- 1、[CV] VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
- 2、[CV] Multiscale Vision Transformers
- 3、[CL] Provable Limitations of Acquiring Meaning from Ungrounded Form: What will Future Language Models Understand?
- 4、[LG] Analyzing Monotonic Linear Interpolation in Neural Network Loss Landscapes
- 5、[CV] KeypointDeformer: Unsupervised 3D Keypoint Discovery for Shape Control
- [CV] On Buggy Resizing Libraries and Surprising Subtleties in FID Calculation
- [AI] The Road Less Travelled: Trying And Failing To Generate Walking Simulators
- [CV] Pri3D: Can 3D Priors Help 2D Representation Learning?
- [CV] Cross-Domain and Disentangled Face Manipulation with 3D Guidance
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
H Akbari, L Yuan, R Qian, W Chuang, S Chang, Y Cui, B Gong
[Google & Columbia University]
VATT:从原始视频、音频和文本中进行多模态自监督学习的Transformer。提出一种基于Transformer架构的自监督多模态表示学习框架,用非卷积Transformer架构,从未标记数据中学习多模态表示。提出的视频-音频-文本Transformer(VATT)将原始信号作为输入,并提取足够丰富的多模态表示,可用于各种下游任务。提出一种简单而有效的技术DropToken,以解决相对注意力模型输入长度的平方训练复杂度,使其更容易用于视觉和原始音频处理。用多模态对比损失从头开始训练VATT,并通过视频行为识别、音频事件分类、图像分类和文本到视频检索等下游任务评估其性能。通过在三种模式间共享权重,研究了一种模式无关的单骨干Transformer。在视频行为识别和音频事件分类中取得了最先进的结果,在图像分类和视频检索任务中也有竞争性的表现,表明通过自监督学习在不同模态中学到的表示具有很强的通用性和可迁移性。
We present a framework for learning multimodal representations from unlabeled data using convolution-free Transformer architectures. Specifically, our Video-Audio-Text Transformer (VATT) takes raw signals as inputs and extracts multimodal representations that are rich enough to benefit a variety of downstream tasks. We train VATT end-to-end from scratch using multimodal contrastive losses and evaluate its performance by the downstream tasks of video action recognition, audio event classification, image classification, and text-to-video retrieval. Furthermore, we study a modality-agnostic single-backbone Transformer by sharing weights among the three modalities. We show that the convolution-free VATT outperforms state-of-the-art ConvNet-based architectures in the downstream tasks. Especially, VATT’s vision Transformer achieves the top-1 accuracy of 82.1% on Kinetics-400, 83.6% on Kinetics-600,and 41.1% on Moments in Time, new records while avoiding supervised pre-training. Transferring to image classification leads to 78.7% top-1 accuracy on ImageNet compared to 64.7% by training the same Transformer from scratch, showing the generalizability of our model despite the domain gap between videos and images. VATT’s audio Transformer also sets a new record on waveform-based audio event recognition by achieving the mAP of 39.4% on AudioSet without any supervised pre-training.
