- 1、[LG] baller2vec: A Multi-Entity Transformer For Multi-Agent Spatiotemporal Modeling
- 2、[LG] ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- 3、[RO] How to Train Your Robot with Deep Reinforcement Learning; Lessons We’ve Learned
- 4、[LG] 1-bit Adam: Communication Efficient Large-Scale Training with Adam’s Convergence Speed
- 5、[LG] PipeTransformer: Automated Elastic Pipelining for Distributed Training of Transformers
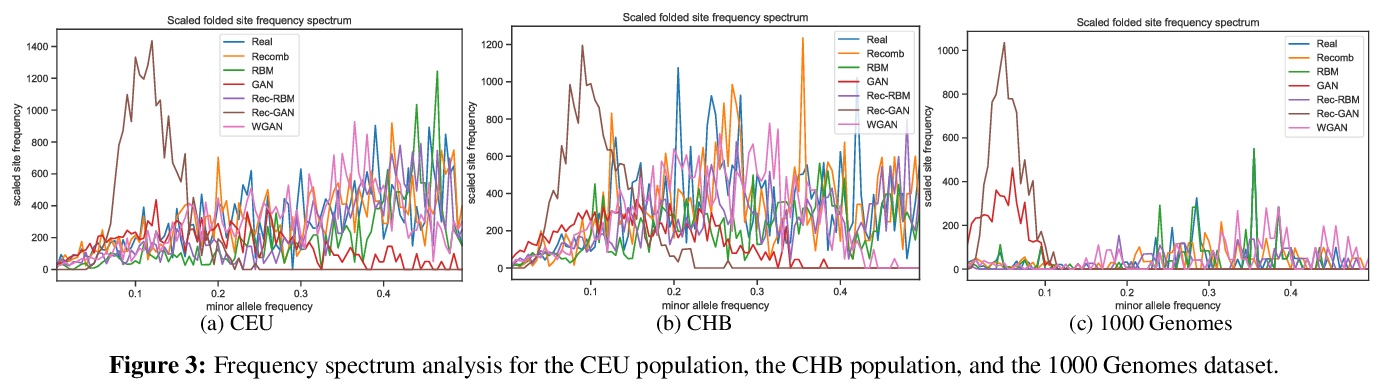
- [AI] Measuring Utility and Privacy of Synthetic Genomic Data
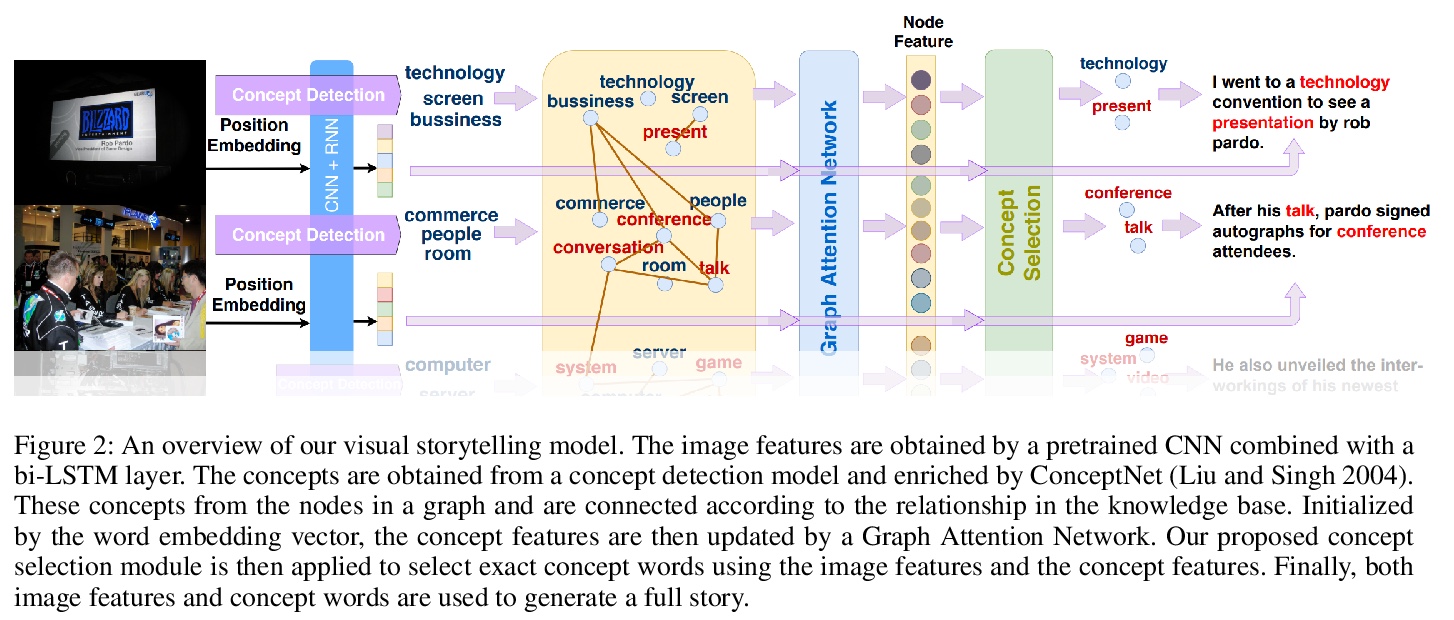
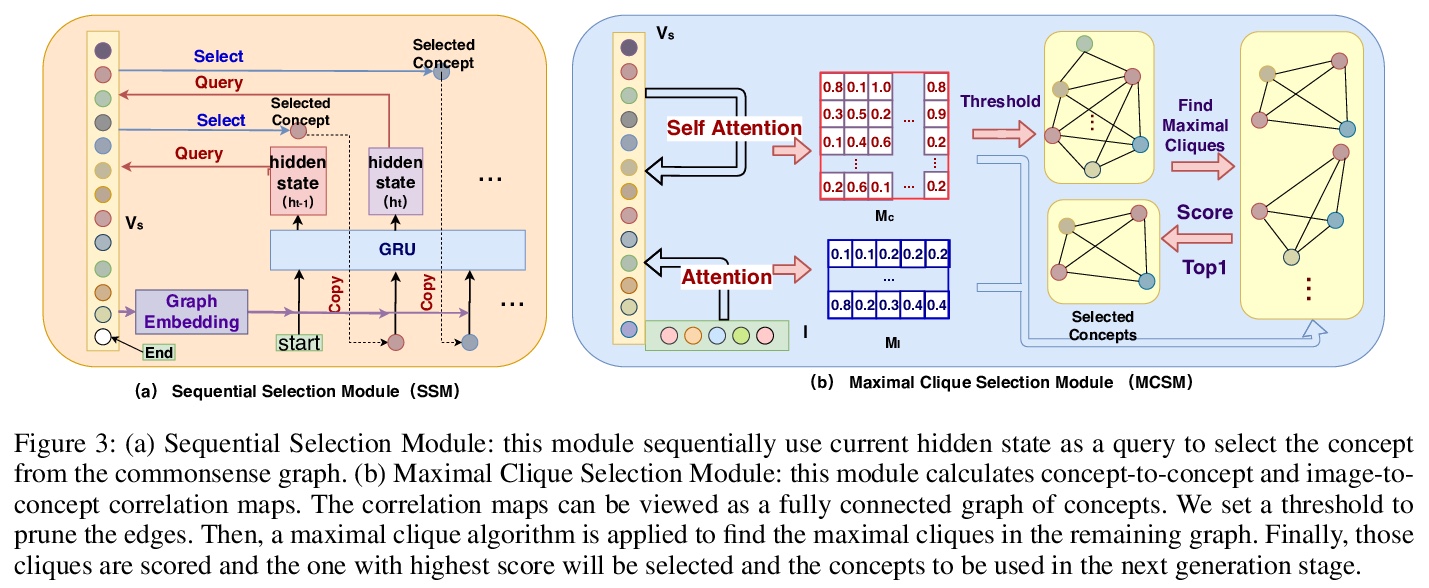
- [CV] Commonsense Knowledge Aware Concept Selection For Diverse and Informative Visual Storytelling
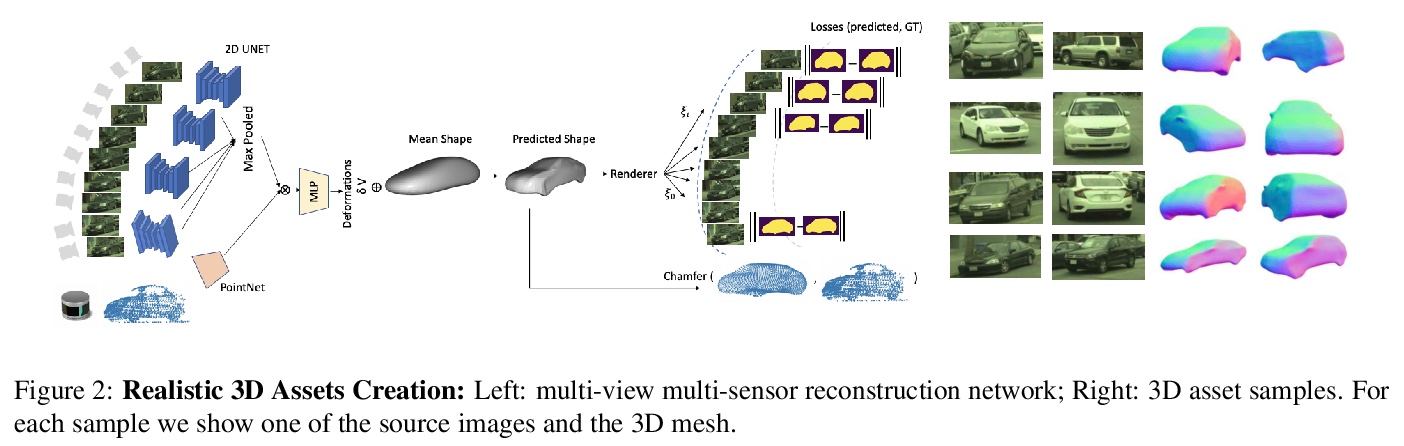
- [CV] GeoSim: Photorealistic Image Simulation with Geometry-Aware Composition
- [LG] tf.data: A Machine Learning Data Processing Framework
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] baller2vec: A Multi-Entity Transformer For Multi-Agent Spatiotemporal Modeling
M A. Alcorn, A Nguyen
[Auburn University]
baller2vec: 面向多球员时空建模的多实体Transformer。提出了标准Transformer的多实体泛化模型baller2vec,在每个时间步骤对由多个无序实体组成的顺序数据进行建模,在最小假设下,同时有效整合跨实体和时间的信息。通过训练baller2vec执行两个不同的篮球相关任务,测试其多球员时空建模的有效性。(1)同时预测球场上所有球员的轨迹和(2)预测球轨迹。baller2vec不仅能很好地学习执行这些任务,似乎还“理解“了篮球比赛,在它的嵌入中编码了球员的特异属性,用注意力头执行篮球相关的功能。有了更多的数据,更多关于实体(例如,球员的年龄、伤病史或比赛分钟数)和比赛(例如,剩下的时间或比分差)的上下文信息作为输入,可能会让baller2vec学习一个更完整的篮球比赛模型。
Multi-agent spatiotemporal modeling is a challenging task from both an algorithmic design and computational complexity perspective. Recent work has explored the efficacy of traditional deep sequential models in this domain, but these architectures are slow and cumbersome to train, particularly as model size increases. Further, prior attempts to model interactions between agents across time have limitations, such as imposing an order on the agents, or making assumptions about their relationships. In this paper, we introduce baller2vec, a multi-entity generalization of the standard Transformer that, with minimal assumptions, can simultaneously and efficiently integrate information across entities and time. We test the effectiveness of baller2vec for multi-agent spatiotemporal modeling by training it to perform two different basketball-related tasks: (1) simultaneously forecasting the trajectories of all players on the court and (2) forecasting the trajectory of the ball. Not only does baller2vec learn to perform these tasks well, it also appears to “understand” the game of basketball, encoding idiosyncratic qualities of players in its embeddings, and performing basketball-relevant functions with its attention heads.
