- 1、[CV] Learn to Dance with AIST++: Music Conditioned 3D Dance Generation
- 2、[LG] Characterizing signal propagation to close the performance gap in unnormalized ResNets
- 3、[CV] DAF:re: A Challenging, Crowd-Sourced, Large-Scale, Long-Tailed Dataset For Anime Character Recognition
- 4、[LG] MLPF: Efficient machine-learned particle-flow reconstruction using graph neural networks
- 5、[LG] Robust Reinforcement Learning on State Observations with Learned Optimal Adversary
- [CV] Generative Zero-shot Network Quantization
- [CL] Zero-shot Generalization in Dialog State Tracking through Generative Question Answering
- [CV] Segmenting Transparent Object in the Wild with Transformer
- [LG] Influence Estimation for Generative Adversarial Networks
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Learn to Dance with AIST++: Music Conditioned 3D Dance Generation
R Li, S Yang, D A. Ross, A Kanazawa
[University of Southern California & Google Research]
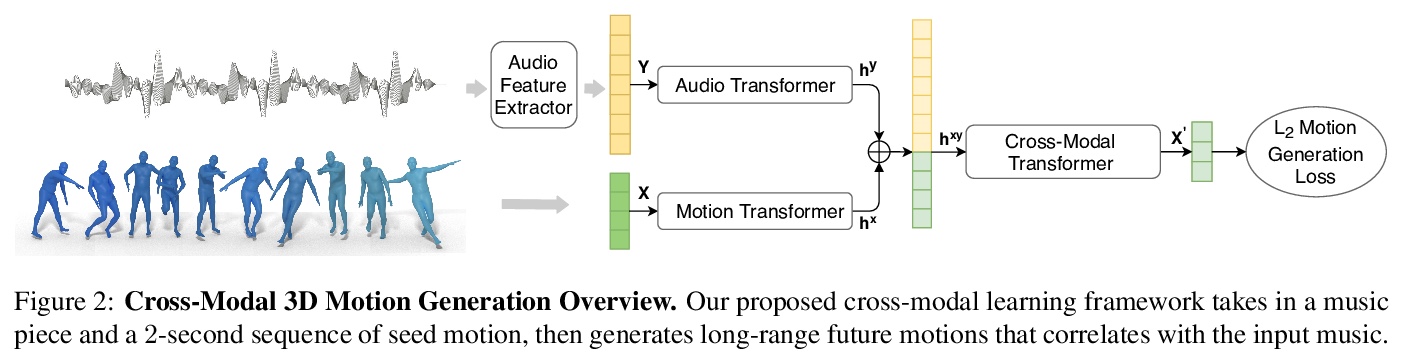
AIST++:基于音乐的3D舞姿生成。提出基于transformer的跨模态学习框架,基于音乐生成3D舞姿。关键组件包括一个深度跨模态transformer,用于学习音乐和舞蹈运动之间的相关性;以及带有future-N监督机制的全注意力,对产生长程非冻结运动至关重要。提出一个新的3D运动和音乐配对的数据集AIST++,从AIST多视角舞蹈视频中重建了该数据集,包含1408个序列110万帧3D舞蹈运动,涵盖10种舞蹈编排类型,伴有多视角摄像机参数。
In this paper, we present a transformer-based learning framework for 3D dance generation conditioned on music. We carefully design our network architecture and empirically study the keys for obtaining qualitatively pleasing results. The