- 1、[CV] Rethinking Spatial Dimensions of Vision Transformers
- 2、[CL] Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence
- 3、[CV] Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval
- 4、[CV] Unconstrained Scene Generation with Locally Conditioned Radiance Fields
- 5、[CV] Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding
- [CL] PnG BERT: Augmented BERT on Phonemes and Graphemes for Neural TTS
- [CV] VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization
- [CV] CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
- [CV] CAMPARI: Camera-Aware Decomposed Generative Neural Radiance Fields
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Rethinking Spatial Dimensions of Vision Transformers
B Heo, S Yun, D Han, S Chun, J Choe, S J Oh
[NAVER AI Lab]
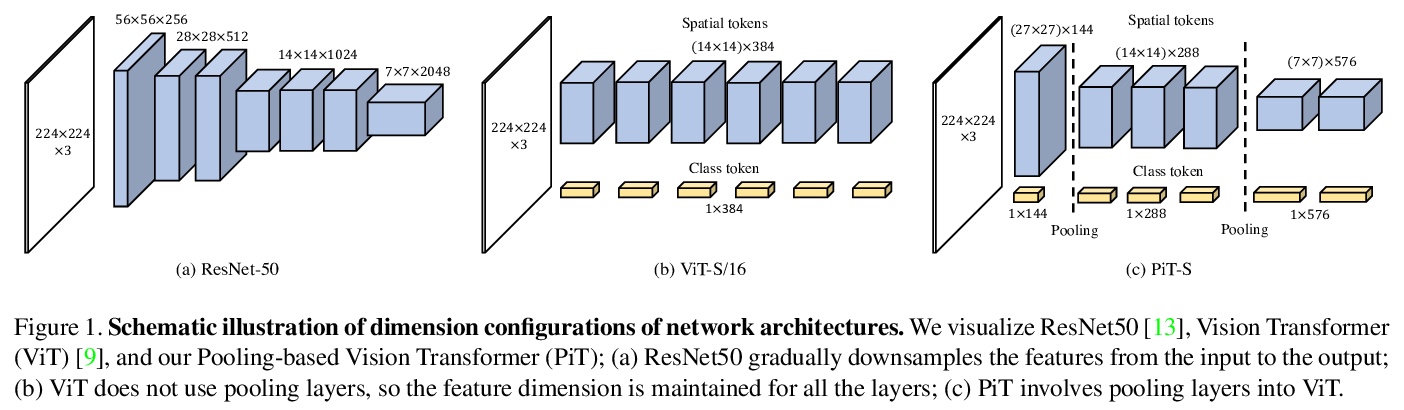
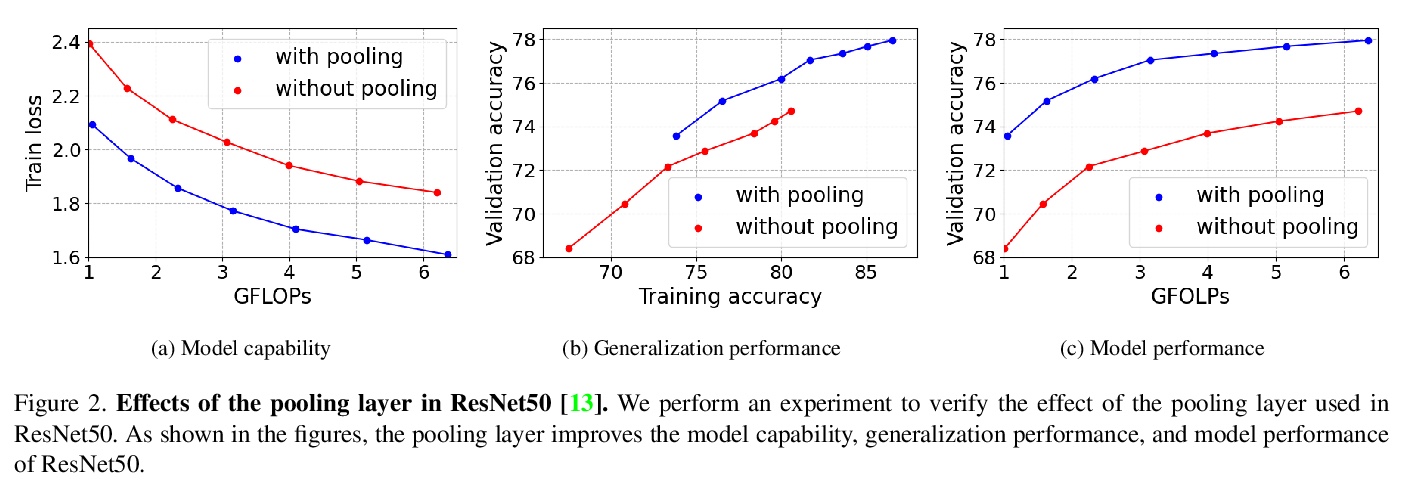
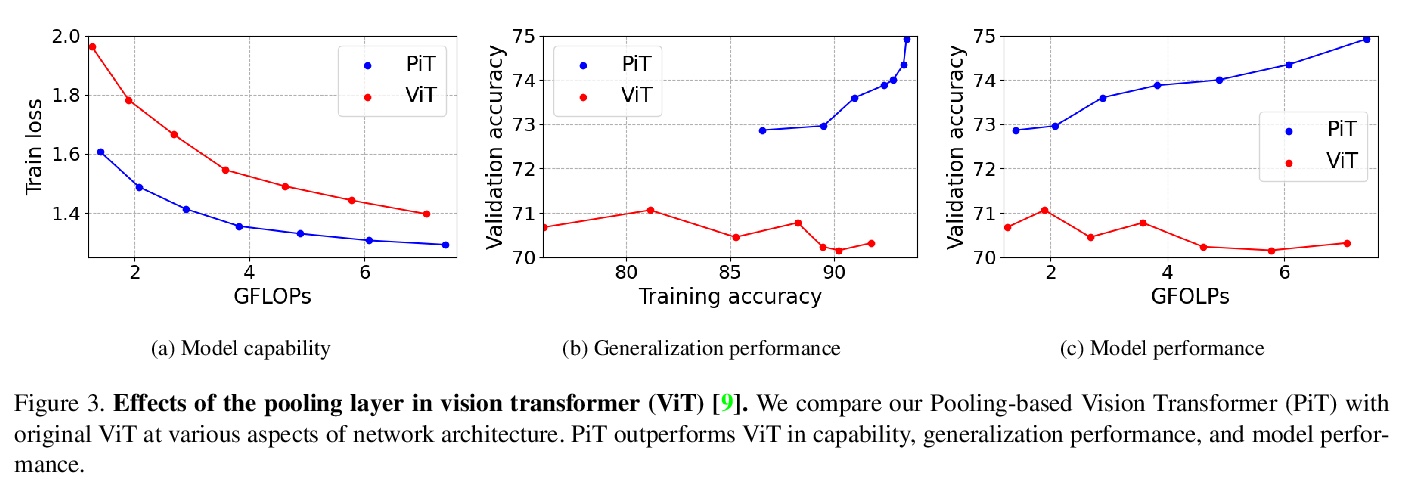
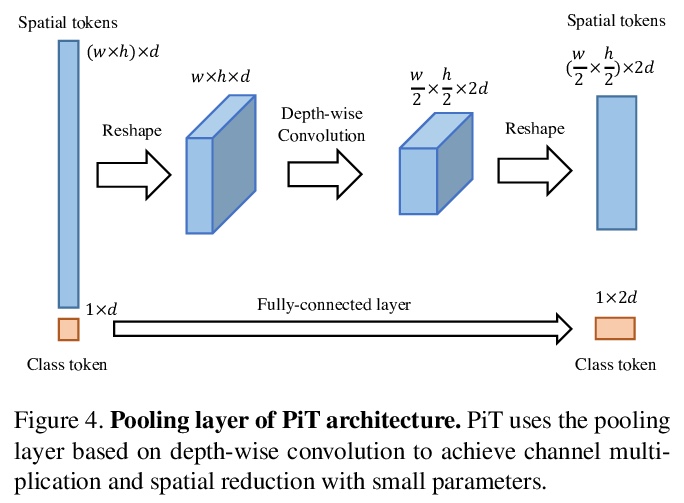
视觉Transformer空间维度的反思。从CNN成功的设计原则出发,研究了空间维度转换的作用及其对Transformer架构的有效性,特别关注CNN的降维原则,随深度增加,传统CNN会增加信道维度,减少空间维度。通过实证表明,这种空间维度的降低对Transformer架构也是有利的,在原有的ViT模型基础上提出一种新的基于池化的视觉Transformer(PiT),实现了对ViT模型能力和泛化性能的提升,也证明了通过考虑空间交互比的池化层对基于自注意力的架构是至关重要的,实验表明PiT在图像分类、目标检测和鲁棒性评估等多个任务上的表现优于基线。
Vision Transformer (ViT) extends the application range of transformers from language processing to computer vision tasks as being an alternative architecture against the existing convolutional neural networks (CNN). Since the transformer-based architecture has been innovative for computer vision modeling, the design convention towards an effective architecture has been less studied yet. From the successful design principles of CNN, we investigate the role of the spatial dimension conversion and its effectiveness on the transformer-based architecture. We particularly attend the dimension reduction principle of CNNs; as the depth increases, a conventional CNN increases channel dimension and decreases spatial dimensions. We empirically show that such a spatial dimension reduction is beneficial to a transformer architecture as well, and propose a novel Pooling-based Vision