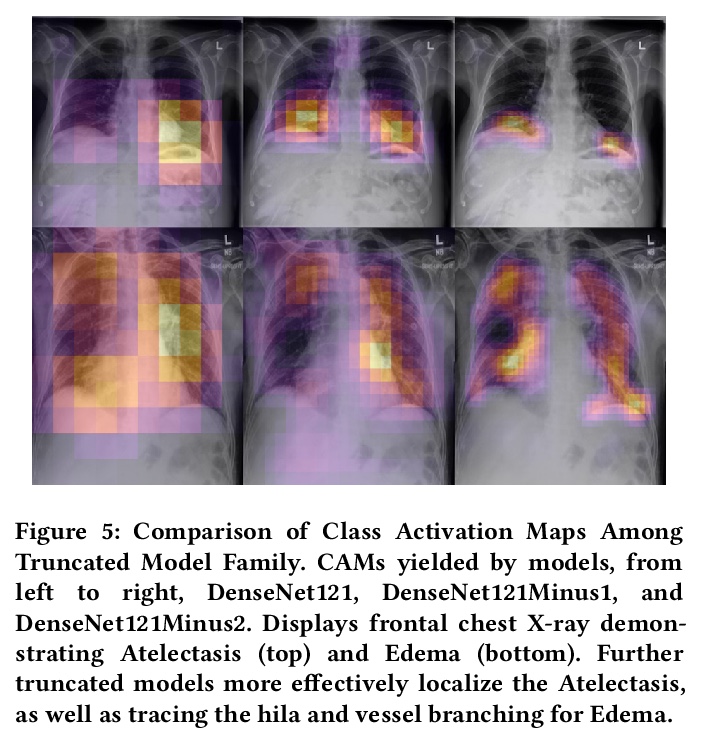
- 1、[CV] CheXtransfer: Performance and Parameter Efficiency of ImageNet Models for Chest X-Ray Interpretation
- 2、[CL] Can a Fruit Fly Learn Word Embeddings?
- 3、[LG] A simple geometric proof for the benefit of depth in ReLU networks
- 4、[CV] Supervised Transfer Learning at Scale for Medical Imaging
- 5、[CL] What Makes Good In-Context Examples for GPT-3?
- [CL] GENIE: A Leaderboard for Human-in-the-Loop Evaluation of Text Generation
- [RO] Learning by Watching: Physical Imitation of Manipulation Skills from Human Videos
- [CL] Joint Energy-based Model Training for Better Calibrated Natural Language Understanding Models
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] CheXtransfer: Performance and Parameter Efficiency of ImageNet Models for Chest X-Ray Interpretation
A Ke, W Ellsworth, O Banerjee, A Y. Ng, P Rajpurkar
[Stanford University]
CheXtransfer: 胸片判读的ImageNet模型性能和参数效率。ImageNet上的更高性能,并不意味着在医学影像任务上也能取得更高性能。比较了16种流行的卷积架构在大型胸部X光片数据集(CheXpert)上的迁移性能和参数效率,发现ImageNet和CheXpert性能之间没有统计学上的显著关系。不管有没有预训练模型,ImageNet性能和CheXpert性能之间都没有关系;对于医学影像任务来说,不用预训练模型时,相比模型族架构的大小,模型族的选择对性能影响更大;ImageNet预训练对各种架构都产生了统计学意义上的性能提升,对于较小的架构有更高的提升;截断预训练模型中的最终块,发现可使模型参数效率平均提高3.25倍,而性能没有统计学上的显著下降。ImageNet和CheXpert性能上的差异,可能源于胸片判读任务和数据属性的独特性,胸片判读任务与自然图像分类的不同之处在于:(1)疾病分类可能取决于少量像素的异常,(2)胸片判读是多任务分类,(3)与许多自然图像分类数据集相比,其类别要少得多。数据属性方面,胸片与自然图像的不同之处在于,X光片是灰度的,在不同的图像中具有相似的空间结构(总是前后、后方或侧方)。
Deep learning methods for chest X-ray interpretation typically rely on pretrained models developed for ImageNet. This paradigm assumes that better ImageNet architectures perform better on chest X-ray tasks and that ImageNet-pretrained weights provide a performance boost over random initialization. In this work, we compare the transfer performance and parameter efficiency of 16 popular convolutional architectures on a large chest X-ray dataset (CheXpert) to investigate these assumptions. First, we find no relationship between ImageNet performance and CheXpert performance for both models without pretraining and models with pretraining. Second, we find that, for models without pretraining, the choice of model family influences performance more than size within a family for medical imaging tasks. Third, we observe that ImageNet pretraining yields a statistically significant boost in performance across architectures, with a higher boost for smaller architectures. Fourth, we examine whether ImageNet architectures are unnecessarily large for CheXpert by truncating final blocks from pretrained models, and find that we can make models 3.25x more parameter-efficient on average without a statistically significant drop in performance. Our work contributes new experimental evidence about the relation of ImageNet to chest x-ray interpretation performance.
