LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
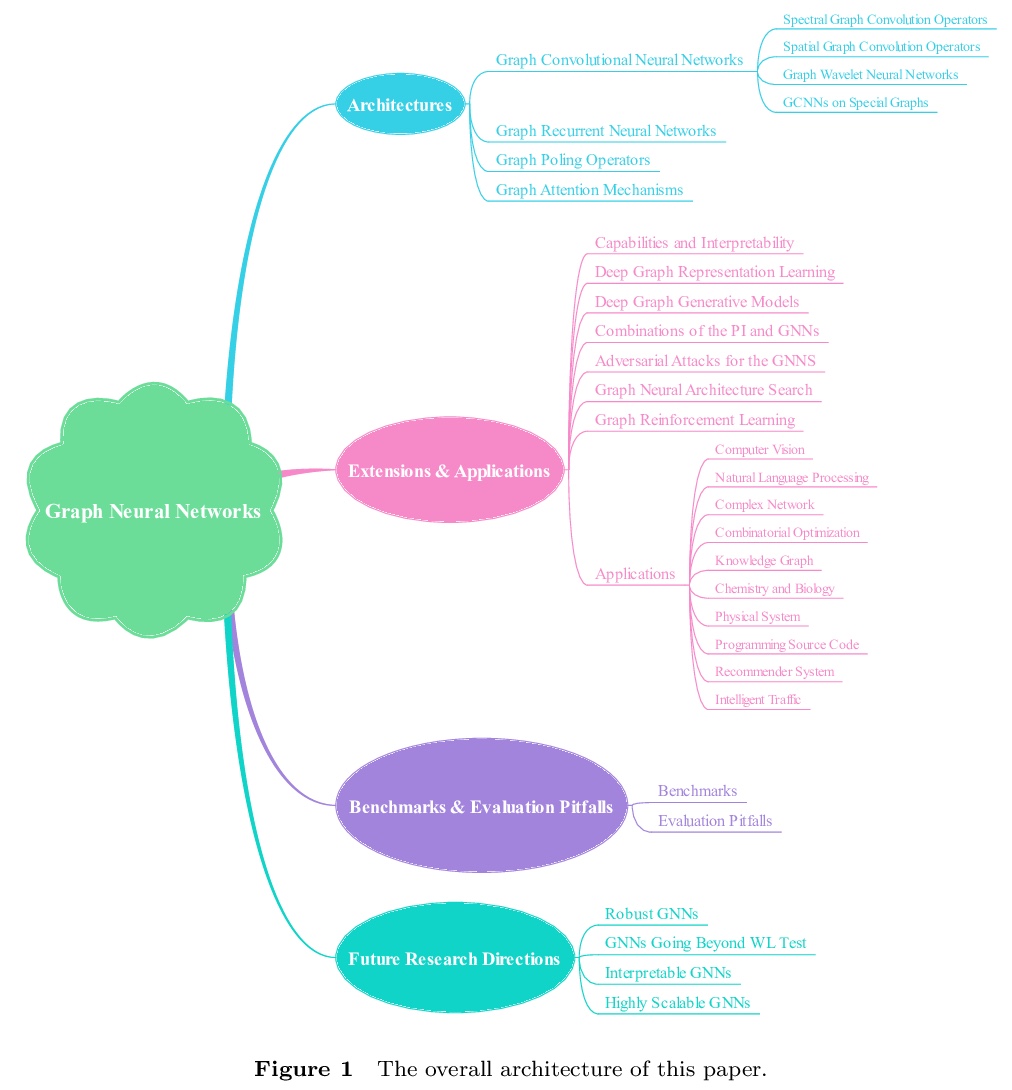
1、[LG] Graph Neural Networks: Taxonomy, Advances and Trends
Y Zhou, H Zheng, X Huang
[Taiyuan University of Technology]
图神经网络:分类、进展和趋势。对图神经网络进行全面的回顾:为图神经网络提供了新的分类方法,参考了400多篇相关文献,展示了图神经网络的全景,所有文献都被划分到了相应类别。为推动图神经网络发展,总结了四个未来的研究方向,以克服面临的挑战。
Graph neural networks provide a powerful toolkit for embedding real-world graphs into low-dimensional spaces according to specific tasks. Up to now, there have been several surveys on this topic. However, they usually lay emphasis on different angles so that the readers can not see a panorama of the graph neural networks. This survey aims to overcome this limitation, and provide a comprehensive review on the graph neural networks. First of all, we provide a novel taxonomy for the graph neural networks, and then refer to up to 400 relevant literatures to show the panorama of the graph neural networks. All of them are classified into the corresponding categories. In order to drive the graph neural networks into a new stage, we summarize four future research directions so as to overcome the facing challenges. It is expected that more and more scholars can understand and exploit the graph neural networks, and use them in their research community.
