- 1、[CV] KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs
- 2、[CV] PlenOctrees for Real-time Rendering of Neural Radiance Fields
- 3、[CV] An Image is Worth 16x16 Words, What is a Video Worth?
- 4、[CV] High-Fidelity Pluralistic Image Completion with Transformers
- 5、[CV] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- [CV] Scaling-up Disentanglement for Image Translation
- [CV] Contrasting Contrastive Self-Supervised Representation Learning Models
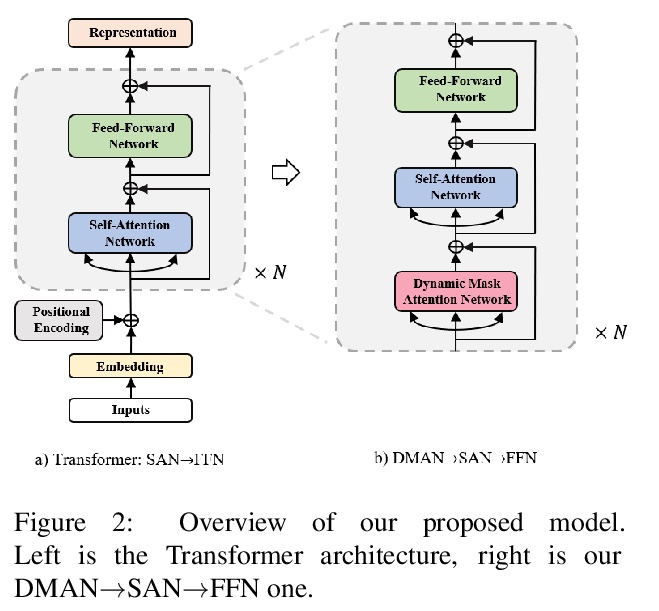
- [CL] Mask Attention Networks: Rethinking and Strengthen Transformer
- [CV] Designing a Practical Degradation Model for Deep Blind Image Super-Resolution
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs
C Reiser, S Peng, Y Liao, A Geiger
[Max Planck Institute for Intelligent Systems]
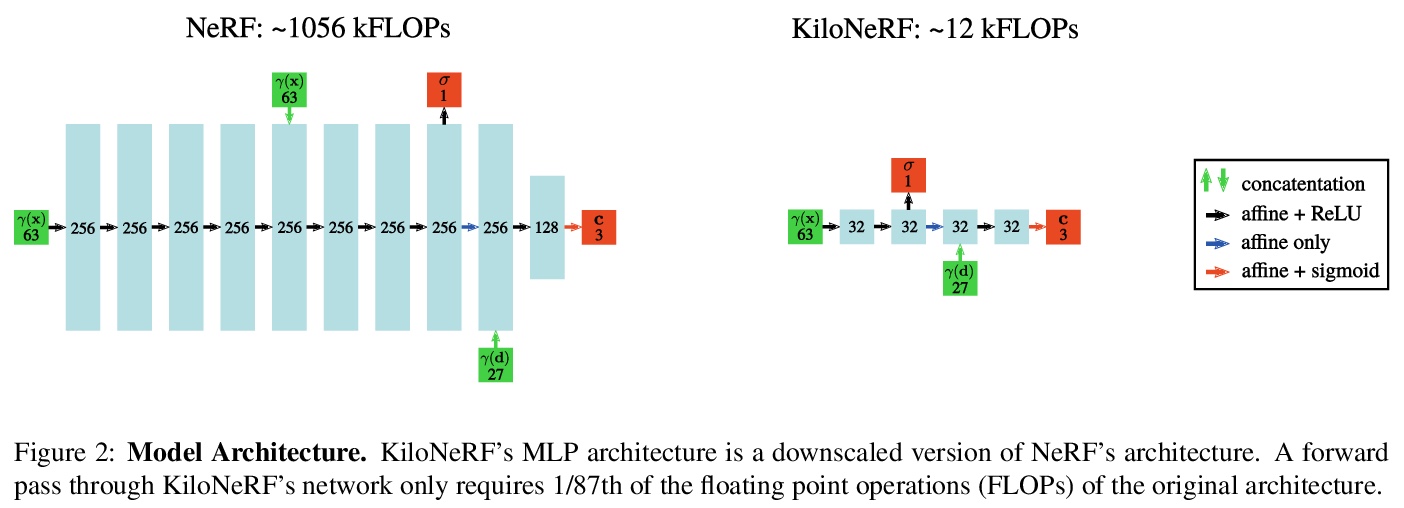
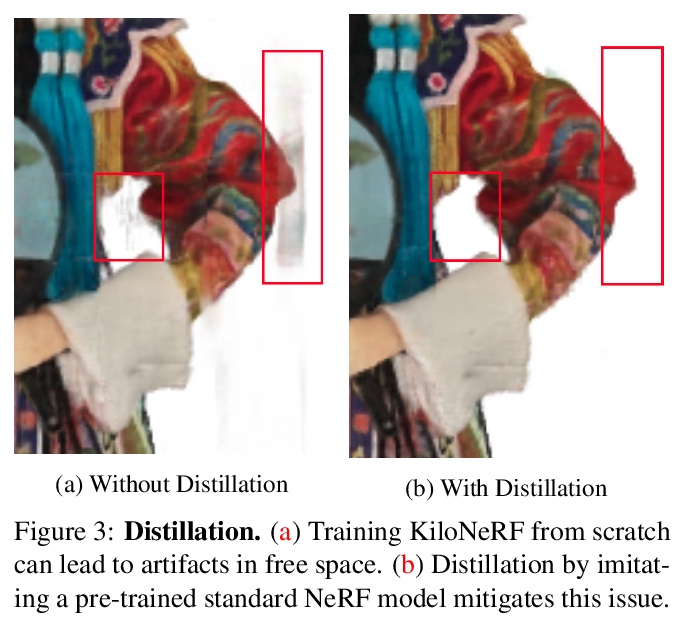
KiloNeRF:用数千小微多层感知器为神经辐射场加速。证明了利用数千个小微MLP代替单个大型MLP,可实现大幅提速。每个单独的MLP只需要表示场景的一部分,可使用更小和更快的评估MLP。将这种分而治之的策略与进一步的优化结合起来,与原始的NeRF模型相比,渲染速度加快了两个数量级,而不会产生高额的存储成本。利用师-生提蒸馏进行训练,可在不牺牲视觉质量的情况下实现加速。所提出的策略也可更广泛地应用于其他依赖于神经函数表示的方法,包括隐式曲面模型。
NeRF synthesizes novel views of a scene with unprecedented quality by fitting a neural radiance field to RGB images. However, NeRF requires querying a deep Multi-Layer Perceptron (MLP) millions of times, leading to slow rendering times, even on modern GPUs. In this paper, we demonstrate that significant speed-ups are possible by utilizing thousands of tiny MLPs instead of one single large MLP. In our setting, each individual MLP only needs to represent parts of the scene, thus smaller and faster-to-evaluate MLPs can be used. By combining this divide-and-conquer strategy with further optimizations, rendering is accelerated by two orders of magnitude compared to the original NeRF model without incurring high storage costs. Further, using teacher-student distillation for training, we show that this speed-up can be achieved without sacrificing visual quality.
