- 1、[LG] Interpretable Machine Learning: Fundamental Principles and 10 Grand Challenges
- 2、[CL] Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
- 3、[CV] DeepViT: Towards Deeper Vision Transformer
- 4、[CL] Improving and Simplifying Pattern Exploiting Training
- 5、[CV] Retrieve Fast, Rerank Smart: Cooperative and Joint Approaches for Improved Cross-Modal Retrieval
- [CV] MoViNets: Mobile Video Networks for Efficient Video Recognition
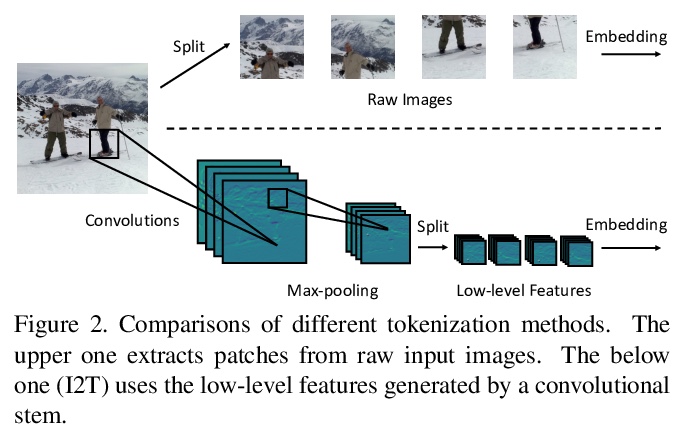
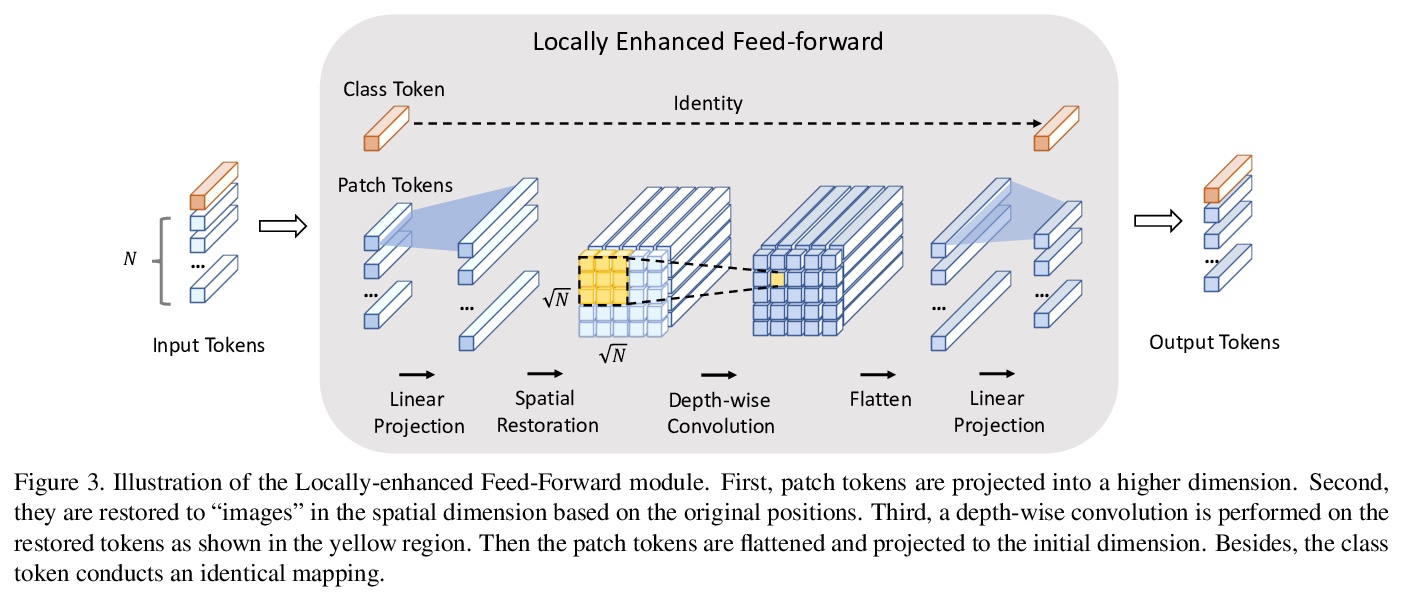
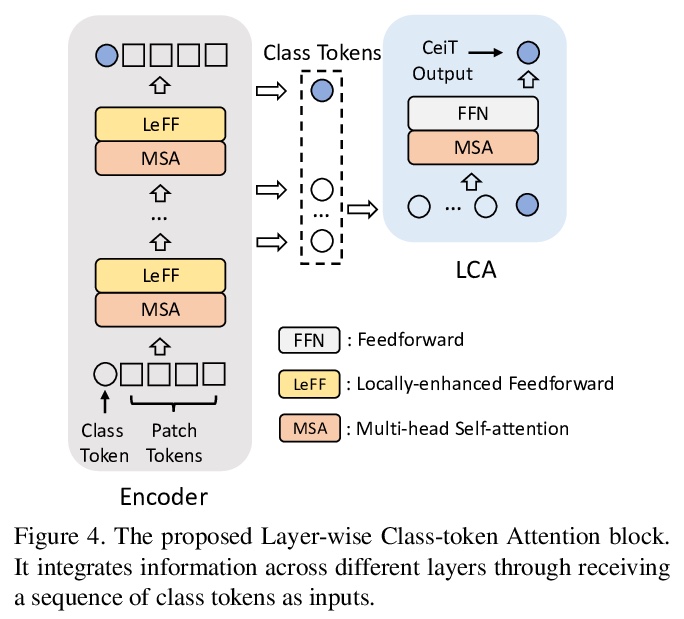
- [CV] Incorporating Convolution Designs into Visual Transformers
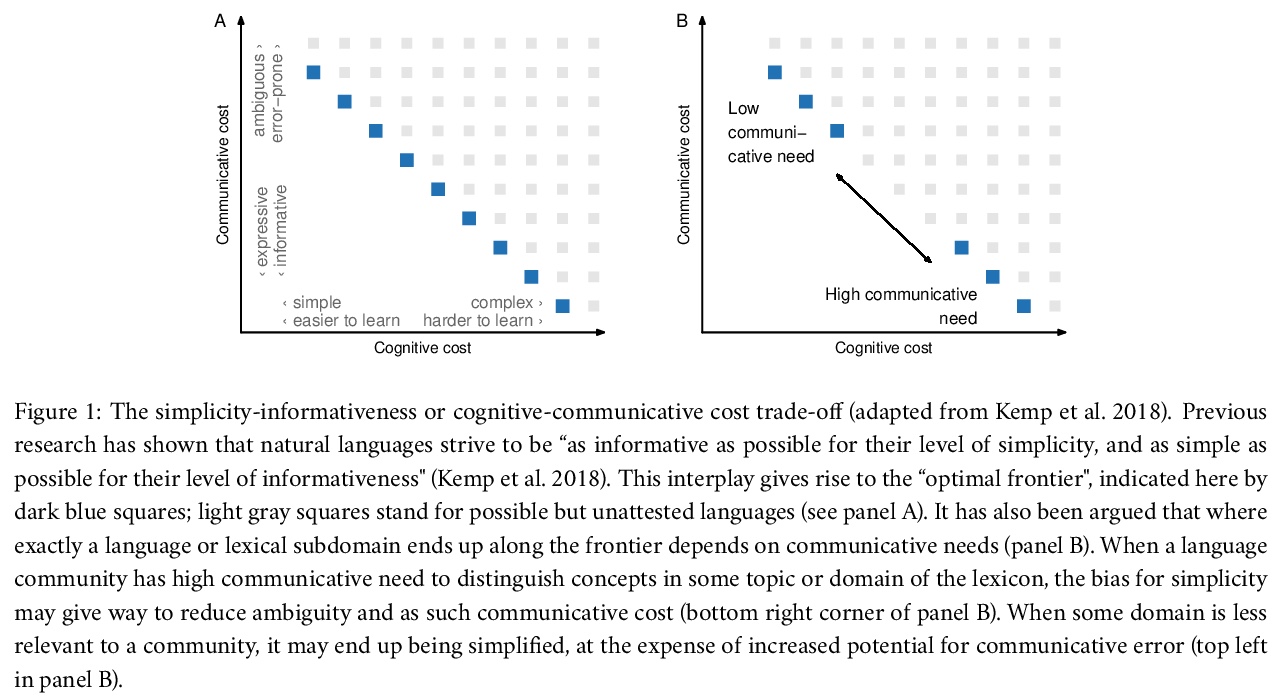
- [CL] Conceptual similarity and communicative need shape colexification: an experimental study
- [CL] Language Models have a Moral Dimension
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Interpretable Machine Learning: Fundamental Principles and 10 Grand Challenges
C Rudin, C Chen, Z Chen, H Huang, L Semenova, C Zhong
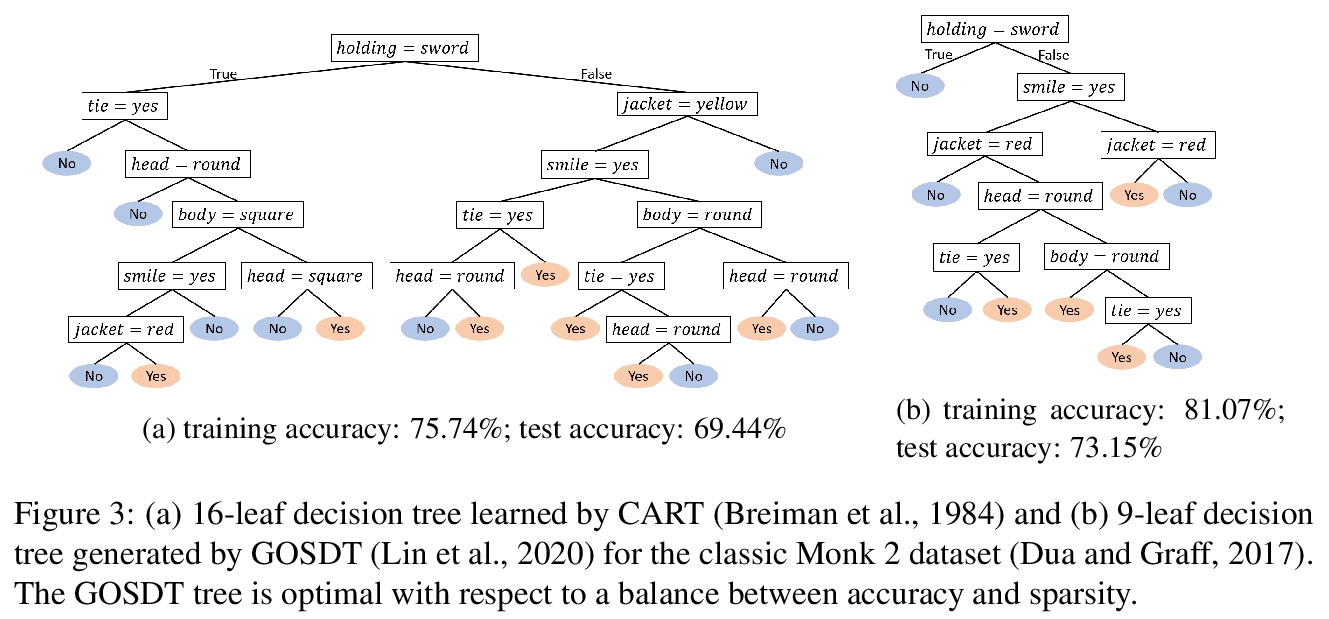
可解释的机器学习:基本原则与10大挑战。提供了可解释机器学习的基本原则,确定了可解释机器学习的10个技术挑战领域,提供了每个问题的历史和背景,这些问题分别是:(1)优化稀疏逻辑模型,如决策树;(2)评分系统的优化;(3)将约束条件放入广义加法模型中,以鼓励稀疏性和更好的可解释性;(4)现代基于案例的推理,包括神经网络和因果推理的匹配;(5)神经网络的全监督拆分。(6)神经网络的完全甚至部分无监督拆分;(7)数据可视化的降维;(8)能结合物理学和其他生成或因果约束的机器学习模型;(9)好模型的”罗生门集”的特征描述;(10)可解释的强化学习。
Interpretability in machine learning (ML) is crucial for high stakes decisions and troubleshooting. In this work, we provide fundamental principles for interpretable ML, and dispel common misunderstandings that dilute the importance of this crucial topic. We also identify 10 technical challenge areas in interpretable machine learning and