LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 ME - 统计方法 (*表示值得重点关注)
1、[ME] *Bayesian Workflow
A Gelman, A Vehtari, D Simpson, C C. Margossian, B Carpenter, Y Yao, L Kennedy, J Gabry, P Bürkner, M Modrák
[Columbia University & Aalto University & University of Toronto]
贝叶斯模型工作流全面综述。数据分析的贝叶斯方法提供了一种强有力的方法来处理所有观测、模型参数和概率论模型结构中的不确定性。概率编程语言使指定和拟合贝叶斯模型变得更容易,但仍给我们留下了许多关于构造、评价和使用这些模型的选择,以及在计算中许多其他挑战。用贝叶斯推理解决现实问题不仅需要统计技术、学科知识和编程,还需要了解数据分析过程中所做的决策。所有这些都可以理解为应用贝叶斯统计的复杂工作流的一部分。除此之外,工作流还包括迭代模型构建、模型检查、计算问题的检验和故障排除、模型理解和模型比较。本文用多个示例场景回顾了工作流的所有这些方面。
The Bayesian approach to data analysis provides a powerful way to handle uncertainty in all observations, model parameters, and model structure using probability theory. Probabilistic programming languages make it easier to specify and fit Bayesian models, but this still leaves us with many options regarding constructing, evaluating, and using these models, along with many remaining challenges in computation. Using Bayesian inference to solve real-world problems requires not only statistical skills, subject matter knowledge, and programming, but also awareness of the decisions made in the process of data analysis. All of these aspects can be understood as part of a tangled workflow of applied Bayesian statistics. Beyond inference, the workflow also includes iterative model building, model checking, validation and troubleshooting of computational problems, model understanding, and model comparison. We review all these aspects of workflow in the context of several examples, keeping in mind that in practice we will be fitting many models for any given problem, even if only a subset of them will ultimately be relevant for our conclusions.
https://weibo.com/1402400261/JsqWgCK4M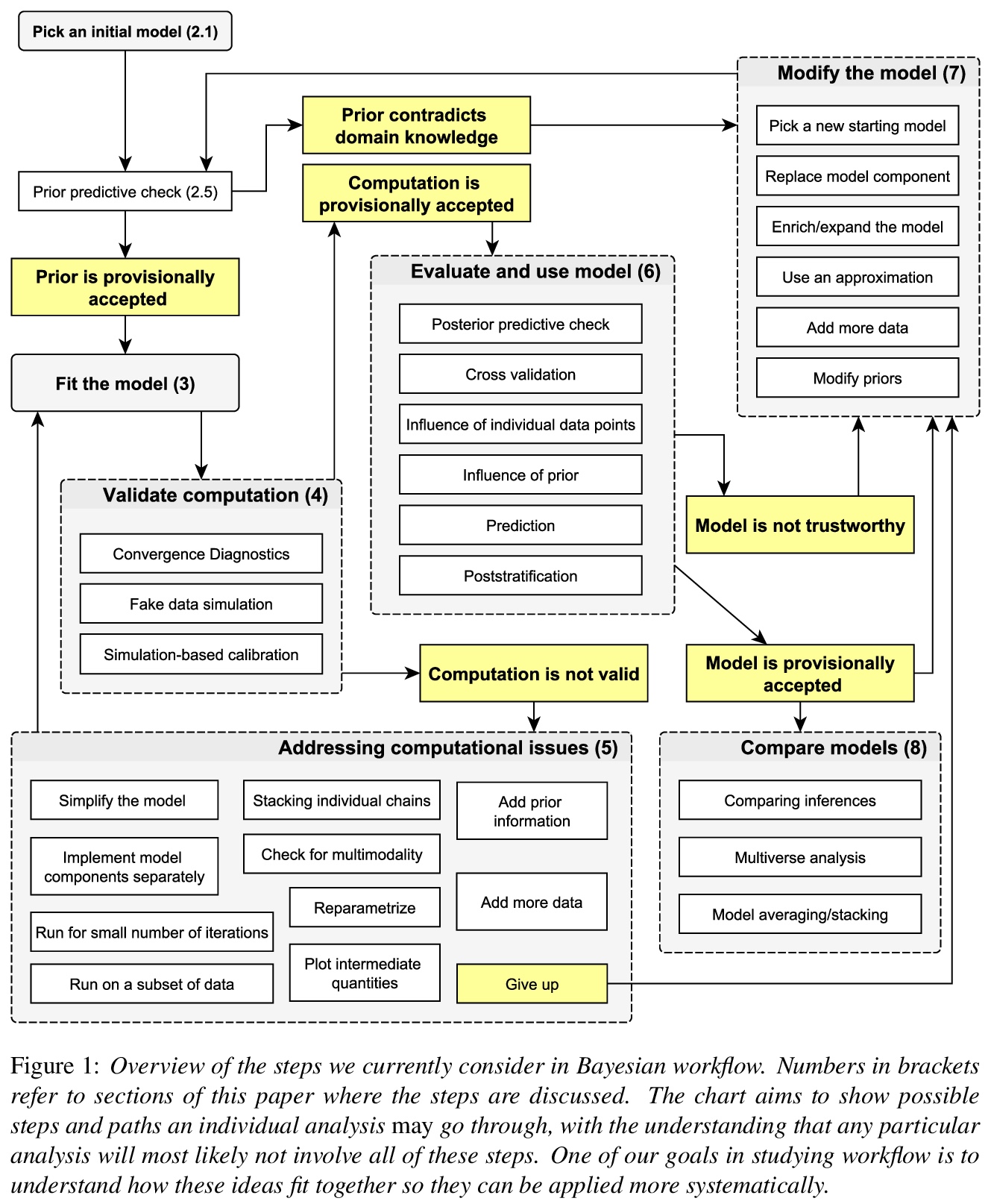
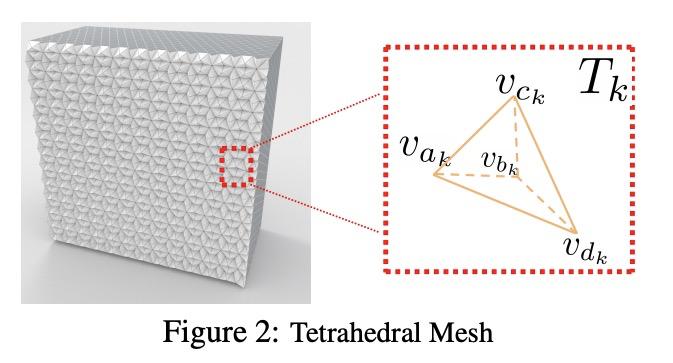
2、[CV] *Learning Deformable Tetrahedral Meshes for 3D Reconstruction
J Gao, W Chen, T Xiang, A Jacobson, M McGuire, S Fidler
[NVIDIA & University of Toronto]
面向3D重建的变形四面体网格学习。在3D重建问题中,引入了变形四面体网格(DefTet)的特殊参数化形式,其优化了顶点放置和占用,具有可微的标准3D重建损失函数。可利用神经网络从含噪点云和单一图像,直接生成四面体网格。该方法取得了可比或更高的重建质量,运行速度明显快于已有工作。**
3D shape representations that accommodate learning-based 3D reconstruction are an open problem in machine learning and computer graphics. Previous work on neural 3D reconstruction demonstrated benefits, but also limitations, of point cloud, voxel, surface mesh, and implicit function representations. We introduce Deformable Tetrahedral Meshes (DefTet) as a particular parameterization that utilizes volumetric tetrahedral meshes for the reconstruction problem. Unlike existing volumetric approaches, DefTet optimizes for both vertex placement and occupancy, and is differentiable with respect to standard 3D reconstruction loss functions. It is thus simultaneously high-precision, volumetric, and amenable to learning-based neural architectures. We show that it can represent arbitrary, complex topology, is both memory and computationally efficient, and can produce high-fidelity reconstructions with a significantly smaller grid size than alternative volumetric approaches. The predicted surfaces are also inherently defined as tetrahedral meshes, thus do not require post-processing. We demonstrate that DefTet matches or exceeds both the quality of the previous best approaches and the performance of the fastest ones. Our approach obtains high-quality tetrahedral meshes computed directly from noisy point clouds, and is the first to showcase high-quality 3D tet-mesh results using only a single image as input.