https://weibo.com/1402400261/JDZvS0ih7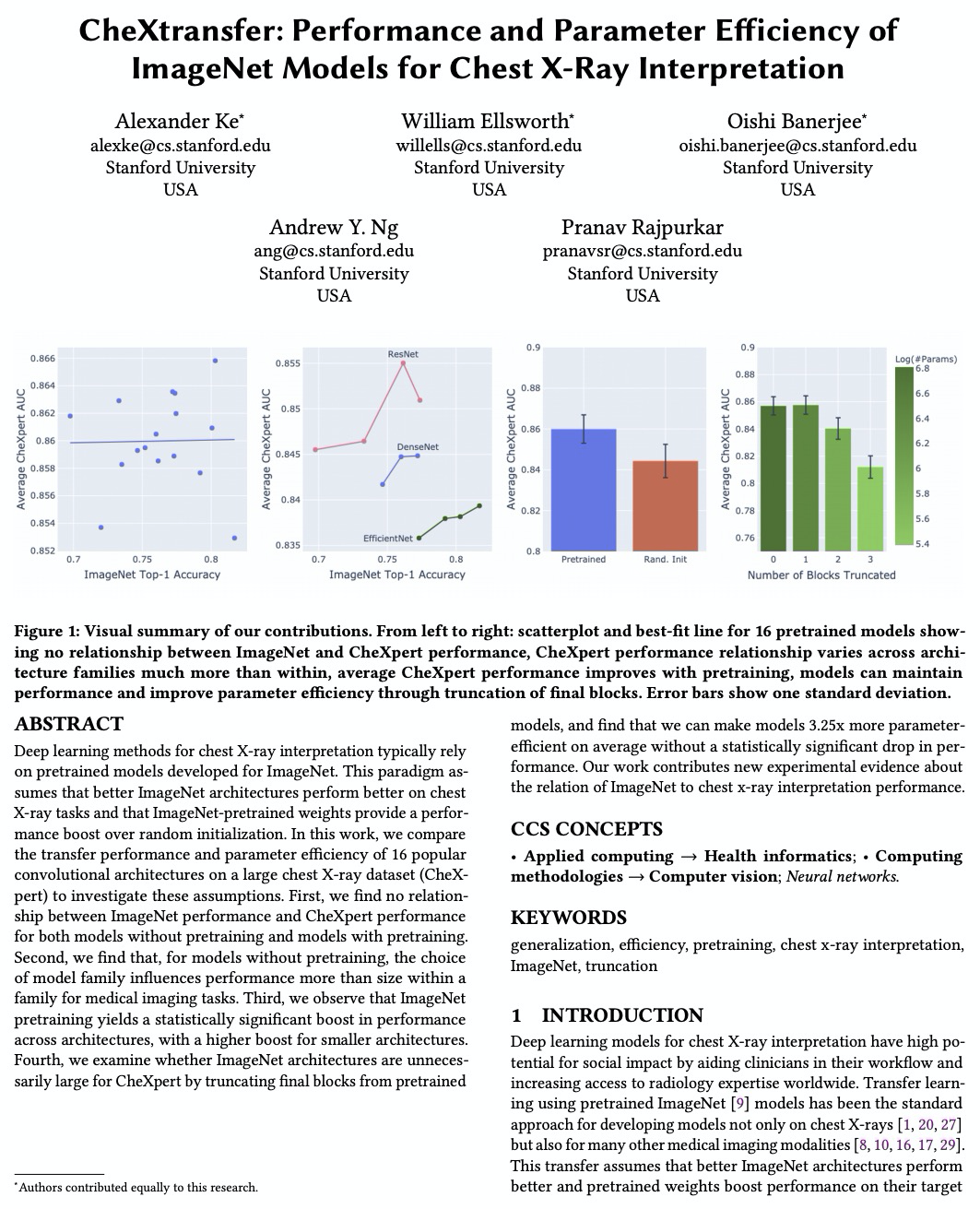
2、[CL] Can a Fruit Fly Learn Word Embeddings?
