- 1、[LG] COMBO: Conservative Offline Model-Based Policy Optimization
- 2、[CL] Non-Autoregressive Text Generation with Pre-trained Language Models
- 3、[CL] Meta Back-translation
- 4、[LG] Capturing the learning curves of generic features maps for realistic data sets with a teacher-student model
- 5、[CL] Differentiable Generative Phonology
- [CV] AlphaNet: Improved Training of Supernet with Alpha-Divergence
- [AI] Quantifying environment and population diversity in multi-agent reinforcement learning
- [LG] Controlling False Discovery Rates Using Null Bootstrapping
- [CL] Revisiting Language Encoding in Learning Multilingual Representations
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[LG] COMBO: Conservative Offline Model-Based Policy Optimization
T Yu, A Kumar, R Rafailov, A Rajeswaran, S Levine, C Finn
[Stanford University & UC Berkeley]
COMBO:保守的基于模型的离线策略优化。提出了保守的基于模型的离线策略优化(COMBO),一种基于模型的离线强化学习算法,对在不支持的状态动作对上评估的Q值进行惩罚,消除了以往基于模型的离线强化学习工作中广泛使用的不确定性量化需求。与之前的无模型离线强化学习方法相比,COMBO实现了更严格的真实策略值下限,保证了安全的策略改进。实验表明,COMBO在广泛研究的离线强化学习基准(包括基于图像的任务)上,与之前无模型和基于模型的离线方法相比,表现相当甚至更好。
Model-based algorithms, which learn a dynamics model from logged experience and perform some sort of pessimistic planning under the learned model, have emerged as a promising paradigm for offline reinforcement learning (offline RL). However, practical variants of such model-based algorithms rely on explicit uncertainty quantification for incorporating pessimism. Uncertainty estimation with complex models, such as deep neural networks, can be difficult and unreliable. We overcome this limitation by developing a new model-based offline RL algorithm, COMBO, that regularizes the value function on out-of-support state-action tuples generated via rollouts under the learned model. This results in a conservative estimate of the value function for out-of-support