Transformer (PiT) upon the original ViT model. We show that PiT achieves the improved model capability and generalization performance against ViT. Throughout the extensive experiments, we further show PiT outperforms the baseline on several tasks such as image classification, object detection and robustness evaluation. Source codes and ImageNet models are available at > this https URL
https://weibo.com/1402400261/K9hGpenth
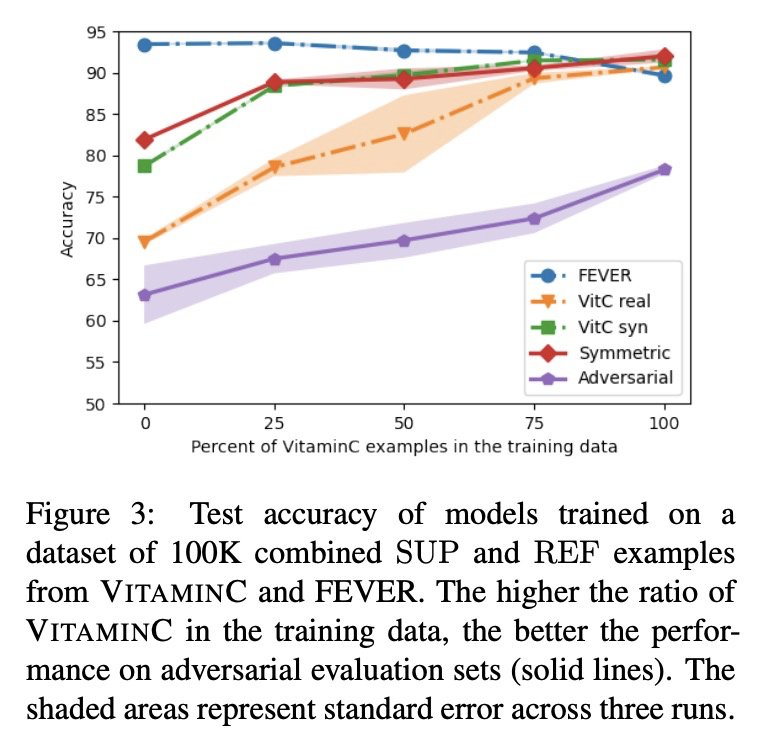
2、[CL] Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence
T Schuster, A Fisch, R Barzilay
[MIT]
对比证据鲁棒事实验证数据集VITAMINC。提出一种对立事实验证范式,要求对数据变化保持敏感。引入支持该范式的新的大规模数据集VITAMINC,用于训练和评估使用对比上下文的事实验证模型。利用维基百科事实修订的新方法,创建了具有挑战性的样本,在这些样本中,每个权利要求与上下文配对,这些上下文在词汇上是相似的,但在事实上是相反的。证明了在VITAMINC上训练会带来更好的标准任务表现,不但提高了分类器对证据细微变化的敏感性,也增加了它们对对抗性样本的鲁棒性。
Typical fact verification models use retrieved written evidence to verify claims. Evidence sources, however, often change over time as more information is gathered and revised. In order to adapt, models must be sensitive to subtle differences in supporting evidence. We present VitaminC, a benchmark infused with challenging cases that require fact verification models to discern and adjust to slight factual changes. We collect over 100,000 Wikipedia revisions that modify an underlying fact, and leverage these revisions, together with additional synthetically constructed ones, to create a total of over 400,000 claim-evidence pairs. Unlike previous resources, the examples in VitaminC are contrastive, i.e., they contain evidence pairs that are nearly identical in language and content, with the exception that one supports a given claim while the other does not. We show that training using this design increases robustness — improving accuracy by 10% on adversarial fact verification and 6% on adversarial natural language inference (NLI). Moreover, the structure of VitaminC leads us to define additional tasks for fact-checking resources: tagging relevant words in the evidence for verifying the claim, identifying factual revisions, and providing automatic edits via factually consistent text generation.
