LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
(*表示值得重点关注)
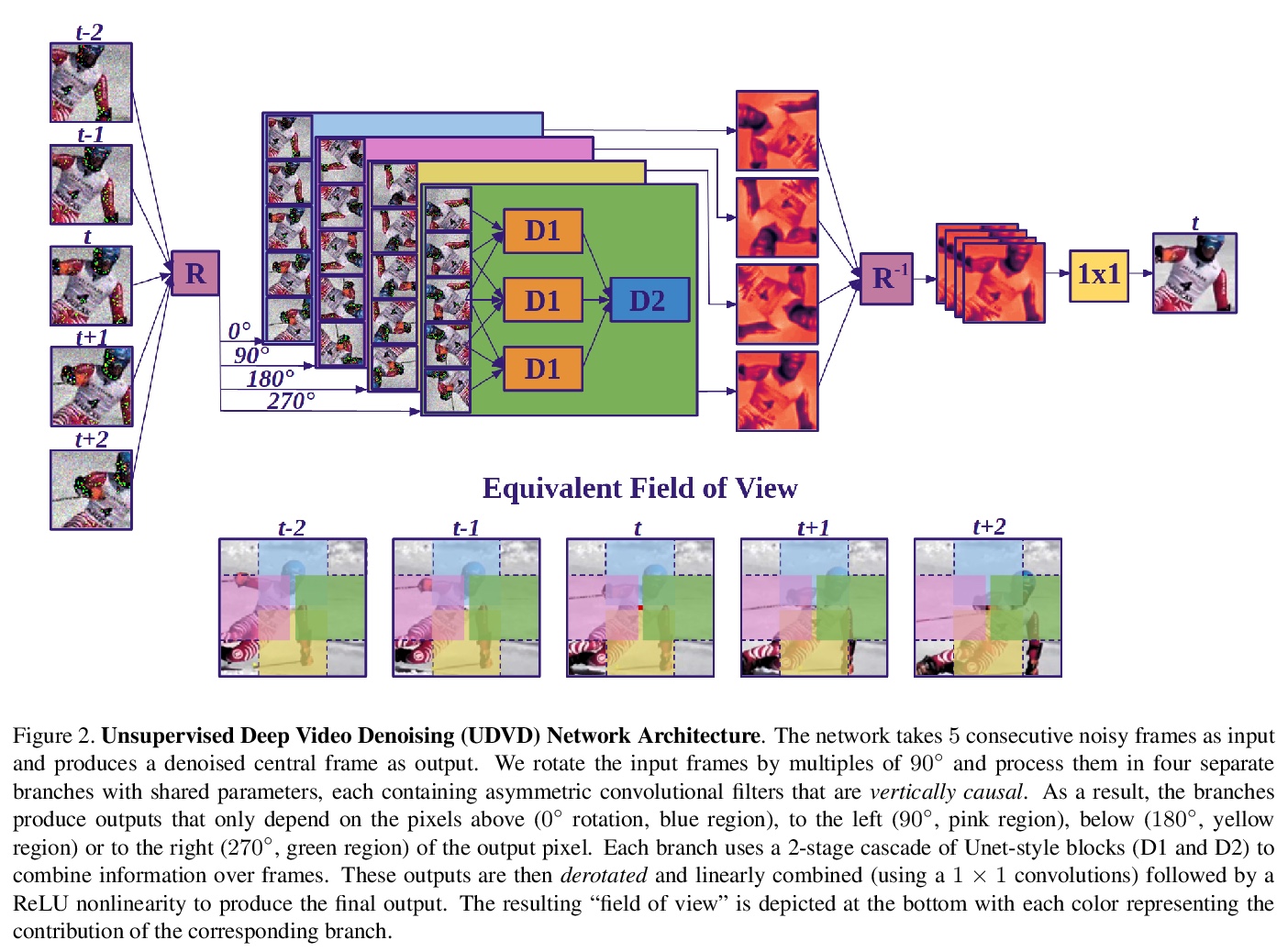
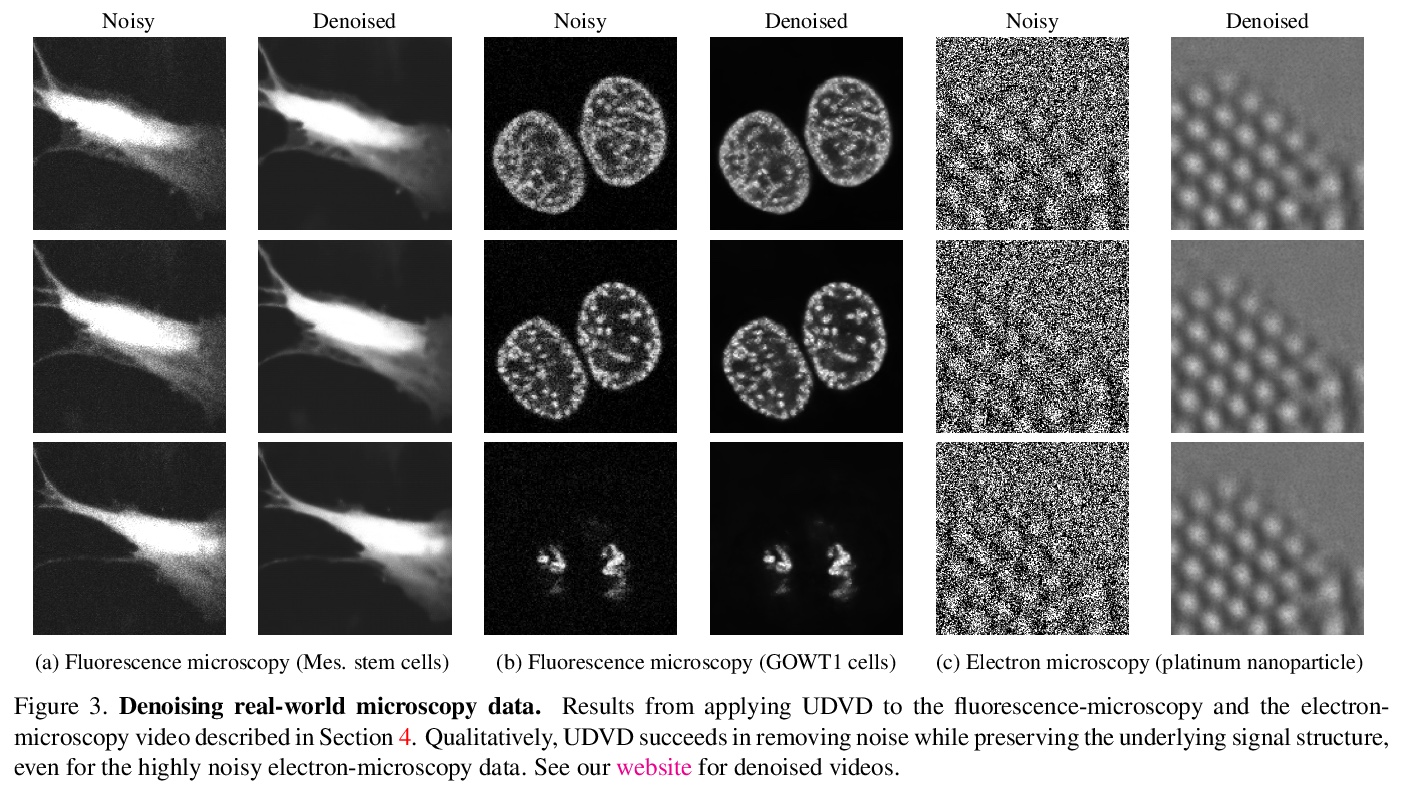
1、** *[CV] Unsupervised Deep Video Denoising
D Y Sheth, S Mohan, J L. Vincent, R Manzorro, P A. Crozier, M M. Khapra, E P. Simoncelli, C Fernandez-Granda
[Indian Institute of Technology Madras & New York University & School for Engineering of Matter, Transport, and Energy]
能学到隐式自适应运动补偿的无监督深度视频去噪。提出一种无监督的深度视频去噪方法,实现了与最先进的有监督方法相当的性能。该方法与数据增强技术相结合,即使在单独的含噪短序列上进行训练,也能实现有效去噪,使得在实际显微镜图像中应用成为可能。对去噪神经网络进行基于梯度的分析,结果显示神经网络学会了执行隐式自适应运动补偿。
Deep convolutional neural networks (CNNs) currently achieve state-of-the-art performance in denoising videos. They are typically trained with supervision, minimizing the error between the network output and ground-truth clean videos. However, in many applications, such as microscopy, noiseless videos are not available. To address these cases, we build on recent advances in unsupervised still image denoising to develop an Unsupervised Deep Video Denoiser (UDVD). UDVD is shown to perform competitively with current state-of-the-art supervised methods on benchmark datasets, even when trained only on a single short noisy video sequence. Experiments on fluorescence-microscopy and electron-microscopy data illustrate the promise of our approach for imaging modalities where ground-truth clean data is generally not available. In addition, we study the mechanisms used by trained CNNs to perform video denoising. An analysis of the gradient of the network output with respect to its input reveals that these networks perform spatio-temporal filtering that is adapted to the