LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、** *[CV] Toward Transformer-Based Object Detection
J Beal, E Kim, E Tzeng, D H Park, A Zhai, D Kislyuk
[Pinterest]
Transformer目标检测探索。提出ViT-FRCNN,一种有竞争力的目标检测解决方案,具有与Transformer相关的几个已知特性,包括大的预训练容量和快速微调性能。研究了在标准检测基干上的改进,包括对域外图像的优越性能,对大目标的更好性能,以及减少对非最大抑制的依赖。ViT-FRCNN为复杂视觉任务(如目标检测)的纯Transformer解决方案开辟了一条新路。
Transformers have become the dominant model in natural language processing, owing to their ability to pretrain on massive amounts of data, then transfer to smaller, more specific tasks via fine-tuning. The Vision Transformer was the first major attempt to apply a pure transformer model directly to images as input, demonstrating that as compared to convolutional networks, transformer-based architectures can achieve competitive results on benchmark classification tasks. However, the computational complexity of the attention operator means that we are limited to low-resolution inputs. For more complex tasks such as detection or segmentation, maintaining a high input resolution is crucial to ensure that models can properly identify and reflect fine details in their output. This naturally raises the question of whether or not transformer-based architectures such as the Vision Transformer are capable of performing tasks other than classification. In this paper, we determine that Vision Transformers can be used as a backbone by a common detection task head to produce competitive COCO results. The model that we propose, ViT-FRCNN, demonstrates several known properties associated with transformers, including large pretraining capacity and fast fine-tuning performance. We also investigate improvements over a standard detection backbone, including superior performance on out-of-domain images, better performance on large objects, and a lessened reliance on non-maximum suppression. We view ViT-FRCNN as an important stepping stone toward a pure-transformer solution of complex vision tasks such as object detection.
