- 1、[LG] Deep Generative Modelling: A Comparative Review of VAEs, GANs, Normalizing Flows, Energy-Based and Autoregressive Models**
- 2、[LG] Efficient Causal Inference from Combined Observational and Interventional Data through Causal Reductions
- 3、[AS] GAN Vocoder: Multi-Resolution Discriminator Is All You Need
- 4、[LG] Reinforcement Learning, Bit by Bit
- 5、[CV] Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos
- [CL] Inductive biases, pretraining and fine-tuning jointly account for brain responses to speech
- [LG] Multi-Format Contrastive Learning of Audio Representations
- [AS] Slow-Fast Auditory Streams For Audio Recognition
- [LG] S4RL: Surprisingly Simple Self-Supervision for Offline Reinforcement Learning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Deep Generative Modelling: A Comparative Review of VAEs, GANs, Normalizing Flows, Energy-Based and Autoregressive Models**
S Bond-Taylor, A Leach, Y Long, C G. Willcocks
[Durham University]
深度生成式建模:VAE、GAN、归一化流、基于能量模型和自回归模型的比较综述。深度生成式建模是一类训练深度神经网络以模拟训练样本分布的技术。相关研究包括各种相互关联的方法,每种方法都在进行包括运行时间、多样性和架构限制在内的权衡。本文涵盖了基于能量模型、变分自编码器、生成式对抗网络、自回归模型、归一化流,此外还有许多混合方法。虽然GANs在样本质量方面已经领先了一段时间,但其他方法之间的差距正在缩小;模式崩溃的减少和更简单的训练目标,使这些模型比以往任何时候都更有吸引力,然而,除了缓慢的运行时间之外,所需参数数量也构成了一个实质性的障碍。尽管如此,最近的工作,特别是在混合建模方面,提供了极端之间的平衡,以额外的模型复杂性为代价,影响了其更广泛的使用。一个明显的亮点是在生成模型中应用创新的数据增强策略,在不需要更强大的架构的情况下提供了令人印象深刻的收益。当涉及到将模型扩展到高维数据时,注意力是一个共性的主题,允许学习长程依赖性;最近在线性注意力方面的进展将有助于扩展到更高的分辨率。隐式网络是另一个有前途的方向,可高效合成任意高分辨率和不规则数据。类似的统一生成模型能够对连续的、不规则的和任意长度的数据进行建模,在不同的尺度和领域,将是未来泛化的关键。
Deep generative modelling is a class of techniques that train deep neural networks to model the distribution of training samples. Research has fragmented into various interconnected approaches, each of which making trade-offs including run-time, diversity, and architectural restrictions. In particular, this compendium covers energy-based models, variational autoencoders, generative adversarial networks, autoregressive models, normalizing flows, in addition to numerous hybrid approaches. These techniques are drawn under a single cohesive framework, comparing and contrasting to explain the premises behind each, while reviewing current state-of-the-art advances and implementations.
