LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、**[LG] Scaling down Deep Learning
S Greydanus
[Oregon State University]
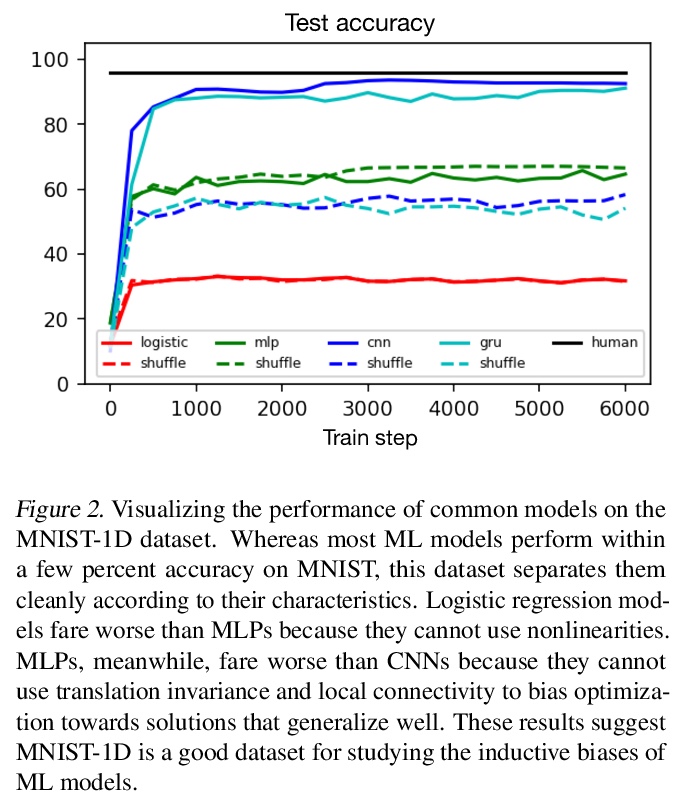
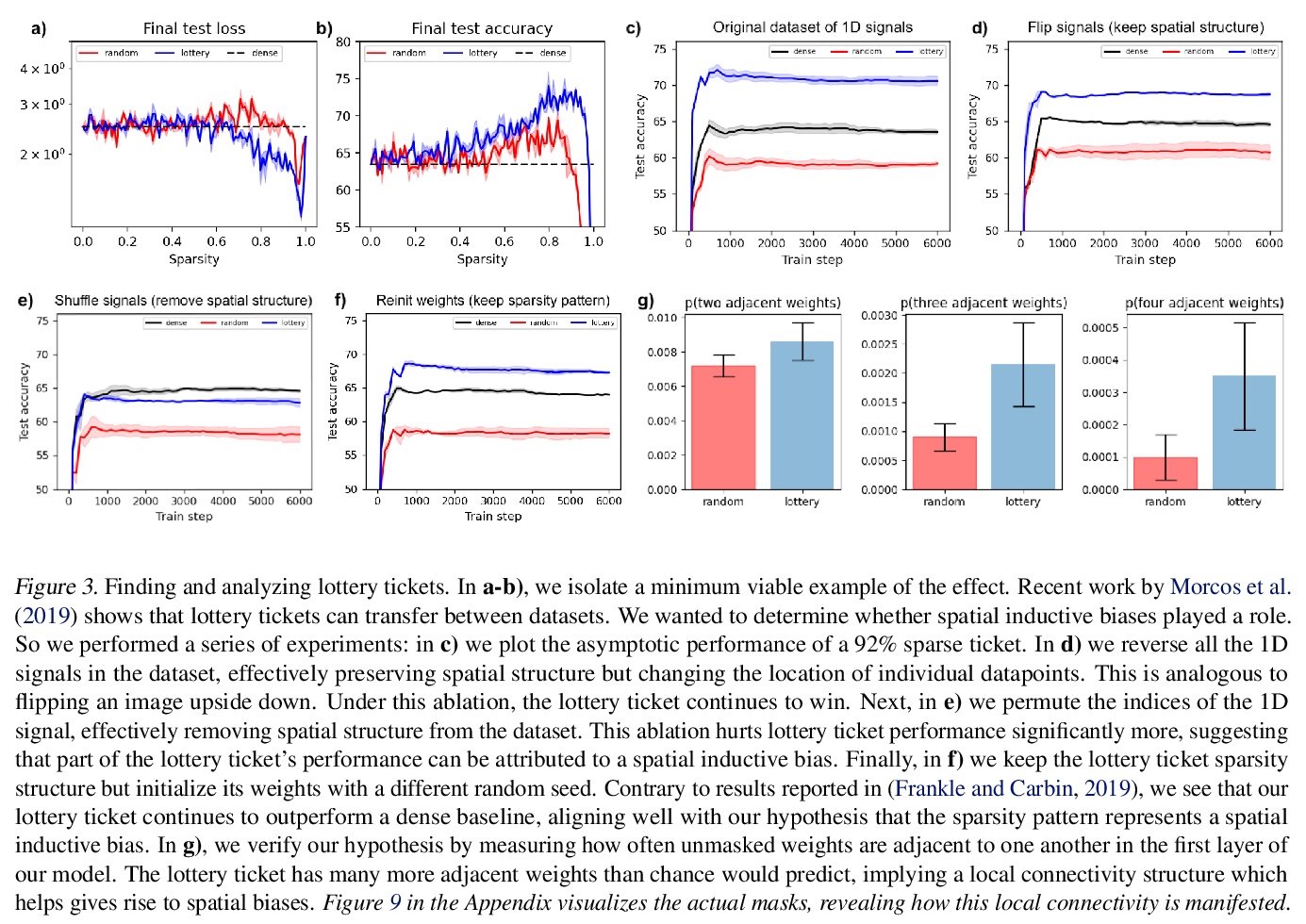
深度学习的规模「收缩」。要探索神经网络扩展的极限,需要先探索神经网络收缩的极限。收缩模型和数据集,观察其行为的细微差别,可以让研究人员在基本的和创造性想法上快速迭代,这种周期性快速迭代,是了解如何将越来越复杂的归纳偏差纳入模型的最佳方式。可以在空间尺度上转移这些归纳偏差,以显著提高大规模模型的样本效率和泛化特性。介绍了MNIST-1D:一个极简、低内存、低计算开销的经典深度学习基准的替代品,其训练样本比MNIST少20倍,但线性、非线性和卷积模型的区别更加明显,准确率分别达到32、68和94%(而这些模型在MNIST上分别能达到94、99+和99+%)。文中还给出了一些示例用例,包括度量彩票空间诱导偏差,观察深度双下降,以及激活函数的元学习。*
Though deep learning models have taken on commercial and political relevance, many aspects of their training and operation remain poorly understood. This has sparked interest in “science of deep learning” projects, many of which are run at scale and require enormous amounts of time, money, and electricity. But how much of this research really needs to occur at scale? In this paper, we introduce MNIST-1D: a minimalist, low-memory, and low-compute alternative to classic deep learning benchmarks. The training examples are 20 times smaller than MNIST examples yet they differentiate more clearly between linear, nonlinear, and convolutional models which attain 32, 68, and 94% accuracy respectively (these models obtain 94, 99+, and 99+% on MNIST). Then we present example use cases which include measuring the spatial inductive biases of lottery tickets, observing deep double descent, and metalearning an activation function.