https://weibo.com/1402400261/JzqBbwlwR
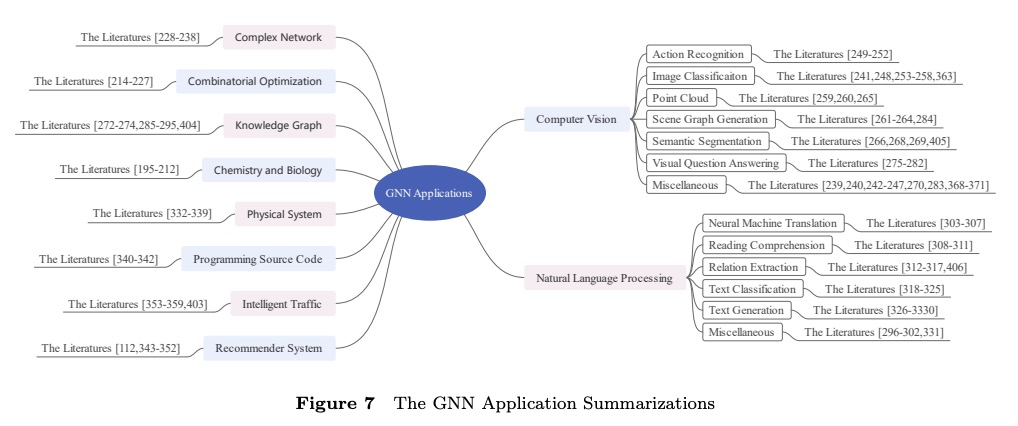
2、[CV] Real-Time High-Resolution Background Matting
S Lin, A Ryabtsev, S Sengupta, B Curless, S Seitz, I Kemelmacher-Shlizerman
[University of Washington]
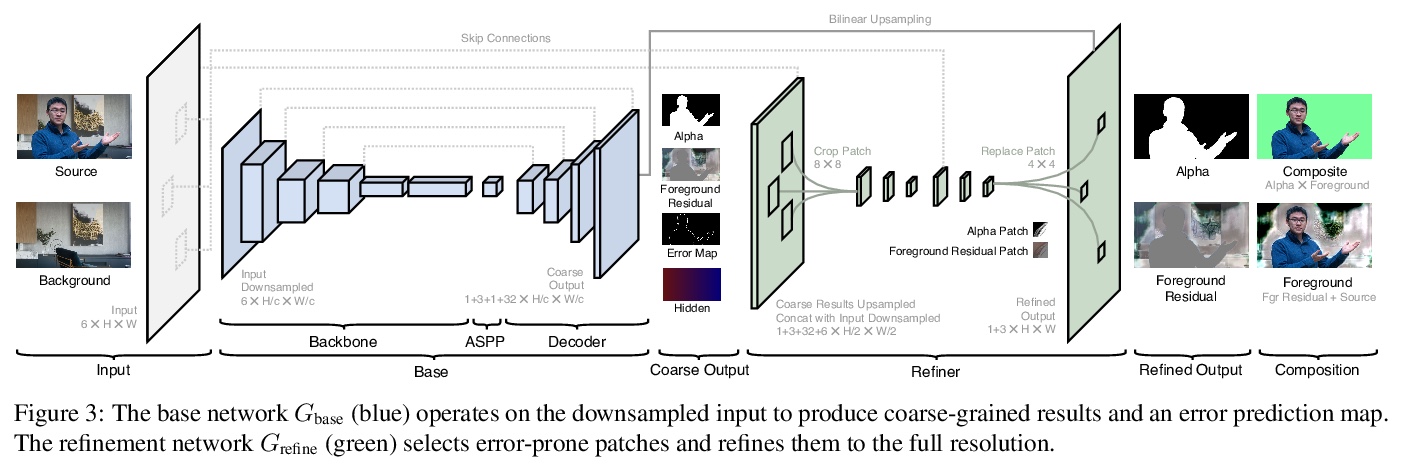
实时高分辨率背景抠图。提出一种实时、高分辨率的背景替换技术,可在4K 30fps和HD 60fps下运行。该方法基于背景抠图,即捕获一帧额外背景,用于恢复半透明抠图和前景层,采用两个神经网络;基础网络计算低分辨率结果,第二个网络在高分辨率下对选定的区块进行完善。只需输入图像和预先捕获的背景图像,可有效地在高分辨率下只对易出错区域进行细化,减少冗余计算,实现实时的高分辨率消隐。引入两个新的大尺度视频和图像抠图数据集,以便推广到现实场景。与之前最先进的背景抠图方法相比,该方法可产生更高质量的结果,在速度和分辨率上都有极大提升。
We introduce a real-time, high-resolution background replacement technique which operates at 30fps in 4K resolution, and 60fps for HD on a modern GPU. Our technique is based on background matting, where an additional frame of the background is captured and used in recovering the alpha matte and the foreground layer. The main challenge is to compute a high-quality alpha matte, preserving strand-level hair details, while processing high-resolution images in real-time. To achieve this goal, we employ two neural networks; a base network computes a low-resolution result which is refined by a second network operating at high-resolution on selective patches. We introduce two largescale video and image matting datasets: VideoMatte240K and PhotoMatte13K/85. Our approach yields higher quality results compared to the previous state-of-the-art in background matting, while simultaneously yielding a dramatic boost in both speed and resolution.
