- 1、[CV] Towards General Purpose Vision Systems
- 2、[CV] Decomposing 3D Scenes into Objects via Unsupervised Volume Segmentation
- 3、[LG] LatentCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions
- 4、[CV] NPMs: Neural Parametric Models for 3D Deformable Shapes
- 5、[CV] Learning monocular 3D reconstruction of articulated categories from motion
- [CV] Language-based Video Editing via Multi-Modal Multi-Level Transformer
- [CV] LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
- [CV] Learning Spatio-Temporal Transformer for Visual Tracking
- [AS] Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Towards General Purpose Vision Systems
T Gupta, A Kamath, A Kembhavi, D Hoiem
[Allen Institute for AI & University of Illinois at Urbana-Champaign]
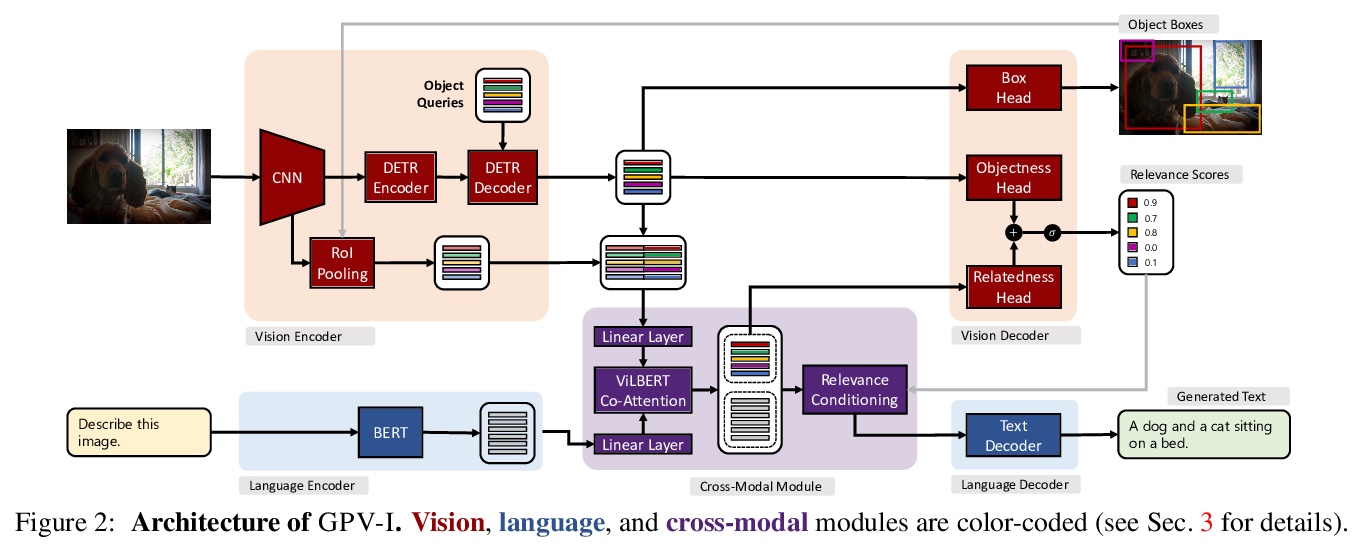
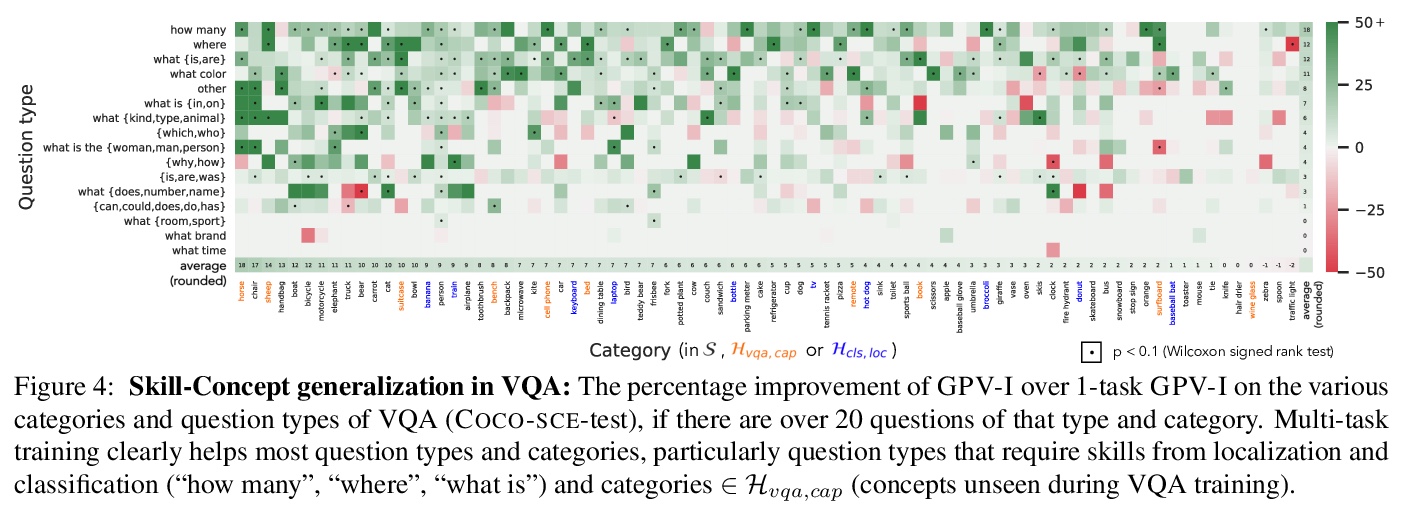
通用视觉系统探索。提出了任务无关的视觉语言系统GPV-I,接受图像和自然语言任务描述,输出边框、置信和文本,支持广泛的视觉任务,如分类、定位、问答、自动描述等。这种通用性并不以牺牲准确度为代价,GPV-I在训练单个任务时,与专项系统相比表现良好,而在联合训练时,则表现优异。与专项系统相比,主要代价是运行时间效率。GPV-I还实现了一定的技能概念泛化,学习速度更快,遗忘速度更慢。评估了系统同时学习多种技能的能力,执行新的技能概念组合任务的能力,以及高效学习新技能而不会遗忘的能力。
A special purpose learning system assumes knowledge of admissible tasks at design time. Adapting such a system to unforeseen tasks requires architecture manipulation such as adding an output head for each new task or dataset. In this work, we propose a task-agnostic vision-language system that accepts an image and a natural language task description and outputs bounding boxes, confidences, and text. The system supports a wide range of vision tasks such as classification, localization, question answering, captioning, and more. We evaluate the system’s ability to learn multiple skills simultaneously, to perform tasks with novel skill-concept combinations, and to learn new skills efficiently and without forgetting.
