LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人 (*表示值得重点关注)
1、[CV] *Unsupervised Monocular Depth Learning in Dynamic Scenes
H Li, A Gordon, H Zhao, V Casser, A Angelova
[Google Research & Waymo LLC]
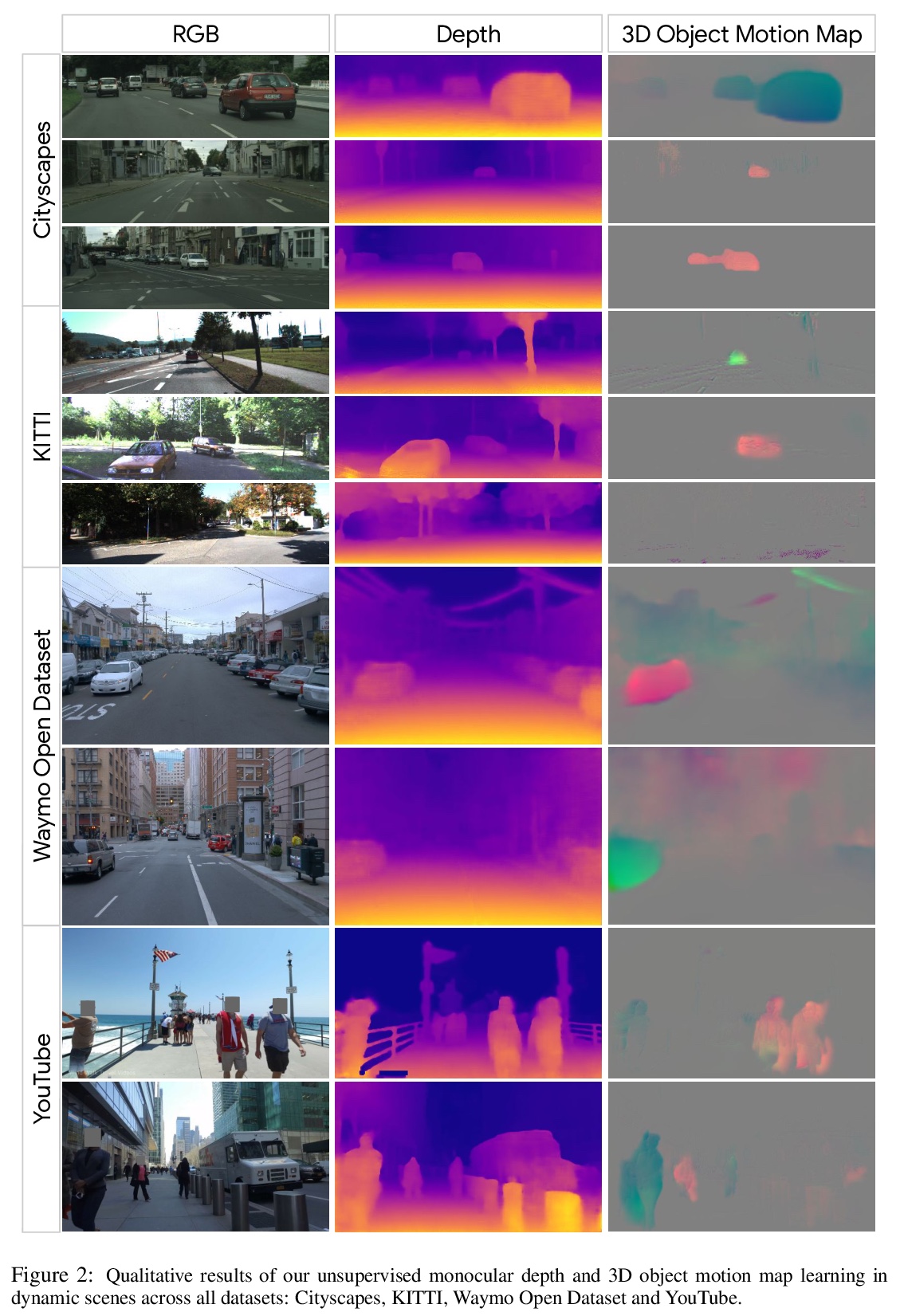
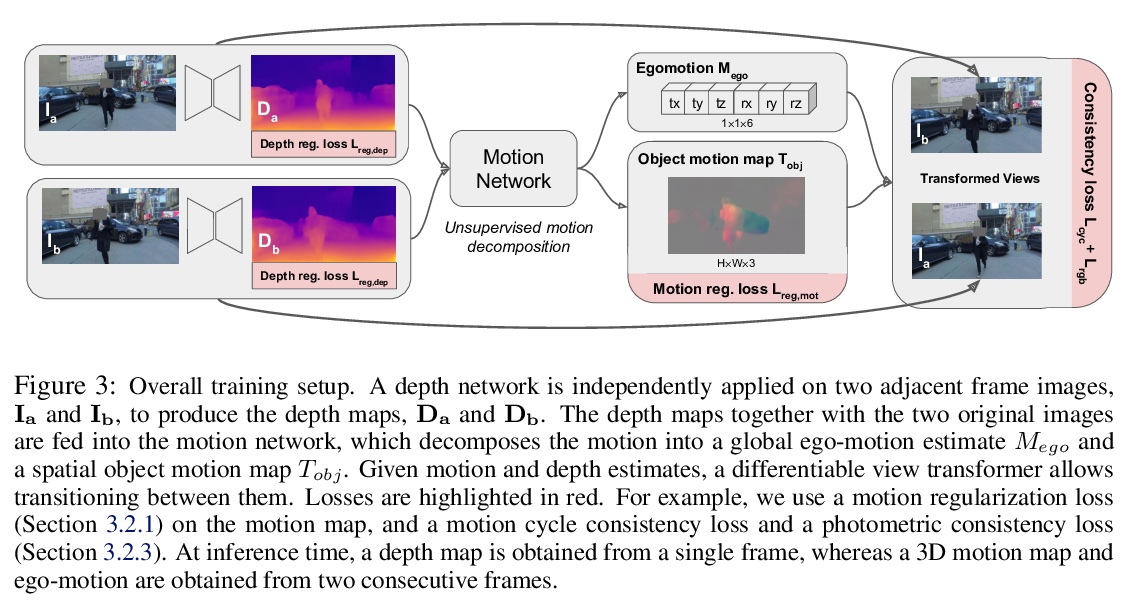
动态场景无监督单目深度学习。提出一种新的无监督深度学习方法,在高动态场景中,联合优化三维运动图和深度图,对估计深度、自运动和目标相对场景的密集三维平移场进行联合训练,以单目的光一致性作为唯一监督来源,可在未标记单目视频上进行训练,不需要任何辅助语义信息。用这种正则化方法,就足以训练单目深度预测模型,其精度超过了之前在动态场景(包括需要语义输入的方法)中所实现的精度。**
We present a method for jointly training the estimation of depth, ego-motion, and a dense 3D translation field of objects relative to the scene, with monocular photometric consistency being the sole source of supervision. We show that this apparently heavily underdetermined problem can be regularized by imposing the following prior knowledge about 3D translation fields: they are sparse, since most of the scene is static, and they tend to be constant for rigid moving objects. We show that this regularization alone is sufficient to train monocular depth prediction models that exceed the accuracy achieved in prior work for dynamic scenes, including methods that require semantic input. Code is at > this https URL .
