- 1、[LG] DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons
- 2、[CV] Face, Body, Voice: Video Person-Clustering with Multiple Modalities
- 3、[LG] How Many Data Points is a Prompt Worth?
- 4、[LG] Protein sequence-to-structure learning: Is this the end(-to-end revolution)?
- 5、[AI] A Measure of Research Taste
- [CV] NeuroGen: activation optimized image synthesis for discovery neuroscience
- [CV] dualFace:Two-Stage Drawing Guidance for Freehand Portrait Sketching
- [LG] Tensor Programs IIb: Architectural Universality of Neural Tangent Kernel Training Dynamics
- [AS] Differentiable Signal Processing With Black-Box Audio Effects
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
1、[LG] DeepDebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons
D Drain, C B. Clement, G Serrato, N Sundaresan
[Microsoft Cloud and AI]
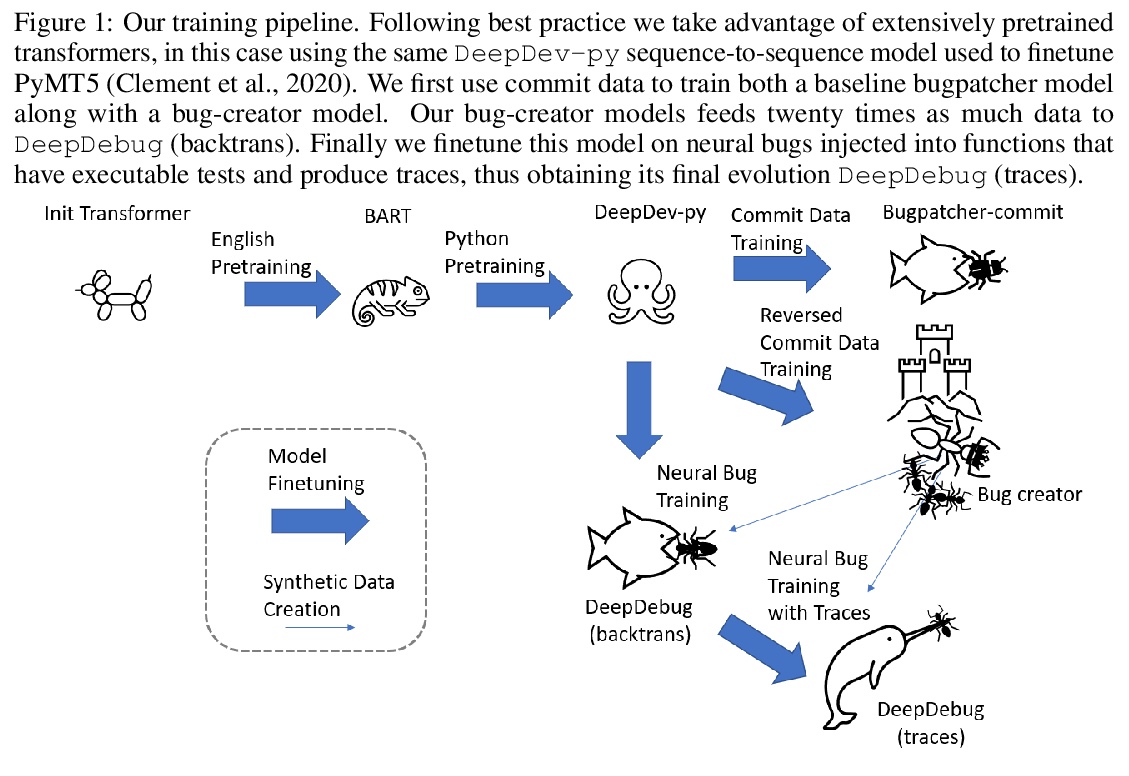
DeepDebug:基于栈追踪、回译和代码骨架的Python代码Bug修复。Bug定位及代码修复联合任务,是软件开发过程的一个组成部分。本文提出DeepDebug,一种使用大型预训练transformer进行自动调试的方法。首先在反转的提交数据上训练错误生成模型,以生成合成错误,将这些合成错误用于两端。首先,直接在200K个代码库的所有函数上,训练一个回译模型。接下来,专注于可执行测试的10K个代码库,并为其中所有通过测试的函数创建错误版本,利用其提供的丰富调试信息,如栈追踪和打印语句,来微调在原始源代码上预训练的模型。最后,通过将上下文窗口扩展到有问题的函数之外,并添加由按优先顺序排列的该函数的父类、imports、签名、文档字符串和方法体组成的骨架来强化所有模型。在QuixBugs基准测试中,修复总数增加了50%以上,同时也将假阳性率从35%降低到5%,将超时时间从6小时降低到1分钟。在自己的可执行测试基准中,模型在不使用trace的情况下,首次尝试就修复了68%的错误,而在添加trace后,首次尝试就修复了75%的错误。
The joint task of bug localization and program repair is an integral part of the software development process. In this work we present DeepDebug, an approach to automated debugging using large, pretrained transformers. We begin by training a bug-creation model on reversed commit data for the purpose of generating synthetic bugs. We apply these synthetic bugs toward two ends. First, we directly train a backtranslation model on all functions from 200K repositories. Next, we focus on 10K repositories for which we can execute tests, and create buggy versions of all functions in those repositories that are covered by passing tests. This provides us with rich debugging information such as stack traces and print statements, which we use to finetune our model which was pretrained on raw source code. Finally, we strengthen all our models by expanding the context window beyond the buggy function itself, and adding a skeleton consisting of that function’s parent class, imports, signatures, docstrings, and method bodies, in order of priority. On the QuixBugs benchmark, we increase the total number of fixes found by over 50%, while also decreasing the false positive rate from 35% to 5% and decreasing the timeout from six hours to one minute. On our own benchmark of executable tests, our model fixes 68% of all bugs on its first attempt without using traces, and after adding traces it fixes 75% on first attempt. We will open-source our framework and validation set for evaluating on executable tests.
https://weibo.com/1402400261/KgSYDfUXQ



2、[CV] Face, Body, Voice: Video Person-Clustering with Multiple Modalities
A Brown, V Kalogeiton, A Zisserman
[University of Oxford]
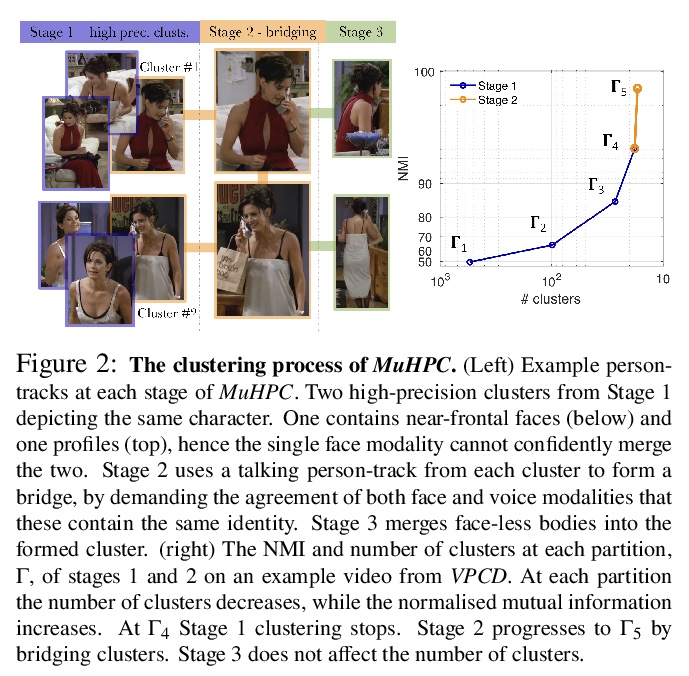
面部、身体、声音:基于多模态的视频人物聚类。本文工作的目的,是对视频中的人物进行聚类——根据人物身份进行分组。之前的方法,专注于人脸聚类这一较窄的任务,而在大多数情况下忽略了其他线索,如人的声音、整体外观(头发、穿着、姿态)以及视频的剪辑结构。同样,目前大多数数据集只评估人脸聚类任务,而不是人物聚类。这限制了它们对下游应用的适用性,如故事理解,这需要人物层面、而不仅仅是人脸层面的推理。本文为解决这两方面的不足做出了以下贡献:首先,提出一种多模态高精度聚类算法,使用多种模态(人脸、身体和声音)作为线索,进行视频中的人物聚类。引入一个视频人物聚类数据集,用于评估多模态人物聚类,包含每个被标注人物的身体轨迹、可见时的人脸轨迹和说话时的声音轨迹,及其相关特征。该数据集是迄今为止最大的同类数据集,涵盖了代表广泛人群的电影和电视节目。展示了使用多模态进行人物聚类的有效性,探索了通过人物共同出现来理解故事这一新的通用任务,并在所有可用的数据集上实现了人物和人物聚类的新水平。
The objective of this work is person-clustering in videos – grouping characters according to their identity. Previous methods focus on the narrower task of face-clustering, and for the most part ignore other cues such as the person’s voice, their overall appearance (hair, clothes, posture), and the editing structure of the videos. Similarly, most current datasets evaluate only the task of face-clustering, rather than person-clustering. This limits their applicability to downstream applications such as story understanding which require person-level, rather than only face-level, reasoning. In this paper we make contributions to address both these deficiencies: first, we introduce a Multi-Modal HighPrecision Clustering algorithm for person-clustering in videos using cues from several modalities (face, body, and voice). Second, we introduce a Video Person-Clustering dataset, for evaluating multi-modal person-clustering. It contains body-tracks for each annotated character, facetracks when visible, and voice-tracks when speaking, with their associated features. The dataset is by far the largest of its kind, and covers films and TV-shows representing a wide range of demographics. Finally, we show the effectiveness of using multiple modalities for person-clustering, explore the use of this new broad task for story understanding through character co-occurrences, and achieve a new state of the art on all available datasets for face and person-clustering.