https://weibo.com/1402400261/JwGUMwu0t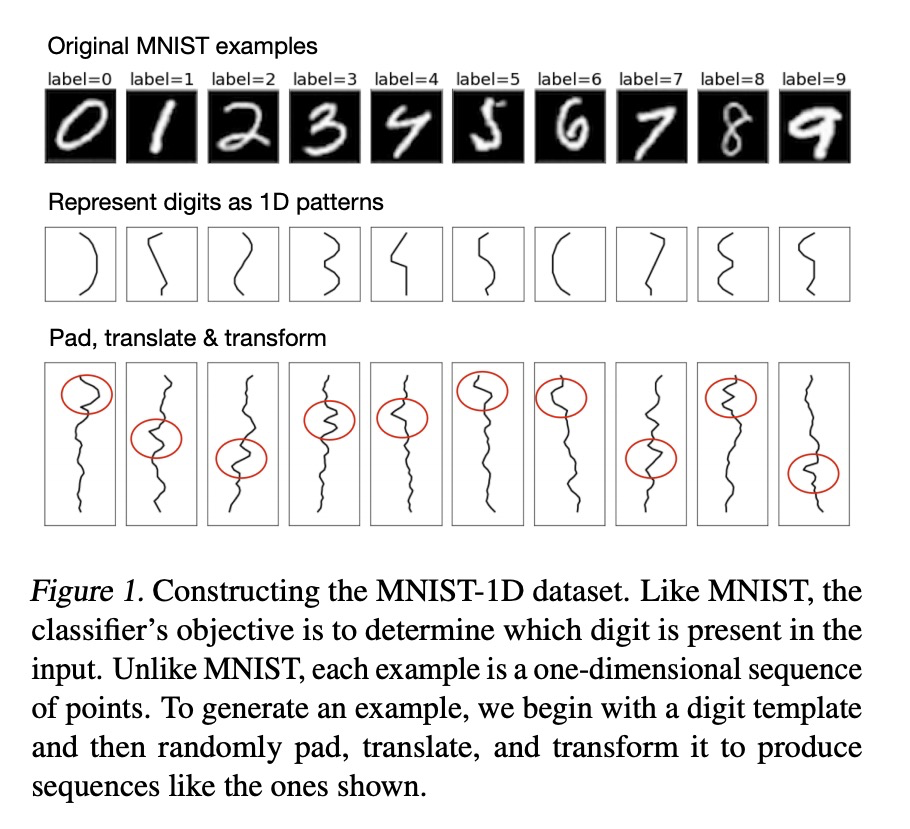
2、**[CV] One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing
T Wang, A Mallya, M Liu
[NVIDIA]
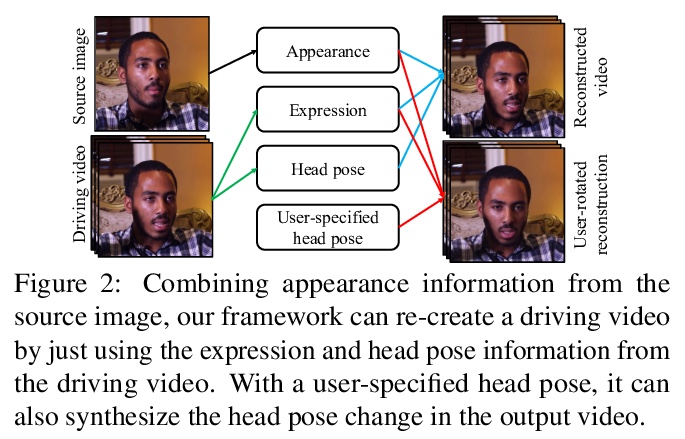
面向视频会议的单样本自由视图说话人头部合成。提出一个用于说话人头部视频合成与压缩的新神经网络框架,采用无监督3D关键点,能将表示分解为特定于人的规范化关键点变换和运动相关变换,仅对关键点变换进行修改,可生成自由视角视频,可在合成过程中进行头部旋转;仅传输关键点变换,可获得比现有方法更好的压缩比,只用十分之一的带宽,就能达到与商业H.264标准相同的视觉质量。这些特性能为用户提供更好的流媒体直播视频体验。*
We propose a neural talking-head video synthesis model and demonstrate its application to video conferencing. Our model learns to synthesize a talking-head video using a source image containing the target person’s appearance and a driving video that dictates the motion in the output. Our motion is encoded based on a novel keypoint representation, where the identity-specific and motion-related information is decomposed unsupervisedly. Extensive experimental validation shows that our model outperforms competing methods on benchmark datasets. Moreover, our compact keypoint representation enables a video conferencing system that achieves the same visual quality as the commercial H.264 standard while only using one-tenth of the bandwidth. Besides, we show our keypoint representation allows the user to rotate the head during synthesis, which is useful for simulating a face-to-face video conferencing experience.