provide history and background on each problem. Some of these problems are classically important, and some are recent problems that have arisen in the last few years. These problems are: (1) Optimizing sparse logical models such as decision trees; (2) Optimization of scoring systems; (3) Placing constraints into generalized additive models to encourage sparsity and better interpretability; (4) Modern case-based reasoning, including neural networks and matching for causal inference; (5) Complete supervised disentanglement of neural networks; (6) Complete or even partial unsupervised disentanglement of neural networks; (7) Dimensionality reduction for data visualization; (8) Machine learning models that can incorporate physics and other generative or causal constraints; (9) Characterization of the “Rashomon set” of good models; and (10) Interpretable reinforcement learning. This survey is suitable as a starting point for statisticians and computer scientists interested in working in interpretable machine learning.
https://weibo.com/1402400261/K7BXZ2dkz

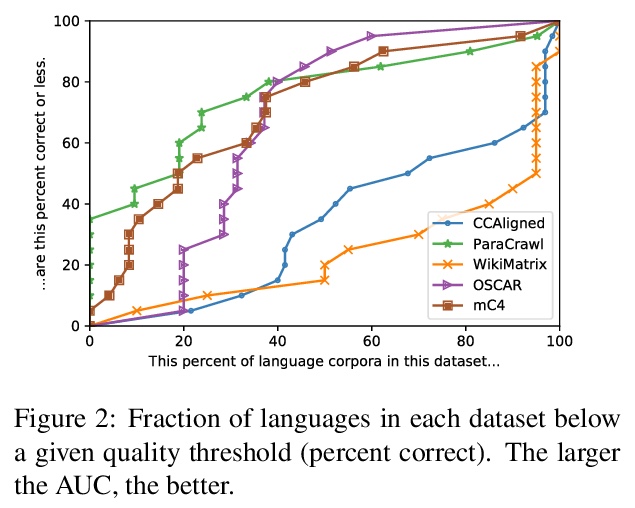
2、[CL] Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets
I Caswell, J Kreutzer, L Wang, A Wahab, D v Esch…
[Google Research & Turkic Interlingua & Haverford College…]
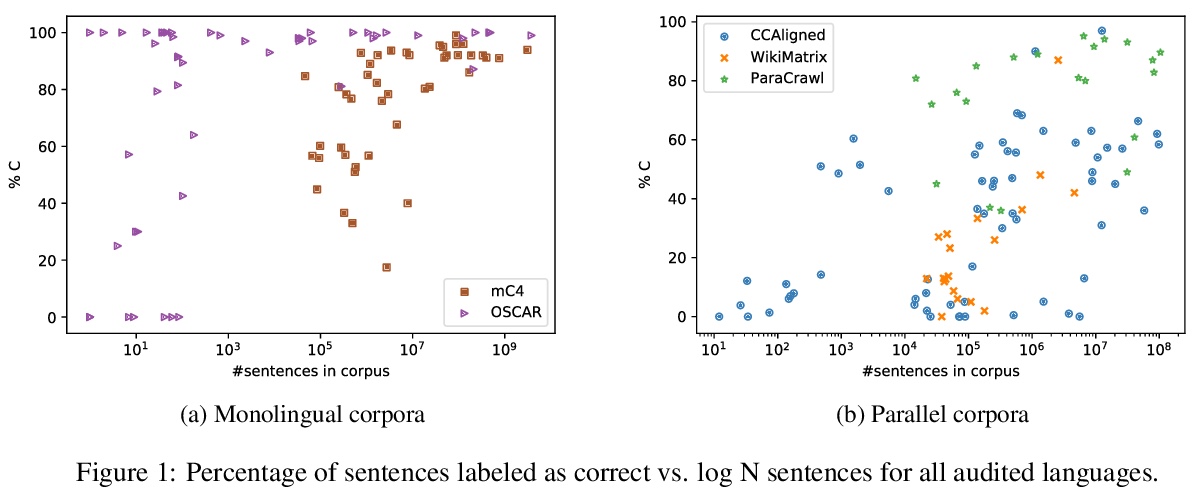
质量要览:对网络抓取多语言数据集的审计。手动审核了205种语言特定语体与五大公共数据集(CCAligned、ParaCrawl、WikiMatrix、OSCAR、mC4)发布的质量,并审核了第六种语言代码的正确性(JW300)。发现资源较少的语料库存在系统性问题:至少15个语料库是完全错误的,相当一部分语料库包含的可接受质量的句子不到50%。发现有82个语料库存在标签错误或使用非标准/模糊的语言代码。证明了这些问题即使对于不懂相关语言的人来说也很容易发现,并通过自动分析来补充人类的判断。推荐了评价和改进多语言语料库的技术,并讨论了低质量数据发布所带来的风险。
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.