critical components include a deep cross-modal transformer, which well learns the correlation between the music and dance motion; and the full-attention with future-N supervision mechanism which is essential in producing long-range non-freezing motion. In addition, we propose a new dataset of paired 3D motion and music called AIST++, which we reconstruct from the AIST multi-view dance videos. This dataset contains 1.1M frames of 3D dance motion in 1408 sequences, covering 10 genres of dance choreographies and accompanied with multi-view camera parameters. To our knowledge it is the largest dataset of this kind. Rich experiments on AIST++ demonstrate our method produces much better results than the state-of-the-art methods both qualitatively and quantitatively.
https://weibo.com/1402400261/JErV8a3HH
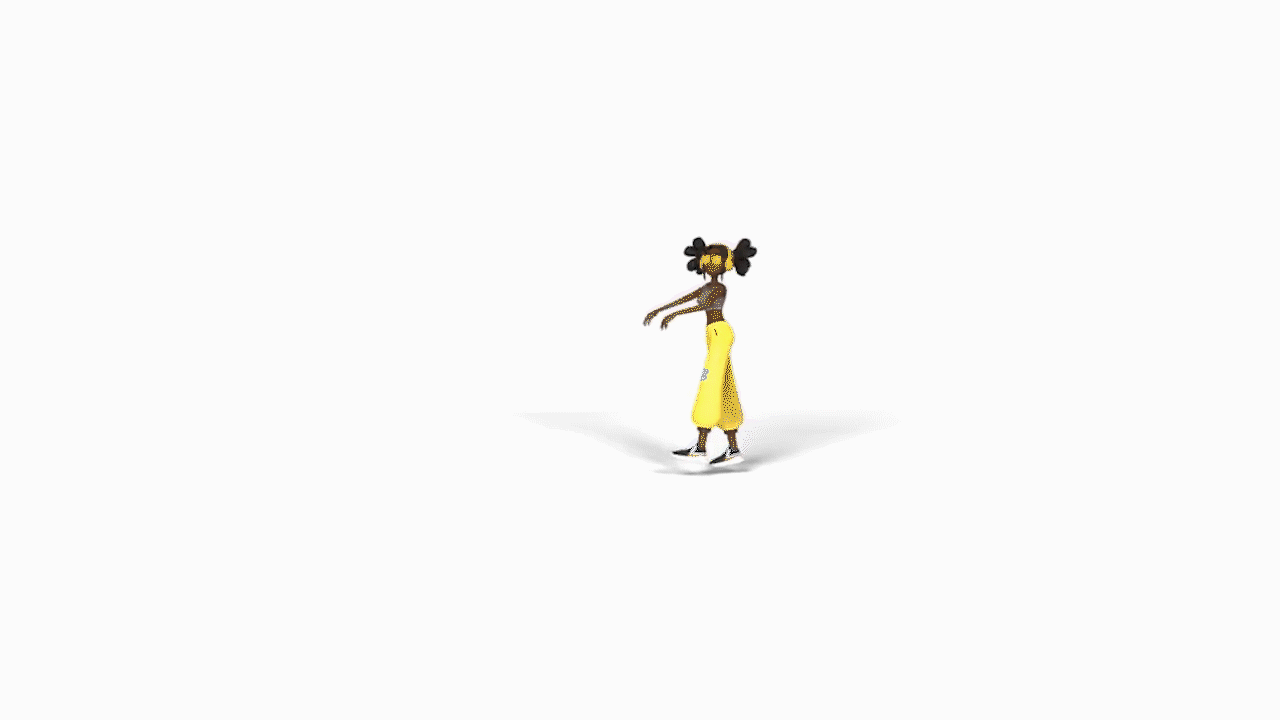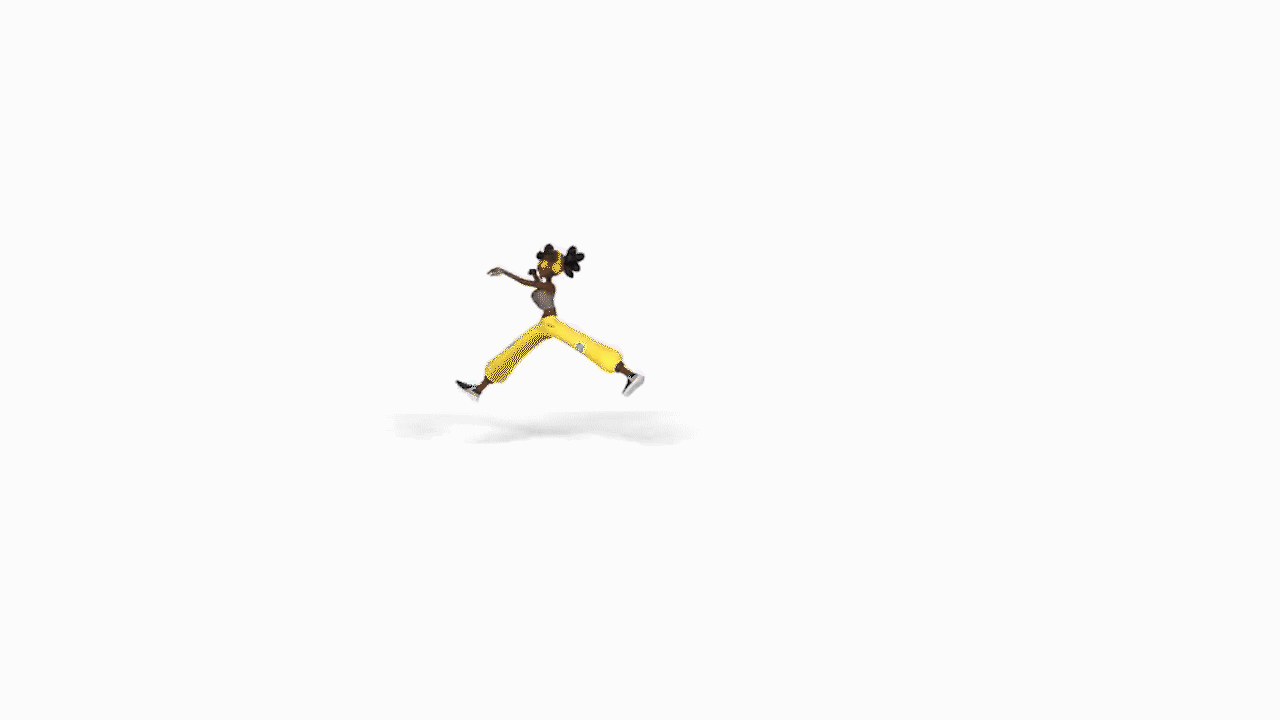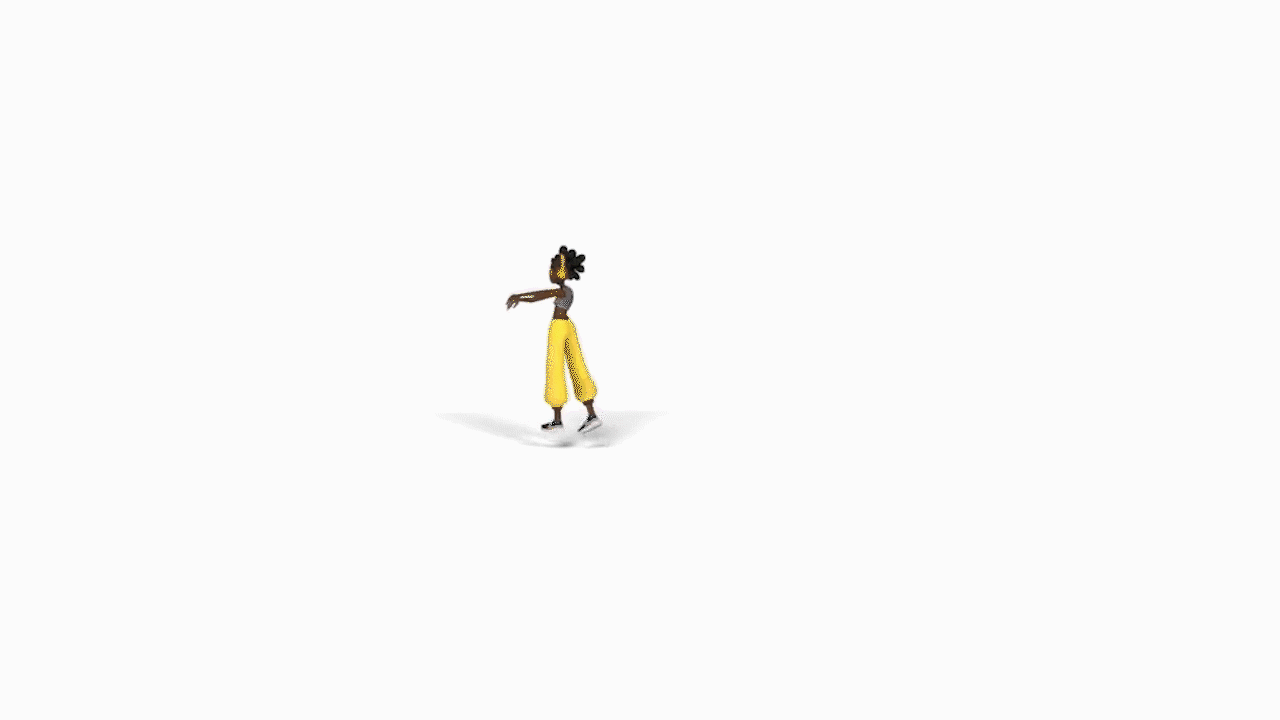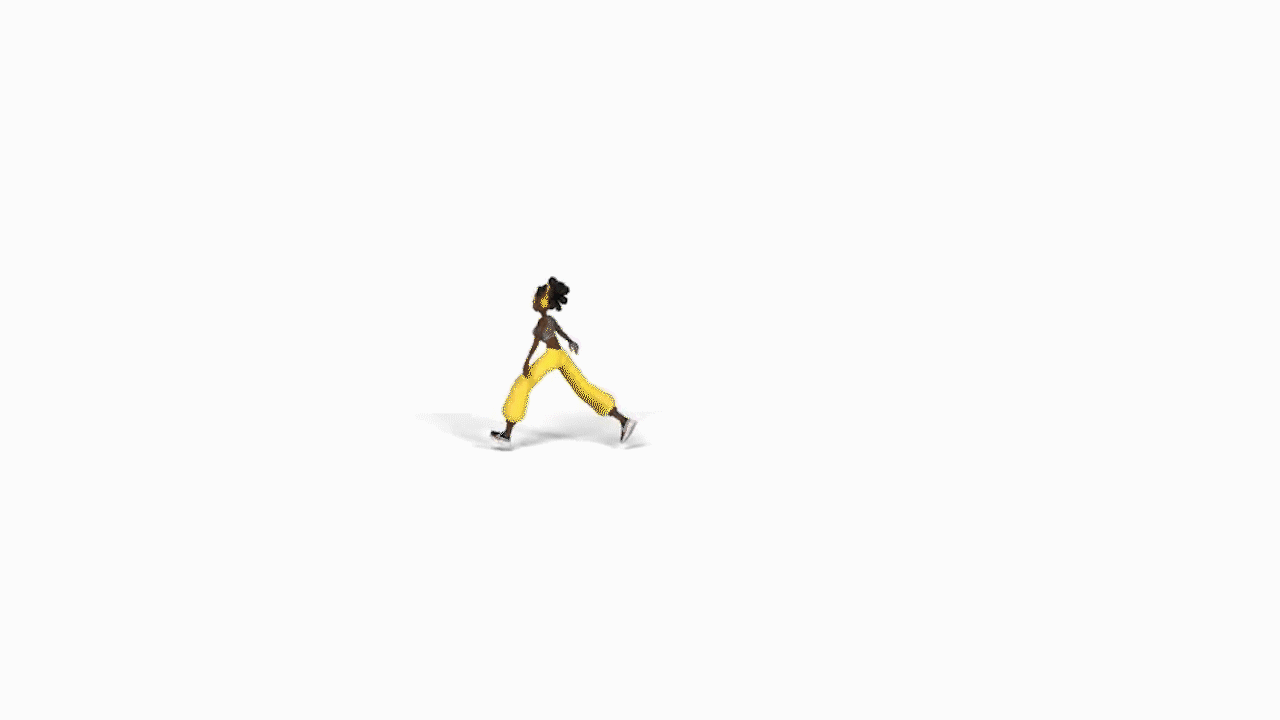

2、[LG] Characterizing signal propagation to close the performance gap in unnormalized ResNets
A Brock, S De, S L. Smith
[Deepmind]
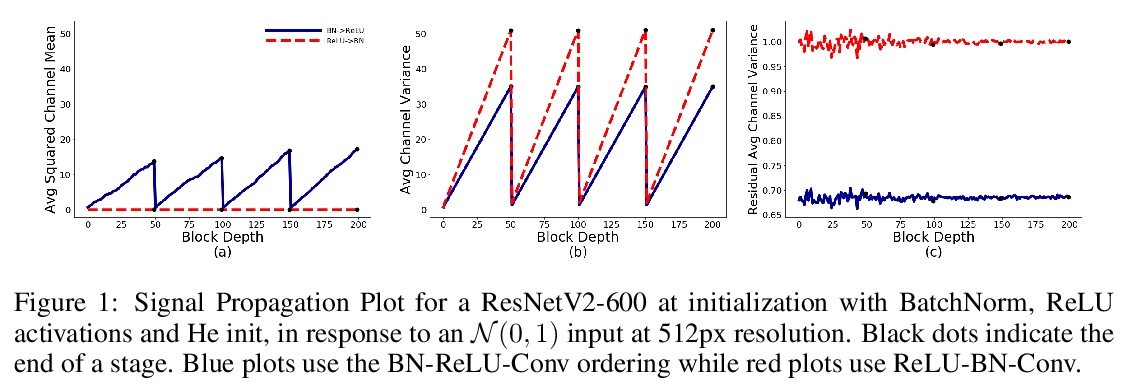
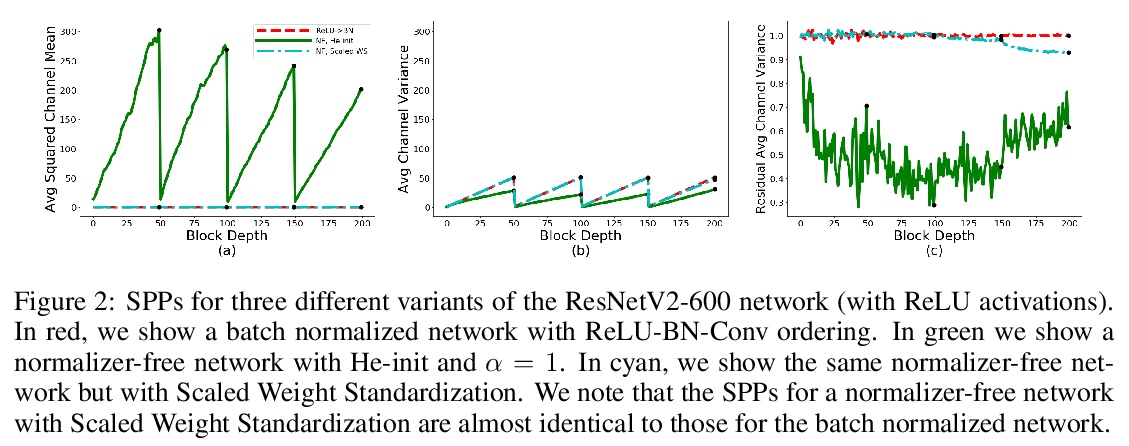
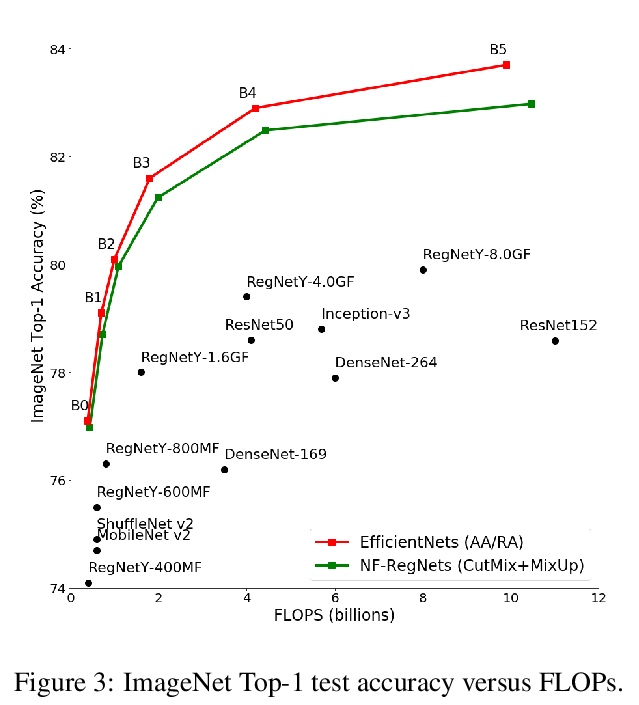
用以缩小非标准化ResNet性能差距的信号传播表征。BatchNorm是最先进图像分类器的关键组件,但它打破了同批量训练实例间的独立性,可能产生运算和内存开销,经常导致意外错误。提出了一套简单的分析工具来表征前向通道上的信号传播,并利用这些工具来设计无需激活标准化层的高性能ResNet。引入了无标准化器网络(Normalizer-Free Networks),一种设计残差网络的简单方法,不需要激活标准化层。其关键是最近提出的权重标准化的改进版本。在FLOP预算范围内,该网络达到了与ImageNet上最先进的EfficientNets竞争的性能。对信号传播的经验分析表明,BatchNorm解决了深度ResNets初始化时的两种关键失败模式。首先,它抑制了残差分支上隐藏激活的规模,防止信号爆炸。第二,它防止了每个通道上激活的均值平方规模超过实例之间激活的方差。Normalizer-Free网络经过精心设计,解决了这两种故障模式。
