LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Rank Consistent Ordinal Regression for Neural Networks with Application to Age Estimation
W Cao, V Mirjalili, S Raschka
[University of Wisconsin-Madison & Michigan State University]
面向年龄估计的秩一致有序回归神经网络。通过扩展二分类开发了用于有序回归CORAL框架,具有有序回归能力的同时保证了二分类的一致性,提高了预测性能。CORAL与架构无关,可以很容易地推广到其他有序回归问题和不同类型的神经网络结构,包括多层感知器和递归神经网络,用于有序回归任务。通过对一组人脸图像数据集的实证评价,表明该方法的预测误差比之前的有序回归网络有很大降低。
In many real-world predictions tasks, class labels include information about the relative ordering between labels, which is not captured by commonly-used loss functions such as multi-category cross-entropy. Recently, ordinal regression frameworks have been adopted by the deep learning community to take such ordering information into account. Using a framework that transforms ordinal targets into binary classification subtasks, neural networks were equipped with ordinal regression capabilities. However, this method suffers from inconsistencies among the different binary classifiers. We hypothesize that addressing the inconsistency issue in these binary classification task-based neural networks improves predictive performance. To test this hypothesis, we propose the COnsistent RAnk Logits (CORAL) framework with strong theoretical guarantees for rank-monotonicity and consistent confidence scores. Moreover, the proposed method is architecture-agnostic and can extend arbitrary state-of-the-art deep neural network classifiers for ordinal regression tasks. The empirical evaluation of the proposed rank-consistent method on a range of face-image datasets for age prediction shows a substantial reduction of the prediction error compared to the reference ordinal regression network.
https://weibo.com/1402400261/Jt2MFnaPB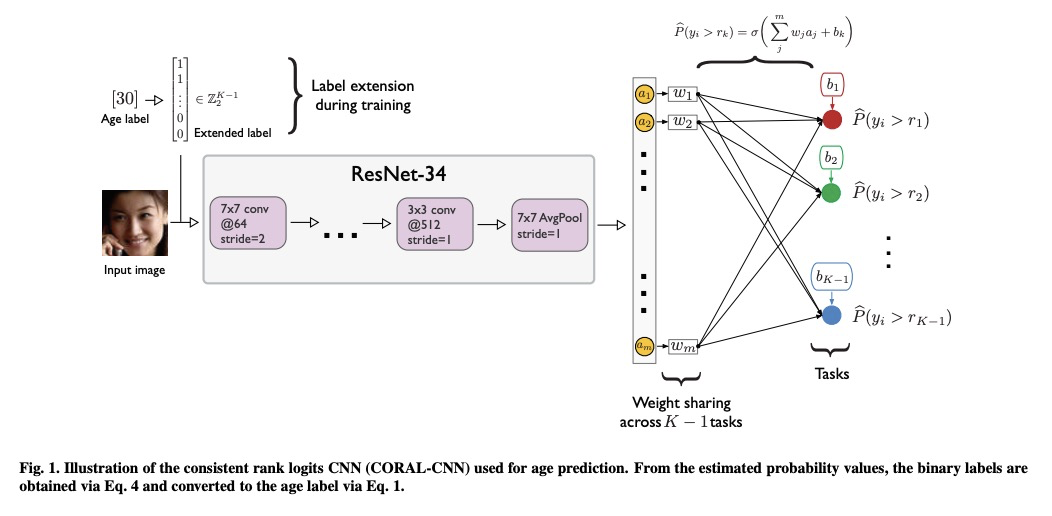
2、[LG] Long Range Arena : A Benchmark for Efficient Transformers
(2020)
长程竞技场(LRA):Transformers性能基准。提出了一个系统的、统一的基准,Long Range Arena,专门针对长程情况下的模型质量进行评价。该基准测试由一套标记序列任务组成,包括各种数据类型和模式,如文本、自然、合成图像和需要相似性、结构和视觉-空间推理的数学表达式。采用新提出的基准,系统评价了十种最新的长程Transformer模型(Reformers, Linformers, Linear Transformers, Sinkhorn Transformers, Performers, Synthesizers, Sparse Transformers, and Longformers)。
Transformers do not scale very well to long sequence lengths largely because of quadratic self-attention complexity. In the recent months, a wide spectrum of efficient, fast Transformers have been proposed to tackle this problem, more often than not claiming superior or comparable model quality to vanilla Transformer models. To this date, there is no well-established consensus on how to evaluate this class of models. Moreover, inconsistent benchmarking on a wide spectrum of tasks and datasets makes it difficult to assess relative model quality amongst many models. This paper proposes a systematic and unified benchmark, Long Range Arena, specifically focused on evaluating model quality under long-context scenarios. Our benchmark is a suite of tasks consisting of sequences ranging from to tokens, encompassing a wide range of data types and modalities such as text, natural, synthetic images, and mathematical expressions requiring similarity, structural, and visual-spatial reasoning. We systematically evaluate ten well-established long-range Transformer models (Reformers, Linformers, Linear Transformers, Sinkhorn Transformers, Performers, Synthesizers, Sparse Transformers, and Longformers) on our newly proposed benchmark suite. Long Range Arena paves the way towards better understanding this class of efficient Transformer models, facilitates more research in this direction, and presents new challenging tasks to tackle.