https://weibo.com/1402400261/K6eYpkWkT
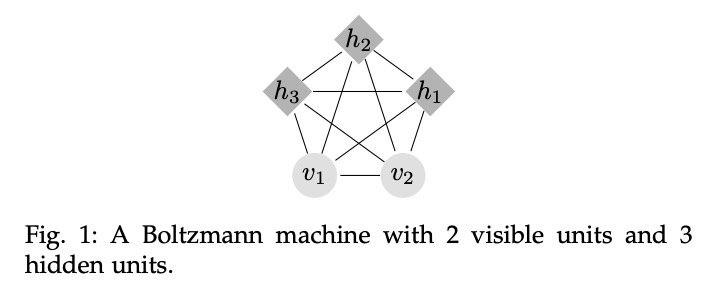
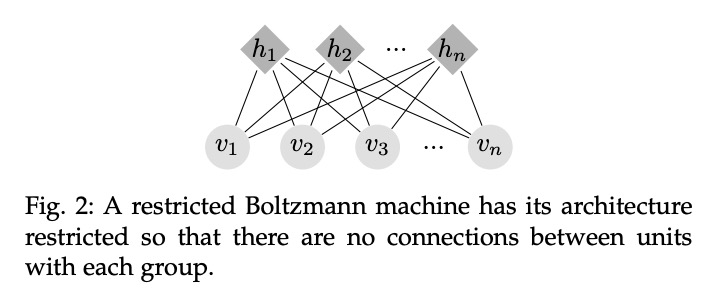
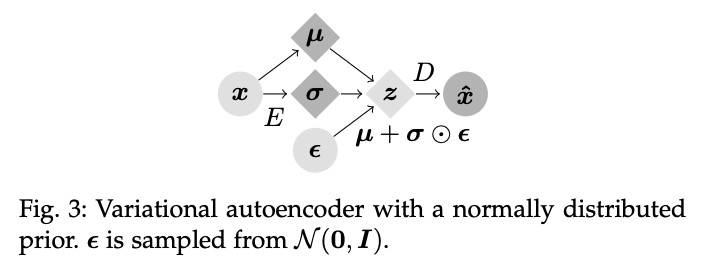
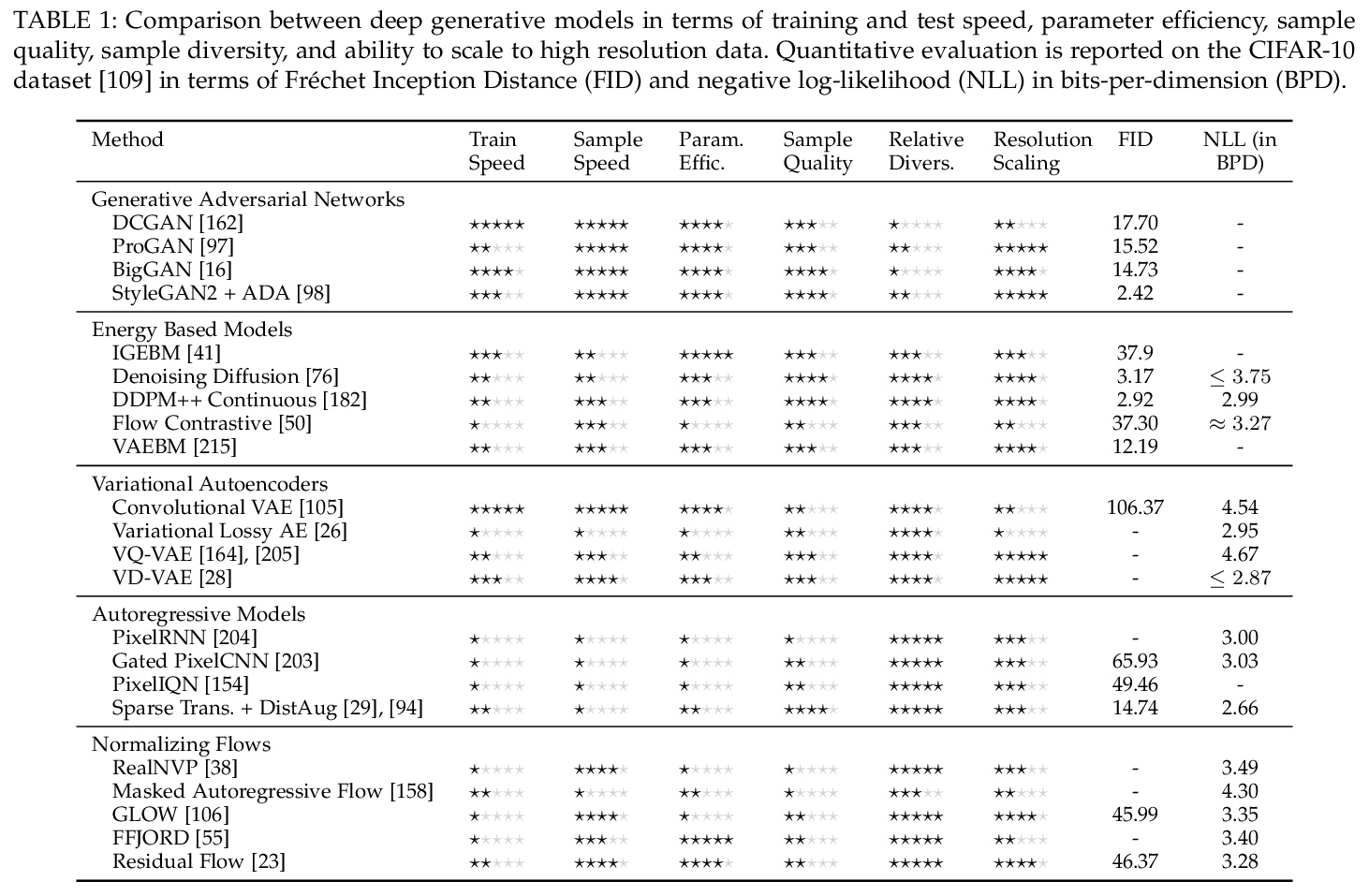
2、[LG] Efficient Causal Inference from Combined Observational and Interventional Data through Causal Reductions
M Ilse, P Forré, M Welling, J M. Mooij
[University of Amsterdam]
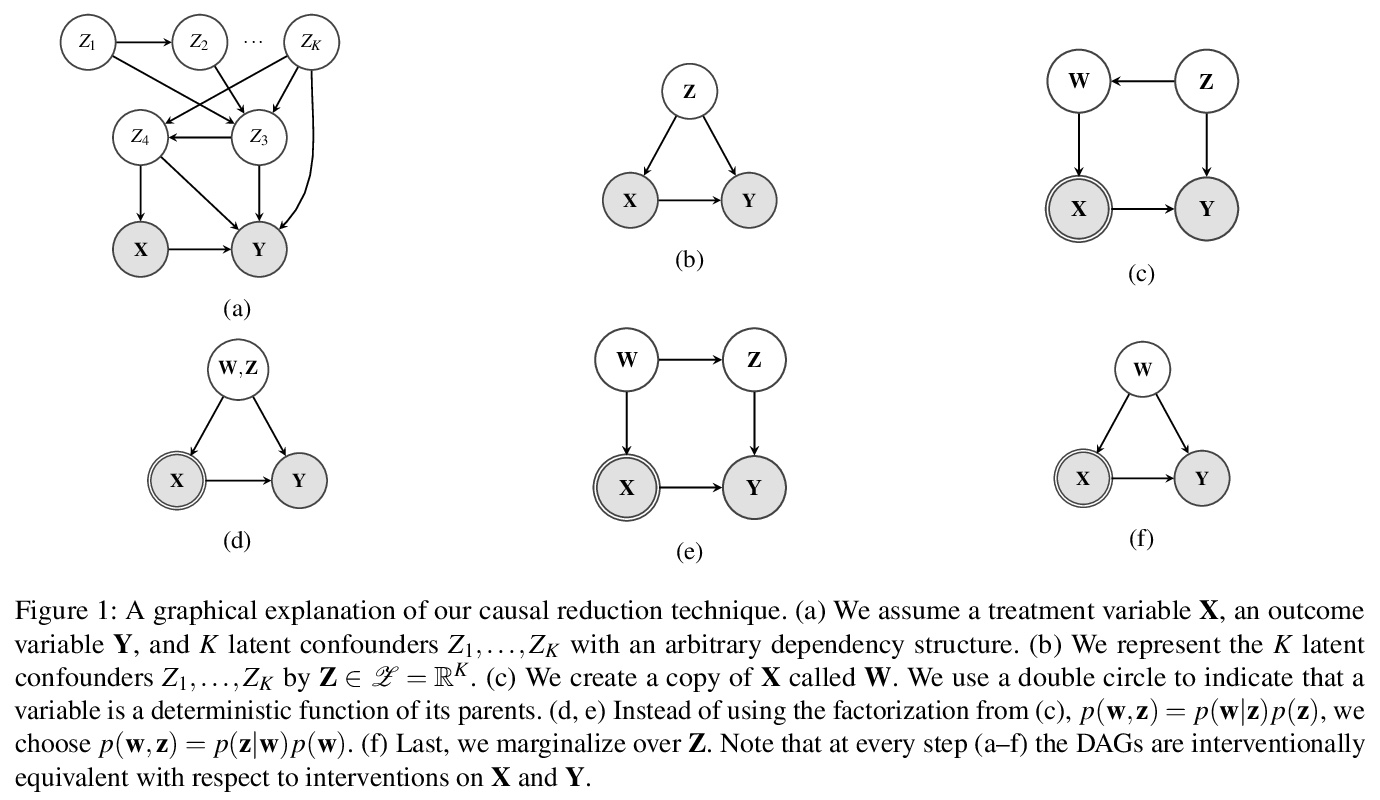
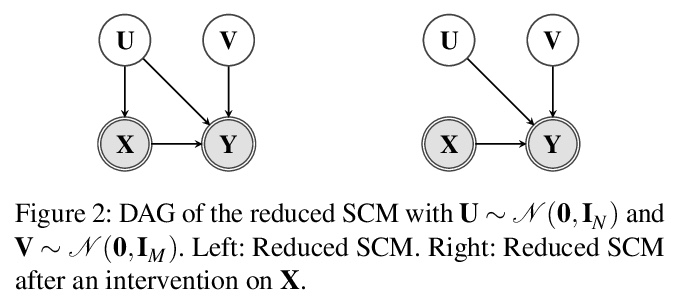
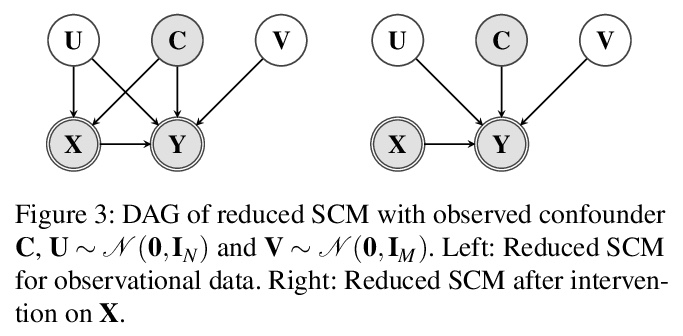
基于因果规约的观察和干预组合数据的有效因果推断。提出一种新的因果规约方法,在不改变因果关系模型所包含的观察和干预分布的前提下,用与处理变量同空间的单个潜混杂因素代替任意数量的可能是高维的潜混杂因素。在规约之后,用一类灵活的变换,即所谓的归一化流,对规约后的因果模型进行参数化。提出一种学习算法,从观察和干预数据中共同估计参数化的规约模型。可从组合数据中以一种原则性的方式估计因果效应。在使用非线性因果机制模拟的数据上进行了一系列实验,发现当加入观察性训练样本时,往往可以在不牺牲准确性的前提下大幅减少干预样本的数量。即使在存在未观察到的混杂因素的情况下,添加观察数据也可能有助于更准确地估计因果效应。
Unobserved confounding is one of the main challenges when estimating causal effects. We propose a novel causal reduction method that replaces an arbitrary number of possibly high-dimensional latent confounders with a single latent confounder that lives in the same space as the treatment variable without changing the observational and interventional distributions entailed by the causal model. After the reduction, we parameterize the reduced causal model using a flexible class of transformations, so-called normalizing flows. We propose a learning algorithm to estimate the parameterized reduced model jointly from observational and interventional data. This allows us to estimate the causal effect in a principled way from combined data. We perform a series of experiments on data simulated using nonlinear causal mechanisms and find that we can often substantially reduce the number of interventional samples when adding observational training samples without sacrificing accuracy. Thus, adding observational data may help to more accurately estimate causal effects even in the presence of unobserved confounders.