https://weibo.com/1402400261/JwH2MkuqT
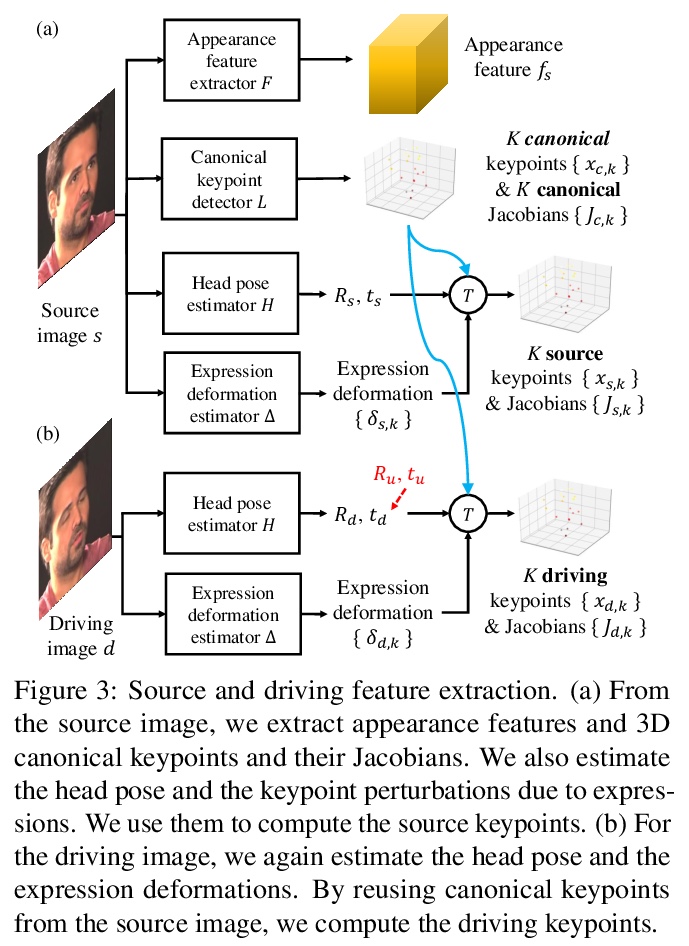

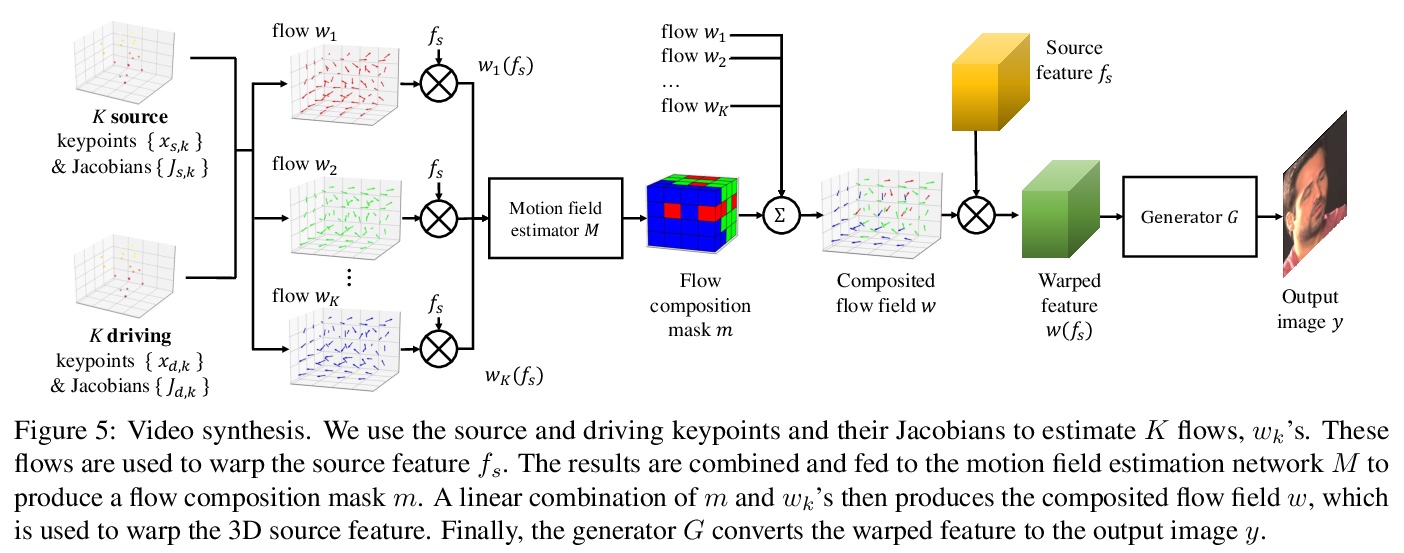
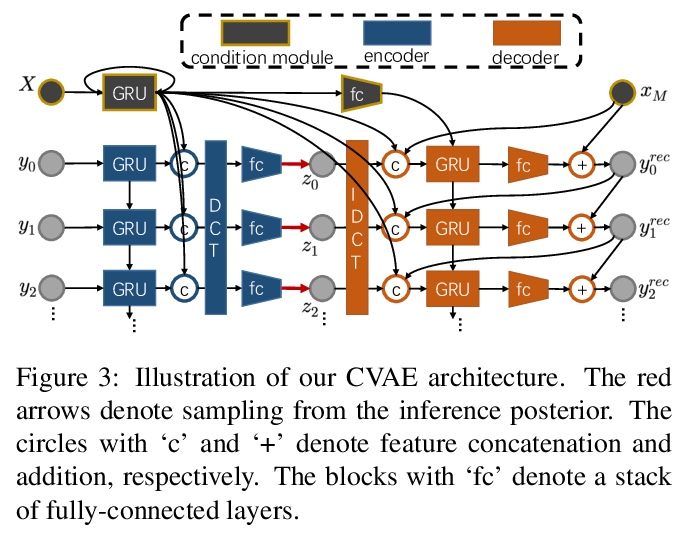
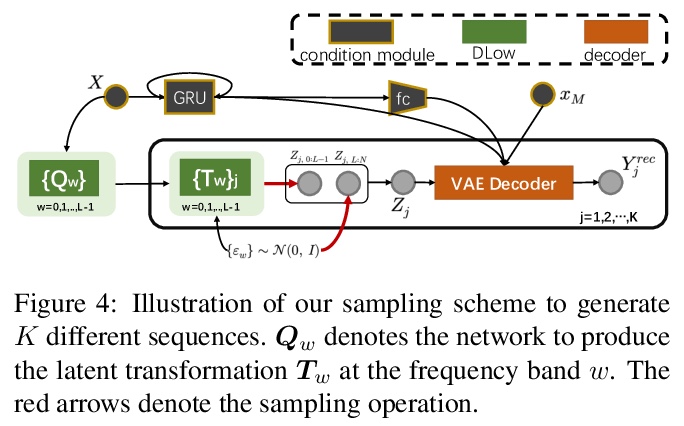
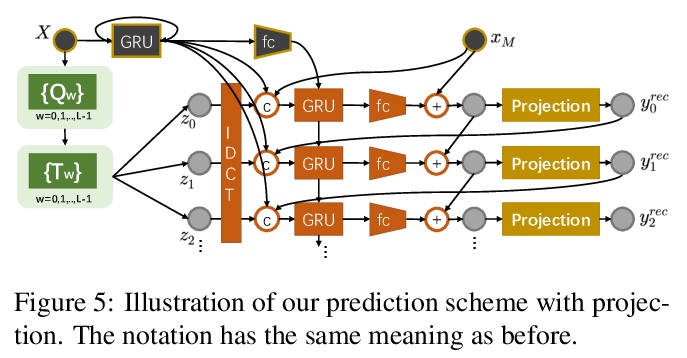
3、** *[CV] We are More than Our Joints: Predicting how 3D Bodies Move
Y Zhang, M J. Black, S Tang
[ETH Zurich & Max Planck Institute for Intelligent Systems]
不仅是关节:3D人体运动预测。提出用来预测三维人体各种可信运动形式的新方法MOJO,不使用关节来表示人体,而是在人体表面用一组稀疏标记,提供更多约束,以利于3D人体恢复。为更好地模拟标记间的相互作用,MOJO引入新的CVAE,用多个潜频率表示运动。为生成运动中的有效人体,MOJO在测试时采用了递归投影方案。与现有的带有新损失或鉴别器的方法相比,MOJO显著消除了刚体变形,且不存在畴隙。
A key step towards understanding human behavior is the prediction of 3D human motion. Successful solutions have many applications in human tracking, HCI, and graphics. Most previous work focuses on predicting a time series of future 3D joint locations given a sequence 3D joints from the past. This Euclidean formulation generally works better than predicting pose in terms of joint rotations. Body joint locations, however, do not fully constrain 3D human pose, leaving degrees of freedom undefined, making it hard to animate