- 1、[CV] A topological solution to object segmentation and tracking
- 2、[AS] BumbleBee: A Transformer for Music
- 3、[CL] ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
- 4、[LG] NeurIPS 2021 Competition proposal: The MineRL BASALT Competition on Learning from Human Feedback
- 5、[LG] Universal Approximation of Functions on Sets
- [CV] Edge-aware Bidirectional Diffusion for Dense Depth Estimation from Light Fields
- [LG] Visualizing the geometry of labeled high-dimensional data with spheres
- [CV] Exploiting & Refining Depth Distributions With Triangulation Light Curtains
- [CL] Scarecrow: A Framework for Scrutinizing Machine Text
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[CV] A topological solution to object segmentation and tracking
T Tsao, D Y. Tsao
[OpticArray Technologies & Division of Biology and Biological Engineering]
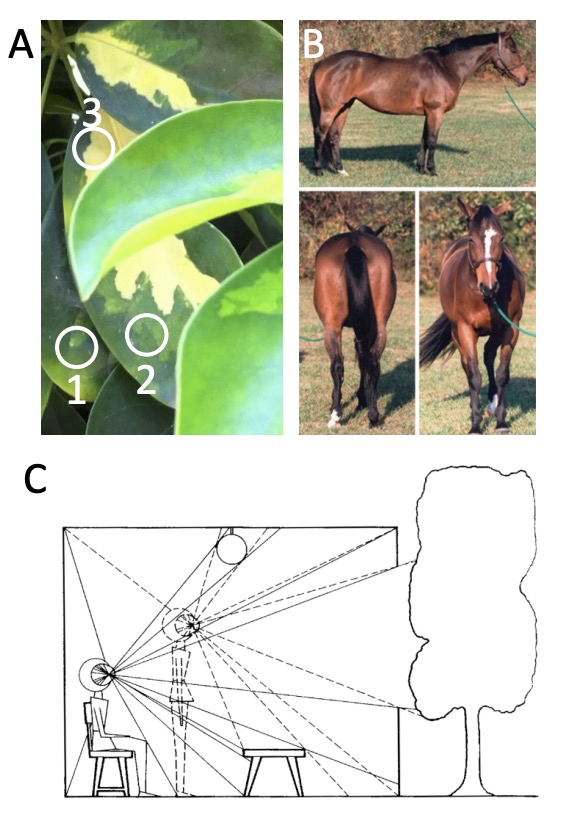
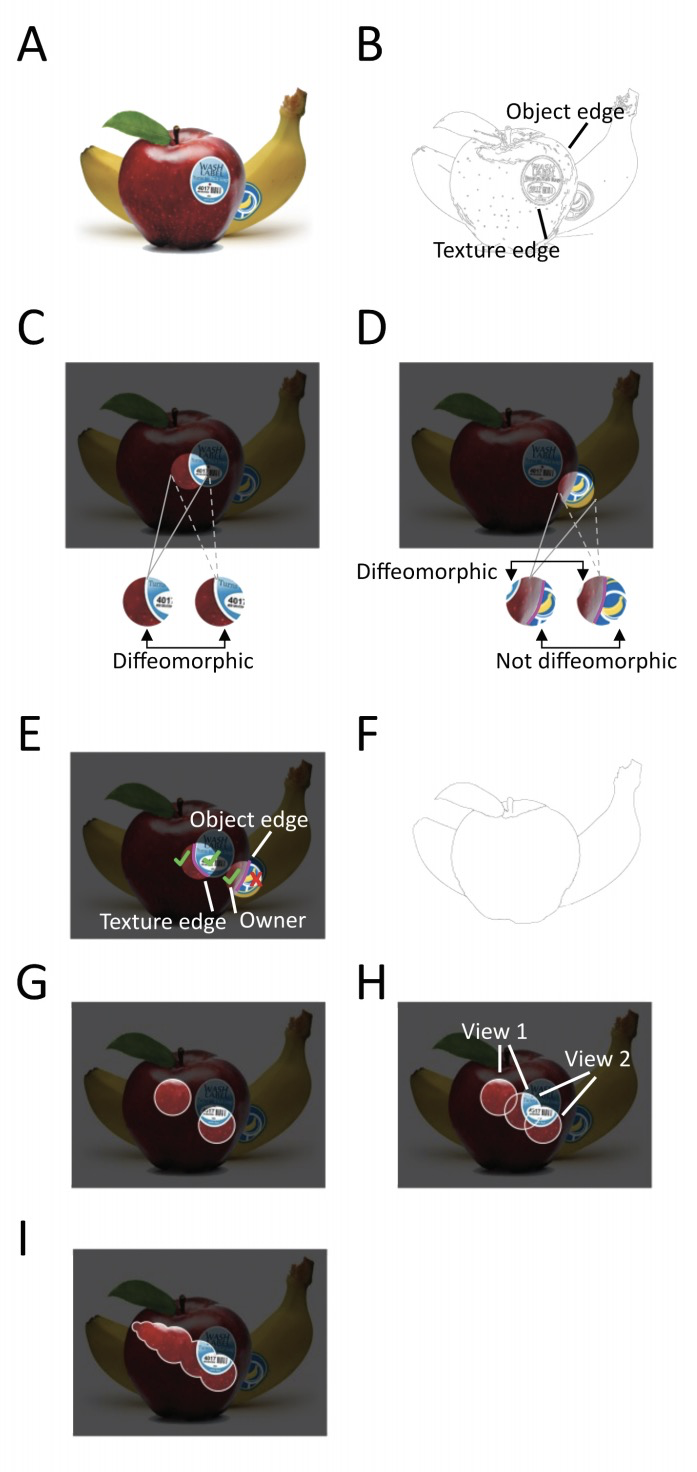
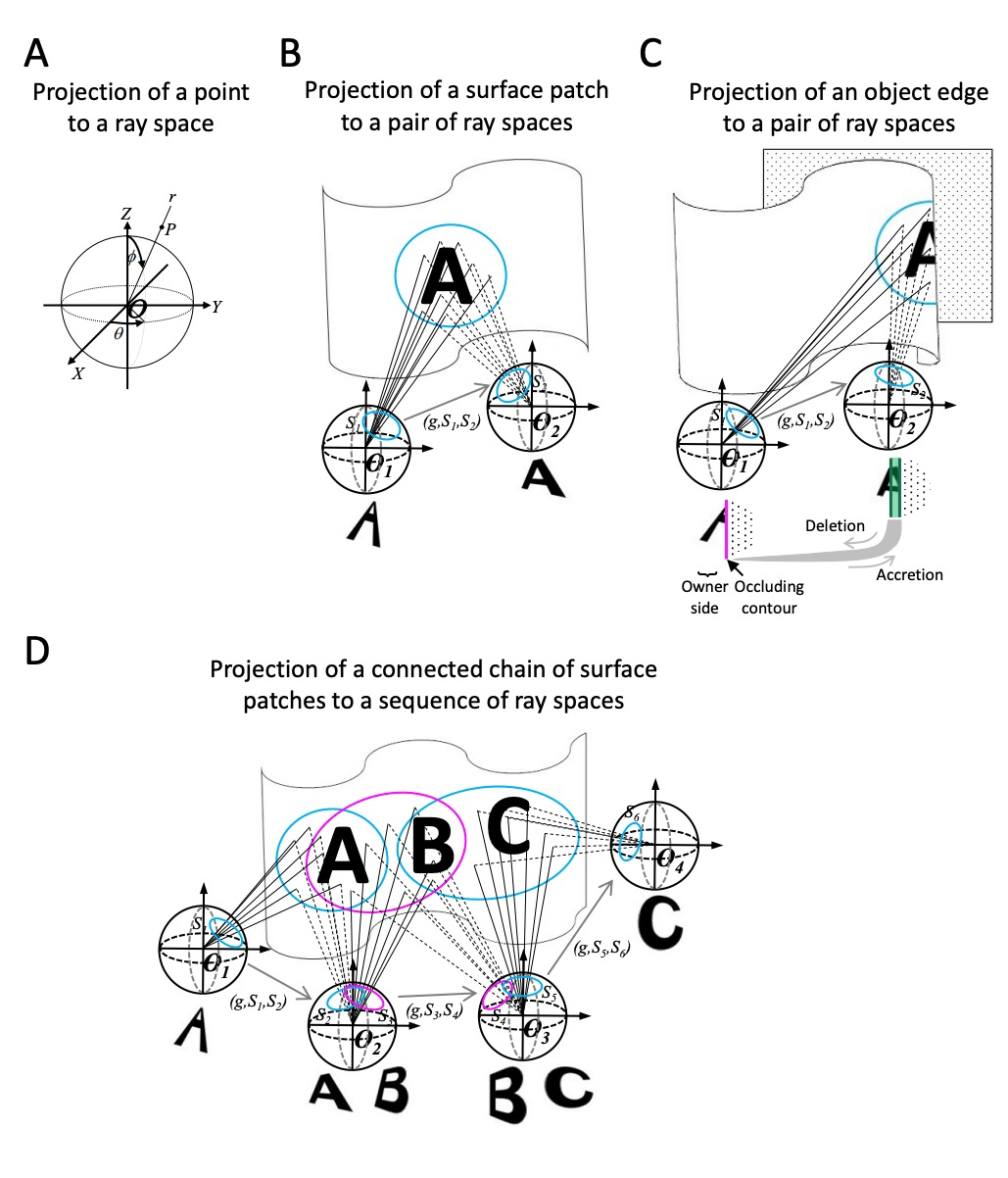
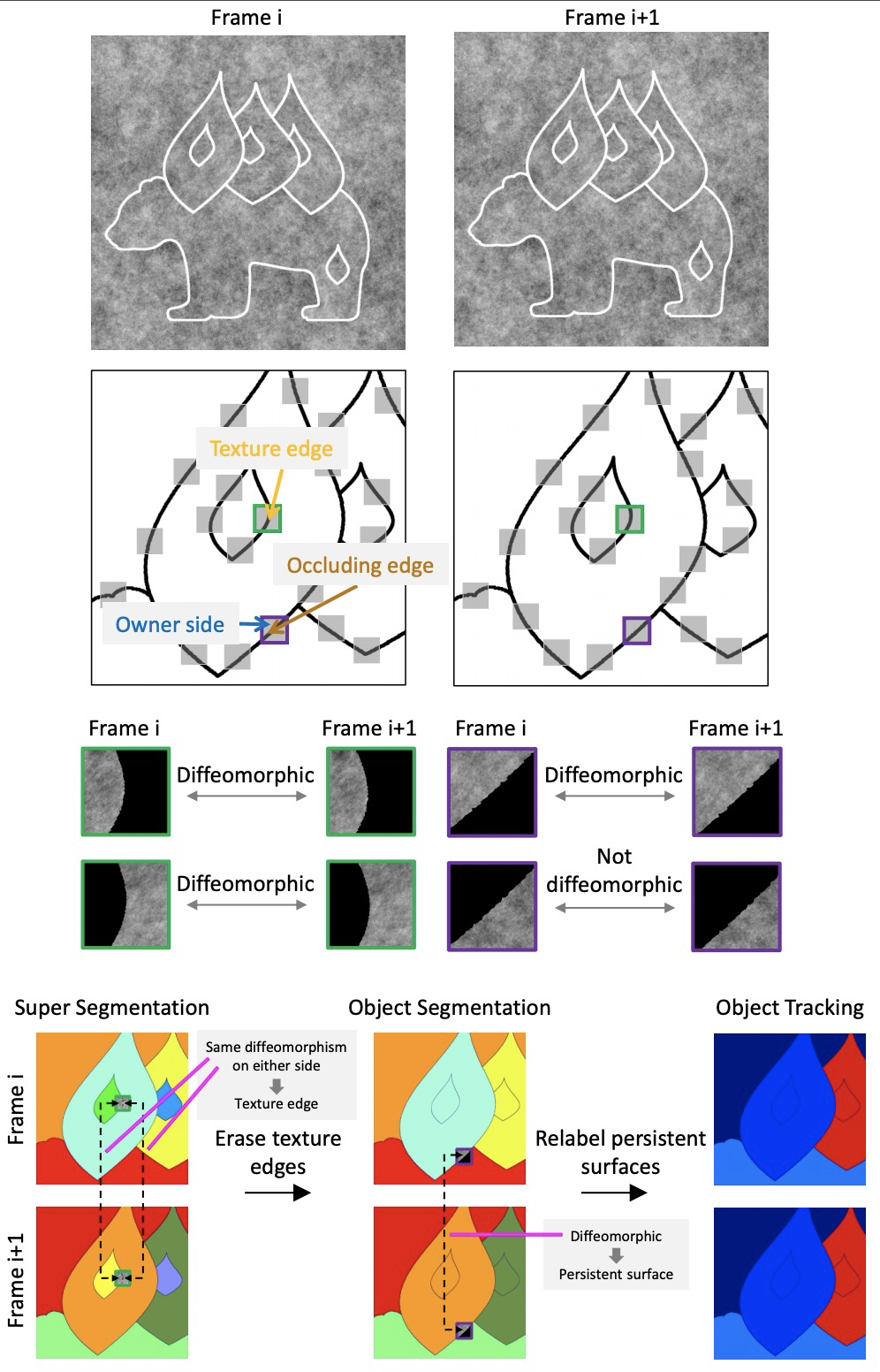
拓扑目标分割与追踪。世界是由物体、地面和天空组成的。对物体的视觉感知需要解决两个基本挑战:将视觉输入分割成离散单元,并跟踪这些单元的身份,其间由于物体变形、视角变化和动态遮挡会导致外观变化。目前接近人类表现的计算机视觉分割和追踪方法都需要学习,这就提出了一个问题:物体是否可以不经学习而被分割和追踪?本文展示了从环境表面反射光线的数学结构,产生一个自然的持久的表面表示,这个表面表示为分割和追踪问题提供了一种解决方案。解释了如何从环境的透视投影中提取表面表示,即连续的表面组件的拓扑标记以及它们的形状和位置的几何描述,其方式不受视角变化和遮挡的影响。描述了如何从连续的视觉输入中产生这种表面表征,并证明该方法可以在杂乱的合成视频中分割和不变地追踪物体,尽管外观发生严重变化,而不需要学习。可以通过检测遮挡的轮廓(携带可见表面的空间分离信息)将图像分割成独立的表面,通过检测差分形态(携带不同视角可见表面之间的重叠关系信息)来跟踪图像序列中的不变表面。不仅从数学上证明了方法的有效性,还证明了它在目标分割和合成视频的不变跟踪方面的计算高效性。