https://weibo.com/1402400261/K14Ppw5zb
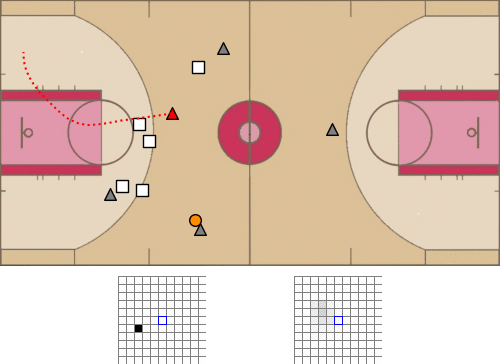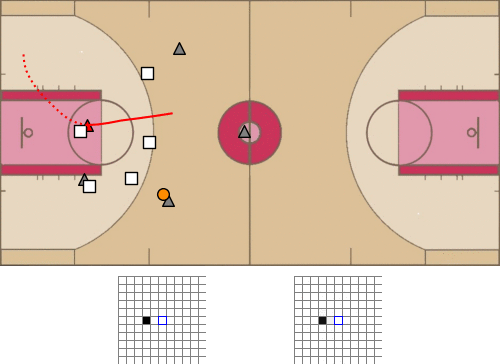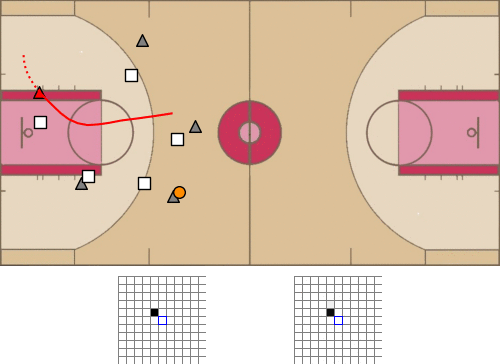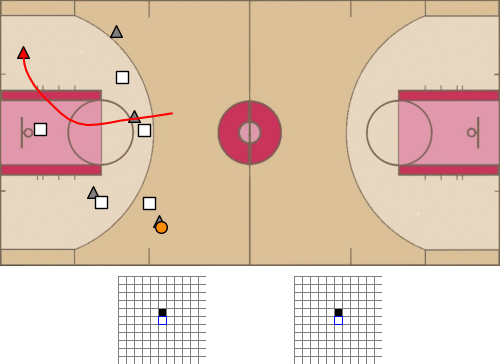
VT
山1
1202
Transformer
Transformer
Z.
Z个
htu3.Anounieworhgmuymom
WIAHtCa3Cm
Ldm
acrosstimestepscorrespondtothesameentity.



2、[LG] ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
W Kim, B Son, I Kim
[Kakao Corporation]
ViLT:无卷积和局部监督的视觉-语言Transformer。提出最小化的视觉-语言预训练模型ViLT(视觉-语言Transformer),某种意义上,视觉输入的处理,采用与处理文本输入相同的无卷积方式而大大简化。ViLT比之前的视觉-语言预训练模型快60倍,和那些大量配备卷积视觉嵌入网络的工作(如Faster R-CNN和ResNets)相比,具有类似或更好的下游任务性能。
Vision-and-Language Pretraining (VLP) has improved performance on various joint vision-and-language downstream tasks. Current approaches for VLP heavily rely on image feature extraction processes, most of which involve region supervisions (e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more computation than the actual multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive power of the visual encoder and its predefined visual vocabulary. In this paper, we present a minimal VLP model, Vision-and-Language Transformer (ViLT), monolithic in the sense that processing of visual inputs is drastically simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to 60 times faster than previous VLP models, yet with competitive or better downstream task performance.
https://weibo.com/1402400261/K14WE6NBm
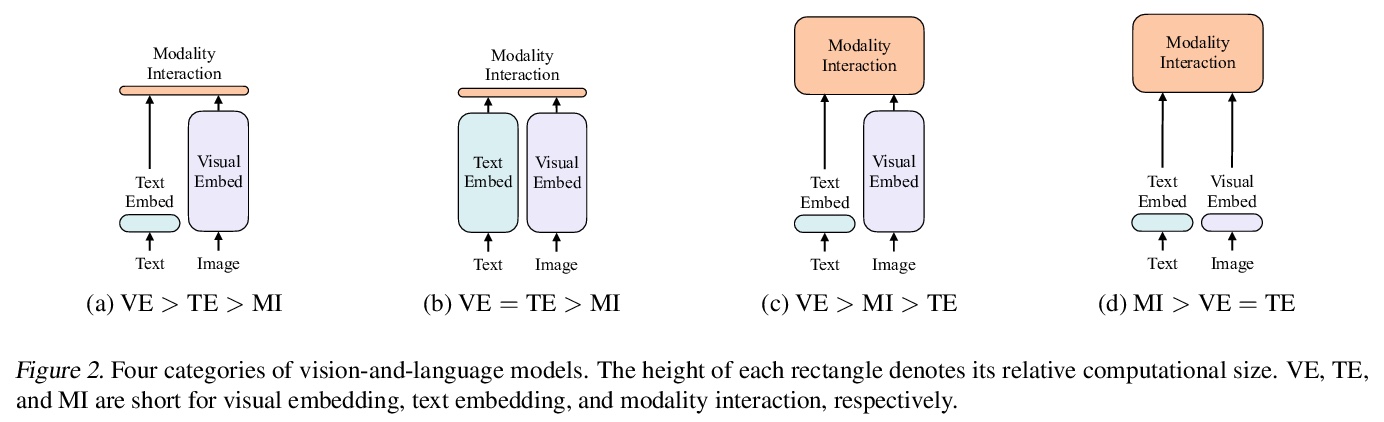
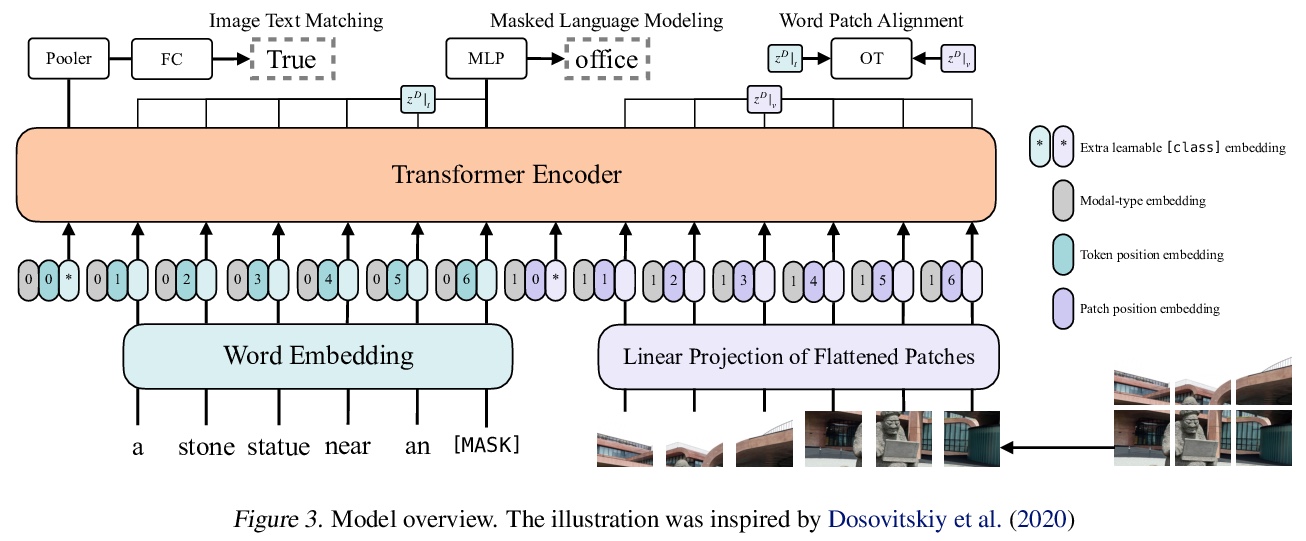

3、[RO] How to Train Your Robot with Deep Reinforcement Learning; Lessons We’ve Learned
J Ibarz, J Tan, C Finn, M Kalakrishnan, P Pastor, S Levine
[Robotics at Google & Everyday Robots]
用深度强化学习训练机器人的经验教训(综述)。介绍了一些涉及机器人深度强化学习的案例研究,讨论了在深度强化学习中普遍面临的挑战,以及如何解决这些挑战。概述了其他突出的挑战,其中许多挑战是现实世界机器人环境所特有的,通常不是主流强化学习研究的重点。本文目标是为有兴趣在现实世界进一步推进深度强化学习进展的机器人学家和机器学习研究人员提供资源。
Deep reinforcement learning (RL) has emerged as a promising approach for autonomously acquiring complex behaviors from low level sensor observations. Although a large portion of deep RL research has focused on applications in video games and simulated control, which does not connect with the constraints of learning in real environments, deep RL has also demonstrated promise in enabling physical robots to learn complex skills in the real world. At the same time,real world robotics provides an appealing domain for evaluating such algorithms, as it connects directly to how humans learn; as an embodied agent in the real world. Learning to perceive and move in the real world presents numerous challenges, some of which are easier to address than