- 1、[LG] Asymmetric self-play for automatic goal discovery in robotic manipulation
- 2、[LG] Model-Based Visual Planning with Self-Supervised Functional Distances
- 3、[LG] Benchmarking Simulation-Based Inference
- 4、[LG] Evaluating the Robustness of Collaborative Agents
- 5、[IR] The Expando-Mono-Duo Design Pattern for Text Ranking with Pretrained Sequence-to-Sequence Models
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Asymmetric self-play for automatic goal discovery in robotic manipulation
O OpenAI, M Plappert, R Sampedro, T Xu, I Akkaya, V Kosaraju, P Welinder, R D’Sa, A Petron, H P d O Pinto, A Paino, H Noh, L Weng, Q Yuan, C Chu, W Zaremba
[OpenAI]
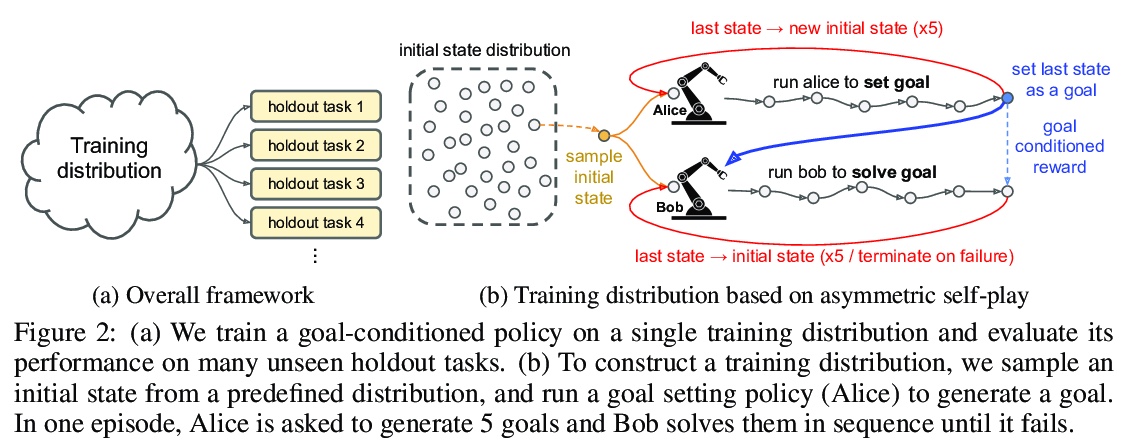
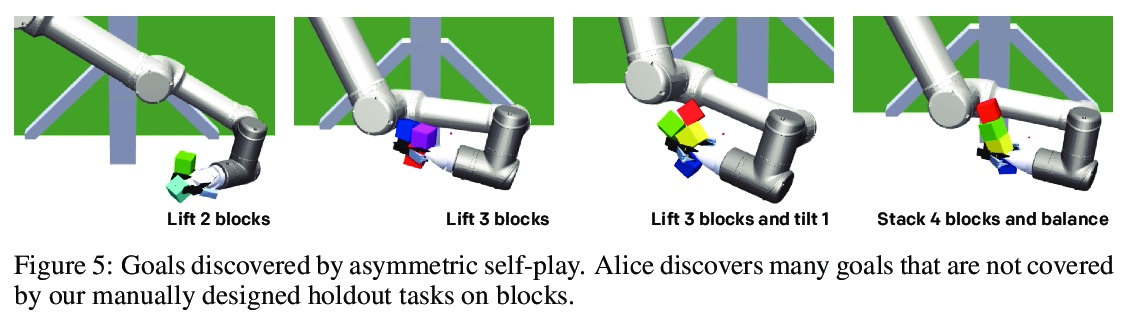
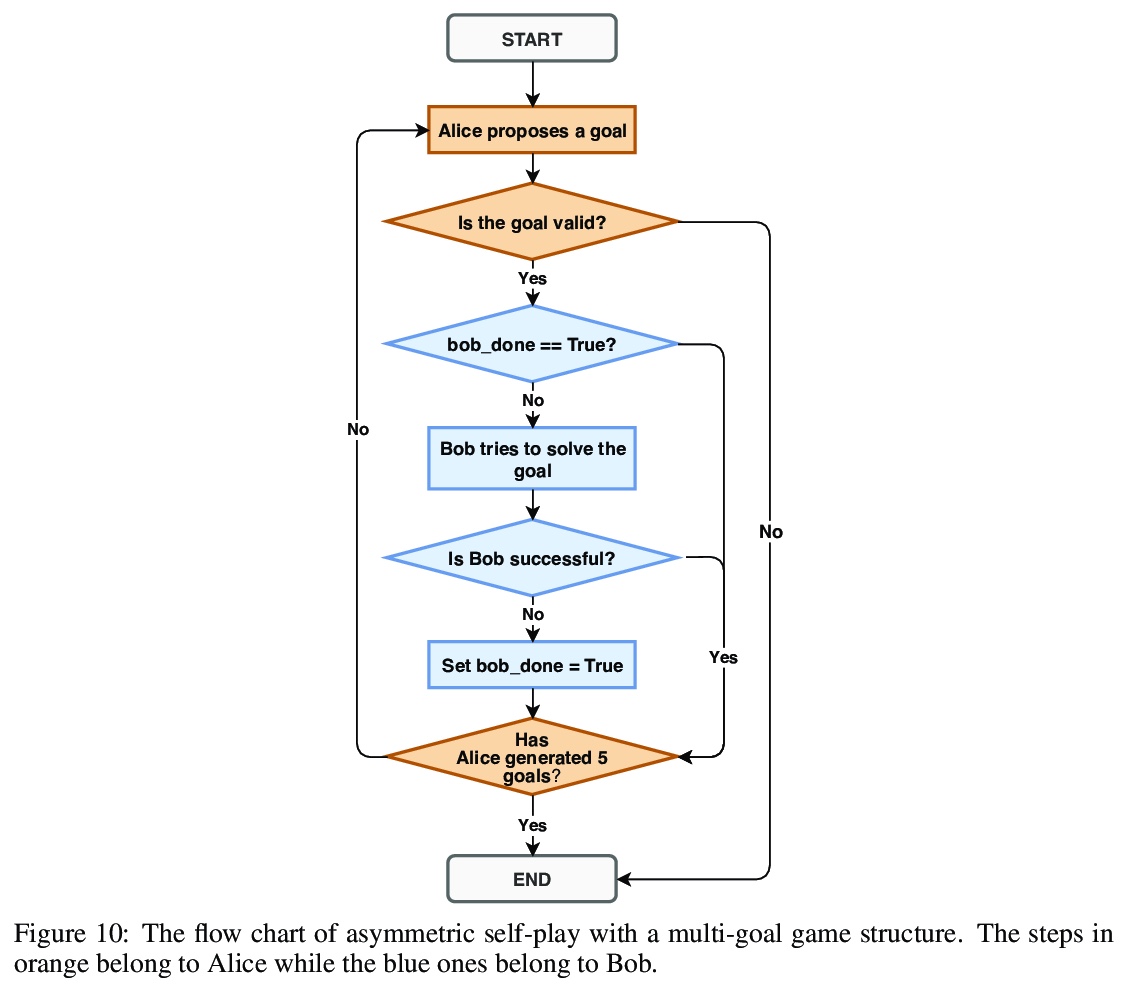
基于非对等自演(self-play)的机器人操纵自动目标发现。训练了一个单独的、有目标条件的策略,可以解决许多机器人操纵任务,包括具有之前未见目标和对象的任务。靠非对等自演来进行目标发现,由两个智能体Alice和Bob进行互动推演。Alice被要求提出具有挑战性的目标,Bob的目标是解决这些目标。这种方法可以在没有任何人工先验的情况下,发现高度多样化和复杂的目标。Bob可以只用稀疏的奖励进行训练,因为Alice和Bob之间的互动形成了一个自然课程,当重新标记为目标条件演示时,Bob可以从Alice的轨迹中学习。该方法是可扩展的,由此产生的单一策略可以泛化到未见任务,如摆放桌子、堆积木和解决简单的谜题。
We train a single, goal-conditioned policy that can solve many robotic manipulation tasks, including tasks with previously unseen goals and objects. We rely on asymmetric self-play for goal discovery, where two agents, Alice and Bob, play a game. Alice is asked to propose challenging goals and Bob aims to solve them. We show that this method can discover highly diverse and complex goals without any human priors. Bob can be trained with only sparse rewards, because the interaction between Alice and Bob results in a natural curriculum and Bob can learn from Alice’s trajectory when relabeled as a goal-conditioned demonstration. Finally, our method scales, resulting in a single policy that can generalize to many unseen tasks such as setting a table, stacking blocks, and solving simple puzzles. Videos of a learned policy is available at > this https URL.
