LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] *Taming Transformers for High-Resolution Image Synthesis
P Esser, R Rombach, B Ommer
[Heidelberg University]
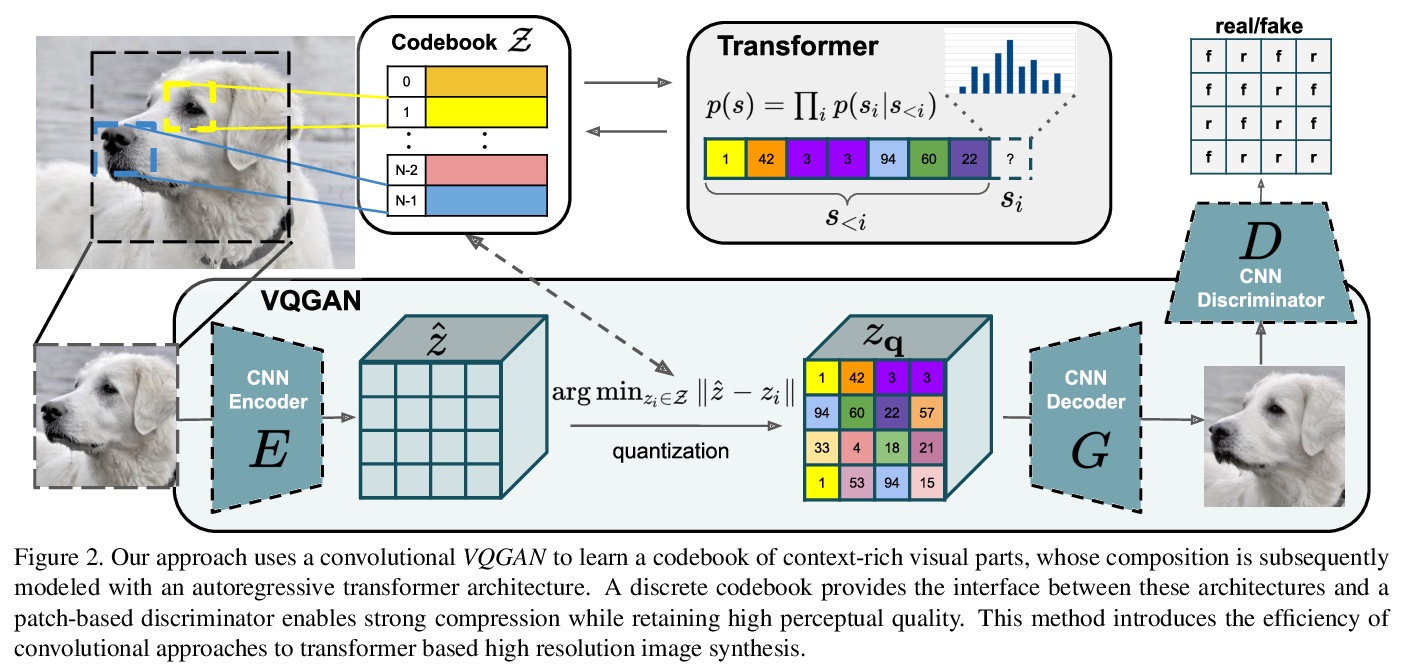
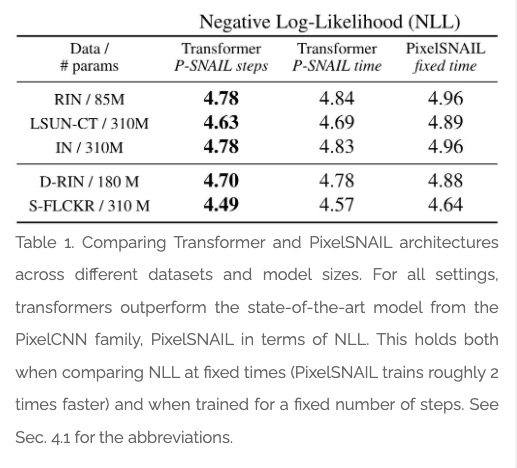
Transformer高分辨率图像合成。解决了之前Transformer局限于低分辨率图像的基本挑战。提出一种方法,将图像表示为感知上丰富的图像成分的合成形式,避免了直接在像素空间对图像建模的二次复杂度。用CNN架构对合成成分进行建模,用Transformer架构对成分进行合成,充分挖掘二者的互补潜力,用基于Transformer的架构实现了高分辨率图像的合成。
Designed to learn long-range interactions on sequential data, transformers continue to show state-of-the-art results on a wide variety of tasks. In contrast to CNNs, they contain no inductive bias that prioritizes local interactions. This makes them expressive, but also computationally infeasible for long sequences, such as high-resolution images. We demonstrate how combining the effectiveness of the inductive bias of CNNs with the expressivity of transformers enables them to model and thereby synthesize high-resolution images. We show how to (i) use CNNs to learn a context-rich vocabulary of image constituents, and in turn (ii) utilize transformers to efficiently model their composition within high-resolution images. Our approach is readily applied to conditional synthesis tasks, where both non-spatial information, such as object classes, and spatial information, such as segmentations, can control the generated image. In particular, we present the first results on semantically-guided synthesis of megapixel images with transformers. Project page at > this https URL .