https://weibo.com/1402400261/JzqEfxx2U

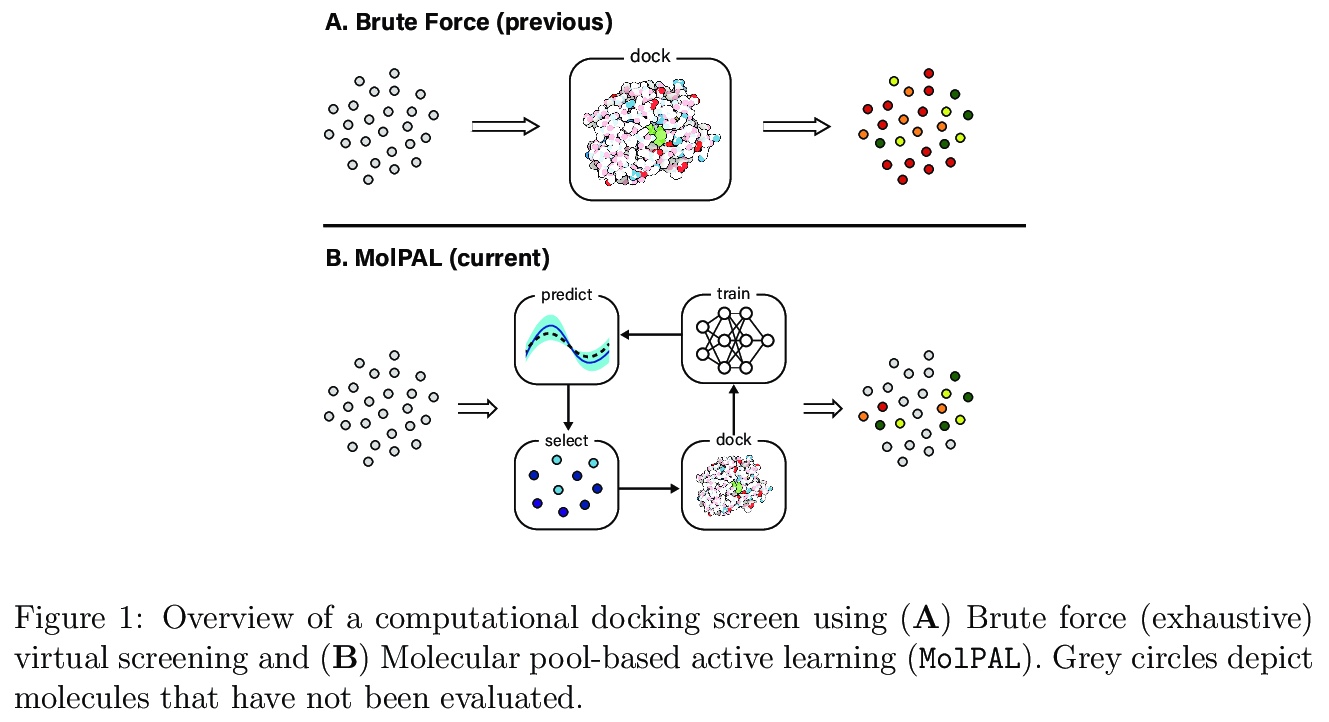
3、[LG] Accelerating high-throughput virtual screening through molecular pool-based active learning
D E. Graff, E I. Shakhnovich, C W. Coley
[MIT]
用分子池主动学习加速高通量虚拟药物筛选。基于结构的虚拟药物筛选是早期药物发现的重要工具,可评价靶蛋白和候选配体间的相互作用。随着虚拟库的不断增长(超过108个分子),对这些库进行彻底的虚拟药物筛选所需的资源也在不断增加。贝叶斯优化技术有助于在虚拟库中进行探索:用库的一个子集的预测亲和力训练代用结构-属性关系模型,用于其余的库成员,将前景最差的化合物排除出评价范围。本文评价了应用于几个蛋白质配体对接数据集的各种替代模型架构、采集函数和采集批量大小,并观察到计算成本的显著降低,即使采用贪婪采集策略,这种模型引导的搜索减轻了筛选越来越大的虚拟库不断增加的计算成本,可加速高通量的虚拟药物筛选。
Structure-based virtual screening is an important tool in early stage drug discovery that scores the interactions between a target protein and candidate ligands. As virtual libraries continue to grow (in excess of > 108 molecules), so too do the resources necessary to conduct exhaustive virtual screening campaigns on these libraries. However, Bayesian optimization techniques can aid in their exploration: a surrogate structure-property relationship model trained on the predicted affinities of a subset of the library can be applied to the remaining library members, allowing the least promising compounds to be excluded from evaluation. In this study, we assess various surrogate model architectures, acquisition functions, and acquisition batch sizes as