https://weibo.com/1402400261/KckcbdLhr
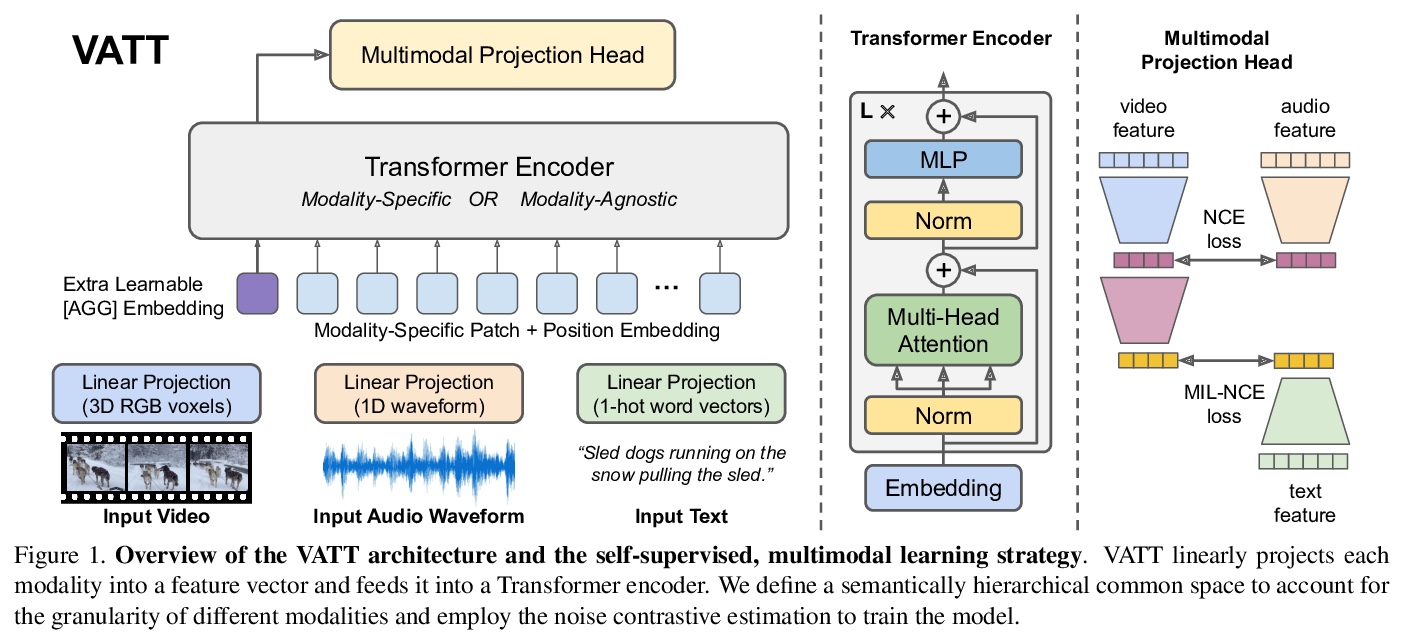
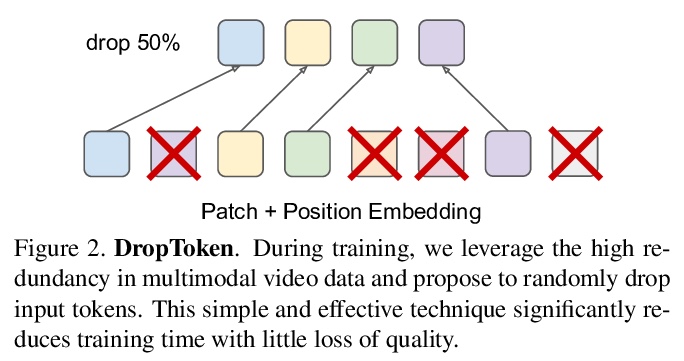
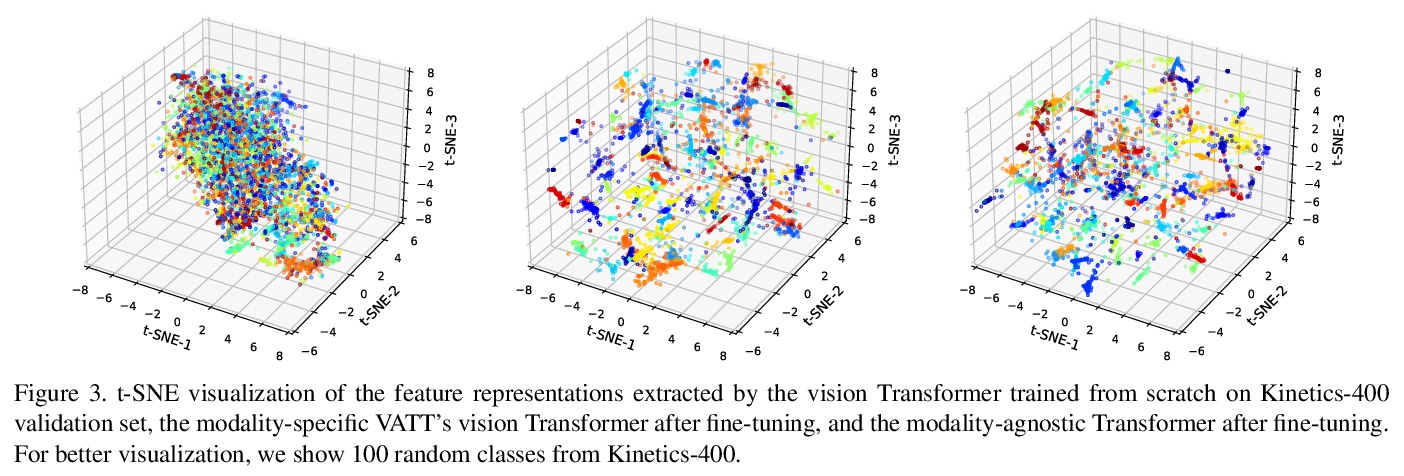
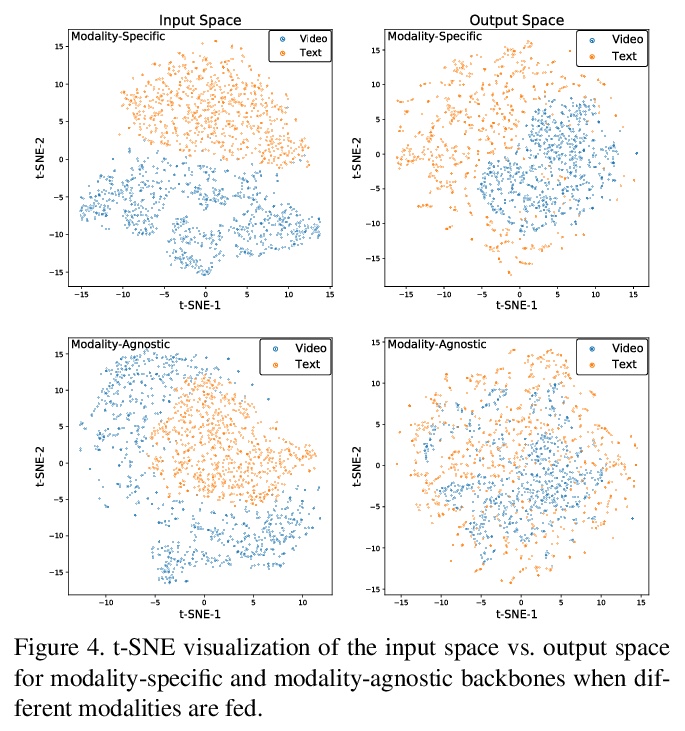
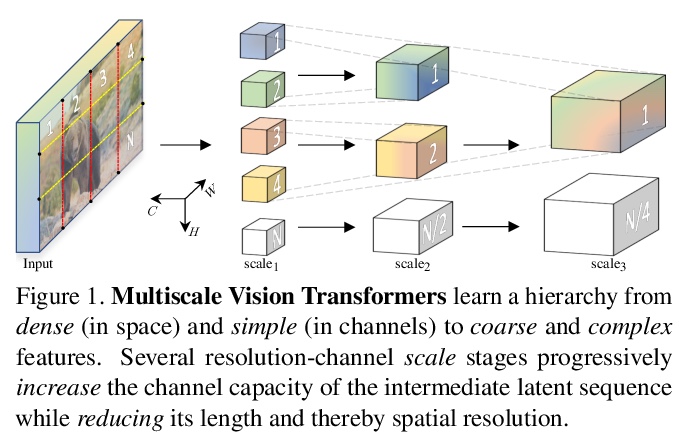
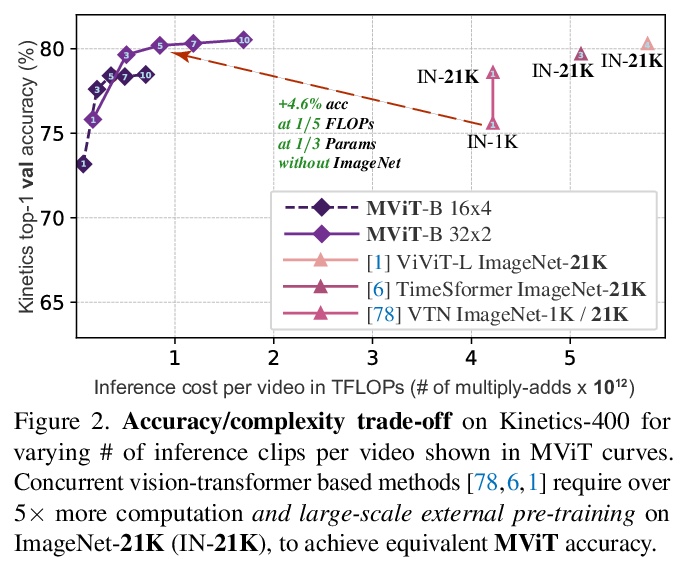
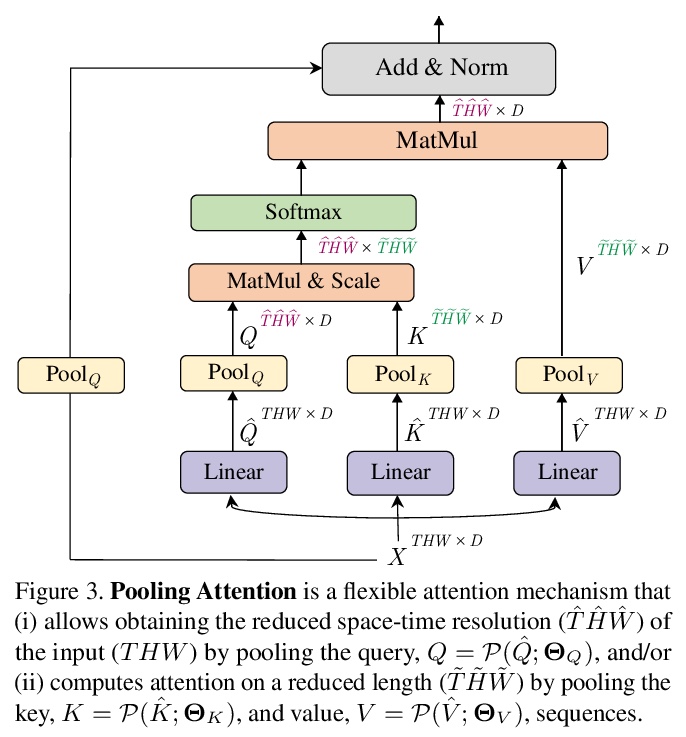
2、[CV] Multiscale Vision Transformers
H Fan, B Xiong, K Mangalam, Y Li, Z Yan, J Malik, C Feichtenhofer
[Facebook AI Research]
多尺度视觉Transformer。提出用于视频和图像识别的多尺度视觉Transformer(MViT),将多尺度特征层次与Transformer模型联系起来,在降低视觉分辨率的同时分层扩展了特征的复杂度。多尺度Transformer有几个通道分辨率尺度段,从输入分辨率和一个小的通道维度开始,这些段分层次地扩大通道容量,同时降低空间分辨率,形成了一个多尺度的特征金字塔,早期层在高空间分辨率下操作,以模拟简单的低层次视觉信息,而更深的层在空间上更粗略,但代表了复杂的高维特征,以模拟视觉语义。评估了基本的架构先验,用于为各种视频识别任务的视觉信号的密集性建模,优于之前的视觉Transformer,这些Transformer依赖于大规模的外部预训练,在计算和参数方面的成本要高5-10倍。进一步删除时间维度,将模型用于图像分类,优于之前的视觉Transformer的工作。
We present Multiscale Vision Transformers (MViT) for video and image recognition, by connecting the seminal idea of multiscale feature hierarchies with transformer models. Multiscale Transformers have several channel-resolution scale stages. Starting from the input resolution and a small channel dimension, the stages hierarchically expand the channel capacity while reducing the spatial resolution. This creates a multiscale pyramid of features with early layers operating at high spatial resolution to model simple low-level visual information, and deeper layers at spatially coarse, but complex, high-dimensional features. We evaluate this fundamental architectural prior for modeling the dense nature of visual signals for a variety of video recognition tasks where it outperforms concurrent vision transformers that rely on large scale external pre-training and are 5-10x more costly in computation and parameters. We further remove the temporal dimension and apply our model for image classification where it outperforms prior work on vision transformers. Code is available at:this https URL
https://weibo.com/1402400261/KckiNBFXk
3、[CL] Provable Limitations of Acquiring Meaning from Ungrounded Form: What will Future Language Models Understand?
