- 1、[LG] Introduction to Normalizing Flows for Lattice Field Theory
- 2、[LG] Is Attention Better Than Matrix Decomposition?
- 3、[CV] JigsawGAN: Self-supervised Learning for Solving Jigsaw Puzzles with Generative Adversarial Networks
- 4、[LG] Long-tail learning via logit adjustment
- 5、[CV] SplitSR: An End-to-End Approach to Super-Resolution on Mobile Devices
- [AI] Formalizing Trust in Artificial Intelligence: Prerequisites, Causes and Goals of Human Trust in AI
- [LG] Rank the Episodes: A Simple Approach for Exploration in Procedurally-Generated Environments
- [CL] Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation
- [SI] VoterFraud2020: a Multi-modal Dataset of Election Fraud Claims on Twitter
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] Introduction to Normalizing Flows for Lattice Field Theory
M S. Albergo, D Boyda, D C. Hackett, G Kanwar, K Cranmer, S Racanière, D J Rezende, P E. Shanahan
[New York University & MIT & DeepMind]
格点场论标准化流介绍。展示了一种用标准化流机器学习模型对格点场论玻尔兹曼分布进行采样的方法,介绍了框架的具体实现,将该框架应用于格点标量场理论和U(1)规范理论,在后者基于流的方法中对规范对称性进行了显式编码。文中包含很多关于构建等变流和流形流的细节和相关代码。
This notebook tutorial demonstrates a method for sampling Boltzmann distributions of lattice field theories using a class of machine learning models known as normalizing flows. The ideas and approaches proposed in > arXiv:1904.12072, > arXiv:2002.02428, and > arXiv:2003.06413 are reviewed and a concrete implementation of the framework is presented. We apply this framework to a lattice scalar field theory and to U(1) gauge theory, explicitly encoding gauge symmetries in the flow-based approach to the latter. This presentation is intended to be interactive and working with the attached Jupyter notebook is recommended.
https://weibo.com/1402400261/JEipY32rU

2、[LG] Is Attention Better Than Matrix Decomposition?
Z Geng, M-H Guo, H Chen, X Li, K Wei, Z Lin
[Peking University & Tsinghua University & Fudan University]
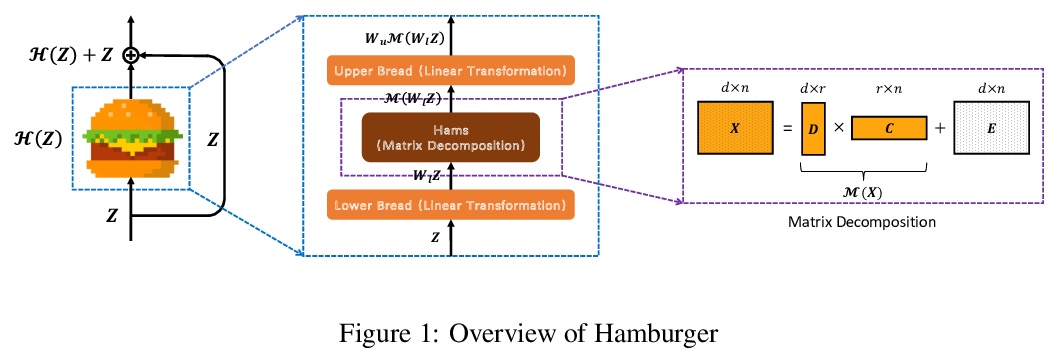
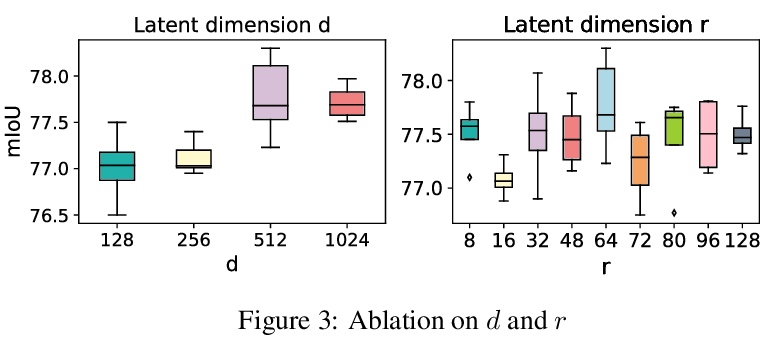
注意力比矩阵分解强吗?就长程依赖编码的性能和计算成本而言,自注意力并不比矩阵分解(MD)模型表现更好。将全局上下文问题建模为低秩补全问题,证明了其优化算法有助于设计全局信息块。在此基础上,采用矩阵分解优化算法,将输入表示分解为子矩阵,重构低秩嵌入,将全局相关性建模表述为低秩补全问题,将目标函数最小化的优化算法转化为模块化架构。所提出的Hamburger是轻量但强大的全局上下文模块,复杂度O(n),在语义分割和图像生成方面远超各种注意力模块。
As an essential ingredient of modern deep learning, attention mechanism, especially self-attention, plays a vital role in the global correlation discovery. However, is hand-crafted attention irreplaceable when modeling the global context? Our intriguing finding is that self-attention is not better than the matrix decomposition (MD) model developed 20 years ago regarding the performance and computational cost for encoding the long-distance dependencies. We model the global context issue as a low-rank completion problem and show that its optimization algorithms can help design global information blocks. This paper then proposes a series of Hamburgers, in which we employ the optimization algorithms for solving MDs to factorize the input representations into sub-matrices and reconstruct a low-rank embedding. Hamburgers with different MDs can perform favorably against the popular global context module self-attention when carefully coping with gradients back-propagated through MDs. Comprehensive experiments are conducted in the vision tasks where it is crucial to learn the global context, including semantic segmentation and image generation, demonstrating significant improvements over self-attention and its variants.
