LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
(*表示值得重点关注)
1、[LG] *Differentially Private Learning Needs Better Features (or Much More Data)
F Tramèr, D Boneh
[Stanford University]
差分隐私学习需要更好的特征(或更多数据)。证明了在许多标准视觉任务上,差分隐私机器学习还没达到它的“AlexNet时刻”:在适度隐私成本约束下,用手工打造的特征训练的线性模型,显著优于端到端深度神经网络。为了超越手工打造特征的性能,隐私学习需要更多的私有数据,或者访问从类似域公开数据上学到的特征。**
We demonstrate that differentially private machine learning has not yet reached its “AlexNet moment” on many canonical vision tasks: linear models trained on handcrafted features significantly outperform end-to-end deep neural networks for moderate privacy budgets. To exceed the performance of handcrafted features, we show that private learning requires either much more private data, or access to features learned on public data from a similar domain. Our work introduces simple yet strong baselines for differentially private learning that can inform the evaluation of future progress in this area.
https://weibo.com/1402400261/JvMr2cCc8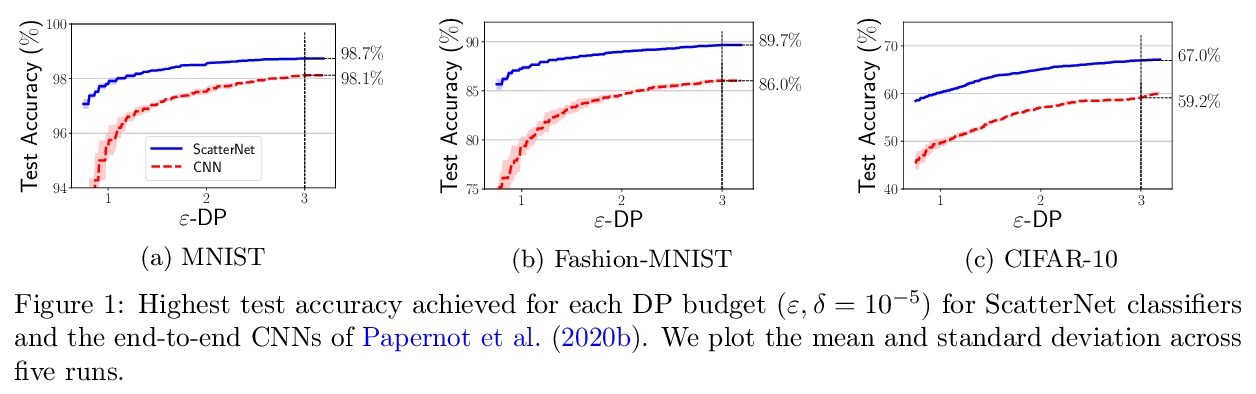

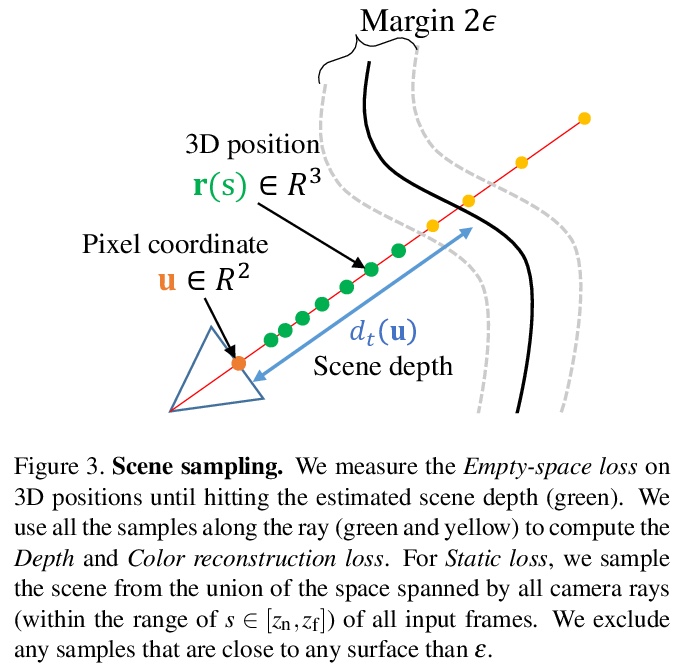
2、[CV] Space-time Neural Irradiance Fields for Free-Viewpoint Video
W Xian, J Huang, J Kopf, C Kim
[Cornell Tech & Virginia Tech & Facebook]
自由视点视频时-空神经辐照场。提出一种简单有效的算法,可从任意视点的单个视频,学习动态场景的时-空辐照场,利用单目视频深度估计,约束神经内隐函数的时变几何形状,设计了静态场景损失和采样策略,跨时域传播场景内容。
We present a method that learns a spatiotemporal neural irradiance field for dynamic scenes from a single video. Our learned representation enables free-viewpoint rendering of the input video. Our method builds upon recent advances in implicit representations. Learning a spatiotemporal irradiance field from a single video poses significant challenges because the video contains only one observation of the scene at any point in time. The 3D geometry of a scene can be legitimately represented in numerous ways since varying geometry (motion) can be explained with varying appearance