https://weibo.com/1402400261/JDnTu2Xy3

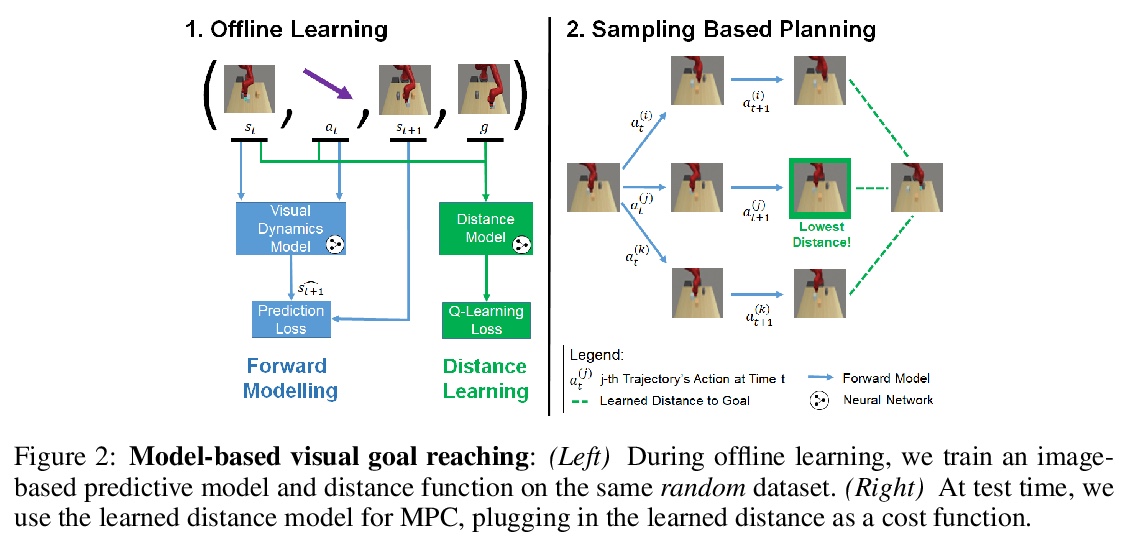
2、[LG] Model-Based Visual Planning with Self-Supervised Functional Distances
S Tian, S Nair, F Ebert, S Dasari, B Eysenbach, C Finn, S Levine
[UC Berkeley & Stanford University & CMU]
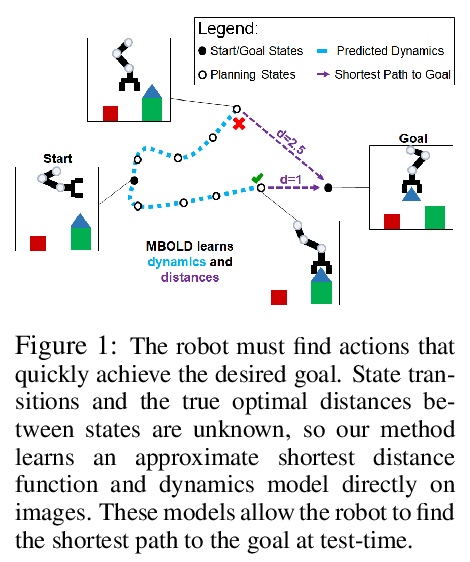
面向基于模型视觉规划的自监督功能距离。提出一种基于模型的视觉目标达成的自监督方法,利用视觉动态模型和由无模型强化学习学习到的动态距离函数。该方法完全用离线未标记数据进行学习,可扩展到大型和多样化的数据集。由于结合了预测模型和习得的动态距离的优势,预测模型可以为规划近程行动提供有效的预测,而动态距离可提供有用的规划成本,捕捉到较长程目标的距离。实验表明,该方法比利用其他奖励定义的基于模型的规划方法以及纯粹的无模型方法更有效地执行目标达成任务。
A generalist robot must be able to complete a variety of tasks in its environment. One appealing way to specify each task is in terms of a goal observation. However, learning goal-reaching policies with reinforcement learning remains a challenging problem, particularly when hand-engineered reward functions are not available. Learned dynamics models are a promising approach for learning about the environment without rewards or task-directed data, but planning to reach goals with such a model requires a notion of functional similarity between observations and goal states. We present a self-supervised method for model-based visual goal reaching, which uses both a visual dynamics model as well as a dynamical distance function learned using model-free reinforcement learning. Our approach learns entirely using offline, unlabeled data, making it practical to scale to large and diverse datasets. In our experiments, we find that our method can successfully learn models that perform a variety of tasks at test-time, moving objects amid distractors with a simulated robotic arm and even learning to open and close a drawer using a real-world robot. In comparisons, we find that this approach substantially outperforms both model-free and model-based prior methods. Videos and visualizations are available here: > this http URL.