https://weibo.com/1402400261/JzA1emq8d
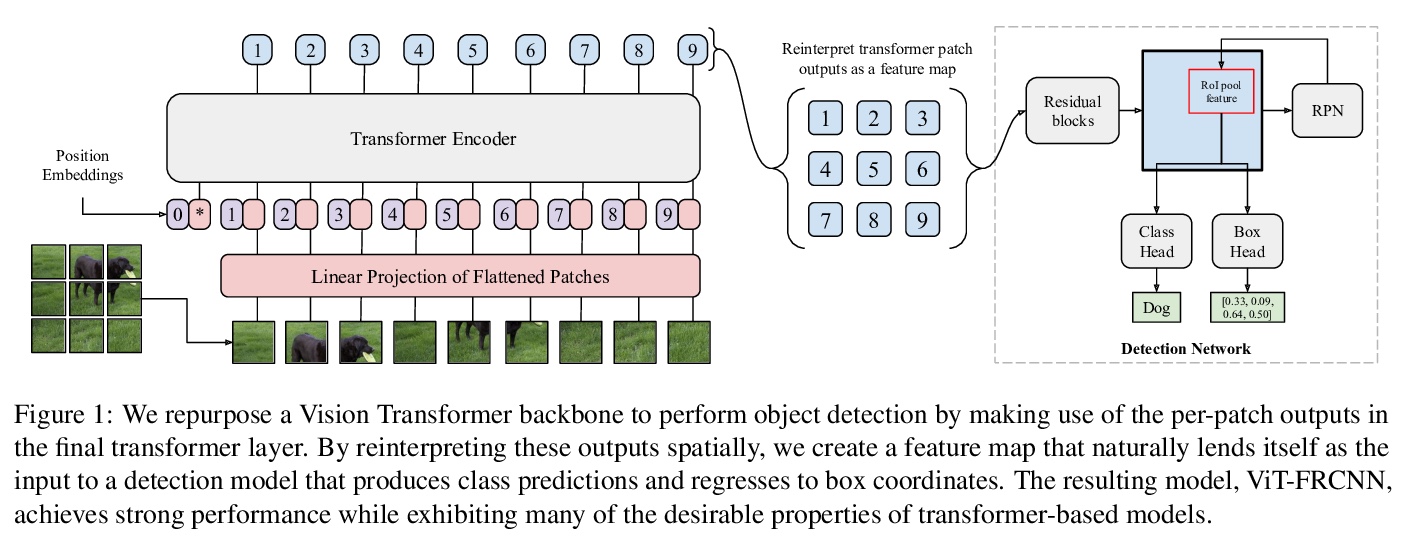
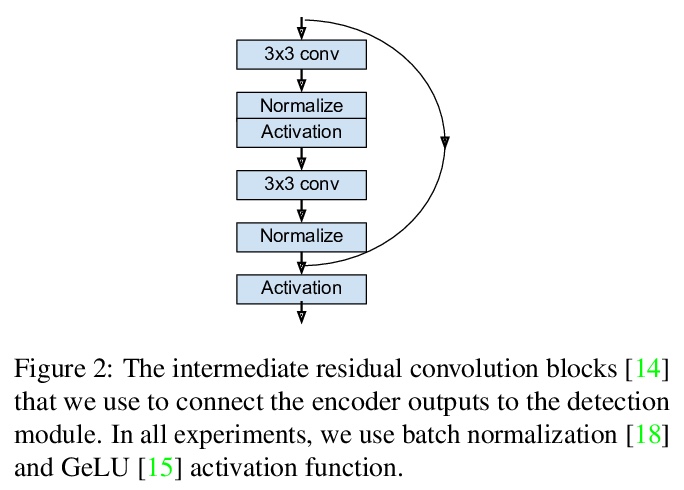
2、** *[CV] Content Masked Loss: Human-Like Brush Stroke Planning in a Reinforcement Learning Painting Agent
P Schaldenbrand, J Oh
[CMU]
内容掩蔽损失:强化学习绘画智能体的仿人笔触序列规划。提出一种仿人笔触规划的强化学习方法,兼顾绘画过程与最终质量。引入了新的内容掩蔽损失,用了目标检测模型来提取特征,用于给画布上人类认为对识别内容很重要的区域分配更高的权重。实验结果表明,在损失函数中添加内容掩蔽,在不牺牲最终绘画结果质量的前提下,极大提高了模型笔触序列的人脸检测能力。内容掩蔽损失提供了一种有效的数据方法,可提高模型笔触序列的仿人能力,而不需要额外的、昂贵的人工标记。
The objective of most Reinforcement Learning painting agents is to minimize the loss between a target image and the paint canvas. Human painter artistry emphasizes important features of the target image rather than simply reproducing it (DiPaola 2007). Using adversarial or L2 losses in the RL painting models, although its final output is generally a work of finesse, produces a stroke sequence that is vastly different from that which a human would produce since the model does not have knowledge about the abstract features in the target image. In order to increase the human-like planning of the model without the use of expensive human data, we introduce a new loss function for use with the model’s reward function: Content Masked Loss. In the context of robot painting, Content Masked Loss employs an object detection model to extract features which are used to assign higher weight to regions of the canvas that a human would find important for recognizing content. The results, based on 332 human evaluators, show that the digital paintings produced by our Content Masked model show detectable subject matter earlier in the stroke sequence than existing methods without compromising on the quality of the final painting.