https://weibo.com/1402400261/Jsr1naAhR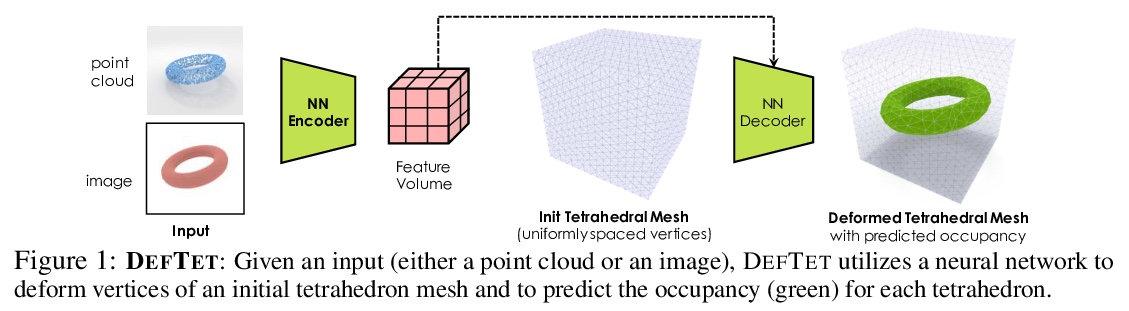


3、[LG] *Targeting for long-term outcomes
J Yang, D Eckles, P Dhillon, S Aral
[MIT & University of Michigan]
以长期收益为目标。通过整合用学习得出的替代性指标来推算长期收益,以推进策略学习实践。证明了基于估算收益的平均处理效果估计的有效性条件,也充分适用于有效的策略评价和优化,这些条件可以在一定程度上放宽,以实现策略优化。通过与基于事实的长期结果的政策进行比较,实证验证了该方法,并表明它们在统计学上是不可分的。运行了两个大规模的自适应实验,结果表明,由替代性指标得出的对长期收益进行优化的策略,优于对长期收益短期代理化的策略。与波士顿环球报目前的策略相比,三年来,本文提出的做法带来了4-5百万美元的净收益。**
Decision-makers often want to target interventions (e.g., marketing campaigns) so as to maximize an outcome that is observed only in the long-term. This typically requires delaying decisions until the outcome is observed or relying on simple short-term proxies for the long-term outcome. Here we build on the statistical surrogacy and off-policy learning literature to impute the missing long-term outcomes and then approximate the optimal targeting policy on the imputed outcomes via a doubly-robust approach. We apply our approach in large-scale proactive churn management experiments at The Boston Globe by targeting optimal discounts to its digital subscribers to maximize their long-term revenue. We first show that conditions for validity of average treatment effect estimation with imputed outcomes are also sufficient for valid policy evaluation and optimization; furthermore, these conditions can be somewhat relaxed for policy optimization. We then validate this approach empirically by comparing it with a policy learned on the ground truth long-term outcomes and show that they are statistically indistinguishable. Our approach also outperforms a policy learned on short-term proxies for the long-term outcome. In a second field experiment, we implement the optimal targeting policy with additional randomized exploration, which allows us to update the optimal policy for each new cohort of customers to account for potential non-stationarity. Over three years, our approach had a net-positive revenue impact in the range of $4-5 million compared to The Boston Globe’s current policies.
