- 1、[LG] LieTransformer: Equivariant self-attention for Lie Groups
- 2、 [CV] Projected Distribution Loss for Image Enhancement
- 3、[CV] Polyblur: Removing mild blur by polynomial reblurring
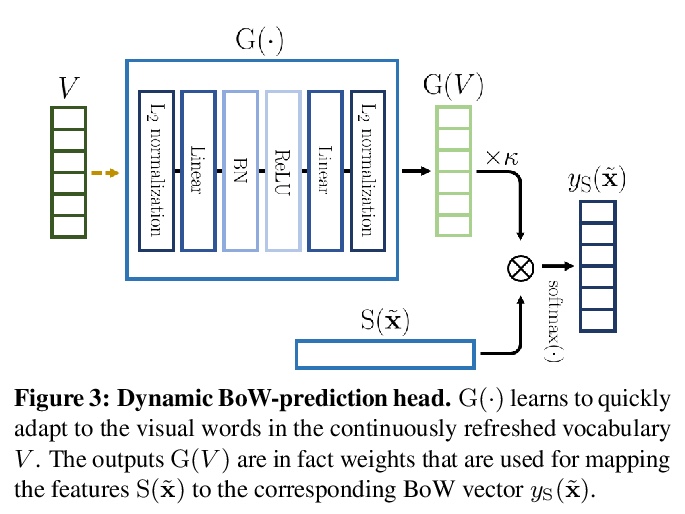
- 4、 [CV] Online Bag-of-Visual-Words Generation for Unsupervised Representation Learning
- 5、[CV] Populating 3D Scenes by Learning Human-Scene Interaction
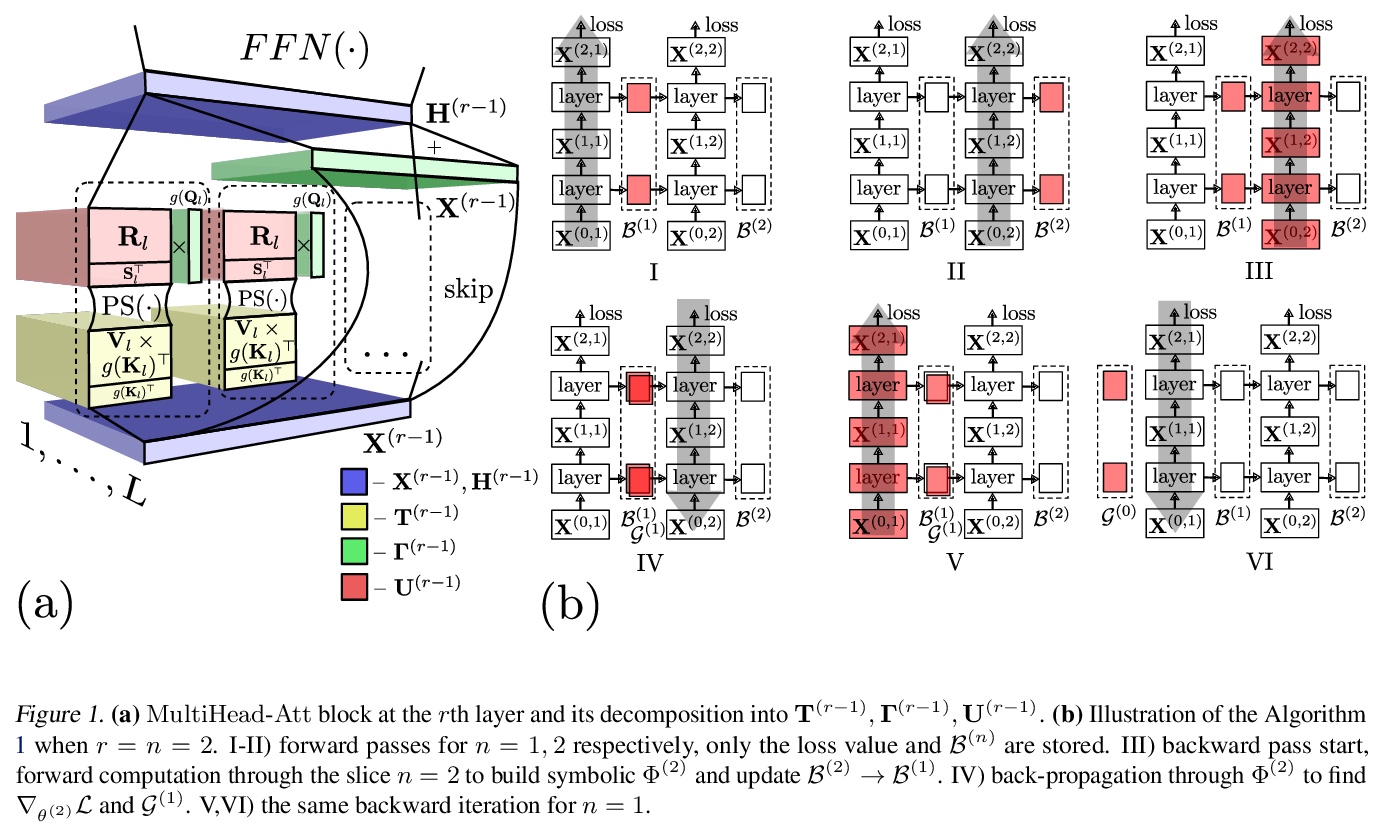
- [LG] Sub-Linear Memory: How to Make Performers SLiM
- [AI] Building LEGO Using Deep Generative Models of Graphs
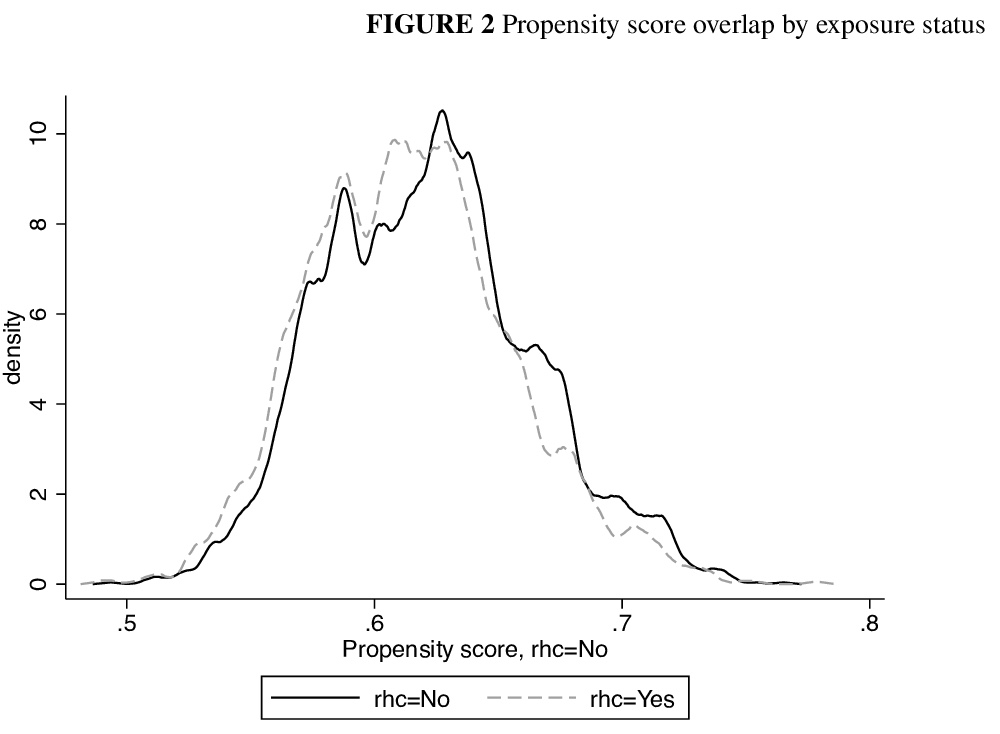
- [ME] Tutorial: Introduction to computational causal inference using reproducible Stata, R and Python code
- [IR] Self-Supervised Learning for Visual Summary Identification in Scientific Publications
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] LieTransformer: Equivariant self-attention for Lie Groups
M Hutchinson, C L Lan, S Zaidi, E Dupont, Y W Teh, H Kim
[University of Oxford & DeepMind]
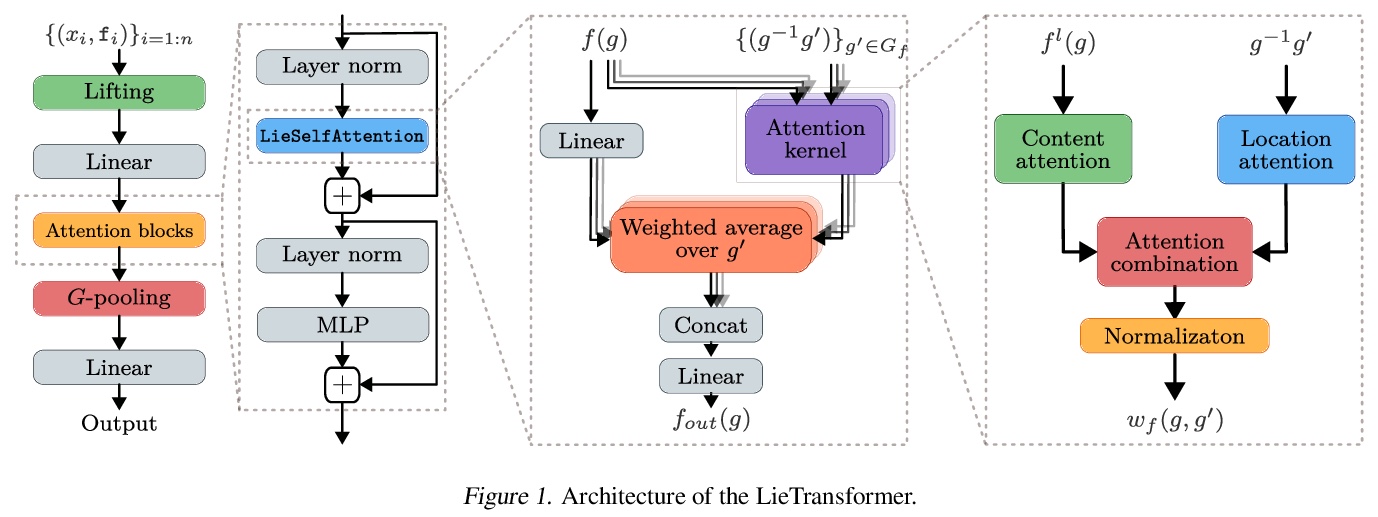
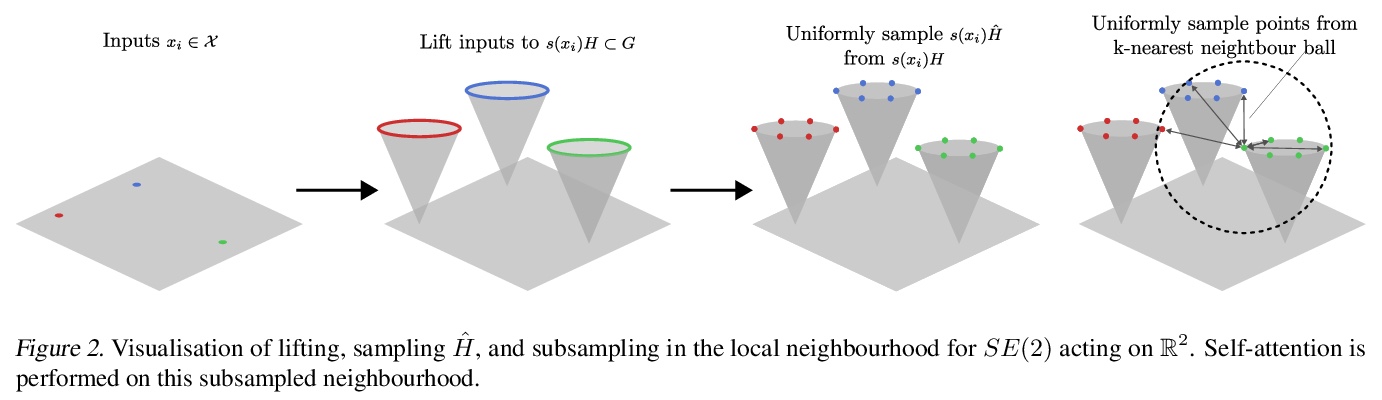
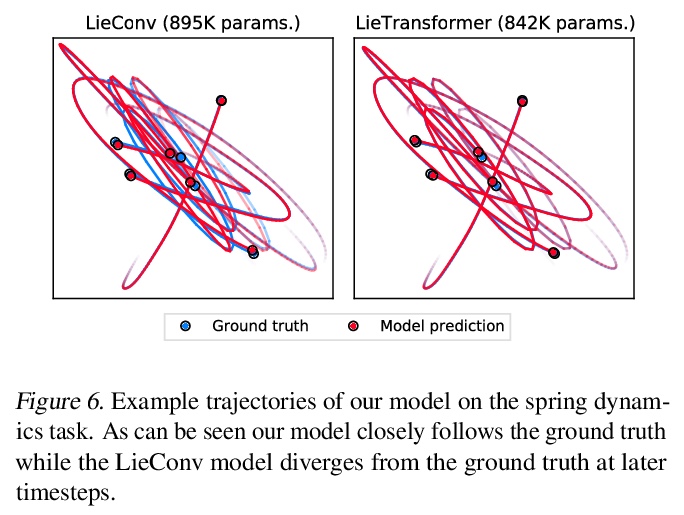
LieTransformer:李群等变自注意力。提出LieTransformer——由LieSelfAttention层组成的体系结构,其与任意李群及其离散子群是等变的。采用一种基于提升的方法,与没有提升的方法相比,放松了对注意力模块的约束。该方法适用于李群及其离散子群作用在齐次空间上的场景。通过实验,在多种任务上证明了方法的通用性,包括点云形状计数,分子性质回归和哈密顿动力学下的粒子轨迹建模等。