https://weibo.com/1402400261/K9AA5BPl7

2、[CV] Decomposing 3D Scenes into Objects via Unsupervised Volume Segmentation
K Stelzner, K Kersting, A R. Kosiorek
[TU Darmstadt & DeepMind, London]
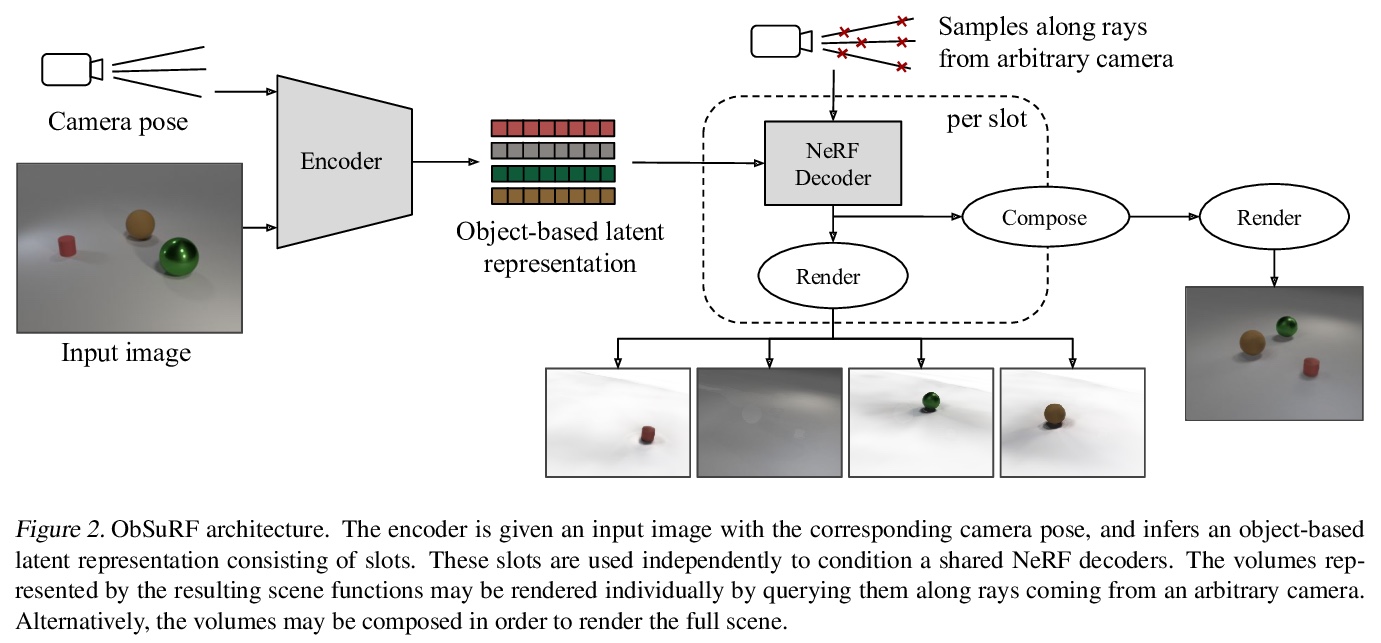
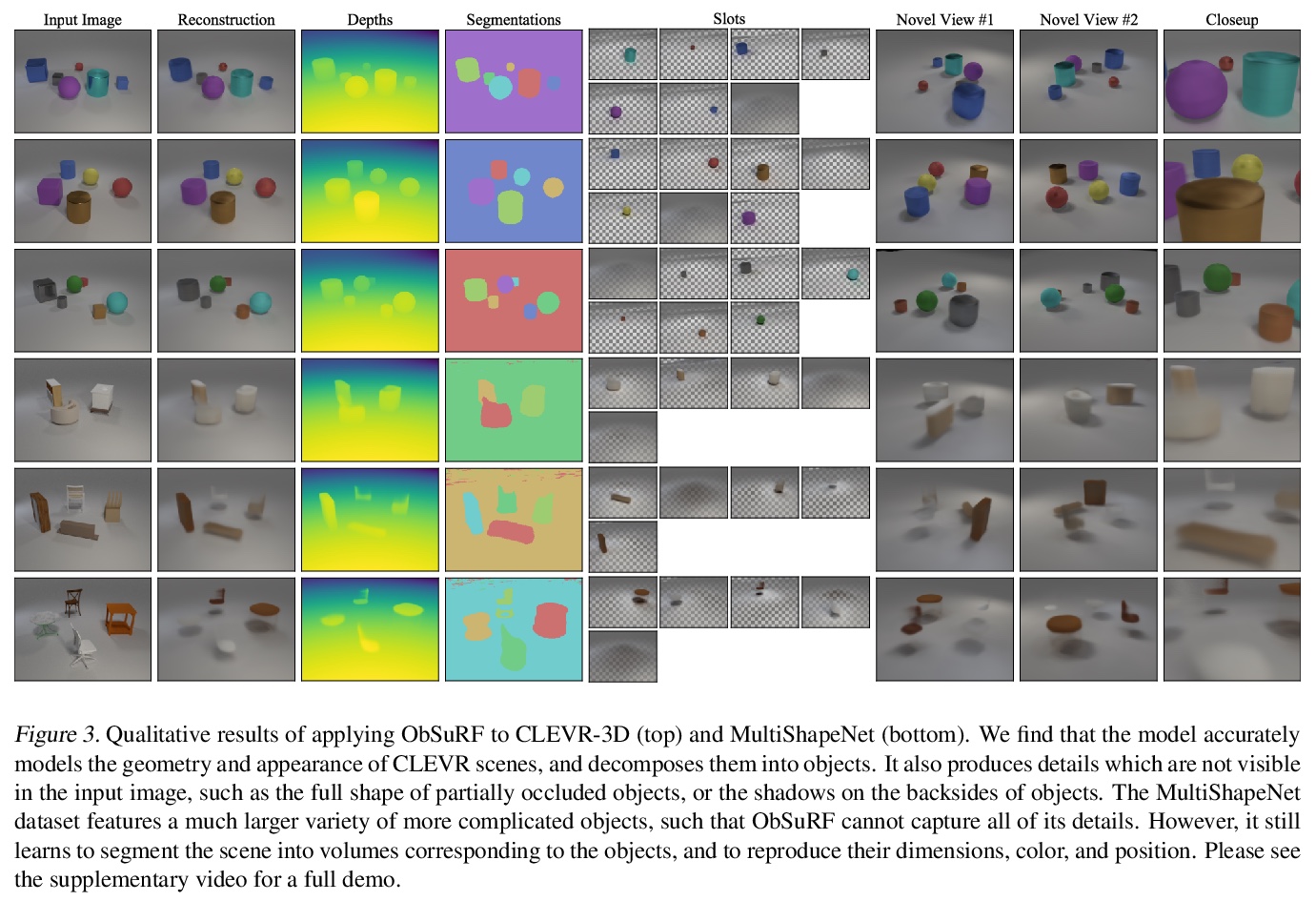
基于无监督体分割的3D场景目标分解。提出ObSuRF,一种将场景单幅图像转化为一组神经辐射场(NeRF)表示的3D模型的方法,每个NeRF对应一个不同目标。编码器网络的一次正向传递输出一组描述场景中目标的潜向量。这些向量被独立作为NeRF解码器的条件,定义每个目标的几何形状和外观。推导出一种新损失,使学习在计算上更加高效,可在RGB-D输入上训练NeRFs,而不需要显式的射线行进。该模型在三个2D图像分割基准上的性能等于或优于最新技术。将其应用于两个多目标3D数据集。一个多视角版本的CLEVR,和一个新的数据集,其中场景是由ShapeNet模型填充的,在对训练场景的RGBD视图进行训练后,ObSuRF不仅能恢复单一输入图像中所描绘的场景的3D几何形状,还能将其分割成目标,尽管在这方面没有接受任何监督。
We present ObSuRF, a method which turns a single image of a scene into a 3D model represented as a set of Neural Radiance Fields (NeRFs), with each NeRF corresponding to a different object. A single forward pass of an encoder network outputs a set of latent vectors describing the objects in the scene. These vectors are used independently to condition a NeRF decoder, defining the geometry and appearance of each object. We make learning more computationally efficient by deriving a novel loss, which allows training NeRFs on RGB-D inputs without explicit ray marching. After confirming that the model performs equal or better than state of the art on three 2D image segmentation benchmarks, we apply it to two multi-object 3D datasets: A multiview version of CLEVR, and a novel dataset in which scenes are