https://weibo.com/1402400261/KgT5g2gWE



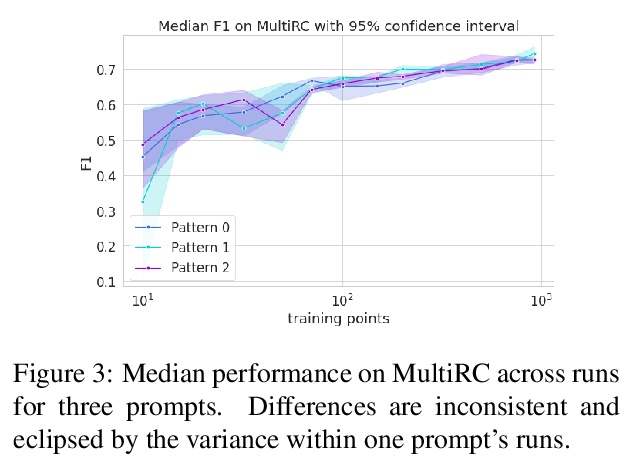
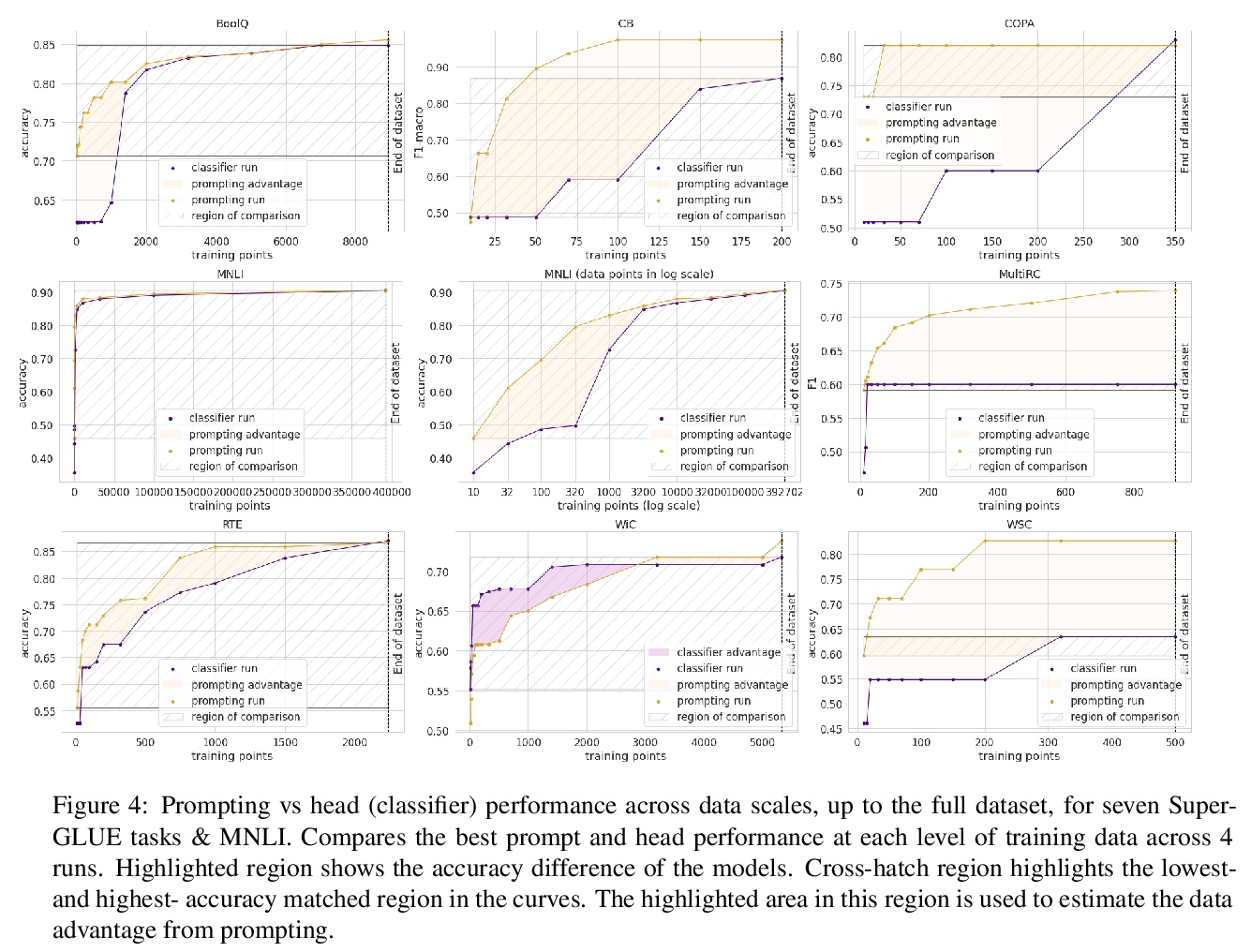
3、[LG] How Many Data Points is a Prompt Worth?
T L Scao, A M. Rush
[Hugging Face]
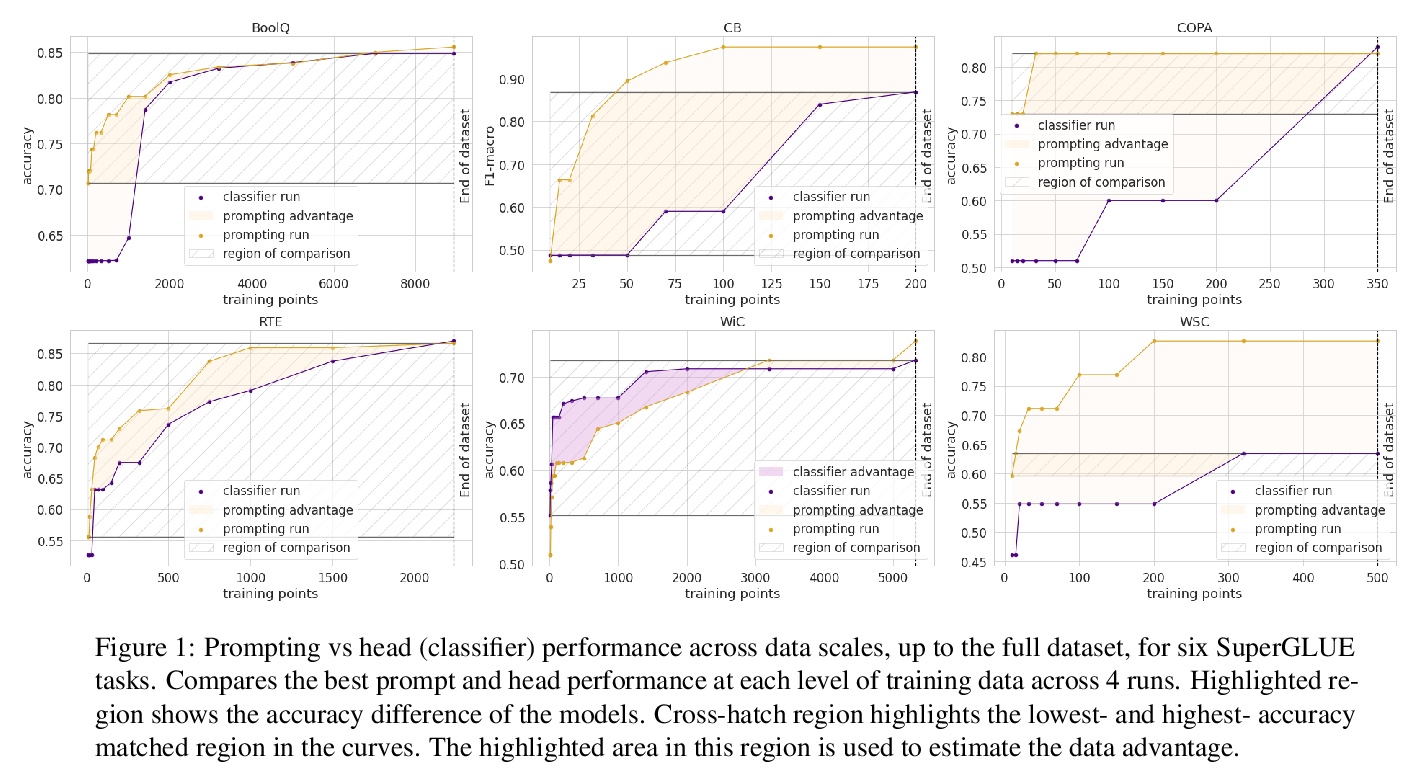
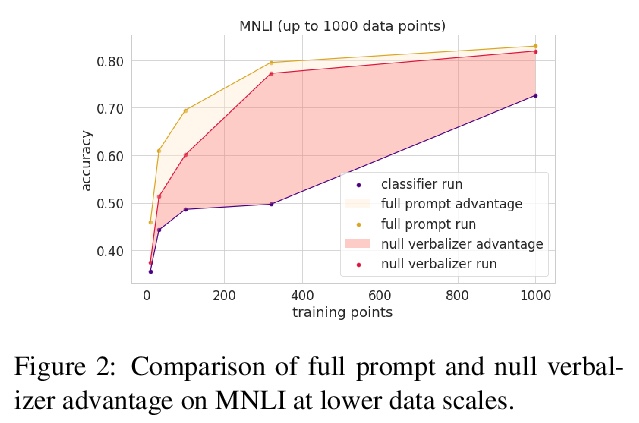
提示收益量化研究。对预训练模型进行分类微调时,研究人员要么用通用的模型头,要么用任务特定的提示(prompt)进行预测。提示的支持者认为,提示提供了一种注入任务特定指导的方法,这在低数据场景下是有益的。本文旨在通过在一个公平的环境中对提示进行严格测试,来量化这种收益:在多种任务和数据规模的平等条件下,比较提示和基于头的微调。通过对多种收益来源的控制,发现提示确实带来了收益,而且这种收益可以在各任务中实现量化。结果显示,在分类任务中,提示平均抵得上100个数据点。提示对模式的选择大多是鲁棒的,甚至可以在没有信息性言语者的情况下学习。
When fine-tuning pretrained models for classification, researchers either use a generic model head or a task-specific prompt for prediction. Proponents of prompting have argued that prompts provide a method for injecting taskspecific guidance, which is beneficial in lowdata regimes. We aim to quantify this benefit through rigorous testing of prompts in a fair setting: comparing prompted and head-based fine-tuning in equal conditions across many tasks and data sizes. By controlling for many sources of advantage, we find that prompting does indeed provide a benefit, and that this benefit can be quantified per task. Results show that prompting is often worth 100s of data points on average across classification tasks.