https://weibo.com/1402400261/K6f5P5Ykz
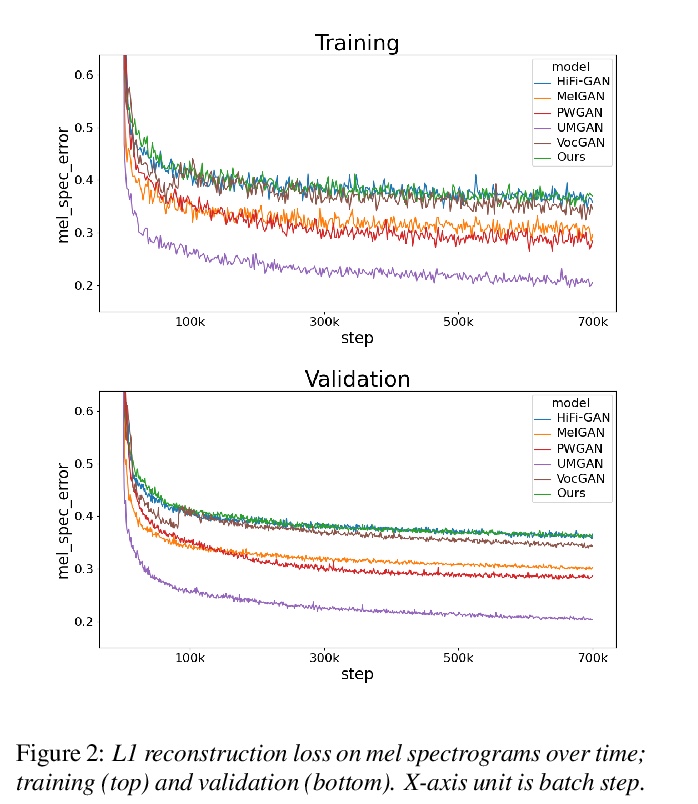
3、[AS] GAN Vocoder: Multi-Resolution Discriminator Is All You Need
J You, D Kim, G Nam, G Hwang, G Chae
[MoneyBrain Inc]
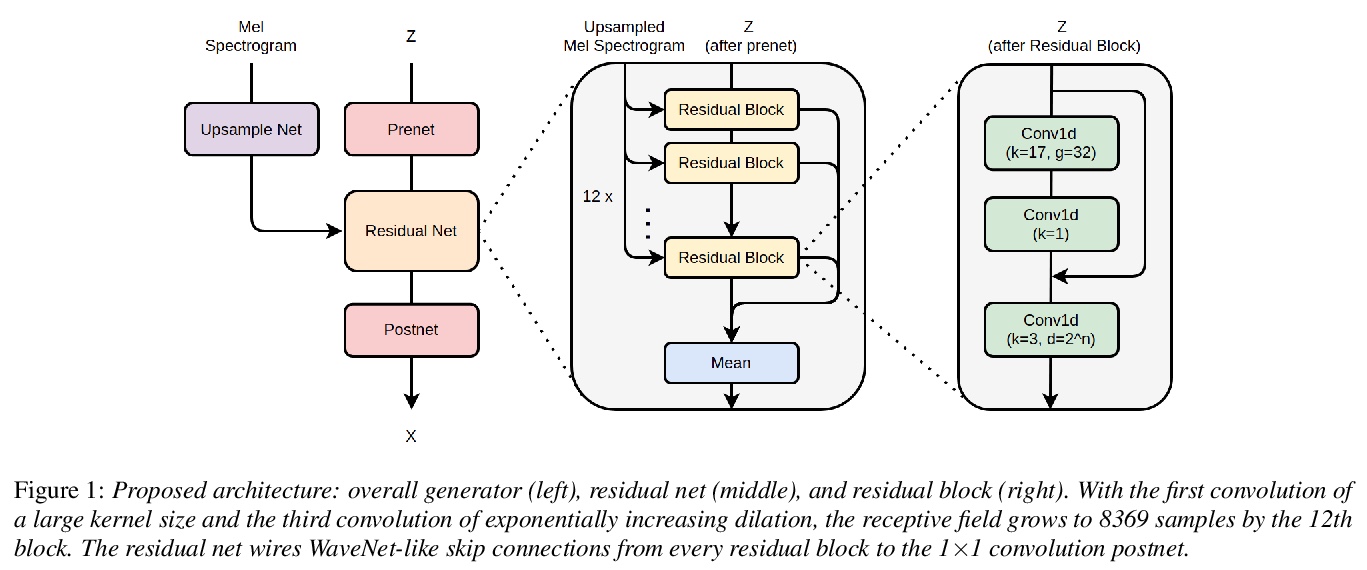
GAN声码器:多分辨率鉴别器是关键。将HiFi-GAN多分辨率鉴别框架与五种不同的最新GAN声码发生器进行了配对。提出的生成器被添加到该集合中,以增强六个生成器的整体多样性的架构特性。对基于GT和基于TTS的合成器的声码器进行MOS和MCD评价,在四个指标中的三个指标中,观察到尽管结构有很大不同,但其性能没有统计学上的差异迹象。这一发现质疑了在GAN环境下从旋律谱图中创建高保真语音信号的真正重要因素,并支持了决定性因素在于多分辨率判别框架的假设。根据实验,提出了三个值得注意的观点:(1)多分辨率判别框架可通用于不同设计理念的生成器;(2)多分辨率判别框架可通用于各种形式的待判别目标(即频谱图、原始波形或中间表示);(3)从MelGAN开始,生成器的容量和线路已经足够强大。
Several of the latest GAN-based vocoders show remarkable achievements, outperforming autoregressive and flow-based competitors in both qualitative and quantitative measures while synthesizing orders of magnitude faster. In this work, we hypothesize that the common factor underlying their success is the multi-resolution discriminating framework, not the minute details in architecture, loss function, or training strategy. We experimentally test the hypothesis by evaluating six different generators paired with one shared multi-resolution discriminating framework. For all evaluative measures with respect to text-to-speech syntheses and for all perceptual metrics, their performances are not distinguishable from one another, which supports our hypothesis.