https://weibo.com/1402400261/Jz7RI8RKh
2、[CV] *Worldsheet: Wrapping the World in a 3D Sheet for View Synthesis from a Single Image
R Hu, D Pathak
[Facebook AI Research & CMU]
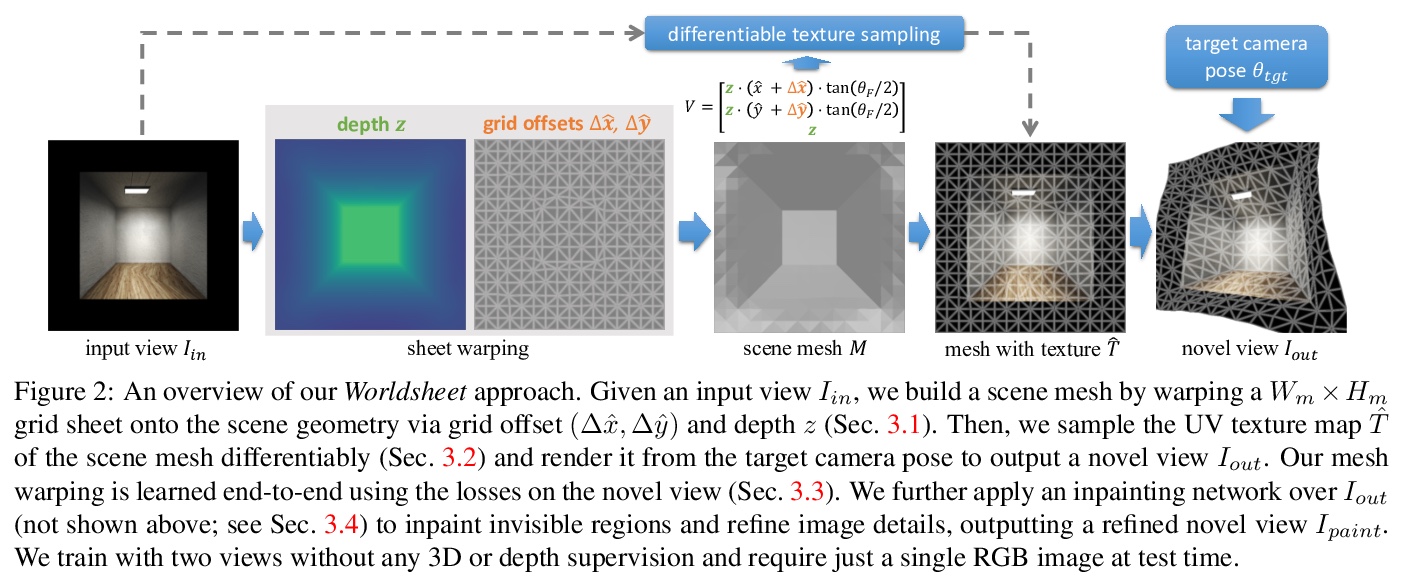
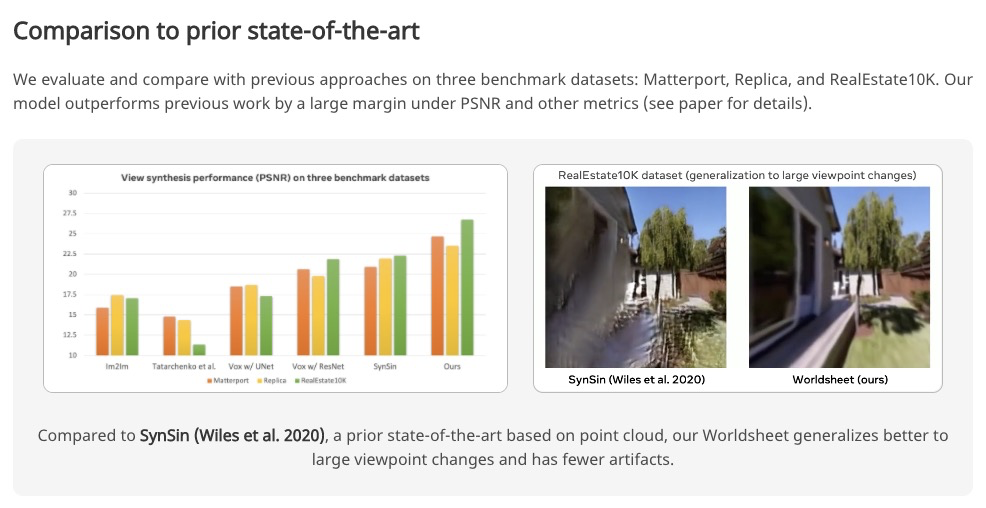
基于Worldsheet的单图像新视图合成。提出Worldsheet,将平面栅格片收缩包覆到输入图像上,与所学的中间深度一致,就能捕捉到足够的底层几何体,以产生任意视点变化的逼真的不可见视图。提出新的可微纹理采样器,可对包裹栅格片进行纹理处理;通过可微渲染将其转化为目标图像。该方法与类别无关,可进行端到端训练,不需要使用任何3D监督,仅用输入和目标视图的二维图像进行监督,且在测试时只需要一张图像。在三个数据集上以较大优势实现了单图像视图合成的最先进性能。
We present Worldsheet, a method for novel view synthesis using just a single RGB image as input. This is a challenging problem as it requires an understanding of the 3D geometry of the scene as well as texture mapping to generate both visible and occluded regions from new view-points. Our main insight is that simply shrink-wrapping a planar mesh sheet onto the input image, consistent with the learned intermediate depth, captures underlying geometry sufficient enough to generate photorealistic unseen views with arbitrarily large view-point changes. To operationalize this, we propose a novel differentiable texture sampler that allows our wrapped mesh sheet to be textured; which is then transformed into a target image via differentiable rendering. Our approach is category-agnostic, end-to-end trainable without using any 3D supervision and requires a single image at test time. Worldsheet consistently outperforms prior state-of-the-art methods on single-image view synthesis across several datasets. Furthermore, this simple idea captures novel views surprisingly well on a wide range of high resolution in-the-wild images in converting them into a navigable 3D pop-up. Video results and code at > this https URL