Batch Normalization is a key component in almost all state-of-the-art image classifiers, but it also introduces practical challenges: it breaks the independence between training examples within a batch, can incur compute and memory overhead, and often results in unexpected bugs. Building on recent theoretical analyses of deep ResNets at initialization, we propose a simple set of analysis tools to characterize signal propagation on the forward pass, and leverage these tools to design highly performant ResNets without activation normalization layers. Crucial to our success is an adapted version of the recently proposed Weight Standardization. Our analysis tools show how this technique preserves the signal in networks with ReLU or Swish activation functions by ensuring that the per-channel activation means do not grow with depth. Across a range of FLOP budgets, our networks attain performance competitive with the state-of-the-art EfficientNets on ImageNet.
https://weibo.com/1402400261/JEs15gpei
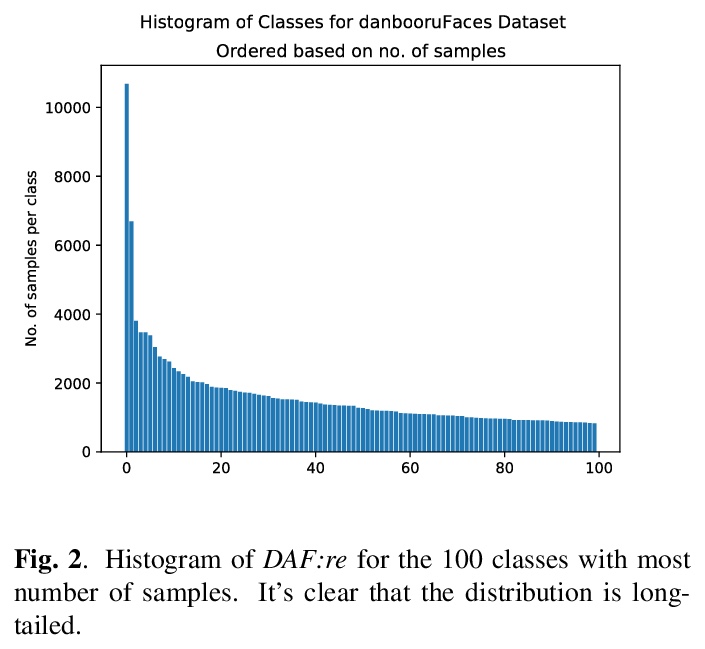
3、[CV] DAF:re: A Challenging, Crowd-Sourced, Large-Scale, Long-Tailed Dataset For Anime Character Recognition
E A Rios, W Cheng, B Lai
[National Chiao Tung University]
