- 1、[CV] MobileStyleGAN: A Lightweight Convolutional Neural Network for High-Fidelity Image Synthesis
- 2、[CV] Escaping the Big Data Paradigm with Compact Transformers
- 3、[CV] Differentiable Patch Selection for Image Recognition
- 4、[CV] LocalViT: Bringing Locality to Vision Transformers
- 5、[LG] Understanding Overparameterization in Generative Adversarial Networks
- [CV] Neural RGB-D Surface Reconstruction
- [CV] Action-Conditioned 3D Human Motion Synthesis with Transformer VAE
- [CV] Pixel Codec Avatars
- [LG] High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] MobileStyleGAN: A Lightweight Convolutional Neural Network for High-Fidelity Image Synthesis
S Belousov
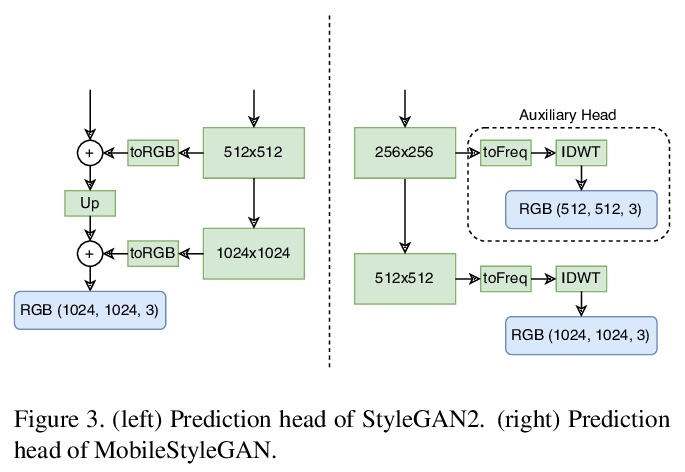
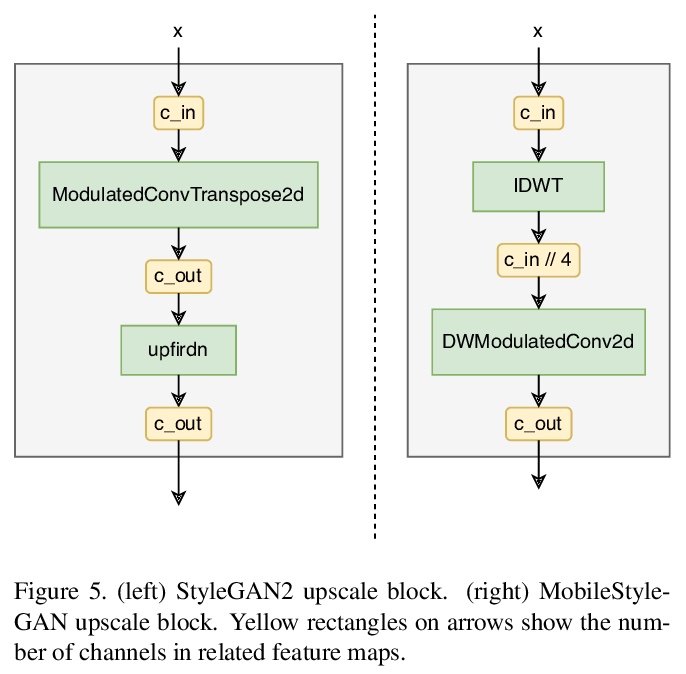
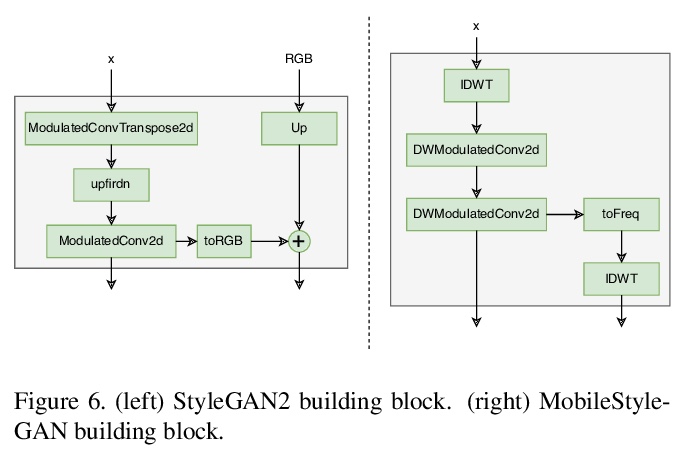
MobileStyleGAN:面向高保真图像合成的轻量卷积神经网络。虽然基于风格的GAN架构在高保真图像合成中产生了最先进的结果,但计算非常复杂。本文专注于基于风格的生成模型的性能优化,分析了StyleGAN2中最难计算的部分,提出了对生成器网络的改变,使得在边缘设备中部署基于风格的生成器网络成为可能。提出基于小波的端到端卷积神经网络,提出深度可分离调制卷积,作为调制卷积的轻量版本,以降低计算复杂度。引入了MobileStyleGAN架构,比StyleGAN2少了x3.5个参数,计算复杂度降低了x9.5,同时提供了相当的质量。
In recent years, the use of Generative Adversarial Networks (GANs) has become very popular in generative image modeling. While style-based GAN architectures yield state-of-the-art results in high-fidelity image synthesis, computationally, they are highly complex. In our work, we focus on the performance optimization of style-based generative models. We analyze the most computationally hard parts of StyleGAN2, and propose changes in the generator network to make it possible to deploy style-based generative networks in the edge devices. We introduce MobileStyleGAN architecture, which has x3.5 fewer parameters and is x9.5 less computationally complex than StyleGAN2, while providing comparable quality.
https://weibo.com/1402400261/KaNMO2qWP

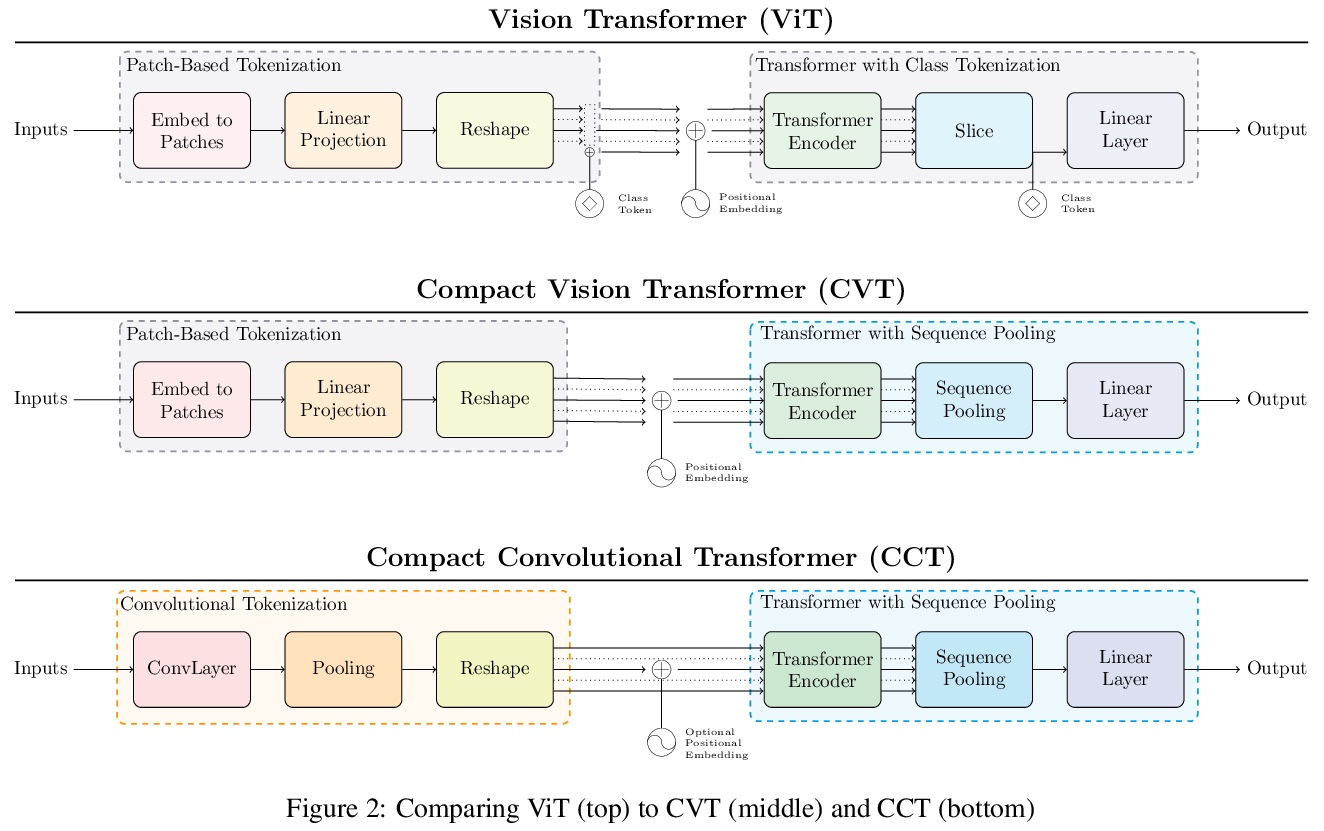
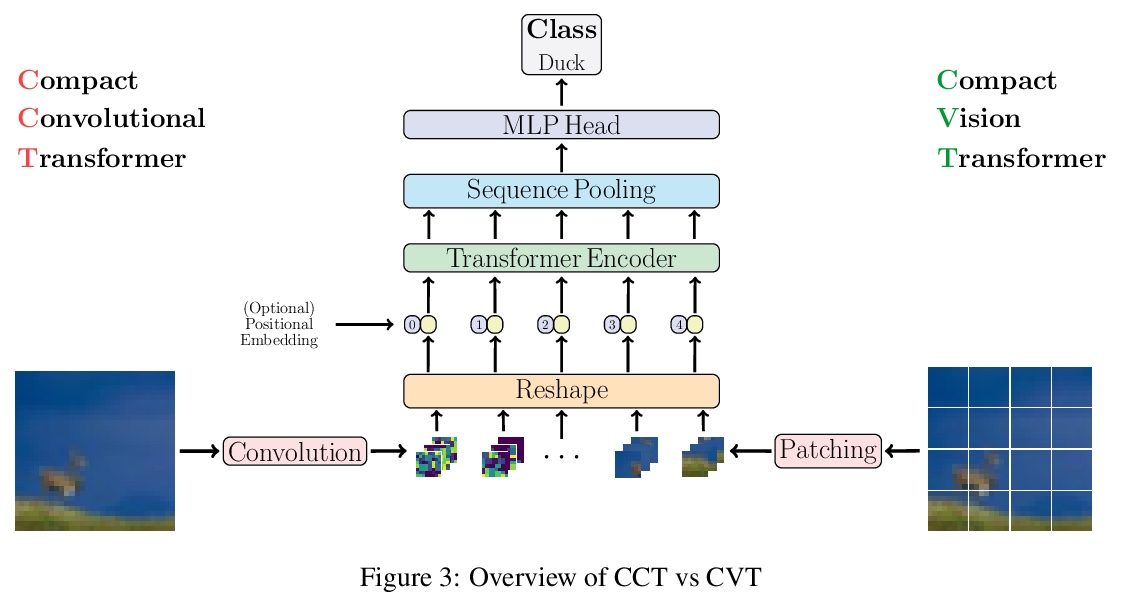
2、[CV] Escaping the Big Data Paradigm with Compact Transformers
A Hassani, S Walton, N Shah, A Abuduweili, J Li, H Shi
[University of Oregon & University of Illinois at Urbana-Champaign]