state-action tuples, without requiring explicit uncertainty estimation. We theoretically show that our method optimizes a lower bound on the true policy value, that this bound is tighter than that of prior methods, and our approach satisfies a policy improvement guarantee in the offline setting. Through experiments, we find that COMBO consistently performs as well or better as compared to prior offline model-free and model-based methods on widely studied offline RL benchmarks, including image-based tasks.
https://weibo.com/1402400261/K2rGZofvY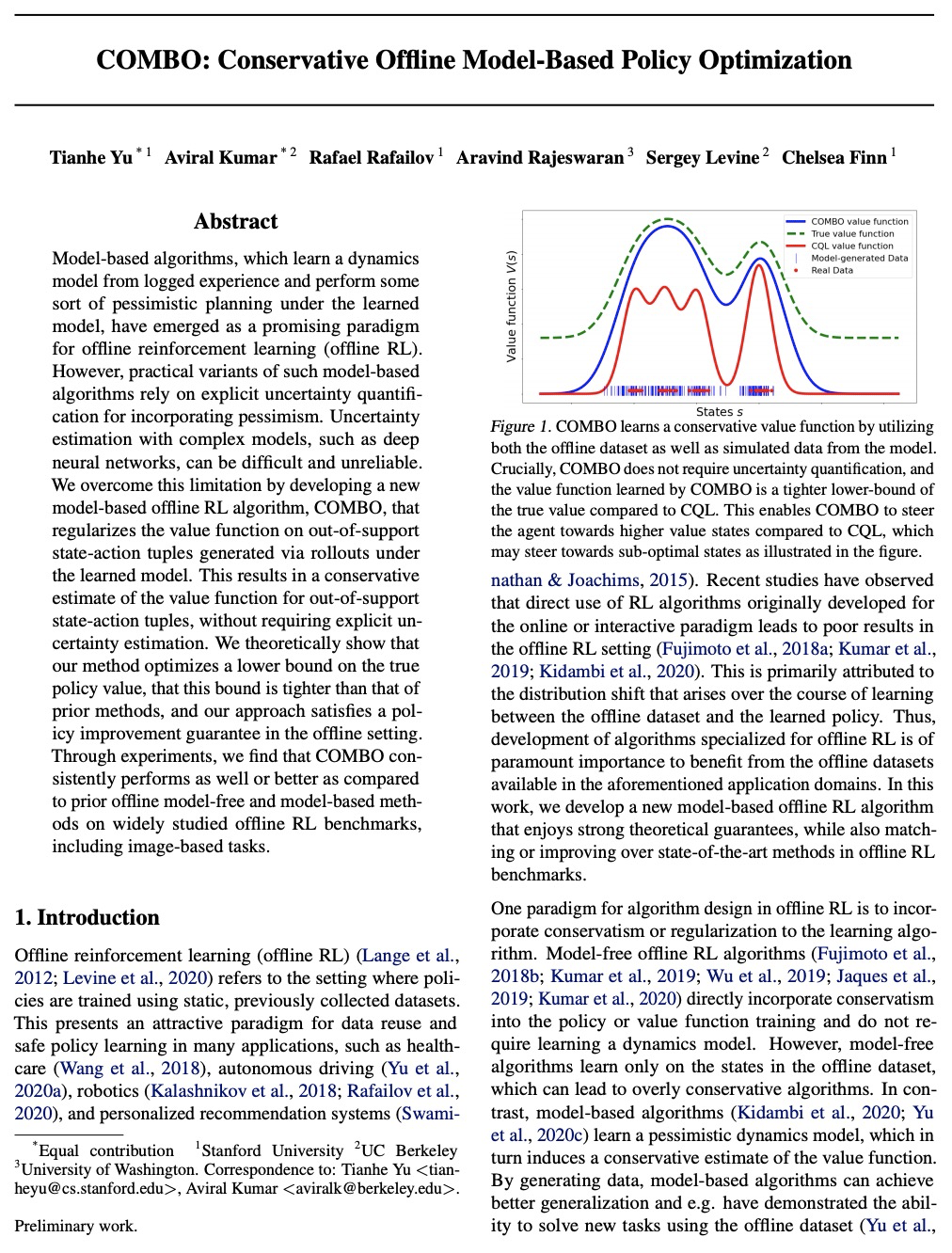

2、[CL] Non-Autoregressive Text Generation with Pre-trained Language Models
Y Su, D Cai, Y Wang, D Vandyke, S Baker, P Li, N Collier
[University of Cambridge & The Chinese University of Hong Kong & Tencent AI Lab & Apple]
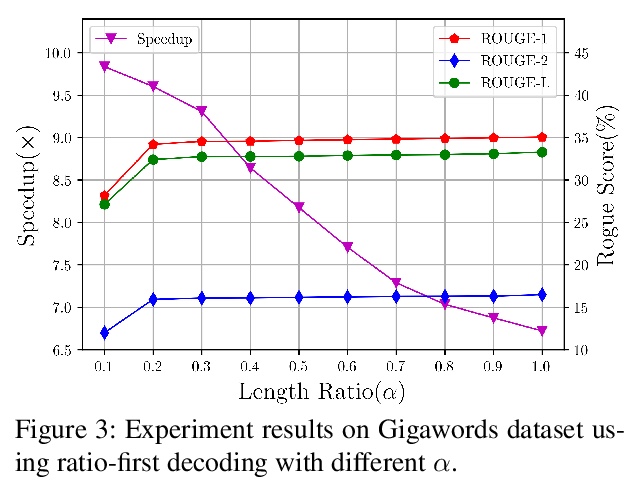
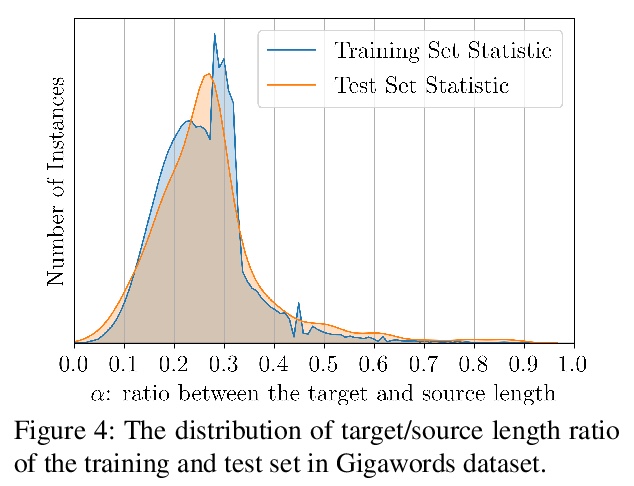
基于预训练语言模型的非自回归文本生成。提出一种新框架,在非自回归生成(NAG)范式下利用BERT进行文本生成,以大大提高性能。提出一种解码机制,允许模型动态确定输出长度,并提出新的上下文感知学习目标,减少了来自输出侧条件独立性假设的错误。引入比率优先解码策略,进一步提高了模型的推理效率。在三个基准数据集上评价了该模型,结果显著优于许多强NAG基线,并与许多强自回归模型表现相当。
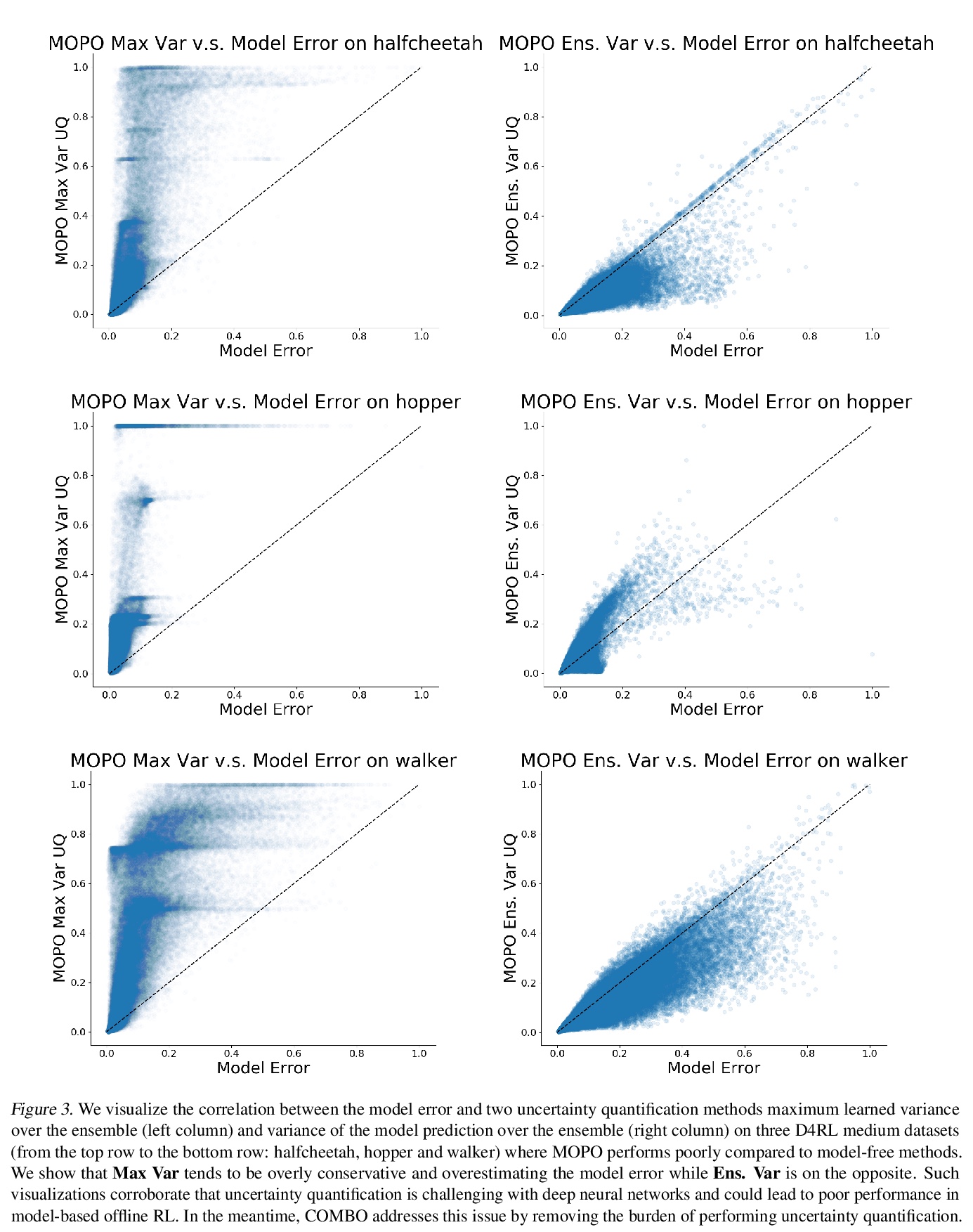
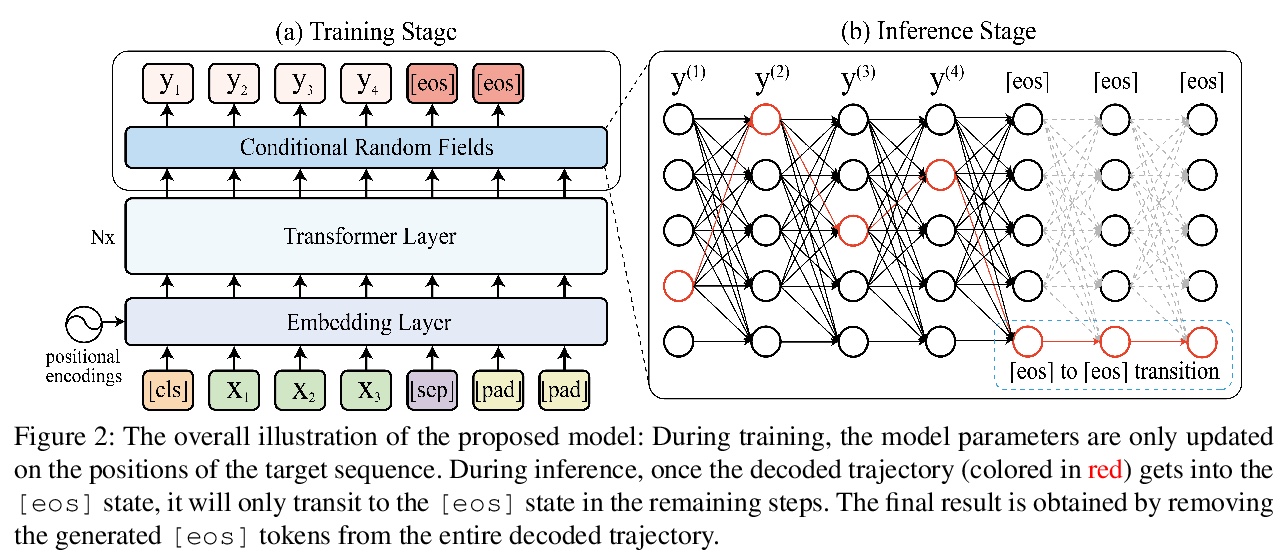
Non-autoregressive generation (NAG) has recently attracted great attention due to its fast inference speed. However, the generation quality of existing NAG models still lags behind their autoregressive counterparts. In this work, we show that BERT can be employed as the backbone of a NAG model to greatly improve performance. Additionally, we devise mechanisms to alleviate the two common problems of vanilla NAG models: the inflexibility of prefixed output length and the conditional independence of individual token predictions. Lastly, to further increase the speed advantage of the proposed model, we propose a new decoding strategy, ratio-first, for applications where