LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] **Liquid Warping GAN with Attention: A Unified Framework for Human Image Synthesis
W Liu, Z Piao, Z Tu, W Luo, L Ma, S Gao
[ShanghaiTech University]
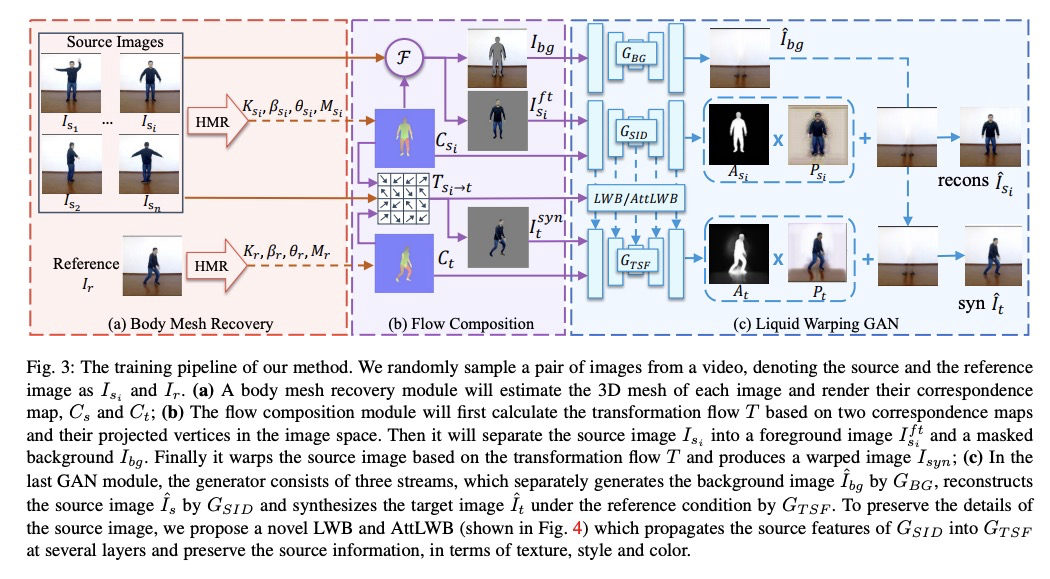
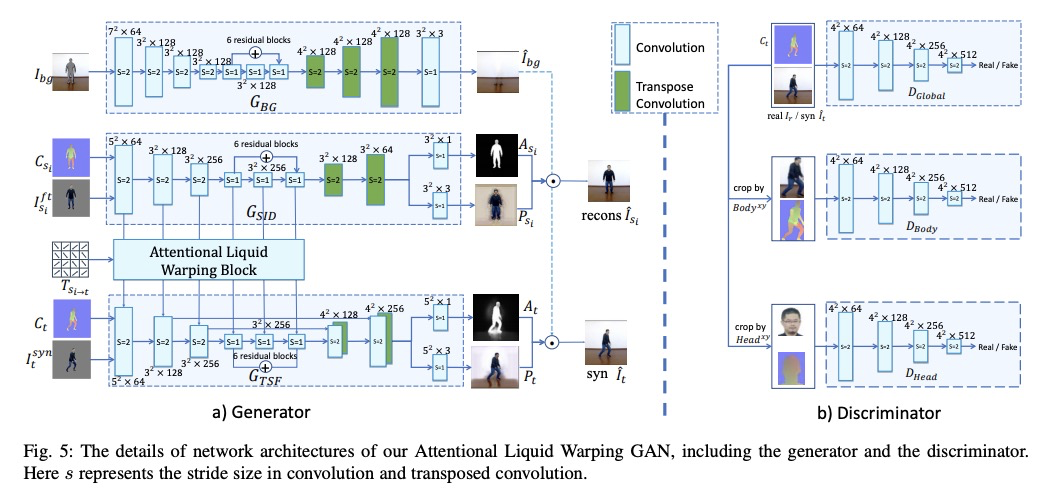
基于注意力液态扭曲GAN实现的人体图像合成统一框架。提出了处理人体运动模仿、外观迁移和新视图合成的统一框架,用人体恢复模块估计三维身体网格,设计了新的扭曲策略——注意力液态扭曲块(AttLWB),在图像和特征空间传播源信息,支持来自多源的更灵活的扭曲。该方法具有快速个性化的特点,在输入图像不在训练集范围内的情况下,可以很好地泛化,合成更高分辨率(512×512和1024×1024)的结果。**
We tackle human image synthesis, including human motion imitation, appearance transfer, and novel view synthesis, within a unified framework. It means that the model, once being trained, can be used to handle all these tasks. The existing task-specific methods mainly use 2D keypoints to estimate the human body structure. However, they only express the position information with no abilities to characterize the personalized shape of the person and model the limb rotations. In this paper, we propose to use a 3D body mesh recovery module to disentangle the pose and shape. It can not only model the joint location and rotation but also characterize the personalized body shape. To preserve the source information, such as texture, style, color, and face identity, we propose an Attentional Liquid Warping GAN with Attentional Liquid Warping Block (AttLWB) that propagates the source information in both image and feature spaces to the synthesized reference. Specifically, the source features are extracted by a denoising convolutional auto-encoder for characterizing the source identity