https://weibo.com/1402400261/K84aZzQFx

2、[CV] PlenOctrees for Real-time Rendering of Neural Radiance Fields
A Yu, R Li, M Tancik, H Li, R Ng, A Kanazawa
[UC Berkeley]
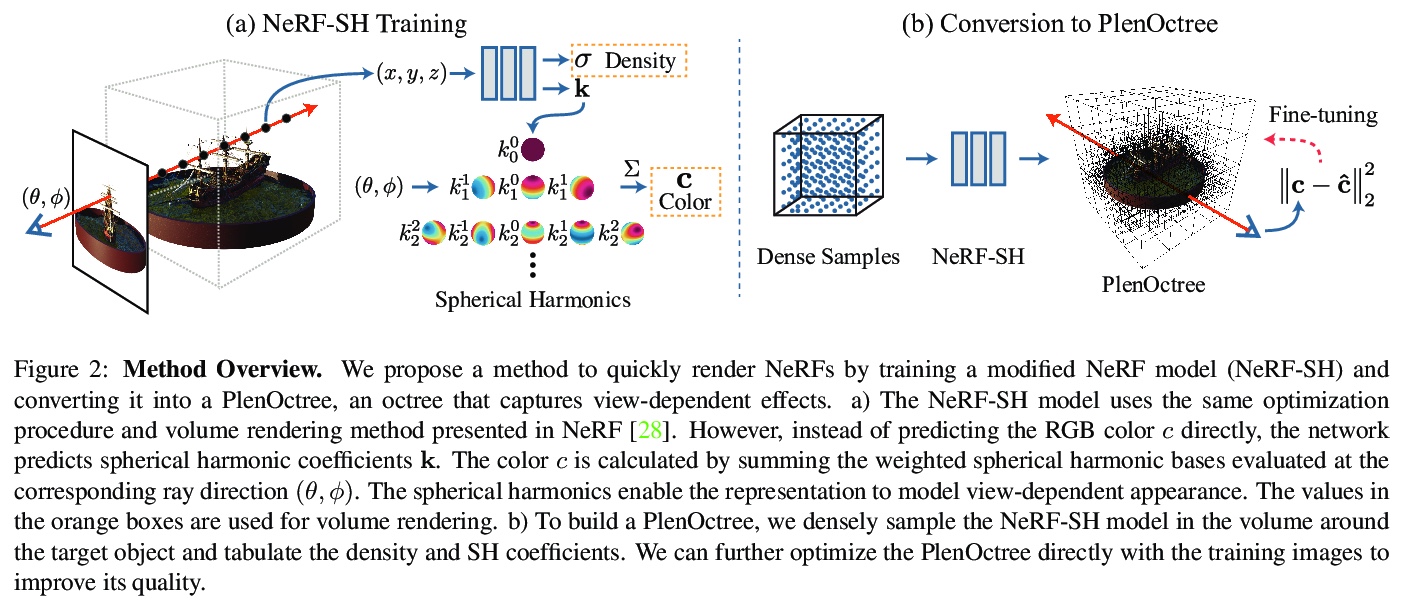
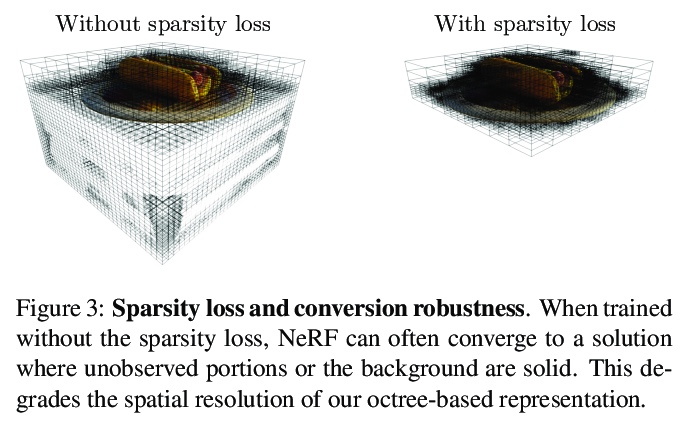
基于PlenOctrees的神经辐射场实时渲染。基于PlenOctrees,为神经辐射场(NeRF)引入了一种新的数据表示方法,可实现对任意目标和场景的实时渲染。不仅可将原始NeRF的渲染方法性能提高3000多倍,由于采用分层数据结构,可产生与NeRF相当或更好质量的图像。训练时间对在实践中采用NeRF构成了另一个障碍,采用PlenOctrees可有效缩短NeRF-SH的有效训练时间。实现了一个基于WebGL的浏览器内查看器,以展示NeRFs在消费级笔记本电脑上的实时和6-DOF渲染能力。
We introduce a method to render Neural Radiance Fields (NeRFs) in real time using PlenOctrees, an octree-based 3D representation which supports view-dependent effects. Our method can render 800x800 images at more than 150 FPS, which is over 3000 times faster than conventional NeRFs. We do so without sacrificing quality while preserving the ability of NeRFs to perform free-viewpoint rendering of scenes with arbitrary geometry and view-dependent effects. Real-time performance is achieved by pre-tabulating the NeRF into a PlenOctree. In order to preserve view-dependent effects such as specularities, we