- 1、[LG] Self-supervised Learning from a Multi-view Perspective
- 2、[CV] Understanding Robustness of Transformers for Image Classification
- 3、[CL] Dodrio: Exploring Transformer Models with Interactive Visualization
- 4、[CV] MedSelect: Selective Labeling for Medical Image Classification Combining Meta-Learning with Deep Reinforcement Learning
- 5、[LG] A Practical Survey on Faster and Lighter Transformers
- [CV] COTR: Correspondence Transformer for Matching Across Images
- [LG] Why Do Local Methods Solve Nonconvex Problems?
- [CV] Describing and Localizing Multiple Changes with Transformers
- [CV] Few-Shot Human Motion Transfer by Personalized Geometry and Texture Modeling
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Self-supervised Learning from a Multi-view Perspective
Y H Tsai, Y Wu, R Salakhutdinov, L Morency
[CMU]
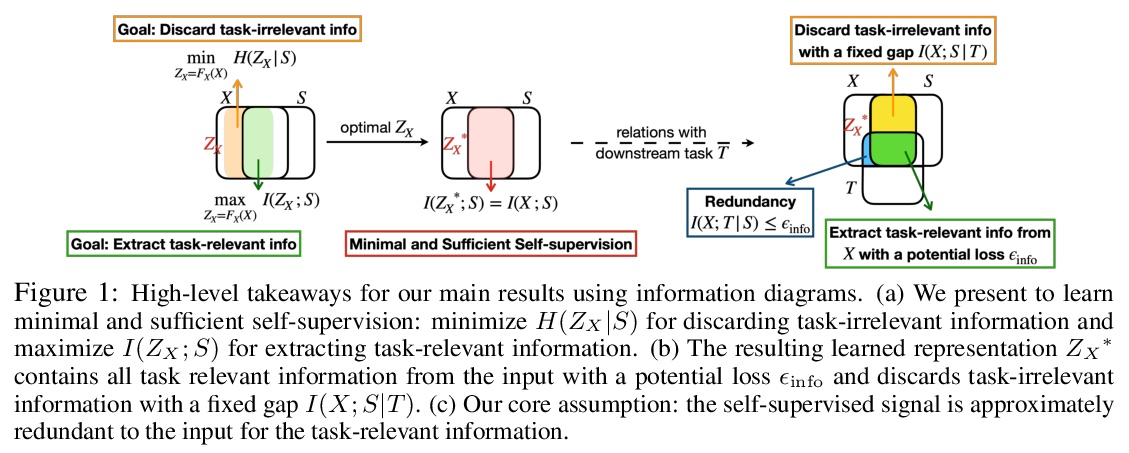
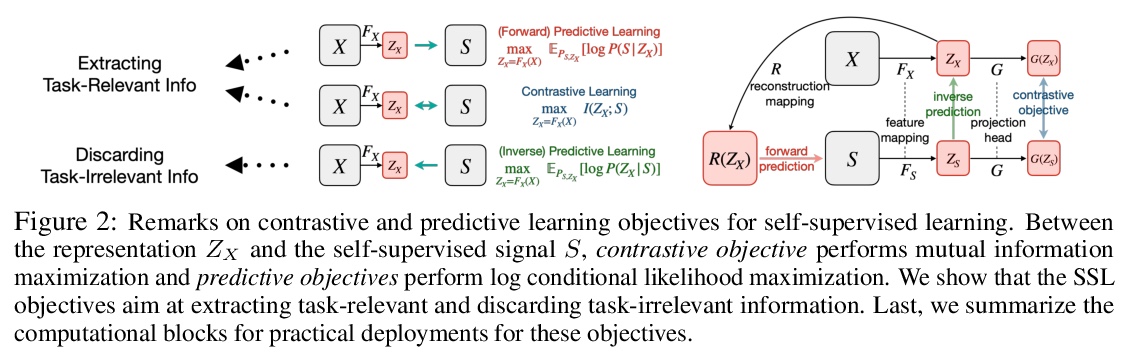
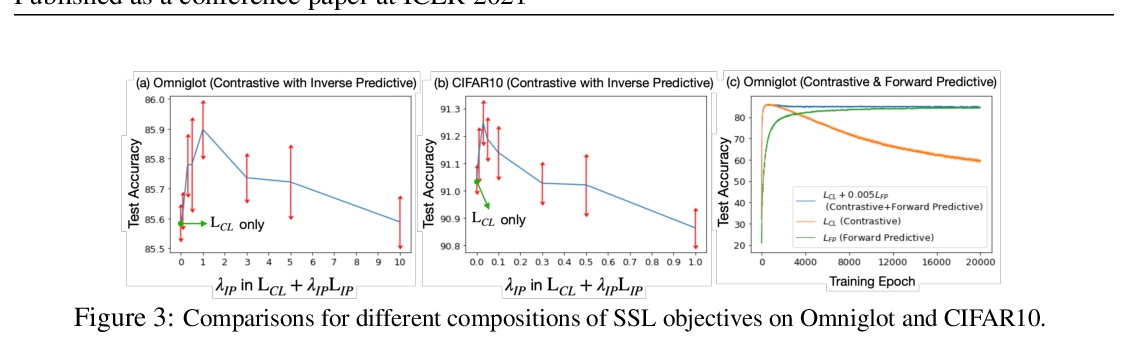
用多视角看自监督学习。从理论和经验两方面研究了自监督学习,很多自监督学习方法的提出,自然遵循多视角观点,即输入(如原始图像)和自监督信号(如增强图像)可看作是数据的两个冗余视角。从这种多视角观点出发,提供了一个信息理论框架,以更好地理解有助于成功自监督学习的特性。证明了自监督学习表征可提取任务相关信息(通过潜损失)并丢弃任务无关信息,提出一个复合目标,弥补了之前对比性学习目标和预测性学习目标之间的差距,并引入一个额外的目标项来丢弃任务不相关信息。
As a subset of unsupervised representation learning, self-supervised representation learning adopts self-defined signals as supervision and uses the learned representation for downstream tasks, such as object detection and image captioning. Many proposed approaches for self-supervised learning follow naturally a multi-view perspective, where the input (e.g., original images) and the self-supervised signals (e.g., augmented images) can be seen as two redundant views of the data. Building from this multi-view perspective, this paper provides an information-theoretical framework to better understand the properties that encourage successful self-supervised learning. Specifically, we demonstrate that self-supervised learned representations can extract task-relevant information and discard task-irrelevant information. Our theoretical framework paves the way to a larger space of self-supervised learning objective design. In particular, we propose a composite objective that bridges the gap between prior contrastive and predictive learning objectives, and introduce an additional objective term to discard task-irrelevant information. To verify our analysis, we conduct controlled experiments to evaluate the impact of the composite objectives. We also explore our framework’s empirical generalization beyond the multi-view perspective, where the cross-view redundancy may not be clearly observed.
https://weibo.com/1402400261/K8wjSoUDC
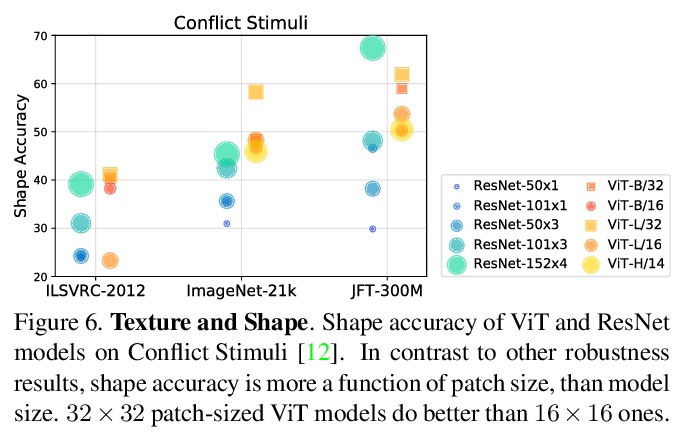
2、[CV] Understanding Robustness of Transformers for Image Classification
S Bhojanapalli, A Chakrabarti, D Glasner, D Li, T Unterthiner, A Veit
[Google Research]
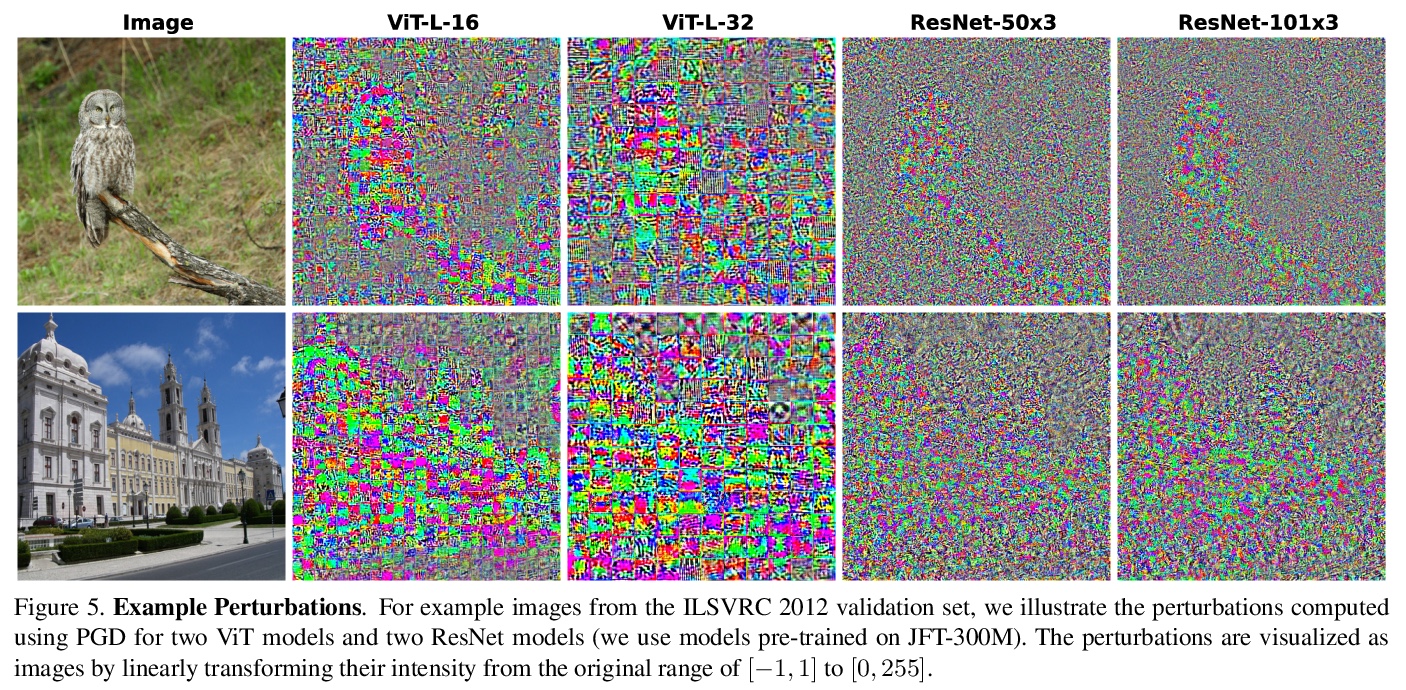
理解Transformer图像分类的鲁棒性。对视觉Transformer(ViT)模型各种不同的鲁棒性度量进行了广泛研究,并将研究结果与ResNet基线进行了比较。研究了对输入扰动的鲁棒性以及对模型扰动的鲁棒性,发现当使用足够数据量进行预训练时,ViT模型在广泛扰动范围内至少与ResNet对应模型一样鲁棒。Transformers对几乎所有单层的移除都是鲁棒的,来自后几层的激活虽然相互之间高度相关,但其在分类中还是发挥了重要作用。
