- 1、[LG] Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
- 2、[CV] X-volution: On the unification of convolution and self-attention
- 3、[LG] Deep Reinforcement Learning in Quantitative Algorithmic Trading: A Review
- 4、[CV] Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering
- 5、[CV] Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
- [AI] Detecting and Adapting to Novelty in Games
- [LG] Solving Schrödinger Bridges via Maximum Likelihood
- [CV] Semantic Correspondence with Transformers
- [LG] A Consciousness-Inspired Planning Agent for Model-Based Reinforcement Learning
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
J Kossen, N Band, C Lyle, A N. Gomez, T Rainforth, Y Gal
[University of Oxford]
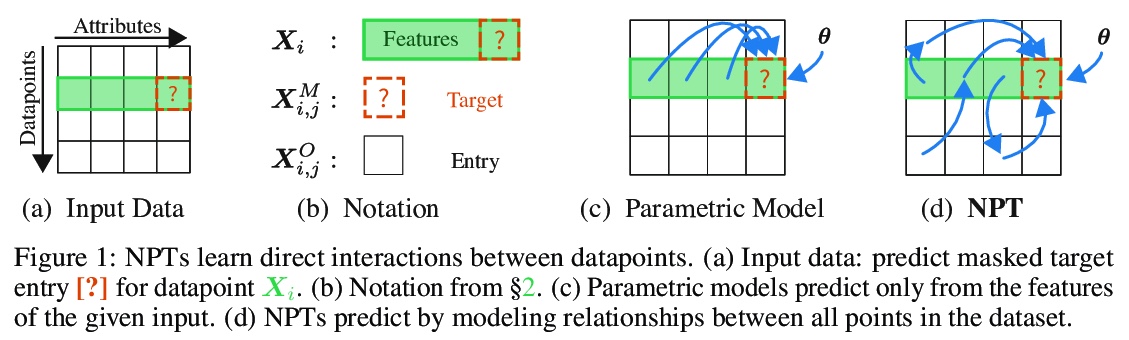
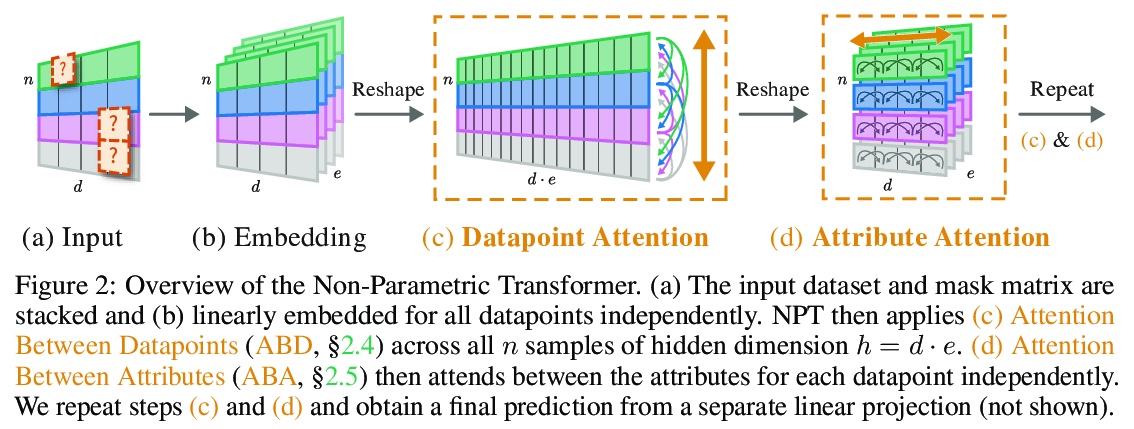
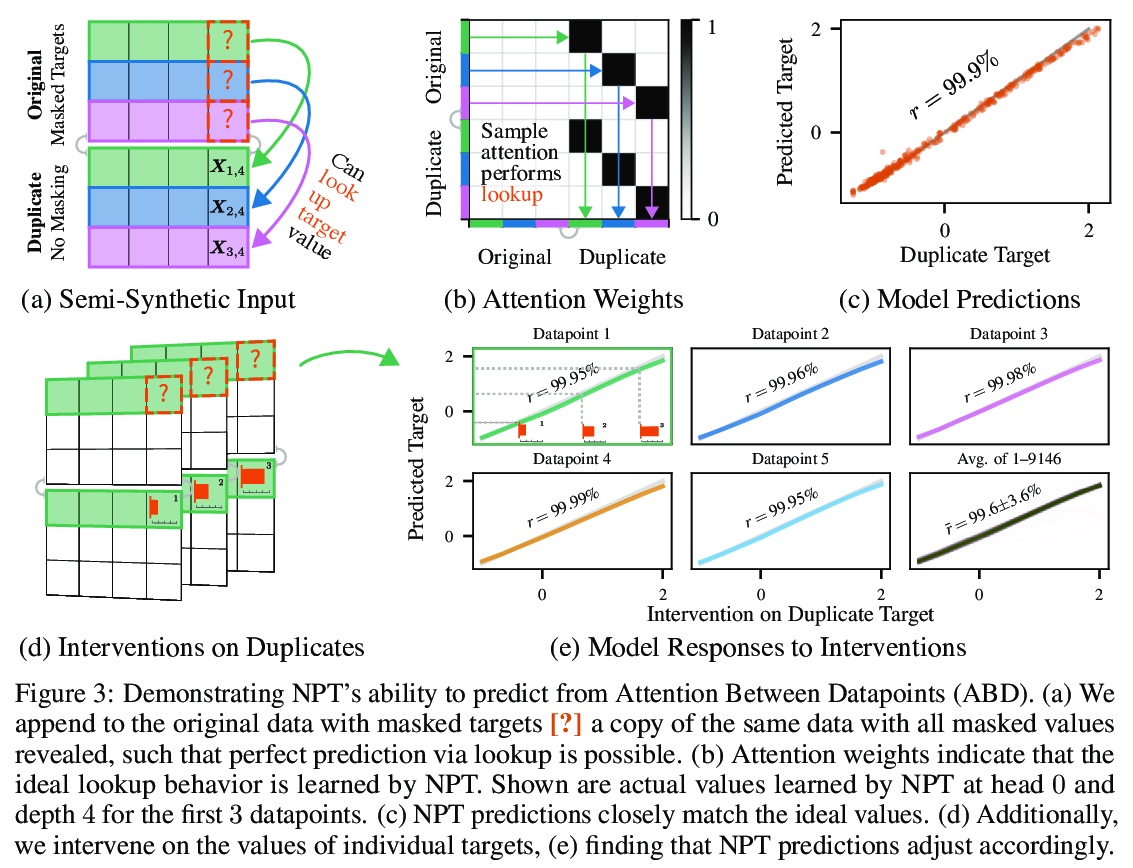
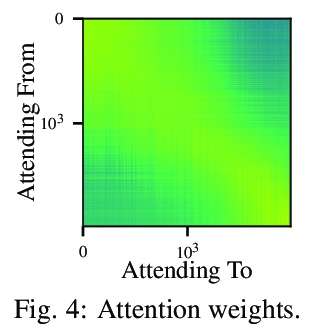
数据点之间的自注意力:在深度学习中超越单独输入-输出对。本文对大多数监督式深度学习的一个常见假设提出了挑战:模型的预测只取决于其参数,以及单一输入的特征。提出一种通用的深度学习架构,将整个数据集作为输入,而不是一次处理一个数据点,用自注意力显式推理数据点间关系,可看作是用参数式注意力机制来实现非参数模型。与传统非参数模型不同,让模型从数据中端到端学习如何利用其他数据点进行预测。实验表明,所提出模型解决了传统深度学习模型无法解决的跨数据点查找和复杂推理任务。展示了在表格数据上极具竞争力的结果,以及在CIFAR-10上的早期结果,并对该模型如何利用各点之间的相互作用进行了深入探讨。
We challenge a common assumption underlying most supervised deep learning: that a model makes a prediction depending only on its parameters and the features of a single input. To this end, we introduce a general-purpose deep learning architecture that takes as input the entire dataset instead of processing one datapoint at a time. Our approach uses self-attention to reason about relationships between datapoints explicitly, which can be seen as realizing non-parametric models using parametric attention mechanisms. However, unlike conventional non-parametric models, we let the model learn end-to-end from the data how to make use of other datapoints for prediction. Empirically, our models solve cross-datapoint lookup and complex reasoning tasks unsolvable by traditional deep learning models. We show highly competitive results on tabular data, early results on CIFAR-10, and give insight into how the model makes use of the interactions between points.