DAF:re: 众包大规模长尾动漫角色识别数据集。提出了大规模众包长尾数据集DAF:re(DanbooruAnimeFaces:revamped),包含近500K幅图像,分布在3000多个类上,用以研究动漫角色识别这一挑战性问题。对DAF:re和moeImouto数据集进行了大量实验,使用了多种模型。从结果可得出结论,虽然ViT模型为基于CNN的图像分类模型提供了很有前途的替代方案,但如果目标是充分利用transformer在计算机视觉应用中的泛化和转移学习能力,还要对不同超参数的影响做更多的工作。
In this work we tackle the challenging problem of anime character recognition. Anime, referring to animation produced within Japan and work derived or inspired from it. For this purpose we present DAF:re (DanbooruAnimeFaces:revamped), a large-scale, crowd-sourced, long-tailed dataset with almost 500 K images spread across more than 3000 classes. Additionally, we conduct experiments on DAF:re and similar datasets using a variety of classification models, including CNN based ResNets and self-attention based Vision Transformer (ViT). Our results give new insights into the generalization and transfer learning properties of ViT models on substantially different domain datasets from those used for the upstream pre-training, including the influence of batch and image size in their training. Additionally, we share our dataset, source-code, pre-trained checkpoints and results, as Animesion, the first end-to-end framework for large-scale anime character recognition: > this https URL
https://weibo.com/1402400261/JEs8ecYPz
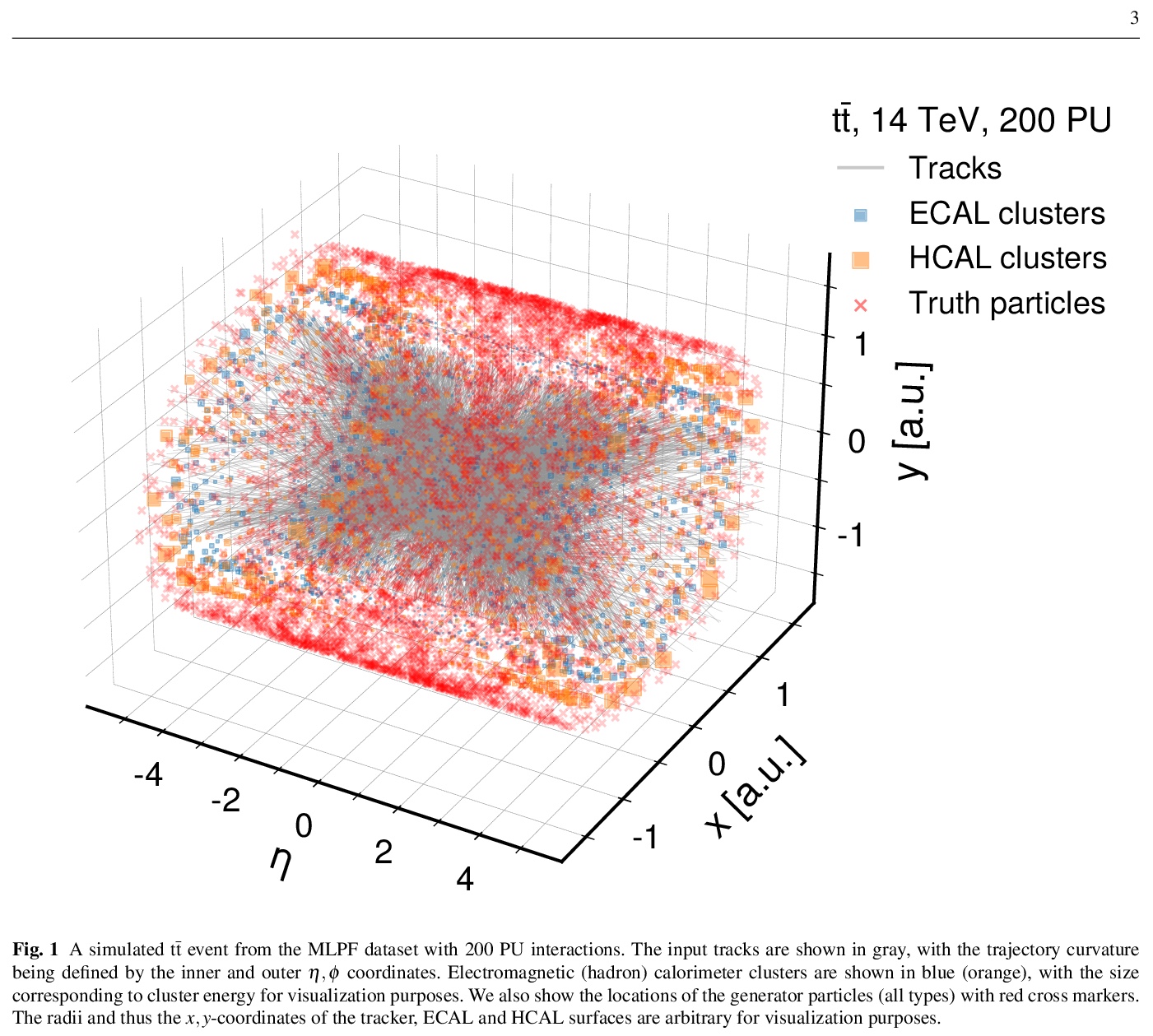
4、[LG] MLPF: Efficient machine-learned particle-flow reconstruction using graph neural networks
J Pata, J Duarte, J Vlimant, M Pierini, M Spiropulu
