LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
(*表示值得重点关注)
1、**[CL] Learning from others’ mistakes: Avoiding dataset biases without modeling them
V Sanh, T Wolf, Y Belinkov, A M. Rush
[Hugging Face & Technion]
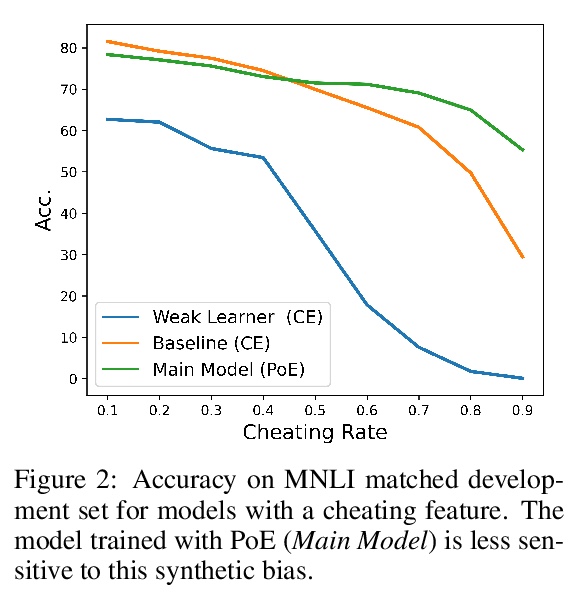
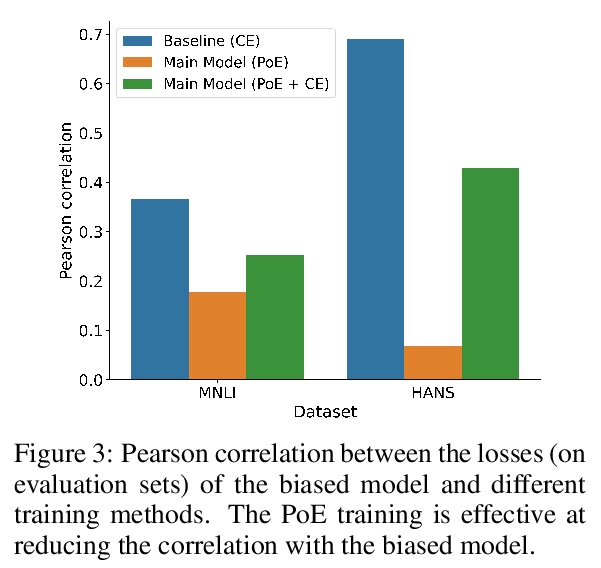
已知错误再发现:无需明确建模避免数据集偏差。提出一种对数据集偏差具有鲁棒性的模型训练的有效方法。利用有限能力的弱学习器和专家训练设置的改进,无需明确知道或建模数据集偏差,就可进行训练,更好地泛化到分布外样本。研究了如何用高能力学习器实现更高的分布外性能和与分布内性能的权衡。**
State-of-the-art natural language processing (NLP) models often learn to model dataset biases and surface form correlations instead of features that target the intended underlying task. Previous work has demonstrated effective methods to circumvent these issues when knowledge of the bias is available. We consider cases where the bias issues may not be explicitly identified, and show a method for training models that learn to ignore these problematic correlations. Our approach relies on the observation that models with limited capacity primarily learn to exploit biases in the dataset. We can leverage the errors of such limited capacity models to train a more robust model in a product of experts, thus bypassing the need to hand-craft a biased model. We show the effectiveness of this method to retain improvements in out-of-distribution settings even if no particular bias is targeted by the biased model.
https://weibo.com/1402400261/JwQk7zb8f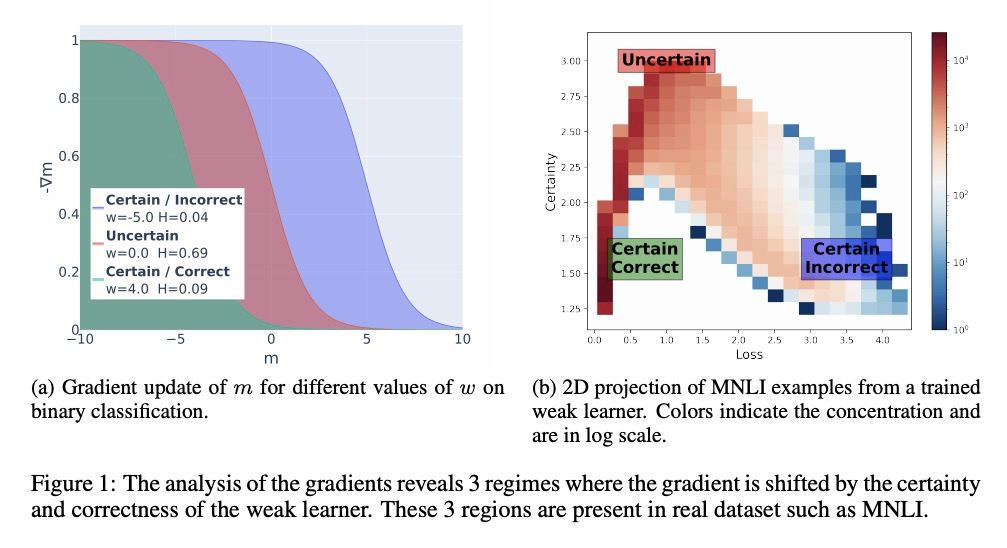
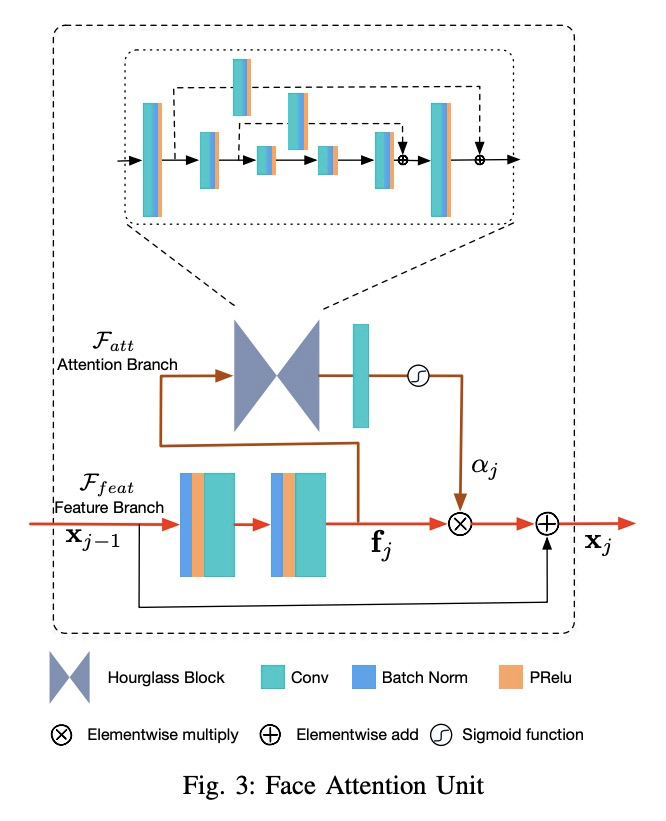
2、** **[CV] Learning Spatial Attention for Face Super-Resolution
C Chen, D Gong, H Wang, Z Li, K K. Wong
[The University of Hong Kong & Tencent AI Lab]
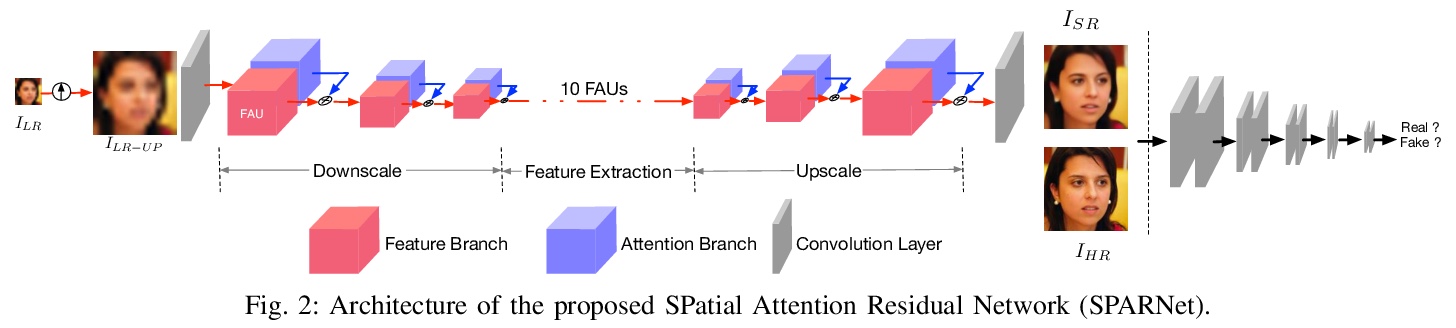
基于空间注意力学习的人脸超分辨率。提出一种用于极低分辨率人脸超分辨率的空间注意力残差网络(SPARNet),SPARNet由叠加的人脸注意单元(FAUs)组成,FAU通过空间注意力分支扩展了残差块。空间注意力机制使网络较少注意特征不丰富区域。也使得SPARNet的训练更加有效和高效。进一步将SPARNet扩展到具有更多通道数和多尺度鉴别器网络的SPARNetHD,在合成数据集上训练的SPARNetHD能为低分辨率人脸图像生成逼真的高分辨率输出(512×512)。与其他方法的定量和定性比较表明,所提出的空间注意力机制有利于恢复低分辨率人脸图像的纹理细节。