https://weibo.com/1402400261/Jz7XbDQUx
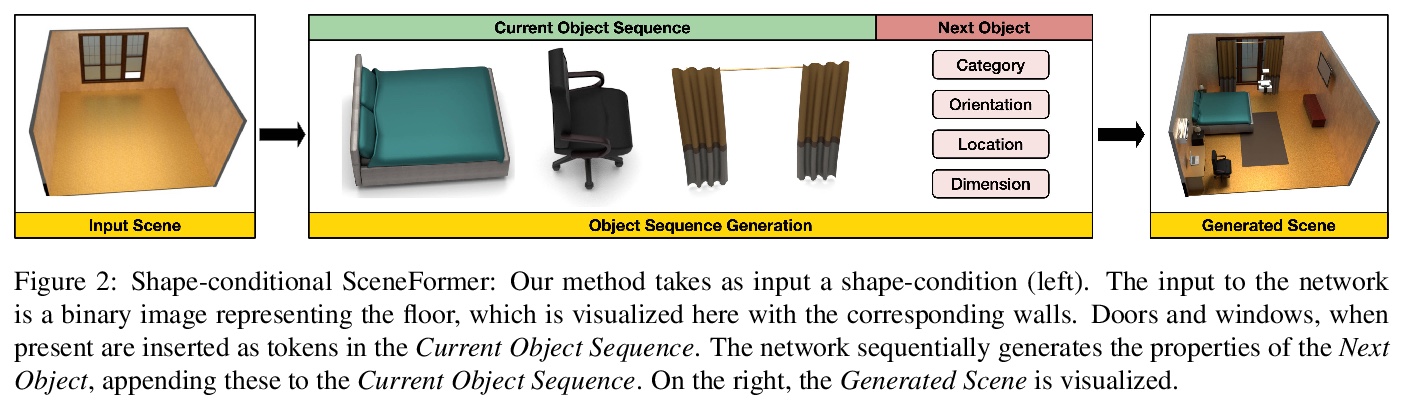
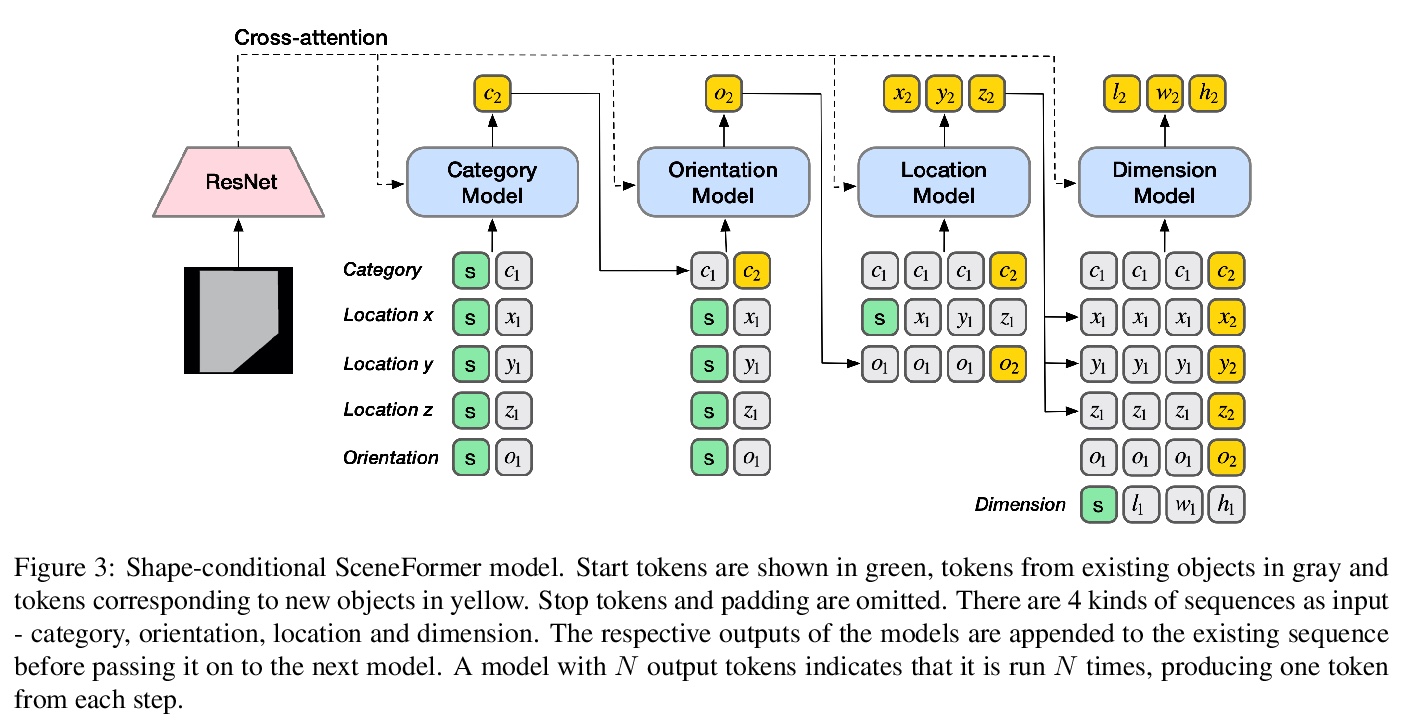
3、[CV] *SceneFormer: Indoor Scene Generation with Transformers
X Wang, C Yeshwanth, M Nießner
[Technical University of Munich]
基于Transformers的室内场景生成。提出SceneFormer,Transformers模型的组合体,不用任何外观信息,利用Transformers的自注意力机制学习物体间关系,用最少的数据生成逼真的室内场景布局,并执行快速推理,可由部分场景实现交互式场景生成。与现有方法相比,该方法可更快地生成场景,具有相同或更好的真实感水平,不再需要昂贵的视觉信息,如图像或网格。该模型可作为场景生成的一般框架,不同任务可通过改变物体属性或条件输入来解决。
The task of indoor scene generation is to generate a sequence of objects, their locations and orientations conditioned on the shape and size of a room. Large scale indoor scene datasets allow us to extract patterns from user-designed indoor scenes and then generate new scenes based on these patterns. Existing methods rely on the 2D or 3D appearance of these scenes in addition to object positions, and make assumptions about the possible relations between objects. In contrast, we do not use any appearance information, and learn relations between objects using the self attention mechanism of transformers. We show that this leads to faster scene generation compared to existing methods with the same or better levels of realism. We build simple and effective generative models conditioned on the room shape, and on text descriptions of the room using only the cross-attention mechanism of transformers. We carried out a user study showing that our generated scenes are preferred over DeepSynth scenes 57.7% of the time for bedroom scenes, and 63.3% for living room scenes. In addition, we generate a scene in 1.48 seconds on average, 20% faster than the state of the art method Fast & Flexible, allowing interactive scene generation.