[National Institute of Chemical Physics and Biophysics (NICPB) & California Institute of Technology & University of California San Diego]
MLPF:基于图神经网络的高效机器学习粒子流重建。提出了MLPF,一种端到端可训练的机器学习粒子流算法,用于重建基于可并行、计算效率高、可扩展的图神经网络和多任务目标的具有大量同时堆积(PU)碰撞事件中的粒子流候选视图,其运行时间与输入大小呈近似线性关系。
In general-purpose particle detectors, the particle flow algorithm may be used to reconstruct a coherent particle-level view of the event by combining information from the calorimeters and the trackers, significantly improving the detector resolution for jets and the missing transverse momentum. In view of the planned high-luminosity upgrade of the CERN Large Hadron Collider, it is necessary to revisit existing reconstruction algorithms and ensure that both the physics and computational performance are sufficient in a high-pileup environment. Recent developments in machine learning may offer a prospect for efficient event reconstruction based on parametric models. We introduce MLPF, an end-to-end trainable machine-learned particle flow algorithm for reconstructing particle flow candidates based on parallelizable, computationally efficient, scalable graph neural networks and a multi-task objective. We report the physics and computational performance of the MLPF algorithm on on a synthetic dataset of ttbar events in HL-LHC running conditions, including the simulation of multiple interaction effects, and discuss potential next steps and considerations towards ML-based reconstruction in a general purpose particle detector.