https://weibo.com/1402400261/K6faRoPrO
4、[LG] Reinforcement Learning, Bit by Bit
X Lu, B V Roy, V Dwaracherla, M Ibrahimi, I Osband, Z Wen
[Google]
强化学习,一点一点来。强化学习智能体在模拟环境中取得了显著的效果,但数据效率对其应用到真实环境构成了阻碍。设计数据高效的智能体需要对信息获取和表示有更深的理解。本文开发了一些概念,建立了一个遗憾约束,这些概念和约束共同提供了原则性的指导。该约束揭示了寻找什么信息,如何寻找信息,以及保留哪些信息的问题。为说明概念,设计了建立在概念上的简单智能体,并展示了计算结果,证明了数据效率的改进。其他学习范式是关于最小化的,强化学习是关于最大化的。强化学习的特点在于其开放式的观点。强化学习智能体学习随着时间的推移改善其行为,而没有规定最终的动态或性能的极限。如果目标取非负值,最小化表明一个明确的期望结果,而最大化则让人联想到对未知的追求。
Reinforcement learning agents have demonstrated remarkable achievements in simulated environments. Data efficiency poses an impediment to carrying this success over to real environments. The design of data-efficient agents calls for a deeper understanding of information acquisition and representation. We develop concepts and establish a regret bound that together offer principled guidance. The bound sheds light on questions of what information to seek, how to seek that information, and it what information to retain. To illustrate concepts, we design simple agents that build on them and present computational results that demonstrate improvements in data efficiency.
https://weibo.com/1402400261/K6fh1eM5G
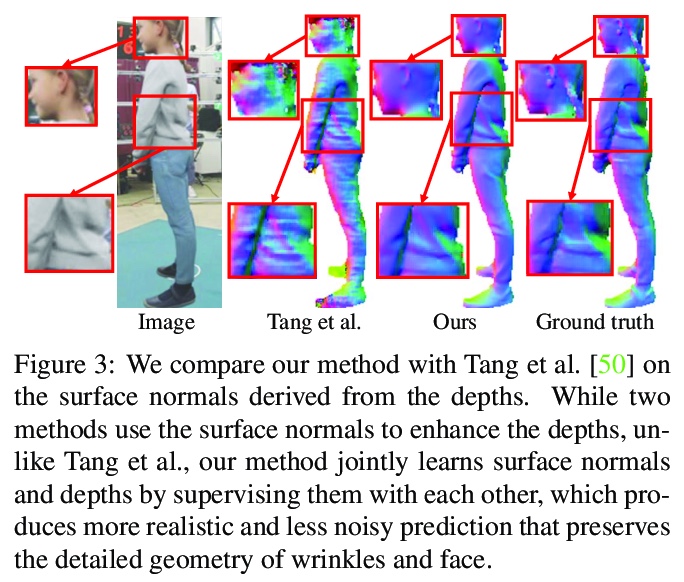
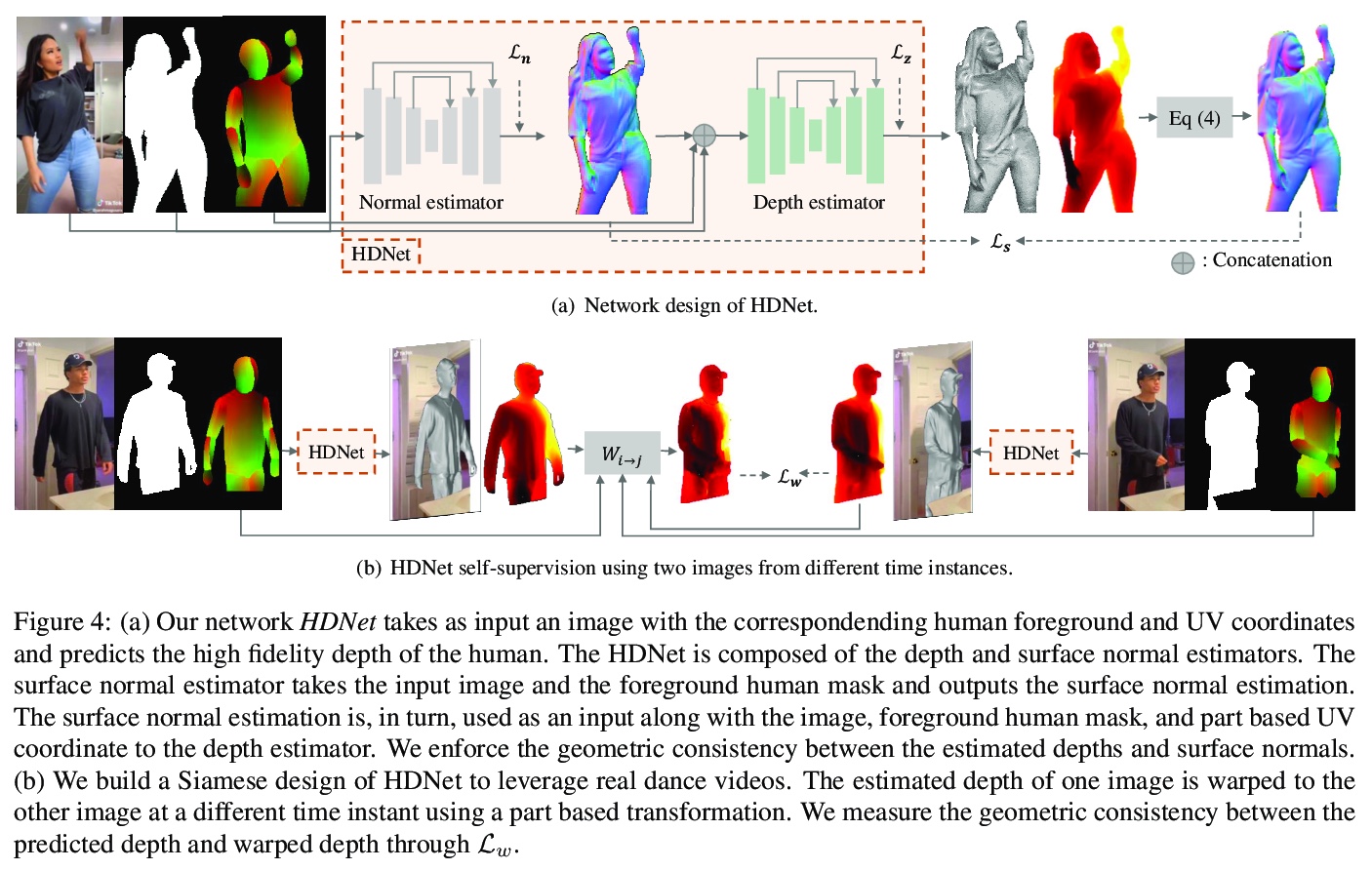
5、[CV] Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos
Y Jafarian, H S Park
[University of Minnesota]
通过看社交媒体舞蹈视频学习高保真着装人体深度。提出一种新方法,利用社交媒体分享的视频数据来预测着装人体的深度,利用局部变换来强制不同姿态的几何一致性,实现深度预测的自监督,联合学习表面法线和深度来生成高保真深度重建。收集了新的TikTok数据集,由社交媒体移动平台TikTok中分享的300多个舞蹈视频序列组成,共计100K以上的图像。该方法与最先进的人体深度估计和人体形状恢复相比,在真实世界的图像上产生了强大的定性和定量预测。
A key challenge of learning the geometry of dressed humans lies in the limited availability of the ground truth data (e.g., 3D scanned models), which results in the performance degradation of 3D human reconstruction when applying to real-world imagery. We address this challenge by leveraging a new data resource: a number of social media dance videos that span diverse appearance, clothing styles, performances, and identities. Each video depicts dynamic movements of the body and clothes of a single person while lacking the 3D ground truth geometry. To utilize these videos, we present a new method to use the local transformation that warps the predicted local geometry of the person from an image to that of another image at a different time instant. This allows self-supervision as enforcing a temporal coherence over the predictions. In addition, we jointly learn the depth along with the surface normals that are highly responsive to local texture, wrinkle, and shade by maximizing their geometric consistency. Our method is end-to-end trainable, resulting in high fidelity depth estimation that predicts fine geometry faithful to the input real image. We demonstrate that our method outperforms the state-of-the-art human depth estimation and human shape recovery approaches on both real and rendered images.
