- 1、[CV] Involution: Inverting the Inherence of Convolution for Visual Recognition
- 2、[LG] Model Complexity of Deep Learning: A Survey
- 3、[LG] Variable-rate discrete representation learning
- 4、[LG] Behavior From the Void: Unsupervised Active Pre-Training
- 5、[CV] SMIL: Multimodal Learning with Severely Missing Modality
- [CV] VideoMoCo: Contrastive Video Representation Learning with Temporally Adversarial Examples
- [CV] Spatially Consistent Representation Learning
- [CV] FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding
- [CV] Dynamical Pose Estimation
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
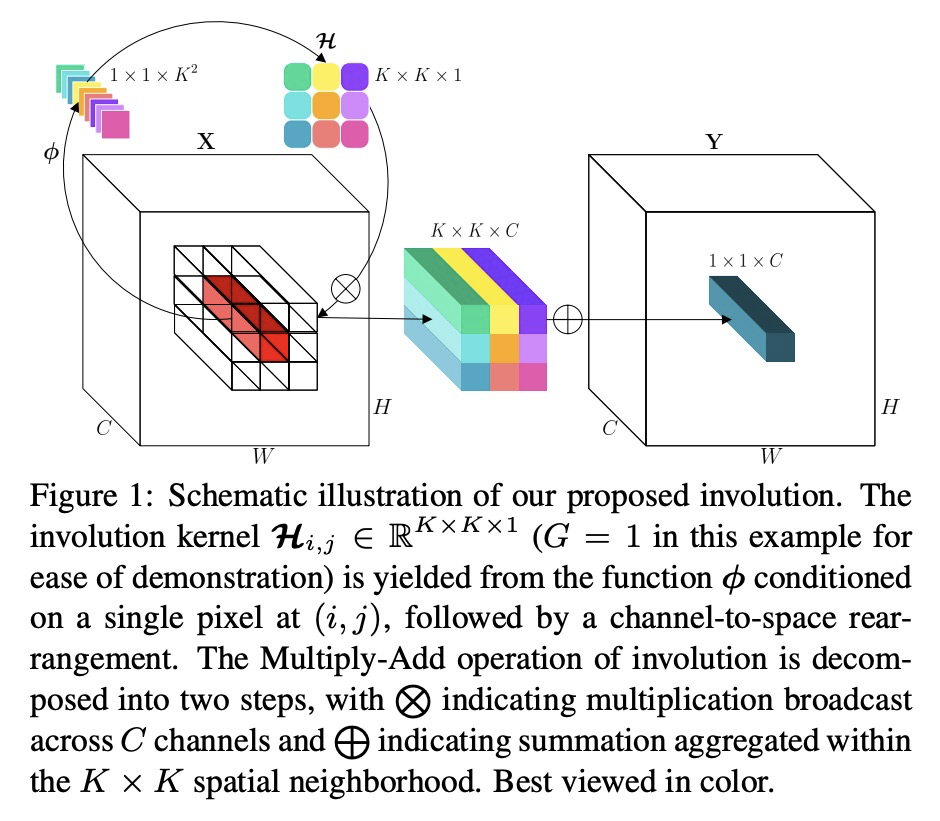
1、[CV] Involution: Inverting the Inherence of Convolution for Visual Recognition
D Li, J Hu, C Wang, X Li, Q She, L Zhu, T Zhang, Q Chen
[The Hong Kong University of Science and Technology & ByteDance AI Lab & Peking University & Beijing University of Posts and Telecommunications]
Involution:面向视觉识别的卷积内蕴反演。为深度神经网络提出一种有效且高效的视觉表示学习操作子Involution(内卷)。解密了最近流行的自注意力操作子,将其作为过复杂实例纳入卷积族,通过Involution视角统一了自注意力和卷积。在一系列视觉任务中,包括图像分类、目标检测、实例和语义分割,都有很好的表现,比基于卷积的同类产品有更好的性能,可以较低的成本提供增强的性能。其性能提升植根于Involution的核心思想,从空间建模的功效到架构设计的效率。
Convolution has been the core ingredient of modern neural networks, triggering the surge of deep learning in vision. In this work, we rethink the inherent principles of standard convolution for vision tasks, specifically spatial-agnostic and channel-specific. Instead, we present a novel atomic operation for deep neural networks by inverting the aforementioned design principles of convolution, coined as involution. We additionally demystify the recent popular self-attention operator and subsume it into our involution family as an over-complicated instantiation. The proposed involution operator could be leveraged as fundamental bricks to build the new generation of neural networks for visual recognition, powering different deep learning models on several prevalent benchmarks, including ImageNet classification, COCO detection and segmentation, together with Cityscapes segmentation. Our involution-based models improve the performance of convolutional baselines using ResNet-50 by up to 1.6% top-1 accuracy, 2.5% and 2.4% bounding box AP, and 4.7% mean IoU absolutely while compressing the computational cost to 66%, 65%, 72%, and 57% on the above benchmarks, respectively. Code and pre-trained models for all the tasks are available at > this https URL.
https://weibo.com/1402400261/K5MMwj2X2


2、[LG] Model Complexity of Deep Learning: A Survey
X Hu, L Chu, J Pei, W Liu, J Bian
[Simon Fraser University & McMaster University & Microsoft Research]
深度学习模型复杂度综述。模型复杂度是深度学习的一个基本问题。本文对深度学习模型复杂度的最新研究进行了系统综述。深度学习的模型复杂度可分为表达能力复杂度和有效模型复杂度。基于模型框架、模型大小、优化过程和数据复杂度等四个重要因素,对这两类模型的现有研究进行了回顾。讨论了深度学习模型复杂度的应用,包括理解模型泛化能力、模型优化及模型选择和设计。最后,提出了几个有趣的未来方向。
Model complexity is a fundamental problem in deep learning. In this paper we conduct a systematic overview of the latest studies on model complexity in deep learning. Model complexity of deep learning can be categorized into expressive capacity and effective model complexity. We review the existing studies on those two categories along four important factors, including model framework, model size, optimization process and data complexity. We also discuss the applications of deep learning model complexity including understanding model generalization capability, model optimization, and model selection and design. We conclude by proposing several interesting future directions.
