- 1、[CV] HumanGAN: A Generative Model of Humans Images
- 2、[CV] Perspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision
- 3、[CV] VDSM: Unsupervised Video Disentanglement with State-Space Modeling and Deep Mixtures of Experts
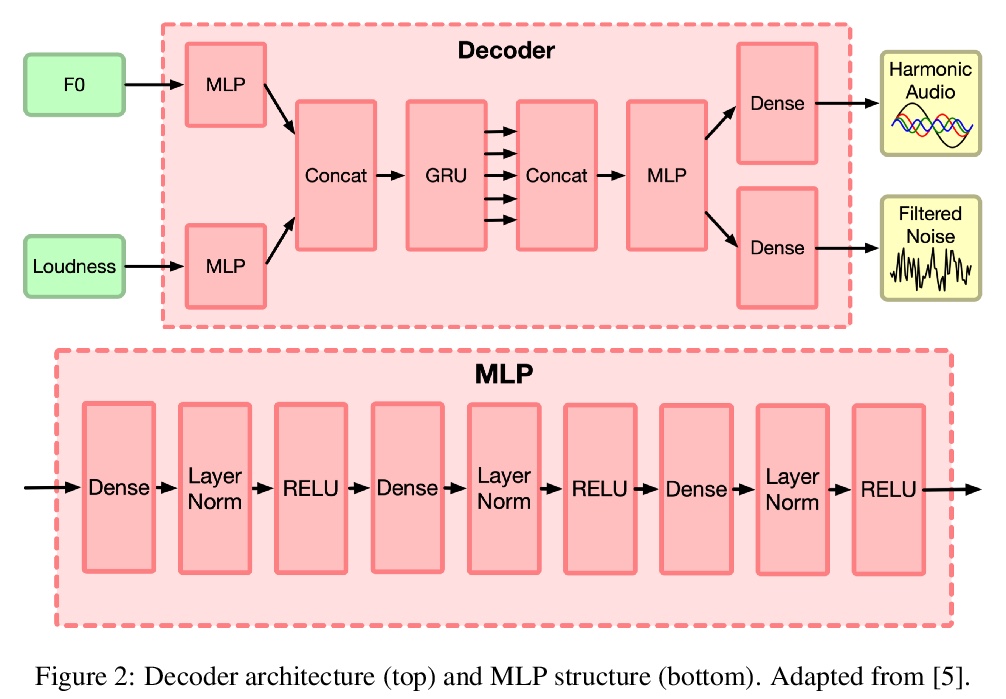
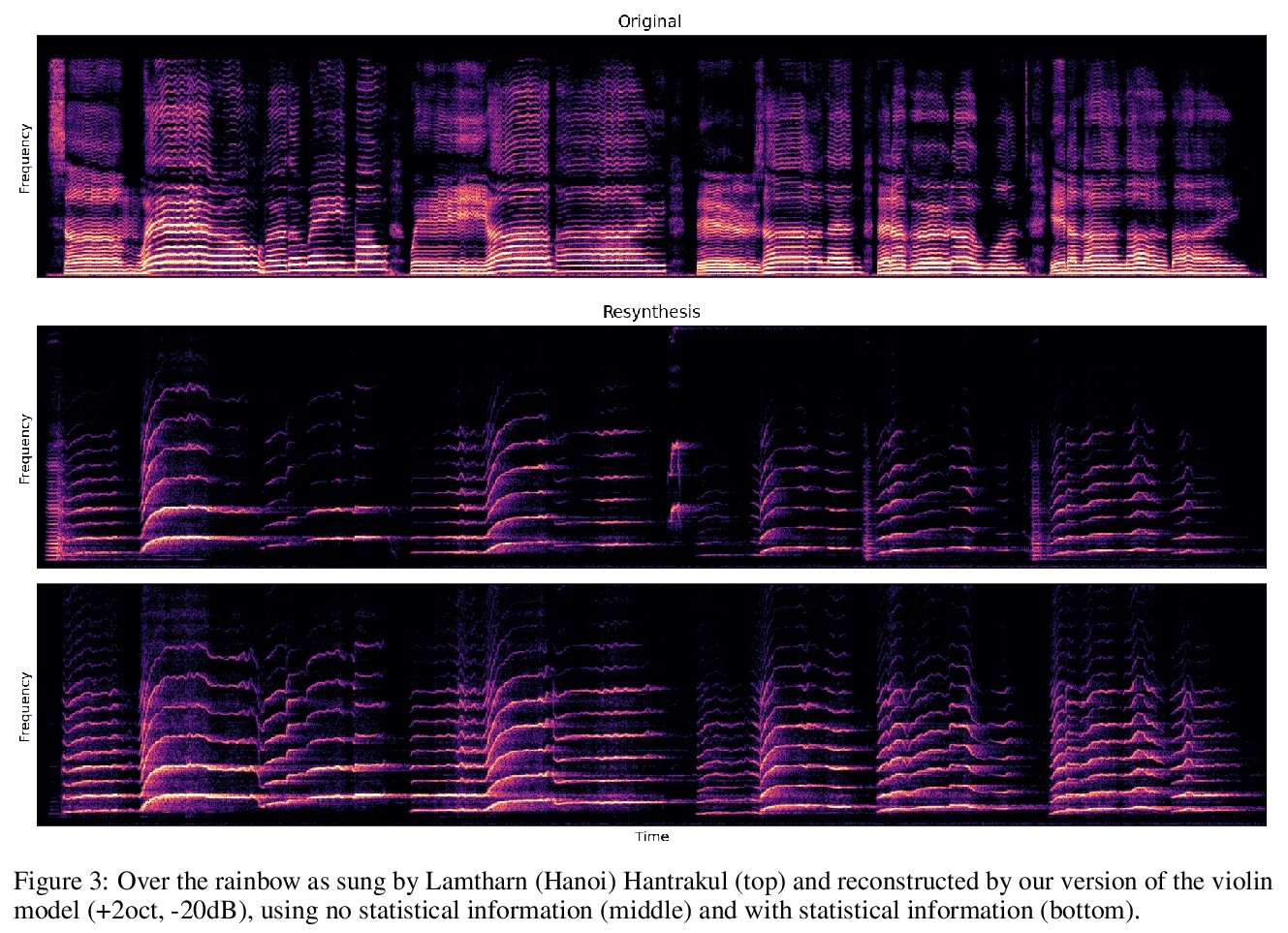
- 4、[AS] Latent Space Explorations of Singing Voice Synthesis using DDSP
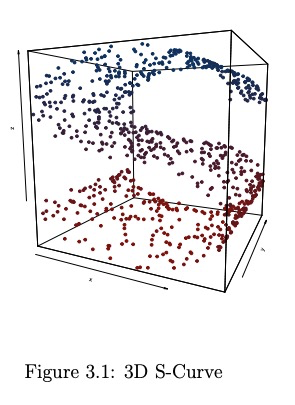
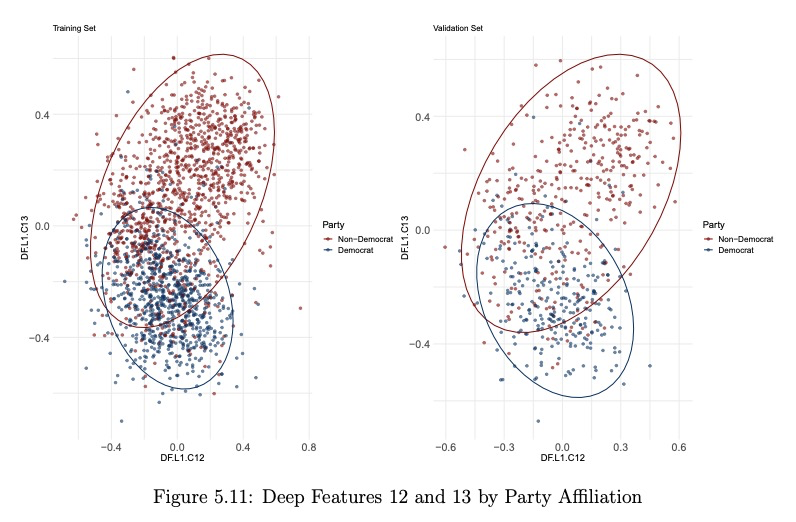
- 5、[LG] Modern Dimension Reduction
- [CL] MERMAID: Metaphor Generation with Symbolism and Discriminative Decoding
- [CV] Searching by Generating: Flexible and Efficient One-Shot NAS with Architecture Generator
- [CV] Neural Reprojection Error: Merging Feature Learning and Camera Pose Estimation
- [CL] Preregistering NLP Research
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] HumanGAN: A Generative Model of Humans Images
