- 1、[LG] A Survey on Neural Network Interpretability
- 2、[CV] Line Segment Detection Using Transformers without Edges
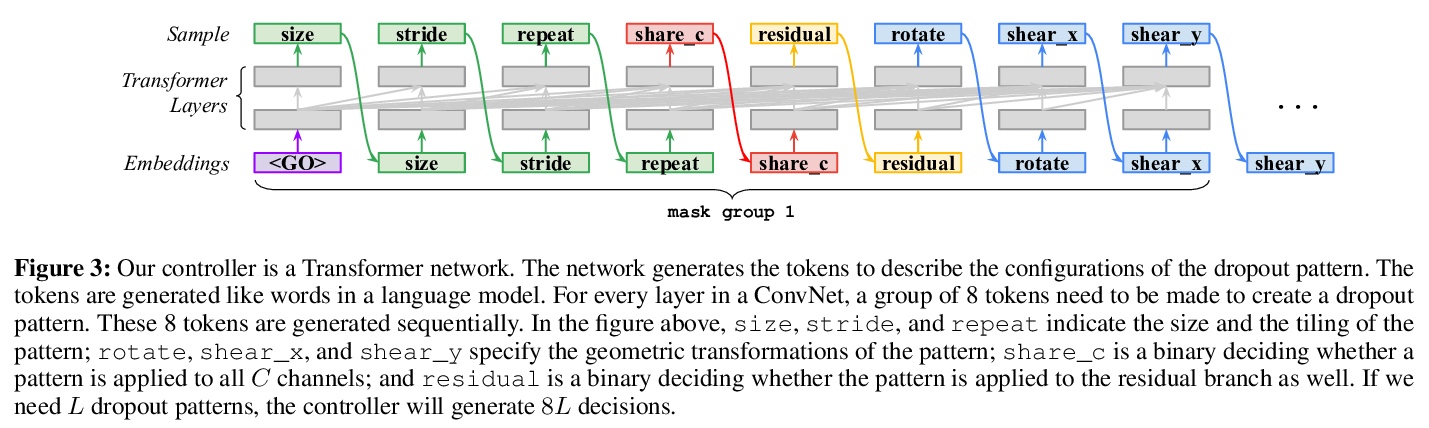
- 3、[LG] AutoDropout: Learning Dropout Patterns to Regularize Deep Networks
- 4、[CV] Self-supervised Visual-LiDAR Odometry with Flip Consistency
- 5、[CV] FcaNet: Frequency Channel Attention Networks
- [CV] Transformer Guided Geometry Model for Flow-Based Unsupervised Visual Odometry
- [CV] Generating Masks from Boxes by Mining Spatio-Temporal Consistencies in Videos
- [CV] Weakly-Supervised Multi-Face 3D Reconstruction
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] A Survey on Neural Network Interpretability
Y Zhang, P Tiňo, A Leonardis, K Tang
[Southern University of Science and Technology & University of Birmingham]
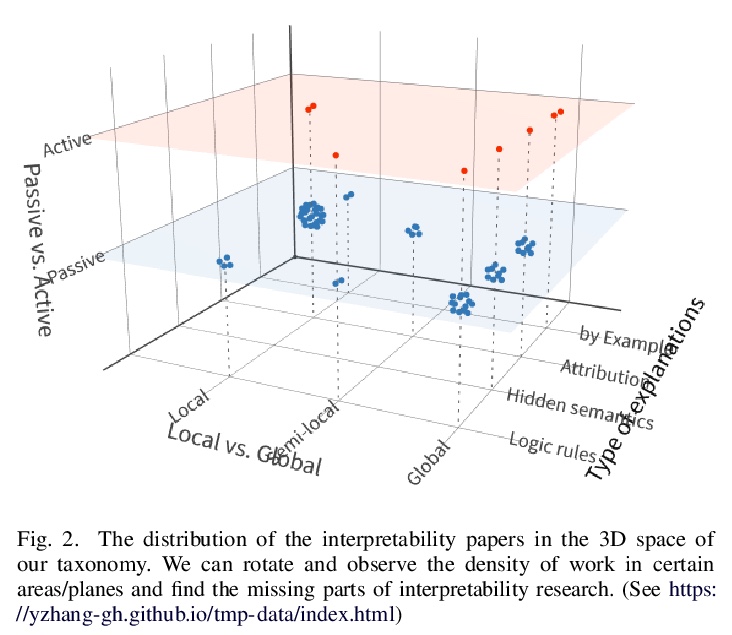
神经网络可解释性研究综述。对神经网络可解释性进行了全面回顾。讨论了可解释性定义,强调了解释形式和领域知识/表示的重要性,包括四种常见的解释类型:逻辑规则、隐含语义、归因和实例解释。总结了可解释性之所以重要的三个基本原因:高可靠性系统的要求、伦理/法律要求和科学的知识发现。主要从三个维度对现有网络解释方法进行了归类:被动与主动、解释类型、全局性与局性部解释。将现有方法在上述分类法所覆盖的3D空间中的分布进行了可视化。
Along with the great success of deep neural networks, there is also growing concern about their black-box nature. The interpretability issue affects people’s trust on deep learning systems. It is also related to many ethical problems, e.g., algorithmic discrimination. Moreover, interpretability is a desired property for deep networks to become powerful tools in other research fields, e.g., drug discovery and genomics. In this survey, we conduct a comprehensive review of the neural network interpretability research. We first clarify the definition of interpretability as it has been used in many different contexts. Then we elaborate on the importance of interpretability and propose a novel taxonomy organized along three dimensions: type of engagement (passive vs. active interpretation approaches), the type of explanation, and the focus (from local to global interpretability). This taxonomy provides a meaningful 3D view of distribution of papers from the relevant literature as two of the dimensions are not simply categorical but allow ordinal subcategories. Finally, we summarize the existing interpretability evaluation methods and suggest possible research directions inspired by our new taxonomy.