https://weibo.com/1402400261/K5MSRxBPD
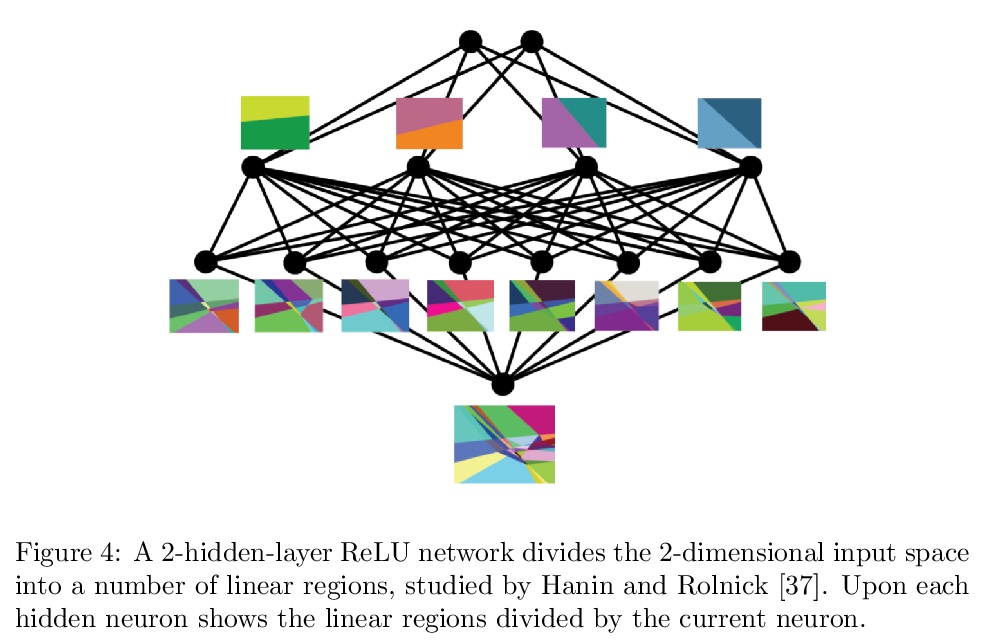
3、[LG] Variable-rate discrete representation learning
S Dieleman, C Nash, J Engel, K Simonyan
[DeepMind]
变速率离散表示学习。提出慢速自编码器(SlowAEs),用于无监督学习序列的高级变速率离散表示,并将其应用于语音。所产生的基于事件表示,会根据输入信号中突出信息的密度,自动增长或缩小,同时对信号忠实重建。为基于事件的表示建模开发了运行长度变换器(RLTs),将其用于构建语音领域的语言模型,可生成语法和语义上连贯的语句和连续性。
https://weibo.com/1402400261/K5MVq0cT8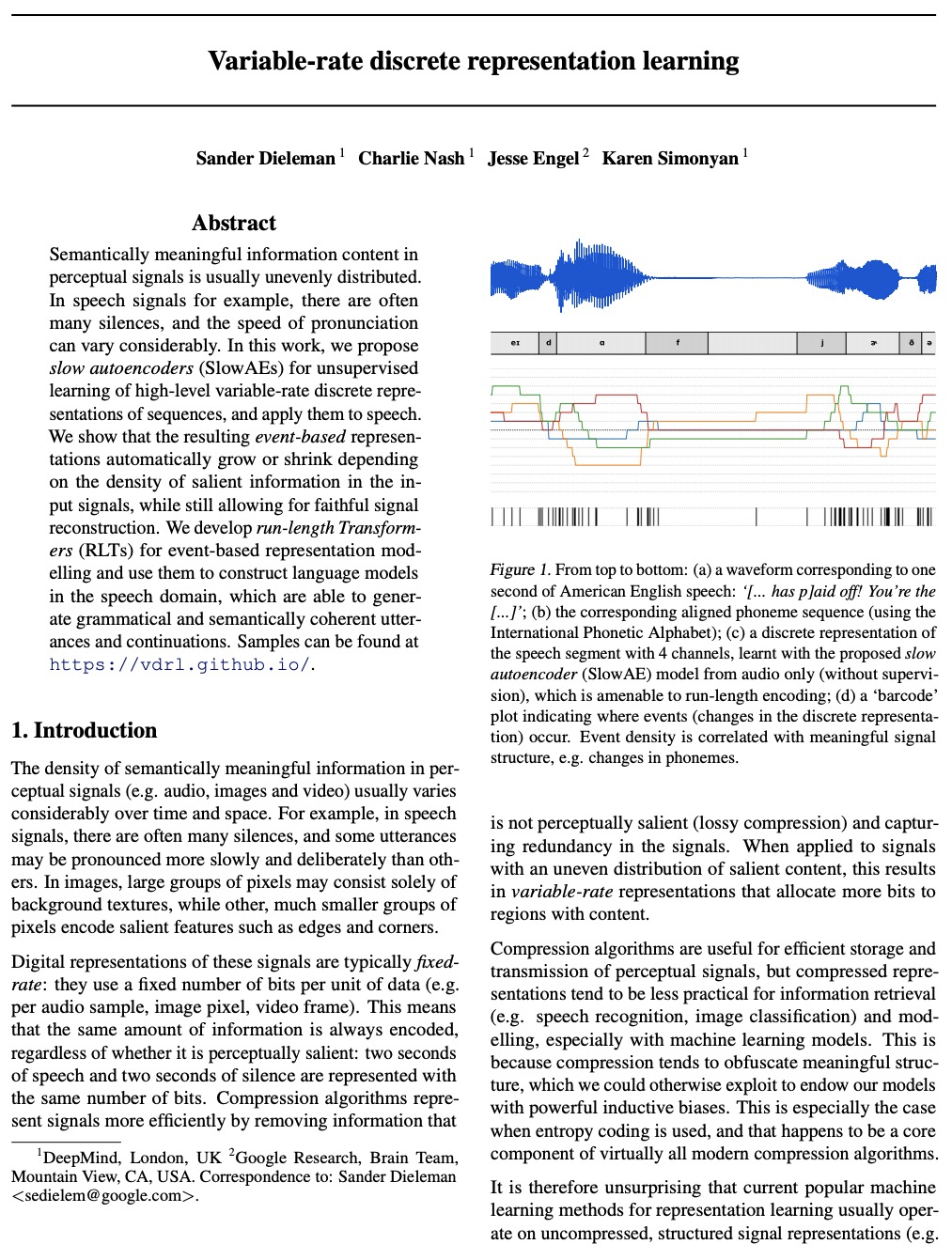


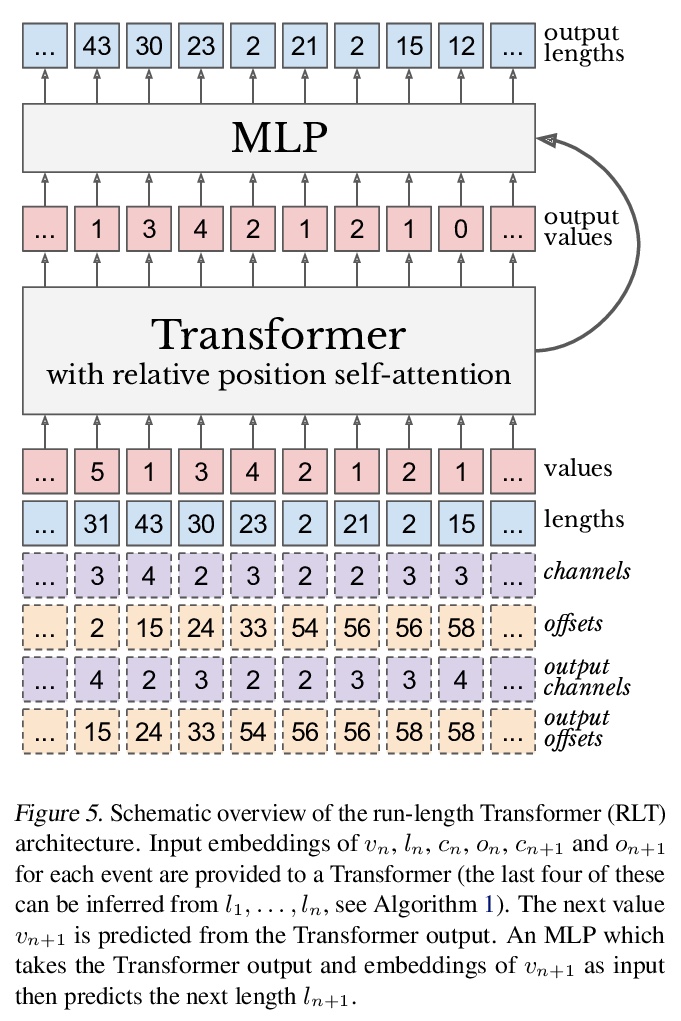
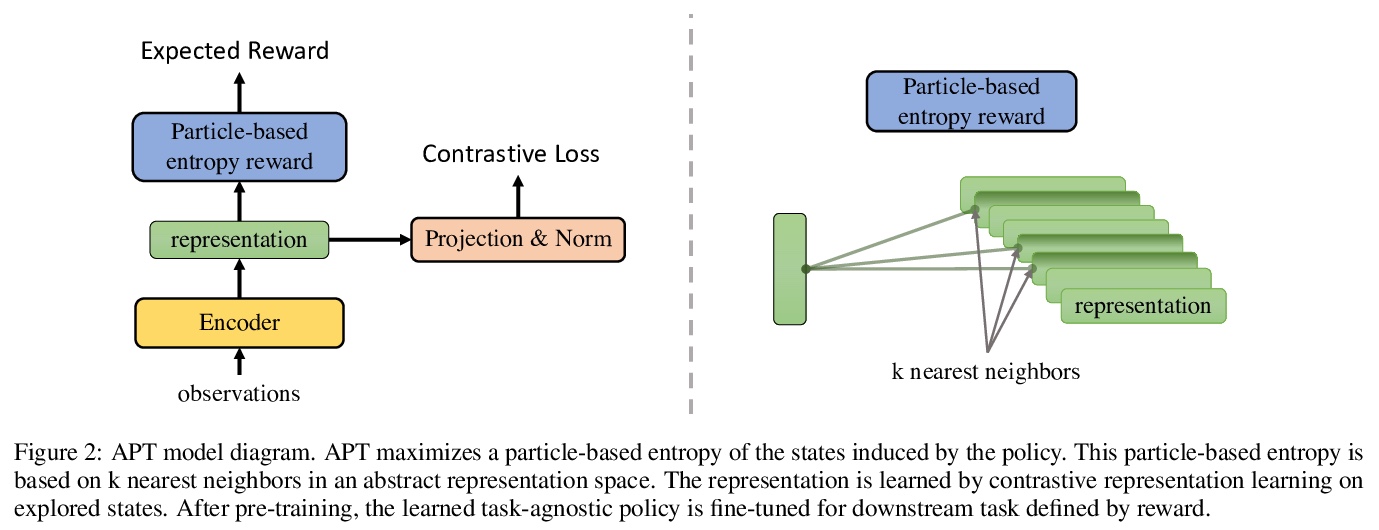
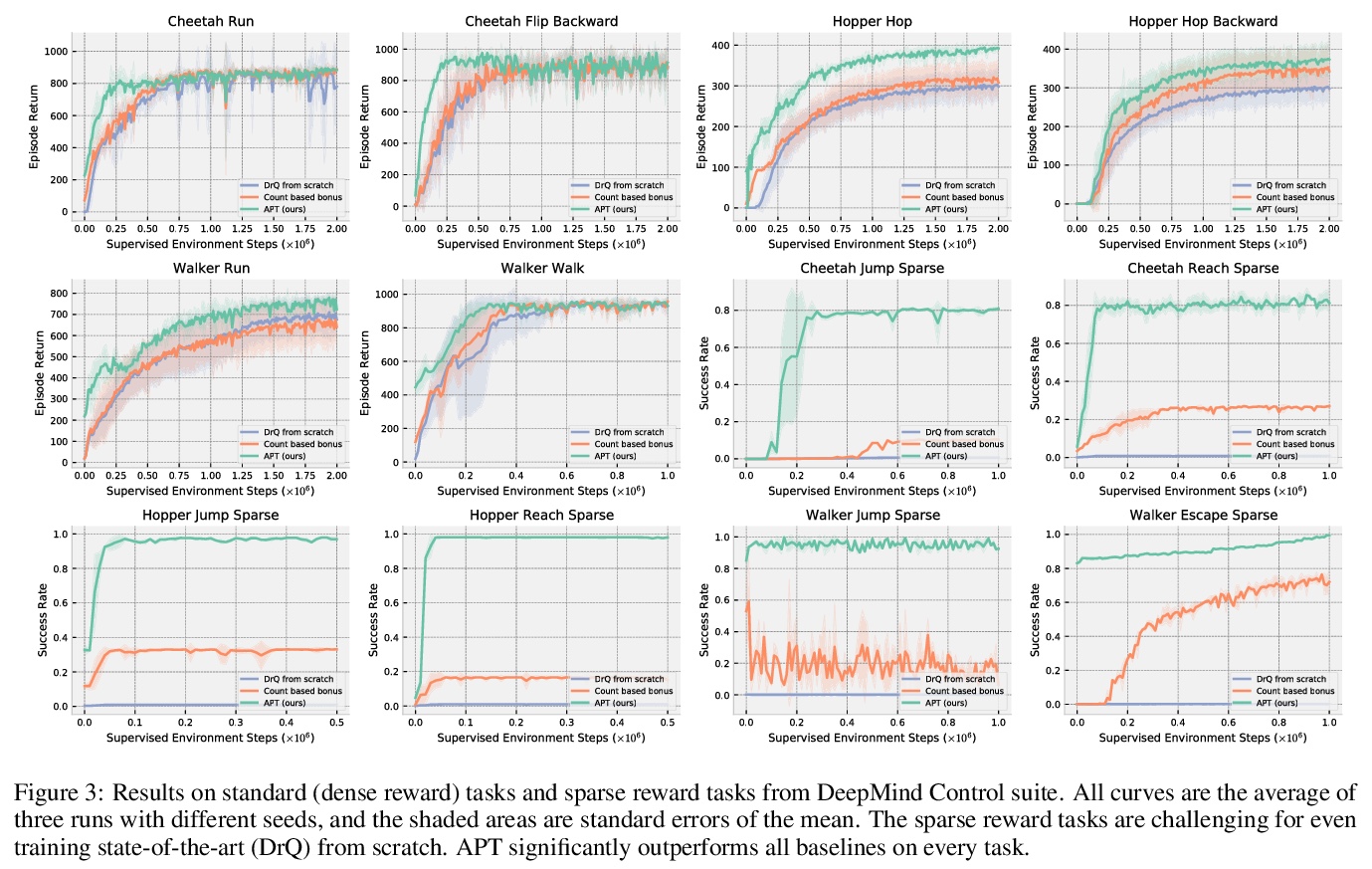
4、[LG] Behavior From the Void: Unsupervised Active Pre-Training
L Hao, A Pieter
[UC Berkeley]
无监督主动预训练。为强化学习引入一种新的无监督预训练方法——主动预训练APT,通过在无奖励环境中主动搜索新状态来学习行为和表征,以解决视觉强化学习无奖励预训练问题,使相同的任务无关的预训练模型能成功处理广泛的强化学习任务集。关键思想是通过最大化在抽象表征空间中计算的非参数熵来探索环境,这避免了具有挑战性的密度建模,在高维观测环境中(如图像观测)能更好地进行扩展。通过在长期无监督预训练阶段后暴露任务特定奖励来实证评价APT。在Atari游戏上,APT在12个游戏上实现了人类水平的性能,与规范的全监督强化学习算法相比,获得了极具竞争力的性能。在DMControl套件上,APT在渐进性能和数据效率方面击败了所有基线,并在极难从头开始训练的任务上大幅提高了性能。APT用总样本的一小部分就达到了全监督的规范强化学习算法的结果,并且优于数据高效有监督强化学习方法。
We introduce a new unsupervised pre-training method for reinforcement learning called APT, which stands for Active Pre-Training. APT learns behaviors and representations by actively searching for novel states in reward-free