https://weibo.com/1402400261/Jsr8ShTYB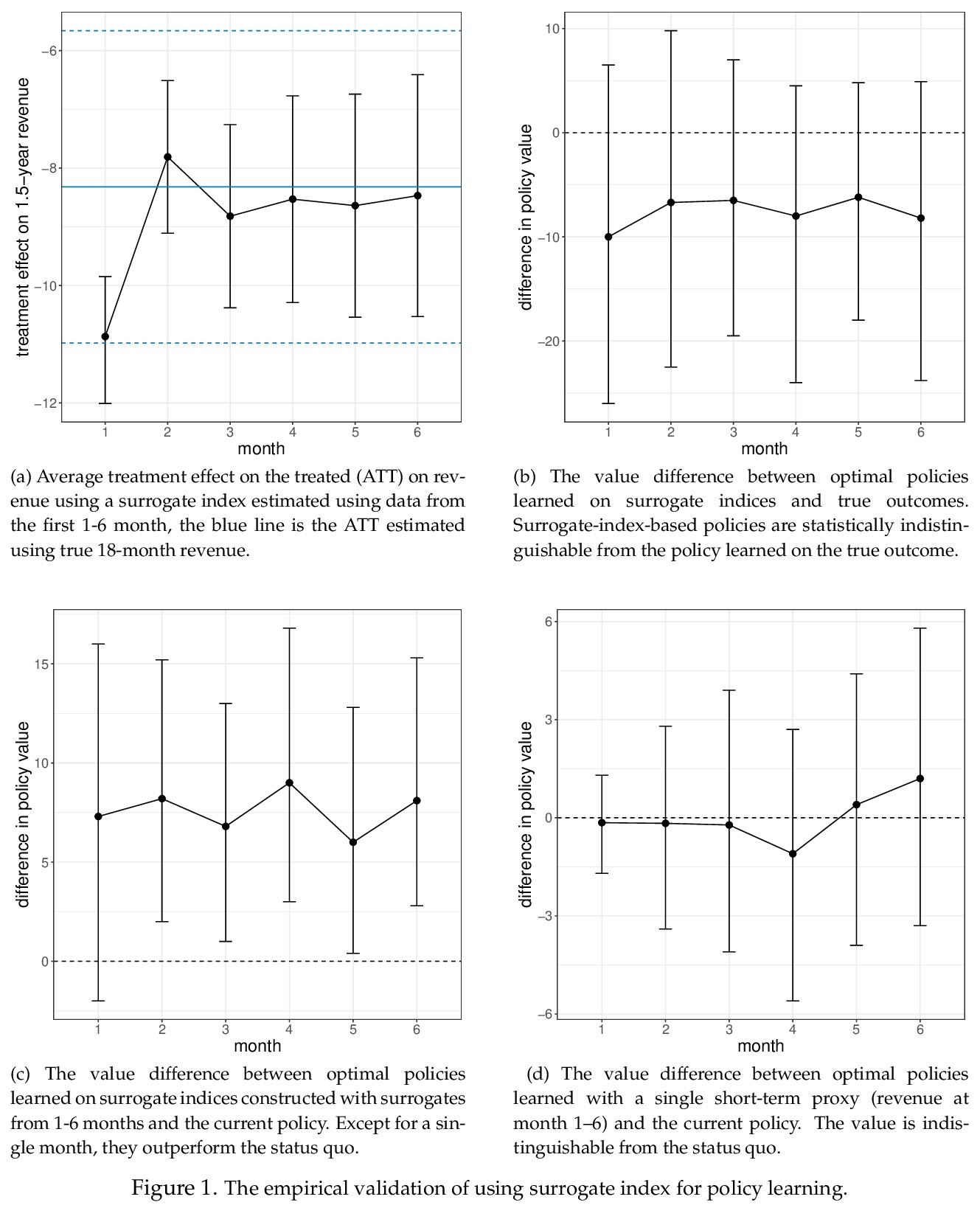
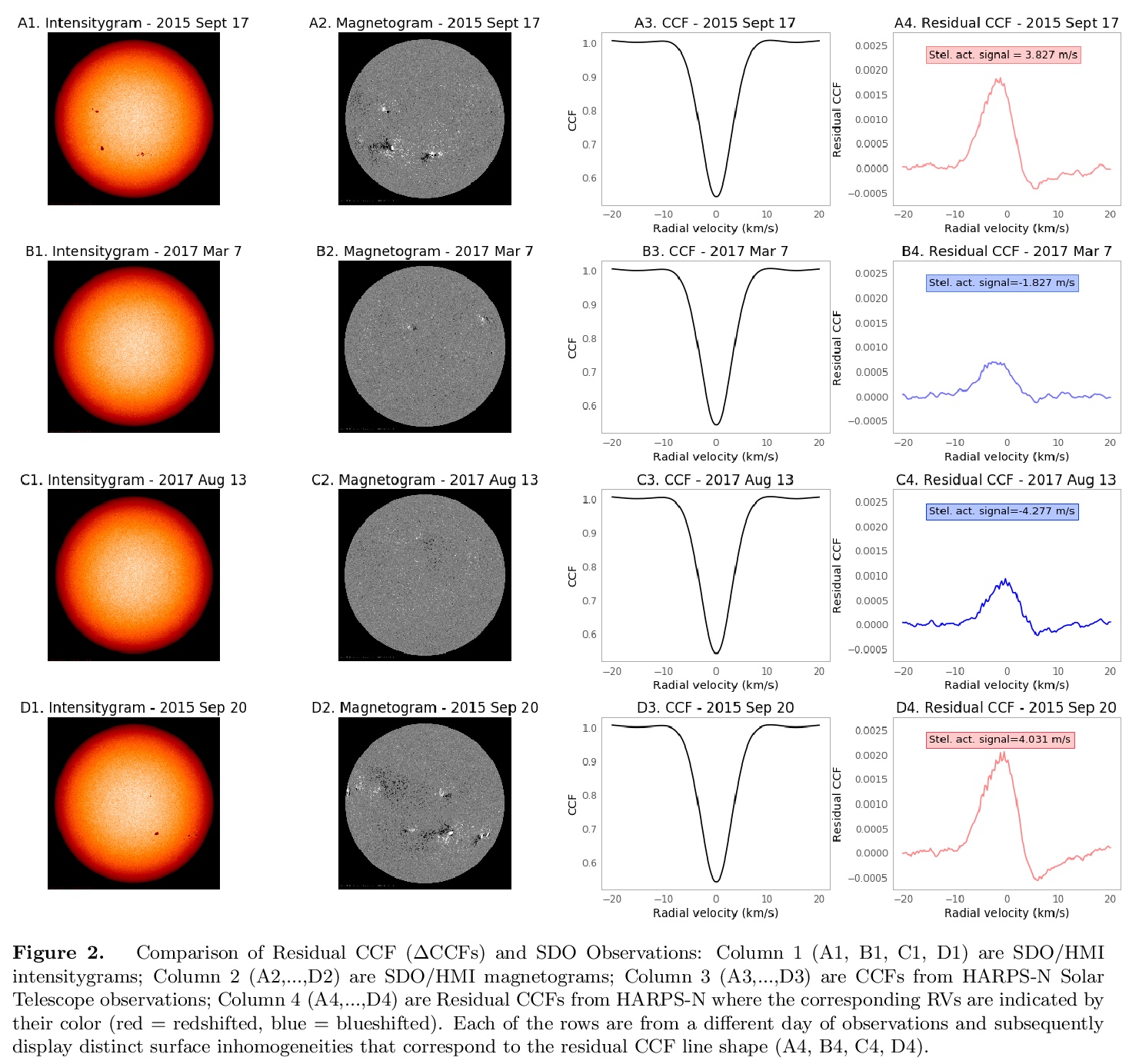
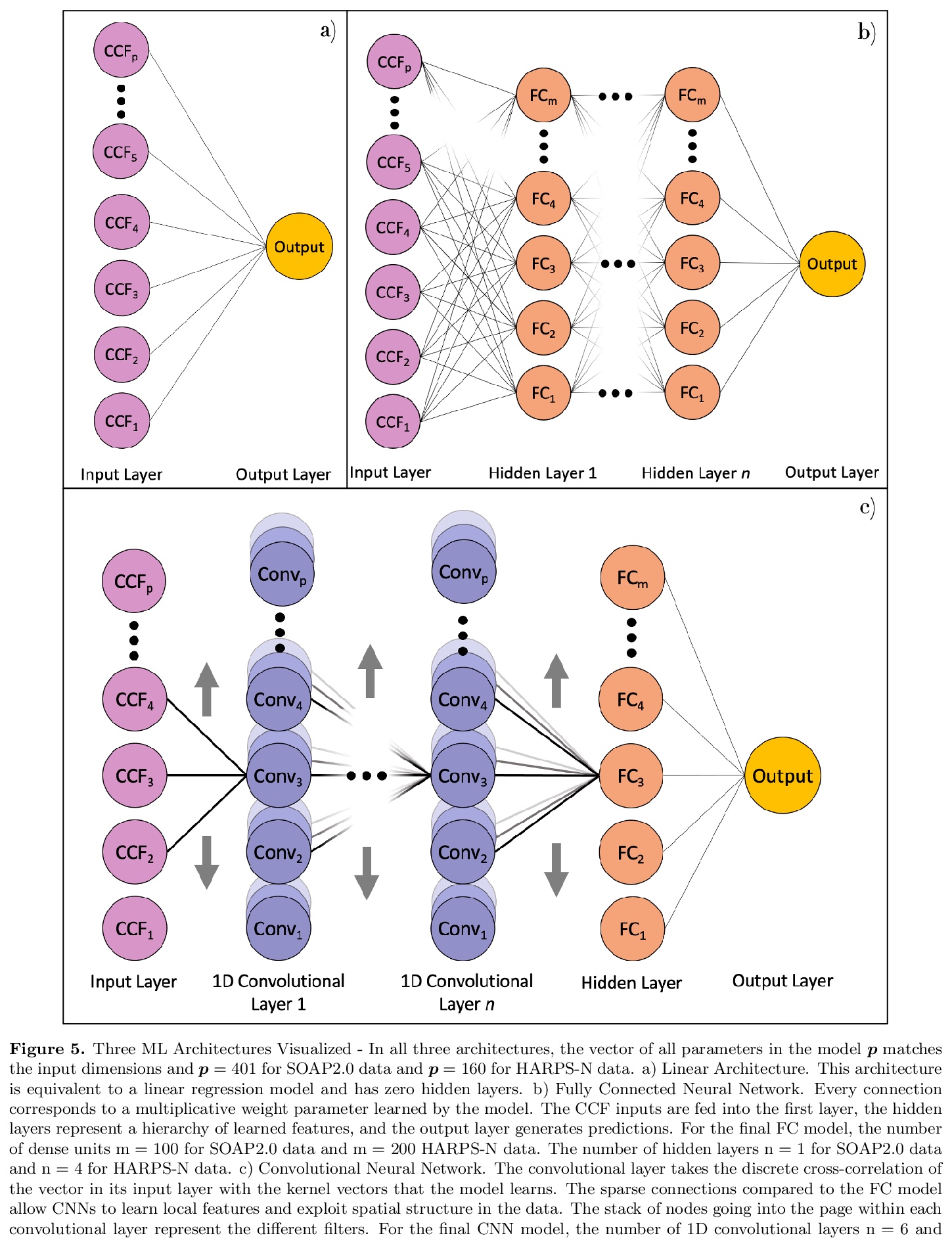
4、[LG] Identifying Exoplanets with Deep Learning. IV. Removing Stellar Activity Signals from Radial Velocity Measurements Using Neural Networks
Z L. d Beurs, A Vanderburg, C J. Shallue, X Dumusque…
[University of Texas at Austin & University of Wisconsin-Madison & Universite de Geneve]
用深度学习识别系外行星——利用神经网络从径向速度测量中去除恒星活动信号。展示了用机器学习技术,如线性回归和神经网络,如何从精确径向速度(RV)观测中有效去除(由星点/光斑带来的)活动信号。在未来,这些或类似的技术,可能会从太阳系外的恒星观测中移除活动信号,最终帮助探测类似太阳恒星周围的具有地球质量的宜居带系外行星。
Exoplanet detection with precise radial velocity (RV) observations is currently limited by spurious RV signals introduced by stellar activity. We show that machine learning techniques such as linear regression and neural networks can effectively remove the activity signals (due to starspots/faculae) from RV observations. Previous efforts focused on carefully filtering out activity signals in time using modeling techniques like Gaussian Process regression (e.g. Haywood et al. 2014). Instead, we systematically remove activity signals using only changes to the average shape of spectral lines, and no information about when the observations were collected. We trained our machine learning models on both simulated data (generated with the SOAP 2.0 software; Dumusque et al. 2014) and observations of the Sun from the HARPS-N Solar Telescope (Dumusque et al. 2015; Phillips et al. 2016; Collier Cameron et al. 2019). We find that these techniques can predict and remove stellar activity from both simulated data (improving RV scatter from 82 cm/s to 3 cm/s) and from more than 600 real observations taken nearly daily over three years with the HARPS-N Solar Telescope (improving the RV scatter from 1.47 m/s to 0.78 m/s, a factor of ~ 1.9 improvement). In the future, these or similar techniques could remove activity signals from observations of stars outside our solar system and eventually help detect habitable-zone Earth-mass exoplanets around Sun-like stars.