factorize the appearance via closed-form spherical basis functions. Specifically, we show that it is possible to train NeRFs to predict a spherical harmonic representation of radiance, removing the viewing direction as an input to the neural network. Furthermore, we show that PlenOctrees can be directly optimized to further minimize the reconstruction loss, which leads to equal or better quality compared to competing methods. Moreover, this octree optimization step can be used to reduce the training time, as we no longer need to wait for the NeRF training to converge fully. Our real-time neural rendering approach may potentially enable new applications such as 6-DOF industrial and product visualizations, as well as next generation AR/VR systems. PlenOctrees are amenable to in-browser rendering as well; please visit the project page for the interactive online demo, as well as video and code: > this https URL
https://weibo.com/1402400261/K84fGBcBq

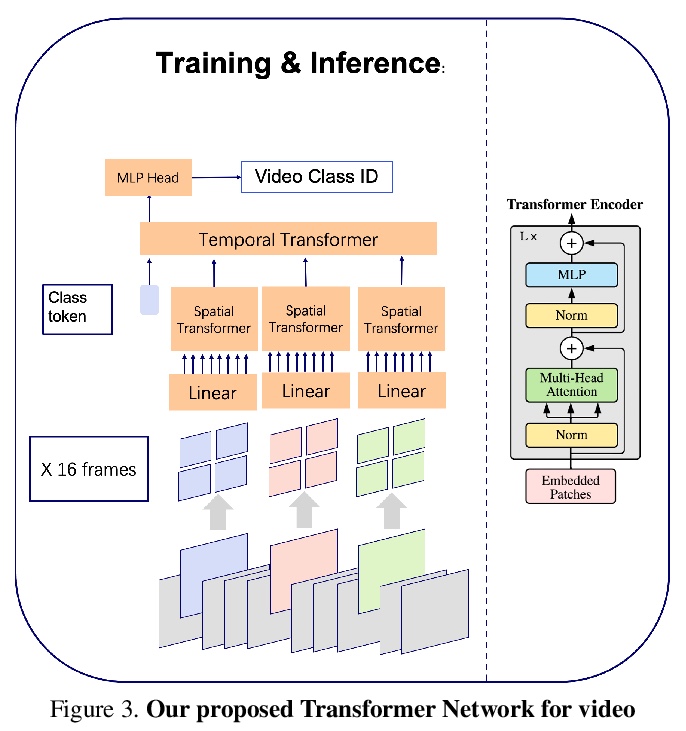
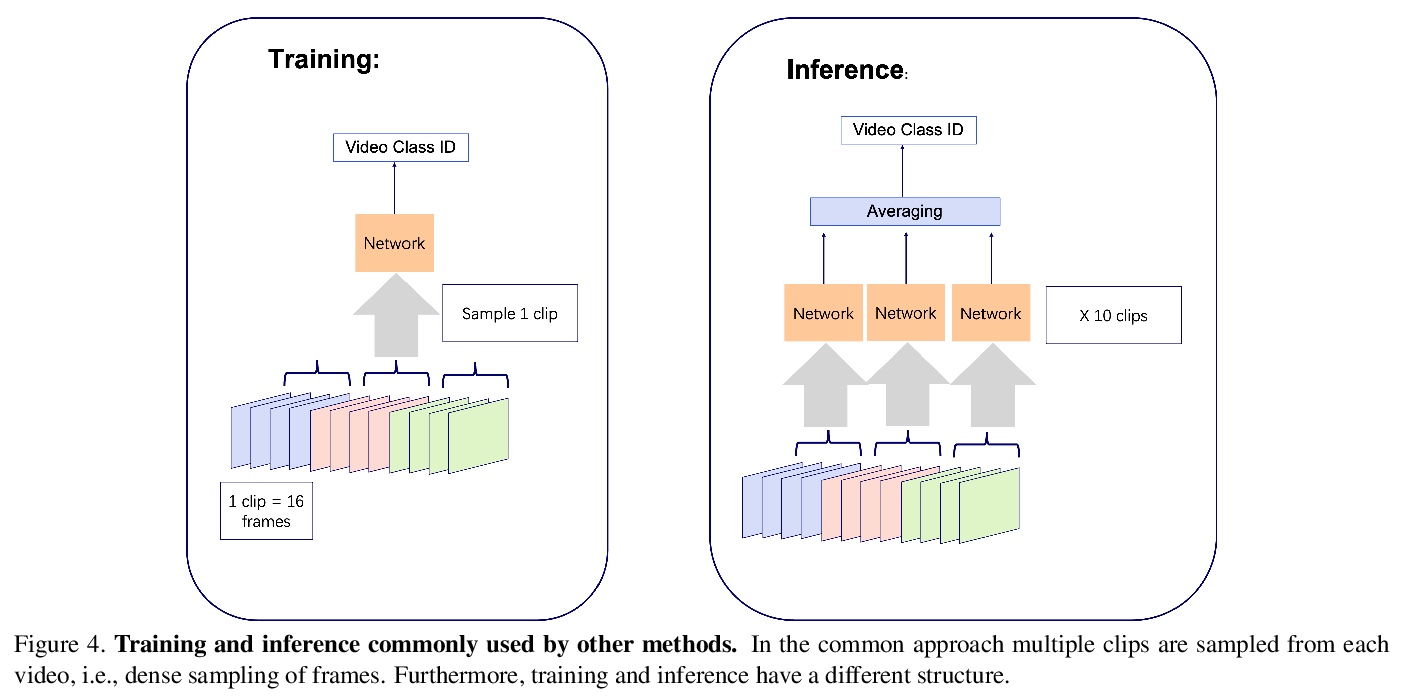
3、[CV] An Image is Worth 16x16 Words, What is a Video Worth?