environments. The key novel idea is to explore the environment by maximizing a non-parametric entropy computed in an abstract representation space, which avoids the challenging density modeling and consequently allows our approach to scale much better in environments that have high-dimensional observations (e.g., image observations). We empirically evaluate APT by exposing task-specific reward after a long unsupervised pre-training phase. On Atari games, APT achieves human-level performance on 12 games and obtains highly competitive performance compared to canonical fully supervised RL algorithms. On DMControl suite, APT beats all baselines in terms of asymptotic performance and data efficiency and dramatically improves performance on tasks that are extremely difficult to train from scratch.
https://weibo.com/1402400261/K5MXUeUrp
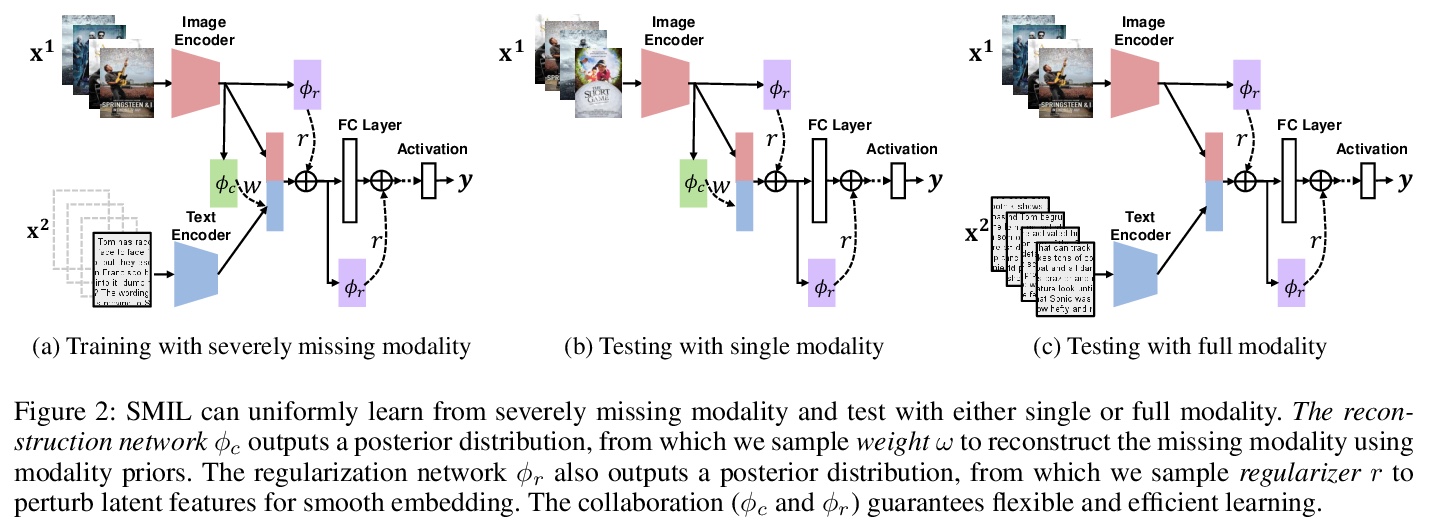
5、[CV] SMIL: Multimodal Learning with Severely Missing Modality
M Ma, J Ren, L Zhao, S Tulyakov, C Wu, X Peng
[University of Delaware & Snap Inc & Rutgers University]
SMIL:模态严重缺失的多模态学习。解决了多模态学习中一个具有挑战性的新问题:具有严重缺失模态的多模态学习。提出一种基于元学习框架的新学习策略SMIL,解决了两个重要的角度:缺失模态重建(灵活性)和特征正则化(效率),用贝叶斯元学习框架来推断其后验,提出一个变分推理框架来估计后验。在三个流行的基准上进行了一系列实验:MM-IMDb、CMU-MOSI和avMNIST。结果证明SMIL比现有方法和生成性基线(包括自编码器和生成性对抗网络)的最先进性能。
A common assumption in multimodal learning is the completeness of training data, i.e., full modalities are available in all training examples. Although there exists research endeavor in developing novel methods to tackle the incompleteness of testing data, e.g., modalities are partially missing in testing examples, few of them can handle incomplete training modalities. The problem becomes even more challenging if considering the case of severely missing, e.g., 90% training examples may have incomplete modalities. For the first time in the literature, this paper formally studies multimodal learning with missing modality in terms of flexibility (missing modalities in training, testing, or both) and efficiency (most training data have incomplete modality). Technically, we propose a new method named SMIL that leverages Bayesian meta-learning in uniformly achieving both objectives. To validate our idea, we conduct a series of experiments on three popular benchmarks: MM-IMDb, CMU-MOSI, and avMNIST. The results prove the state-of-the-art performance of SMIL over existing methods and generative baselines including autoencoders and generative adversarial networks. Our code is available at > this https URL.