applied to several protein-ligand docking datasets and observe significant reductions in computational costs, even when using a greedy acquisition strategy; for example, 87.9% of the top-50000 ligands can be found after testing only 2.4% of a 100M member library. Such model-guided searches mitigate the increasing computational costs of screening increasingly large virtual libraries and can accelerate high-throughput virtual screening campaigns with applications beyond docking.
https://weibo.com/1402400261/JzqJqsW1d
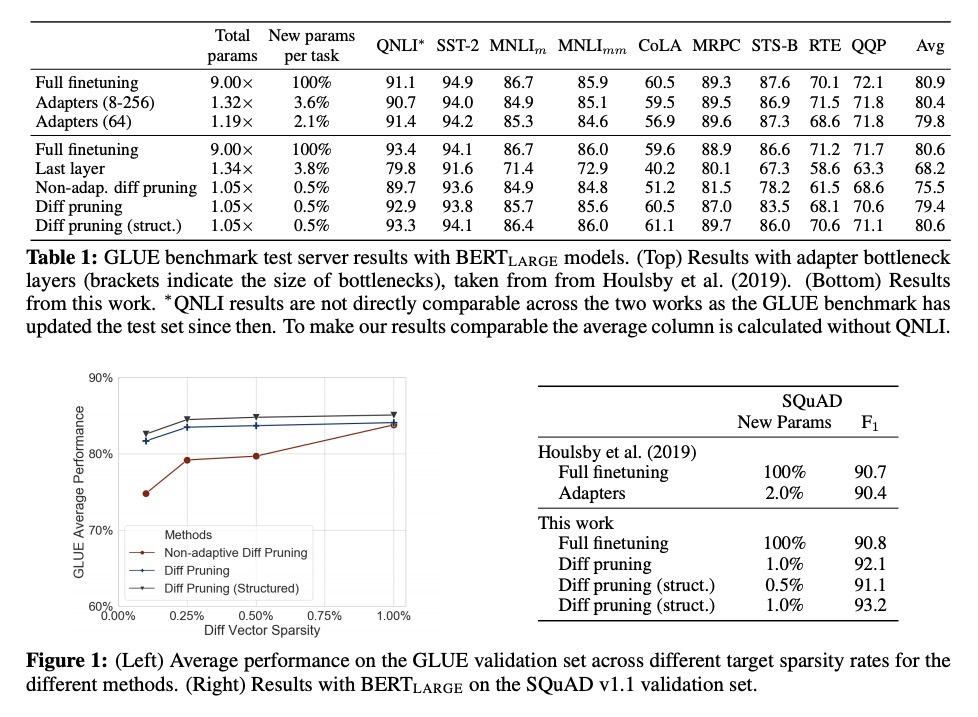
4、** **[CL] Parameter-Efficient Transfer Learning with Diff Pruning
D Guo, A M. Rush, Y Kim
[Harvard University & Cornell University & MIT-IBM Watson AI]
用Diff Pruning实现参数高效的迁移学习。diff pruning方法将微调视为特定于任务的差向量的学习过程,差向量用于预训练的参数向量,参数向量保持固定,且在不同任务间共享。训练期间,用L0-norm惩罚的可微近似自适应修剪差向量,以鼓励稀疏性。随任务数量增加,差修剪变得更加参数高效,而存储共享预训练模型的成本保持不变。用Diff Pruning微调的模型,每个任务只需修改0.5%的预训练模型参数,即可在GLUE基准上匹配全微调基线的性能。
While task-specific finetuning of pretrained networks has led to significant empirical advances in NLP, the large size of networks makes finetuning difficult to deploy in multi-task, memory-constrained settings. We propose diff pruning as a simple approach to enable parameter-efficient transfer learning within the pretrain-finetune framework. This approach views finetuning as learning a task-specific diff vector that is applied on top