The world is composed of objects, the ground, and the sky. Visual perception of objects requires solving two fundamental challenges: segmenting visual input into discrete units, and tracking identities of these units despite appearance changes due to object deformation, changing perspective, and dynamic occlusion. Current computer vision approaches to segmentation and tracking that approach human performance all require learning, raising the question: can objects be segmented and tracked without learning? Here, we show that the mathematical structure of light rays reflected from environment surfaces yields a natural representation of persistent surfaces, and this surface representation provides a solution to both the segmentation and tracking problems. We describe how to generate this surface representation from continuous visual input, and demonstrate that our approach can segment and invariantly track objects in cluttered synthetic video despite severe appearance changes, without requiring learning.
https://weibo.com/1402400261/KobzHi9pi 
2、[AS] BumbleBee: A Transformer for Music
L Fenaux, M J Quintero
[University of Toronto]
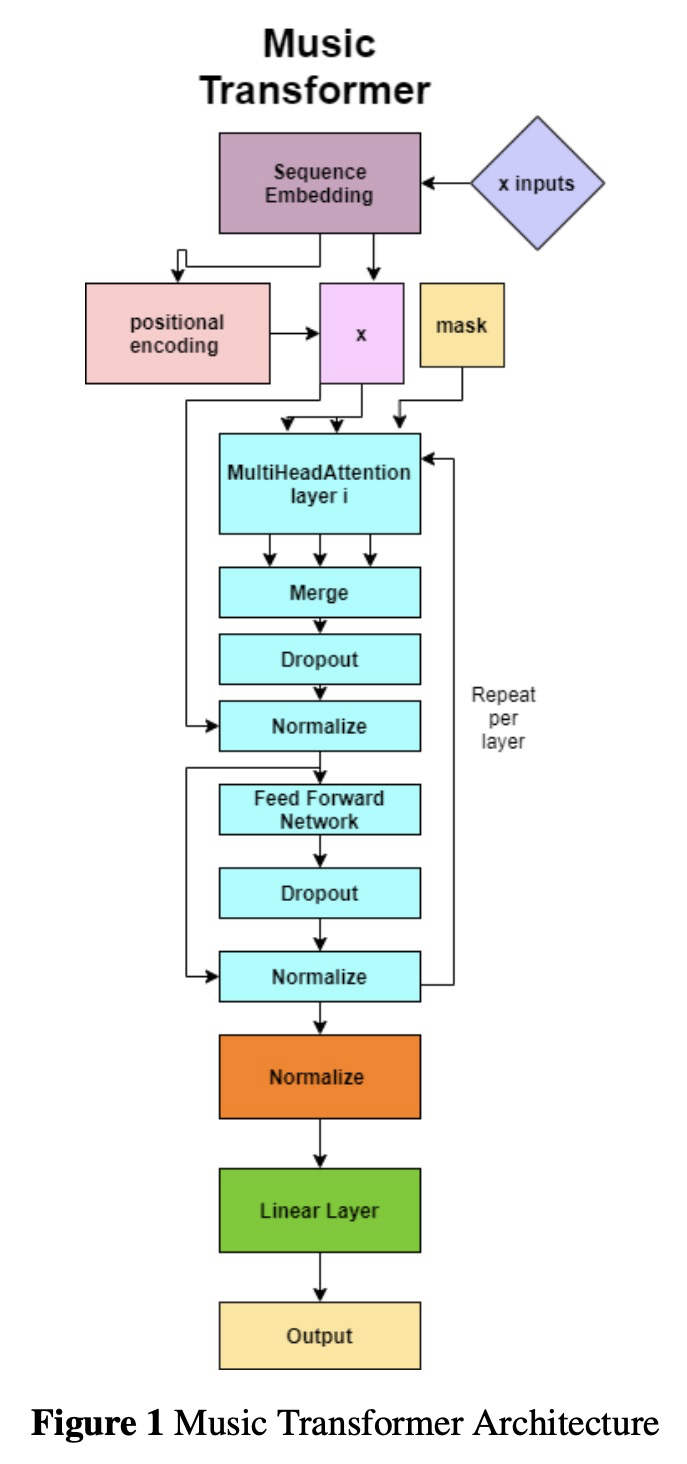
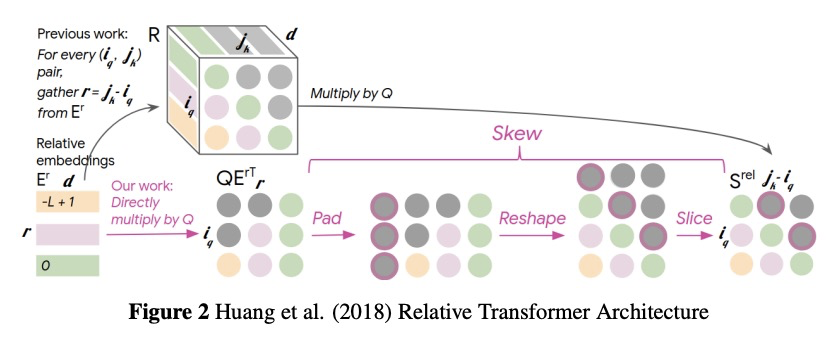
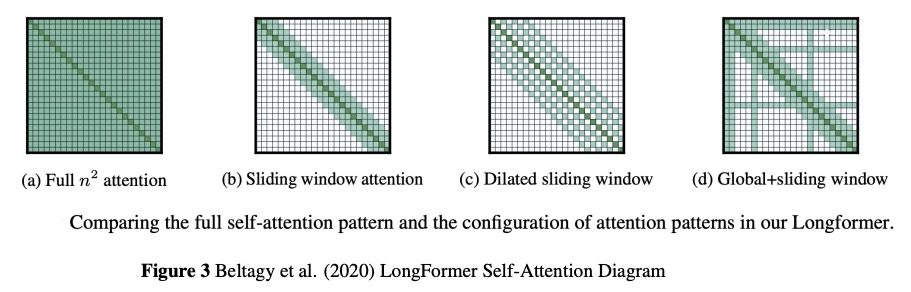
BumbleBee:面向音乐的Transformer。本文介绍BumbleBee,一种可生成MIDI音乐数据的Transformer模型。通过实现一个长式生成模型来解决应用于长序列的Transformer问题,该模型使用扩张的滑动窗口来计算注意力层。将该结果与音乐Transformer和长短时记忆(LSTM)的结果进行了比较,结果表明Relative Transformer优于Longformer,因为音乐本身是相对的,而Longformer被限制在了局部注意力上。