General image super-resolution techniques have difficulties in recovering detailed face structures when applying to low resolution face images. Recent deep learning based methods tailored for face images have achieved improved performance by jointly trained with additional task such as face parsing and landmark prediction. However, multi-task learning requires extra manually labeled data. Besides, most of the existing works can only generate relatively low resolution face images (e.g., > 128×128), and their applications are therefore limited. In this paper, we introduce a novel SPatial Attention Residual Network (SPARNet) built on our newly proposed Face Attention Units (FAUs) for face super-resolution. Specifically, we introduce a spatial attention mechanism to the vanilla residual blocks. This enables the convolutional layers to adaptively bootstrap features related to the key face structures and pay less attention to those less feature-rich regions. This makes the training more effective and efficient as the key face structures only account for a very small portion of the face image. Visualization of the attention maps shows that our spatial attention network can capture the key face structures well even for very low resolution faces (e.g., > 16×16). Quantitative comparisons on various kinds of metrics (including PSNR, SSIM, identity similarity, and landmark detection) demonstrate the superiority of our method over current state-of-the-arts. We further extend SPARNet with multi-scale discriminators, named as SPARNetHD, to produce high resolution results (i.e., > 512×512). We show that SPARNetHD trained with synthetic data cannot only produce high quality and high resolution outputs for synthetically degraded face images, but also show good generalization ability to real world low quality face images. Codes are available at > this https URL.