others, and some of which are often not considered in RL research that focuses only on simulated domains. In this review article, we present a number of case studies involving robotic deep RL. Building off of these case studies, we discuss commonly perceived challenges in deep RL and how they have been addressed in these works. We also provide an overview of other outstanding challenges, many of which are unique to the real-world robotics setting and are not often the focus of mainstream RL research. Our goal is to provide a resource both for roboticists and machine learning researchers who are interested in furthering the progress of deep RL in the real world.
https://weibo.com/1402400261/K153qyAZC



4、[LG] 1-bit Adam: Communication Efficient Large-Scale Training with Adam’s Convergence Speed
H Tang, S Gan, A A Awan, S Rajbhandari, C Li, X Lian, J Liu, C Zhang, Y He
[Microsoft & University of Rochester & ETH Zurich]
1-bit Adam:具有Adam收敛速度的通信高效的大规模训练。提出了1比特Adam,可减少高达5倍的通信量,提供更好的可扩展性,并提供与非压缩Adam相同的收敛速度。(经过一个热身阶段后)Adam的方差(非线性项)会变得稳定,可作为其余训练(压缩阶段)的固定前提条件。在多达256个GPU上的实验表明,1比特Adam使得BERT-Large预训练吞吐量提高了3.3倍,SQuAD微调的吞吐量提高了2.9倍。
Scalable training of large models (like BERT and GPT-3) requires careful optimization rooted in model design, architecture, and system capabilities. From a system standpoint, communication has become a major bottleneck, especially on commodity systems with standard TCP interconnects that offer limited network bandwidth. Communication compression is an important technique to reduce training time on such systems. One of the most effective methods is error-compensated compression, which offers robust convergence speed even under 1-bit compression. However, state-of-the-art error compensation techniques only work with basic optimizers like SGD and momentum SGD, which are linearly dependent on the gradients. They do not work with non-linear gradient-based optimizers like Adam, which offer state-of-the-art convergence efficiency and accuracy for models like BERT. In this paper, we propose 1-bit Adam that reduces the communication volume by up to > 5×, offers much better scalability, and provides the same convergence speed as uncompressed Adam. Our key finding is that Adam’s variance (non-linear term) becomes stable (after a warmup phase) and can be used as a fixed precondition for the rest of the training (compression phase). Experiments on up to 256 GPUs show that 1-bit Adam enables up to > 3.3× higher throughput for BERT-Large pre-training and up to > 2.9× higher throughput for SQuAD fine-tuning. In addition, we provide theoretical analysis for our proposed work.