https://weibo.com/1402400261/Js8bRlk2H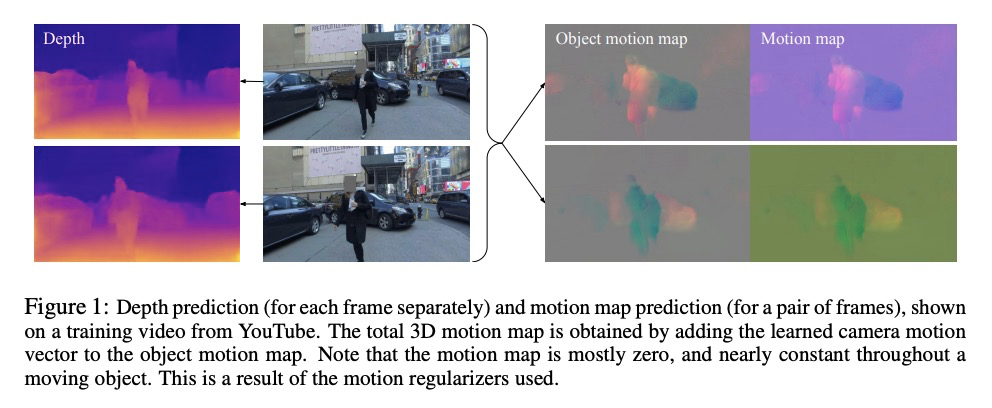
2、[CV] *Viewmaker Networks: Learning Views for Unsupervised Representation Learning
A Tamkin, M Wu, N Goodman
[Stanford University]
Viewmaker Networks:无监督表示学习视图学习。提出了viewmaker网络,学习生成输入依赖视图的生成模型,用于对比学习,用该网络能高效学习视图,将其作为表示学习过程的一部分,而不依赖于特定领域的知识或大量昂贵的预训练过程。**
Many recent methods for unsupervised representation learning involve training models to be invariant to different “views,” or transformed versions of an input. However, designing these views requires considerable human expertise and experimentation, hindering widespread adoption of unsupervised representation learning methods across domains and modalities. To address this, we propose viewmaker networks: generative models that learn to produce input-dependent views for contrastive learning. We train this network jointly with an encoder network to produce adversarial > ℓp perturbations for an input, which yields challenging yet useful views without extensive human tuning. Our learned views, when applied to CIFAR-10, enable comparable transfer accuracy to the the well-studied augmentations used for the SimCLR model. Our views significantly outperforming baseline augmentations in speech (+9% absolute) and wearable sensor (+17% absolute) domains. We also show how viewmaker views can be combined with handcrafted views to improve robustness to common image corruptions. Our method demonstrates that learned views are a promising way to reduce the amount of expertise and effort needed for unsupervised learning, potentially extending its benefits to a much wider set of domains.
https://weibo.com/1402400261/Js8fO0pUi


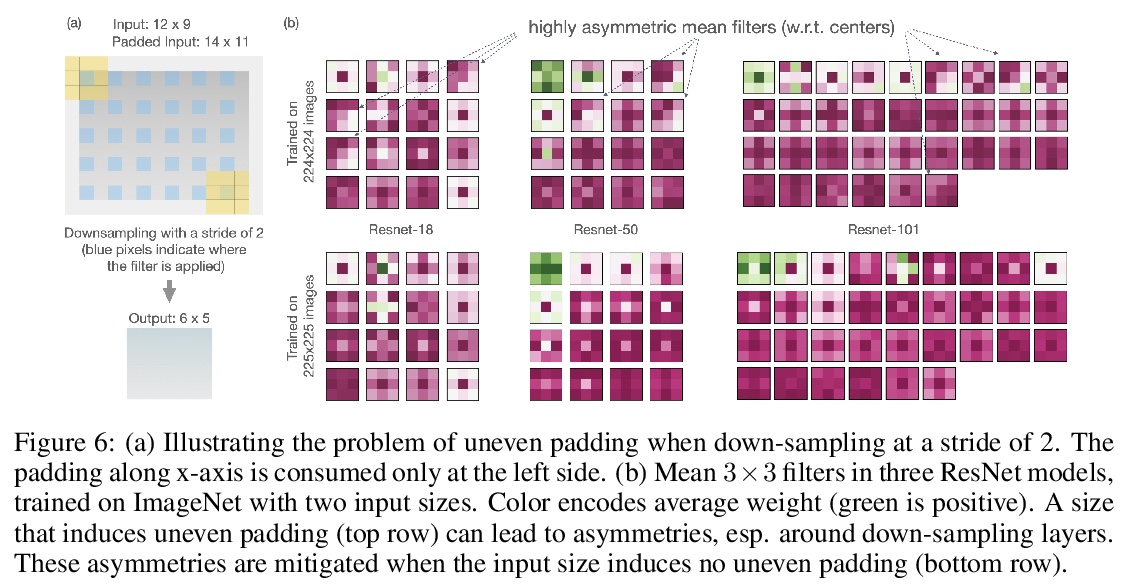
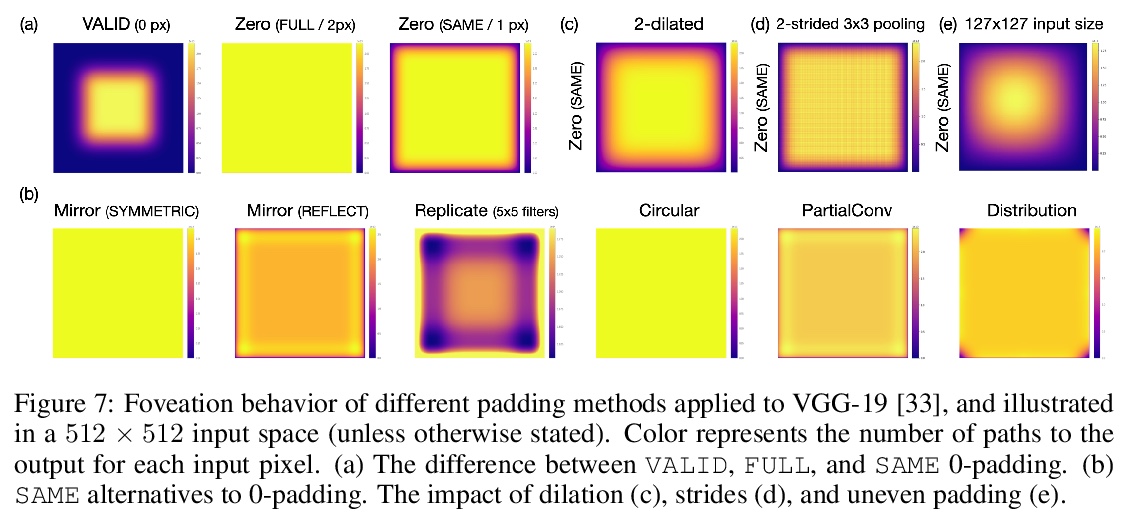
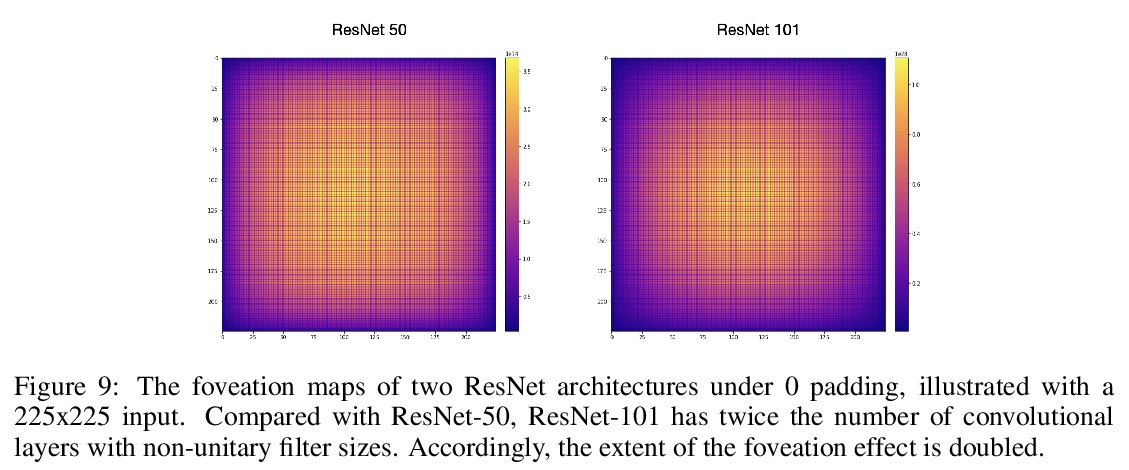
3、[CV] *Mind the Pad — CNNs can Develop Blind Spots
B Alsallakh, N Kokhlikyan, V Miglani, J Yuan, O Reblitz-Richardson
[Facebook AI & NYU]
Padding对CNN表示的影响。CNN中的Padding机制,会以扭曲内核和特征图伪影的形式,导致空间偏差。由于卷积算法几个方面特性,Padding机制会不均匀应用填充,导致学习权重不对称。当不均匀应用于特征图四边时,伪影会因广泛使用的0-padding而更加显著。提出了缓解空间偏差的解决方案,并演示了如何提高模型精度。**
We show how feature maps in convolutional networks are susceptible to spatial bias. Due to a combination of architectural choices, the activation at certain locations is systematically elevated or weakened. The major source of this bias is the padding mechanism. Depending on several aspects of convolution arithmetic, this mechanism can apply the padding unevenly, leading to asymmetries in the learned weights. We demonstrate how such bias can be detrimental to certain tasks such as small object detection: the activation is suppressed if the stimulus lies in the impacted area, leading to blind spots and misdetection. We propose solutions to mitigate spatial bias and demonstrate how they can improve model accuracy.