and vice versa. We address this ambiguity by constraining the time-varying geometry of our dynamic scene representation using the scene depth estimated from video depth estimation methods, aggregating contents from individual frames into a single global representation. We provide an extensive quantitative evaluation and demonstrate compelling free-viewpoint rendering results.
https://weibo.com/1402400261/JvMA9czmr

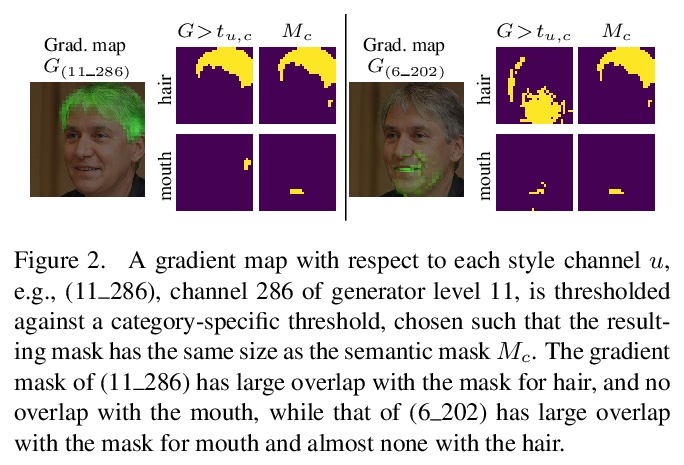
3、[CV] StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation
Z Wu, D Lischinski, E Shechtman
[Hebrew University & Adobe Research]
StyleGAN图像生成解缠控制。提出了通道级风格参数空间StyleSpace,比之前的其他中间潜空间解缠效果更好。提出一种发现大量样式通道的方法,每个通道都显示出以高度局部化和分离方式控制某个独特的视觉属性;采用一种简单方法,用预训练分类器或少量示例图像来识别控制特定属性的样式通道。
We explore and analyze the latent style space of StyleGAN2, a state-of-the-art architecture for image generation, using models pretrained on several different datasets. We first show that StyleSpace, the space of channel-wise style parameters, is significantly more disentangled than the other intermediate latent spaces explored by previous works. Next, we describe a method for discovering a large collection of style channels, each of which is shown to control a distinct visual attribute in a highly localized and disentangled manner. Third, we propose a simple method for identifying style channels that control a specific attribute, using a pretrained classifier or a small number of example images. Manipulation of visual attributes via these StyleSpace controls is shown to be better disentangled than via those proposed in previous works. To show this, we make use of a newly proposed Attribute Dependency metric. Finally, we demonstrate the applicability of StyleSpace controls to the manipulation of real images. Our findings pave the way to semantically meaningful and well-disentangled image manipulations via simple and intuitive interfaces.