a realistic human from only the joints. Note that the 3D joints can be viewed as a sparse point cloud. Thus the problem of human motion prediction can be seen as point cloud prediction. With this observation, we instead predict a sparse set of locations on the body surface that correspond to motion capture markers. Given such markers, we fit a parametric body model to recover the 3D shape and pose of the person. These sparse surface markers also carry detailed information about human movement that is not present in the joints, increasing the naturalness of the predicted motions. Using the AMASS dataset, we train MOJO, which is a novel variational autoencoder that generates motions from latent frequencies. MOJO preserves the full temporal resolution of the input motion, and sampling from the latent frequencies explicitly introduces high-frequency components into the generated motion. We note that motion prediction methods accumulate errors over time, resulting in joints or markers that diverge from true human bodies. To address this, we fit SMPL-X to the predictions at each time step, projecting the solution back onto the space of valid bodies. These valid markers are then propagated in time. Experiments show that our method produces state-of-the-art results and realistic 3D body animations. The code for research purposes is at > this https URL
https://weibo.com/1402400261/JwH8R7Wos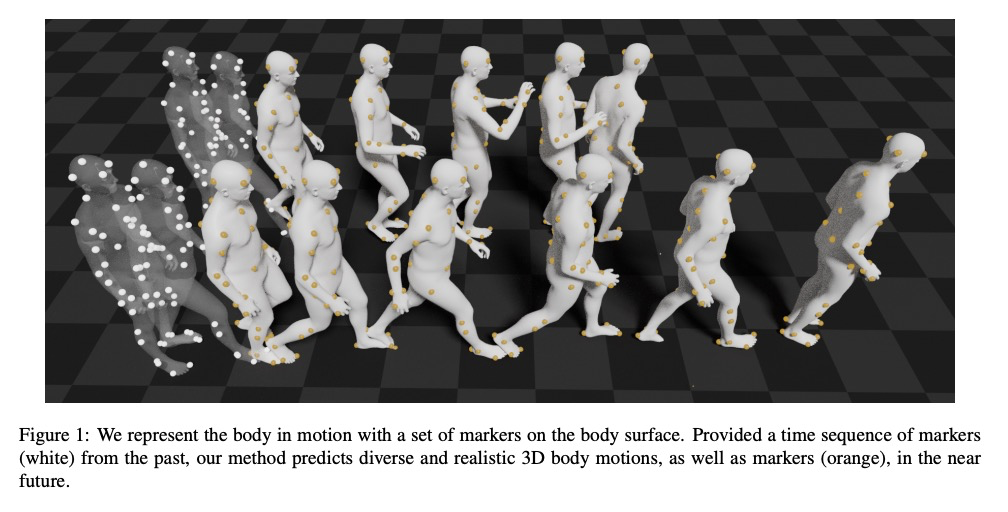
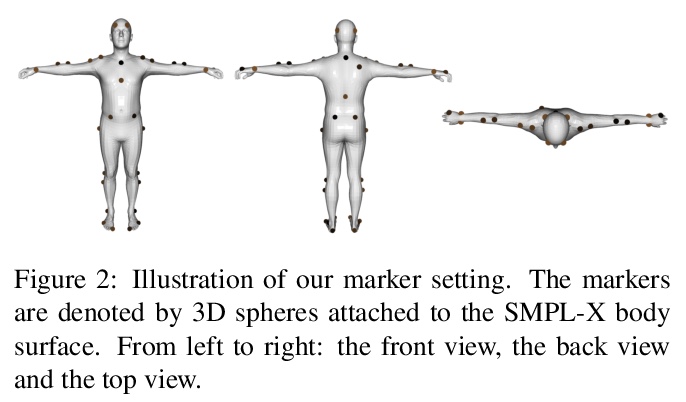

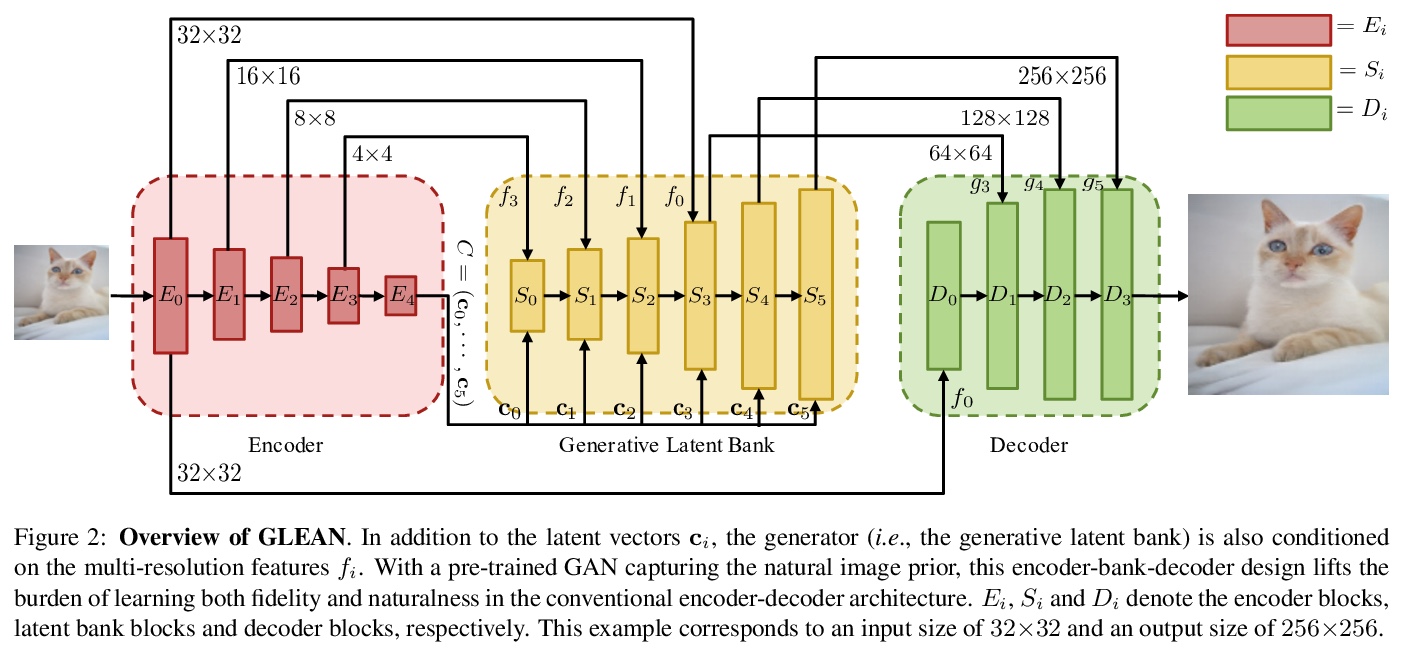
4、** **[CV] GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution
K C.K. Chan, X Wang, X Xu, J Gu, C C Loy
[Nanyang Technological University & Tencent PCG & SenseBrain]
基于生成式预训练潜储库的高倍率图像超分辨率。提出一种利用预训练GANs进行大规模超分辨率的新方法GLEAN,最高可达64倍放大因子。预训练GAN可作为编码器-储库-解码器架构的生成式潜在库。借助潜储库中丰富的先验,只需要简单的前向传递,即可重建逼真的高分辨图像。将基于GAN的字典的概念进行推广,GLEAN不仅可扩展到不同架构,还可以扩展到各种成像任务,如图像去噪、内绘制和着色等。
We show that pre-trained Generative Adversarial Networks (GANs), e.g., StyleGAN, can be used as a latent bank to improve the restoration quality of large-factor image super-resolution (SR). While most existing SR approaches attempt to generate realistic textures through learning with adversarial loss, our method, Generative LatEnt bANk (GLEAN), goes