https://weibo.com/1402400261/JDo4Ii28A
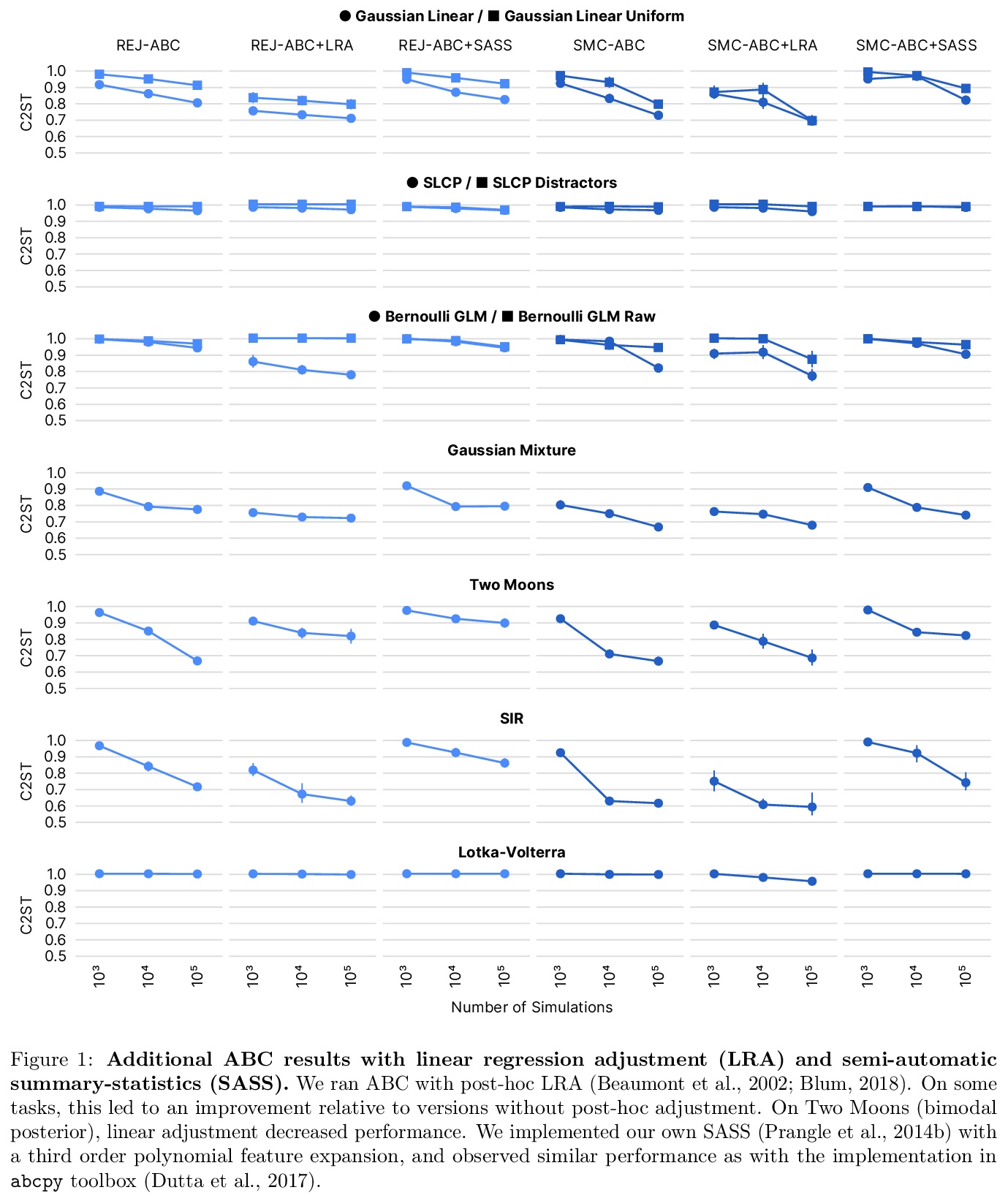
3、[LG] Benchmarking Simulation-Based Inference
J Lueckmann, J Boelts, D S. Greenberg, P J. Gonçalves, J H. Macke
[Technical University of Munich & Research Center caesar]
基于模拟的推理(SBI)的初步基准。提供了一个带有推理任务和合适的性能指标的基准,初步选择的算法包括最近采用神经网络和经典近似贝叶斯计算的方法。性能度量的选择至关重要,即使是最先进的算法也有很大的改进空间,序列估计可提高样本效率。基于神经网络的方法通常表现出更好的性能,但没有全局最佳算法。
Recent advances in probabilistic modelling have led to a large number of simulation-based inference algorithms which do not require numerical evaluation of likelihoods. However, a public benchmark with appropriate performance metrics for such ‘likelihood-free’ algorithms has been lacking. This has made it difficult to compare algorithms and identify their strengths and weaknesses. We set out to fill this gap: We provide a benchmark with inference tasks and suitable performance metrics, with an initial selection of algorithms including recent approaches employing neural networks and classical Approximate Bayesian Computation methods. We found that the choice of performance metric is critical, that even state-of-the-art algorithms have substantial room for improvement, and that sequential estimation improves sample efficiency. Neural network-based approaches generally exhibit better performance, but there is no uniformly best algorithm. We provide practical advice and highlight the potential of the benchmark to diagnose problems and improve algorithms. The results can be explored interactively on a companion website. All code is open source, making it possible to contribute further benchmark tasks and inference algorithms.