https://weibo.com/1402400261/JwQtGlN8X
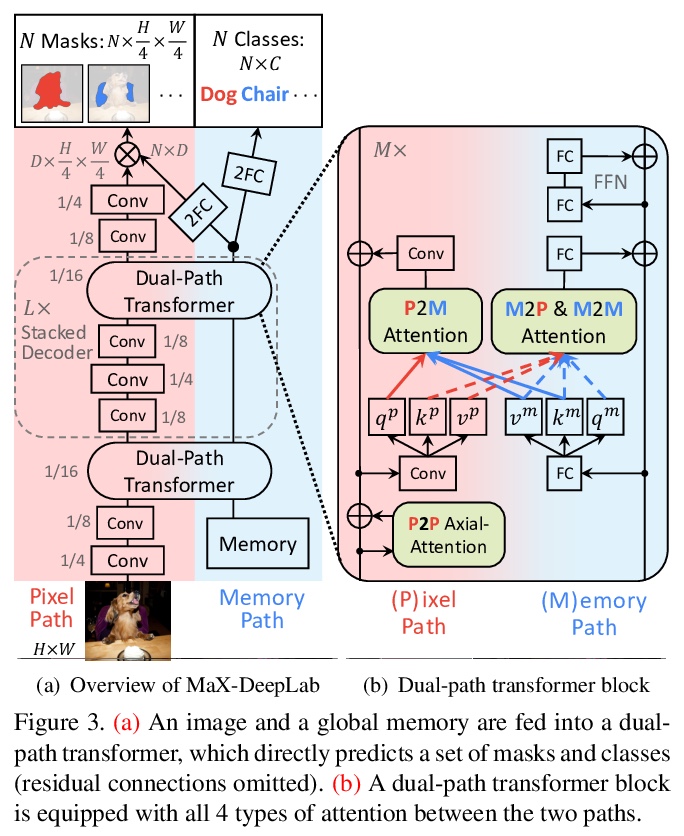
3、**[CV] MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers
H Wang, Y Zhu, H Adam, A Yuille, L Chen
[Johns Hopkins University & Google Research]
MaX-DeepLab:掩膜transformer端到端全景分割。通过掩膜transformer直接预测类标记掩模,通过二部图匹配用全景质量启发损失进行训练,避免了许多人工设计的先验需求,比如目标边框、物体合并等等。掩模transformer采用双路径架构,除CNN路径外,还引入了全局记忆路径,可与任意CNN层直接通信。**
We present MaX-DeepLab, the first end-to-end model for panoptic segmentation. Our approach simplifies the current pipeline that depends heavily on surrogate sub-tasks and hand-designed components, such as box detection, non-maximum suppression, thing-stuff merging, etc. Although these sub-tasks are tackled by area experts, they fail to comprehensively solve the target task. By contrast, our MaX-DeepLab directly predicts class-labeled masks with a mask transformer, and is trained with a panoptic quality inspired loss via bipartite matching. Our mask transformer employs a dual-path architecture that introduces a global memory path in addition to a CNN path, allowing direct communication with any CNN layers. As a result, MaX-DeepLab shows a significant 7.1% PQ gain in the box-free regime on the challenging COCO dataset, closing the gap between box-based and box-free methods for the first time. A small variant of MaX-DeepLab improves 3.0% PQ over DETR with similar parameters and M-Adds. Furthermore, MaX-DeepLab, without test time augmentation, achieves new state-of-the-art 51.3% PQ on COCO test-dev set.