https://weibo.com/1402400261/JCagzzNPR


2、[CV] Line Segment Detection Using Transformers without Edges
Y Xu, W Xu, D Cheung, Z Tu
[UC San Diego]
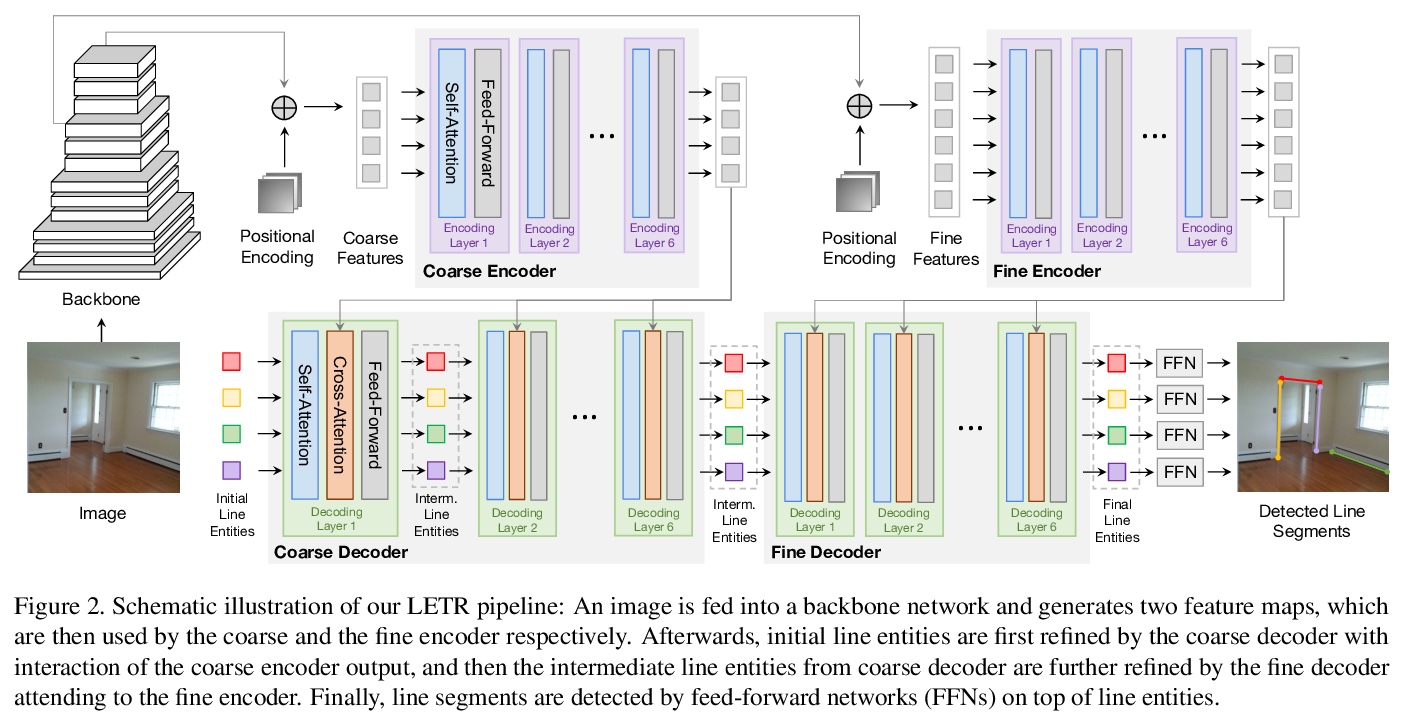
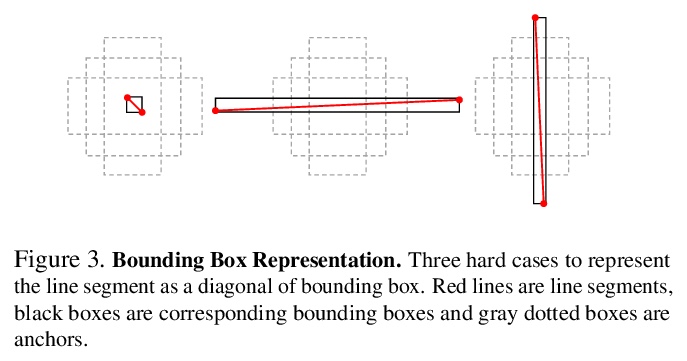
基于Transformer的无边缘线段检测。提出基于多尺度编码器/解码器transformer结构的线段检测器LETR。通过将线段检测问题以整体端到端方式构造,在没有明确边缘/结点/区域检测和启发式指导的感知分组过程中进行检测。采用直接的端点距离损失,使得线体可超越基于边框的表示方式,直接表示和学习线段。
In this paper, we present a holistically end-to-end algorithm for line segment detection with transformers that is post-processing and heuristics-guided intermediate processing (edge/junction/region detection) free. Our method, named LinE segment TRansformers (LETR), tackles the three main problems in this domain, namely edge element detection, perceptual grouping, and holistic inference by three highlights in detection transformers (DETR) including tokenized queries with integrated encoding and decoding, self-attention, and joint queries respectively. The transformers learn to progressively refine line segments through layers of self-attention mechanism skipping the heuristic design in the previous line segmentation algorithms. We equip multi-scale encoder/decoder in the transformers to perform fine-grained line segment detection under a direct end-point distance loss that is particularly suitable for entities such as line segments that are not conveniently represented by bounding boxes. In the experiments, we show state-of-the-art results on Wireframe and YorkUrban benchmarks. LETR points to a promising direction for joint end-to-end detection of general entities beyond the standard object bounding box representation.
https://weibo.com/1402400261/JCanW87xH