https://weibo.com/1402400261/JEiy44nKR
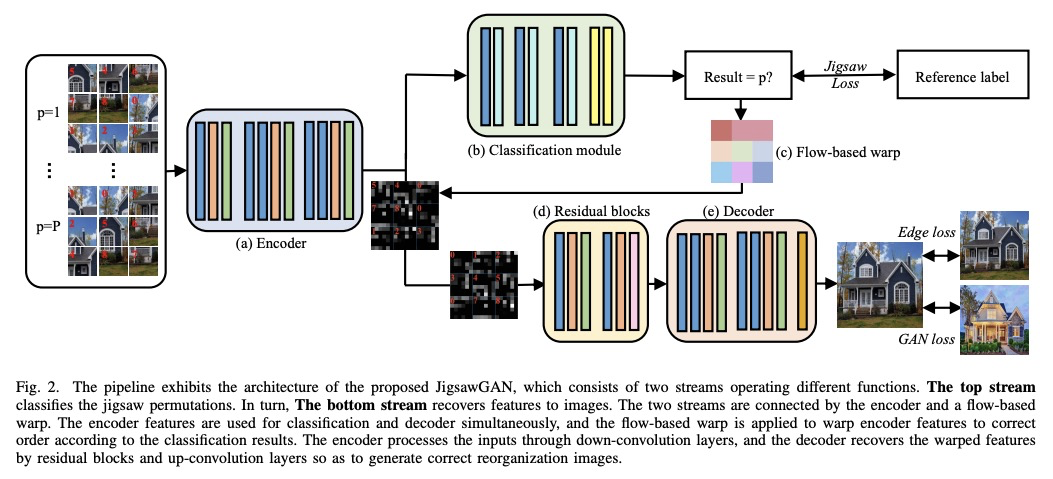
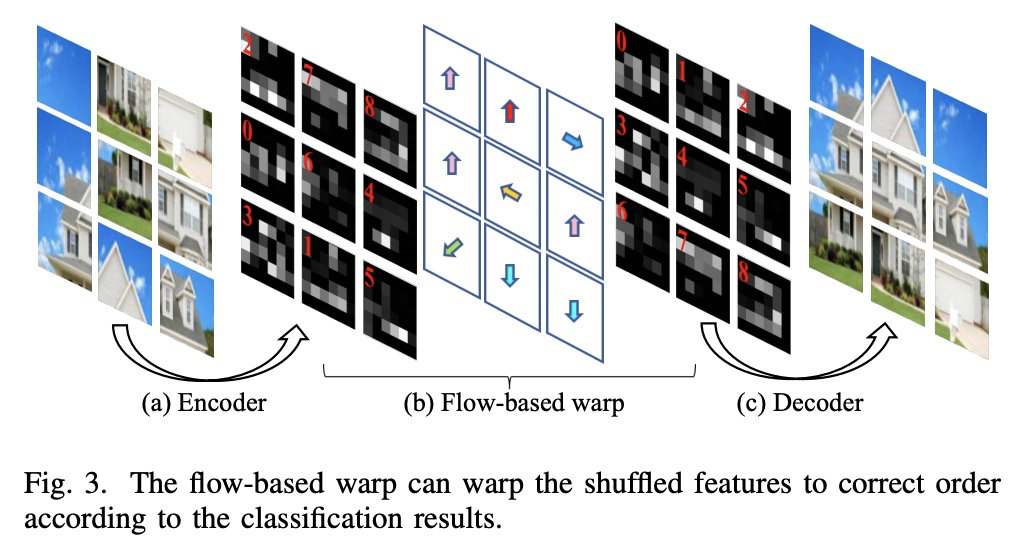
3、[CV] JigsawGAN: Self-supervised Learning for Solving Jigsaw Puzzles with Generative Adversarial Networks
R Li, S Liu, G Wang, G Liu, B Zeng
[University of Electronic Science and Technology of China & Megvii Technology]
JigsawGAN:用生成式对抗网络自监督学习解决拼图问题。提出JigsawGAN,一种基于GAN的自监督方法,用于解决原始图像先验知识不可知的拼图问题。所提出方法可应用拼图块边缘信息和生成图像的语义信息,对于更准确地解决拼图问题很有帮助。JigsawGAN包含两个分支,分类分支对拼图组合进行分类,GAN分支对具有正确顺序的图像进行特征恢复。引入GAN损失和新的边缘损失,分别聚焦于语义和边缘两类信息对网络进行约束。
The paper proposes a solution based on Generative Adversarial Network (GAN) for solving jigsaw puzzles. The problem assumes that an image is cut into equal square pieces, and asks to recover the image according to pieces information. Conventional jigsaw solvers often determine piece relationships based on the piece boundaries, which ignore the important semantic information. In this paper, we propose JigsawGAN, a GAN-based self-supervised method for solving jigsaw puzzles with unpaired images (with no prior knowledge of the initial images). We design a multi-task pipeline that includes, (1) a classification branch to classify jigsaw permutations, and (2) a GAN branch to recover features to images with correct orders. The classification branch is constrained by the pseudo-labels generated according to the shuffled pieces. The GAN branch concentrates on the image semantic information, among which the generator produces the natural images to fool the discriminator with reassembled pieces, while the discriminator distinguishes whether a given image belongs to the synthesized or the real target manifold. These two branches are connected by a flow-based warp that is applied to warp features to correct order according to the classification results. The proposed method can solve jigsaw puzzles more efficiently by utilizing both semantic information and edge information simultaneously. Qualitative and quantitative comparisons against several leading prior methods demonstrate the superiority of our method.