https://weibo.com/1402400261/K5N1fBxCD

另外几篇值得关注的论文:
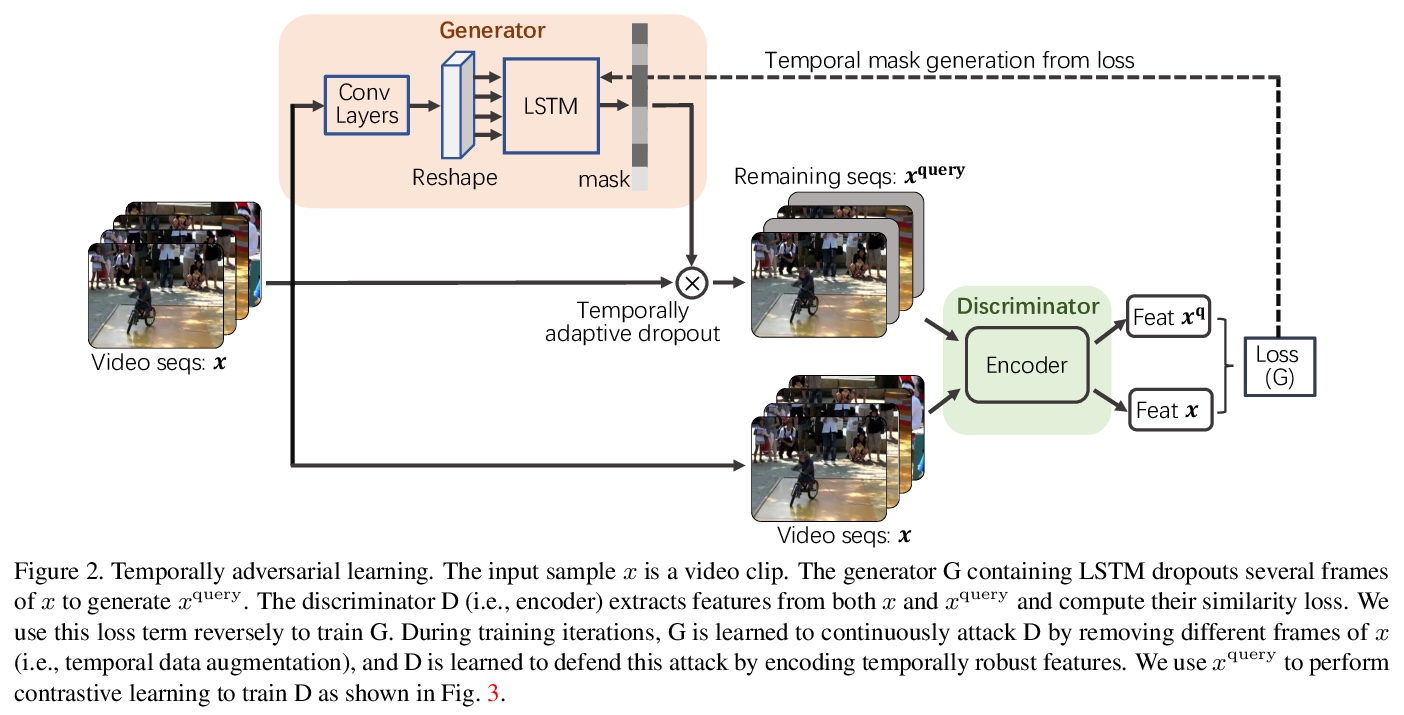
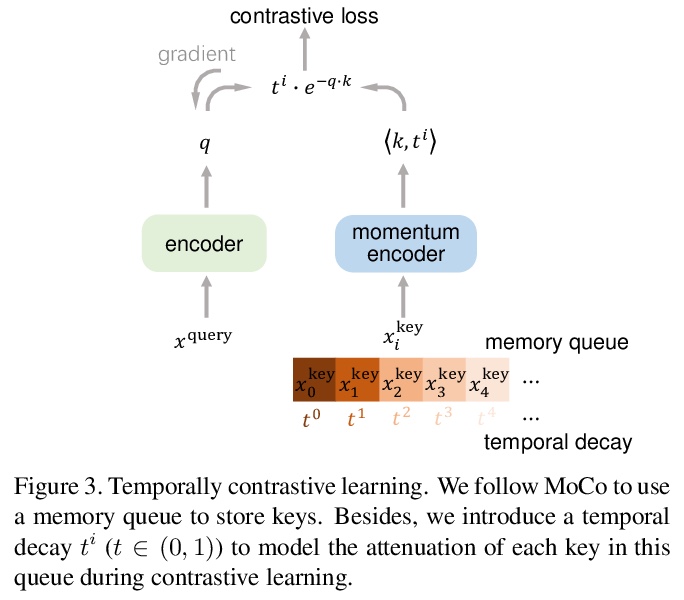
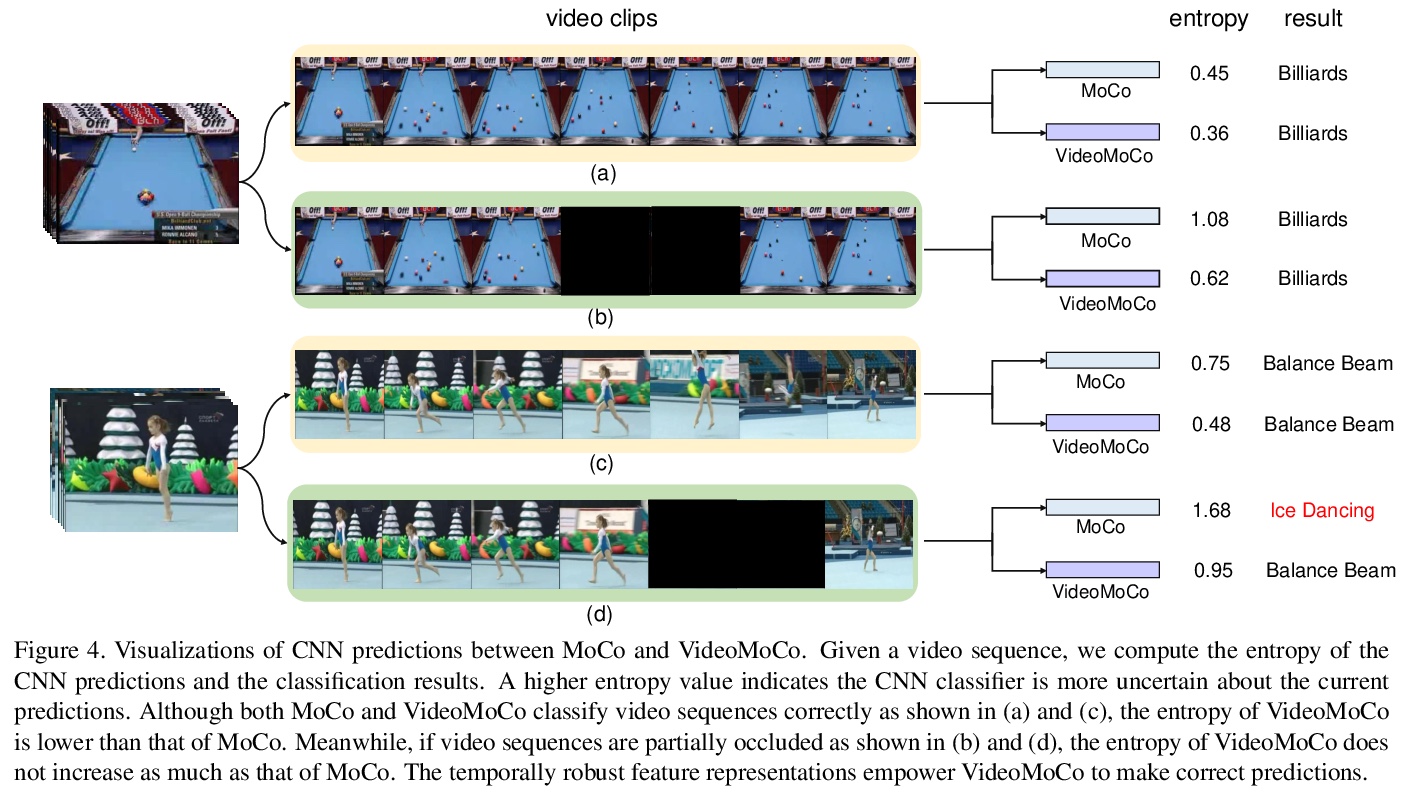
[CV] VideoMoCo: Contrastive Video Representation Learning with Temporally Adversarial Examples
VideoMoCo:时间对抗样本对比视频表示学习