https://weibo.com/1402400261/JwQxZax3C

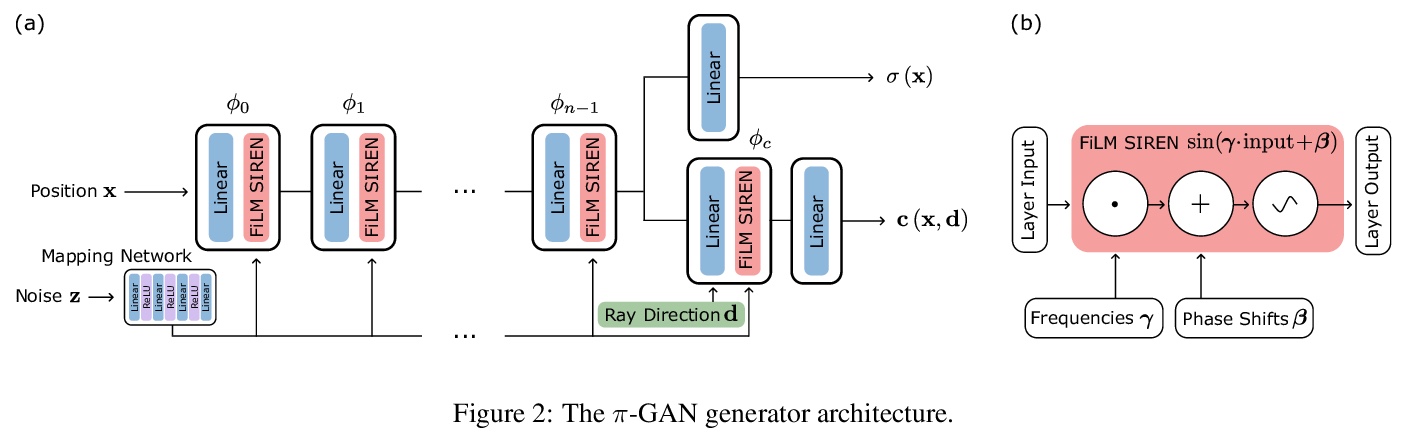
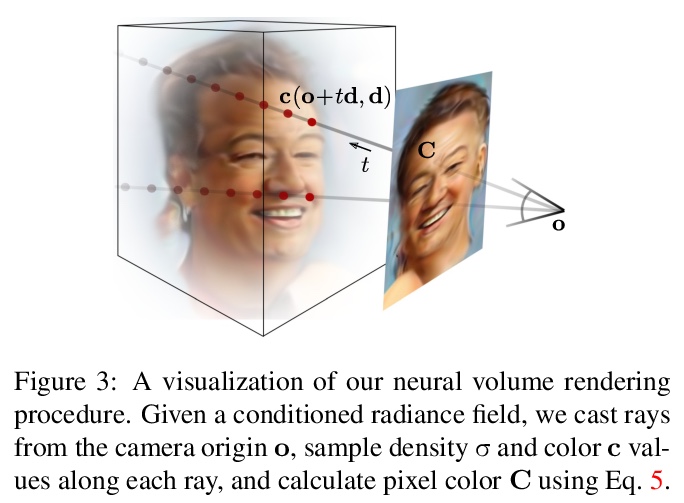
4、[CV] pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis
E R. Chan, M Monteiro, P Kellnhofer, J Wu, G Wetzstein
[Stanford University]
pi-GAN:面向3D感知图像合成的周期隐式生成对抗网络。提出周期隐式生成对抗网络(π-GAN or pi-GAN),用于高质量3D感知图像合成。π-GAN利用具有周期激活函数的神经表示和体渲染,将场景表示为具有精细细节的视图一致的3D表示。
We have witnessed rapid progress on 3D-aware image synthesis, leveraging recent advances in generative visual models and neural rendering. Existing approaches however fall short in two ways: first, they may lack an underlying 3D representation or rely on view-inconsistent rendering, hence synthesizing images that are not multi-view consistent; second, they often depend upon representation network architectures that are not expressive enough, and their results thus lack in image quality. We propose a novel generative model, named Periodic Implicit Generative Adversarial Networks (> π-GAN or pi-GAN), for high-quality 3D-aware image synthesis. > π-GAN leverages neural representations with periodic activation functions and volumetric rendering to represent scenes as view-consistent 3D representations with fine detail. The proposed approach obtains state-of-the-art results for 3D-aware image synthesis with multiple real and synthetic datasets.
https://weibo.com/1402400261/JwQGjCcGR
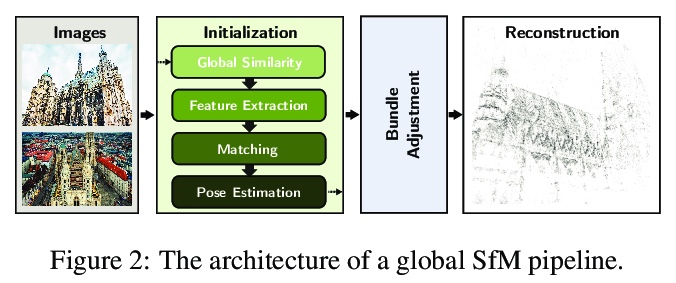
5、** **[CV] Efficient Initial Pose-graph Generation for Global SfM
D Barath, D Mishkin, I Eichhardt, I Shipachev, J Matas
[Czech Technical University in Prague & SZTAKI]
高效全局SfM初始姿态图生成。提出针对全局运动结构(SfM)算法的初始姿态图加速生成方法,基于图像对往往连续匹配的现象提出两种新方法,为了将速度提高一个数量级,提出根据先前估计的内值概率对对应进行排序,将特征匹配速度提高了17倍,姿态估计速度提高了5倍。
We propose ways to speed up the initial pose-graph generation for global Structure-from-Motion algorithms. To avoid forming tentative point correspondences by FLANN and geometric verification by RANSAC, which are the most time-consuming steps of the pose-graph creation, we propose two new methods - built on the fact that image pairs usually are matched consecutively. Thus, candidate relative poses can be recovered from paths in the partly-built pose-graph. We propose a heuristic for the A* traversal, considering global similarity of images and the quality of the pose-graph edges. Given a relative pose from a path, descriptor-based feature matching is made “light-weight” by exploiting the known epipolar geometry. To speed up PROSAC-based sampling when RANSAC is applied, we propose a third method to order the correspondences by their inlier probabilities from previous estimations. The algorithms are tested on 402130 image pairs from the 1DSfM dataset and they speed up the feature matching 17 times and pose estimation 5 times.