We will introduce BumbleBee, a transformer model that will generate MIDI music data . We will tackle the issue of transformers applied to long sequences by implementing a longformer generative model that uses dilating sliding windows to compute the attention layers. We will compare our results to that of the music transformer and Long-Short term memory (LSTM) to benchmark our results. This analysis will be performed using piano MIDI files, in particular , the JSB Chorales dataset that has already been used for other research works (Huang et al., 2018)
https://weibo.com/1402400261/KobFeFTBE 
3、[CL] ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Y Sun, S Wang, S Feng, S Ding, C Pang, J Shang, J Liu, X Chen, Y Zhao, Y Lu, W Liu, Z Wu, W Gong, J Liang, Z Shang, P Sun, W Liu, X Ouyang, D Yu, H Tian, H Wu, H Wang
[Baidu]
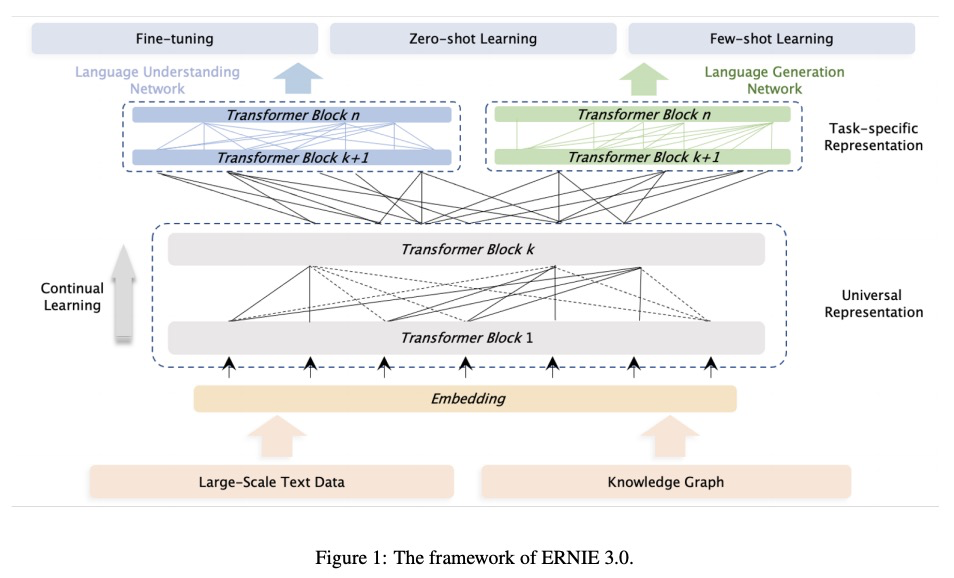
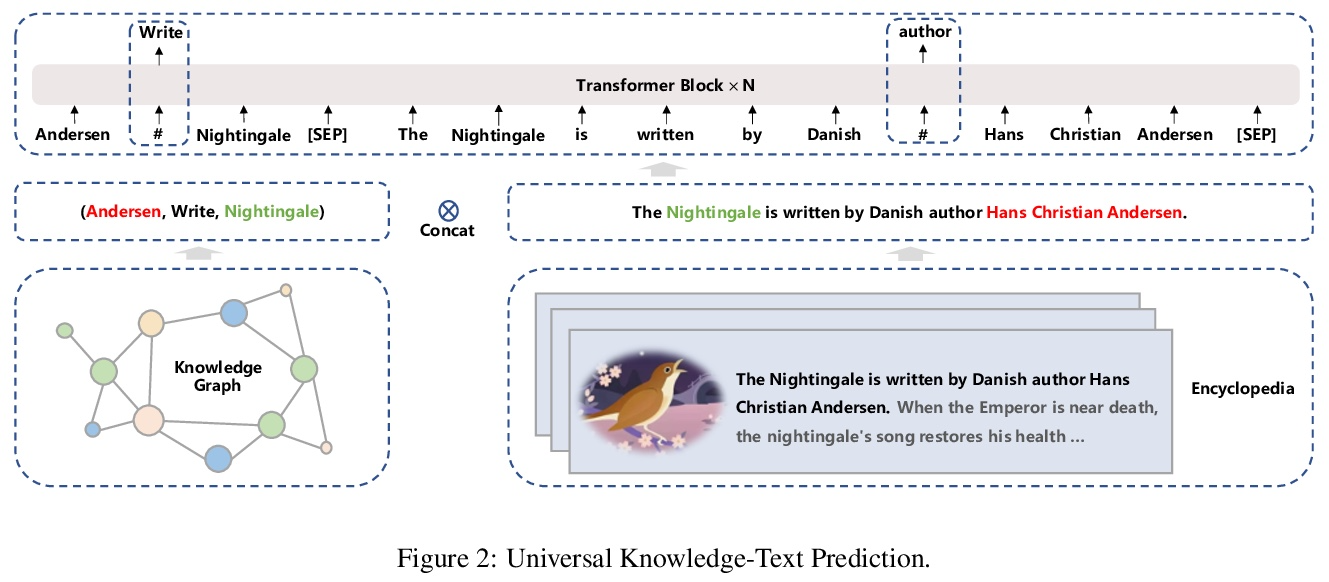
ERNIE 3.0:面向语言理解与生成的大规模知识强化预训练。预训练模型在各种自然语言处理(NLP)任务中取得了最先进的结果。最近的工作(如T5和GPT-3)表明,扩大预训练语言模型的规模可提高其泛化能力。特别是拥有1750亿个参数的GPT-3模型,显示了其强大的任务无关零样本/少样本学习能力。尽管很成功,但这些大规模模型是在没有引入语言知识和世界知识等知识的情况下对纯文本进行训练。此外,大多数大规模模型是以自回归方式进行训练的,这种传统的微调方法在解决下游语言理解任务时表现出相对较弱的性能。为解决上述问题,本文提出一种统一框架ERNIE 3.0,用于预训练大规模知识增强模型,它融合了自回归网络和自动编码网络,训练后的模型可以很容易地通过零样本学习、少样本学习或微调来适应自然语言理解和生成任务。在由普通文本和大规模知识图谱组成的4TB语料库上用100亿个参数训练该模型。实证结果表明,该模型在54个中文NLP任务上的表现优于最先进的模型,其英文版本在SuperGLUE基准测试(2021年7月3日)上取得了第一名,比人类表现高出了+0.8%(90.6%对89.8%)。
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 [1] and GPT-3 [2] have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE [3] benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).