well. Furthermore, our proposed method can support a more flexible warping from multiple sources. To further improve the generalization ability of the unseen source images, a one/few-shot adversarial learning is applied. In detail, it firstly trains a model in an extensive training set. Then, it finetunes the model by one/few-shot unseen image(s) in a self-supervised way to generate high-resolution (512 x 512 and 1024 x 1024) results. Also, we build a new dataset, namely iPER dataset, for the evaluation of human motion imitation, appearance transfer, and novel view synthesis. Extensive experiments demonstrate the effectiveness of our methods in terms of preserving face identity, shape consistency, and clothes details. All codes and dataset are available on > this https URL.
https://weibo.com/1402400261/JuItb0w5R
2、[LG] *Design Space for Graph Neural Networks
J You, R Ying, J Leskovec
[Stanford University]
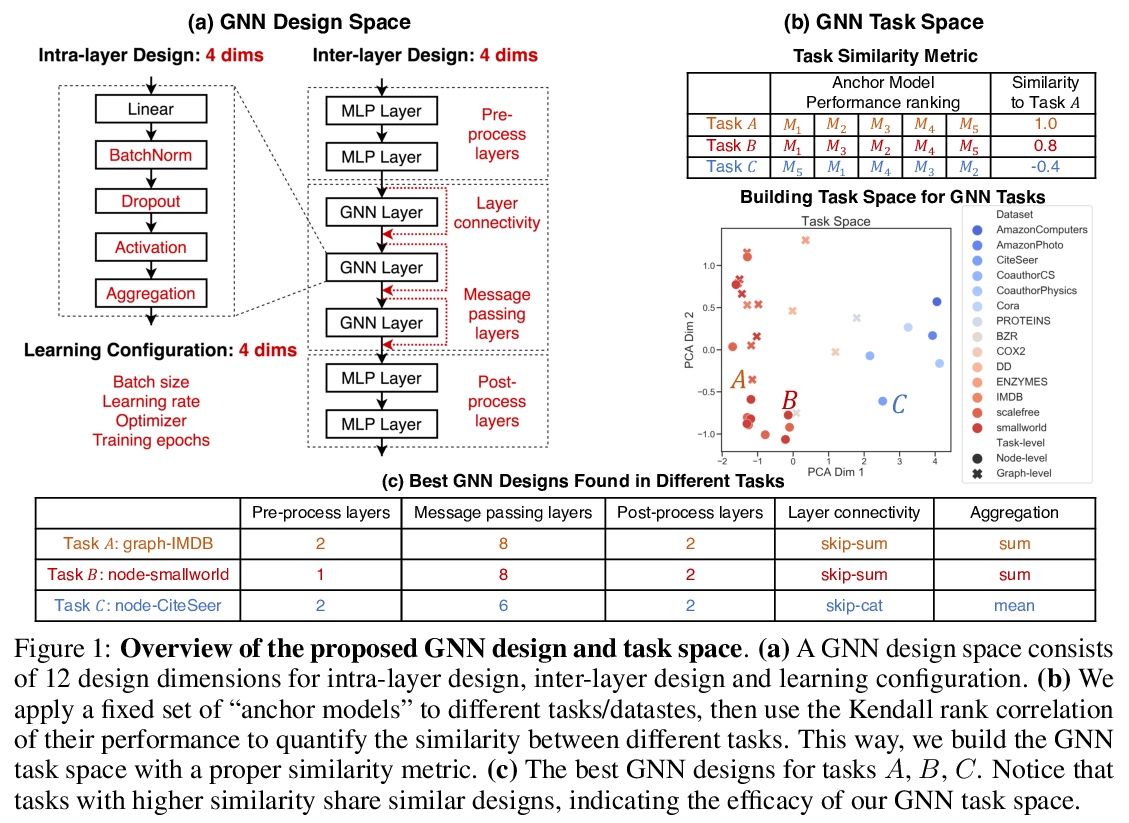
图神经网络(GNN)设计空间。定义并系统地研究了GNN的架构设计空间,包括超过32种不同的预测任务的315000种不同的设计。提出了一种建立通用GNN设计空间和具有定量相似性度量的GNN任务空间的原则方法。发布了GraphGym,一个用于探索不同GNN设计和任务的强大平台,具有模块化的GNN实现、标准化的GNN评价和可复现、可扩展的实验管理。**
The rapid evolution of Graph Neural Networks (GNNs) has led to a growing number of new architectures as well as novel applications. However, current research focuses on proposing and evaluating specific architectural designs of GNNs, as opposed to studying the more general design space of GNNs that consists of a Cartesian product of different design dimensions, such as the number of layers or the type of the aggregation function. Additionally, GNN