https://weibo.com/1402400261/Jt2SFCVRI
3、[CL] **CharBERT: Character-aware Pre-trained Language Model
W Ma, Y Cui, C Si, T Liu, S Wang, G Hu
[iFLYTEK Research & Harbin Institute of Technology & University of Maryland]
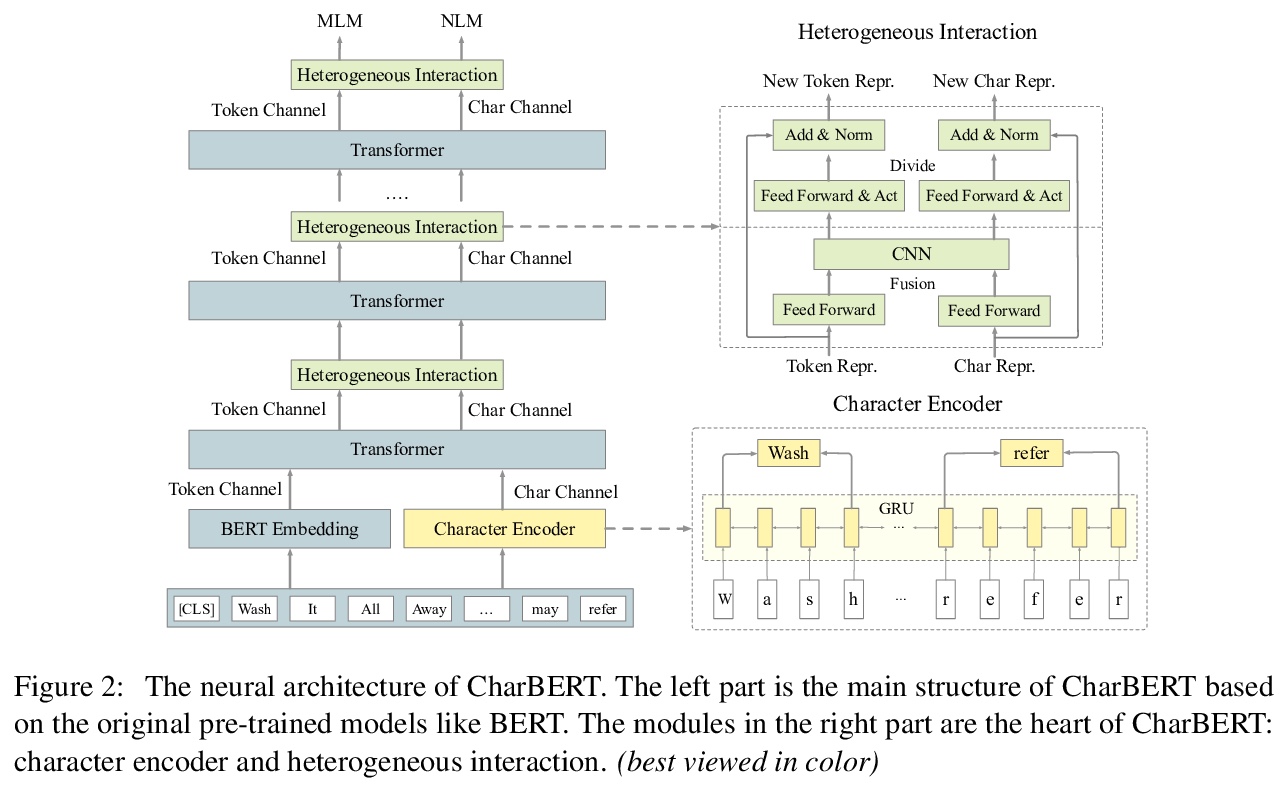
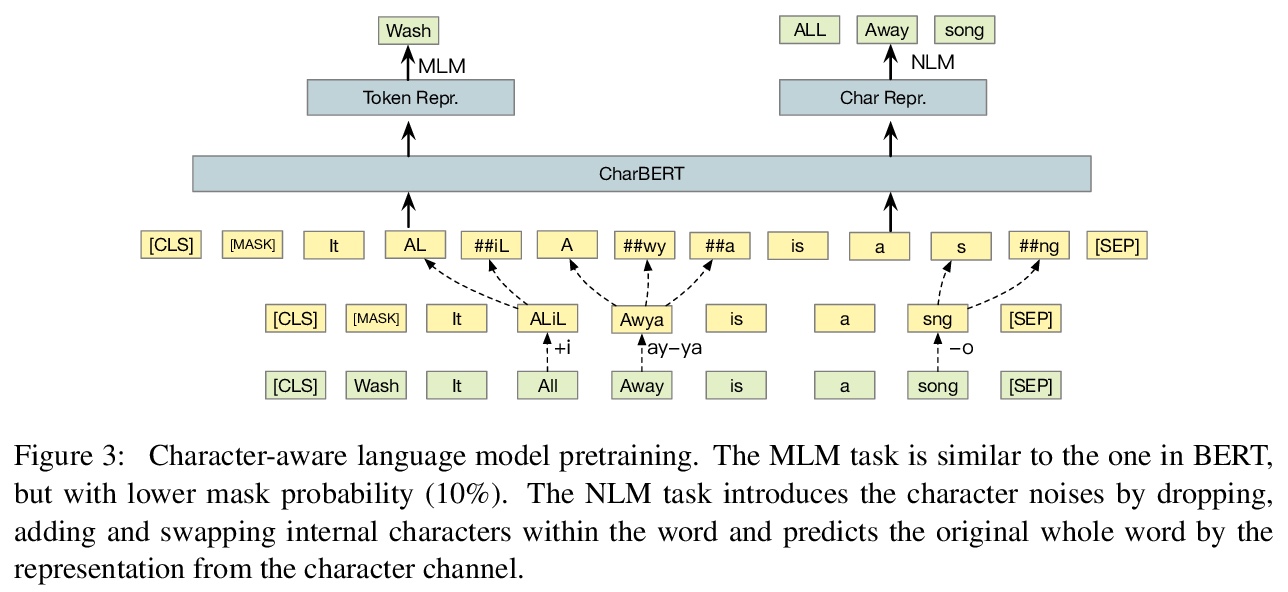
CharBERT:字符感知预训练语言模型。为解决目前预训练语言模型的不完整建模和缺乏鲁棒性问题,提出一种新的预训练模型CharBERT,将字符级信息注入预训练语言模型。通过序列GRU层从字符构造表示形式,对子词和字符采用双通道结构。提出一种新的无监督字符表示学习的预训练任务NLM。**
Most pre-trained language models (PLMs) construct word representations at subword level with Byte-Pair Encoding (BPE) or its variations, by which OOV (out-of-vocab) words are almost avoidable. However, those methods split a word into subword units and make the representation incomplete and fragile. In this paper, we propose a character-aware pre-trained language model named CharBERT improving on the previous methods (such as BERT, RoBERTa) to tackle these problems. We first construct the contextual word embedding for each token from the