Group equivariant neural networks are used as building blocks of group invariant neural networks, which have been shown to improve generalisation performance and data efficiency through principled parameter sharing. Such works have mostly focused on group equivariant convolutions, building on the result that group equivariant linear maps are necessarily convolutions. In this work, we extend the scope of the literature to non-linear neural network modules, namely self-attention, that is emerging as a prominent building block of deep learning models. We propose the LieTransformer, an architecture composed of LieSelfAttention layers that are equivariant to arbitrary Lie groups and their discrete subgroups. We demonstrate the generality of our approach by showing experimental results that are competitive to baseline methods on a wide range of tasks: shape counting on point clouds, molecular property regression and modelling particle trajectories under Hamiltonian dynamics.
https://weibo.com/1402400261/JzJsGidW5
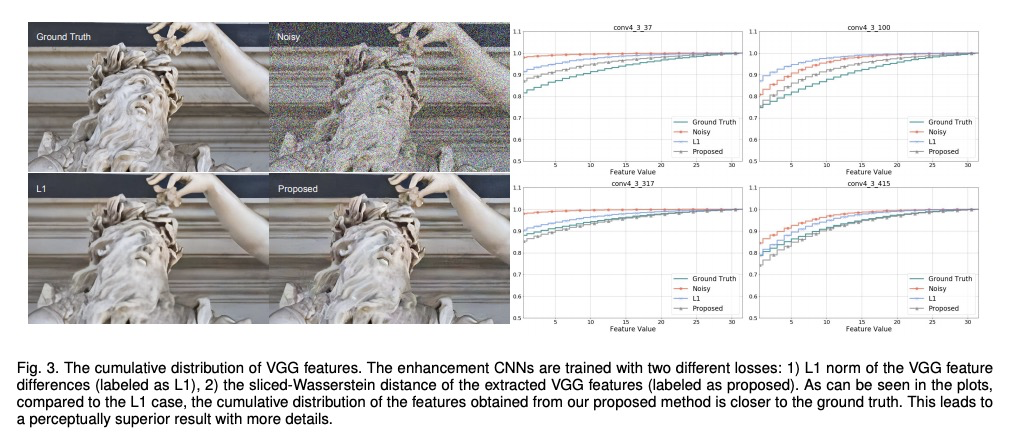
2、 [CV] Projected Distribution Loss for Image Enhancement
M Delbracio, H Talebi, P Milanfar
[Google Research]
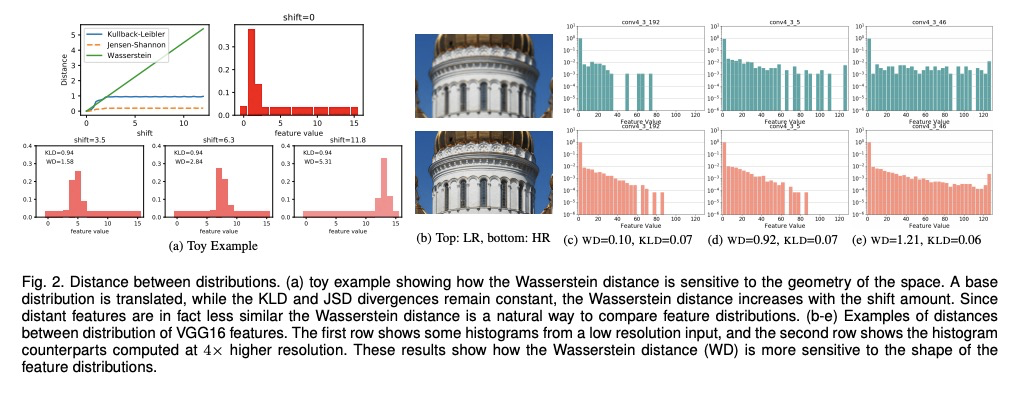
面向图像增强的投影分布损失。提出一种可替代的感知损失——投影分布损失,可用于训练任意图像恢复模型。证明了聚合CNN激活间1D-Wasserstein距离比现有方法更可靠,可显著提高增强模型的感知性能。所提出的投影分布损失,基于一维边际分布的比较,易于实现。在多种图像应用,如去噪、超分辨率、去马赛克、去模糊和JPEG去伪影等方面,所提出的学习损失优于目前最先进的基于参考的感知损失。
Features obtained from object recognition CNNs have been widely used for measuring perceptual similarities between images. Such differentiable metrics can be used as perceptual learning losses to train image enhancement models. However, the choice of the distance function between input and target features may have a consequential impact on the performance of the trained model. While using the norm of the difference between extracted features leads to limited hallucination of details, measuring the distance between distributions of features may generate more textures; yet also more unrealistic details and artifacts. In this paper, we demonstrate that aggregating 1D-Wasserstein distances between CNN activations is more reliable than the existing approaches, and it can significantly improve the perceptual performance of enhancement models. More explicitly, we show that in imaging applications such as denoising, super-resolution, demosaicing, deblurring and JPEG artifact removal, the proposed learning loss outperforms the current state-of-the-art on reference-based perceptual losses. This means that the proposed learning loss can be plugged into different imaging frameworks and produce perceptually realistic results.