https://weibo.com/1402400261/KobJY7zjM 
4、[LG] NeurIPS 2021 Competition proposal: The MineRL BASALT Competition on Learning from Human Feedback
R Shah, C Wild, S H. Wang, N Alex, B Houghton, W Guss, S Mohanty, A Kanervisto, S Milani, N Topin, P Abbeel, S Russell, A Dragan
[UC Berkeley & OpenAI & CMU]
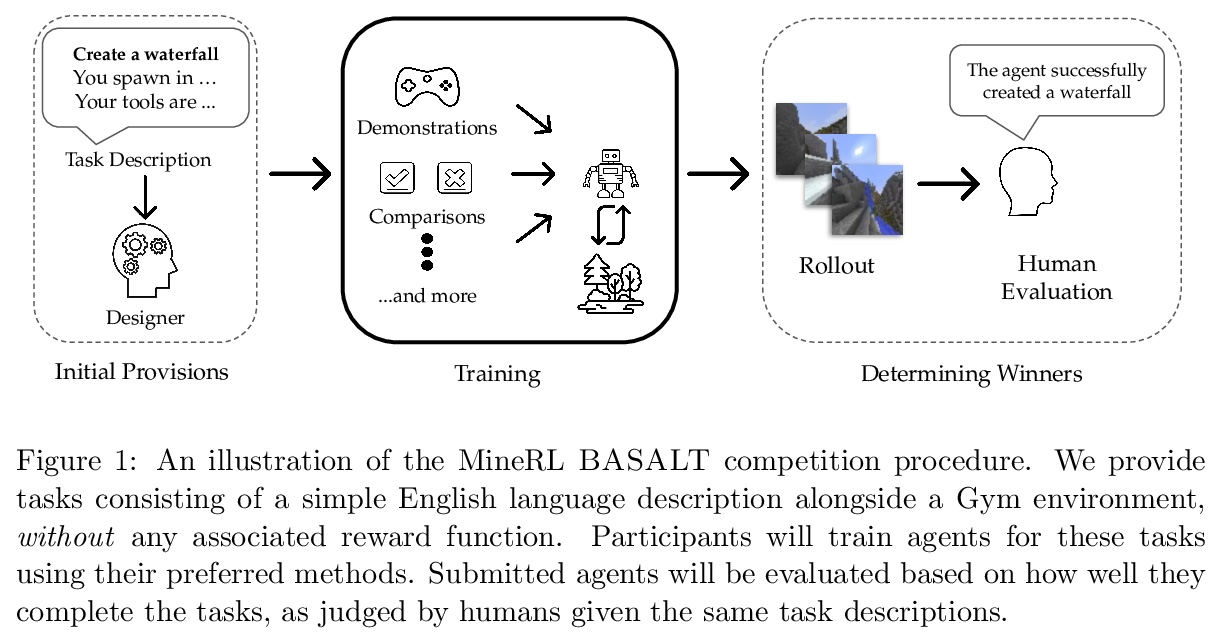
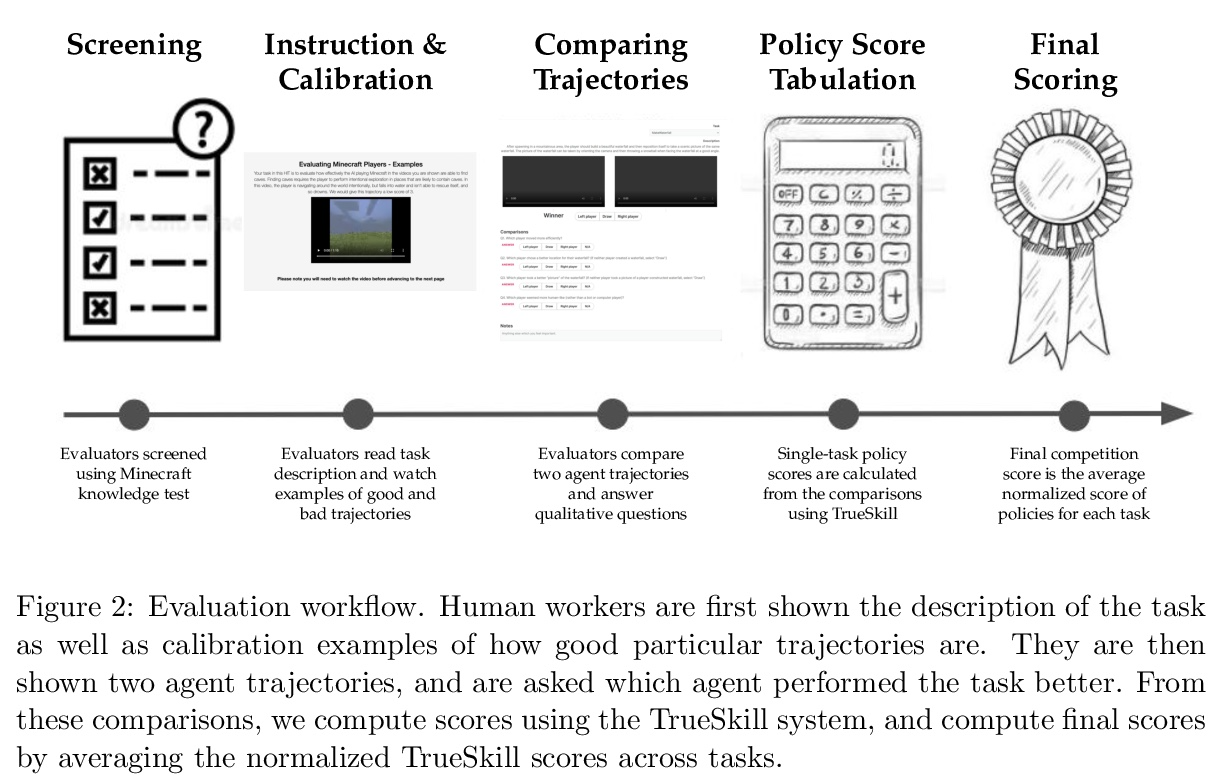
NeurIPS 2021比赛提案:从人类反馈中学习的MineRL BASALT比赛。过去的十年里,人们对深度学习研究的兴趣大大增加,许多公开的成功案例都证明了它的潜力。因此,这些系统现在正被纳入商业产品中。随之而来的是一个额外的挑战:如何建立人工智能系统,以解决那些没有明确的、定义清晰的规范的任务?虽然已经提出了多种解决方案,但在这次比赛中,特别关注一个问题:从人类反馈中学习。不使用预定的奖励函数或使用带有预定类别的标记数据集来训练人工智能系统,而是使用来自某种形式的人类反馈的学习信号来训练人工智能系统,这种信号可以随着对任务理解的变化或人工智能系统能力的提高而不断发展。MineRL BASALT竞赛旨在推动对这一重要技术类别的研究。在《Minecraft》中设计了一套四个任务,预计很难写出硬编码的奖励函数。这些任务由一段自然语言定义:例如,”创造一个瀑布并拍摄一张风景照片”,并有额外的澄清细节。参与者必须为每个任务训练一个单独的智能体,使用他们想=到的任何方法。然后由阅读过任务描述的人对智能体进行评估。为帮助参与者开始工作,提供了四个任务中每个任务的人类演示数据集,以及利用这些演示的模仿学习基线。
The last decade has seen a significant increase of interest in deep learning research, with many public successes that have demonstrated its potential. As such, these systems are now being incorporated into commercial products. With this comes an additional challenge: how can we build AI systems that solve tasks where there is not a crisp, well-defined specification? While multiple solutions have been proposed, in this competition we focus on one in particular: learning from human feedback. Rather than training AI systems using a predefined reward function or using a labeled dataset with a predefined set of categories, we instead train the AI system using a learning signal derived from some form of human feedback, which can evolve over time as the understanding of the task changes, or as the capabilities of the AI system improve. The MineRL BASALT competition aims to spur forward research on this important class of techniques. We design a suite of four tasks in Minecraft for which we expect it will be hard to write down hardcoded reward functions. These tasks are defined by a paragraph of natural language: for example, “create a waterfall and take a scenic picture of it”, with additional clarifying details. Participants must train a separate agent for each task, using any method they want. Agents are then evaluated by humans who have read the task description. To help participants get started, we provide a dataset of human demonstrations on each of the four tasks, as well as an imitation learning baseline that leverages these demonstrations.