https://weibo.com/1402400261/JwQJvEinb

另外几篇值得关注的论文:
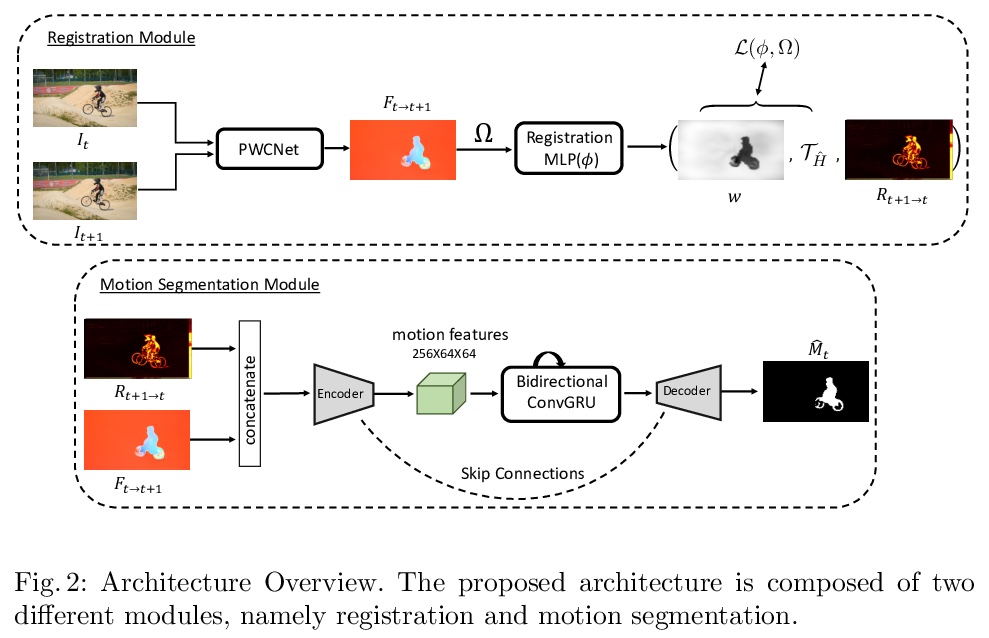
[CV] Betrayed by Motion: Camouflaged Object Discovery via Motion Segmentation
通过运动分割发现伪装目标
H Lamdouar, C Yang, W Xie, A Zisserman
[University of Oxford]
https://weibo.com/1402400261/JwQPpvJlu
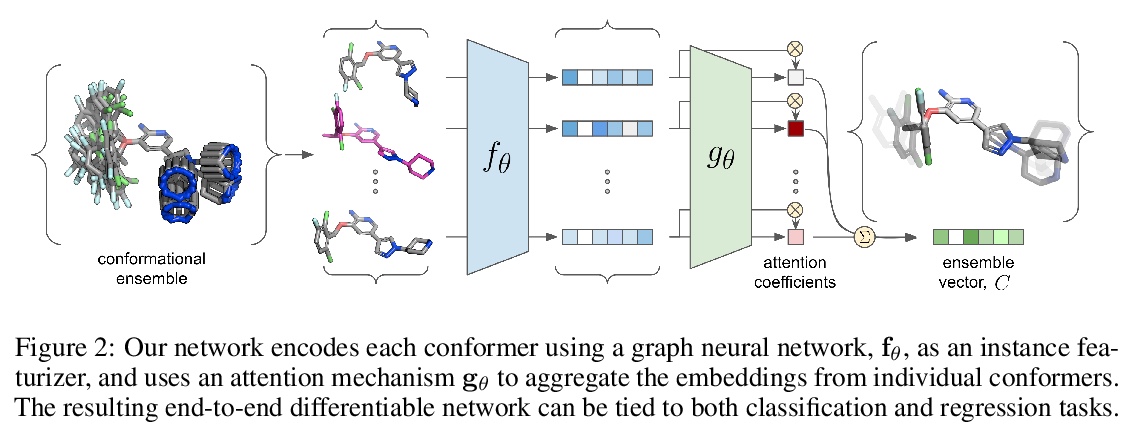