Y Liang, C K. Ryali, B Hoover, L Grinberg, S Navlakha, M J. Zaki, D Krotov
[MIT-IBM Watson AI Lab & UC San Diego & IBM Research & Cold Spring Harbor Laboratory & RPI]
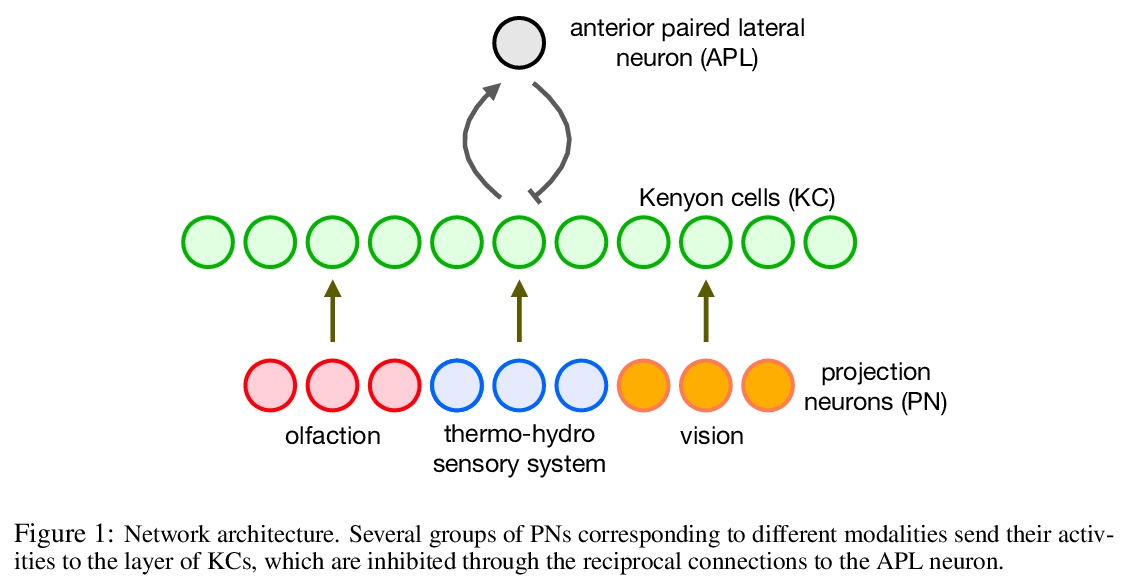
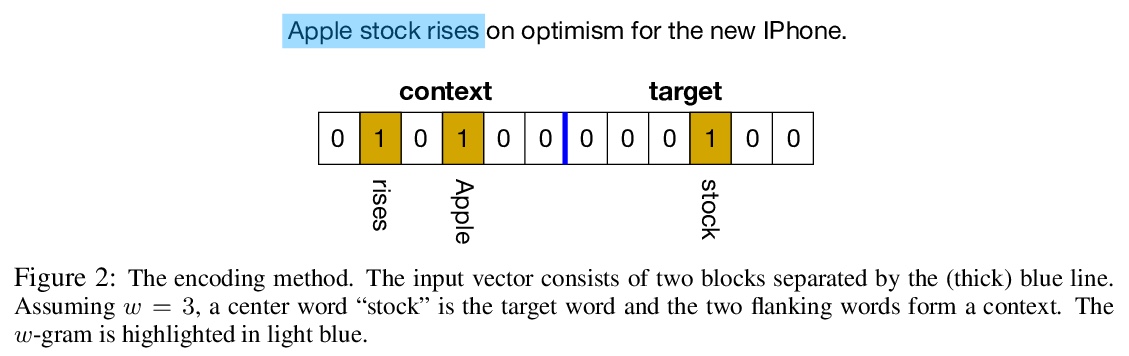
果蝇大脑能学会词嵌入吗?可以,而且更高效。尝试将神经科学研究得最好的网络之一——果蝇脑中的KC网络——的核心算法,用于解决一个明确定义的机器学习任务,即从文本中学习词嵌入。实验证明,该网络确实可以学习单词及其上下文之间的相关性,产生高质量的词嵌入。与传统方法(如BERT、GloVe)用密集表示进行词嵌入不同,果蝇网络算法以稀疏二进制哈希码形式编码词的语义及其上下文。在语义相似性任务上,果蝇词嵌入在短哈希长度的情况下,优于常见的最先进连续词嵌入的二值化方法。在词上下文任务上,果蝇网络的表现优于GloVe近3%,word2vec超过6%,但输给BERT 3.5%。然而,与BERT相比,虽然分类精度上存在微小差距,但获得果蝇嵌入只需要少得多的计算资源。这一结果进一步说明,与经典(非生物)算法相比,生物启发算法可能具有更高的计算效率,虽然准确性方面会略有损失。
The mushroom body of the fruit fly brain is one of the best studied systems in neuroscience. At its core it consists of a population of Kenyon cells, which receive inputs from multiple sensory modalities. These cells are inhibited by the anterior paired lateral neuron, thus creating a sparse high dimensional representation of the inputs. In this work we study a mathematical formalization of this network motif and apply it to learning the correlational structure between words and their context in a corpus of unstructured text, a common natural language processing (NLP) task. We show that this network can learn semantic representations of words and can generate both static and context-dependent word embeddings. Unlike conventional methods (e.g., BERT, GloVe) that use dense representations for word embedding, our algorithm encodes semantic meaning of words and their context in the form of sparse binary hash codes. The quality of the learned representations is evaluated on word similarity analysis, word-sense disambiguation, and document classification. It is shown that not only can the fruit fly network motif achieve performance comparable to existing methods in NLP, but, additionally, it uses only a fraction of the computational resources (shorter training time and smaller memory footprint).