populated by ShapeNet models. We find that after training ObSuRF on RGB-D views of training scenes, it is capable of not only recovering the 3D geometry of a scene depicted in a single input image, but also to segment it into objects, despite receiving no supervision in that regard.
https://weibo.com/1402400261/K9AE1D4V8
3、[LG] LatentCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions
O K Yüksel, E Simsar, E G Er, P Yanardag
[EPFL & TUM & Bogazici University]
LatentCLR:无监督可解释方向发现的对比学习方法。提出一种基于特征散度的对比学习方法,以自监督方式发现预训练的GAN模型(如StyleGAN2和BigGAN)潜空间中的可解释方向。证明了该方法能在各种数据集上找到多种不同的、细粒度的方向,所获得的方向具有高度的可迁移性,可迁移到其他ImageNet类。
Recent research has shown great potential for finding interpretable directions in the latent spaces of pre-trained Generative Adversarial Networks (GANs). These directions provide controllable generation and support a wide range of semantic editing operations such as zoom or rotation. The discovery of such directions is often performed in a supervised or semi-supervised fashion and requires manual annotations, limiting their applications in practice. In comparison, unsupervised discovery enables finding subtle directions a priori hard to recognize. In this work, we propose a contrastive-learning-based approach for discovering semantic directions in the latent space of pretrained GANs in a self-supervised manner. Our approach finds semantically meaningful dimensions compatible with state-of-the-art methods.