designs are often specialized to a single task, yet few efforts have been made to understand how to quickly find the best GNN design for a novel task or a novel dataset. Here we define and systematically study the architectural design space for GNNs which consists of 315,000 different designs over 32 different predictive tasks. Our approach features three key innovations: (1) A general GNN design space; (2) a GNN task space with a similarity metric, so that for a given novel task/dataset, we can quickly identify/transfer the best performing architecture; (3) an efficient and effective design space evaluation method which allows insights to be distilled from a huge number of model-task combinations. Our key results include: (1) A comprehensive set of guidelines for designing well-performing GNNs; (2) while best GNN designs for different tasks vary significantly, the GNN task space allows for transferring the best designs across different tasks; (3) models discovered using our design space achieve state-of-the-art performance. Overall, our work offers a principled and scalable approach to transition from studying individual GNN designs for specific tasks, to systematically studying the GNN design space and the task space. Finally, we release GraphGym, a powerful platform for exploring different GNN designs and tasks. GraphGym features modularized GNN implementation, standardized GNN evaluation, and reproducible and scalable experiment management.
https://weibo.com/1402400261/JuIxV0hZ1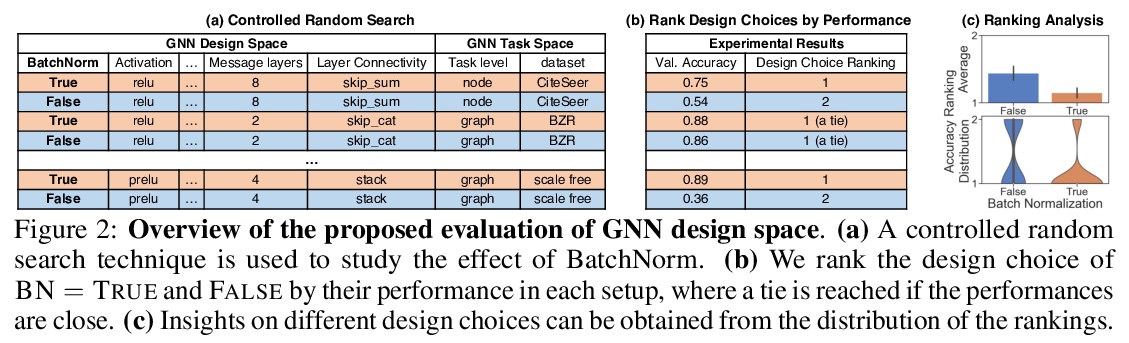