K Sarkar, L Liu, V Golyanik, C Theobalt
[Max Planck Institute for Informatics]
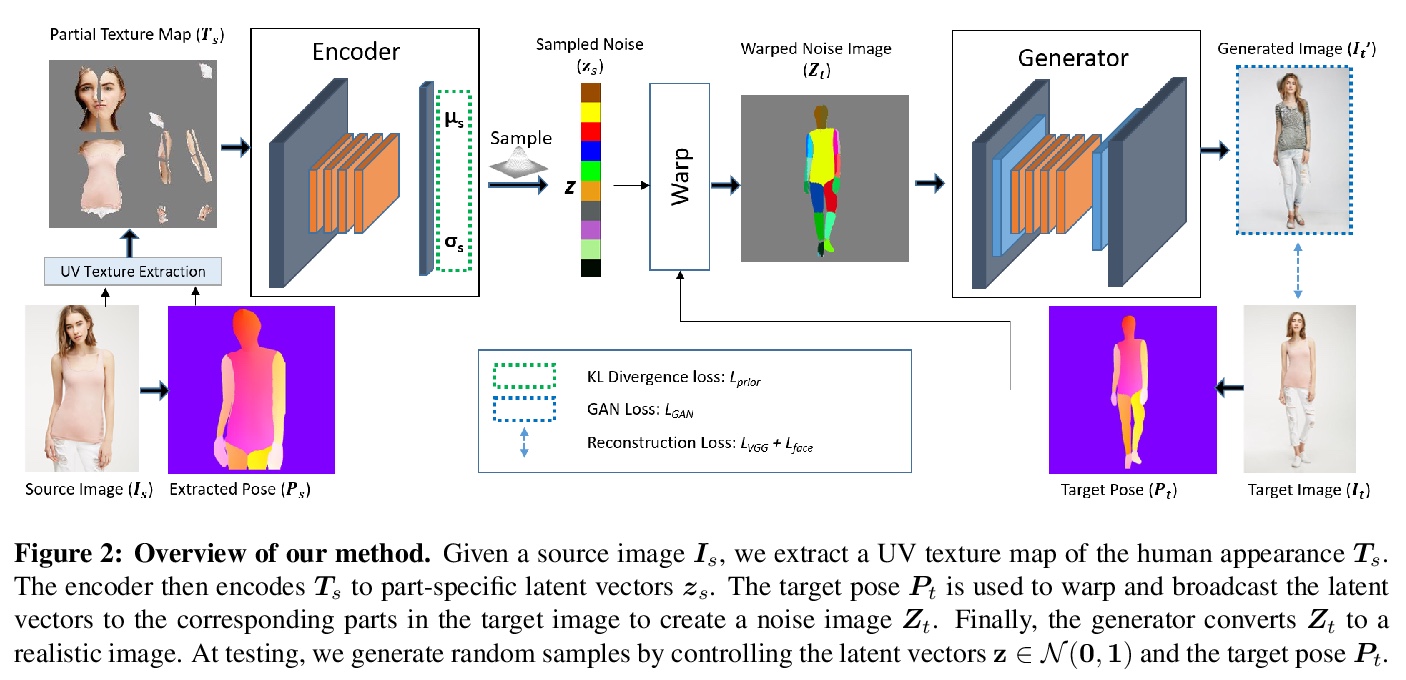
HumanGAN人类图像生成模型。提出一种针对着装人类全身图像的生成模型,可控制身体姿态,以及在身体部位层面独立控制和采样外观及着装风格。采用基于变分自编码器的框架来引发外观空间的随机性。为实现姿态和外观解缠,从与姿态无关的外观空间中编码部分特定潜向量的后置概率,并在执行重建之前,将编码后的向量变形到不同姿态。用姿态条件图像生成、姿态迁移,以及组件和服装迁移等实验,证明了该模型在真实性、多样性和输出分辨率方面,均超出最先进模型。
Generative adversarial networks achieve great performance in photorealistic image synthesis in various domains, including human images. However, they usually employ latent vectors that encode the sampled outputs globally. This does not allow convenient control of semantically-relevant individual parts of the image, and is not able to draw samples that only differ in partial aspects, such as clothing style. We address these limitations and present a generative model for images of dressed humans offering control over pose, local body