the output lengths can be approximately estimated beforehand. For a comprehensive evaluation, we test the proposed model on three text generation tasks, including text summarization, sentence compression and machine translation. Experimental results show that our model significantly outperforms existing non-autoregressive baselines and achieves competitive performance with many strong autoregressive models. In addition, we also conduct extensive analysis experiments to reveal the effect of each proposed component.
https://weibo.com/1402400261/K2rM7DW96
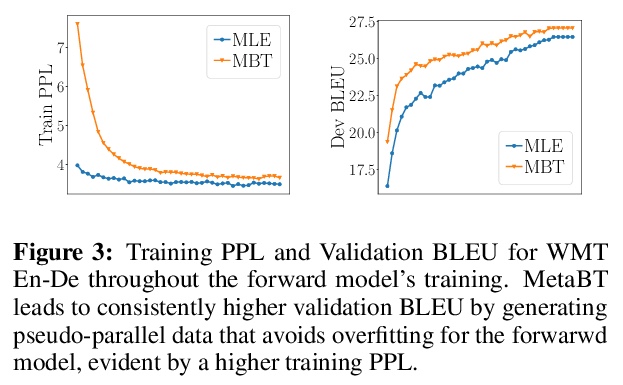
3、[CL] Meta Back-translation
H Pham, X Wang, Y Yang, G Neubig
[CMU]
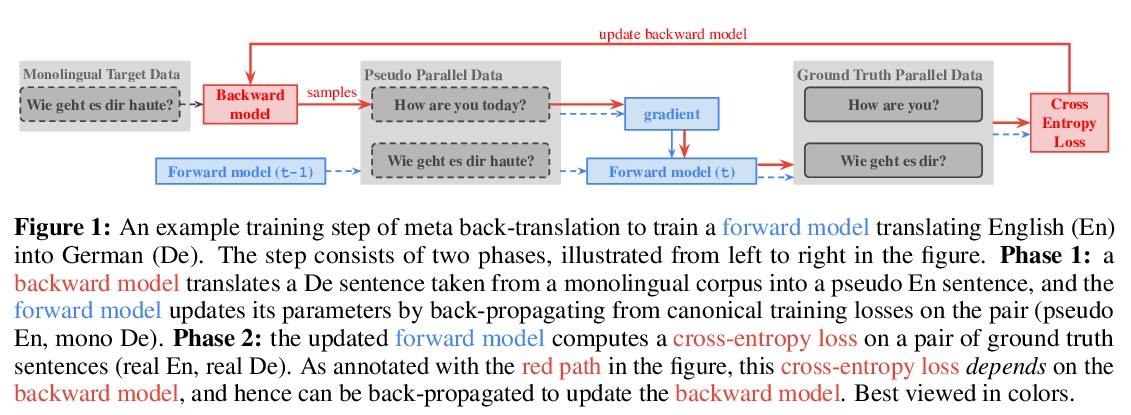
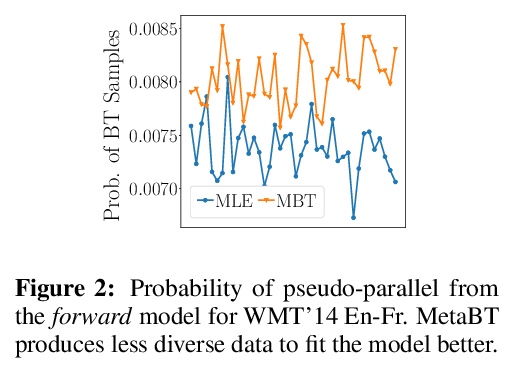
元回译(MetaBT)。提出了元回译(MetaBT),一种学习调整回译模型的算法,以生成对前向模型训练最有效的数据。MetaBT从预训练的回译模型中生成伪平行数据,自适应预训练好的回译模型,用其生成的伪平行数据训练前向翻译模型,使其在验证集上表现良好。实验表明,MetaBT在标准神经网络机器翻译环境和多语言环境下都优于现有的强方法。
Back-translation is an effective strategy to improve the performance of Neural Machine Translation~(NMT) by generating pseudo-parallel data. However, several recent works have found that better translation quality of the pseudo-parallel data does not necessarily lead to better final translation models, while lower-quality but more diverse data often yields stronger results. In this paper, we propose a novel method to generate pseudo-parallel data from a pre-trained back-translation model. Our method is a meta-learning algorithm which adapts a pre-trained back-translation model so that the pseudo-parallel data it generates would train a forward-translation model to do well on a validation set. In our evaluations in both the standard datasets WMT En-De’14 and WMT En-Fr’14, as well as a multilingual translation setting, our method leads to significant improvements over strong baselines. Our code will be made available.