https://weibo.com/1402400261/K6fmV6cFS

另外几篇值得关注的论文:
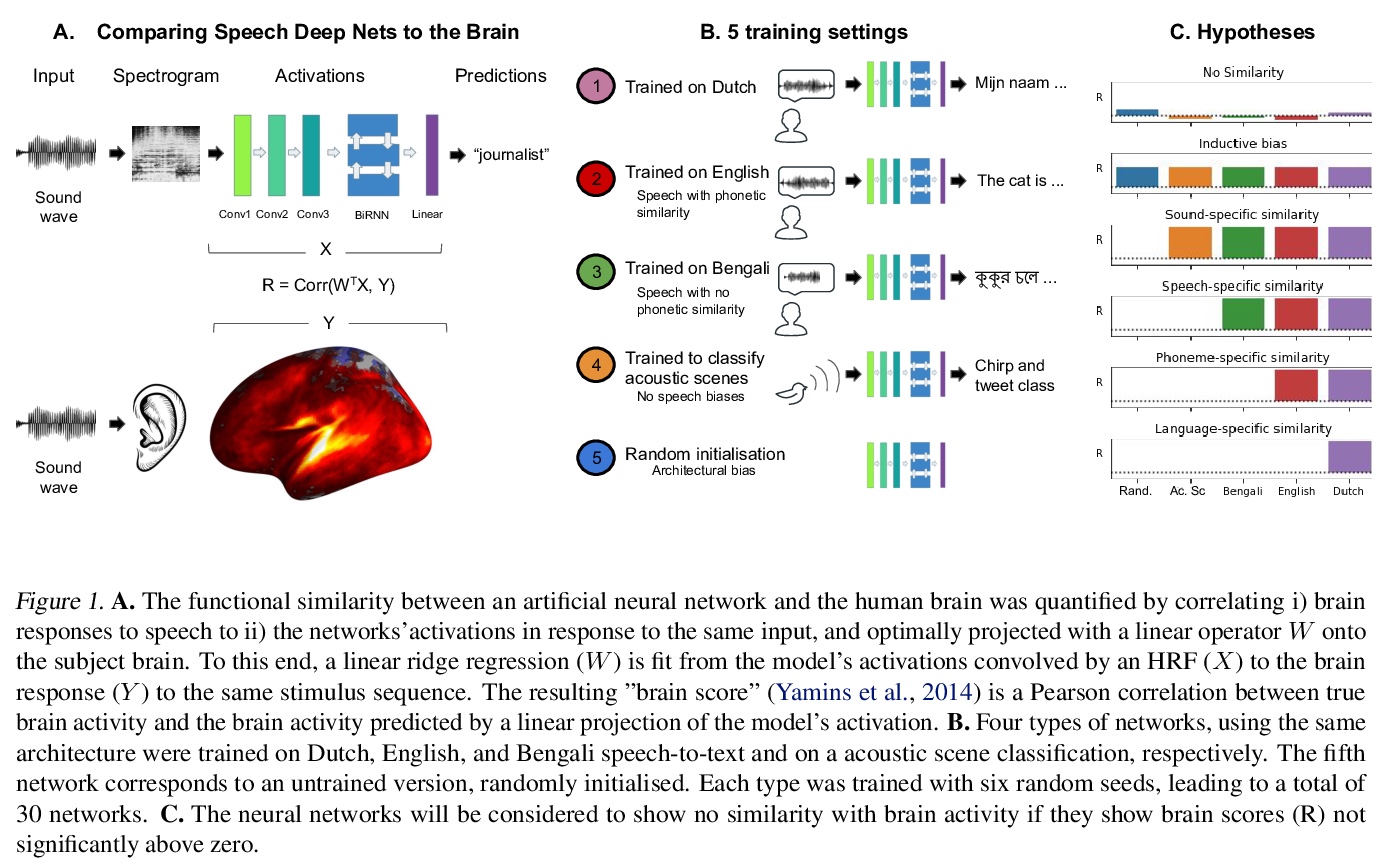
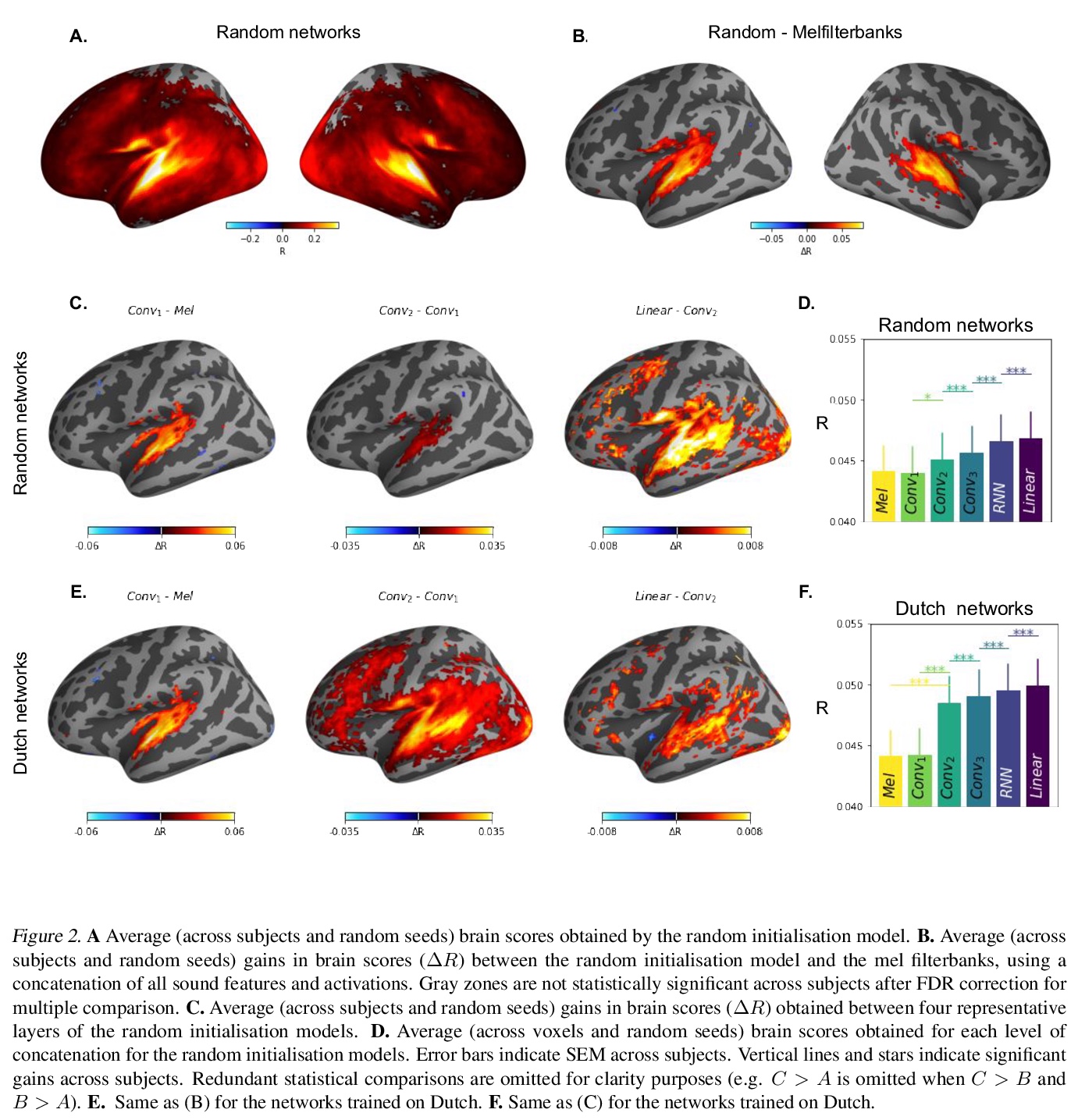
[CL] Inductive biases, pretraining and fine-tuning jointly account for brain responses to speech
用归纳偏差、预训练和微调联合解释大脑对言语的反应
J Millet, J King
[Facebook AI Research]