https://weibo.com/1402400261/JzAbb1S0c



3、** **[CV] Objectron: A Large Scale Dataset of Object-Centric Videos in the Wild with Pose Annotations
A Ahmadyan, L Zhang, J Wei, A Ablavatski, M Grundmann
[Google]
Objectron:大型以对象为中心包含姿态标记的视频数据集,包含以对象为中心的短视频,为9个类别提供了姿态标记,包括14,819个标记视频中的400万张标记图片。基于设备上的AR库开发了高效、可扩展的数据收集和标记框架。提出一种新的3D目标检测评价指标——基于联合的3D交叉。展示了在Objectron数据集上训练的两阶段3D目标检测模型作为基线的结果,显示了数据集在3D目标检测任务中的应用。
3D object detection has recently become popular due to many applications in robotics, augmented reality, autonomy, and image retrieval. We introduce the Objectron dataset to advance the state of the art in 3D object detection and foster new research and applications, such as 3D object tracking, view synthesis, and improved 3D shape representation. The dataset contains object-centric short videos with pose annotations for nine categories and includes 4 million annotated images in 14,819 annotated videos. We also propose a new evaluation metric, 3D Intersection over Union, for 3D object detection. We demonstrate the usefulness of our dataset in 3D object detection tasks by providing baseline models trained on this dataset. Our dataset and evaluation source code are available online at > http://www.objectron.dev
https://weibo.com/1402400261/JzAiyauj0


4、** **[LG] Characterising Bias in Compressed Models
S Hooker, N Moorosi, G Clark, S Bengio, E Denton
[Google Research]
压缩模型中的偏差。通过剪枝、量化等方法可实现深度网络的压缩,且对前n指标的影响可忽略不计,但整体的准确性隐藏了不成比例的高错误的一部分样本,称为子集压缩识别范例(CIE)。对CIE样本来说,压缩会放大现有算法的偏差。修剪不成比例地影响表现不足特征的性能,可能会导致公平性问题。考虑到CIE是一个相对较小的子集,但在模型中是很大的错误贡献者,建议将它作为人在环路的审计工具,以显示数据集的可控子集,方便领域专家进一步检查或标记。
The popularity and widespread use of pruning and quantization is driven by the severe resource constraints of deploying deep neural networks to environments with strict latency, memory and energy requirements. These techniques achieve high levels of compression with negligible impact on top-line metrics (top-1 and top-5 accuracy). However, overall accuracy hides disproportionately