https://weibo.com/1402400261/JzJAxtHh3

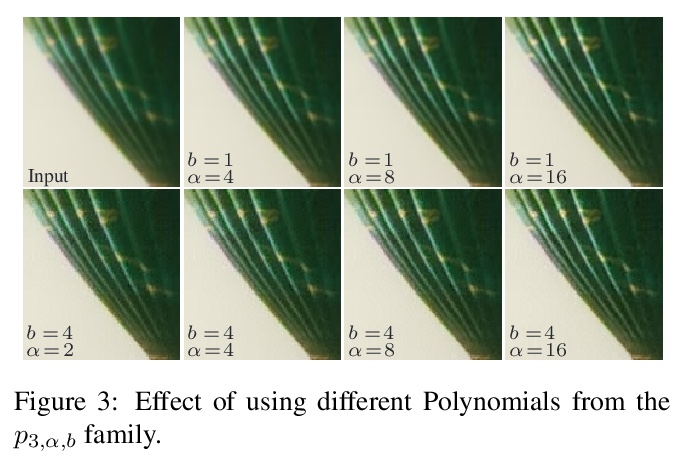
3、[CV] Polyblur: Removing mild blur by polynomial reblurring
M Delbracio, I Garcia-Dorado, S Choi, D Kelly, P Milanfar
[Google Research]
Polyblur:用多项式重模糊来消除轻度模糊。提出一种去除自然图像中轻度模糊的高效盲复原方法。专注于去除经常出现的损害图像质量的轻微模糊,通常由小失焦、镜头模糊或轻微相机运动产生。首先用编码了模糊方向和强度的简单梯度特征来估计参数化模糊核,通过将模糊核的多种应用结合在一起,以一种精心构造的方式去除估计的模糊,控制噪声放大的同时,进行近似反演。为估计模糊,引入一种简单鲁棒基于对清晰自然图像中梯度分布的经验观察的算法。该方法可以在几分之一秒的时间内,对现代手机上的1200万像素图像进行轻度模糊估计和去除。
We present a highly efficient blind restoration method to remove mild blur in natural images. Contrary to the mainstream, we focus on removing slight blur that is often present, damaging image quality and commonly generated by small out-of-focus, lens blur, or slight camera motion. The proposed algorithm first estimates image blur and then compensates for it by combining multiple applications of the estimated blur in a principled way. To estimate blur we introduce a simple yet robust algorithm based on empirical observations about the distribution of the gradient in sharp natural images. Our experiments show that, in the context of mild blur, the proposed method outperforms traditional and modern blind deblurring methods and runs in a fraction of the time. Our method can be used to blindly correct blur before applying off-the-shelf deep super-resolution methods leading to superior results than other highly complex and computationally demanding techniques. The proposed method estimates and removes mild blur from a 12MP image on a modern mobile phone in a fraction of a second.