https://weibo.com/1402400261/Js8lG3aml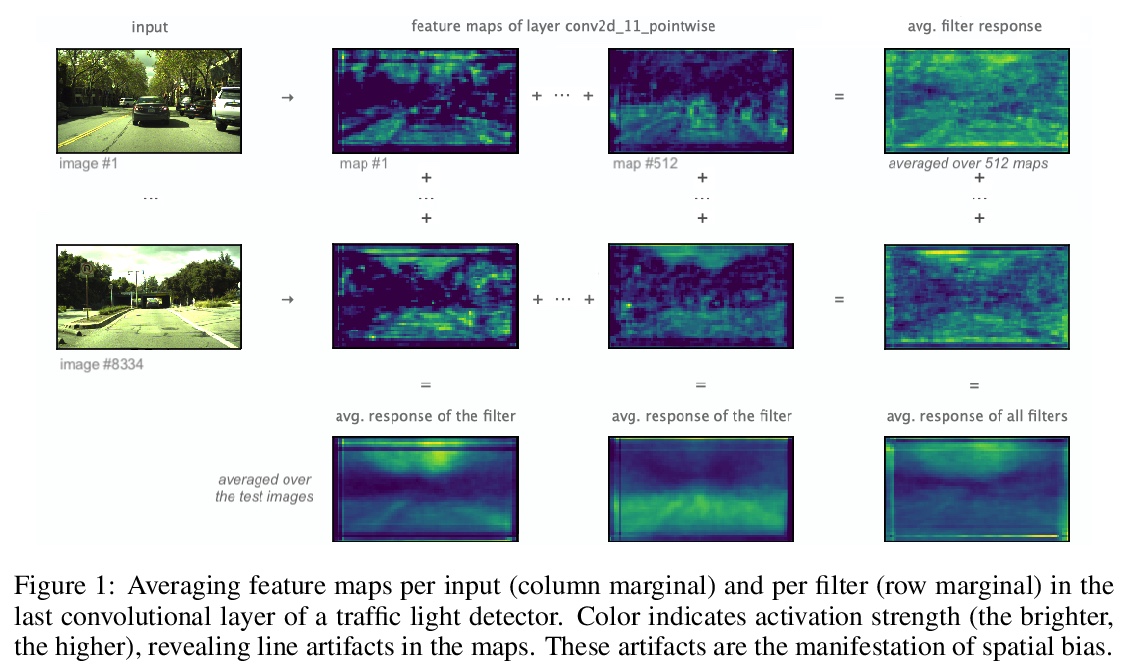
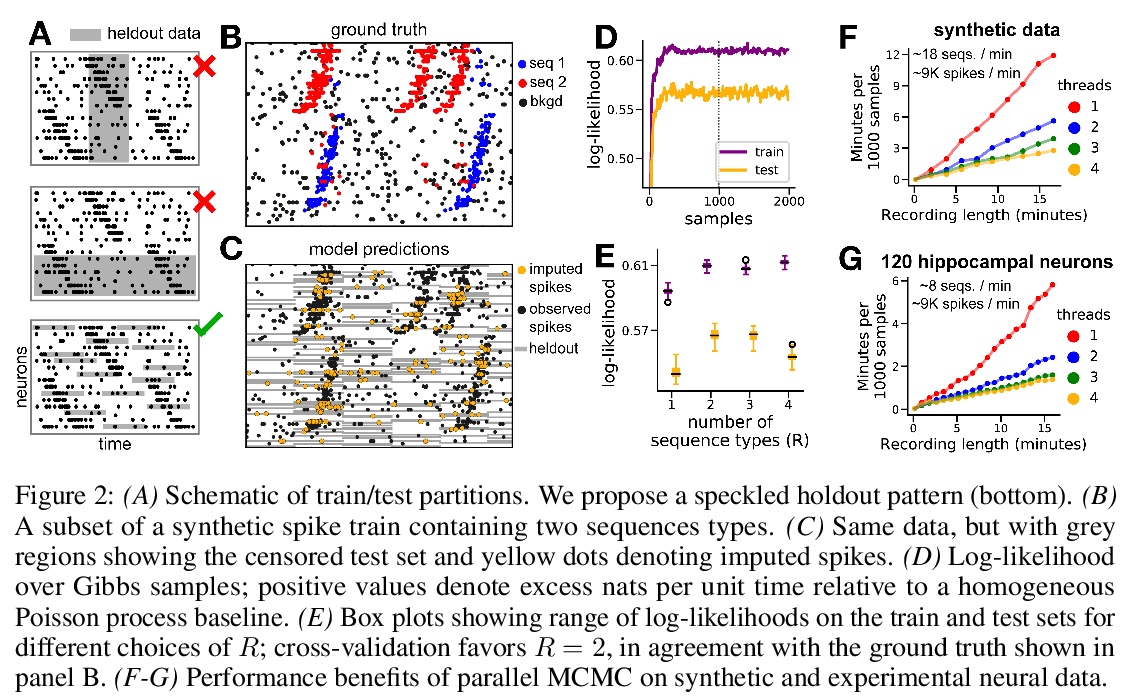
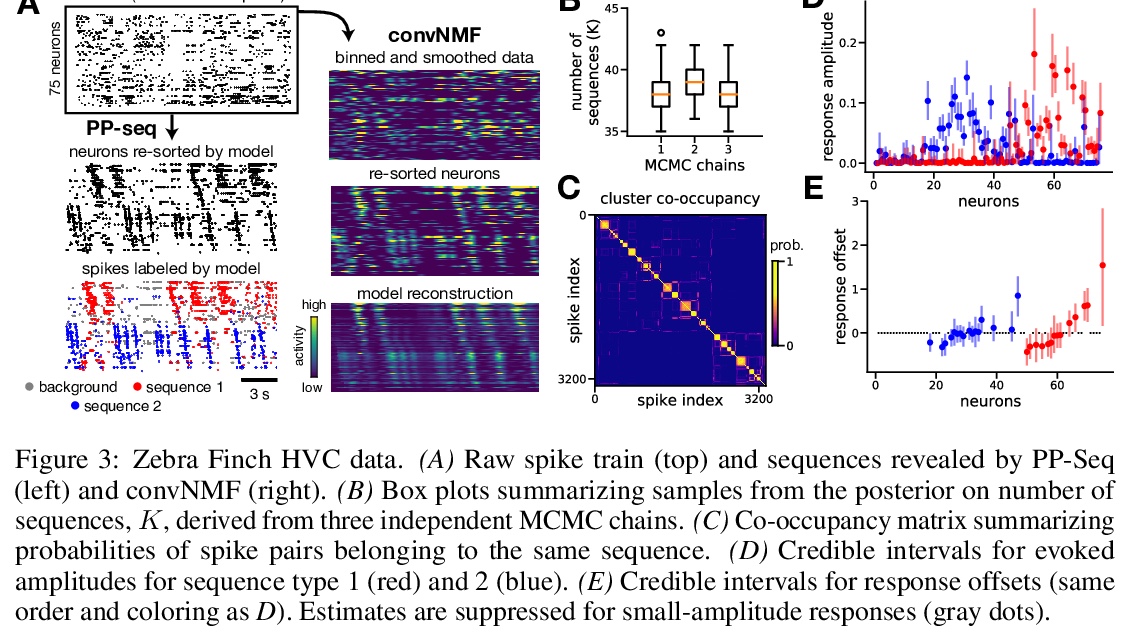
4、[LG] **Point process models for sequence detection in high-dimensional neural spike trains
A H. Williams, A Degleris, Y Wang, S W. Linderman
[Stanford University & Columbia University]
用点处理模型(PP-Seq)实现高维神经脉冲序列序列检测。灵感来自卷积NMF,在单脉冲级别刻画细粒度序列,将序列出现表示为连续时间内的少量标记事件,这种序列事件的超稀疏表示,为脉冲序列建模开辟了新的可能性。用笔记本电脑即可在几分钟内将PP-Seq应用到包含数十万脉冲的数据集上。**
Sparse sequences of neural spikes are posited to underlie aspects of working memory, motor production, and learning. Discovering these sequences in an unsupervised manner is a longstanding problem in statistical neuroscience. Promising recent work utilized a convolutive nonnegative matrix factorization model to tackle this challenge. However, this model requires spike times to be discretized, utilizes a sub-optimal least-squares criterion, and does not provide uncertainty estimates for model predictions or estimated parameters. We address each of these shortcomings by developing a point process model that characterizes fine-scale sequences at the level of individual spikes and represents sequence occurrences as a small number of marked events in continuous time. This ultra-sparse representation of sequence events opens new possibilities for spike train modeling. For example, we introduce learnable time warping parameters to model sequences of varying duration, which have been experimentally observed in neural circuits. We demonstrate these advantages on experimental recordings from songbird higher vocal center and rodent hippocampus.