https://weibo.com/1402400261/KobND0znL 
5、[LG] Universal Approximation of Functions on Sets
E Wagstaff, F B. Fuchs, M Engelcke, M A. Osborne, I Posner
[University of Oxford]
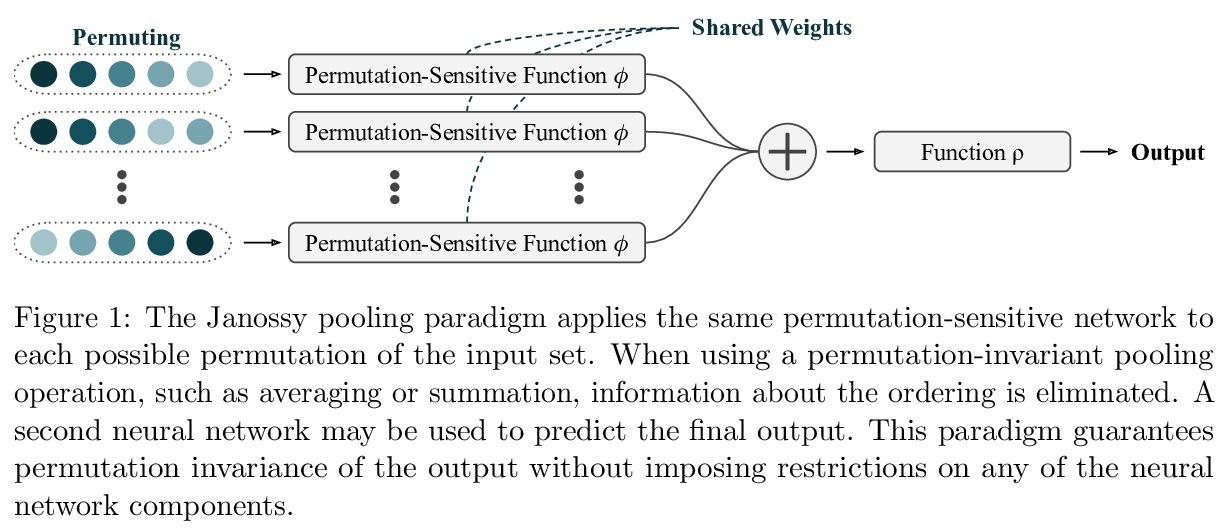
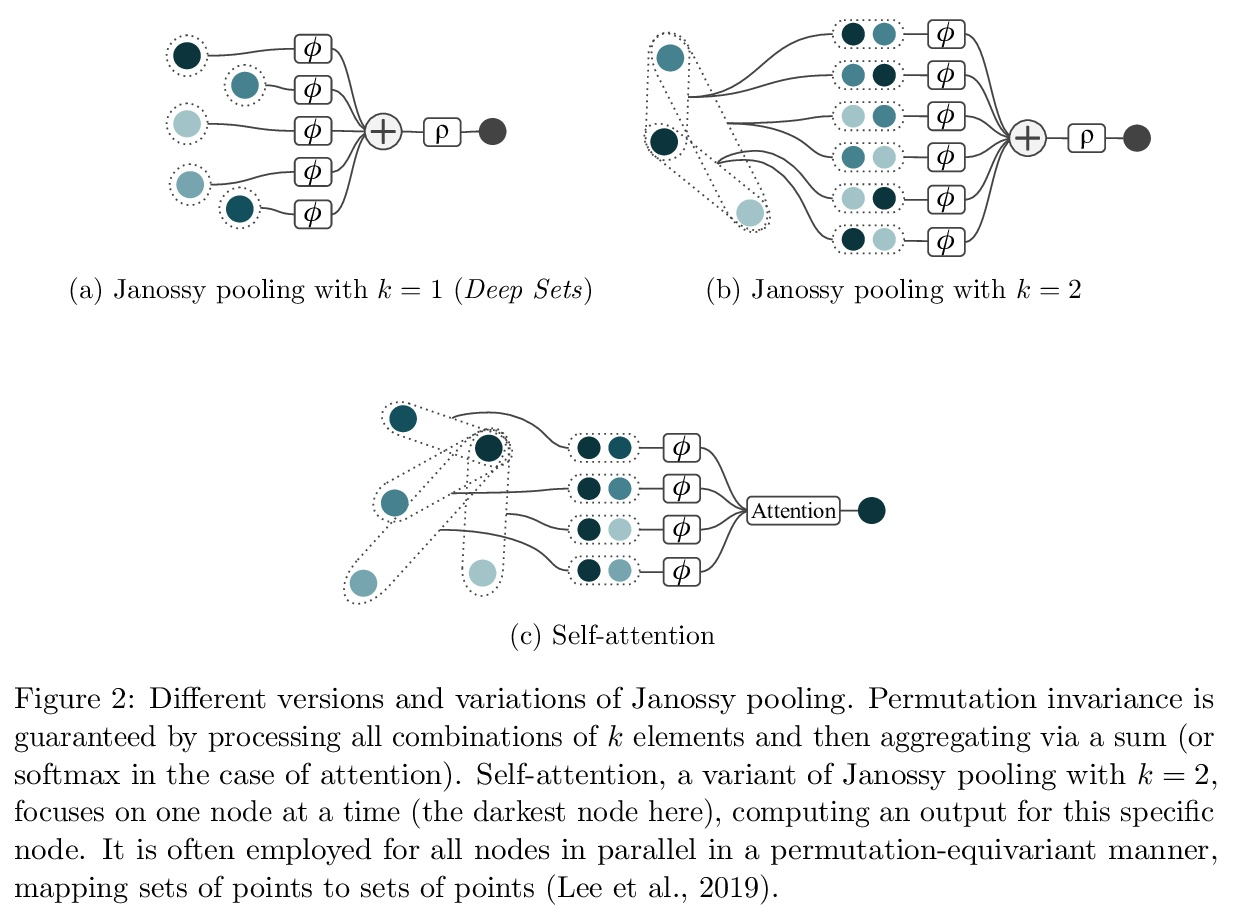
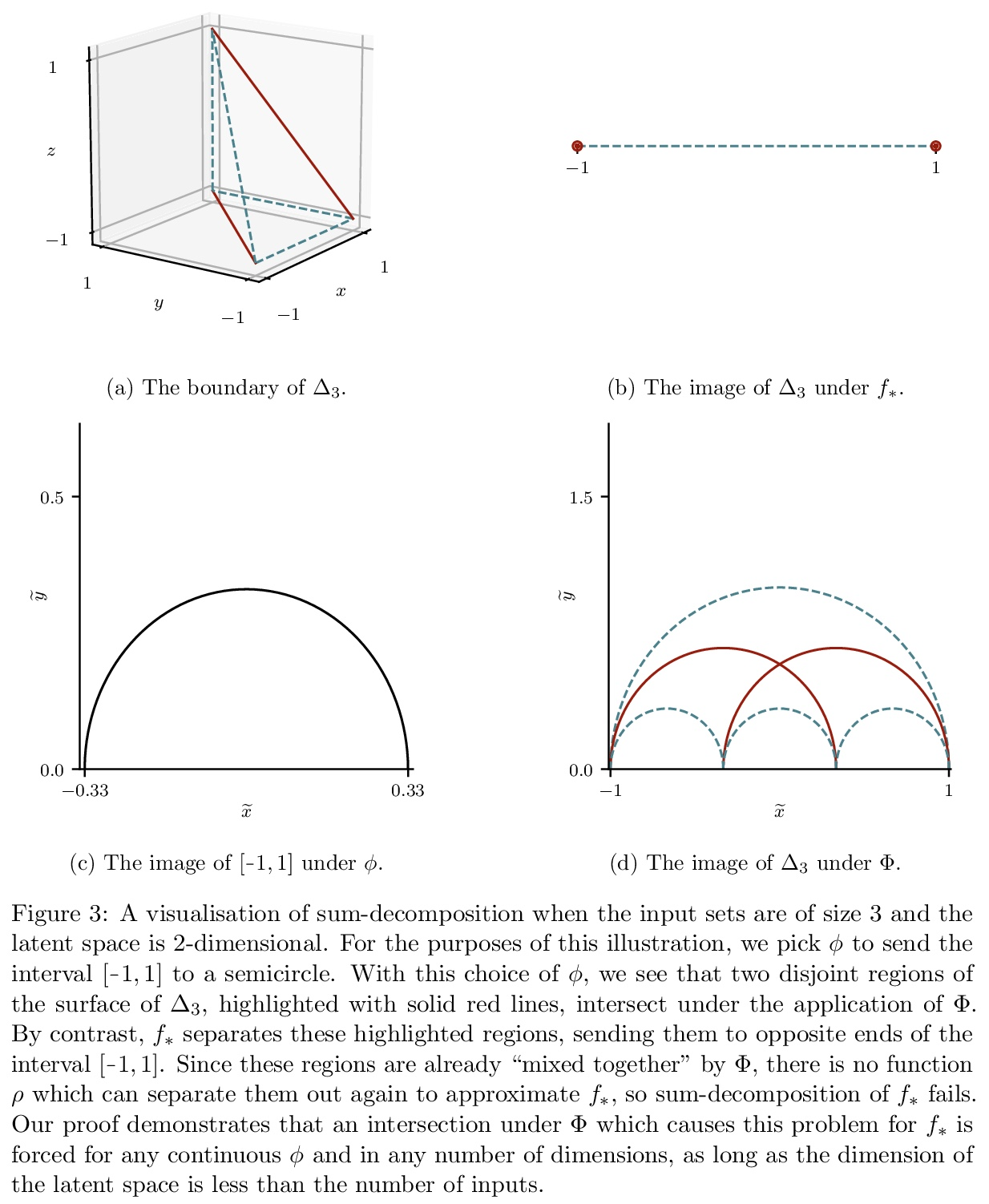
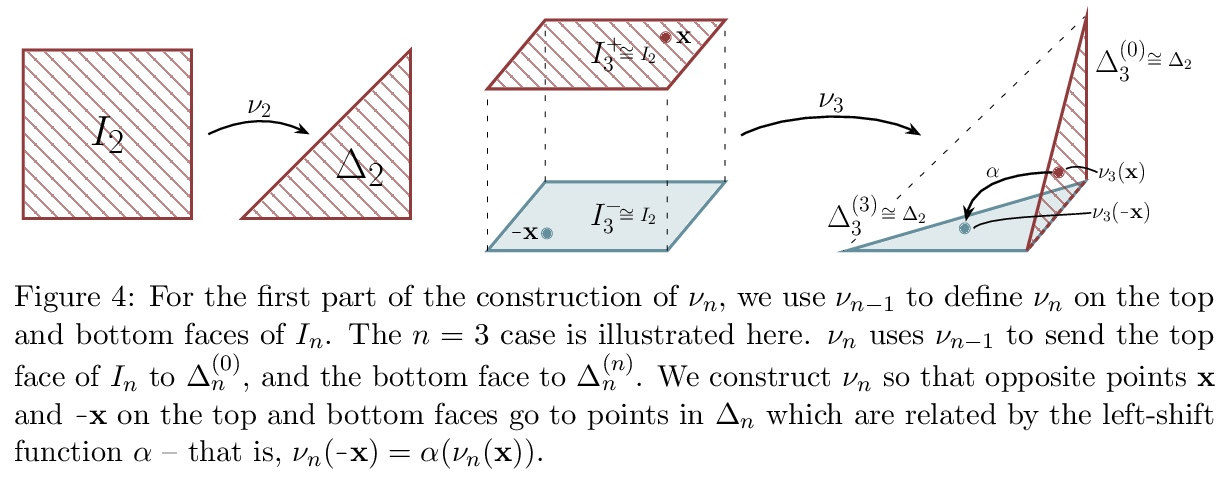
集合上函数的通用近似。集合上函数,或者置换不变函数的建模,是机器学习的一项长期挑战。Deep Sets是一种流行的方法,被认为是连续集合函数的通用近似器。本文对Deep Sets进行了理论分析,表明只有在模型的潜空间足够高维的情况下才能保证这种普遍的近似性。如果潜空间甚至比必要维度低一个维度,都会存在这样的分段仿射函数,根据最坏情况误差判断,Deep Sets的表现不会比näve常数基线好。Deep Sets可以被看作是Janossy pooling范式的最有效化身。本文认为该范式包含了目前最流行的集合学习方法。基于这种联系,讨论了本结果对集合学习更广泛的影响,并确定了一些关于Janossy集合的普遍开放问题。
Modelling functions of sets, or equivalently, permutation-invariant functions, is a longstanding challenge in machine learning. Deep Sets is a popular method which is known to be a universal approximator for continuous set functions. We provide a theoretical analysis of Deep Sets which shows that this universal approximation property is only guaranteed if the model’s latent space is sufficiently high-dimensional. If the latent space is even one dimension lower than necessary, there exist piecewise-affine functions for which Deep Sets performs no better than a näıve constant baseline, as judged by worst-case error. Deep Sets may be viewed as the most efficient incarnation of the Janossy pooling paradigm. We identify this paradigm as encompassing most currently popular set-learning methods. Based on this connection, we discuss the implications of our results for set learning more broadly, and identify some open questions on the universality of Janossy pooling in general.