https://weibo.com/1402400261/JEiIdtbBC
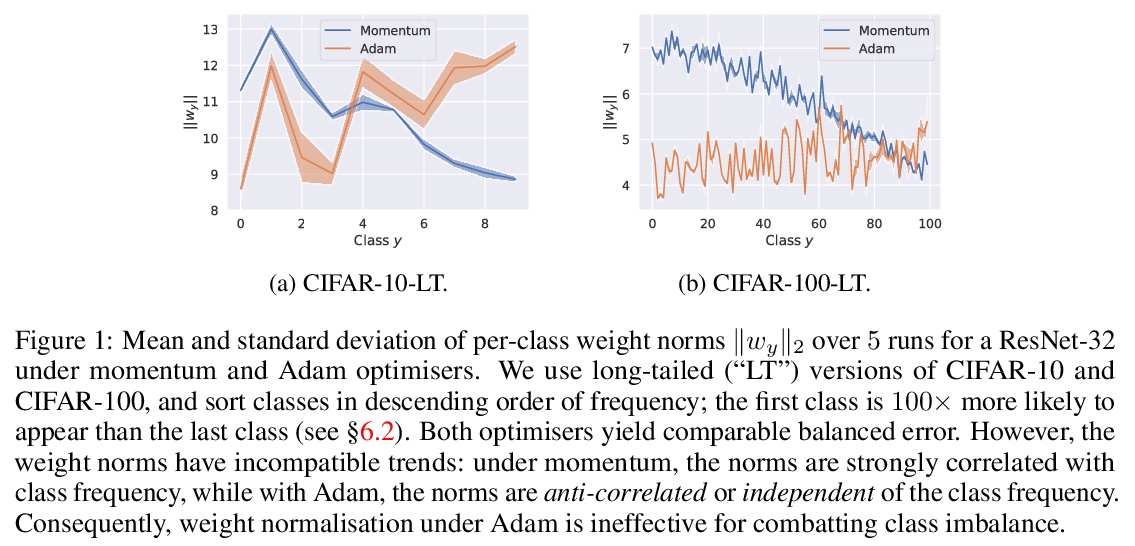
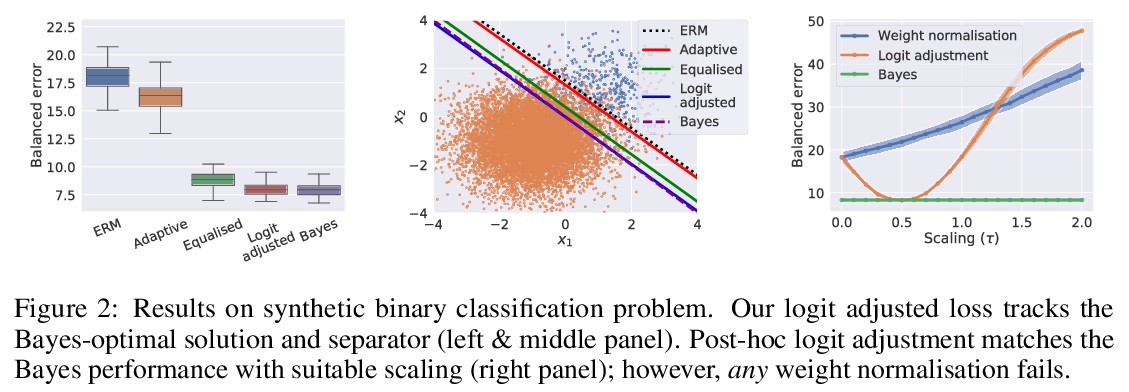
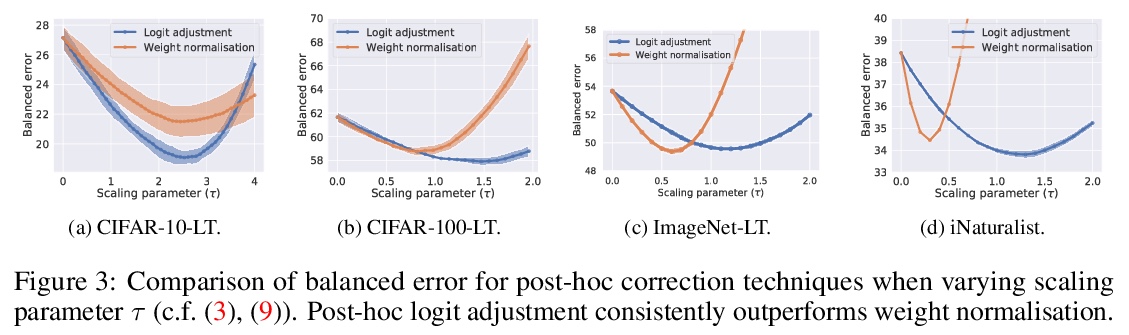
4、[LG] Long-tail learning via logit adjustment
AK Menon, S Jayasumana, AS Rawat, H Jain, A Veit…
[Google Research]
基于logit调整的长尾(非平衡)学习。现实世界的分类问题通常表现出不平衡或长尾标签分布,其中许多标签只有少数相关样本,对此类标签的泛化提出了挑战。本文建立了基于logit调整的长尾学习统计框架,为事后归一化和损失修正技术提供了统一视角,同时克服其局限性。提出了logit调整的两种实现方式:事后应用,或者在训练过程中应用。在四个具有长尾标签分布的真实世界数据集上,证明了所提出的logit调整技术与几种基线相比的有效性。
Real-world classification problems typically exhibit an imbalanced or long-tailed label distribution, wherein many labels have only a few associated samples. This poses a challenge for generalisation on such labels, and also makes naive learning biased towards dominant labels. In this paper, we present a statistical framework