https://weibo.com/1402400261/Jsrhbg3o2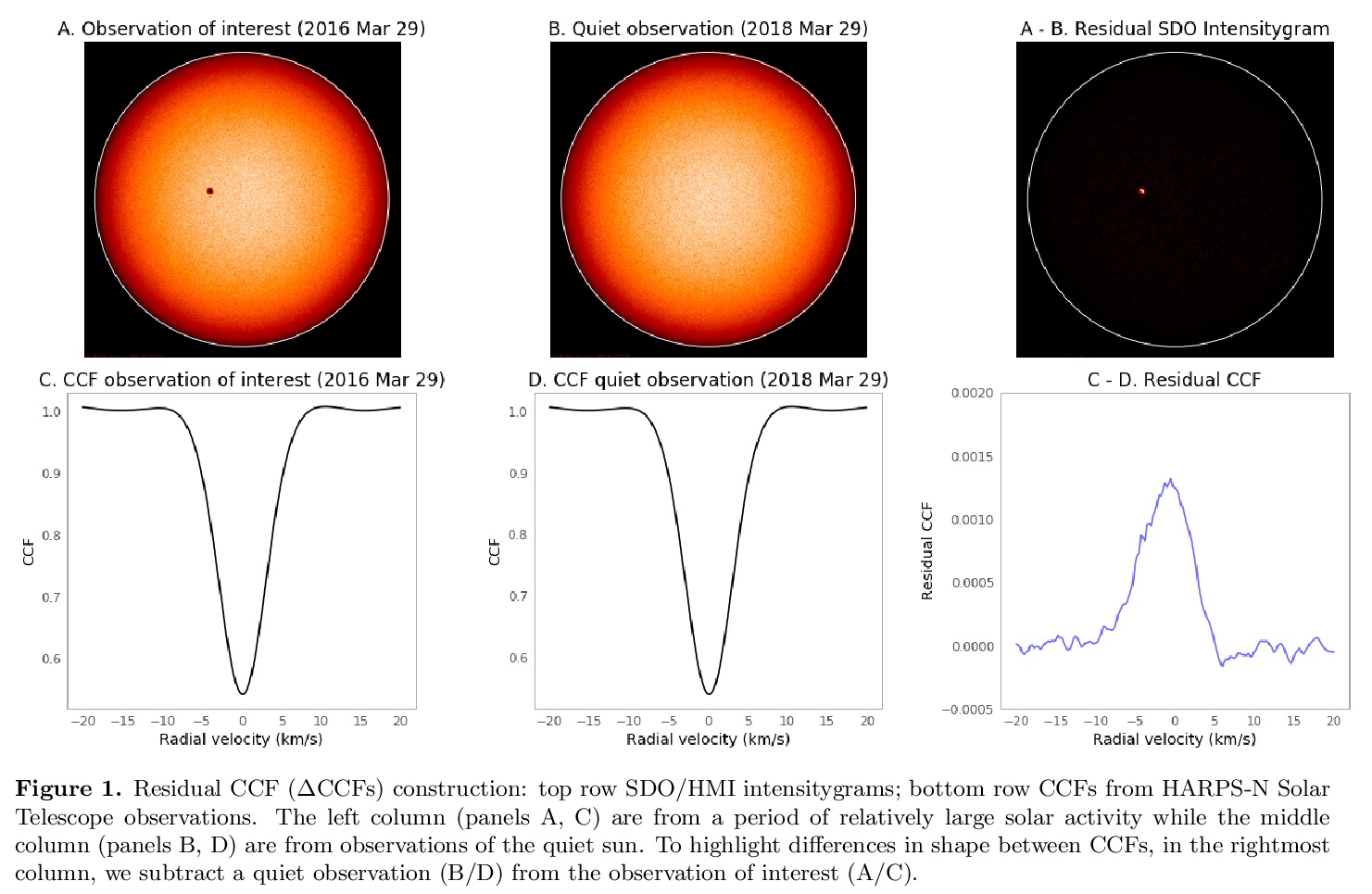
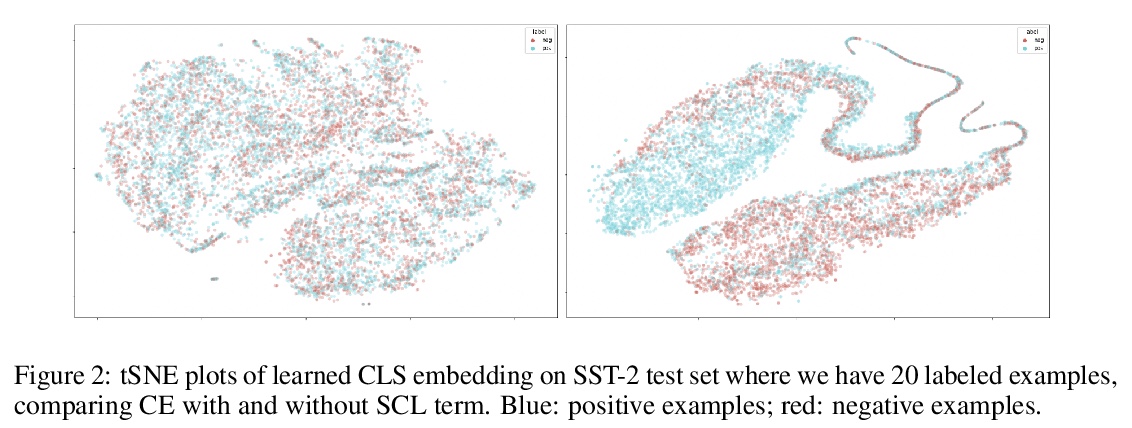
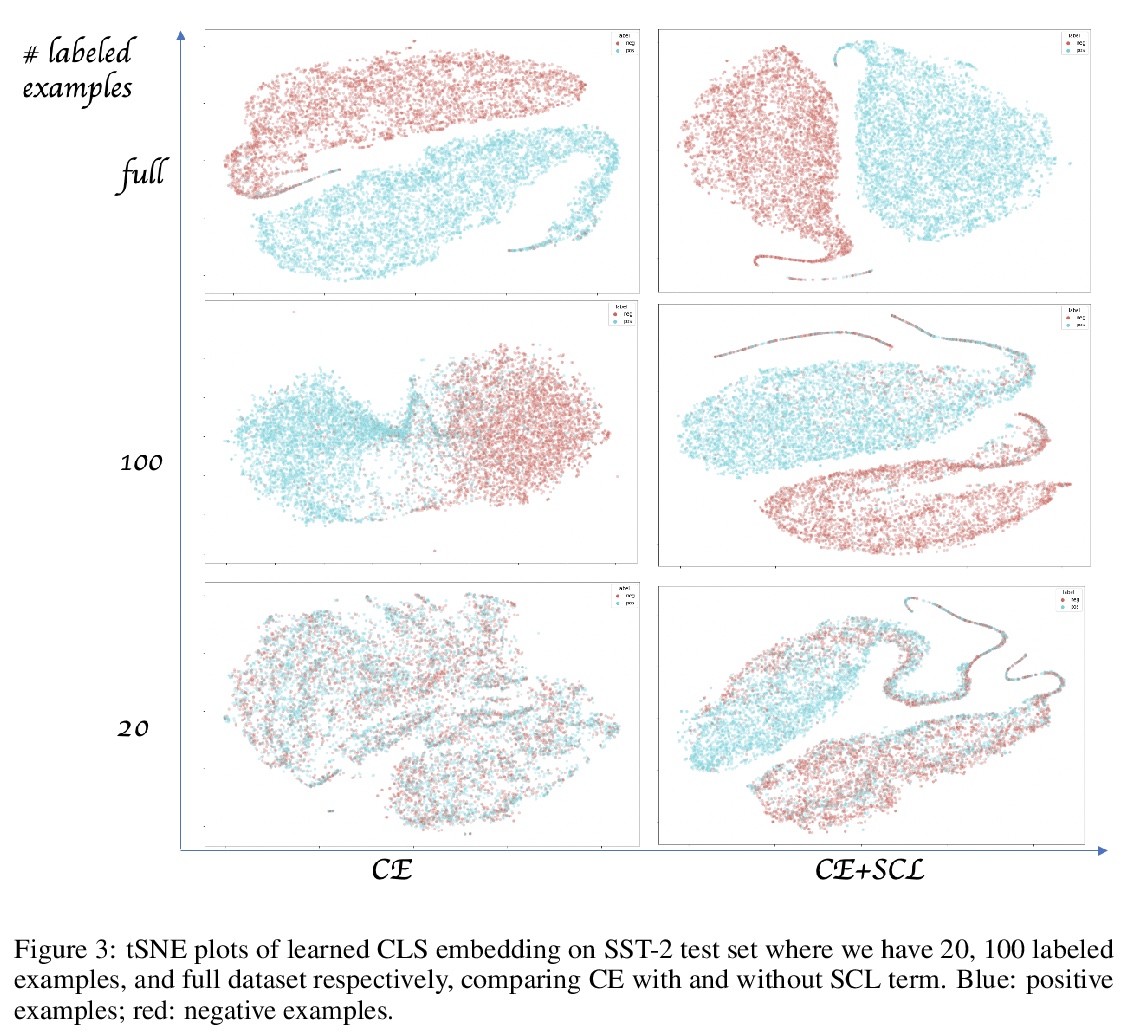
5、[CL] **Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning
B Gunel, J Du, A Conneau, V Stoyanov
[Stanford University & Facebook AI]
有监督对比学习预训练语言模型微调。提出了用于微调预训练语言模型的有监督对比学习目标,在多个基准数据集上展示了在强RoBERTa-Large基线上的改进。所提目标使模型对训练数据中不同程度的噪声更具鲁棒性,可用有限标记任务数据更好地泛化到相关任务。**
State-of-the-art natural language understanding classification models follow two-stages: pre-training a large language model on an auxiliary task, and then fine-tuning the model on a task-specific labeled dataset using cross-entropy loss. Cross-entropy loss has several shortcomings that can lead to sub-optimal generalization