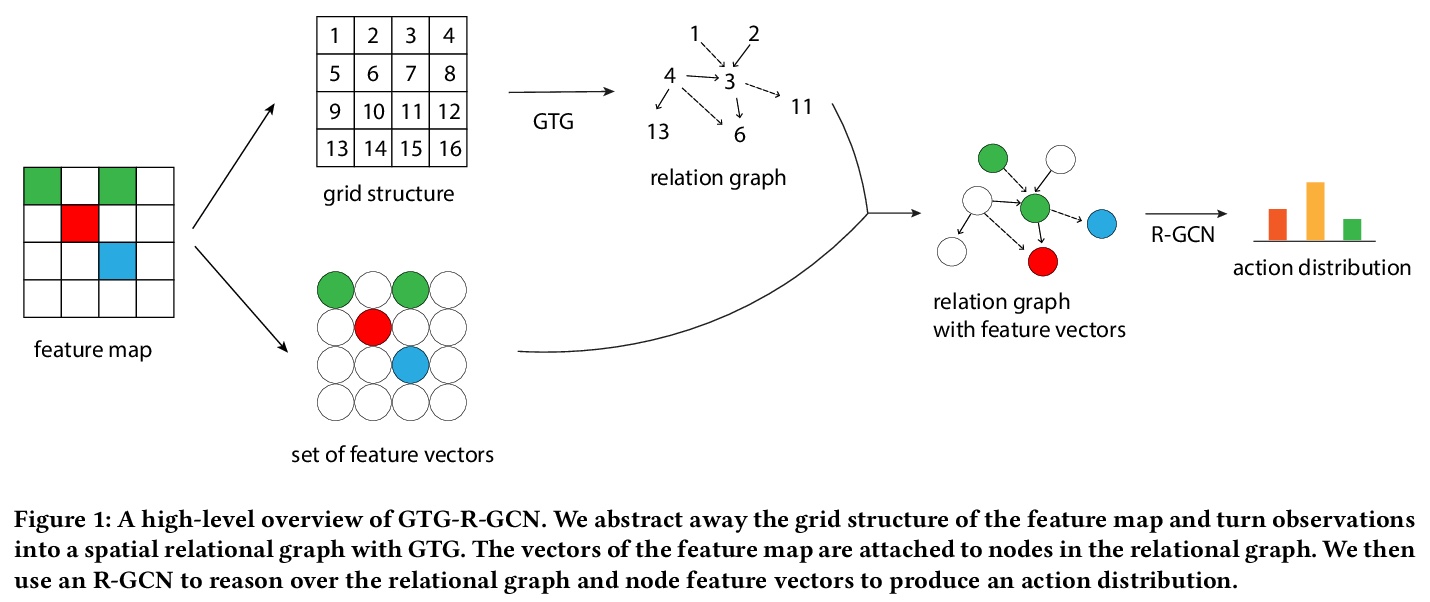
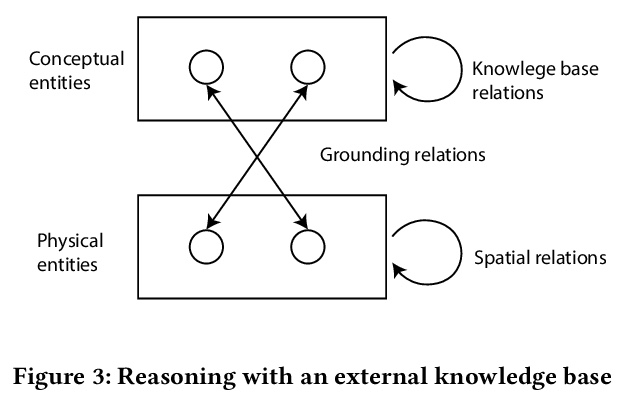
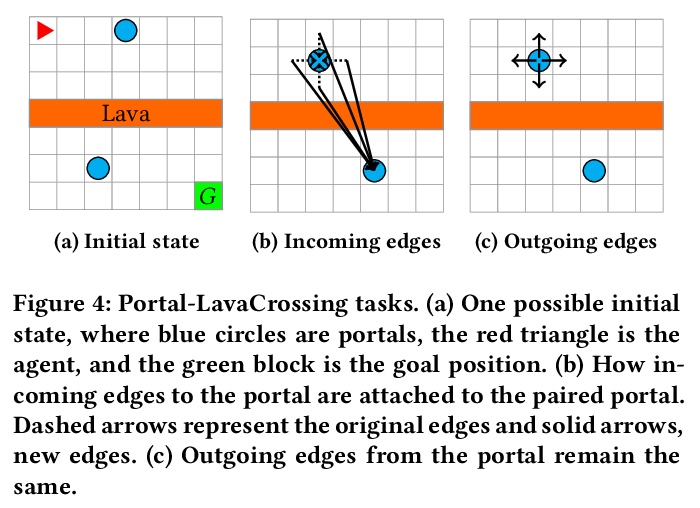
[LG] Grid-to-Graph: Flexible Spatial Relational Inductive Biases for Reinforcement Learning
Grid-to-Graph:强化学习的灵活空间关系归纳偏差
Z Jiang, P Minervini, M Jiang, T Rocktaschel