https://weibo.com/1402400261/JzJGdsSPX

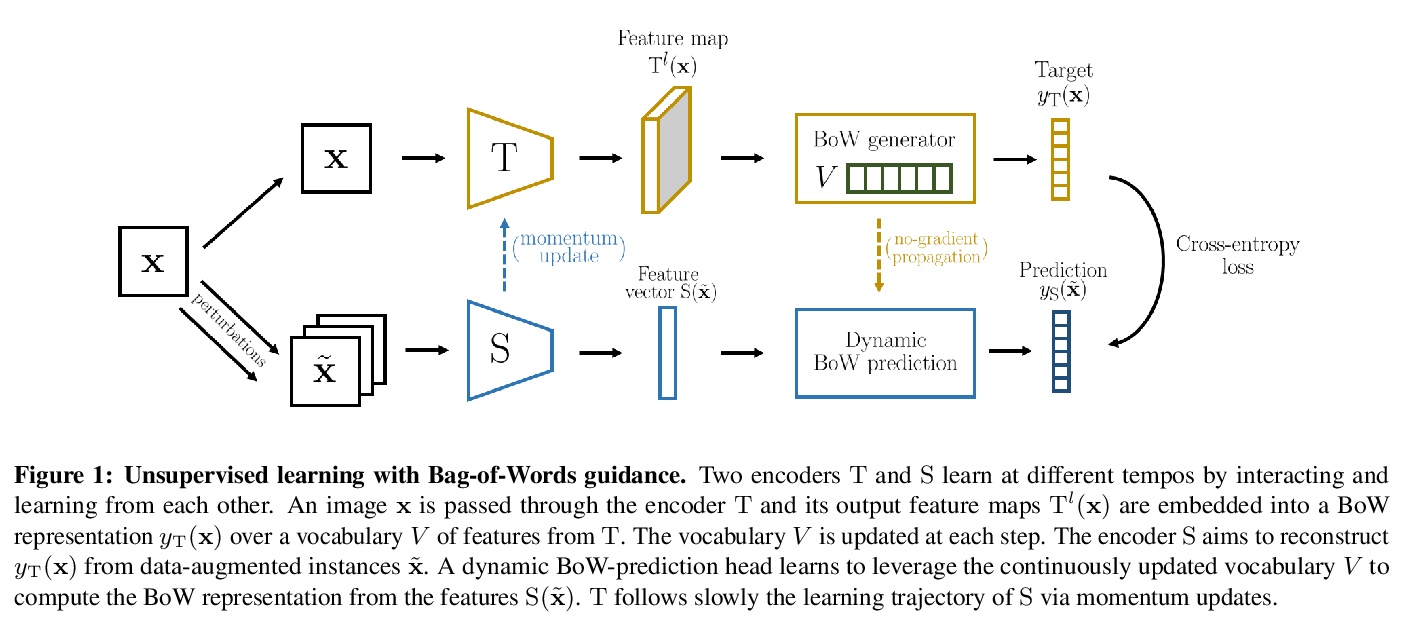
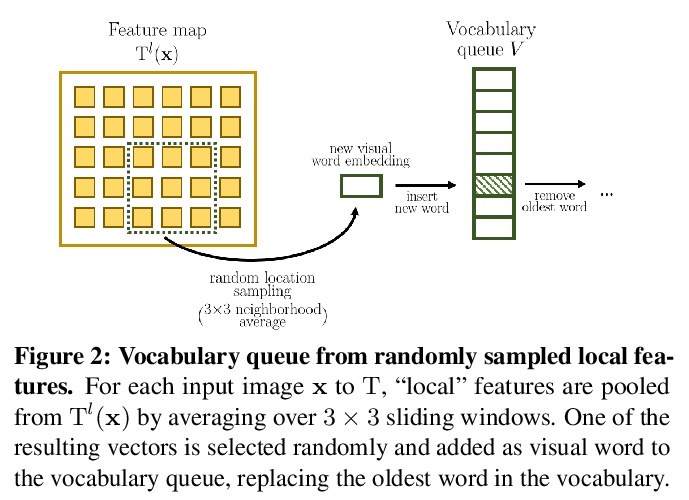
4、 [CV] Online Bag-of-Visual-Words Generation for Unsupervised Representation Learning
S Gidaris, A Bursuc, G Puy, N Komodakis, M Cord, P Pérez
[valeo.ai & University of Crete]
无监督表示学习的在线视觉词袋生成。提出一种新的无监督师-生方案OBoW,通过训练卷积网络来重建图像的视觉词袋(BoW)表示,将同一图像的扰动版本作为输入来学习表示。该策略执行教师网络(生成BoW目标)和学生网络(学习表示)的在线训练,以及视觉词词汇表(用于BoW目标)的在线更新,有效实现了全在线Bow引导的无监督学习。实验结果超越了大多数之前最先进方法。
Learning image representations without human supervision is an important and active research field. Several recent approaches have successfully leveraged the idea of making such a representation invariant under different types of perturbations, especially via contrastive-based instance discrimination training. Although effective visual representations should indeed exhibit such invariances, there are other important characteristics, such as encoding contextual reasoning skills, for which alternative reconstruction-based approaches might be better suited.With this in mind, we propose a teacher-student scheme to learn representations by training a convnet to reconstruct a bag-of-visual-words (BoW) representation of an image, given as input a perturbed version of that same image. Our strategy performs an online training of both the teacher network (whose role is to generate the BoW targets) and the student network (whose role is to learn representations), along with an online update of the visual-words vocabulary (used for the BoW targets). This idea effectively enables fully online BoW-guided unsupervised learning. Extensive experiments demonstrate the interest of our BoW-based strategy which surpasses previous state-of-the-art methods (including contrastive-based ones) in several applications. For instance, in downstream tasks such Pascal object detection, Pascal classification and Places205 classification, our method improves over all prior unsupervised approaches, thus establishing new state-of-the-art results that are also significantly better even than those of supervised pre-training. We provide the implementation code at > this https URL.
