- 1、 [LG] Scaling Laws for Transfer
- 2、[LG] Information-Theoretic Generalization Bounds for Stochastic Gradient Descent
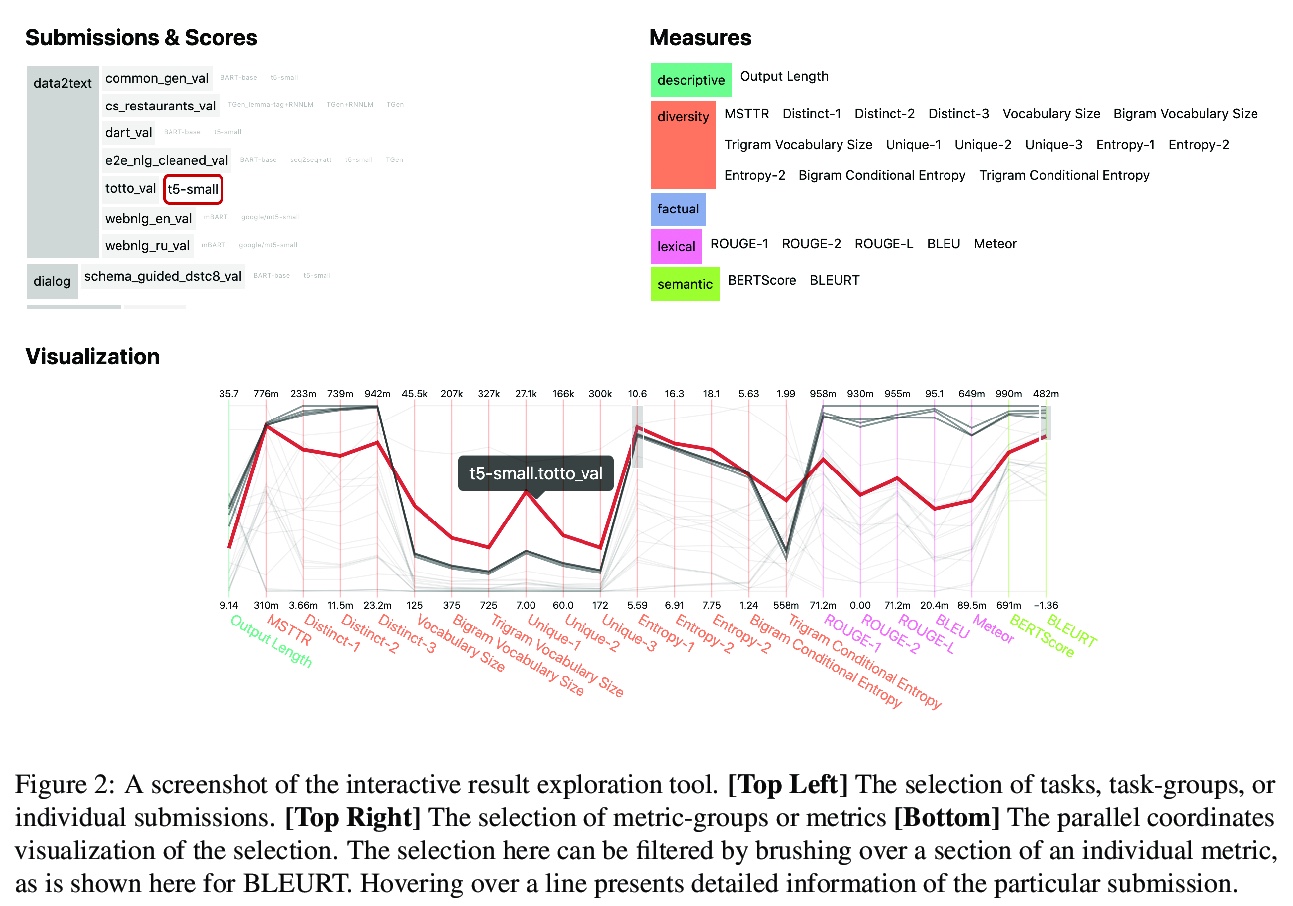
- 3、[CL] The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
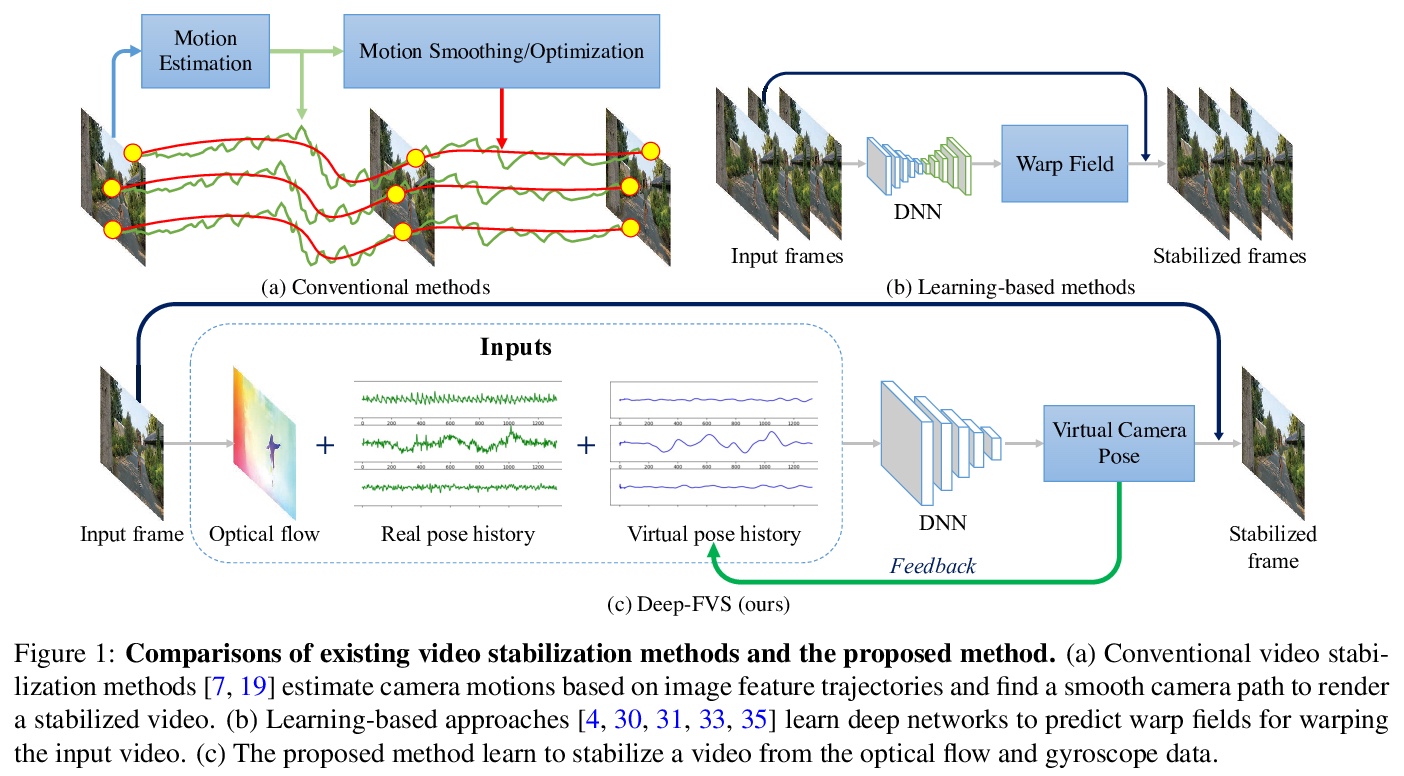
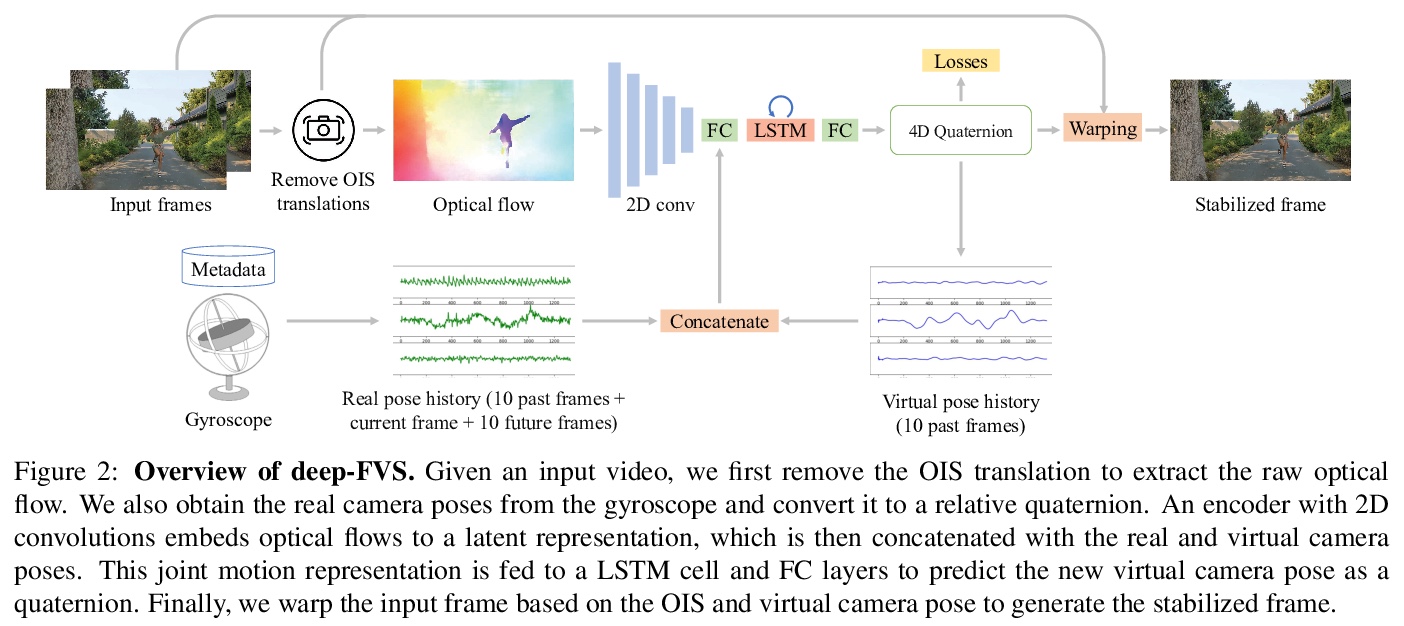
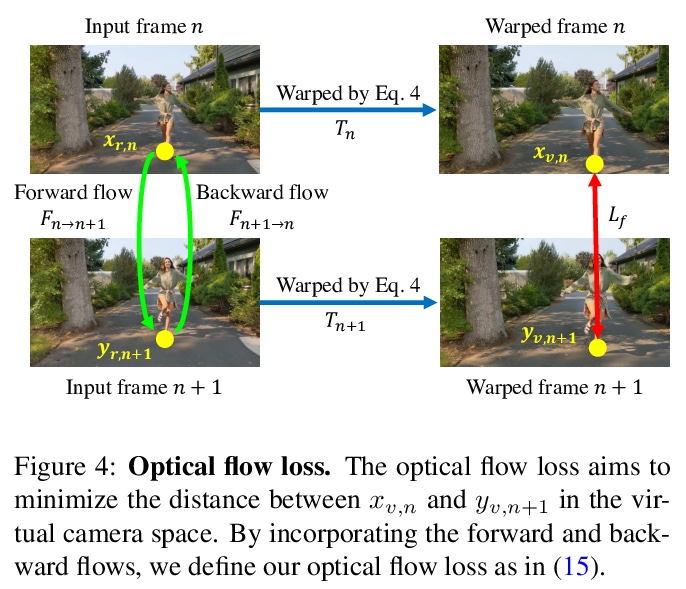
- 4、[CV] Deep Online Fused Video Stabilization
- 5、[LG] Generating images from caption and vice versa via CLIP-Guided Generative Latent Space Search
- [CL] Neural Data Augmentation via Example Extrapolation
- [LG] Metrics and continuity in reinforcement learning
