- 1、[CV] Learning to Resize Images for Computer Vision Tasks
- 2、[CV] FastNeRF: High-Fidelity Neural Rendering at 200FPS
- 3、[LG] Requirement Engineering Challenges for AI-intense Systems Development
- 4、[CV] Large Scale Image Completion via Co-Modulated Generative Adversarial Networks
- 5、[CV] Using latent space regression to analyze and leverage compositionality in GANs
- [CL] All NLP Tasks Are Generation Tasks: A General Pretraining Framework
- [CL] GPT Understands, Too
- [CL] Situated Language Learning via Interactive Narratives
- [CV] Neural Parts: Learning Expressive 3D Shape Abstractions with Invertible Neural Networks
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] Learning to Resize Images for Computer Vision Tasks
H Talebi, P Milanfar
[Google Research]
面向计算机视觉任务的图像缩放学习。提出一种专注于调整图像大小的预处理效果学习框架,以提升图像识别模型性能,该框架不受任何像素或感知损失限制,其结果呈现出不同于传统图像处理和超分辨率结果的机器自适应视觉效果。典型的线性缩放器可以用学习得到的缩放器替代,可大幅提高性能。虽然经典的缩放器通常会得到更好的降级图像感知质量,而学习型缩放器不一定能提供更好的视觉质量,但其反而能提高任务性能。将缩放器与各种分类模型进行了匹配,表明其能有效适应各模型,并持续改进基线图像分类器。所提缩放器模型允许在任意缩放因子下对图像进行降维,可方便地搜索底层任务的最优分辨率。将所提缩放器扩展到图像质量评价(IQA),表明其可成功适应该任务。
For all the ways convolutional neural nets have revolutionized computer vision in recent years, one important aspect has received surprisingly little attention: the effect of image size on the accuracy of tasks being trained for. Typically, to be efficient, the input images are resized to a relatively small spatial resolution (e.g. 224x224), and both training and inference are carried out at this resolution. The actual mechanism for this re-scaling has been an afterthought: Namely, off-the-shelf image resizers such as bilinear and bicubic are commonly used in most machine learning software frameworks. But do these resizers limit the on task performance of the trained networks? The answer is yes. Indeed, we show that the typical linear resizer can be replaced with learned resizers that can substantially improve performance. Importantly, while the classical resizers typically result in better perceptual quality of the downscaled images, our proposed learned resizers do not necessarily give better visual quality, but instead improve task performance. Our