https://weibo.com/1402400261/K156tnQnv
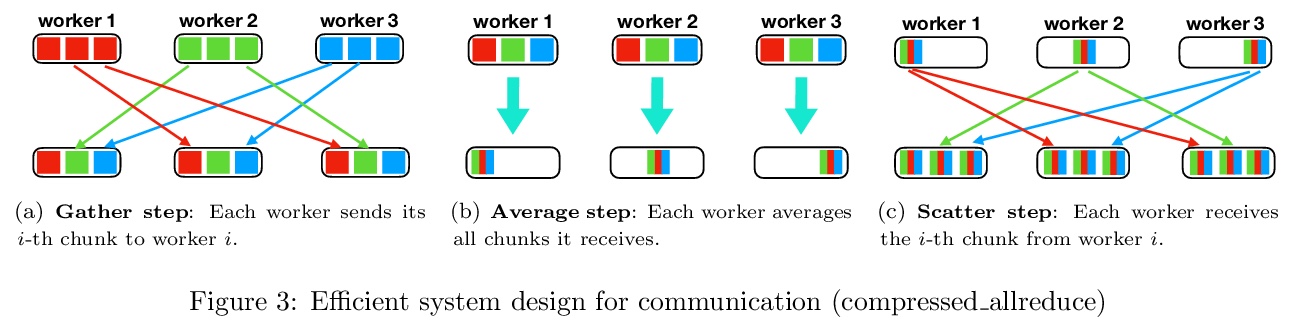

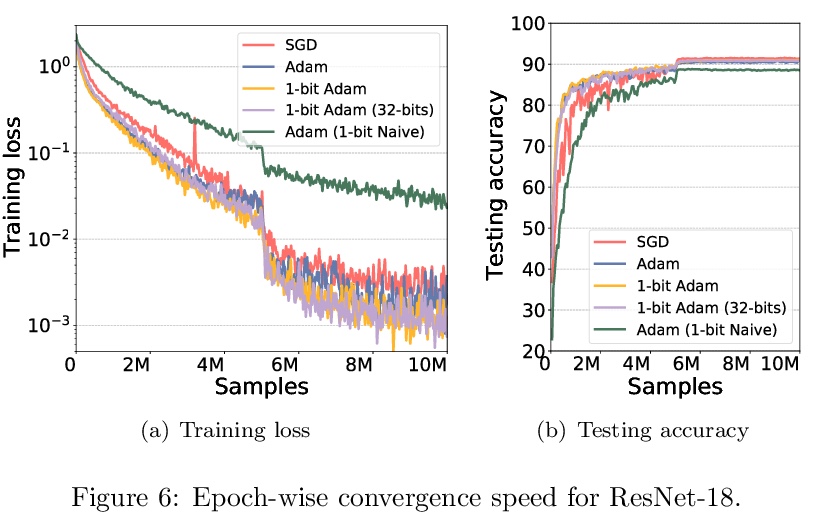
5、[LG] PipeTransformer: Automated Elastic Pipelining for Distributed Training of Transformers
C He, S Li, M Soltanolkotabi, S Avestimehr
[University of Southern California & Facebook AI]
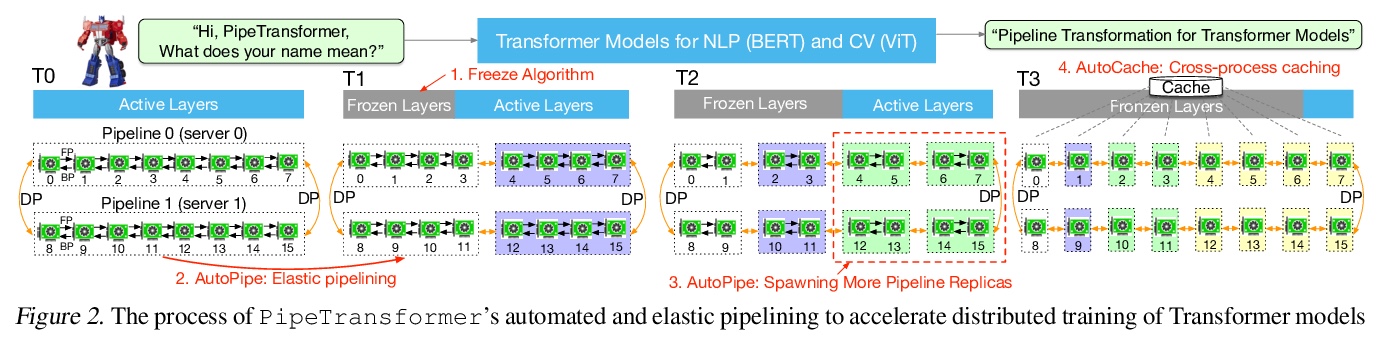
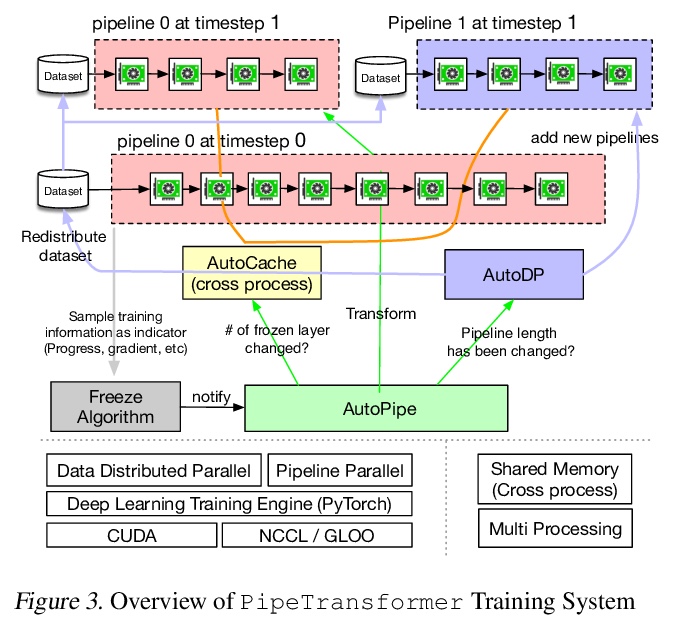
PipeTransformer:面向Transformer分布式训练的自动化弹性管线。提出了结合弹性管线并行和数据并行、用于分布式训练的整体解决方案PipeTransformer,通过逐步冻结管线中的层,将剩余活动层打包到更少的GPU中,分支更多的管线副本以增加数据并行宽度。对ViT和BERT模型的评价表明,与最先进基线相比,PipeTransformer在没有精度损失的情况下实现了高达2.83倍的速度提升。
The size of Transformer models is growing at an unprecedented pace. It has only taken less than one year to reach trillion-level parameters after the release of GPT-3 (175B). Training such models requires both substantial engineering efforts and enormous computing resources, which are luxuries most research teams cannot afford. In this paper, we propose PipeTransformer, which leverages automated and elastic pipelining and data parallelism for efficient distributed training of Transformer models. PipeTransformer automatically adjusts the pipelining and data parallelism by identifying and freezing some layers during the training, and instead allocates resources for training of the remaining active layers. More specifically, PipeTransformer dynamically excludes converged layers from the pipeline, packs active layers into fewer GPUs, and forks more replicas to increase data-parallel width. We evaluate PipeTransformer using Vision Transformer (ViT) on ImageNet and BERT on GLUE and SQuAD datasets. Our results show that PipeTransformer attains a 2.4 fold speedup compared to the state-of-the-art baseline. We also provide various performance analyses for a more comprehensive understanding of our algorithmic and system-wise design. We also develop open-sourced flexible APIs for PipeTransformer, which offer a clean separation among the freeze algorithm, model definitions, and training accelerations, hence allowing it to be applied to other algorithms that require similar freezing strategies.