[University College London]
https://weibo.com/1402400261/K1ezrAm0d

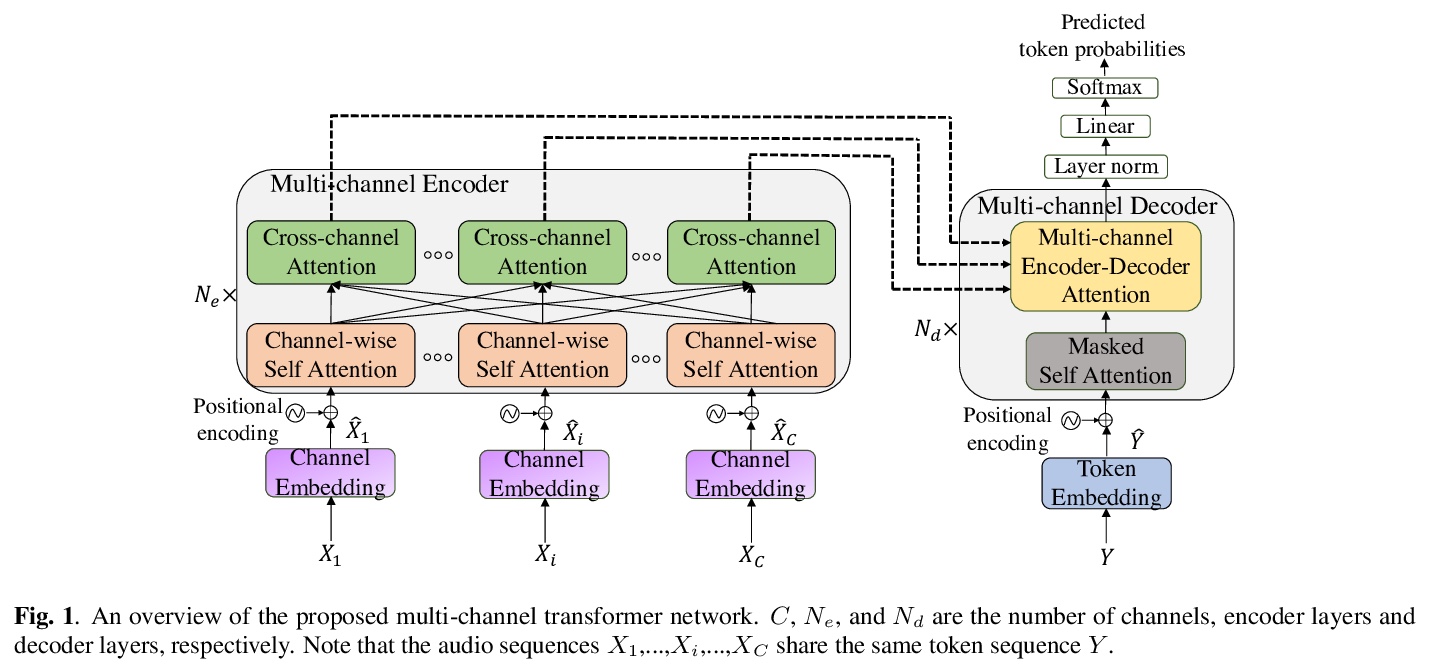
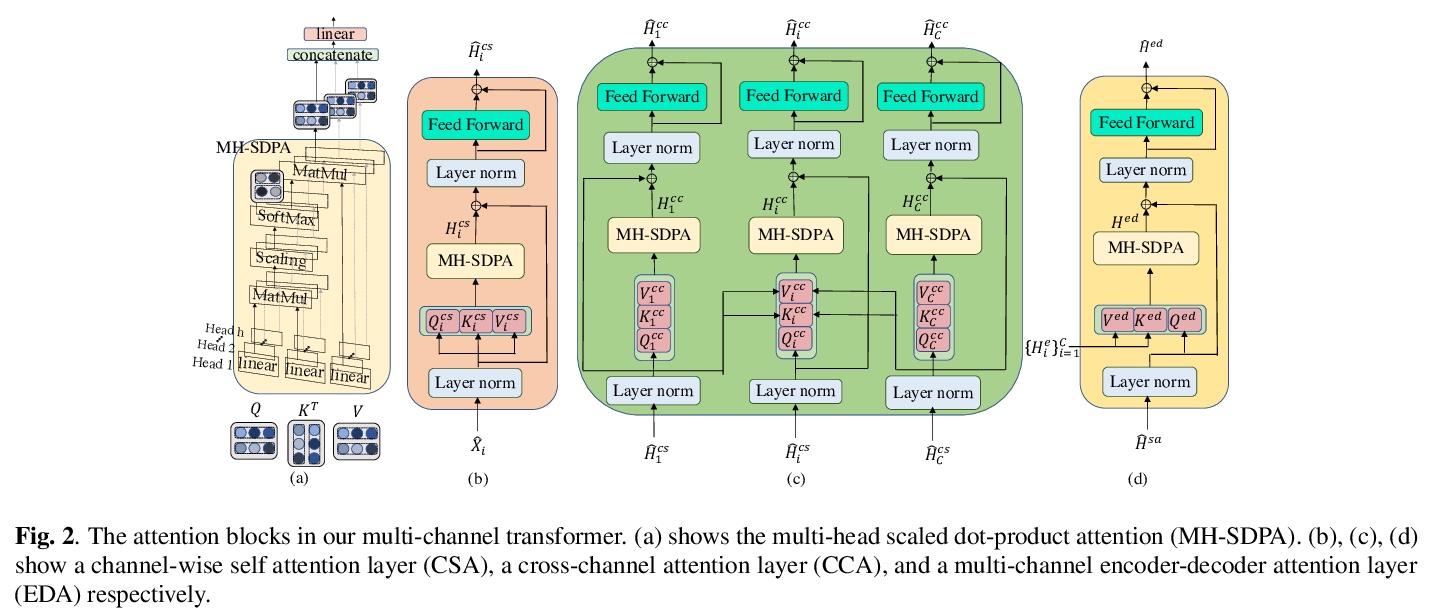
[AS] End-to-End Multi-Channel Transformer for Speech Recognition
端到端多通道Transformer语音识别
F Chang, M Radfar, A Mouchtaris, B King, S Kunzmann
[Amazon]