https://weibo.com/1402400261/K2rQcDJIm
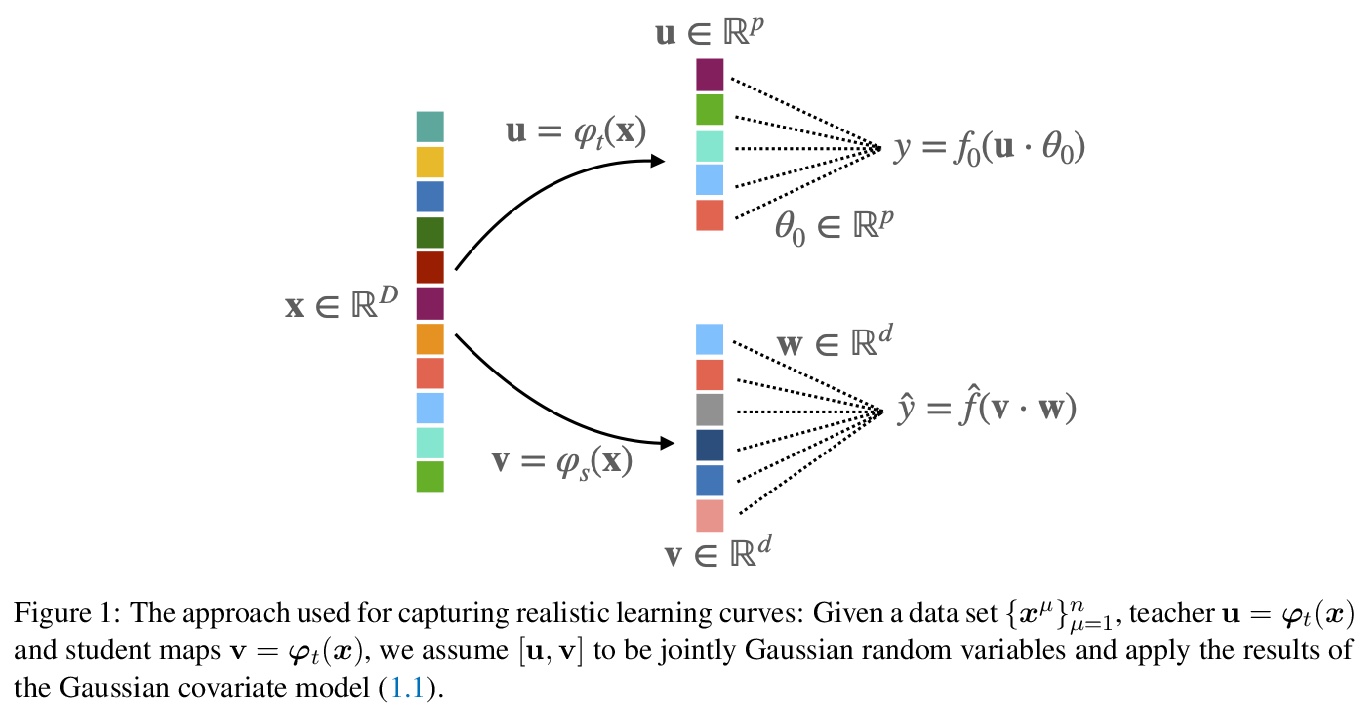
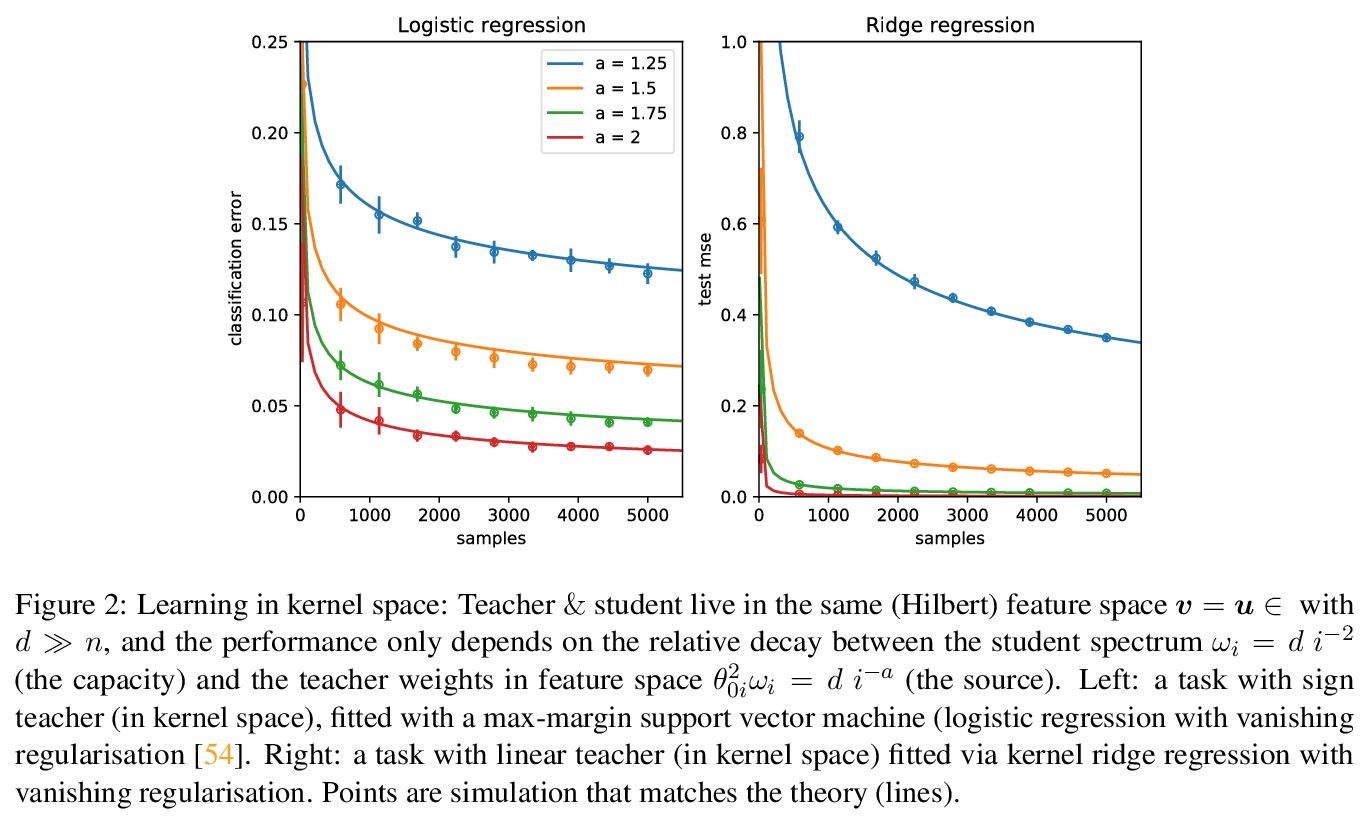
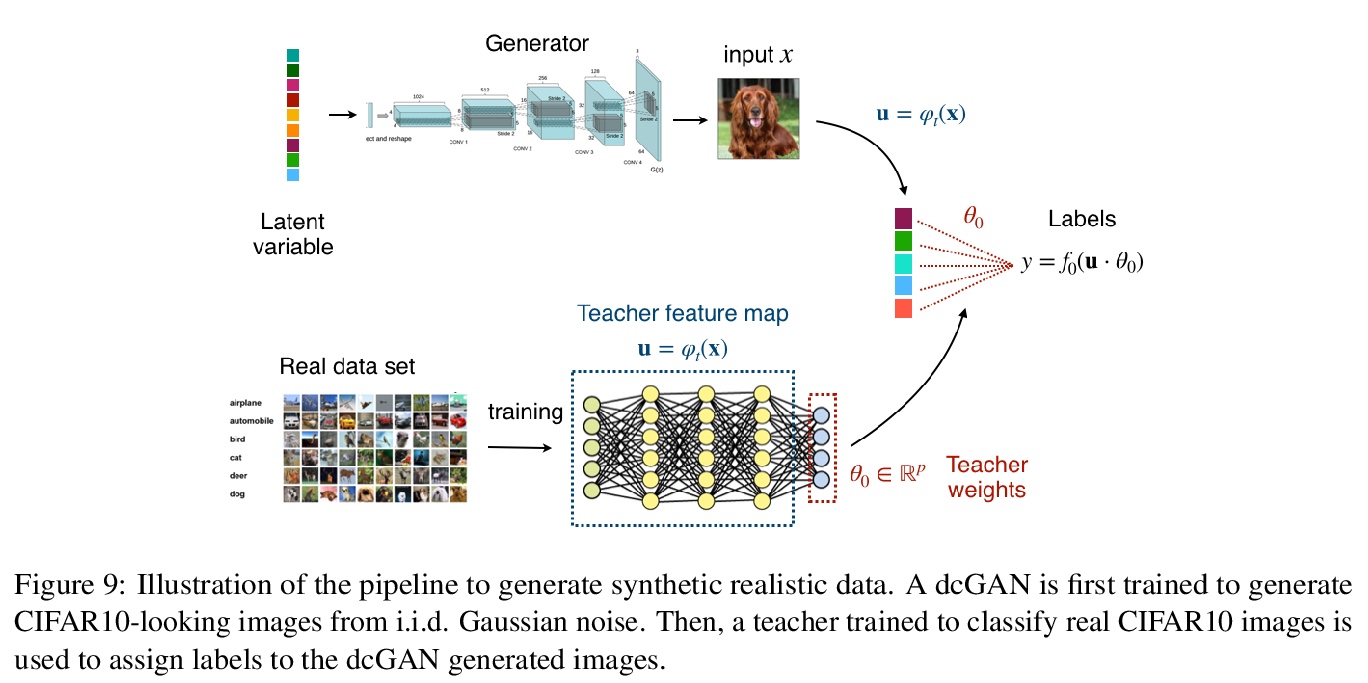
4、[LG] Capturing the learning curves of generic features maps for realistic data sets with a teacher-student model
B Loureiro, C Gerbelot, H Cui, S Goldt, F Krzakala, M Mézard, L Zdeborová
[École Fédérale Polytechnique de Lausanne (EPFL) & Université PSL & International School of Advanced Studies (SISSA)]
用教师-学生模型捕捉现实数据集通用特征图学习曲线。讨论了用教师-学生模型解决高维监督学习任务的一般化,教师和学生可以在用固定但通用的特征图生成的不同空间上行动,通过对高维高斯协方差模型的严格研究来实现。证明了一个严格的公式,用于计算该模型的渐进训练损失和通过经验风险最小化实现的泛化误差。指出在一些情况下,模型的学习曲线抓住了用内核回归和分类学习的现实数据集的曲线,用开箱即用的特征图,如随机投影或散射变换,或用预学习的,如通过训练多层神经网络学习的特征。讨论了高斯师生框架的有效性和局限性,作为一个典型的案例分析,捕捉真实数据集上实践中遇到的学习曲线。
Teacher-student models provide a powerful framework in which the typical case performance of high-dimensional supervised learning tasks can be studied in closed form. In this setting, labels are assigned to data - often taken to be Gaussian i.i.d. - by a teacher model, and the goal is to characterise the typical performance of the student model in recovering the parameters that generated the labels. In this manuscript we discuss a generalisation of this setting where the teacher and student can act on different spaces, generated with fixed, but generic feature maps. This is achieved via the rigorous study of a high-dimensional Gaussian covariate model. Our contribution is two-fold: First, we prove a rigorous formula for the asymptotic training loss and generalisation error achieved by empirical risk minimization for this model. Second, we present a number of situations where the learning curve of the model captures the one of a realistic data set learned with kernel regression and classification, with out-of-the-box feature maps such as random projections or scattering transforms, or with pre-learned ones - such as the features learned by training multi-layer neural networks. We discuss both the power and the limitations of the Gaussian teacher-student framework as a typical case analysis capturing learning curves as encountered in practice on real data sets.