https://weibo.com/1402400261/JzJMjoYlD
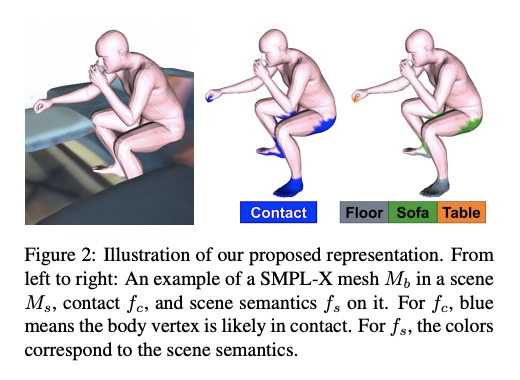
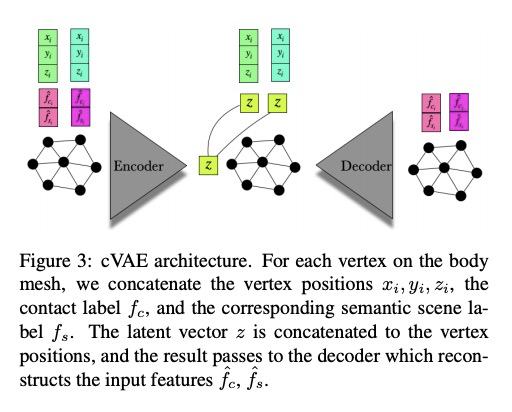
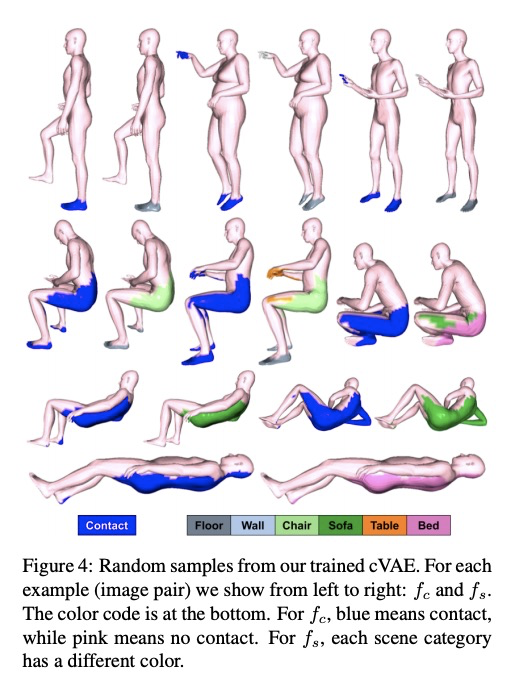
5、[CV] Populating 3D Scenes by Learning Human-Scene Interaction
M Hassan, P Ghosh, J Tesch, D Tzionas, M J. Black
[Max Planck Institute for Intelligent Systems]
基于人-场景交互学习的3D场景填充。引入新的人-场景交互(HSI)模型,对临近关系进行编码,即POSA(临近/接触性姿态)。交互表示以躯体为中心,编码了身体和场景之间的联系和语义关系,能很好地推广到新的场景。POSA增强了SMPL-X参数化人体模型,对每个网格顶点,模型会对其与场景表面的接触概率和相应的语义场景标签进行编码。POSA可用于从单目RGB图像估计人体姿态。
Humans live within a 3D space and constantly interact with it to perform tasks. Such interactions involve physical contact between surfaces that is semantically meaningful. Our goal is to learn how humans interact with scenes and leverage this to enable virtual characters to do the same. To that end, we introduce a novel Human-Scene Interaction (HSI) model that encodes proximal relationships, called POSA for “Pose with prOximitieS and contActs”. The representation of interaction is body-centric, which enables it to generalize to new scenes. Specifically, POSA augments the SMPL-X parametric human body model such that, for every mesh vertex, it encodes (a) the contact