https://weibo.com/1402400261/JDZHZmYK8
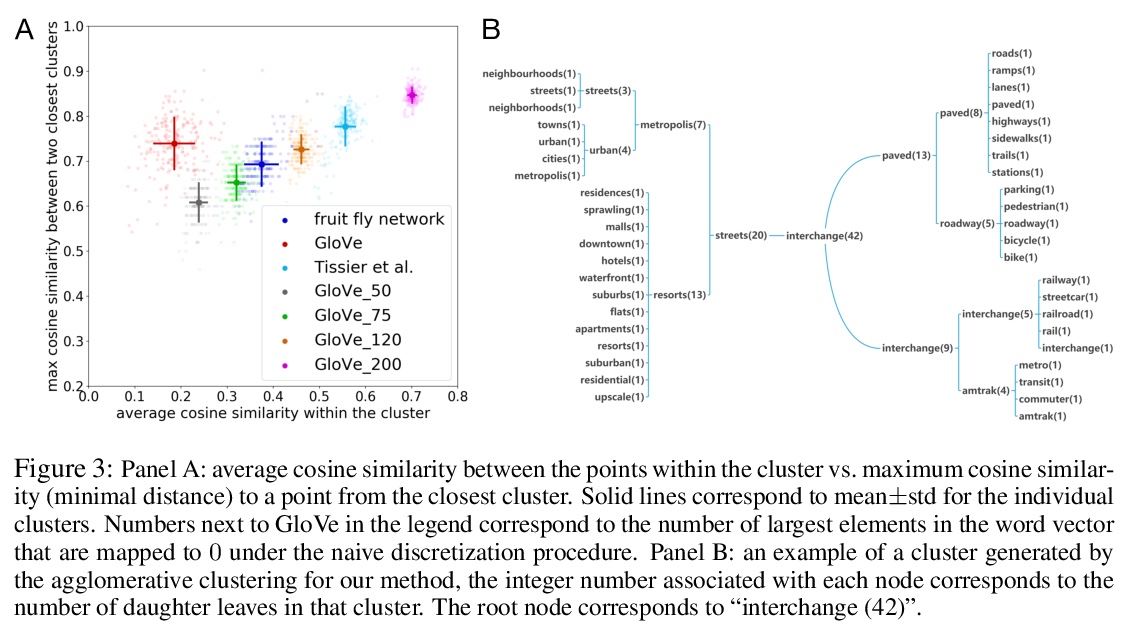

3、[LG] A simple geometric proof for the benefit of depth in ReLU networks
A Amrami, Y Goldberg
[Bar Ilan University]
ReLU网络深度效益的简单几何证明。提供了一个简单证明,证明了在ReLU多层前馈网络中深度带来的好处。构造性证明基于几何论证和空间折叠结构,只用到了基本的数学概念和证明技术。
We present a simple proof for the benefit of depth in multi-layer feedforward network with rectified activation (“depth separation”). Specifically we present a sequence of classification problems indexed by > m such that (a) for any fixed depth rectified network there exist an > m above which classifying problem > m correctly requires exponential number of parameters (in > m); and (b) for any problem in the sequence, we present a concrete neural network with linear depth (in > m) and small constant width (> ≤4) that classifies the problem with zero error.The constructive proof is based on geometric arguments and a space folding construction.While stronger bounds and results exist, our proof uses substantially simpler tools and techniques, and should be accessible to undergraduate students in computer science and people with similar backgrounds.