particular spatial structures and motion of the underlying content. We interpret this as an implicit and highly effective form of motion compensation, a widely used paradigm in traditional video denoising, compression, and analysis. Code and iPython notebooks for our analysis are available in > this https URL .
https://weibo.com/1402400261/Jwxsr0sWY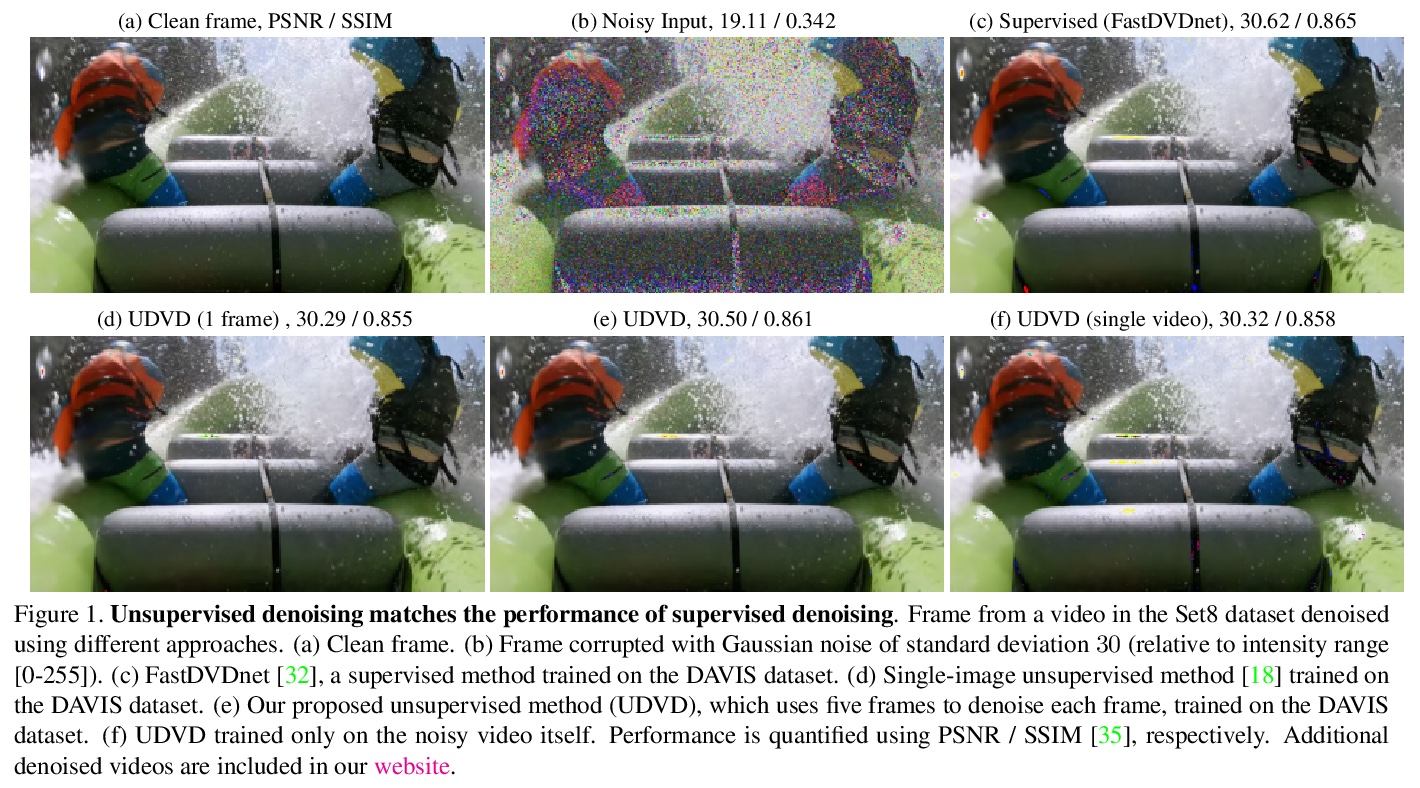
2、** **[LG] General Invertible Transformations for Flow-based Generative Modeling
J M. Tomczak
[Vrije Universiteit Amsterdam]
基于流生成建模的通用可逆变换。提出一类新的可逆变换,证明了许多经典的可逆变换可由该命题推导出来。提出了双耦合层,介绍了它们如何在基于流的模型中用于整数值(整数离散流)。
In this paper, we present a new class of invertible transformations. We indicate that many well-known invertible tranformations in reversible logic and reversible neural networks could be derived from our proposition. Next, we propose two new coupling layers that are important building blocks of flow-based generative models. In the preliminary experiments on toy digit data, we present how these new coupling layers could be used in Integer Discrete Flows (IDF), and that they achieve better results than standard coupling layers used in IDF and RealNVP.
https://weibo.com/1402400261/Jwxwn8jSj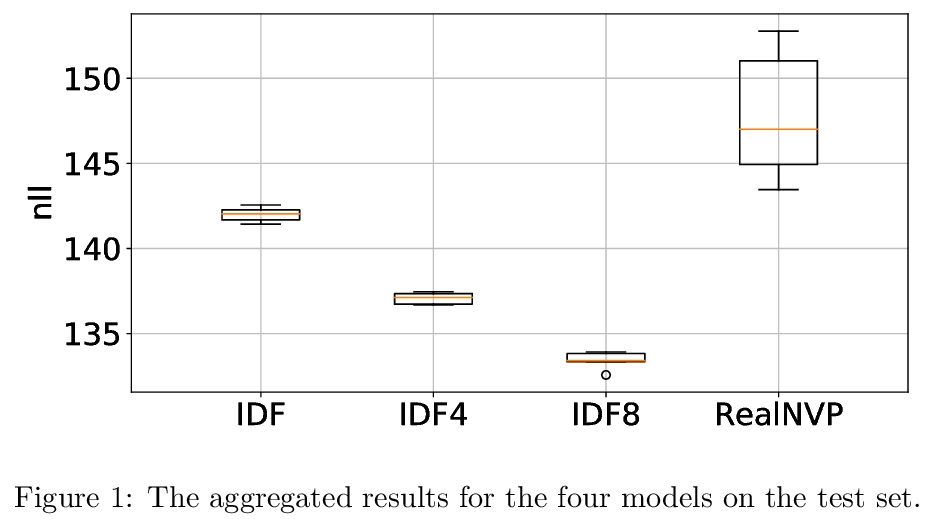

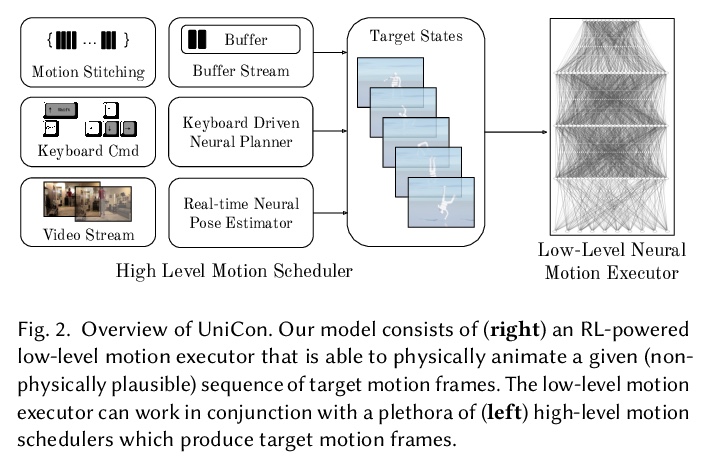
3、** **[CV] UniCon: Universal Neural Controller For Physics-based Character Motion
T Wang, Y Guo, M Shugrina, S Fidler
[NVIDIA]
UniCon:面向基于物理的角色运动的通用神经控制器。提出基于物理的通用神经控制器(UniCon),在大规模运动数据集上学习,来掌握数千种不同风格运动。UniCon是两级框架,包括高级运动调度器和强化学习驱动的低级动作执行器,引入了新的目标函数和训练技术,在性能上取得了显著飞跃。与之前方法相比,UniCon控制器具有更好的鲁棒性和泛化性,一旦完成训练,动作执行器可以与不同的高级调度器结合,无需再次训练,适用于各种实时交互应用。
The field of physics-based animation is gaining importance due to the increasing demand for realism in video games and films, and has recently seen wide adoption of data-driven techniques, such as deep reinforcement learning (RL), which learn control from (human) demonstrations. While RL has shown impressive results at reproducing individual motions and interactive locomotion, existing methods are limited in their ability to generalize to new motions and their ability to compose a complex motion sequence interactively. In this paper, we propose a physics-based universal neural controller (UniCon) that learns to master thousands of motions with different styles by learning on large-scale motion datasets. UniCon is a two-level framework that consists of a high-level motion scheduler and an RL-powered low-level motion executor, which is our key innovation. By systematically analyzing existing multi-motion RL frameworks, we introduce a novel objective function and training techniques which make a significant leap in performance. Once trained, our motion executor can be combined with different high-level schedulers without the need for retraining, enabling a variety of real-time interactive applications. We show that UniCon can support keyboard-driven control, compose motion sequences drawn from a large pool of locomotion and acrobatics skills and teleport a person captured on video to a physics-based virtual avatar. Numerical and qualitative results demonstrate a significant improvement in efficiency, robustness and generalizability of UniCon over prior state-of-the-art, showcasing transferability to unseen motions, unseen humanoid models and unseen perturbation.