learned image resizer is jointly trained with a baseline vision model. This learned CNN-based resizer creates machine friendly visual manipulations that lead to a consistent improvement of the end task metric over the baseline model. Specifically, here we focus on the classification task with the ImageNet dataset, and experiment with four different models to learn resizers adapted to each model. Moreover, we show that the proposed resizer can also be useful for fine-tuning the classification baselines for other vision tasks. To this end, we experiment with three different baselines to develop image quality assessment (IQA) models on the AVA dataset.
https://weibo.com/1402400261/K70dQ6K0c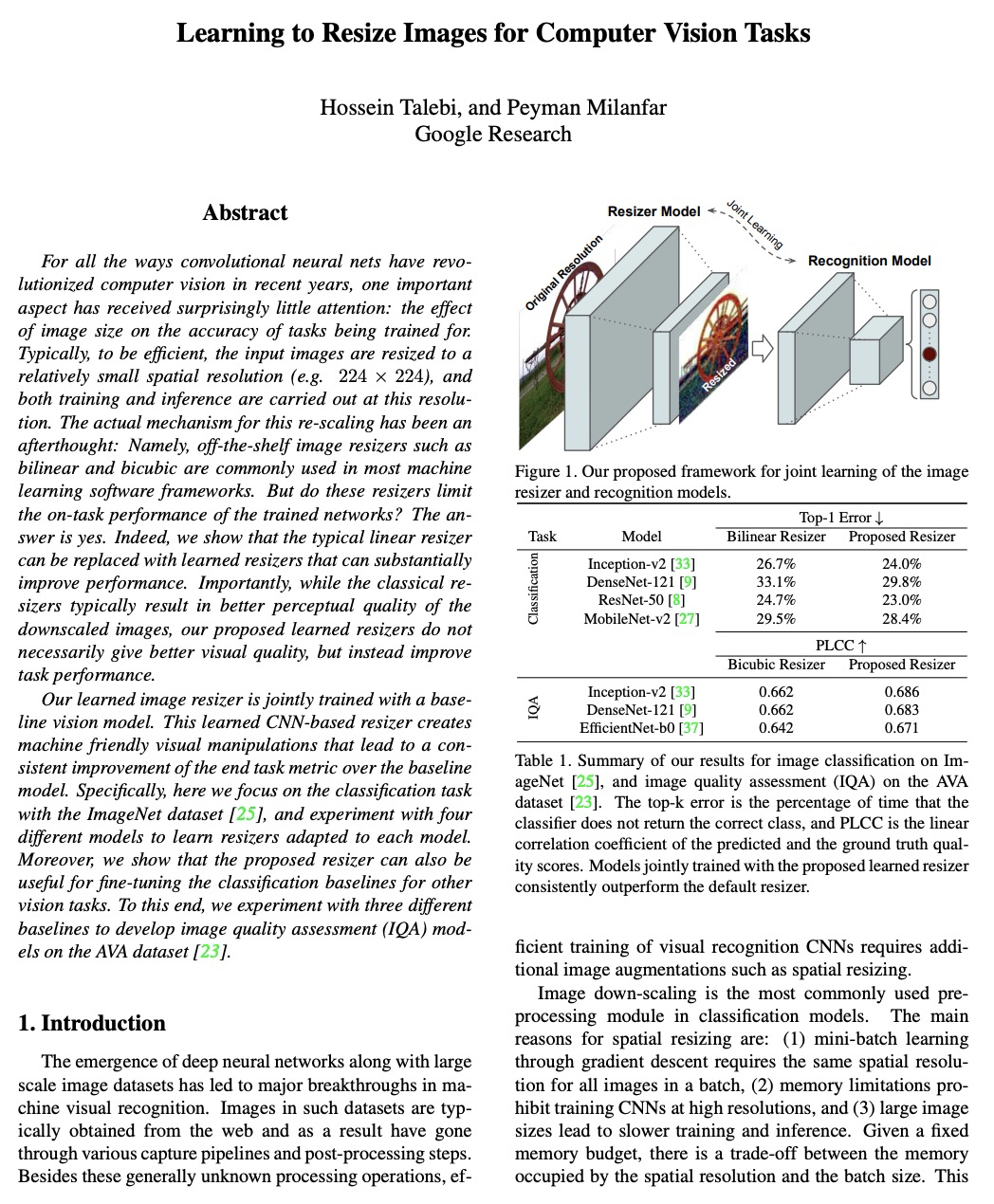


2、[CV] FastNeRF: High-Fidelity Neural Rendering at 200FPS
S J. Garbin, M Kowalski, M Johnson, J Shotton, J Valentin
[Microsoft]
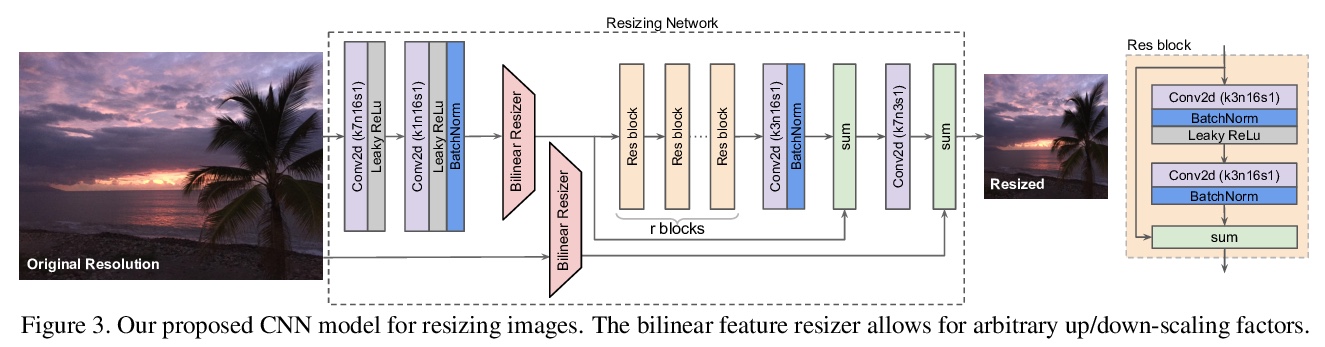
FastNeRF:200FPS的高保真神经渲染。提出NeRF的一种新型扩展FastNeRF,可在高端消费级GPU上以200Hz甚至更高的速度渲染照片级逼真图像。通过对其函数逼近器进行因子化,实现了使渲染受内存约束而非计算约束的缓存策略,实现了相对NeRF和竞争方法的显著加速,使得NeRF可应用于实时场景。实验表明,所提方法比原来的NeRF算法快3000倍,比现有加速NeRF的工作至少快一个数量级,同时保持了视觉质量和可扩展性。
Recent work on Neural Radiance Fields (NeRF) showed how neural networks can be used to encode complex 3D environments that can be rendered photorealistically from novel viewpoints. Rendering these images is very computationally demanding and recent improvements are still a long way from enabling interactive rates, even on high-end hardware. Motivated by scenarios on mobile and mixed reality devices, we propose FastNeRF, the first NeRF-based system capable of rendering high fidelity photorealistic images at 200Hz on a high-end consumer GPU. The core of our method is a graphics-inspired factorization that allows for (i) compactly caching a deep radiance map at each position in space, (ii) efficiently querying that map using ray directions to estimate the pixel values in the rendered image. Extensive experiments show that the proposed method is 3000 times faster than the original NeRF algorithm and at least an order of magnitude faster than existing work on accelerating NeRF, while maintaining visual quality and extensibility.