https://weibo.com/1402400261/JDogT0tr9
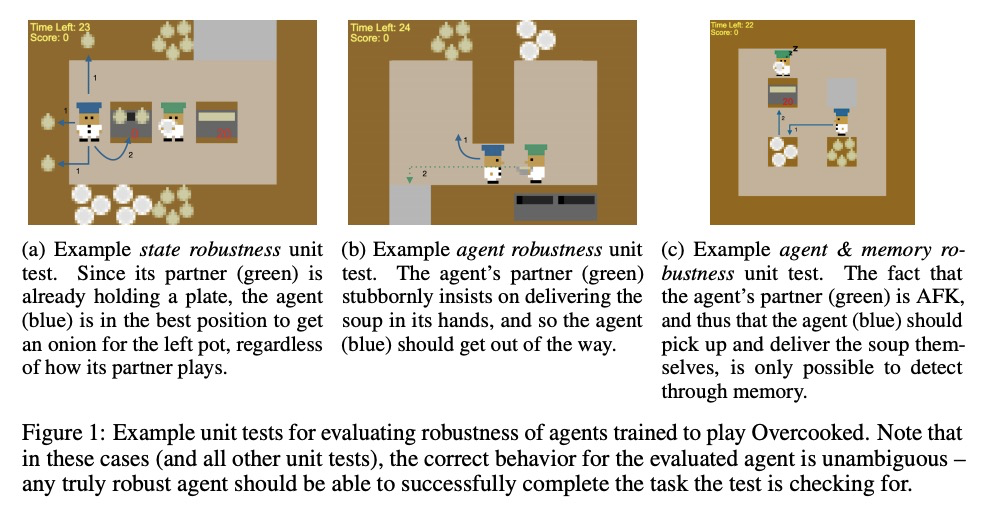
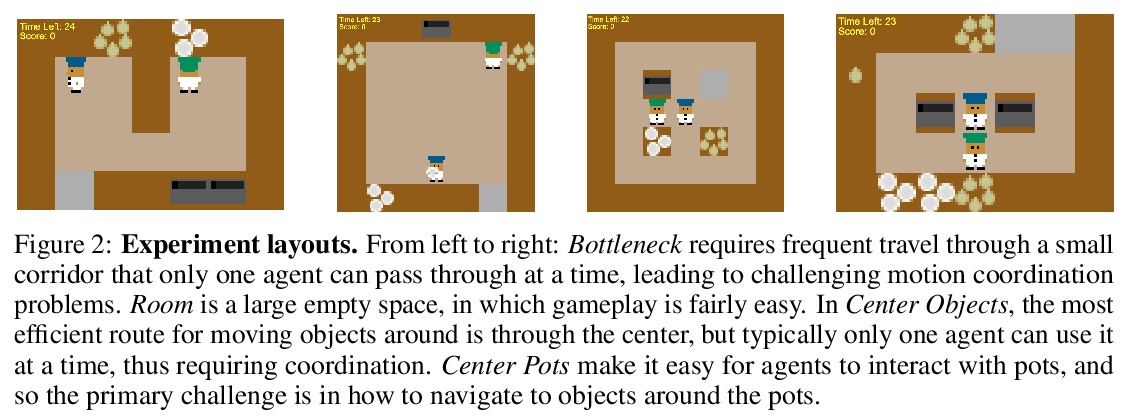
4、[LG] Evaluating the Robustness of Collaborative Agents
P Knott, M Carroll, S Devlin, K Ciosek, K Hofmann, A. D. Dragan, R Shah
[University of Nottingham & UC Berkeley & Microsoft Research]
协同智能体的鲁棒性评价。从软件工程中的单元测试实践中得到启发,建议在设计与人协同的智能体时,在可能的伙同行为和可能遇到的状态中寻找潜在的边缘用例,并编写测试,检查智能体在这些边缘用例中的行为是否合理。
In order for agents trained by deep reinforcement learning to work alongside humans in realistic settings, we will need to ensure that the agents are robust. Since the real world is very diverse, and human behavior often changes in response to agent deployment, the agent will likely encounter novel situations that have never been seen during training. This results in an evaluation challenge: if we cannot rely on the average training or validation reward as a metric, then how can we effectively evaluate robustness? We take inspiration from the practice of unit testing in software engineering. Specifically, we suggest that when designing AI agents that collaborate with humans, designers should search for potential edge cases in possible partner behavior and possible states encountered, and write tests which check that the behavior of the agent in these edge cases is reasonable. We apply this methodology to build a suite of unit tests for the Overcooked-AI environment, and use this test suite to evaluate three proposals for improving robustness. We find that the test suite provides significant insight into the effects of these proposals that were generally not revealed by looking solely at the average validation reward.