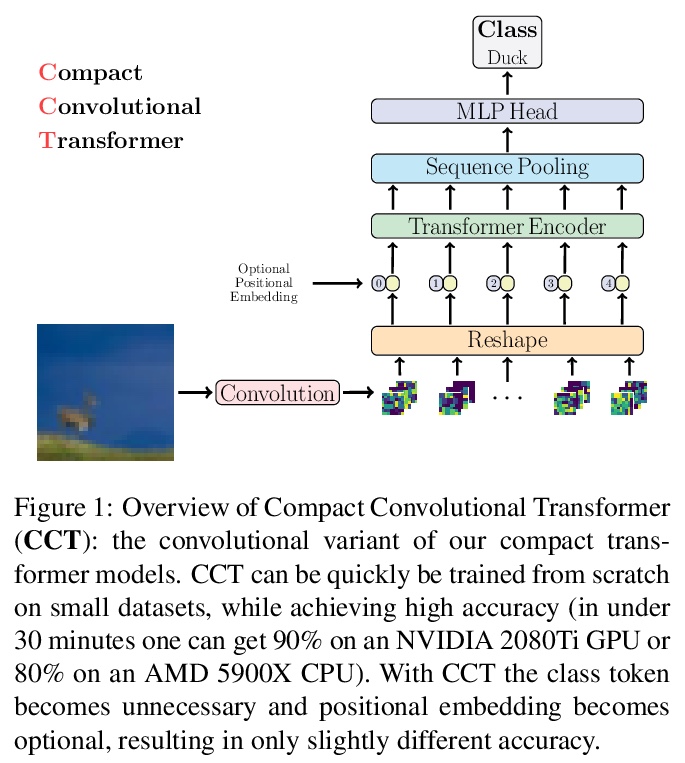
用紧凑Transformer打破”数据饥渴”神话。只要有合适的大小和标记化,Transformer可以在小数据集上与最先进的CNN正面竞争。提出ViT-Lite,可在CIFAR10等小数据集上高效、高精度地训练。提出紧凑视觉Transformer(Compact Vision Transformer,CVT),采用新的序列池化策略,消除了视觉Transformer中传统的类token设计需求,使其更加精确。提出Compact Convolutional Transformer(CCT),以提高性能并为输入图像大小提供灵活性,证明这些变体与其他变体相比,对位置嵌入的依赖性并不高。证明了CCT模型速度极快,用单个NVIDIA 2080Ti GPU在CIFAR-10上获得了90%的准确率,在CPU(AMD 5900X)上训练时获得了80%的准确率,两者都在30分钟之内。由于模型具有相对较少的参数,可在大多数GPU上进行训练,即使研究人员无法获得顶级硬件。
With the rise of Transformers as the standard for language processing, and their advancements in computer vision, along with their unprecedented size and amounts of training data, many have come to believe that they are not suitable for small sets of data. This trend leads to great concerns, including but not limited to: limited availability of data in certain scientific domains and the exclusion of those with limited resource from research in the field. In this paper, we dispel the myth that transformers are “data hungry” and therefore can only be applied to large sets of data. We show for the first time that with the right size and tokenization, transformers can perform head-to-head with state-of-the-art CNNs on small datasets. Our model eliminates the requirement for class token and positional embeddings through a novel sequence pooling strategy and the use of convolutions. We show that compared to CNNs, our compact transformers have fewer parameters and MACs, while obtaining similar accuracies. Our method is flexible in terms of model size, and can have as little as 0.28M parameters and achieve reasonable results. It can reach an accuracy of 94.72% when training from scratch on CIFAR-10, which is comparable with modern CNN based approaches, and a significant improvement over previous Transformer based models. Our simple and compact design democratizes transformers by making them accessible to those equipped with basic computing resources and/or dealing with important small datasets. Our code and pre-trained models will be made publicly available at > this https URL.