https://weibo.com/1402400261/KgTafFpEd
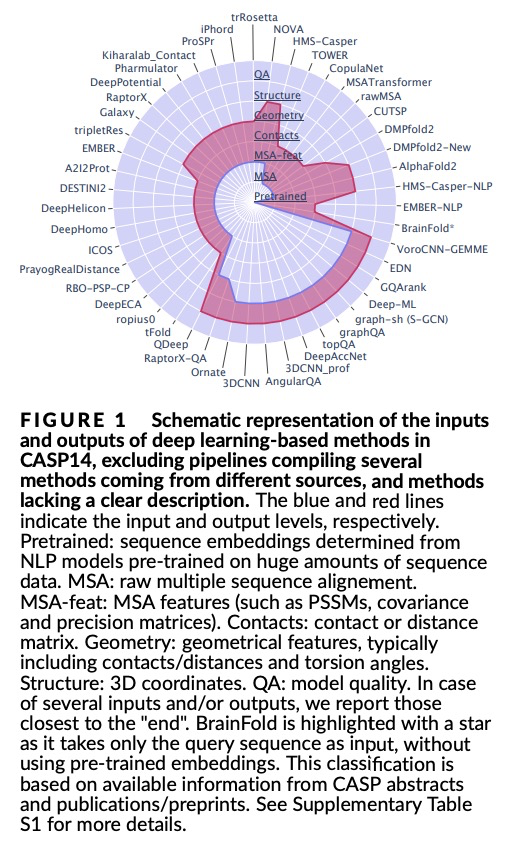
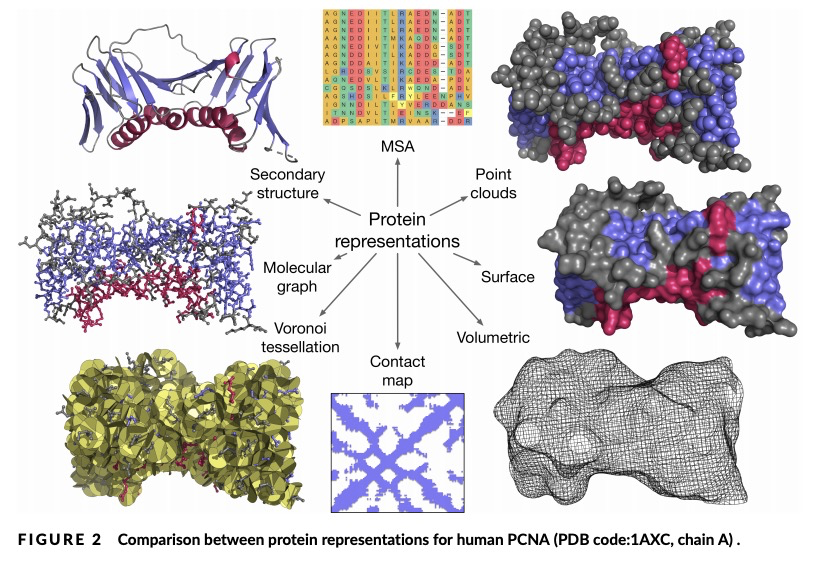
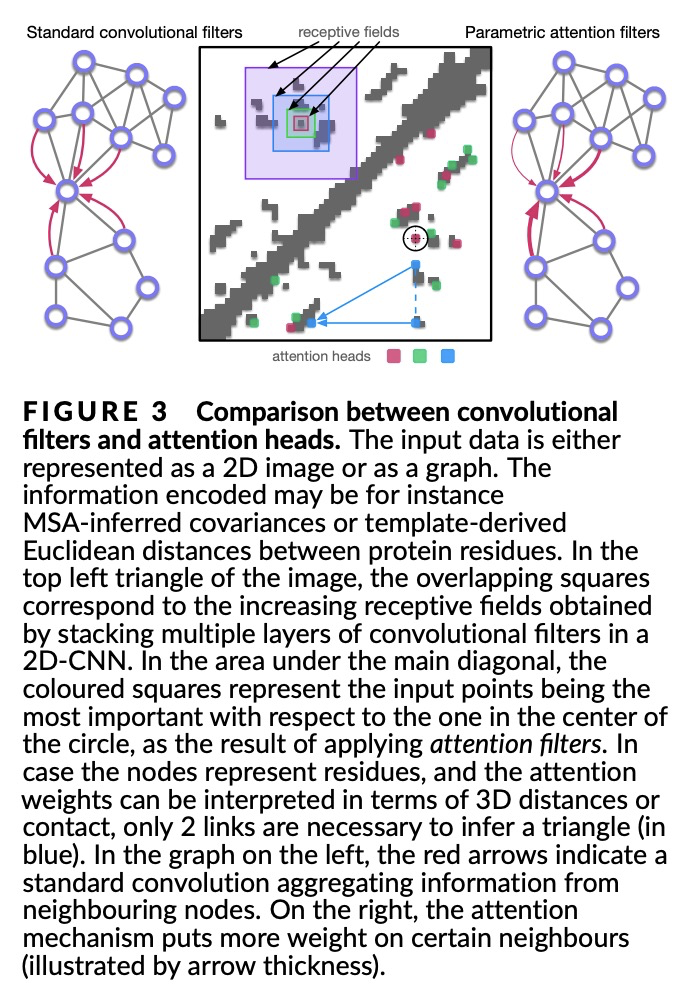
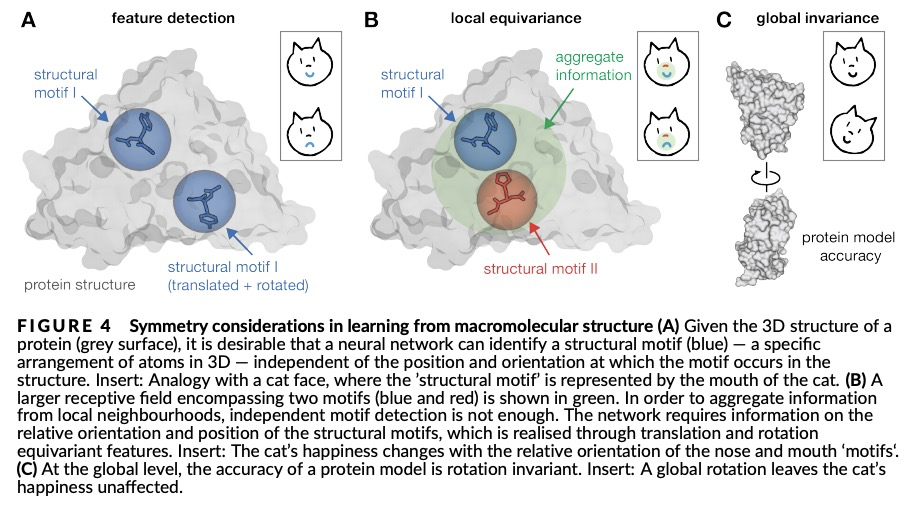
4、[LG] Protein sequence-to-structure learning: Is this the end(-to-end revolution)?