- [CV] Occluded Video Instance Segmentation
- [CL] Generative Spoken Language Modeling from Raw Audio
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、 [LG] Scaling Laws for Transfer
D Hernandez, J Kaplan, T Henighan, S McCandlish
[OpenAI & Johns Hopkins University]
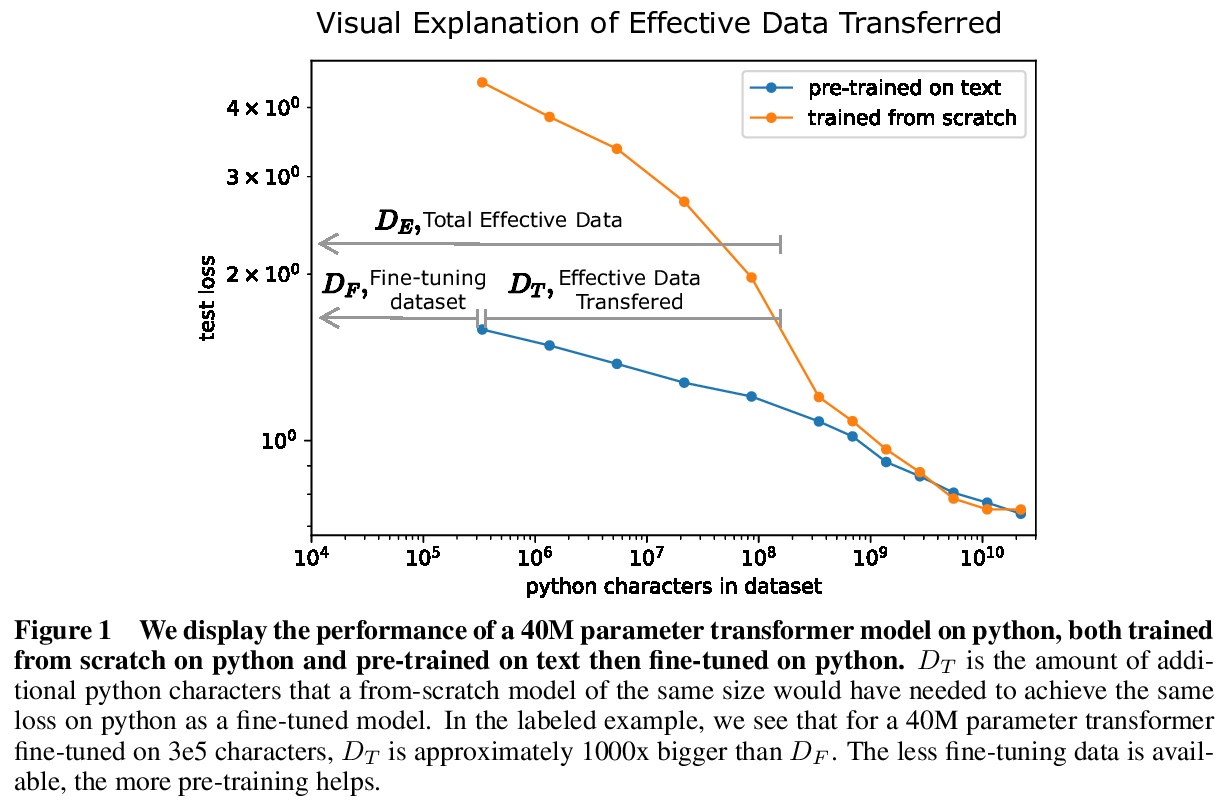
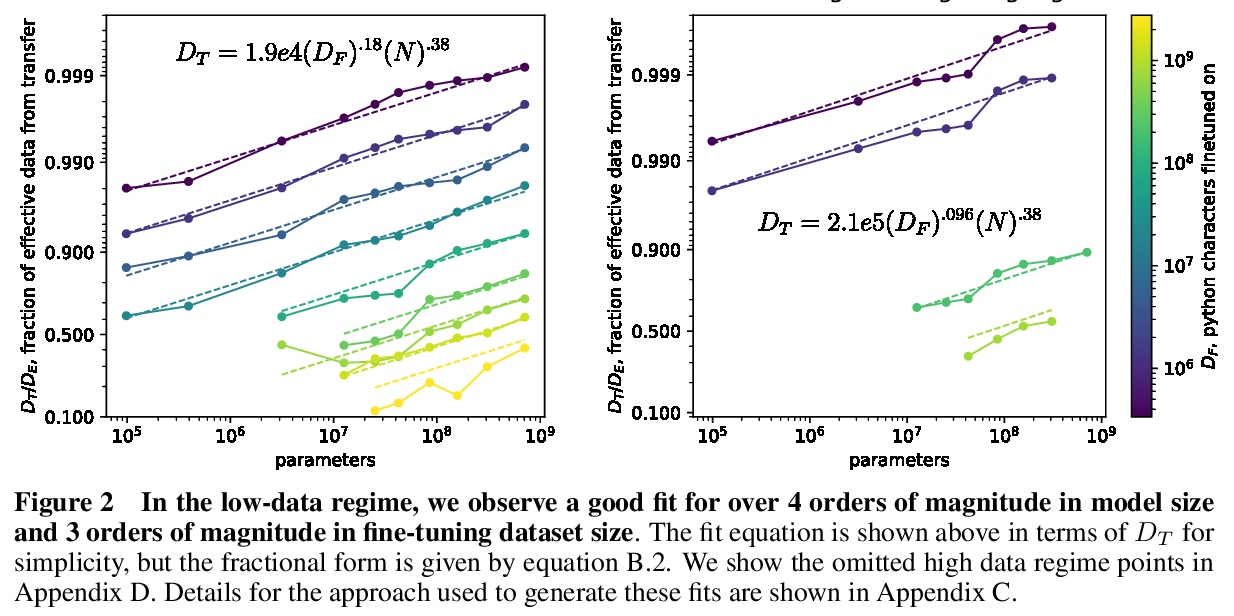
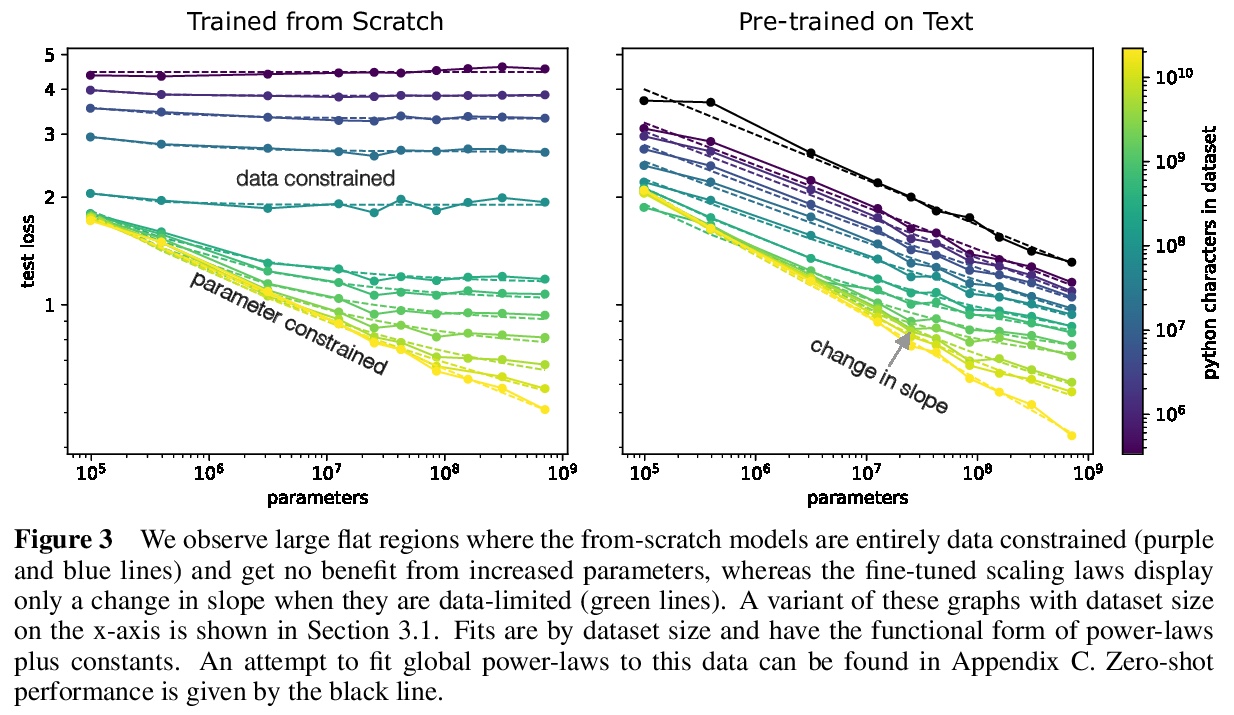
迁移学习的定标律。研究在无监督、微调设置下,分布之间迁移学习的经验定标律。在固定大小的数据集上从头开始训练越来越大的神经网络时,最终会受限于数据,停止性能改进(交叉熵损失)。对大型语言数据集上的预训练模型进行训练,性能增益的斜率会变小,但并不为零。通过观察从头训练相同规模的transformer需要多少数据才能达到相同的损失,来计算从预训练“迁移”的有效数据。发现在低数据状态下,有效迁移数据可以用幂律很好地进行描述,预训练有效地增加了微调数据集的大小。迁移,像整体性能一样,可以根据参数、数据和计算进行可预测的扩展。
We study empirical scaling laws for transfer learning between distributions in an unsupervised, fine-tuning setting. When we train increasingly large neural networks from-scratch on a fixed-size dataset, they eventually become data-limited and stop improving in performance (cross-entropy loss). When we do the same for models pre-trained on a large language dataset, the slope in performance gains is merely reduced rather than going to zero. We calculate the effective data “transferred” from pre-training by determining how much data a transformer of the same size would have required to achieve the same loss when training from scratch. In other words, we focus on units of data while holding everything else fixed. We find that the effective data transferred is described well in the low data regime by a power-law of parameter count and fine-tuning dataset size. We believe the exponents in these power-laws correspond to measures of the generality of a model and proximity of distributions (in a directed rather than symmetric sense). We find that pre-training effectively multiplies the fine-tuning dataset size. Transfer, like overall performance, scales predictably in terms of parameters, data, and compute.