https://weibo.com/1402400261/JDZT50QZb
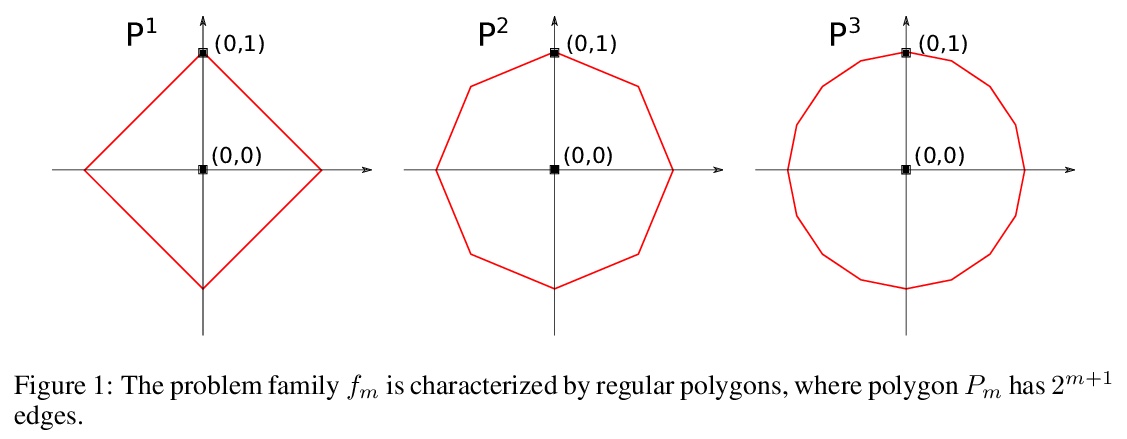
4、[CV] Supervised Transfer Learning at Scale for Medical Imaging
B Mustafa, A Loh, J Freyberg, P MacWilliams, A Karthikesalingam, N Houlsby, V Natarajan
[Google]
医学影像的规模化有监督迁移学习。研究了大规模有监督预训练对医学影像方面的应用,用更大的架构和更大的预训练数据集,可在各种不同的医疗领域中产生显著改进,尽管与预训练数据存在显著差异。研究了大规模预训练网络在三个不同的成像任务上的应用:胸部X光、乳房X光和皮肤病,研究了迁移性能和在医疗领域部署的关键属性,包括:分布外泛化、数据效率、子组公平性和不确定性估计,发现对其中一些属性,从自然图像到医学图像的迁移确实非常有效,但只有在足够的规模下才会如此。
Transfer learning is a standard technique to improve performance on tasks with limited data. However, for medical imaging, the value of transfer learning is less clear. This is likely due to the large domain mismatch between the usual natural-image pre-training (e.g. ImageNet) and medical images. However, recent advances in transfer learning have shown substantial improvements from scale. We investigate whether modern methods can change the fortune of transfer learning for medical imaging. For this, we study the class of large-scale pre-trained networks presented by Kolesnikov et al. on three diverse imaging tasks: chest radiography, mammography, and dermatology. We study both transfer performance and critical properties for the deployment in the medical domain, including: out-of-distribution generalization, data-efficiency, sub-group fairness, and uncertainty estimation. Interestingly, we find that for some of these properties transfer from natural to medical images is indeed extremely effective, but only when performed at sufficient scale.