E Laine, S Eismann, A Elofsson, S Grudinin
[Sorbonne Université & Stanford University & Stockholm University & Univ. Grenoble Alpes]
蛋白质序列-结构学习综述。深度学习的潜力在蛋白质结构预测领域得到了广泛关注,在CASP13之后变得无可争议。在CASP14中,深度学习将该领域提升到了意料之外的水平,达到了接近实验的准确性。这一成功来自于从其他机器学习领域迁移而来的进展,以及专门设计用来处理蛋白质序列和结构及其抽象的方法。新出现的方法包括:(i) 几何学习,即在图、三维Voronoi镶嵌和点云等表征上进行学习;(ii) 基于注意力的预训练蛋白质语言模型;(iii) 保留三维空间对称性的等价架构;(iv) 使用大型元基因组数据库;(v) 蛋白质表征的组合;(vi) 真正的端到端架构,即从序列开始返回三维结构的可微模型。本文对过去两年中开发的、在CASP14中广泛使用的新深度学习方法进行了综述,并提出了自己的看法。
The potential of deep learning has been recognized in the protein structure prediction community for some time, and became indisputable after CASP13. In CASP14, deep learning has boosted the field to unanticipated levels reaching near-experimental accuracy. This success comes from advances transferred from other machine learning areas, as well as methods specifically designed to deal with protein sequences and structures, and their abstractions. Novel emerging approaches include (i) geometric learning, i.e. learning on representations such as graphs, 3D Voronoi tessellations, and point clouds; (ii) pre-trained protein language models leveraging attention; (iii) equivariant architectures preserving the symmetry of 3D space; (iv) use of large meta-genome databases; (v) combinations of protein representations; (vi) and finally truly end-to-end architectures, i.e. differentiable models starting from a sequence and returning a 3D structure. Here, we provide an overview and our opinion of the novel deep learning approaches developed in the last two years and widely used in CASP14.