https://weibo.com/1402400261/JEsdpmGKU
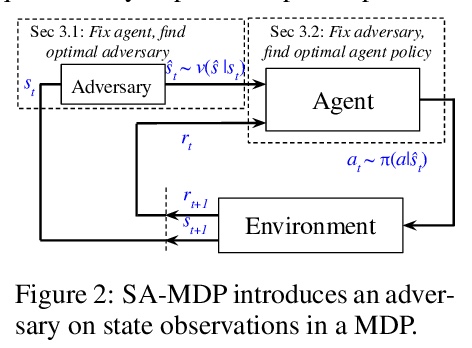
5、[LG] Robust Reinforcement Learning on State Observations with Learned Optimal Adversary
H Zhang, H Chen, D Boning, C Hsieh
[UCLA & MIT]
基于习得最优对手状态观测的鲁棒强化学习。提出了对强化学习智能体的状态观测最优对抗性攻击,明显强于许多现有的对抗性攻击。展示了习得对手交替训练(ATLA)框架,将智能体与习得最优对手一起训练,以有效提高攻击下的智能体鲁棒性。LSTM参数化的历史依赖性策略可以帮助提高稳健性。该方法与现有基于正则化的技术是正交的,可以与状态对抗正则化相结合,实现强对抗攻击下的最先进的鲁棒性。
We study the robustness of reinforcement learning (RL) with adversarially perturbed state observations, which aligns with the setting of many adversarial attacks to deep reinforcement learning (DRL) and is also important for rolling out real-world RL agent under unpredictable sensing noise. With a fixed agent policy, we demonstrate that an optimal adversary to perturb state observations can be found, which is guaranteed to obtain the worst case agent reward. For DRL settings, this leads to a novel empirical adversarial attack to