https://weibo.com/1402400261/JvMG6cjRk

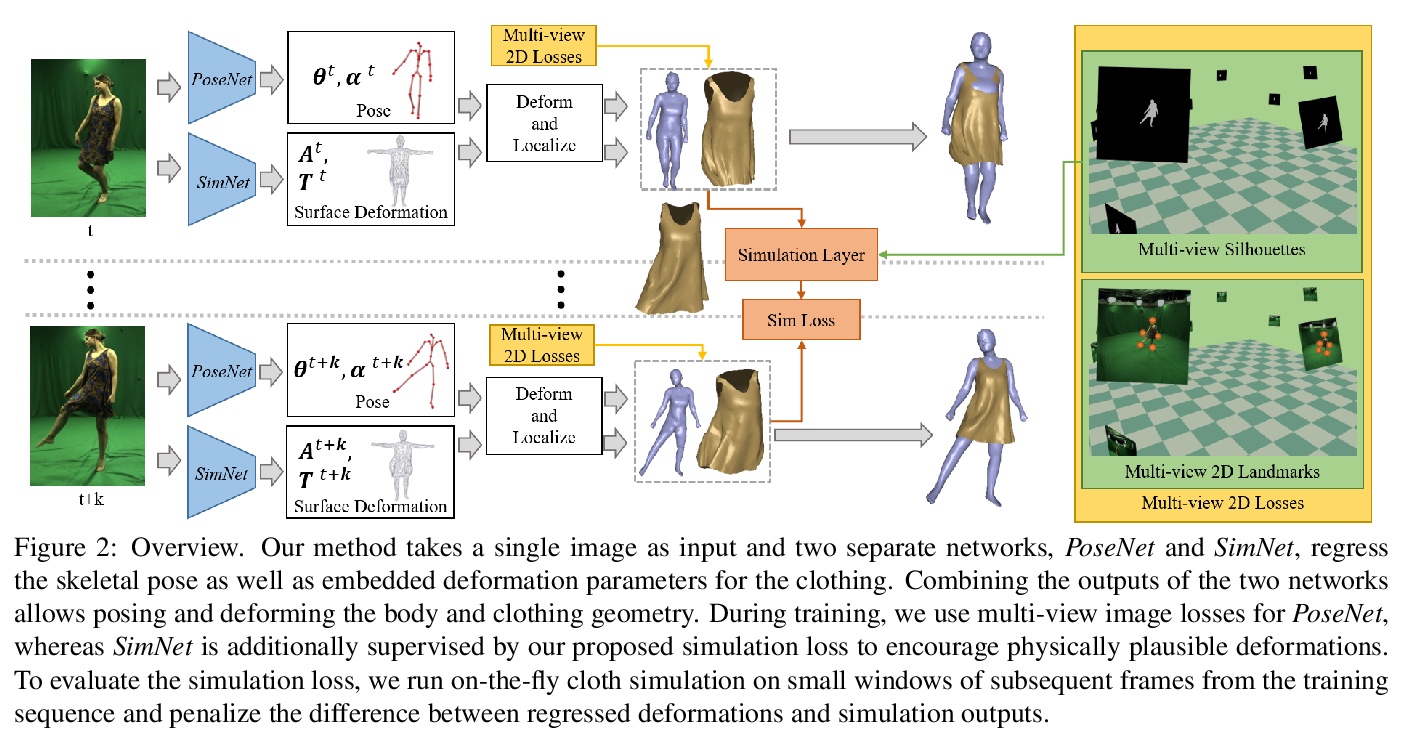
4、[CV] Deep Physics-aware Inference of Cloth Deformation for Monocular Human Performance Capture
Y Li, M Habermann, B Thomaszewski, S Coros, T Beeler, C Theobalt
[Max Planck Institute for Informatics & ETH Zurich & Google]
单目人体演出捕捉布料变形的深度物理感知推断。提出一种基于物理感知的深度学习方法,用于单目人体动作捕捉,在网络层运行中进行物理仿真,强化了物理学的合理性,以弥补仅用多视图图像的缺点。
https://weibo.com/1402400261/JvMJc14Lv

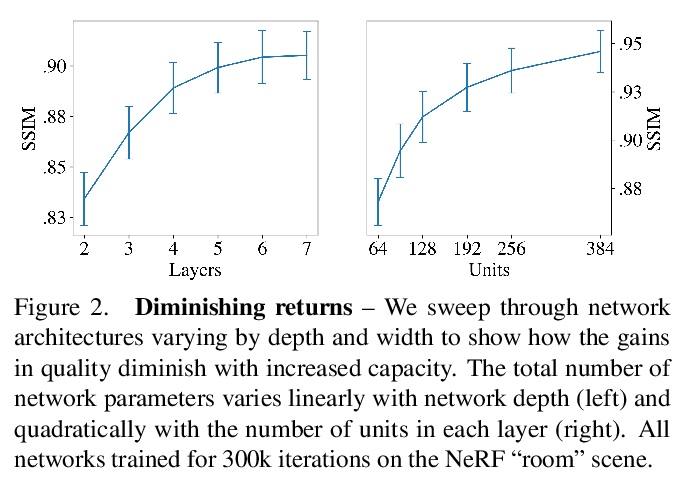
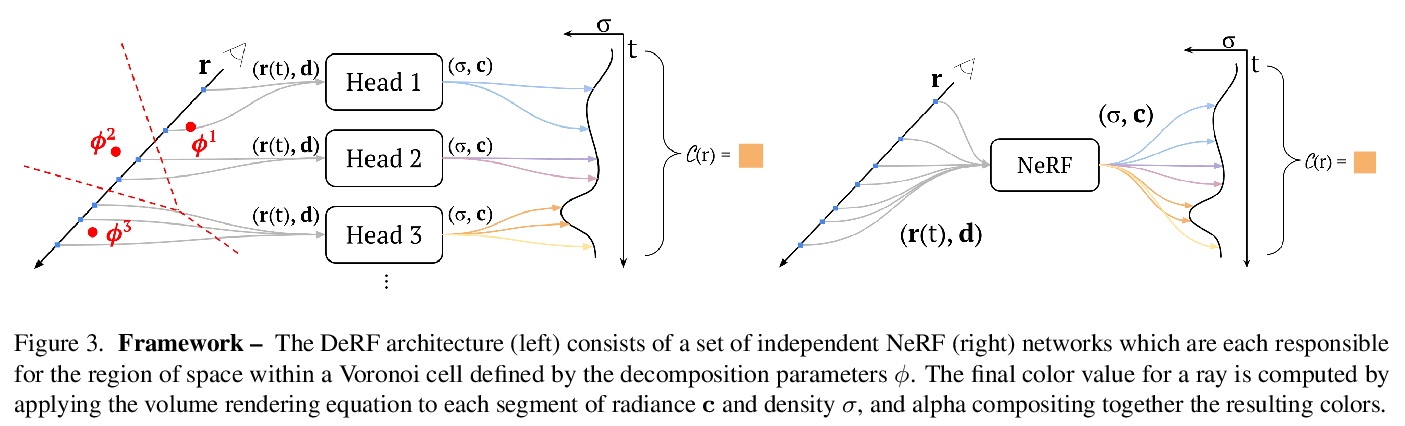
5、[CV] **DeRF: Decomposed Radiance Fields
D Rebain, W Jiang, S Yazdani, K Li, K M Yi, A Tagliasacchi
[University of British Columbia & University of Toronto]
DeRF:分解辐射场。提出一种通过空间分解,提高神经网络渲染推理效率的分解辐射场方法。通过将场景分解为多个单元,规避了神经网络渲染收益递减的问题:增加网络容量,并不会直接转化为更好的渲染质量。借助Voronoi分解的推理管道适合GPU计算,因此该方法不仅渲染速度更快,还可提供更高质量的图像。**
With the advent of Neural Radiance Fields (NeRF), neural networks can now render novel views of a 3D scene with quality that fools the human eye. Yet, generating these images is very computationally intensive, limiting their applicability in practical scenarios. In this paper, we propose a technique based on spatial decomposition capable of mitigating this issue. Our key observation is that there are diminishing returns in employing larger (deeper and/or wider) networks. Hence, we propose to spatially decompose a scene and dedicate smaller networks for each decomposed part. When working together, these networks can render the whole scene. This allows us near-constant inference time regardless of the number of decomposed parts. Moreover, we show that a Voronoi spatial decomposition is preferable for this purpose, as it is provably compatible with the Painter’s Algorithm for efficient and GPU-friendly rendering. Our experiments show that for real-world scenes, our method provides up to 3x more efficient inference than NeRF (with the same rendering quality), or an improvement of up to 1.0~dB in PSNR (for the same inference cost).