sequential character representations, then fuse the representations of characters and the subword representations by a novel heterogeneous interaction module. We also propose a new pre-training task named NLM (Noisy LM) for unsupervised character representation learning. We evaluate our method on question answering, sequence labeling, and text classification tasks, both on the original datasets and adversarial misspelling test sets. The experimental results show that our method can significantly improve the performance and robustness of PLMs simultaneously. Pretrained models, evaluation sets, and code are available at > this https URL>
https://weibo.com/1402400261/Jt2Y6glGU
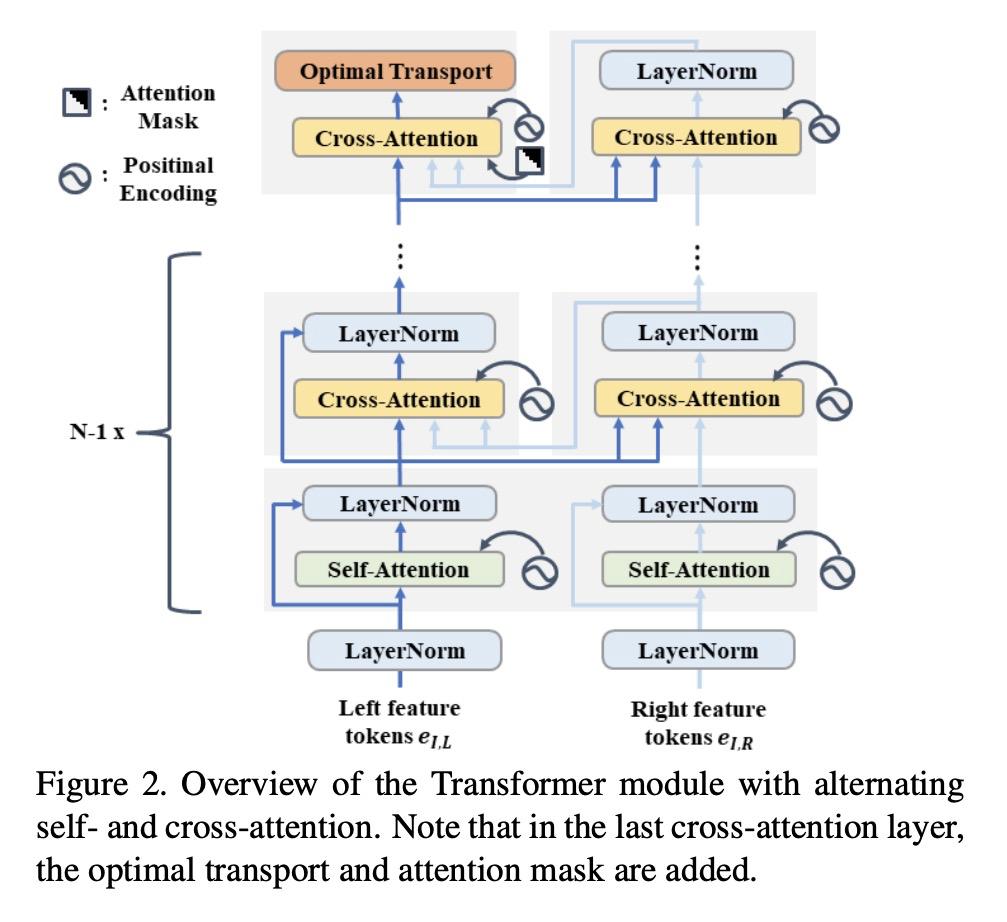
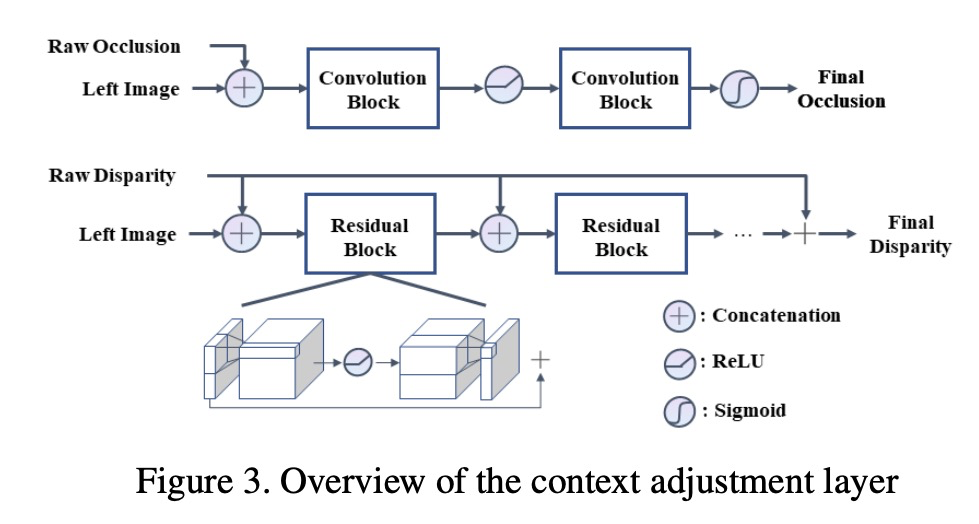
4、[CV] **Revisiting Stereo Depth Estimation From a Sequence-to-Sequence Perspective with Transformers
Z Li, X Liu, F X. Creighton, R H. Taylor, M Unberath
[Johns Hopkins University]
从Transformer序列到序列角度重新思考立体深度估计。提出一种名为STereo TRansformer的端到端网络架构,用基于位置信息和注意力的密集像素匹配,替代了高计算成本的体构造,兼具CNN和Transformer架构的优点,实现了:1)放宽固定视差范围的限制;2)识别遮挡区域,提供了估计的置信度;3)在匹配过程中施加了唯一性约束。**
Stereo depth estimation relies on optimal correspondence matching between pixels on epipolar lines in the left and right image to infer depth. Rather than matching individual pixels, in this work, we revisit the problem from a sequence-to-sequence correspondence perspective to replace cost volume construction with dense pixel matching using position information and attention. This approach, named STereo TRansformer (STTR), has several advantages: It 1) relaxes the limitation of a fixed disparity range, 2) identifies occluded regions and provides confidence of estimation, and 3) imposes uniqueness constraints during the matching process. We report promising results on both synthetic and real-world datasets and demonstrate that STTR generalizes well across different domains, even without fine-tuning. Our code is publicly available at > this https URL.