https://weibo.com/1402400261/K159JdbSU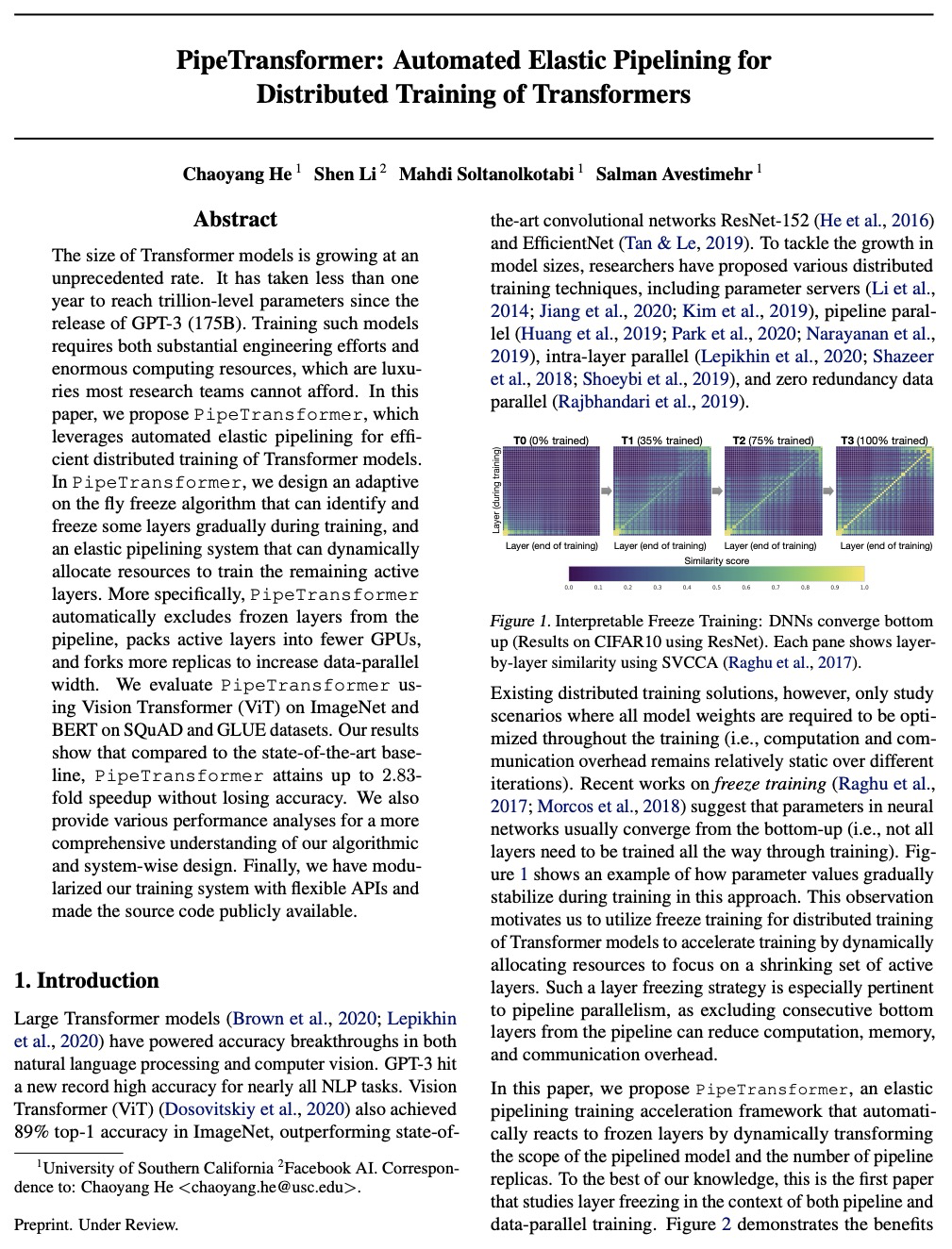
另外几篇值得关注的论文:
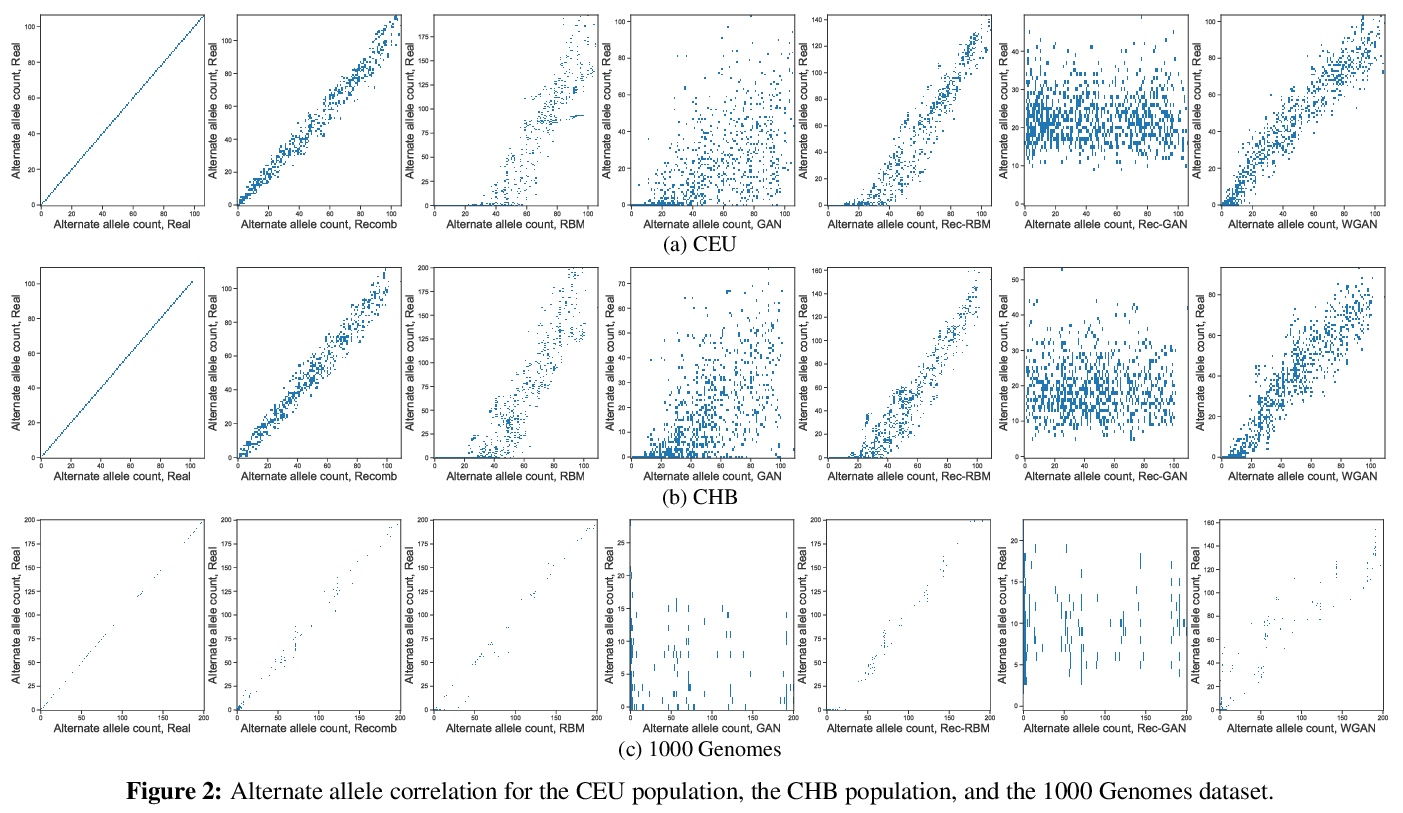
[AI] Measuring Utility and Privacy of Synthetic Genomic Data
合成基因组数据效用和隐私的度量
B Oprisanu, G Ganev, E D Cristofaro
[UCL]
https://weibo.com/1402400261/K15fbzxst

[CV] Commonsense Knowledge Aware Concept Selection For Diverse and Informative Visual Storytelling
面向多样化和信息化视觉故事的常识知识感知概念选择