https://weibo.com/1402400261/Kjary2oPv
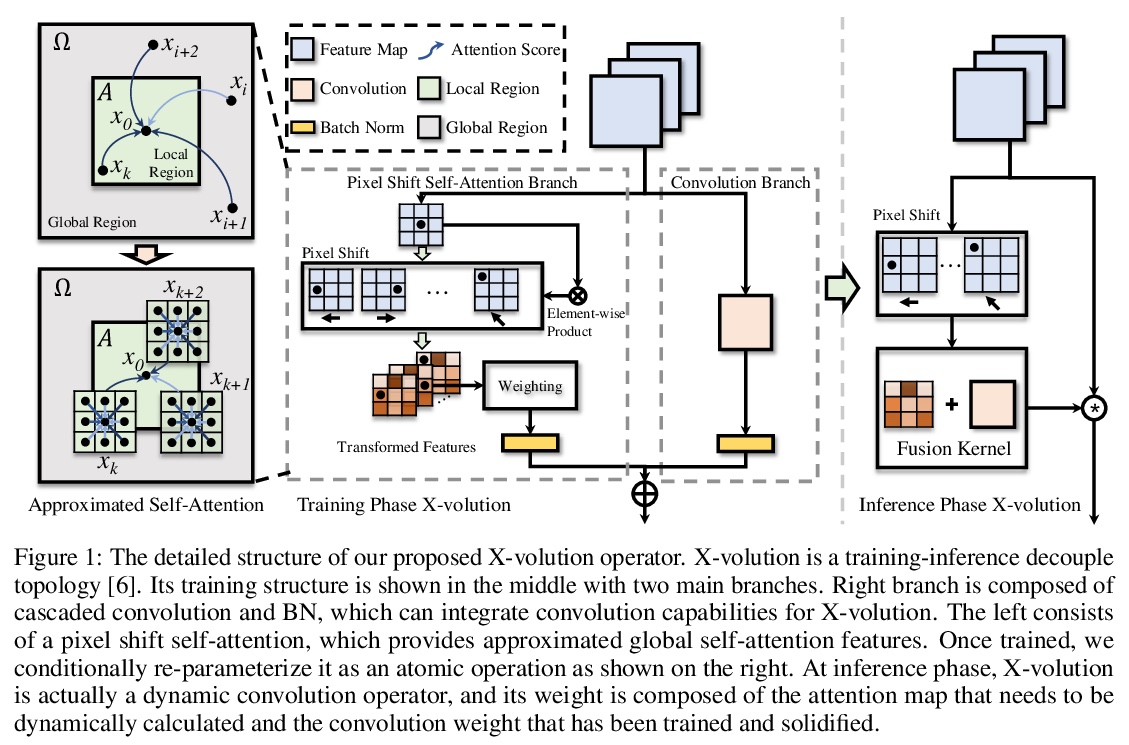
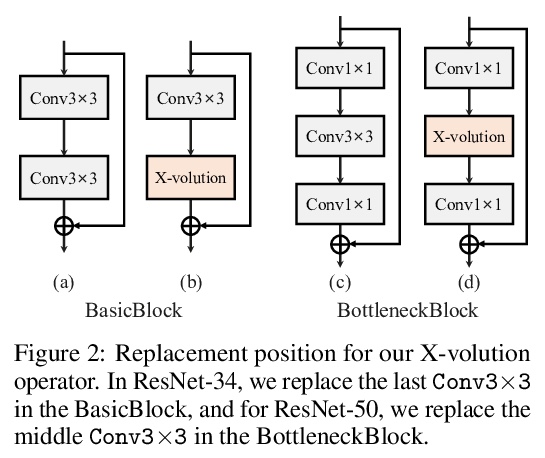
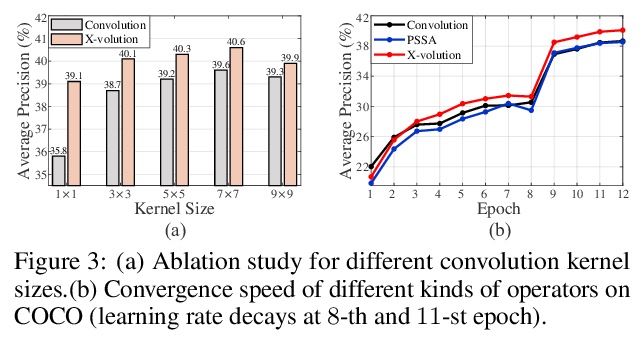
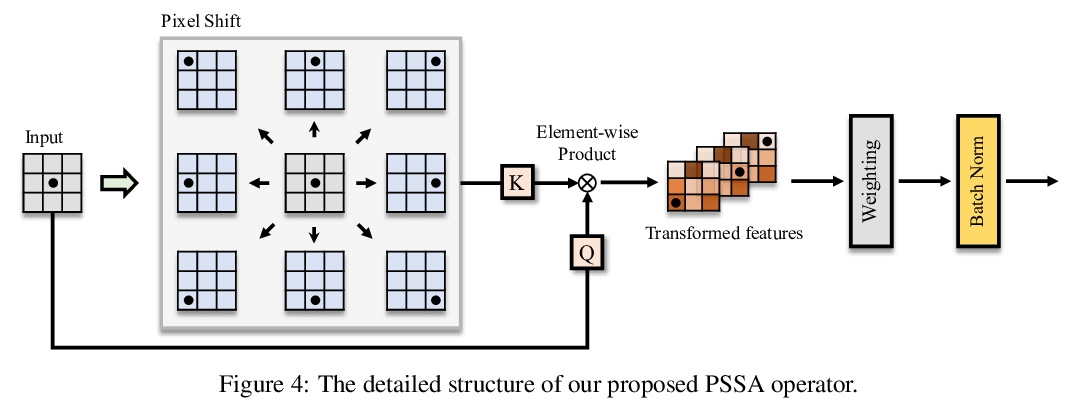
2、[CV] X-volution: On the unification of convolution and self-attention
X Chen, H Wang, B Ni
[Huawei Hisilicon]
X-volution:卷积和自注意力的统一。卷积和自注意力,作为深度神经网络的两个基本构件,前者以线性方式提取局部图像特征,后者则以非局部方式编码高阶上下文关系,虽然本质上是互补的,即一阶和高阶的关系,但由于其异质计算模式,以及视觉任务中全局点阵负担过重,目前的架构,无论CNN还是Transformer,都缺乏在一个计算模块中同时应用两种操作的原则性方法。本文从理论上推导出一种全局自注意力的近似方案,通过对变换特征的卷积操作来近似自注意力。基于该方案,实现了一种由卷积和自注意力操作组成的多分支基础模块,可统一局部和非局部特征的相互作用。经过训练,该多分支模块可通过结构上的重参数化,有条件地转化为单一标准卷积操作,形成X-volution纯卷积风格算子,可作为原子操作插入到任意现代网络。广泛实验表明,所提出的X-volution实现了极具竞争力的视觉理解的改进(在ImageNet分类中达到+1.2%的最高准确率,在COCO检测和分割中达到+1.7的框AP和+1.5的掩模AP)。
Convolution and self-attention are acting as two fundamental building blocks in deep neural networks, where the former extracts local image features in a linear way while the latter non-locally encodes high-order contextual relationships. Though essentially complementary to each other, i.e., first-/high-order, stat-of-the-art architectures, i.e., CNNs or transformers, lack a principled way to simultaneously apply both operations in a single computational module, due to their heterogeneous computing pattern and excessive burden of global dot-product for visual tasks. In this work, we theoretically derive a global self-attention approximation scheme, which approximates self-attention via the convolution operation on transformed features. Based on the approximate scheme, we establish a multi-branch elementary module composed of both convolution and self-attention operation, capable of unifying both local and non-local feature interaction. Importantly, once trained, this multi-branch module could be conditionally converted into a single standard convolution operation via structural re-parameterization, rendering a pure convolution styled operator named X-volution, ready to be plugged into any modern networks as an atomic operation. Extensive experiments demonstrate that the proposed X-volution, achieves highly competitive visual understanding improvements (+1.2% top-1 accuracy on ImageNet classification, +1.7 box AP and +1.5 mask AP on COCO detection and segmentation).