that unifies and generalises several recent proposals to cope with these challenges. Our framework revisits the classic idea of logit adjustment based on the label frequencies, which encourages a large relative margin between logits of rare positive versus dominant negative labels. This yields two techniques for long-tail learning, where such adjustment is either applied post-hoc to a trained model, or enforced in the loss during training. These techniques are statistically grounded, and practically effective on four real-world datasets with long-tailed label distributions.
https://weibo.com/1402400261/JEiO1Foks
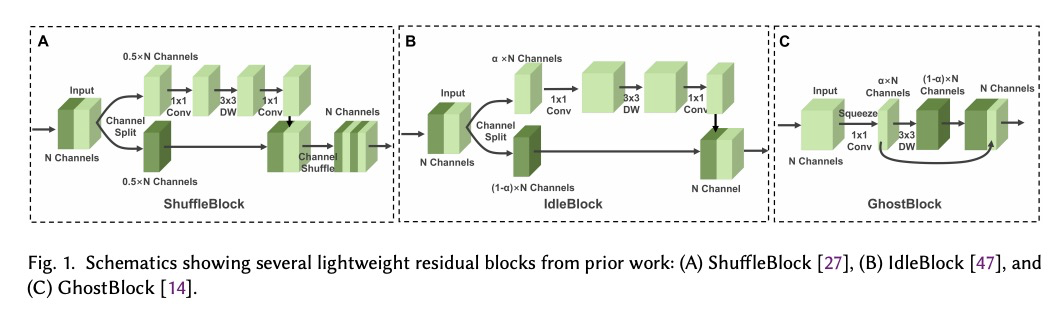
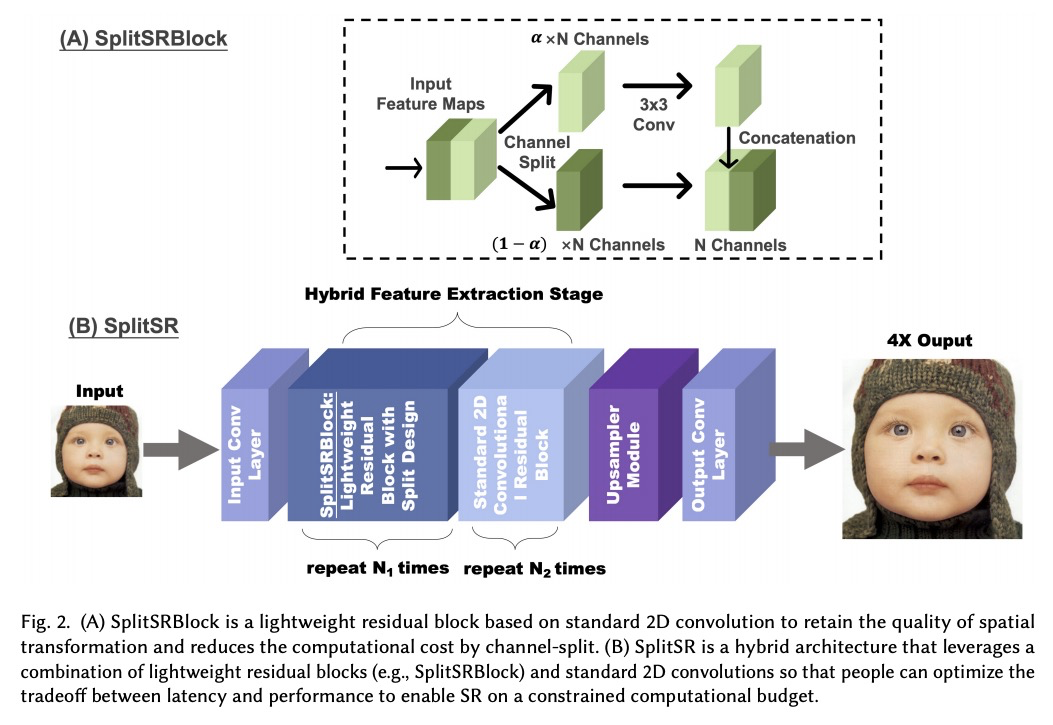
5、[CV] SplitSR: An End-to-End Approach to Super-Resolution on Mobile Devices
X Liu, Y Li, J Fromm, Y Wang, Z Jiang, A Mariakakis, S Patel