of the pretrained parameter vector, which remains fixed and is shared across different tasks. The diff vector is adaptively pruned during training with a differentiable approximation to the L0-norm penalty to encourage sparsity. Diff pruning becomes parameter-efficient as the number of tasks increases, as it requires storing only the nonzero positions and weights of the diff vector for each task, while the cost of storing the shared pretrained model remains constant. It further does not require access to all tasks during training, which makes it attractive in settings where tasks arrive in stream or the set of tasks is unknown. We find that models finetuned with diff pruning can match the performance of fully finetuned baselines on the GLUE benchmark while only modifying 0.5% of the pretrained model’s parameters per task.
https://weibo.com/1402400261/JzqOwjE8Y
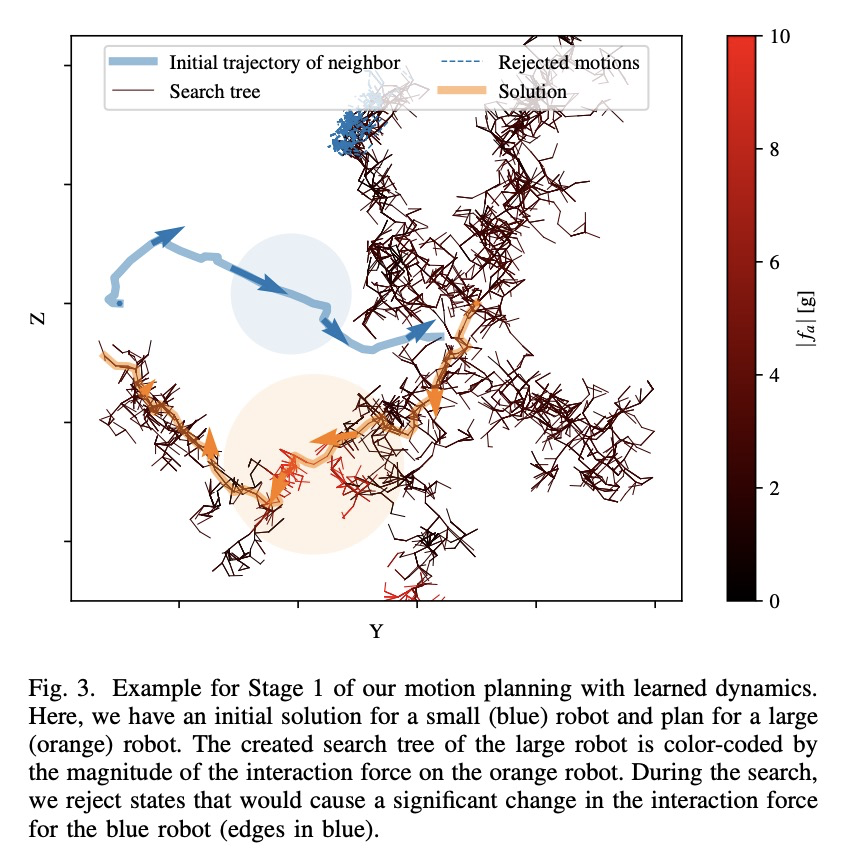
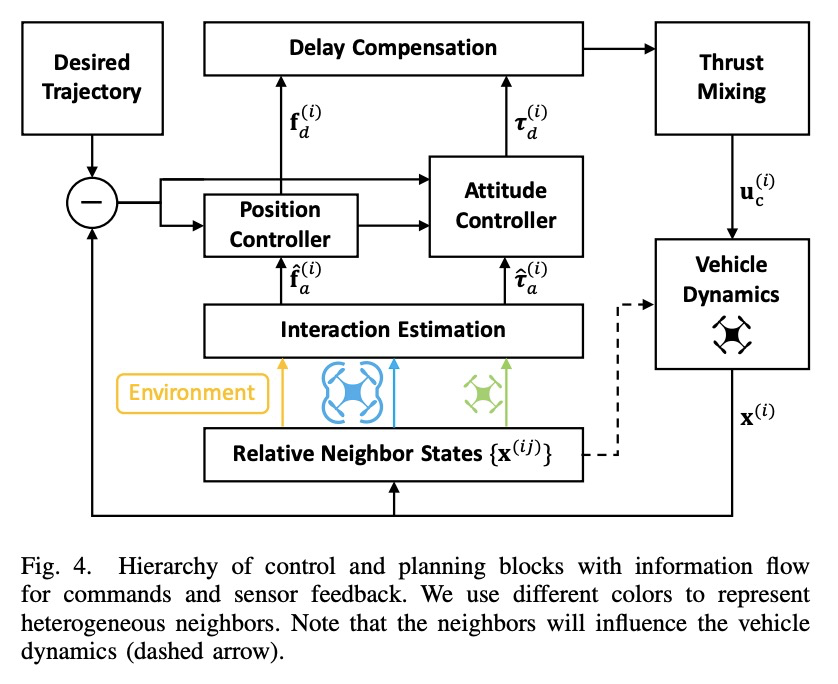
5、[RO] Neural-Swarm2: Planning and Control of Heterogeneous Multirotor Swarms using Learned Interactions
G Shi, W Hönig, X Shi, Y Yue, S Chung
[California Institute of Technology]
用习得相互作用规划和控制异质多旋翼无人机群。提出Neural-Swarm2,基于学习的运动规划和控制方法,允许异质多旋翼无人机群安全地近距离飞行。引入高效的深度网络体系结构异质深度集,仅依赖相邻飞行器的相对位置和速度,学习多个四旋翼飞行器间的相互作用力,还可模拟地面效应和其他未建模动力学,通过观察将物理环境作为特殊的邻近飞行器。实验结果表明,Neural-Swarm2可推广到训练样本外的更大群体,显著优于基线非线性跟踪控制器,在最坏情况下跟踪误差可减少三倍。
We present Neural-Swarm2, a learning-based method for motion planning and control that allows heterogeneous multirotors in a swarm to safely fly in close proximity. Such operation for drones is challenging due to complex aerodynamic interaction forces, such as downwash generated by nearby drones and ground effect. Conventional planning and control methods neglect capturing these interaction forces, resulting in sparse swarm configuration during flight. Our approach combines a physics-based nominal dynamics model with learned Deep Neural Networks (DNNs) with strong Lipschitz properties. We evolve two techniques to accurately predict the aerodynamic interactions between heterogeneous multirotors: i) spectral normalization for stability and generalization guarantees of unseen data and ii) heterogeneous deep sets for supporting any number of heterogeneous neighbors in a permutation-invariant manner without reducing expressiveness. The learned residual dynamics benefit both the proposed interaction-aware multi-robot motion planning and the nonlinear tracking control designs because the learned interaction forces reduce the modelling errors. Experimental results demonstrate that Neural-Swarm2 is able to generalize to larger swarms beyond training cases and significantly outperforms a baseline nonlinear tracking controller with up to three times reduction in worst-case tracking errors.