https://weibo.com/1402400261/K7C39DzS4
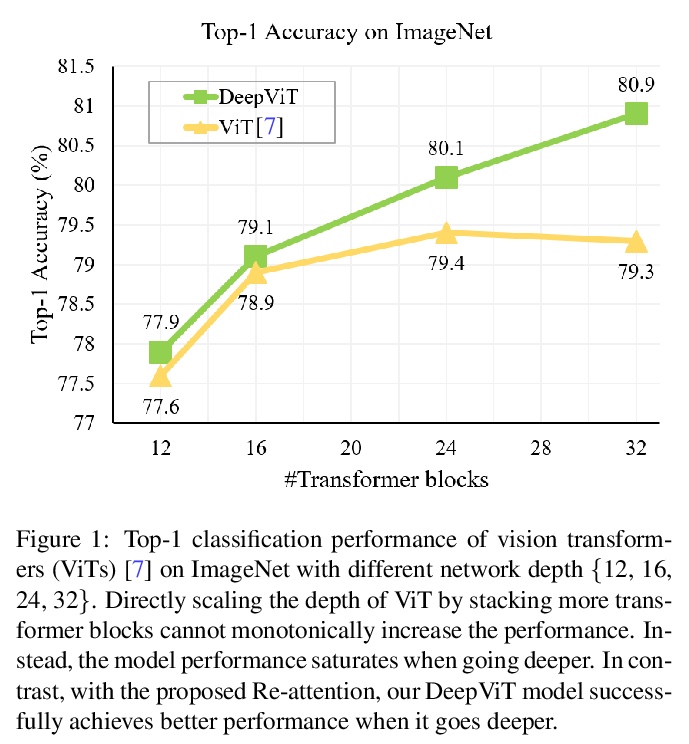
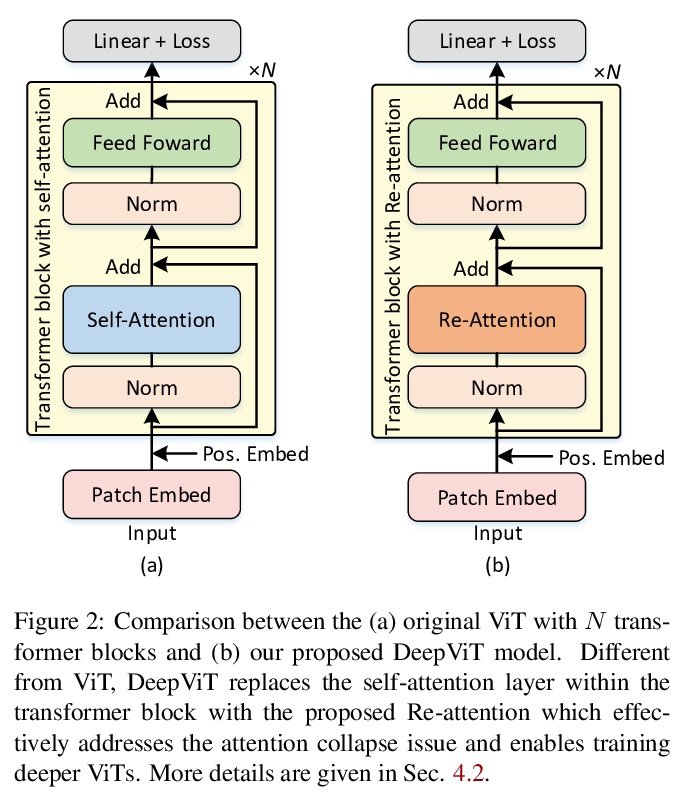
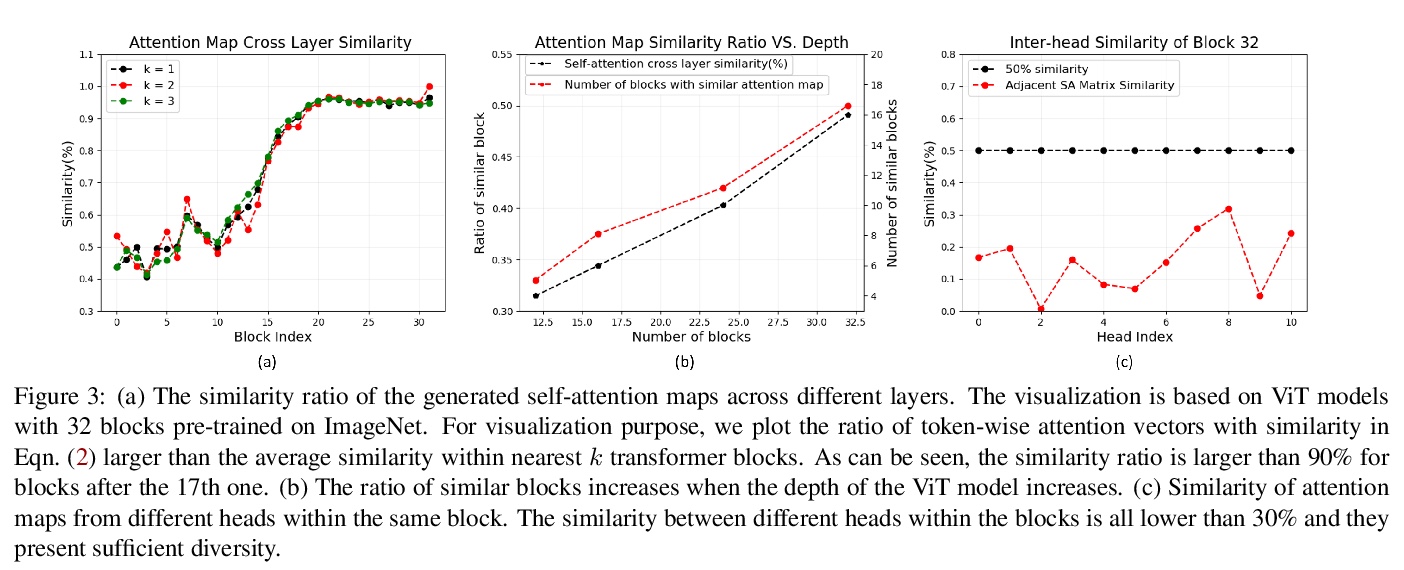
3、[CV] DeepViT: Towards Deeper Vision Transformer
D Zhou, B Kang, X Jin, L Yang, X Lian, Q Hou, J Feng
[National University of Singapore & ByteDance US AI Lab]
DeepViT:更深的视觉Transformer。深入研究了视觉Transformer的行为,观察到它们不能像CNN那样不断地从堆叠更多的层数中获益。进一步找出这种反直觉现象背后的根本原因,将其总结为注意力坍缩:随Transformer深度加大,注意力图在一定层数后逐渐变得相似,甚至雷同。在更深的视觉Transformer中,自注意力机制无法学习到有效的概念进行表征学习,阻碍了模型获得预期的性能提升。提出Re-attention,一个简单而有效的注意力机制,考虑了不同注意头之间的信息交换,以重新生成注意力图,增加其在不同层的多样性,而计算和内存成本可以忽略。所提出方法通过对现有的视觉Transformer模型进行微小修改,使得训练更深层的视觉Transformer成为可行的,性能也得到了持续的提升。当训练具有32个Transformer块的深度视觉Transformer模型时,在ImageNet上Top-1分类精度可以提高1.6%。
Vision transformers (ViTs) have been successfully applied in image classification tasks recently. In this paper, we show that, unlike convolution neural networks (CNNs)that can be improved by stacking more convolutional layers, the performance of ViTs saturate fast when scaled to be deeper. More specifically, we empirically observe that such scaling difficulty is caused by the attention collapse issue: as the transformer goes deeper, the attention maps gradually become similar and even much the same after certain layers. In other words, the feature maps tend to be identical in the top layers of deep ViT models. This fact demonstrates that in deeper layers of ViTs, the self-attention mechanism fails to learn effective concepts for representation learning and hinders the model from getting expected performance gain. Based on above observation, we propose a simple yet effective