https://weibo.com/1402400261/K6fqLxIVo
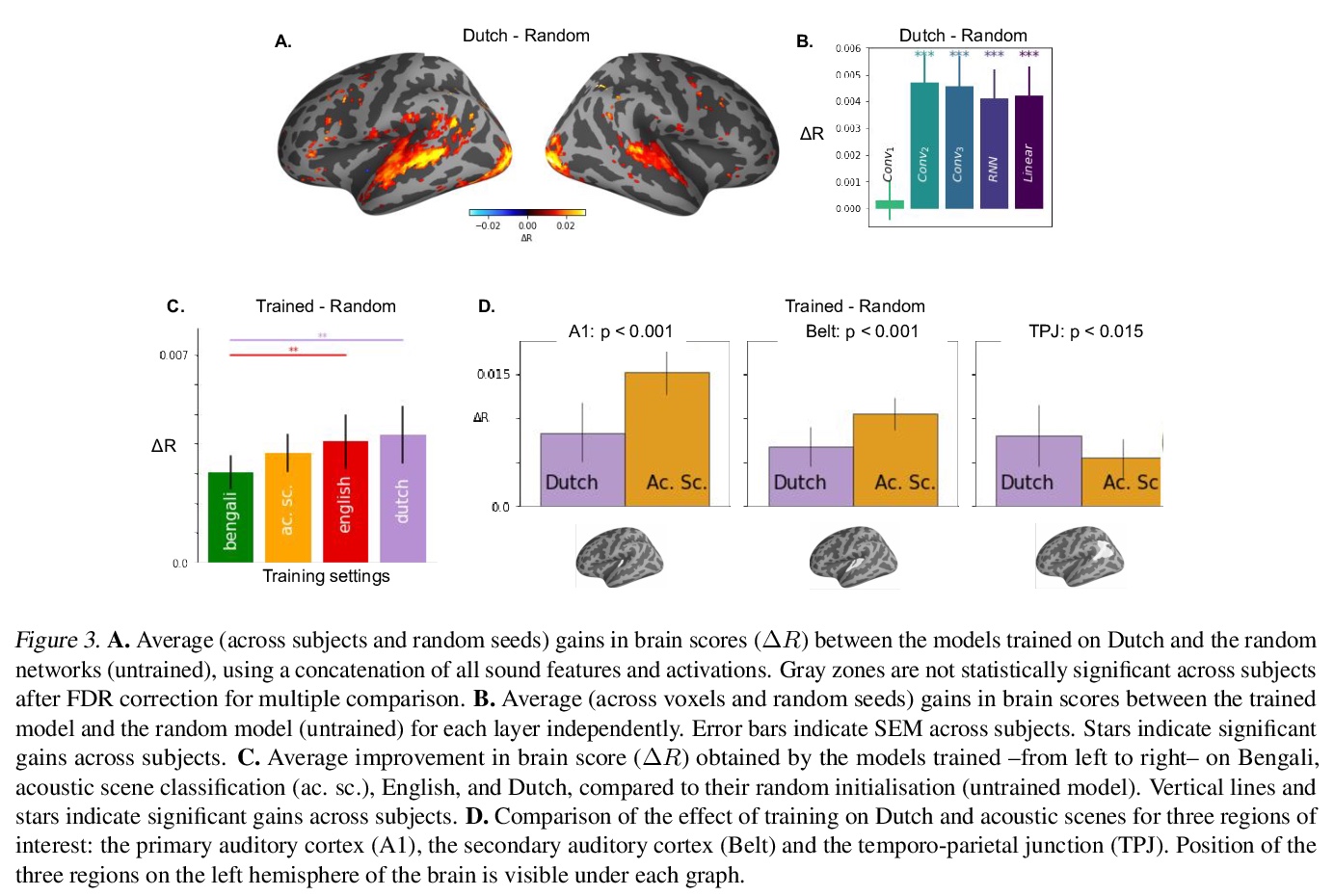
[LG] Multi-Format Contrastive Learning of Audio Representations
音频表示的多格式对比学习
L Wang, A v d Oord
[Google DeepMind]
https://weibo.com/1402400261/K6fscbDrE
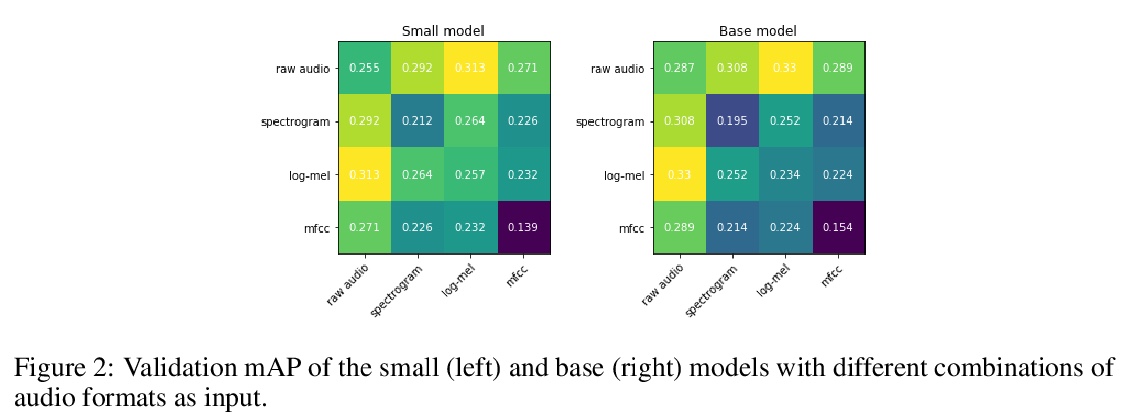