RL agents via a learned adversary that is much stronger than previous ones. To enhance the robustness of an agent, we propose a framework of alternating training with learned adversaries (ATLA), which trains an adversary online together with the agent using policy gradient following the optimal adversarial attack framework. Additionally, inspired by the analysis of state-adversarial Markov decision process (SA-MDP), we show that past states and actions (history) can be useful for learning a robust agent, and we empirically find a LSTM based policy can be more robust under adversaries. Empirical evaluations on a few continuous control environments show that ATLA achieves state-of-the-art performance under strong adversaries. Our code is available at > this https URL.
https://weibo.com/1402400261/JEshMChiS


另外几篇值得关注的论文:
[CV] Generative Zero-shot Network Quantization
生成式零样本网络量化
X He, Q Hu, P Wang, J Cheng
[CASIA]
https://weibo.com/1402400261/JEswloicr

[CL] Zero-shot Generalization in Dialog State Tracking through Generative Question Answering
生成式问答对话状态跟踪的零样本泛化
S Li, J Cao, M Sridhar, H Zhu, S Li, W Hamza, J McAuley
[Amazon Alexa AI & UC San Diego & AWS AI]
https://weibo.com/1402400261/JEsAy0OaC

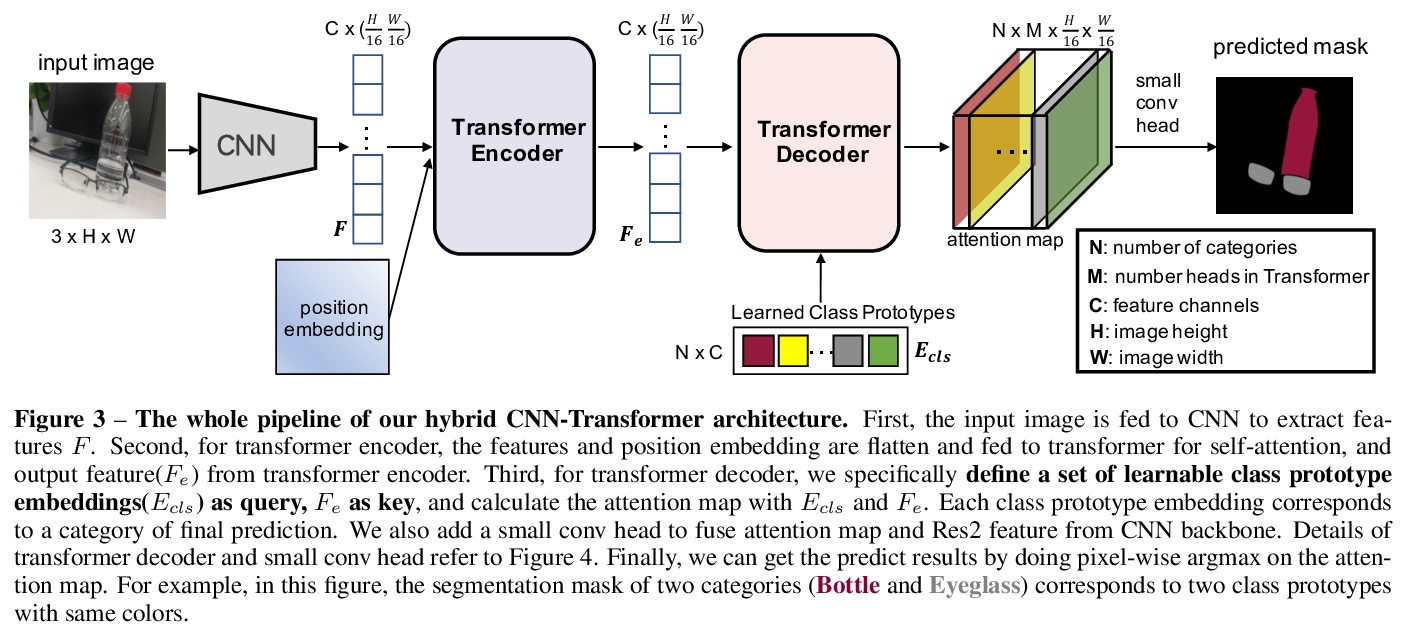
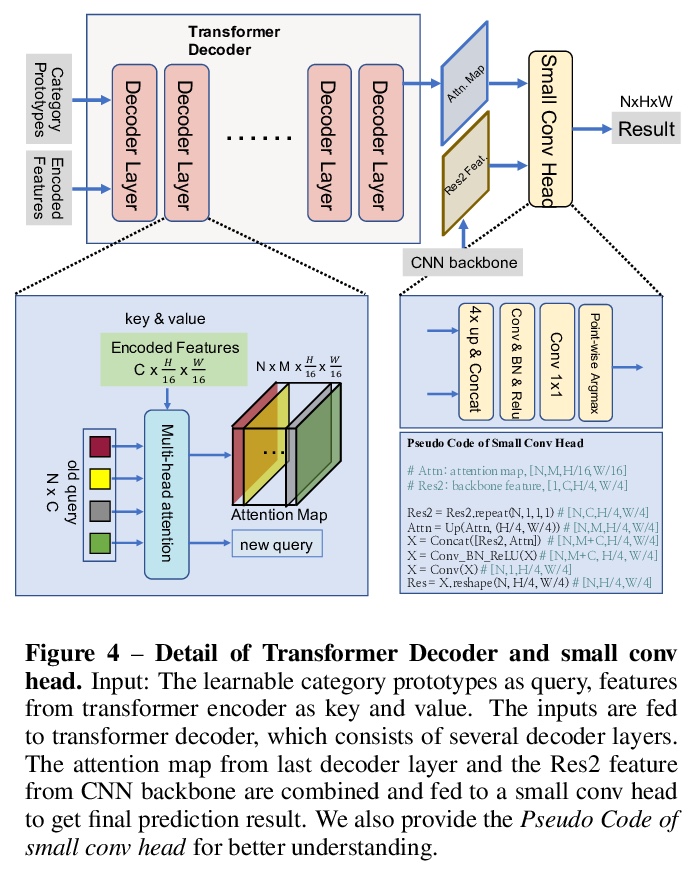
[CV] Segmenting Transparent Object in the Wild with Transformer
基于Transformer的真实场景透明目标分割
E Xie, W Wang, W Wang, P Sun, H Xu, D Liang, P Luo
[The University of Hong Kong & Sensetime Research & Nanjing University & Huawei Noah’s Ark Lab]
https://weibo.com/1402400261/JEsEBrkCT

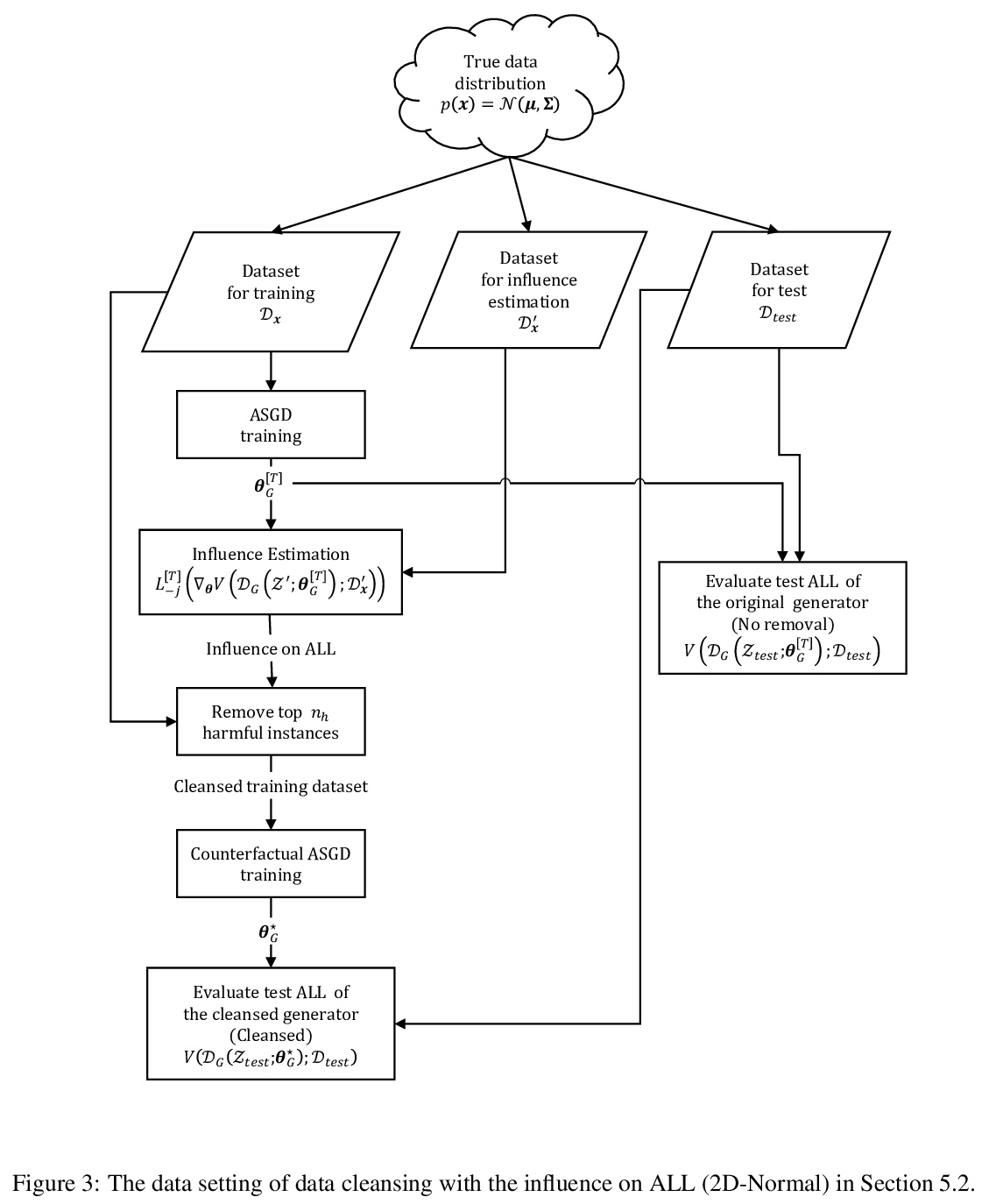
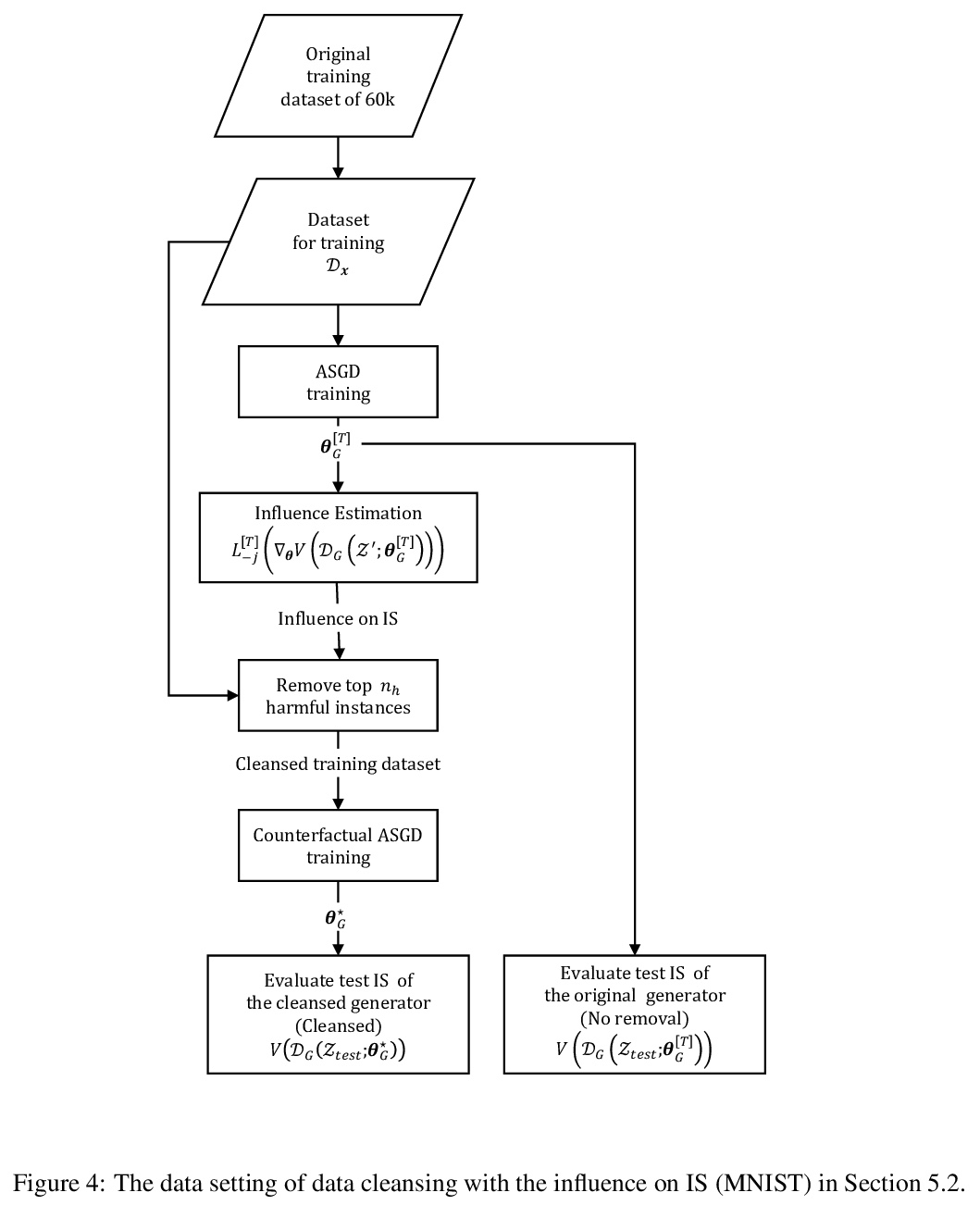
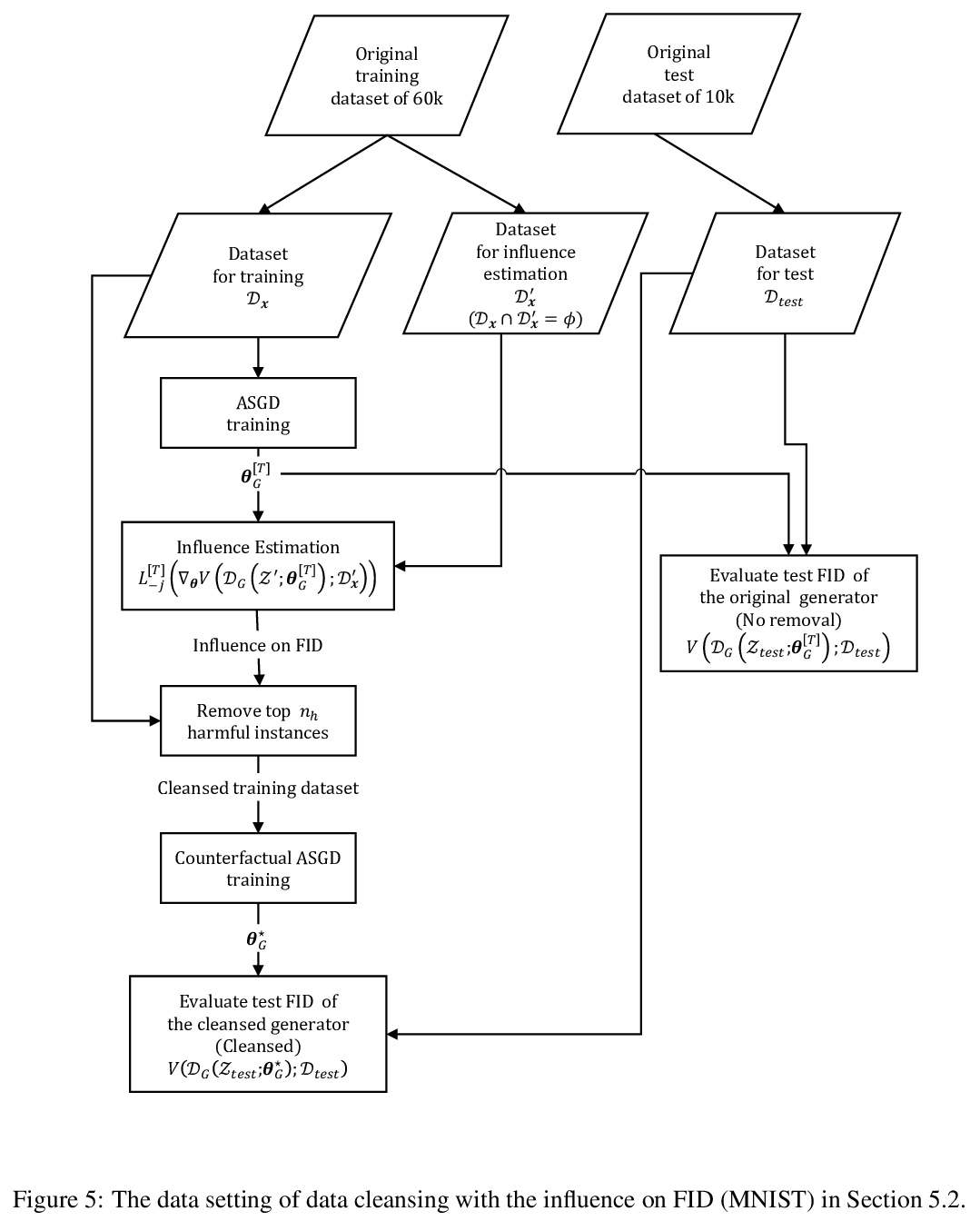
[LG] Influence Estimation for Generative Adversarial Networks
生成对抗网络影响估计
N Terashita, H Ohashi, Y Nonaka, T Kanemaru
[Hitachi, Ltd]
https://weibo.com/1402400261/JEsGV8rxy

若有收获,就点个赞吧
0 人点赞