Deep Convolutional Neural Networks (CNNs) have long been the architecture of choice for computer vision tasks. Recently, Transformer-based architectures like Vision Transformer (ViT) have matched or even surpassed ResNets for image classification. However, details of the Transformer architecture — such as the use of non-overlapping patches — lead one to wonder whether these networks are as robust. In this paper, we perform an extensive study of a variety of different measures of robustness of ViT models and compare the findings to ResNet baselines. We investigate robustness to input perturbations as well as robustness to model perturbations. We find that when pre-trained with a sufficient amount of data, ViT models are at least as robust as the ResNet counterparts on a broad range of perturbations. We also find that Transformers are robust to the removal of almost any single layer, and that while activations from later layers are highly correlated with each other, they nevertheless play an important role in classification.
https://weibo.com/1402400261/K8wse8gHj

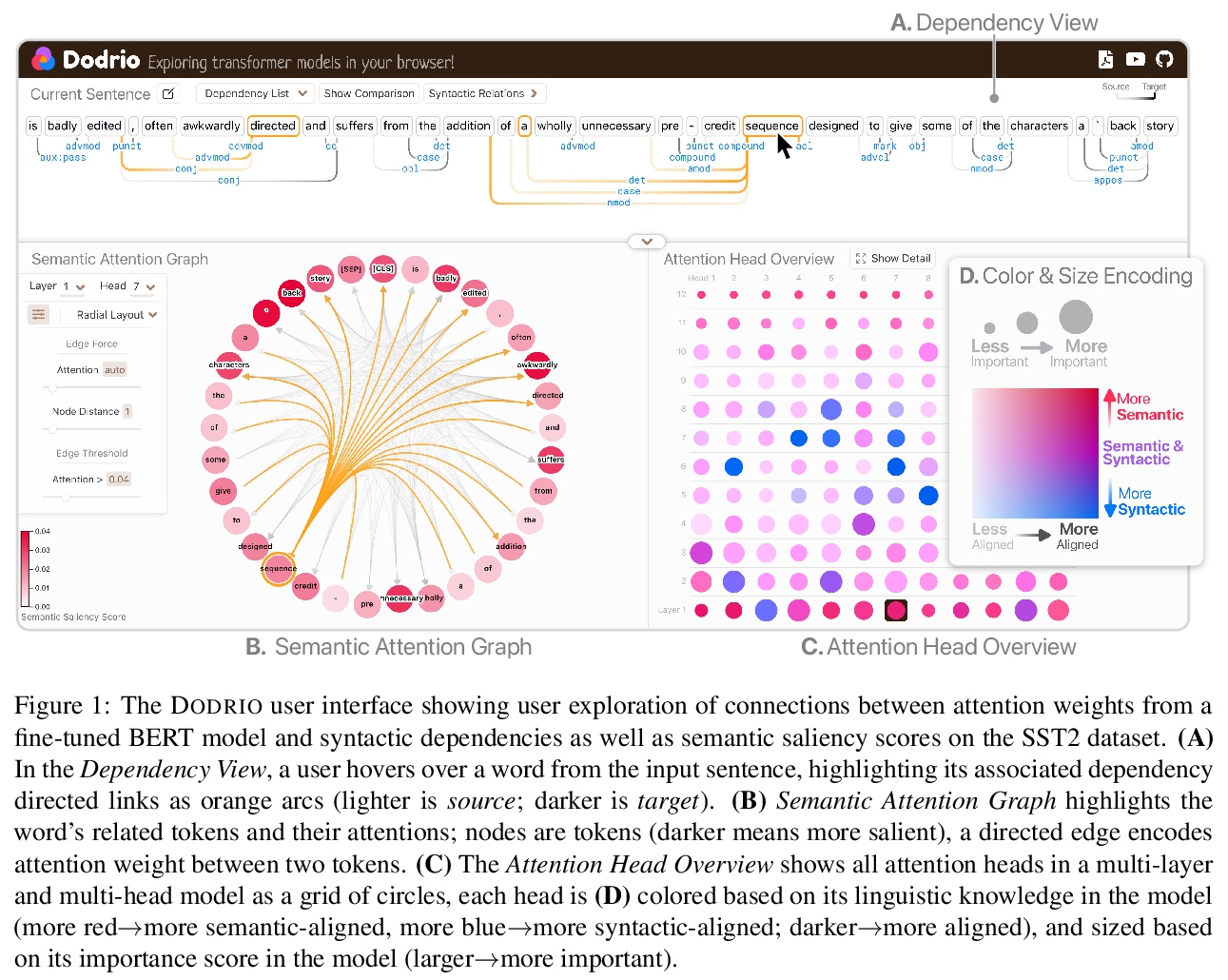
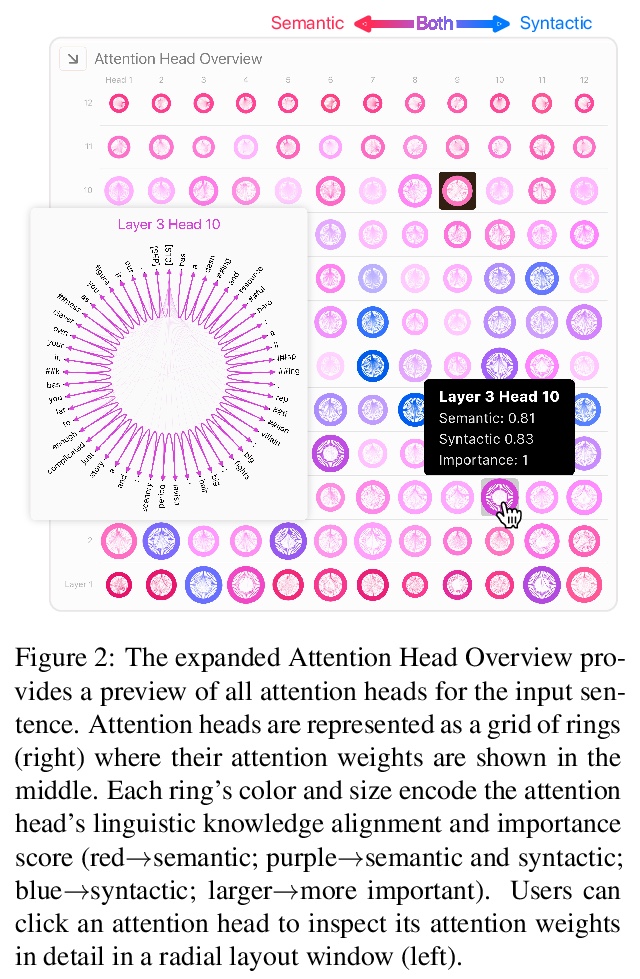
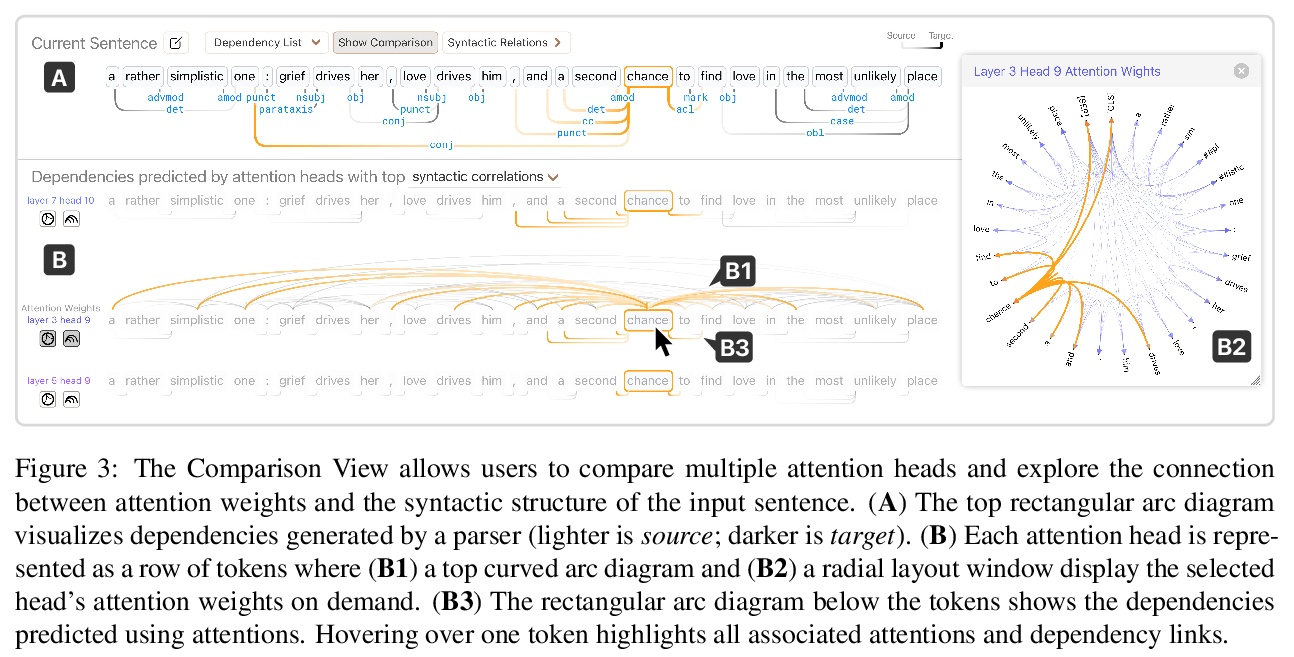
3、[CL] Dodrio: Exploring Transformer Models with Interactive Visualization
Z J. Wang, R Turko, D H Chau
[Georgia Tech]
DODRIO:Transformer模型的交互可视化探索。介绍了开源交互式可视化工具DODRIO,以帮助NLP研究人员和从业人员分析基于Transformer的语言模型中的注意力机制。DODRIO紧密整合了一个概览,总结了不同注意力头的作用,以及帮用户将注意力权重与输入文本中句法结构和语义信息进行比较的详细视图。为方便对注意力权重和语言知识进行可视化比较,DODRIO应用不同的图可视化技术来表示较长输入文本的注意力权重。案例研究强调了DODRIO如何为理解基于Transformer的模型中的注意力机制提供见解。