W Merrill, Y Goldberg, R Schwartz, N A. Smith
[Allen Institute for AI & Hebrew University of Jerusalem]
从无根据文本形式获取意义的可证限制。未来的语言模型能理解什么?用数十亿标记训练的语言模型,最近在许多NLP任务上取得了空前的成果。这种成功提出这样一个问题:原则上,一个系统是否能在没有获得任何形式根据的基础上”理解”原始文本。本文正式研究了没有根据的系统获得意义的能力。分析集中在”断言”的作用上:原始文本中的语境提供了关于潜在语义的间接线索,研究断言是否使系统能模拟保留语义关系的表述,如等价关系。发现如果语言中所有表达都是指称透明的,那么断言就能实现语义模拟。然而,如果语言使用像变量绑定这样的非透明模式,一些表达式的抽象意义就无法从断言中计算出来,尽管它们是唯一定义的,语义模拟会成为一个无法计算的问题。这意味着断言没有为图灵完备的系统提供足够的信号来完全”理解”这些文本。讨论了该形式模型和自然语言之间的差异,探讨了该结果如何泛化到一个模态设定和其他语义关系,这些结果提供了一种正式的方法,来描述是否有可能从字符串的分布属性模拟语言的语义上限。
Language models trained on billions of tokens have recently led to unprecedented results on many NLP tasks. This success raises the question of whether, in principle, a system can ever “understand” raw text without access to some form of grounding. We formally investigate the abilities of ungrounded systems to acquire meaning. Our analysis focuses on the role of “assertions”: contexts within raw text that provide indirect clues about underlying semantics. We study whether assertions enable a system to emulate representations preserving semantic relations like equivalence. We find that assertions enable semantic emulation if all expressions in the language are referentially transparent. However, if the language uses non-transparent patterns like variable binding, we show that emulation can become an uncomputable problem. Finally, we discuss differences between our formal model and natural language, exploring how our results generalize to a modal setting and other semantic relations. Together, our results suggest that assertions in code or language do not provide sufficient signal to fully emulate semantic representations. We formalize ways in which ungrounded language models appear to be fundamentally limited in their ability to “understand”.
https://weibo.com/1402400261/KcknwrHVs