https://weibo.com/1402400261/KaNR53AET
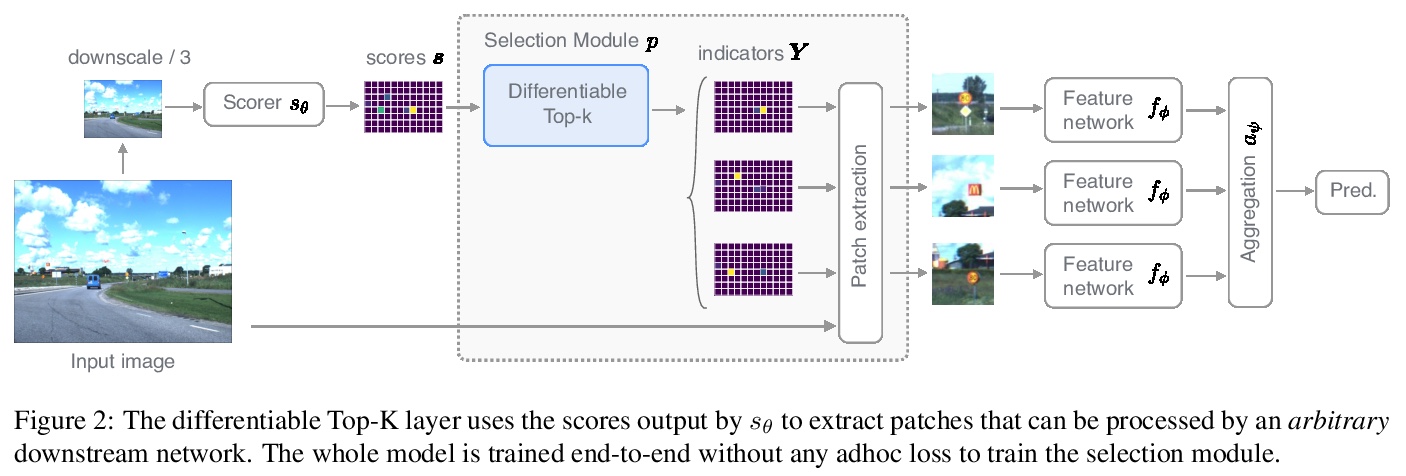
3、[CV] Differentiable Patch Selection for Image Recognition
J Cordonnier, A Mahendran, A Dosovitskiy, D Weissenborn, J Uszkoreit, T Unterthiner
[EPFL & Google Research]
面向图像识别的可微图块选择。提出一种基于可微Top-K算子的方法,以选择输入中最相关的部分,从而有效地处理高分辨率图像。该方法可与任意下游神经网络对接,以一种灵活的方式从不同的图块中聚合信息,可使用反向传播对整个模型进行端到端训练。展示了交通标志识别、斑块间关系推理和细粒度识别的结果,在训练过程中不使用目标/组件边框标记。
https://weibo.com/1402400261/KaNWHpqEm


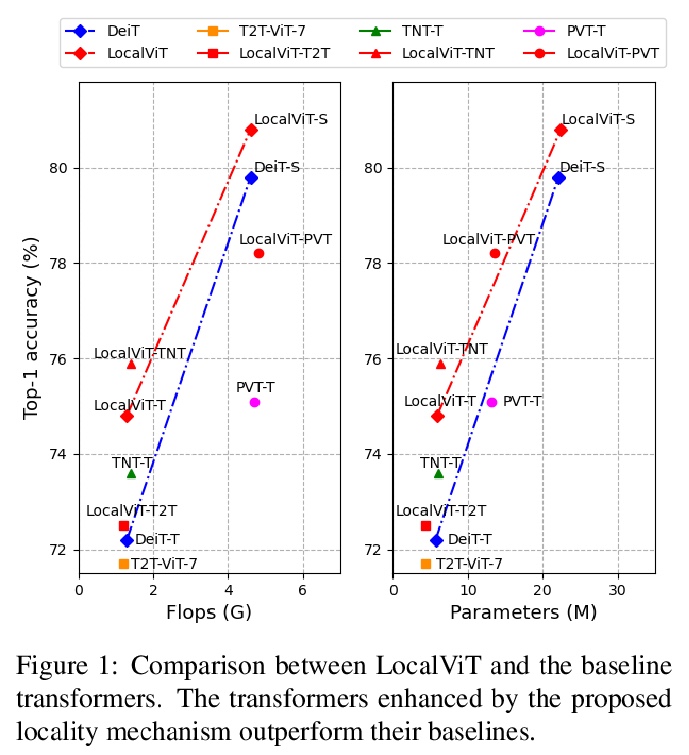
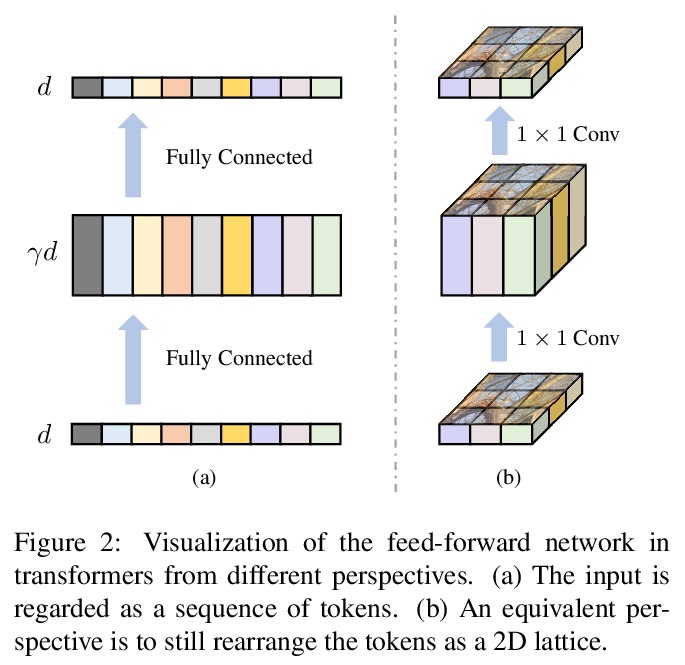
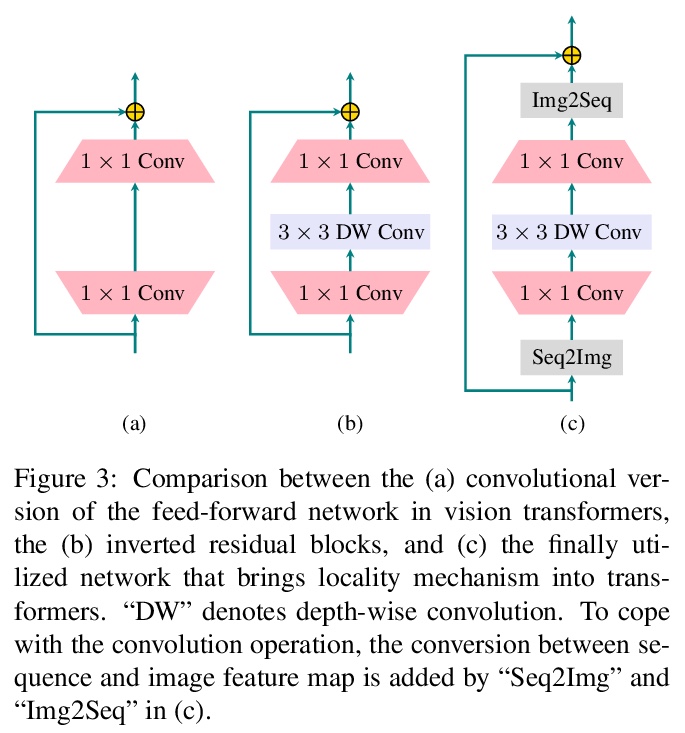
4、[CV] LocalViT: Bringing Locality to Vision Transformers
Y Li, K Zhang, J Cao, R Timofte, L V Gool
[ETH Zurich]
LocalViT:将局部性引入视觉Transformer。通过引入深度卷积,为视觉Transformer引入局部性机制。新的Transformer架构结合了全局关系建模的自注意力机制和局部信息聚合的局部性机制。分析了引入的局部性机制的基本特性,逐个分析了各部分的影响(深度卷积、非线性激活函数、层位置和隐含维度扩展比)。将这些思想应用于视觉Transformer,包括DeiT、T2T-ViT、PVT和TNT。实验表明,所提出的简单技术可以很好地推广到各种Transformer架构中。
We study how to introduce locality mechanisms into vision transformers. The transformer network originates from machine translation and is particularly good at modelling long-range dependencies within a long sequence. Although the global interaction between the token embeddings could be well modelled by the self-attention mechanism of transformers, what is lacking a locality mechanism for information exchange within a local region. Yet, locality is essential for images since it pertains to structures like lines, edges, shapes, and even objects.We add locality to vision transformers by introducing depth-wise convolution into the feed-forward network. This seemingly simple solution is inspired by the comparison between feed-forward networks and inverted residual blocks. The importance of locality mechanisms is validated in two ways: 1) A wide range of design choices (activation function, layer placement, expansion ratio) are available for incorporating locality mechanisms and all proper choices can lead to a performance gain over the baseline, and 2) The same locality mechanism is successfully applied to 4 vision transformers, which shows the generalization of the locality concept. In particular, for ImageNet2012 classification, the locality-enhanced transformers outperform the baselines DeiT-T and PVT-T by 2.6% and 3.1% with a negligible increase in the number of parameters and computational effort. Code is available at > this https URL.