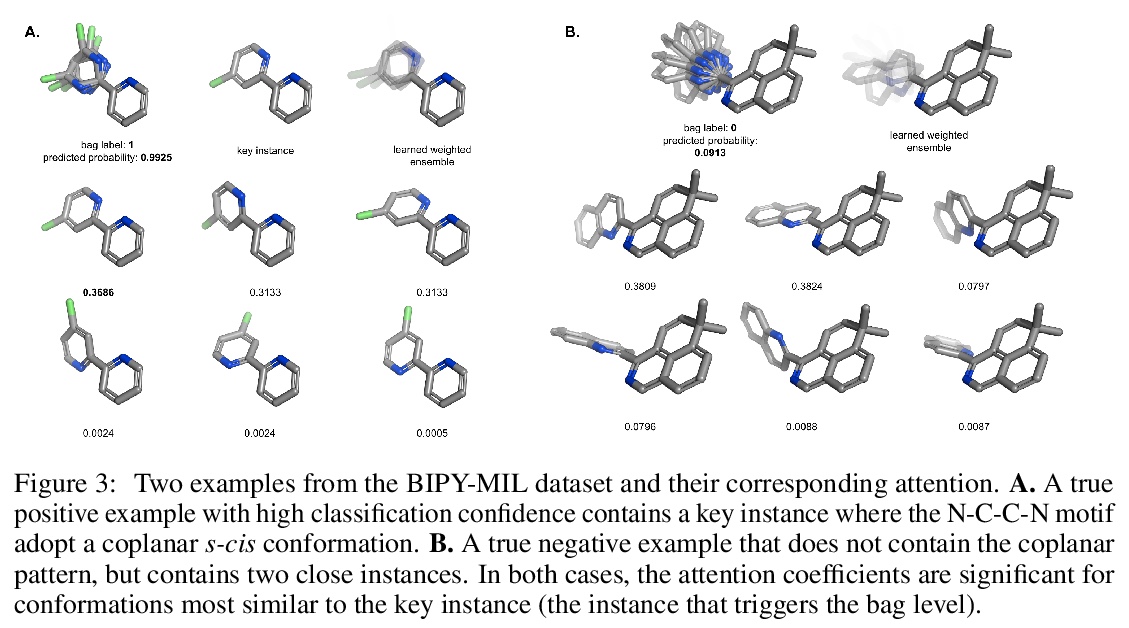
[LG] Attention-Based Learning on Molecular Ensembles
基于注意力的分子集成学习
K V. Chuang, M J. Keiser
[University of California, San Francisco]
https://weibo.com/1402400261/JwQRFzuua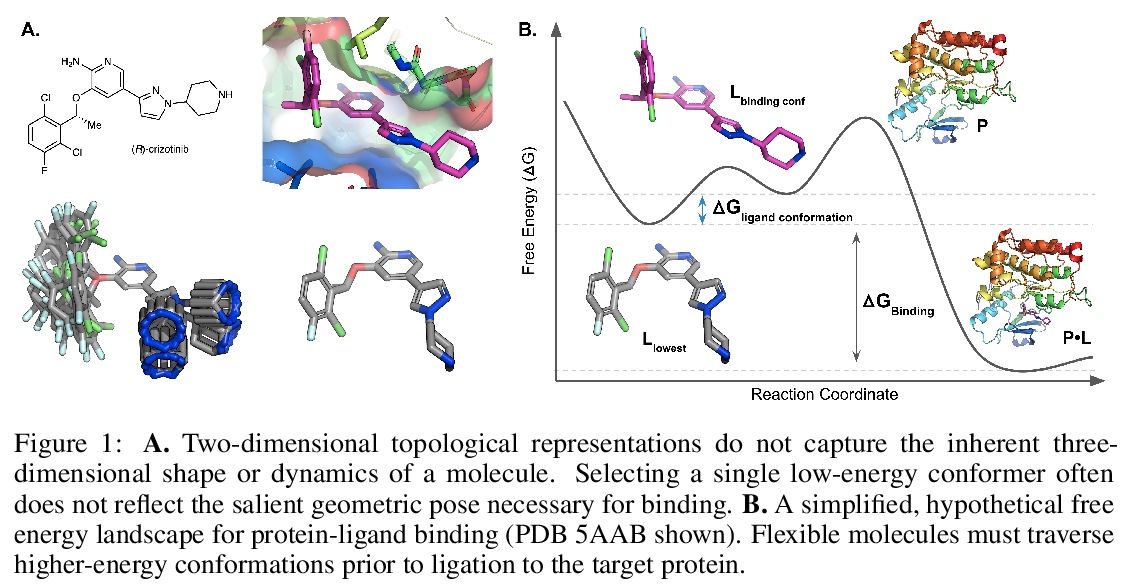
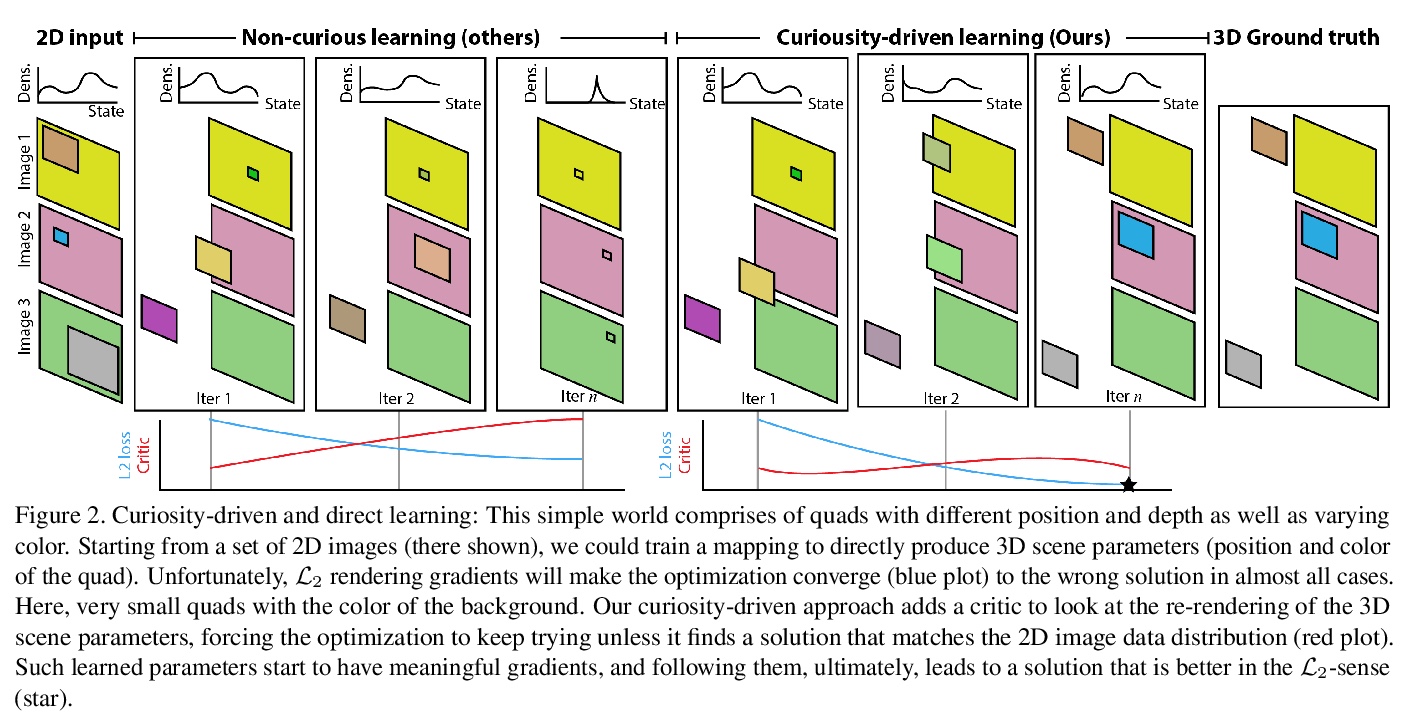