Why do large pre-trained transformer-based models perform so well across a wide variety of NLP tasks? Recent research suggests the key may lie in multi-headed attention mechanism’s ability to learn and represent linguistic information. Understanding how these models represent both syntactic and semantic knowledge is vital to investigate why they succeed and fail, what they have learned, and how they can improve. We present Dodrio, an open-source interactive visualization tool to help NLP researchers and practitioners analyze attention mechanisms in transformer-based models with linguistic knowledge. Dodrio tightly integrates an overview that summarizes the roles of different attention heads, and detailed views that help users compare attention weights with the syntactic structure and semantic information in the input text. To facilitate the visual comparison of attention weights and linguistic knowledge, Dodrio applies different graph visualization techniques to represent attention weights with longer input text. Case studies highlight how Dodrio provides insights into understanding the attention mechanism in transformer-based models. Dodrio is available at > this https URL.
https://weibo.com/1402400261/K8wC3b0Ip
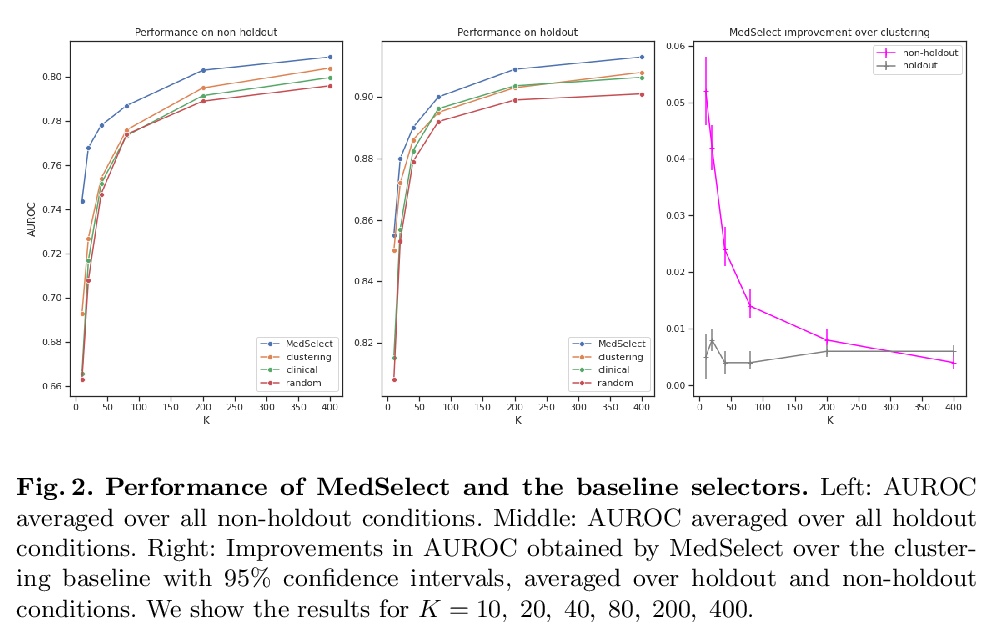
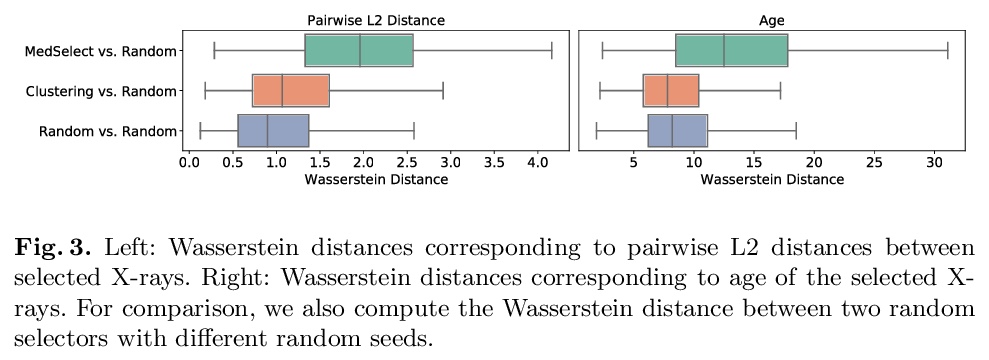
4、[CV] MedSelect: Selective Labeling for Medical Image Classification Combining Meta-Learning with Deep Reinforcement Learning
A Smit, D Vrabac, Y He, A Y. Ng, A L. Beam, P Rajpurkar
[Stanford University & Harvard T.H. Chan School of Public Health]
MedSelect: 结合元学习与深度强化学习的选择性标记医学图像分类。提出一种使用元学习和深度强化学习的选择性学习方法MedSelect,用于在有限的标记资源环境下进行医学图像解释,MedSelect由一个可训练的深度学习选择器和一个非参数选择器组成,前者用通过对比训练获得的图像嵌入来确定要标记的图像,后者用余弦相似度对未见图像进行分类。实验证明MedSelect学习了一种有效的选择策略,在胸腔X光片解读的可见和不可见医疗条件下,表现优于基线选择策略。对MedSelect执行的选择进行了分析,比较了潜嵌入和临床特征的分布,发现与表现最强的基线相比有显著差异。