https://weibo.com/1402400261/K0jpe4msK
2、[LG] Information-Theoretic Generalization Bounds for Stochastic Gradient Descent
G Neu
[Universitat Pompeu Fabra]
随机梯度下降的信息论泛化界。研究了随机梯度下降(SGD)在优化一般非凸损失函数时的泛化特性。提供了广义误差的上界,该上界取决于沿SGD计算的迭代路径评价的随机梯度的局部统计。上界所依赖的关键因素是梯度的变化(相对于数据分布)和目标函数沿SGD路径的局部平滑度,以及损失函数对最终输出扰动的敏感性。关键技术手段是将之前用于分析SGD随机化变体的信息论泛化界与迭代的扰动分析相结合。
We study the generalization properties of the popular stochastic gradient descent method for optimizing general non-convex loss functions. Our main contribution is providing upper bounds on the generalization error that depend on local statistics of the stochastic gradients evaluated along the path of iterates calculated by SGD. The key factors our bounds depend on are the variance of the gradients (with respect to the data distribution) and the local smoothness of the objective function along the SGD path, and the sensitivity of the loss function to perturbations to the final output. Our key technical tool is combining the information-theoretic generalization bounds previously used for analyzing randomized variants of SGD with a perturbation analysis of the iterates.
https://weibo.com/1402400261/K0jLgbdXG
3、[CL] The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
S Gehrmann, T Adewumi, K Aggarwal…
[Amelia R&D, New York & CMU & Charles University, Prague…]
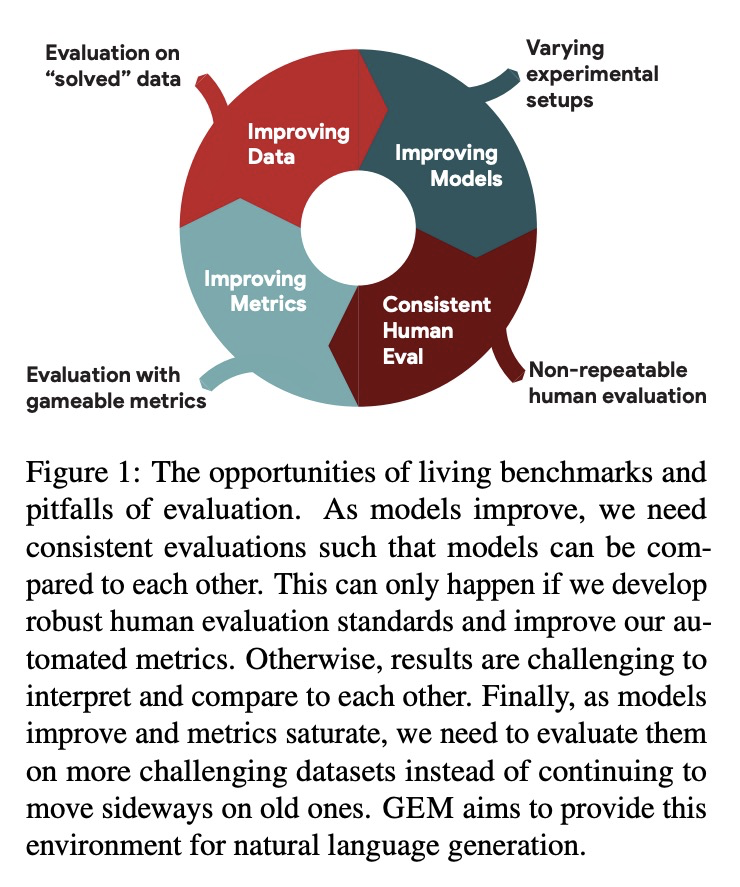
GEM基准:自然语言生成及其评价与度量指标。介绍了以评价为重点的在线自然语言生成基准GEM。其目的是提供一个环境,在这个环境中,模型可以很容易地应用于一系列广泛的语料库,并对评价策略进行测试。对基准的定期更新,将有助于自然语言生成研究变得更加多语言,并与模型一起发展。
We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models.This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
https://weibo.com/1402400261/K0jR6qoHZ
4、[CV] Deep Online Fused Video Stabilization
Z Shi, F Shi, W Lai, C Liang, Y Liang
[University of Wisconsin Madison & Google]
深度在线融合视频稳定。提出一种深度网络,用传感器数据(陀螺仪)和图像内容(光流),通过无监督学习来稳定视频。该网络将光流与真实/虚拟摄像机姿态历史融合成一个联合运动表示。用LSTM块推导出新的虚拟摄像机姿态,用来生成稳定画面的变形网格。提出了新的相对运动表示、新的无监督损失函数和多阶段训练。通过实验,证明了所提出的方法优于最新的替代解决方案。
We present a deep neural network (DNN) that uses both sensor data (gyroscope) and image content (optical flow) to stabilize videos through unsupervised learning. The network fuses optical flow with real/virtual camera pose histories into a joint motion representation. Next, the LSTM block infers the new virtual camera pose, and this virtual pose is used to generate a warping grid that stabilizes the frame. Novel relative motion representation as well as a multi-stage training process are presented to optimize our model without any supervision. To the best of our knowledge, this is the first DNN solution that adopts both sensor data and image for stabilization. We validate the proposed framework through ablation studies and demonstrated the proposed method outperforms the state-of-art alternative solutions via quantitative evaluations and a user study.