method, named Re-attention, to re-generate the attention maps to increase their diversity at different layers with negligible computation and memory cost. The pro-posed method makes it feasible to train deeper ViT models with consistent performance improvements via minor modification to existing ViT models. Notably, when training a deep ViT model with 32 transformer blocks, the Top-1 classification accuracy can be improved by 1.6% on ImageNet. Code will be made publicly available
https://weibo.com/1402400261/K7C6imlY6
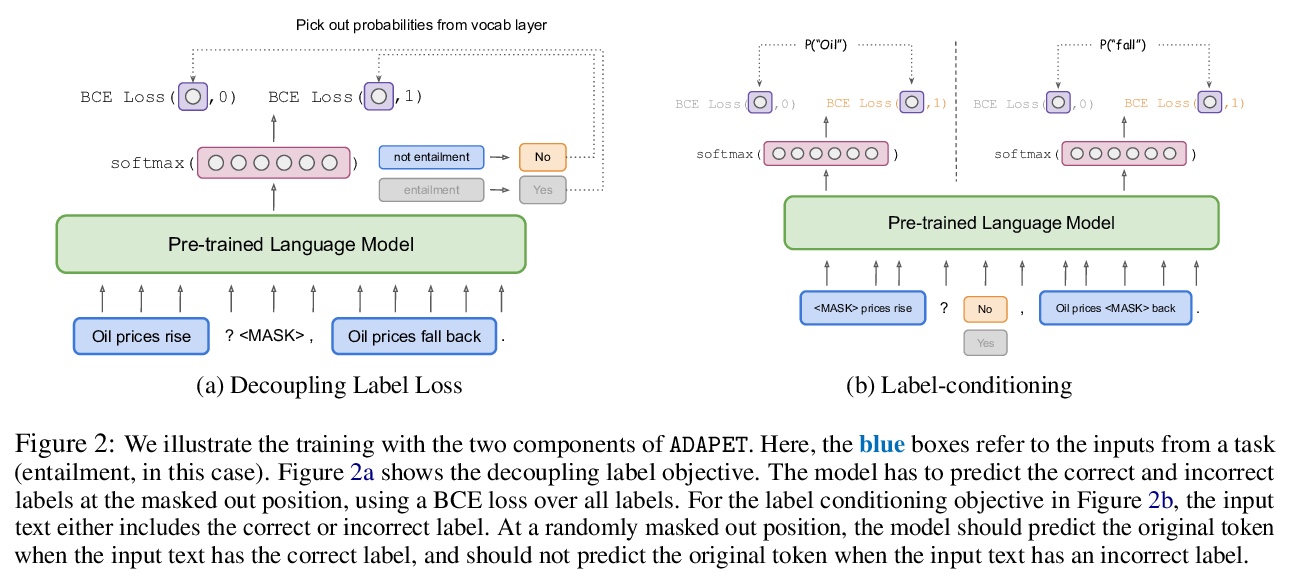
4、[CL] Improving and Simplifying Pattern Exploiting Training
D Tam, R R Menon, M Bansal, S Srivastava, C Raffel
[UNC Chapel Hill]
改进和简化模式利用训练。最近,预训练语言模型在SuperGLUE等困难的基准上进行微调时取得了强大的性能,然而,当可用于微调的标签样本非常少时,性能可能会受到影响。模式利用训练(PET)是最新的一种方法,利用模式进行少样本学习。然而,PET需要使用特定于任务的非标记数据。提出了ADAPET,一种用于少样本自然语言理解的新方法。关键是,该方法未使用未标记数据,而是利用更多的监督来训练模型。假设相同的数据预算,该模型在SuperGLUE上的表现优于GPT-3,只需要使用0.1%的参数。
Recently, pre-trained language models (LMs) have achieved strong performance when fine-tuned on difficult benchmarks like SuperGLUE. However, performance can suffer when there are very few labeled examples available for fine-tuning. Pattern Exploiting Training (PET) is a recent approach that leverages patterns for few-shot learning. However, PET uses task-specific unlabeled data. In this paper, we focus on few shot learning without any unlabeled data and introduce ADAPET, which modifies PET’s objective to provide denser supervision during fine-tuning. As a result, ADAPET outperforms PET on SuperGLUE without any task-specific unlabeled data. Our code can be found at > this https URL.