https://weibo.com/1402400261/Jt34PpWbw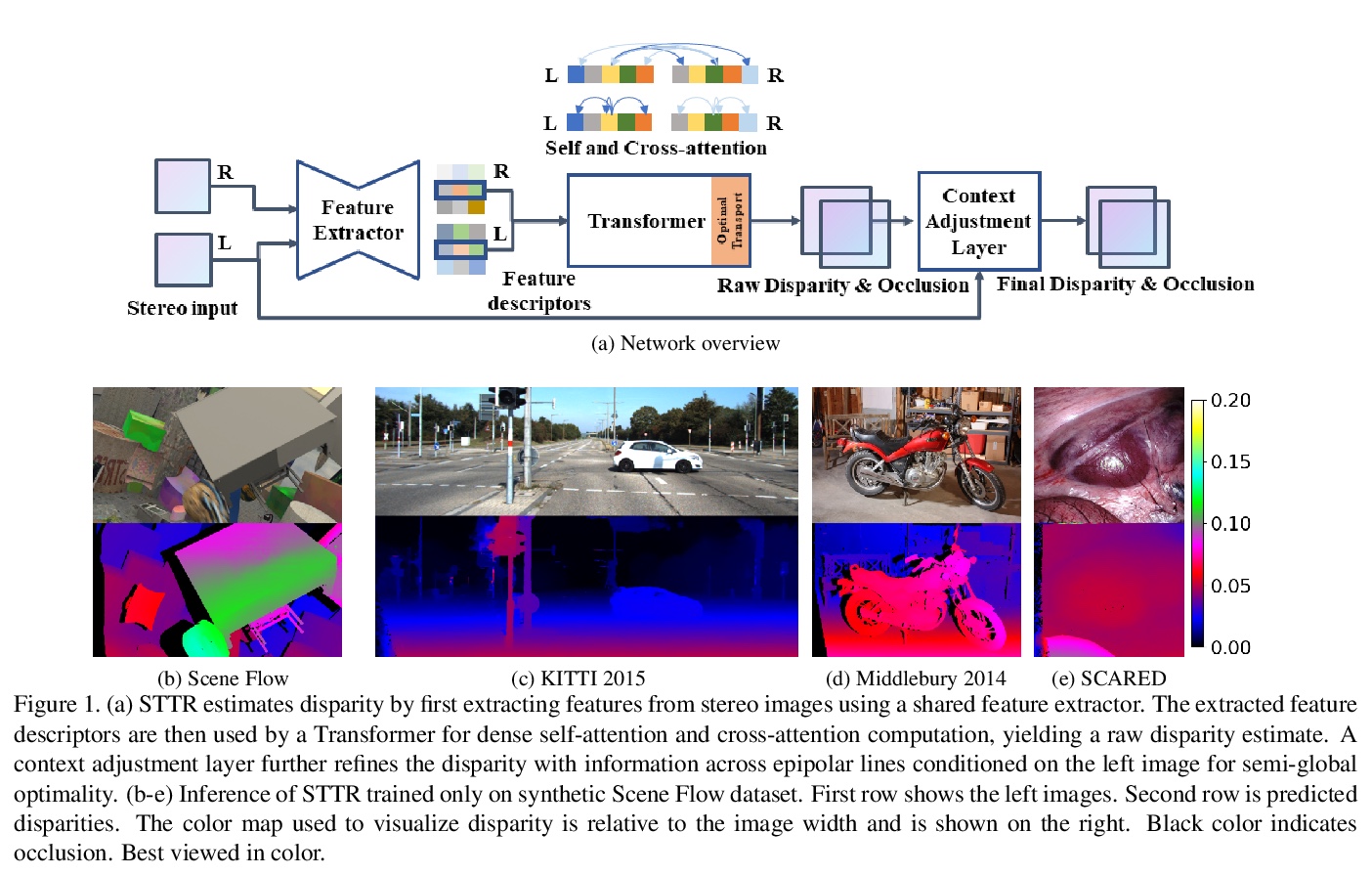
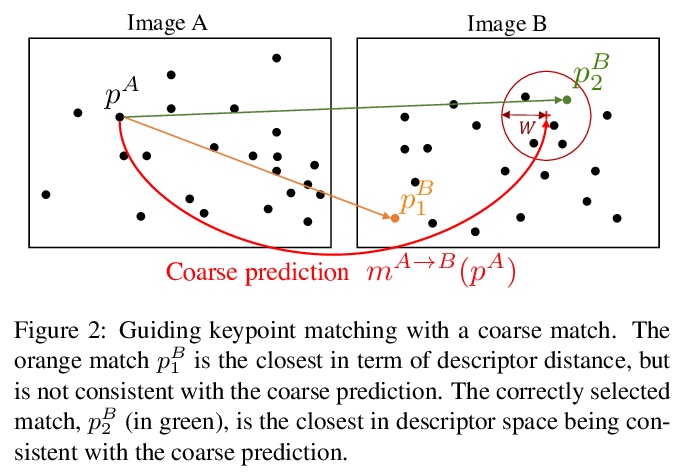
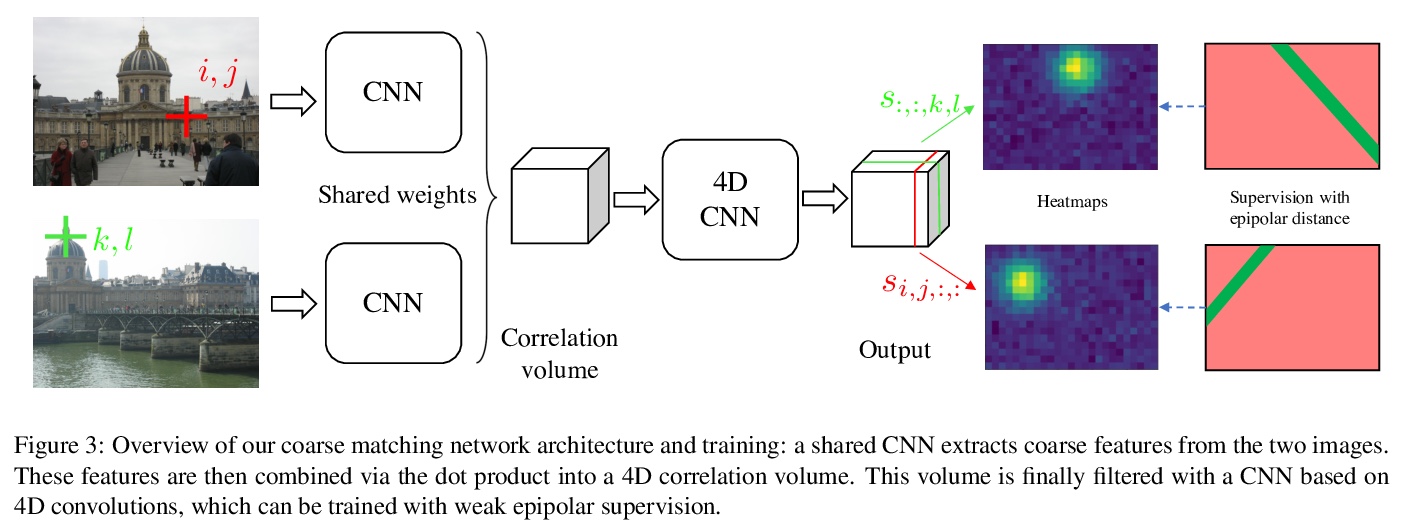
5、[CV] Learning to Guide Local Feature Matches
F Darmon, M Aubry, P Monasse
[Thales LAS France & Univ. Gustave Eiffel]
局部特征匹配引导学习。提出了一种新的局部特征匹配方法,用深度学习模型来预测图像之间的粗匹配,并用来指导经典特征匹配。该方法可将SIFT的结果提升到与最先进的深度描述子(如Superpoint、ContextDesc或D2-Net)相似水平,并可提高这些描述子的性能。
We tackle the problem of finding accurate and robust keypoint correspondences between images. We propose a learning-based approach to guide local feature matches via a learned approximate image