high errors on a small subset of examples; we call this subset Compression Identified Exemplars (CIE). We further establish that for CIE examples, compression amplifies existing algorithmic bias. Pruning disproportionately impacts performance on underrepresented features, which often coincides with considerations of fairness. Given that CIE is a relatively small subset but a great contributor of error in the model, we propose its use as a human-in-the-loop auditing tool to surface a tractable subset of the dataset for further inspection or annotation by a domain expert. We provide qualitative and quantitative support that CIE surfaces the most challenging examples in the data distribution for human-in-the-loop auditing.
https://weibo.com/1402400261/JzAms9Rps
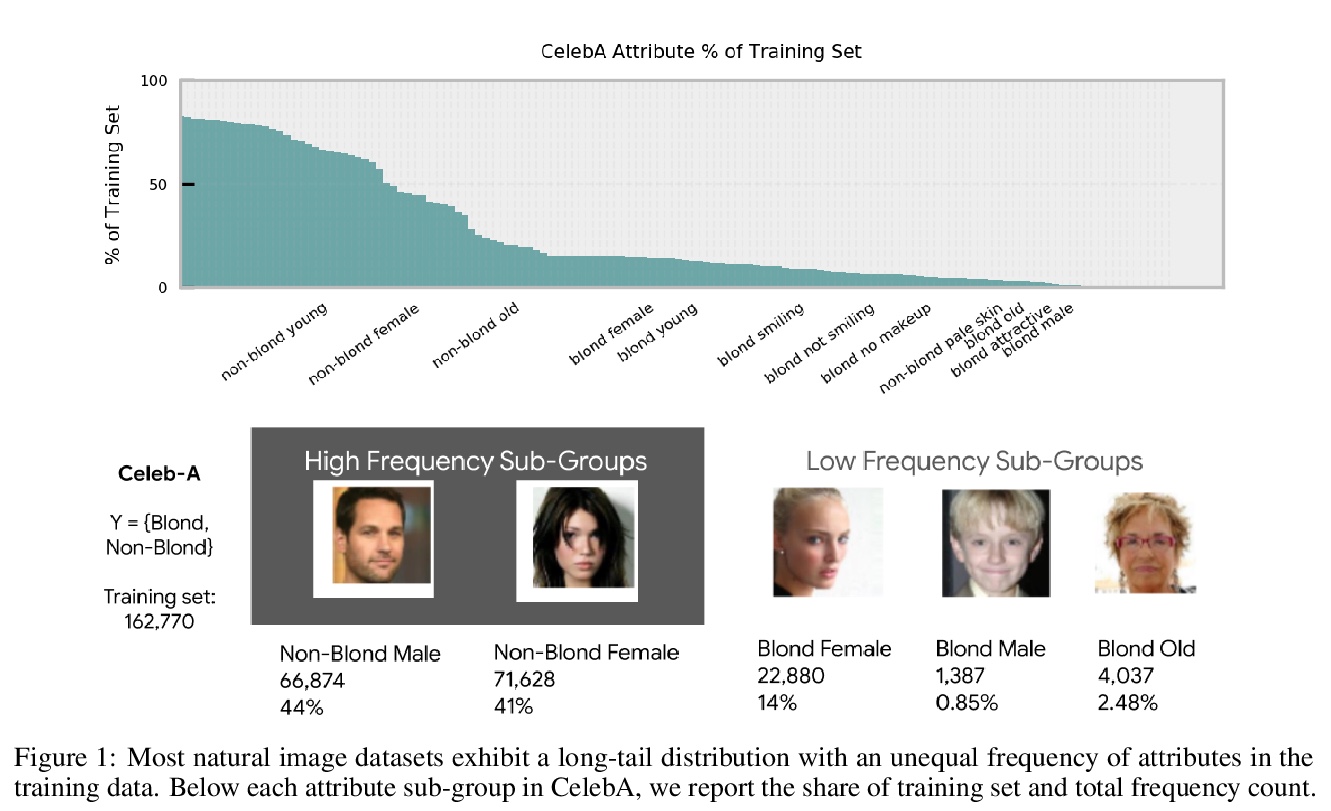

5、** **[AI] Deep Learning and the Global Workspace Theory
R VanRullen, R Kanai
[CerCo & Universite de Toulouse]
深度学习与全局工作空间理论。全局工作空间理论指的是一个大型系统,将信息整合并分布在由专门模块组成的网络中,以创造更高层次的认知和意识形式。本文认为,考虑用深度学习技术来显式实现这一理论的时机已经成熟,提出了一种基于多潜在空间(针对不同任务、不同感官输入和/或模式训练的神经网络)之间的无监督神经转换的路线图,以创建一个独特的、非线性的全局潜在工作空间(GLW)。文中还对GLW潜在的功能优势进行了阐述。
Recent advances in deep learning have allowed Artificial Intelligence (AI) to reach near human-level performance in many sensory, perceptual, linguistic or cognitive tasks. There is a growing need, however, for novel, brain-inspired cognitive architectures. The Global Workspace theory refers to a large-scale system integrating and distributing information among networks of specialized modules to create higher-level forms of cognition and awareness. We argue that the time is ripe to consider explicit implementations of this theory using deep learning techniques. We propose a roadmap based on unsupervised neural translation between multiple latent spaces (neural networks trained for distinct tasks, on distinct sensory inputs and/or modalities) to create a unique, amodal global latent workspace (GLW). Potential functional advantages of GLW are reviewed.