https://weibo.com/1402400261/Js8rg6D3N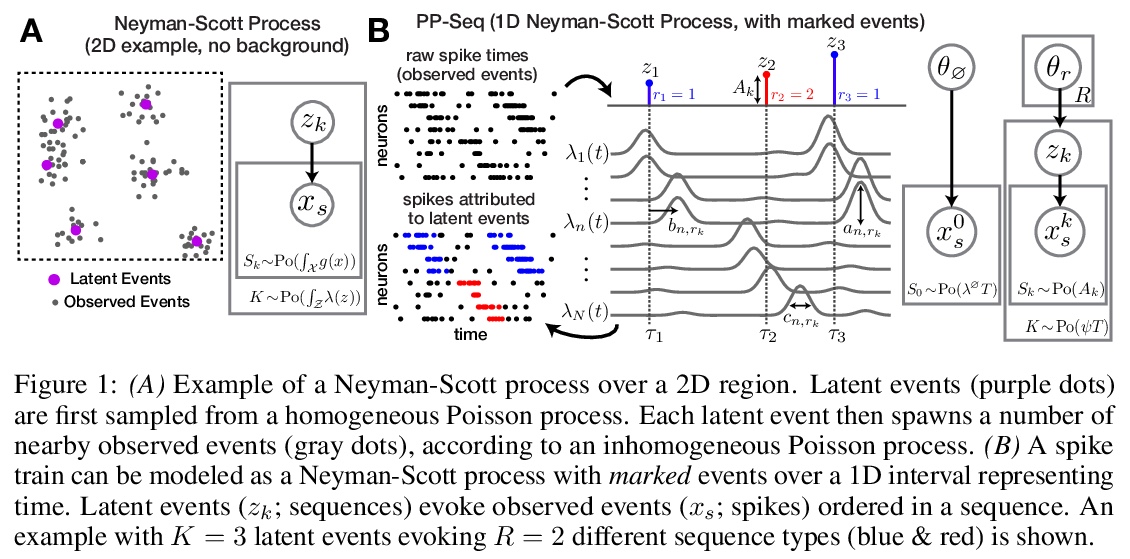
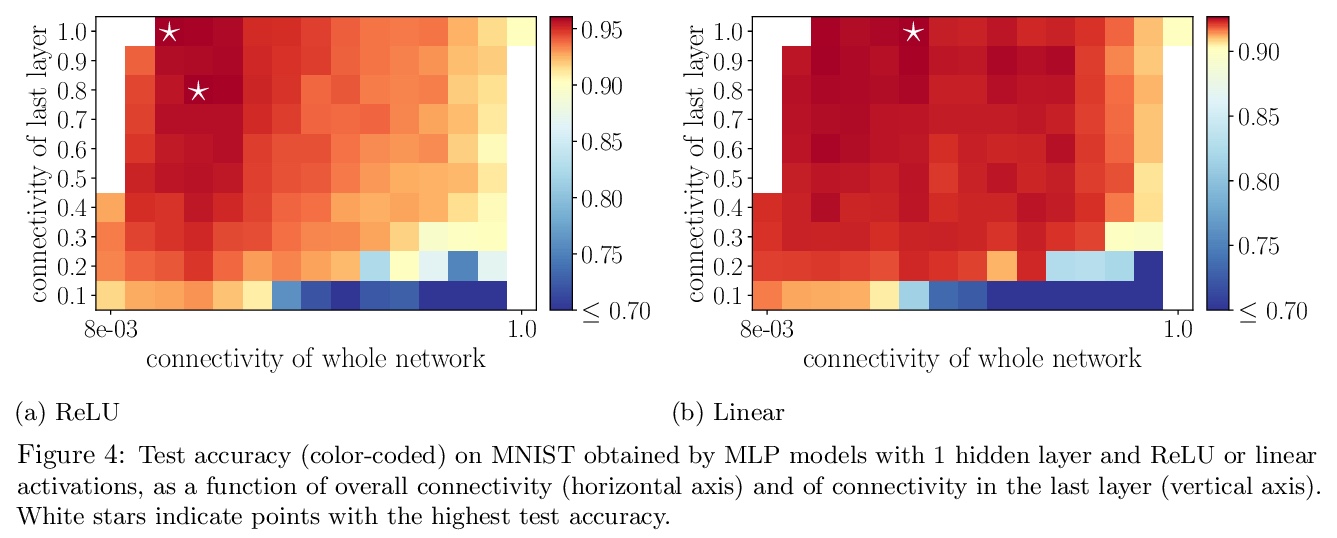
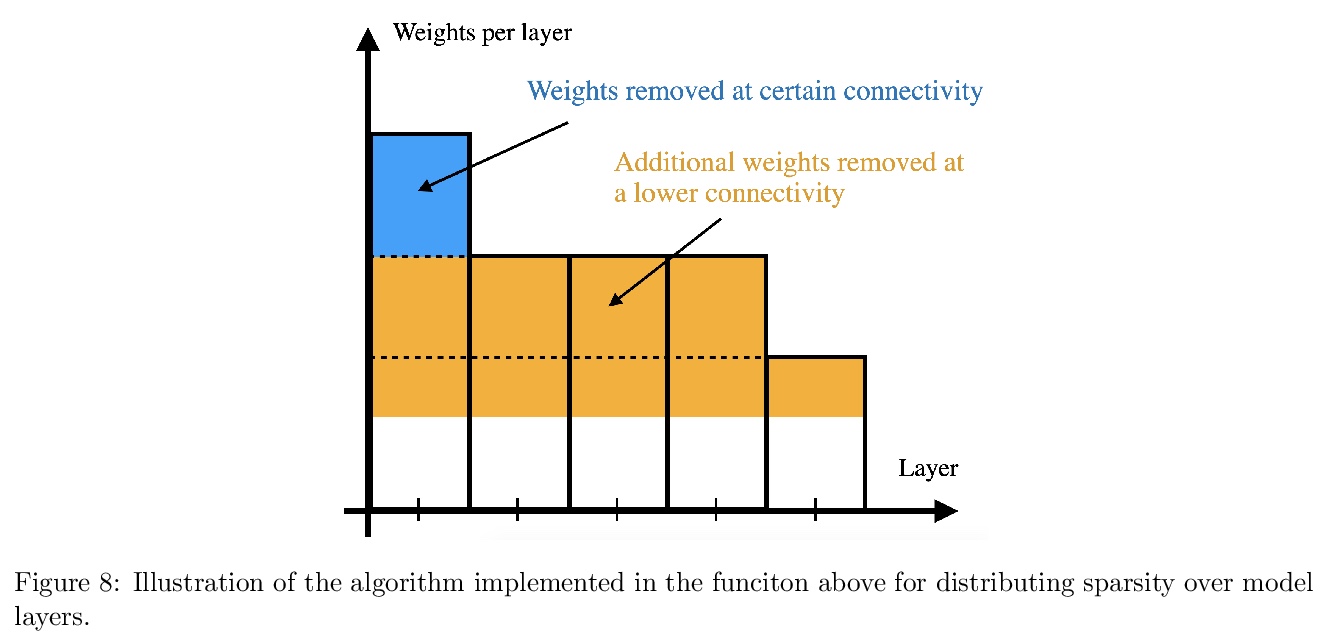
5、[LG] Are wider nets better given the same number of parameters?