https://weibo.com/1402400261/JDZZlB7su
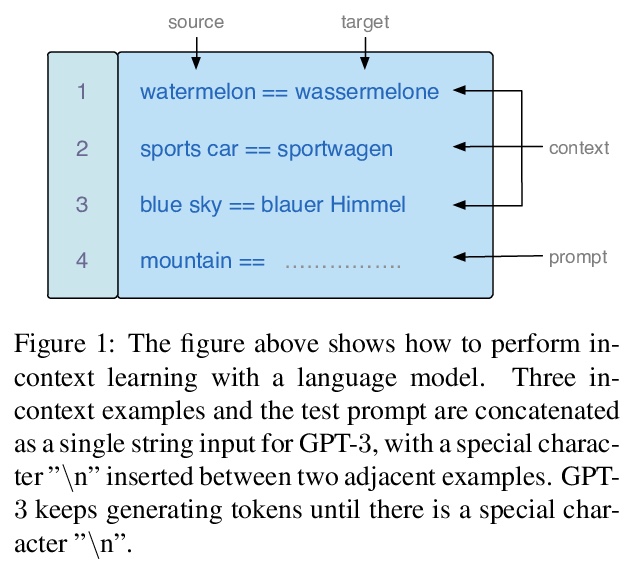
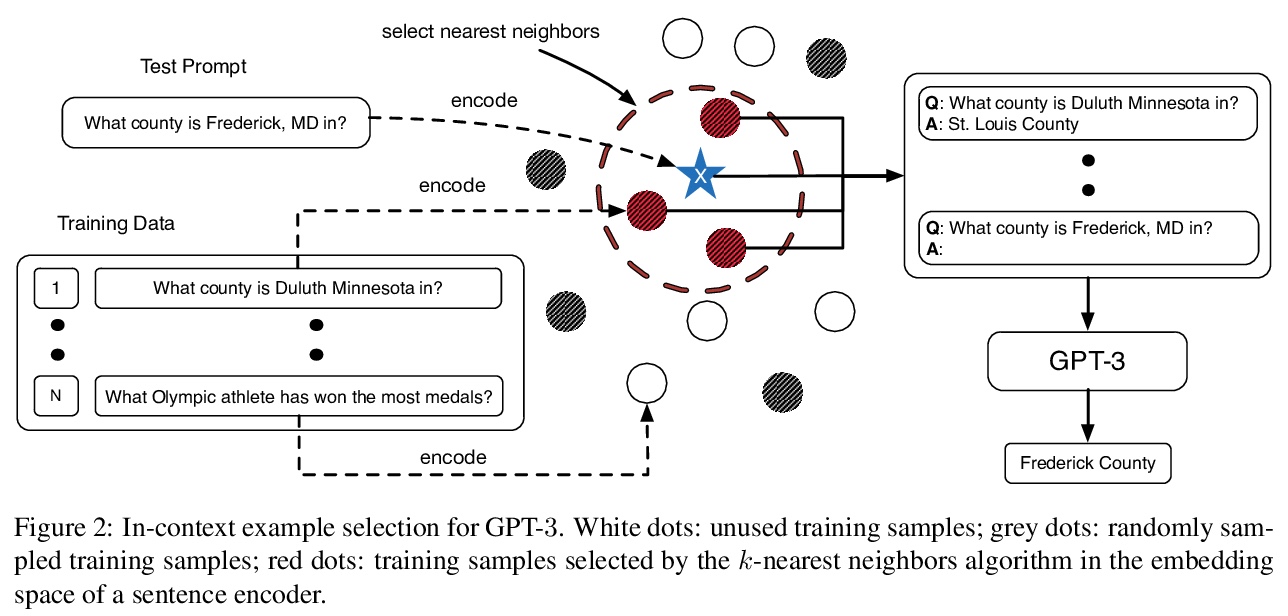
5、[CL] What Makes Good In-Context Examples for GPT-3?
J Liu, D Shen, Y Zhang, B Dolan, L Carin, W Chen
[Duke University & Microsoft Dynamics 365 AI & Microsoft Research]
如何提高GPT-3上下文内(In-Context)样本性能。提出KATE,一种非参数选择方法,根据与测试样本的语义相似性来检索上下文内样本。在几个自然语言理解和生成任务上,相比随机采样基线,所提出方法显著提高了GPT-3性能。在任务相关的数据集上对检索句嵌入进行微调,也会产生进一步的经验收益。
GPT-> 3 has attracted lots of attention due to its superior performance across a wide range of NLP tasks, especially with its powerful and versatile in-context few-shot learning ability. Despite its success, we found that the empirical results of GPT-> 3 depend heavily on the choice of in-context examples. In this work, we investigate whether there are more effective strategies for judiciously selecting in-context examples (relative to random sampling) that better leverage GPT-> 3’s few-shot capabilities. Inspired by the recent success of leveraging a retrieval module to augment large-scale neural network models, we propose to retrieve examples that are semantically-similar to a test sample to formulate its corresponding prompt. Intuitively, the in-context examples selected with such a strategy may serve as more informative inputs to unleash GPT-> 3’s extensive knowledge. We evaluate the proposed approach on several natural language understanding and generation benchmarks, where the retrieval-based prompt selection approach consistently outperforms the random baseline. Moreover, it is observed that the sentence encoders fine-tuned on task-related datasets yield even more helpful retrieval results. Notably, significant gains are observed on tasks such as table-to-text generation (41.9% on the ToTTo dataset) and open-domain question answering (45.5% on the NQ dataset). We hope our investigation could help understand the behaviors of GPT-> 3 and large-scale pre-trained LMs in general and enhance their few-shot capabilities.