3、[LG] AutoDropout: Learning Dropout Patterns to Regularize Deep Networks
H Pham, Q V. Le
[Google Research & CMU]
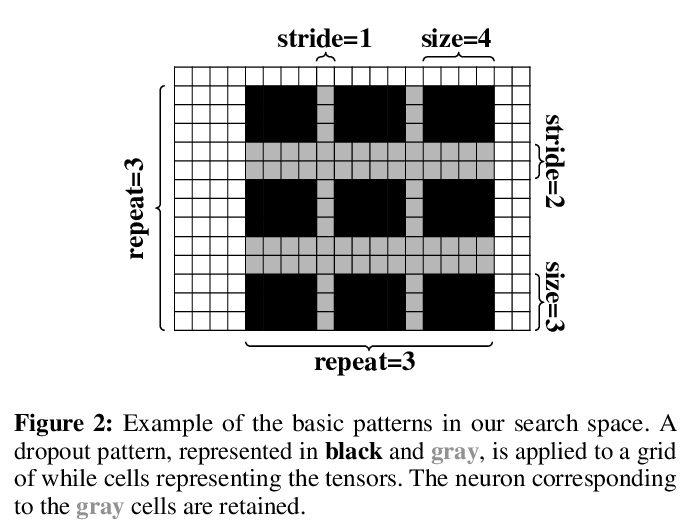
AutoDropout:面向深度网络正则化的Dropout模式学习。提出了一种自动dropout的算法,可以自动设计dropout模式来正则化神经网络。一个控制器学习在目标网络(如ConvNet或Transformer)的每个通道和层产生一个dropout模式,然后,目标网络将被训练成dropout模式,其产生的验证性能被用作控制器学习的信号。该算法成功发现了dropout模式,改善了用于图像分类的各种卷积网络的性能,以及用于语言建模和机器翻译的Transformer模型。
Neural networks are often over-parameterized and hence benefit from aggressive regularization. Conventional regularization methods, such as Dropout or weight decay, do not leverage the structures of the network’s inputs and hidden states. As a result, these conventional methods are less effective than methods that leverage the structures, such as SpatialDropout and DropBlock, which randomly drop the values at certain contiguous areas in the hidden states and setting them to zero. Although the locations of dropout areas random, the patterns of SpatialDropout and DropBlock are manually designed and fixed. Here we propose to learn the dropout patterns. In our method, a controller learns to generate a dropout pattern at every channel and layer of a target network, such as a ConvNet or a Transformer. The target network is then trained with the dropout pattern, and its resulting validation performance is used as a signal for the controller to learn from. We show that this method works well for both image recognition on CIFAR-10 and ImageNet, as well as language modeling on Penn Treebank and WikiText-2. The learned dropout patterns also transfers to different tasks and datasets, such as from language model on Penn Treebank to Engligh-French translation on WMT 2014. Our code will be available.