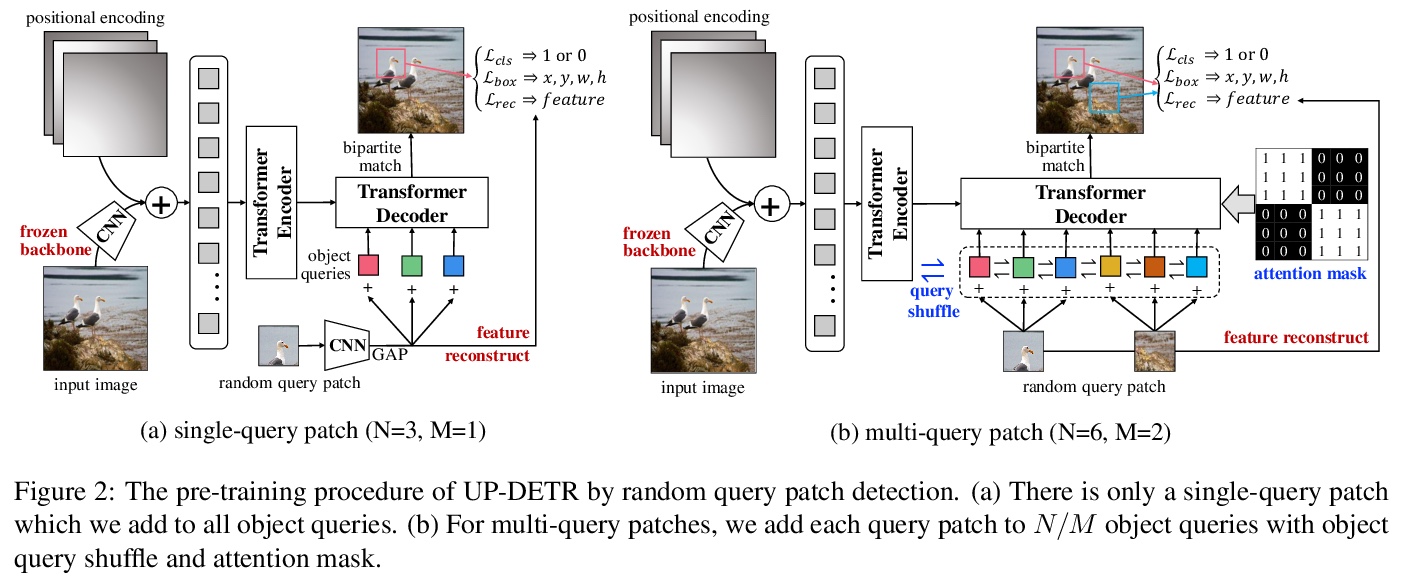
3、[CV] *UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
Z Dai, B Cai, Y Lin, J Chen
[South China University of Technology & Tencent Wechat AI]
UP-DETR:Transformer目标检测无监督预训练。提出了随机查询区块检测,用于在DETR中对Transformer进行无监督预训练——从给定图像中随机裁剪区块,将其作为查询提供给解码器,对模型进行预训练,从原始图像中检测出这些查询区块。采用无监督预训练的UP-DETR性能显著优于DETR,在PASCAL VOC上具有更高的精度和更快的收敛速度。**
Object detection with transformers (DETR) reaches competitive performance with Faster R-CNN via a transformer encoder-decoder architecture. Inspired by the great success of pre-training transformers in natural language processing, we propose a pretext task named random query patch detection to unsupervisedly pre-train DETR (UP-DETR) for object detection. Specifically, we randomly crop patches from the given image and then feed them as queries to the decoder. The model is pre-trained to detect these query patches from the original image. During the pre-training, we address two critical issues: multi-task learning and multi-query localization. (1) To trade-off multi-task learning of classification and localization in the pretext task, we freeze the CNN backbone and propose a patch feature reconstruction branch which is jointly optimized with patch detection. (2) To perform multi-query localization, we introduce UP-DETR from single-query patch and extend it to multi-query patches with object query shuffle and attention mask. In our experiments, UP-DETR significantly boosts the performance of DETR with faster convergence and higher precision on PASCAL VOC and COCO datasets. The code will be available soon.