https://weibo.com/1402400261/Jz86FEuO7
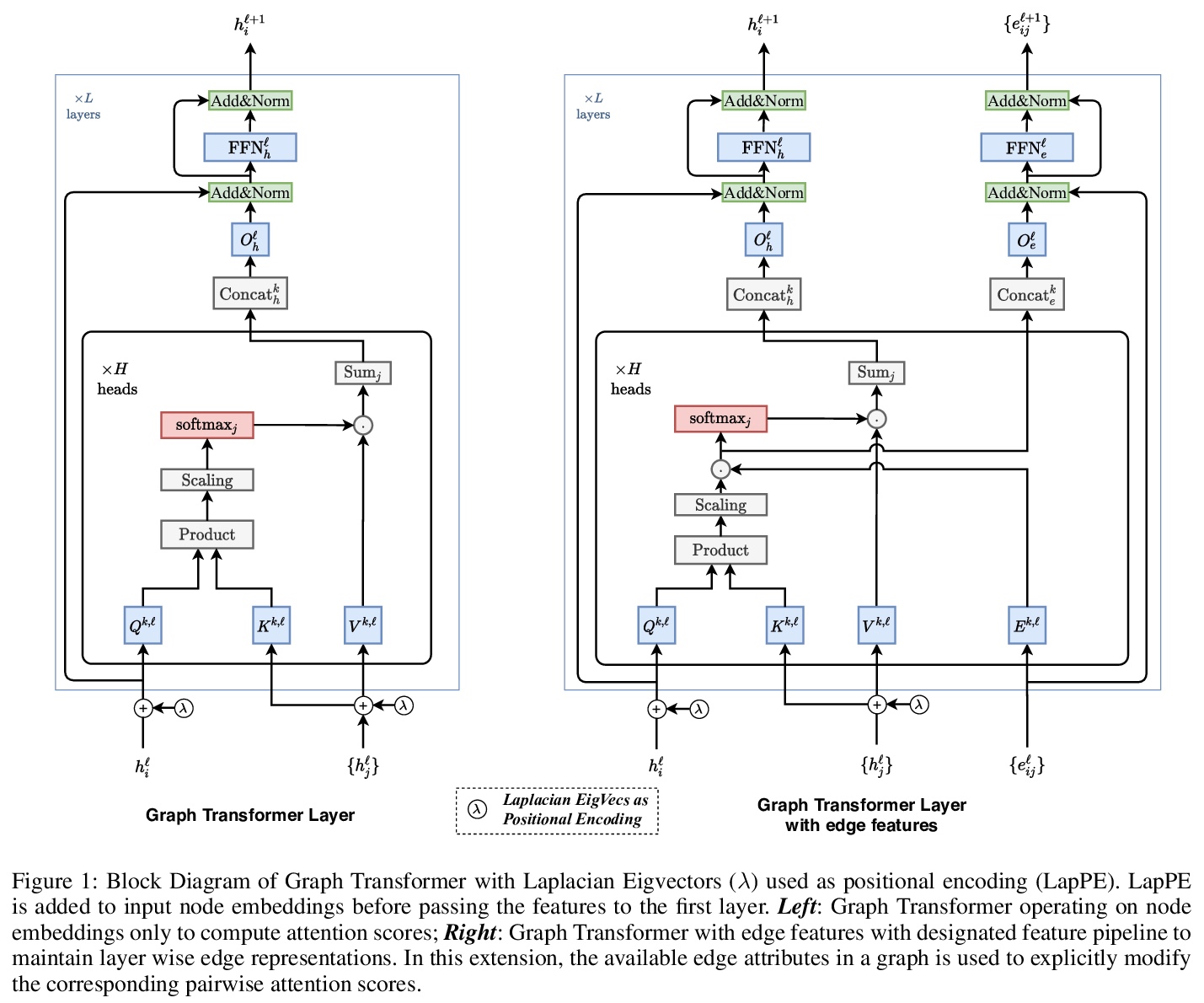
4、** **[LG] A Generalization of Transformer Networks to Graphs
V P Dwivedi, X Bresson
[Nanyang Technological University]
适用于图的Transformer网络。提出了一种简单有效的方法,对任意图构建Transformer网络,引入具有四个新属性的图Transformer,其中,注意力机制是图中每个节点的邻域连通度的函数;位置编码由拉普拉斯特征向量表示,很自然地推广了常用于NLP的正弦位置编码;用批归一化层代替层归一化层,训练速度更快,泛化性能更好;体系结构扩展到边缘特征表示,进一步增强了Transformer的通用性。
We propose a generalization of transformer neural network architecture for arbitrary graphs. The original transformer was designed for Natural Language Processing (NLP), which operates on fully connected graphs representing all connections between the words in a sequence. Such architecture does not leverage the graph connectivity inductive bias, and can perform poorly when the graph topology is important and has not been encoded into the node features. We introduce a graph transformer with four new properties compared to the standard model. First, the attention mechanism is a function of the neighborhood connectivity for each node in the graph. Second, the positional encoding is represented by the Laplacian eigenvectors, which naturally generalize the sinusoidal positional encodings often used in NLP. Third, the layer normalization is replaced by a batch normalization layer, which provides faster training and better generalization performance. Finally, the architecture is extended to edge feature representation, which can be critical to tasks s.a. chemistry (bond type) or link prediction (entity relationship in knowledge graphs). Numerical experiments on a graph benchmark demonstrate the performance of the proposed graph transformer architecture. This work closes