https://weibo.com/1402400261/K70jOnVas

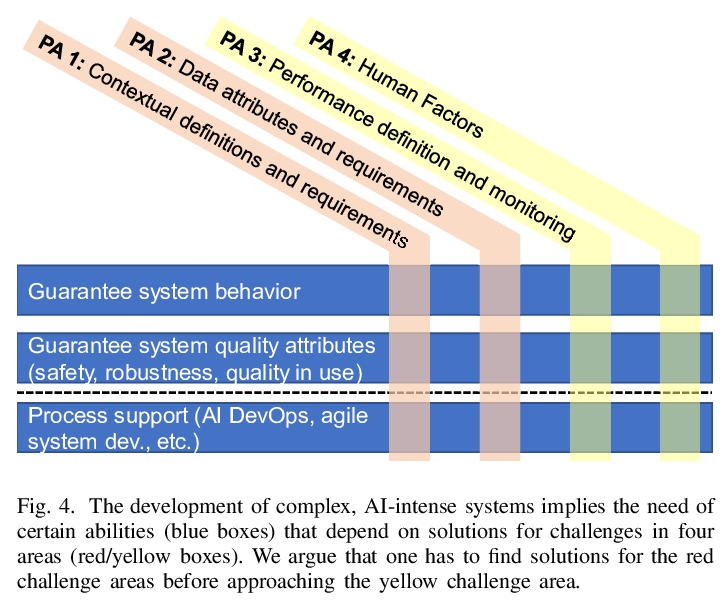
3、[LG] Requirement Engineering Challenges for AI-intense Systems Development
H Heyn, E Knauss, A P Muhammad, O Erikssonz, J Linder, P Subbiah, S K Pradhan, S Tungal
[University of Gothenburg & Veoneer Sweden AB]
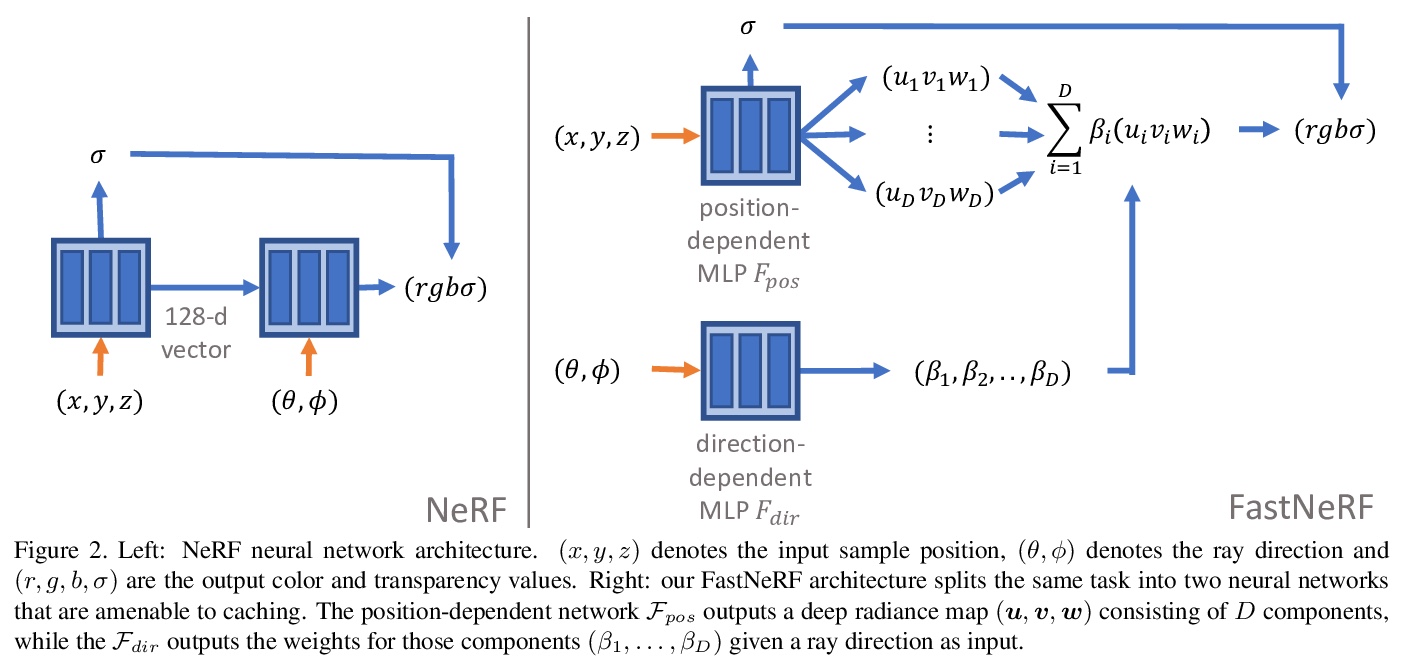
AI密集型系统开发的需求工程挑战。强大的计算和通信技术的存在,以及AI的进步,使得新一代复杂的AI密集型系统和应用成为可能。这些系统和应用有望在社会层面带来令人振奋的进步,但也为其发展带来了新的挑战。重大的挑战与定义和确保此类系统和应用的行为和质量属性有关。本文旨在介绍最近启动的VEDLIoT项目中需求和系统工程研究的初步路线图,从与工业、交通和家庭自动化相关的复杂、AI密集型系统和应用的相关使用案例中具体推导出四个挑战领域:理解、确定和指定(一)场景定义和需求,(二)数据属性和需求,(三)性能定义和监控,以及(四)人为因素对系统验收和成功的影响。解决这些挑战意味着将新的需求工程方法集成到复杂的、AI密集型系统和应用的开发方法中的过程支持。本文详细介绍了这些挑战,并提出了研究路线图。
Availability of powerful computation and communication technology as well as advances in artificial intelligence enable a new generation of complex, AI-intense systems and applications. Such systems and applications promise exciting improvements on a societal level, yet they also bring with them new challenges for their development. In this paper we argue that significant challenges relate to defining and ensuring behaviour and quality attributes of such systems and applications. We specifically derive four challenge areas from relevant use cases of complex, AI-intense systems and applications related to industry, transportation, and home automation: understanding, determining, and specifying (i) contextual definitions and requirements, (ii) data attributes and requirements, (iii) performance definition and monitoring, and (iv) the impact of human factors on system acceptance and success. Solving these challenges will imply process support that integrates new requirements engineering methods into development approaches for complex, AI-intense systems and applications. We present these challenges in detail and propose a research roadmap.