part appearance and garment style. This is the first method to solve various aspects of human image generation such as global appearance sampling, pose transfer, parts and garment transfer, and parts sampling jointly in a unified framework. As our model encodes part-based latent appearance vectors in a normalized pose-independent space and warps them to different poses, it preserves body and clothing appearance under varying posture. Experiments show that our flexible and general generative method outperforms task-specific baselines for pose-conditioned image generation, pose transfer and part sampling in terms of realism and output resolution.
https://weibo.com/1402400261/K6owy7X8M


2、[CV] Perspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision
A Shin, M Ishii, T Narihira
[Sony Corporation]
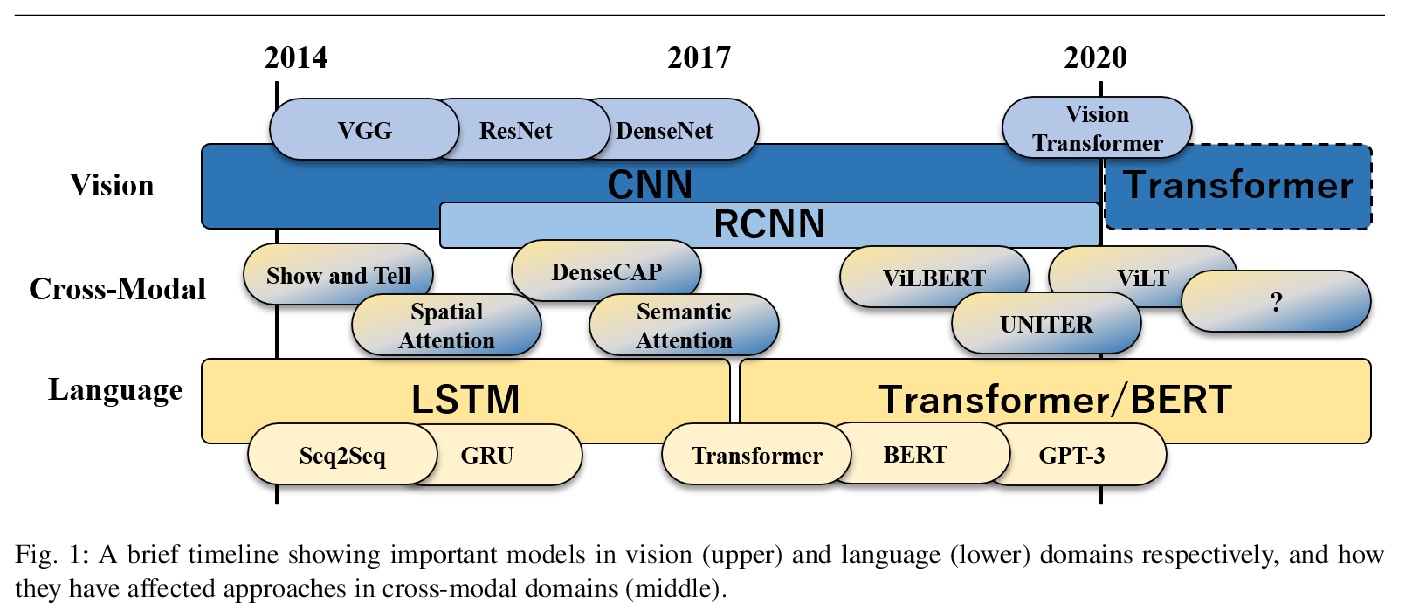
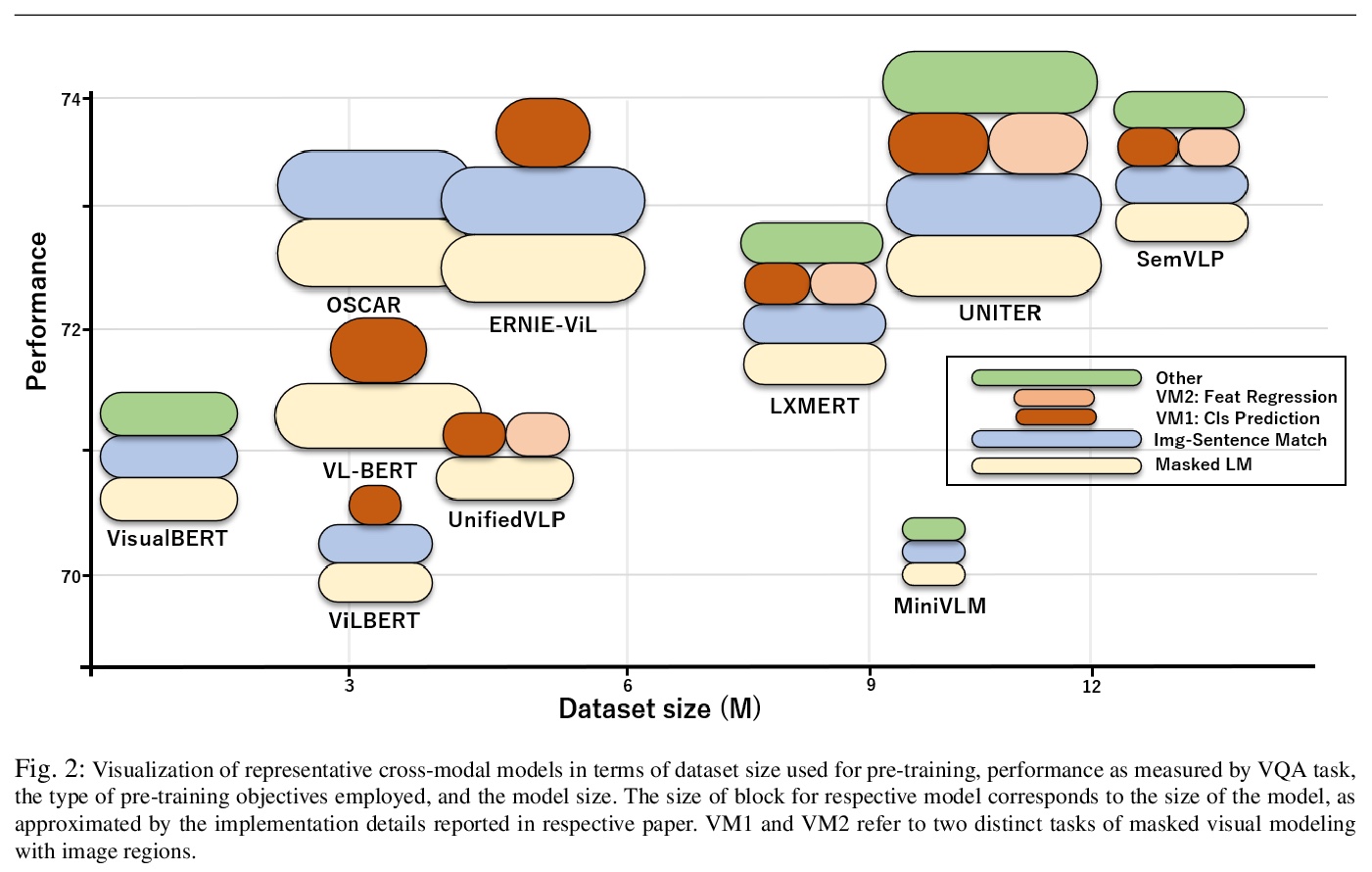