We propose a selective learning method using meta-learning and deep reinforcement learning for medical image interpretation in the setting of limited labeling resources. Our method, MedSelect, consists of a trainable deep learning selector that uses image embeddings obtained from contrastive pretraining for determining which images to label, and a non-parametric selector that uses cosine similarity to classify unseen images. We demonstrate that MedSelect learns an effective selection strategy outperforming baseline selection strategies across seen and unseen medical conditions for chest X-ray interpretation. We also perform an analysis of the selections performed by MedSelect comparing the distribution of latent embeddings and clinical features, and find significant differences compared to the strongest performing baseline. We believe that our method may be broadly applicable across medical imaging settings where labels are expensive to acquire.
https://weibo.com/1402400261/K8wG4fR4f

5、[LG] A Practical Survey on Faster and Lighter Transformers
Q Fournier, G M Caron, D Aloise
[Polytechnique Montreal & Mila - Quebec AI Institute]
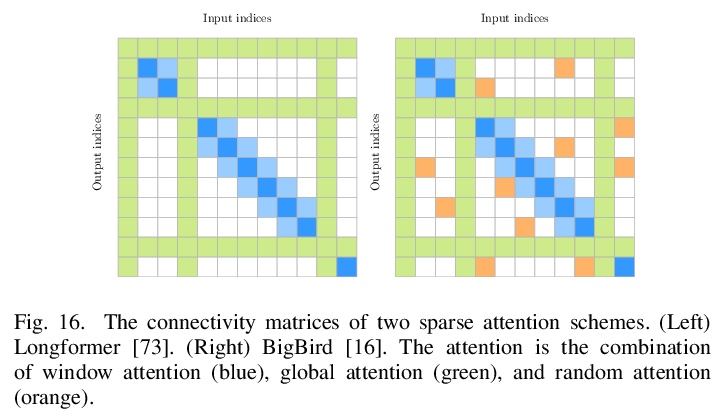
更快更轻的Transformer实践综述。Transformer是完全基于注意力机制的模型,能将输入序列的任意两个位置联系起来,从而对任意的长程依赖性进行建模。Transformer改善了众多序列建模任务的现状,但其有效性是以相对于序列长度的二次计算和内存复杂性为代价的,这阻碍了其应用。针对该问题,产生了大量的解决方案,如参数共享、修剪、混合精度和知识蒸馏等。最近,研究者们直接解决了Transformer的局限性,设计了Longformer、Reformer、Linformer和Performer等低复杂度的替代方案。但由于解决方案的范围广泛,要确定在实践中应用哪种方法来满足容量、计算和内存之间的理想权衡逐渐成为一种挑战。本综述通过调研流行方法来解决该问题,使Transformer变得更快、更轻,并对这些方法的优势、局限性和基本假设进行全面解释。
Recurrent neural networks are effective models to process sequences. However, they are unable to learn long-term dependencies because of their inherent sequential nature. As a solution, Vaswani et al. introduced the Transformer, a model solely based on the attention mechanism that is able to relate any two positions of the input sequence, hence modelling arbitrary long dependencies. The Transformer has improved the state-of-the-art across numerous sequence modelling tasks. However, its effectiveness comes at the expense of a quadratic computational and memory complexity with respect to the sequence length, hindering its adoption. Fortunately, the deep learning community has always been interested in improving the models’ efficiency, leading to a plethora of solutions such as parameter sharing, pruning, mixed-precision, and knowledge distillation. Recently, researchers have directly addressed the Transformer’s limitation by designing lower-complexity alternatives such as the Longformer, Reformer, Linformer, and Performer. However, due to the wide range of solutions, it has become challenging for the deep learning community to determine which methods to apply in practice to meet the desired trade-off between capacity, computation, and memory. This survey addresses this issue by investigating popular approaches to make the Transformer faster and lighter and by providing a comprehensive explanation of the methods’ strengths, limitations, and underlying assumptions.