https://weibo.com/1402400261/JwxAniPjW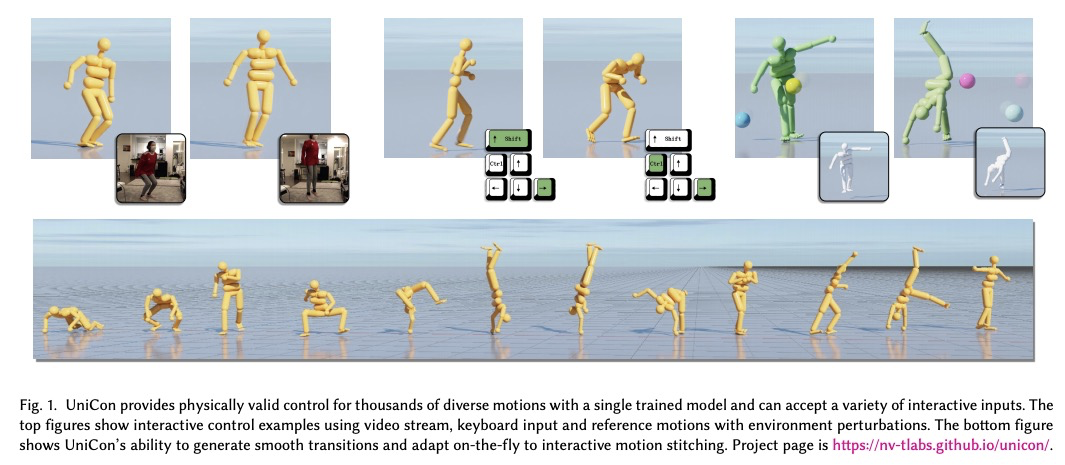

4、** **[CV] End-to-End Video Instance Segmentation with Transformers
Y Wang, Z Xu, X Wang, C Shen, B Cheng, H Shen, H Xia
[Meituan & The University of Adelaide]
基于Transformer的端到端视频实例分割。提出基于Transformer的视频实例分割框架VisTR,将视频实例分割(VIS)任务作为端到端并行序列解码/预测问题。对于由多个图像帧组成的输入视频片段,VisTR直接按顺序输出视频中每个实例的掩膜序列。其核心是一种新的、高效的实例序列匹配和分割策略,在序列级对实例进行整体的管理和分割。VisTR在相似度学习的同一视角下进行实例分割和跟踪,大大简化了整个流程。
Video instance segmentation (VIS) is the task that requires simultaneously classifying, segmenting and tracking object instances of interest in video. Recent methods typically develop sophisticated pipelines to tackle this task. Here, we propose a new video instance segmentation framework built upon Transformers, termed VisTR, which views the VIS task as a direct end-to-end parallel sequence decoding/prediction problem. Given a video clip consisting of multiple image frames as input, VisTR outputs the sequence of masks for each instance in the video in order directly. At the core is a new, effective instance sequence matching and segmentation strategy, which supervises and segments instances at the sequence level as a whole. VisTR frames the instance segmentation and tracking in the same perspective of similarity learning, thus considerably simplifying the overall pipeline and is significantly different from existing approaches. Without bells and whistles, VisTR achieves the highest speed among all existing VIS models, and achieves the best result among methods using single model on the YouTube-VIS dataset. For the first time, we demonstrate a much simpler and faster video instance segmentation framework built upon Transformers, achieving competitive accuracy. We hope that VisTR can motivate future research for more video understanding tasks.