https://weibo.com/1402400261/KaNZcAFuJ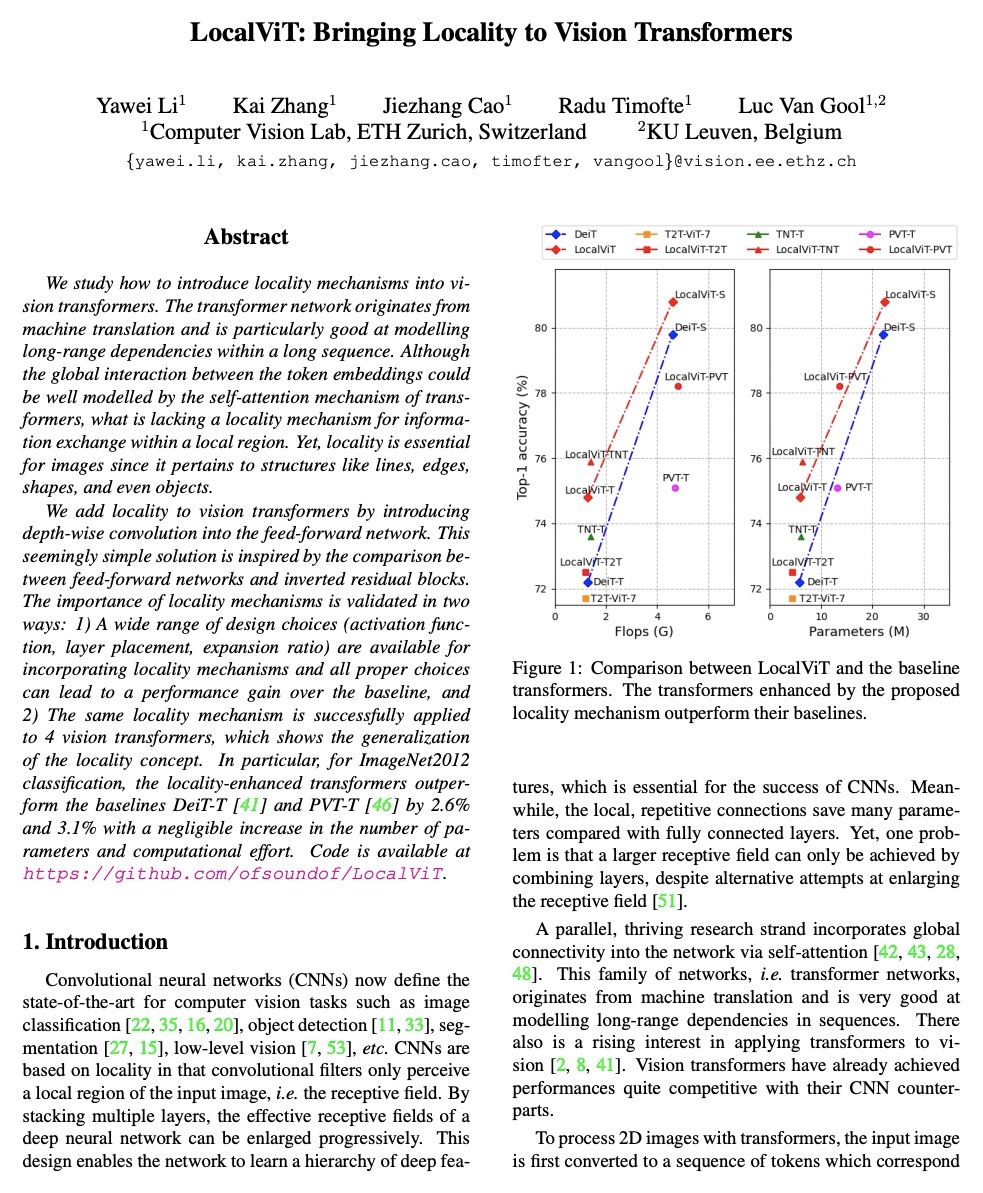
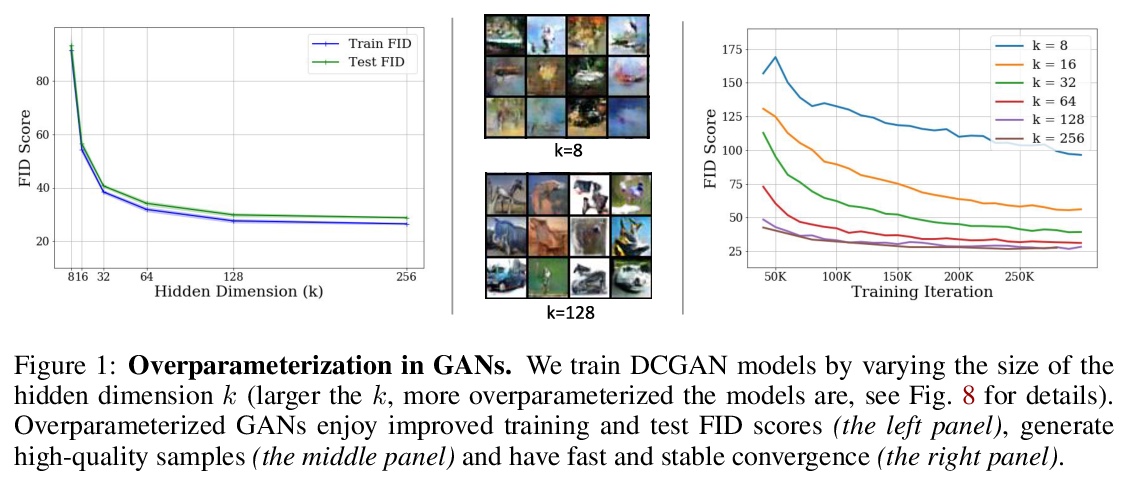
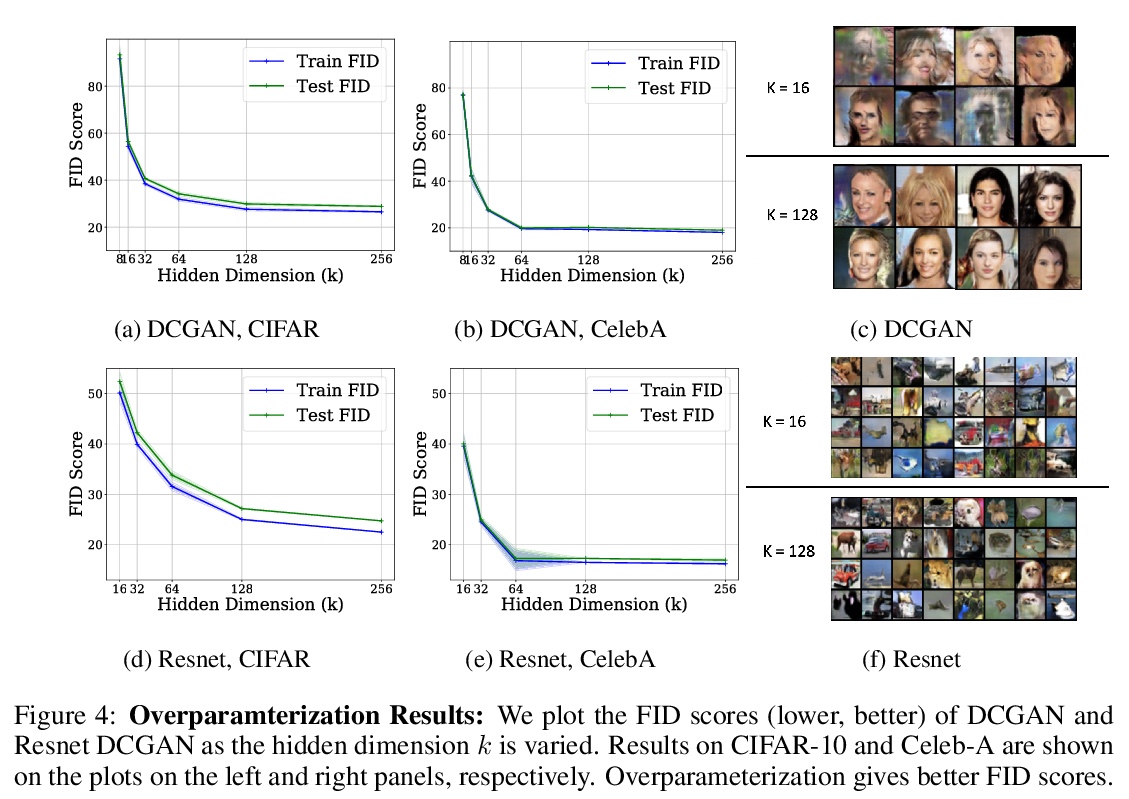
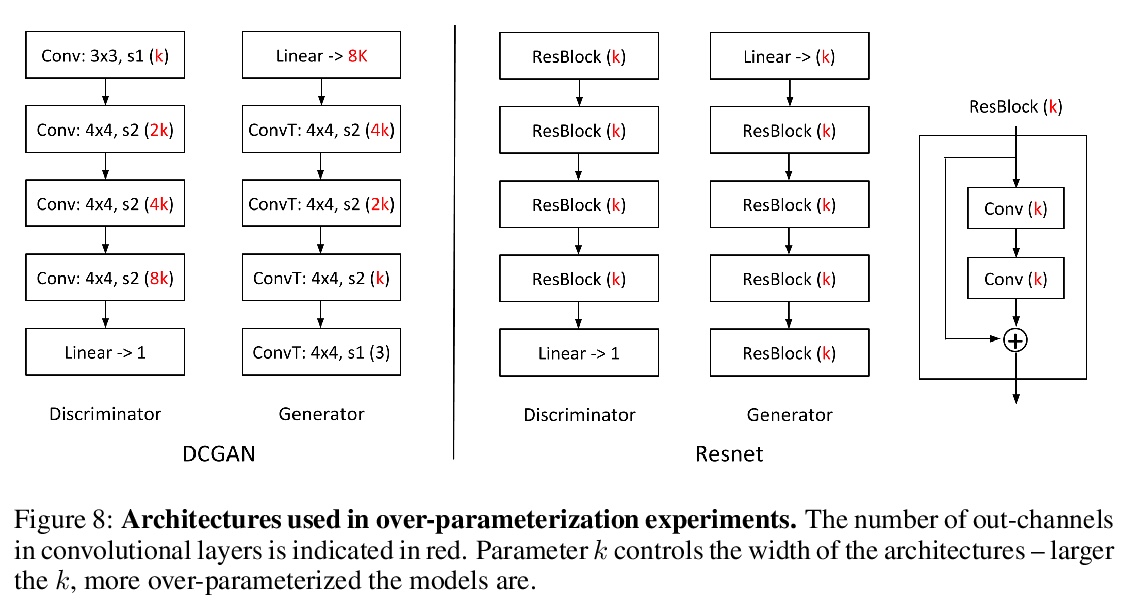
5、[LG] Understanding Overparameterization in Generative Adversarial Networks
Y Balaji, M Sajedi, N M Kalibhat, M Ding, D Stöger, M Soltanolkotabi, S Feizi
[University of Maryland & University of Southern California]
理解GAN过参数化。从理论和经验两方面,对模型过参数化在GAN中的重要性进行了综合分析。从理论上证明,在一个具有单层神经网络发生器和线性判别器的过参数化GAN模型中,GDA会收敛到底层非凸凹最小-最大问题的全局鞍点。通过建立与线性时变动态系统的联系,提供了一个理论框架来分析一般过参数化GAN(包括更深的生成器和随机特征判别器)在某些一般条件下的同步GDA的全局收敛性。利用CIFAR-10和Celeb-A数据集上的几个大规模实验,对模型过参数化在GAN中的作用进行了全面的实证研究,观察到过参数化改善了GAN的训练误差、泛化误差、样本质量以及GDA的收敛率和稳定性。
A broad class of unsupervised deep learning methods such as Generative Adversarial Networks (GANs) involve training of overparameterized models where the number of