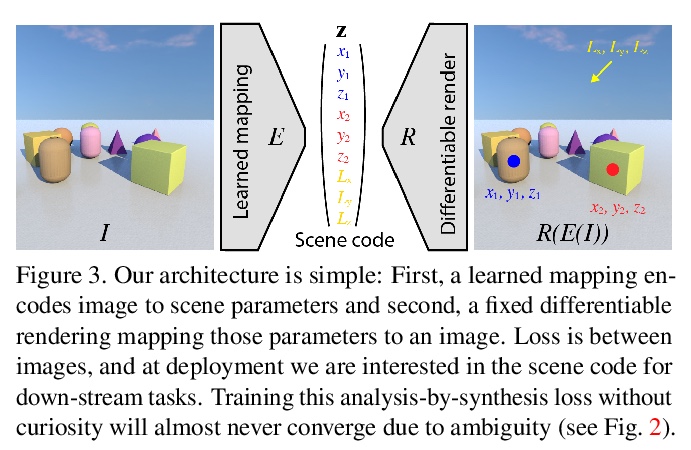
[CV] Curiosity-driven 3D Scene Structure from Single-image Self-supervision
好奇驱动的单图像自监督3D场景结构
D Griffiths, J Boehm, T Ritschel
[University College London]
https://weibo.com/1402400261/JwQUwxhSs
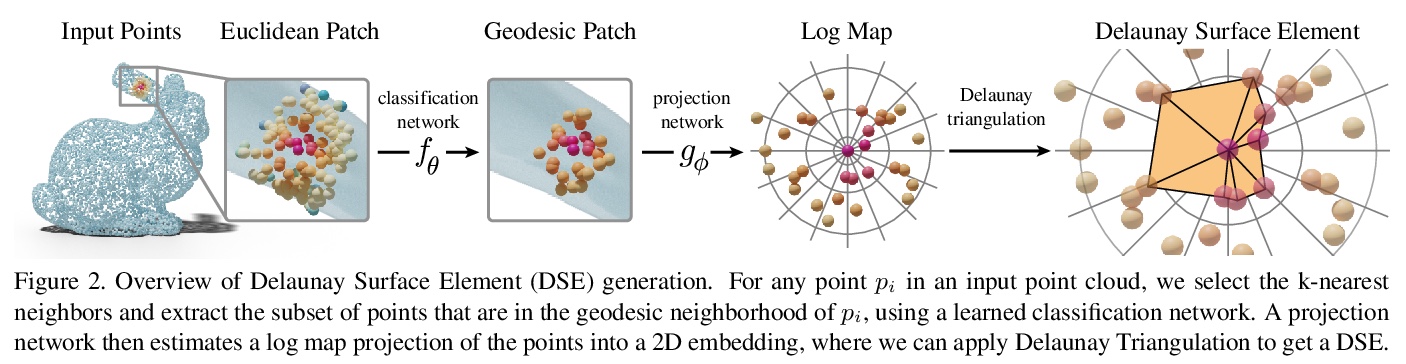
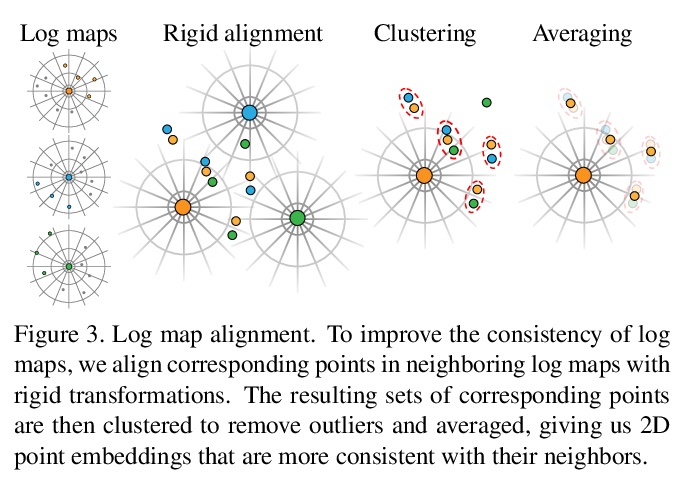