https://weibo.com/1402400261/JwxEH5cpN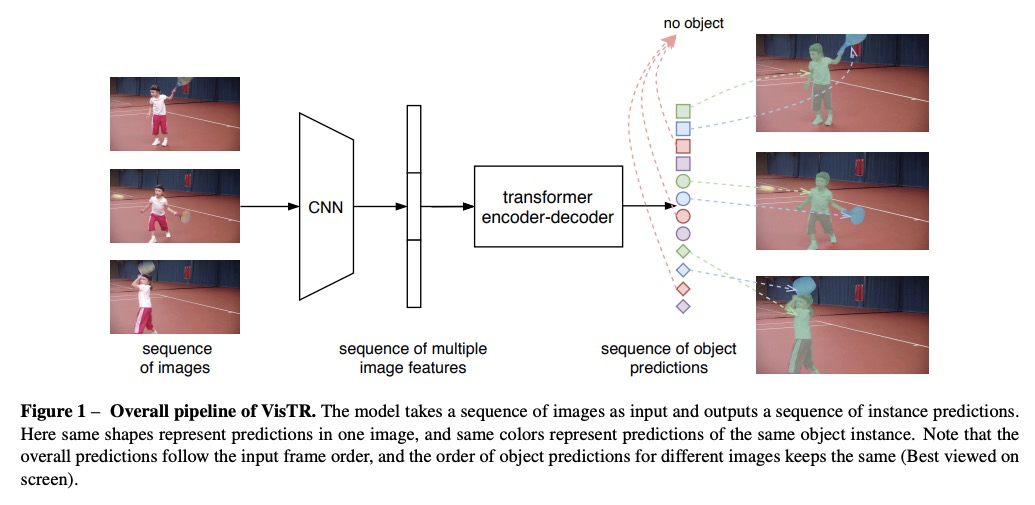


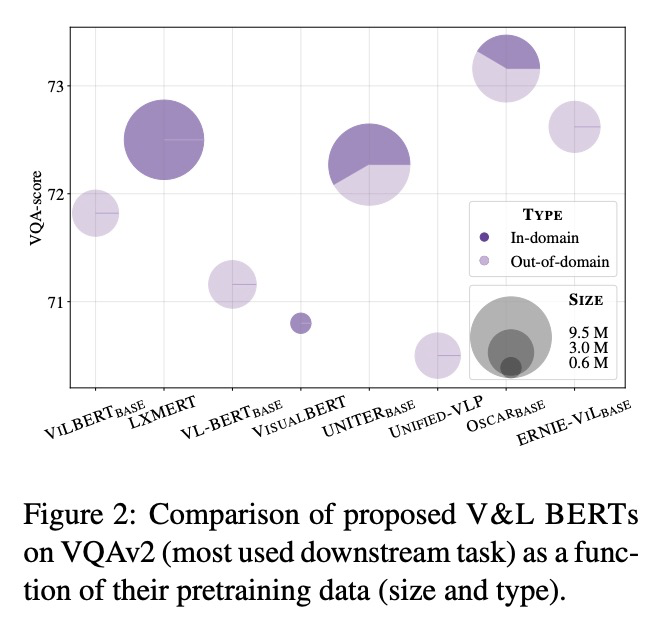
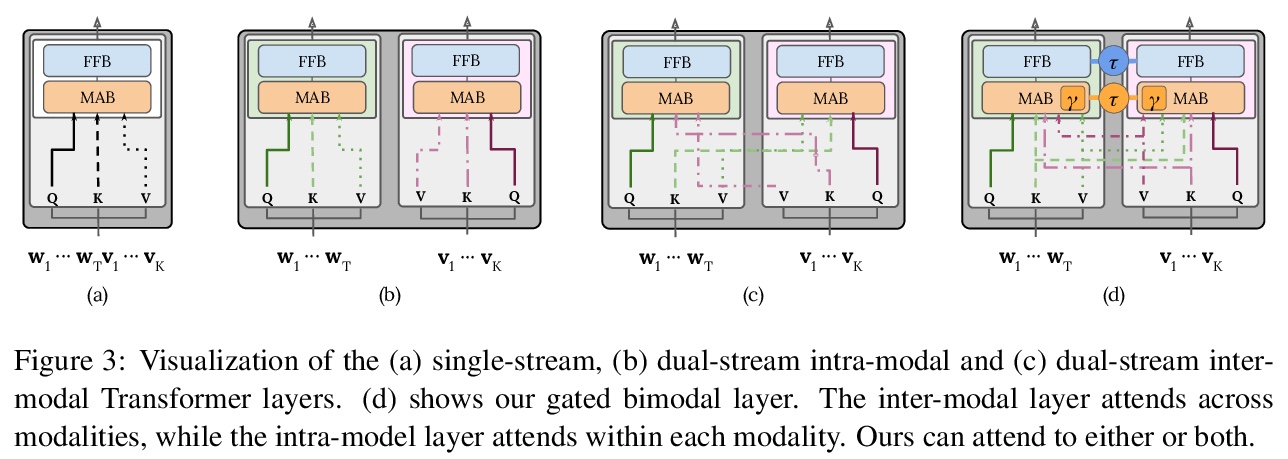
5、[CL] Multimodal Pretraining Unmasked: Unifying the Vision and Language BERTs
E Bugliarello, R Cotterell, N Okazaki, D Elliott
[University of Copenhagen & University of Cambridge & Tokyo Institute of Technology]
多模态预训练研究:视觉和BERT语言模型的统一。研究了对视觉和BERT语言模型进行预训练的单流和双流式编码器,提出了统一的数学框架,在此框架下,最近提出的视觉和BERT语言模型预训练可看作特殊情况。在预训练和微调中,由于随机初始化,多模态模型性能会发生显著变化,用相同的超参数和数据进行训练时,被测试模型可获得类似性能。单流和双流式模型系列是统一的,嵌入层对模型的最终性能具有关键作用。
Large-scale pretraining and task-specific fine-tuning is now the standard methodology for many tasks in computer vision and natural language processing. Recently, a multitude of methods have been proposed for pretraining vision and language BERTs to tackle challenges at the intersection of these two key areas of AI. These models can be categorized into either single-stream or dual-stream encoders. We study the differences between these two categories, and show how they can be unified under a single theoretical framework. We then conduct controlled experiments to discern the empirical differences between five V&L BERTs. Our experiments show that training data and hyperparameters are responsible for most of the differences between the reported results, but they also reveal that the embedding layer plays a crucial role in these massive models.