https://weibo.com/1402400261/K70neh9cc


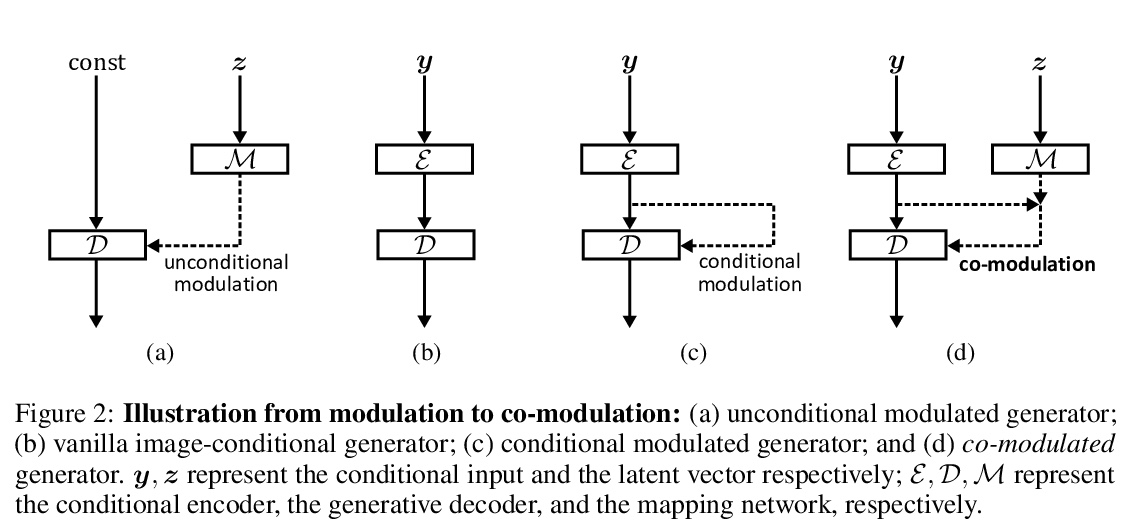
4、[CV] Large Scale Image Completion via Co-Modulated Generative Adversarial Networks
S Zhao, J Cui, Y Sheng, Y Dong, X Liang, E I Chang, Y Xu
[Tsinghua University & Vacaville Christian Schools & The High School Affiliated to Renmin University of China & Microsoft Research & Beihang University]
基于同调生成对抗网络的大规模图像补全。提出了同调生成对抗网络,一种通用的新方法,通过对条件和随机风格表示的共同调制,弥补了图像条件和最近调制的无条件生成架构之间的差距。提出了新的配对/非配对感知判别得分(P-IDS/U-IDS),通过特征空间的线性可分离性,鲁棒地衡量补全画像与真实图像相比的感知保真度。实验表明,在自由形式的图像补全方面,无论在质量还是多样性方面,都比最先进的方法性能优越,且易于推广到图像到图像变换。
Numerous task-specific variants of conditional generative adversarial networks have been developed for image completion. Yet, a serious limitation remains that all existing algorithms tend to fail when handling large-scale missing regions. To overcome this challenge, we propose a generic new approach that bridges the gap between image-conditional and recent modulated unconditional generative architectures via co-modulation of both conditional and stochastic style representations. Also, due to the lack of good quantitative metrics for image completion, we propose the new Paired/Unpaired Inception Discriminative Score (P-IDS/U-IDS), which robustly measures the perceptual fidelity of inpainted images compared to real images via linear separability in a feature space. Experiments demonstrate superior performance in terms of both quality and diversity over state-of-the-art methods in free-form image completion and easy generalization to image-to-image translation. Code is available at > this https URL.