https://weibo.com/1402400261/K9AJ8qkxC


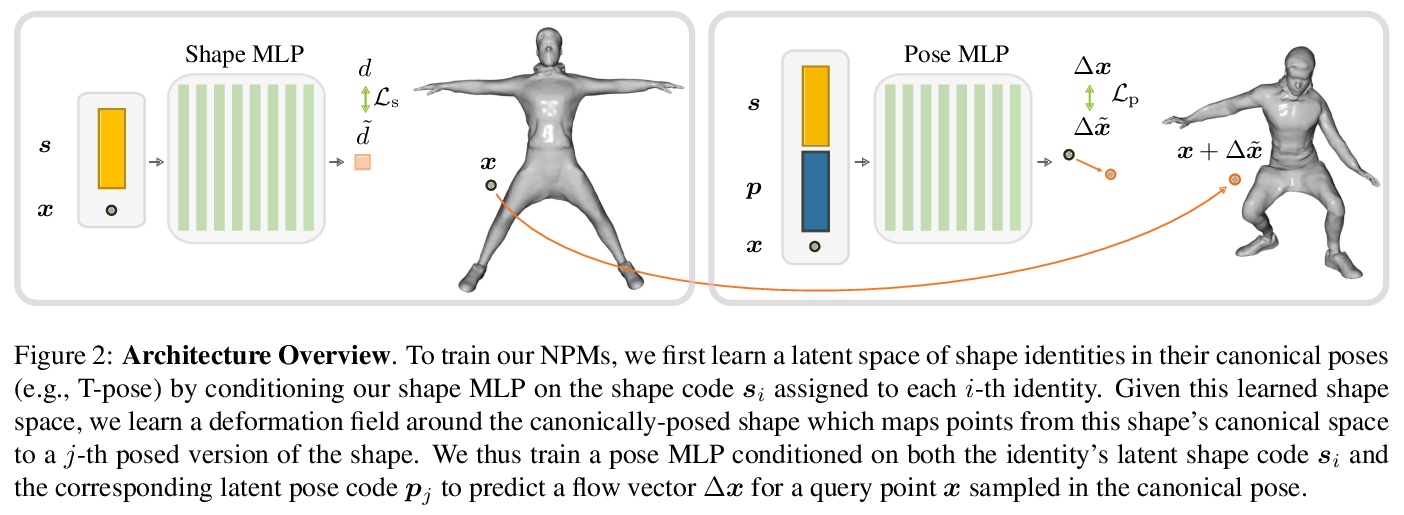
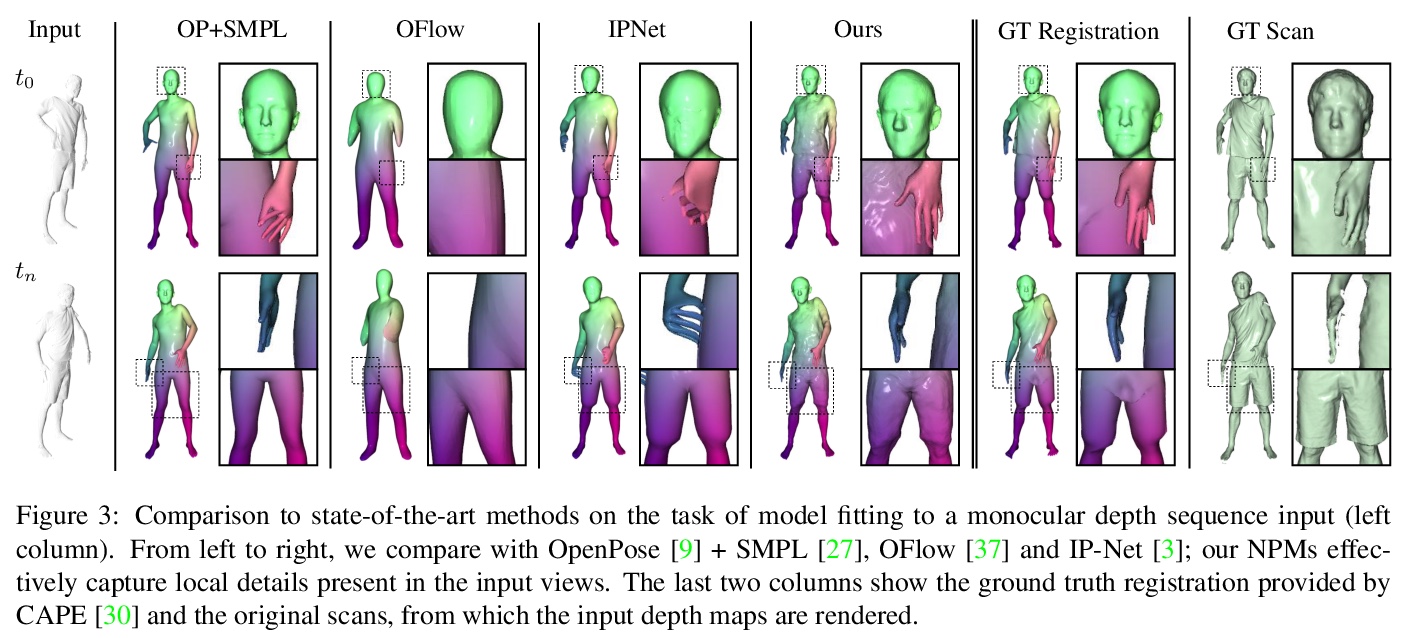
4、[CV] NPMs: Neural Parametric Models for 3D Deformable Shapes
P Palafox, A Božič, J Thies, M Nießner, A Dai
[Technical University of Munich]
NPMs:3D可变形状神经参数化模型。提出一种替代传统参数化3D可变形模型的方法,形状和姿态通过两个前馈网络解缠成独立的潜空间,这些潜空间是单独从数据中学习的,不需要特定领域的知识,如(关节)运动链或部件数量。学习参数模型的构建具有不相干的形状和姿态表示,可准确地表示动态物体的4D序列。通过正则化,能在形状和姿态潜空间上进行测试时优化,以应对将模型拟合到单目深度序列的挑战性任务,同时保留数据中的细节。
Parametric 3D models have enabled a wide variety of tasks in computer graphics and vision, such as modeling human bodies, faces, and hands. However, the construction of these parametric models is often tedious, as it requires heavy manual tweaking, and they struggle to represent additional complexity and details such as wrinkles or clothing. To this end, we propose Neural Parametric Models (NPMs), a novel, learned alternative to traditional, parametric 