https://weibo.com/1402400261/JvMMOfsZk
其他几篇值得关注的论文:
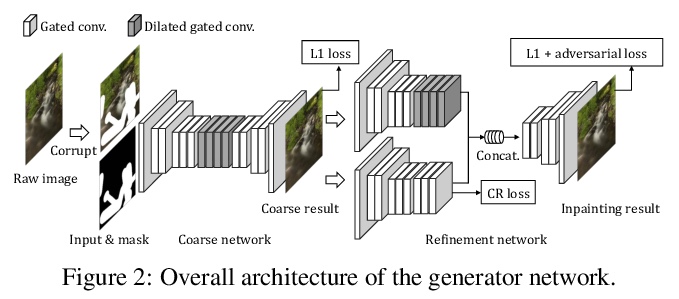
[CV] Image Inpainting with Contextual Reconstruction Loss
上下文重建损失图像补全
Y Zeng, Z Lin, H Lu, V M. Patel
[Tencent Lightspeed & Quantum Studios & Adobe Research & Dalian University of Technology & Johns Hopkins University]
https://weibo.com/1402400261/JvMPWav9r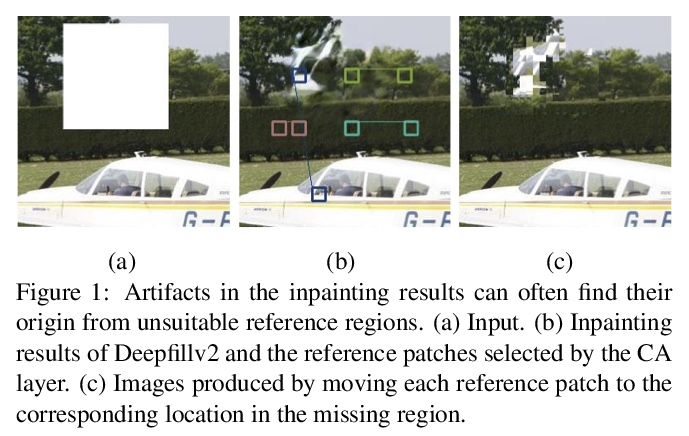

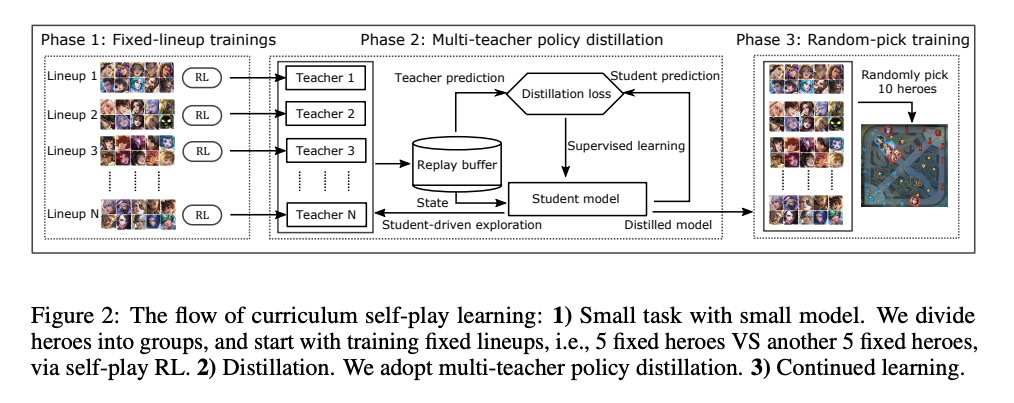
[LG] Towards Playing Full MOBA Games with Deep Reinforcement Learning