https://weibo.com/1402400261/K70sA7to6

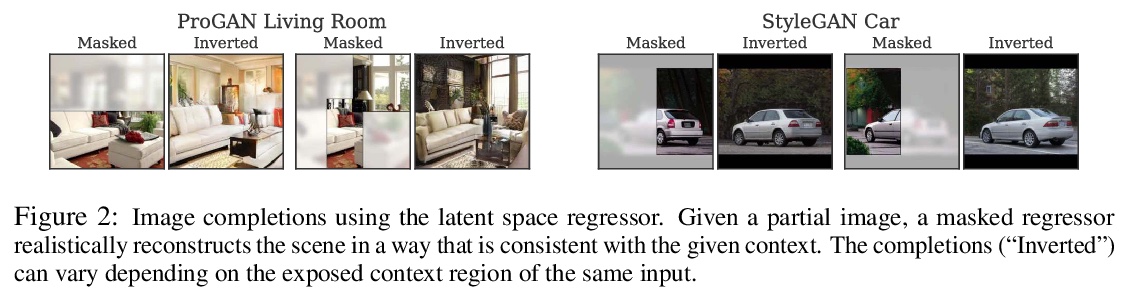
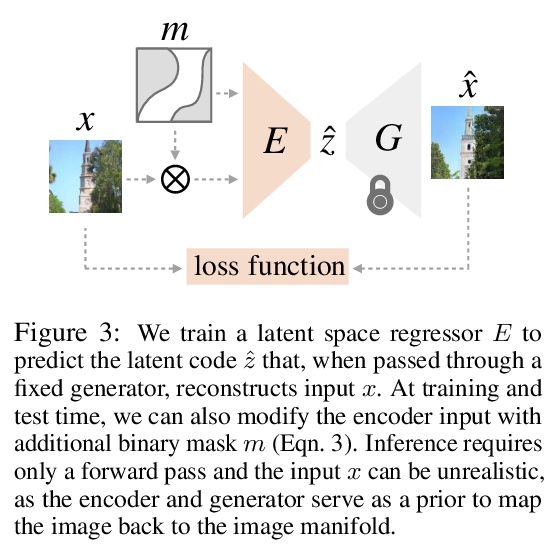
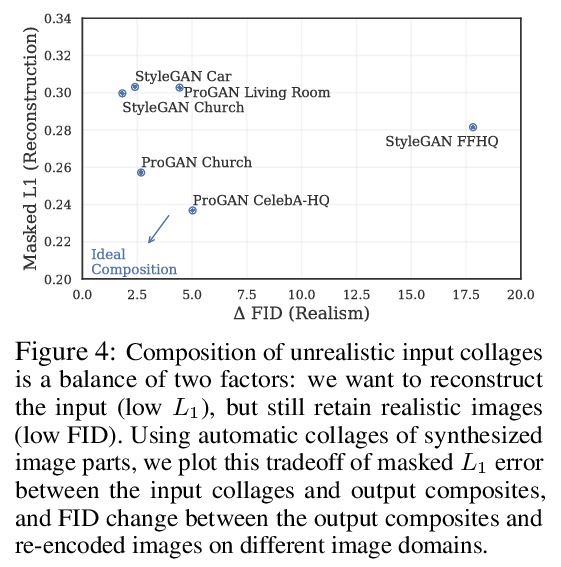
5、[CV] Using latent space regression to analyze and leverage compositionality in GANs
L Chai, J Wulff, P Isola
[MIT CSAIL]
基于潜空间回归的GAN合成性分析和利用。研究将潜空间回归作为理解GAN合成属性的探针,提出了一种潜回归模型,可学习在不完整图像和缺失像素的情况下进行图像重建,并表明回归器和生成器的组合形成了一个强大的图像先验,能在推理时从随机图像部分的图块中创建复合图像,并保持全局一致性。生成器的表示在潜代码中已经是合成性的,与在潜空间中直接编辑相比,回归方法能对单个图像部分进行更本地化的编辑。
In recent years, Generative Adversarial Networks have become ubiquitous in both research and public perception, but how GANs convert an unstructured latent code to a high quality output is still an open question. In this work, we investigate regression into the latent space as a probe to understand the compositional properties of GANs. We find that combining the regressor and a pretrained generator provides a strong image prior, allowing us to create composite images from a collage of random image parts at inference time while maintaining global consistency. To compare compositional properties across different generators, we measure the trade-offs between reconstruction of the unrealistic input and image quality of the regenerated samples. We find that the regression approach enables more localized editing of individual image parts compared to direct editing in the latent space, and we conduct experiments to quantify this independence effect. Our method is agnostic to the semantics of edits, and does not require labels or predefined concepts during training. Beyond image composition, our method extends to a number of related applications, such as image inpainting or example-based image editing, which we demonstrate on several GANs and datasets, and because it uses only a single forward pass, it can operate in real-time. Code is available on our project page: > this https URL.