https://weibo.com/1402400261/K8wMkxqx7
另外几篇值得关注的论文:
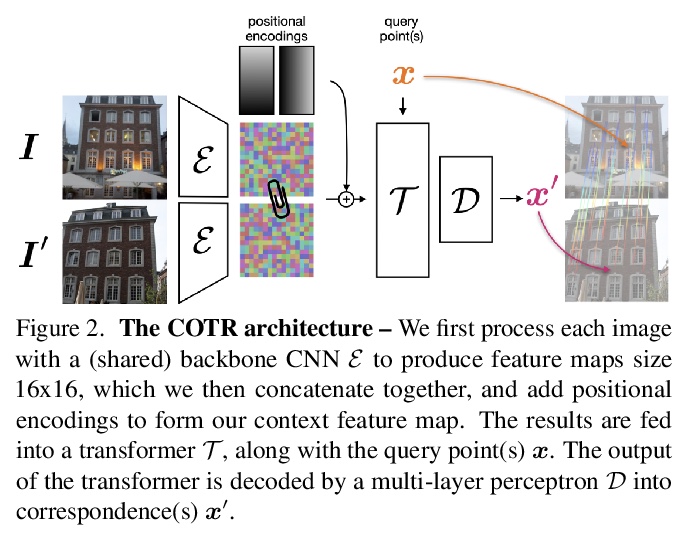
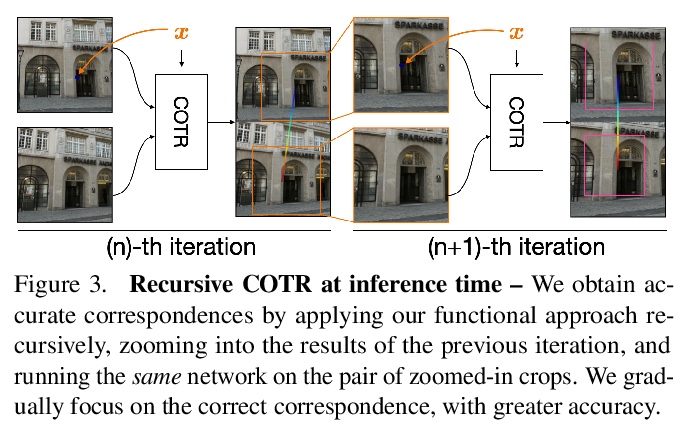
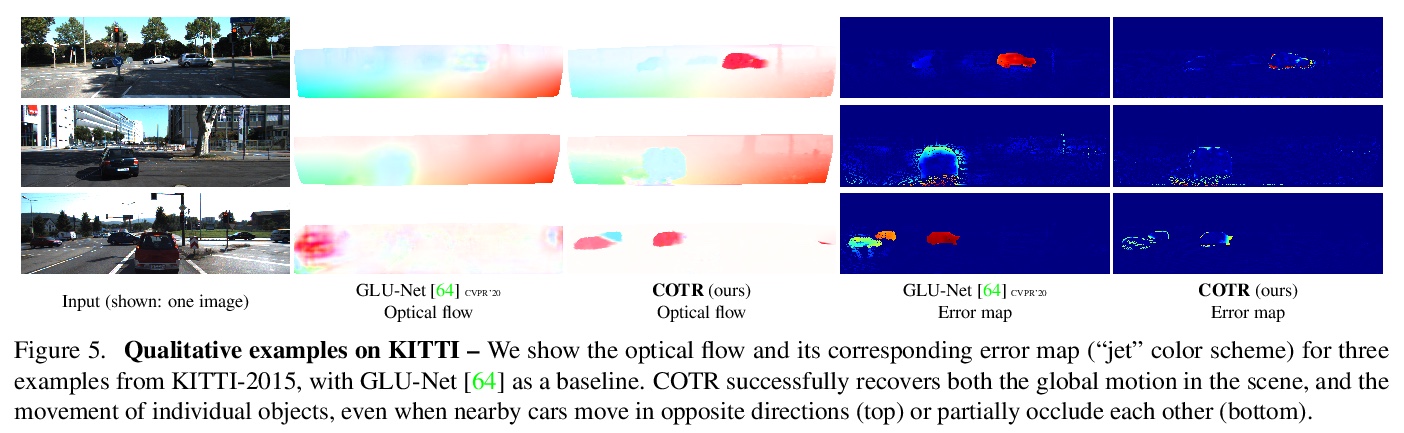
[CV] COTR: Correspondence Transformer for Matching Across Images
COTR:对应Transformer跨图像匹配
W Jiang, E Trulls, J Hosang, A Tagliasacchi, K M Yi
[University of British Columbia & Google Research]
https://weibo.com/1402400261/K8wQxc8d5

[LG] Why Do Local Methods Solve Nonconvex Problems?
为什么局部方法解决非凸问题?