https://weibo.com/1402400261/JzqV0vEPQ
另外几篇值得关注的论文:
[AS] MLS: A Large-Scale Multilingual Dataset for Speech Research
MLS:面向语音研究的大规模多语言数据集
V Pratap, Q Xu, A Sriram, G Synnaeve, R Collobert
[Facebook AI Research]
https://weibo.com/1402400261/JzqZAb2YB
[LG] In-N-Out: Pre-Training and Self-Training using Auxiliary Information for Out-of-Distribution Robustness
In-N-Out:用辅助信息进行预训练和自训练,以获得分布外鲁棒性
S M Xie, A Kumar, R Jones, F Khani, T Ma, P Liang
[Stanford University]
https://weibo.com/1402400261/Jzr14EaqY


[RO] ViNG: Learning Open-World Navigation with Visual Goals
ViNG:视觉目标开放世界导航学习
D Shah, B Eysenbach, G Kahn, N Rhinehart, S Levine
[UC Berkeley & CMU]
https://weibo.com/1402400261/Jzr351gwe



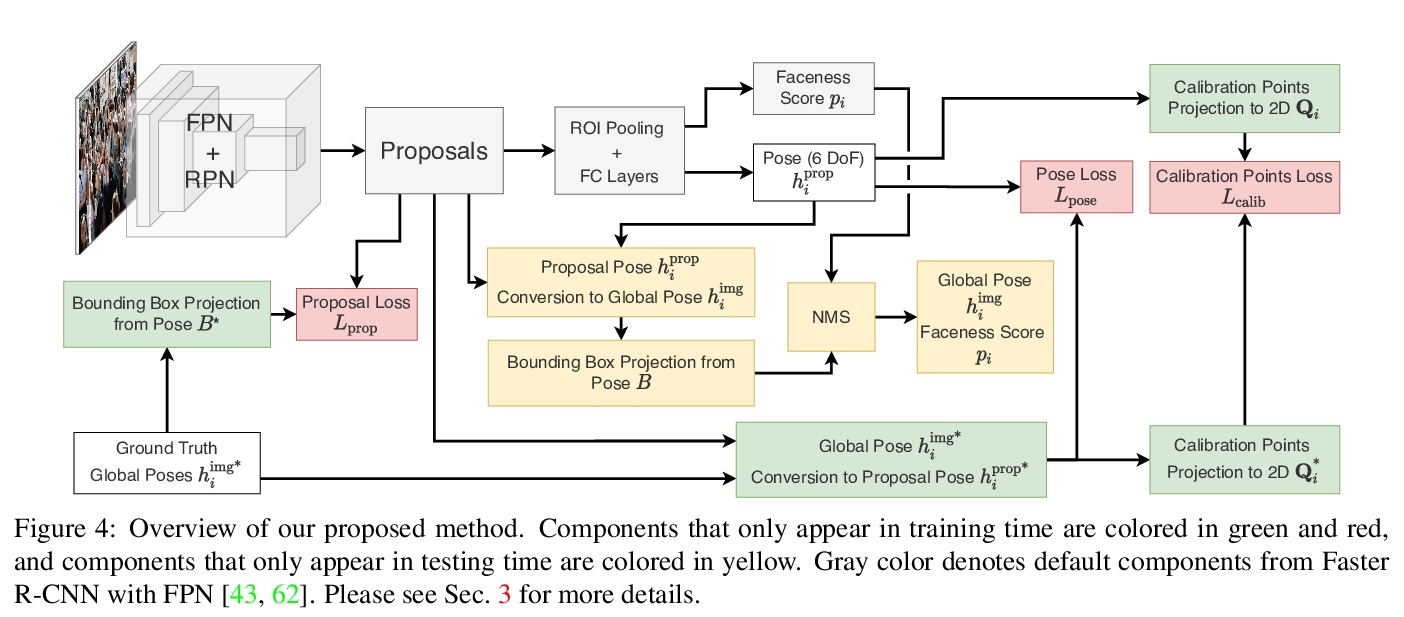
[CV] img2pose: Face Alignment and Detection via 6DoF, Face Pose Estimation
img2pose:无需人脸检测和特征点定位的实时6自由度3D人脸姿态估计方法
V Albiero, X Chen, X Yin, G Pang, T Hassner
[University of Notre Dame & Facebook AI]
https://weibo.com/1402400261/Jzr55uIC3


若有收获,就点个赞吧
0 人点赞