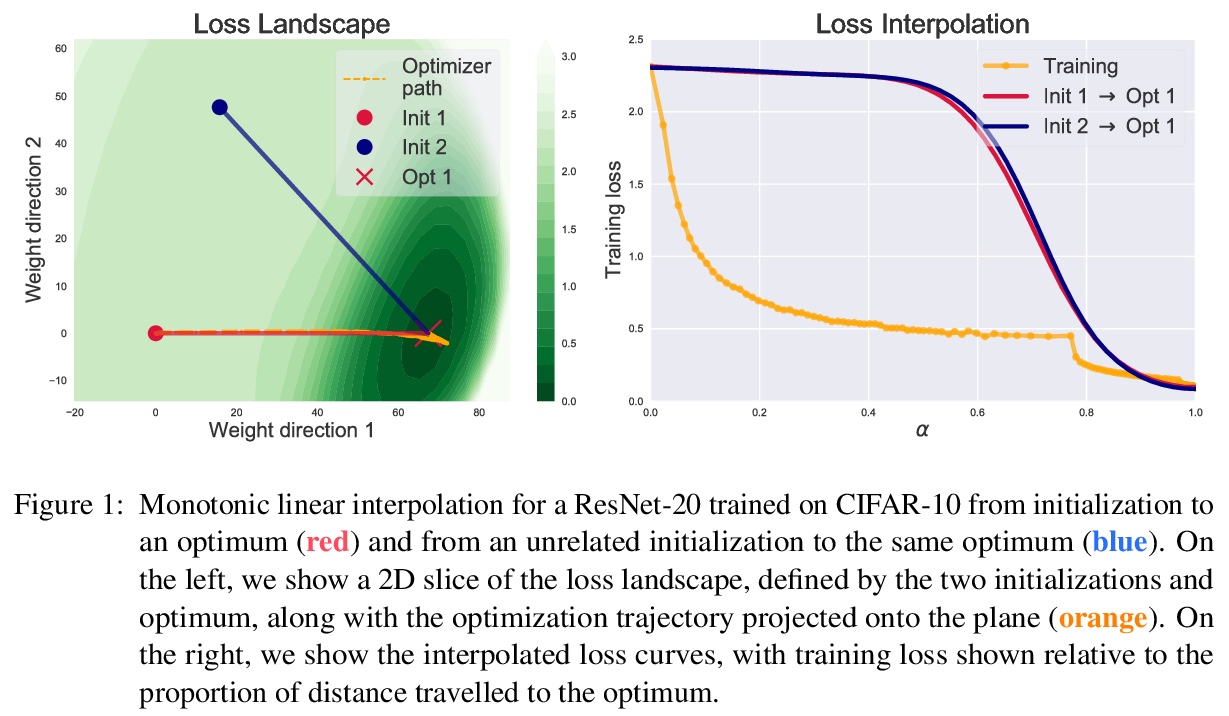
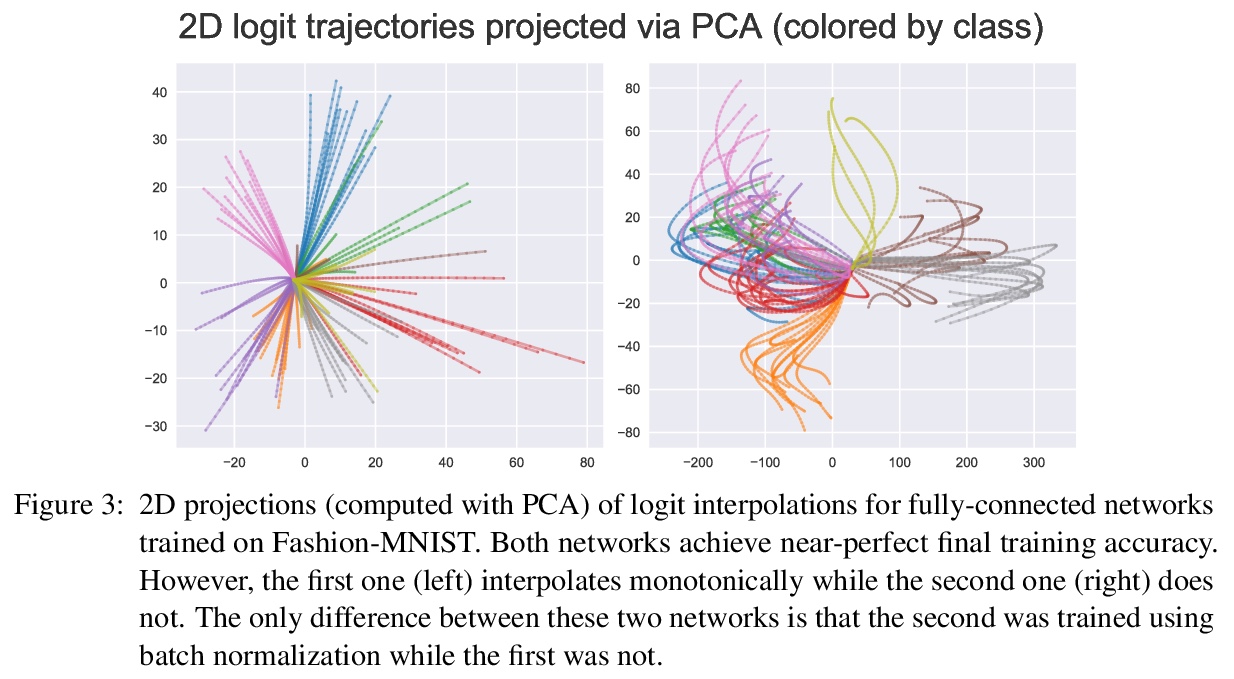
4、[LG] Analyzing Monotonic Linear Interpolation in Neural Network Loss Landscapes
J Lucas, J Bae, M R. Zhang, S Fort, R Zemel, R Grosse
[University of Toronto & Stanford University]
神经网络损失地貌单调线性插值分析。神经网络初始参数和经随机梯度下降法(SGD)训练收敛后参数之间的线性插值,通常会导致训练目标的单调下降。Goodfellow等人首次观察到这种单调线性插值(MLI)特性,尽管神经网络具有非凸目标和高度的非线性训练动态性,但该特性仍然存在。本文对这一特性的几个假设进行了评估,利用微分几何学工具,在函数空间的内插路径和网络的单调性之间建立联系——证明了神经网络最小化MSE满足MLI特性的充分条件。虽然MLI特性在不同的设置下(如网络结构和学习问题)都是成立的,但实践表明,通过鼓励权重远离初始化,违反MLI特性的网络可以系统地产生。MLI特性提出了关于神经网络的损失地貌几何的重要问题,并强调了进一步研究其全局特性的必要性。
Linear interpolation between initial neural network parameters and converged parameters after training with stochastic gradient descent (SGD) typically leads to a monotonic decrease in the training objective. This Monotonic Linear Interpolation (MLI) property, first observed by Goodfellow et al. (2014) persists in spite of the non-convex objectives and highly non-linear training dynamics of neural networks. Extending this work, we evaluate several hypotheses for this property that, to our knowledge, have not yet been explored. Using tools from differential geometry, we draw connections between the interpolated paths in function space and the monotonicity of the network - providing sufficient conditions for the MLI property under mean squared error. While the MLI property holds under various settings (e.g. network architectures and learning problems), we show in practice that networks violating the MLI property can be produced systematically, by encouraging the weights to move far from initialization. The MLI property raises important questions about the loss landscape geometry of neural networks and highlights the need to further study their global properties.
https://weibo.com/1402400261/KcktDxxfx