https://weibo.com/1402400261/K9hMkdlrx


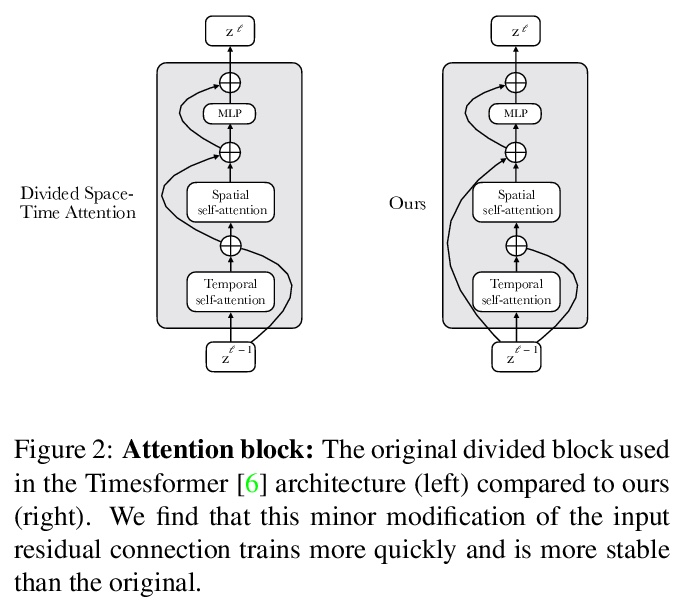
3、[CV] Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval
M Bain, A Nagrani, G Varol, A Zisserman
[University of Oxford]
时间冻结:基于视频和图像联合编码器的端到端检索。提出一种端到端可训练模型,旨在利用大规模图像和视频字幕数据集。该模型是对ViT和Timesformer架构的改编和扩展,由空间和时间注意力构成,可在图像和视频文本数据集上进行训练,既可独立训练,也可联合训练。设计了一个课程学习计划表,由图像开始,通过时间嵌入插值在视频数据集上训练,逐渐学会关注越来越多的时间上下文,这提高了效率,可用更少的GPU时间来训练模型。引入一个名为WebVid-2M的新数据集,由2.5M个从网络上爬取的视频-文本对组成。尽管在小一个数量级的数据集上进行训练,该方法在标准的下游视频检索基准上产生了最先进的结果,包括MSR-VTT、MSVD、DiDeMo和LSMDC。
Our objective in this work is video-text retrieval - in particular a joint embedding that enables efficient text-to-video retrieval. The challenges in this area include the design of the visual architecture and the nature of the training data, in that the available large scale video-text training datasets, such as HowTo100M, are noisy and hence competitive performance is achieved only at scale through large amounts of compute. We address both these challenges in this paper. We propose an end-to-end trainable model that is designed to take advantage of both large-scale image and video captioning datasets. Our model is an adaptation and extension of the recent ViT and Timesformer architectures, and consists of attention in both space and time. The model is flexible and can be trained on both image and video text datasets, either independently or in conjunction. It is trained with a curriculum learning schedule that begins by treating images as ‘frozen’ snapshots of video, and then gradually learns to attend to increasing temporal context when trained on video datasets. We also provide a new video-text pretraining dataset WebVid-2M, comprised of over two million videos with weak captions scraped from the internet. Despite training on datasets that are an order of magnitude smaller, we show that this approach yields state-of-the-art results on standard downstream video-retrieval benchmarks including MSR-VTT, MSVD, DiDeMo and LSMDC.
https://weibo.com/1402400261/K9hRjxMW0

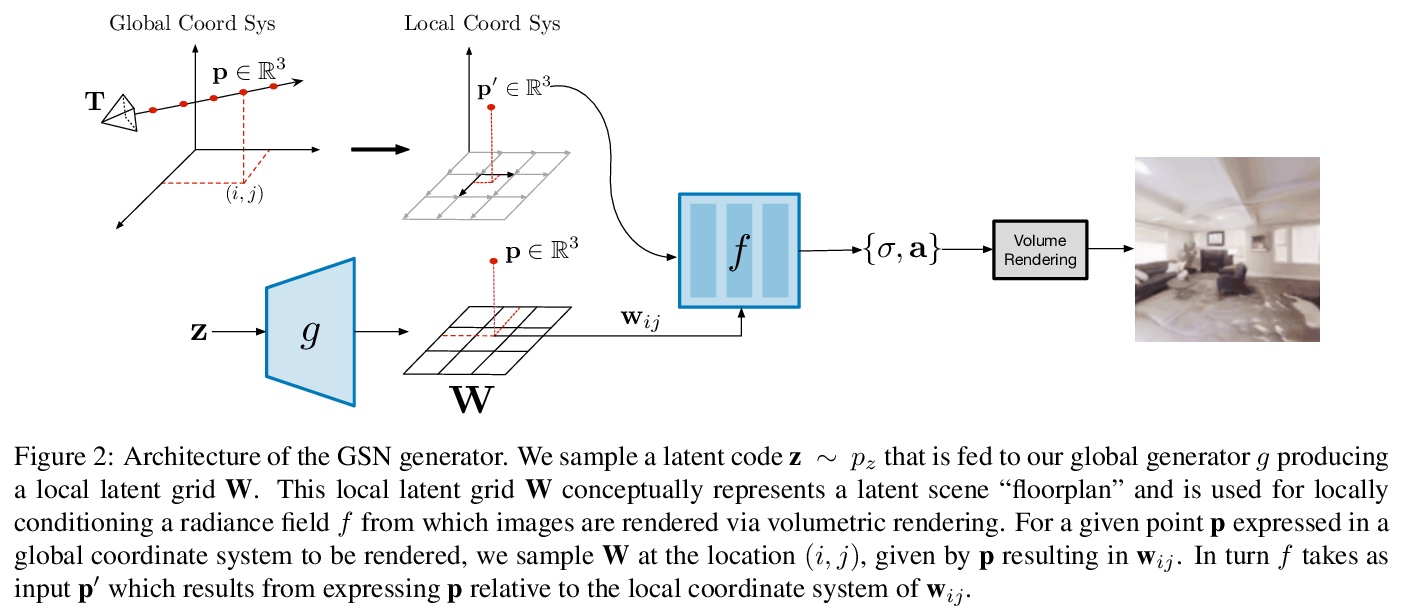
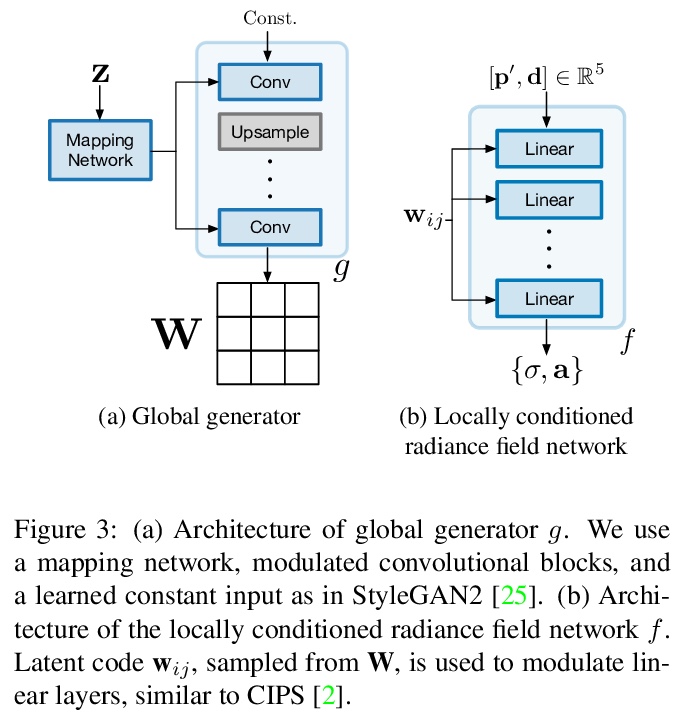
4、[CV] Unconstrained Scene Generation with Locally Conditioned Radiance Fields
T DeVries, M A Bautista, N Srivastava, G W. Taylor, J M. Susskind
[Apple & University of Guelph]
基于局部条件辐射场的无约束场景生成。提出生成式场景网络(GSN),可学习将场景分解为许多局部辐射场的集合,这些辐射场可以用一个自由移动的摄像机渲染出来,从先验采样的场景上的渲染轨迹是平滑和一致的,保持了场景的一致性。该模型可用作生成新场景的先验,或者只给定稀疏的2D观测值来完成一个场景。该分解方案可扩展到更大、更复杂的场景,同时保留细节和多样性,通过学习到的先验,可从与之前观察视点有显著差异的视点进行高质量渲染。与现有模型相比,GSN在几个不同的场景数据集上产生了更高质量的场景渲染。
We tackle the challenge of learning a distribution over complex, realistic, indoor scenes. In this paper, we introduce Generative Scene Networks (GSN), which learns to decompose scenes into a collection of many local radiance fields that can be rendered from a free moving camera. Our model can be used as a prior to generate new scenes, or to complete a scene given only sparse 2D observations. Recent work has shown that generative models of radiance fields can capture properties such as multi-view consistency and view-dependent lighting. However, these models are specialized for constrained viewing of single objects, such as cars or faces. Due to the size and complexity of realistic indoor environments, existing models lack the representational capacity to adequately capture them. Our decomposition scheme scales to larger and more complex scenes while preserving details and diversity, and the learned prior enables high-quality rendering from viewpoints that are significantly different from observed viewpoints. When compared to existing models, GSN produces quantitatively higher-quality scene renderings across several different scene datasets.