https://weibo.com/1402400261/JuIAt5xCX
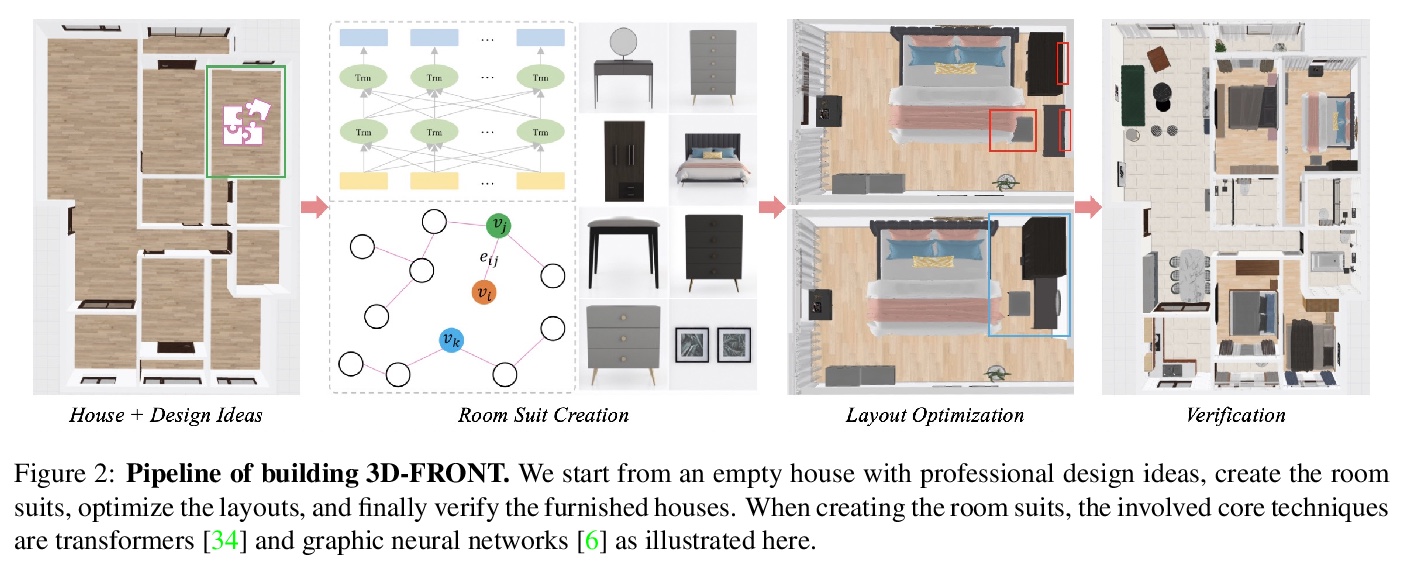
4、[CV] **3D-FRONT: 3D Furnished Rooms with layOuts and semaNTics
H Fu, B Cai, L Gao, L Zhang, C Li, Z Xun, C Sun, Y Fei, Y Zheng, Y Li, Y Liu, P Liu, L Ma, L Weng, X Hu, X Ma, Q Qian, R Jia, B Zhao, H Zhang
[Alibaba Group & Chinese Academy of Sciences & Simon Fraser University]
3D-FRONT: 带布局和语义的3D装饰房间。提出新的大规模合成室内三维场景数据集3D-FRONT,提供大规模公开收集的专业设计房间布局与高质量纹理CAD网格模型,包含18797个包含3D物体的房间,7302件家具都有高质量的纹理,超过现有的公开场景数据集。发布了一个轻量渲染工具Trescope,支持2D图像的基准渲染和3D前端标记。**
We introduce 3D-FRONT (3D Furnished Rooms with layOuts and semaNTics), a new, large-scale, and comprehensive repository of synthetic indoor scenes highlighted by professionally designed layouts and a large number of rooms populated by high-quality textured 3D models with style compatibility. From layout semantics down to texture details of individual objects, our dataset is freely available to the academic community and beyond. Currently, 3D-FRONT contains 18,797 rooms diversely furnished by 3D objects, far surpassing all publicly available scene datasets. In addition, the 7,302 furniture objects all come with high-quality textures. While the floorplans and layout designs are directly sourced from professional creations, the interior designs in terms of furniture styles, color, and textures have been carefully curated based on a recommender system we develop to attain consistent styles as expert designs. Furthermore, we release Trescope, a light-weight rendering tool, to support benchmark rendering of 2D images and annotations from 3D-FRONT. We demonstrate two applications, interior scene synthesis and texture synthesis, that are especially tailored to the strengths of our new dataset. The project page is at: > this https URL
https://weibo.com/1402400261/JuIFykCiR .
.