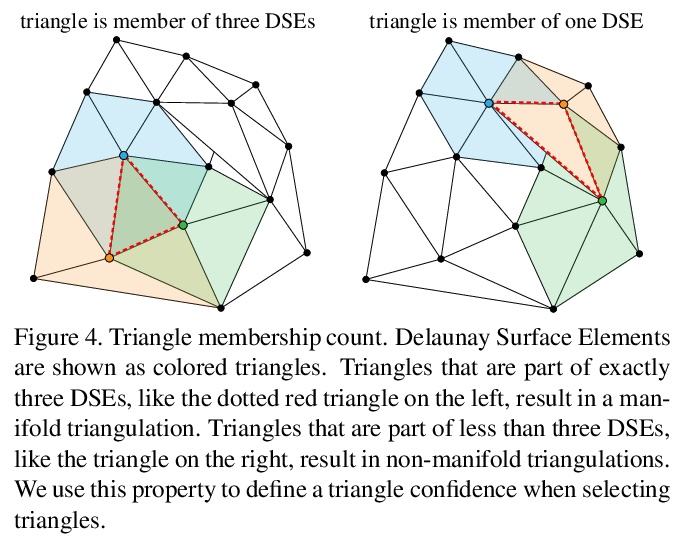
[CV] Learning Delaunay Surface Elements for Mesh Reconstruction
面向网格重建的Delaunay曲面元素学习
M Rakotosaona, P Guerrero, N Aigerman, N Mitra, M Ovsjanikov
[Ecole Polytechnique & Adobe Research]
https://weibo.com/1402400261/JwR1dDTxS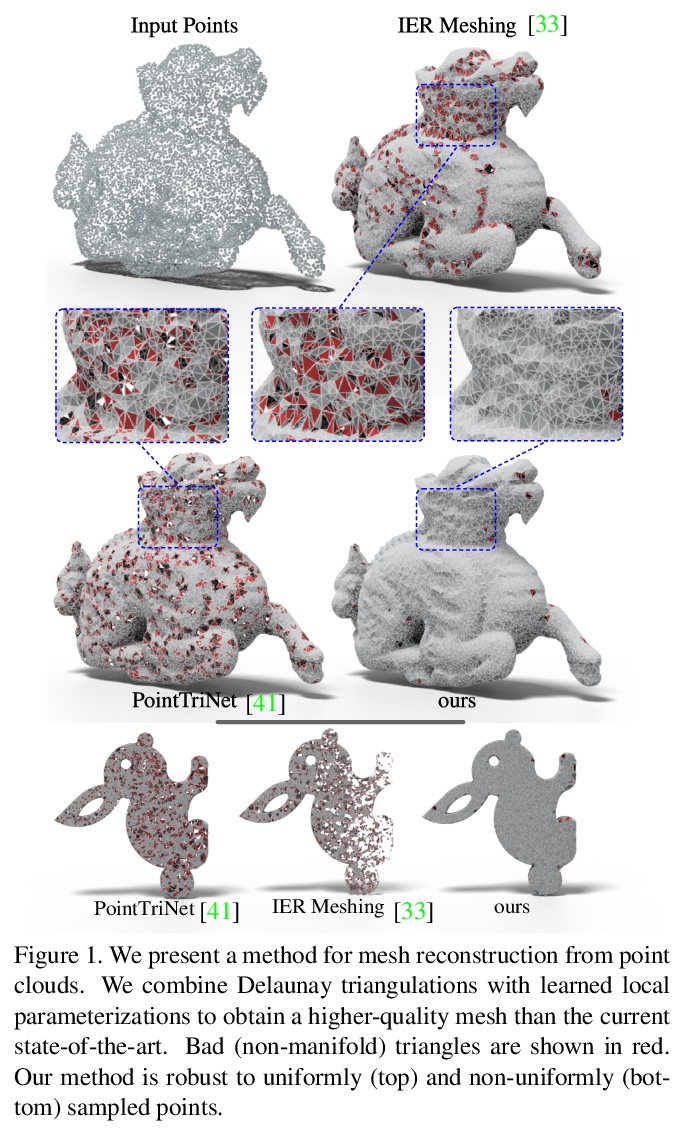

若有收获,就点个赞吧
0 人点赞