the gap between the original transformer, which was designed for the limited case of line graphs, and graph neural networks, that can work with arbitrary graphs. As our architecture is simple and generic, we believe it can be used as a black box for future applications that wish to consider transformer and graphs.
https://weibo.com/1402400261/Jz8aXCbQx
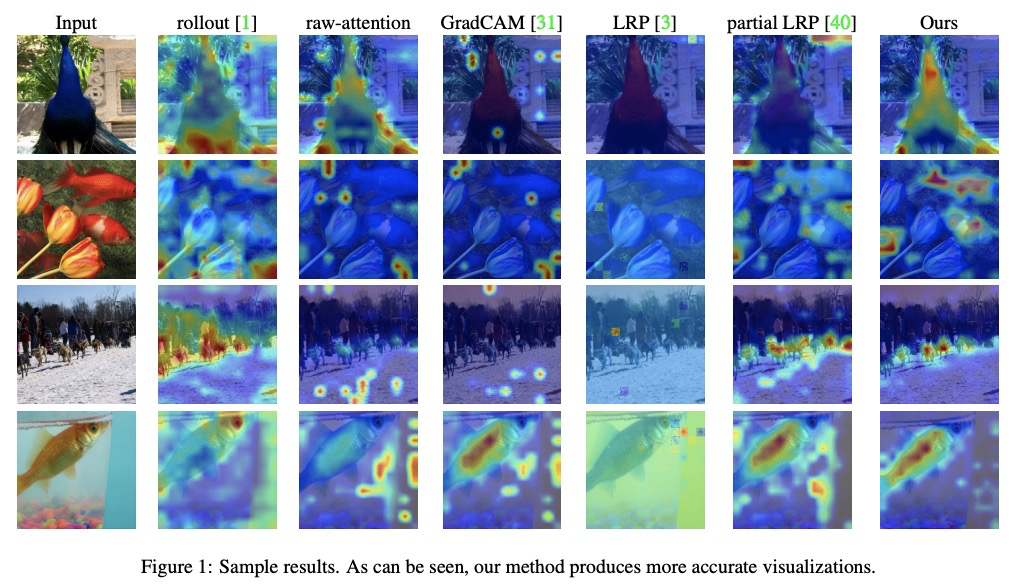
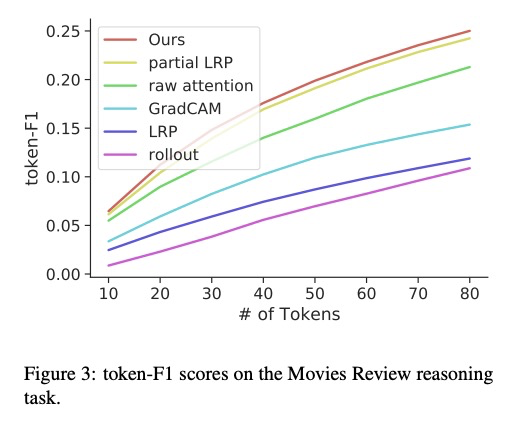
5、[CV] Transformer Interpretability Beyond Attention Visualization
H Chefer, S Gur, L Wolf
[Tel Aviv University & Facebook AI Research]
不依赖注意力可视化的Transformer可解释性。提出了一种新的计算Transformer网络关联度的方法,基于深度泰勒分解原理分配局部相关度,并通过各层传播这些相关度分数,这种传播涉及到注意力层和跳接,对现有方法提出了挑战。
Self-attention techniques, and specifically Transformers, are dominating the field of text processing and are becoming increasingly popular in computer vision classification tasks. In order to visualize the parts of the image that led to a certain classification, existing methods either rely on the obtained attention maps, or employ heuristic propagation along the attention graph. In this work, we propose a novel way to compute relevancy for Transformer networks. The method assigns local relevance based on the deep Taylor decomposition principle and then propagates these relevancy scores through the layers. This propagation involves attention layers and skip connections, which challenge existing methods. Our solution is based on a specific formulation that is shown to maintain the total relevancy across layers. We benchmark our method on very recent visual Transformer networks, as well as on a text classification problem, and demonstrate a clear advantage over the existing explainability methods.