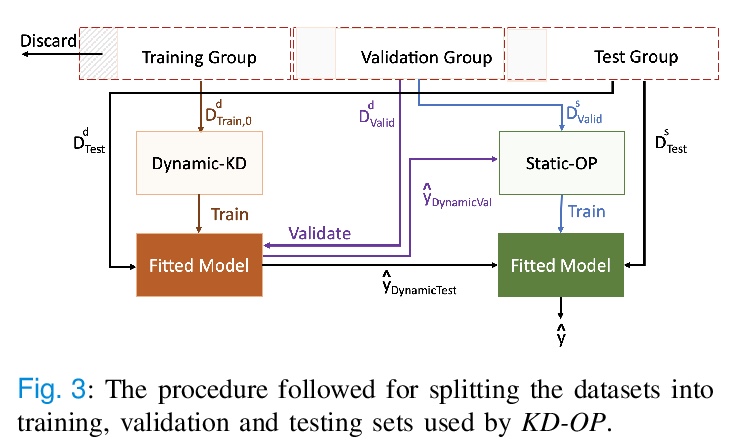
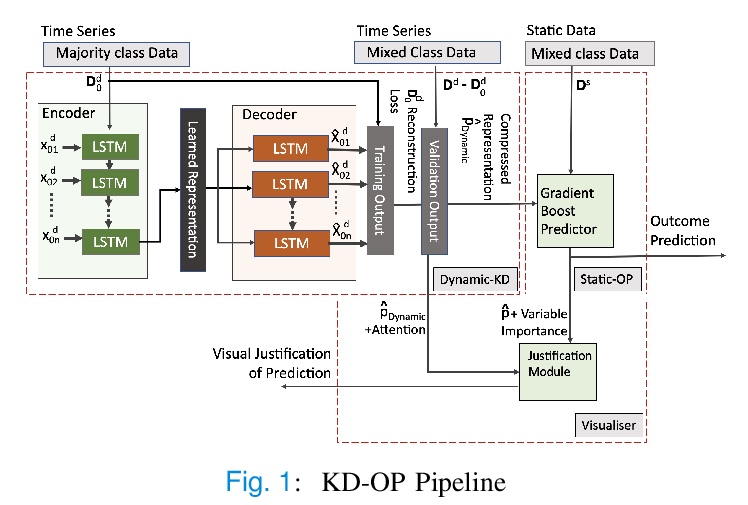
5、[LG] **A Knowledge Distillation Ensemble Framework for Predicting Short and Long-term Hospitalisation Outcomes from Electronic Health Records Data
Z M Ibrahim, D Bean, T Searle, H Wu, A Shek, Z Kraljevic, J Galloway, S Norton, J T Teo, R J Dobson
[King’s College London & University College London]
电子病例数据长短期住院结果预测知识蒸馏集成框架。提供了高度可扩展和鲁棒的机器学习框架KD-OP,根据入院24小时内的时间序列生命体征和实验室结果自动预测死亡率和ICU入院情况,可用于评估患者在一段时间内的逆境风险,并根据患者的静态特征和动态信号为其预测提供可视化的理由。KD-OP由两个堆叠模块组成,每个模块都从病人数据的角度进行预测:动态时间序列和静态特征。模块的堆叠用于模拟临床医生的做法,通过考虑病人生理的时间特征和时不变特征之间的相互作用,做出预后决定。**
The ability to perform accurate prognosis of patients is crucial for proactive clinical decision making, informed resource management and personalised care. Existing outcome prediction models suffer from a low recall of infrequent positive outcomes. We present a highly-scalable and robust machine learning framework to automatically predict adversity represented by mortality and ICU admission from time-series vital signs and laboratory results obtained within the first 24 hours of hospital admission. The stacked platform comprises two components: a) an unsupervised LSTM Autoencoder that learns an optimal representation of the time-series, using it to differentiate the less frequent patterns which conclude with an adverse event from the majority patterns that do not, and b) a gradient boosting model, which relies on the constructed representation to refine prediction, incorporating static features of demographics, admission details and clinical summaries. The model is used to assess a patient’s risk of adversity over time and provides visual justifications of its prediction based on the patient’s static features and dynamic signals. Results of three case studies for predicting mortality and ICU admission show that the model outperforms all existing outcome prediction models, achieving PR-AUC of 0.93 (95> CI: 0.878 - 0.969) in predicting mortality in ICU and general ward settings and 0.987 (95> CI: 0.985-0.995) in predicting ICU admission.