https://weibo.com/1402400261/JzAsS8e76
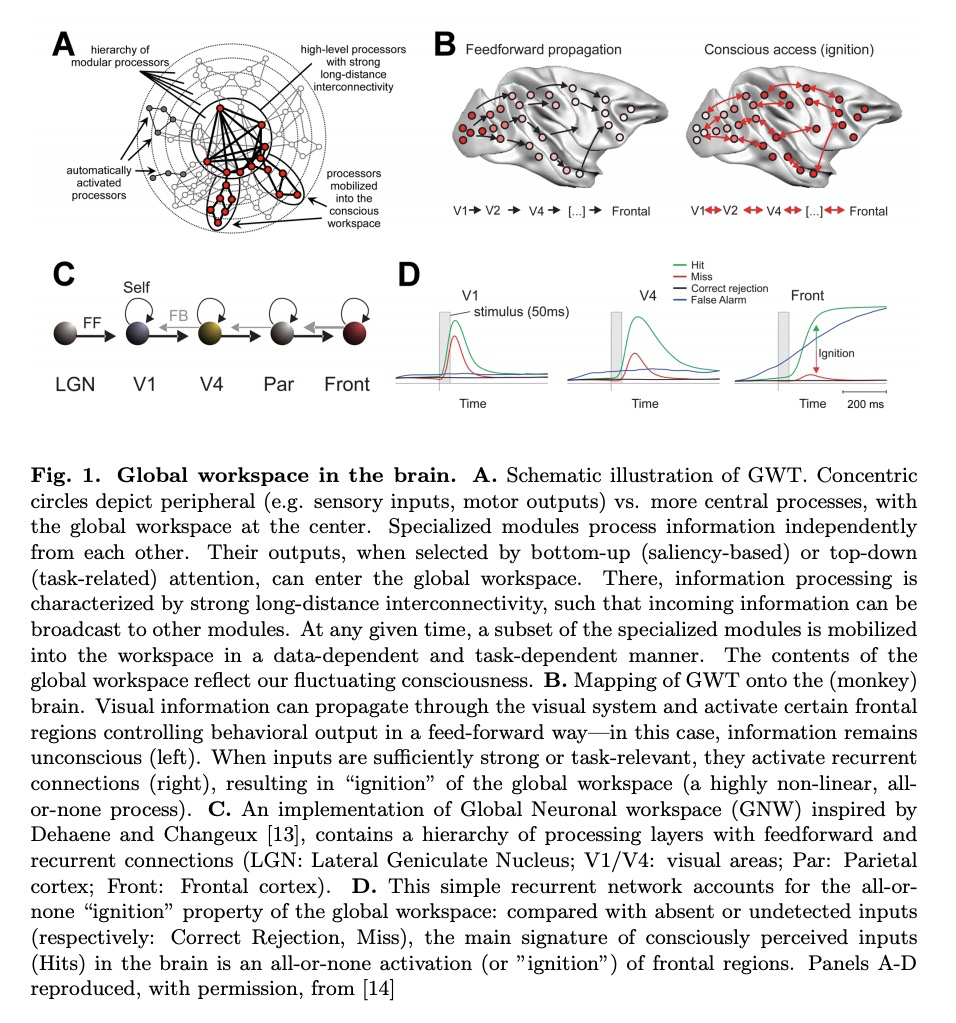
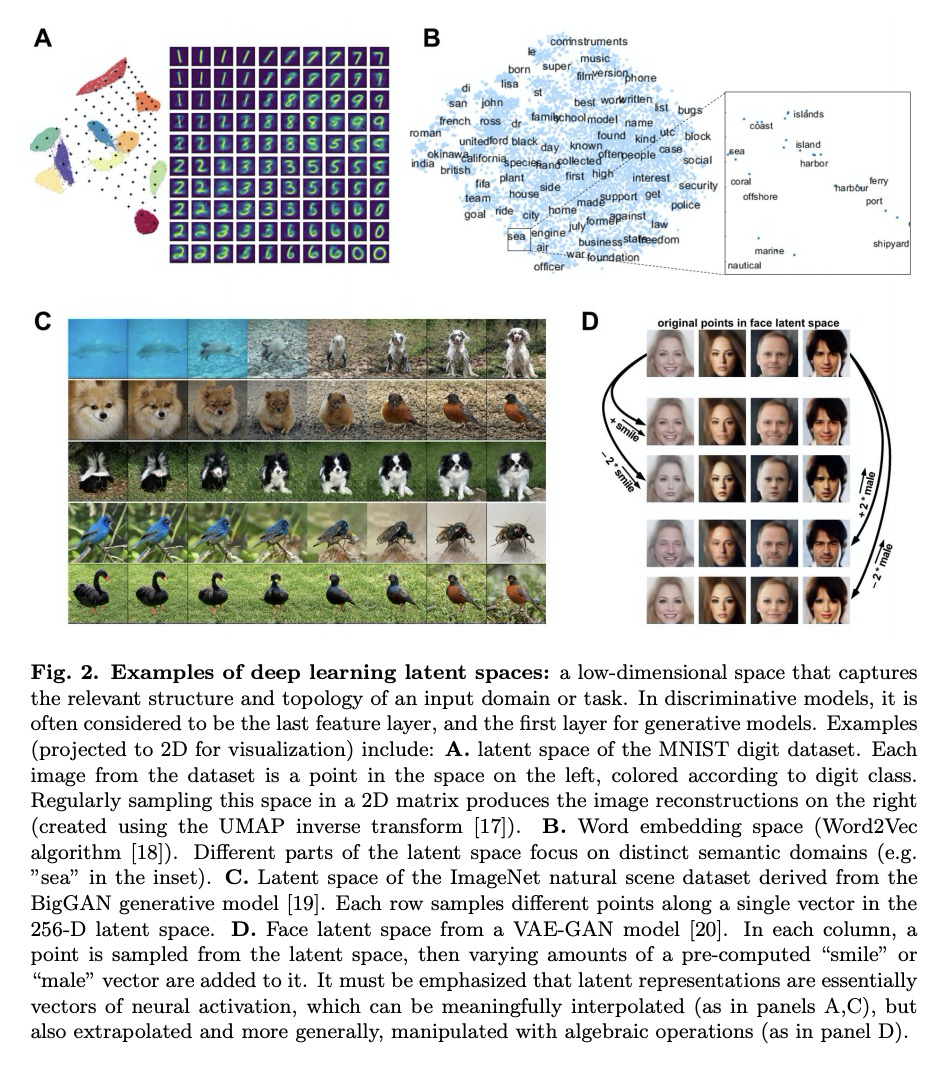

另外几篇值得关注的论文:
[CV] Relightable 3D Head Portraits from a Smartphone Video
用智能手机视频生成逼真3D头像
A Sevastopolsky, S Ignatiev, G Ferrer, E Burnaev, V Lempitsky
[Samsung AI Center & Skolkovo Institute of Science and Technology (Skoltech)]