parameters of the model exceeds a certain threshold. A large body of work in supervised learning have shown the importance of model overparameterization in the convergence of the gradient descent (GD) to globally optimal solutions. In contrast, the unsupervised setting and GANs in particular involve non-convex concave mini-max optimization problems that are often trained using Gradient Descent/Ascent (GDA). The role and benefits of model overparameterization in the convergence of GDA to a global saddle point in non-convex concave problems is far less understood. In this work, we present a comprehensive analysis of the importance of model overparameterization in GANs both theoretically and empirically. We theoretically show that in an overparameterized GAN model with a > 1-layer neural network generator and a linear discriminator, GDA converges to a global saddle point of the underlying non-convex concave min-max problem. To the best of our knowledge, this is the first result for global convergence of GDA in such settings. Our theory is based on a more general result that holds for a broader class of nonlinear generators and discriminators that obey certain assumptions (including deeper generators and random feature discriminators). We also empirically study the role of model overparameterization in GANs using several large-scale experiments on CIFAR-10 and Celeb-A datasets. Our experiments show that overparameterization improves the quality of generated samples across various model architectures and datasets. Remarkably, we observe that overparameterization leads to faster and more stable convergence behavior of GDA across the board.
https://weibo.com/1402400261/KaO4UfJQn
另外几篇值得关注的论文:
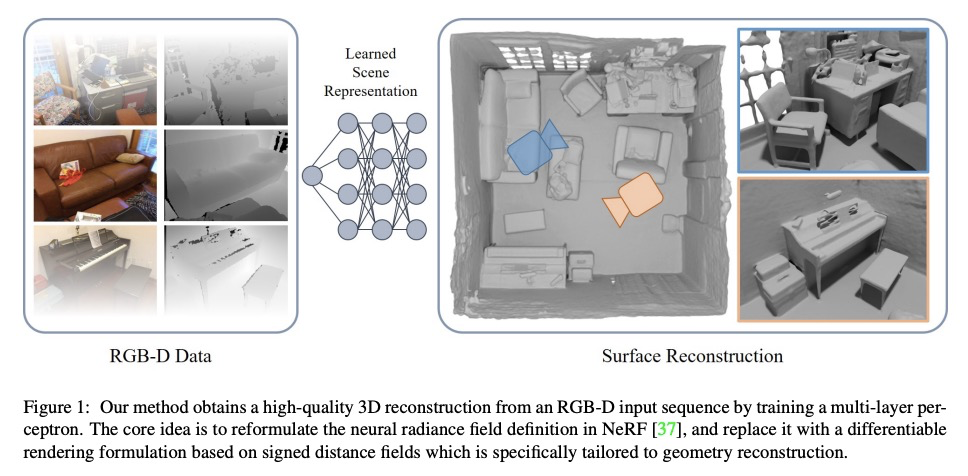
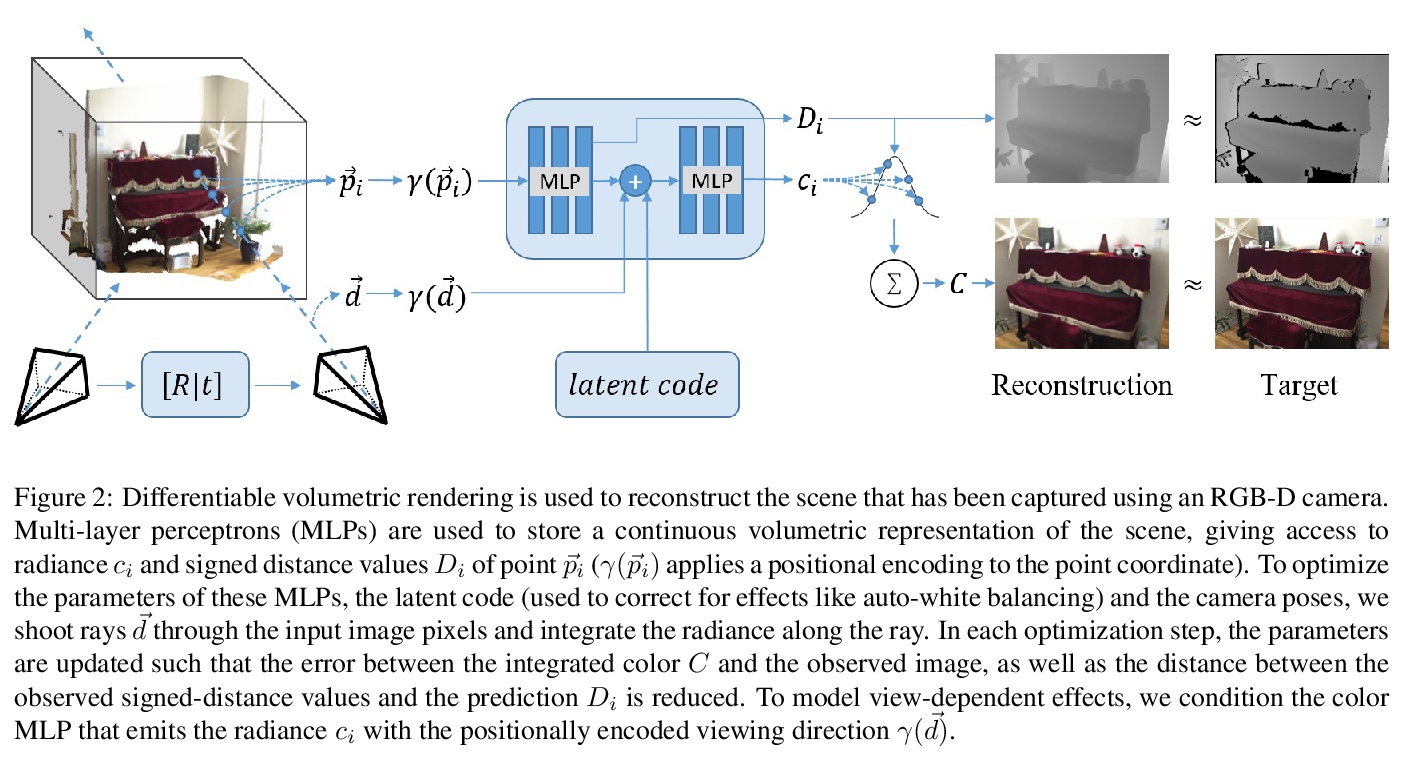
[CV] Neural RGB-D Surface Reconstruction
神经网络RGB-D表面重建
D Azinović, R Martin-Brualla, D B Goldman, M Nießner, J Thies
[Technical University of Munich & Google Research]
https://weibo.com/1402400261/KaO8qEZF9

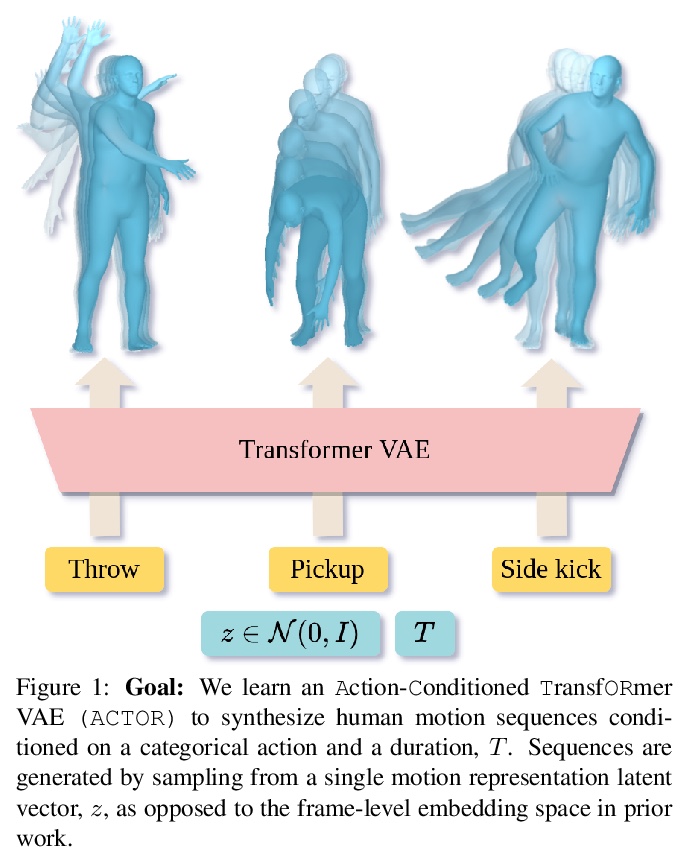
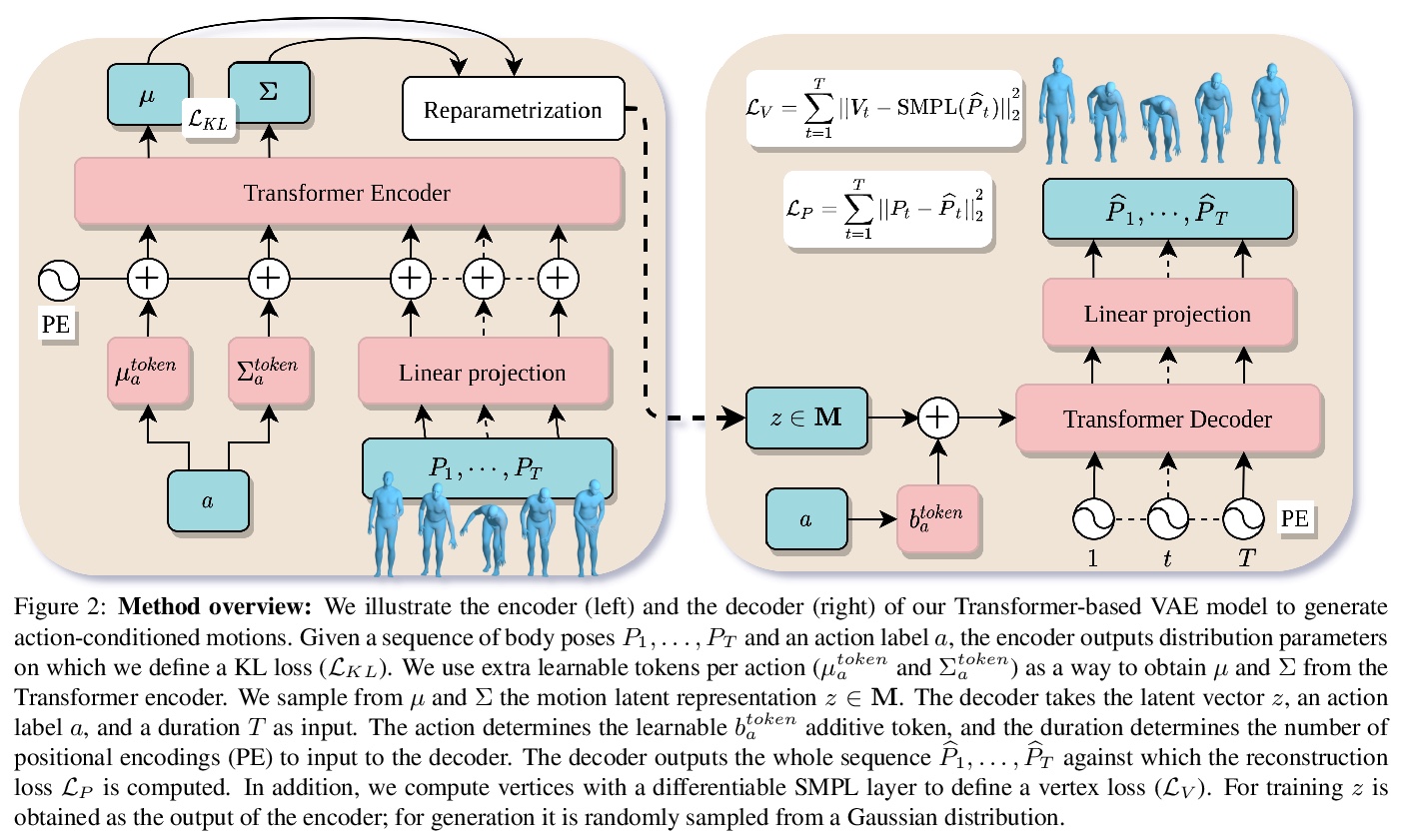
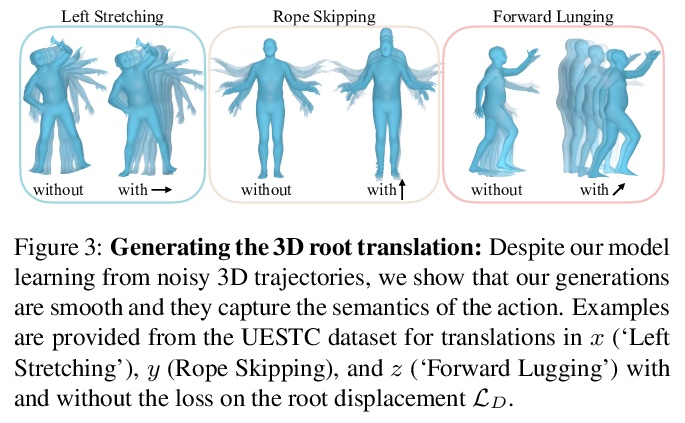
[CV] Action-Conditioned 3D Human Motion Synthesis with Transformer VAE
基于Transformer VAE的动作条件3D人体运动合成
M Petrovich, M J. Black, G Varol
[Univ Gustave Eiffel & Max Planck Institute for Intelligent Systems]
https://weibo.com/1402400261/KaOhYwbDZ
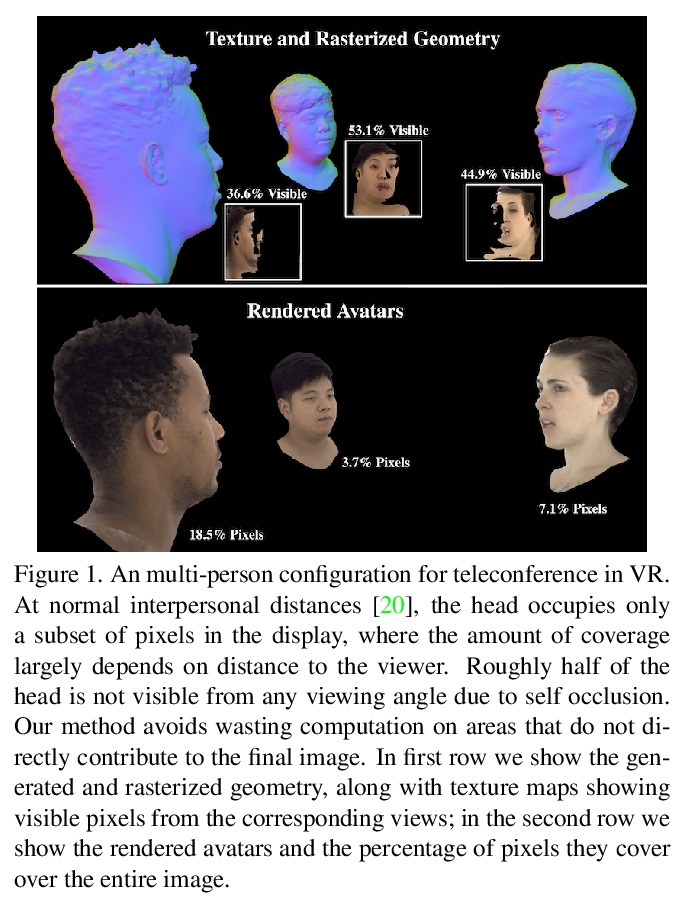
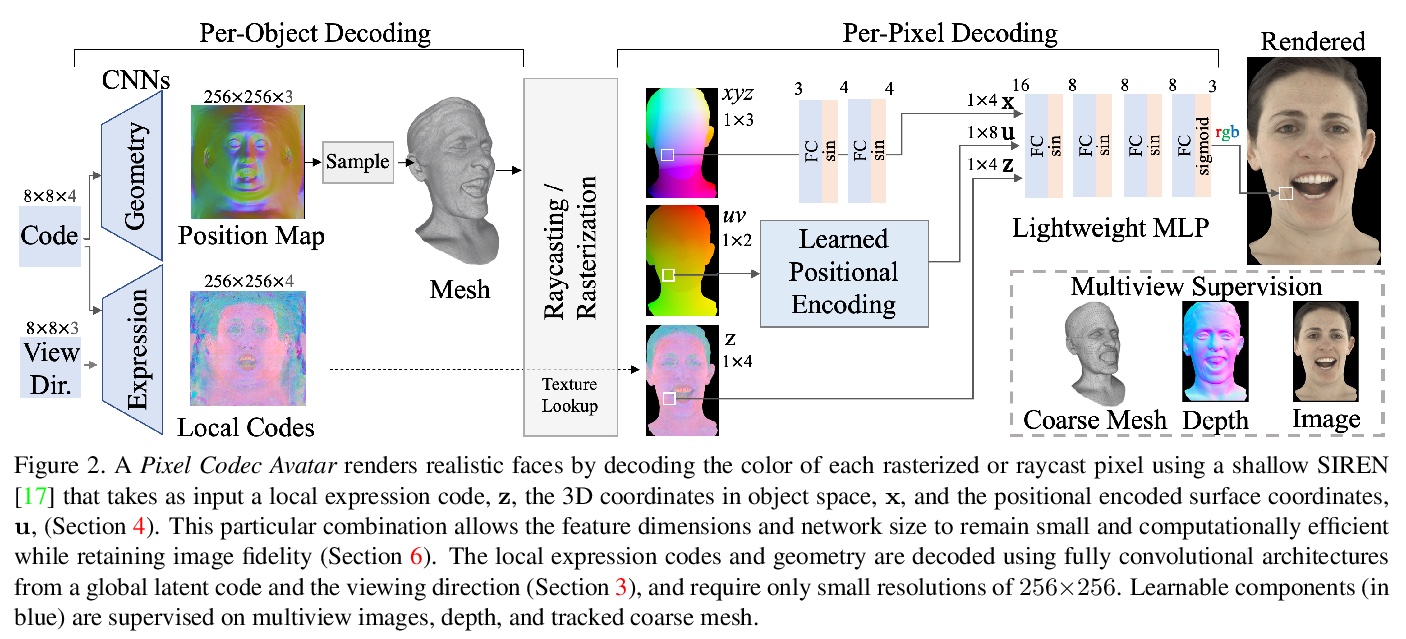
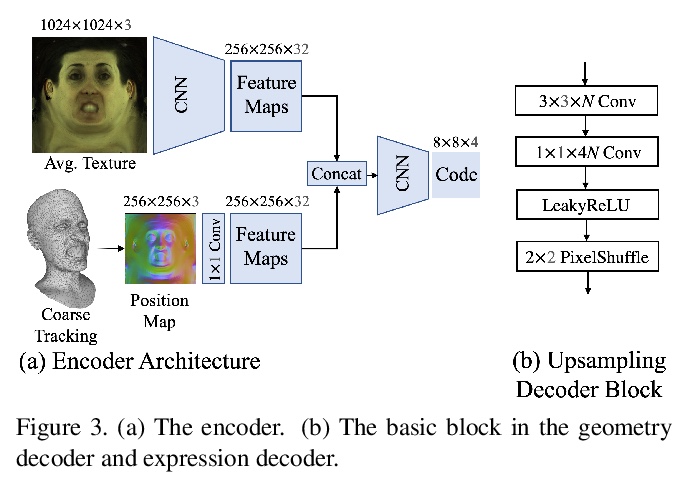
[CV] Pixel Codec Avatars
像素编解码虚拟化身
S Ma, T Simon, J Saragih, D Wang, Y Li, F D L Torre, Y Sheikh