https://weibo.com/1402400261/JuIJsDNB1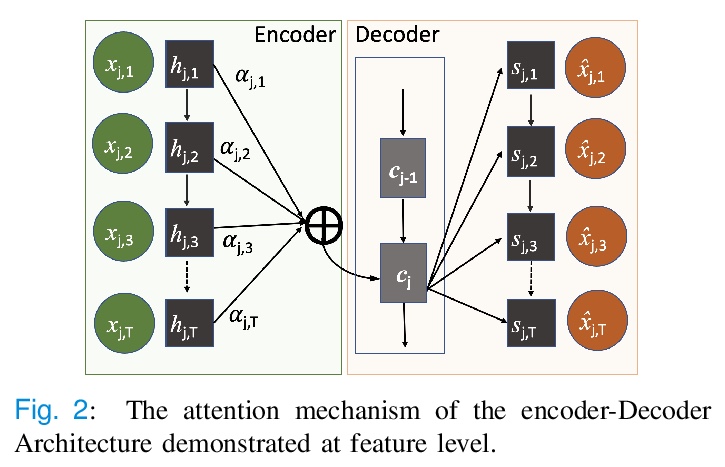
另外几篇值得关注的论文:
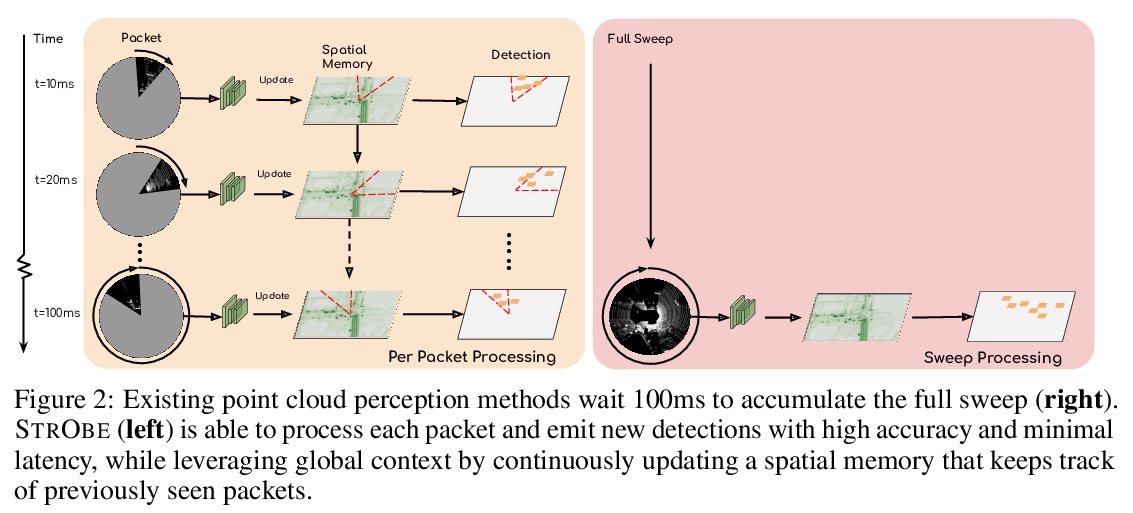
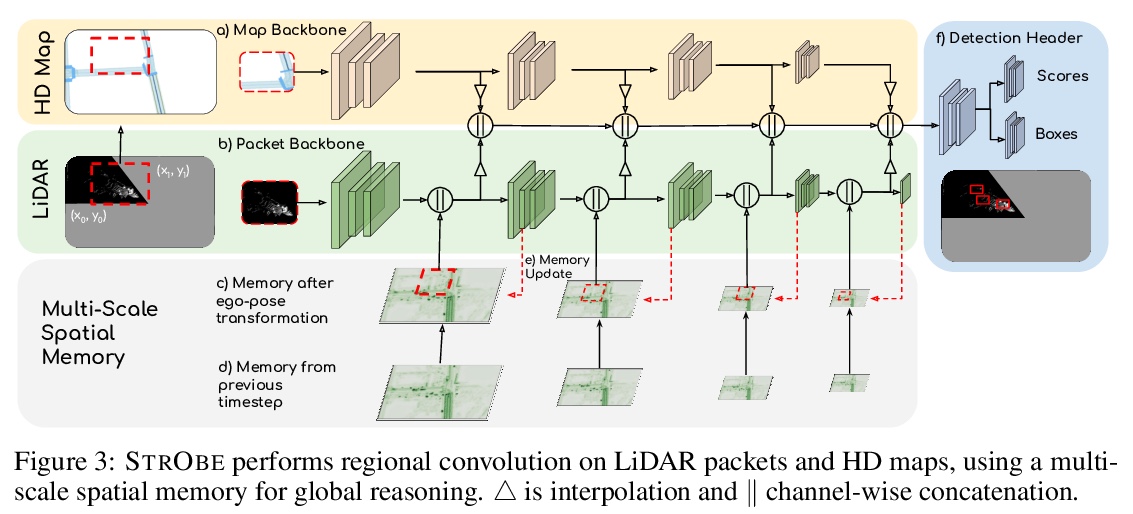
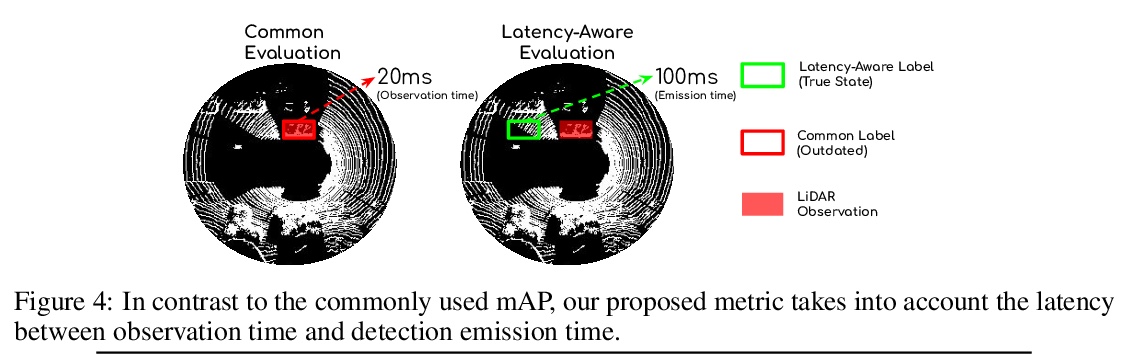