3D models, which does not require hand-crafted, object-specific constraints. In particular, we learn to disentangle 4D dynamics into latent-space representations of shape and pose, leveraging the flexibility of recent developments in learned implicit functions. Crucially, once learned, our neural parametric models of shape and pose enable optimization over the learned spaces to fit to new observations, similar to the fitting of a traditional parametric model, e.g., SMPL. This enables NPMs to achieve a significantly more accurate and detailed representation of observed deformable sequences. We show that NPMs improve notably over both parametric and non-parametric state of the art in reconstruction and tracking of monocular depth sequences of clothed humans and hands. Latent-space interpolation as well as shape / pose transfer experiments further demonstrate the usefulness of NPMs.
https://weibo.com/1402400261/K9ANKtATB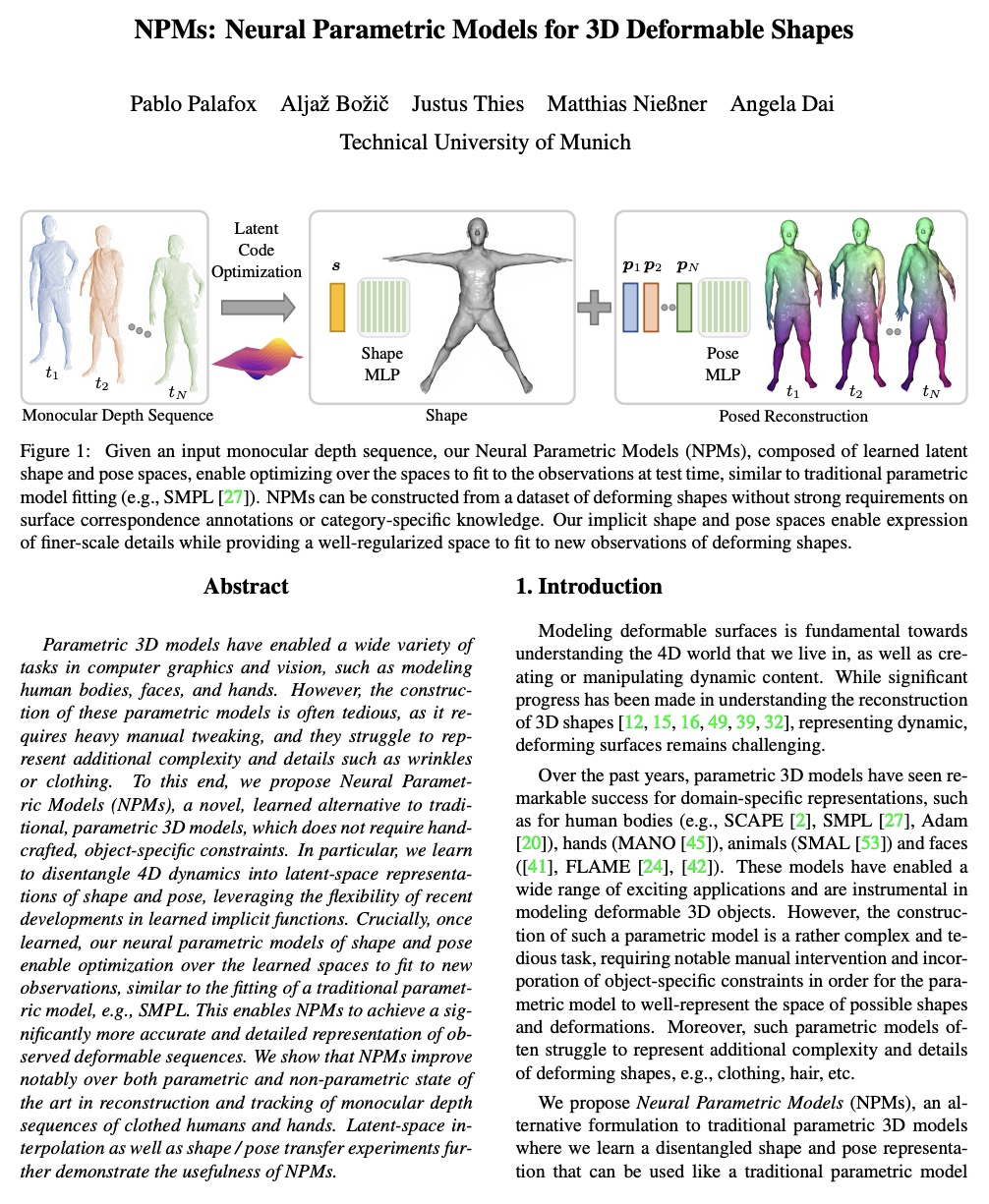

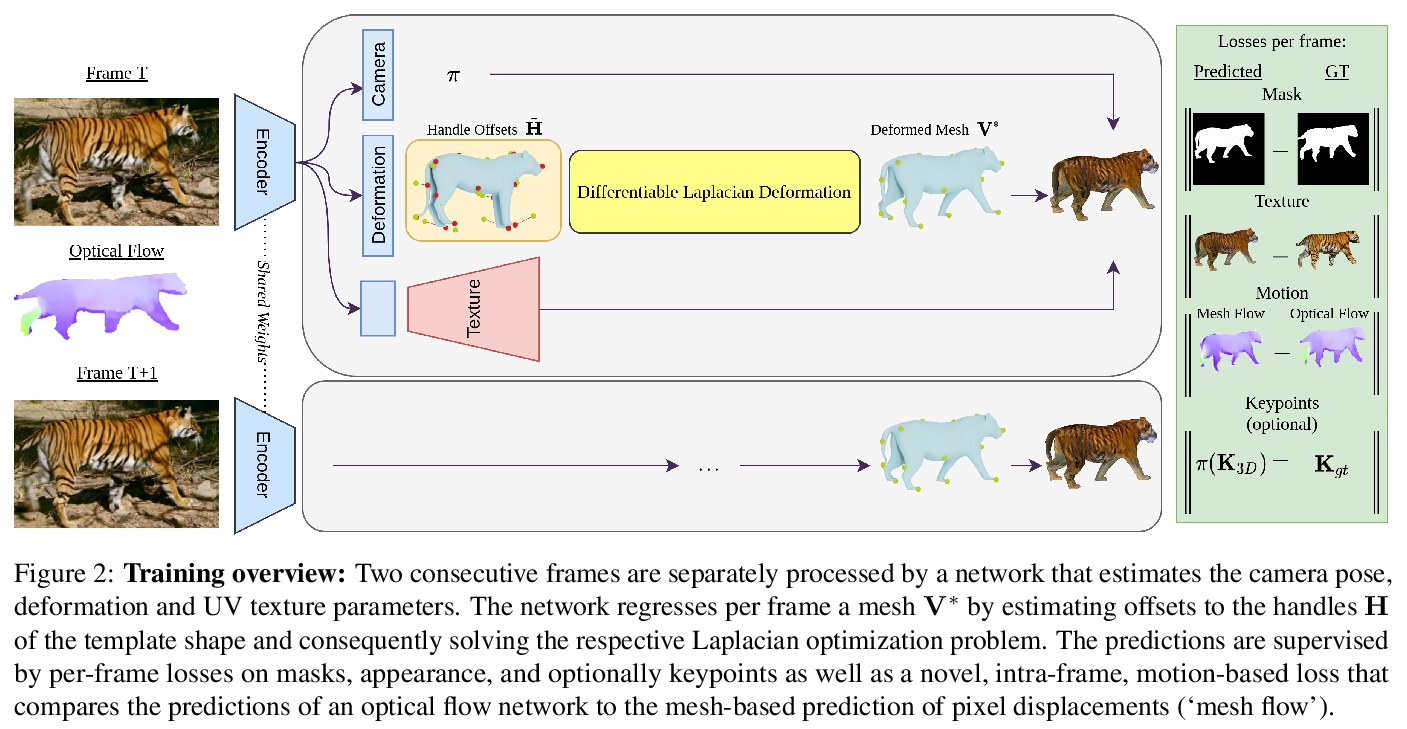
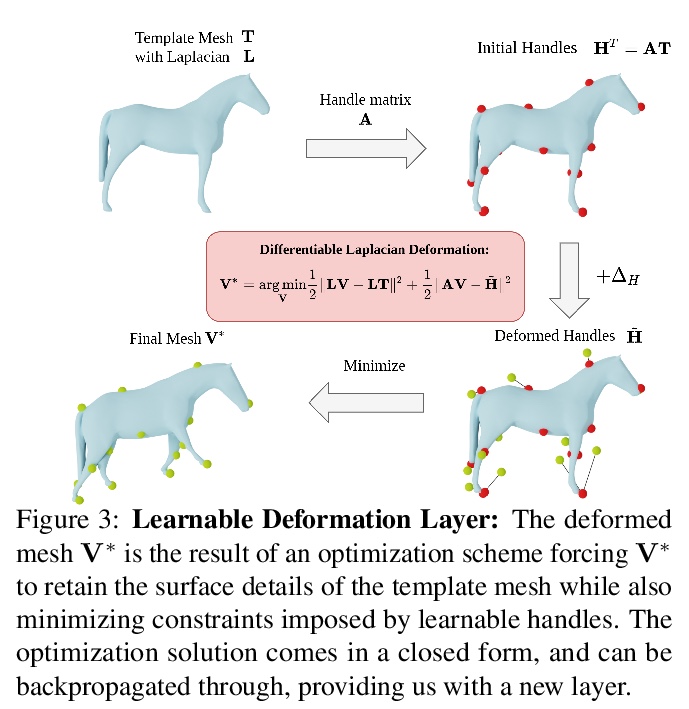
5、[CV] Learning monocular 3D reconstruction of articulated categories from motion
F Kokkinos, I Kokkinos
[University College London]
从运动中学习关节类单目3D重建。提出一种可解释的3D模板变形模型,通过少量局部的、可学习的控键的位移,来控制3D曲面。将这种操作映射为一个依赖于网格-拉平正则化的结构层,可以以端到端方式进行训练。提出一种按样本进行数值优化的方法,可对视频中的网格位移和摄像机进行联合优化,提高训练和测试时后处理的准确性。完全依靠每个类别收集的一小部分视频进行监督,也能获得具有不同形状、视点和纹理的多关节目标类别的最先进的重建结果。
Monocular 3D reconstruction of articulated object categories is challenging due to the lack of training data and the inherent ill-posedness of the problem. In this work we use video self-supervision, forcing the consistency of consecutive 3D reconstructions by a motion-based cycle loss. This largely improves both optimization-based and learning-based 3D mesh reconstruction. We further introduce an interpretable model of 3D template