probability with the scene surface and (b) the corresponding semantic scene label. We learn POSA with a VAE conditioned on the SMPL-X vertices, and train on the PROX dataset, which contains SMPL-X meshes of people interacting with 3D scenes, and the corresponding scene semantics from the PROX-E dataset. We demonstrate the value of POSA with two applications. First, we automatically place 3D scans of people in scenes. We use a SMPL-X model fit to the scan as a proxy and then find its most likely placement in 3D. POSA provides an effective representation to search for “affordances” in the scene that match the likely contact relationships for that pose. We perform a perceptual study that shows significant improvement over the state of the art on this task. Second, we show that POSA’s learned representation of body-scene interaction supports monocular human pose estimation that is consistent with a 3D scene, improving on the state of the art. Our model and code will be available for research purposes at > this https URL.
https://weibo.com/1402400261/JzJSIu6dQ
[LG] Sub-Linear Memory: How to Make Performers SLiM
亚线性记忆:降低Transformer训练的资源开销
V Likhosherstov, K Choromanski, J Davis, X Song, A Weller
[University of Cambridge & Google Brain & DeepMind]
https://weibo.com/1402400261/JzJXNx48G
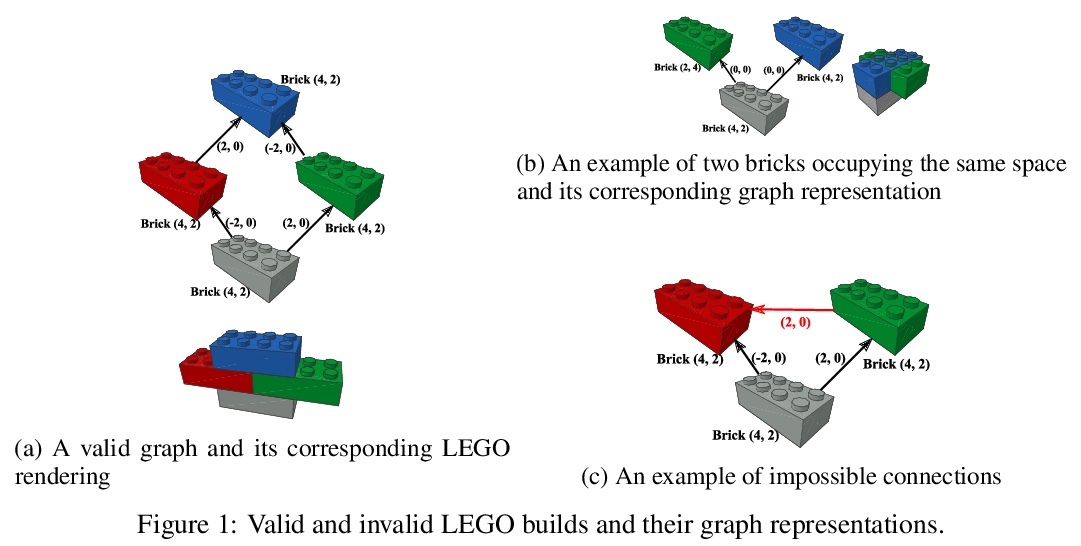
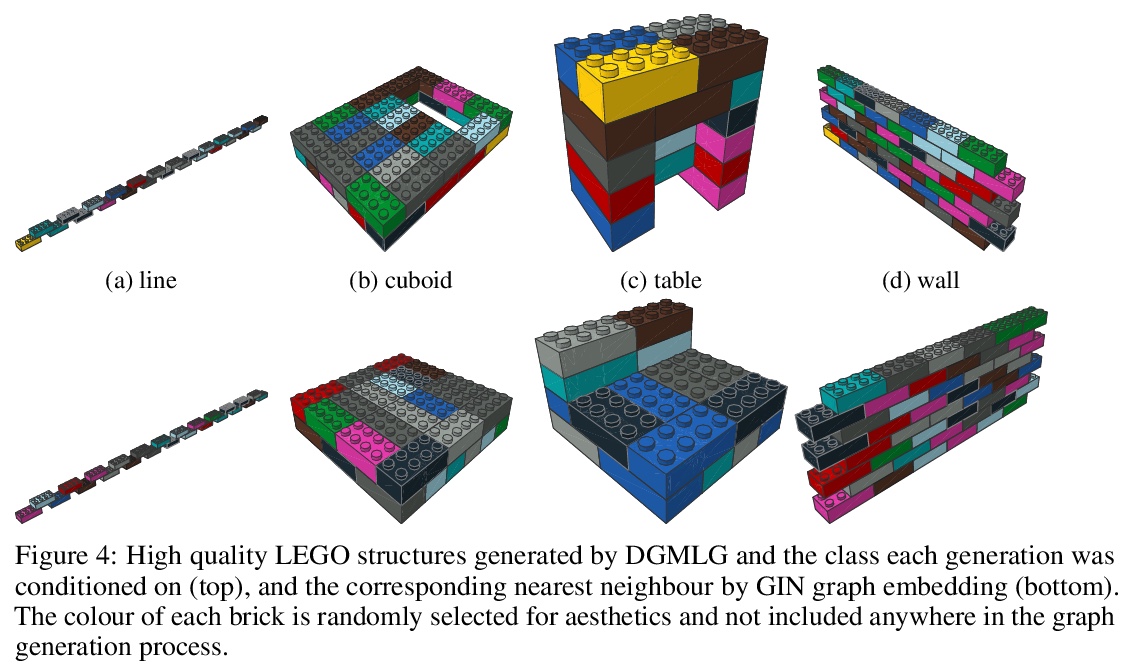
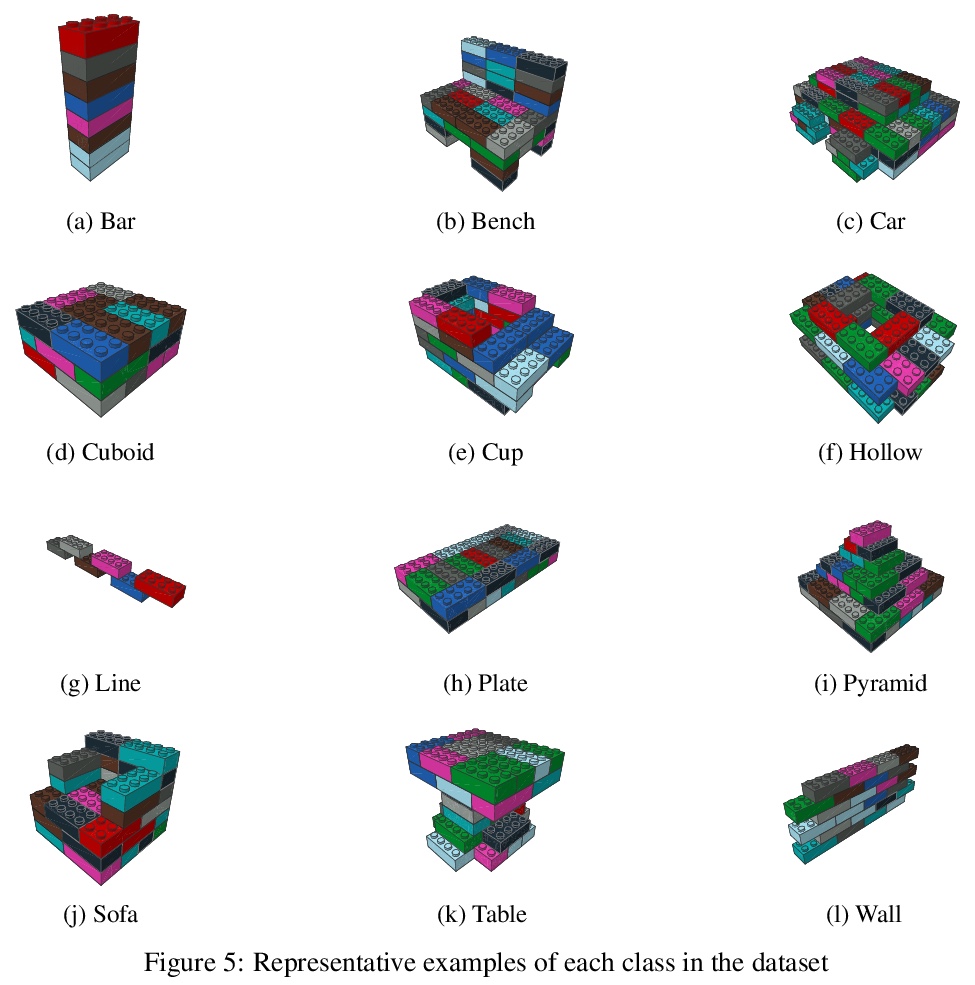
[AI] Building LEGO Using Deep Generative Models of Graphs
用图深度生成模型搭乐高
R Thompson, E Ghalebi, T DeVries, G W. Taylor
[University of Guelph]
https://weibo.com/1402400261/JzK0FpbCB
[ME] Tutorial: Introduction to computational causal inference using reproducible Stata, R and Python code
教程:基于可复现Stata/R/Python代码的计算因果推理介绍
M J. Smith, C Maringe, B Rachet, M A. Mansournia, P N. Zivich, S R. Cole, M A Luque-Fernandez
[London School of Hygiene and Tropical Medicine & Tehran University of Medical Sciences]
https://weibo.com/1402400261/JzK2Mjpx2
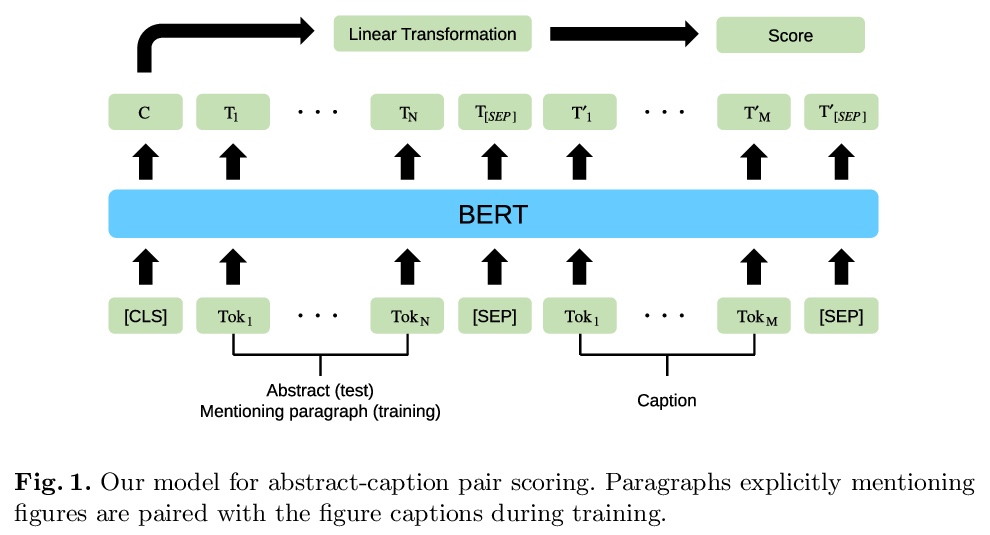
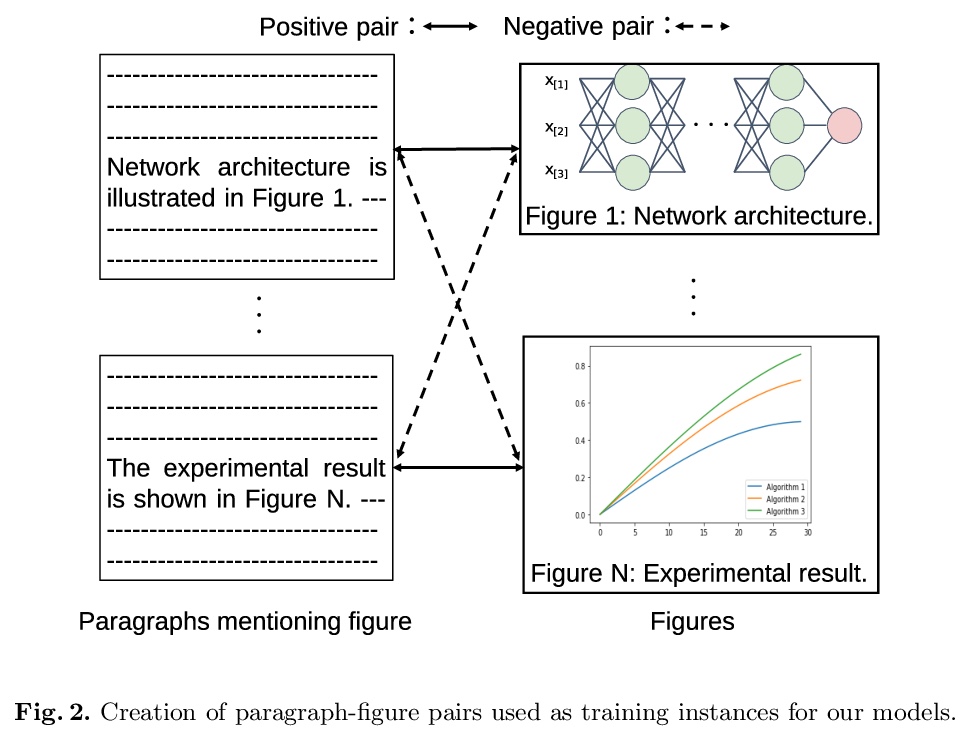
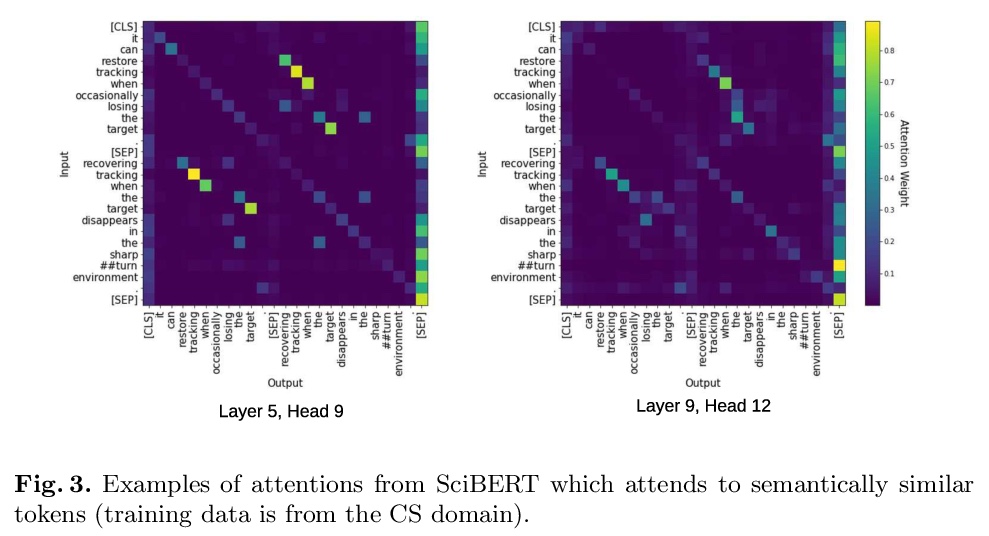
[IR] Self-Supervised Learning for Visual Summary Identification in Scientific Publications
面向科技论文视觉摘要识别的自监督学习
S Yamamoto, A Lauscher, S P Ponzetto, G Glavaš, S Morishima
[Waseda University & University of Mannheim]
https://weibo.com/1402400261/JzK4yh22a

若有收获,就点个赞吧
0 人点赞