https://weibo.com/1402400261/KgTeO9XLg
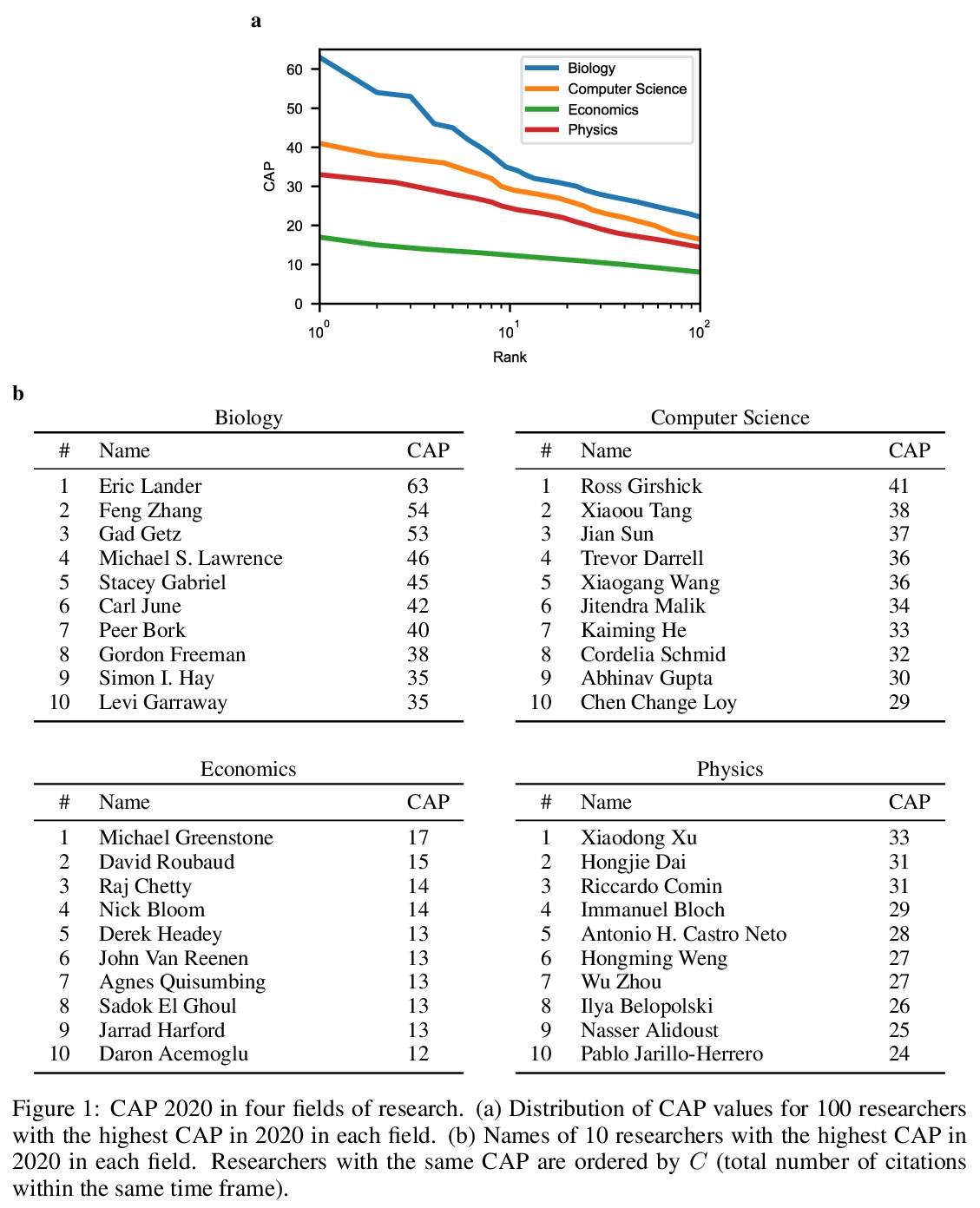
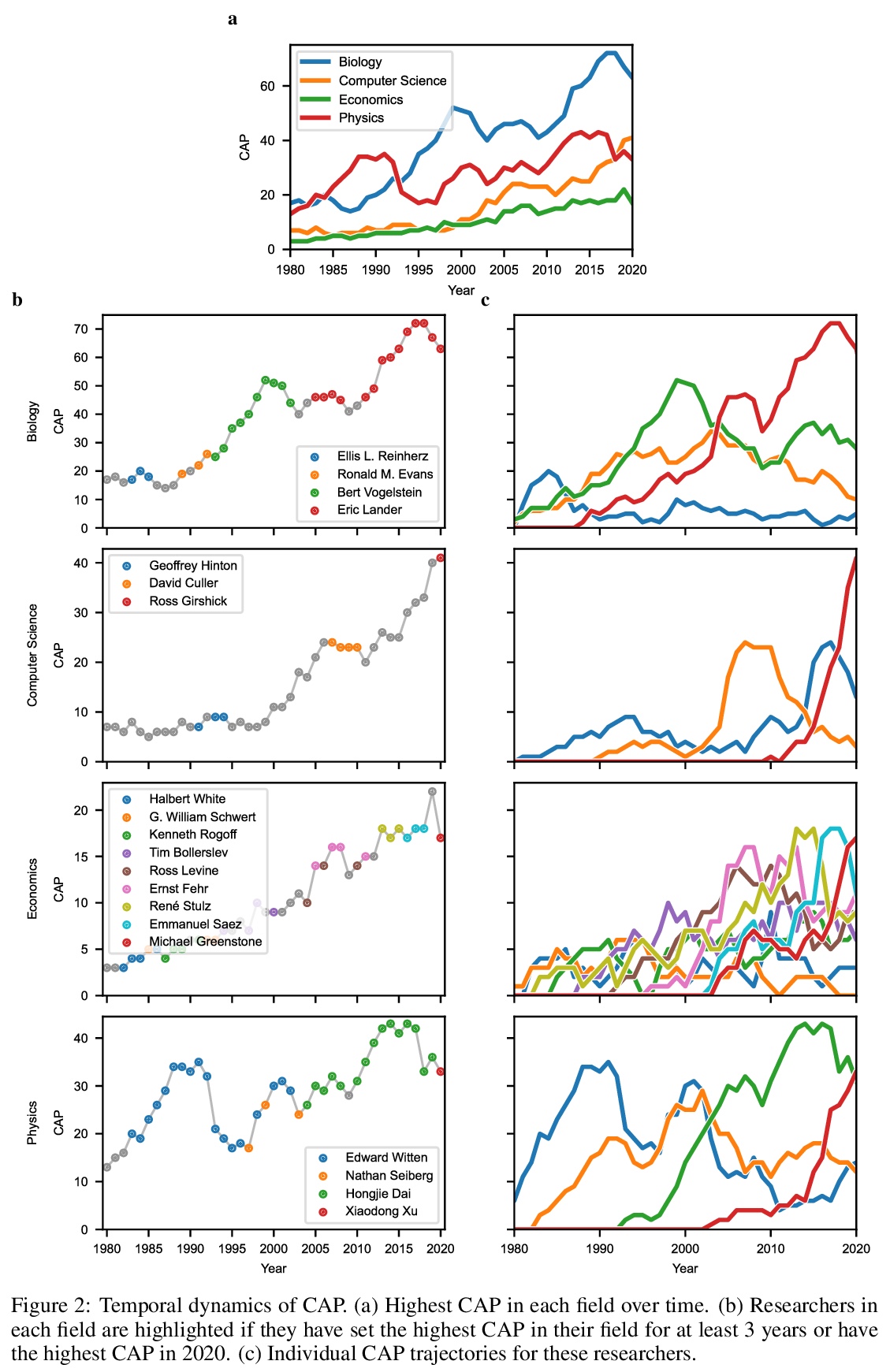
5、[AI] A Measure of Research Taste
V Koltun, D Hafner
[Intel]
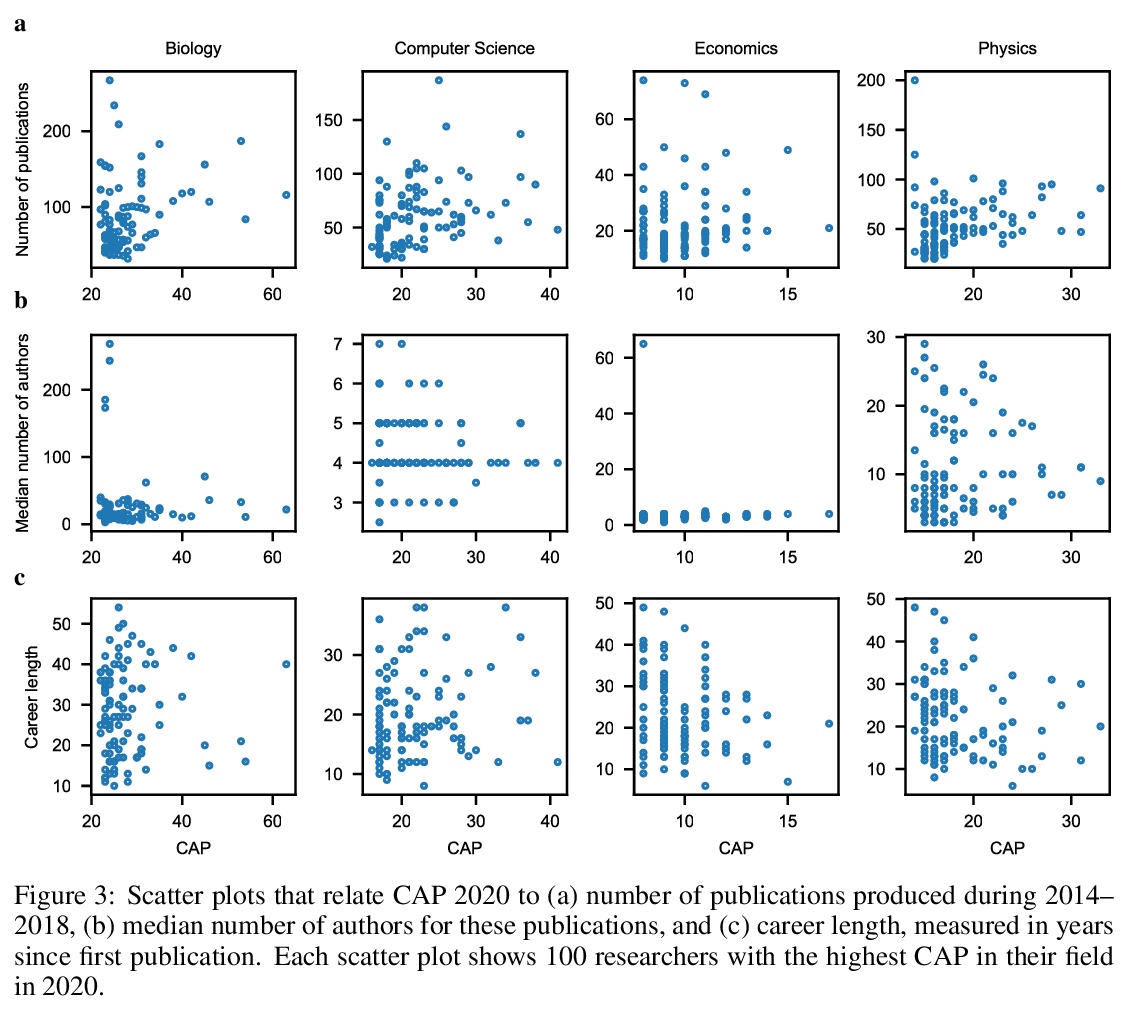
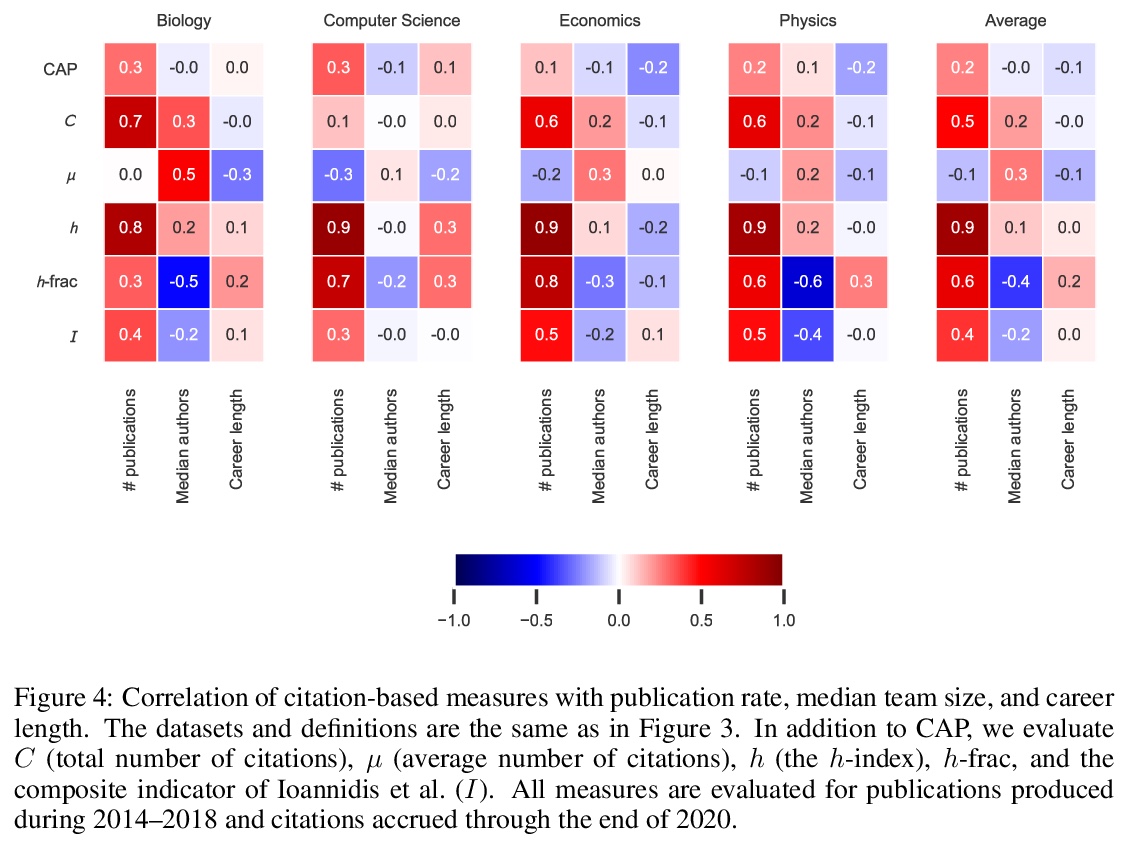
研究品味的衡量标准。研究人员通常是通过基于引用的指标进行评估的。这种指标可以为聘用、晋升和资助决策提供参考。有种担心在于,这种流行的基于引用的衡量标准,会激励研究人员最大限度地发表文章,这种激励可能不是科学进步的最佳选择。本文提出了一种基于引用的衡量标准,既鼓励产出,也鼓励品味:研究人员专注于有影响力的贡献的能力。所提出的措施,CAP,平衡了出版物的影响和数量,激励研究人员考虑一个出版物是否是对文献的有益补充。CAP是简单、可解释和无参数的。使用一个拥有数百万出版物和数亿引用的语料库,以每年的时间粒度分析了生物学、计算机科学、经济学和物理学中高引用率研究人员的CAP的特点。CAP产生的结果在质量上是可信的,与之前的指标相比有许多优势。
Researchers are often evaluated by citation-based metrics. Such metrics can inform hiring, promotion, and funding decisions. Concerns have been expressed that popular citation-based metrics incentivize researchers to maximize the production of publications. Such incentives may not be optimal for scientific progress. Here we present a citation-based measure that rewards both productivity and taste: the researcher’s ability to focus on impactful contributions. The presented measure, CAP, balances the impact of publications and their quantity, thus incentivizing researchers to consider whether a publication is a useful addition to the literature. CAP is simple, interpretable, and parameter-free. We analyze the characteristics of CAP for highly-cited researchers in biology, computer science, economics, and physics, using a corpus of millions of publications and hundreds of millions of citations with yearly temporal granularity.