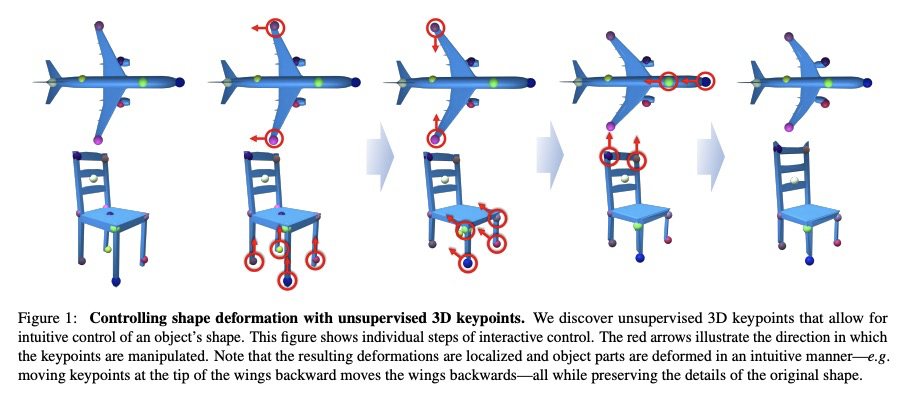
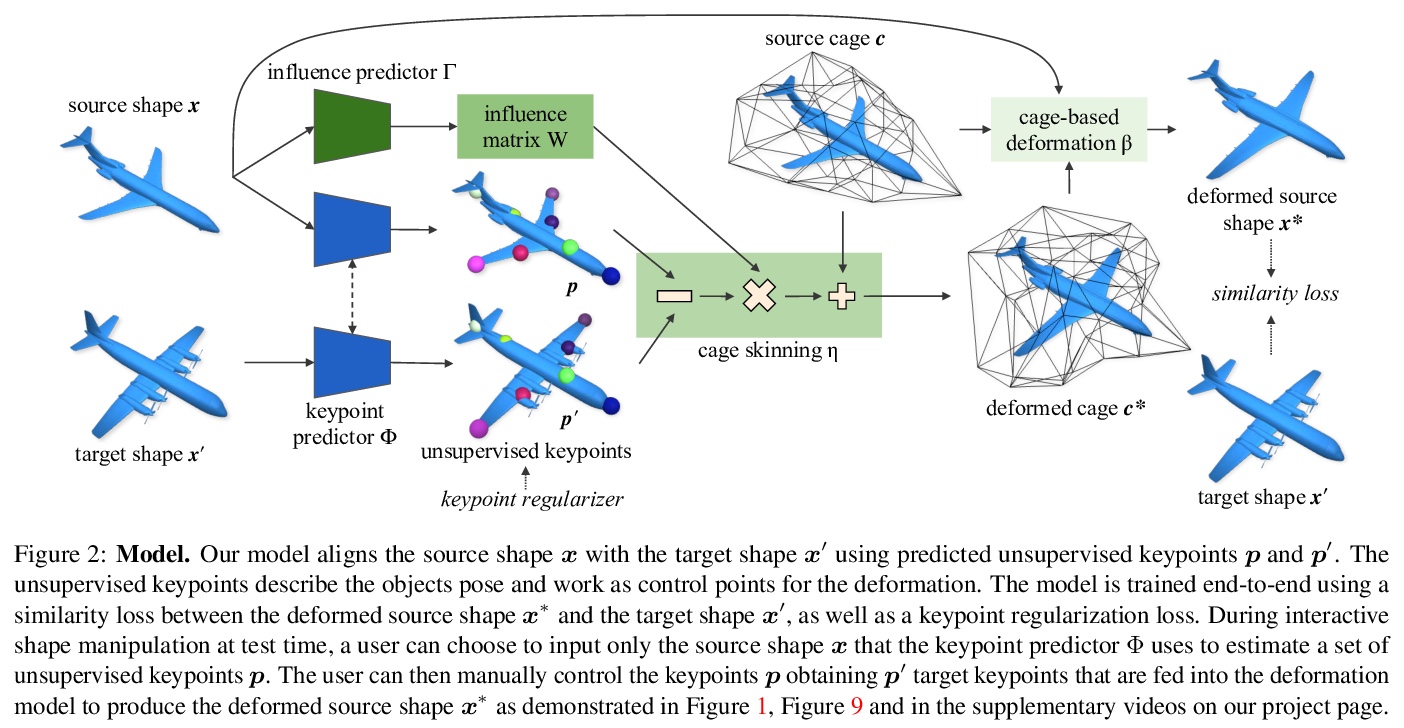
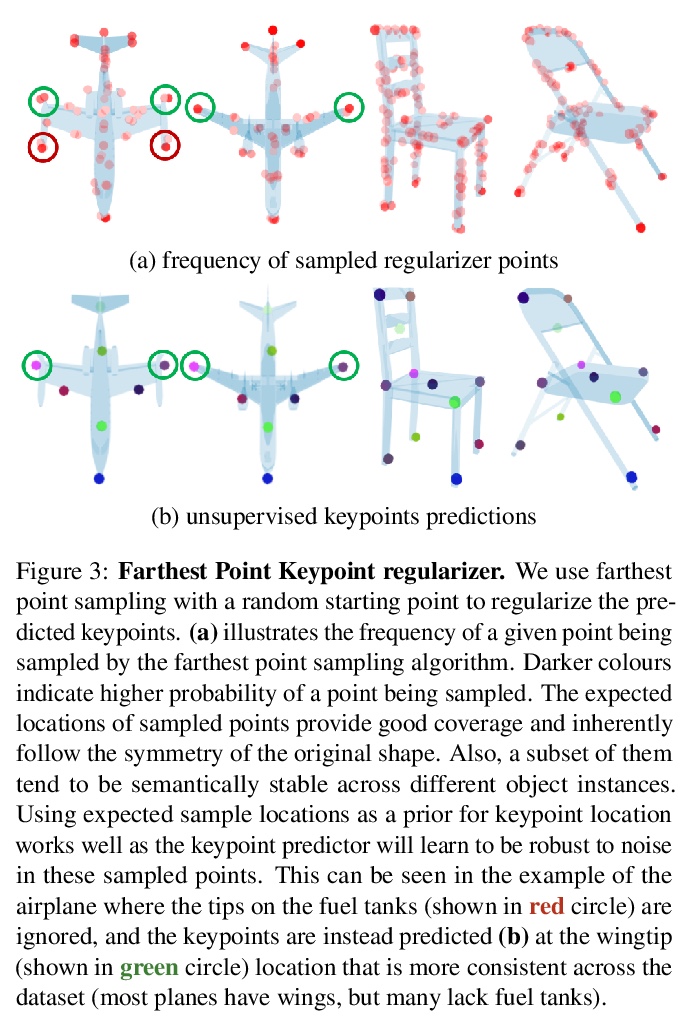
5、[CV] KeypointDeformer: Unsupervised 3D Keypoint Discovery for Shape Control
T Jakab, R Tucker, A Makadia, J Wu, N Snavely, A Kanazawa
[University of Oxford & UC Berkeley & Stanford University & Google Research]
KeypointDeformer: 面向形状控制的无监督3D关键点发现。提出KeypointDeformer,通过自动发现3D关键点进行3D形状控制的新的无监督方法,将问题看作是源3D物体与同一物体类别的目标3D物体对齐的问题,通过比较两物体的潜表示来分析这两物体的形状差异,这种潜表示是以无监督方式学习的3D关键点的形式存在。源物体和目标物体的3D关键点之间的差异,为形状变形算法提供信息,该算法将源物体变形为目标物体。整个模型是端到端的学习,关键点预测和变形模型都是无监督的。该方法产生了直观的、语义一致的形状变形控制。3D关键点在不同的物体类别实例中是一致的,能提供稀疏的对应关系,尽管形状变化很大。由是无监督的,可以很容易地部署到新的物体类别,而不需要对3D关键点和变形进行标注。
We introduce KeypointDeformer, a novel unsupervised method for shape control through automatically discovered 3D keypoints. We cast this as the problem of aligning a source 3D object to a target 3D object from the same object category. Our method analyzes the difference between the shapes of the two objects by comparing their latent representations. This latent representation is in the form of 3D keypoints that are learned in an unsupervised way. The difference between the 3D keypoints of the source and the target objects then informs the shape deformation algorithm that deforms the source object into the target object. The whole model is learned end-to-end and simultaneously discovers 3D keypoints while learning to use them for deforming object shapes. Our approach produces intuitive and semantically consistent control of shape deformations. Moreover, our discovered 3D keypoints are consistent across object category instances despite large shape variations. As our method is unsupervised, it can be readily deployed to new object categories without requiring annotations for 3D keypoints and deformations.