https://weibo.com/1402400261/K2rTPemPA
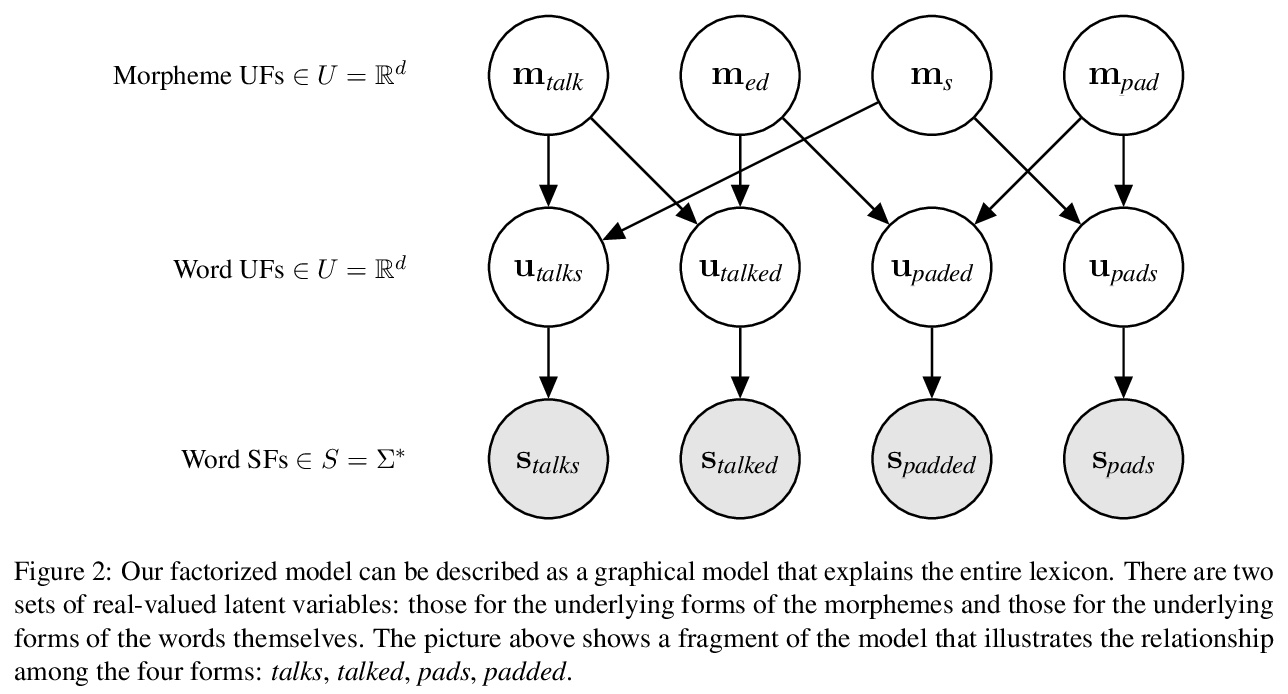
5、[CL] Differentiable Generative Phonology
S Wu, E M Ponti, R Cotterell
[Johns Hopkins University & Mila Montreal & University of Cambridge]
可微生成语音学。将语音生成系统实现为一个可端到端的神经模型,而不是作为一组规则或约束条件。与传统语音学不同,该模型中基本形式(UF)是R中的连续向量,而不是离散字符串,UF是自动发现的,而不是由语言学家提出的,可扩展到现实词汇的大小,可自动地、大规模地学习基本形式(UF)和表面形式(SF)。
The goal of generative phonology, as formulated by Chomsky and Halle (1968), is to specify a formal system that explains the set of attested phonological strings in a language. Traditionally, a collection of rules (or constraints, in the case of optimality theory) and underlying forms (UF) are posited to work in tandem to generate phonological strings. However, the degree of abstraction of UFs with respect to their concrete realizations is contentious. As the main contribution of our work, we implement the phonological generative system as a neural model differentiable end-to-end, rather than as a set of rules or constraints. Contrary to traditional phonology, in our model, UFs are continuous