https://weibo.com/1402400261/K9hVBvu32

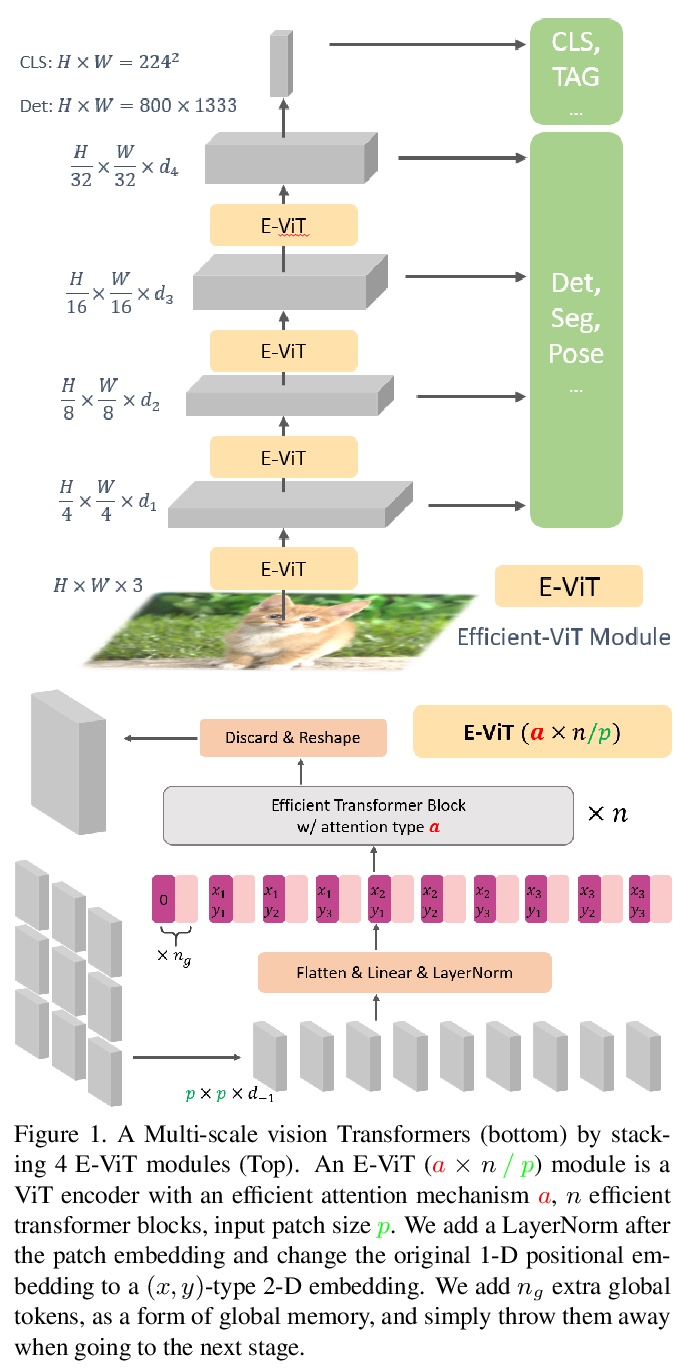
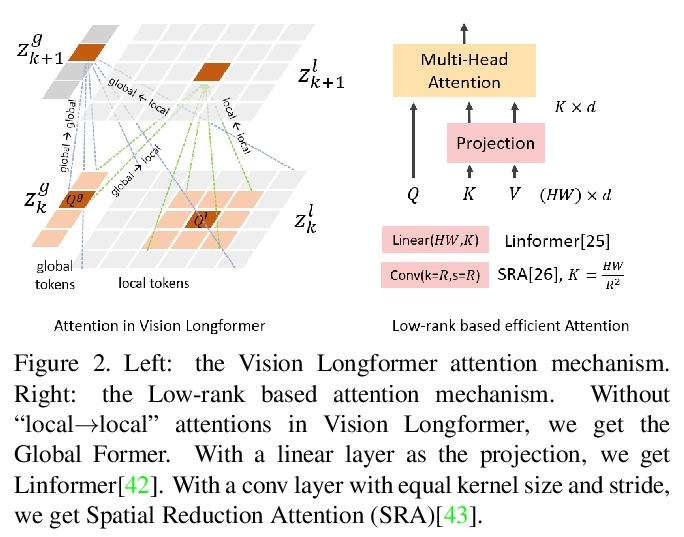
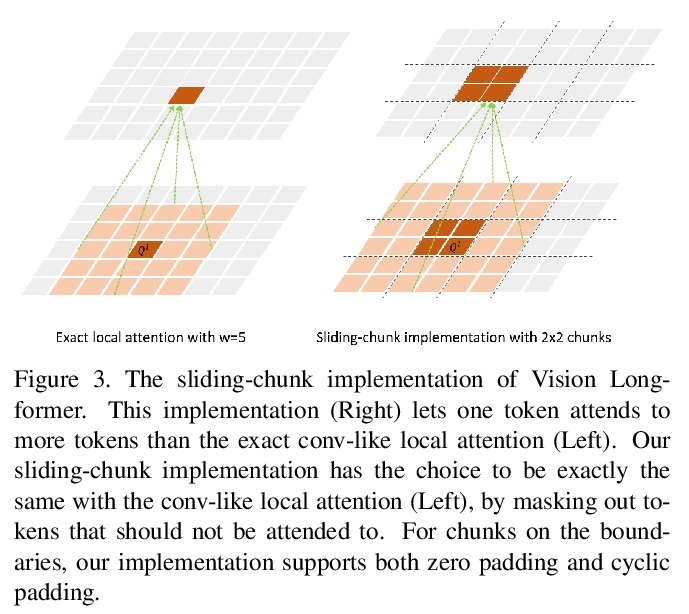
5、[CV] Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding
P Zhang, X Dai, J Yang, B Xiao, L Yuan, L Zhang, J Gao
[Microsoft Corporation ]
多尺度视觉Longformer:面向于高分辨率图像编码的视觉Transformer。提出一种新的视觉Transformer,利用多尺度模型结构和二维Longformer的注意力机制,实现了高效的高分辨率图像编码。通过多尺度模型结构,提供了多尺度的图像编码,且计算成本可控。通过视觉Longformer的注意力机制,实现了输入token数量的线性复杂度。实验表明,所提出的ViT在图像分类、目标检测和分割任务上显著优于强基线,包括之前的ViT模型、其ResNet对等模型等。
This paper presents a new Vision Transformer (ViT) architecture Multi-Scale Vision Longformer, which significantly enhances the ViT of \cite{dosovitskiy2020image} for encoding high-resolution images using two techniques. The first is the multi-scale model structure, which provides image encodings at multiple scales with manageable computational cost. The second is the attention mechanism of vision Longformer, which is a variant of Longformer \cite{beltagy2020longformer}, originally developed for natural language processing, and achieves a linear complexity w.r.t. the number of input tokens. A comprehensive empirical study shows that the new ViT significantly outperforms several strong baselines, including the existing ViT models and their ResNet counterparts, and the Pyramid Vision Transformer from a concurrent work \cite{wang2021pyramid}, on a range of vision tasks, including image classification, object detection, and segmentation. The models and source code used in this study will be released to public soon.