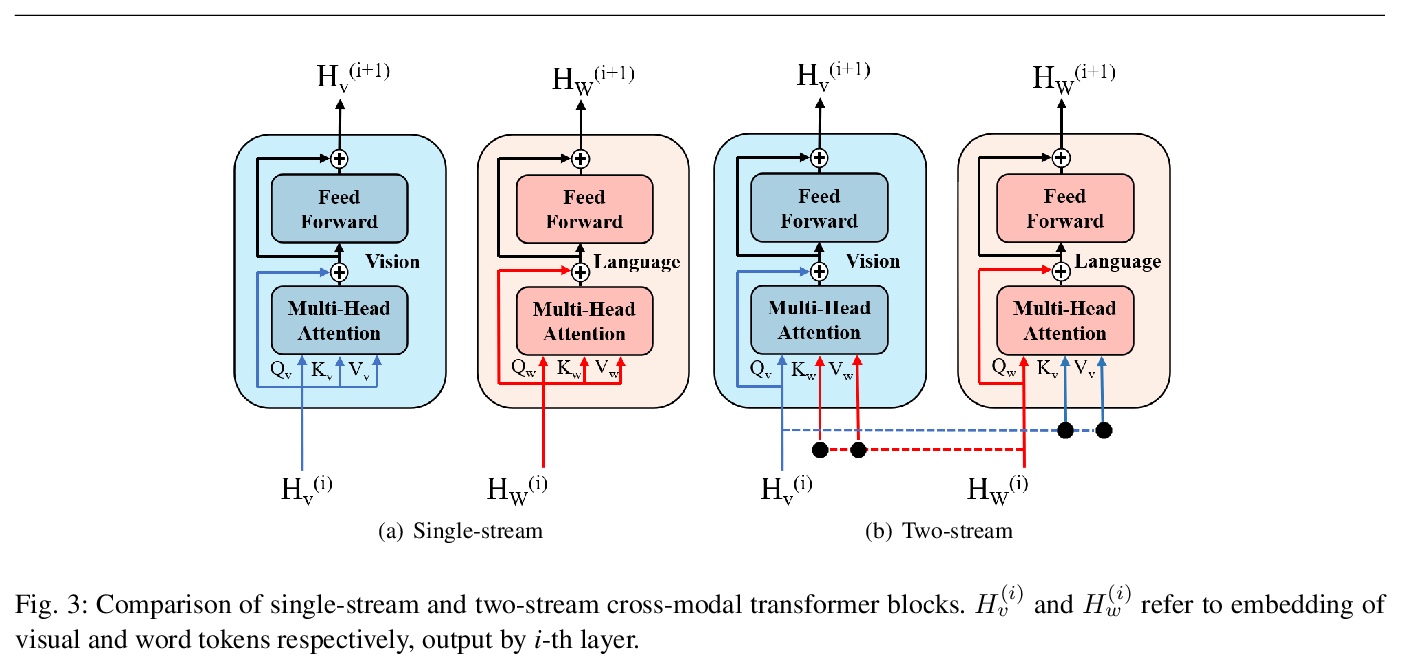
面向语言-视觉跨模态任务的Transformer架构前景和展望。回顾了基于Transformer的模型在语言和视觉跨模态任务中的关键里程碑和最新趋势,重点是预训练方案和网络架构。在语言领域,跨模态模型的性能主要取决于模型大小、数据集大小和预训练目标等方面。介绍了将Transformer架构应用于视觉表示的工作,并讨论了基于Transformer的跨模态模型的潜在前景,如Transformer排他性模型、数据效率模型和生成式任务模型的潜力。
Transformer architectures have brought about fundamental changes to computational linguistic field, which had been dominated by recurrent neural networks for many years. Its success also implies drastic changes in cross-modal tasks with language and vision, and many researchers have already tackled the issue. In this paper, we review some of the most critical milestones in the field, as well as overall trends on how transformer architecture has been incorporated into visuolinguistic cross-modal tasks. Furthermore, we discuss its current limitations and speculate upon some of the prospects that we find imminent.