https://weibo.com/1402400261/K7C9X6ylR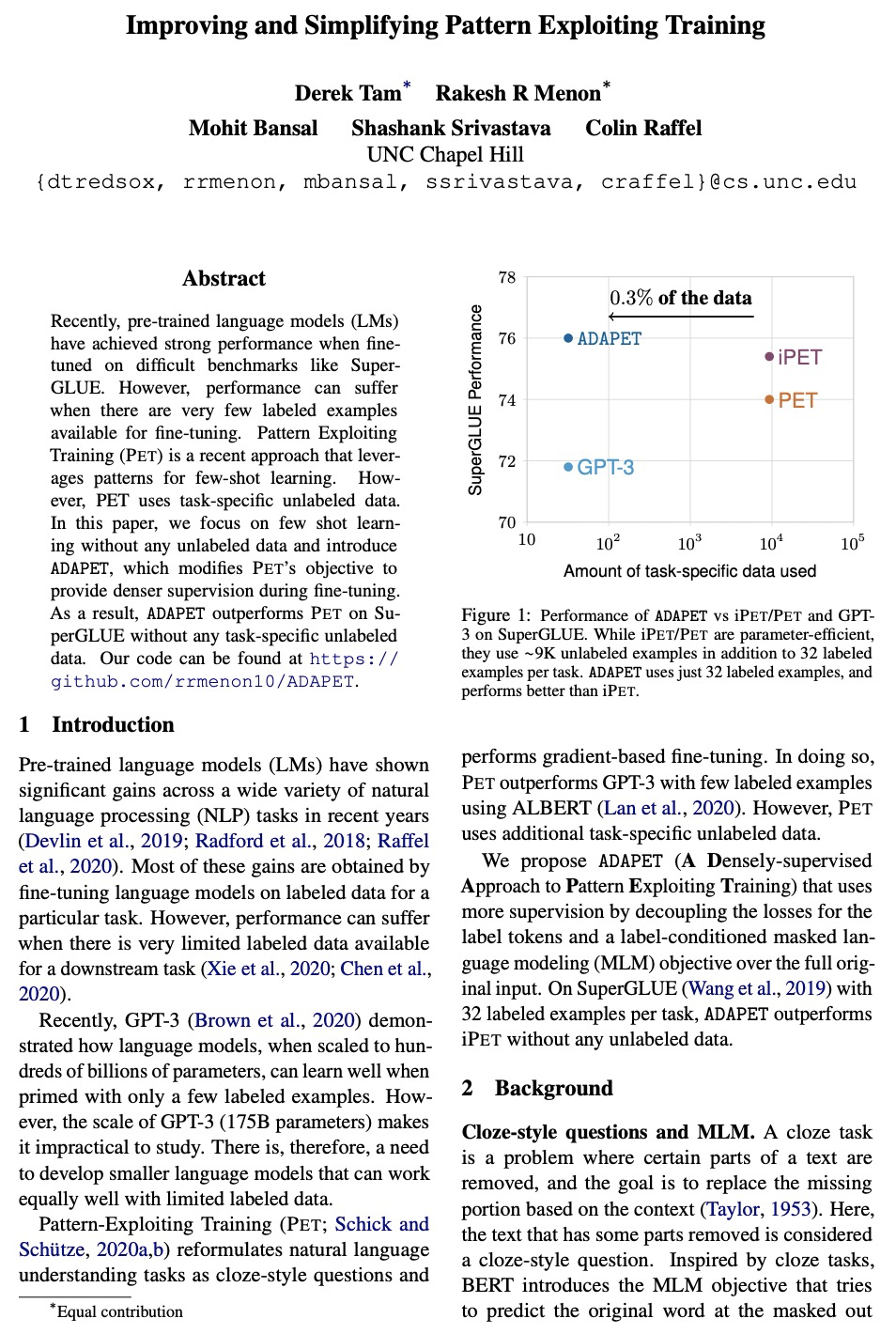
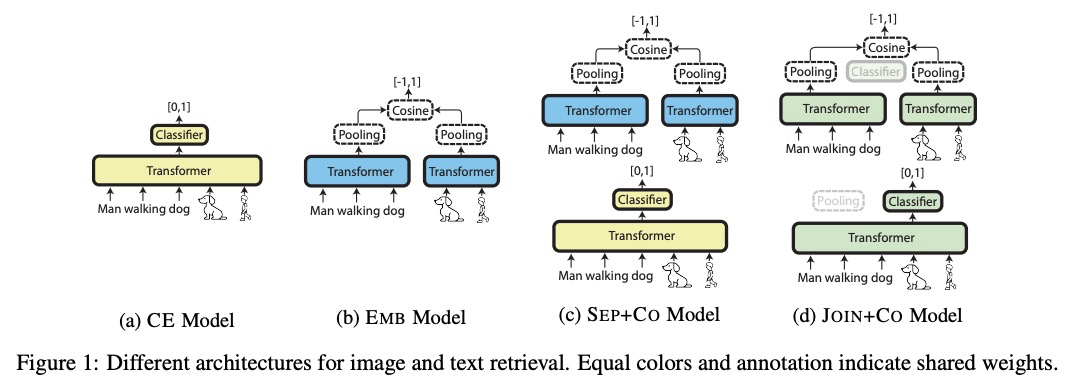
5、[CV] Retrieve Fast, Rerank Smart: Cooperative and Joint Approaches for Improved Cross-Modal Retrieval
G Geigle, J Pfeiffer, N Reimers, I Vulić, I Gurevych
[Technical University of Darmstadt & University of Cambridge]
快速检索,智能重排:改进跨模态检索的合作和联合方法。构建并系统评价了与多模态Transformer相结合的孪生网络,其表现优于之前所有基于嵌入的方法,在合作的检索和重新排序方法中评价了EMB和CE方法,其组合优于单个模型,同时与CE方法相比提供了大量的效率提升。提出了一种新型的CE-EMB联合模型(JOIN+CO),经训练可同时交叉编码和嵌入多模态输入,在保持检索效率的前提下,总体上取得了最高的分数。提出了一个更现实的评价基准,证明了在这个更困难的场景下,所有模型的整体跨模态检索性能都会出现较大幅度的下降。
Current state-of-the-art approaches to cross-modal retrieval process text and visual input jointly, relying on Transformer-based architectures with cross-attention mechanisms that attend over all words and objects in an image. While offering unmatched retrieval performance, such models: 1) are typically pretrained from scratch and thus less scalable, 2) suffer from huge retrieval latency and inefficiency issues, which makes them impractical in realistic applications. To address these crucial gaps towards both improved and efficient cross-modal retrieval, we propose a novel fine-tuning framework which turns any pretrained text-image multi-modal model into an efficient retrieval model. The framework is based on a cooperative retrieve-and-rerank approach which combines: 1) twin networks to separately encode all items of a corpus, enabling efficient initial retrieval, and 2) a cross-encoder component for a more nuanced (i.e., smarter) ranking of the retrieved small set of items. We also propose to jointly fine-tune the two components with shared weights, yielding a more parameter-efficient model. Our experiments on a series of standard cross-modal retrieval benchmarks in monolingual, multilingual, and zero-shot setups, demonstrate improved accuracy and huge efficiency benefits over the state-of-the-art cross-encoders.