A Golubeva, B Neyshabur, G Gur-Ari
[University of Waterloo & Google]
参数规模不变情况下网络宽度对性能的影响。比较了在保持参数个数的情况下,增加模型宽度的不同方法。对于权值张量中随机静态稀疏模式初始化的模型,网络宽度是良好性能的决定因素,而权值数量是次要的,只要可训练性得到保证。初始化时稀疏有限宽模型核与无限宽模型核之间的距离是模型性能的有效指标。
Empirical studies demonstrate that the performance of neural networks improves with increasing number of parameters. In most of these studies, the number of parameters is increased by increasing the network width. This begs the question: Is the observed improvement due to the larger number of parameters, or is it due to the larger width itself? We compare different ways of increasing model width while keeping the number of parameters constant. We show that for models initialized with a random, static sparsity pattern in the weight tensors, network width is the determining factor for good performance, while the number of weights is secondary, as long as trainability is ensured. As a step towards understanding this effect, we analyze these models in the framework of Gaussian Process kernels. We find that the distance between the sparse finite-width model kernel and the infinite-width kernel at initialization is indicative of model performance.
https://weibo.com/1402400261/Js8wg3OaT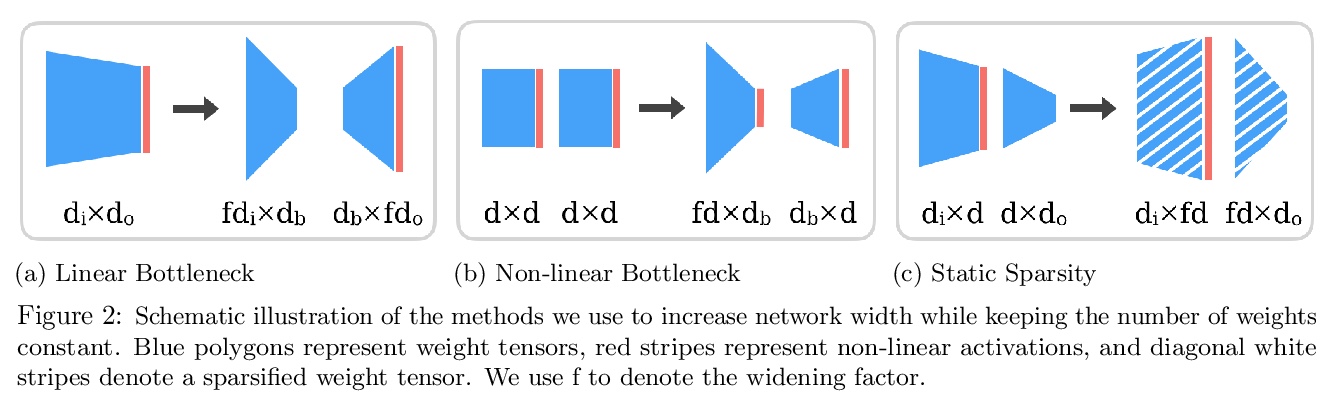
另外几篇值得关注的论文:
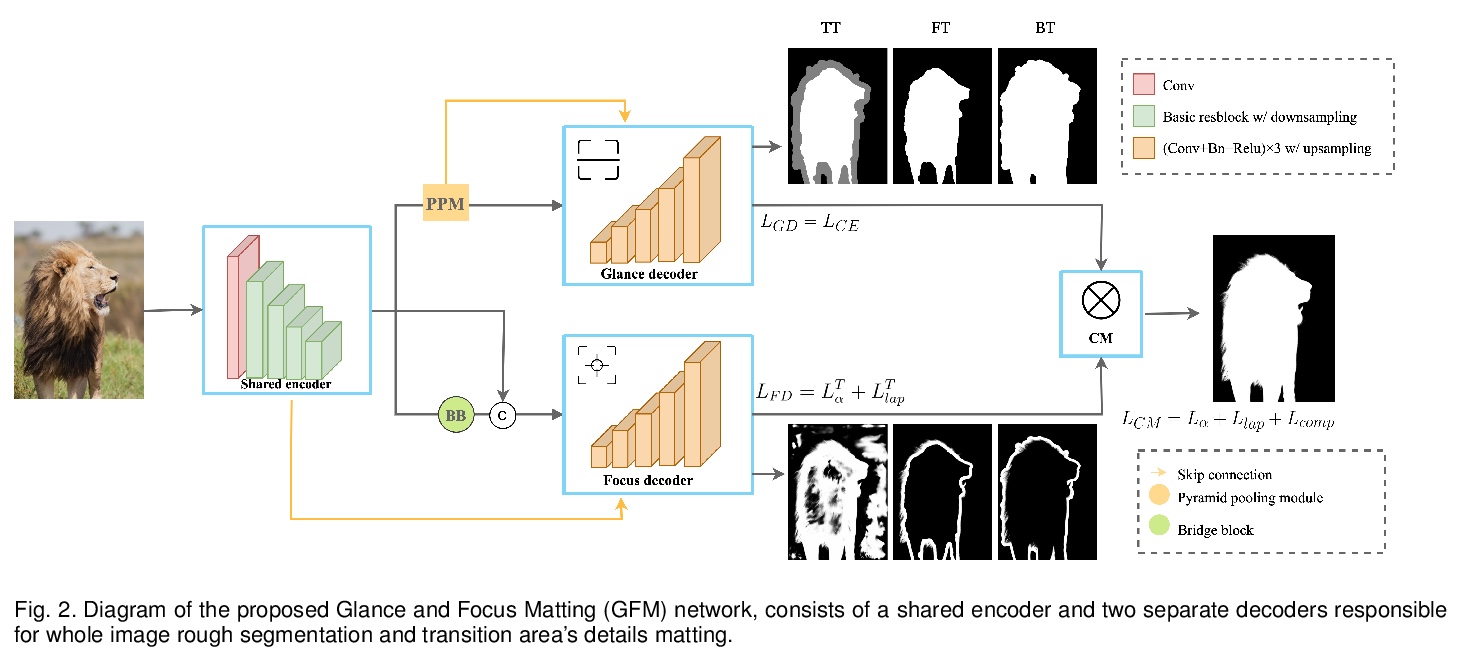
[CV] End-to-end Animal Image Matting
端到端动物图像抠图
J Li, J Zhang, S J. Maybank, D Tao
[The University of Sydney & Birkbeck College]
https://weibo.com/1402400261/Js8Aq0Bge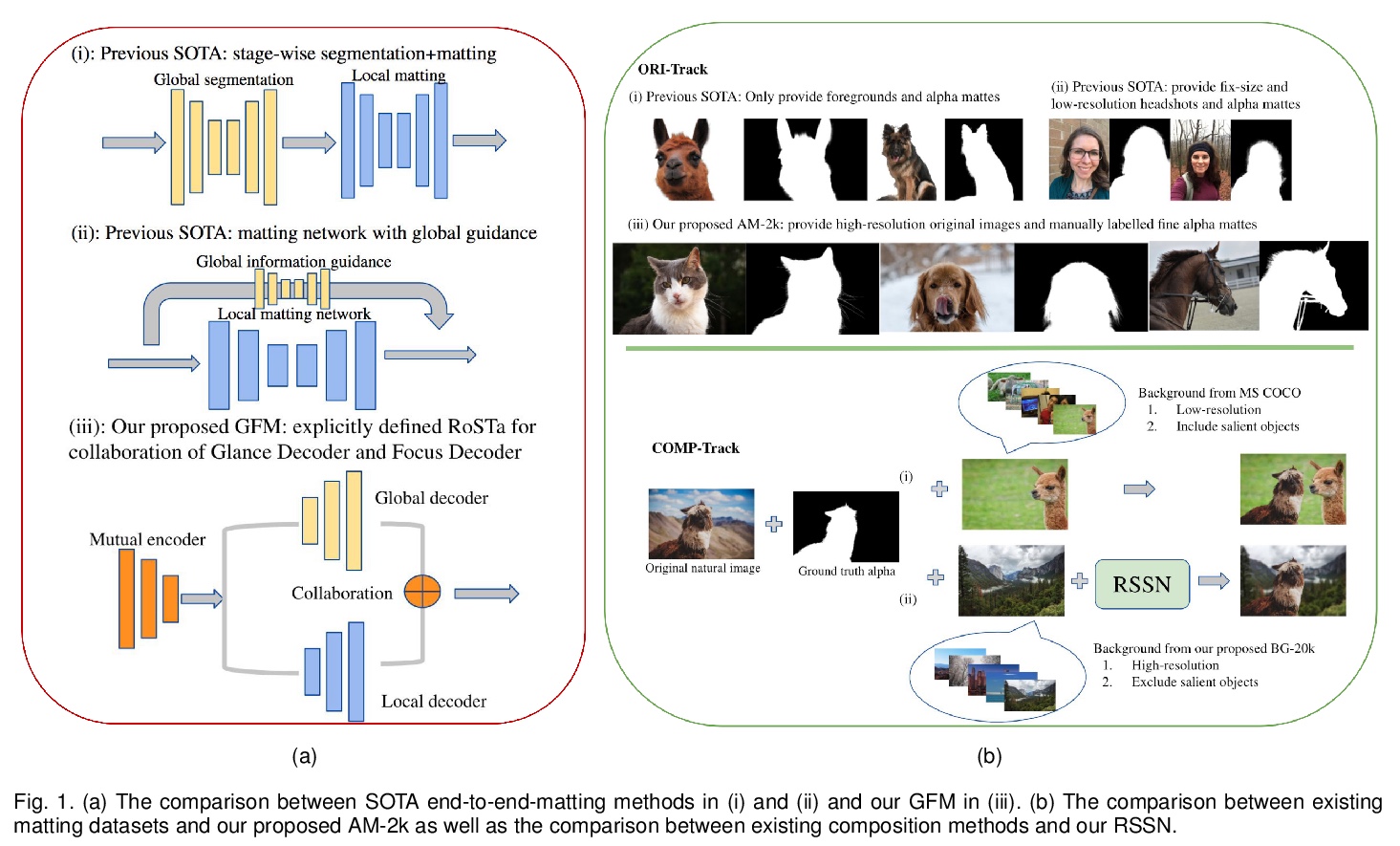

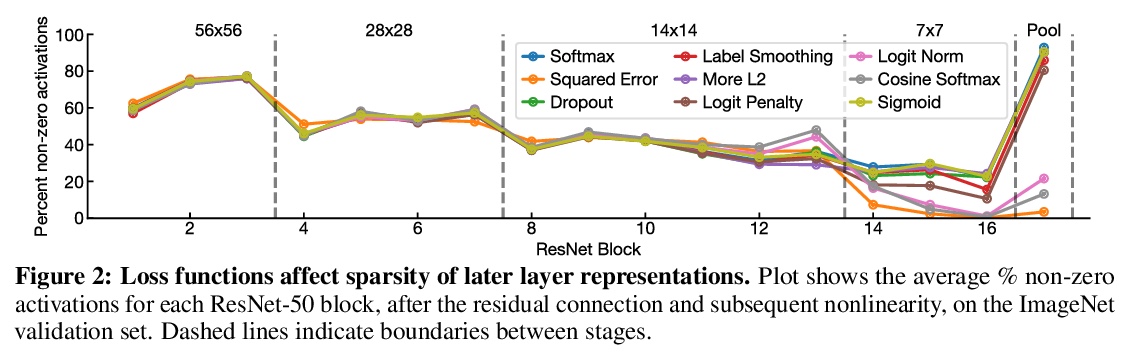
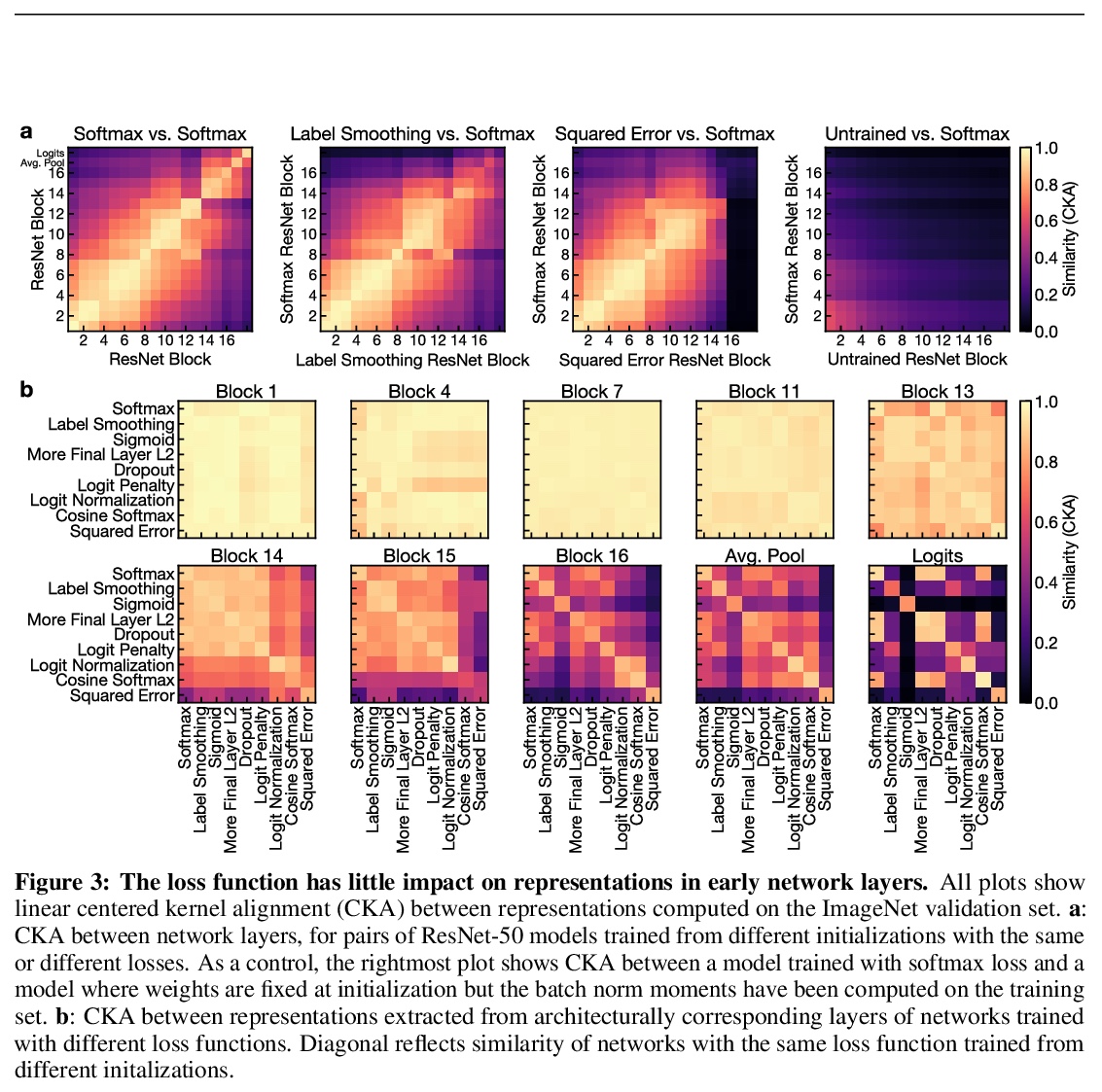
[CV] What’s in a Loss Function for Image Classification?