https://weibo.com/1402400261/K6oACevLF
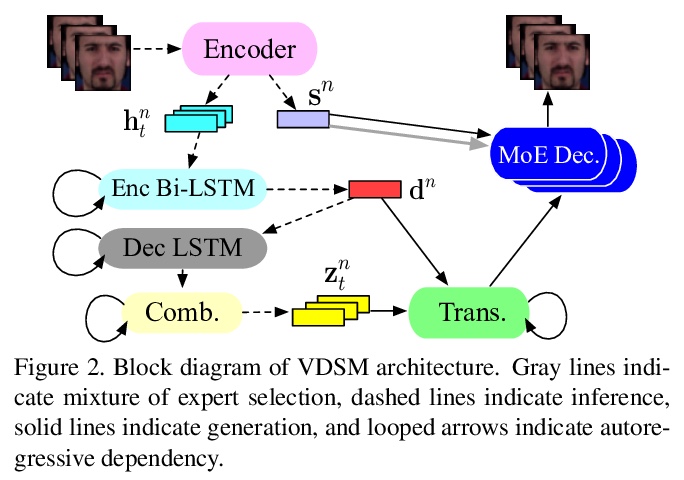
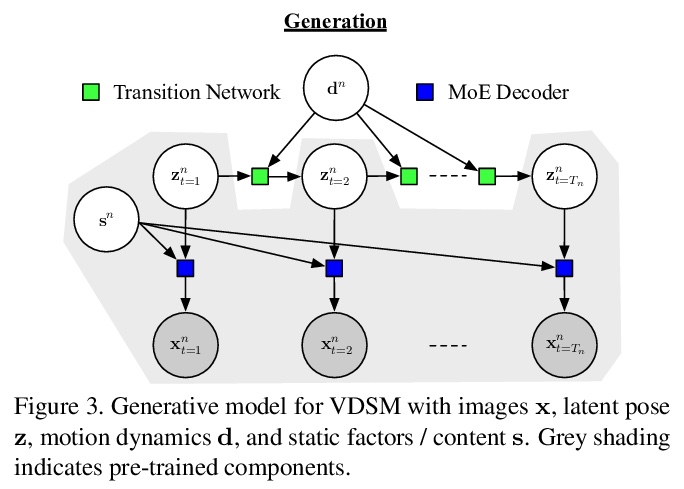
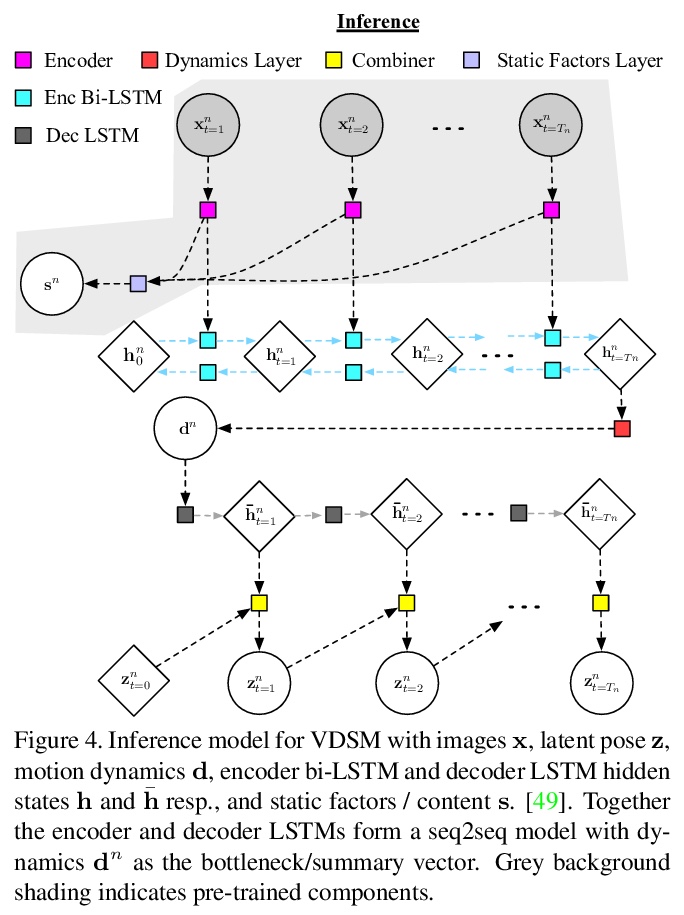
3、[CV] VDSM: Unsupervised Video Disentanglement with State-Space Modeling and Deep Mixtures of Experts
M J. Vowels, N C Camgoz, R Bowden
[University of Surrey]
VDSM:基于状态空间建模和专家深度混合的无监督视频解缠。提出一种面向视频解缠的无监督深度状态空间模型(VDSM),结合一系列的归纳偏差,包括分层潜结构、动态先验、seq2seq网络和专家混合解码器,对潜时变因素和动态因素进行解缠。VDSM为视频中的目标或人的身份以及正在执行的动作学习单独的解缠表征。在一系列定性和定量任务中对VDSM进行评价,包括身份和动态迁移、序列生成、弗雷切特初始距离和因子分类,VDSM提供了最先进性能,并超过了对抗式方法,即使这些方法使用额外监督。
Disentangled representations support a range of downstream tasks including causal reasoning, generative modeling, and fair machine learning. Unfortunately, disentanglement has been shown to be impossible without the incorporation of supervision or inductive bias. Given that supervision is often expensive or infeasible to acquire, we choose to incorporate structural inductive bias and present an unsupervised, deep State-Space-Model for Video Disentanglement (VDSM). The model disentangles latent time-varying and dynamic factors via the incorporation of hierarchical structure with a dynamic prior and a Mixture of Experts decoder. VDSM learns separate disentangled representations for the identity of the object or person in the video, and for the action being performed. We evaluate VDSM across a range of qualitative and quantitative tasks including identity and dynamics transfer, sequence generation, Fréchet Inception Distance, and factor classification. VDSM provides state-of-the-art performance and exceeds adversarial methods, even when the methods use additional supervision.