https://weibo.com/1402400261/JwxIatQ94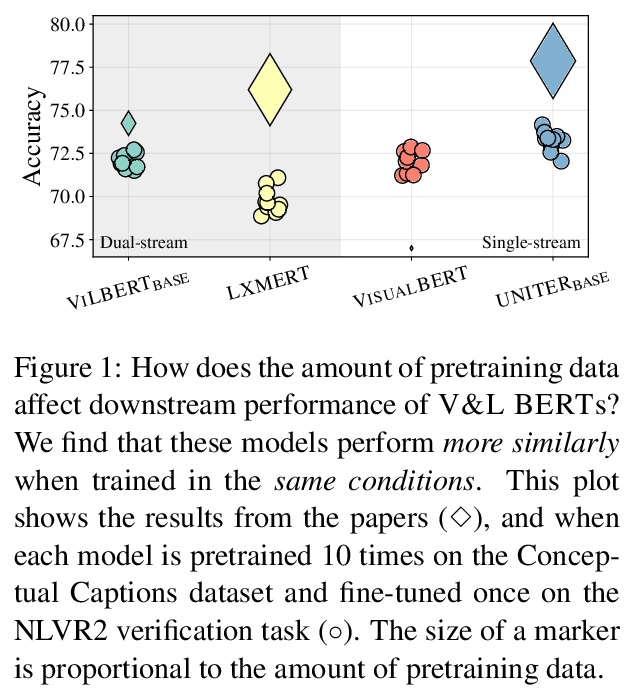
另外几篇值得关注的论文:
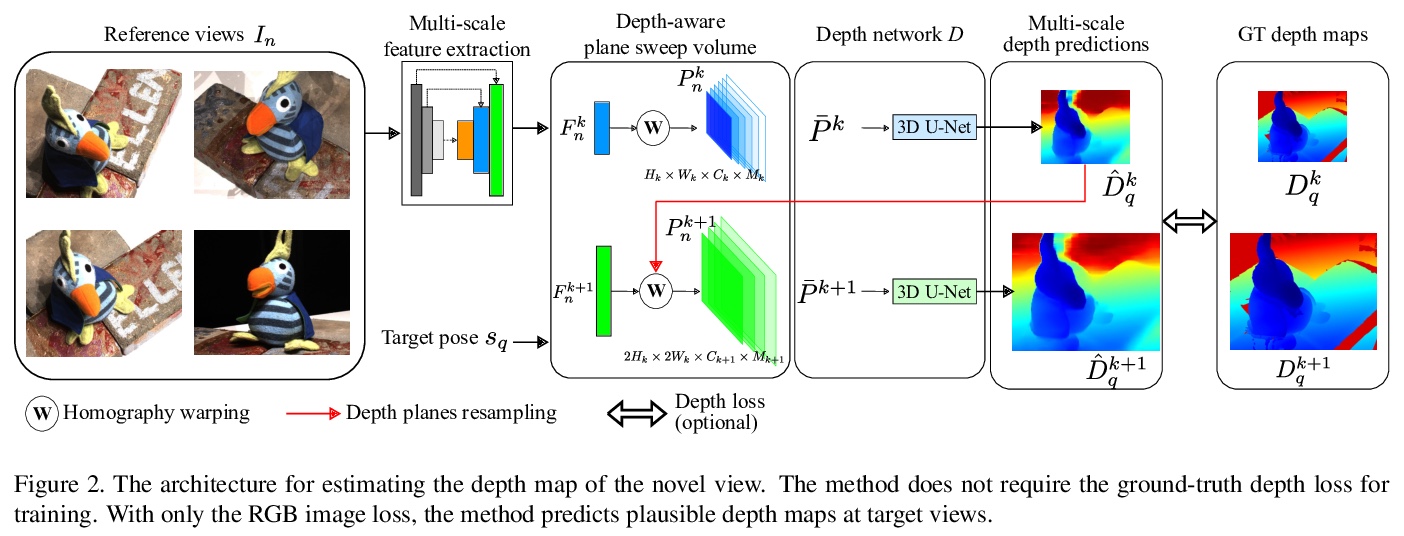
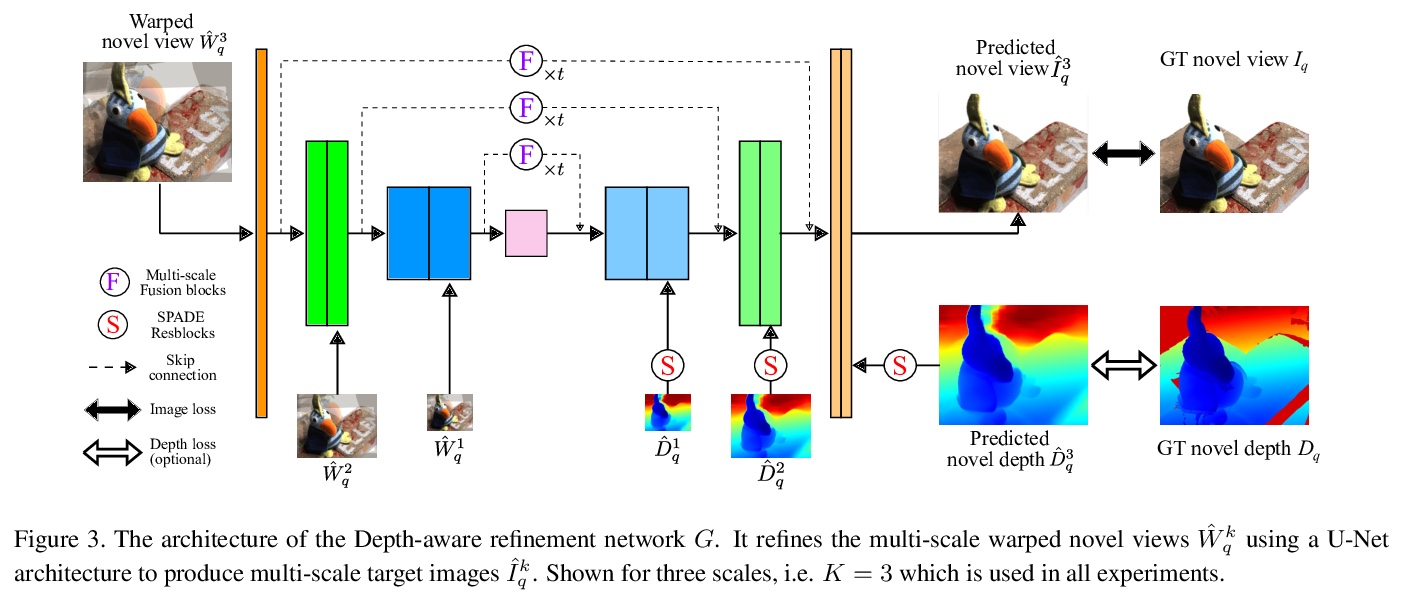
[CV] RGBD-Net: Predicting color and depth images for novel views synthesis
RGBD-Net:面向新视图合成的颜色/深度图预测
P Nguyen, A Karnewar, L Huynh, E Rahtu, J Matas, J Heikkila
[Czech Technical University in Prague & University of Oulu]