and instability. Driven by the intuition that good generalization requires capturing the similarity between examples in one class and contrasting them with examples in other classes, we propose a supervised contrastive learning (SCL) objective for the fine-tuning stage. Combined with cross-entropy, the SCL loss we propose obtains improvements over a strong RoBERTa-Large baseline on multiple datasets of the GLUE benchmark in both the high-data and low-data regimes, and it does not require any specialized architecture, data augmentation of any kind, memory banks, or additional unsupervised data. We also demonstrate that the new objective leads to models that are more robust to different levels of noise in the training data, and can generalize better to related tasks with limited labeled task data.
https://weibo.com/1402400261/Jsrk3eLG8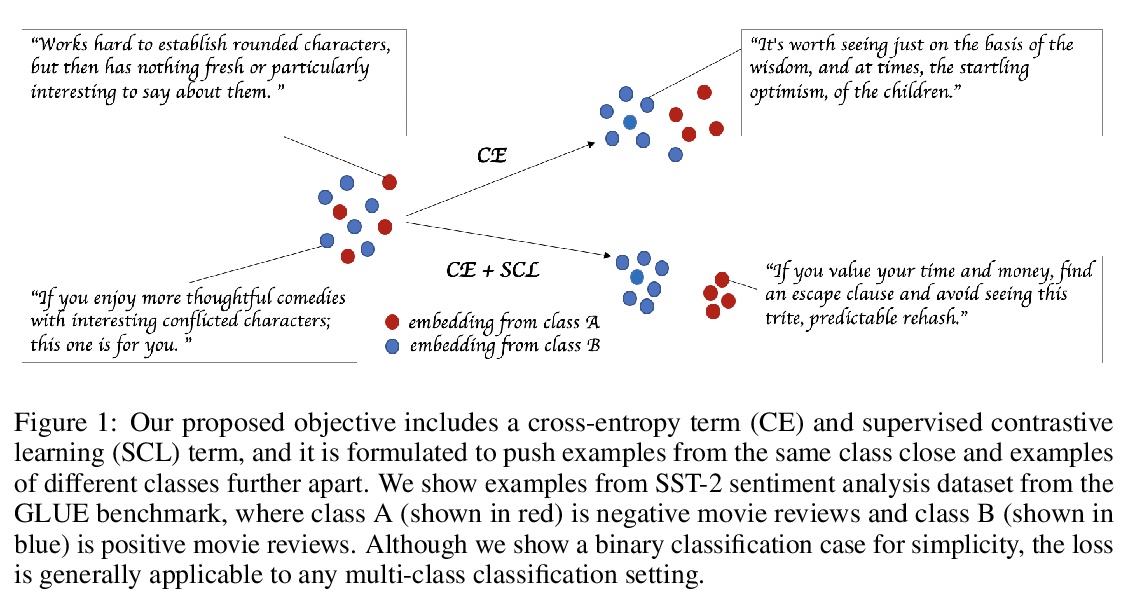
另外几篇值得关注的论文:
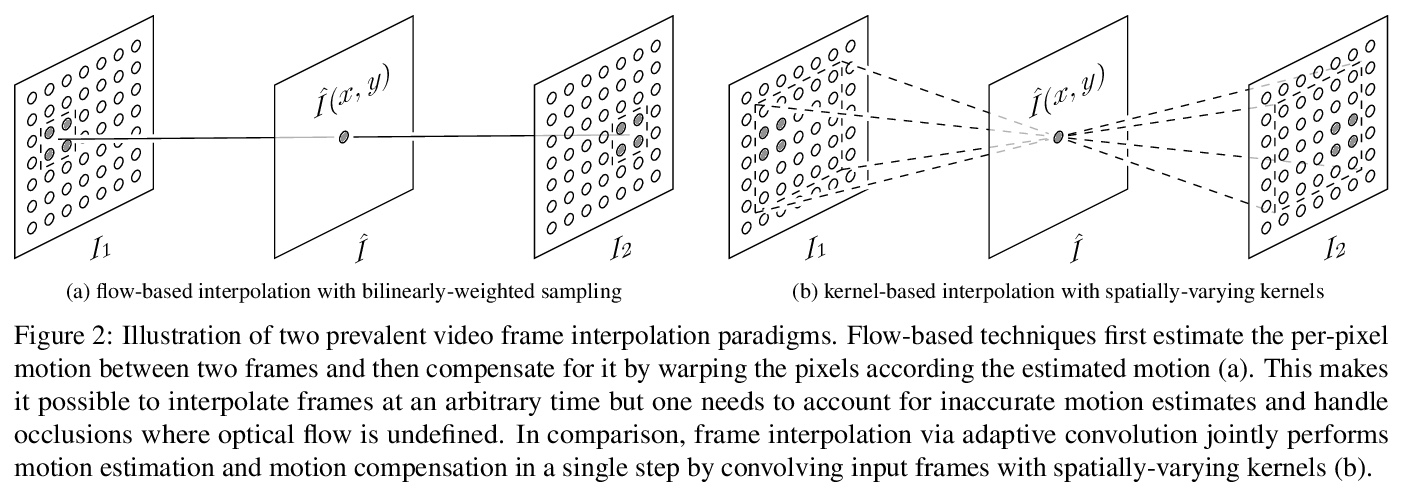
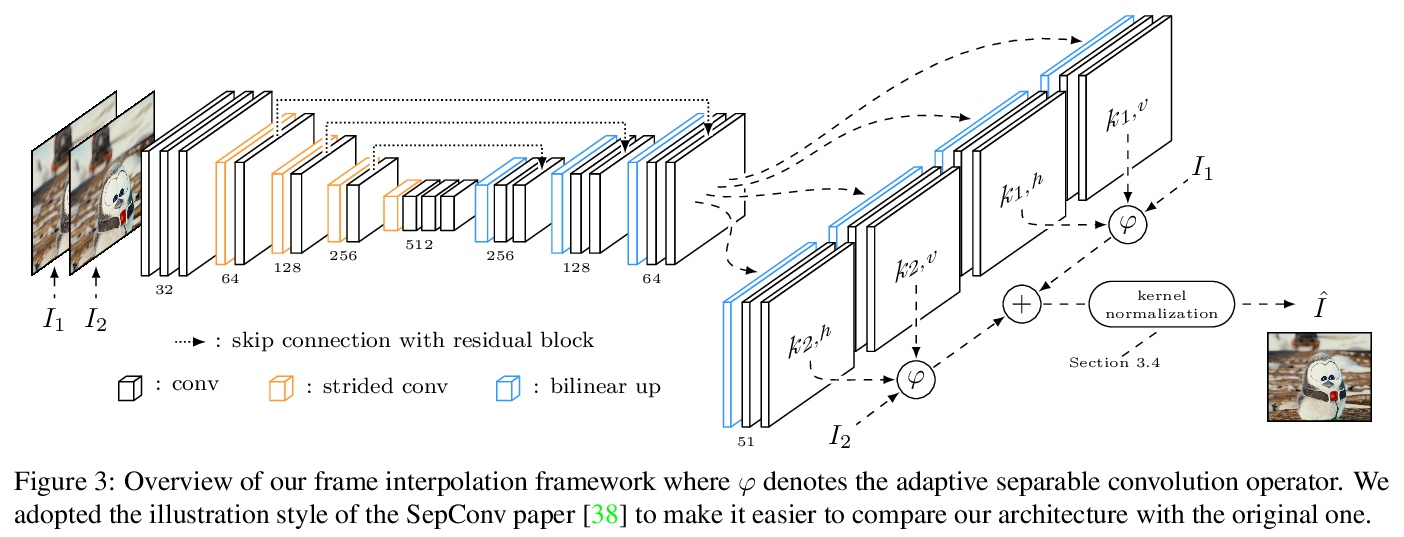
[CV] Revisiting Adaptive Convolutions for Video Frame Interpolation
自适应卷积视频帧插值的进一步研究
S Niklaus, L Mai, O Wang
[Adobe Research]
https://weibo.com/1402400261/Jsro5aEkI
[LG] The Complexity of Gradient Descent: CLS = PPAD ∩ PLS
梯度下降复杂度:CLS = PPAD ∩ PLS
J Fearnley, P W. Goldberg, A Hollender, R Savani
[University of Liverpool & University of Oxford]
https://weibo.com/1402400261/JsrqvzTKR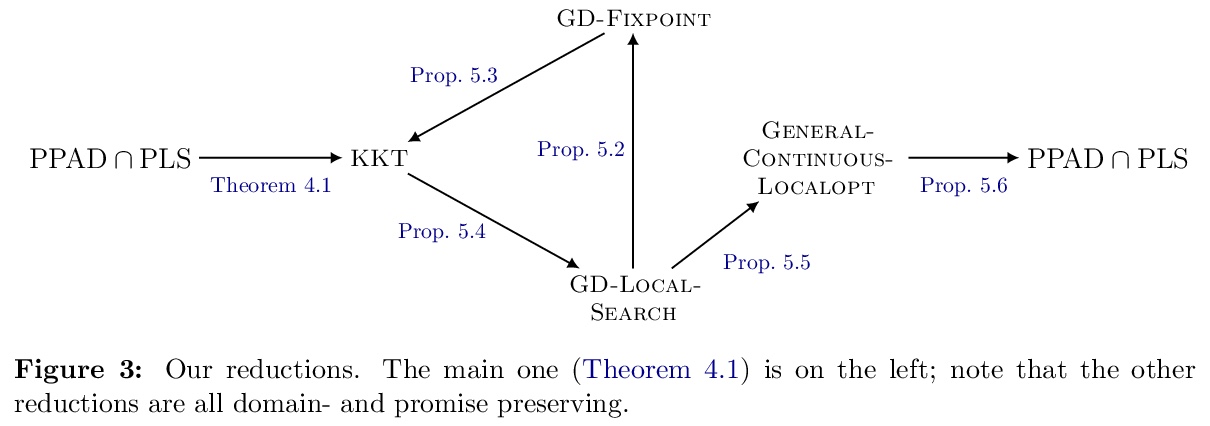

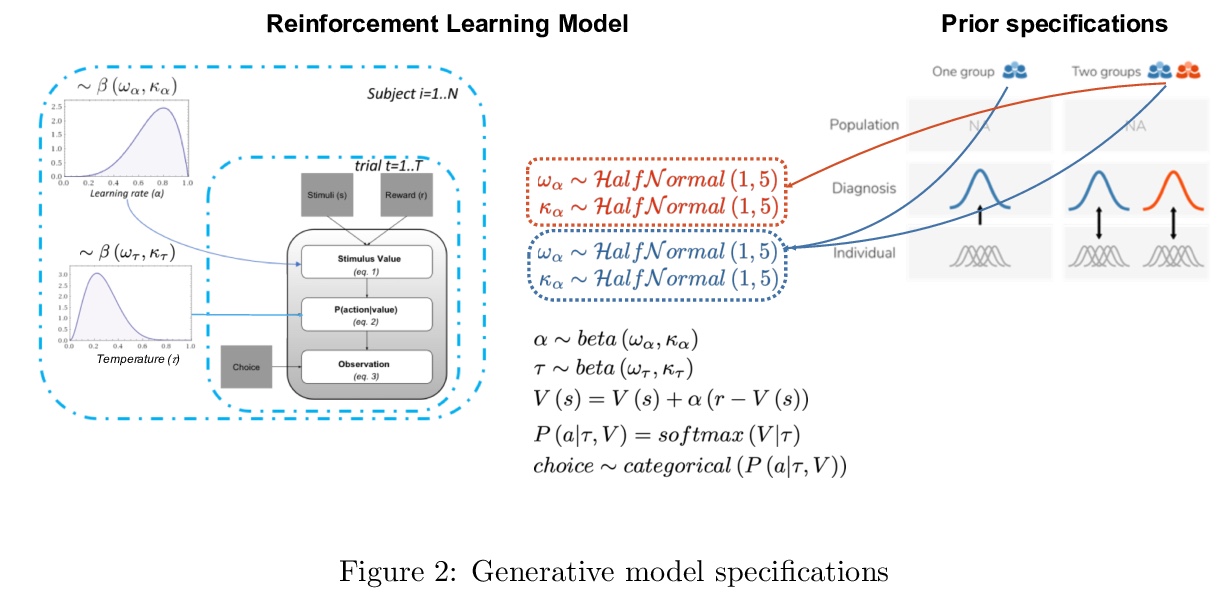