[University of Washington & Tsinghua Univiersity & University of Toronto]
SplitSR:移动设备上的端到端超分辨率。提出一种新的端到端手机端超分辨率系统SplitSR,在现代超分辨率架构中引入分裂设计,利用现代深度学习编译器进行底层运算器优化,实现了5倍的推理速度提升,与之前最先进系统相比,准确度也有所提升。
Super-resolution (SR) is a coveted image processing technique for mobile apps ranging from the basic camera apps to mobile health. Existing SR algorithms rely on deep learning models with significant memory requirements, so they have yet to be deployed on mobile devices and instead operate in the cloud to achieve feasible inference time. This shortcoming prevents existing SR methods from being used in applications that require near real-time latency. In this work, we demonstrate state-of-the-art latency and accuracy for on-device super-resolution using a novel hybrid architecture called SplitSR and a novel lightweight residual block called SplitSRBlock. The SplitSRBlock supports channel-splitting, allowing the residual blocks to retain spatial information while reducing the computation in the channel dimension. SplitSR has a hybrid design consisting of standard convolutional blocks and lightweight residual blocks, allowing people to tune SplitSR for their computational budget. We evaluate our system on a low-end ARM CPU, demonstrating both higher accuracy and up to 5 times faster inference than previous approaches. We then deploy our model onto a smartphone in an app called ZoomSR to demonstrate the first-ever instance of on-device, deep learning-based SR. We conducted a user study with 15 participants to have them assess the perceived quality of images that were post-processed by SplitSR. Relative