https://weibo.com/1402400261/JwxPKzg53
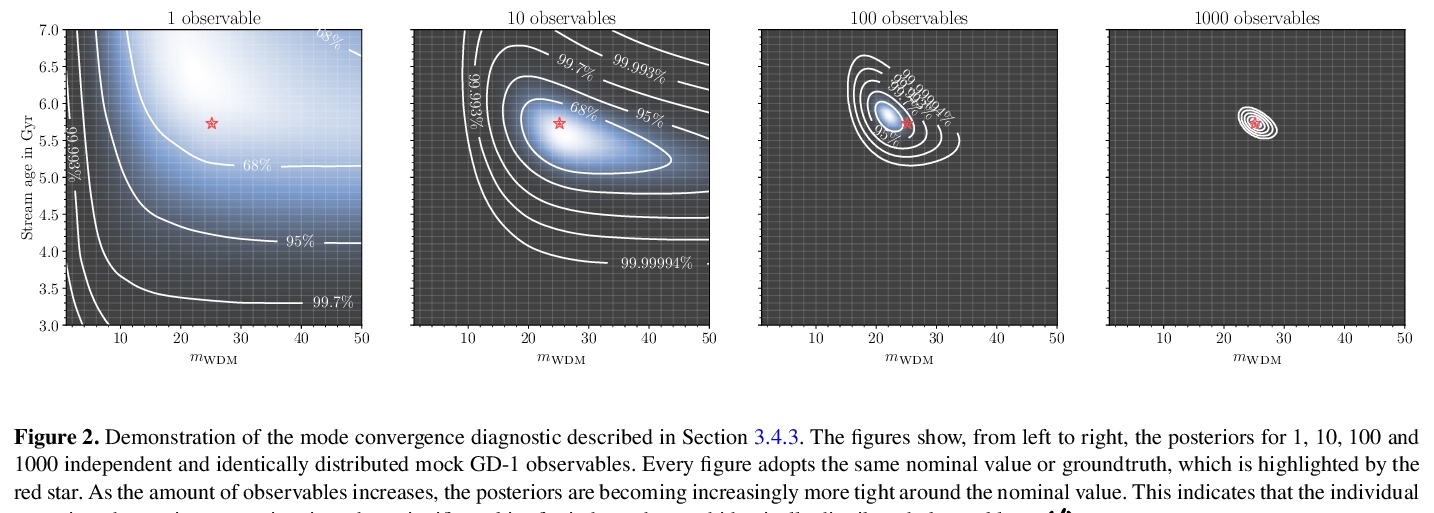
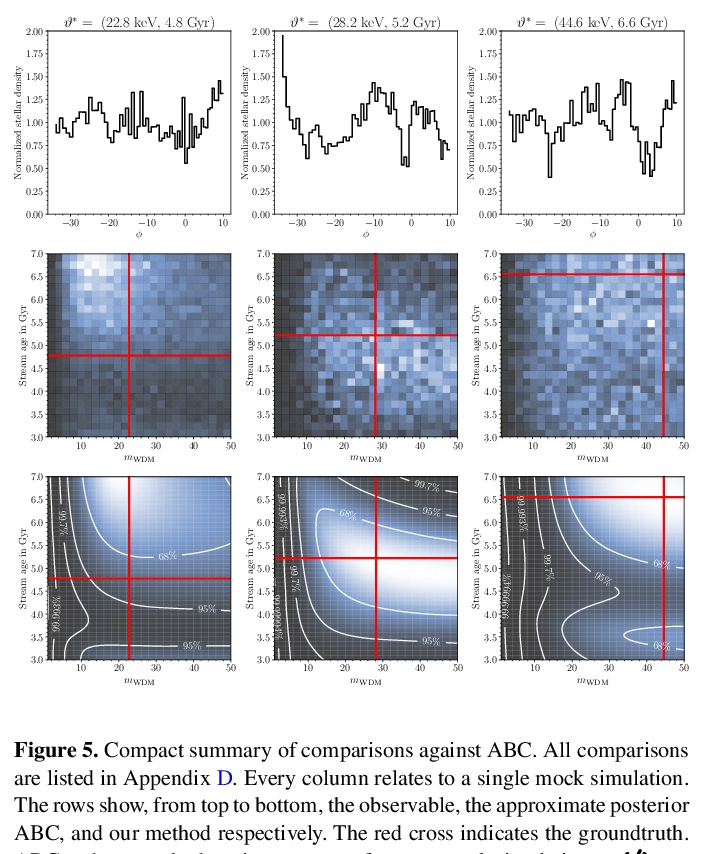
[LG] Towards constraining warm dark matter with stellar streams through neural simulation-based inference
基于神经仿真推理的恒星流约束暖暗物质粒子性质预测
J Hermans, N Banik, C Weniger, G Bertone, G Louppe
[University of Liège & Texas A&M University & University of Amsterdam]