matching. Our approach can boost the results of SIFT to a level similar to state-of-the-art deep descriptors, such as Superpoint, ContextDesc, or D2-Net and can improve performance for these descriptors. We introduce and study different levels of supervision to learn coarse correspondences. In particular, we show that weak supervision from epipolar geometry leads to performances higher than the stronger but more biased point level supervision and is a clear improvement over weak image level supervision. We demonstrate the benefits of our approach in a variety of conditions by evaluating our guided keypoint correspondences for localization of internet images on the YFCC100M dataset and indoor images on theSUN3D dataset, for robust localization on the Aachen day-night benchmark and for 3D reconstruction in challenging conditions using the LTLL historical image data.
https://weibo.com/1402400261/Jt39zu6i8
另外几篇值得关注的论文:
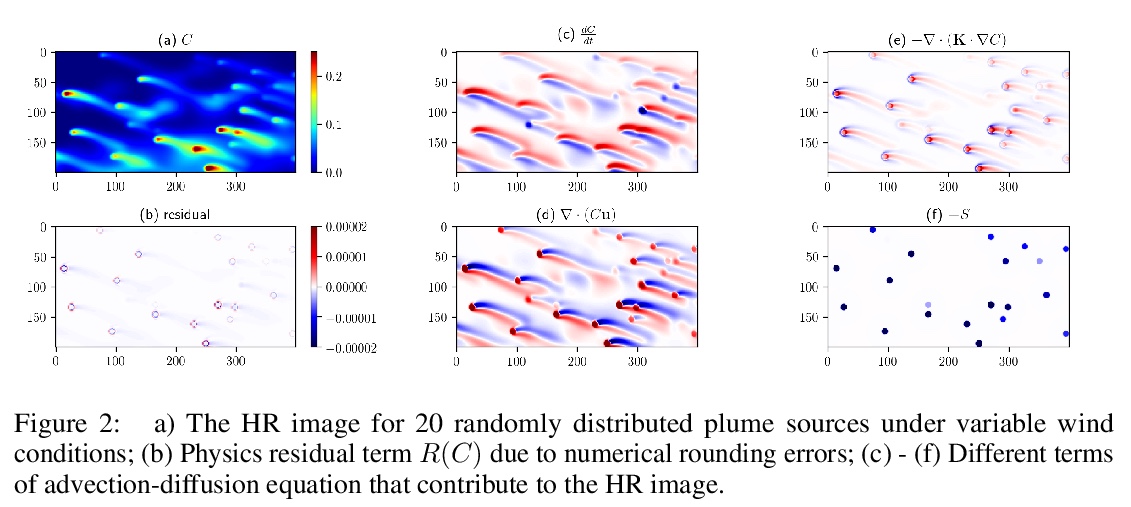
[CV] Physics-Informed Neural Network Super Resolution for Advection-Diffusion Models
平流扩散模型的物理信息神经网络超分辨率
C Wang, E Bentivegna, W Zhou, L Klein, B Elmegreen
[IBM Research]
https://weibo.com/1402400261/Jt31Wqhg0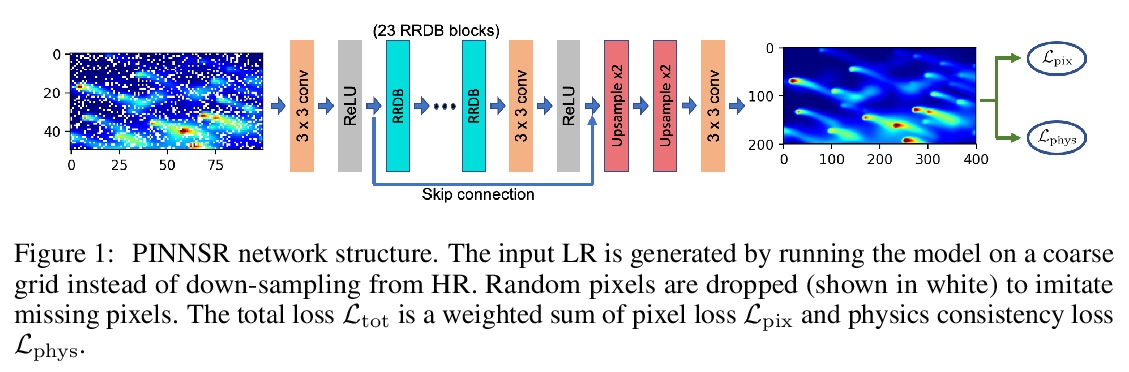