beyond existing practices by directly leveraging rich and diverse priors encapsulated in a pre-trained GAN. But unlike prevalent GAN inversion methods that require expensive image-specific optimization at runtime, our approach only needs a single forward pass to generate the upscaled image. GLEAN can be easily incorporated in a simple encoder-bank-decoder architecture with multi-resolution skip connections. Switching the bank allows the method to deal with images from diverse categories, e.g., cat, building, human face, and car. Images upscaled by GLEAN show clear improvements in terms of fidelity and texture faithfulness in comparison to existing methods.
https://weibo.com/1402400261/JwHeLeLTM

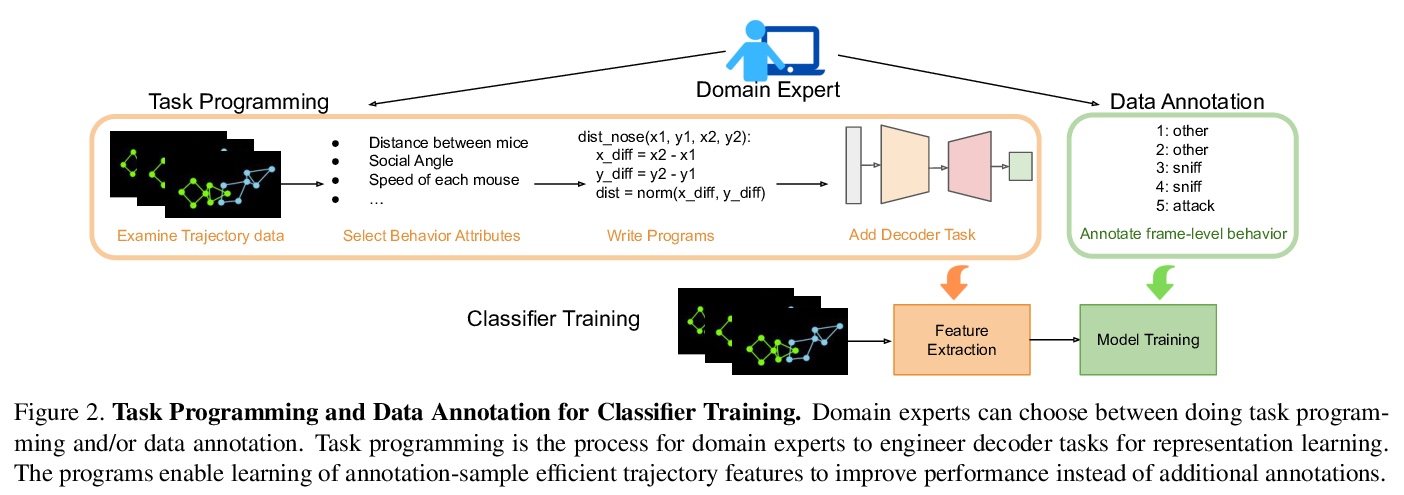
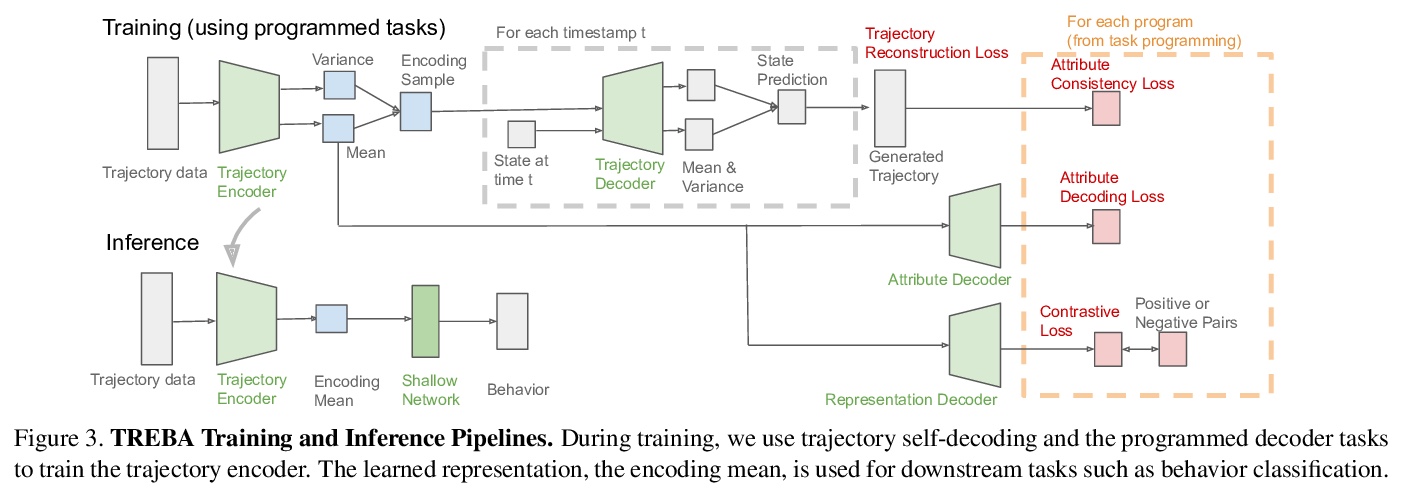
5、** **[CV] Task Programming: Learning Data Efficient Behavior Representations
J J. Sun, A Kennedy, E Zhan, Y Yue, P Perona
[Caltech & Northwestern University]
任务编程:数据高效的行为表示学习。提出TREBA,一种基于多任务自监督学习、用于行为分析的标记-样本高效轨迹嵌入学习方法,其中任务通过“任务编程”的过程由领域专家有效地设计,用程序显式编码来自领域专家的结构化知识。通过构建少量已编程任务来换取数据标记时间,大大减少领域专家的人工工作。