https://weibo.com/1402400261/Jz8j0E10W
另外几篇值得关注的论文:
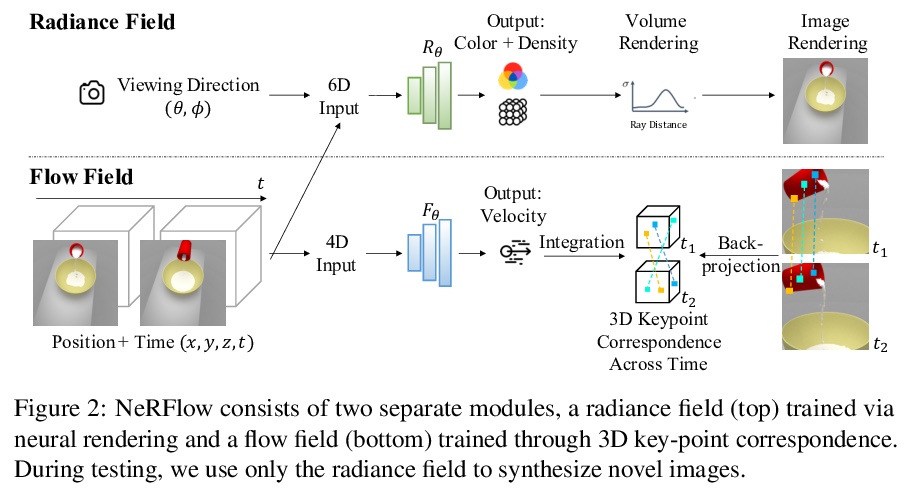
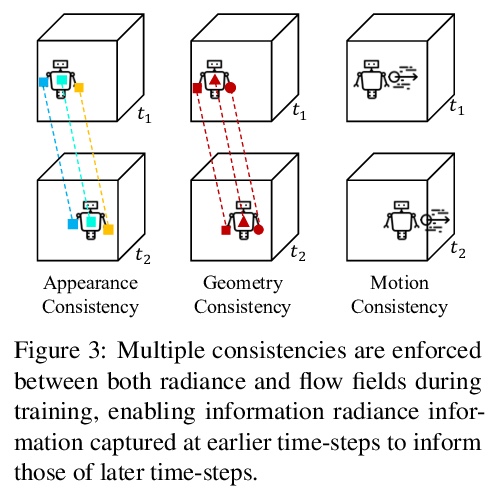
[CV] Neural Radiance Flow for 4D View Synthesis and Video Processing
神经辐射流4D视图合成与视频处理
Y Du, Y Zhang, H Yu, J B. Tenenbaum, J Wu
[MIT CSAIL & Stanford University]
https://weibo.com/1402400261/Jz8nJhWIv

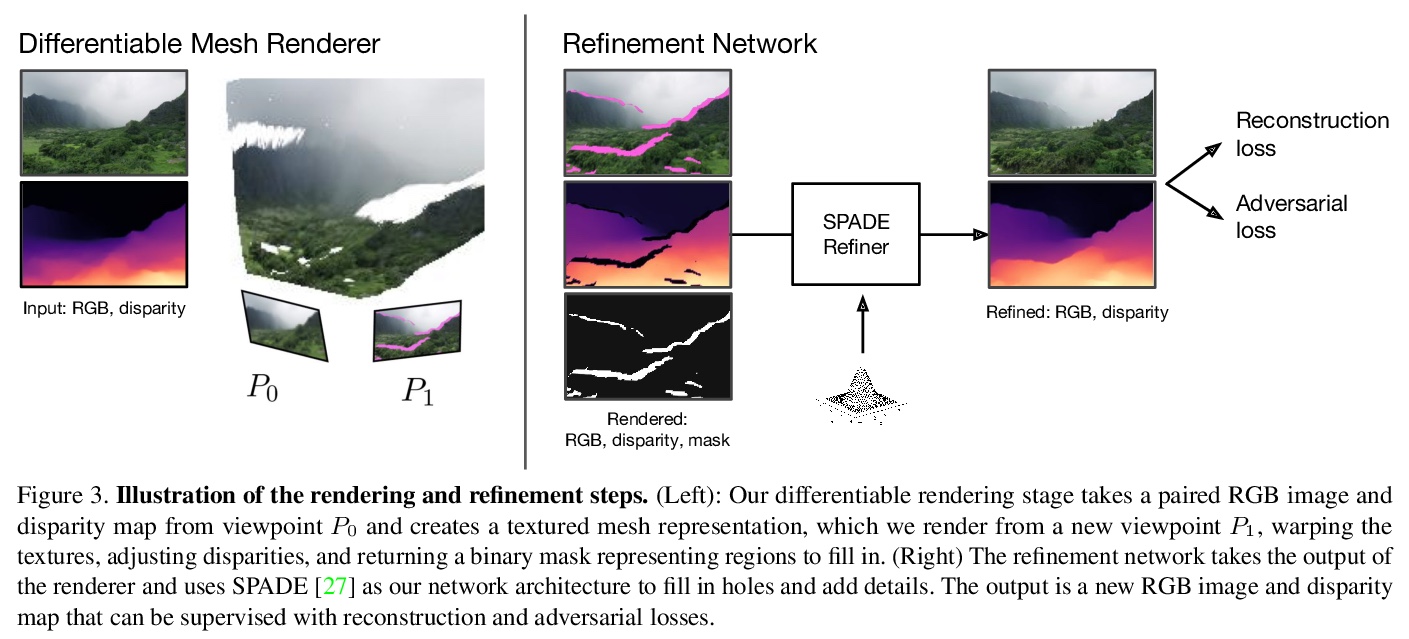