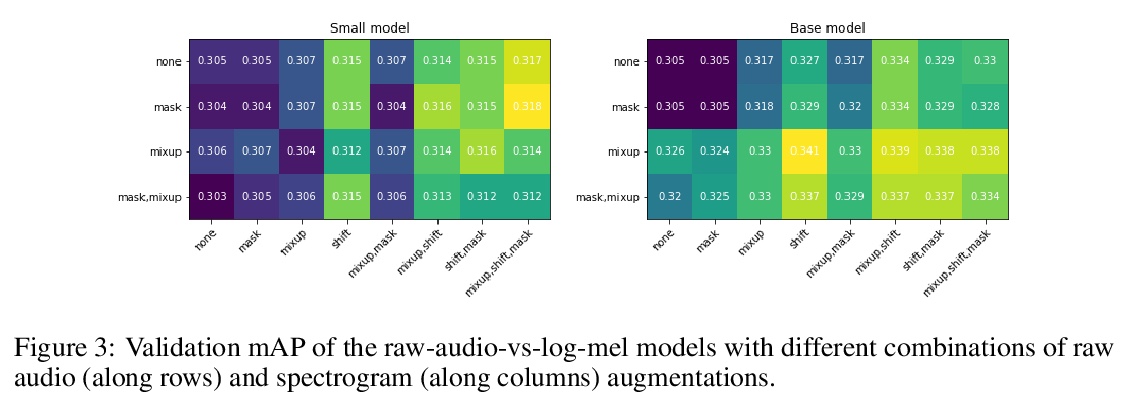
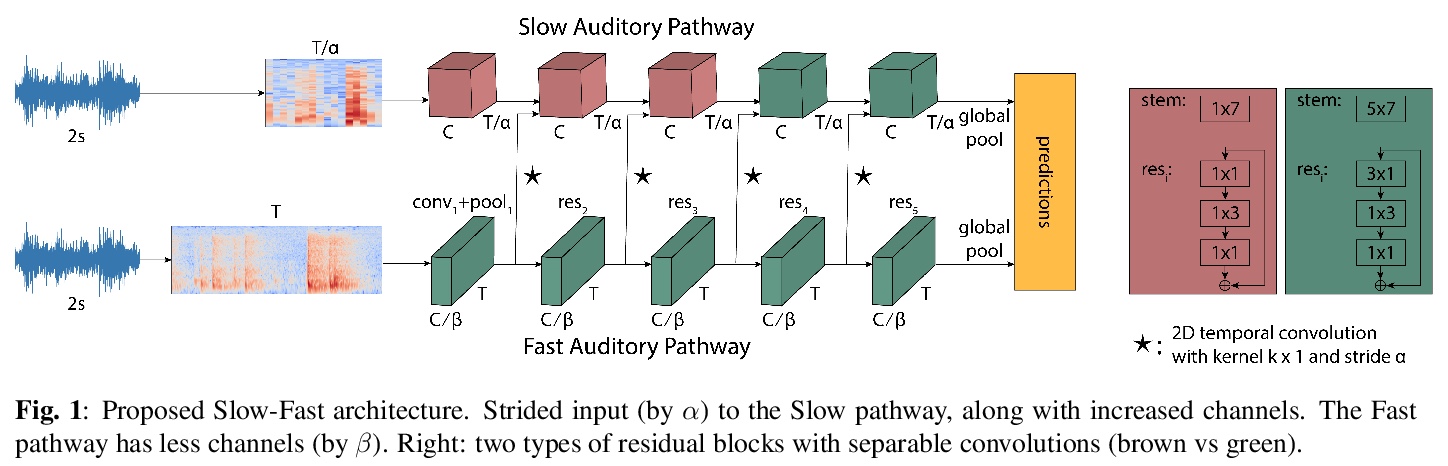
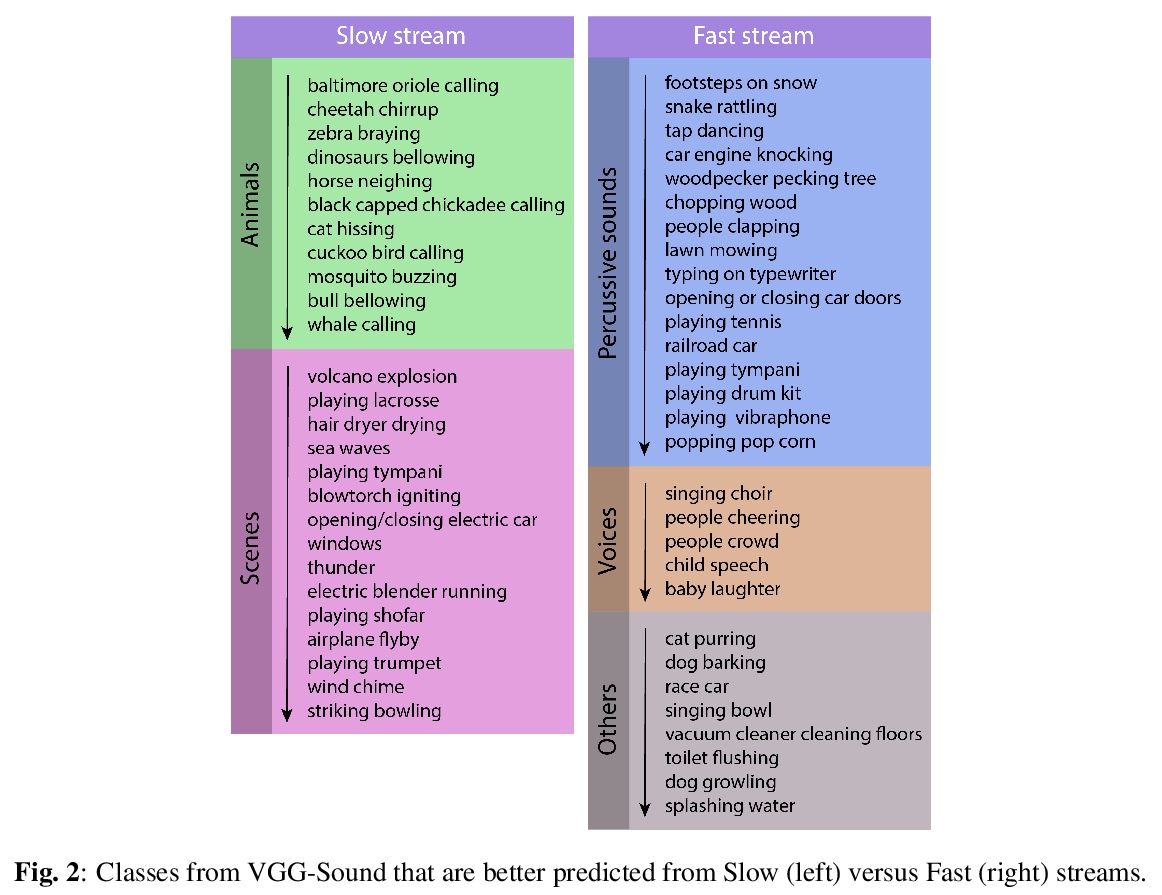
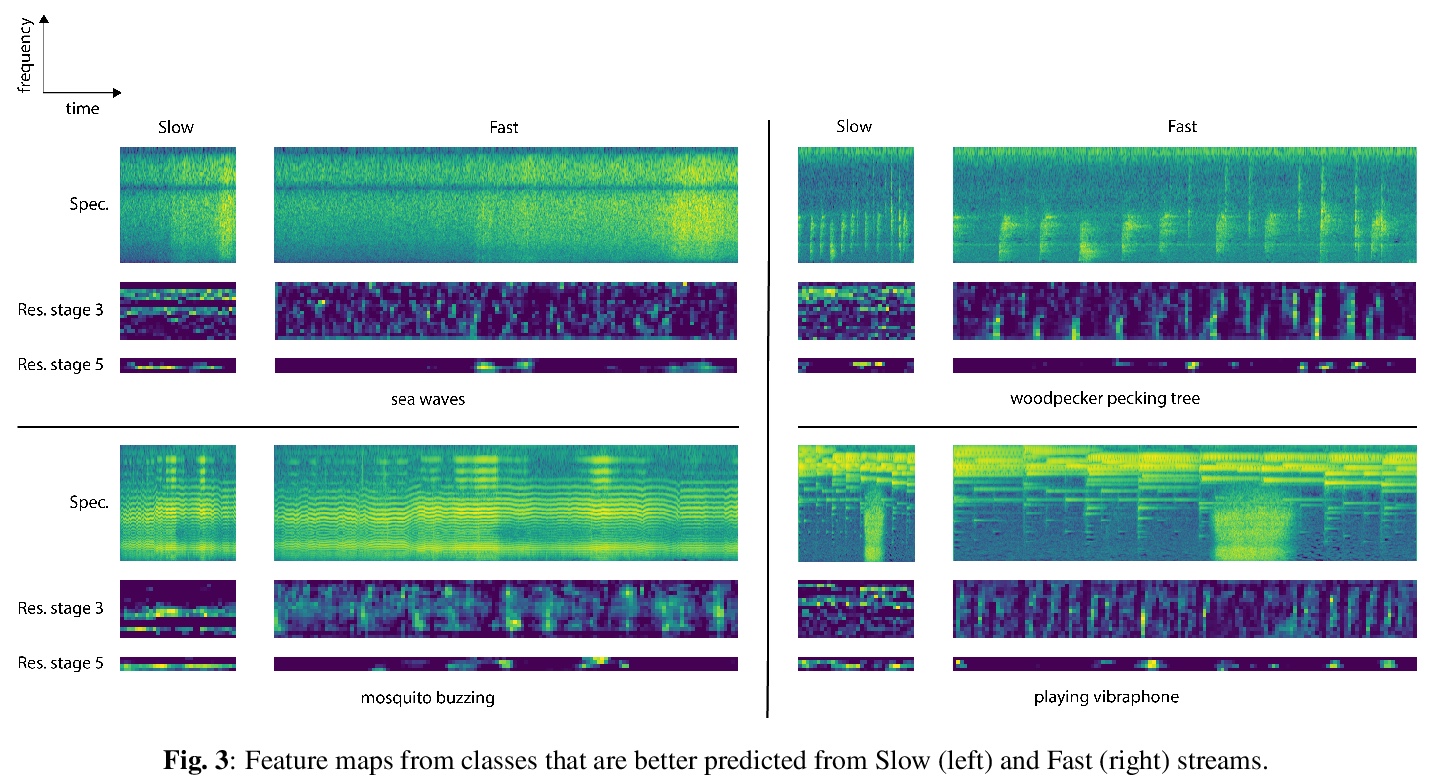
[AS] Slow-Fast Auditory Streams For Audio Recognition
面向音频识别的快-慢听觉流
E Kazakos, A Nagrani, A Zisserman, D Damen
[University of Bristol & University of Oxford]