T Pan, Y Song, T Yang, W Jiang, W Liu
[Tencent AI Lab & Tencent Data Platform]
https://weibo.com/1402400261/K5N4neYGY

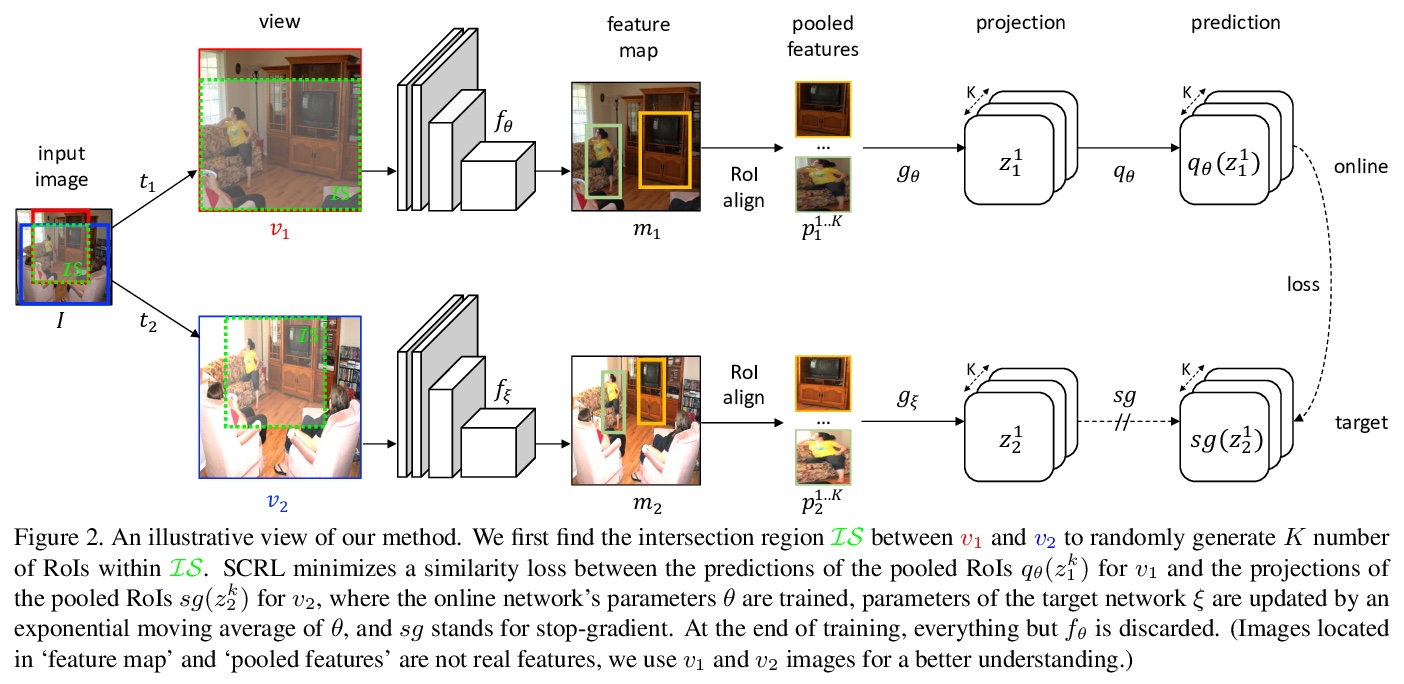
[CV] Spatially Consistent Representation Learning
空间一致表示学习
B Roh, W Shin, I Kim, S Kim
[Kakao Brain]