https://weibo.com/1402400261/JCatMoooU


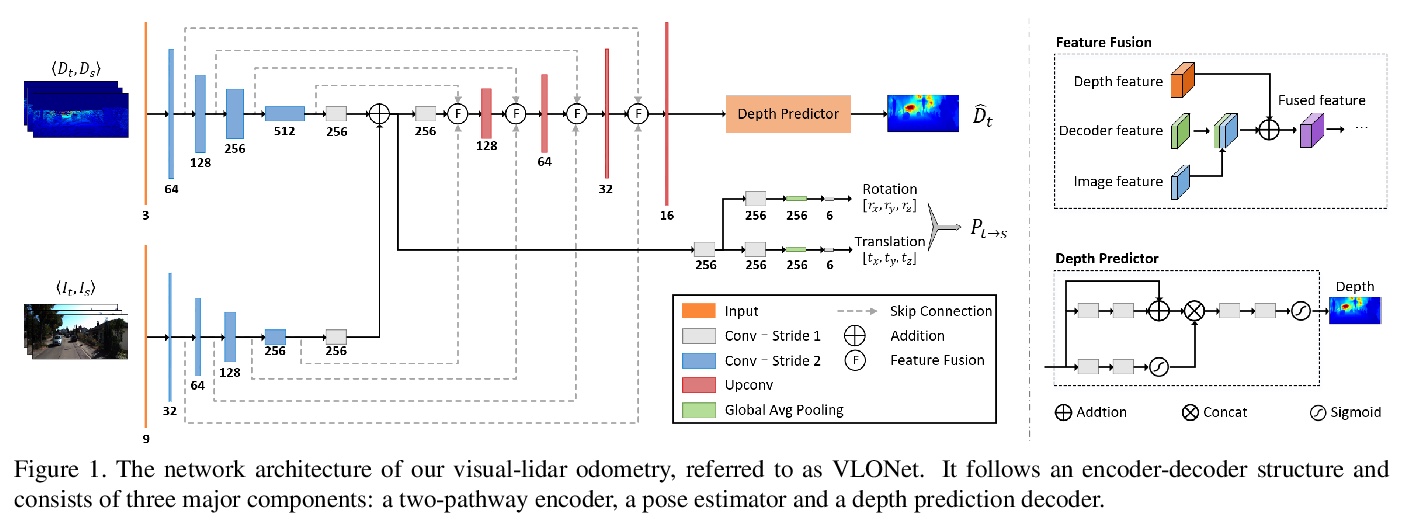
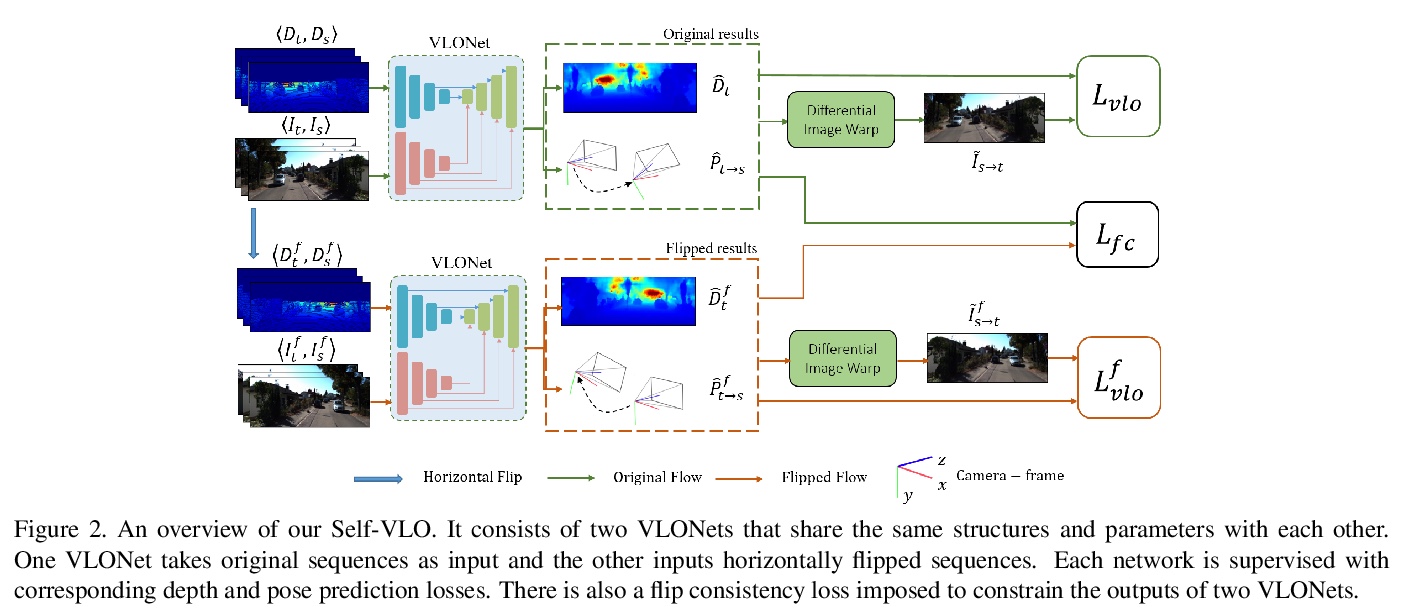
4、[CV] Self-supervised Visual-LiDAR Odometry with Flip Consistency
B Li, M Hu, S Wang, L Wang, X Gong
[Zhejiang University & Zhejiang Lab]
具有翻转一致性的自监督激光雷达视觉测距法。提出了一种自监督激光雷达视觉里程测量法,利用丰富的视觉信息和准确的深度信息,来提高自运动估计性能。采用siamese架构,设计了自适应加权的翻转一致性损失,来促进视觉里程测量在自监督下的学习,无需人工标注。在KITTI上的实验验证了所提出方法的有效性。
Most learning-based methods estimate ego-motion by utilizing visual sensors, which suffer from dramatic lighting variations and textureless scenarios. In this paper, we incorporate sparse but accurate depth measurements obtained from lidars to overcome the limitation of visual methods. To this end, we design a self-supervised visual-lidar odometry (Self-VLO) framework. It takes both monocular images and sparse depth maps projected from 3D lidar points as input, and produces pose and depth estimations in an end-to-end learning manner, without using any ground truth labels. To effectively fuse two modalities, we design a two-pathway encoder to extract features from visual and depth images