https://weibo.com/1402400261/KobRCk2jL 
另外几篇值得关注的论文:
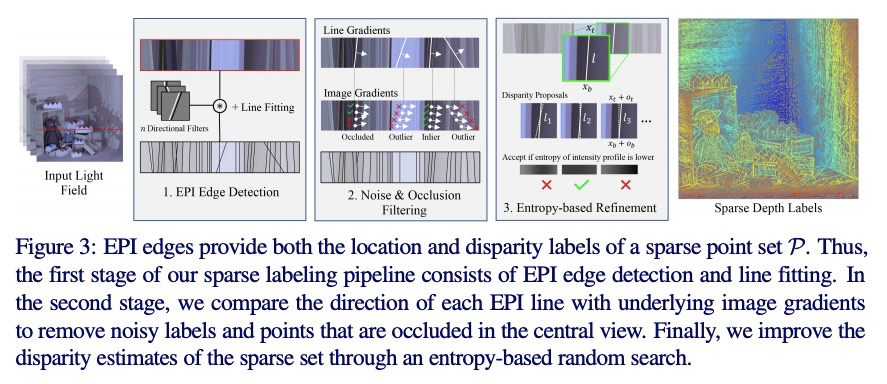
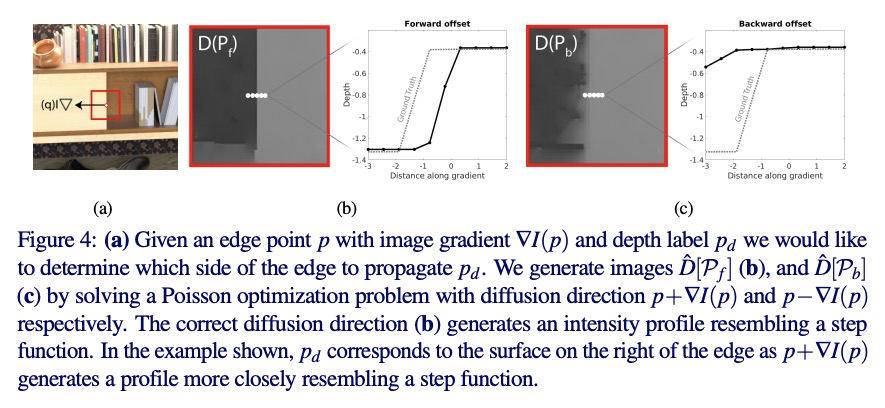
[CV] Edge-aware Bidirectional Diffusion for Dense Depth Estimation from Light Fields
面向光场密集深度估计的边缘感知双向扩散
N Khan, M H. Kim, J Tompkin
[Brown University & KAIST]
https://weibo.com/1402400261/Koc0a99oI 


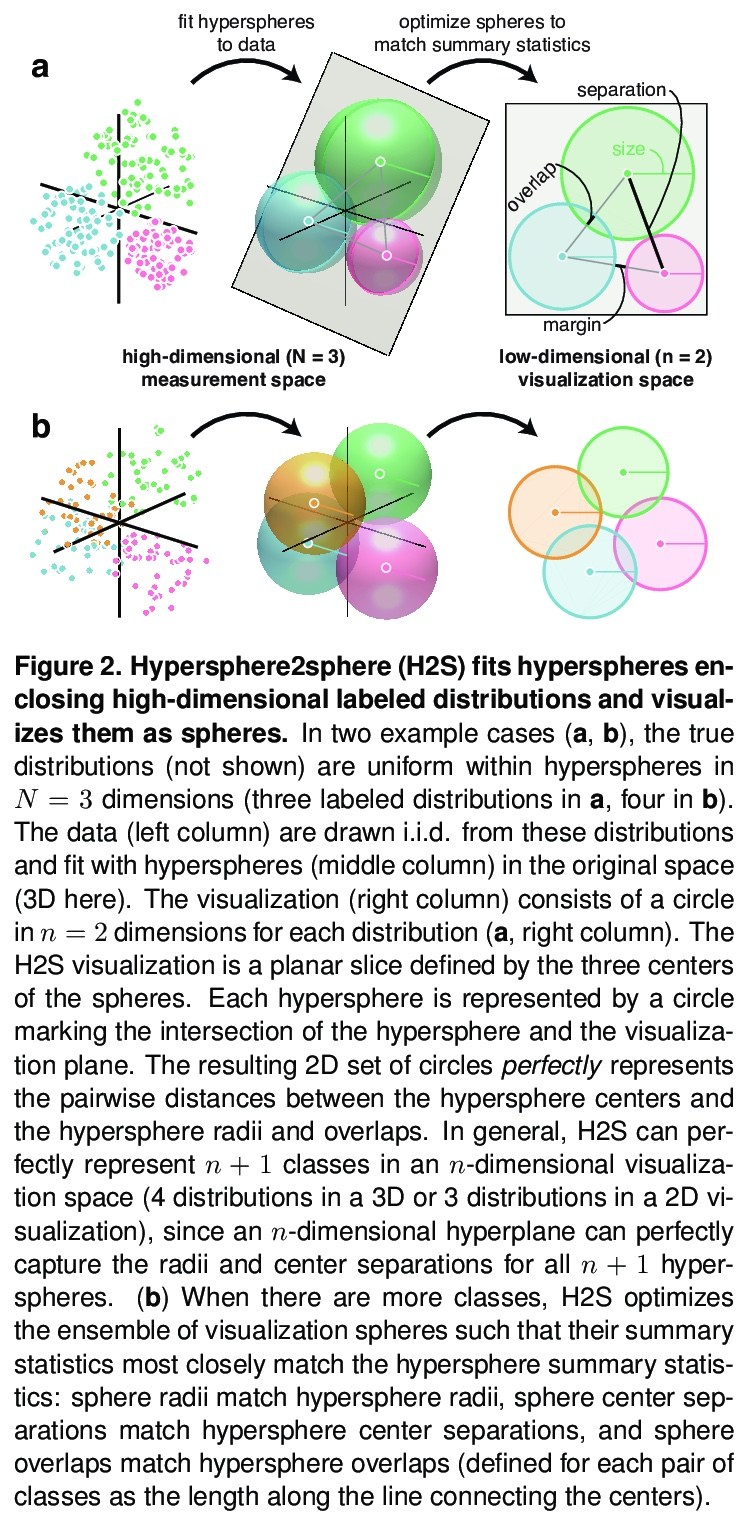
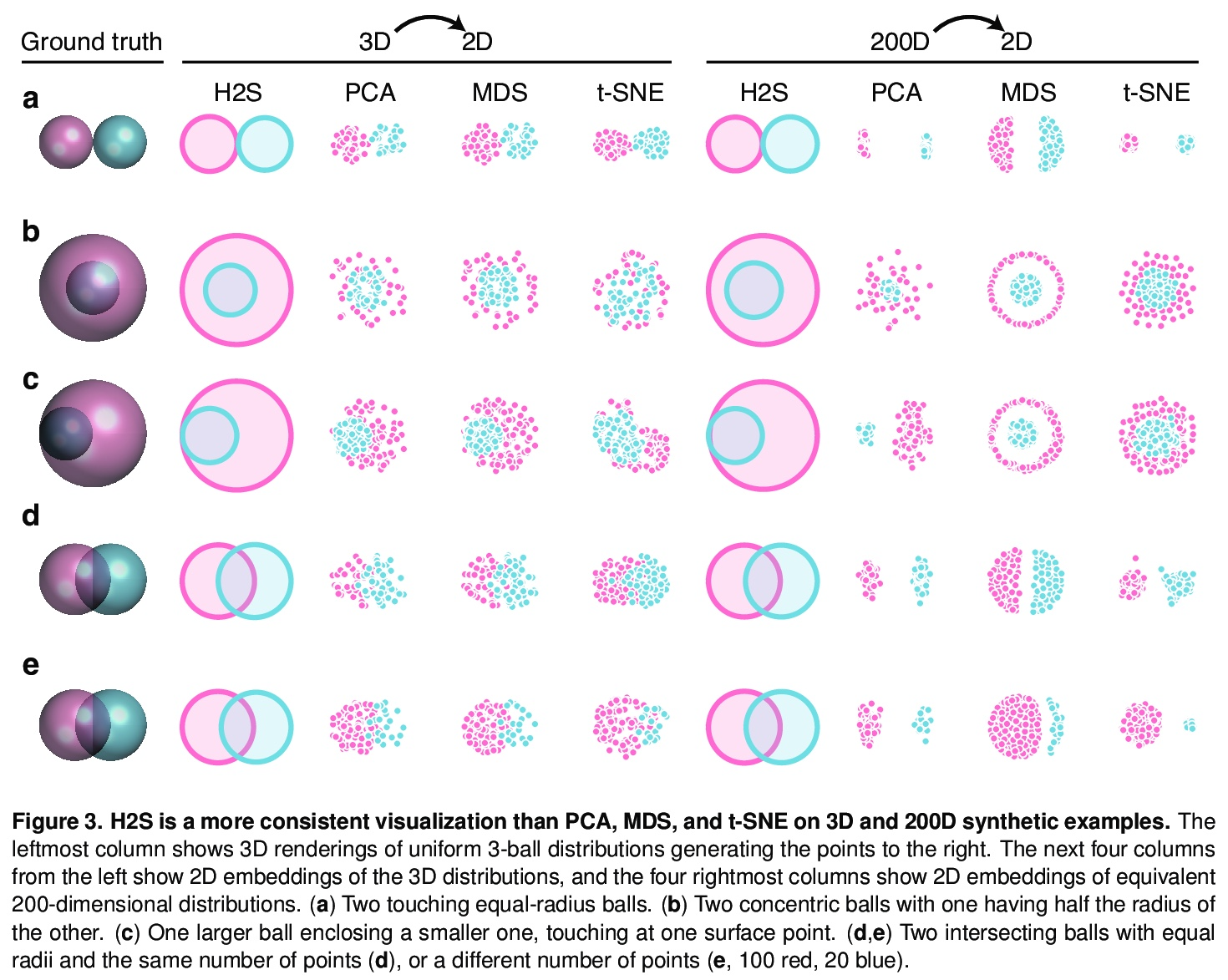
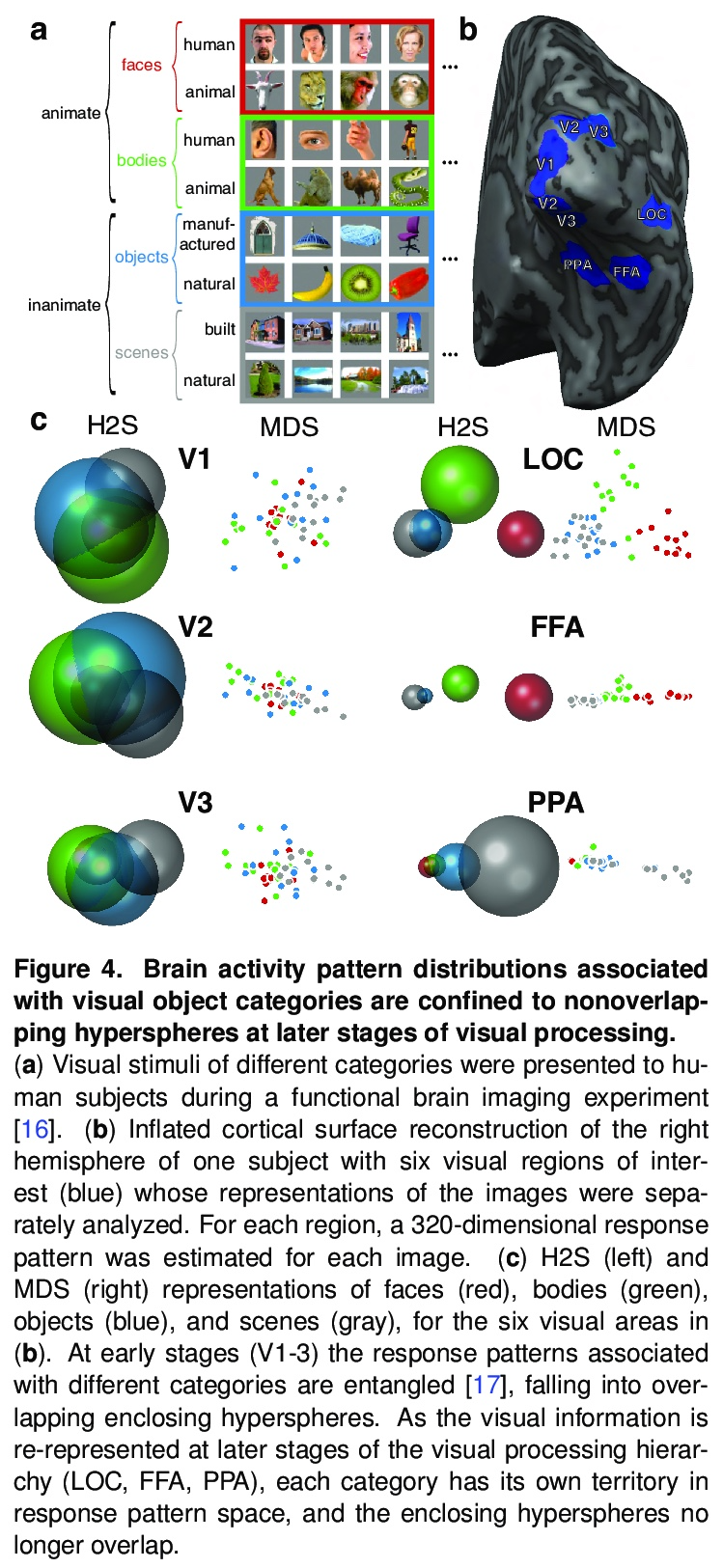