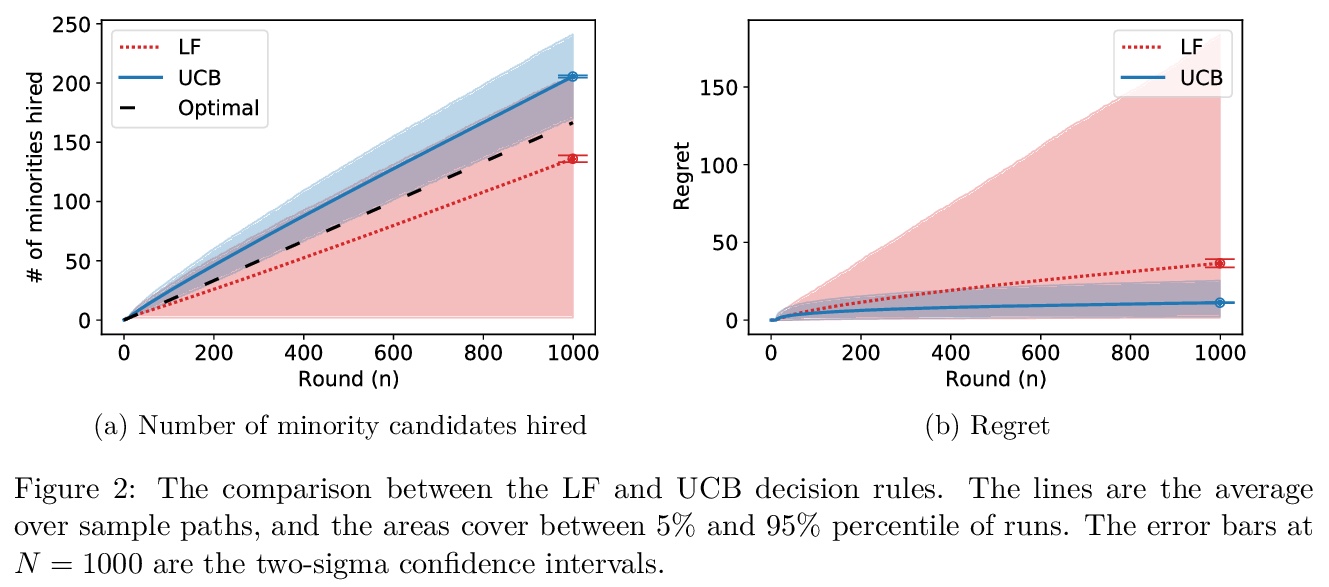
[LG] On Statistical Discrimination as a Failure of Social Learning: A Multi-Armed Bandit Approach
用多臂老虎机模型分析统计歧视
J Komiyama, S Noda
[New York University & University of British Columbia]
https://weibo.com/1402400261/Jt3fDhJdC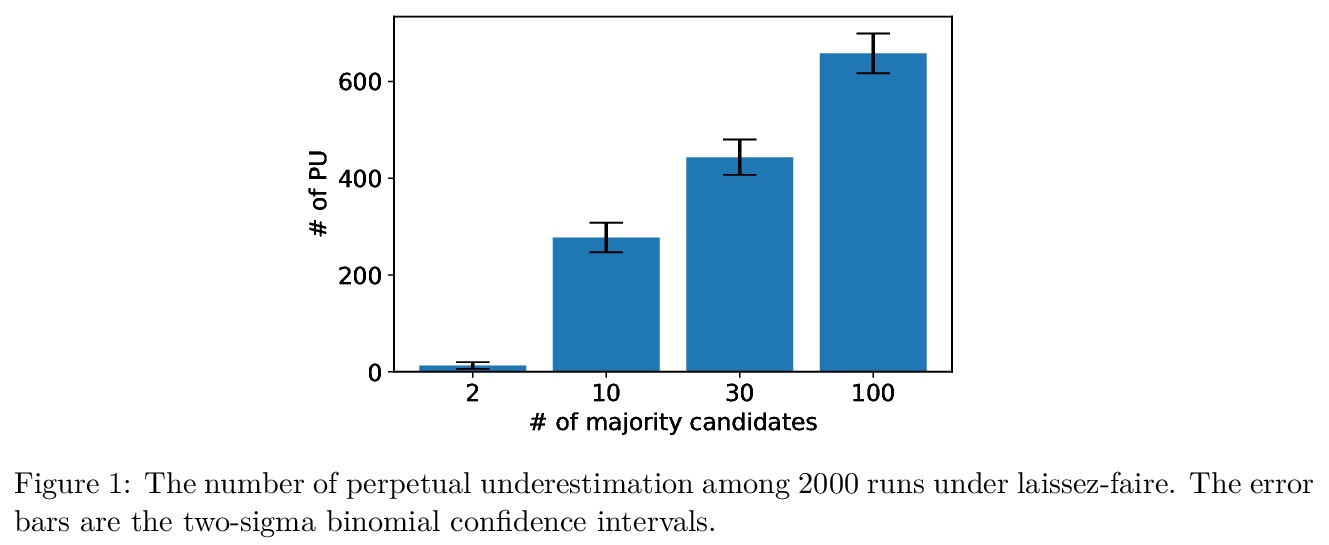
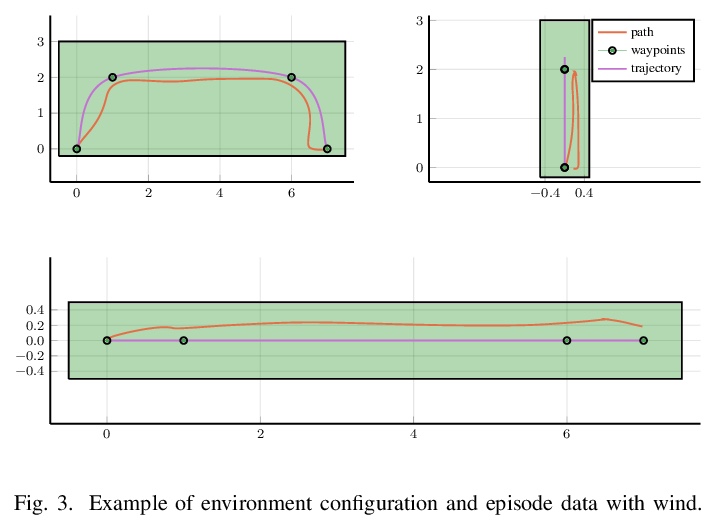
[LG] Runtime Safety Assurance Using Reinforcement Learning
强化学习运行时安全保证
C Lazarus, J G. Lopez, M J. Kochenderfer
[Stanford University & GE Research]
https://weibo.com/1402400261/Jt3hCgwPH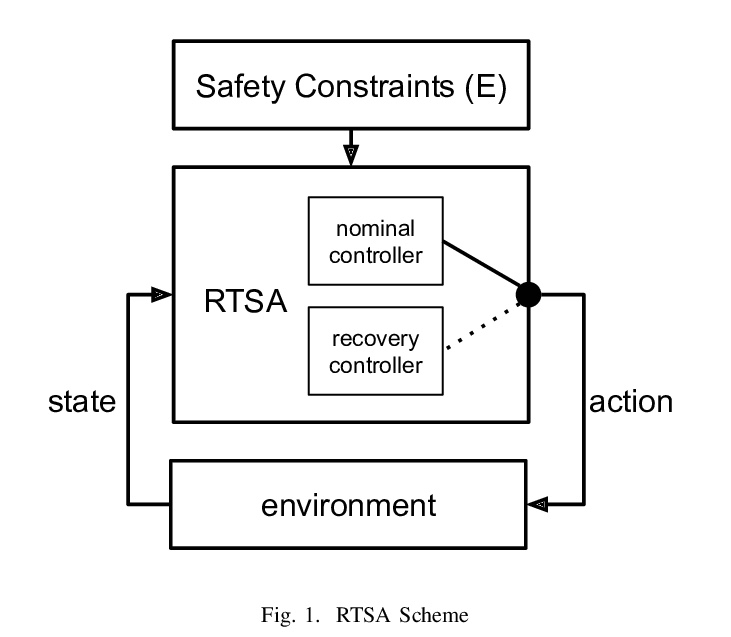

若有收获,就点个赞吧
0 人点赞