[LG] Recommendations for Bayesian hierarchical model specifications for case-control studies in mental health
面向精神健康病例对照研究的贝叶斯层次模型规范建议
V Valton, T Wise, O J. Robinson
[University College London]
https://weibo.com/1402400261/Jsrsry6rb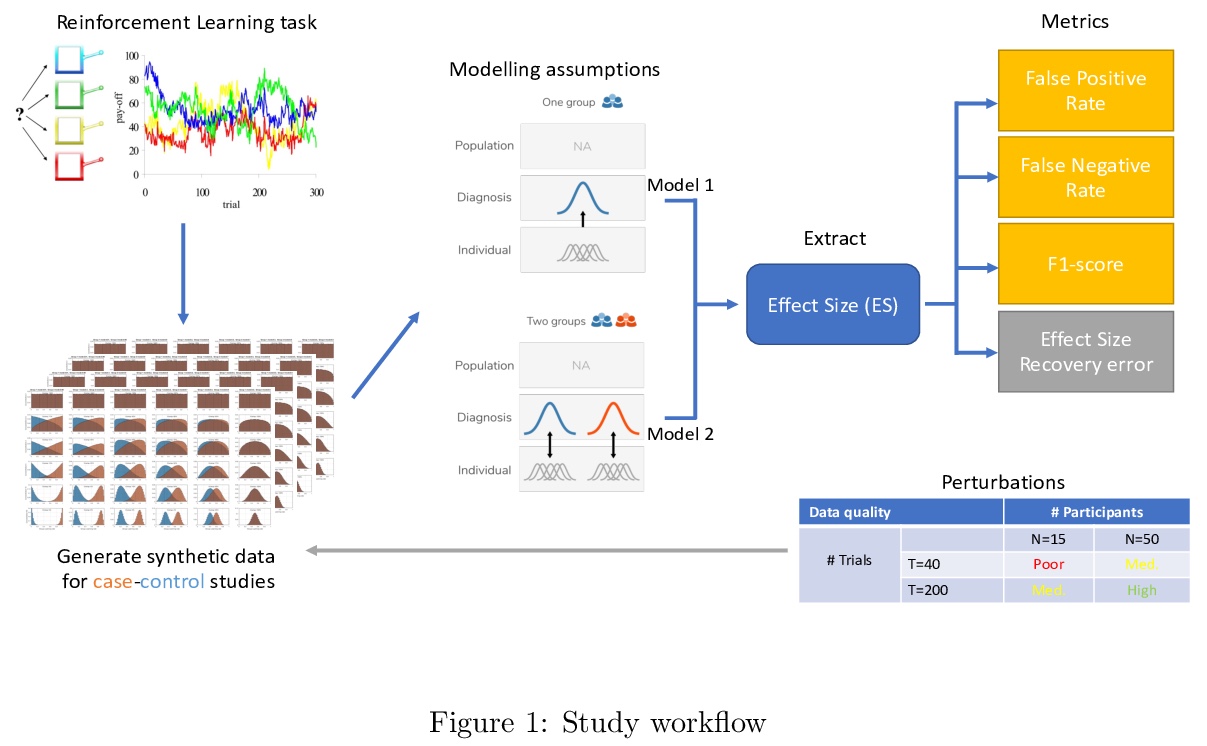
[LG] Representation Matters: Improving Perception and Exploration for Robotics
面向机器人感知/探索提升的表示优化
M Wulfmeier, A Byravan, T Hertweck, I Higgins, A Gupta, T Kulkarni, M Reynolds, D Teplyashin, R Hafner, T Lampe, M Riedmiller
[DeepMind]
https://weibo.com/1402400261/Jsruk0SOX
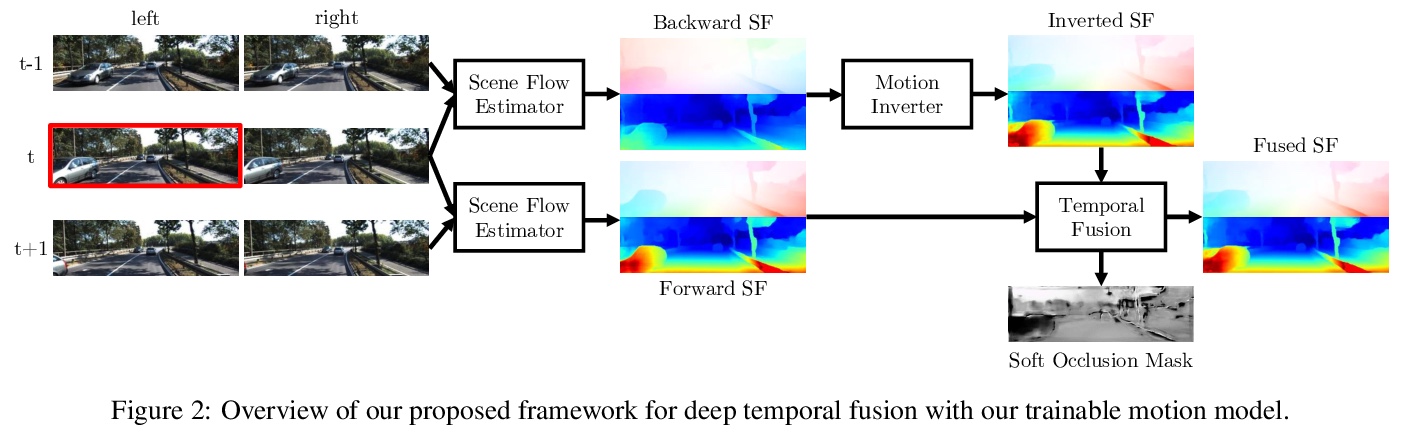
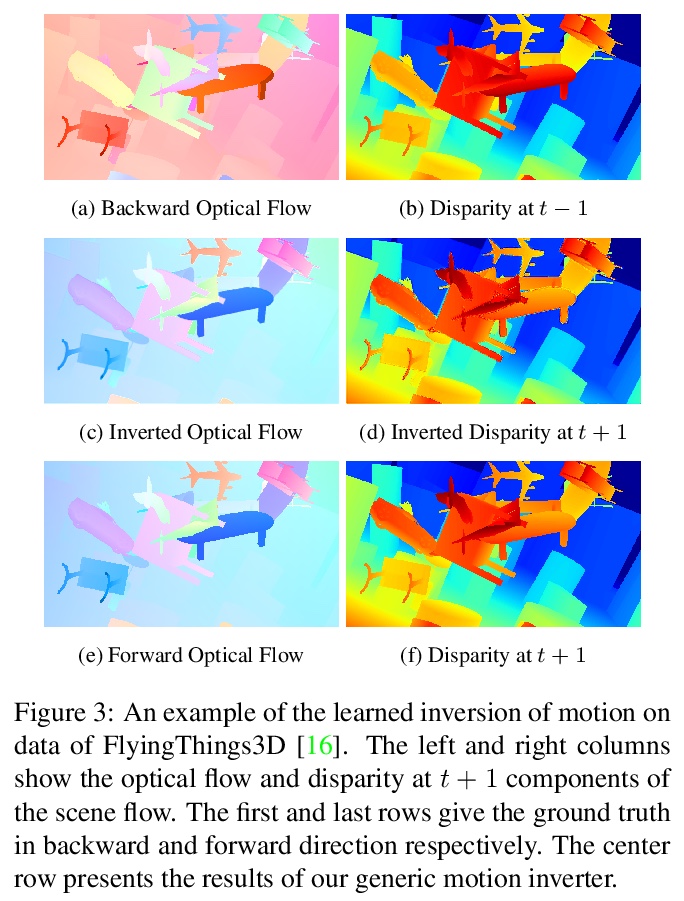
[CV] A Deep Temporal Fusion Framework for Scene Flow Using a Learnable Motion Model and Occlusions
基于可学习运动模型和遮挡的场景流深度时间融合框架
R Schuster, C Unger, D Stricker