https://weibo.com/1402400261/K6oFv6e5X
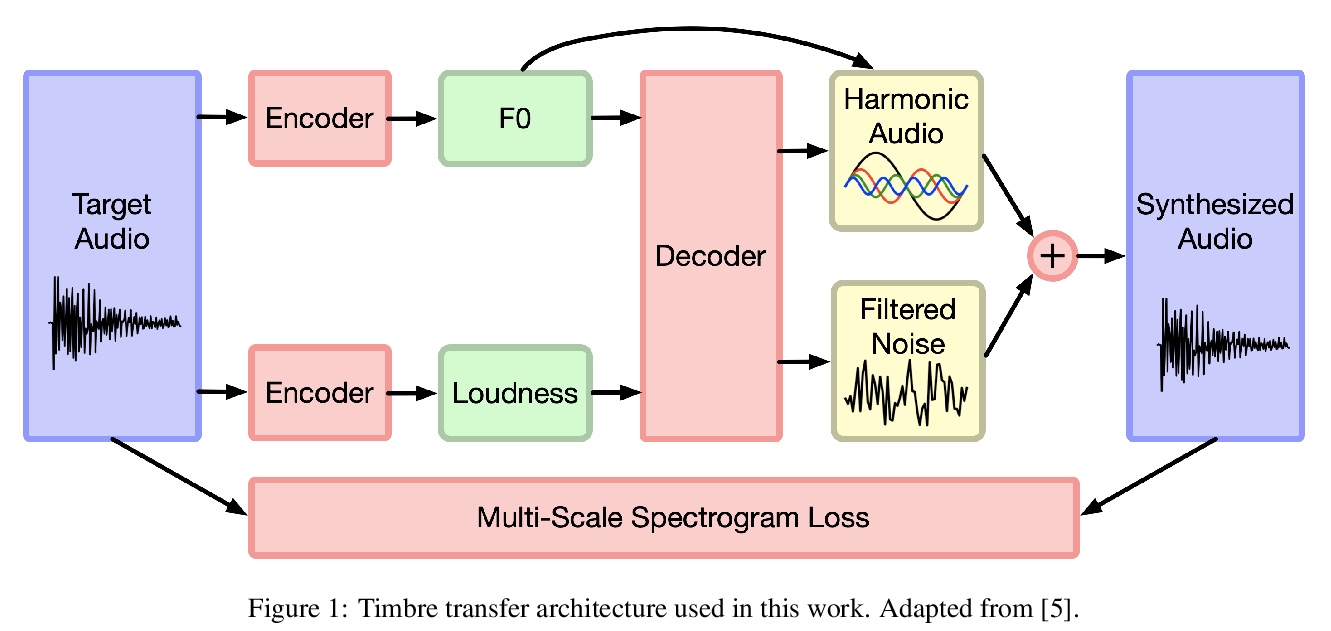
4、[AS] Latent Space Explorations of Singing Voice Synthesis using DDSP
J Alonso, C Erkut
[Aalborg University Copenhagen]
DDSP歌声合成潜空间探索。提出一种轻量级架构,基于可微数字信号处理(DDSP)库,用小型未处理音频数据集进行12小时训练后,输出仅以音高和振幅为条件的类似歌曲的语句,结果中旋律和歌手的声音都是可以识别的。引入了两个零配置工具来训练新的模型并进行实验。结果表明,潜空间既能提高对歌手的识别,也能改善对歌词的理解。
Machine learning based singing voice models require large datasets and lengthy training times. In this work we present a lightweight architecture, based on the Differentiable Digital Signal Processing (DDSP) library, that is able to output song-like utterances conditioned only on pitch and amplitude, after twelve hours of training using small datasets of unprocessed audio. The results are promising, as both the melody and the singer’s voice are recognizable. In addition, we present two zero-configuration tools to train new models and experiment with them. Currently we are exploring the latent space representation, which is included in the DDSP library, but not in the original DDSP examples. Our results indicate that the latent space improves both the identification of the singer as well as the comprehension of the lyrics. Our code is available at > this https URL with links to the zero-configuration notebooks, and our sound examples are at > this https URL .