https://weibo.com/1402400261/KckyR5m39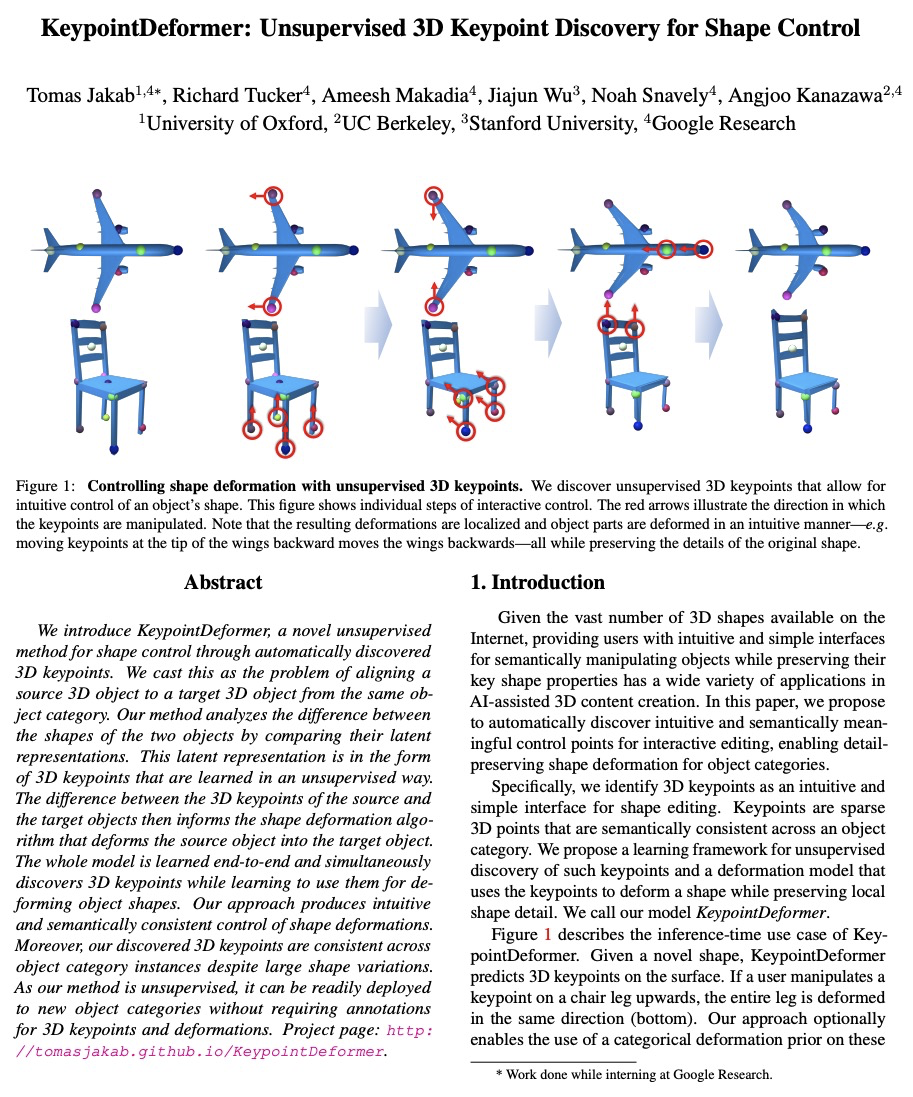
另外几篇值得关注的论文:
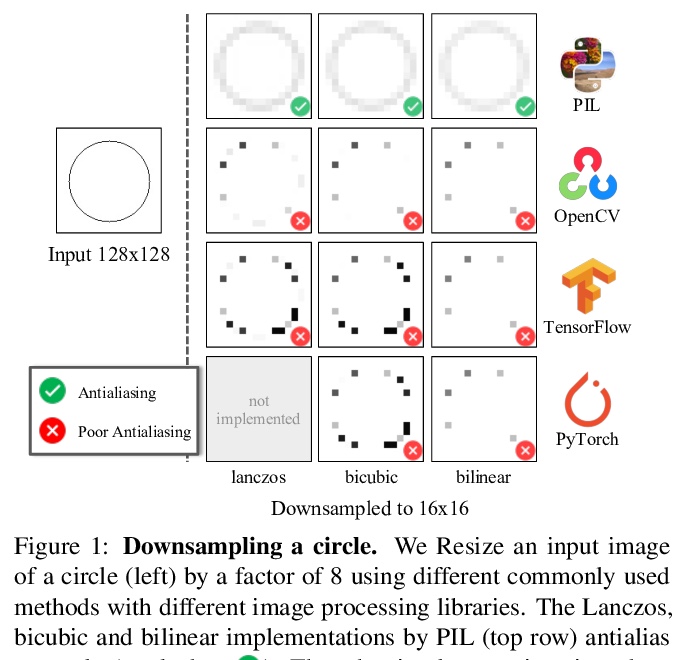
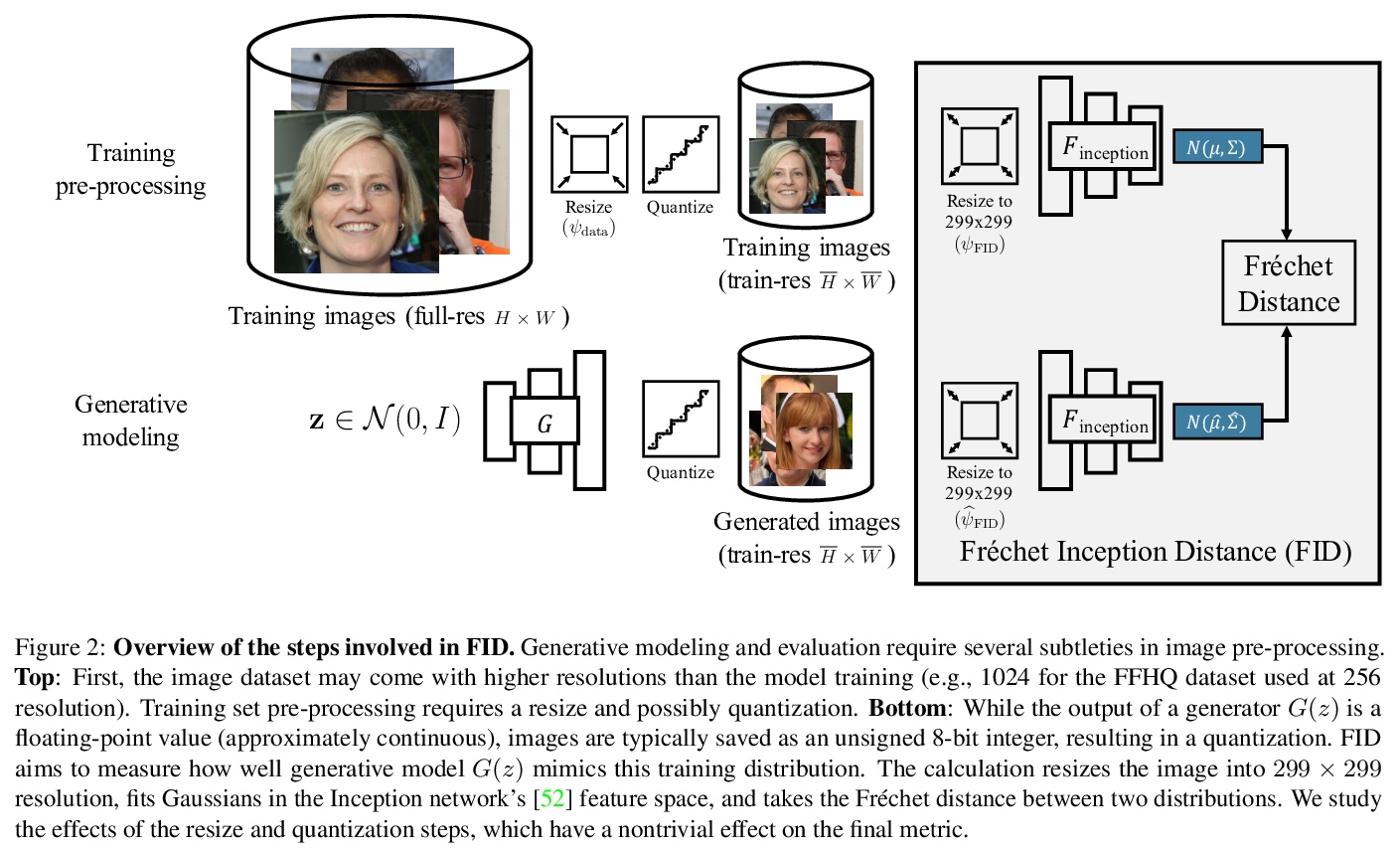
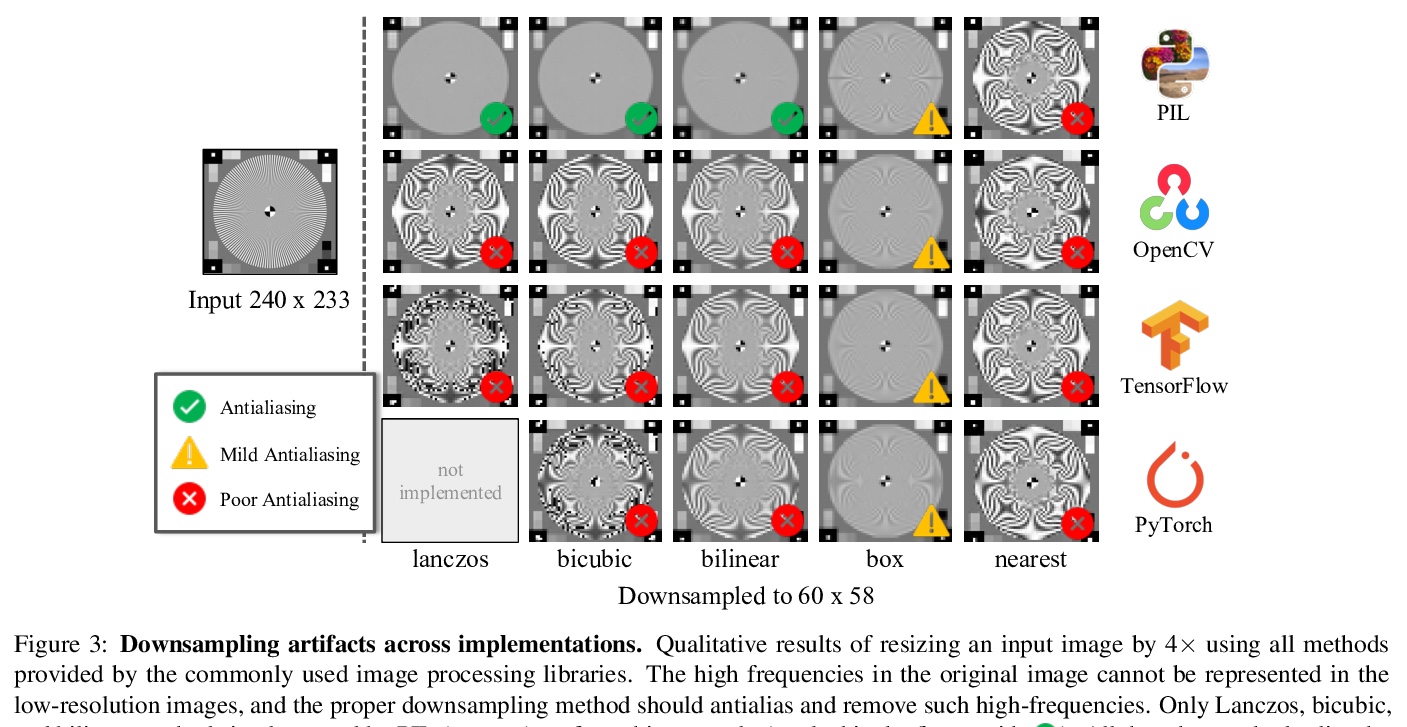
[CV] On Buggy Resizing Libraries and Surprising Subtleties in FID Calculation
FID对各种图像处理库不一致且经常不正确实现的敏感性
G Parmar, R Zhang, J Zhu
[CMU & Adobe Research]