https://weibo.com/1402400261/KjawPCD8T
3、[LG] Deep Reinforcement Learning in Quantitative Algorithmic Trading: A Review
T Pricope
[The University of Edinburgh]
深度强化学习量化算法交易综述。股票算法交易已成为当今金融市场的主力,大部分交易现在都是全自动化的。深度强化学习(DRL)智能体在国际象棋和围棋等许多复杂游戏中被证明是一种不可忽视的力量。可以把股票市场的历史价格序列和运动,看作是一个复杂的不完美信息环境,利用算法使回报利润最大化、风险最小化。本文回顾了迄今为止深度强化学习在金融领域人工智能子领域所取得的进展,更进一步,即自动化的低频量化股票交易。回顾到的许多研究只有想法的概念验证,在非现实环境中进行实验,而没有实时的交易应用。大多数工作,尽管与既定的基线策略相比,在统计学上有明显的性能改进,但没有获得像样的盈利。此外,缺乏在实时、在线交易平台上的实验测试,也缺乏对建立在不同类型深度强化学习上的智能体或人工交易者的有意义的比较。本文结论是,深度强化学习在股票交易中显示出巨大的应用潜力,可以在强大的假设条件下与专业交易员相媲美,但该研究仍处于非常早期的发展阶段。
Algorithmic stock trading has become a staple in today’s financial market, the majority of trades being now fully automated. Deep Reinforcement Learning (DRL) agents proved to be to a force to be reckon with in many complex games like Chess and Go. We can look at the stock market historical price series and movements as a complex imperfect information environment in which we try to maximize return profit and minimize risk. This paper reviews the progress made so far with deep reinforcement learning in the subdomain of AI in finance, more precisely, automated low-frequency quantitative stock trading. Many of the reviewed studies had only proof-of-concept ideals with experiments conducted in unrealistic settings and no real-time trading applications. For the majority of the works, despite all showing statistically significant improvements in performance compared to established baseline strategies, no decent profitability level was obtained. Furthermore, there is a lack of experimental testing in real-time, online trading platforms and a lack of meaningful comparisons between agents built on different types of DRL or human traders. We conclude that DRL in stock trading has showed huge applicability potential rivalling professional traders under strong assumptions, but the research is still in the very early stages of development.