[Facebook Reality Labs Research]
https://weibo.com/1402400261/KaOjNnOSm

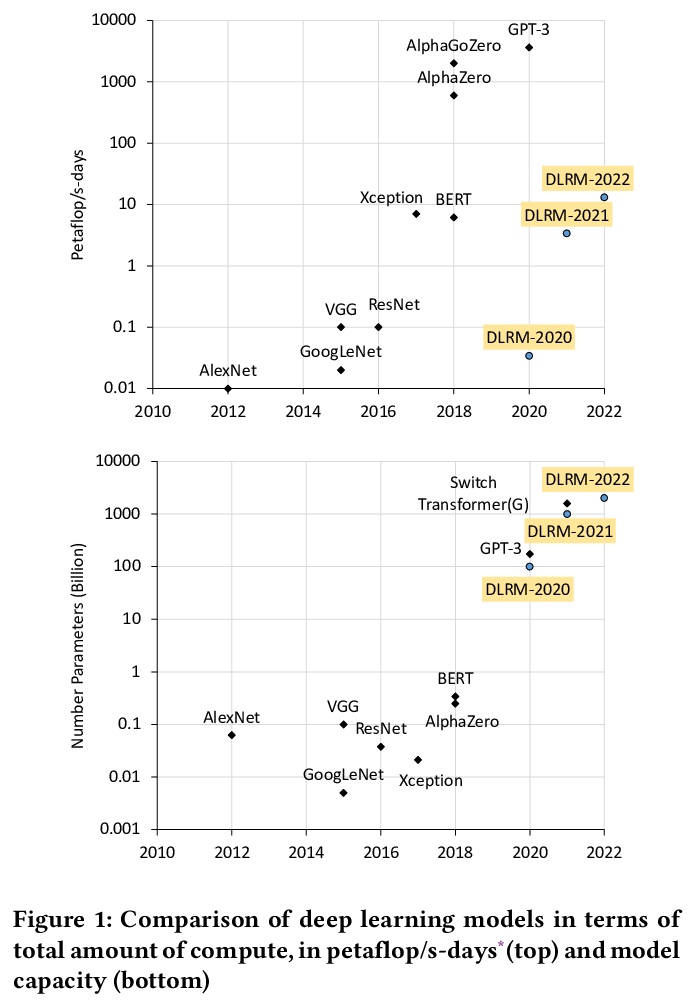
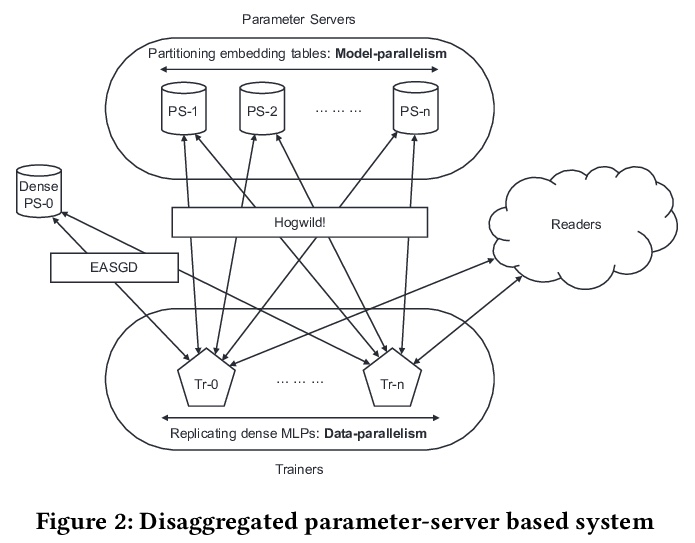
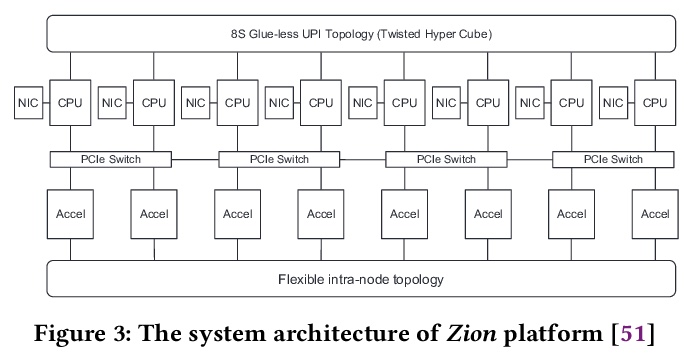
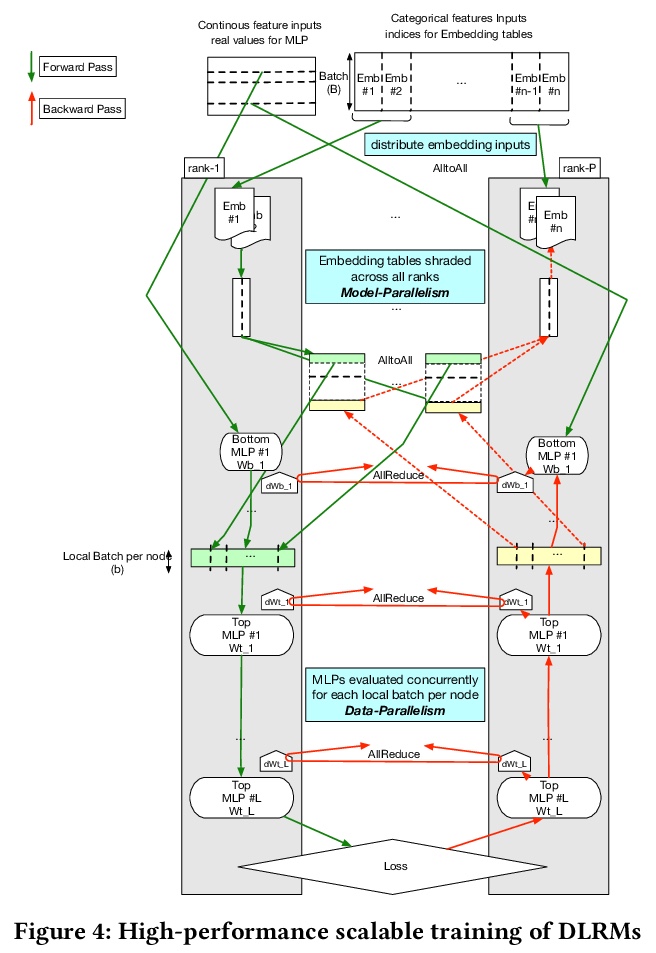
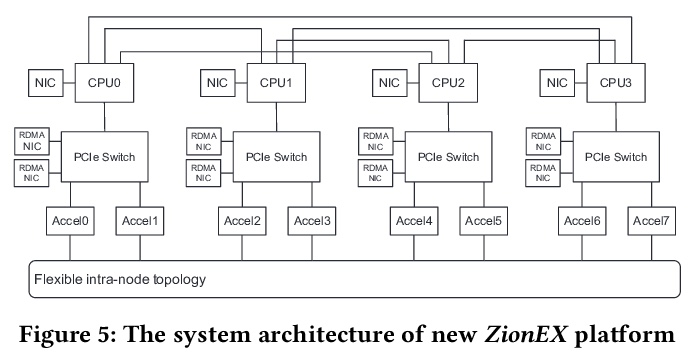
[LG] High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
大规模深度学习推荐模型高性能分布式训练
D Mudigere, Y Hao, J Huang, A Tulloch, S Sridharan, X Liu, M Ozdal, J Nie, J Park, L Luo, J (Amy)Yang, L Gao, D Ivchenko, A Basant, Y Hu, J Yang, E K. Ardestani, X Wang, R Komuravelli, C Chu, S Yilmaz, H Li, J Qian, Z Feng, Y Ma, J Yang, E Wen, H Li, L Yang, C Sun, W Zhao, K Dhulipala, K Kishore, T Graf, A Eisenman, K K Matam, A Gangidi, P Bhattacharya, G J Chen, M Krishnan, K Nair, P Lapukhov, M Naumov, L Qiao, M Smelyanskiy, B Jia, V Rao
[Facebook]
https://weibo.com/1402400261/KaOmys4B5

若有收获,就点个赞吧
0 人点赞