and fuse the encoded features with those in decoders at multiple scales by our fusion module. We also adopt a siamese architecture and design an adaptively weighted flip consistency loss to facilitate the self-supervised learning of our VLO. Experiments on the KITTI odometry benchmark show that the proposed approach outperforms all self-supervised visual or lidar odometries. It also performs better than fully supervised VOs, demonstrating the power of fusion.
https://weibo.com/1402400261/JCaBfuWeI
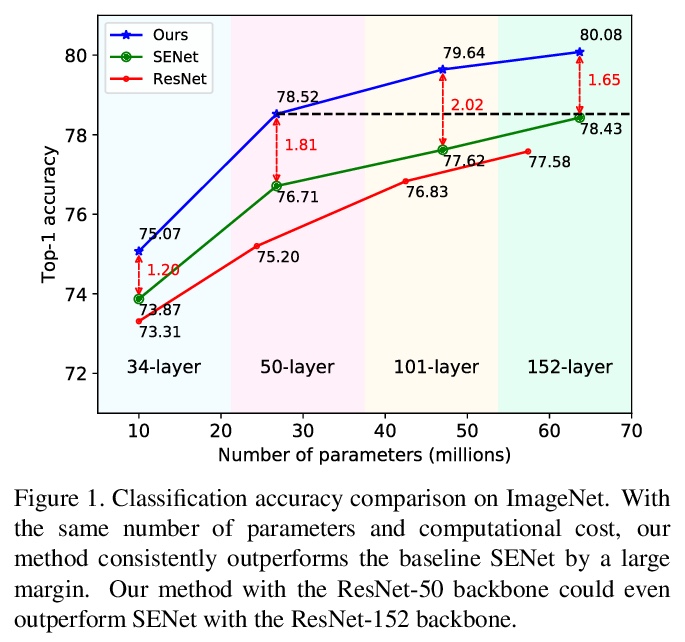
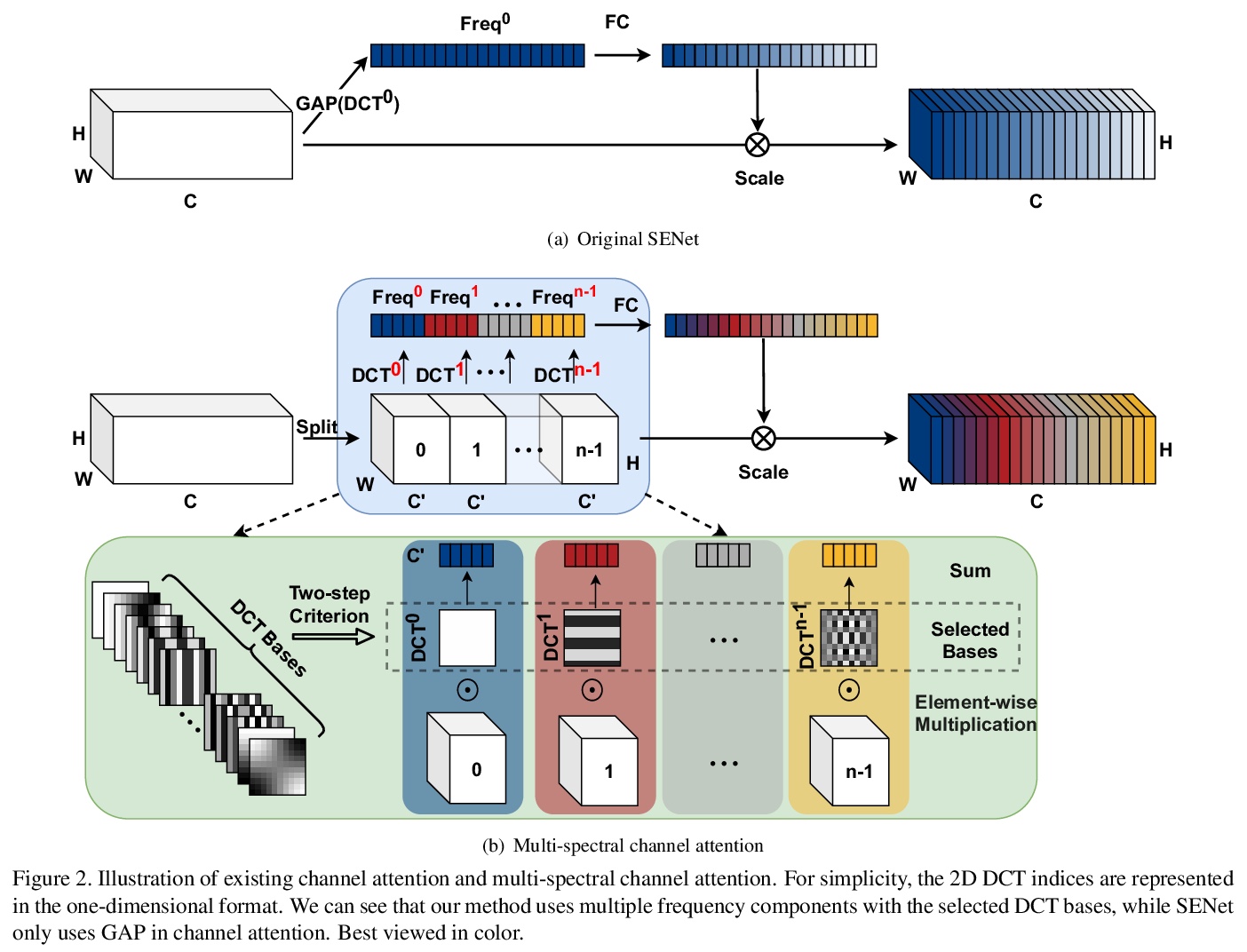
5、[CV] FcaNet: Frequency Channel Attention Networks
Z Qin, P Zhang, F Wu, X Li
[Zhejiang University]
FcaNet:频域注意力网络。用频率分析重新思考通道注意力,在频率分析基础上,从数学上证明了常规GAP是频域特征分解的特例,将信道注意力机制的预处理推广到频域,提出具有新型多谱信道注意的FcaNet。在多谱框架中探索了不同的频率分量组合,提出两步选择频率分量的准则。在相同参数数量和计算成本下,该方法明显优于SENet,与其他通道注意力方法相比,在图像分类、目标检测和实例分割方面也取得了最先进的性能。
Attention mechanism, especially channel attention, has gained great success in the computer vision field. Many works focus on how to design efficient channel attention mechanisms while ignoring a fundamental problem, i.e., using global average pooling (GAP) as the unquestionable pre-processing method. In this work, we start from a different view and rethink channel attention using frequency analysis. Based on the frequency analysis, we mathematically prove that the conventional GAP is a special case of the feature decomposition in the frequency domain. With the proof, we naturally generalize the pre-processing of channel attention mechanism in the frequency domain and propose FcaNet with novel multi-spectral channel attention. The proposed method is simple but effective. We can change only one line of code in the calculation to implement our method within existing channel attention methods. Moreover, the proposed method achieves state-of-the-art results compared with other channel attention methods on image classification, object detection, and instance segmentation tasks. Our method could improve by 1.8% in terms of Top-1 accuracy on ImageNet compared with the baseline SENet-50, with the same number of parameters and the same computational cost. Our code and models will be made publicly available.