to bilinear interpolation — the existing standard for on-device SR — participants showed a statistically significant preference when looking at both images (Z=-9.270, p<0.01) and text (Z=-6.486, p<0.01).
[https://weibo.com/1402400261/JEj0bspGH](https://weibo.com/1402400261/JEj0bspGH)
另外几篇值得关注的论文:
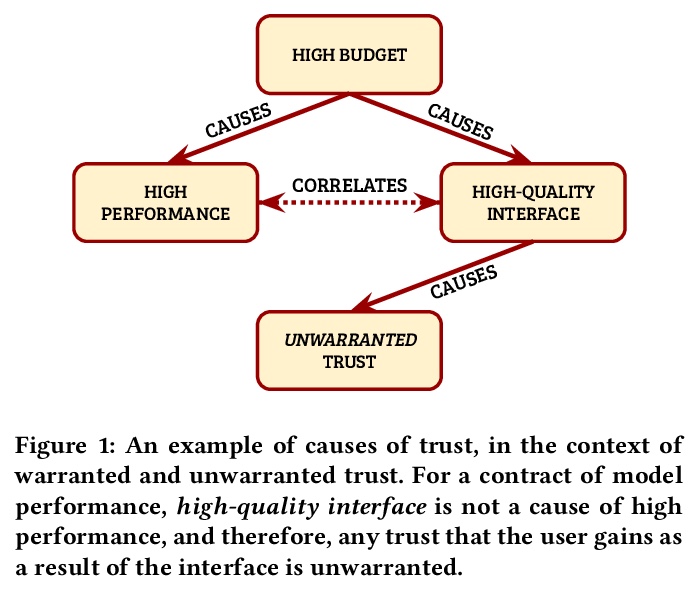
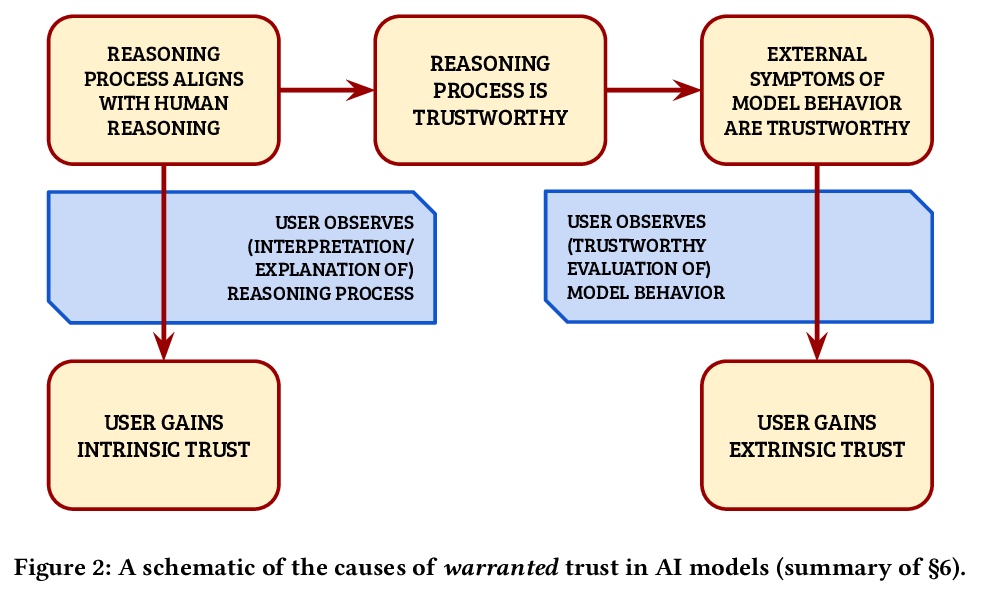
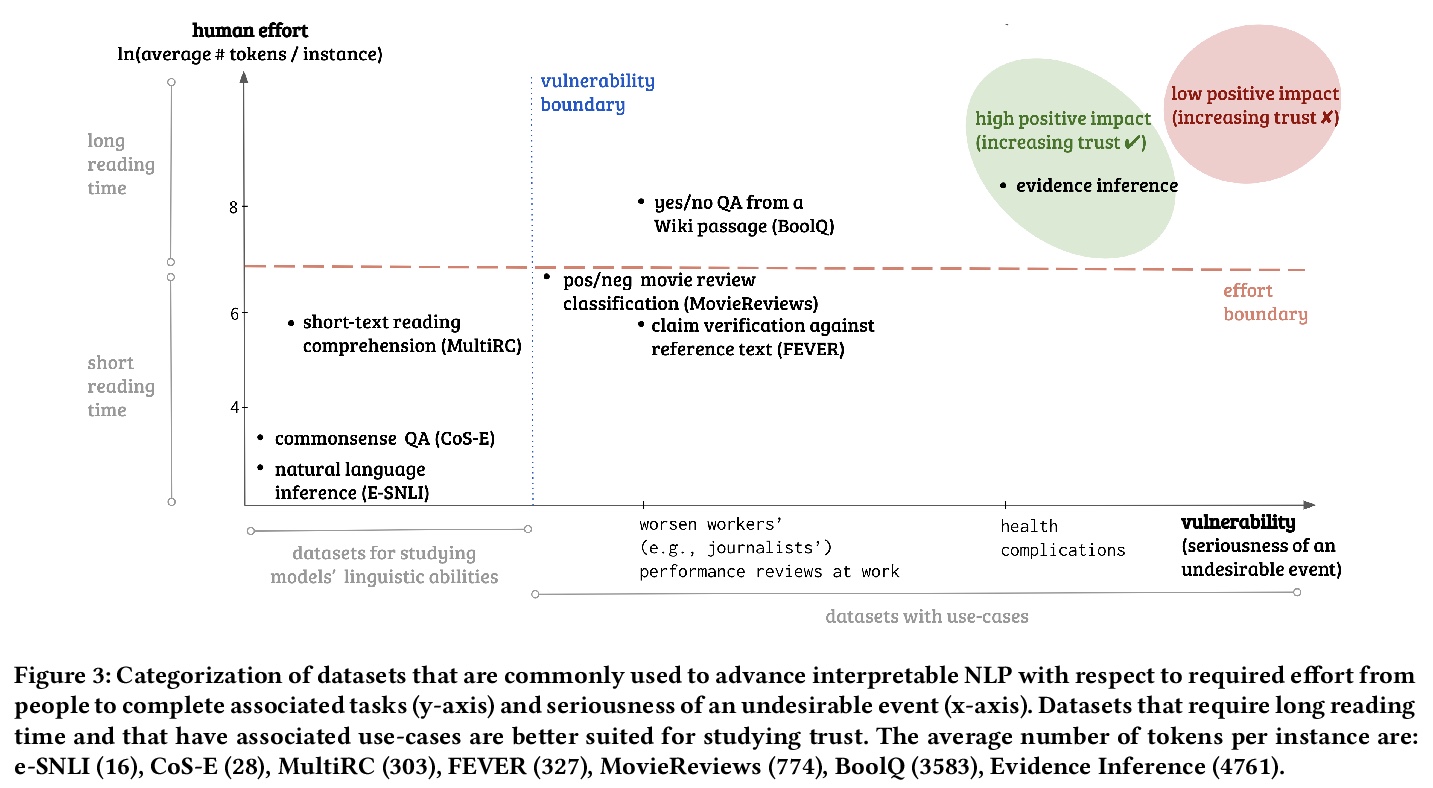
[AI] Formalizing Trust in Artificial Intelligence: Prerequisites, Causes and Goals of Human Trust in AI
人工智能信任的形式化:前提、原因和目标
A Jacovi, A Marasović, T Miller, Y Goldberg
[Bar Ilan University & Allen Institute for Artificial Intelligence & The University of Melbourne]
https://weibo.com/1402400261/JEj3GEBPf
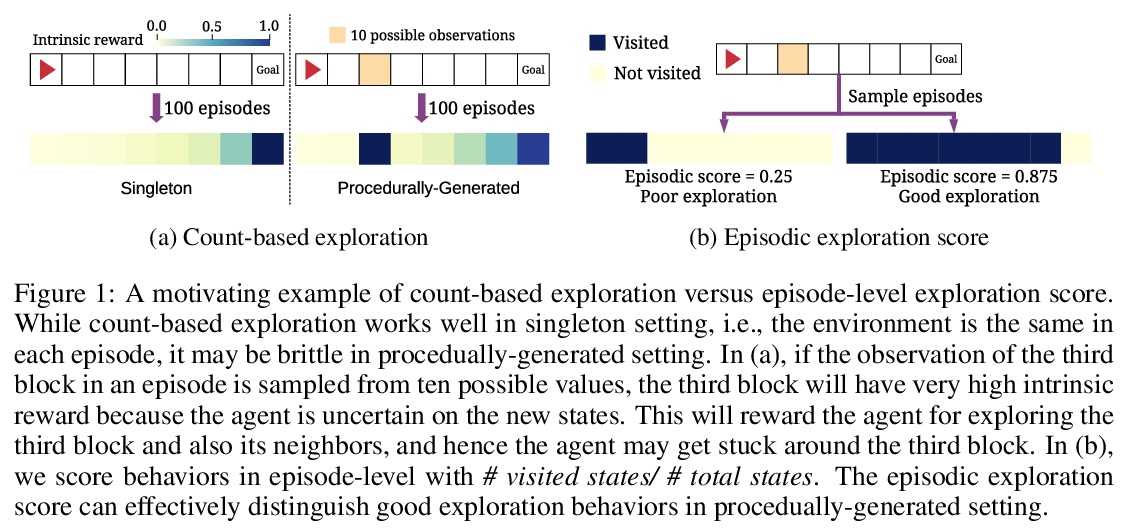
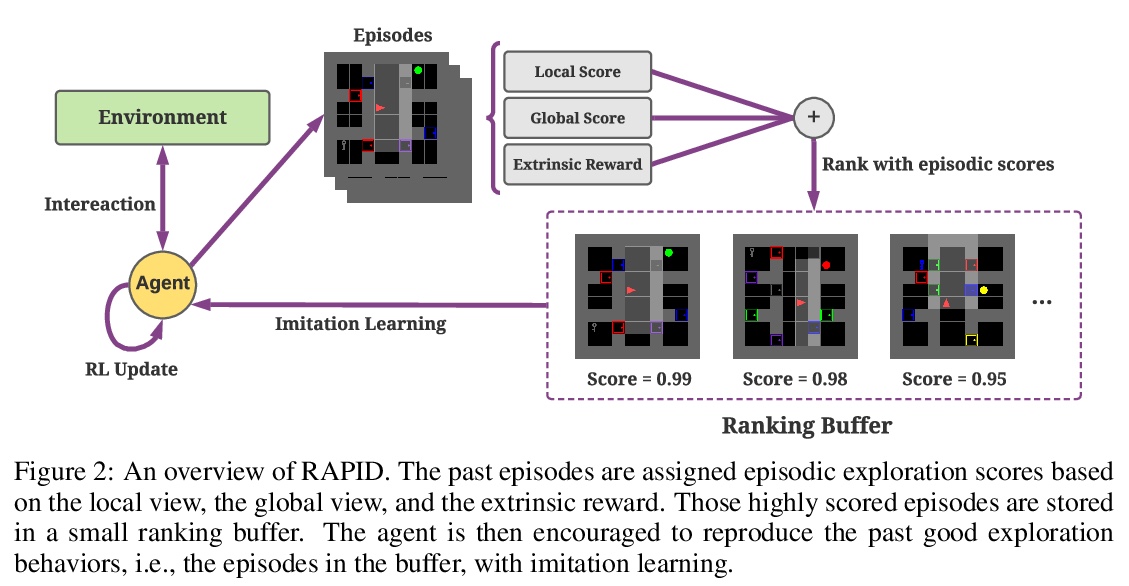