https://weibo.com/1402400261/K5N6shdWo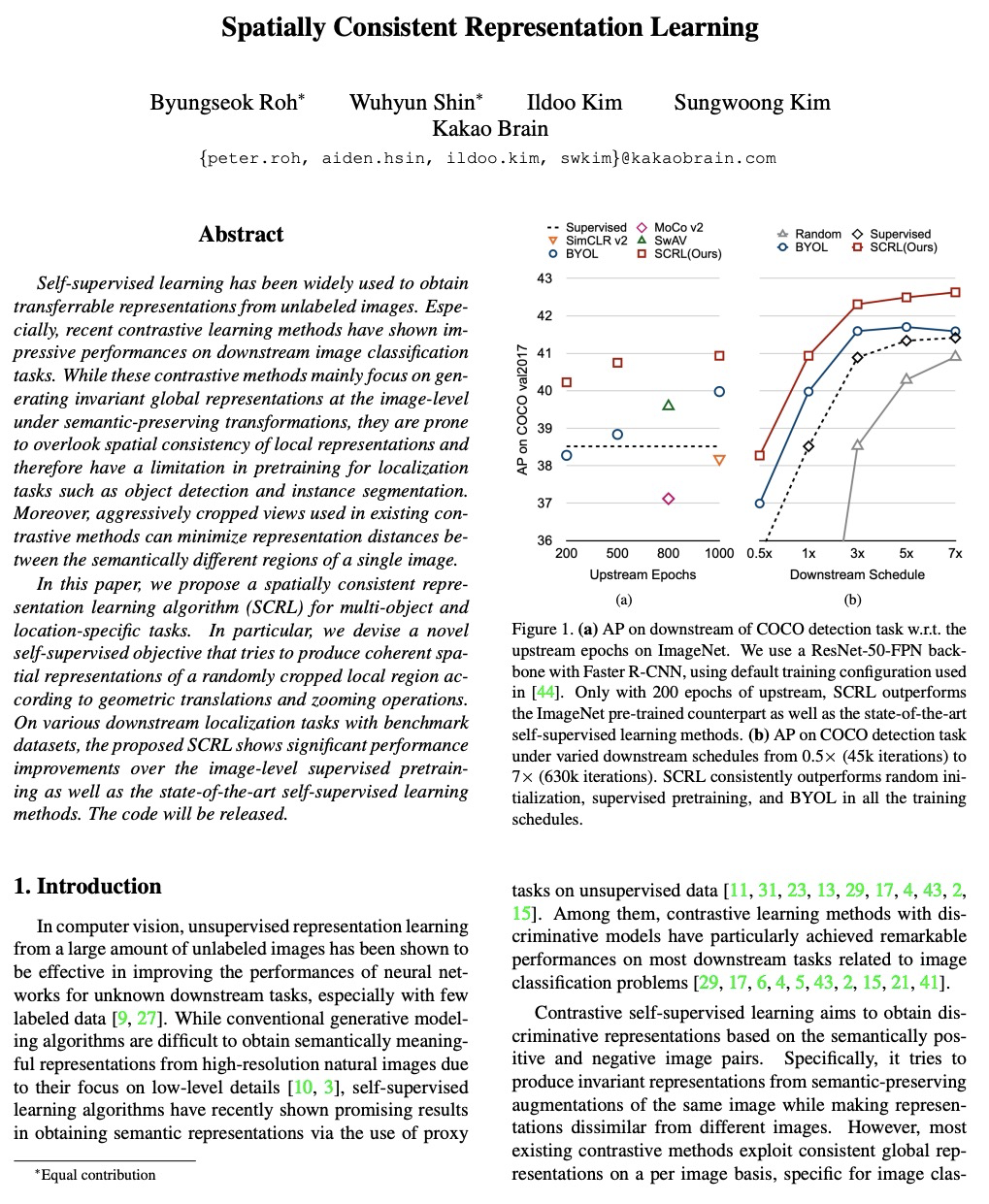

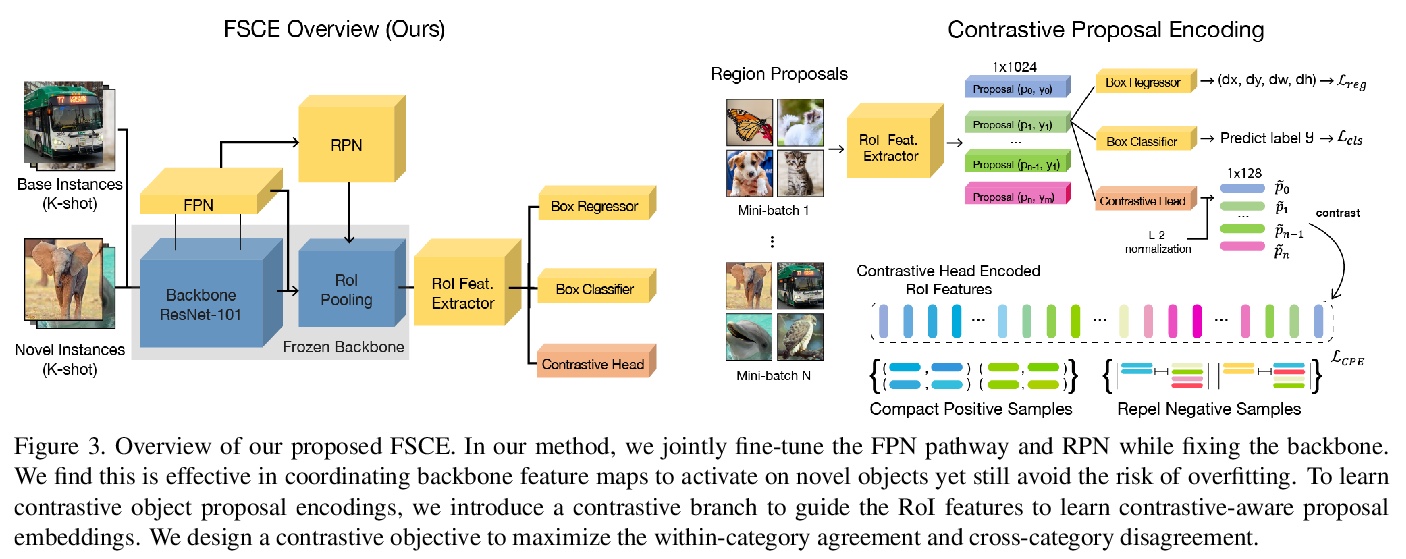
[CV] FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding
FSCE:基于对比候选编码的少样本目标检测
B Sun, B Li, S Cai, Y Yuan, C Zhang
[University of Southern California & MEGVII Technology]
https://weibo.com/1402400261/K5N7MtgAS