https://weibo.com/1402400261/JCaFX4DCw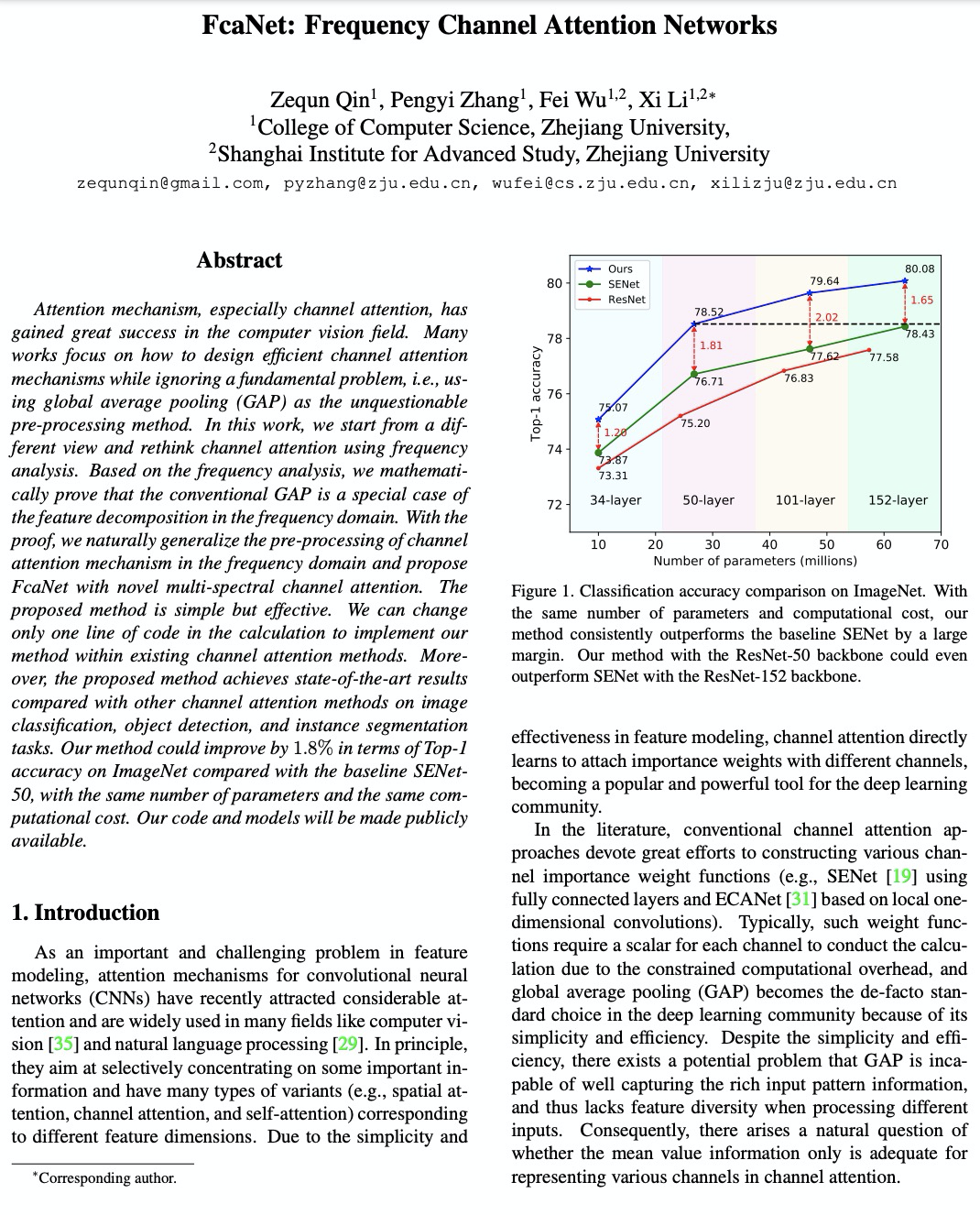
另外几篇值得关注的论文:
[CV] Transformer Guided Geometry Model for Flow-Based Unsupervised Visual Odometry
面向基于流无监督视觉里程计的Transformer引导几何模型
X Li, Y Hou, P Wang, Z Gao, M Xu, W Li
[Tianjing University & Alibaba Group & Zhengzhou University]
https://weibo.com/1402400261/JCaMgiqJh
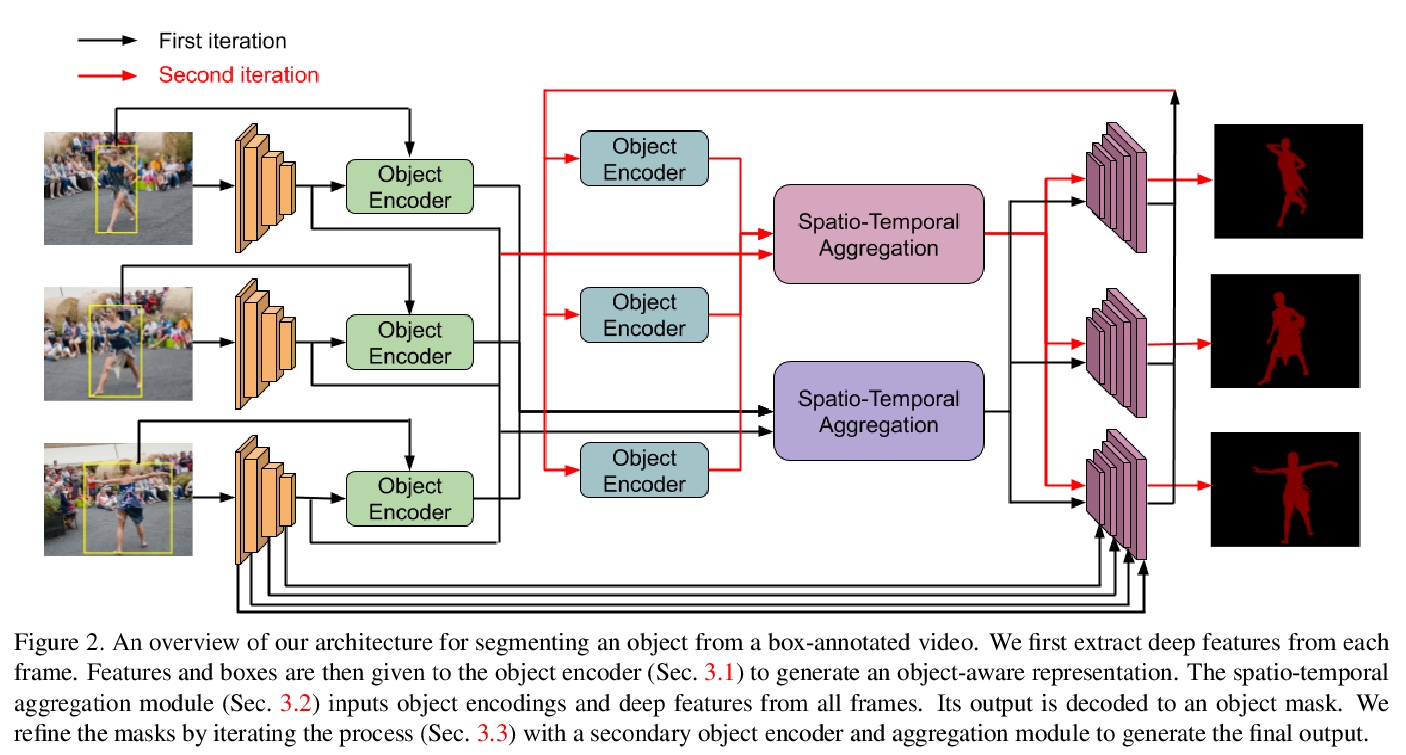