https://weibo.com/1402400261/K9hZPl1Nq
另外几篇值得关注的论文:
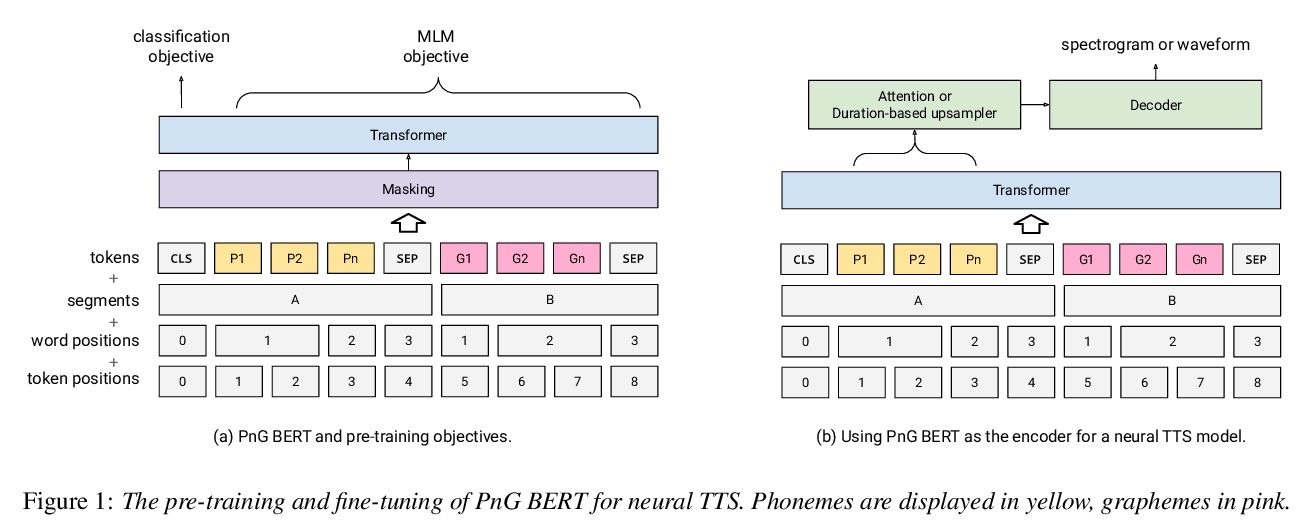
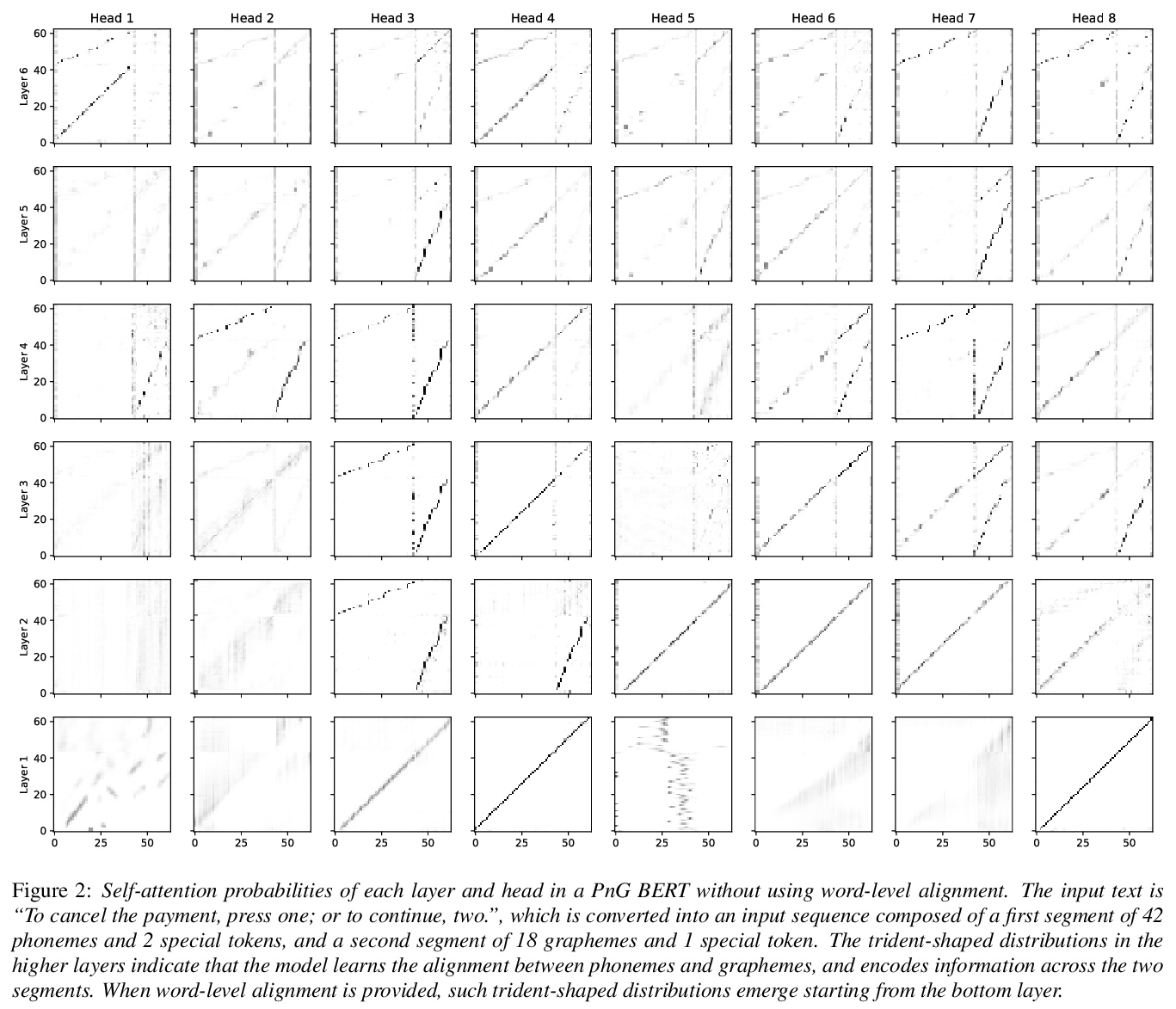
[CL] PnG BERT: Augmented BERT on Phonemes and Graphemes for Neural TTS
PnG BERT:神经网络TTS的音素词素增强BERT
Y Jia, H Zen, J Shen, Y Zhang, Y Wu
[Google Research]