https://weibo.com/1402400261/JzAwIFeHr


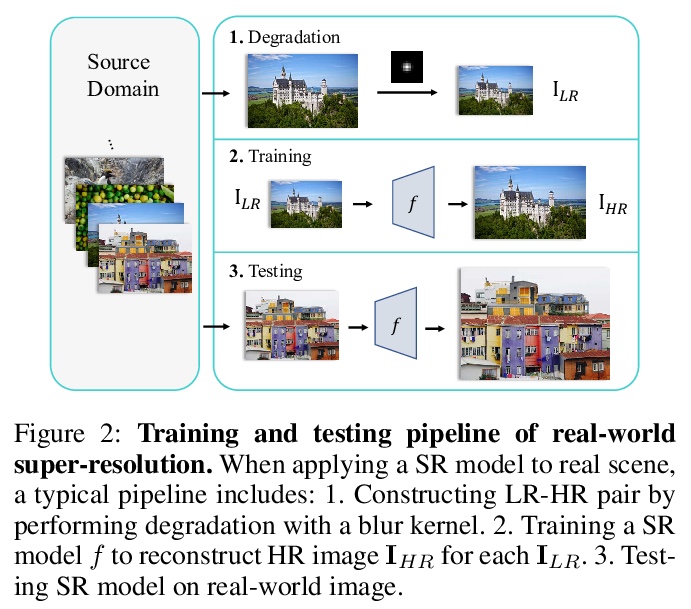
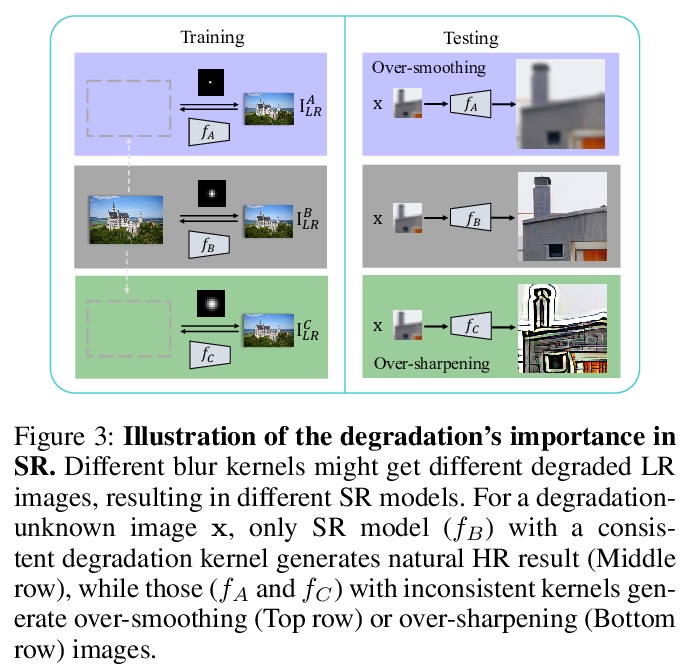
[CV] Frequency Consistent Adaptation for Real World Super Resolution
真实世界超分辨率的频一致自适应
X Ji, G Tao, Y Cao, Y Tai, T Lu, C Wang, J Li, F Huang
[Nanjing University & Tencent Youtu Lab]