https://weibo.com/1402400261/KckDGaULv
[AI] The Road Less Travelled: Trying And Failing To Generate Walking Simulators
少有人走的路:生成行走模拟器的尝试与失败
M Cook
[Queen Mary University of London]
https://weibo.com/1402400261/KckHwn2k0


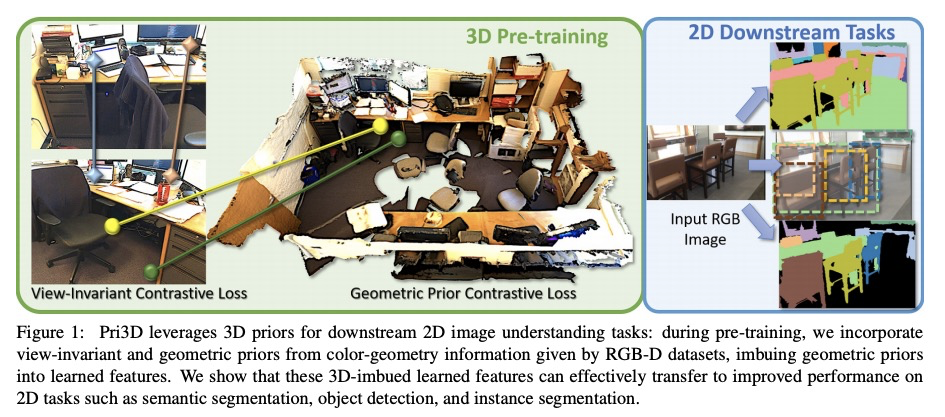
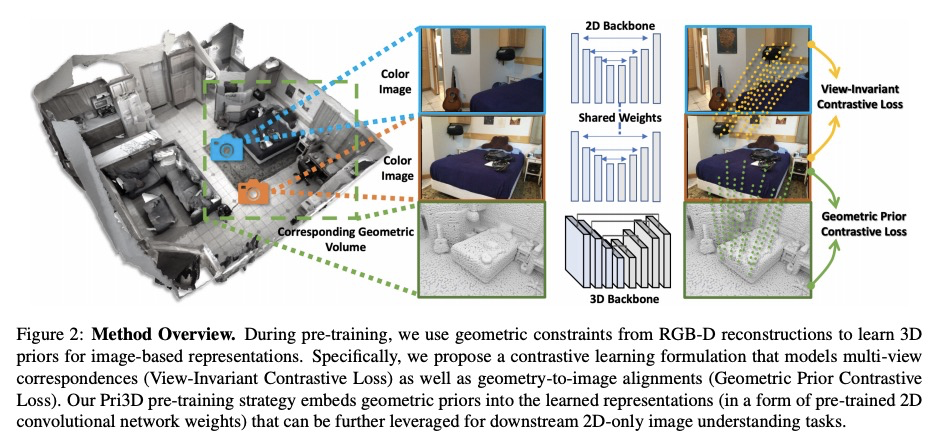
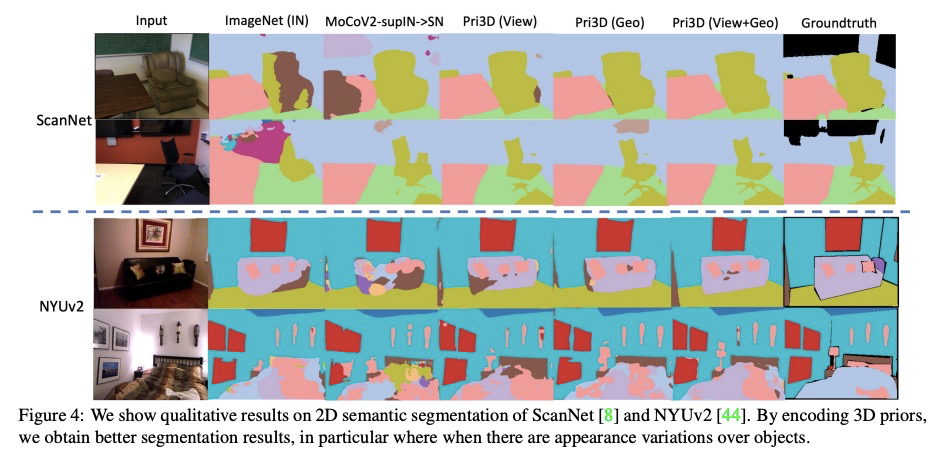
[CV] Pri3D: Can 3D Priors Help 2D Representation Learning?