https://weibo.com/1402400261/K0jXH5nCd

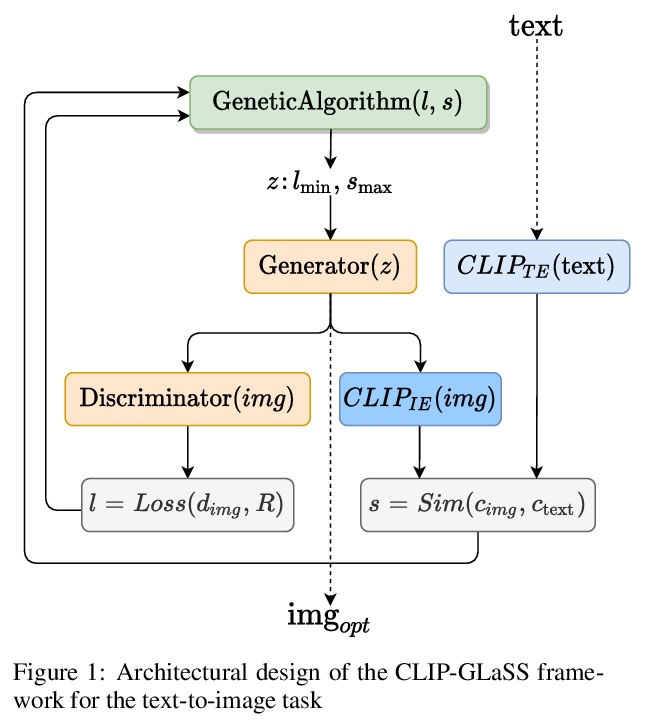
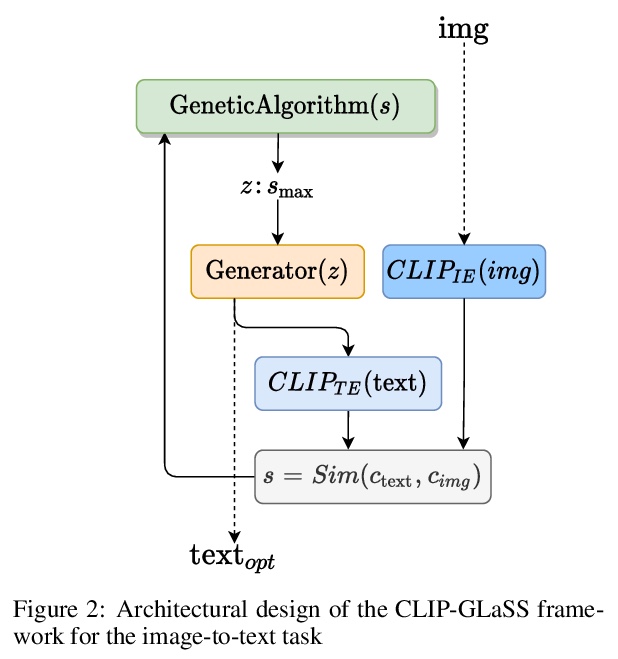
5、[LG] Generating images from caption and vice versa via CLIP-Guided Generative Latent Space Search
F A. Galatolo, M G.C.A. Cimino, G Vaglini
[University of Pisa]
基于CLIP引导生成式潜空间搜索的描述-图像双向生成。提出了新的零样本框架CLIP-GLaSS,以生成与给定描述(或图像)对应的图像(或描述)。CLIP-GLaSS基于CLIP网络,以描述(或图像)为输入,生成与输入具有最相似嵌入的图像(或描述),该最佳图像(或描述)经过遗传算法探索后由生成网络生成。
In this research work we present GLaSS, a novel zero-shot framework to generate an image(or a caption) corresponding to a given caption(or image). GLaSS is based on the CLIP neural network which given an image and a descriptive caption provides similar embeddings. Differently, GLaSS takes a caption (or an image) as an input, and generates