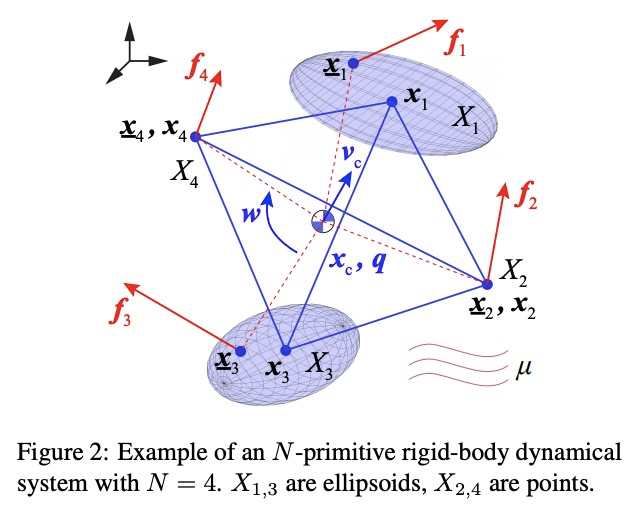
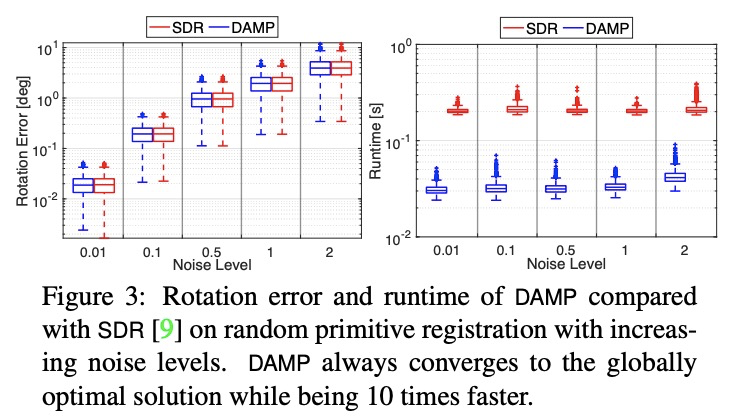
[CV] Dynamical Pose Estimation
动态姿态估计
H Yang, C Doran, J Slotine
[MIT & University of Cambridge]
https://weibo.com/1402400261/K5N9O2ivH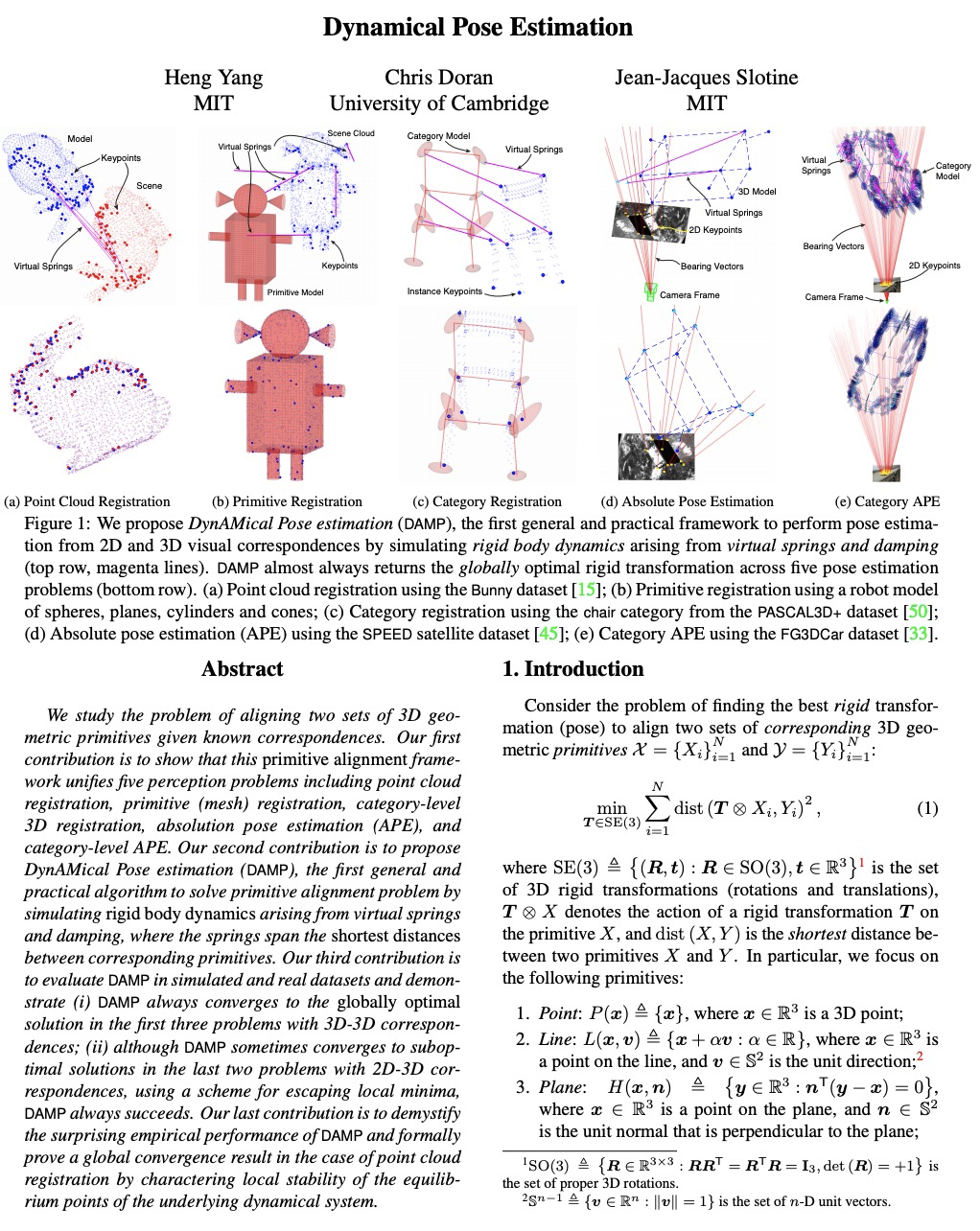

若有收获,就点个赞吧
0 人点赞