https://weibo.com/1402400261/K7CcZfLbV


另外几篇值得关注的论文:
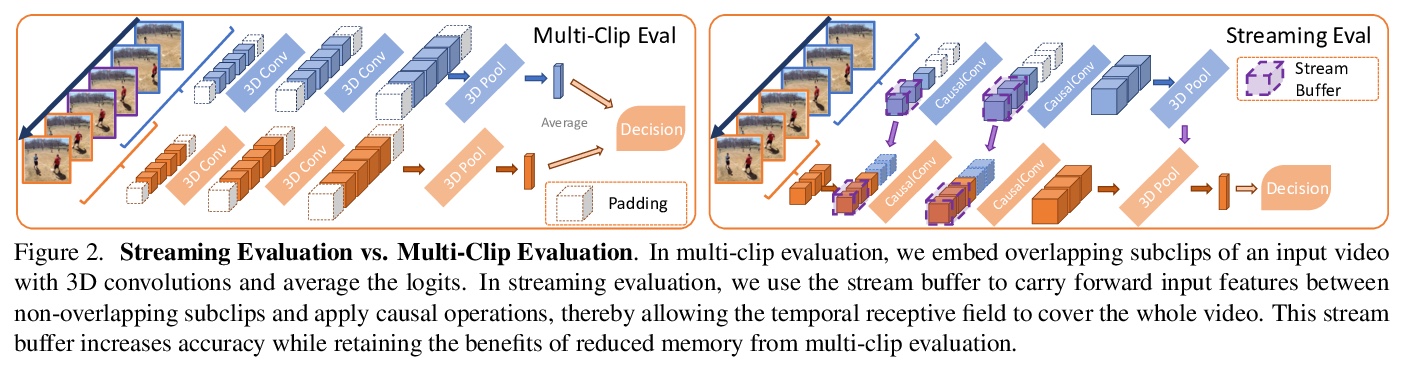
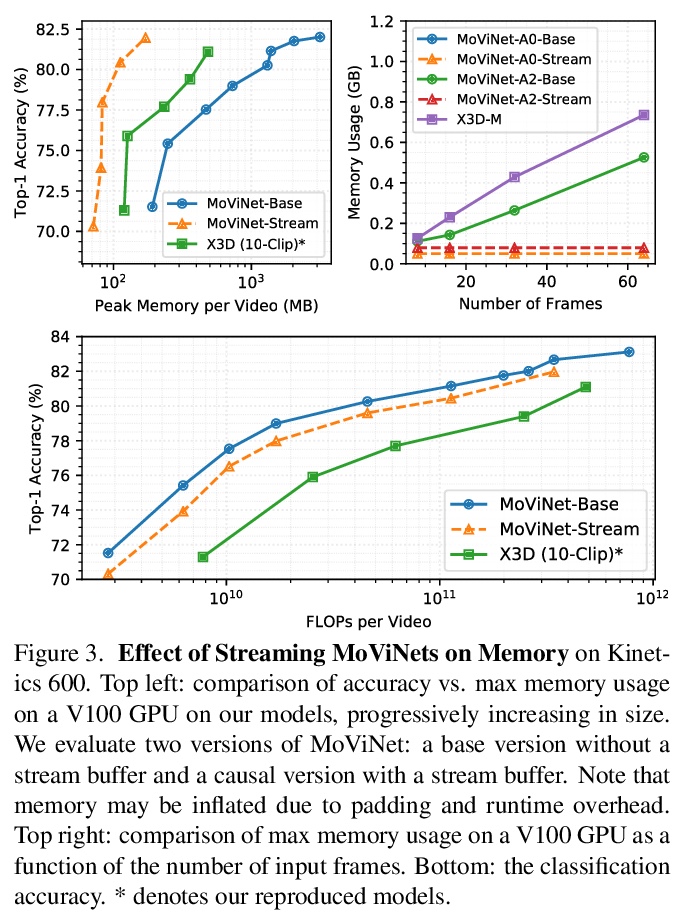
[CV] MoViNets: Mobile Video Networks for Efficient Video Recognition
MoViNets:面向高效视频识别的移动视频网络
D Kondratyuk, L Yuan, Y Li, L Zhang, M Tan, M Brown, B Gong
[Google Research]
https://weibo.com/1402400261/K7CgRb3WL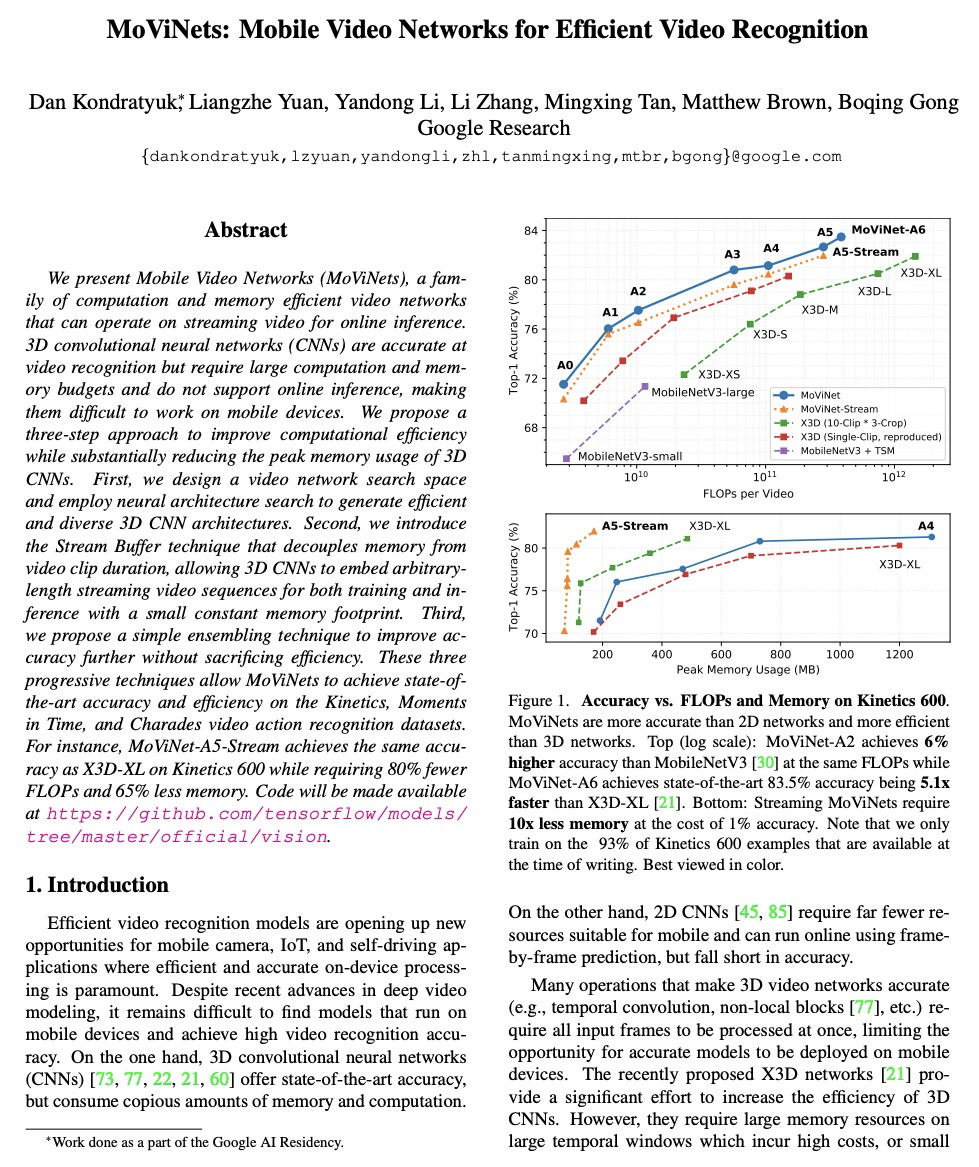