the image (or the caption) whose CLIP embedding is most similar to the input one. This optimal image (or caption) is produced via a generative network after an exploration by a genetic algorithm. Promising results are shown, based on the experimentation of the image generators BigGAN and StyleGAN2, and of the text generator GPT2.
https://weibo.com/1402400261/K0k5XscQY

另外几篇值得关注的论文:
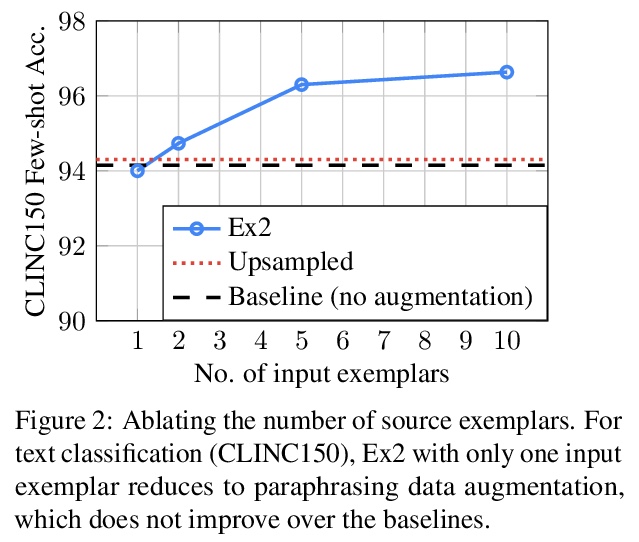
[CL] Neural Data Augmentation via Example Extrapolation
基于样本外推的神经网络数据增强
K Lee, K Guu, L He, T Dozat, H W Chung
[Google Research]
https://weibo.com/1402400261/K0kbbBqbg
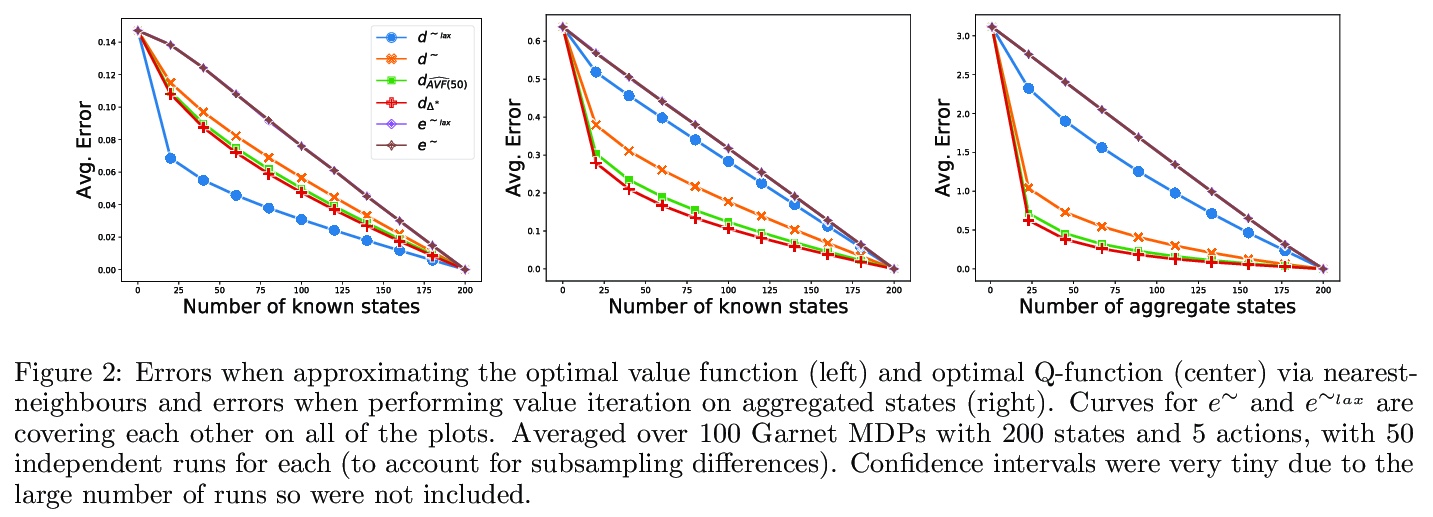
[LG] Metrics and continuity in reinforcement learning
强化学习的度量和连续性
C L Lan, M G. Bellemare, P S Castro
[University of Oxford & Google Research]