[CV] StrObe: Streaming Object Detection from LiDAR Packets
StrObe:激光雷达数据包流目标检测
D Frossard, S Suo, S Casas, J Tu, R Hu, R Urtasun
[Uber Advanced Technologies Group]
https://weibo.com/1402400261/JuIN2zNW8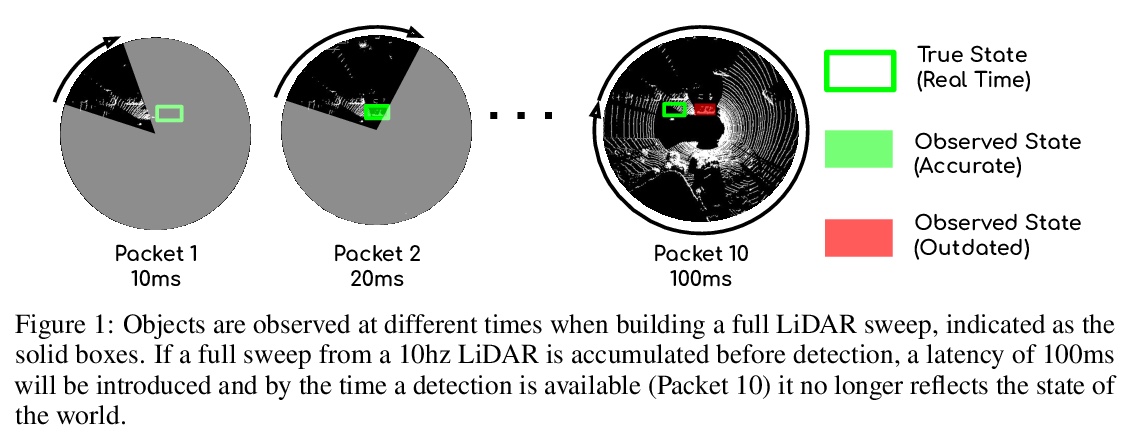


若有收获,就点个赞吧
0 人点赞