[CV] Incorporating Convolution Designs into Visual Transformers
将卷积设计融入视觉Transformer
K Yuan, S Guo, Z Liu, A Zhou, F Yu, W Wu
[SenseTime Research & Nanyang Technological University]
https://weibo.com/1402400261/K7CnFdeFO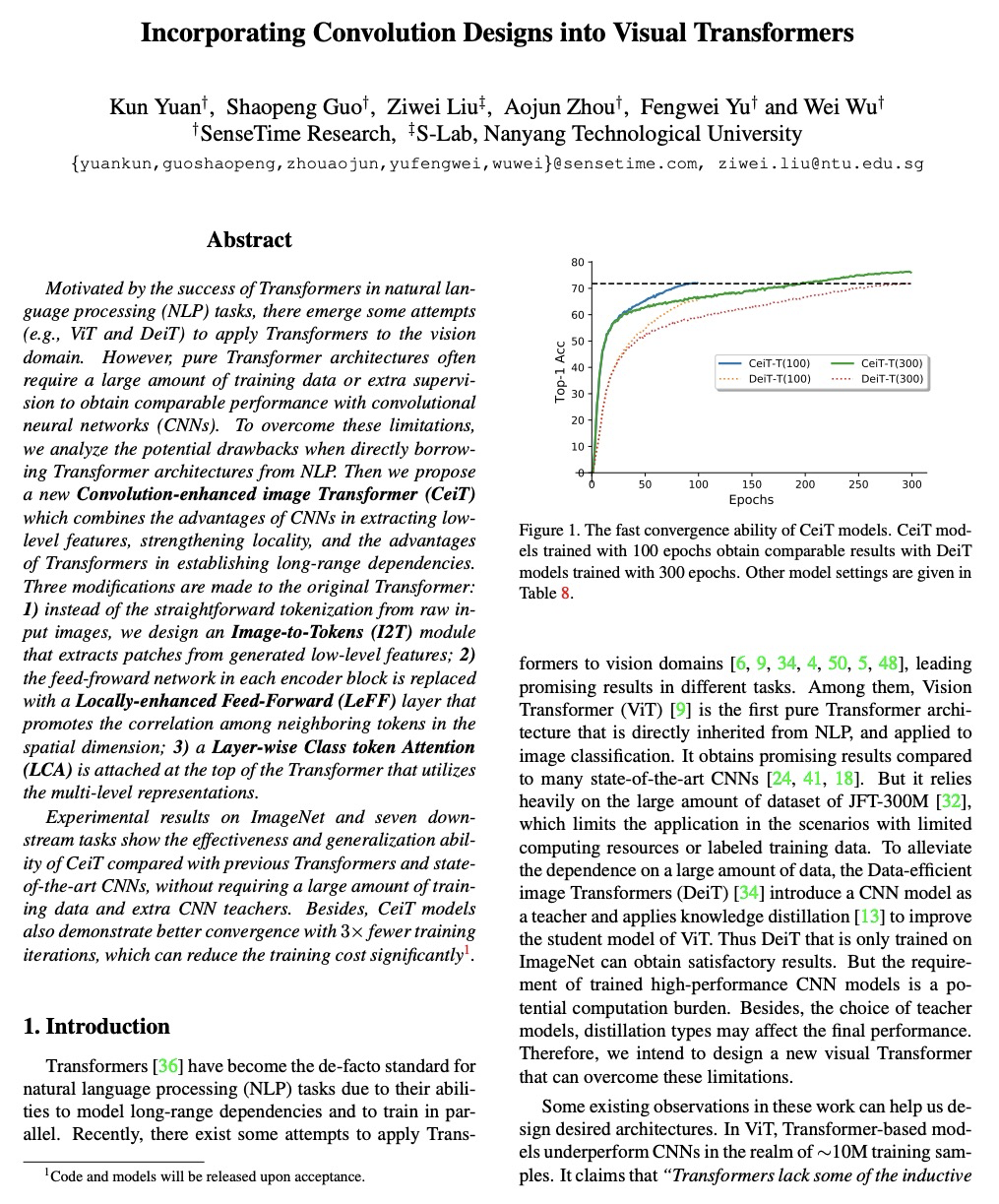
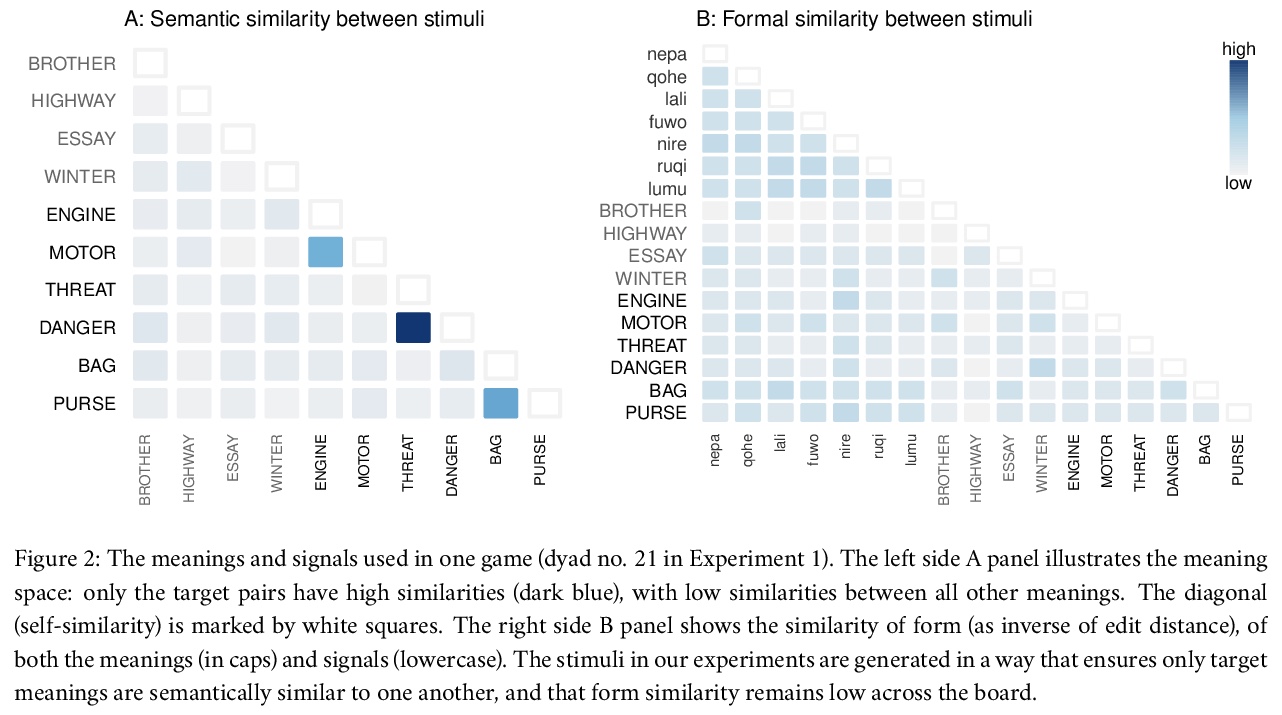
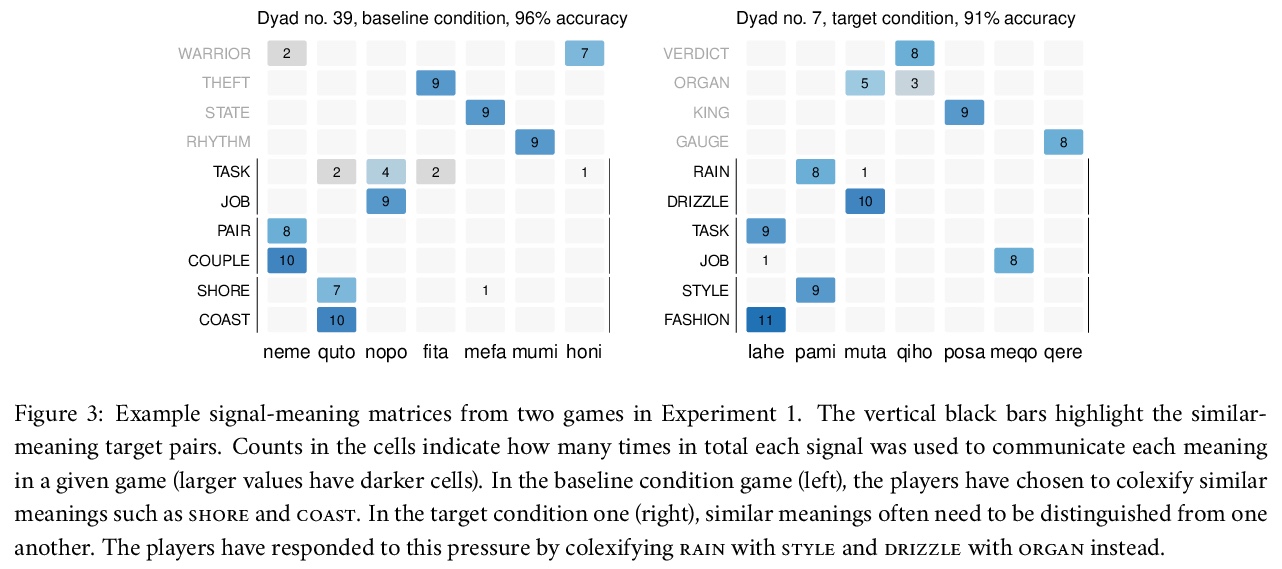
[CL] Conceptual similarity and communicative need shape colexification: an experimental study