https://weibo.com/1402400261/K70wUF92m

另外几篇值得关注的论文;
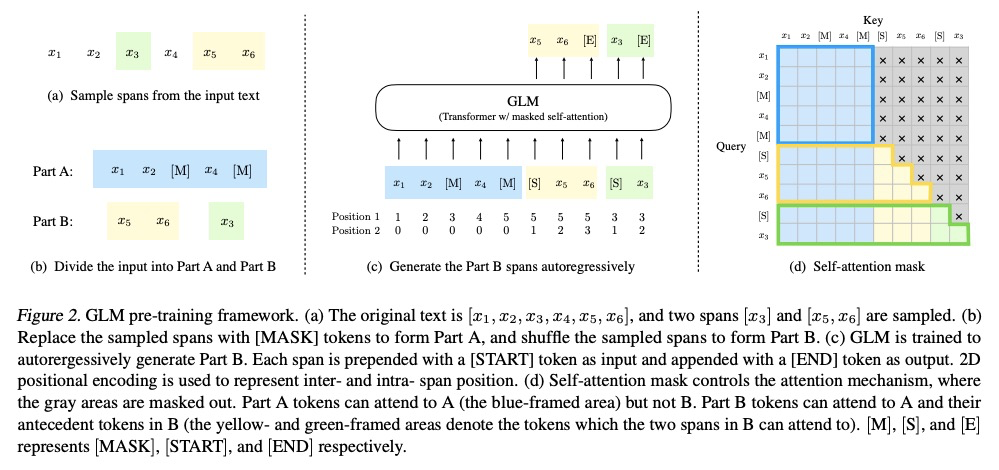
[CL] All NLP Tasks Are Generation Tasks: A General Pretraining Framework
所有NLP任务都是生成任务:一个通用的预处理框架
Z Du, Y Qian, X Liu, M Ding, J Qiu, Z Yang, J Tang
[Tsinghua Univerisity & Recurrent AI]
https://weibo.com/1402400261/K70D5jVrv
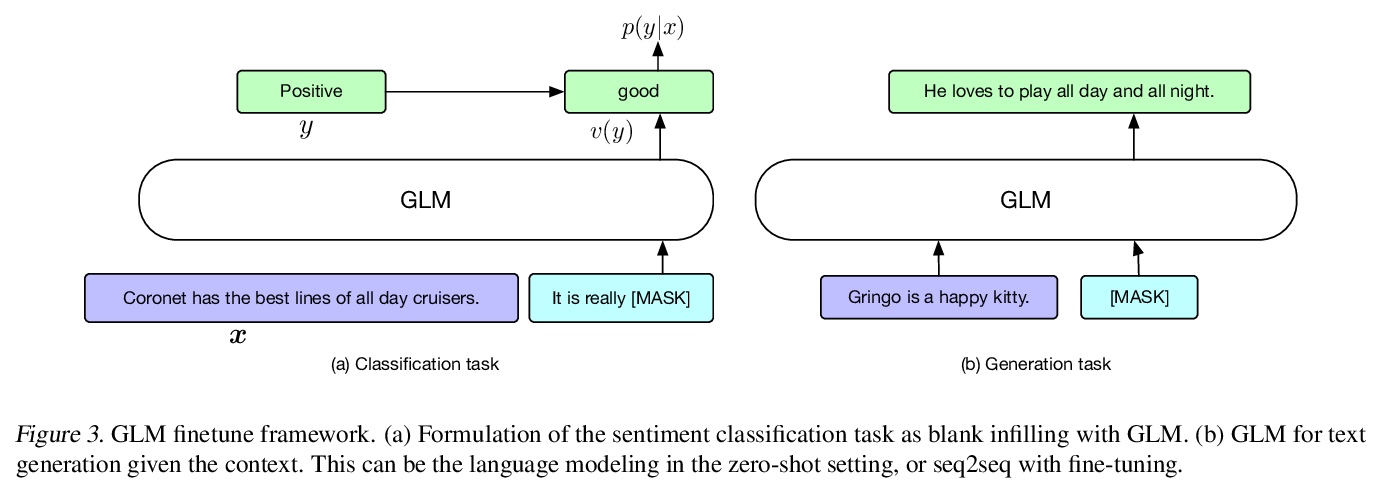
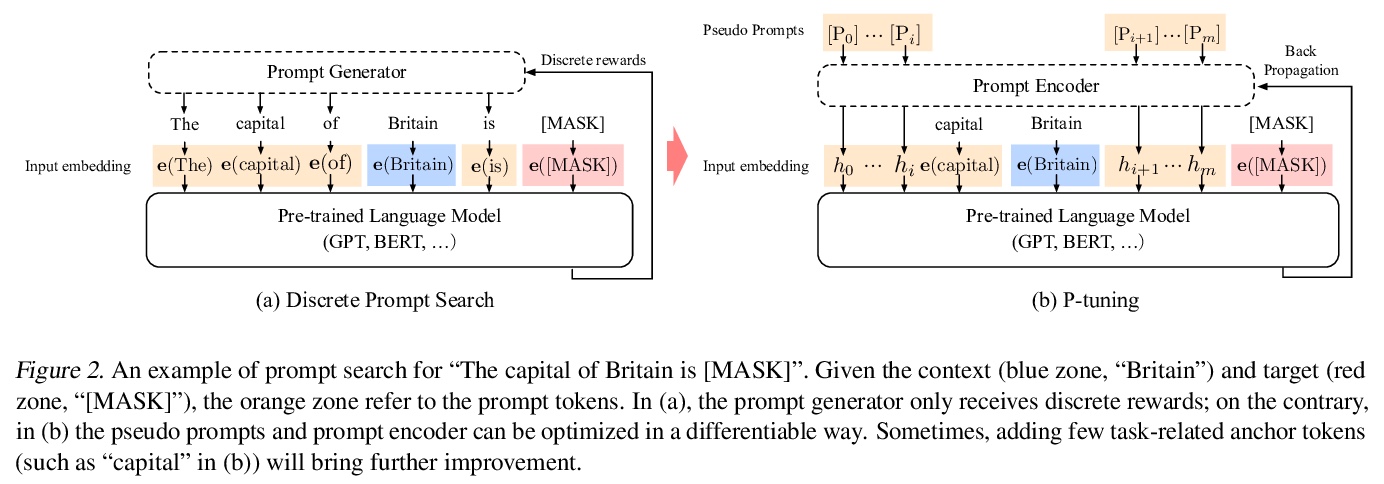