https://weibo.com/1402400261/K6oKnlctL
5、[LG] Modern Dimension Reduction
P D. Waggoner
[University of Chicago]
现代降维技术。数据不仅在社会中无处不在,而且在规模和维度上都越来越复杂。降维为研究者和学者们提供了让这种复杂的高维数据空间变得更简单、更易管理的能力。本文为读者提供了一套现代无监督降维技术及数百行R代码,将原来的高维数据空间有效地表示在一个简化的低维子空间中。从最早的降维技术主成分分析开始,利用真实的社会科学数据,介绍并指导读者应用以下技术:局部线性嵌入、t-分布随机邻域嵌入(t-SNE)、统一流形逼近和投影、自组织映射和深度自编码器。其结果是为处理现代社会中常见的高维数据的复杂性提供了一个储备充足的无监督算法工具箱。
https://weibo.com/1402400261/K6oSrDmJP

另外几篇值得关注的论文:
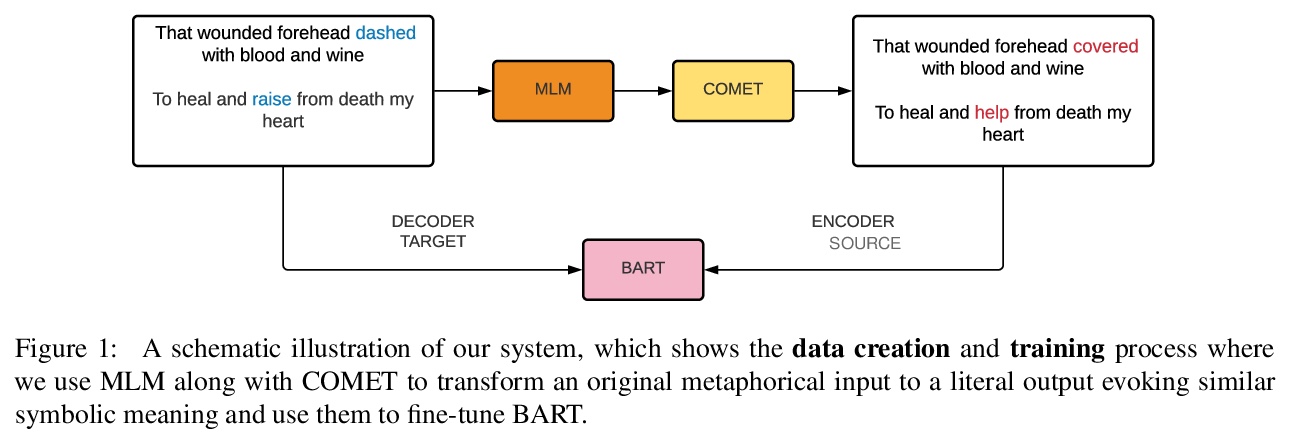
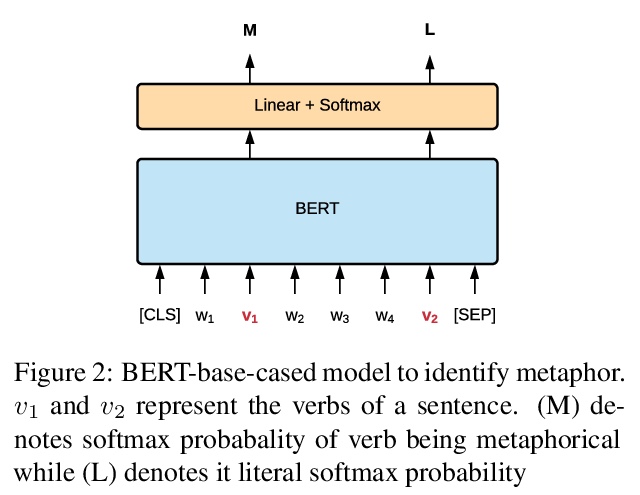
[CL] MERMAID: Metaphor Generation with Symbolism and Discriminative Decoding
MERMAID:符号主义隐喻生成与区分解码
T Chakrabarty, X Zhang, S Muresan, N Peng
[Columbia University & University of California, Los Angeles]
https://weibo.com/1402400261/K6oVBwYJn