[LG] Visualizing the geometry of labeled high-dimensional data with spheres
已标记高维数据几何形状的球体可视化
A D Zaharia, A S Potnis, A Walther, N Kriegeskorte
[Columbia University & Realeyes]
https://weibo.com/1402400261/Koc3W8IRo 
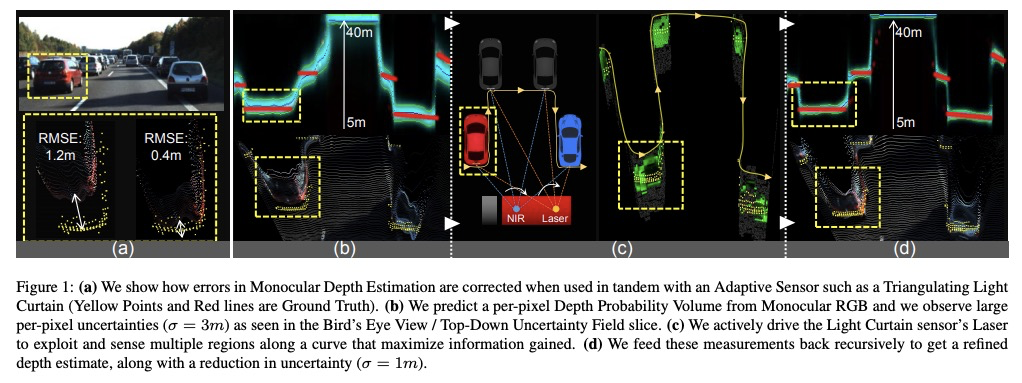
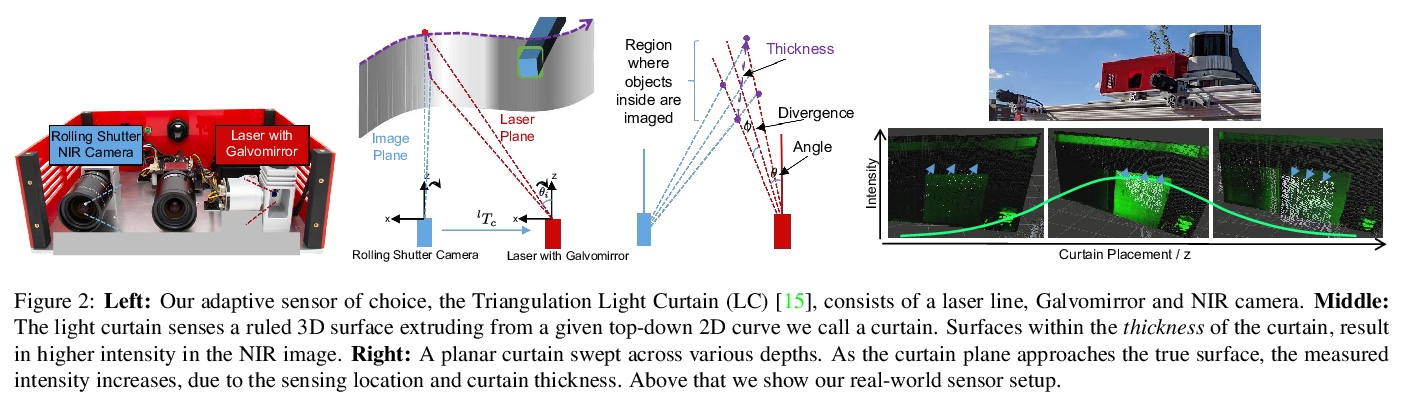
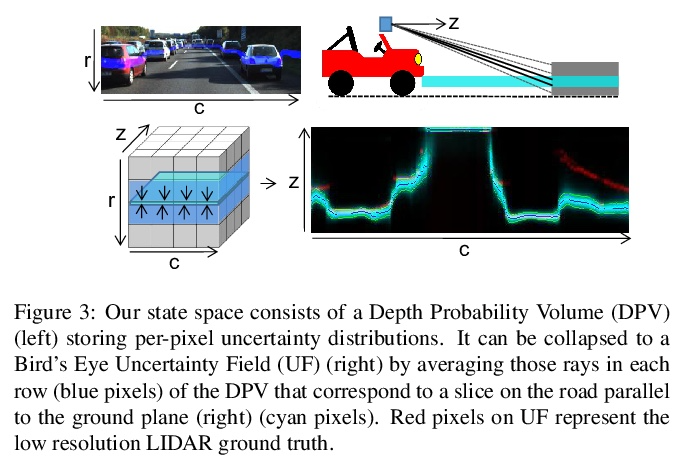
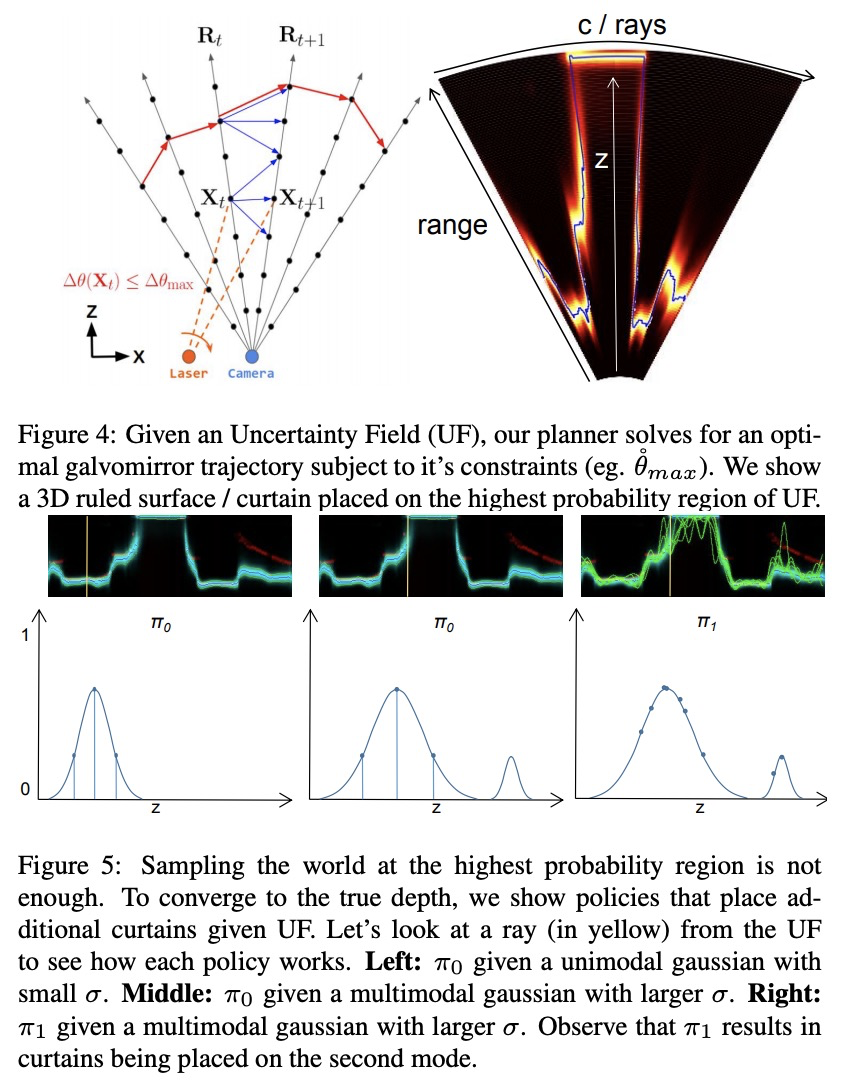
[CV] Exploiting & Refining Depth Distributions With Triangulation Light Curtains