G Sharir, A Noy, L Zelnik-Manor
[Alibaba Group]
基于Transformer的高效视频动作识别方法。完全基于Transformer表示时空视觉数据,在视频帧上应用全局注意力,从而更好地利用每一帧中的突出信息,实现了一种新的视频动作识别方法。受NLP启发,将视频建模为一个段落,并统一选择建模为句子的帧。这种建模方式可利用Transformer来捕捉不同帧之间复杂的时空依赖关系,从而基于一小部分视频数据进行准确的预测。该方法是输入高效的,预测精度与最先进的方法相当,同时速度快了好几个数量级,可很好地支持对延迟敏感的应用,如识别和视频检索。在Kinetics数据集上,以每段视频减少×30帧的情况下达到了78.8的top-1精度,推理速度比目前领先的方法快×40。
Leading methods in the domain of action recognition try to distill information from both the spatial and temporal dimensions of an input video. Methods that reach State of the Art (SotA) accuracy, usually make use of 3D convolution layers as a way to abstract the temporal information from video frames. The use of such convolutions requires sampling short clips from the input video, where each clip is a collection of closely sampled frames. Since each short clip covers a small fraction of an input video, multiple clips are sampled at inference in order to cover the whole temporal length of the video. This leads to increased computational load and is impractical for real-world applications. We address the computational