Pri3D:3D先验是否有助于2D表示学习?
J Hou, S Xie, B Graham, A Dai, M Nießner
[Technical University of Munich & Facebook AI Research]
https://weibo.com/1402400261/KckJDxLbt

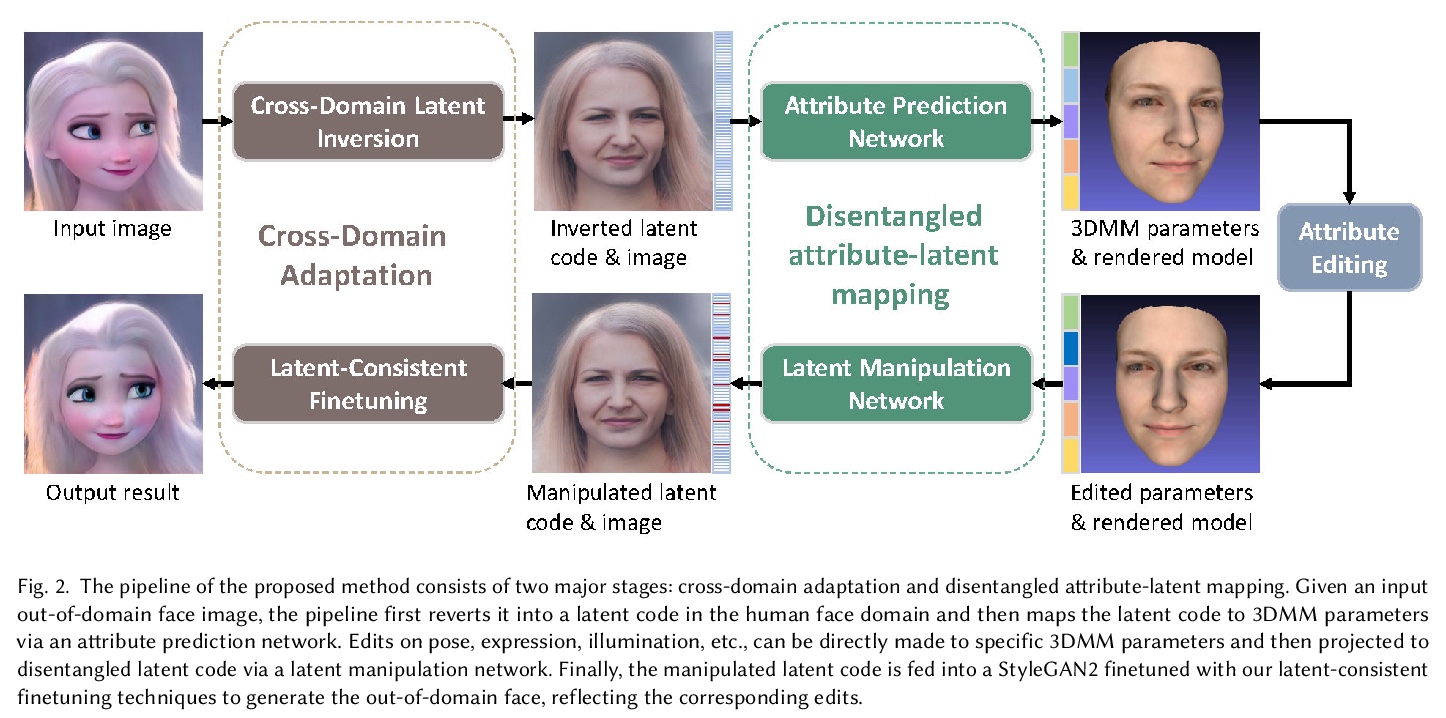
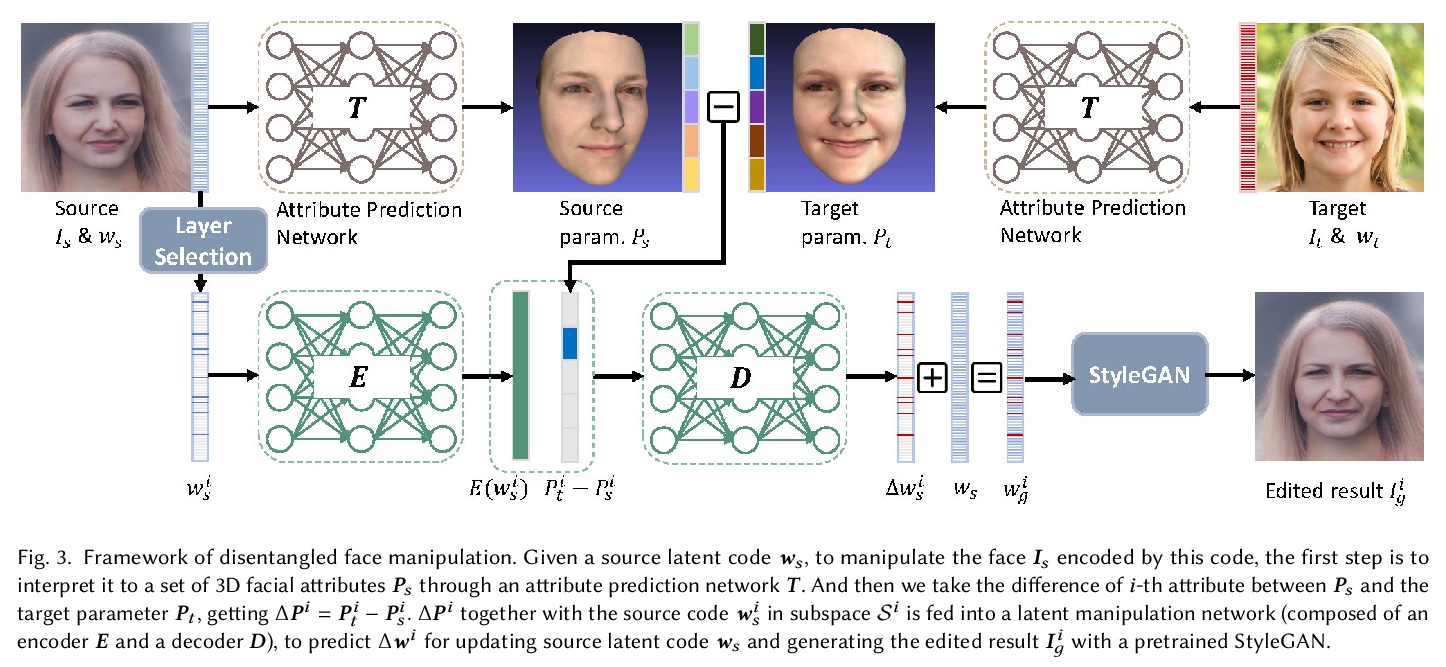
[CV] Cross-Domain and Disentangled Face Manipulation with 3D Guidance
3D引导跨域解缠人脸操纵
C Wang, M Chai, M He, D Chen, J Liao
[City University of Hong Kong & Snap Inc & USC Institute for Creative Technologies & Microsoft Cloud AI]
https://weibo.com/1402400261/KckNntfDY



若有收获,就点个赞吧
0 人点赞