https://weibo.com/1402400261/K6ftnsqWj
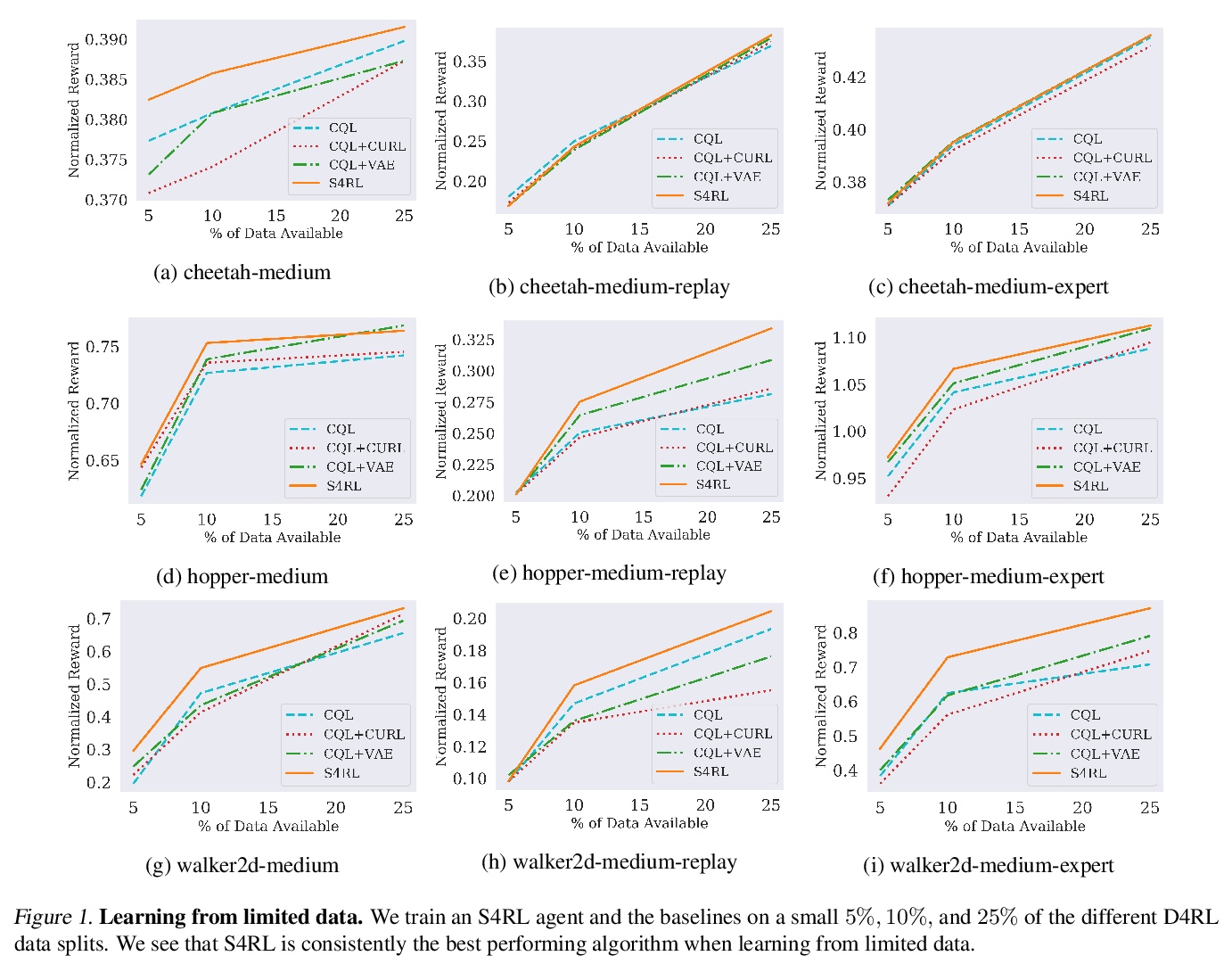
[LG] S4RL: Surprisingly Simple Self-Supervision for Offline Reinforcement Learning
S4RL:超简单的离线强化学习自监督
S Sinha, A Garg
[University of Toronto]
https://weibo.com/1402400261/K6fuQpPbw

若有收获,就点个赞吧
0 人点赞