图像分类中的各种损失函数和输出层正则化策略
S Kornblith, H Lee, T Chen, M Norouzi
[Google Research]
https://weibo.com/1402400261/Js8C1gutX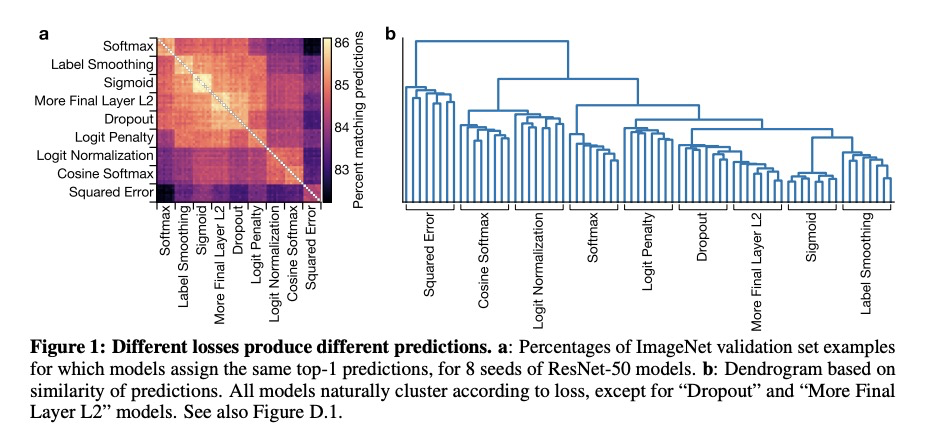
[LG] Representation learning for improved interpretability and classification accuracy of clinical factors from EEG
面向提高脑电图临床因素可解释性和分类准确性的表示学习
G Honke, I Higgins, N Thigpen, V Miskovic, K Link, P Gupta, J Klawohn, G Hajcak
[Google & DeepMind]
https://weibo.com/1402400261/Js8E21MVS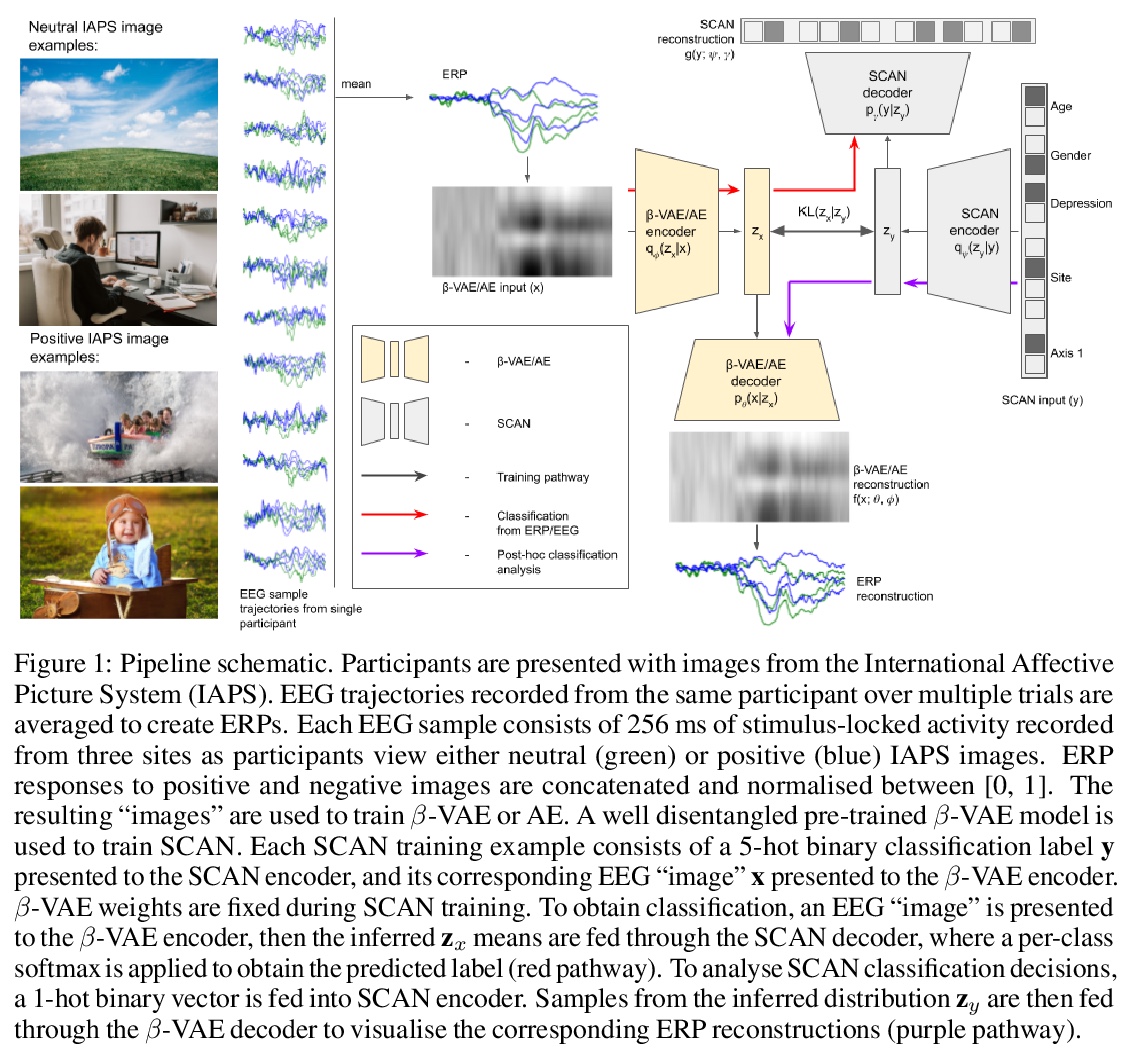
[CL] Topic-Preserving Synthetic News Generation: An Adversarial Deep Reinforcement Learning Approach
保留主题的合成新闻生成:一种对抗深度强化学习方法
A Mosallanezhad, K Shu, H Liu
[Arizona State University & Illinois Institute of Technology]