https://weibo.com/1402400261/KjaAlb5CE
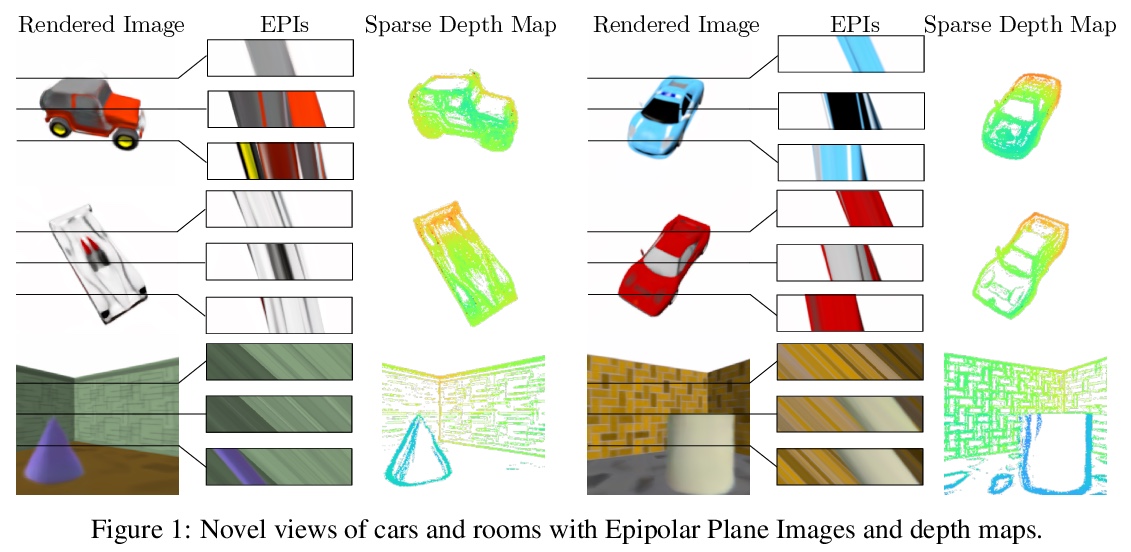
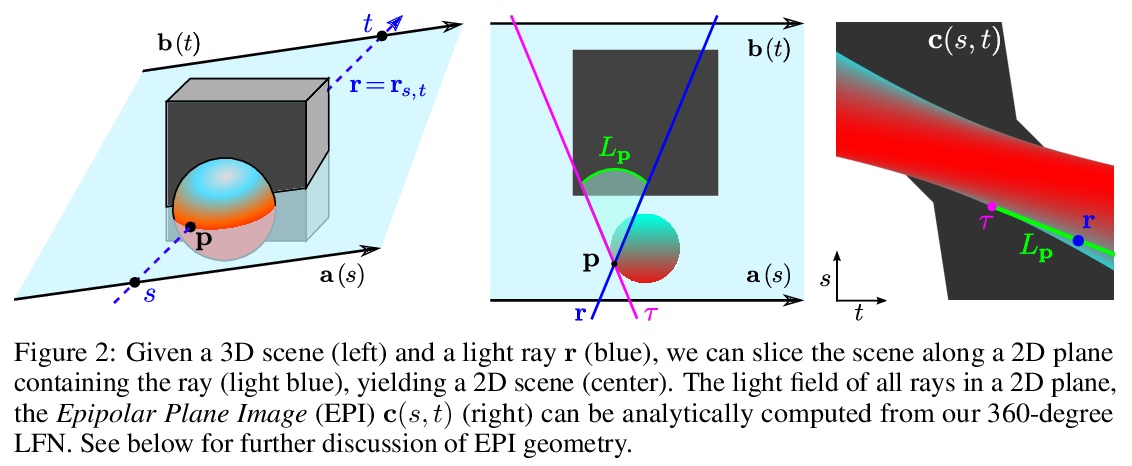
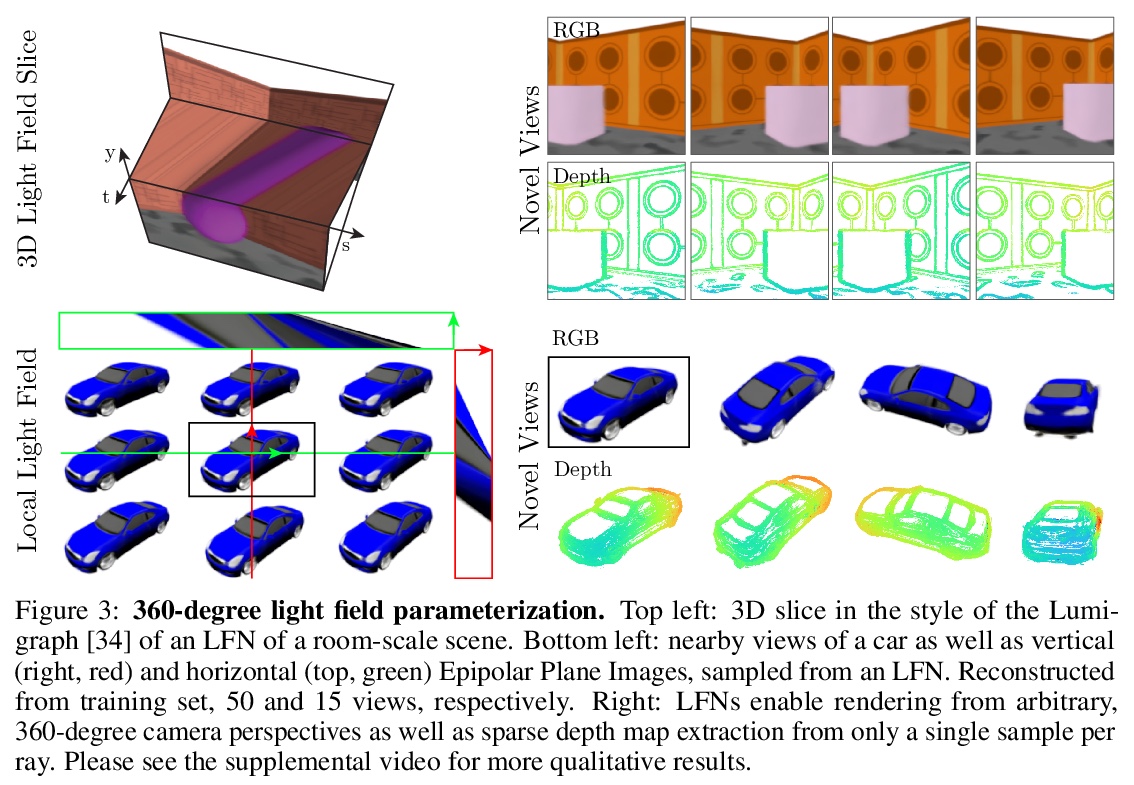
4、[CV] Light Field Networks: Neural Scene Representations with Single-Evaluation Rendering
V Sitzmann, S Rezchikov, W T. Freeman, J B. Tenenbaum, F Durand
[MIT CSAIL & Columbia University]
光场网络:单评估渲染神经网络场景表示。从2D观察中推断3D场景的表示,是计算机图形学、计算机视觉和人工智能的一个基本问题。新兴的3D结构神经场景表示,是一种很有前途的3D场景理解方法。本文提出一种新的神经网络场景表示,即光场网络(LFN),在360度4D光场中,通过神经隐表示参数化来表示基础3D场景的几何和外观。渲染来自LFN的一条光线,只需要一次网络评估,而3D结构化神经场景表示的光线匹配或体渲染器每条光线需要进行数百次评估。在简单场景设置下,用元学习得到LFN先验,多视图一致的光场重建只需要单幅图像的观察。时间和记忆复杂度大大降低,可进行实时渲染。通过LFN存储360度光场的成本,比Lumigraph等传统方法低两个数量级。利用神经隐表示的分析性和光空间的新参数化方法,进一步证明了从LFN中提取稀疏深度图的能力。
Inferring representations of 3D scenes from 2D observations is a fundamental problem of computer graphics, computer vision, and artificial intelligence. Emerging 3D-structured neural scene representations are a promising approach to 3D scene understanding. In this work, we propose a novel neural scene representation, Light Field Networks or LFNs, which represent both geometry and appearance of the underlying 3D scene in a 360-degree, four-dimensional light field parameterized via a neural implicit representation. Rendering a ray from an LFN requires only a single network evaluation, as opposed to hundreds of evaluations per ray for ray-marching