用深度强化学习玩”王者荣耀”、Dota2等全MOBA游戏
D Ye, G Chen, W Zhang, S Chen, B Yuan, B Liu, J Chen, Z Liu, F Qiu, H Yu, Y Yin, B Shi, L Wang, T Shi, Q Fu, W Yang, L Huang, W Liu
[Tencent AI Lab & Tencent TiMi L1 Studio]
https://weibo.com/1402400261/JvMRqCwjk

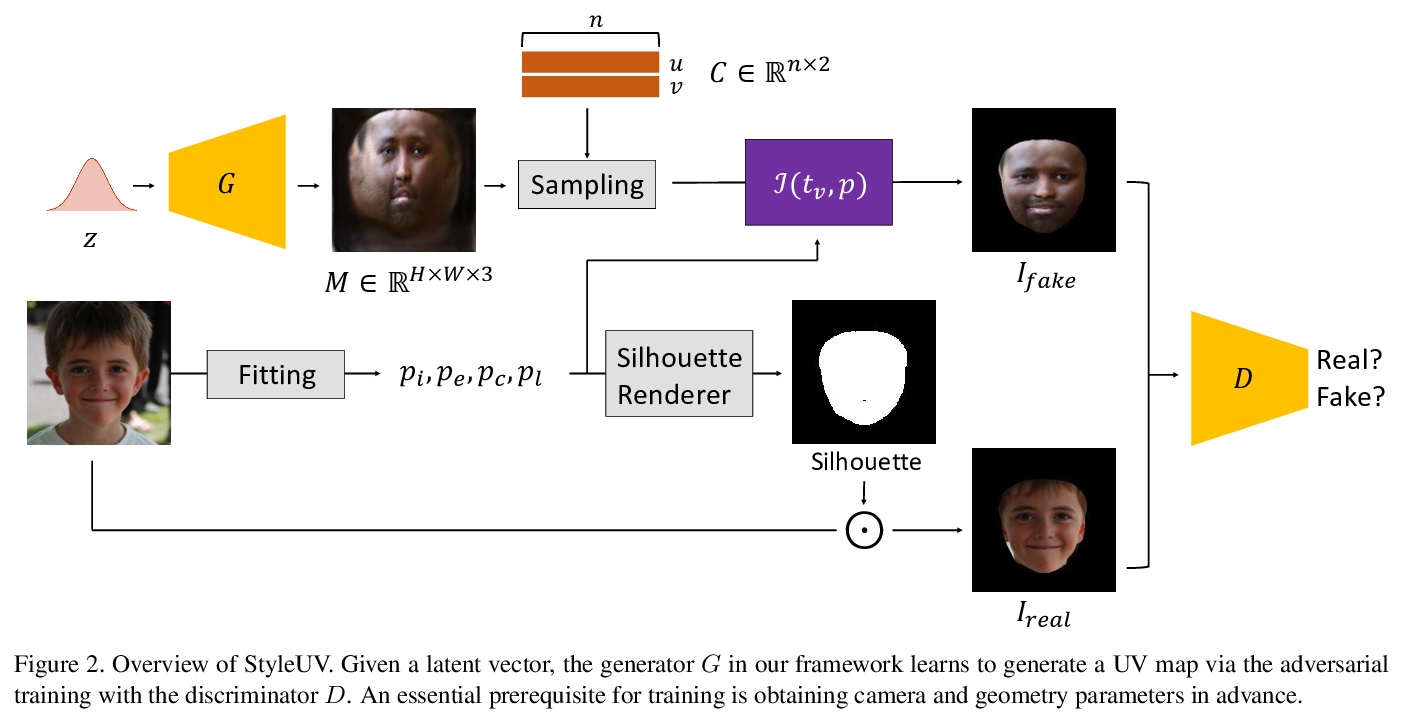
[CV] StyleUV: Diverse and High-fidelity UV Map Generative Model
StyleUV:多样化高保真的UV贴图生成模型
M Lee, W Cho, M Kim, D Inouye, N Kwak