https://weibo.com/1402400261/Js8Fu72vY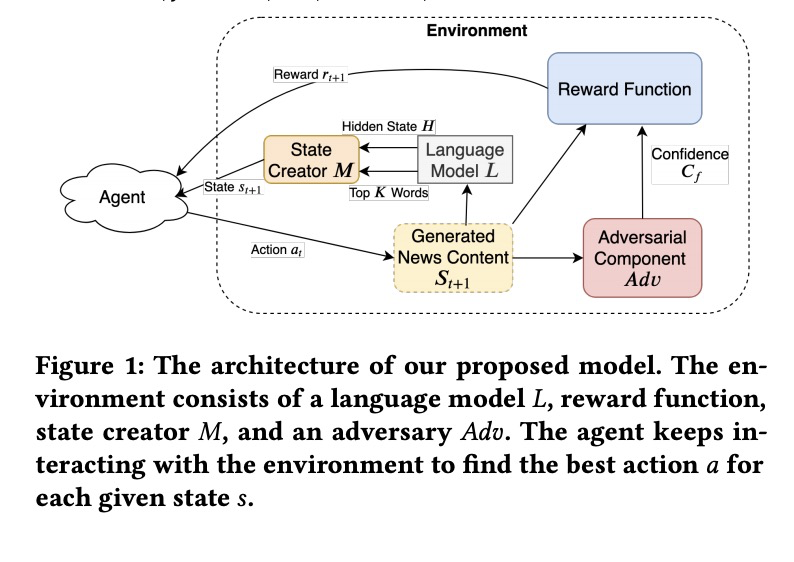
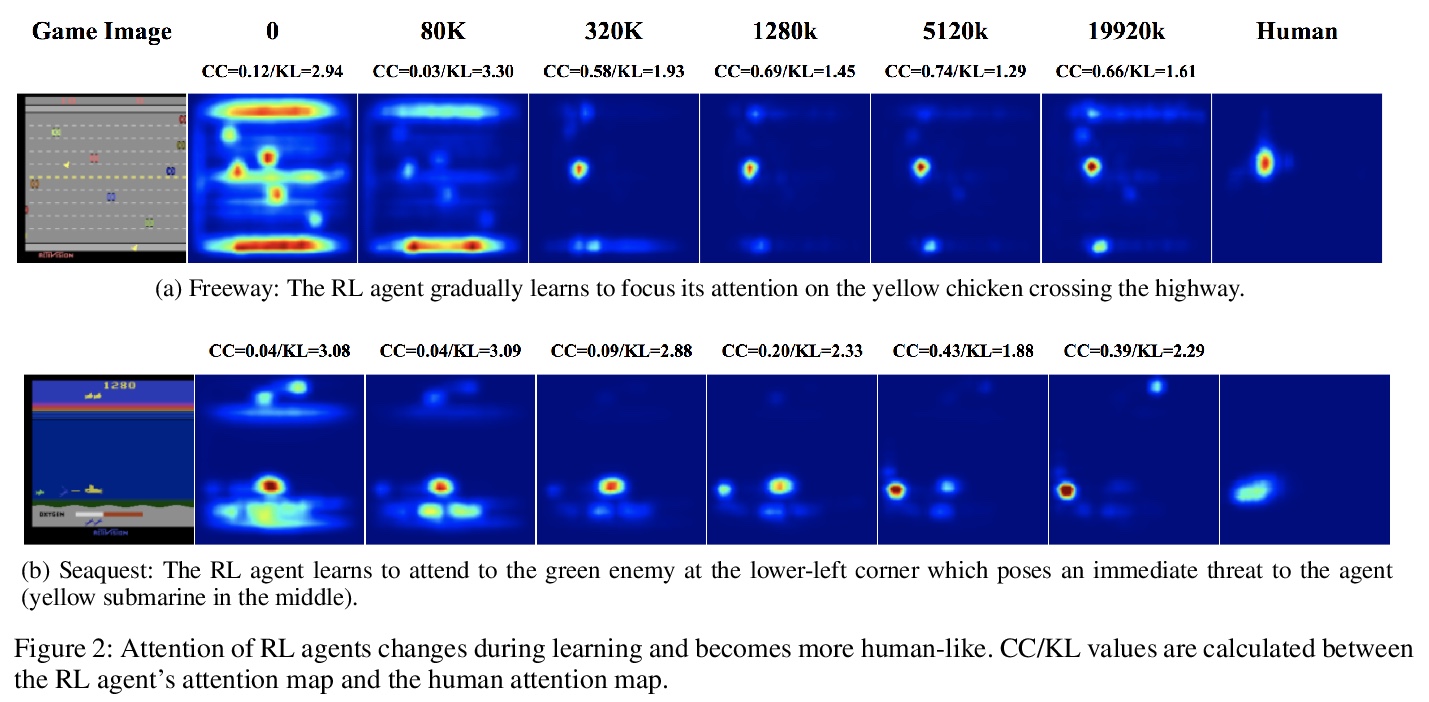
[LG] Human versus Machine Attention in Deep Reinforcement Learning Tasks
深度强化学习任务中的注意力:人 vs. 机器
R Zhang, B Liu, Y Zhu, S Guo, M Hayhoe, D Ballard, P Stone
[The University of Texas at Austin]
https://weibo.com/1402400261/Js8HbBmEM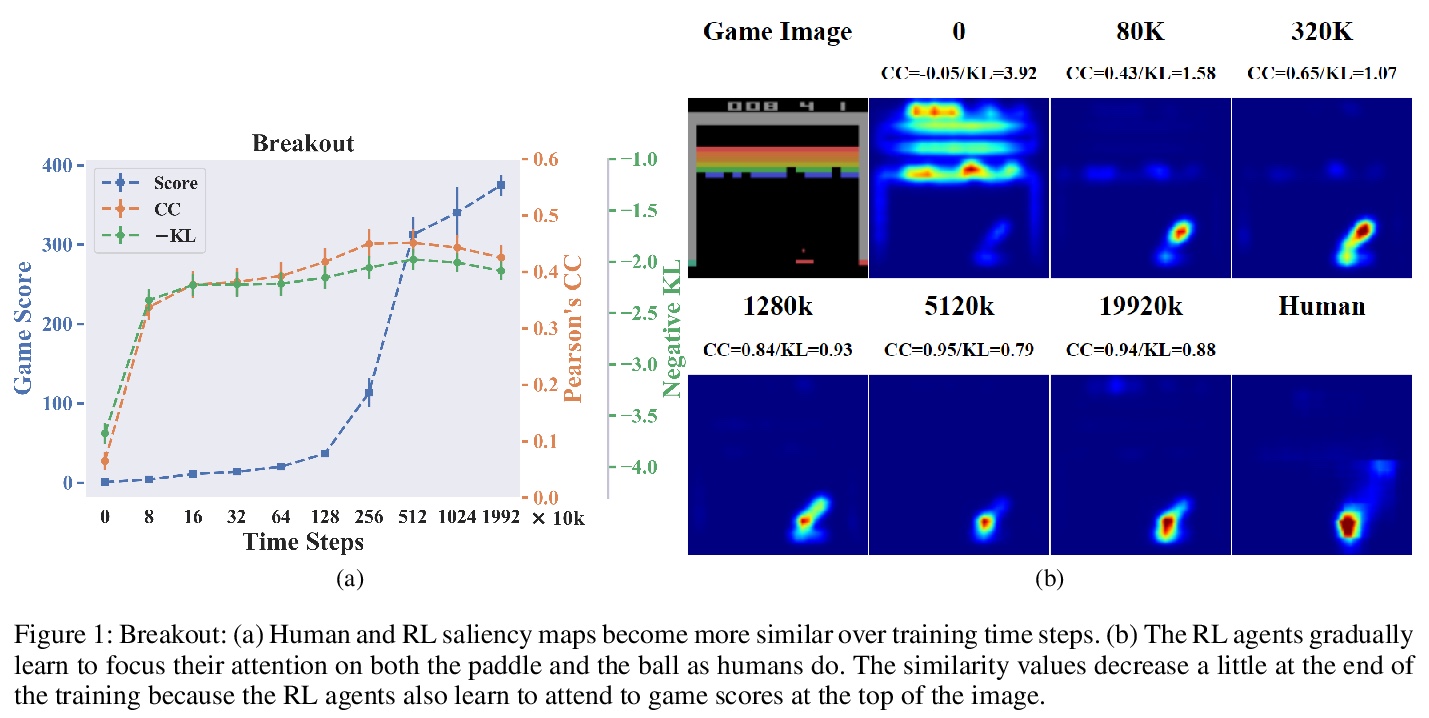
[IR] Multimodal Metric Learning for Tag-based Music Retrieval
基于标签音乐检索的多模态度量学习
M Won, S Oramas, O Nieto, F Gouyon, X Serra
[Universitat Pompeu & Pandora]
https://weibo.com/1402400261/Js8Ir0yYu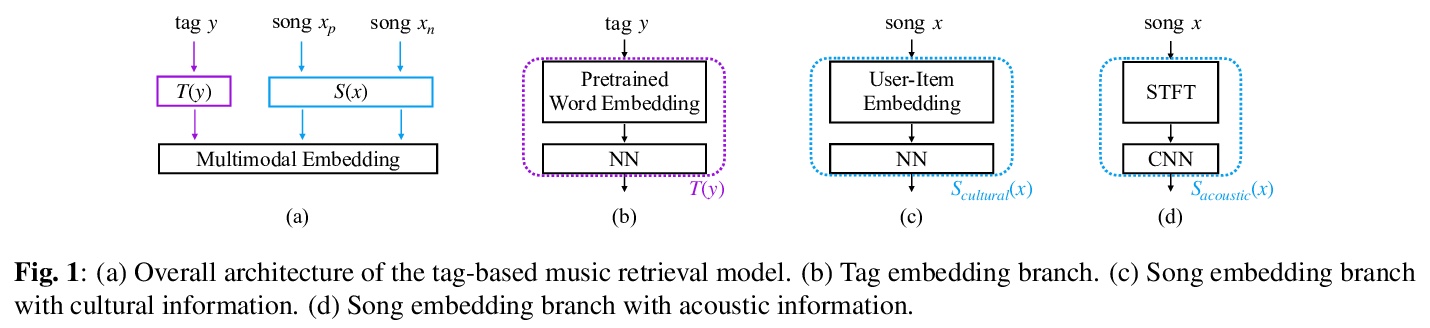

若有收获,就点个赞吧
0 人点赞