https://weibo.com/1402400261/KgTi4mp8r
另外几篇值得关注的论文:
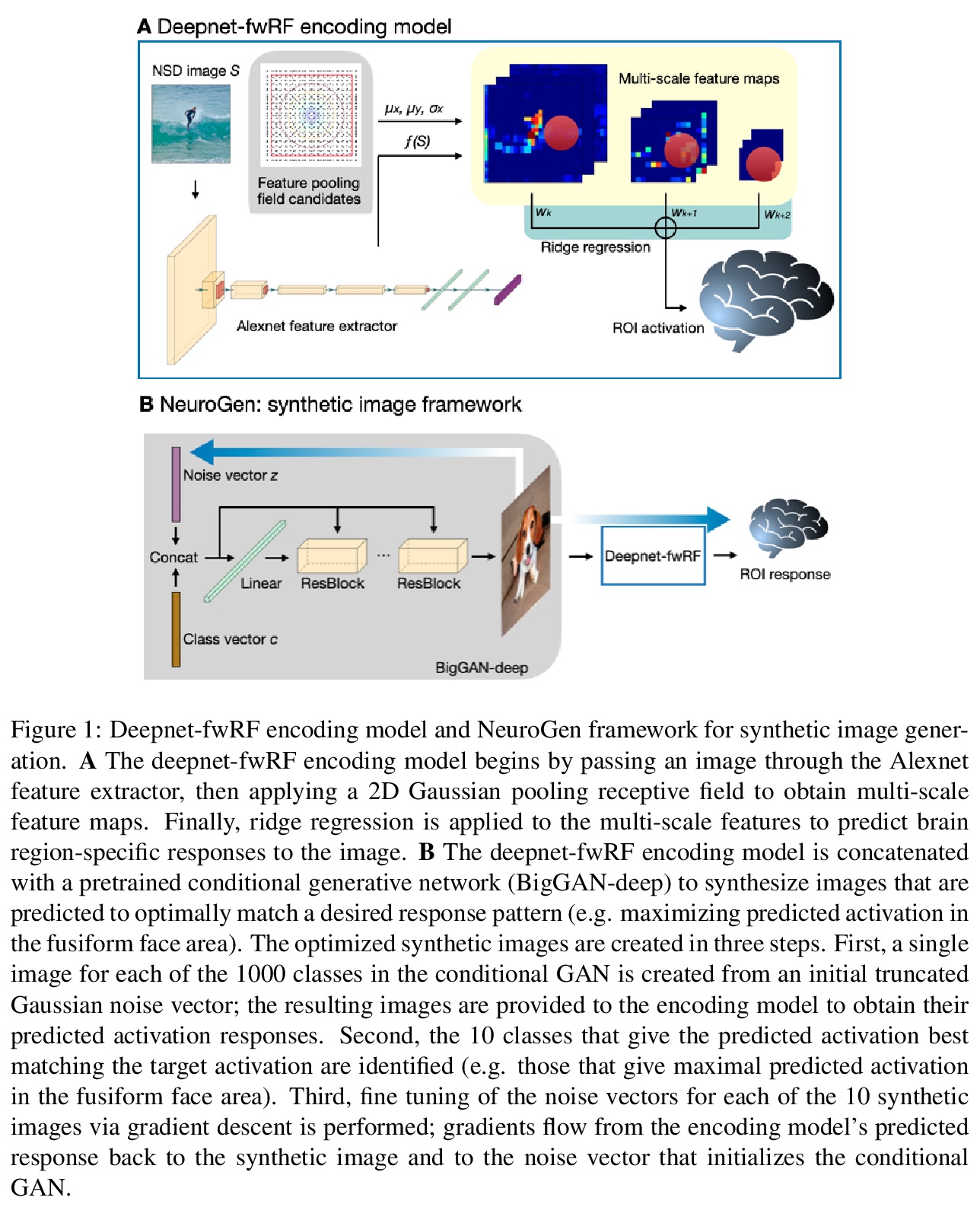
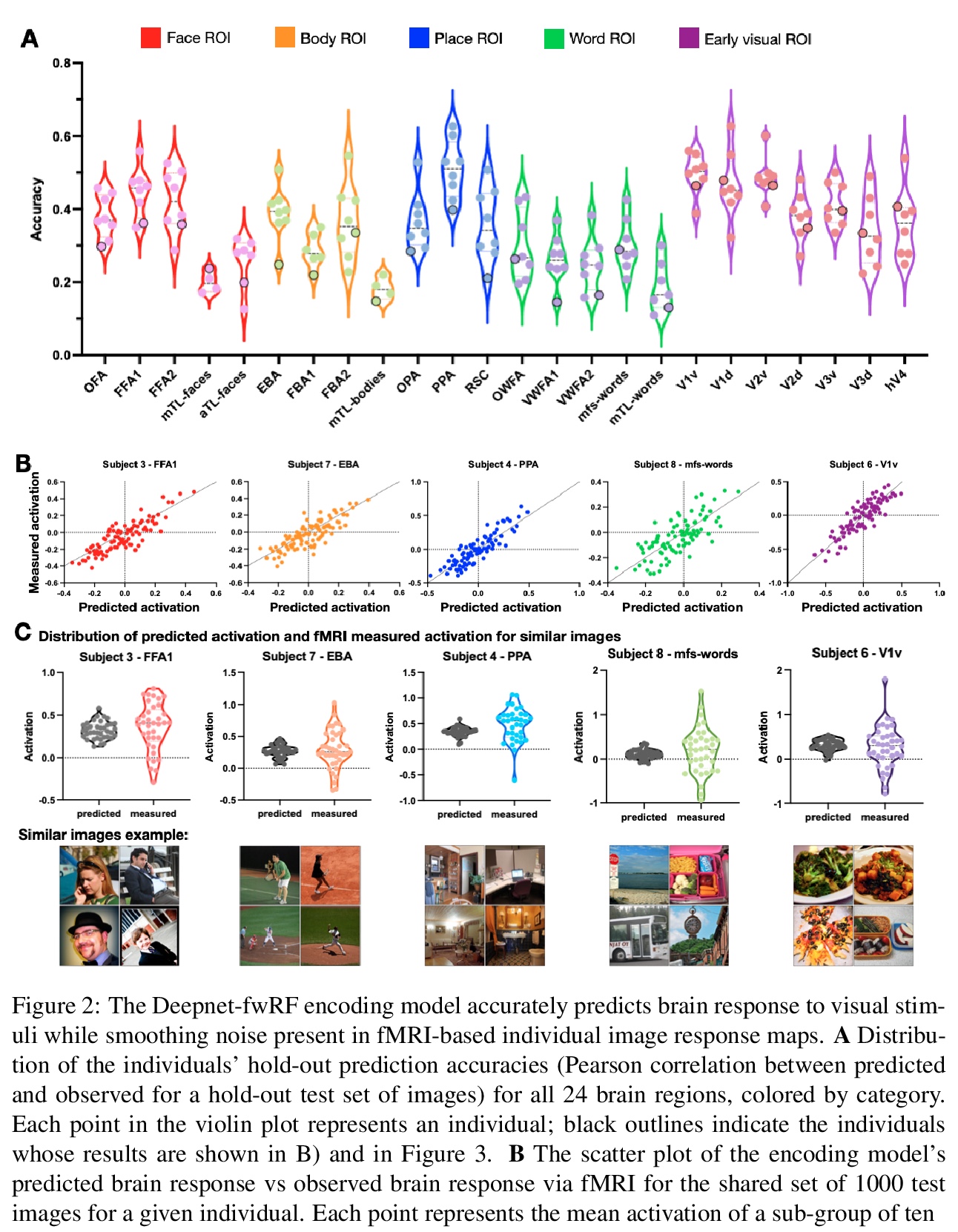
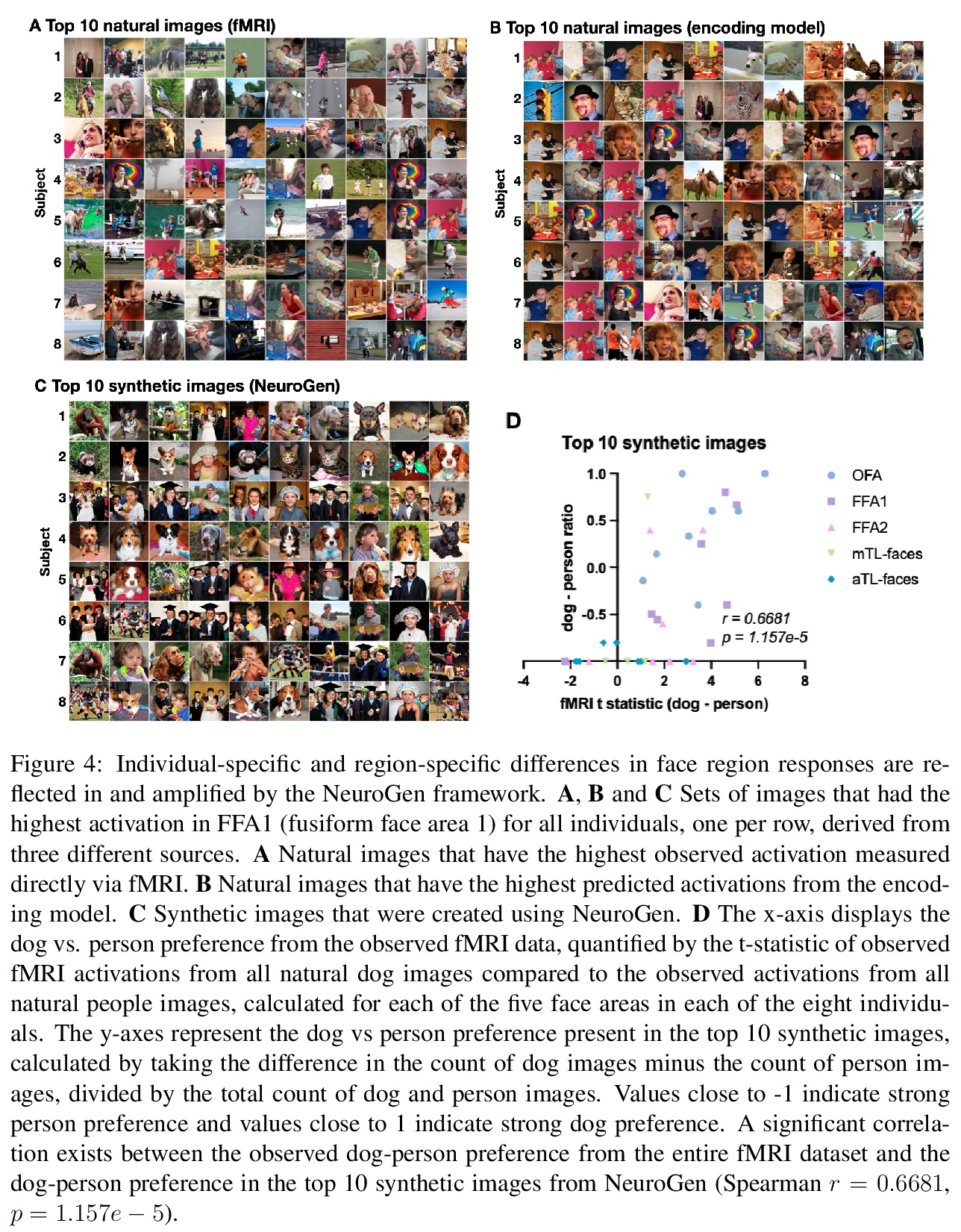
[CV] NeuroGen: activation optimized image synthesis for discovery neuroscience
NeuroGen:基于激活优化图像合成的神经科学发现架构
Z Gu, K W. Jamison, M Khosla, E J. Allen, Y Wu, T Naselaris, K Kay, M R. Sabuncu, A Kuceyeski
[Cornell University & Weill Cornell Medicine & University of Minnesota]
https://weibo.com/1402400261/KgTmynF8e

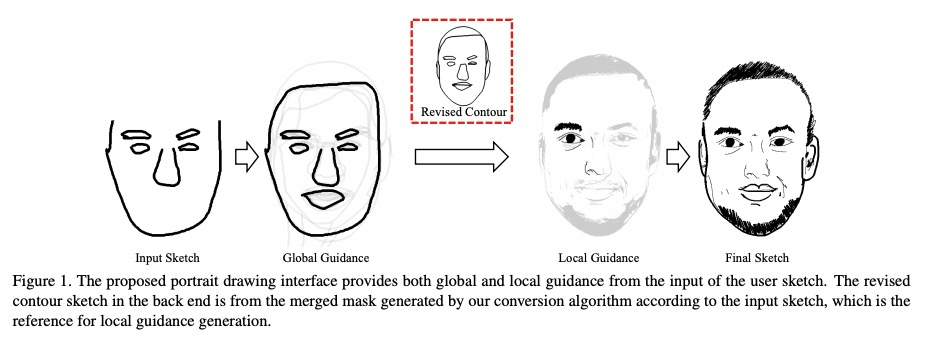
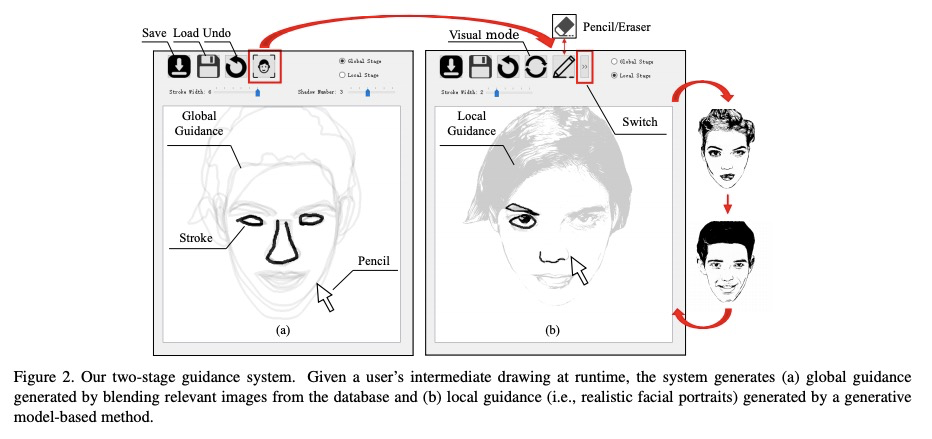