[Seoul National University & Purdue University & NAVER WEBTOON]
https://weibo.com/1402400261/JvMTD5n6o
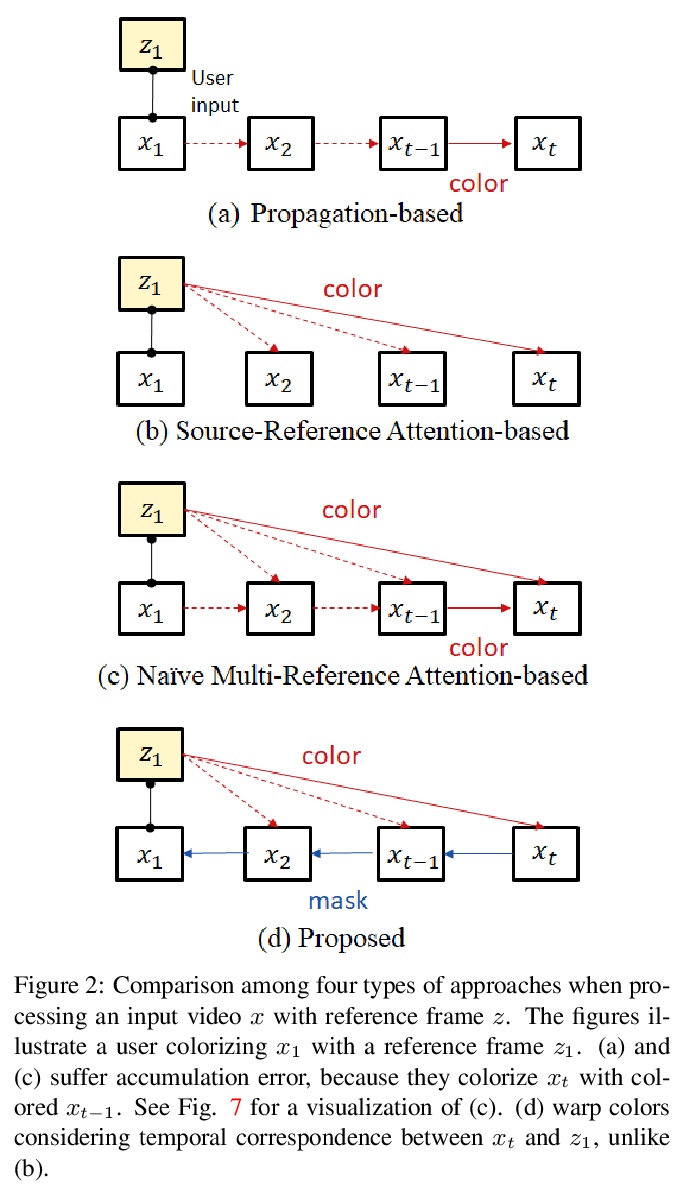
[CV] Reference-Based Video Colorization with Spatiotemporal Correspondence
基于参照的时空对应视频着色
N Akimoto, A Hayakawa, A Shin, T Narihira
[Sony Corporation]
https://weibo.com/1402400261/JvMVW7yt5

[CV] Play Fair: Frame Attributions in Video Models
公平竞争:视频模型帧属性
W Price, D Damen
[University of Bristol]
https://weibo.com/1402400261/JvMZd8Q9E


若有收获,就点个赞吧
0 人点赞