[CV] Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image
无限自然:从单一图像生成自然场景的连续视图
A Liu, R Tucker, V Jampani, A Makadia, N Snavely, A Kanazawa
[Google Research]
https://weibo.com/1402400261/Jz8qlugfy

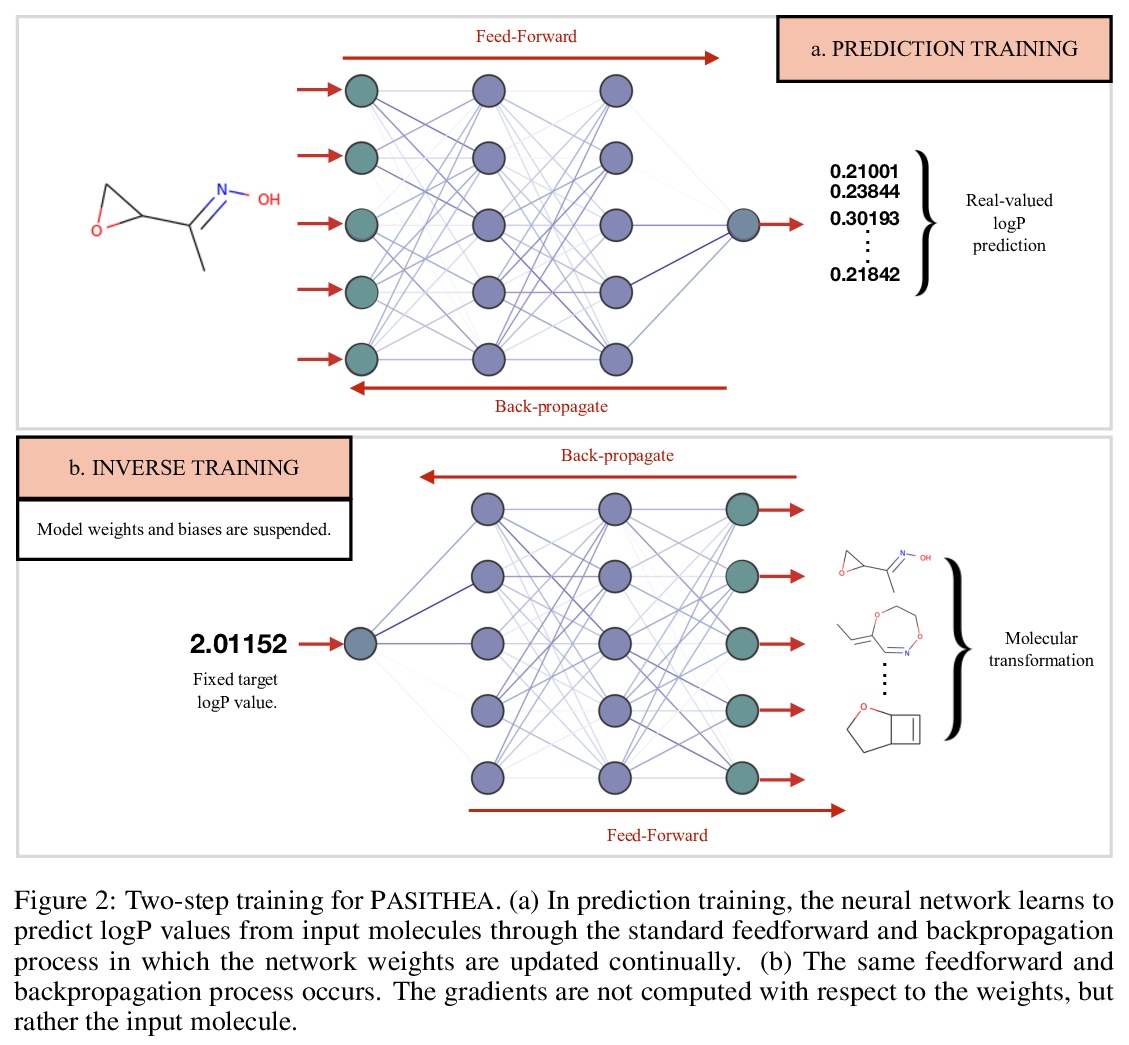
[LG] Deep Molecular Dreaming: Inverse machine learning for de-novo molecular design and interpretability with surjective representations
深度分子梦:面向分子设计的逆向机器学习
C Shen, M Krenn, S Eppel, A Aspuru-Guzik