[CL] GPT Understands, Too
GPT在自然语言理解方面同样具有竞争力
X Liu, Y Zheng, Z Du, M Ding, Y Qian, Z Yang, J Tang
[Tsinghua University & MIT & Recurrent AI]
https://weibo.com/1402400261/K70FgpBoW
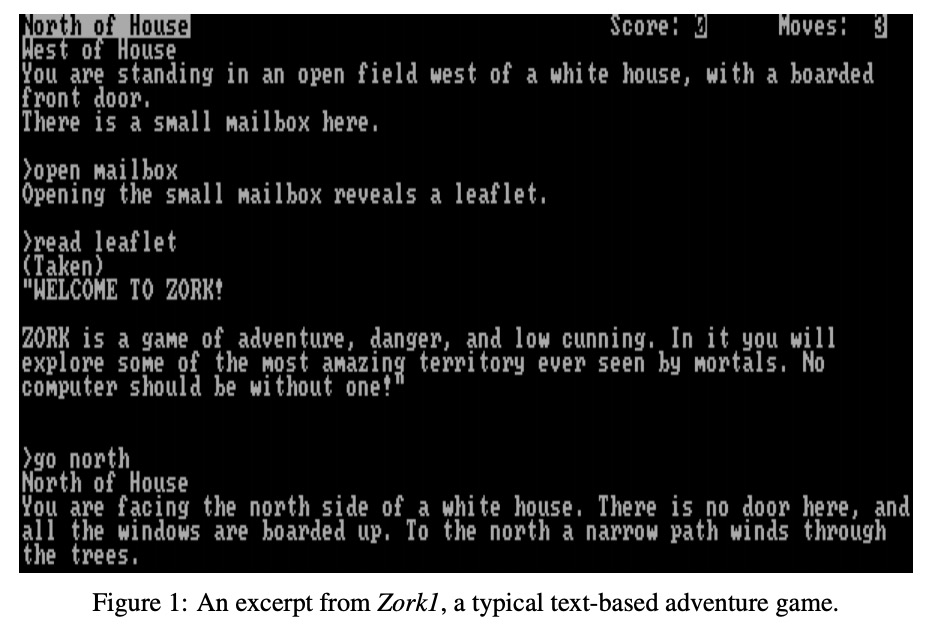
[CL] Situated Language Learning via Interactive Narratives
通过交互叙事进行情境语言学习
P Ammanabrolu, M O. Riedl
[Georgia Institute of Technology]
https://weibo.com/1402400261/K70Js6FAt