H Chen, Y Huang, H Takamura, H Nakayama
[The University of Tokyo & Tokyo Institute of Technology]
https://weibo.com/1402400261/K15iMnH3X
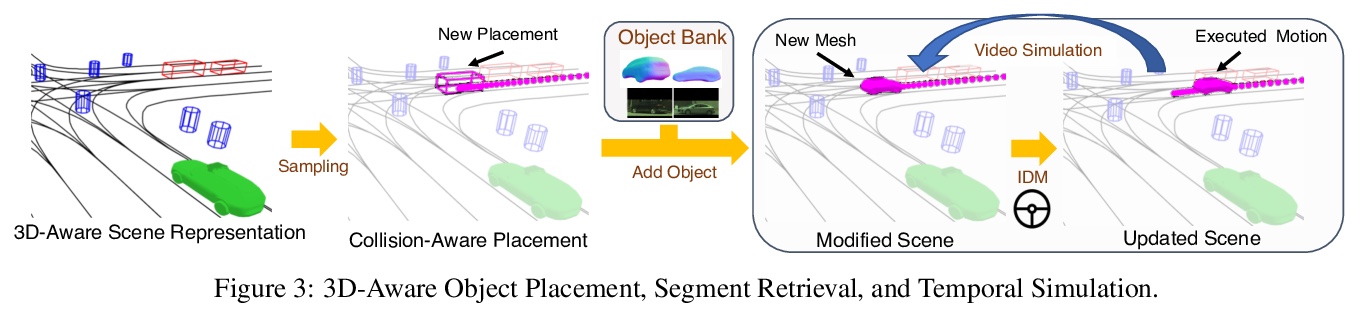
[CV] GeoSim: Photorealistic Image Simulation with Geometry-Aware Composition
GeoSim:几何感知合成真实感图像仿真
Y Chen, F Rong, S Duggal, S Wang, X Yan, S Manivasagam, S Xue, E Yumer, R Urtasun
[Uber Advanced Technologies Group]