or volumetric based renderers in 3D-structured neural scene representations. In the setting of simple scenes, we leverage meta-learning to learn a prior over LFNs that enables multi-view consistent light field reconstruction from as little as a single image observation. This results in dramatic reductions in time and memory complexity, and enables real-time rendering. The cost of storing a 360-degree light field via an LFN is two orders of magnitude lower than conventional methods such as the Lumigraph. Utilizing the analytical differentiability of neural implicit representations and a novel parameterization of light space, we further demonstrate the extraction of sparse depth maps from LFNs.
https://weibo.com/1402400261/KjaDNEidM

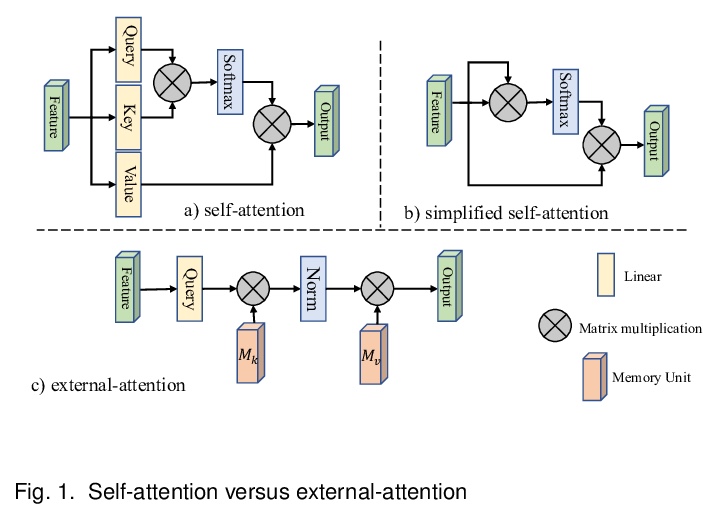
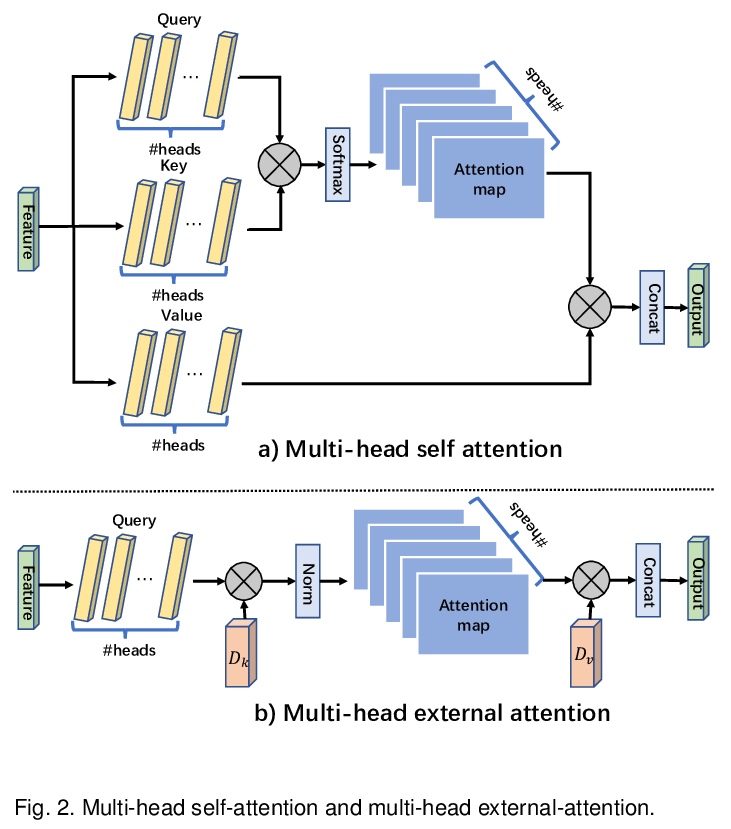
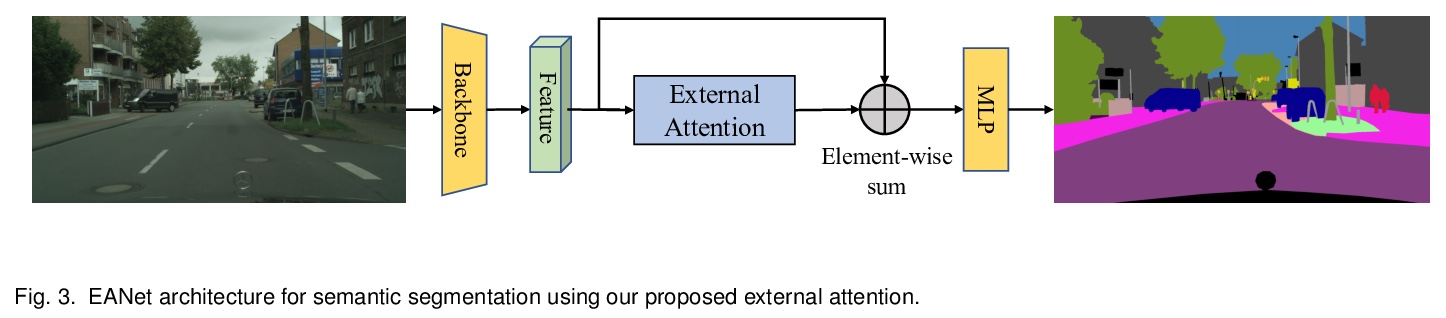
5、[CV] Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
M Guo, Z Liu, T Mu, S Hu
[Tsinghua University]
超越自注意力:面向视觉任务的双线性层外部注意力。注意力机制,尤其是自注意力,在视觉任务的深度特征表示中发挥了越来越重要的作用。自注意力通过计算特征的加权和,来更新每个位置的特征,用所有位置的成对亲和力来捕捉单个样本的长程依赖。然而,自注意力具有二次复杂度,且忽略了不同样本间的潜在相关性。本文提出一种新的注意力机制,即外部注意力,基于两个外部的、小的、可学习的、共享的记忆,通过简单使用两个级联线性层和两个规范化层来实现,可方便地替代现有流行架构中的自注意力。外部注意力具有线性复杂度,并隐式考虑了所有数据样本间的相关性。进一步将多头机制纳入外部注意力,构成全MLP架构,即外部注意力MLP(EAMLP),用于图像分类。在图像分类、目标检测、语义分割、实例分割、图像生成和点云分析方面的大量实验表明,该方法提供了与自注意力机制及其一些变体相当或更高的结果,而且计算和内存成本低得多。
Attention mechanisms, especially self-attention, have played an increasingly important role in deep feature representation for visual tasks. Self-attention updates the feature at each position by computing a weighted sum of features using pair-wise affinities across all positions to capture the long-range dependency within a single sample. However, self-attention has quadratic complexity and ignores potential correlation between different samples. This paper proposes a novel attention mechanism which we call external attention, based on two external, small, learnable, shared memories, which can be implemented easily by simply using two cascaded linear layers and two normalization layers; it conveniently replaces self-attention in existing popular architectures. External attention has linear complexity and implicitly considers the correlations between all data samples. We further incorporate the multi-head mechanism into external attention to provide an all-MLP architecture, external attention MLP (EAMLP), for image classification. Extensive experiments on image classification, object detection, semantic segmentation, instance segmentation, image generation, and point cloud analysis reveal that our method provides results comparable or superior to the self-attention mechanism and some of its variants, with much lower computational and memory costs.