https://weibo.com/1402400261/K1eBrriYB
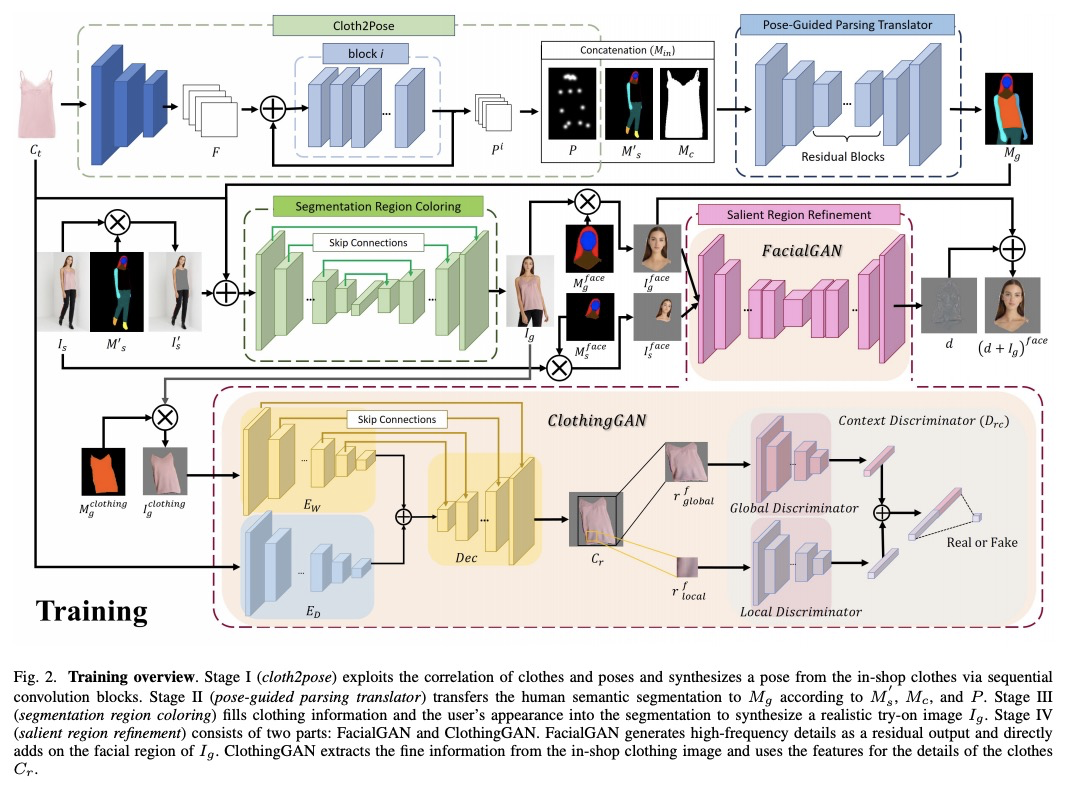
[CV] Template-Free Try-on Image Synthesis via Semantic-guided Optimization
基于语义引导优化的无模板试穿图像合成
C Chou, C Chen, C Hsieh, H Shuai, J Liu, W Cheng
[ National Chiao Tung University & National Chung Hsing University & Peking University]