https://weibo.com/1402400261/K15m4ujEj


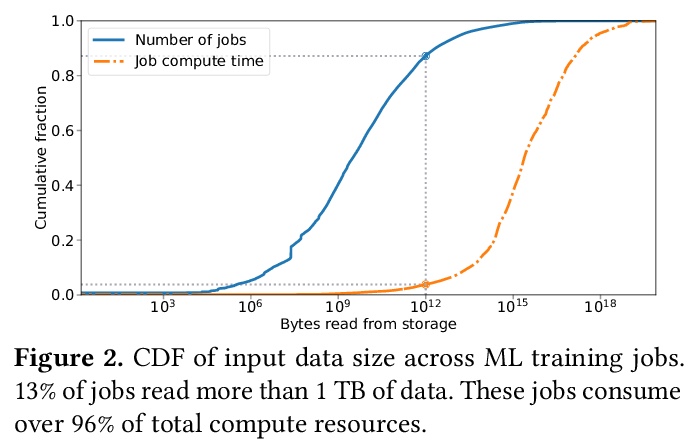
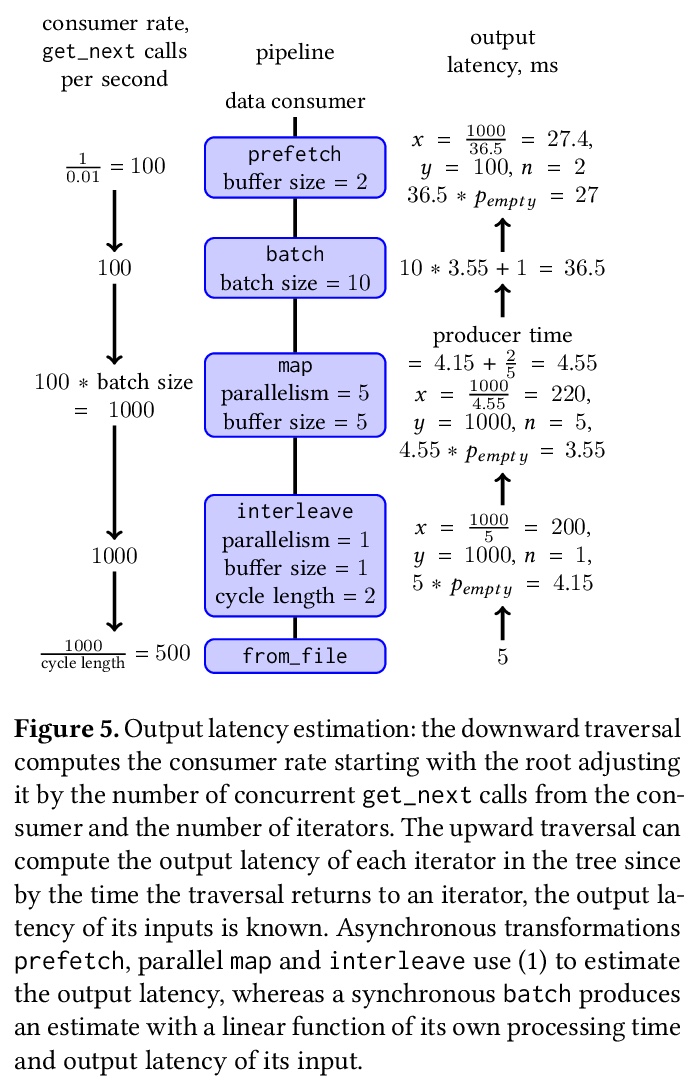
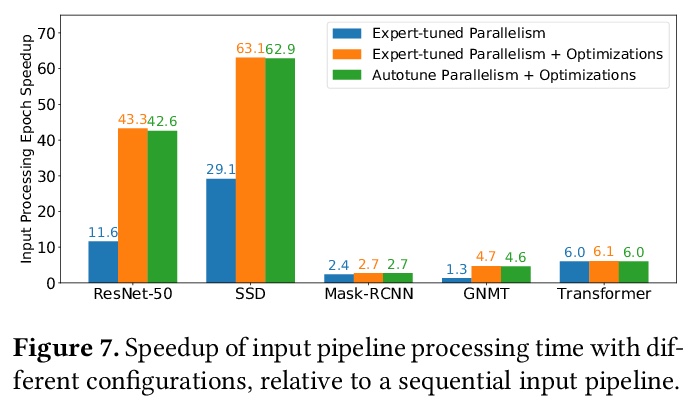
[LG] tf.data: A Machine Learning Data Processing Framework
tf.data:机器学习数据处理框架
D G. Murray, J Simsa, A Klimovic, I Indyk
[Microsoft & Google & ETH Zurich]
https://weibo.com/1402400261/K15nuAYYe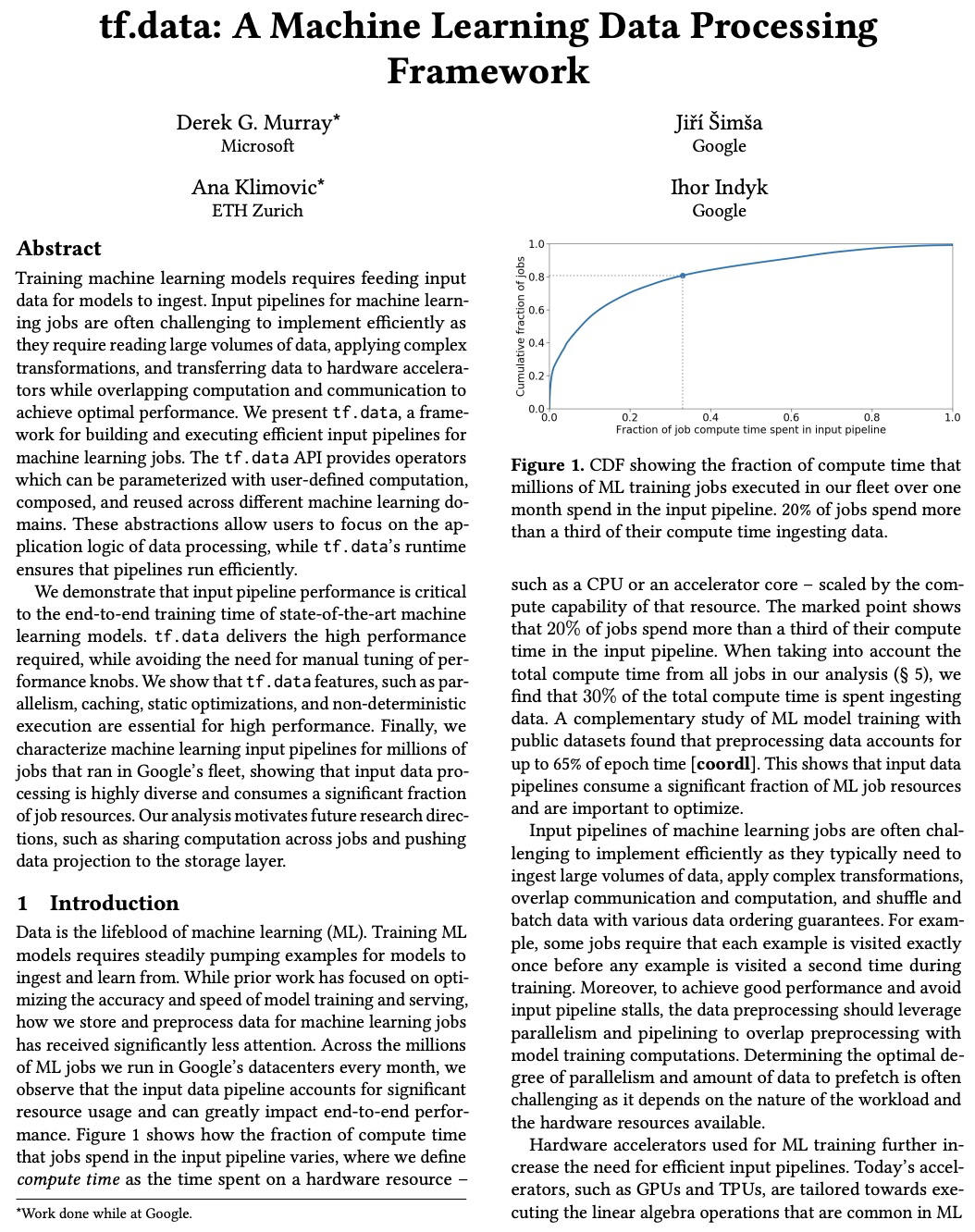

若有收获,就点个赞吧
0 人点赞