https://weibo.com/1402400261/JDomSqhYS
5、[IR] The Expando-Mono-Duo Design Pattern for Text Ranking with Pretrained Sequence-to-Sequence Models
R Pradeep, R Nogueira, J Lin
[University of Waterloo]
利用预训练的序列到序列模型进行文本排序的Expando-Mono-Duo设计模式。提出一种处理文本排序问题的设计模式Expando-Mono-Duo,在不同领域的一些ad hoc检索任务中得到了实证验证。其核心,是标准多阶段排序架构内的预训练序列到序列模型。”Expando “指的是在倒排索引之前,用文档扩展技术来丰富文本的关键词表示。”Mono “和 “Duo “指的是重排序管道中基于点级模型和成对模型的组件,这些组件对使用关键词搜索检索的初始候选文本进行重排序。
We propose a design pattern for tackling text ranking problems, dubbed “Expando-Mono-Duo”, that has been empirically validated for a number of ad hoc retrieval tasks in different domains. At the core, our design relies on pretrained sequence-to-sequence models within a standard multi-stage ranking architecture. “Expando” refers to the use of document expansion techniques to enrich keyword representations of texts prior to inverted indexing. “Mono” and “Duo” refer to components in a reranking pipeline based on a pointwise model and a pairwise model that rerank initial candidates retrieved using keyword search. We present experimental results from the MS MARCO passage and document ranking tasks, the TREC 2020 Deep Learning Track, and the TREC-COVID challenge that validate our design. In all these tasks, we achieve effectiveness that is at or near the state of the art, in some cases using a zero-shot approach that does not exploit any training data from the target task. To support replicability, implementations of our design pattern are open-sourced in the Pyserini IR toolkit and PyGaggle neural reranking library.
https://weibo.com/1402400261/JDovXfzTd


若有收获,就点个赞吧
0 人点赞