https://weibo.com/1402400261/KjaHX5bp0

另外几篇值得关注的论文:
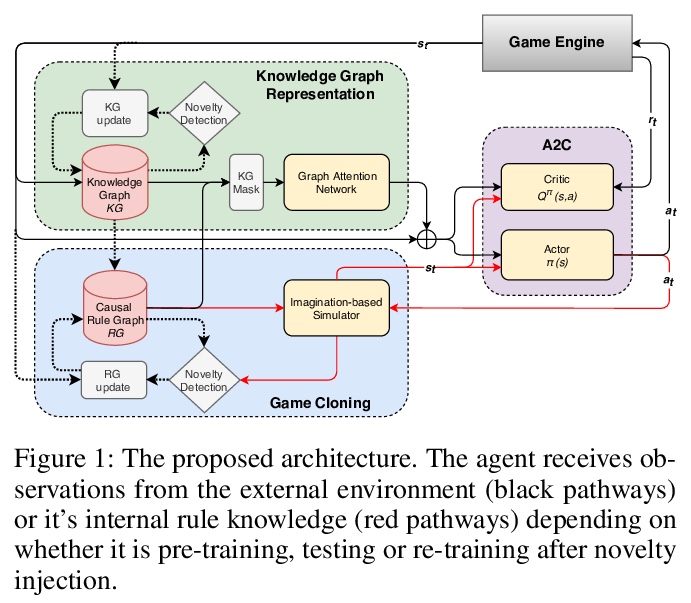
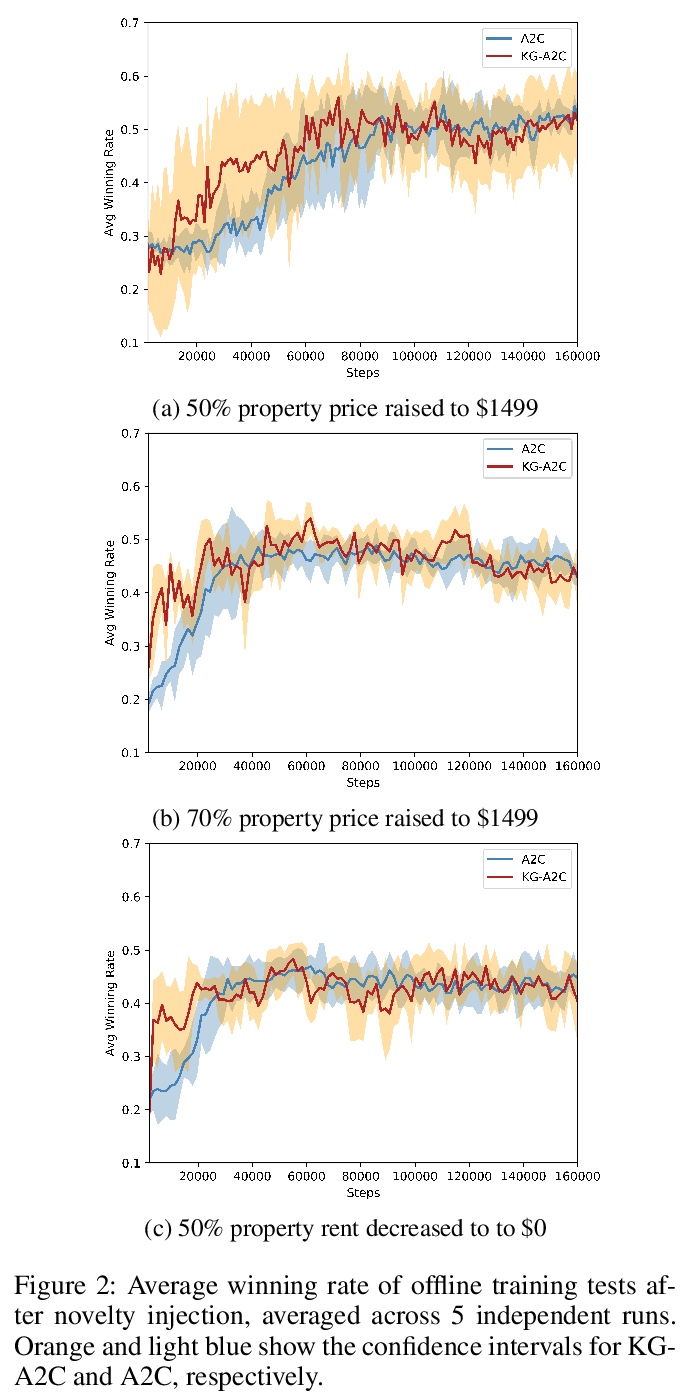
[AI] Detecting and Adapting to Novelty in Games
游戏新奇性的检测与自适应
X Peng, J C. Balloch, M O. Riedl
[Georgia Institute of Technology]
https://weibo.com/1402400261/KjaKGkL5a
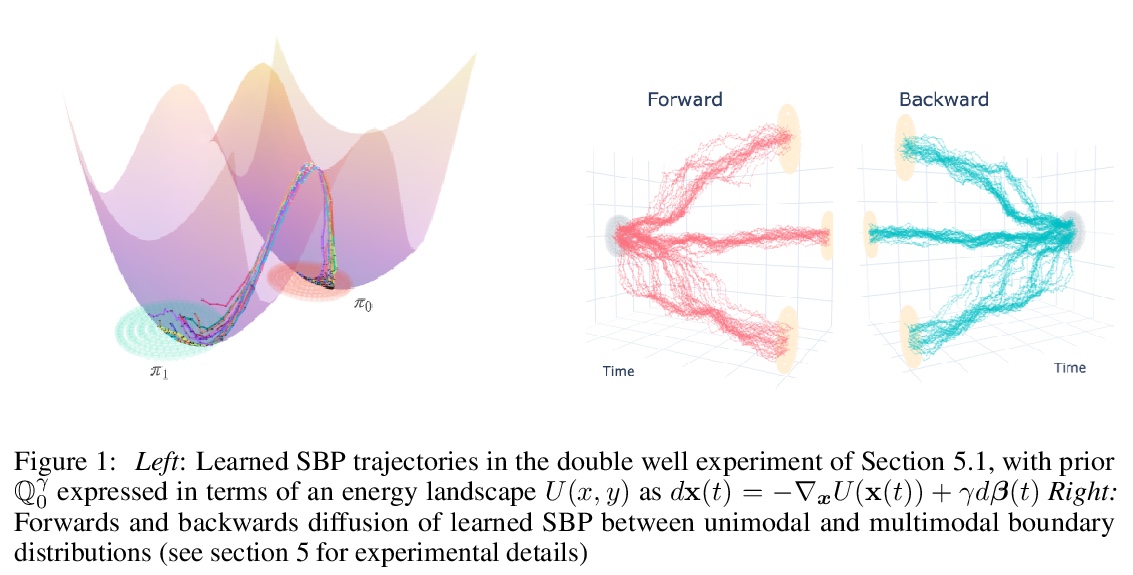
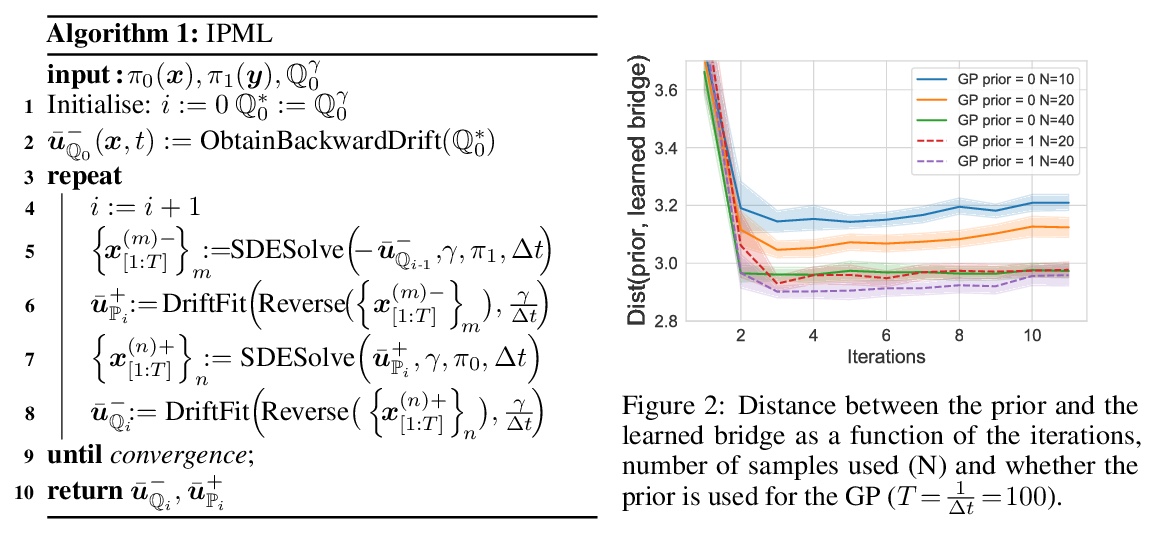
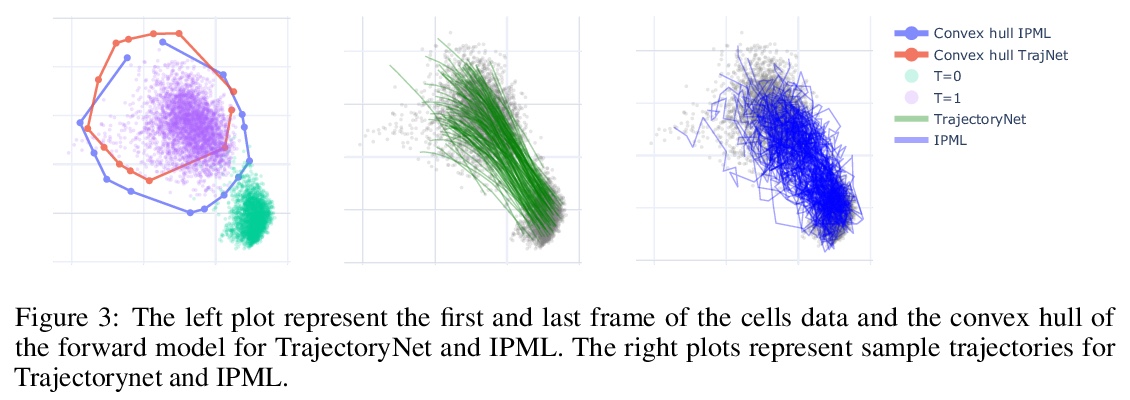
[LG] Solving Schrödinger Bridges via Maximum Likelihood
用最大似然法解薛定谔桥问题
F Vargas, P Thodoroff, N D. Lawrence, A Lamacraft