vectors in > ℝd, rather than discrete strings. As a consequence, UFs are discovered automatically rather than posited by linguists, and the model can scale to the size of a realistic vocabulary. Moreover, we compare several modes of the generative process, contemplating: i) the presence or absence of an underlying representation in between morphemes and surface forms (SFs); and ii) the conditional dependence or independence of UFs with respect to SFs. We evaluate the ability of each mode to predict attested phonological strings on 2 datasets covering 5 and 28 languages, respectively. The results corroborate two tenets of generative phonology, viz. the necessity for UFs and their independence from SFs. In general, our neural model of generative phonology learns both UFs and SFs automatically and on a large-scale.
https://weibo.com/1402400261/K2rXthqlM
另外几篇值得关注的论文:
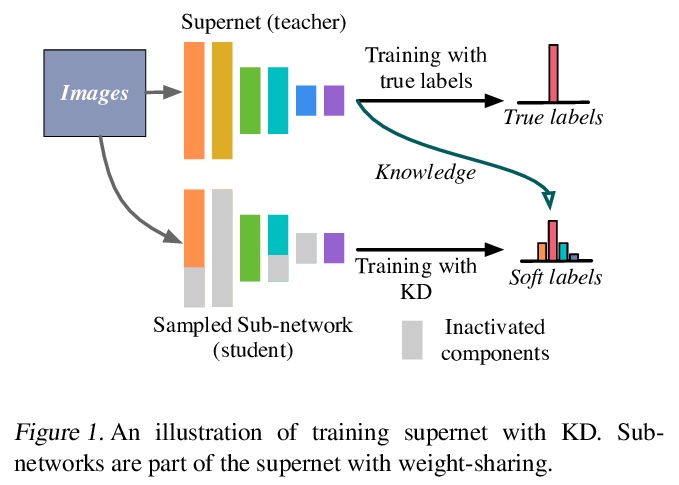
[CV] AlphaNet: Improved Training of Supernet with Alpha-Divergence
AlphaNet:用基于α-散度的知识提炼方法改善supernet的训练
D Wang, C Gong, M Li, Q Liu, V Chandra