https://weibo.com/1402400261/K9i8NrWck
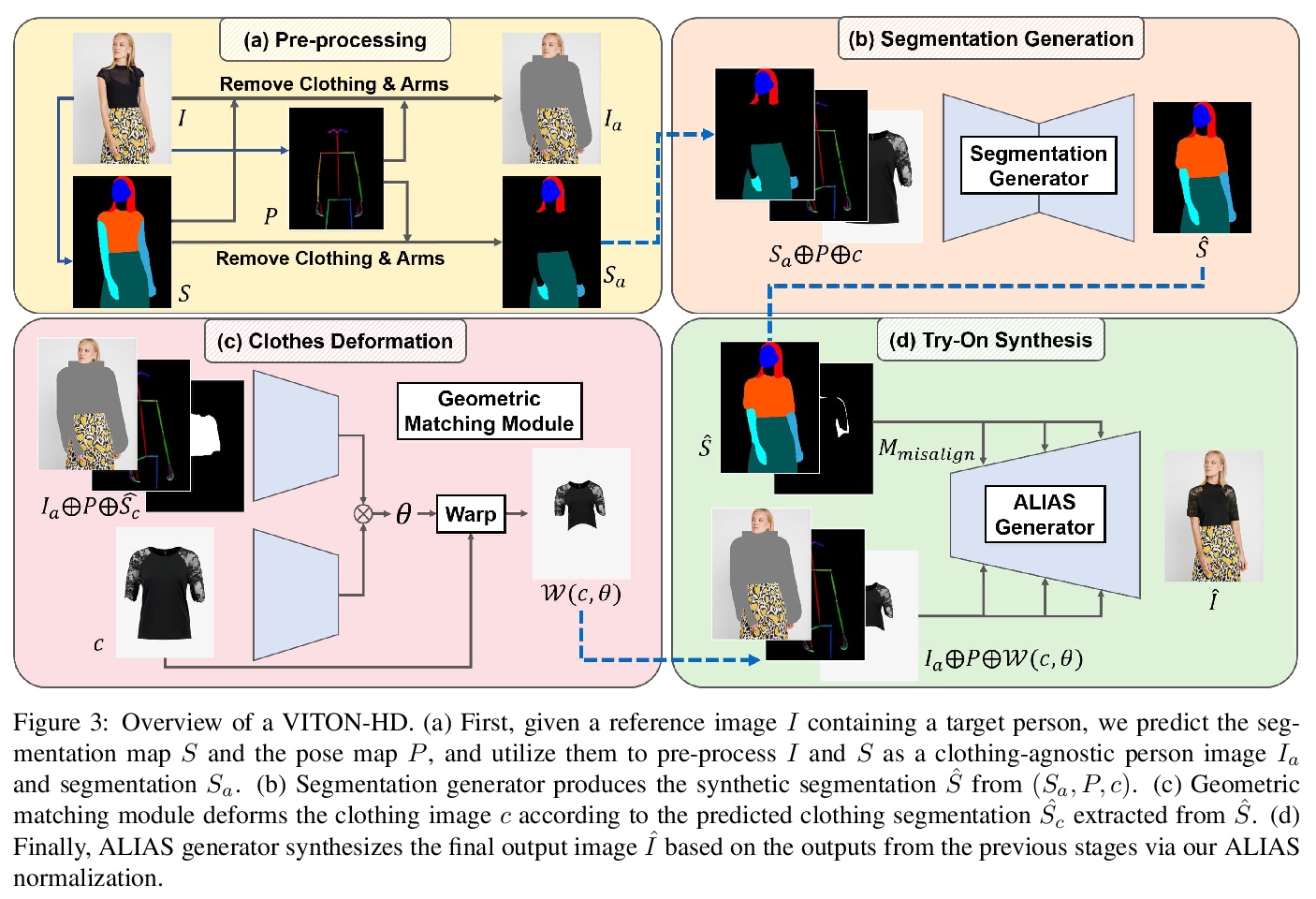
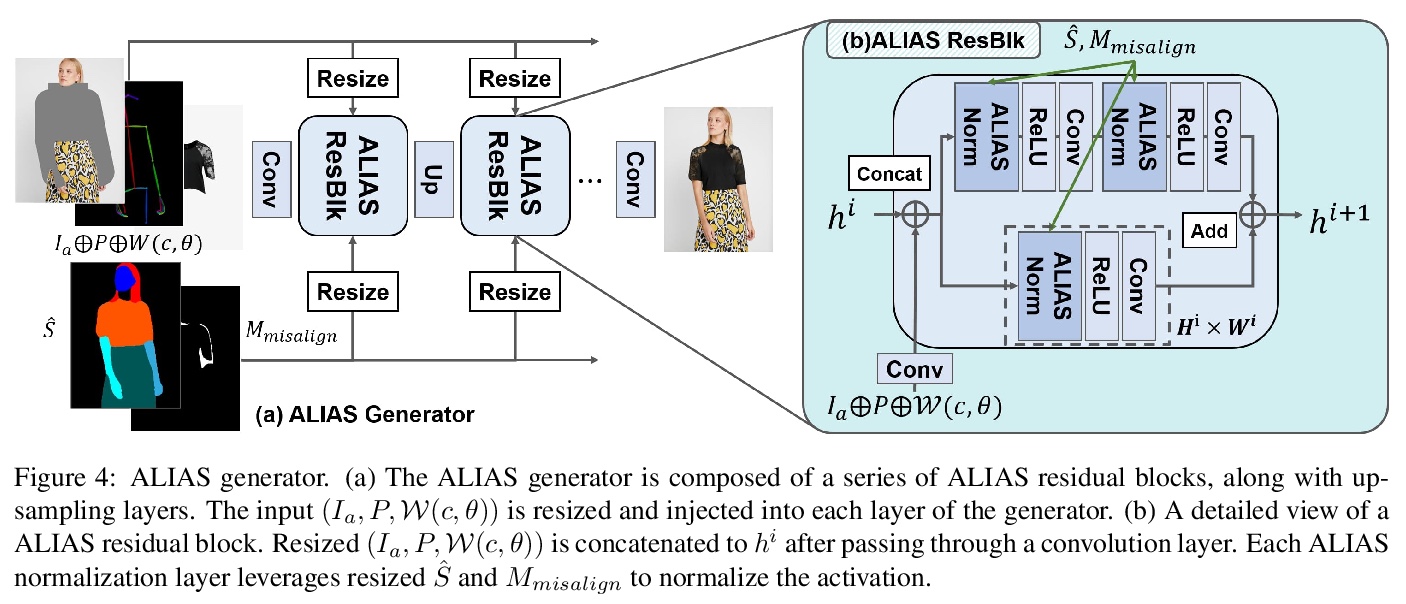
[CV] VITON-HD: High-Resolution Virtual Try-On via Misalignment-Aware Normalization
VITON-HD:基于错位感知标准化的高分辨率虚拟试穿
S Choi, S Park, M Lee, J Choo
[KAIST]
https://weibo.com/1402400261/K9ib4nQia