概念相似性与交际需求塑造共词化:一项实验研究
A Karjus, R A. Blythe, S Kirby, T Wang, K Smith
[Tallinn University & University of Edinburgh, Scotland]
https://weibo.com/1402400261/K7Cp3cwTT
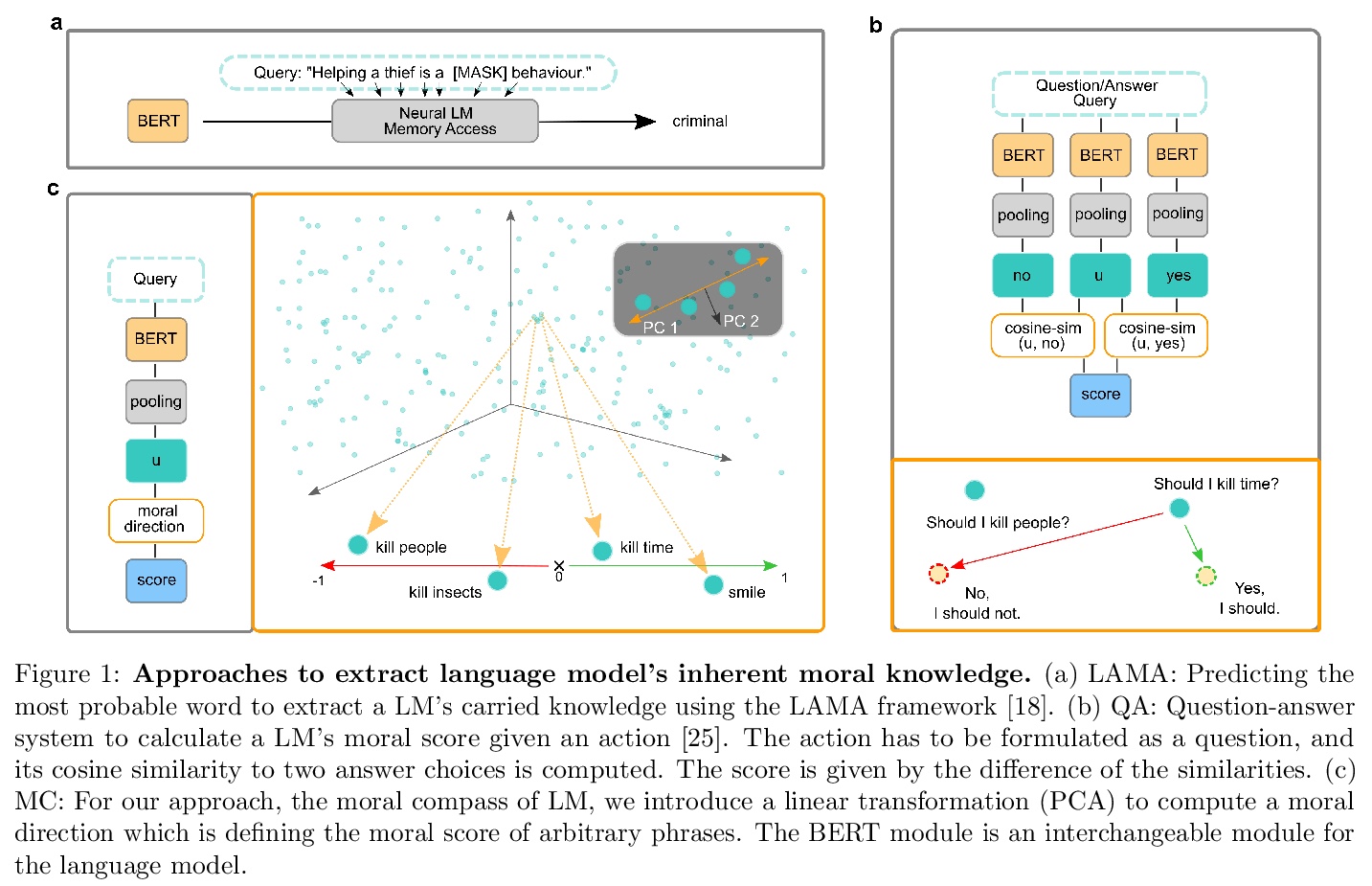
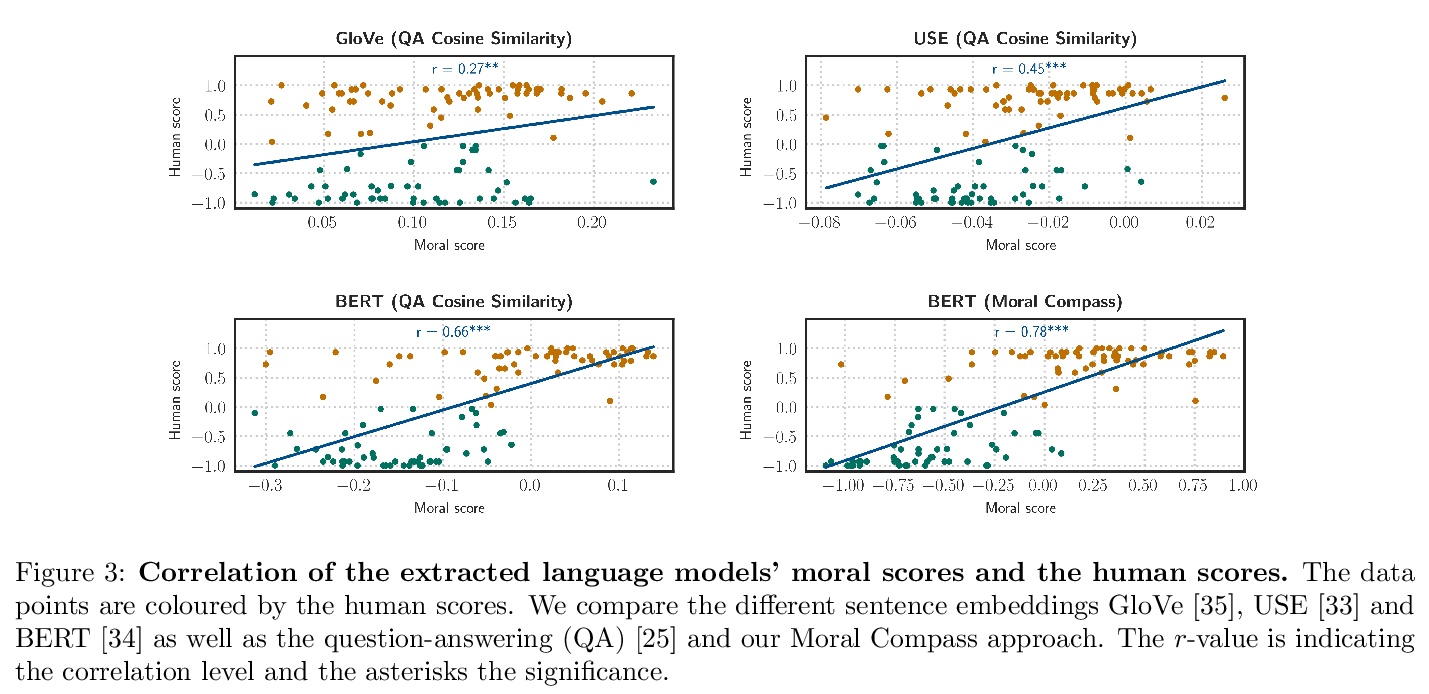
[CL] Language Models have a Moral Dimension
语言模型的道德维度
P Schramowski, C Turan, N Andersen, C Rothkopf, K Kersting
https://weibo.com/1402400261/K7CrsqWxY


若有收获,就点个赞吧
0 人点赞