https://weibo.com/1402400261/K1eLu1o2y

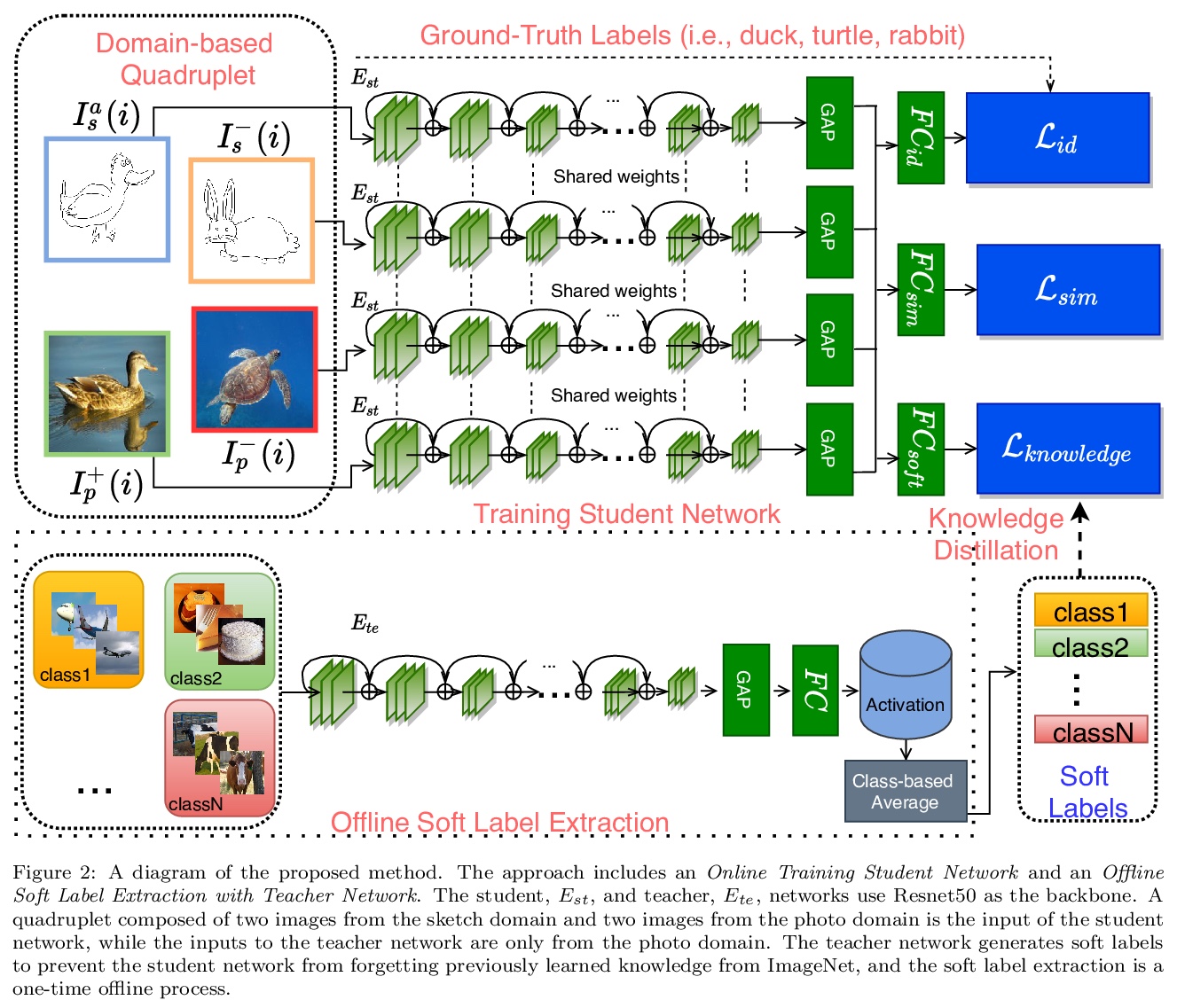
[CV] An Efficient Framework for Zero-Shot Sketch-Based Image Retrieval
高效零样本草图图像检索框架
O Tursun, S Denman, S Sridharan, E Goan, C Fookes
[Queensland University of Technology]
https://weibo.com/1402400261/K1eOikyDZ




若有收获,就点个赞吧
0 人点赞