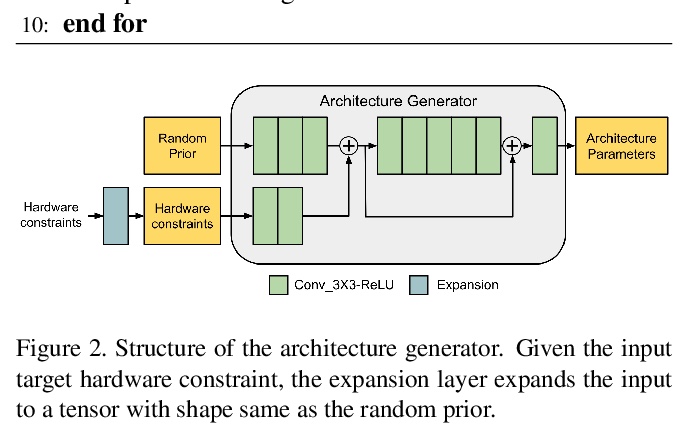
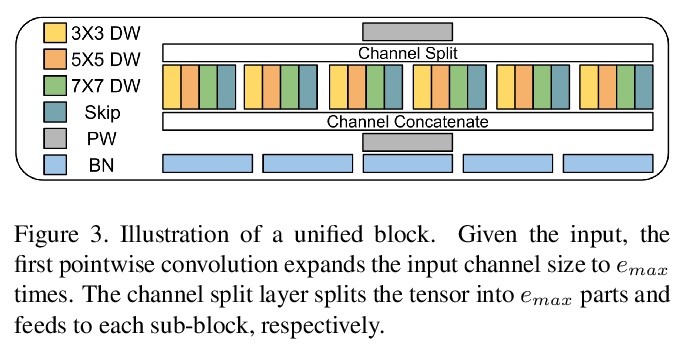
[CV] Searching by Generating: Flexible and Efficient One-Shot NAS with Architecture Generator
通过生成进行搜索:基于架构生成器的灵活高效单样本NAS
S Huang, W Chu
[National Cheng Kung University]
https://weibo.com/1402400261/K6oX2ebQN
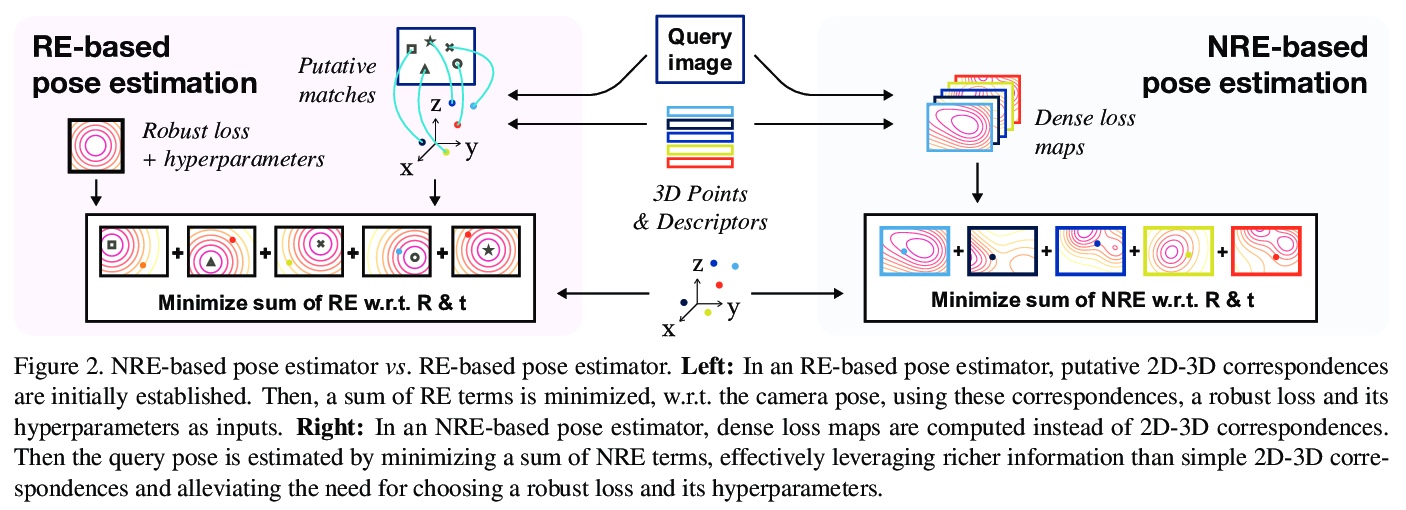
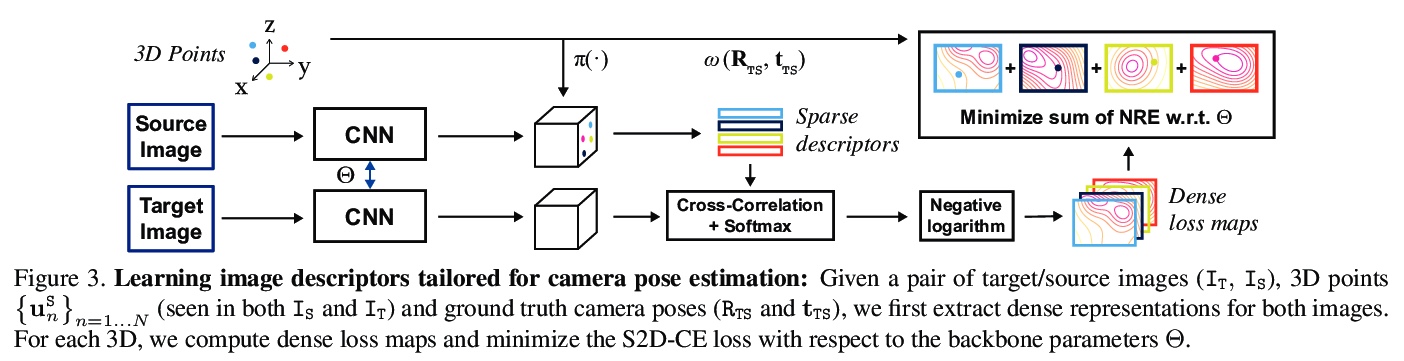
[CV] Neural Reprojection Error: Merging Feature Learning and Camera Pose Estimation
神经重投影误差:特征学习与摄像机姿态估计的融合
H Germain, V Lepetit, G Bourmaud
[Univ Gustave Eiffel & University of Bordeaux]
https://weibo.com/1402400261/K6oZ2xKmW

[CL] Preregistering NLP Research
预注册NLP研究
E v Miltenburg, C v d Lee, E Krahmer
[Tilburg University]
https://weibo.com/1402400261/K6p0a3Jfh

若有收获,就点个赞吧
0 人点赞