Specialized domain knowledge is often necessary to accurately annotate training sets for in-depth analysis, but can be burdensome and time-consuming to acquire from domain experts. This issue arises prominently in automated behavior analysis, in which agent movements or actions of interest are detected from video tracking data. To reduce annotation effort, we present TREBA: a method to learn annotation-sample efficient trajectory embedding for behavior analysis, based on multi-task self-supervised learning. The tasks in our method can be efficiently engineered by domain experts through a process we call “task programming”, which uses programs to explicitly encode structured knowledge from domain experts. Total domain expert effort can be reduced by exchanging data annotation time for the construction of a small number of programmed tasks. We evaluate this trade-off using data from behavioral neuroscience, in which specialized domain knowledge is used to identify behaviors. We present experimental results in three datasets across two domains: mice and fruit flies. Using embeddings from TREBA, we reduce annotation burden by up to a factor of 10 without compromising accuracy compared to state-of-the-art features. Our results thus suggest that task programming can be an effective way to reduce annotation effort for domain experts.
https://weibo.com/1402400261/JwHl0mBUj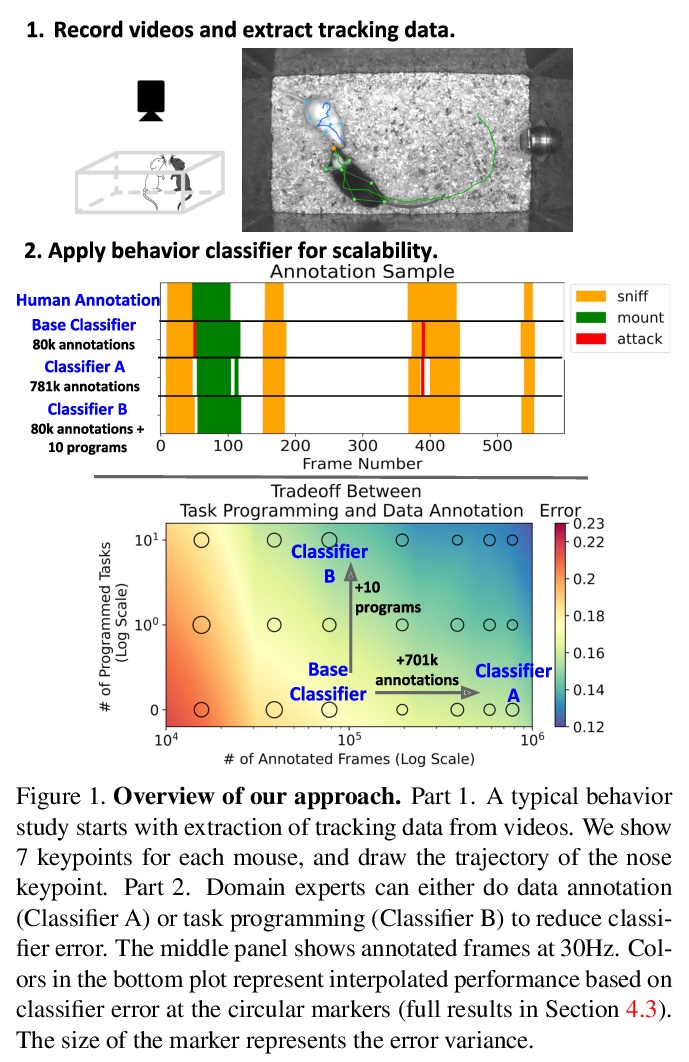
另外几篇值得关注的论文:
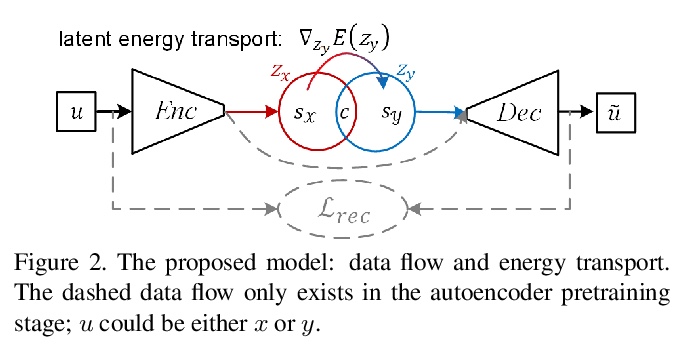
[CV] Unpaired Image-to-Image Translation via Latent Energy Transport
基于潜能量传输的非配对图像-图像变换
Y Zhao, C Chen
[University at Buffalo]
https://weibo.com/1402400261/JwHskbUtQ
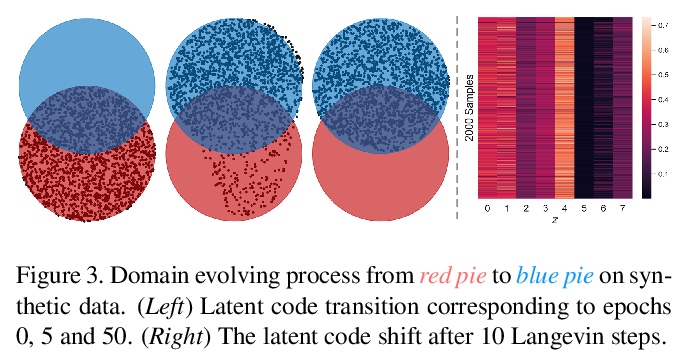
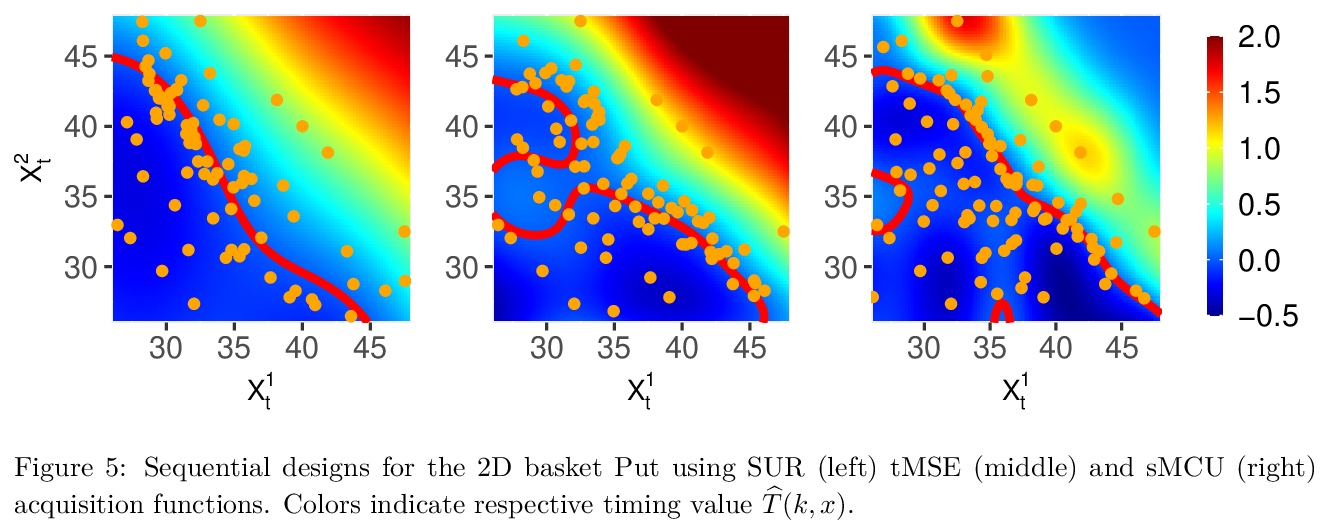
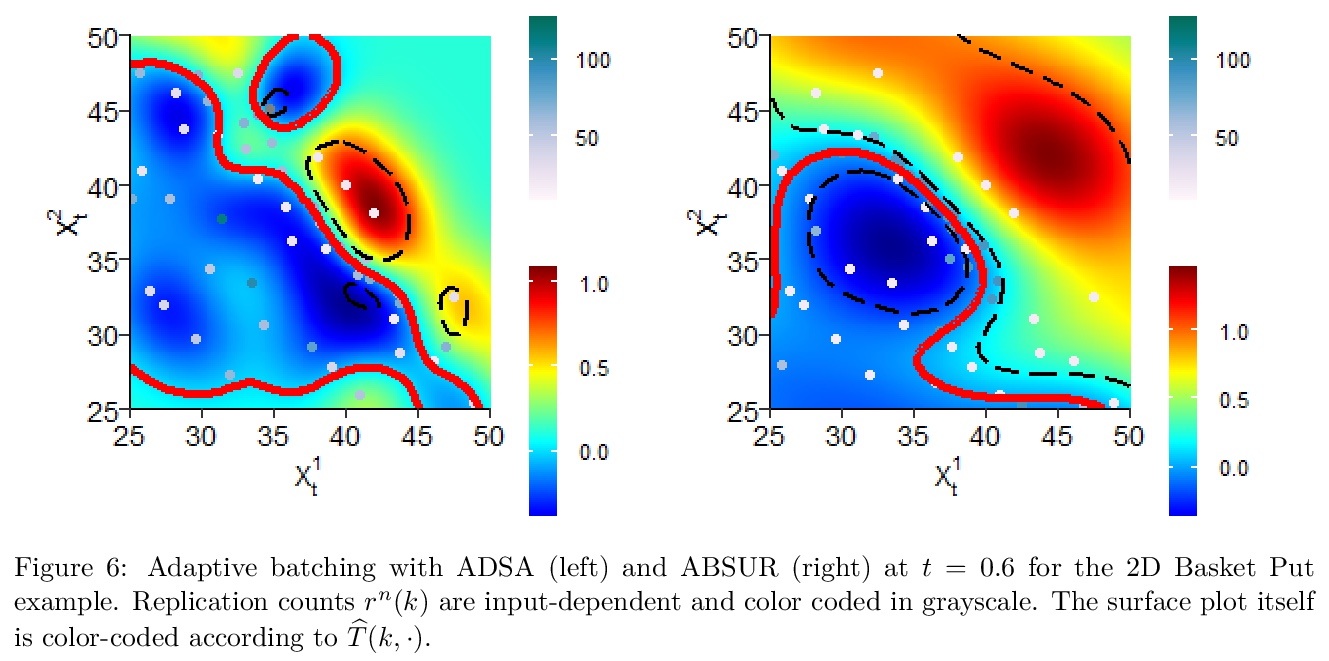
[LG] mlOSP: Towards a Unified Implementation of Regression Monte Carlo Algorithms
mlOSP:回归蒙特卡罗算法统一实现
M Ludkovski
[University of California, Santa Barbara]
https://weibo.com/1402400261/JwHuRDka9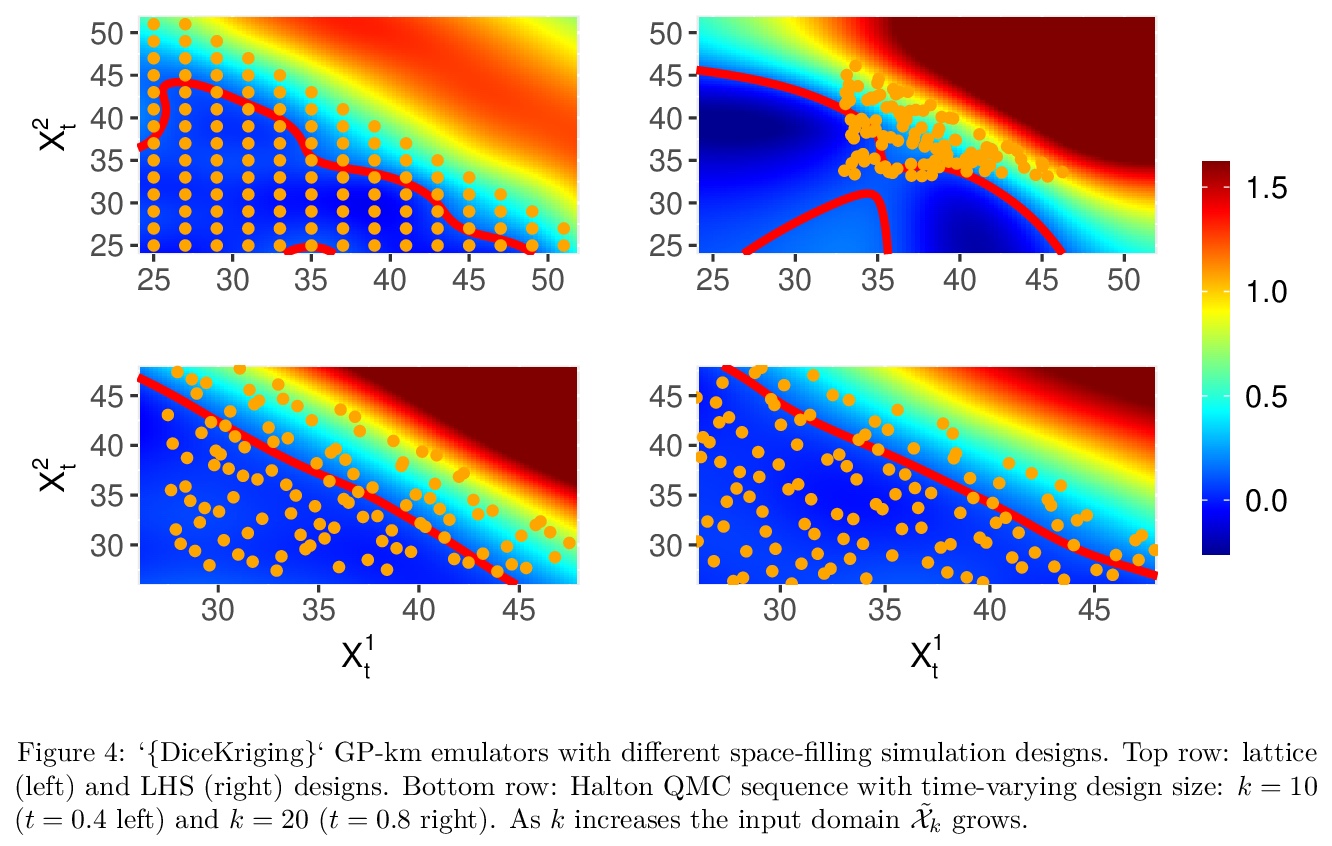
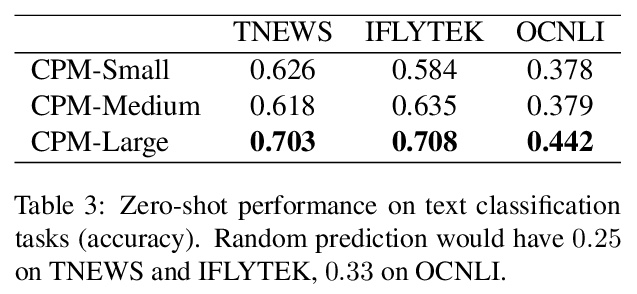
[CL] CPM: A Large-scale Generative Chinese Pre-trained Language Model
CPM:大规模生成式中文预训练语言模型
Z Zhang, X Han, H Zhou…
[Tsinghua University & BAAI]
https://weibo.com/1402400261/JwHwu9O6R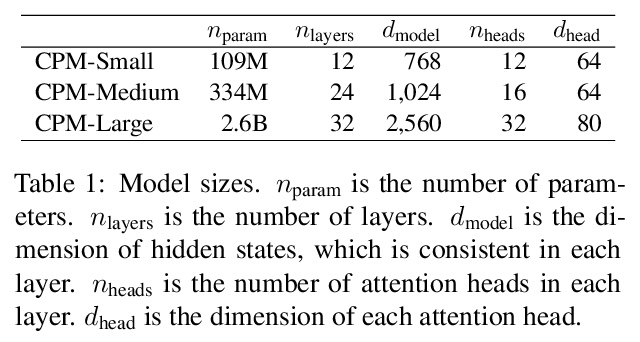


若有收获,就点个赞吧
0 人点赞