[LG] Rank the Episodes: A Simple Approach for Exploration in Procedurally-Generated Environments
Rank the Episodes:在程序生成环境中探索的简单方法
D Zha, W Ma, L Yuan, X Hu, J Liu
[Texas A&M University & Kwai Inc]
https://weibo.com/1402400261/JEj647SHG

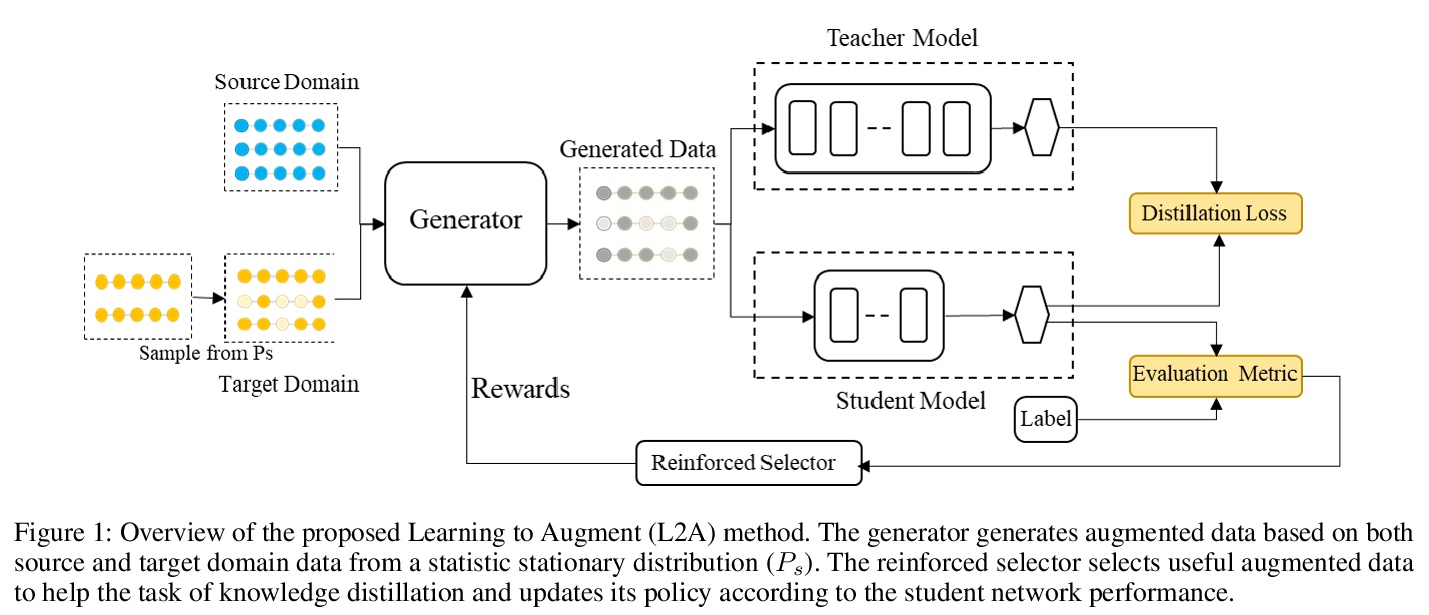
[CL] Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation
数据稀缺域BERT知识蒸馏增广学习
L Feng, M Qiu, Y Li, H Zheng, Y Shen
[Tsinghua University & Alibaba Group & Sun-Yat Sen University]
https://weibo.com/1402400261/JEjcDhZGw
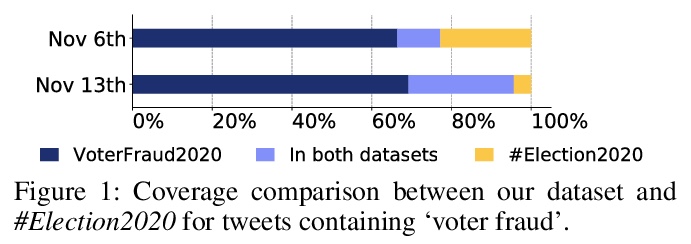
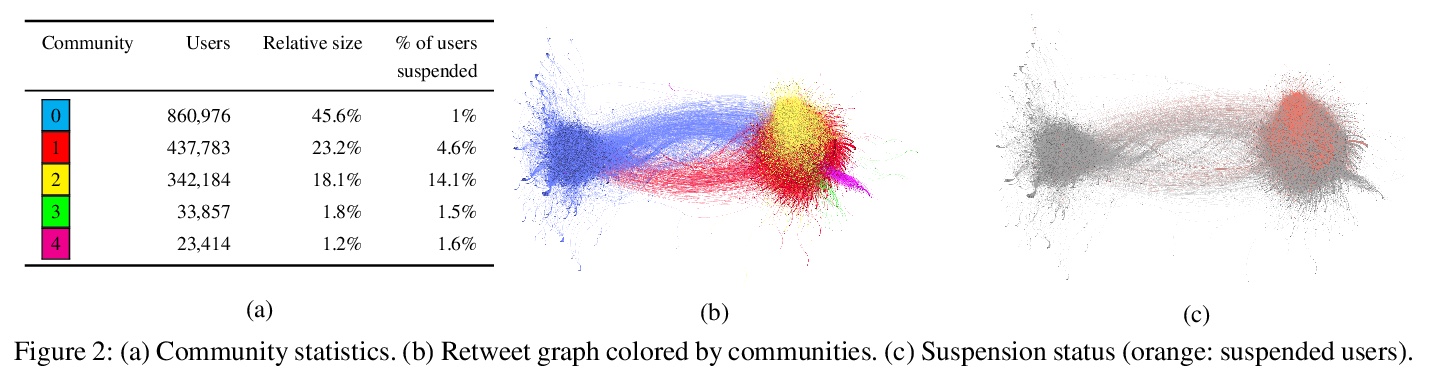
[SI] VoterFraud2020: a Multi-modal Dataset of Election Fraud Claims on Twitter
VoterFraud2020:Twitter选举舞弊指控多模态数据集
A Abilov, Y Hua, H Matatov, O Amir, M Naaman
[Cornell Tech & Technion]
https://weibo.com/1402400261/JEjf6EyyZ

若有收获,就点个赞吧
0 人点赞