https://weibo.com/1402400261/K0keesSc0
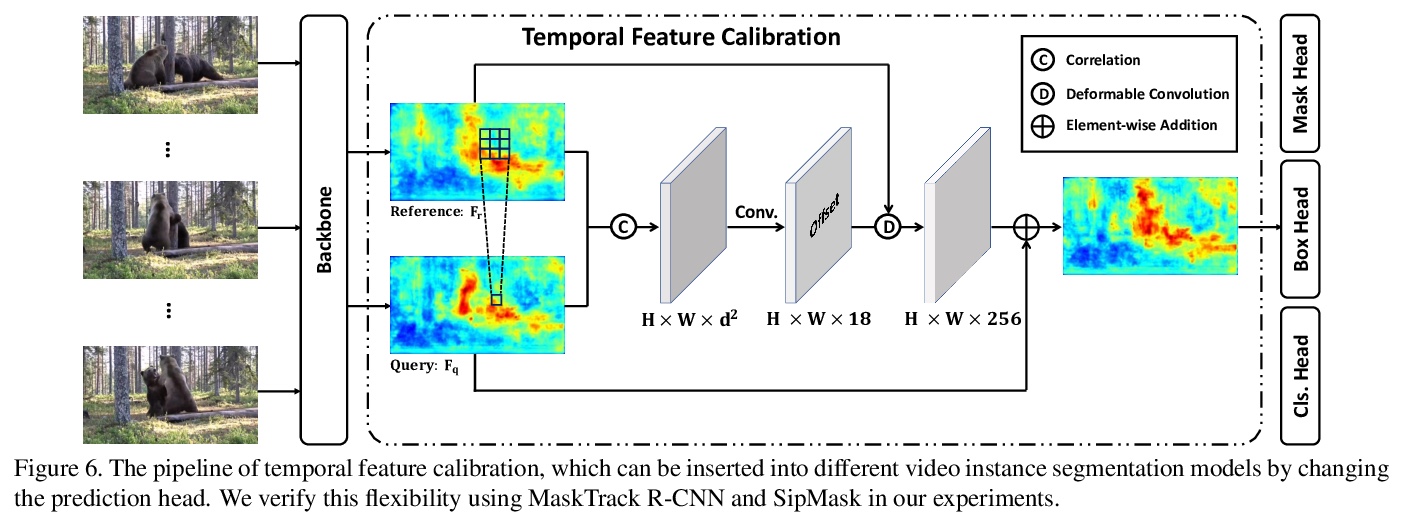
[CV] Occluded Video Instance Segmentation
遮挡视频实例分割
J Qi, Y Gao, X Liu, Y Hu, X Wang, X Bai, P H.S. Torr, S Belongie, A Yuille, S Bai
[Huazhong University of Science and Technology & Alibaba Youku Cognitive and Intelligent Lab & University of Oxford & Cornell University & Johns Hopkins University]
https://weibo.com/1402400261/K0kjShoEl


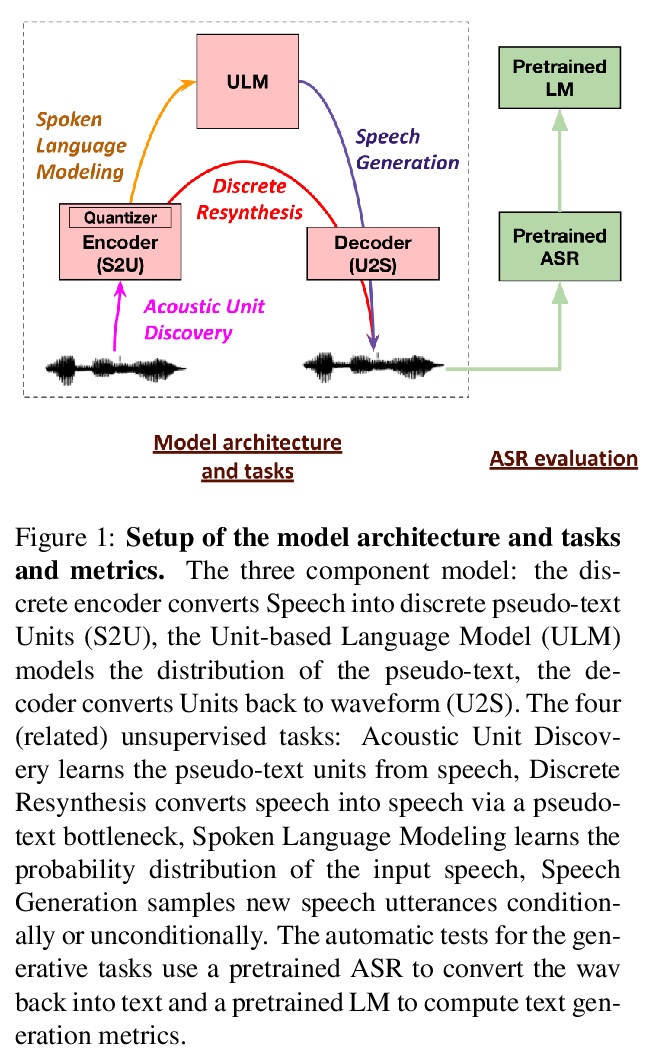
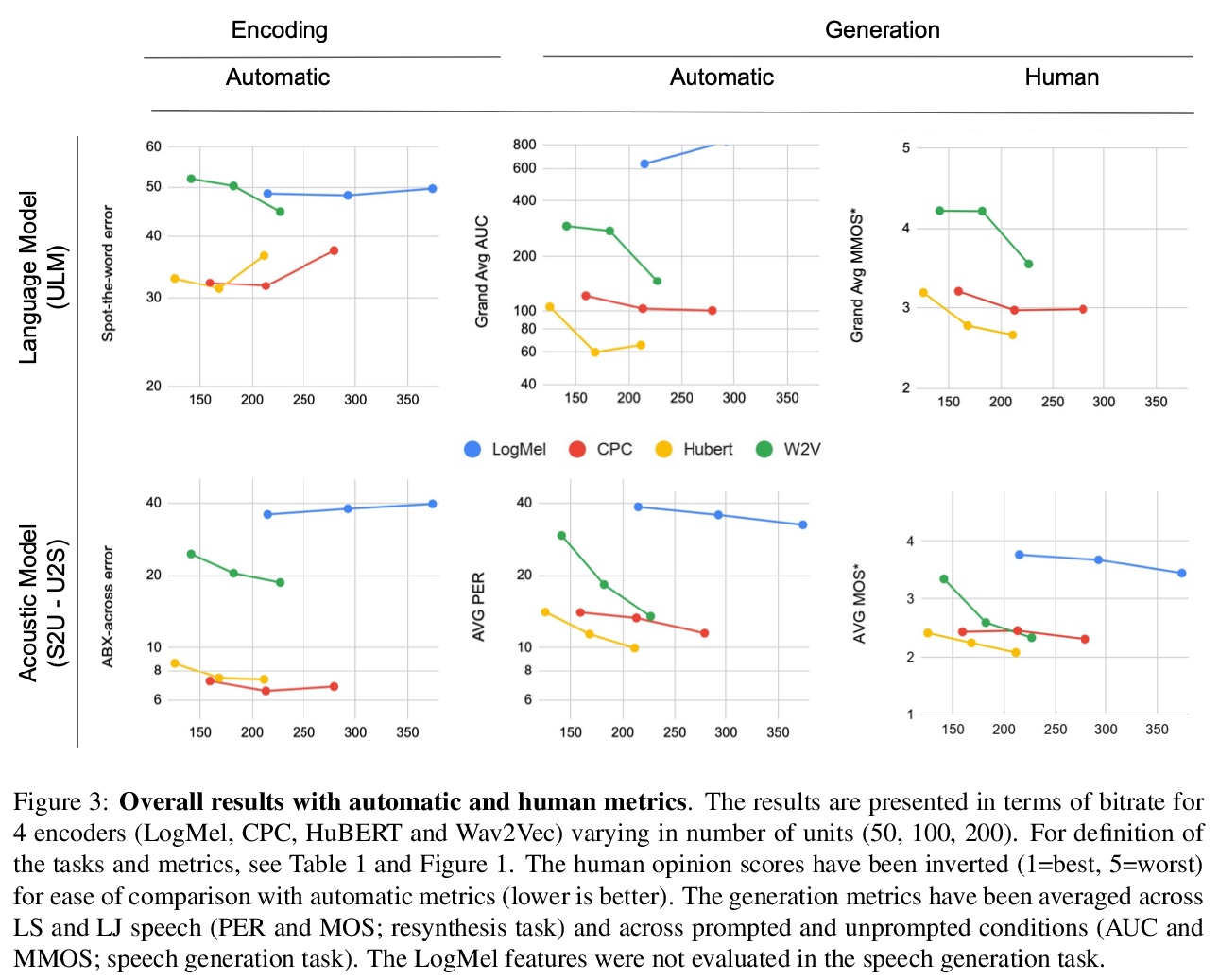
[CL] Generative Spoken Language Modeling from Raw Audio
原始音频(无文本/标注)的生成式口语建模
K Lakhotia, E Kharitonov, W Hsu, Y Adi, A Polyak, B Bolte, T Nguyen, J Copet, A Baevski, A Mohamed, E Dupoux
[Facebook AI Research]
https://weibo.com/1402400261/K0klMdHTa


若有收获,就点个赞吧
0 人点赞