https://weibo.com/1402400261/JE0fqhQoI
另外几篇值得关注的论文:
[CL] GENIE: A Leaderboard for Human-in-the-Loop Evaluation of Text Generation
GENIE:面向文本生成人在环路评价的排行榜
D Khashabi, G Stanovsky, J Bragg, N Lourie, J Kasai, Y Choi, N A. Smith, D S. Weld
[Allen Institute for AI & Hebrew University of Jerusalem & University of Washington]
https://weibo.com/1402400261/JE0uKlyeZ

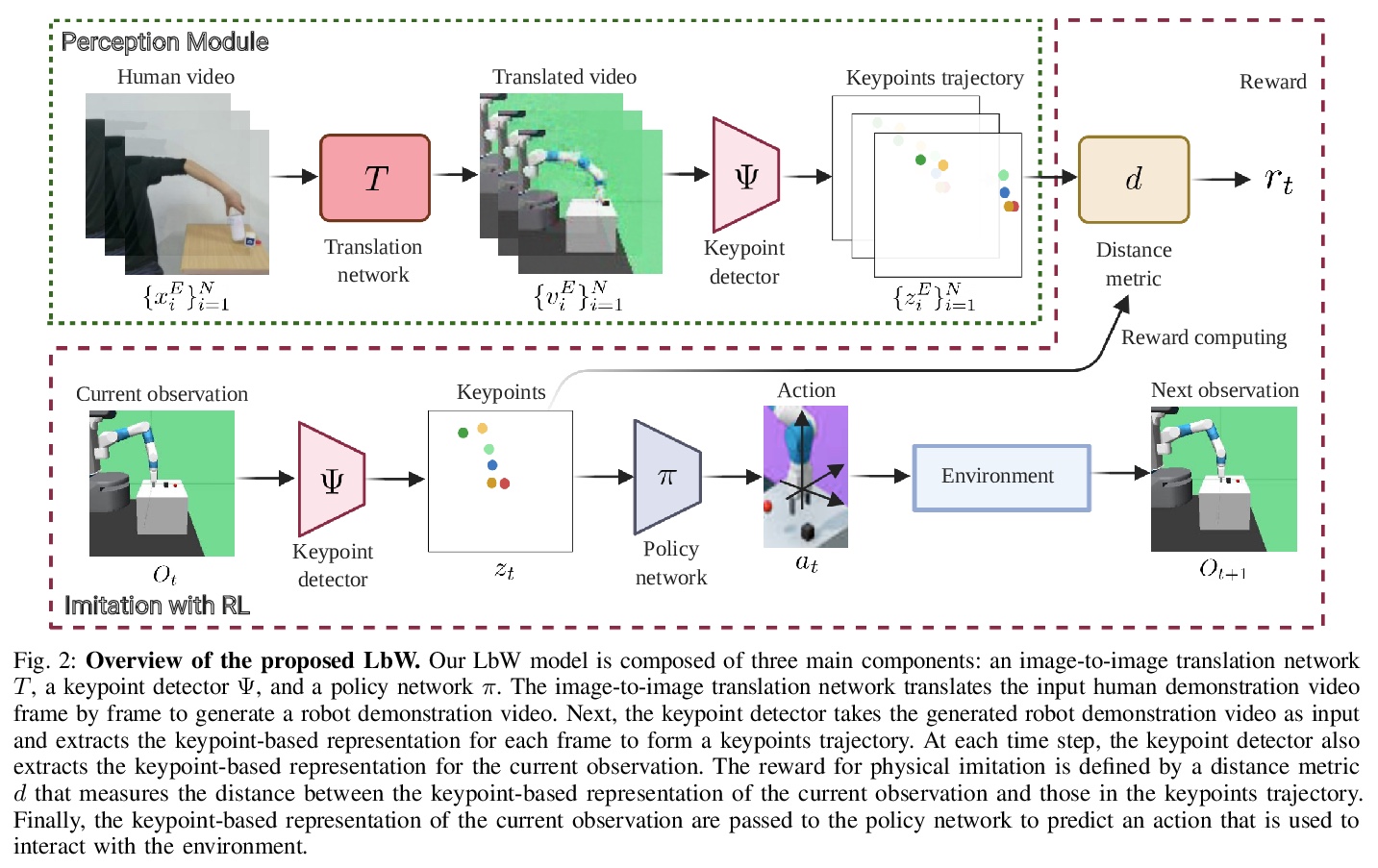
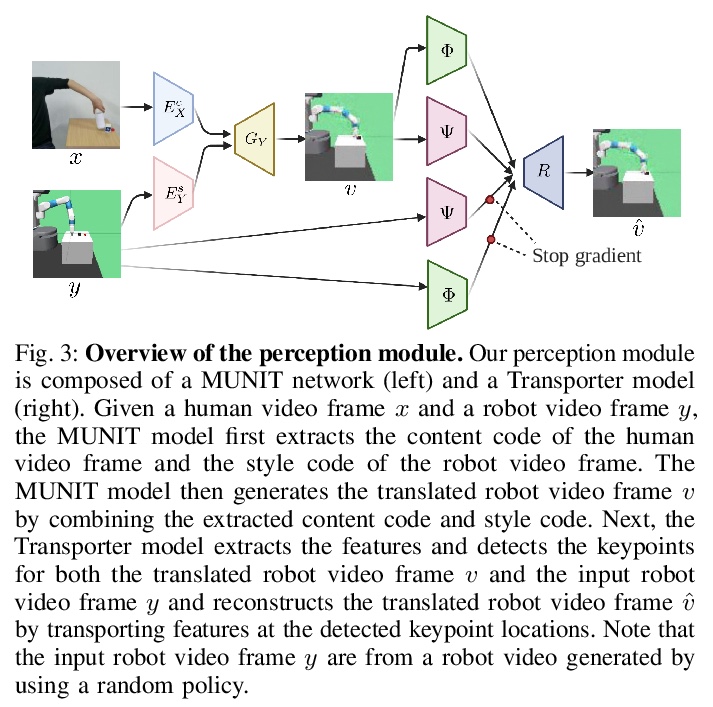
[RO] Learning by Watching: Physical Imitation of Manipulation Skills from Human Videos