https://weibo.com/1402400261/JzAy6lQdR
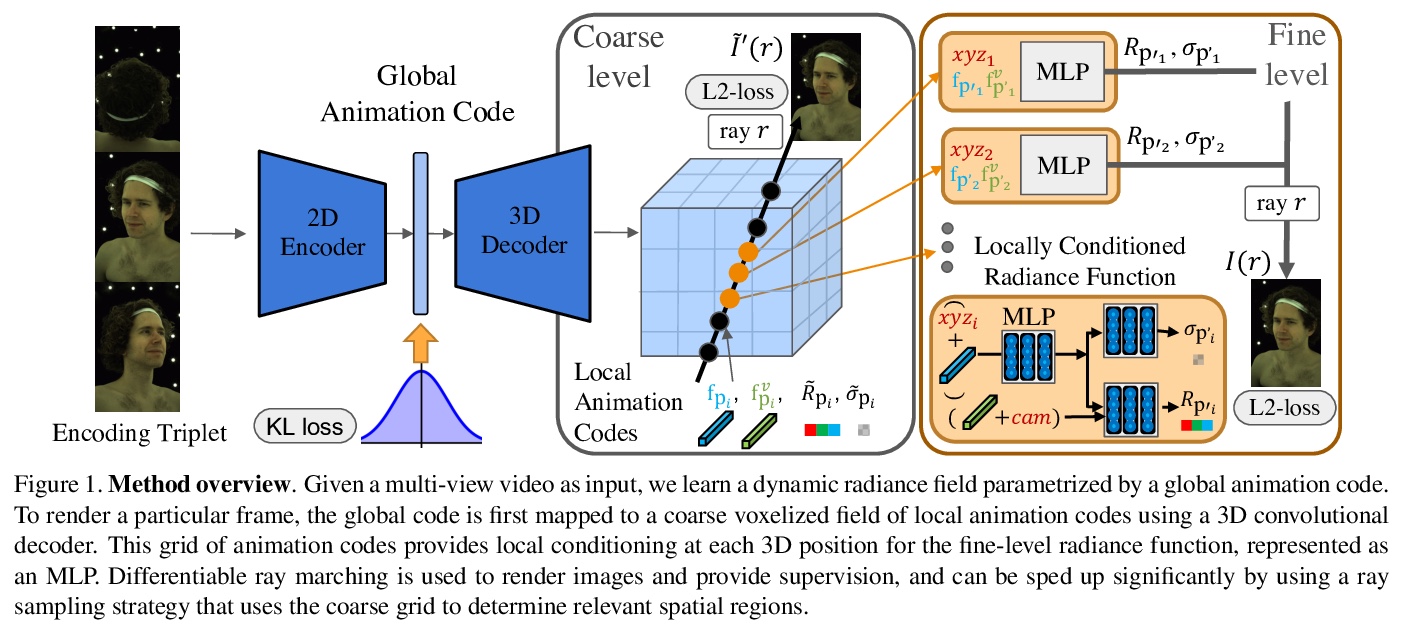
[CV] Learning Compositional Radiance Fields of Dynamic Human Heads
动态头部合成辐射场学习
Z Wang, T Bagautdinov, S Lombardi, T Simon, J Saragih, J Hodgins, M Zollhöfer
[CMU & Facebook Reality Labs]
https://weibo.com/1402400261/JzAAtwaEb
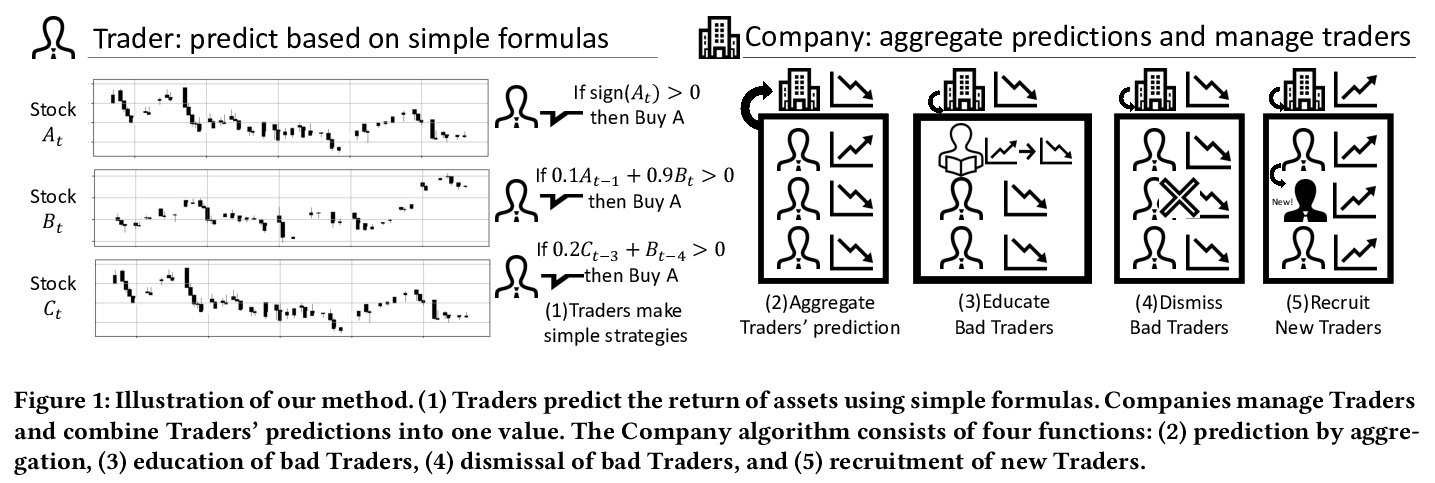
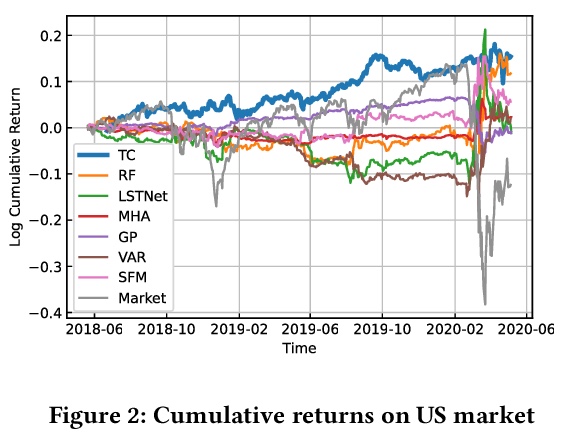
[LG] Trader-Company Method: A Metaheuristic for Interpretable Stock Price Prediction
Trader-Company方法:一种可解释的元启发式股价预测方法
K Ito, K Minami, K Imajo, K Nakagawa
[Preferred Networks & Nomura Asset Management Co., Ltd.]
https://weibo.com/1402400261/JzABZbtUf

若有收获,就点个赞吧
0 人点赞