[DFKI - German Research Center for Artificial Intelligence & BMW Group]
https://weibo.com/1402400261/JsrwaBsBL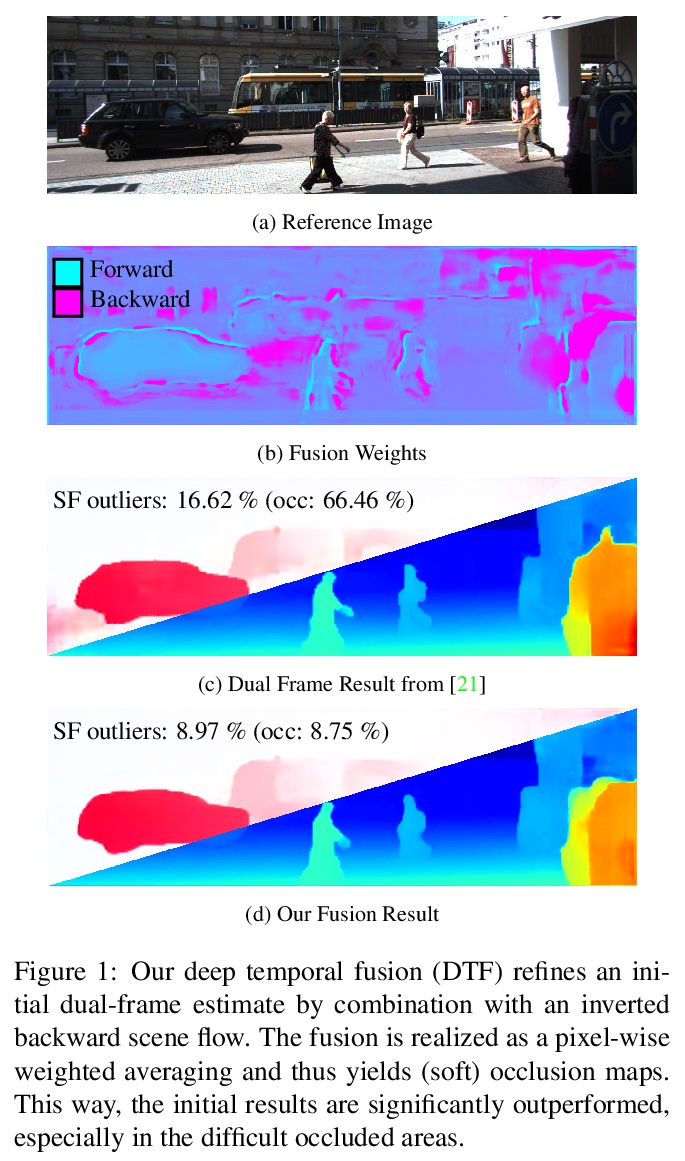
[LG] Enabling certification of verification-agnostic networks via memory-efficient semidefinite programming
通过存储器高效半定规划实现验证不可知网络认证
S Dathathri, K Dvijotham, A Kurakin, A Raghunathan, J Uesato, R Bunel, S Shankar, J Steinhardt, I Goodfellow, P Liang, P Kohli
[DeepMind & Google Brain & Stanford & UC Berkeley]
https://weibo.com/1402400261/JsrxD6eZM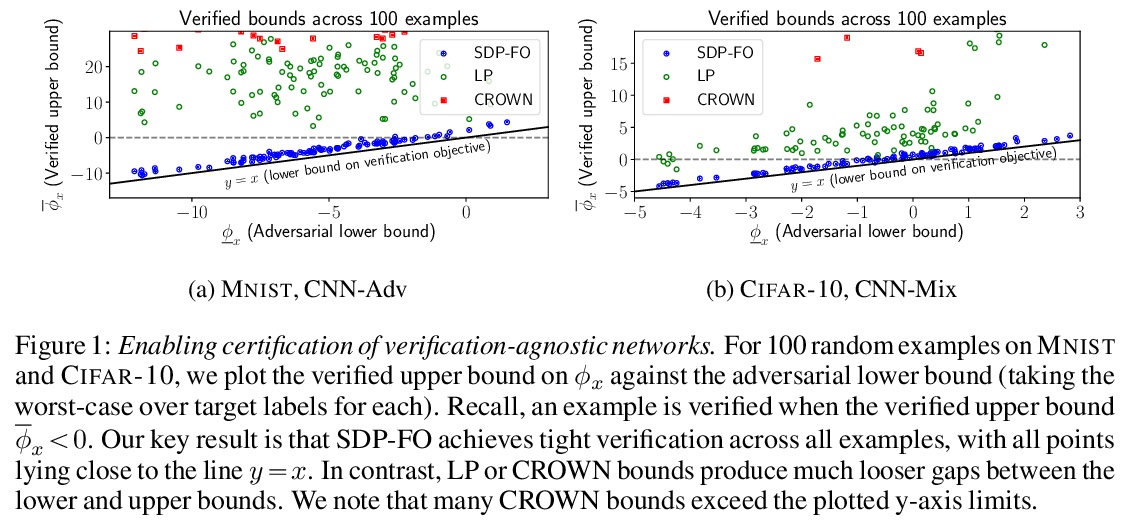

[RO] Policy Transfer via Kinematic Domain Randomization and Adaptation
基于运动域随机化和自适应的策略迁移
I Exarchos, Y Jiang, W Yu, C. K Liu
[Stanford University & Google]
https://weibo.com/1402400261/JsrCruFRz

若有收获,就点个赞吧
0 人点赞