利用三角光幕开发和改进深度分布
Y Raaj, S Ancha, R Tamburo, D Held, SG Narasimhan
[CMU]
https://weibo.com/1402400261/Koc65cwlm 
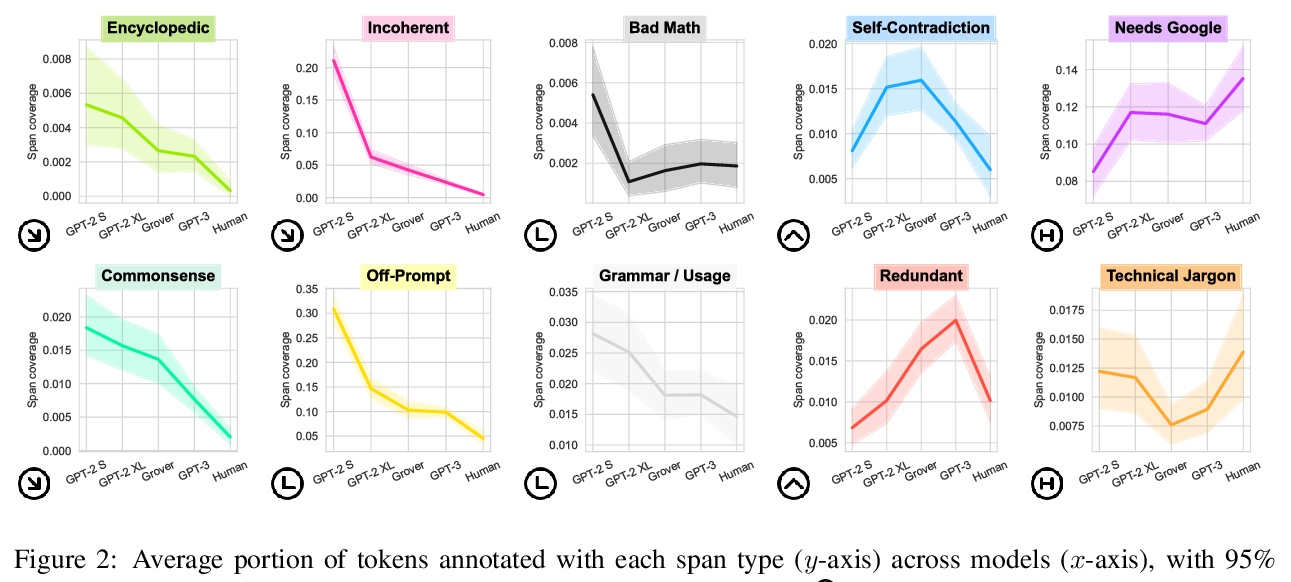
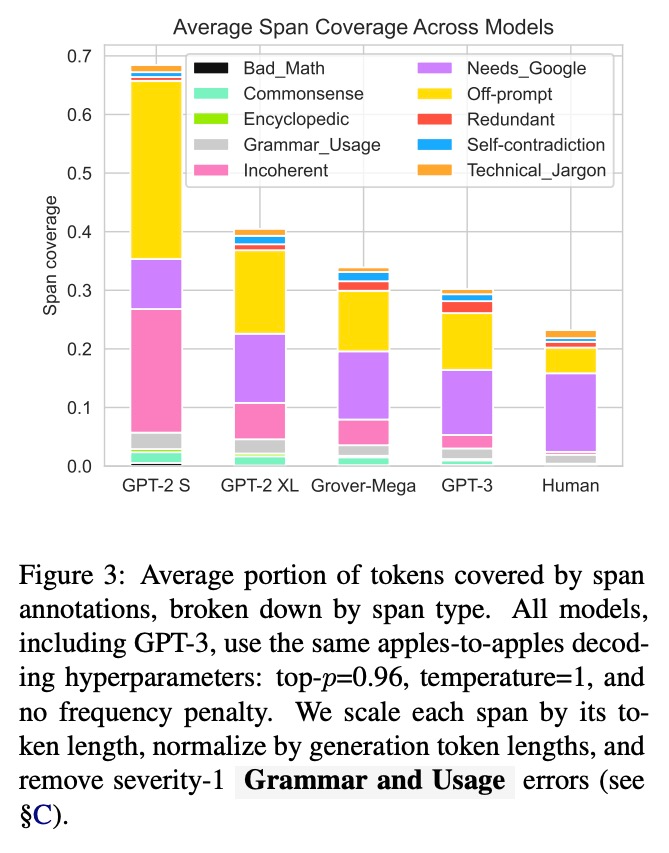
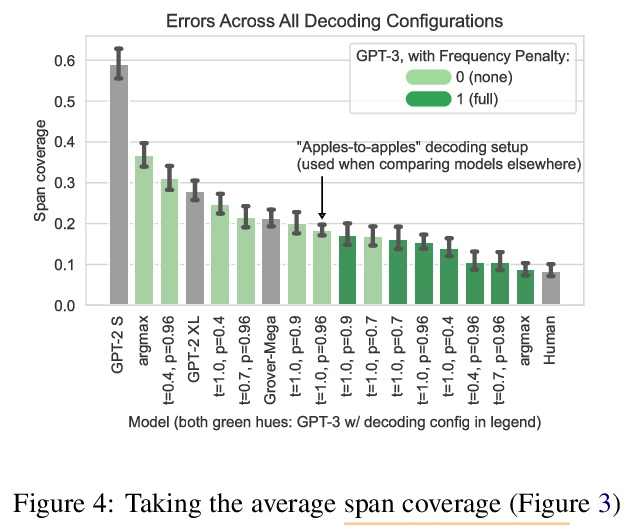
[CL] Scarecrow: A Framework for Scrutinizing Machine Text
Scarecrow:机器文本审查框架
Y Dou, M Forbes, R Koncel-Kedziorski, N A. Smith, Y Choi
[University of Washington]
https://weibo.com/1402400261/Koc8c1f2y 


若有收获,就点个赞吧
0 人点赞