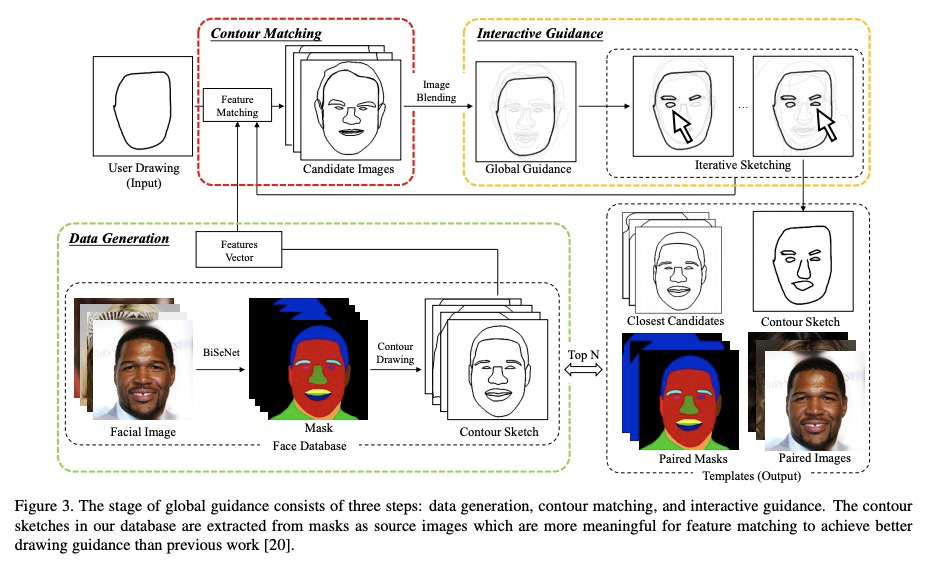
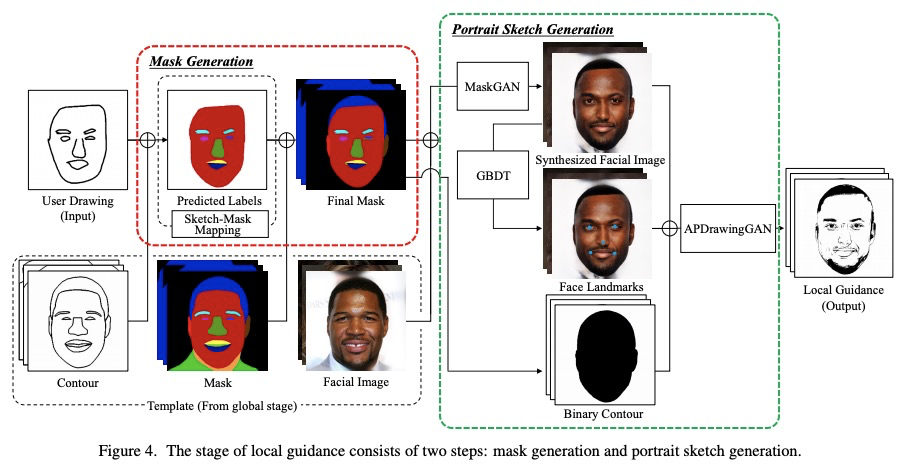
[CV] dualFace:Two-Stage Drawing Guidance for Freehand Portrait Sketching
dualFace:手绘人像素描的两阶段绘画指导
Z Huang, Y Peng, T Hibino, C Zhao, H Xie, T Fukusato, K Miyata
[Japan Advanced Institute of Science and Technology & The University of Tokyo]
https://weibo.com/1402400261/KgTpKms2j
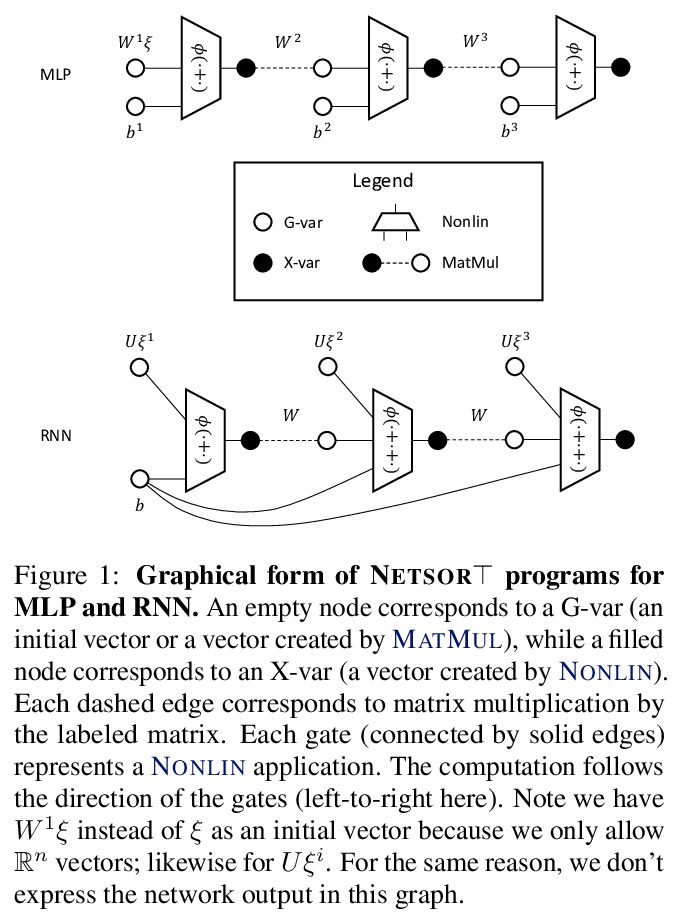
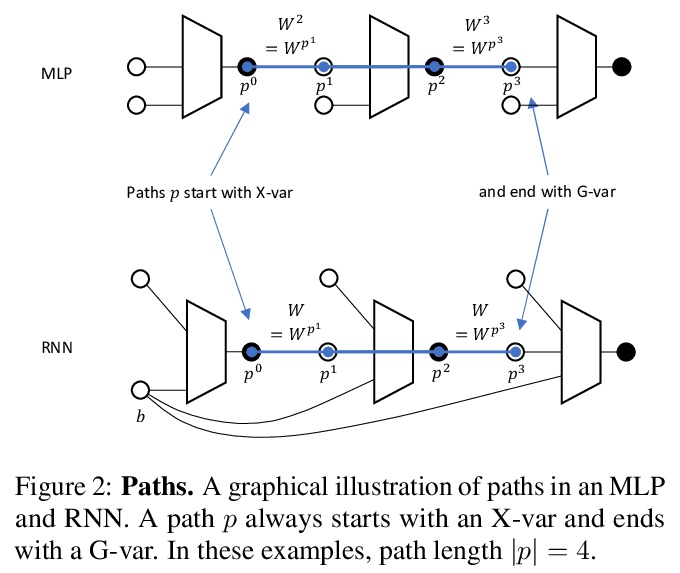
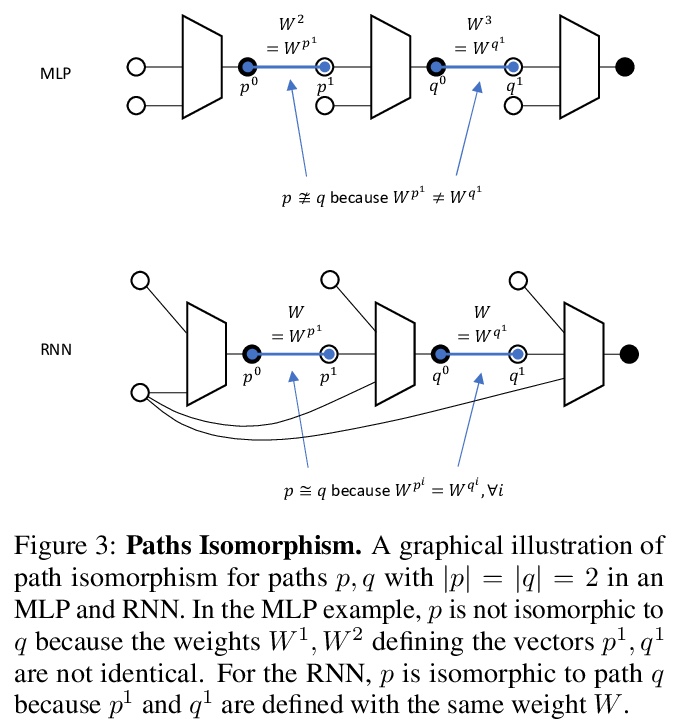
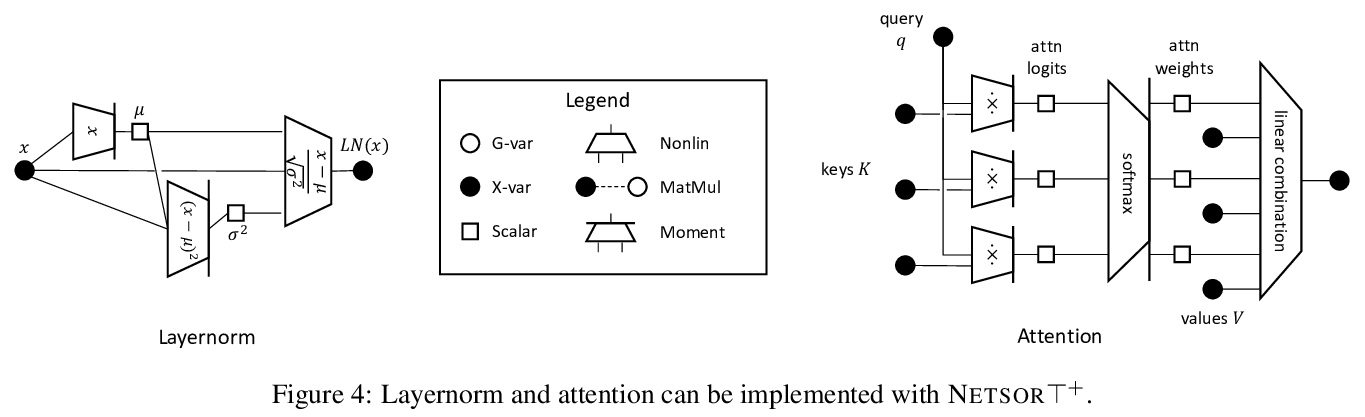
[LG] Tensor Programs IIb: Architectural Universality of Neural Tangent Kernel Training Dynamics