[Facebook & The University of Texas at Austin]
https://weibo.com/1402400261/K2s0E4hxc
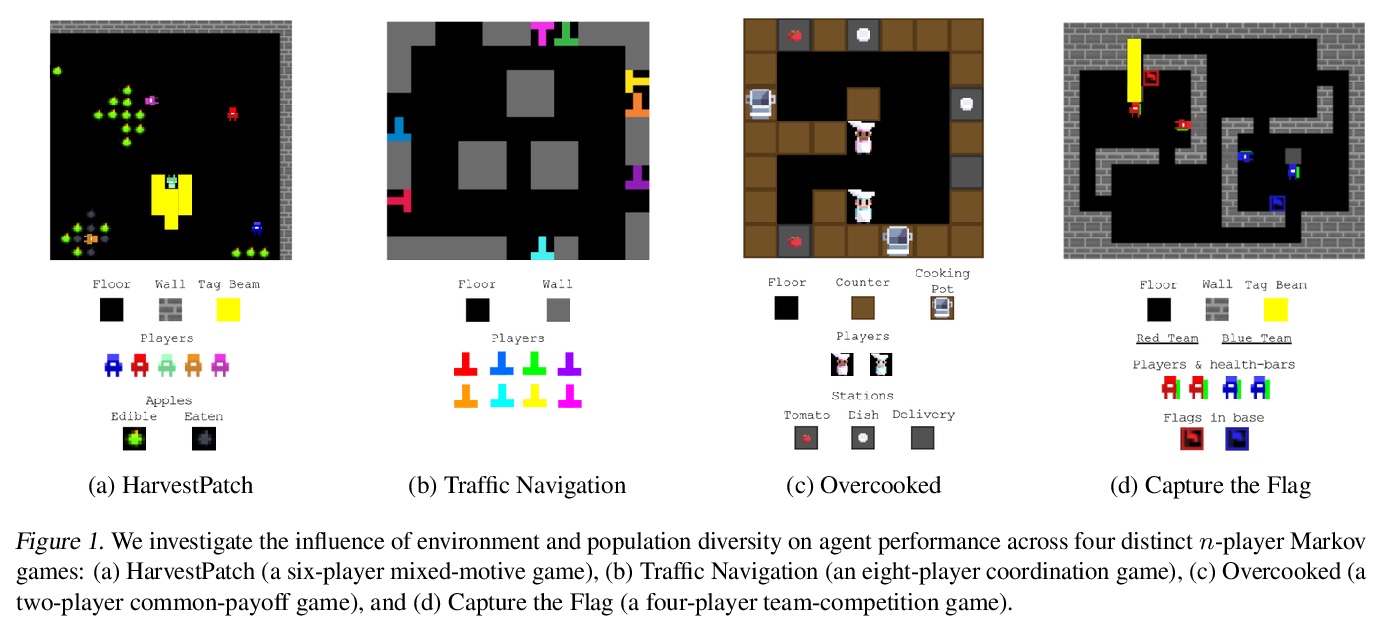
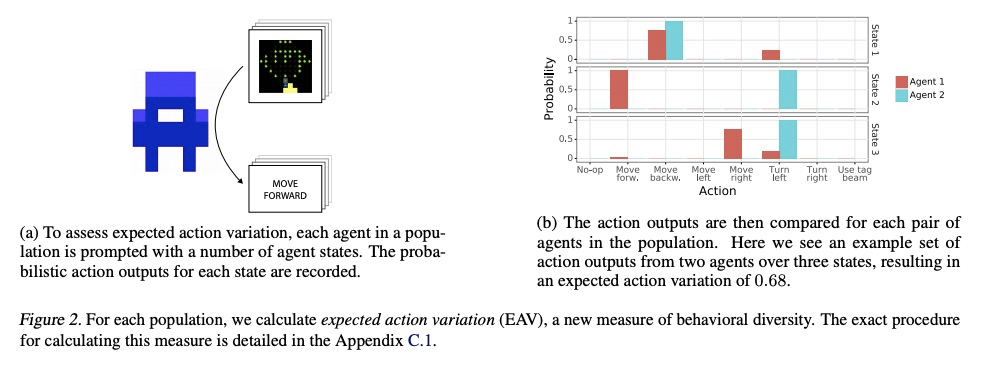
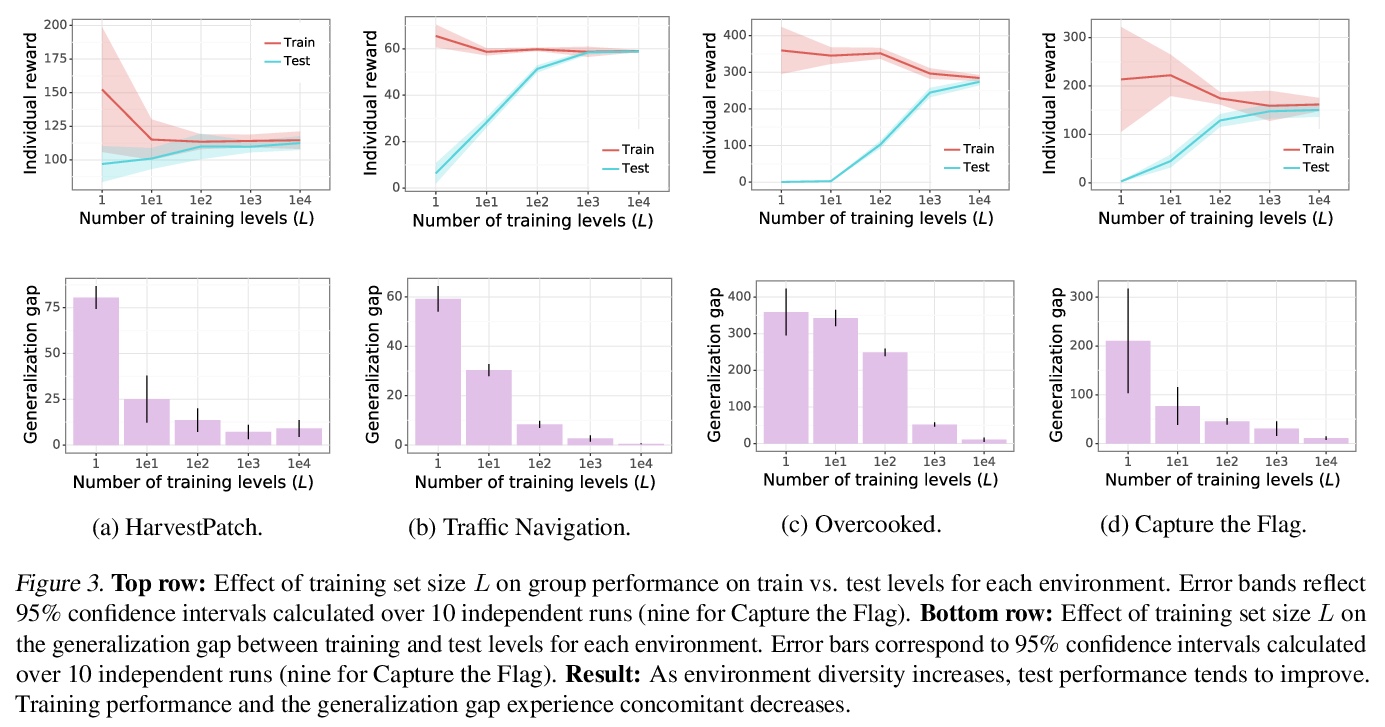
[AI] Quantifying environment and population diversity in multi-agent reinforcement learning
多智能体强化学习中环境和种群多样性的量化
K R. McKee, J Z. Leibo, C Beattie, R Everett
[DeepMind]
https://weibo.com/1402400261/K2s3f5KI9
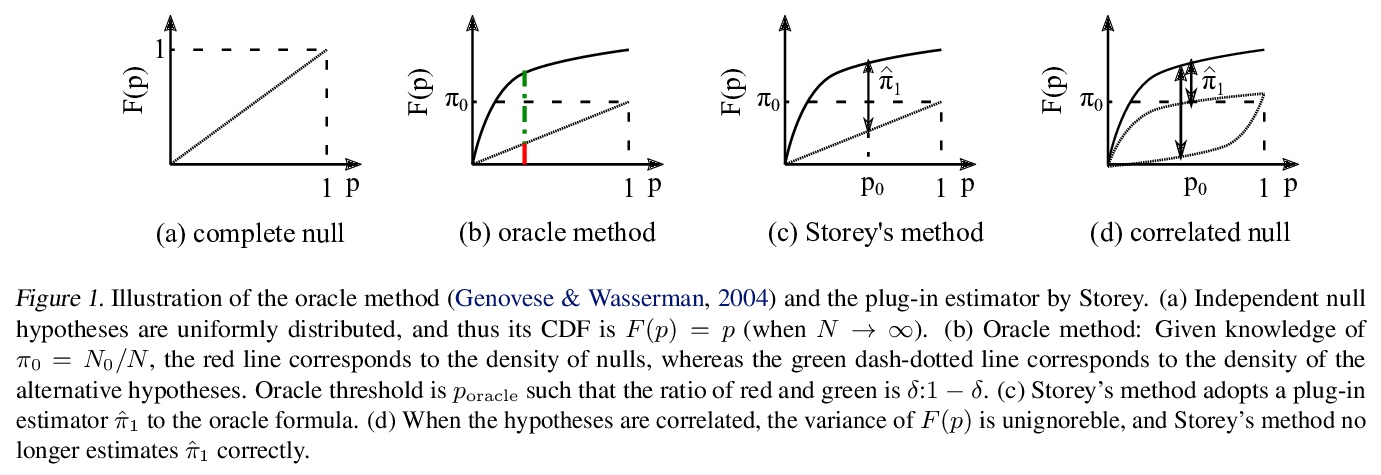
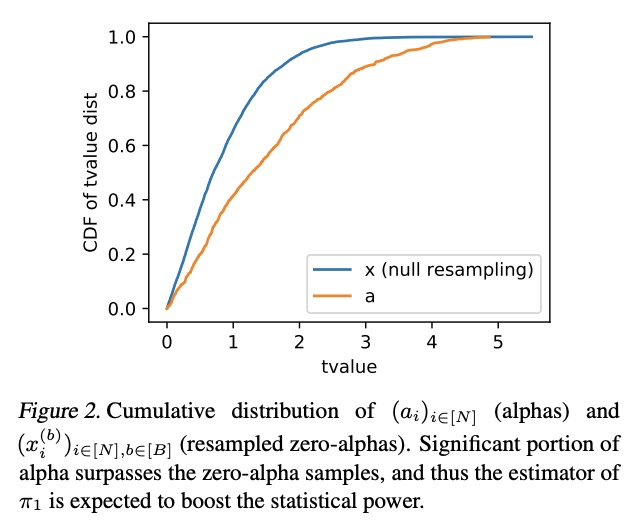
[LG] Controlling False Discovery Rates Using Null Bootstrapping
基于Null Bootstrapping的虚假发现率控制
J Komiyama, M Abe, K Nakagawa, K McAlinn
[New York University & Nomura Asset Management Co. & Temple University]
https://weibo.com/1402400261/K2s5oElBQ
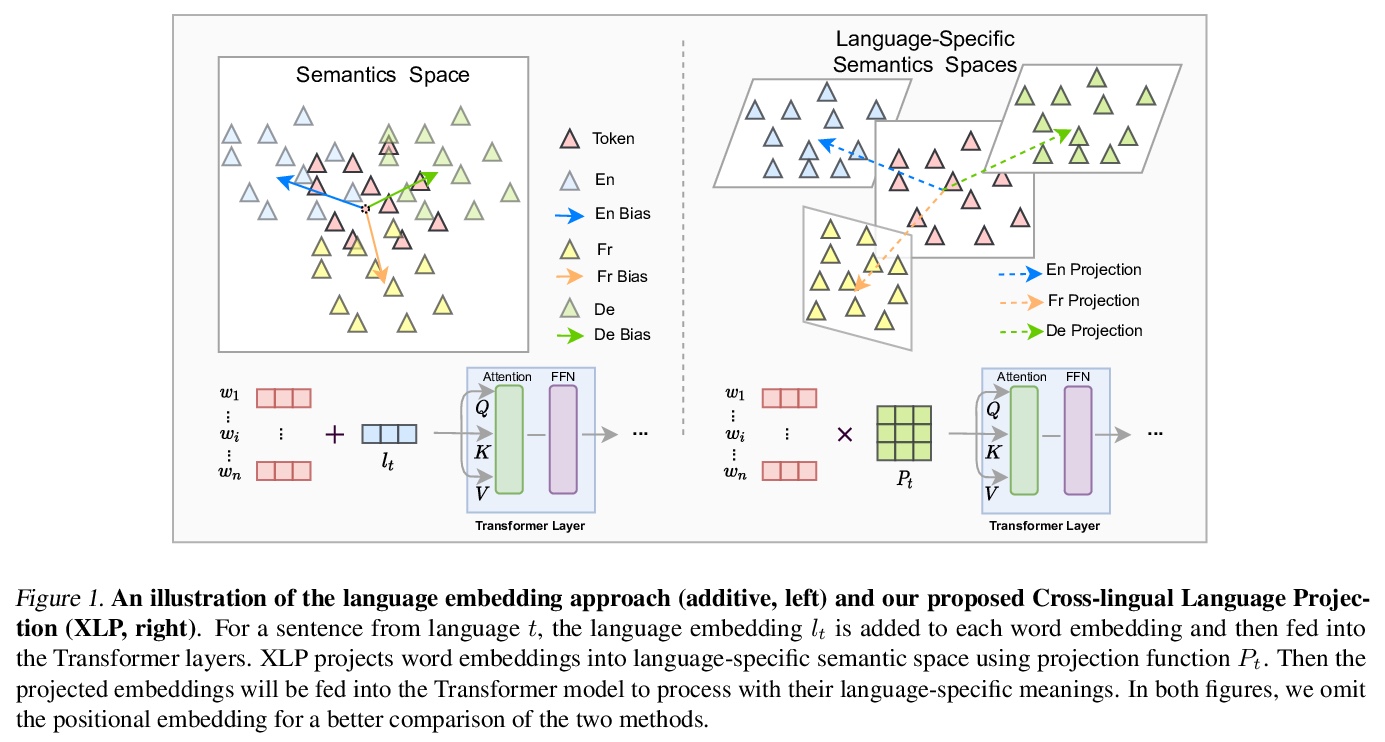
[CL] Revisiting Language Encoding in Learning Multilingual Representations
多语种表示学习语言编码的反思
S Luo, K Gao, S Zheng, G Ke, D He, L Wang, T Liu
[Peking University & Huazhong University of Science and Technology & Microsoft Research]
https://weibo.com/1402400261/K2s7kkWSD




若有收获,就点个赞吧
0 人点赞