T Ma
[Stanford University]
https://weibo.com/1402400261/K8wT4EEjz

[CV] Describing and Localizing Multiple Changes with Transformers
用Transformer描述和定位多变性
Y Qiu, S Yamamoto, K Nakashima, R Suzuki, K Iwata, H Kataoka, Y Satoh
[National Institute of Advanced Industrial Science and Technology (AIST)]
https://weibo.com/1402400261/K8wVvnWdc


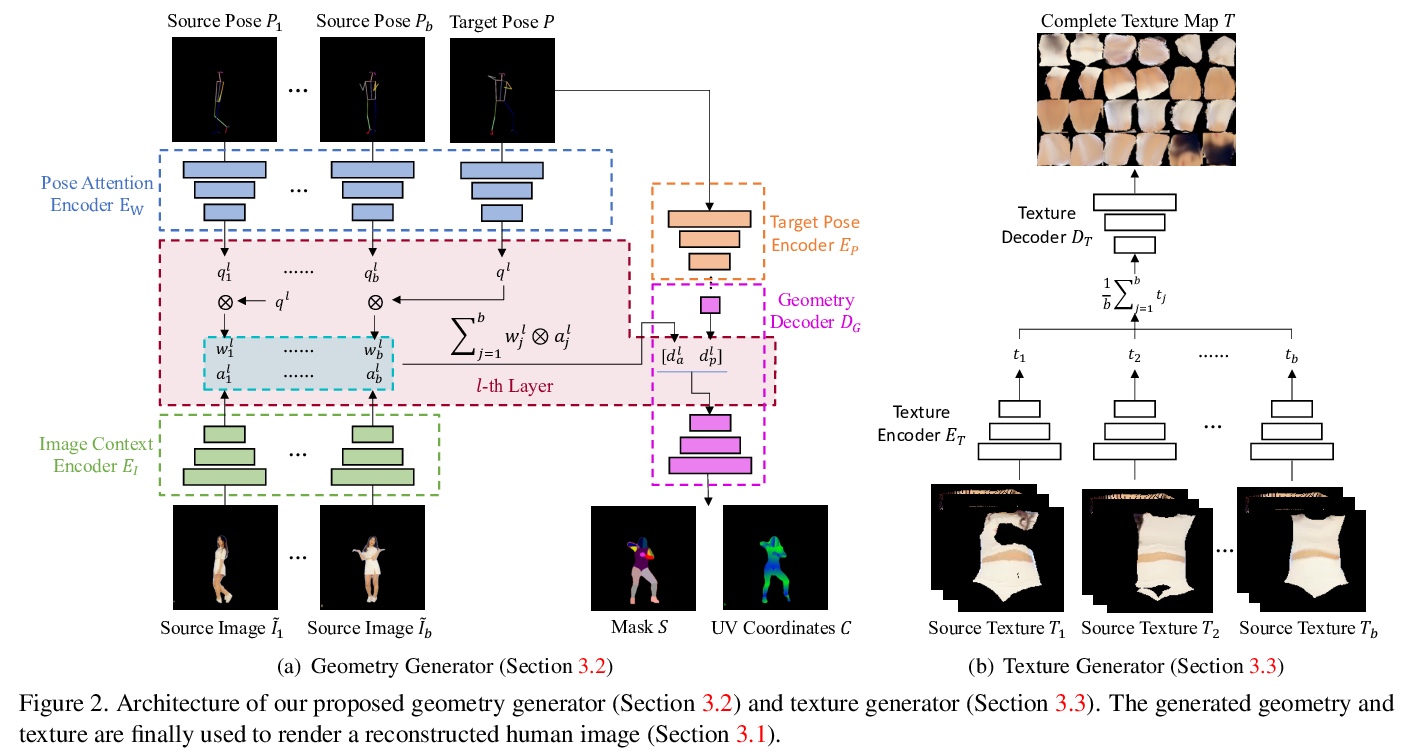
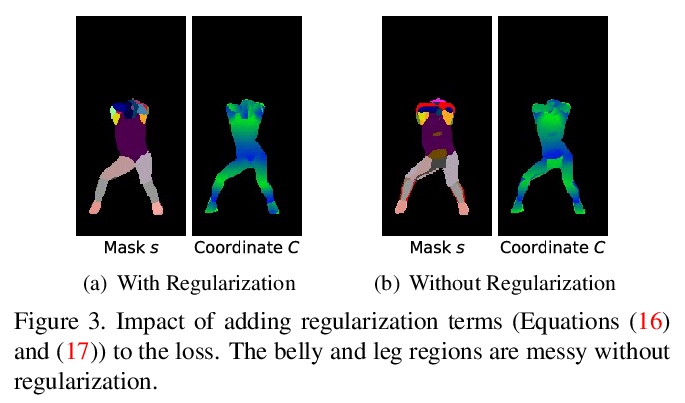
[CV] Few-Shot Human Motion Transfer by Personalized Geometry and Texture Modeling
基于个性化几何与纹理建模的少样本人体运动迁移
Z Huang, X Han, J Xu, T Zhang
[The Hong Kong University of Science and Technology & Huya Inc]
https://weibo.com/1402400261/K8wZLtEDe

若有收获,就点个赞吧
0 人点赞