边看边学:从人类视频学习操纵技能的物理模仿
H Xiong, Q Li, Y Chen, H Bharadhwaj, S Sinha, A Garg
[University of Toronto]
https://weibo.com/1402400261/JE0xgEkdX
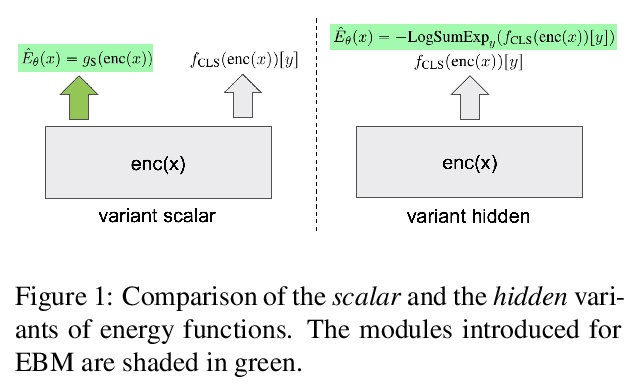
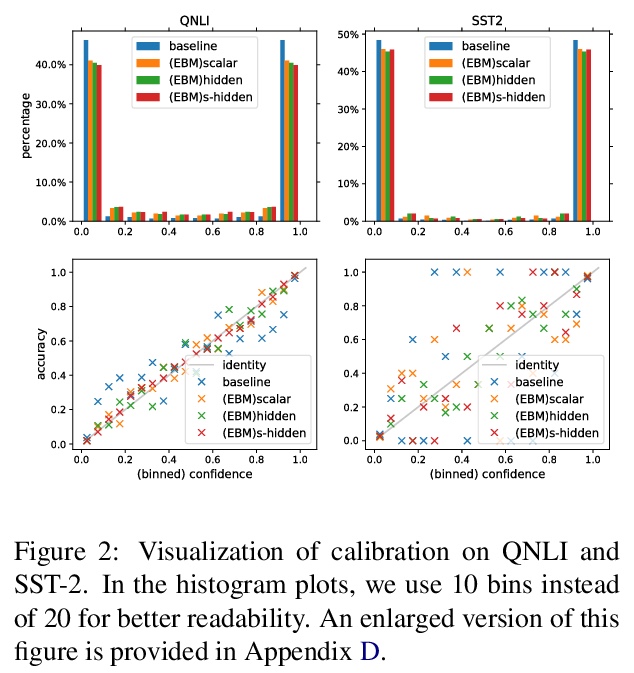
[CL] Joint Energy-based Model Training for Better Calibrated Natural Language Understanding Models
面向更好校准自然语言理解模型的联合基于能量模型训练
T He, B McCann, C Xiong, E Hosseini-Asl
[MIT & Salesforce Research]
https://weibo.com/1402400261/JE0z35ToN

若有收获,就点个赞吧
0 人点赞