[Cambridge University]
https://weibo.com/1402400261/KjaMluvp1

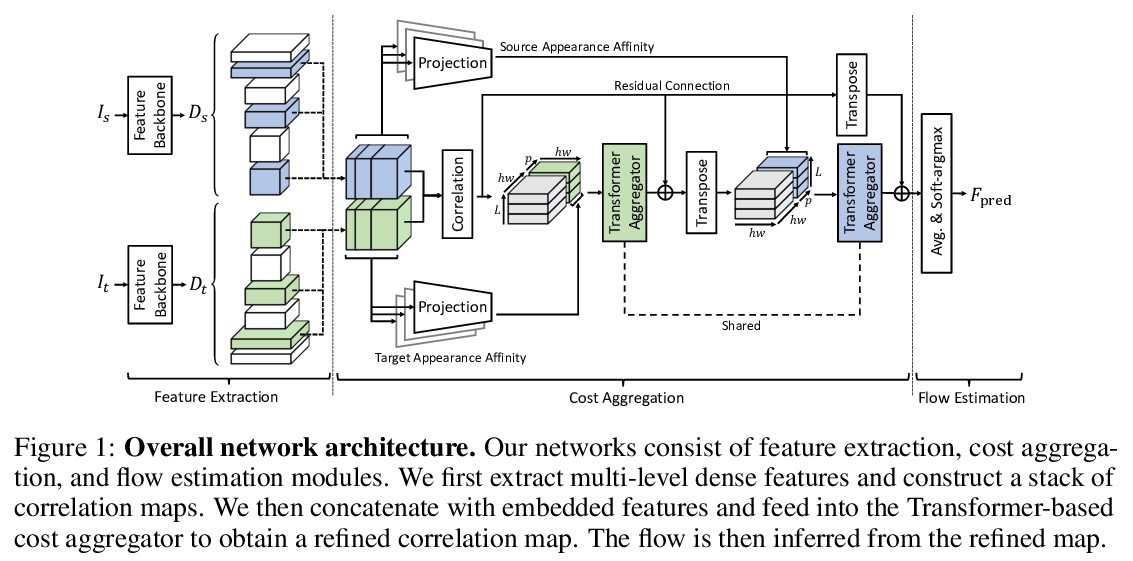
[CV] Semantic Correspondence with Transformers
基于Transformer的语义对应
S Cho, S Hong, S Jeon, Y Lee, K Sohn, S Kim
[Yonsei University & Korea University]
https://weibo.com/1402400261/KjaOj0SMf



[LG] A Consciousness-Inspired Planning Agent for Model-Based Reinforcement Learning
基于模型强化学习的意识启发规划智能体
M Zhao, Z Liu, S Luan, S Zhang, D Precup, Y Bengio
[McGill University & Université de Montréal]
https://weibo.com/1402400261/KjaPBCxZh

若有收获,就点个赞吧
0 人点赞