bottleneck by significantly reducing the number of frames required for inference. Our approach relies on a temporal transformer that applies global attention over video frames, and thus better exploits the salient information in each frame. Therefore our approach is very input efficient, and can achieve SotA results (on Kinetics dataset) with a fraction of the data (frames per video), computation and latency. Specifically on Kinetics-400, we reach 78.8 top-1 accuracy with > ×30 less frames per video, and > ×40 faster inference than the current leading method. Code is available at: > this https URL
https://weibo.com/1402400261/K84j1dDFi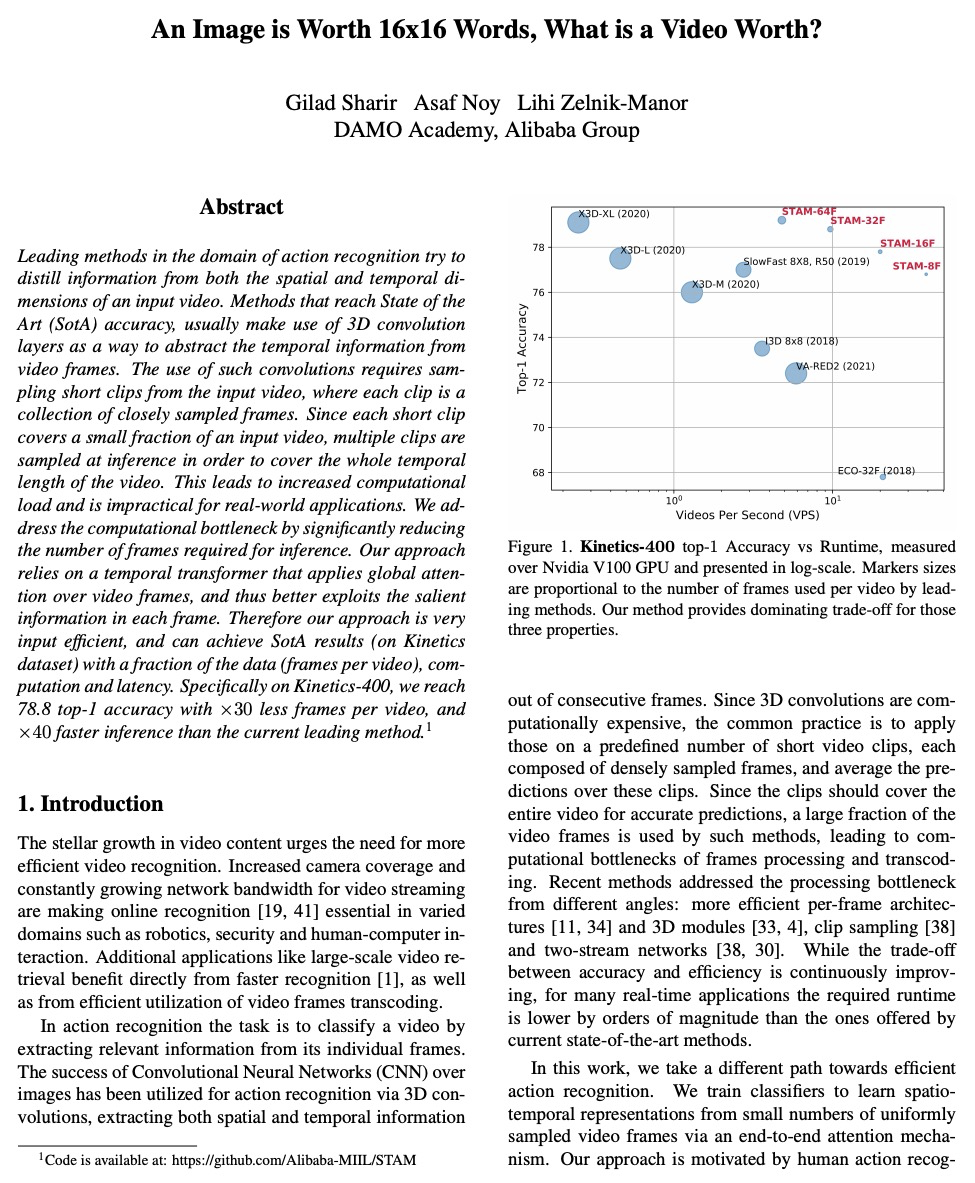

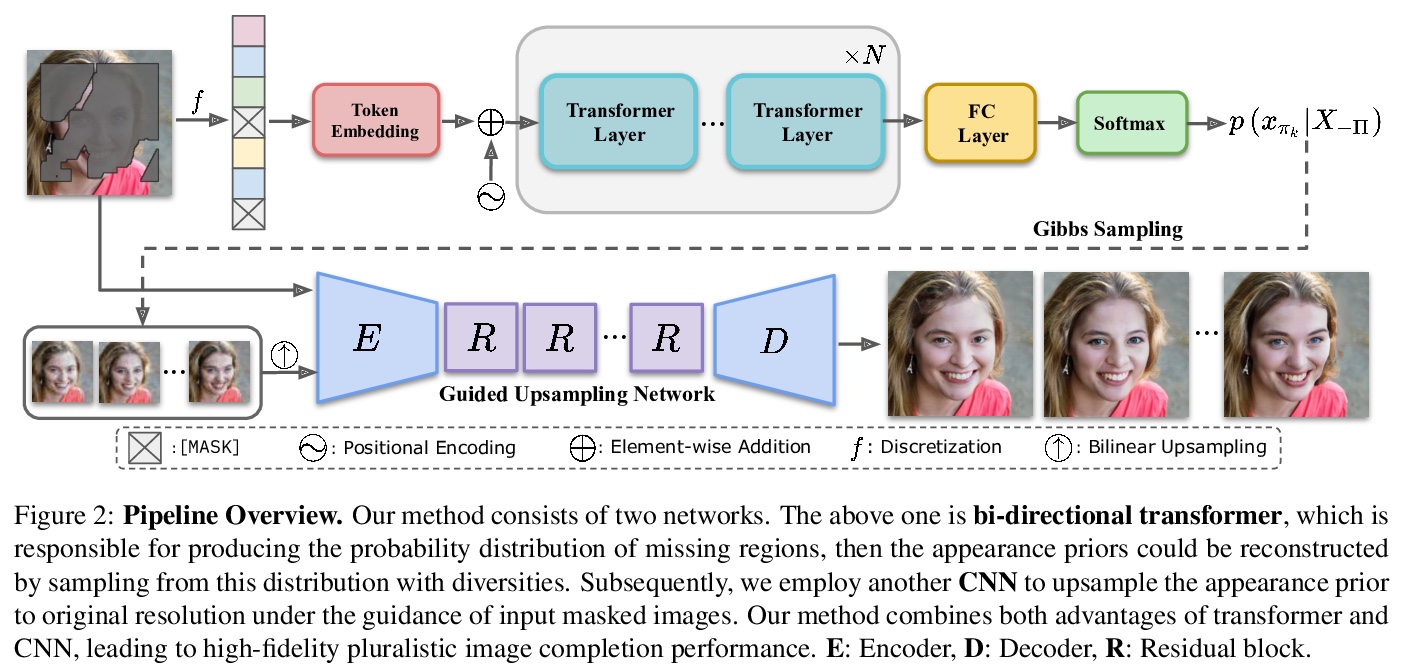
4、[CV] High-Fidelity Pluralistic Image Completion with Transformers
Z Wan, J Zhang, D Chen, J Liao
[City University of Hong Kong & Microsoft Cloud + AI]
基于Transformer的高保真多元图像补全。为多元图像补全提出了一种互补方案:用Transformer进行外观前期重建、用CNN进行纹理补全——前者Transformer将多元相干结构与一些粗纹理一起恢复,而后者CNN则在高分辨率遮挡图像粗先验引导下完善局部纹理细节。所提出方法在三方面超越了现有方法:1)即使与确定性补全方法相比,图像保真度也有较大提升;2)对于多元补全方法具有更好的多样性和更高的清晰度;3)在大掩模和通用数据集(如ImageNet)上具有卓越的泛化能力。