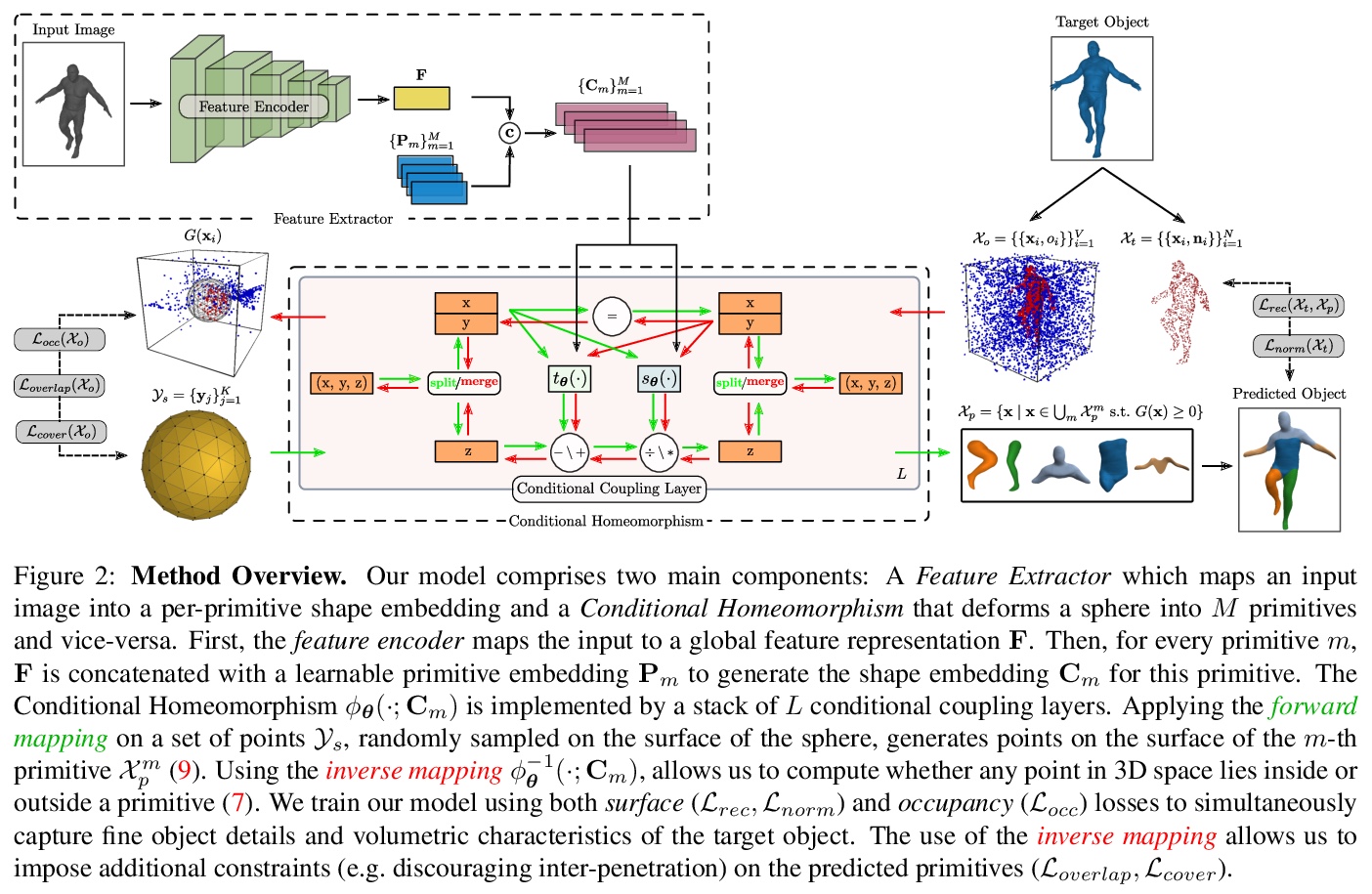
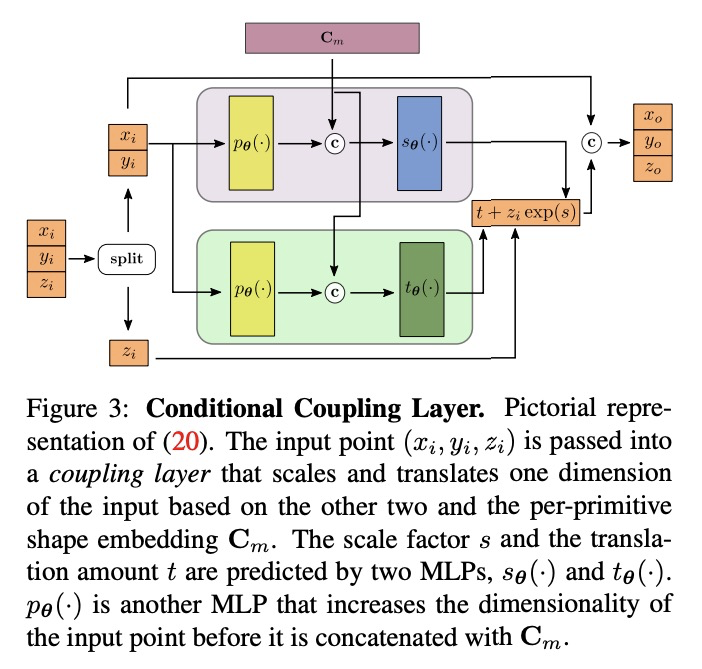
[CV] Neural Parts: Learning Expressive 3D Shape Abstractions with Invertible Neural Networks
Neural Parts:基于可逆神经网络的三维形状抽象表达学习
D Paschalidou, A Katharopoulos, A Geiger, S Fidler
[Max Planck Institute for Intelligent Systems Tubingen & Idiap Research Institute & NVIDIA]
https://weibo.com/1402400261/K70OTh5g8

若有收获,就点个赞吧
0 人点赞