https://weibo.com/1402400261/JwxRFD7A1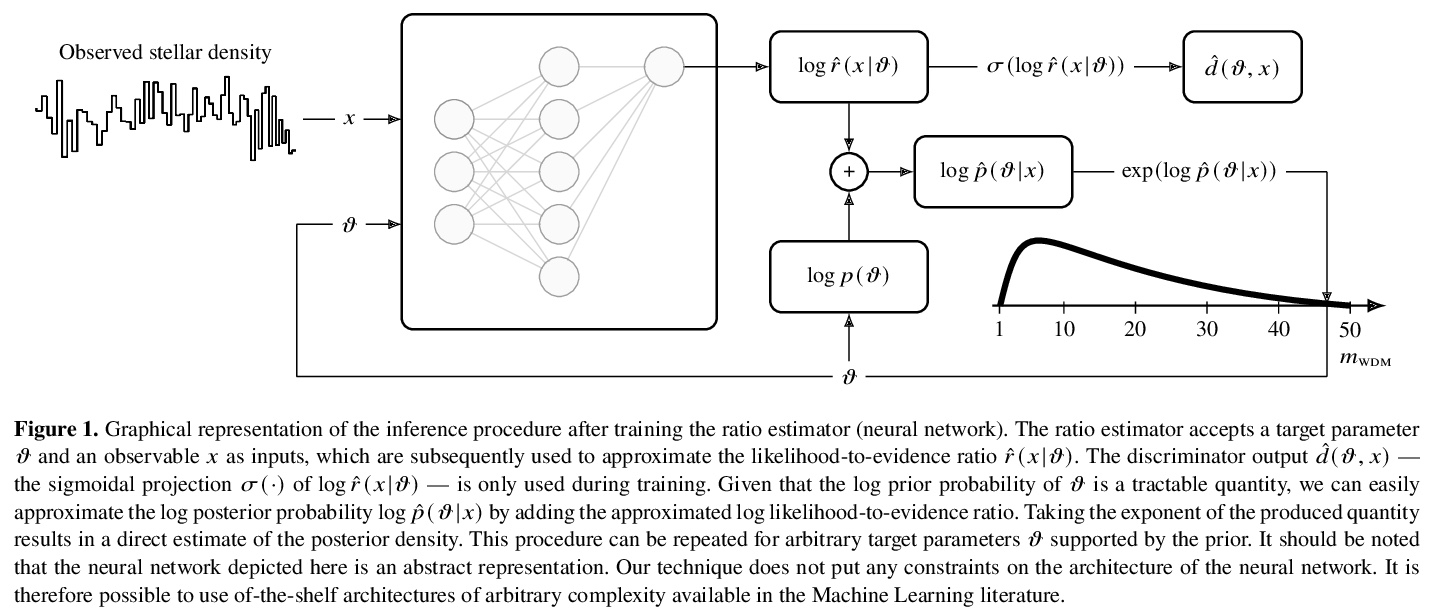
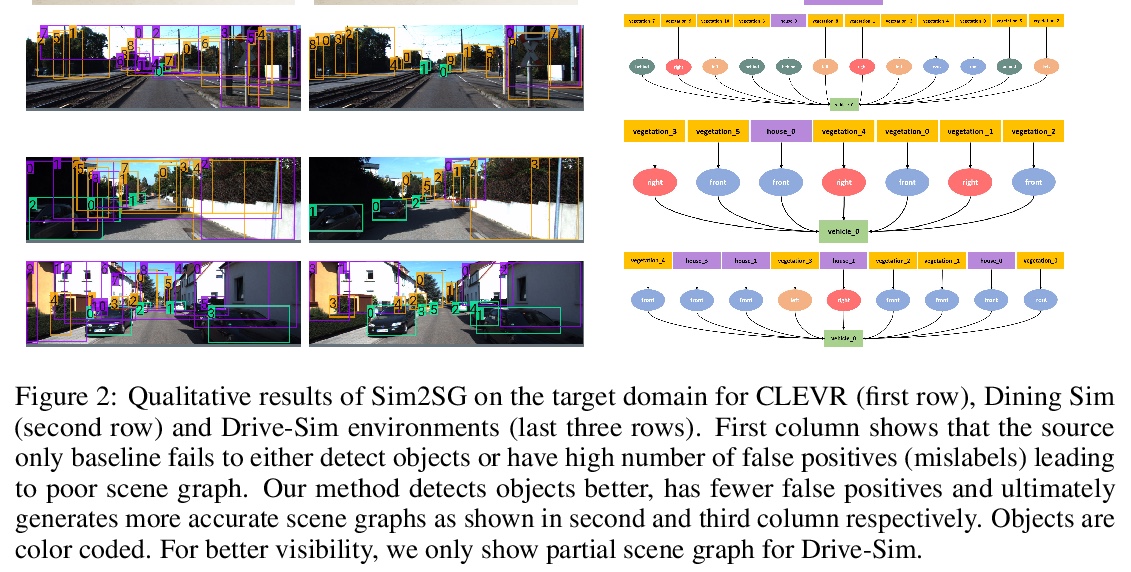
[CV] Sim2SG: Sim-to-Real Scene Graph Generation for Transfer Learning
Sim2SG:面向迁移学习的模拟-真实场景图生成
A Prakash, S Debnath, J Lafleche, E Cameracci, G State, M T. Law
[NVIDIA]
https://weibo.com/1402400261/JwxUgqhIz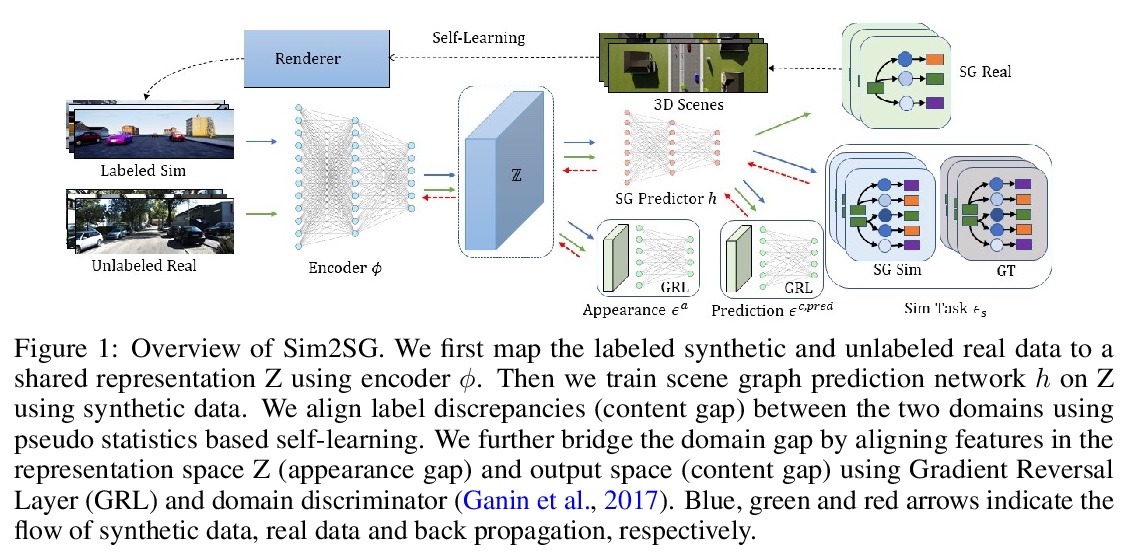


若有收获,就点个赞吧
0 人点赞