deformations that controls a 3D surface through the displacement of a small number of local, learnable handles. We formulate this operation as a structured layer relying on mesh-laplacian regularization and show that it can be trained in an end-to-end manner. We finally introduce a per-sample numerical optimisation approach that jointly optimises over mesh displacements and cameras within a video, boosting accuracy both for training and also as test time post-processing. While relying exclusively on a small set of videos collected per category for supervision, we obtain state-of-the-art reconstructions with diverse shapes, viewpoints and textures for multiple articulated object categories.
https://weibo.com/1402400261/K9ASnDinf
另外几篇值得关注的论文:
[CV] Language-based Video Editing via Multi-Modal Multi-Level Transformer
基于多模态多级Transformer的基于语言视频编辑
T Fu, X E Wang, S T. Grafton, M P. Eckstein, W Y Wang
[UC Santa Barbara & UC Santa Cruz]
https://weibo.com/1402400261/K9AW0cOT9



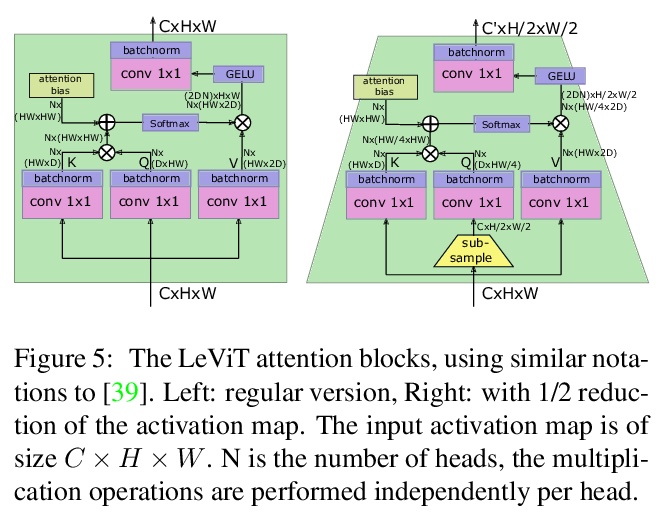
[CV] LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
LeViT:用于图像分类快速推理的视觉Transformer混合神经网络
B Graham, A El-Nouby, H Touvron, P Stock, A Joulin, H Jégou, M Douze
https://weibo.com/1402400261/K9AZ8FXik


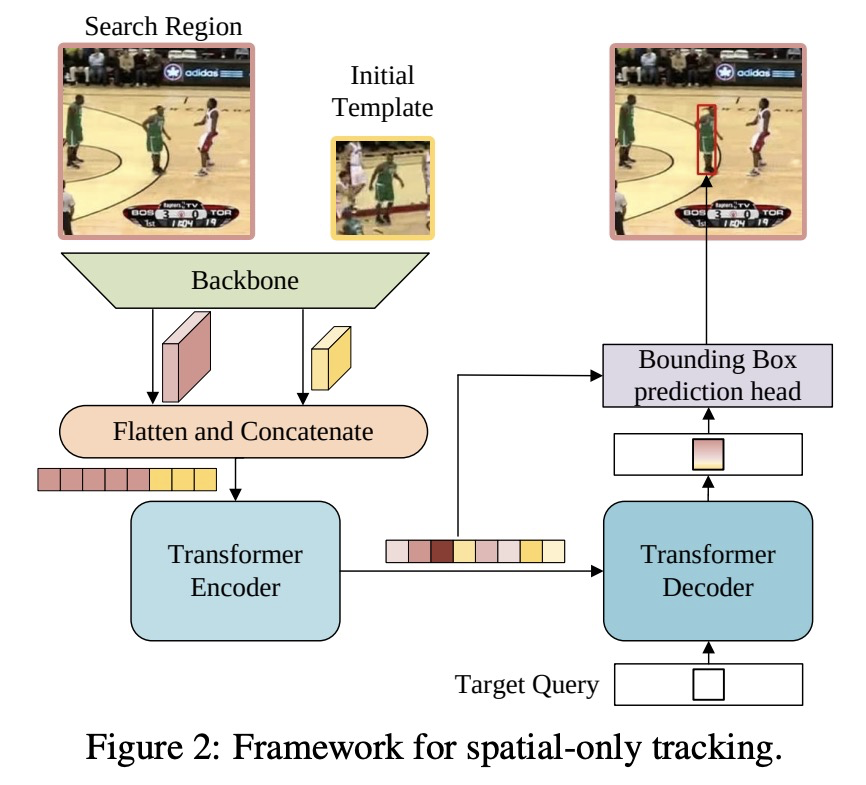
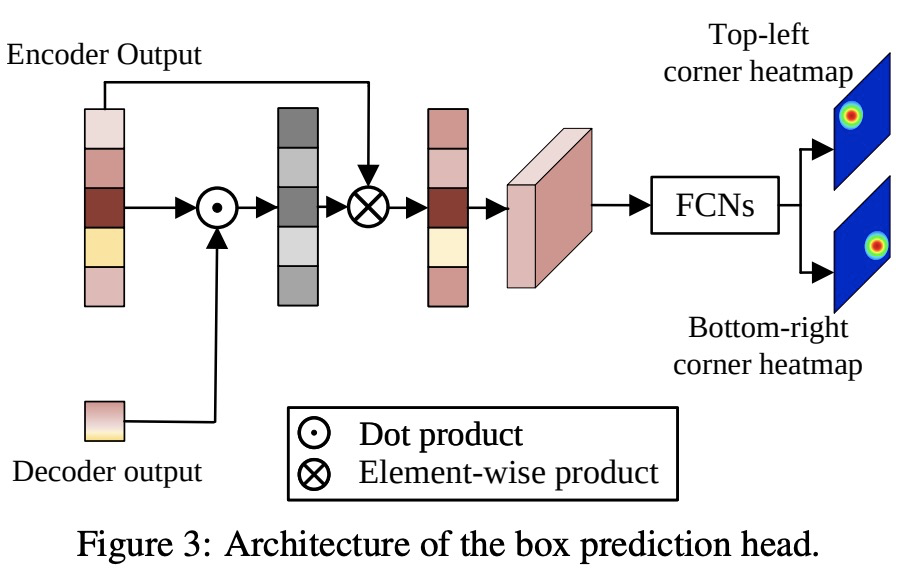
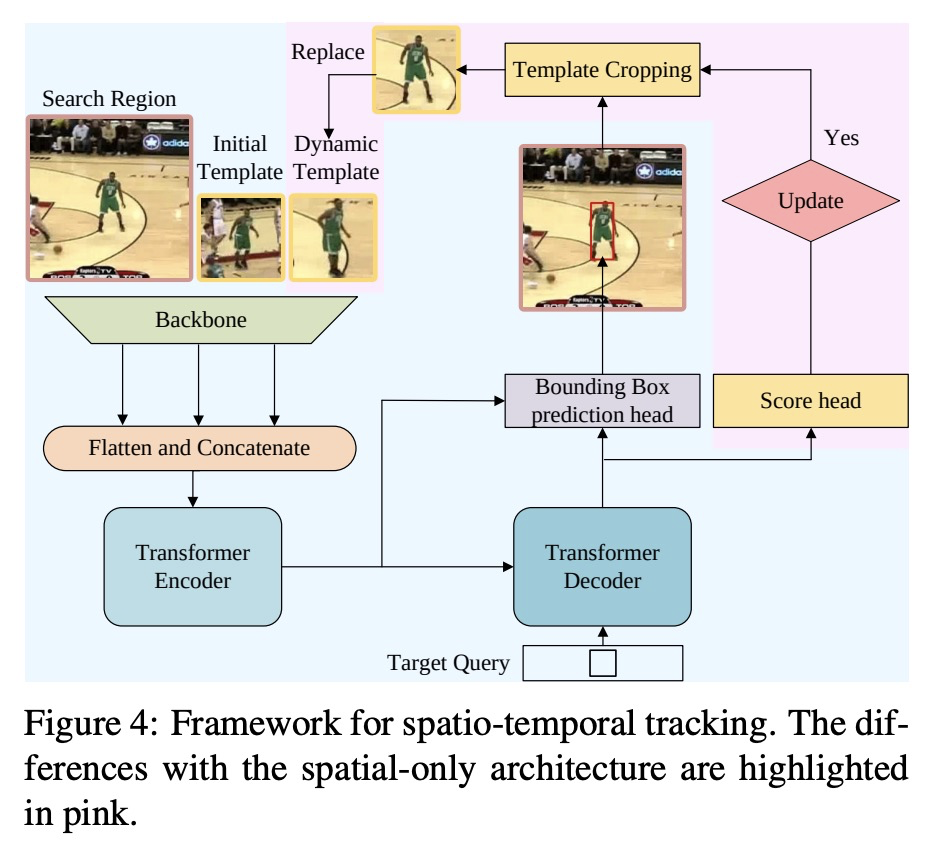
[CV] Learning Spatio-Temporal Transformer for Visual Tracking
面向视觉跟踪的时空Transformer学习
B Yan, H Peng, J Fu, D Wang, H Lu
[Dalian University of Technology & Microsoft Research Asia]
https://weibo.com/1402400261/K9B3ZaTTs
[AS] Robust wav2vec 2.0: Analyzing Domain Shift in Self-Supervised Pre-Training
Robust wav2vec 2.0:自监督预训练中域迁移分析
W Hsu, A Sriram, A Baevski, T Likhomanenko, Q Xu, V Pratap, J Kahn, A Lee, R Collobert, G Synnaeve, M Auli
https://weibo.com/1402400261/K9B8p7iAk

若有收获,就点个赞吧
0 人点赞