Image completion has made tremendous progress with convolutional neural networks (CNNs), because of their powerful texture modeling capacity. However, due to some inherent properties (e.g., local inductive prior, spatial-invariant kernels), CNNs do not perform well in understanding global structures or naturally support pluralistic completion. Recently, transformers demonstrate their power in modeling the long-term relationship and generating diverse results, but their computation complexity is quadratic to input length, thus hampering the application in processing high-resolution images. This paper brings the best of both worlds to pluralistic image completion: appearance prior reconstruction with transformer and texture replenishment with CNN. The former transformer recovers pluralistic coherent structures together with some coarse textures, while the latter CNN enhances the local texture details of coarse priors guided by the high-resolution masked images. The proposed method vastly outperforms state-of-the-art methods in terms of three aspects: 1) large performance boost on image fidelity even compared to deterministic completion methods; 2) better diversity and higher fidelity for pluralistic completion; 3) exceptional generalization ability on large masks and generic dataset, like ImageNet.
https://weibo.com/1402400261/K84vVCiPq
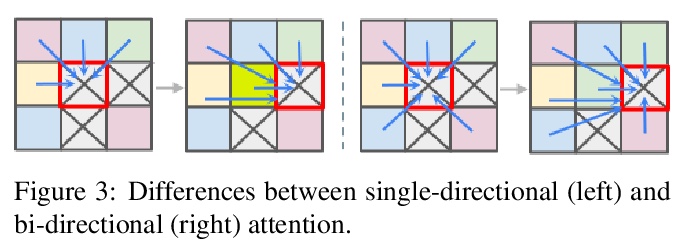

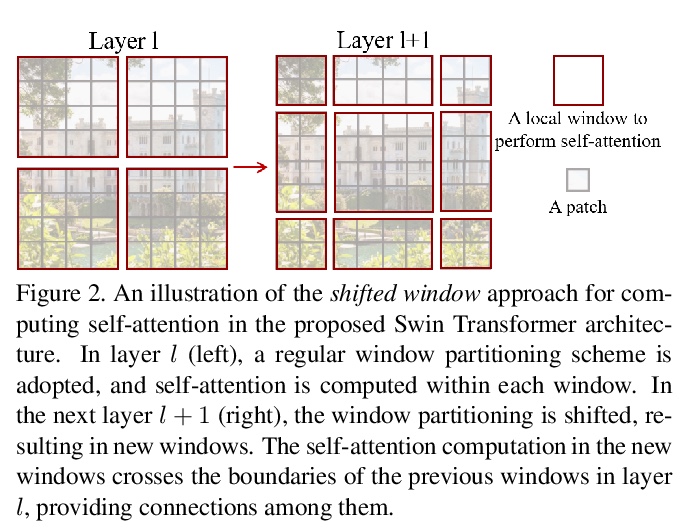
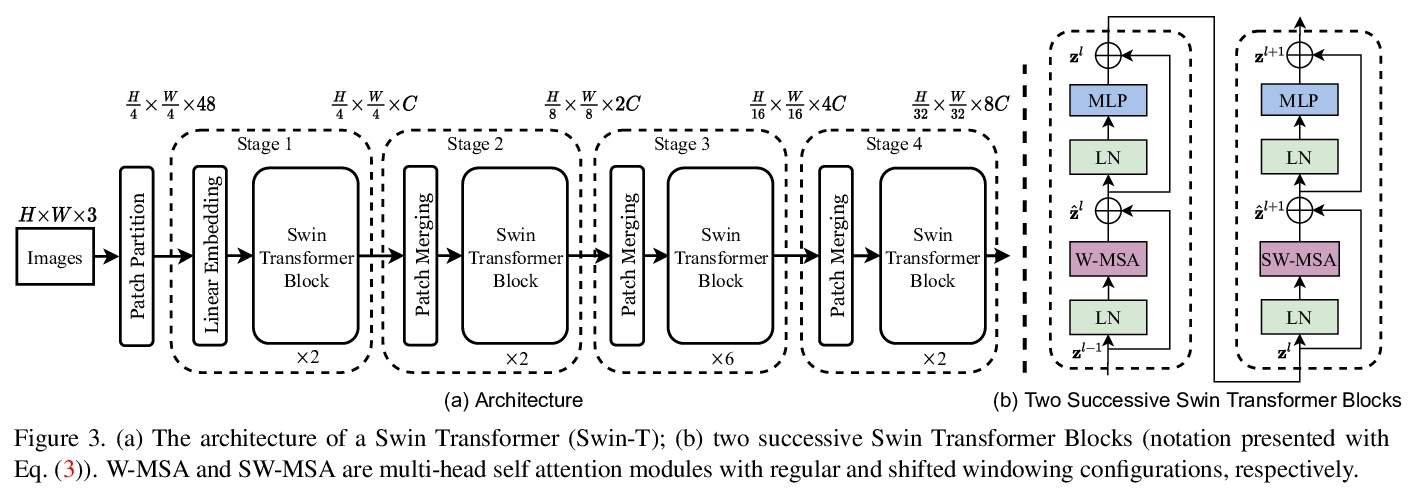
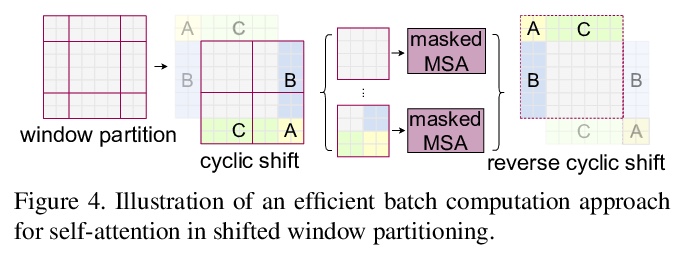
5、[CV] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Z Liu, Y Lin, Y Cao, H Hu, Y Wei, Z Zhang, S Lin, B Guo
[Microsoft Research Asia]
Swin Transformer:基于移位窗口的层次视觉Transformer。提出一种分层Transformer,其表示方式是通过移位窗口计算的。移位窗口方案通过将自注意力计算限制在非重叠的本地窗口,同时允许跨窗口连接,从而带来更高的效率。这种分层架构具有在各种尺度下建模的灵活性,并且具有与图像大小相关的线性计算复杂性。Swin Transformer在COCO对象检测和ADE20K语义分割上达到了最先进的性能,大大超过了之前的最佳方法。
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (86.4 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The code and models will be made publicly available at > this https URL.
https://weibo.com/1402400261/K84AYwNAD
另外几篇值得关注的论文:
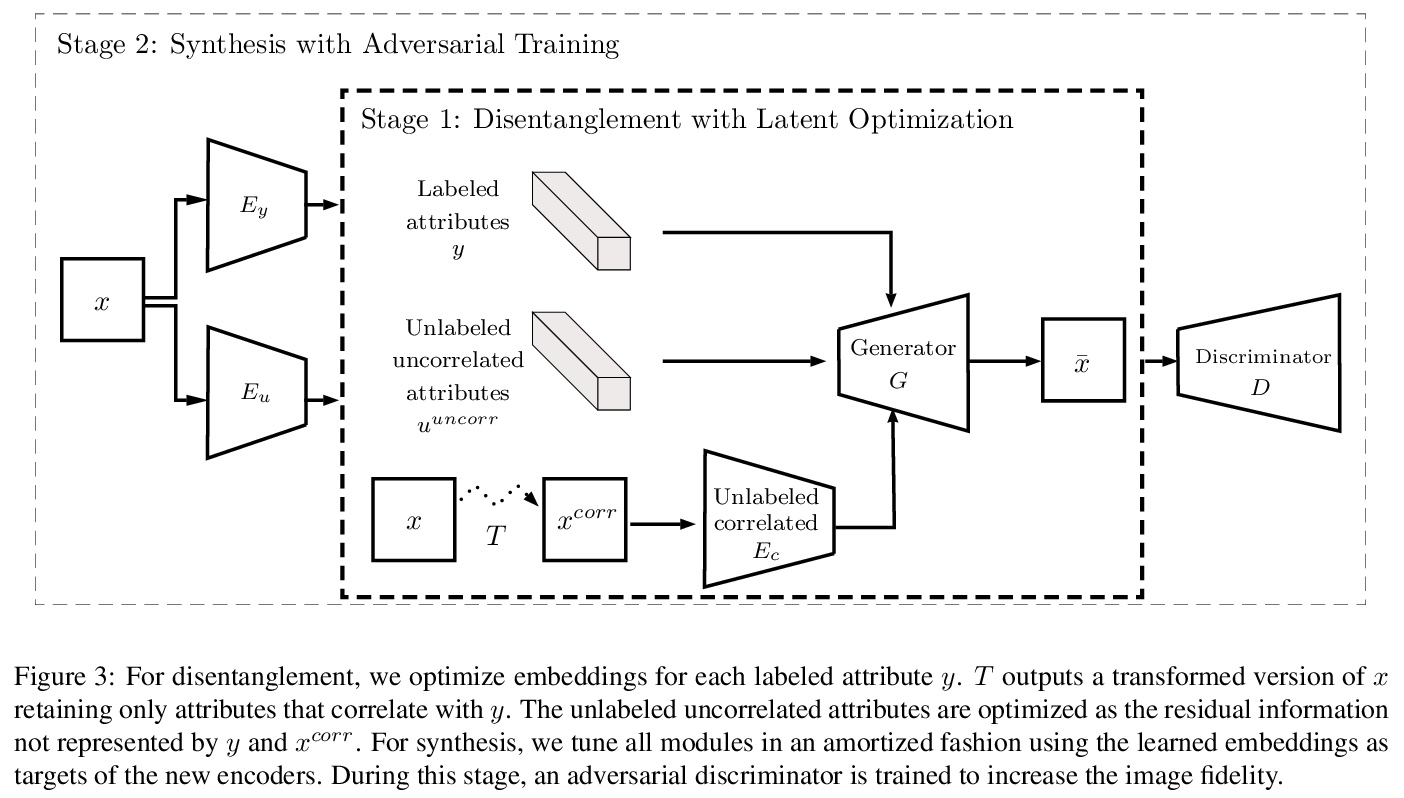
[CV] Scaling-up Disentanglement for Image Translation
图像变换的放大解缠
A Gabbay, Y Hoshen
[The Hebrew University of Jerusalem]
https://weibo.com/1402400261/K84HqCx0L


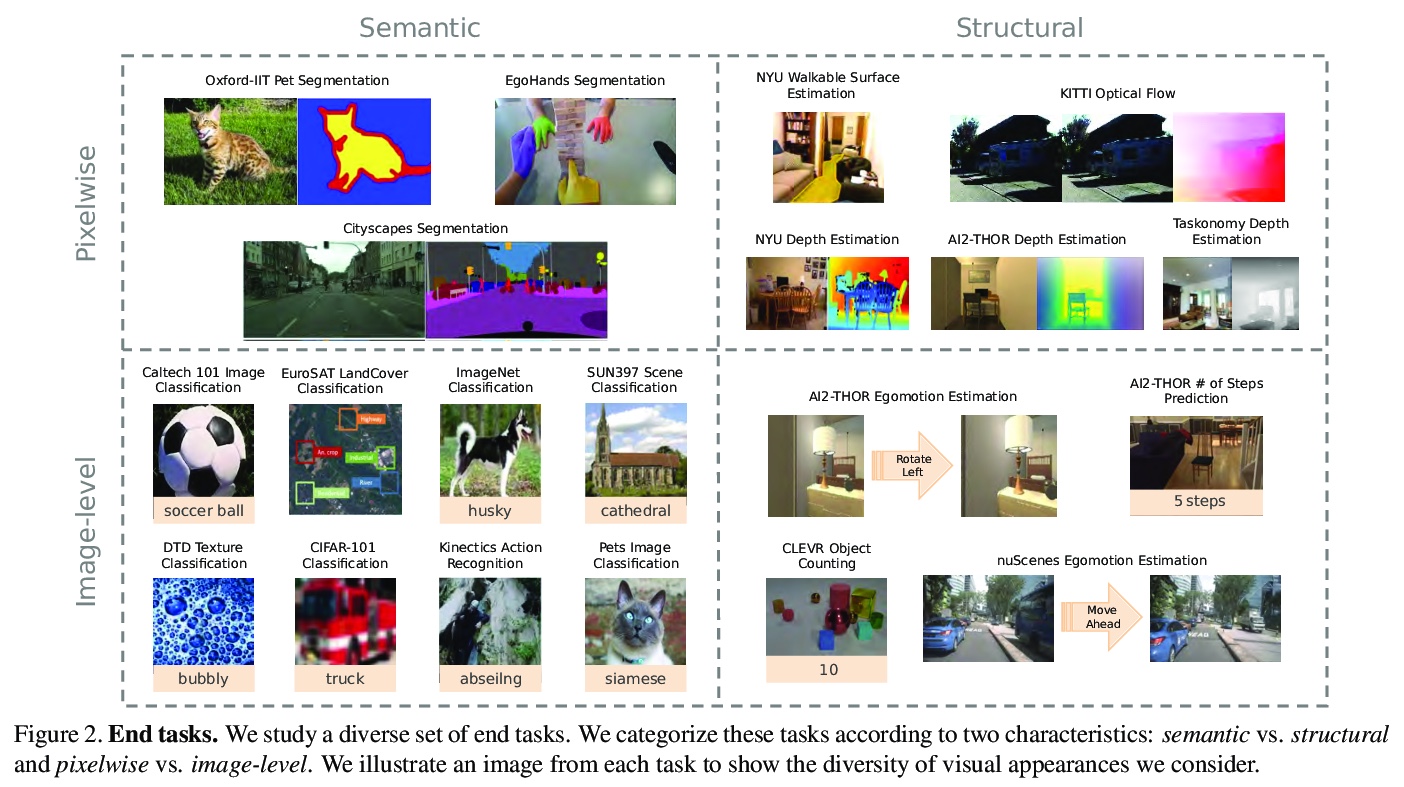
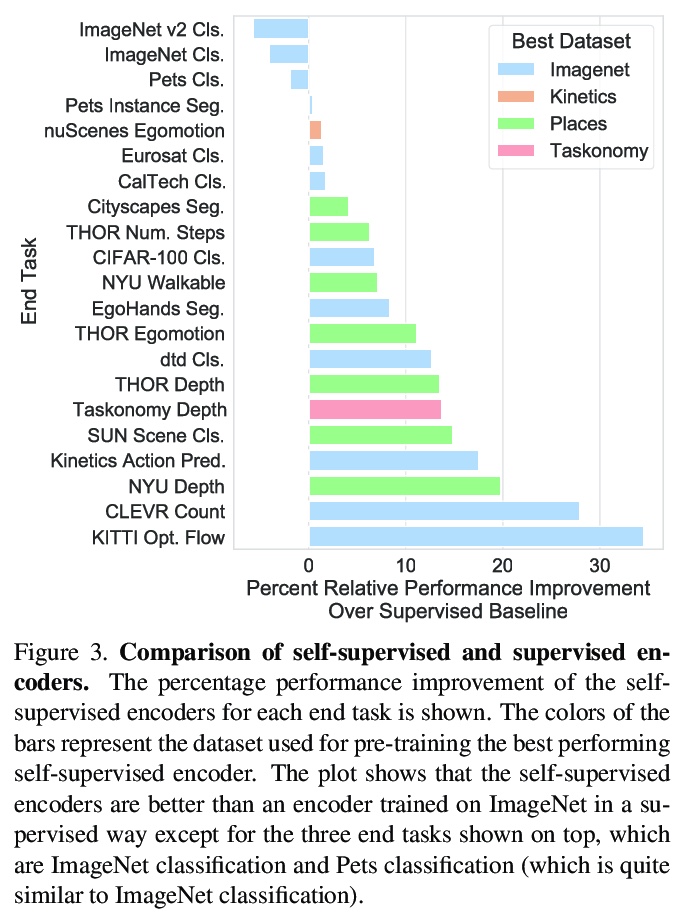
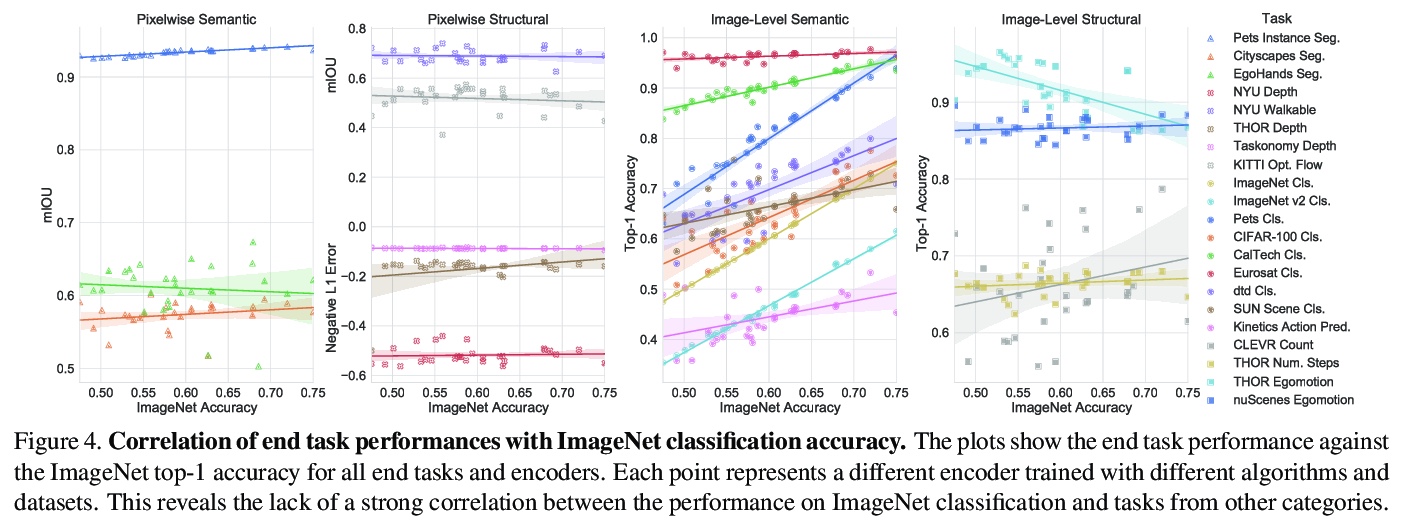
[CV] Contrasting Contrastive Self-Supervised Representation Learning Models
对比自监督表征学习模型
K Kotar, G Ilharco, L Schmidt, K Ehsani, R Mottaghi
[Allen Institute for AI & University of Washington]
https://weibo.com/1402400261/K84Loea9Z
[CL] Mask Attention Networks: Rethinking and Strengthen Transformer
掩模注意力网络:Transformer的反思与强化
Z Fan, Y Gong, D Liu, Z Wei, S Wang, J Jiao, N Duan, R Zhang, X Huang
[Fudan University & Microsoft Research Asia & DAMO Academy]
https://weibo.com/1402400261/K84MtBqyK
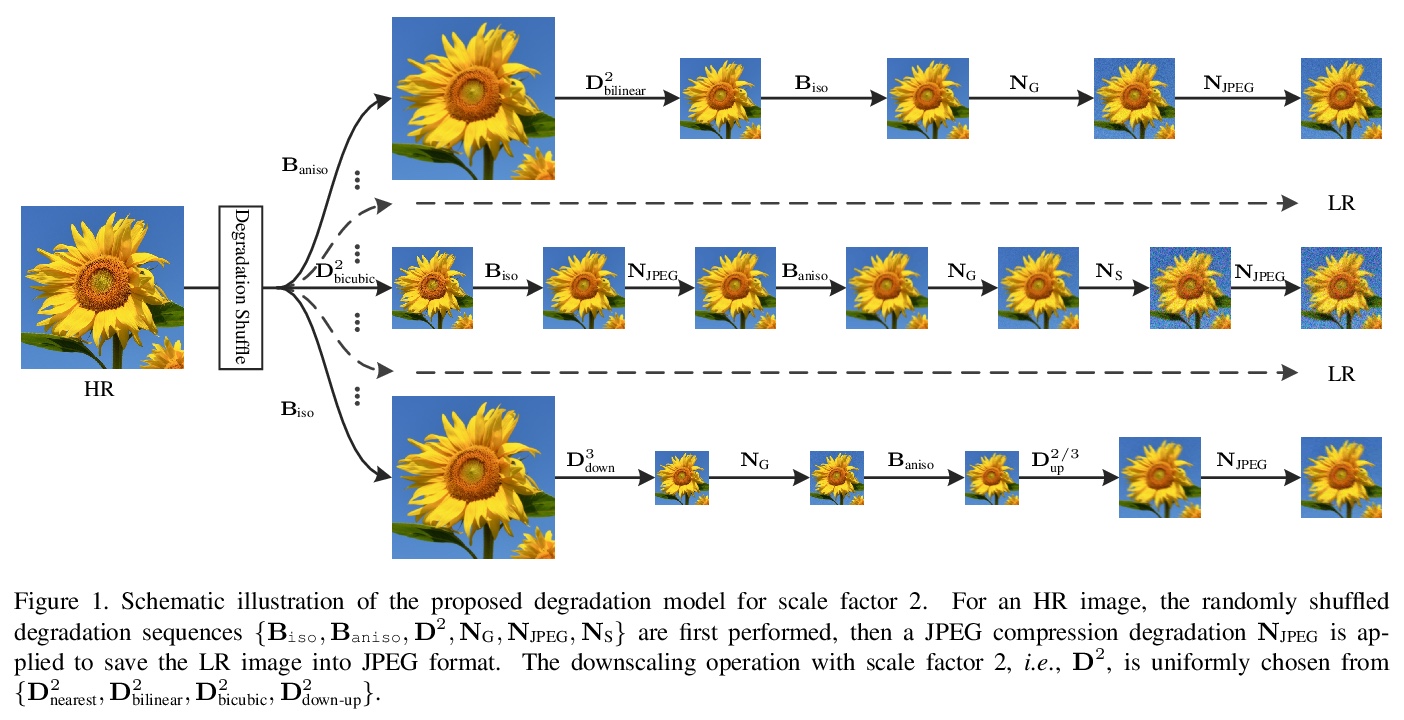
[CV] Designing a Practical Degradation Model for Deep Blind Image Super-Resolution
一种实用的深度图像盲超分辨率退化模型设计
K Zhang, J Liang, L V Gool, R Timofte
[ETH Zurich]
https://weibo.com/1402400261/K84NQmAsp



若有收获,就点个赞吧
0 人点赞