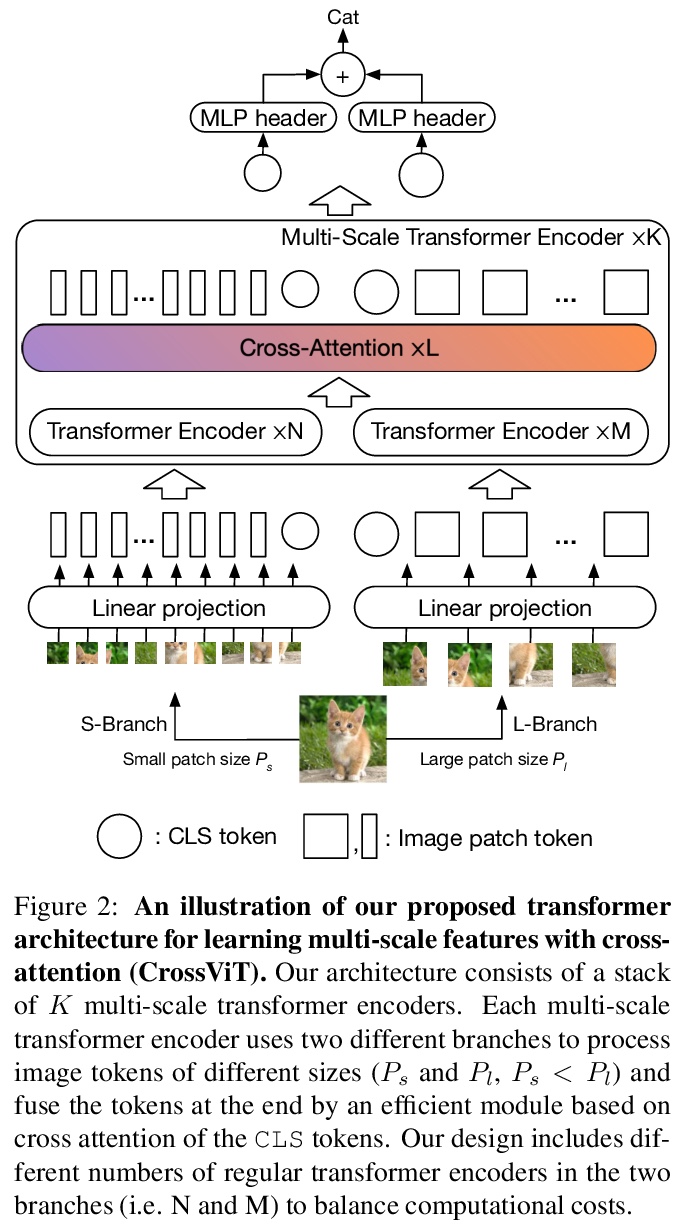
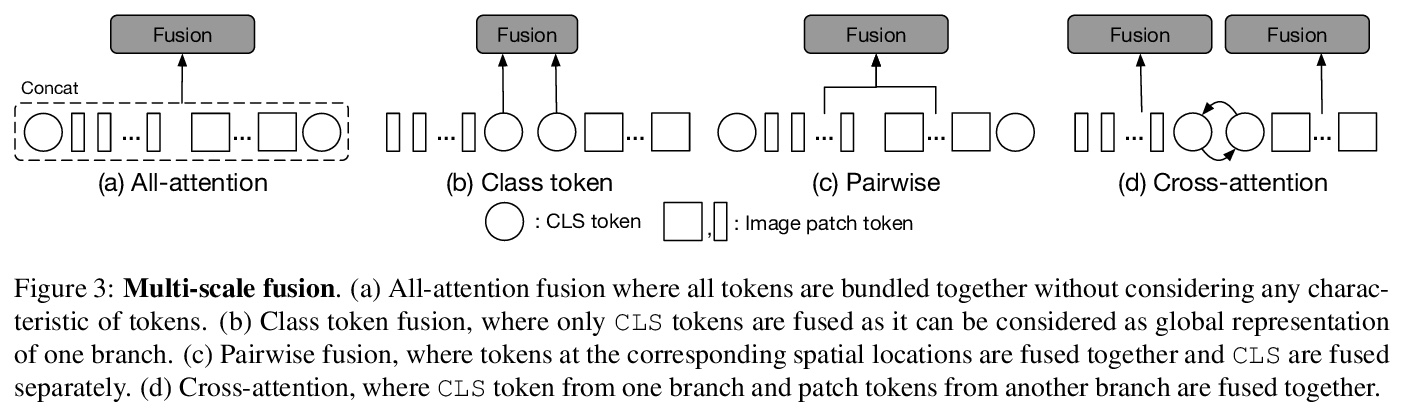
[CV] CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
CrossViT:面向图像分类的交叉注意力多尺度视觉Transformer
C Chen, Q Fan, R Panda
[MIT-IBM Watson AI Lab]
https://weibo.com/1402400261/K9icdzsQJ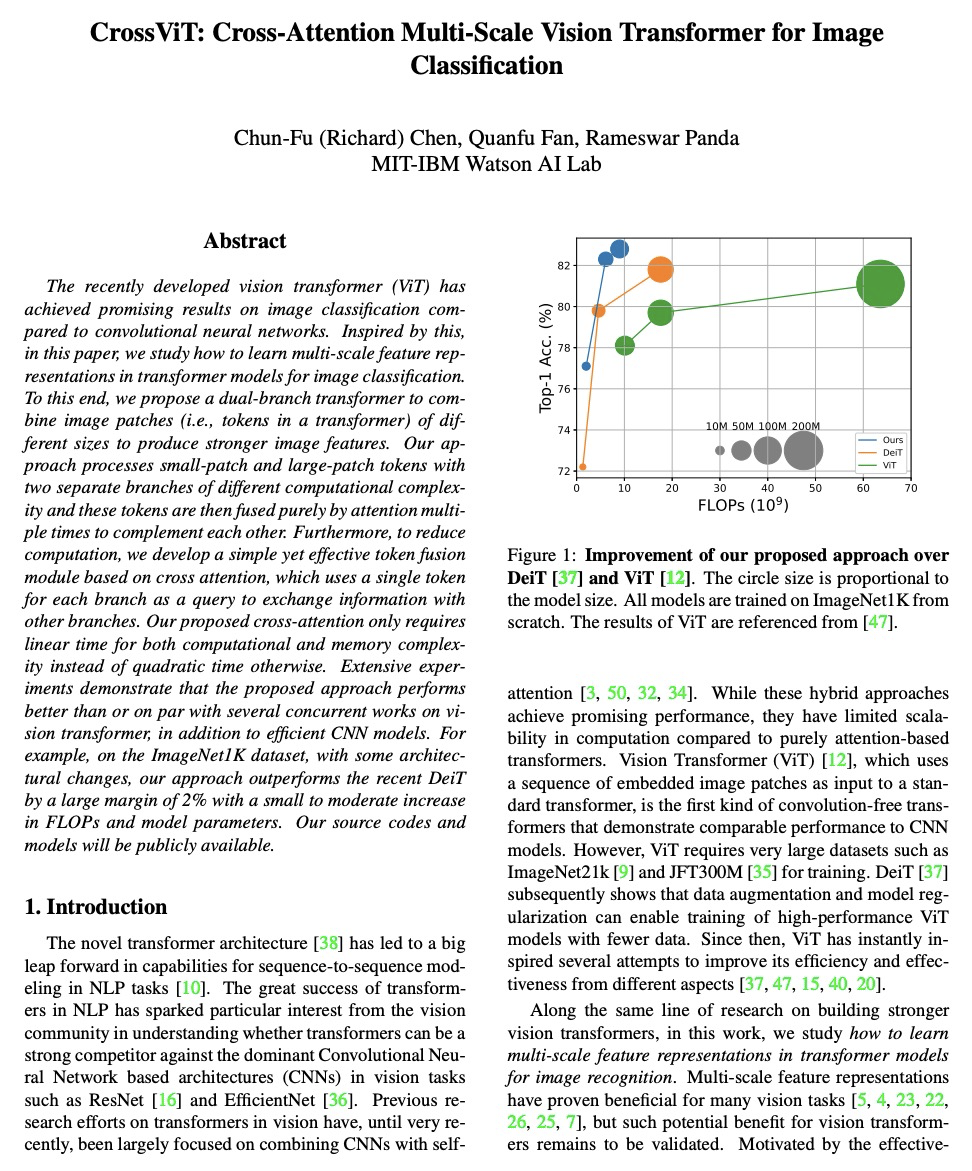