Tensor Programs IIb:神经切线核训练动力学的结构普适性
G Yang, E Littwin
[Microsoft Research & Apple Research]
https://weibo.com/1402400261/KgTrFFIgd
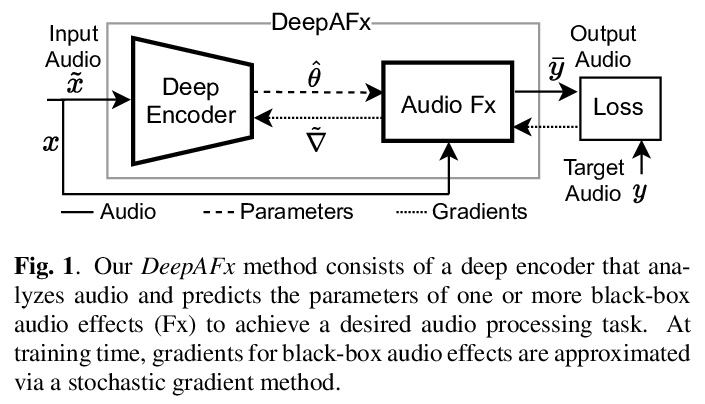
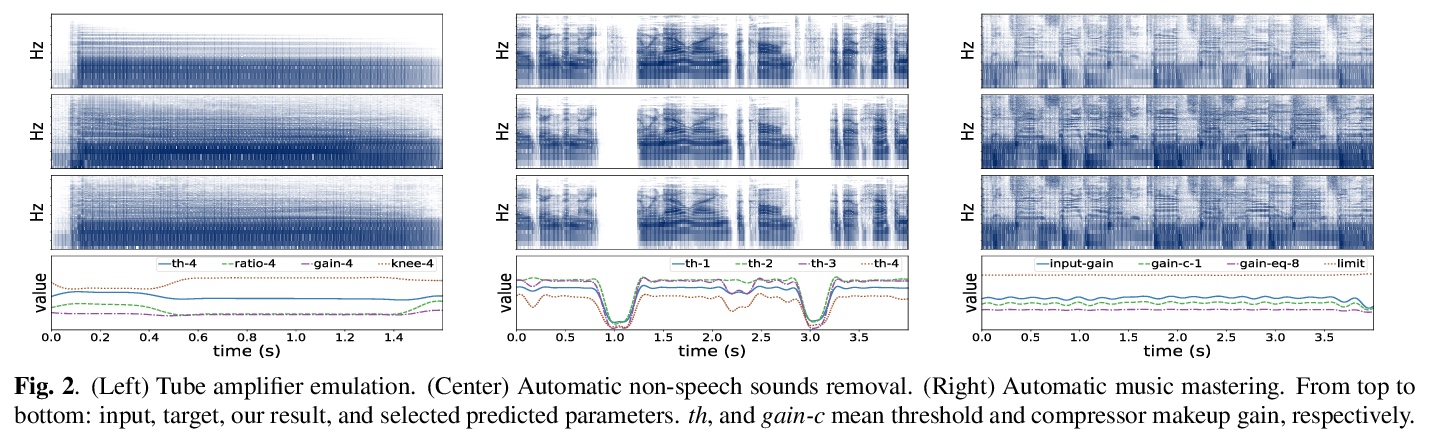
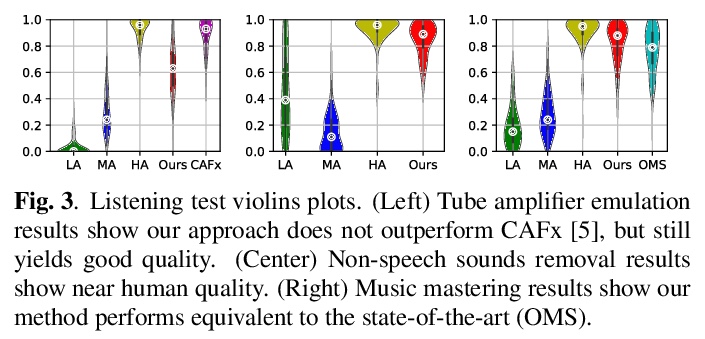
[AS] Differentiable Signal Processing With Black-Box Audio Effects
黑盒音效可微信号处理
M A. M Ramírez, O Wang, P Smaragdis, N J. Bryan
[Adobe Research & Queen Mary University of London & University of Illinois at Urbana-Champaign]
https://weibo.com/1402400261/KgTw4qbaH

若有收获,就点个赞吧
0 人点赞