[University of Toronto]
https://weibo.com/1402400261/Jz8sDDcjM


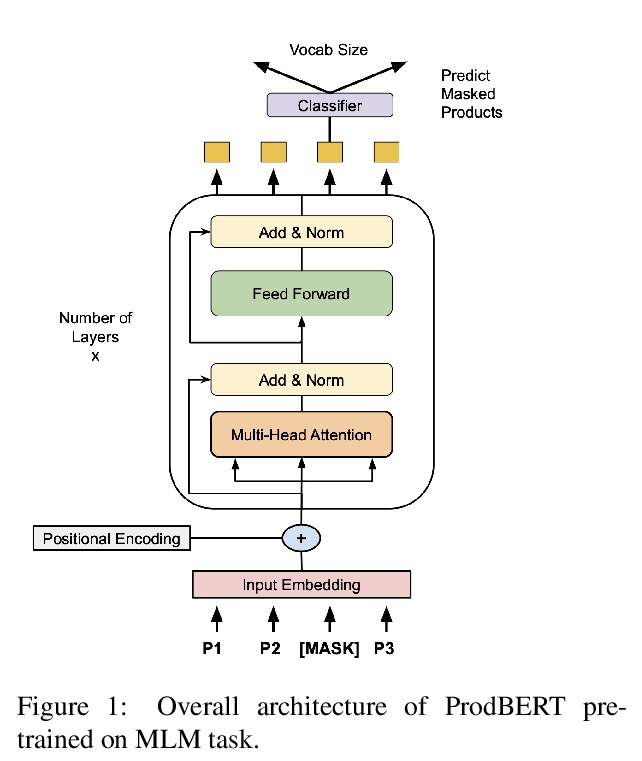
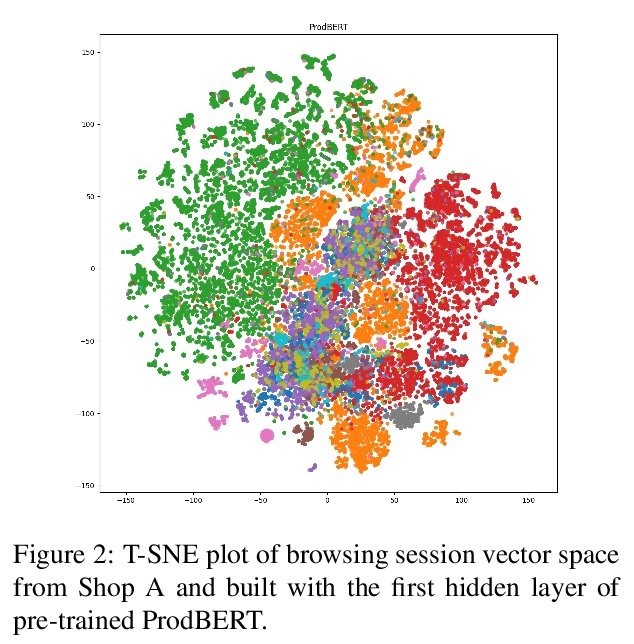
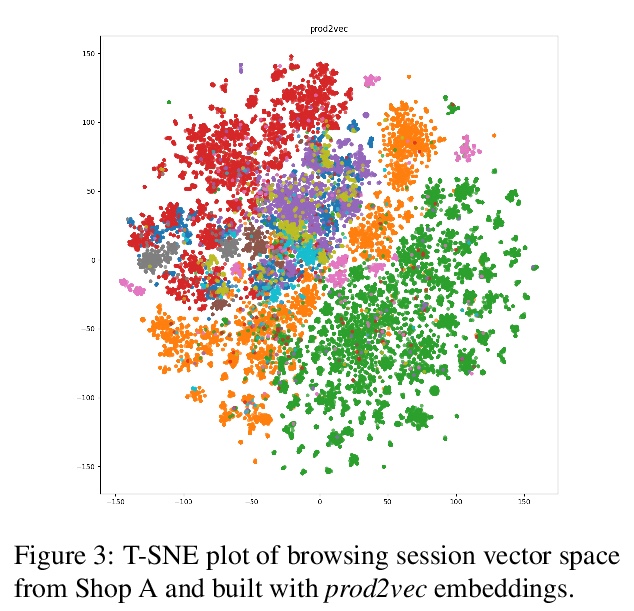
[CL] BERT Goes Shopping: Comparing Distributional Models for Product Representations
产品表示的分布式模型比较
F Bianchi, B Yu, J Tagliabue
[Bocconi University & Coveo]
https://weibo.com/1402400261/Jz8vstCHC

若有收获,就点个赞吧
0 人点赞