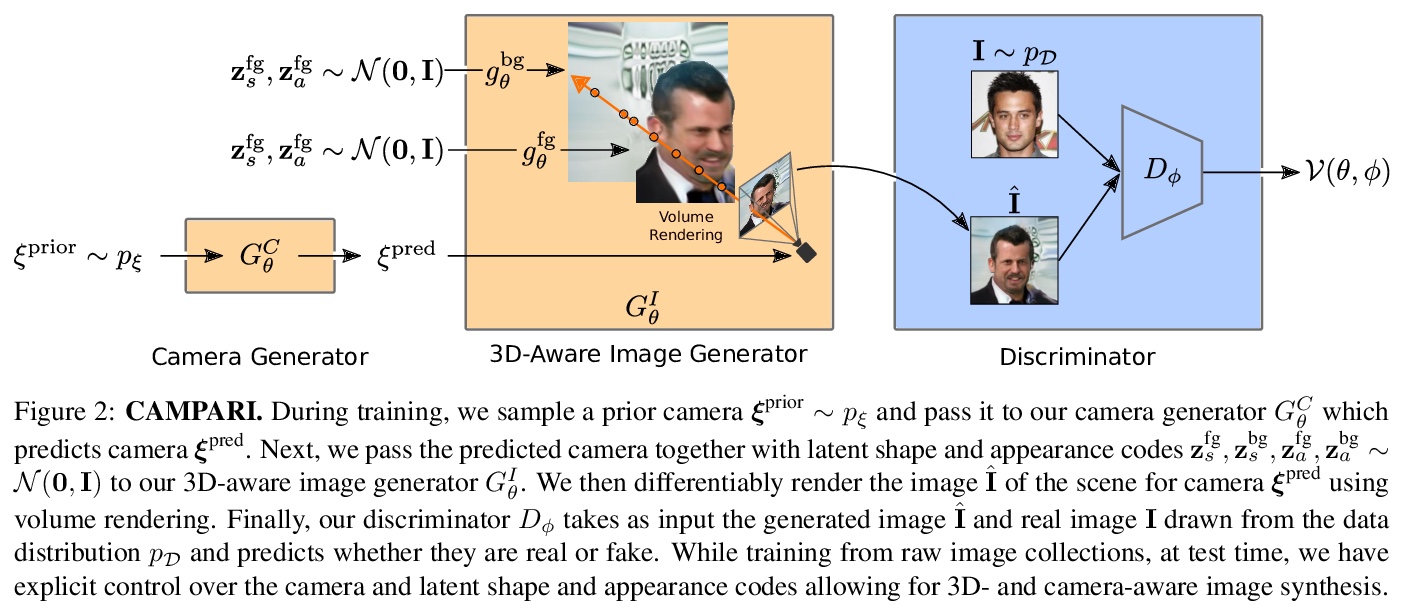
[CV] CAMPARI: Camera-Aware Decomposed Generative Neural Radiance Fields
CAMPARI:摄像机感知分解生成神经辐射场
M Niemeyer, A Geiger
[Max Planck Institute for Intelligent Systems]
https://weibo.com/1402400261/K9idy4rQg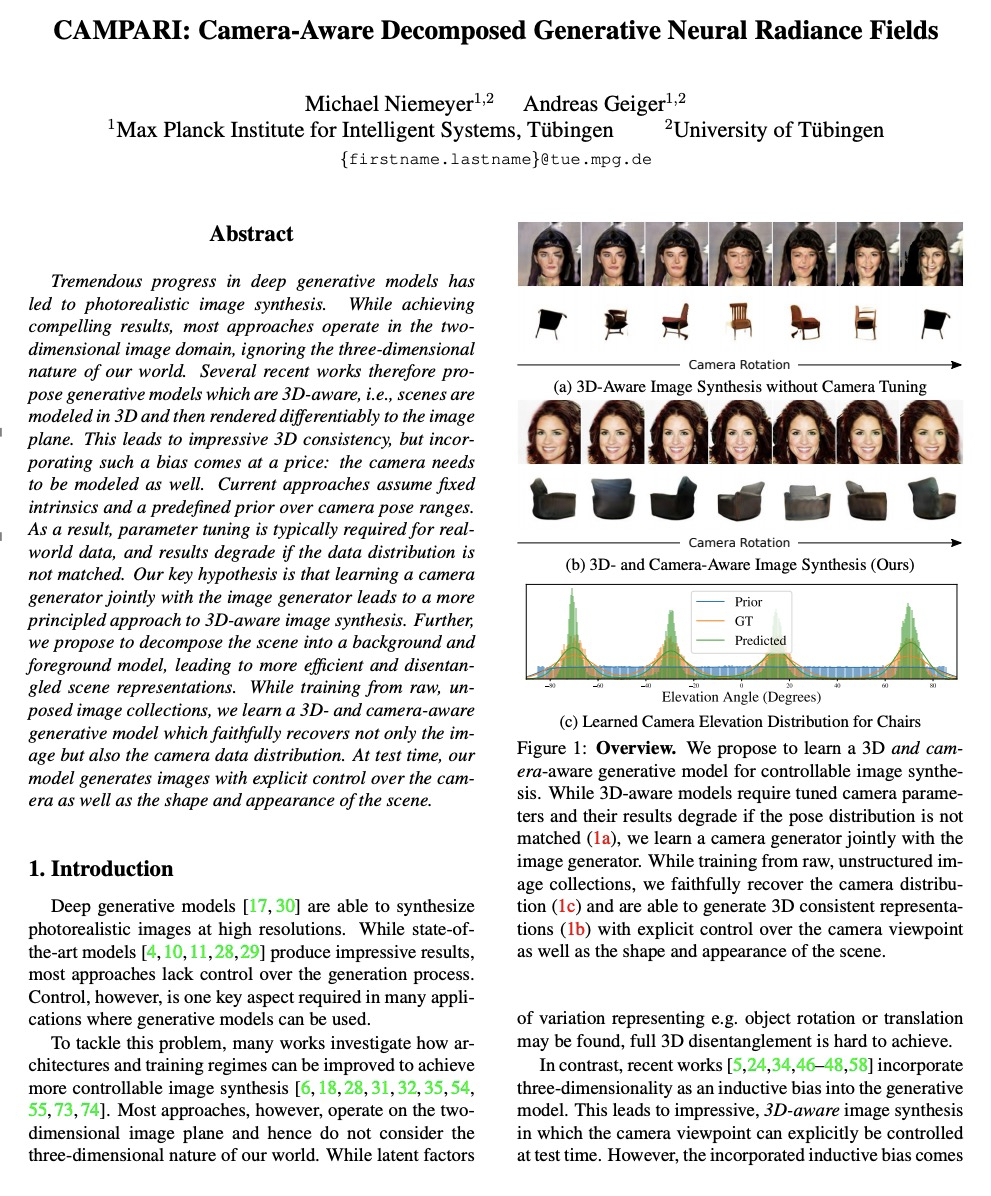


若有收获,就点个赞吧
0 人点赞