[CV] Generating Masks from Boxes by Mining Spatio-Temporal Consistencies in Videos
通过挖掘视频时-空一致性从包围框生成蒙板
B Zhao, G Bhat, M Danelljan, L V Gool, R Timofte
[ETH Zurich]
https://weibo.com/1402400261/JCaQ8zISx

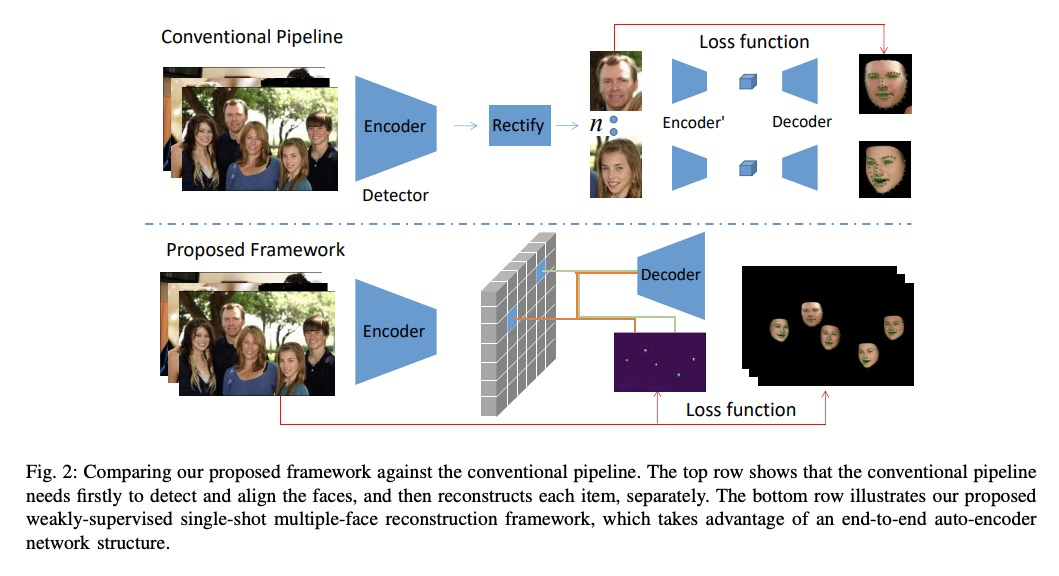
[CV] Weakly-Supervised Multi-Face 3D Reconstruction
弱监督多人脸3D重建
J Zhang, L Lin, J Zhu, S C.H. Hoi
[Zhejiang University]
https://weibo.com/1402400261/JCaTp2U8L


若有收获,就点个赞吧
0 人点赞
